The GraphQL schema language is great! It is certainly the best way to communicate anything about a GraphQL service. No wonder all documentations now use it!
The Schema Language
Imagine that you’re building a blog app (with GraphQL) that has "Articles" and "Comments" . You can start thinking about its API schema by basing it on what you plan for its UI. For example, the main page will probably have a list of articles and an item on that list might display a title, subtitle, author’s name, publishing date, length (in reading minutes), and a featured image. A simplified version of Medium itself if you may:
We can use the schema-language to plan what you need so far for that main page. A basic schema might look like:
type Query {
articleList: [Article!]!
}
type Article {
id: ID!
title: String!
subTitle: String
featuredImageUrl: String
readingMinutes: Int!
publishedAt: String!
author: Author!
}
type Author {
name: String!
}
When a user navigates to an article, they’ll see the details of that article. We’ll need the API to support a way to retrieve an Article object by its id. Let’s say an article can also have rich UI elements like headers and code snippets. We would need to support a rich-text formatting language like Markdown. We can make the API return an article’s content in either Markdown or HTML through a field argument (format: HTML). Let’s also plan to display a "likes" counter in that view.
Put all these ideas on paper! The schema language is the most concise structured way to describe them:
type Query {
# ...
article(id: String!): Article!
}
enum ContentFormat {
HTML
MARKDOWN
}
type Article {
# ...
content(format: ContentFormat): String!
likes: Int!
}
The one article’s UI view will also display the list of comments available on an article. Let’s keep the comment UI view simple and plan it to have a text content and an author name fields:
type Article {
# ...
commentList: [Comment!]!
}
type Comment {
id: ID!
content: String!
author: Author!
}
Let’s focus on just these features. This is a good starting point that’s non-trivial. To offer these capabilities we’ll need to implement custom resolving logic for computed fields like content(format: HTML) and readingMinutes. We’ll also need to implement 1–1 and 1-many db relationships.
Did you notice how I came up with the whole schema description so far just by thinking in terms of the UI. How cool is that? You can give this simple schema language text to the front-end developers on your team and they can start building the front-end app right away! They don’t need to wait for your server implementation. They can even use some of the great tools out there to have a mock GraphQL server that resolves these types with random test data.
The schema is often compared to a contract. You always start with a contract.
Building a GraphQL Schema
When you’re ready to start implementing your GraphQL service, you have 2 main options (in JavaScript) today:
- You can "build" a non-executable schema using the full schema language text that we have and then attach a set of resolver functions to make that schema executable. You can do that with GraphQL.js itself or with Apollo Server. Both support this method which is commonly known as "schema-first" or "SDL-first". I’ll refer to it here as the "full-schema-string method".
- You can use JavaScript objects instantiated from the various constructor classes that are available in the GraphQL.js API (like
GraphQLSchema,GraphQLObjectType,GraphQLUnionType, and many others). In this approach, you don’t use the schema-language text at all. You just create objects. This method is commonly known as "code-first" or "resolvers-first" but I don’t think these names fairly represent it. I’ll refer to it here as the "object-based method".
Both approaches have advantages and disadvantages.
The schema language is a great programming-language-agnostic way to describe a GraphQL schema. It’s a human-readable format that’s easy to work with. The frontend people on your team will absolutely love it. It enables them to participate in the design of the API and, more importantly, start using a mocked version of it right away. The schema language text can serve as an early version of the API documentation.
However, completely relying on the full schema language text to create a GraphQL schema has a few drawbacks. You’ll have to put in some effort to make the code modularized and clear and you have to rely on coding patterns and tools to keep the schema-language text consistent with the tree of resolvers (AKA resolvers map). These are solvable problems.
The biggest problem I see with the full-schema-string method is that you lose some flexibility in your code. You don’t have objects associated with types. You just have strings! And although these strings make your types more readable, in many cases you’ll need the flexibility over the readability.
The object-based method is flexible and easier to extend and manage. It does not suffer from any of the mentioned problems. You have to be modular with it because your schema is a bunch of objects. You also don’t need to merge modules together because these objects are designed and expected to work as a tree.
The only problem I see with the object-based method is that you have to deal with a lot more code around what’s important to manage in your modules (types and resolvers). A lot of developers see that as "noise" and you can’t blame them. We’ll work through an example to see that.
