
原文: The Python Handbook – Learn Python for Beginners
这本Python编程手册遵循“80/20定律”:使用20%的时间学习80%的内容。
我认为这种方法可以为学习者提供一个对Python全面的了解。
本手册并没有涵盖与Python相关的全部内容。它专注于这门编程语言的核心主题,并且试图简化那些复杂的内容。
我希望这本手册可以帮助您实现:学习Python的基础
Note: 您可以获取这本手册的PDF、ePub或者Mobi版本
Enjoy it!
目录
- Python介绍
- 如何安装Python
- 如何运行Python程序
- Python 2 vs Python 3
- Python基础
- Python数据类型
- Python运算符
- Python三元运算符
- Python字符串
- Python布尔值
- Python数字
- Python常量
- Python枚举
- Python用户输入
- Python控制语句
- Python列表
- Python元组
- Python字典
- Python集合
- Python函数
- Python对象
- Python循环
- Python类
- Python模块
- Python标准库
- Python PEP8风格指导
- Python代码调试
- Python变量作用域
- Python接收从命令行传入的参数
- Python的Lambda函数
- Python递归
- Python嵌套函数
- Python闭包
- Python装饰器
- Python文档字符串
- Python反射
- Python注解
- Python异常
- Python中with语句
- Python如何使用pip安装第三方包
- Python列表推导式
- Python多态
- Python运算符重载
- Python虚拟环境
- 总结
Python介绍
Python正在逐步“占领”编程世界。它的受欢迎度和使用度正在以计算机历史中前所未有的方式实现增长。
Python在各种应用场景下都表现出色——Shell 脚本、自动化的任务和Web 开发只是其基本的应用。
Python是做数据分析和机器学习的首选语言,但是它也可以用来创建游戏或者在嵌入式设备上工作。
最重要的是,Python是世界上多所大学介绍计算机科学课程时选择的编程语言。
许多学生选择Python作为自己的第一门编程语言来学习。很多人正在学习Python,将来还会有更多人学习它。并且对于学习者中的大部分人来说,Python将是他们唯一需要的编程语言。
基于其独特的情况,Python在未来很有可能会更快地发展。
Python这门编程语言的特点是简单易上手、可读性强、非常直接、易于理解。
Python的生态系统非常庞大,可能需要一个图书馆才能容纳你所想象到的一切。
因为其直观的语法、庞大的社区和充满活力的生态系统,Python是一门适合编程初学者的高级编程语言。
Python也受到不同领域的专家赞赏。
从技术上讲,Python是一种解释型语言,它不像编译型语言(例如C或Java)那样具有中间编译阶段。
和许多解释型语言一样,Python是动态类型的,这意味着您不必声明所使用的变量的类型,并且变量不必为特定类型。
这有利有弊。特别是,您编写程序的速度会更快,但另一方面,您从工具中获得防止出现可能错误的帮助会较少。这意味着您只有在执行程序时才能发现某些问题。
Python支持多种编程范式,包括面向过程编程、面向对象编程和函数式编程。它足够灵活,可以适应不同的需求。
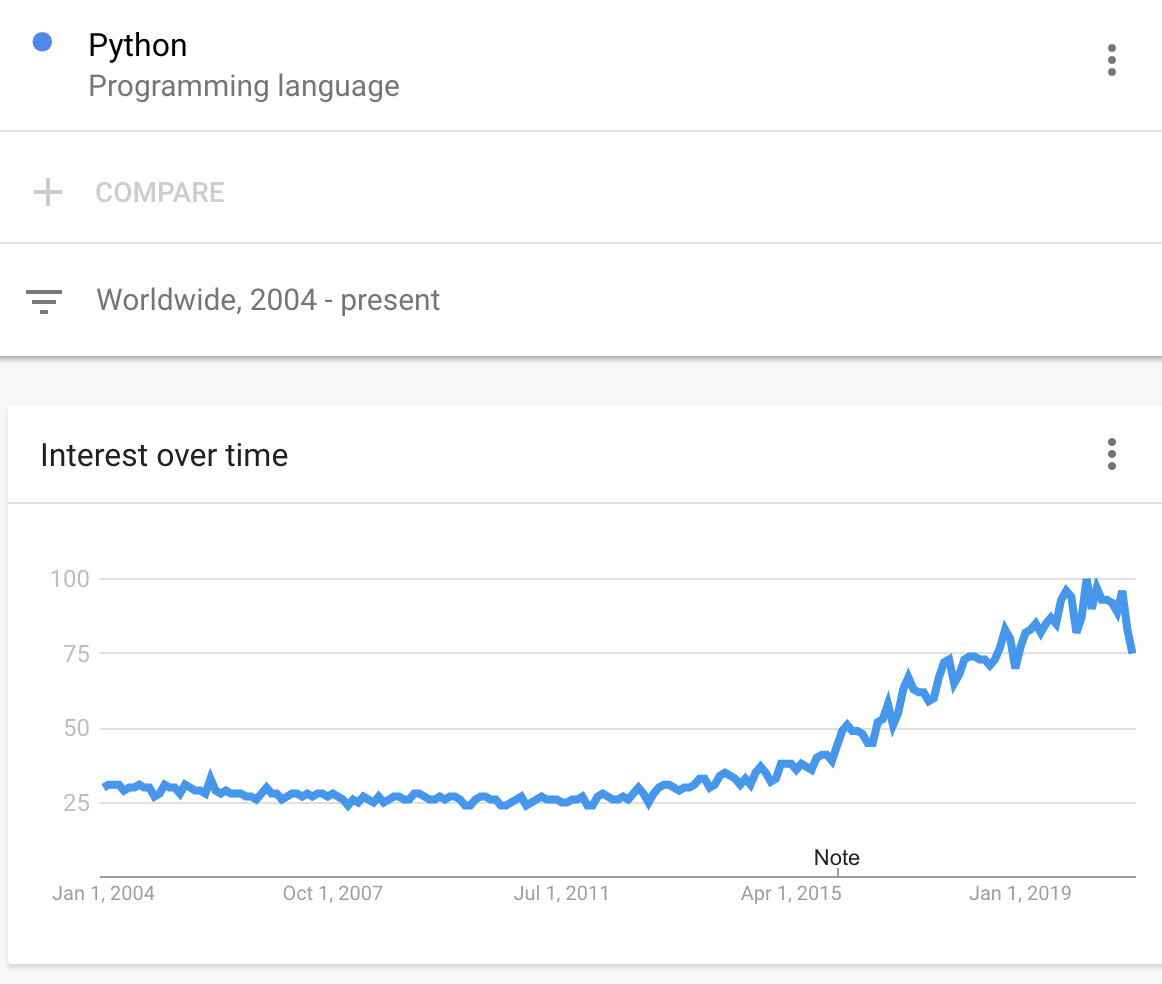
自从Python由Guido van Rossum于1991年创建后,它便越来越受欢迎——尤其是在过去5年中,正如这张Google趋势信息图所示:
开始Python编程非常容易。您只需从python.org选择适用于Windows、macOS或Linux的官方软件包安装,然后就可以开始使用Python了。
如果您是编程新手,我将会在接下来的内容中引导您从零开始成为一名Python程序员。
即使您目前是一名专门研究另一种编程语言的程序员,Python也值得您了解,因为我认为它只会继续发展壮大。
像C++和Rust这样相对于Python来说更“低级”的语言,对于专业程序员来说可能很棒,但是初学者如果从这两门语言开始学习编程,会感到畏惧,而且需要很长时间才能掌握。
另一方面,Python是一种适用于任何人——学生、使用Excel完成日常工作的人、科学家等等——的编程语言。
这是每个对编程感兴趣的人都应该首先学习的语言。
如何安装Python
进入https://www.python.org ,选择下载菜单(Downloads),然后选择您的操作系统,将出现一个带有官方软件包下载链接的面板:
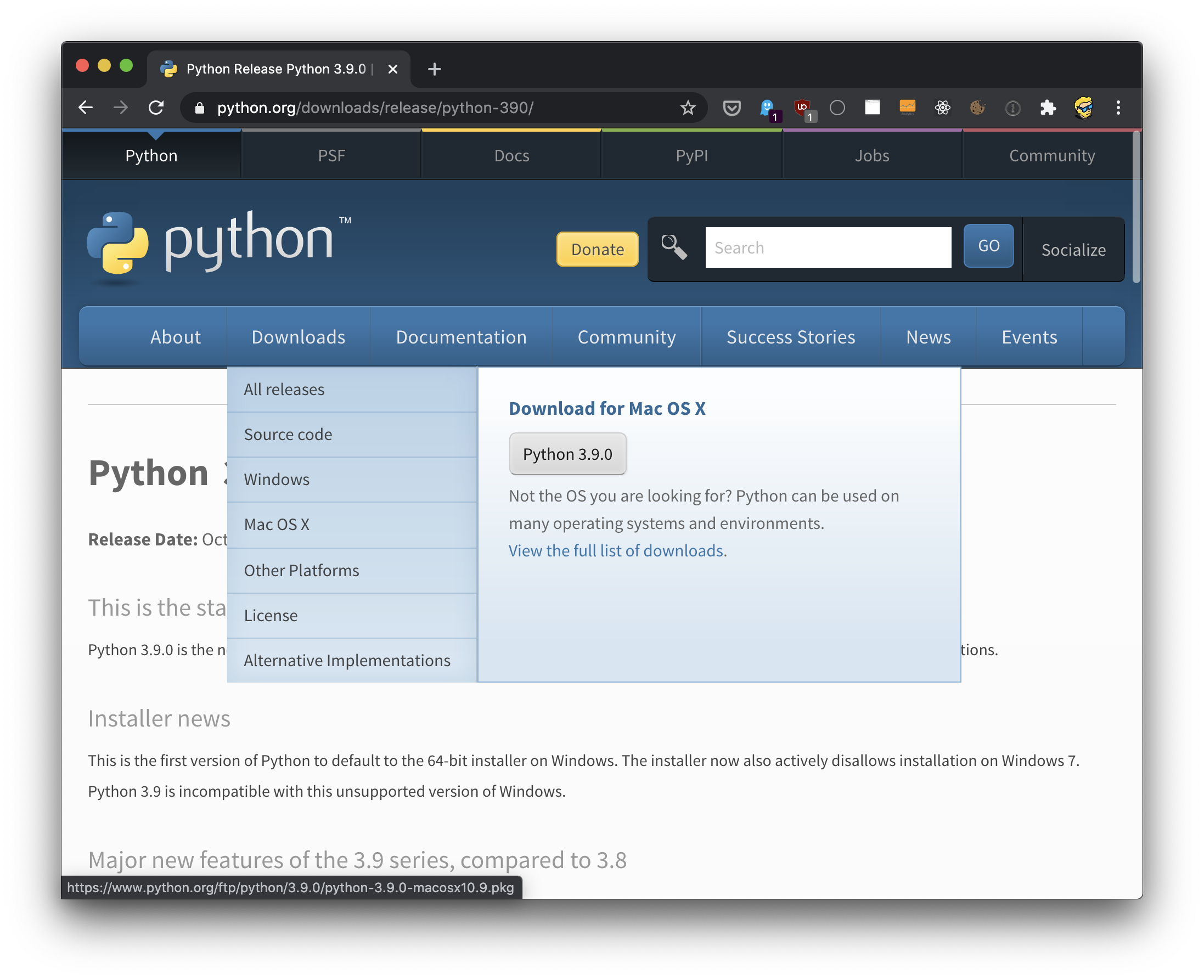
请确保遵循关于您电脑所用的操作系统的特定说明。如果是在macOS上安装,您可以在https://flaviocopes.com/python-installation-macos/ 上找到详细指南。
如何运行Python程序
您可以使用几种不同的方式来运行Python程序。
特别地,使用交互式环境(输入Python代码后,便立即执行它),和将Python程序保存到文件中,然后再执行它,这二者之间存在区别。
让我们从交互式环境开始。
如果您打开终端并输入python,将在终端窗口上看到如下内容:
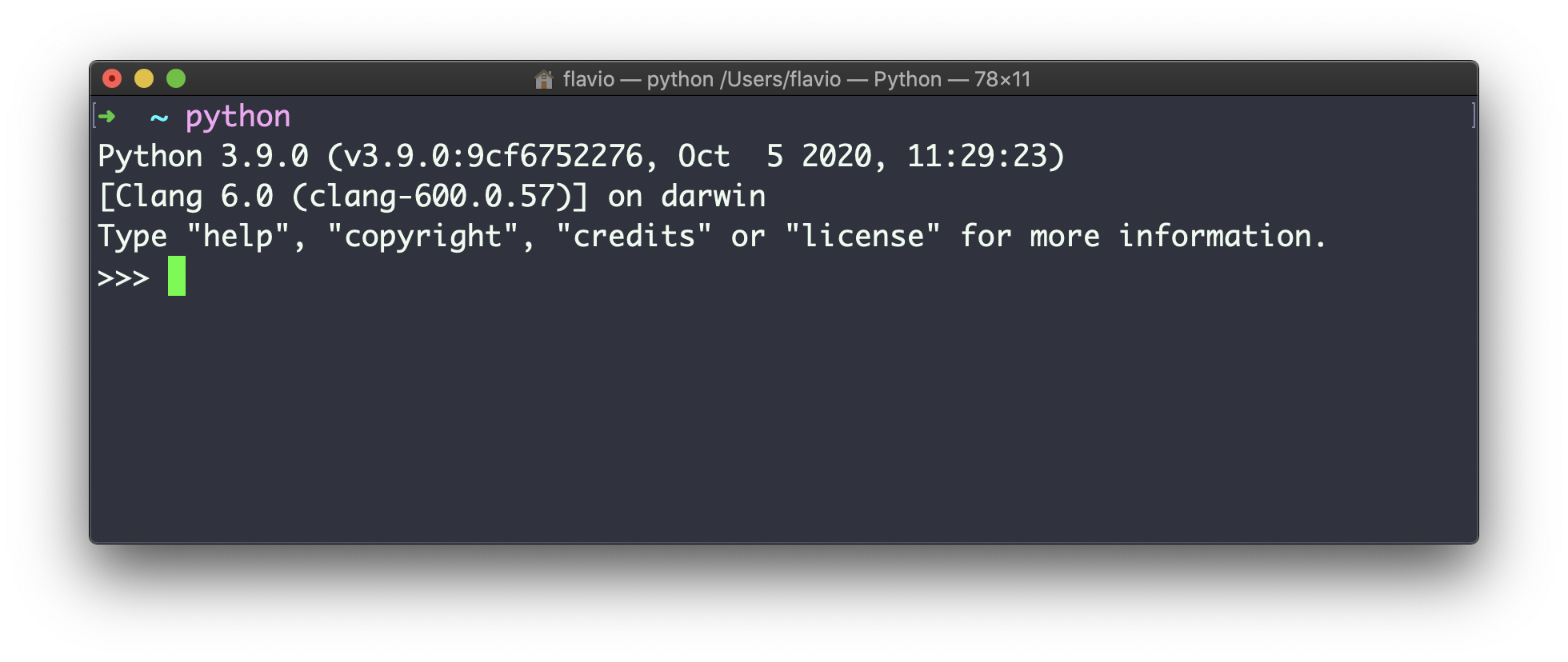
这是Python REPL(交互式解释器,即读取-评估-打印-循环)。
注意>>>符号和之后的光标。,您可以在此处输入任何Python代码,然后按 enter 键运行它。
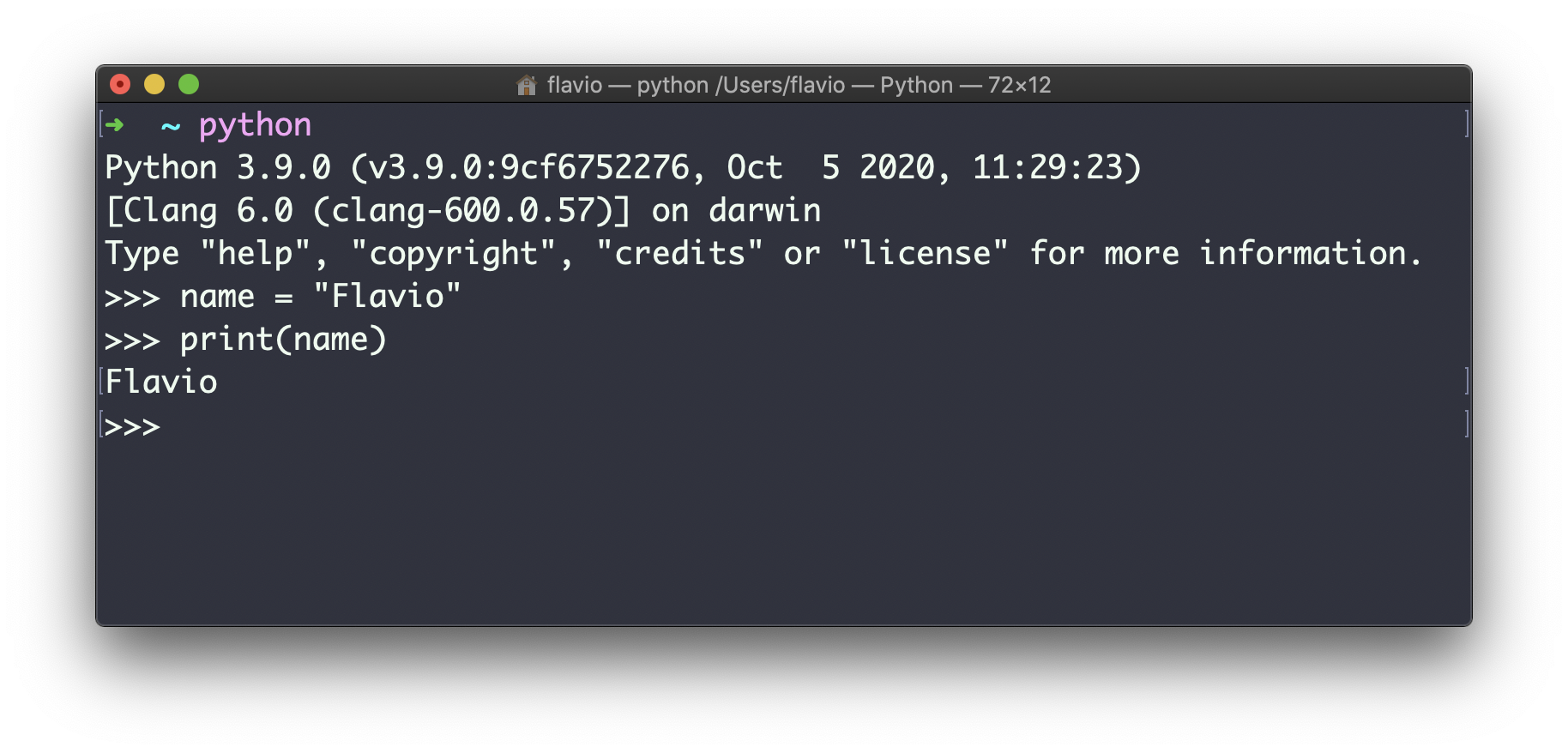
例如尝试定义一个新变量
name = "Flavio"
然后使用print()打印name的值:
print(name)
请注意:在REPL中,您也可以只输入
name,然后按enter键,您会看到name的值。但是在写到文件中的程序里,如果这样做,您将看不到任何输出——您需要使用print()代替这种写法。
您在此处编写的任何Python代码行都将立即执行。
输入quit()可以退出这个Python REPL。
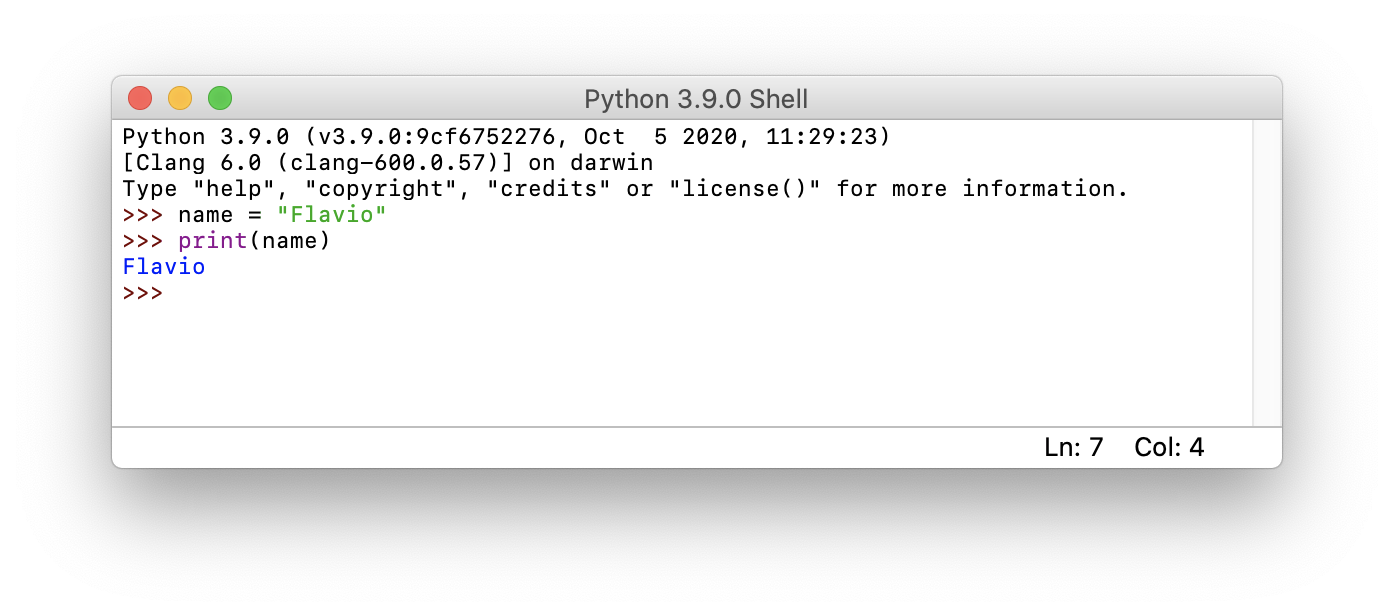
您可以使用Python自动安装的IDLE应用程序使用相同的交互式环境:
这对您来说可能更方便,因为与使用终端相比,使用鼠标可以更轻松地四处移动和复制/粘贴。
以上是Python默认附带的基础内容。不过我建议您安装IPython,它可能是您能找到的最好的Python命令行REPL应用程序。
使用下面的命令安装它
pip install ipython
上面的命令需要确保pip可执行文件的路径在您的环境变量中,安装好之后运行ipython:
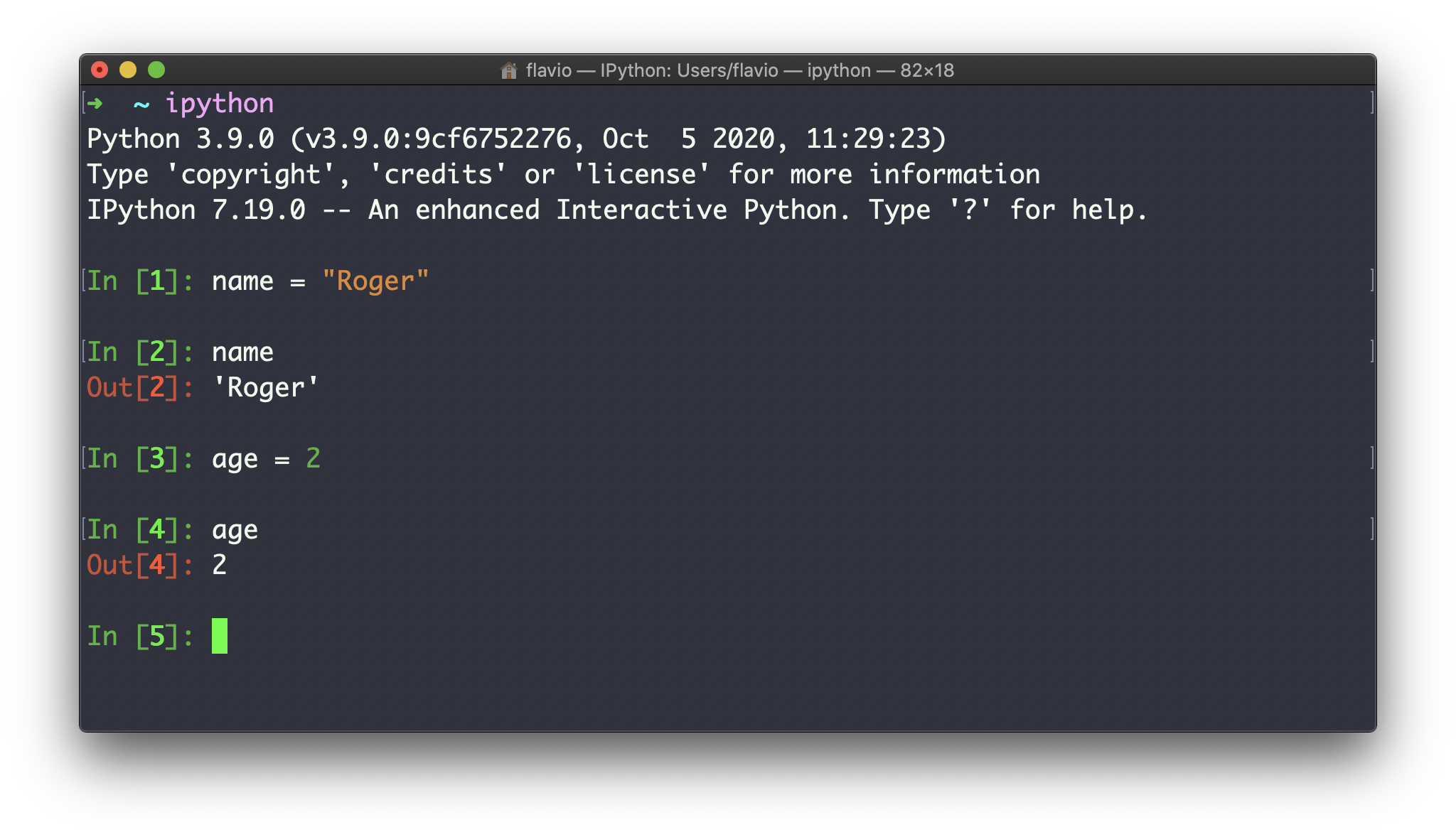
ipython是另一个让您使用Python REPL的接口,并提供了一些不错的功能,如语法高亮、代码补全等等。
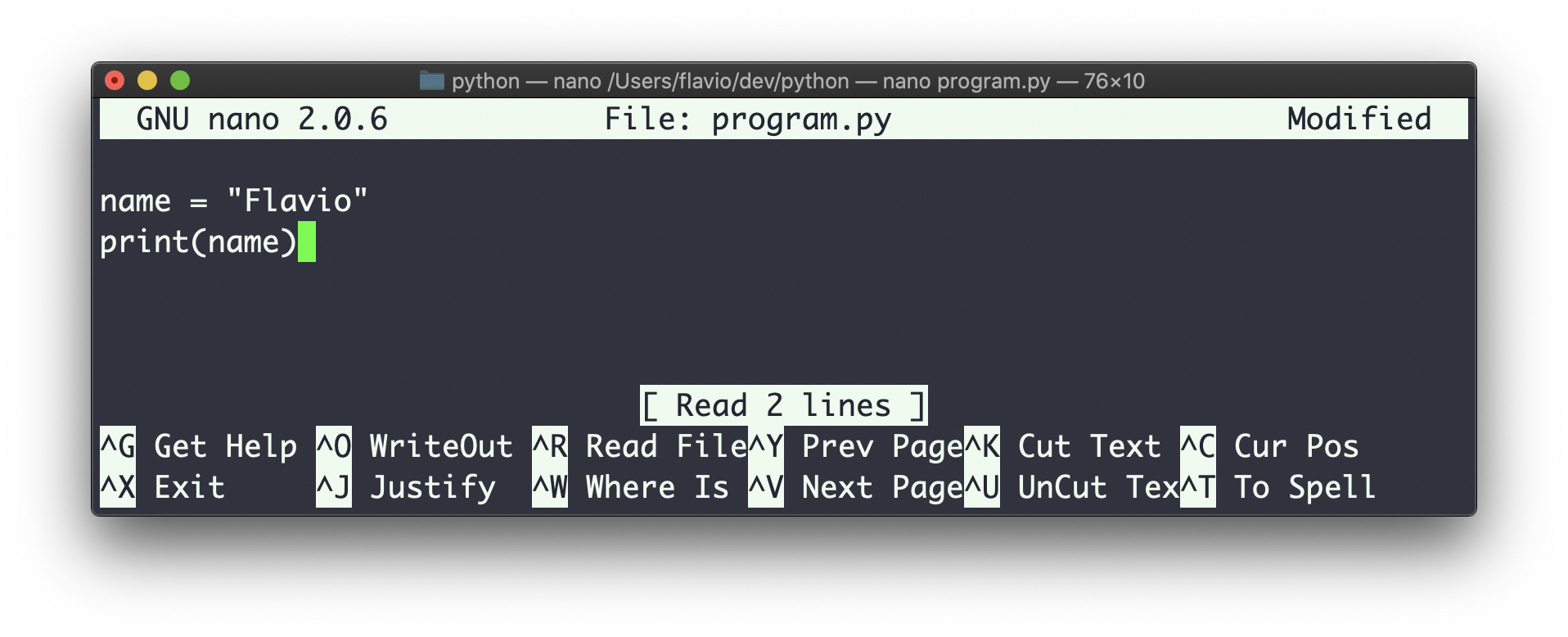
运行Python程序的第二种方法是将Python程序代码写入文件,例如program.py:
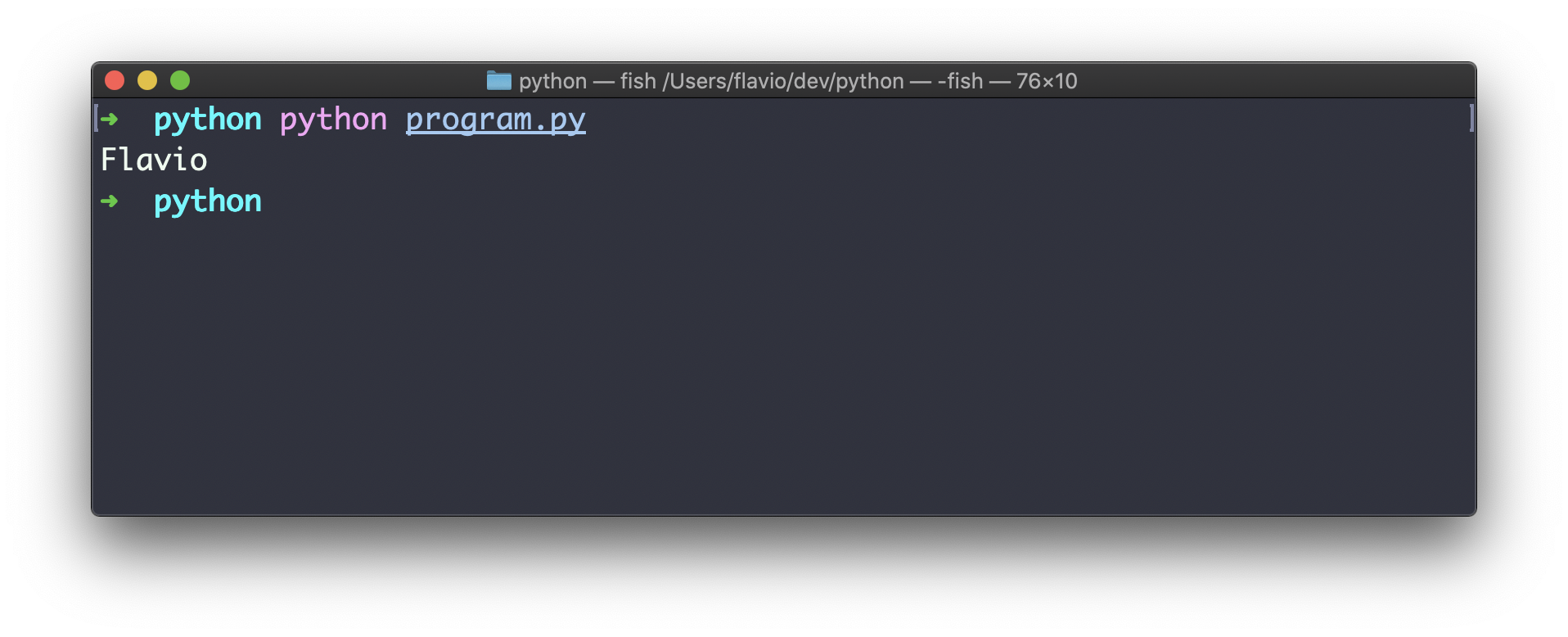
然后用python program.py运行它:
请注意,我们约定使用
.py扩展名保存Python程序文件。
在这种情况下,程序作为一个整体被执行,而不是一次运行一行。而这就是我们运行程序的典型方式。
我们使用REPL进行快速的代码原型设计和学习。
在Linux和macOS上,也可以将Python程序文件转换为shell脚本,方法是在文件最前面加上一个特殊行,用来指示使用哪个可执行文件来运行它。
在我的系统上,Python解释器的路径是/usr/bin/python3,所以我在第一行输入#!/usr/bin/python3:
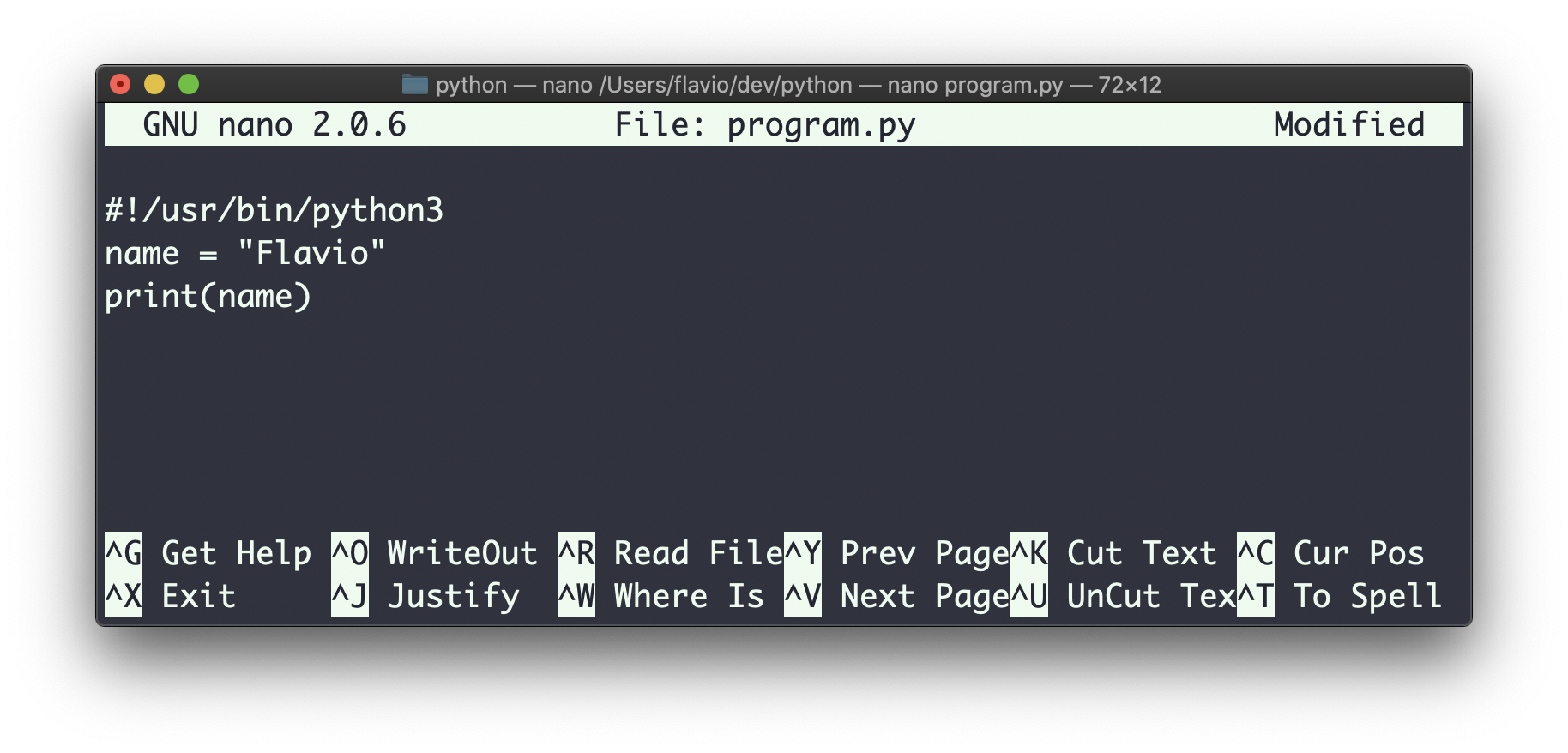
然后我可以对文件设置执行权限:
chmod u+x program.py
然后我可以使用下面的命令运行程序
./program.py
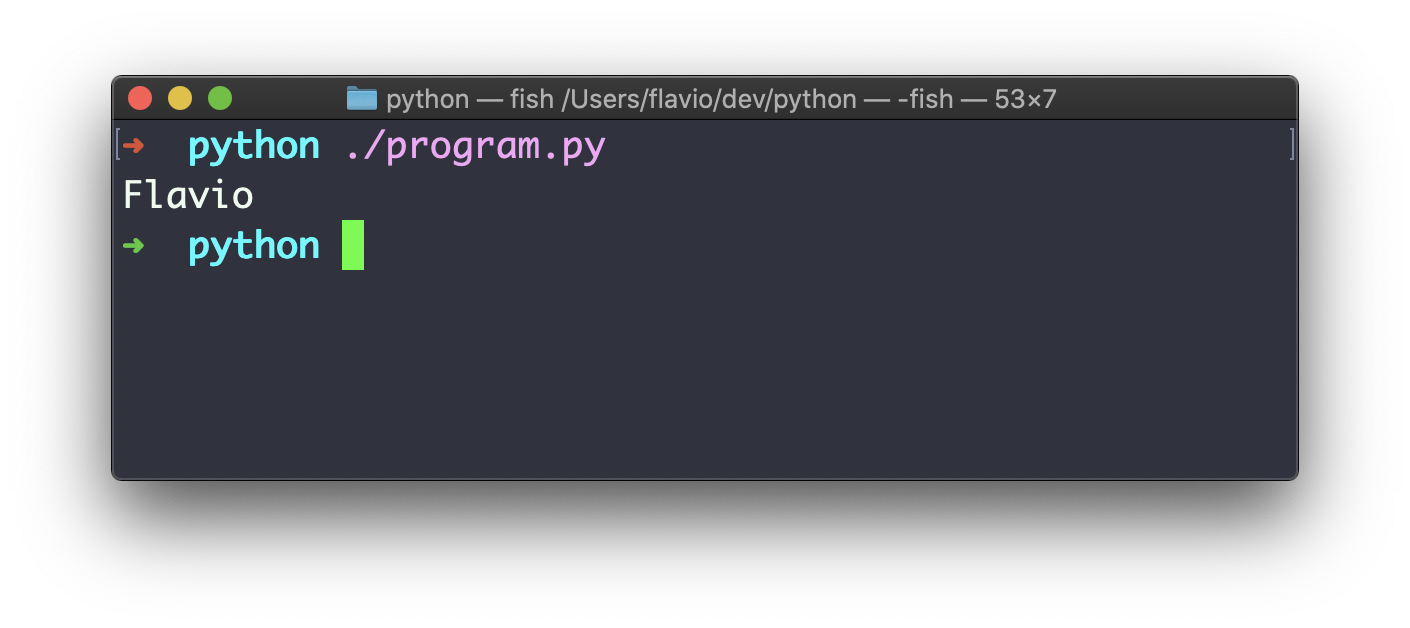
这在您编写与终端交互的脚本时特别有用。
我们还有许多其它方式可以运行Python程序。
一种方法是使用VS Code,尤其是Microsoft官方的Python扩展插件:
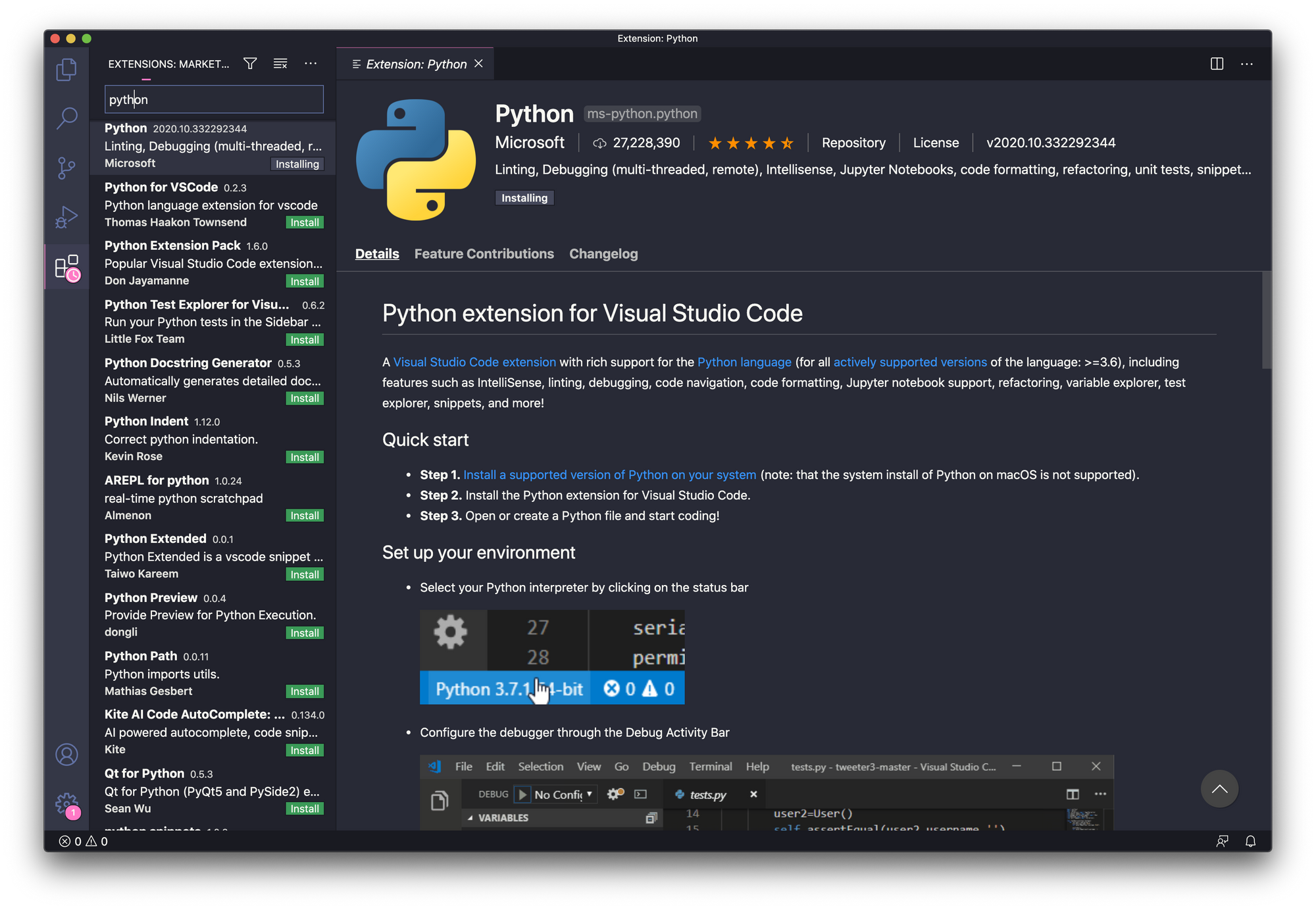
安装好此扩展插件后,您将可以使用Python代码自动补全、语法错误检查、自动格式化和使用pylint进行代码检查,以及一些特殊命令,包括:
Python: Start REPL 用于在VS Code的集成终端中运行REPL:
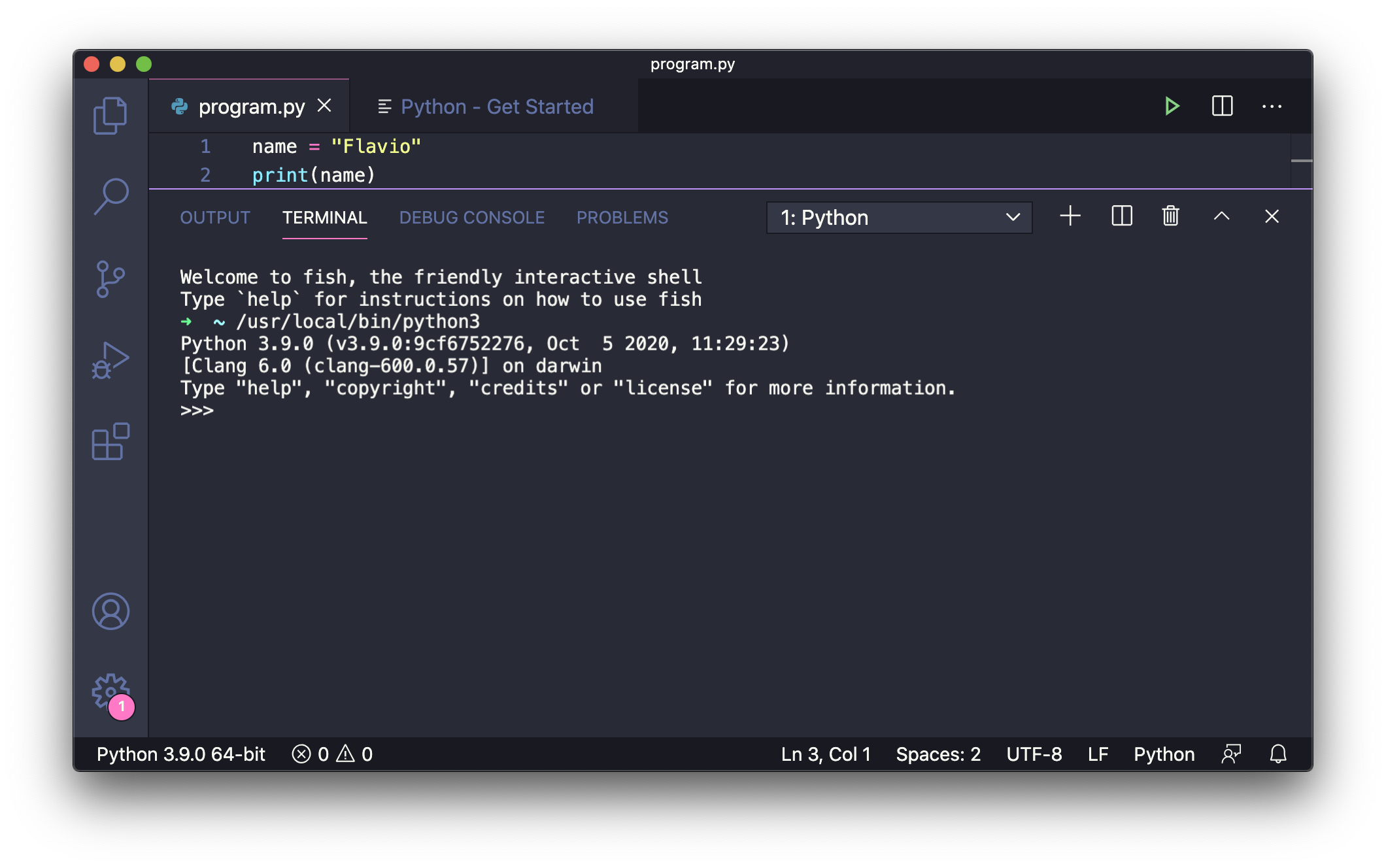
Python: Run Python File in Terminal 用于在终端中运行当前文件:
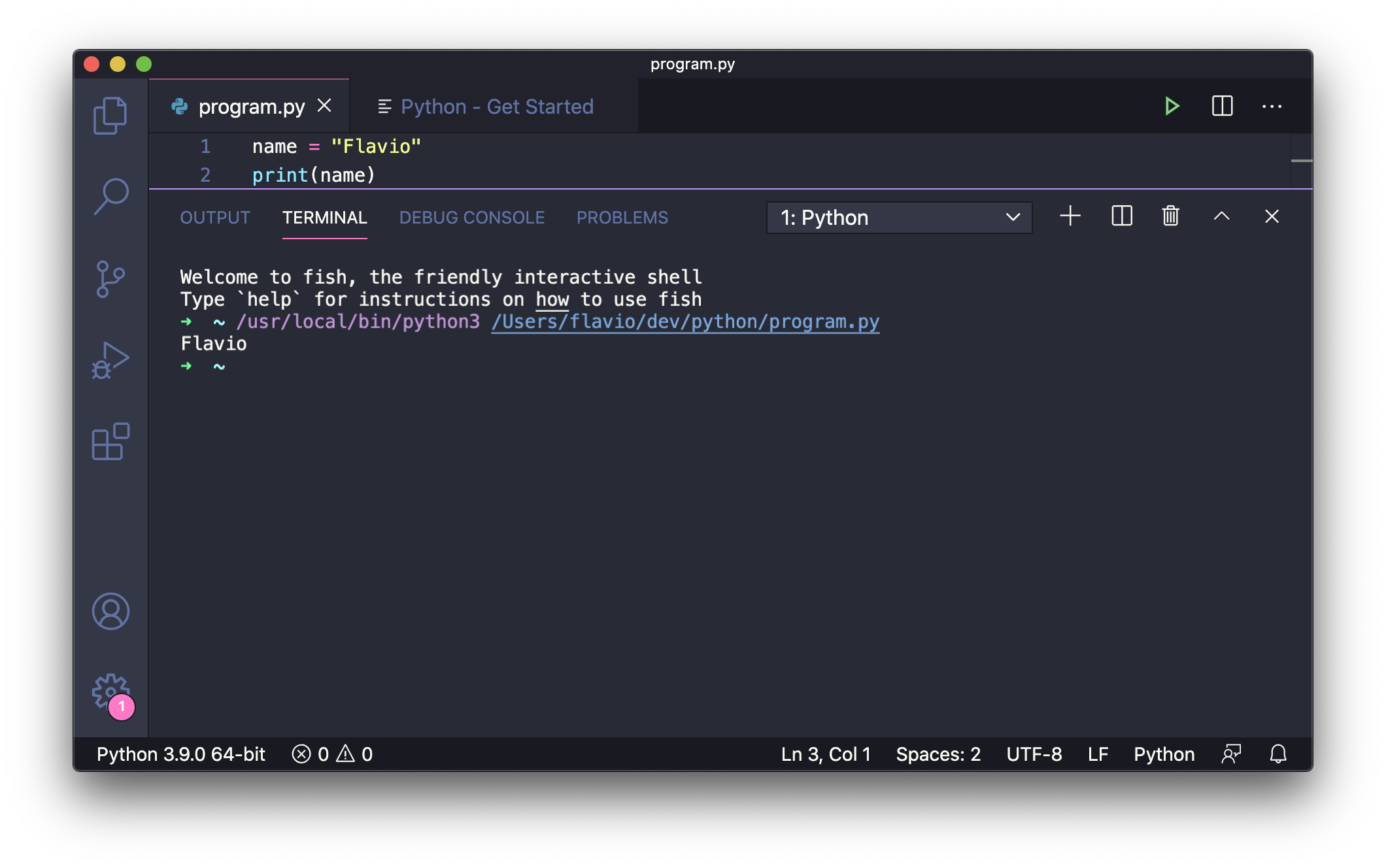
Python: Run Current File in Python Interactive Window 在 Python 交互窗口中运行当前文件:
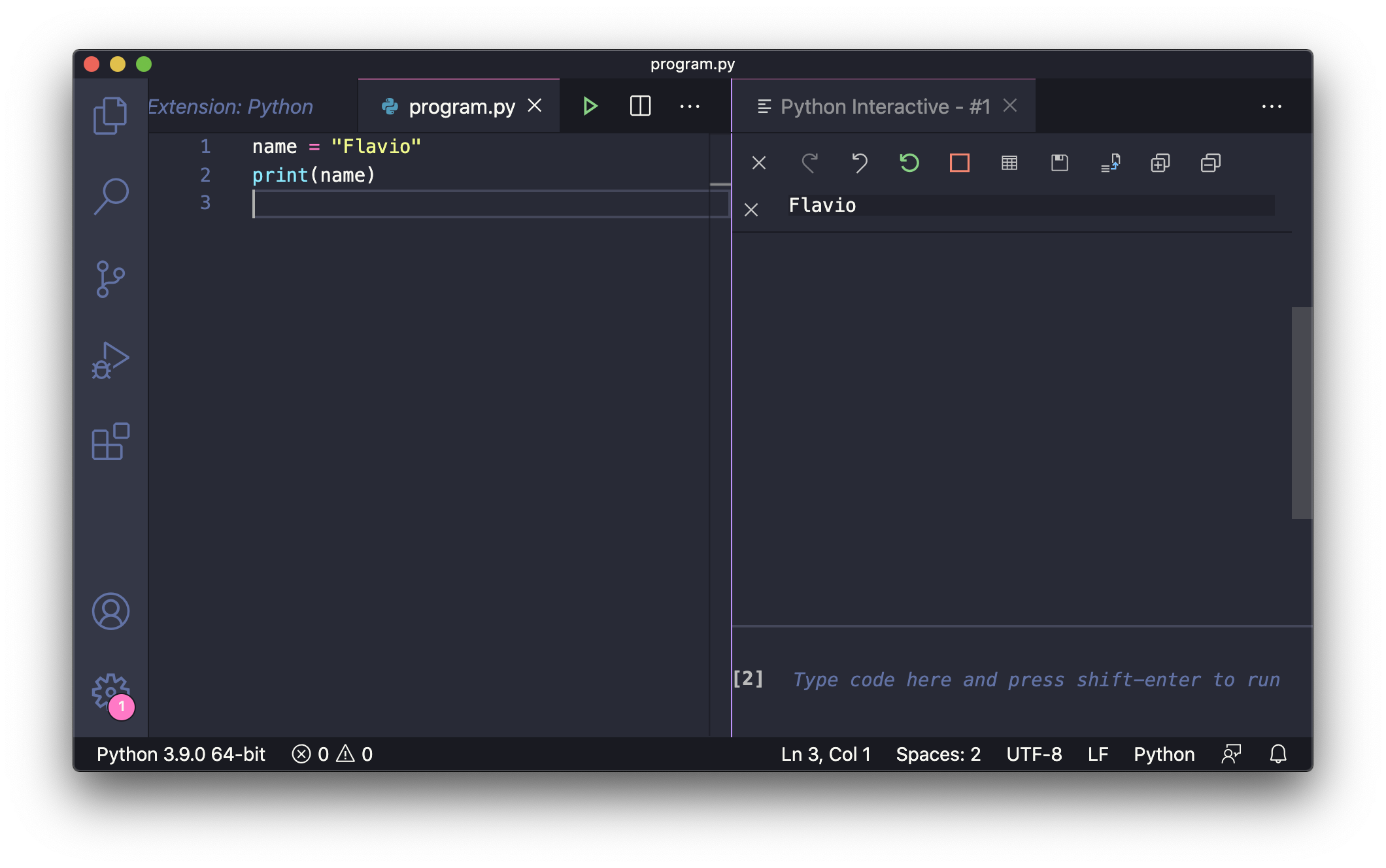
以及很多其它命令。只需打开命令面板(查看 -> 命令面板,或按下Cmd+Shift+P)并输入python,即可查看所有与Python相关的命令:
另一种轻松运行Python代码的方法是repl.it,这是一个非常不错的网站,它提供了一个编程环境,您可以使用任何语言创建并运行程序,包括Python:
使用这个网站要先注册(免费注册),然后在“create a repl”下单击Python:
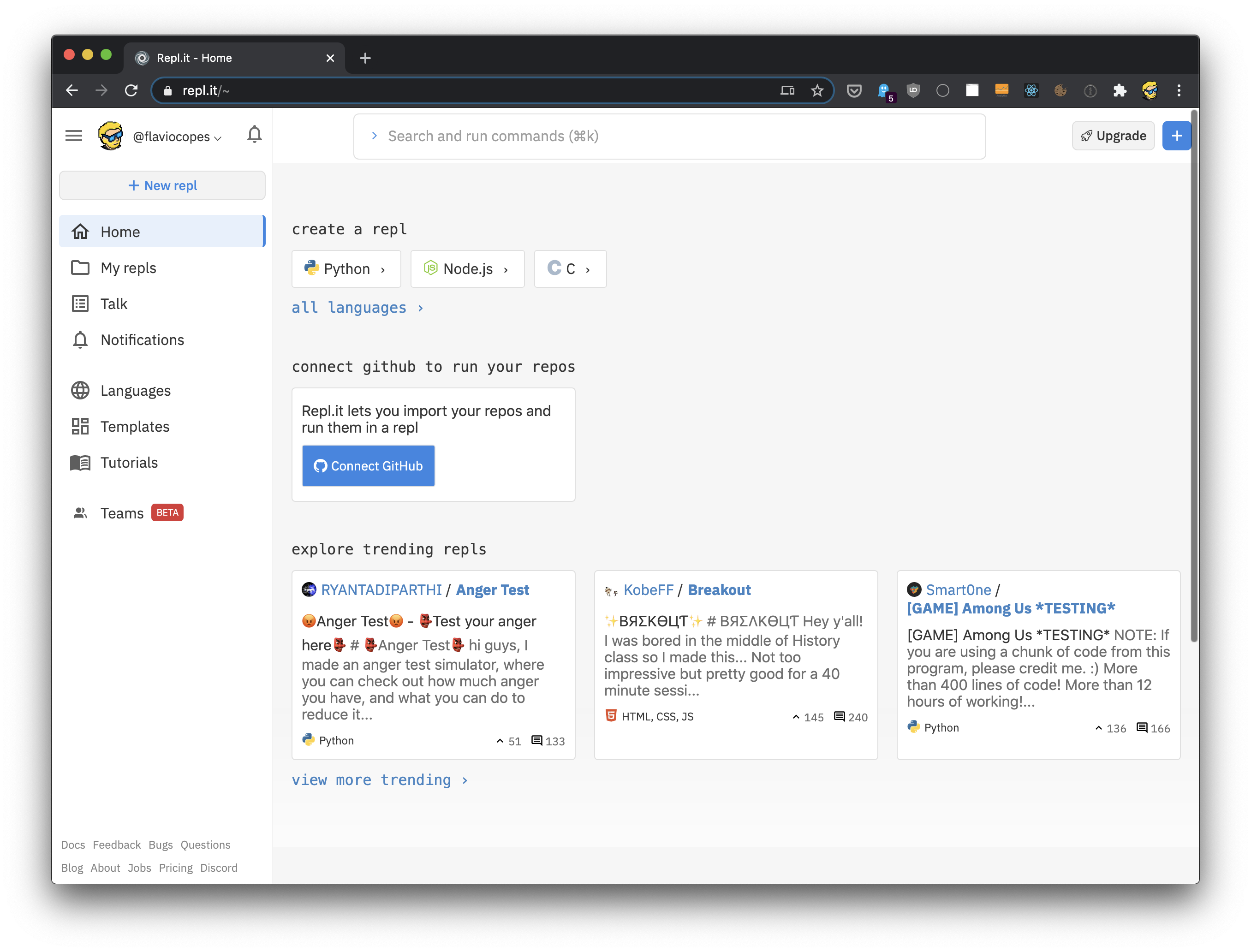
然后您将看到一个带有main.py文件的编辑器,这样就已经准备好了编写Python代码:
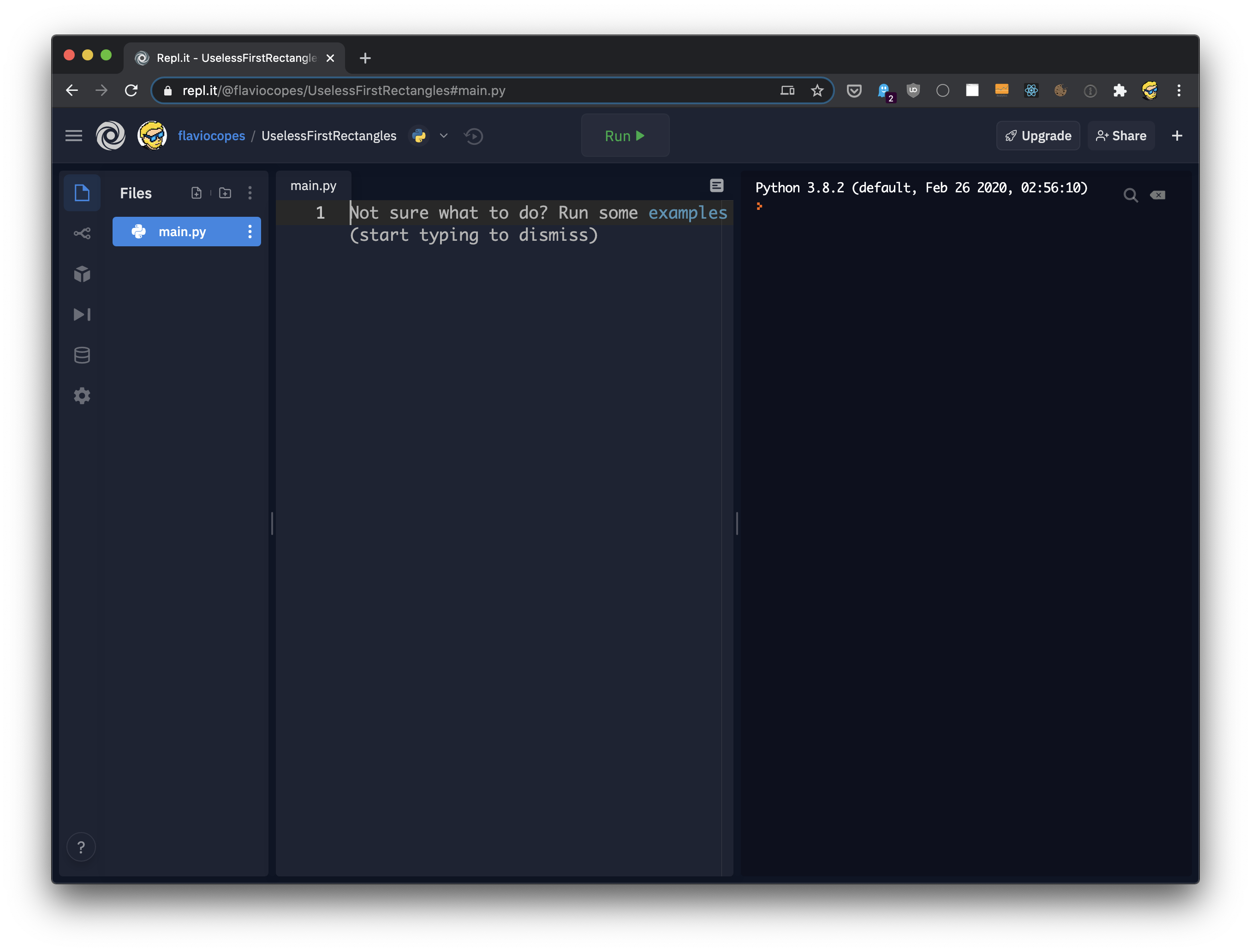
一旦您写好一些代码后,单击“Run”就可以在窗口右侧运行它:
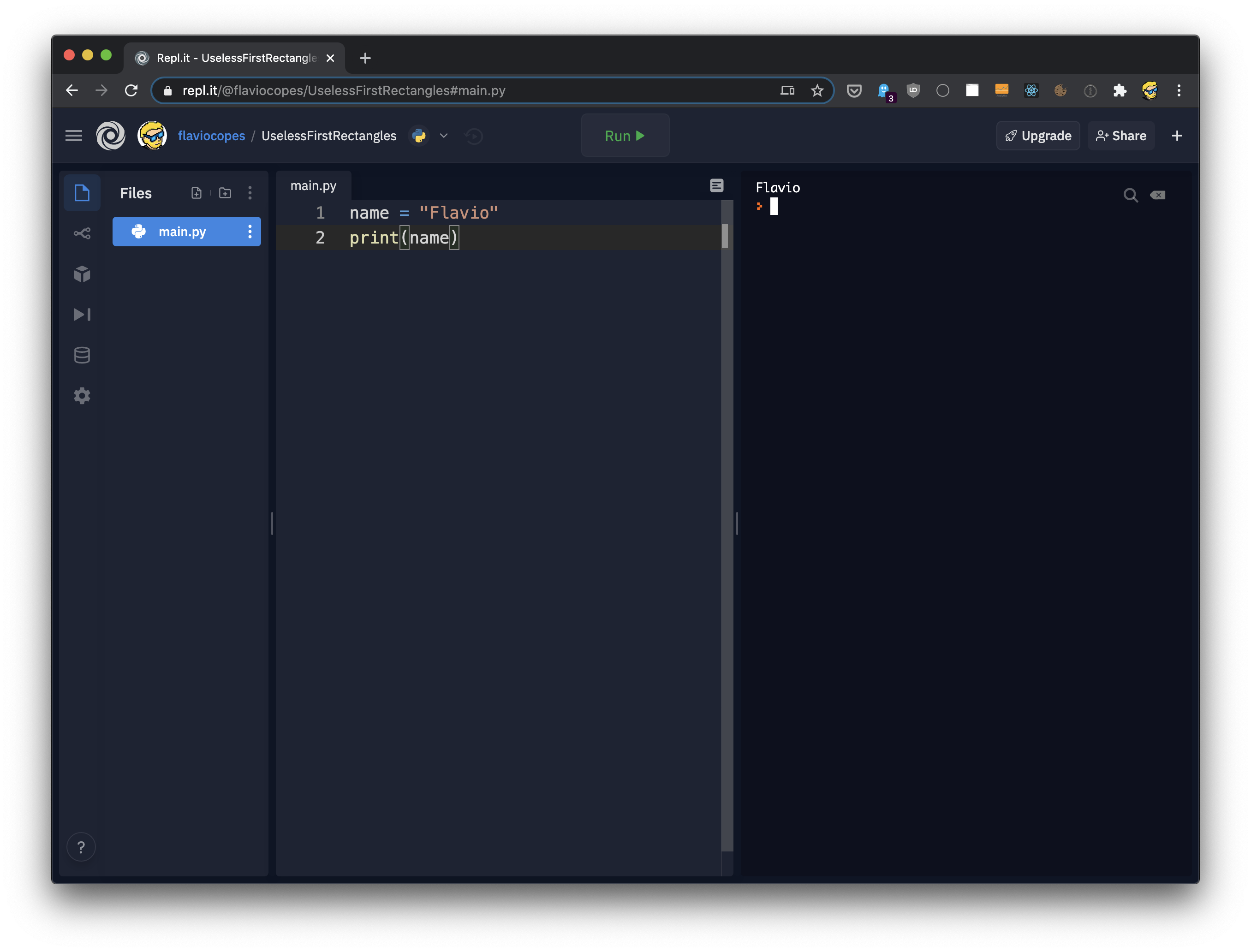
我认为repl.it很方便,因为:
- 您只需分享链接即可轻松分享代码
- 它允许多人处理相同的代码
- 它可以托管长时间运行的程序
- 您可以在上面安装第三方包
- 它为您提供用于复杂应用程序的键值数据库
Python 2 vs Python 3
我们一开始就应该讨论的一个关键主题是Python 2与Python 3。
Python 3于2008年被推出,其后作为主要的Python版本一直在被持续开发,而Python 2则通过错误修复和安全补丁进行维护,直到2020年初。
在那一天,对Python 2的支持停止。
许多程序仍然使用Python 2编写,并且组织仍在积极致力于这些程序,因为迁移到Python 3并非易事,升级这些程序需要大量工作。并且重要文件的大型迁移总是会引入新的bug。
但是对应新的代码程序,除非您必须遵守组织设置的强制使用Python 2的规则,否则应使用Python 3进行编写。
本书重点介绍 Python 3。
Python 基础
Python中的变量
我们可以通过使用赋值运算符=为“标签”赋值,从而创建一个新的Python变量。
在下面这个示例中,我们将字符串"Roger"分配给变量name:
name = "Roger"
下面是一个给变量age赋值为数字的示例:
age = 8
一个变量的名字可以由字符、数字和_下划线字符组成。变量名不能以数字开头。以下都是有效的变量名:
name1
AGE
aGE
a11111
my_name
_name
以下都是无效的变量名:
123
test!
name%
除此之外,任何输入都是有效的变量名,除非它是Python的关键字,如for、if、while、import等就是关键字。
无需记住它们,因为如果您使用其中任何一个关键字作为变量名,Python都会提醒您,并且您会逐渐视它们为Python语法的一部分。
Python表达式和语句
我们可以_构造_任意一个有返回值的表达式代码,例如
1 + 1
"Roger"
另一方面,语句是对值的操作。例如,下面是2个语句:
name = "Roger"
print(name)
程序由一系列语句组成。每个语句占一行,但您可以使用分号在一行中包含多个语句:
name = "Roger"; print(name)
注释
在Python程序中,井号之后的所有内容都被忽略,并被视为注释:
#this is a commented line
name = "Roger" # this is an inline comment
Python中的缩进
Python中的缩进是有意义的。
您不能像这样随意缩进:
name = "Flavio"
print(name)
对于其它一些语言,空格是没有意义的,但是在Python中,缩进很重要。
在上面这种情况下,如果您尝试运行这个程序,您会得到一个IndentationError: unexpected indent错误,因为缩进有特殊的含义。
一个缩进中的所有内容属于一个块,如控制语句块或条件块,函数或类主体。 我们稍后会看到更多关于这些内容的解释。
Python数据类型
Python有几种内置类型。
如果您创建name变量并为其分配值"Roger",则此变量现在自动表示String数据类型。
name = "Roger"
您可以使用type()函数检查变量的类型,即将变量作为参数,然后将函数返回结果与str进行比较:
name = "Roger"
type(name) == str # True
或者使用isinstance():
name = "Roger"
isinstance(name, str) # True
请注意,要在REPL之外查看
True值,您需要将此代码包装在print()中,但为了清楚起见,我避免使用它。
我们在这里使用了str,但这种方法同样适用于其它数据类型。