If you’re creating a small-scope and well-defined GraphQL service, using the full-schema-string method is probably okay. However, in bigger and more agile projects I think the more flexible and more powerful object-based method is the way to go.
You should still leverage the schema-language text even if you’re using the object-based method. At jsComplete, we use the object-based method but every time the schema is built we use the graphql.printSchema function to write the complete schema to a file. We commit and track that file in the Git repository of the project and that proved to be a very helpful practice!To compare the 2 methods, I’ve implemented an executable schema for the blog example we started with using both of them. I’ve omitted some code for brevity but kept what matters for the comparison.
The full-schema-string method
We start with the schema-language text which defines 3 main custom types (Article, Comment, and Author). The fields under the main Query type are article and articleList which will directly resolve objects from the database. However, since the GraphQL schema we planned has custom features around an article object and since we have relations that we need to resolve as well we’ll need to have custom resolvers for the 3 main custom GraphQL types.
Here are a few screenshots for the code I wrote to represent the full-schema-string method. I’ve used Apollo Server here but this is also possible with vanilla GraphQL.js (and a bit more code).
Please note that this is just ONE way of implementing the full-schema-string method for this service. There are countless other ways. I am just presenting the simplest modular way here to help us understand the true advantages and disadvantages.
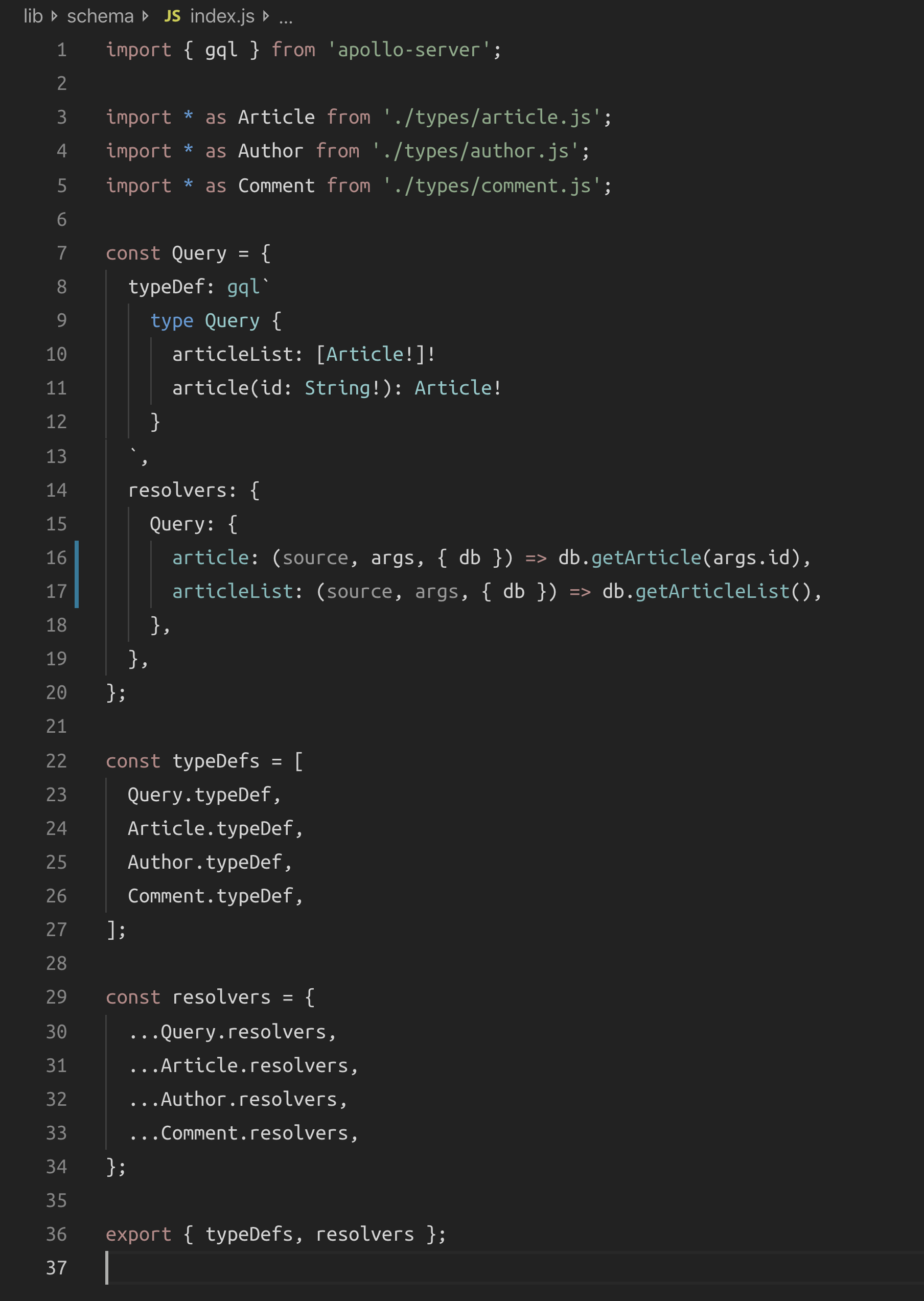
This is nice! We can see the types in the schema in one place. It’s clear where the schema starts. We’re able to modularize the code by type/feature.
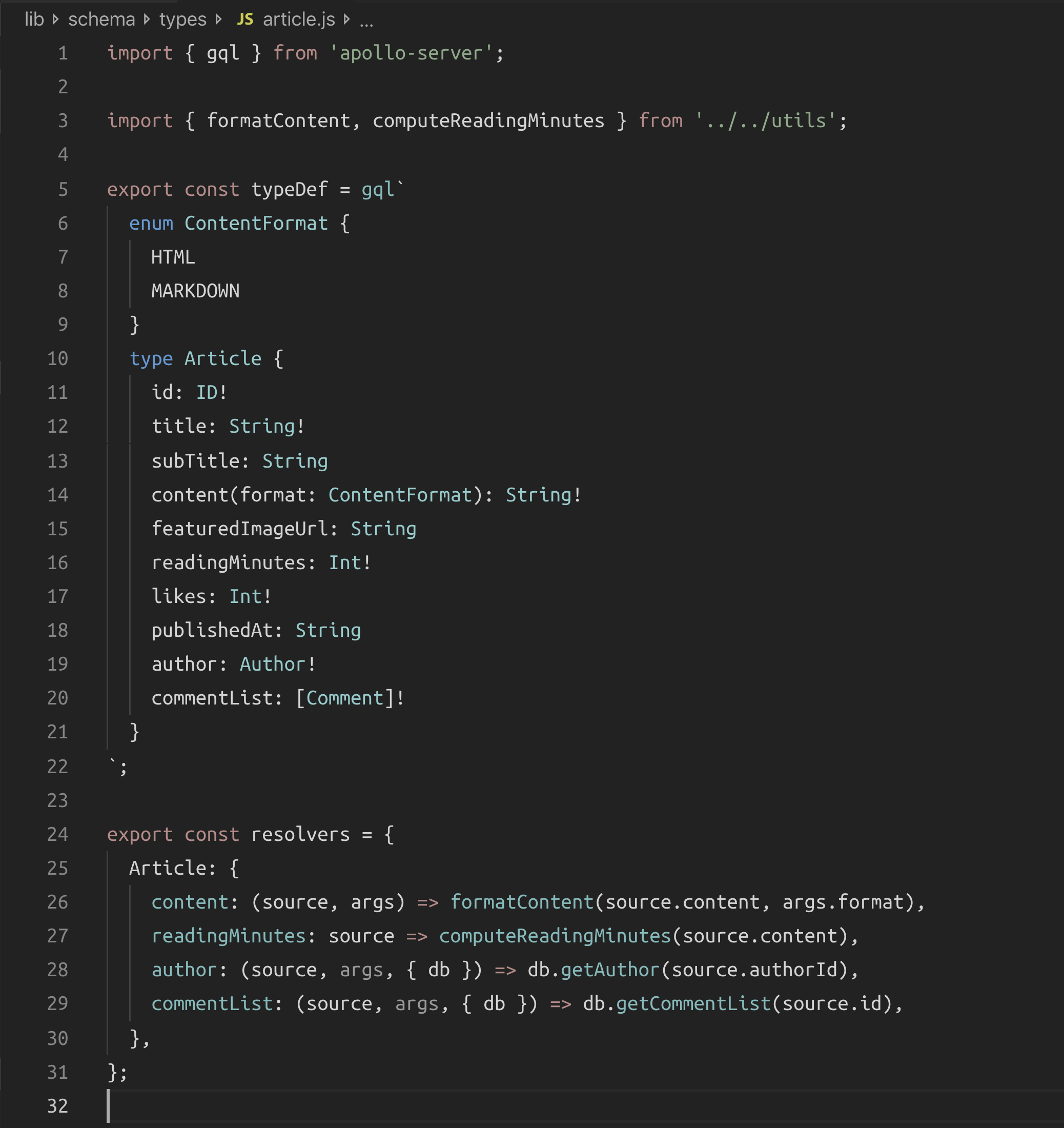
This again is really great! Resolvers are co-located with the types they implement. There is no noise. This file beautifully contains what matters in a very readable format. I love it!