首先,我们有数字。整数使用int表示,浮点数(分数)的类型为float:
age = 1
type(age) == int # True
fraction = 0.1
type(fraction) == float # True
您已经了解了如何从字面值创建某一类型的变量,如下所示:
name = "Flavio"
age = 20
Python自动从变量值检测数据类型。
您还可以通过向类构造器传递字面值或变量名,来创建特定类型的变量:
name = str("Flavio")
anotherName = str(name)
您还可以使用类构造器,将一种类型转换为另一种类型。Python将尝试转换为正确的值,例如从字符串中提取数字:
age = int("20")
print(age) # 20
fraction = 0.1
intFraction = int(fraction)
print(intFraction) # 0
这称为casting。当然,这种转换并不总是有效,具体取决于传递的值。如果您在上面的字符串中写了test而不是20,您会得到一个ValueError: invalid literal for int() with base 10: 'test'错误。
这些只是基础的数据类型。Python中有更多其它数据类型:
complex复数bool布尔值list列表tuple元组range范围dict字典set集合
以及更多!
我们很快就会探索它们。
Python运算符
我们使用Python运算符来对值和变量进行运算操作。
我们可以根据它们执行操作的类型来划分运算符:
- 赋值运算符
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
再加上一些其它有趣的运算符,比如is和in。
Python赋值运算符
赋值运算符用于为变量赋值:
age = 8
或者将变量的值分配给另一个变量:
age = 8
anotherVariable = age
从Python 3.8开始,可以使用_海象运算符_:=为变量赋值,同时该运算可作为另一个操作的一部分。例如在if或循环的条件部分。这个稍后再谈。
Python算术运算符
Python有许多算术运算符:+、-、*、/(除法)、%(取余)、**(求幂)和 //(向下取整除法) :
1 + 1 # 2
2 - 1 # 1
2 * 2 # 4
4 / 2 # 2
4 % 3 # 1
4 ** 2 # 16
4 // 2 # 2
请注意,操作数之间不需要空格,但加上空格有利于可读性。
-也可用作一元运算符表示负号:
print(-4) # -4
+也可用于连接字符串:
"Roger" + " is a good dog"
# Roger is a good dog
我们可以将赋值运算符与算术运算符结合起来:
+=-=*=/=%=- 以及等等
例子:
age = 8
age += 1
# age is now 9
Python比较运算符
Python定义了一些比较运算符:
==!=><>=<=
您可以使用这些运算符获取根据比较结果得到的布尔值(True或False):
a = 1
b = 2
a == b # False
a != b # True
a > b # False
a <= b # True
Python布尔运算符
Python为我们提供了以下布尔运算符:
notandor
当使用True或False属性时,它们的作用类似于逻辑与、逻辑或和逻辑非,并且经常用于 if 条件表达式判断:
condition1 = True
condition2 = False
not condition1 # False
condition1 and condition2 # False
condition1 or condition2 # True
但是,请注意可能的混淆:
表达式中使用or,则表达式的结果是第一个为非假值(假值:False、0、''、[]..)的操作数,否则返回最后一个操作数作为表达式的值。
print(0 or 1) # 1
print(False or 'hey') # 'hey'
print('hi' or 'hey') # 'hi'
print([] or False) # 'False'
print(False or []) # '[]'
Python文档将其(x or y)描述为如果x为假,则为y,否则为x。(译者:or碰到真值就停,没有真值就走到最后)
and运算操作仅在第一个操作数为真时,才计算第二个操作数。因此,如果第一个操作数是假值(假值:False、0、''、[]..),它会返回那个操作数。否则,它就会计算第二个操作数:
print(0 and 1) # 0
print(1 and 0) # 0
print(False and 'hey') # False
print('hi' and 'hey') # 'hey'
print([] and False ) # []
print(False and [] ) # False
Python文档将其(x and y)描述为如果x为假,则为x,否则为y。(译者:or碰到假值就停,没有假值就走到最后)
Python位运算符
一些运算符用于处理位和二进制数:
&执行二进制与操作|执行二进制或操作^执行二进制异或操作~执行二进制非操作<<二进制左移操作>>二进制右移操作
一般很少使用位运算符,仅在非常特定的情况下使用,但是值得一提。
Python中的is和in
is被称为identity operator(验证运算符),用于比较两个对象,如果两者是同一个对象,则返回true。稍后将详细介绍对象。
in被称为membership operator(成员运算符),用于判断一个值是否包含在一个列表或序列中。稍后将详细介绍列表和其他序列数据类型。
Python三元运算符
使用Python三元运算符,您可以快速定义条件语句。
假设您有一个函数,它将age变量与18进行比较,并根据结果返回True或False。
可以不这样写:
def is_adult(age):
if age > 18:
return True
else:
return False
您可以通过使用三元运算符这种方式来实现它:
(译者:感觉这个例子不太好,因为这里写成return age > 18会更好,换成这个例子return "age大于18" if age > 18 else "age小于等于18"会更好理解一些)
def is_adult(age):
return True if age > 18 else False
首先定义条件为真的结果,然后判断条件,最后定义条件为假的结果:
<条件为真得到的结果> if <条件表达式> else <条件为假得到的结果>
Python字符串
Python中的字符串是用单引号或双引号括起来的一串字符:
"Roger"
'Roger'
您可以将字符串赋值给变量:
name = "Roger"
您可以使用+运算符连接两个字符串:
phrase = "Roger" + " is a good dog"
您也可以使用+=将一个字符串添加到另一个字符串后面:
name = "Roger"
name += " is a good dog"
print(name) # Roger is a good dog
您可以使用str类构造函数将数字转换为字符串:
str(8) # "8"
这对于连接数字和字符串来说很重要:
print("Roger is " + str(8) + " years old") # Roger is 8 years old
当使用特殊语法定义时,字符串可以是多行的,将字符串括在一组3个引号中:
print("""Roger is
8
years old
""")
# double quotes, or single quotes
print('''
Roger is
8
years old
''')
字符串具有一组内置方法,例如:
isalpha()检查字符串是否只包含字母字符,并且不为空字符串isalnum()检查字符串是否只包含字母字符或数字字符,并且不为空isdecimal()检查字符串是否只包含十进制字符,并且不为空lower()获取字符串的小写版本islower()检查字符串是否全为小写upper()获取字符串的大写版本isupper()检查字符串是否全为大写title()获取字符串的“标题化”版本(译者:所有单词首字母大写)startsswith()检查字符串是否以特定子字符串开头endswith()检查字符串是否以特定子字符串结尾replace()替换字符串的一部分split()按特定分隔符拆分字符串strip()修剪字符串中的空格join()将字符串添加到另一个字符串(译者:实际上是将字符串添加到另一个可迭代对象生成的字符串中)find()查找特定子字符串在字符串中的位置
以及其它等等。
这些方法都不会改变原始字符串,它们将会返回一个新的、修改后的字符串。例如:
name = "Roger"
print(name.lower()) # "roger"
print(name) # "Roger"
您也可以使用一些全局函数来处理字符串。
这里我特别想到了len(),它返回给您指定字符串的长度:
name = "Roger"
print(len(name)) # 5
in运算符可以让您检查字符串是否包含某个子字符串:
name = "Roger"
print("ger" in name) # True
转义是一种将特殊字符添加到字符串中的方法。
例如,如何将双引号添加到被双引号包裹的字符串中?