The modularity here is only possible with Apollo Server. If we’re to do this with vanilla GraphQL.js we will have to monkey with data objects to make them suitable to be a "resolvers tree". The mixing between the data structures and the resolvers graph is not ideal.
So what’s the downside here?
If you use this method then all your types have to be written in that certain way that relies on the schema language text. You have less flexibility. You can’t use constructors to create some types when you need to. You’re locked down to this string-based approach.
If you’re okay with that then ignore the rest of this article. Just use this method. It is so much cleaner than the alternative.
The object-based method
Let’s now look at the object-based approach. Here’s the starting point of an executable schema built using that method:
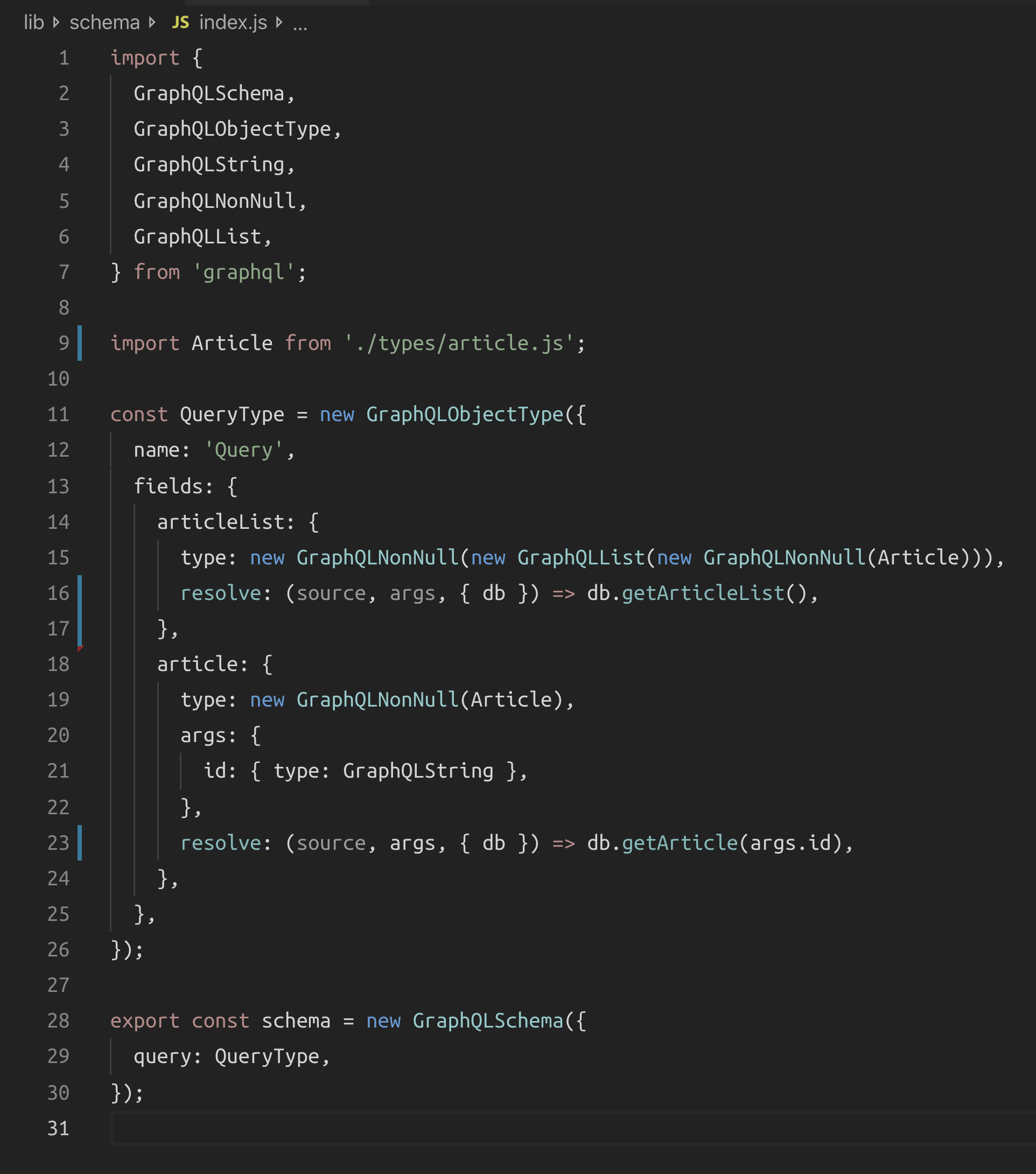
We don’t need a separate resolvers object. Resolvers are part of the schema object itself. That makes them easier to maintain. This code is also easier to programmatically extend and analyze!