name = "Roger"
"Ro"Ger"将不起作用,因为Python会认为字符串以"Ro"结尾。
方法是使用\反斜杠字符转义字符串内的双引号:
name = "Ro\"ger"
这也适用于单引号\',以及其它特殊格式字符,如制表符\t、换行符\n和反斜杠\\。
给定一个字符串,并给定一个索引(从0开始),您就可以使用方括号获取指定位置上的字符,从而获取特定内容:
name = "Roger"
name[0] # 'R'
name[1] # 'o'
name[2] # 'g'
使用负数将从末尾开始计数:
name = "Roger"
name[-1] # "r"
您还可以使用范围,即使用我们所说的切片:
name = "Roger"
name[0:2] # "Ro"
name[:2] # "Ro"
name[2:] # "ger"
Python布尔值
Python提供了bool类型,它可以有两个值:True 和 False(首字母大写)。
done = False
done = True
布尔值对于条件控制结构特别有用,例如if语句:
done = True
if done:
# run some code here
else:
# run some other code
在判断值为True或False时,如果该值不是bool布尔类型,我们有一些取决于我们所检查值类型的规则:
- 数字除
0以外,始终为True - 字符串仅在是空字符串时为
False - 列表、元组、集合和字典仅在其为空时为
False
您可以通过以下方式检查值是否为布尔值:
done = True
type(done) == bool # True
或者使用isinstance(),需要传递2个参数:变量和bool类:
done = True
isinstance(done, bool) # True
全局函数any()在处理布尔值时也非常有用,当作为参数传递的可迭代对象(如列表)中的任意一个值是 True时,它就会返回 True(译者:类似or):
book_1_read = True
book_2_read = False
read_any_book = any([book_1_read, book_2_read]) # True
全局函数all()相类似,但是是当传递给它的所有值都是True时,才返回 True(译者:类似and):
ingredients_purchased = True
meal_cooked = False
ready_to_serve = all([ingredients_purchased, meal_cooked]) # False
Python数字
Python中的数字有3种类型:int、float和complex。
Python整数
整数使用int表示,您可以使用字面值定义整数:
age = 8
您还可以使用int()构造函数定义一个整数:
age = int(8)
您可以使用全局函数type()检查变量是否为int类型:
type(age) == int # True
Python浮点数
浮点数(分数)的类型为float,您可以使用字面值定义浮点数:
fraction = 0.1
或者使用float()构造函数:
fraction = float(0.1)
您可以使用全局函数type()检查变量是否为float类型:
type(fraction) == float # True
Python复数
复数属于complex类型。
您可以使用字面值定义它们:
complexNumber = 2+3j
或者使用complex()构造函数:
complexNumber = complex(2, 3)
一旦您定义了一个复数,您就可以得到它的实部和虚部:
complexNumber.real # 2.0
complexNumber.imag # 3.0
同样,您可以使用全局函数type()检查变量是否为complex类型:
type(complexNumber) == complex #True
Python中数字的算术运算
您可以使用算术运算符对数字执行算术运算:+、-、*、/(除法)、%(取余)、**(求幂)和//(向下取整除法):
1 + 1 # 2
2 - 1 # 1
2 * 2 # 4
4 / 2 # 2
4 % 3 # 1
4 ** 2 # 16
4 // 2 # 2
您还可以使用复合赋值运算符
+=-=*=/=%=- 其它等等
这样可以快速对变量执行运算操作:
age = 8
age += 1 # age: 9
Python内置函数
有2个内置函数可以帮助处理数字:
abs()返回一个数字的绝对值。
给定一个数字,round()返回四舍五入到最接近整数的值:
round(0.12) # 0
您可以指定第二个参数来设置舍入到小数点的精度:
round(0.12, 1) # 0.1
Python标准库提供了其它几个数学实用函数和常量:
math包提供通用的数学函数和常量cmath包提供了处理复数的方法decimal包提供了处理小数和浮点数的方法fractions包提供了处理有理数的方法
稍后我们将分别探讨其中的一些。
Python常量
Python中无法强制改变的值是常量。
比较常用的是枚举:
class Constants(Enum):
WIDTH = 1024
HEIGHT = 256
并使用Constants.WIDTH.value这样的表达获取每个值。
没有人可以重新分配该值。
否则,如果您想依赖命名约定(来定义常量),您可以遵守这个规则——声明大写的永远不应该改变的变量:
WIDTH = 1024
没有人会阻止您覆盖这个值,Python也不会阻止。(译者:全大写的变量表示不应改变的常量,这只是一种约定)
正如您将来会看到的,大多数Python代码都采用这种命名约定的写法。
Python枚举
枚举是绑定到常量值的可读名称。
要使用枚举,请从enum标准库模块中导入Enum:
from enum import Enum
然后您可以用这种方式初始化一个新的枚举:
class State(Enum):
INACTIVE = 0
ACTIVE = 1
这样做后,您可以引用作为常量的State.INACTIVE和State.ACTIVE。
现在,如果您尝试打印State.ACTIVE,例如:
print(State.ACTIVE)
它不会返回1,而是返回State.ACTIVE。
枚举中分配的数字可以达到相同的效果:print(State(1))将打印State.ACTIVE。使用方括号符号State['ACTIVE']也是如此。
但是,您可以使用State.ACTIVE.value获取具体值。
您可以列出枚举的所有可能值:
list(State) # [<State.INACTIVE: 0>, <State.ACTIVE: 1>]
您可以获取总数:
len(State) # 2
Python用户输入
在Python命令行程序中,您可以使用print()函数向用户显示信息:
name = "Roger"
print(name)
我们也可以使用input()接受来自用户的输入:
print('What is your age?')
age = input()
print('Your age is ' + age)
这种方法在运行时获取输入,这意味着程序(执行到input()时)将停止执行,等待用户输入内容并按下enter键。
您还可以在程序调用时接受输入并进行更复杂的输入处理,稍后我们将看到如何做到这一点。
这适用于命令行程序。其它类型的应用程序需要使用不同的方式来接受输入。
Python控制语句
当您处理布尔值和返回布尔值的表达式时,您可以根据它们的值为True或False来采取不同的方式。
在Python中,我们使用if语句来做到这一点:
condition = True
if condition == True:
# do something
当条件解析为True时,就像上面的情况一样,if下面的代码块被执行。
什么是代码块?代码块是向右侧缩进一级(通常为4个空格)的部分:
condition = True
if condition == True:
print("The condition")
print("was true")
代码块可以由单行或多行组成,并在您移回到上一个缩进级别时结束:
condition = True
if condition == True:
print("The condition")
print("was true")
print("Outside of the if")
如果if的条件测试结果为False,结合if则可以执行else块:
condition = True
if condition == True:
print("The condition")
print("was True")
else:
print("The condition")
print("was False")
如果前面的if检查是False,您可以使用elif执行另一个条件检查:
condition = True
name = "Roger"
if condition == True:
print("The condition")
print("was True")
elif name == "Roger":
print("Hello Roger")
else:
print("The condition")
print("was False")
如果condition为False并且name变量的值为"Roger",则执行本例中的第二个代码块。
在一个if语句中,您只可以进行一次if和 else检查,但可以进行多个elif检查:
condition = True
name = "Roger"
if condition == True:
print("The condition")
print("was True")
elif name == "Roger":
print("Hello Roger")
elif name == "Syd":
print("Hello Syd")
elif name == "Flavio":
print("Hello Flavio")
else:
print("The condition")
print("was False")
if和 else也可以内联使用,这让我们可以根据条件返回一个值或另一个值。
例子:
a = 2
result = 2 if a == 0 else 3
print(result) # 3
Python列表
列表是Python中一种基本的数据结构。
使用列表,您可以将多个值组合在一起,并使用一个名称引用它们。
例如:
dogs = ["Roger", "Syd"]
一个列表中可以保存不同数据类型的值:
items = ["Roger", 1, "Syd", True]
您可以使用in运算符检查某个元素是否在列表中:
print("Roger" in items) # True
当然也可以定义空的列表:
items = []
您可以通过从零开始的索引引用列表中的元素:
items[0] # "Roger"
items[1] # 1
items[3] # True
使用相同的表示法,您可以更改存储在特定索引处的值:
items[0] = "Roger"
您还可以使用index():
items.index(0) # "Roger"
items.index(1) # 1
就像字符串(索引)一样,使用负索引将从末尾开始数:
items[-1] # True
您还可以使用切片提取列表的一部分:
items[0:2] # ["Roger", 1]
items[2:] # ["Syd", True]
使用全局函数len()获取列表中包含的元素数目,这与我们用来获取字符串长度的方法相同:
len(items) # 4
您可以使用list的append()方法将新元素添加到列表中:
items.append("Test")
或者使用extend()方法:
items.extend(["Test"])
您还可以使用+=运算符:
items += ["Test"]
# items is ['Roger', 1, 'Syd', True, 'Test']
注意:使用
extend()或+=不要忘记方括号。不要执行items += "Test"或items.extend("Test"),否则Python会在列表中添加4个单独的字符,即['Roger', 1, 'Syd', True, 'T'、'e'、's'、't']
使用remove()方法删除元素:
items.remove("Test")
您可以添加多个元素:
items += ["Test1", "Test2"]
# or
items.extend(["Test1", "Test2"])
这些方法会将元素加到列表的末尾。
要在列表中间的特定索引处添加元素,请使用insert()方法:
items.insert("Test", 1) # add "Test" at index 1
要在特定索引处添加多个项目,您需要使用切片:
items[1:1] = ["Test1", "Test2"]
# 译者:这里实际上是先删除再添加,就该例子来说,先删除[1:1]的元素(切片是左闭右开,所有[1:1]没有选中任何元素),再在删除的位置上添加
#。 比如s = [1,2,3]; s[0:2] = ['a', 'b', 'c']; --> 执行完前面两个语句,s就变为['a', 'b', 'c', 3]
使用sort()方法对列表进行排序:
items.sort()
注意:sort()仅在列表包含可比较的值时才有效。例如,无法比较字符串和整数,如果您尝试(对元素之间不可比较的列表进行排序),您将看到到类似
TypeError: '<' not supported between 'int' and 'str'的错误。
(针对字符串排序)sort()方法首先排序大写字母,然后是小写字母。要解决此问题,请使用:
items.sort(key=str.lower)
(使用sort方法)排序会修改原始列表内容。为避免这种情况,您可以先复制列表
itemscopy = items[:]
或者使用全局函数sorted():
print(sorted(items, key=str.lower))
这将返回一个排好序的新列表,而不是修改原始列表。
Python元组
元组是Python中另一种基本的数据结构。
它允许您创建不可变的对象组。这意味着一旦创建了元组,就无法修改它。您不能添加或删除元组中的元素。
元组的创建方式类似于列表,但是是使用括号而不是方括号:
names = ("Roger", "Syd")
元组是有序的,就像列表一样,所以您可以通过一个索引来获取具体位置的值:
names[0] # "Roger"
names[1] # "Syd"
您也可以使用index()方法:
names.index('Roger') # 0
names.index('Syd') # 1
与字符串和列表一样,使用负索引将从末尾开始:
names[-1] # True
您可以使用函数len()计算元组中的元素个数:
len(names) # 2
您可以使用in运算符检查元素是否在元组中:
print("Roger" in names) # True
您还可以使用切片提取元组的一部分:
names[0:2] # ('Roger', 'Syd')
names[1:] # ('Syd',)
您可以使用全局函数sorted()创建元组排好序的版本:
(译者:请注意,元组没有sort方法,因为元组是不可改变的)
sorted(names)
您可以使用+运算符从现有元组创建一个新元组:
newTuple = names + ("Vanille", "Tina")
Python字典
字典是Python中非常重要的一种数据结构。
列表允许您创建值的集合,而字典允许您创建键/值对的集合。
这是有一个键/值对的字典示例:
dog = { 'name': 'Roger' }
键可以是任何不可变的值,例如字符串、数字或元组,该值可以是您想要的任何值。
一个字典可以包含多个键/值对:
dog = { 'name': 'Roger', 'age': 8 }
您可以使用此表示法访问单个键对应的值:
dog['name'] # 'Roger'
dog['age'] # 8
使用相同的表示法,您可以更改在特定索引(键)对应的值:
dog['name'] = 'Syd'
另一种方法是使用get()方法,该方法可以添加默认值(译者:即字典中没有该键时返回的值):
dog.get('name') # 'Roger'
dog.get('test', 'default') # 'default'
pop()方法检索键的值,然后从字典中删除该键/值对:
dog.pop('name') # 'Roger'
popitem()方法检索并删除最后一个插入字典的键/值对:
dog.popitem()
您可以使用in运算符检查键是否包含在字典中:
'name' in dog # True
使用keys()方法获取字典中的键,并将结果传递给list()构造函数:
list(dog.keys()) # ['name', 'age']
使用values()方法获取字典中的值,使用items()方法获取键/值对组成的元组:
print(list(dog.values()))
# ['Roger', 8]
print(list(dog.items()))
# [('name', 'Roger'), ('age', 8)]
使用全局函数len()获取字典长度,这与获取字符串或列表的长度相同:
len(dog) # 2
您可以通过这种方式将新的键/值对添加到字典中:
dog['favorite food'] = 'Meat'
您可以使用del语句从字典中删除键/值对:
del dog['favorite food']
要复制字典,请使用copy()方法:
(译者:这种方式是浅拷贝)
dogCopy = dog.copy()
Python集合
集合是Python另一个重要的数据结构。
可以说它像元组一样工作,但集合不是有序的,而且是可变的。
或者我们可以说它像字典一样工作,但它们没有键。
集合还有一个不可变的版本,称为frozenset。
您可以使用以下语法创建集合:
names = {"Roger", "Syd"}
您将它们视为数学上的集合,会更好理解。
您可以求两个集合的交集:
set1 = {"Roger", "Syd"}
set2 = {"Roger"}
intersect = set1 & set2 # {'Roger'}
您可以创建两个集合的并集:
set1 = {"Roger", "Syd"}
set2 = {"Luna"}
union = set1 | set2
# {'Syd', 'Luna', 'Roger'}
您可以得到两个集合的差集:
set1 = {"Roger", "Syd"}
set2 = {"Roger"}
difference = set1 - set2 # {'Syd'}
您可以检查一个集合是否是另一个集合的超集(也即一个集合是另一个集合的子集):
set1 = {"Roger", "Syd"}
set2 = {"Roger"}
isSuperset = set1 > set2 # True
您可以使用全局函数len()计算集合中的元素个数:
names = {"Roger", "Syd"}
len(names) # 2
您可以通过将集合传递给list()构造函数来获取集合元素的列表:
names = {"Roger", "Syd"}
list(names) # ['Syd', 'Roger']
您可以使用in运算符检查元素是否在集合中:
print("Roger" in names) # True
Python函数
函数可以创建一组指令,我们在需要时运行这些指令。
函数在Python和其它许多编程语言中是必不可少的。它帮助我们创建有意义的程序,因为我们可以使用函数将程序分解为可管理的部分,并且促进了代码的可读性和重用性。
这是一个名为hello的函数示例,它打印"Hello!":
def hello():
print('Hello!')
函数定义:有一个名称(hello)和一个由一组指令组成的主体(即冒号后面的部分),主体在右侧缩进一级。
要运行这个函数,我们必须调用它。这是调用函数的语法:
hello()
我们可以调用这个函数一次或多次。
函数名hello非常重要,它应该是描述性的,这样任何调用该函数的人都可以理解它的作用。
一个函数可以接受一个或多个参数:
def hello(name):
print('Hello ' + name + '!')
这种情况下,我们通过传递参数来调用函数
hello('Roger')
我们称_parameters_为函数定义中函数所接受的值(形参),称_arguments_为我们调用函数时所传递给函数的值(实参)。对这种区别感到困惑是很正常的。
如果(调用函数时)未指定参数,则参数可以具有默认值:
def hello(name='my friend'):
print('Hello ' + name + '!')
hello()
# Hello my friend!
以下是如何接受多个参数:
def hello(name, age):
print('Hello ' + name + ', you are ' + str(age) + ' years old!')
在这种情况下,我们调用函数并传递一组参数:
hello('Roger', 8)
形参通过引用传递。Python中的所有内容都是对象,但其中一些是不可变的,包括整数、布尔值、浮点数、字符串和元组。这意味着如果您将它们作为参数传递给函数,并在函数内部修改它们的值,则新值不会反映在函数外部:
def change(value):
value = 2
val = 1
change(val)
print(val) # 1
如果您传递一个可变的对象,并且(在函数内部)更改了它的一个属性,则该更改将反映在外部。
函数可以使用return语句返回一个值。例如我们返回 name 参数:
def hello(name):
print('Hello ' + name + '!')
return name
当函数执行到return语句时,该函数结束。
我们可以省略该返回值:
def hello(name):
print('Hello ' + name + '!')
return
我们可以在条件中包含return语句,这是在不满足起始条件时结束函数的常用方法:
def hello(name):
if not name:
return
print('Hello ' + name + '!')
如果我们调用该函数并传递一个计算结果为False的表达式,比如一个空字符串,函数在到达print()语句之前终止。
您可以使用逗号分隔来返回多个值:
def hello(name):
print('Hello ' + name + '!')
return name, 'Roger', 8
在这种情况下,调用 hello('Syd') 返回值是一个包含这 3 个值的元组:('Syd', 'Roger', 8)。
Python对象
Python中的一切都是对象。
原始类型(整数、字符串、浮点数……)的值也是对象。 同时列表、元组、字典和一切也都是对象。
对象具有可以使用点语法访问的属性和方法。
例如,尝试定义一个int类型的新变量:
age = 8
age现在可以访问为int对象定义的属性和方法。
这包括访问该数字的实部和虚部,例如:
print(age.real) # 8
print(age.imag) # 0
print(age.bit_length()) # 4
# bit_length()方法返回该数字的二进制表示法所需的位数
列表类型的变量可以使用一组方法:
items = [1, 2]
items.append(3)
items.pop()
这些(可使用的)方法取决于变量的数据类型。
Python提供的全局函数id()可让您检查特定对象在内存中的位置。
id(age) # 140170065725376
您(电脑上查看的age)的内存地址值会不一样——这里只是作为一个例子来展示。
如果给变量赋不同的值,它的地址会改变,因为变量已经指向存储在内存中另一个位置的另一个值:
age = 8
print(id(age)) # 140535918671808
age = 9
print(id(age)) # 140535918671840
但是,如果您使用对象的方法修改该对象,其内存地址将保持不变:
items = [1, 2]
print(id(items)) # 140093713593920
items.append(3)
print(items) # [1, 2, 3]
print(id(items)) # 140093713593920
仅当您将变量重新赋一个值时,地址才会更改。
一些类型的对象是_可变的_,而另一些是_不可变的_。这取决于对象本身。
如果对象提供改变其内容的方法,那么它是可变的。否则它是不可变的。
Python定义的大多数类型都是不可变的, 例如int ,没有任何方法可以改变它的值。如果您增加它的值,
age = 8
age = age + 1
# 或者
age += 1
然后您使用id(age)检查,您会发现age前后指向不同的内存位置。原来的值并没有发生改变,age只是指向另一个值。
Python循环
循环是编程的重要组成部分。
在 Python 中,我们有2种循环:while循环和for循环。
Python中的while循环
while循环是使用while关键字定义的,它重复执行自己的块,直到判断条件为False:
condition = True
while condition == True:
print("The condition is True")
这是一个永远不会停下来的无限循环。
让我们在第一次迭代后立即停止循环:
condition = True
while condition == True:
print("The condition is True")
condition = False
print("After the loop")
在这种情况下,将执行第一次迭代,因为此时判断条件为True。在第二次迭代时,判断条件为False,因此执行循环外的下一条指令。
通常有一个计数器用于在一些周期后停止迭代:
count = 0
while count < 10:
print("The condition is True")
count = count + 1
print("After the loop")
Python中的for循环
使用for循环,我们可以让Python执行一个预先确定循环次数的代码块,并且不需要单独的变量和条件来检查它的值。
例如,我们可以迭代列表中的元素:
items = [1, 2, 3, 4]
for item in items:
print(item)
或者,您可以使用range()函数迭代特定次数:
for item in range(04):
print(item)
range(4)创建一个从0开始并包含4个元素的序列:[0, 1, 2, 3]。
如果要获取索引,您应该将序列包装到enumerate()函数中:
items = [1, 2, 3, 4]
for index, item in enumerate(items):
print(index, item)
Python中的Break和continue
while和 for循环都可以在代码块内被中断,这需要使用两个特殊关键字:break和continue。
continue停止当前迭代并告诉Python执行下一个迭代。
break完全停止循环,并继续执行循环外的下一条指令。
这里第一个示例打印 1, 3, 4。第二个示例打印 1:
items = [1, 2, 3, 4]
for item in items:
if item == 2:
continue
print(item)
items = [1, 2, 3, 4]
for item in items:
if item == 2:
break
print(item)
Python类
除了使用Python提供的数据类型之外,我们还可以声明自定义的类,并使用类实例化对象。
对象是类的实例。类是对象的类型。
我们可以这样定义一个类:
class <class_name>:
# 自定义的类
例如,让我们定义一个Dog类
class Dog:
# Dog类
一个类里面可以定义方法:
class Dog:
# Dog类
def bark(self):
print('WOF!')
self作为方法的参数,指向当前实例对象,定义类的方法时必须指定self。(译者:大多数情况下如此,有些特殊的方法不用指定)
我们使用以下语法创建一个类的实例对象,即创建一个object:
roger = Dog()
现在roger是Dog类型的对象。
如果运行
print(type(roger))
您会看到<class '__main__.Dog'>
当我们从类中创建新对象时,我们使用一种被称为构造函数的特殊方法__init__()来初始化一个或多个属性:
class Dog:
# the Dog class
def __init__(self, name, age):
self.name = name
self.age = age
def bark(self):
print('WOF!')
我们这样使用它:
roger = Dog('Roger', 8)
print(roger.name) # 'Roger'
print(roger.age) # 8
roger.bark() # 'WOF!'
类的一个重要特性是继承。
我们创建一个可以使用walk()方法的Animal 类:
class Animal:
def walk(self):
print('Walking..')
然后Dog类继承Animal类:
class Dog(Animal):
def bark(self):
print('WOF!')
现在创建Dog类的新对象,它将具有walk()方法,因为Dog类继承自Animal类:
roger = Dog()
roger.walk() # 'Walking..'
roger.bark() # 'WOF!'
Python模块
每个Python文件都是一个模块。
您可以从其它文件导入模块,这是任何具有一定复杂性的程序的基础,因为它促进了合理的组织结构和代码重用。
在典型的Python程序中,一个文件作为入口点,那么其它文件是模块,并公开可以从模块中调用的函数。(译者:不只是可以公开函数,类、常量等等都行)
文件dog.py包含以下代码:
def bark():
print('WOF!')
我们可以使用import从另一个文件中导入这个模块。一旦我们这样做了,我们就可以使用dog.bark()来引用该函数:
import dog
dog.bark()
或者,我们可以使用from .. import语法直接导入函数:
from dog import bark
bark()
第一个策略导入文件中定义的所有内容。
第二个策略只选择导入我们需要的东西。
这些模块(的形式)取决于您的程序,导入(方法)取决于所导入模块(即文件)在文件系统中的位置。
假设您将dog.py文件放在lib文件夹中。
在该文件夹中,您需要创建一个名为__init__.py的空文件来告诉Python该文件夹包含模块。
现在您可以选择从lib中导入dog:
from lib import dog
dog.bark()
或者您可以从lib.dog导入特定dog模块函数:
from lib.dog import bark
bark()
Python标准库
Python通过其标准库公开了许多内置功能。
标准库是各种应用程序的集合,包括数学应用,代码调试,以及图形用户界面创建等等。
您可以在此处找到标准库模块的完整列表:https://docs.python.org/3/library/index.html
一些比较重要的模块是:
math数学计算相关应用程序re正则表达式的使用json处理json数据datetime处理日期sqlite3使用SQLiteos操作系统实用程序random生成随机数statistics数学统计相关应用程序requests执行HTTP网络请求http创建HTTP服务器urllib管理URL
接下来介绍如何_使用_标准库的一个模块。您已经知道如何使用自己创建的模块,即从程序文件夹中的其它文件导入。
标准库提供的模块也是如此使用:
import math
math.sqrt(4) # 2.0
或者
from math import sqrt
sqrt(4) # 2.0
我们很快将单独探索最重要的模块,以了解我们可以用其做什么。
Python PEP8风格指导
编写代码时,应遵守所使用的编程语言的一些约定。
如果您从一开始就学习正确的命名和格式约定,那么将更容易阅读其他人编写的代码,同样其他人也会发现您的代码易于阅读。
Python在PEP8样式指南中定义了其代码风格约定。PEP即_Python Enhancement Proposals_,它描述了Python语言所有增强和讨论的地方。
有很多PEP提案,都可以在https://www.python.org/dev/peps/ 上找到。
PEP8是最早和最重要的提案之一,它定义了格式和以"pythonic"方式编写Python代码的一些规则。
您可以在此处阅读其完整内容:https://www.python.org/dev/peps/pep-0008/ ,下面是几点总结,您可以从这里快速开始:
- 使用空格而不是制表符缩进
- 使用4个空格缩进
- Python文件用UTF-8编码
- 一行代码最多80列
- 每个语句写在自己所在的一行上
- 函数、变量名和文件名使用小写,单词之间用下划线分隔(例如snake_case)
- 类名单词首字母大写(例如CamelCase)
- 包名是小写的,单词之间没有下划线
- 不应该改变的常量全用大写字母
- 变量名应该有意义
- 添加有用的注释,但应该避免为非常易懂的代码添加注释
- 在运算符两边添加空格
- 不要使用不必要的空格
- 在函数(的定义)前添加一个空行
- 在类中的方法之间添加一个空行
- 在函数/方法内部,可以使用空行分隔相关的代码块,以提高可读性
Python代码调试
调试代码是您应该学习的最佳技能之一,因为在许多困难的情况下,它将为您提供帮助。
每种编程语言都有其调试器。Python使用pdb调试代码,可通过标准库获得。
您可以通过在代码中添加一个断点来进行调试:
breakpoint()
如果需要,您可以添加更多断点。
当Python解释器在您的代码中遇到断点时,它会停止执行代码,并会告诉您下一条将运行的指令是什么。
接下来您可以做一些事情。
您可以键入任何变量的名称来检查其值。
您可以按n跳到当前函数的下一行。如果下一行代码调用了函数,调试器不会进入它们,并将它们视为"黑匣子"。
您可以按 s跳到当前函数的下一行。如果下一行是调用一个函数,则调试器会进入该函数,然后您可以一次运行该函数的一条指令。
您可以按c继续正常执行剩下的程序,而无需逐步执行。
您可以按q停止程序的执行。
调试对于评估程序的结果很有用,当您有复杂的迭代或要修改的算法时,了解如何使用它尤其有用。
Python变量作用域
当您声明一个变量时,该变量在程序的某些部分中可见,这具体取决于您声明它的位置。
如果您在函数之外声明它,则该变量对声明之后的任何代码都是可见的,包括(这之后定义的)函数:
age = 8
def test():
print(age)
print(age) # 8
test() # 8
我们称这种变量为全局变量。
如果您在函数内部定义变量,则该变量是局部变量,并且仅在该函数内部可见。在函数之外,它是不可访问的:
def test():
age = 8
print(age)
test() # 8
print(age)
# 这些这个print会报错 NameError: name 'age' is not defined
Python接收从命令行传入的参数
当我们从命令行调用程序时,Python提供了几种方法来处理传递的参数。
到目前为止,您已经使用过REPL来执行程序,或使用如下方法执行Python代码
python <文件名>.py
(像上面)这样做时,您可以传递附加的参数和选项,如下所示:
python <文件名>.py <参数1>
python <文件名>.py <参数1> <参数2>
处理这些参数的基本方法是使用标准库中的sys模块。
您可以获取在sys.argv列表中传递的参数:
import sys
print(len(sys.argv))
print(sys.argv)
sys.argv列表的第一项包含所运行文件的名称,例如 ['main.py']。
这是一种简单的方法,但您必须自己做很多工作。您需要验证参数,确保它们的类型是正确的,如果用户没有正确使用程序,您需要向他们打印反馈信息。
Python在标准库中提供了另一个包来帮助您:argparse。
您首先导入argparse并调用argparse.ArgumentParser(),传递程序的描述:
import argparse
parser = argparse.ArgumentParser(
description='This program prints the name of my dogs'
)
然后继续添加想要接受的参数。
例如,在下面这个程序中,我们接受一个-c选项来传递颜色,就像这样(执行代码文件):python program.py -c red
import argparse
parser = argparse.ArgumentParser(
description='This program prints a color HEX value'
)
parser.add_argument('-c', '--color', metavar='color', required=True, help='the color to search for')
args = parser.parse_args()
print(args.color) # 'red'
如果未指定参数,程序将报错:
➜ python python program.py
usage: program.py [-h] -c color
program.py: error: the following arguments are required: -c
program.py: error: 程序运行需要如下参数: -c
您可以使用choices将选项设置为一组特定值:
parser.add_argument('-c', '--color', metavar='color', required=True, choices={'red','yellow'}, help='the color to search for')
➜ python python program.py -c blue
usage: program.py [-h] -c color
program.py: error: argument -c/--color: invalid choice: 'blue' (choose from 'yellow', 'red')
program.py: error: argument -c/--color: 无效的选择: 'blue' (该选项只能为'yellow'或'red')
还有更多选择,但以上是基础。
也有提供此功能的社区包,例如Click和Python Prompt Toolkit。
Python的Lambda函数
Lambda函数(也称为匿名函数)是没有名称且只有一个表达式作为其主体的小型函数。
在Python中,它们是使用lambda关键字定义的:
lambda <参数> : <表达式>
主体必须是单个表达式,而不是语句。
这很重要:表达式返回值,语句不返回。
最简单的lambda函数示例是将数字的值加倍:
lambda num : num * 2
Lambda函数可以接受更多参数:
lambda a, b : a * b
无法直接调用Lambda函数,但您可以将它们分配给变量:
multiply = lambda a, b : a * b
print(multiply(2, 2)) # 4
Lambda函数的实用性在于与其它Python功能结合使用,例如结合map()、filter()和reduce()。
Python递归
Python中的函数可以调用自身,这就是递归。递归在许多情况下都非常有用。
解释递归的常用方法是实现阶乘计算。
一个数字n的阶乘是数字n乘以n-1,再乘以n-2,以此类推,直到数字1:
3! = 3 * 2 * 1 = 6
4! = 4 * 3 * 2 * 1 = 24
5! = 5 * 4 * 3 * 2 * 1 = 120
使用递归,我们可以编写一个计算任意数阶乘的函数:
def factorial(n):
if n == 1: return 1
return n * factorial(n-1)
print(factorial(3)) # 6
print(factorial(4)) # 24
print(factorial(5)) # 120
如果在 factorial() 函数中调用factorial(n)而不是factorial(n-1),则会导致无限递归。 默认情况下,Python将在1000次调用时停止递归,此时您将收到RecursionError错误。
递归在很多地方都有用,它可以帮助我们在没有其它更好方法的情况下简化代码,所以了解这种技术是件好事。
Python嵌套函数
Python中函数可以嵌套在其它函数中。
在函数内部定义的函数仅在该函数内可见。
这对于创建在函数内有用,但在函数外无用的程序很有用。
您可能会问:如果它没有害处,我为什么要“隐藏”这个功能?