It’s also so much more code that’s harder to read and reason about! Wait until you see the rest of the code. I couldn’t take the Article type screenshot on the laptop screen. I had to use a bigger screen.
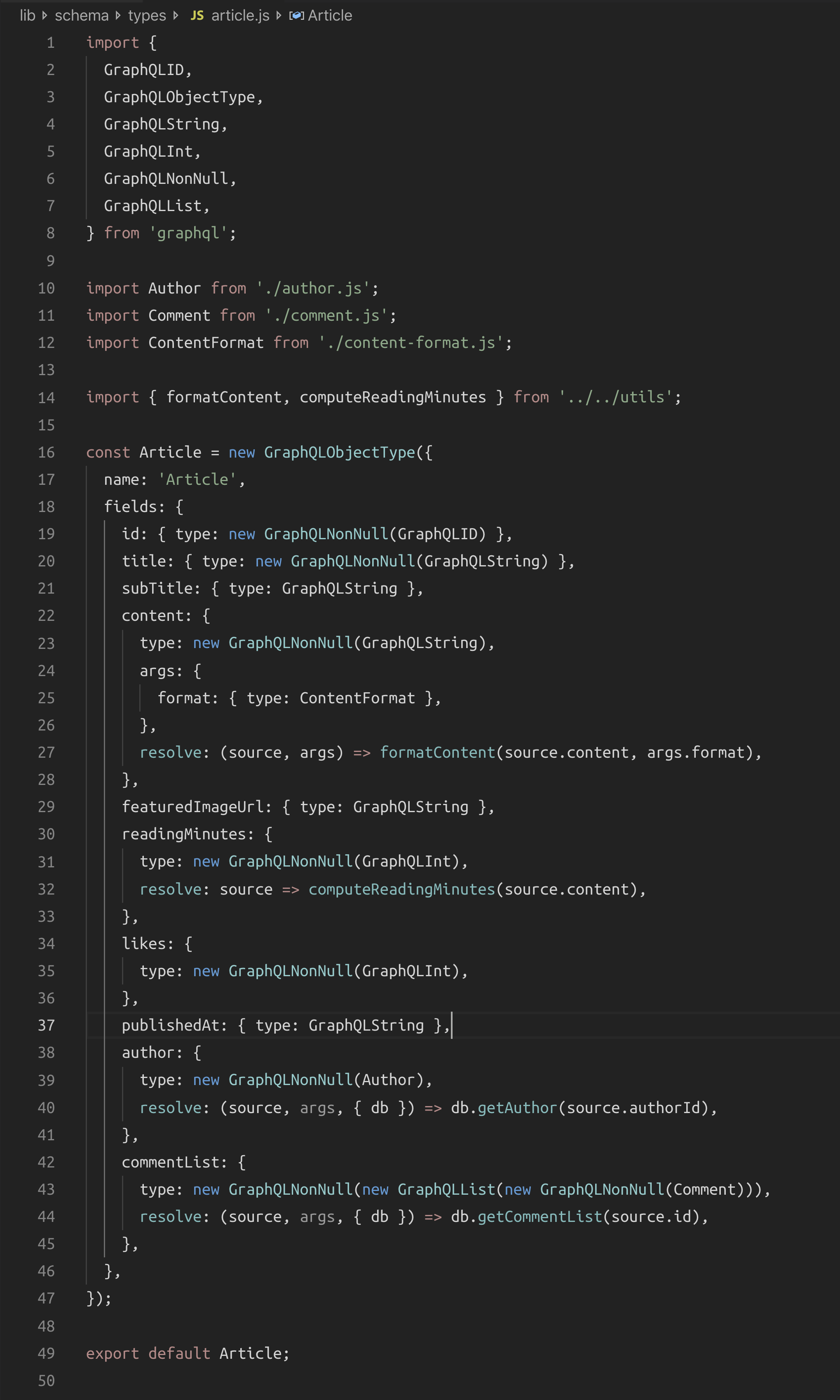
No wonder the full-schema-string method is popular! There is certainly a lot of "noise" to deal with here. Types are not clear at first glance. Custom resolvers are mixed in one big configuration object.
My favorite part is when you need to create a non-null list of non-null items like [Article!]!. Did you see what I had to write?
new GraphQLNonNull(new GraphQLList(new GraphQLNonNull(Article))),
However, while this is indeed a lot more code that’s harder to understand, it is still a better option than having one big string (or multiple strings combined into one) and one big root resolvers object (or multiple resolvers objects combined into one). It’s better than having all the dependencies of your app managed in one single entry point.
There is a lot of power in modularizing your code using objects (that may depend on each other). It’s cleaner that way and it also makes writing tests and validations easier. You get more helpful error messages when you debug problems. Modern editors can provide more helpful hints in general. Most importantly, you have a lot more flexibility to do anything with these objects. The GraphQL.js constructors API itself also uses JavaScript objects. There is so much you can do with them.
But the noise is real too.
The object-based method without the noise
I am sticking with the object-based method but I sure wish the JavaScript GraphQL implementations had a better API that can give us some of the power of the full-schema-string method.
Wouldn’t be nice if we can write the Article type logic exactly as we did in the full-schema-string method but in a way that generates the flexible GraphQLObjectType that we can plug into an object-based schema?
Something like:
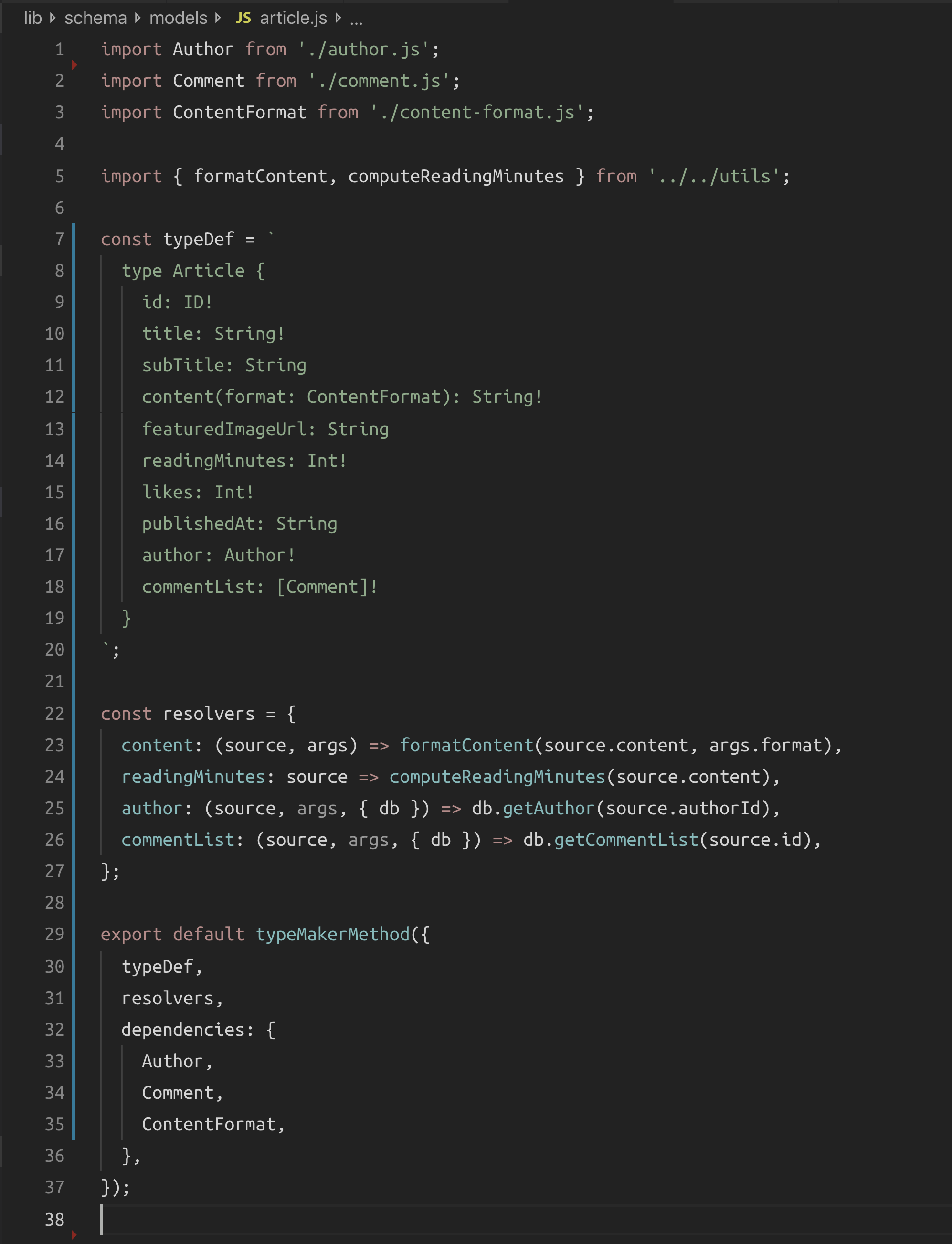
Wouldn’t that be ideal? We get the benefits of the full-schema-string method for this type but with no lockdown! Other types in the system can be maintained differently. Maybe other types will be dynamically constructed using a different maker logic!
All we need to make this happen is a magical typeMakerMethod to take the parts that matter and transform them into the complete GraphQLObjectType for Article.
The typeMakerMethod will need to parse a string into an AST, use that to build a GraphQLObjectType, then merge the set of custom resolver functions with the fieldsconfiguration that’ll be parsed from the typeDef string.
I like a challenge so I dug a little bit deeper to see how hard would it be to implement the typeMakerMethod. I knew I couldn’t use the graphql.buildSchema function because it only parses one full schema string to make a non executable schema object. I needed a lower-level part that parses a string that has exactly ONE type and then attaches custom resolvers to it. So I started reading the source code of GraphQL.js to look for clues. A few cups of coffee later, I found some answers (in 2 places):

That’s the core method used in buildSchema to construct ONE type from a type definition node (which we can easily get by parsing the typeDef string).
And:

That’s how easy it is to extend an object type and attach any logic needed in fields and interfaces!
All I needed to do is put a few pieces together and the dream can be true.
Ladies and gentlemen. I present to you the magical "typeMakerMethod" (which I named objectType):
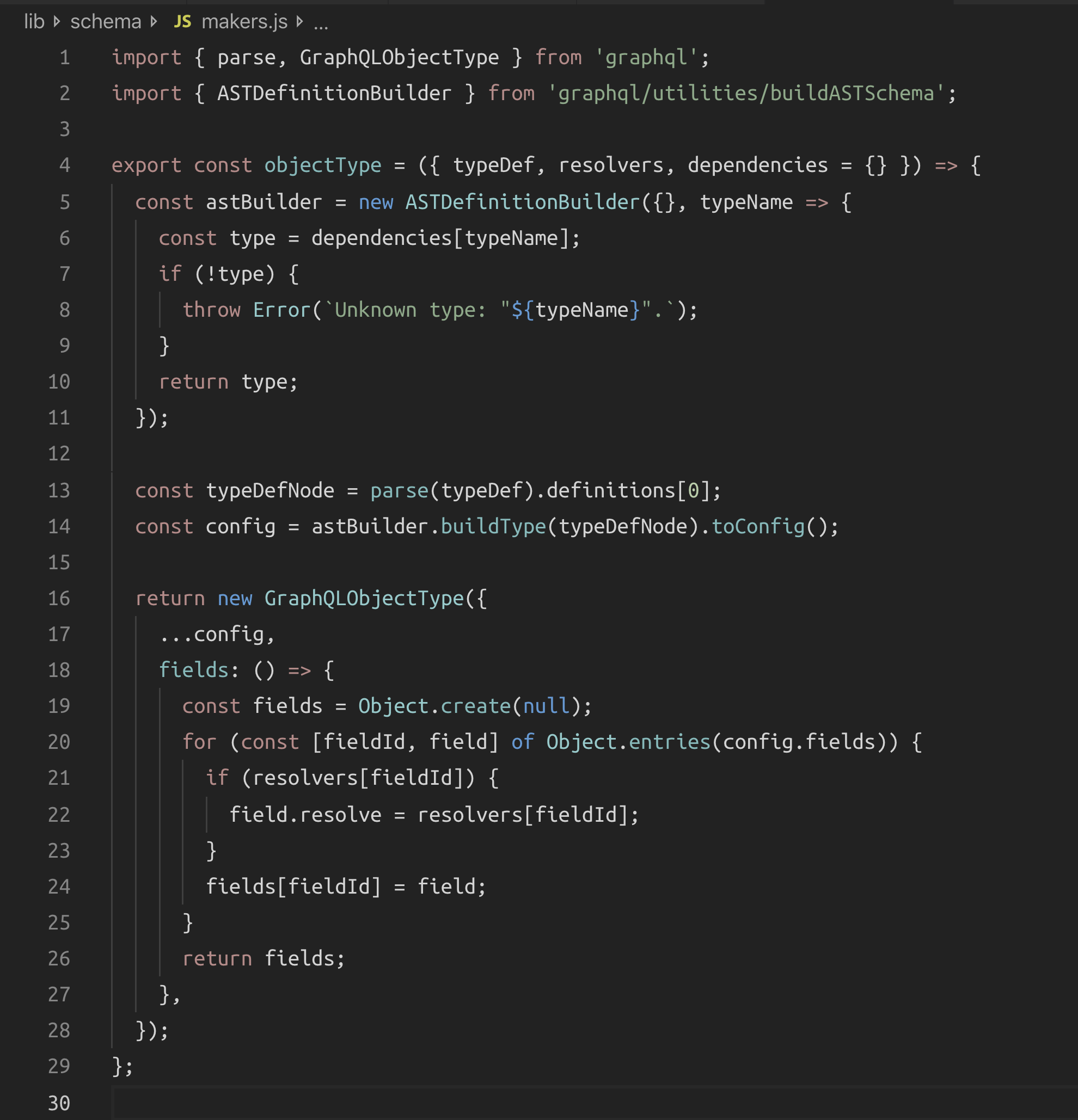
That’s it (in its most basic form)! This will take a typeDef string that defines a single GraphQL type, an object of resolvers and a map of dependencies (for that type), and it’ll return a GraphQLObjectType ready to be plugged into your object-based schema as if it was defined normally with the object constructor.
Now you can use the object-based method but you have the option to define SOME types using an approach similar to the full-schema-string method. You have the power.
What do you think of this approach? I’d love to hear your feedback!
Please note that theobjectTypecode above is just the basic use case. There are many other use cases that require further code. For example, if the types have circular dependencies (article→author→article) then this version ofobjectTypewill not work. We can delay the loading of the circular dependencies until we’re in thefieldsthunk (which is the current approach to solve this problem in the object-based method). We can also use the "extend" syntax to design the schema in a way that avoids circular dependencies in the first place. I’ve skipped this part to keep the example simple.
If you’d like to give it a spin I published a more polished version of objectType and a few other maker functions like it under the graphql-makers npm package.Originally published at https://jscomplete.com on June 9, 2019.