因为最好隐藏函数本地并且在其它地方没有用的功能。
另外,这样我们可以使用闭包(稍后会详细介绍)。
这里是一个例子:
def talk(phrase):
def say(word):
print(word)
words = phrase.split(' ')
for word in words:
say(word)
talk('I am going to buy the milk')
如果要从内部函数访问外部函数中定义的变量,首先需要将其声明为nonlocal:
def count():
count = 0
def increment():
nonlocal count
count = count + 1
print(count)
increment()
count()
这对闭包特别有用,我们将在接下来的说明中看到。
Python闭包
如果函数返回一个嵌套函数,则该嵌套函数可以访问在该函数中定义的变量,即使该函数不再处于运行状态。
这是一个简单的计数器示例。
def counter():
count = 0
def increment():
nonlocal count
count = count + 1
return count
return increment
increment = counter()
print(increment()) # 1
print(increment()) # 2
print(increment()) # 3
我们返回increment()这个内部函数,即使counter()函数已经结束,increment仍然可以访问count变量的状态。
Python装饰器
装饰器是一种可以以任何方式增强或改变函数工作方式的方法。
装饰器是用@符号定义的,@后面跟装饰器名称,(装饰器用在)在函数定义之前。
例子:
@logtime
def hello():
print('hello!')
这个hello函数分配了logtime装饰器。
每当我们调用hello()时,装饰器也都会被调用。
装饰器是一个以函数为参数的函数,它将(被装饰的)函数包装在内部函数中,该内部函数执行必须完成的工作,然后返回这个内部函数。 换句话说:
def logtime(func):
def wrapper():
# do something before
val = func()
# do something after
return val
return wrapper
Python文档字符串
文档非常重要,不仅可以用于告知其他人(自己写的)函数/类/方法/模块的目标是什么,还可以帮助您(在较长时间后)理解自己的代码。
当您在6或12个月后会看您的的代码时,可能不记得写代码时脑海中的所有想法。这个时候阅读您的代码并理解它在做什么将变得非常困难。
注释是帮助自己(和他人)摆脱这种困境的一种方式:
# this is a comment
num = 1 # this is another comment
另一种方法是使用docstrings。
文档字符串的实用性在于它们遵循约定,因此它们可以被自动处理。
这是您为函数定义文档字符串的方式:
def increment(n):
"""Increment a number"""
return n + 1
这是为类和方法定义文档字符串的方式:
class Dog:
"""A class representing a dog"""
def __init__(self, name, age):
"""Initialize a new dog"""
self.name = name
self.age = age
def bark(self):
"""Let the dog bark"""
print('WOF!')
通过在文件顶部放置一个文档字符串来解释记录一个模块,例如,假设这是dog.py:
"""Dog module
This module does ... bla bla bla and provides the following classes:
- Dog
...
"""
class Dog:
"""A class representing a dog"""
def __init__(self, name, age):
"""Initialize a new dog"""
self.name = name
self.age = age
def bark(self):
"""Let the dog bark"""
print('WOF!')
文档字符串可以跨越多行:
def increment(n):
"""Increment
a number
"""
return n + 1
Python将处理这些(文档字符串),您可以使用全局函数help()来获取类/方法/函数/模块的文档。
例如调用help(increment)会给返回这个:
Help on function increment in module
__main__:
increment(n)
Increment
a number
格式化文档字符串有许多不同的标准,您可以选择遵守自己喜欢的标准。
我喜欢谷歌的标准: https://github.com/google/styleguide/blob/gh-pages/pyguide.md#38-comments-and-docstrings
(遵循)标准可以使用工具来提取文档字符串并自动为您的代码生成文档。
Python反射
可以使用反射来分析函数、变量和对象。
首先,使用全局函数help()(如果以文档字符串的形式提供)我们可以获得文档。
然后,您可以使用print()获取有关函数的信息:
def increment(n):
return n + 1
print(increment)
# <function increment at 0x7f420e2973a0>
或者(获取)对象(的信息):
class Dog():
def bark(self):
print('WOF!')
roger = Dog()
print(roger)
# <__main__.Dog object at 0x7f42099d3340>
我们可以使用type()函数获取对象的类型:
print(type(increment))
# <class 'function'>
print(type(roger))
# <class '__main__.Dog'>
print(type(1))
# <class 'int'>
print(type('test'))
# <class 'str'>
全局函数dir()可以找出对象的所有方法和属性:
print(dir(roger))
# ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'bark']
全局函数id()显示任意对象在内存中的位置:
print(id(roger)) # 140227518093024
print(id(1)) # 140227521172384
这对于检查两个变量是否指向同一个对象会很有用。
inspect标准库模块为我们提供了更多获取对象信息的工具,您可以在这里查看
Python注解
Python是动态类型的,我们不必指定变量、函数参数或函数返回值的类型。
注解允许我们(可选地)这样做。
这是一个没有注解的函数:
def increment(n):
return n + 1
这是带有注解的相同函数:
def increment(n: int) -> int:
return n + 1
您还可以注解变量:
count: int = 0
Python将忽略这些注解。 一个名为mypy的工具可以独立运行,也可以集成到VS Code或PyCharm等IDE中,以便在您编码时自动检查静态类型错误。它还将帮助您在运行代码之前捕获类型不匹配的错误。
这是一个很大的帮助,尤其是当您的软件规模变得很大并且需要重构代码时。
Python异常
处理错误很重要,Python为我们提供了异常处理来做到这一点。
如果将代码行包装到try:块中:
try:
# 一些代码
如果发生错误,Python会提醒您,您可以使用except块确认发生了哪种错误:
try:
# 一些代码
except <ERROR1>:
# 处理 <ERROR1>
except <ERROR2>:
# 处理 <ERROR2>
要捕获所有异常,您可以使用不包含任何错误类型的except块:
try:
# 一些代码
except <ERROR1>:
# 处理 <ERROR1>
except:
# 捕获其它所有错误
如果没有发现异常,则将运行else块:
try:
# 一些代码
except <ERROR1>:
# 处理 <ERROR1>
except <ERROR2>:
# 处理 <ERROR2>
else:
# 没有抛出异常,代码成功运行
finally块允许您在任何情况下执行某些操作,无论是否发生错误:
try:
# 一些代码
except <ERROR1>:
# 处理 <ERROR1>
except <ERROR2>:
# 处理 <ERROR2>
else:
# 没有抛出异常,代码成功运行
finally:
# 任何情况下都将运行的代码
将发生的具体错误取决于您正在执行的操作。
例如,如果您正在读取一个文件,可能会得到一个EOFError。如果您将一个数除以零,将会得到一个ZeroDivisionError。如果发生类型转换问题,您可能会得到一个TypeError。
试试这个代码:
result = 2 / 0
print(result)
程序将因错误而终止:
Traceback (most recent call last):
File "main.py", line 1, in <module>
result = 2 / 0
ZeroDivisionError: division by zero
并且错误(代码行)之后的代码将不会被执行。
在try:块中添加该操作可以让我们优雅地恢复(错误)并继续执行程序:
try:
result = 2 / 0
except ZeroDivisionError:
print('Cannot divide by zero!')
finally:
result = 1
print(result) # 1
您也可以在自己的代码中使用raise语句引发异常:
raise Exception('An error occurred!')
这会抛出一个异常,您可以使用以下方法拦截它:
try:
raise Exception('An error occurred!')
except Exception as error:
print(error)
您还可以扩展Exception来定义自己的异常类:
class DogNotFoundException(Exception):
pass
这里
pass的意思是“什么都没有”,当我们定义一个没有方法的类或没有代码的函数时,我们必须使用它。
try:
raise DogNotFoundException()
except DogNotFoundException:
print('Dog not found!')
Python中with语句
with语句对于简化异常处理非常有帮助。
例如,在处理文件时,每次打开文件都必须记得关闭它。
with使这个过程变得透明(即对程序员不可见)。
(使用with)可以不像下面这样写:
filename = '/Users/flavio/test.txt'
try:
file = open(filename, 'r')
content = file.read()
print(content)
finally:
file.close()
您可以这样写:
filename = '/Users/flavio/test.txt'
with open(filename, 'r') as file:
content = file.read()
print(content)
换句话说,Python有内置的隐式异常处理,其会自动为我们调用close()。
上面的例子只是为了介绍with的功能,而不是说它仅在处理文件方面对我们有帮助。
Python如何使用pip安装第三方包
Python标准库包含大量实用的程序,可以简化我们的开发需求,但是没有什么能满足_一切_。
这就是个人和公司创建第三方包,并将它们作为开源软件提供给整个社区的原因。
这些模块都收集在一个地方,可在https://pypi.org 获得Python包索引,并且可以使用pip将它们(第三方模块)安装在您的系统上。
在撰写本文时,有超过270,000个免费第三方包可供我们使用。
如果您按照Python安装说明进行操作,您应该已经安装了
pip。
使用命令pip install可以安装任何第三方包:
pip install <package>
或者,如果您确实遇到了问题,也可以通过python -m运行它:
python -m pip install <package>
例如,您可以安装 requests 包,这是一个流行的 HTTP 库:
pip install requests
一旦这样做,它就可以用于您所有的Python脚本,因为包是全局安装的。
(第三方包安装的)具体位置取决于您的操作系统。
在运行Python 3.9的macOS上,位置是/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages。
使用以下命令将第三方包升级到最新版本:
pip install –U <package>
使用以下命令安装指定版本的第三方包:
pip install <package>==<version>
使用以下命令卸载一个第三方包:
pip uninstall <package>
使用以下命令显示已安装第三方包的详细信息,包括版本、文档网站和作者信息:
pip show <package>
Python列表推导式
列表推导式以一种非常简洁的方式创建列表。
假设有一个列表:
numbers = [1, 2, 3, 4, 5]
您可以使用列表推导式创建一个新列表,该列表由numbers列表元素的2次幂组成:
numbers_power_2 = [n**2 for n in numbers]
# [1, 4, 9, 16, 25]
列表推导是一种有时比循环更受欢迎的语法,因为当(有些)操作写在一行时其更具可读性:
numbers_power_2 = []
for n in numbers:
numbers_power_2.append(n**2)
同样有时也比map()更好:
numbers_power_2 = list(map(lambda n : n**2, numbers))
Python多态
多态将一个功能泛化,因此它可以在不同的类型上工作。多态是面向对象编程中的一个重要概念。
我们可以在不同的类上定义相同的方法:
class Dog:
def eat():
print('Eating dog food')
class Cat:
def eat():
print('Eating cat food')
然后我们可以生成对象,无论对象属于哪个类,我们都可以调用eat()方法,但是会得到不同的结果:
animal1 = Dog()
animal2 = Cat()
animal1.eat()
animal2.eat()
我们构建了一个通用接口,不需要知道动物是猫还是狗。
译者:这个例子不太好,不完整,看下面这个例子:
In [1]: class Animal:
...: def eat(self):
...: print("animal eating ...")
...:
In [2]: class Dog(Animal):
...: def eat(self):
...: print("dog eating ...")
...:
In [3]: class Cat(Animal):
...: def eat(self):
...: print("cat eating ...")
...:
In [4]: a = Animal()
In [5]: d = Dog()
In [6]: c = Cat()
In [7]: a.eat()
animal eating ...
In [8]: d.eat()
dog eating ...
In [9]: c.eat()
cat eating ...
译者:多态实际上是看运行时对象具体的类型,在Java中,是可以这样写的Animal dog = new Dog(),即创建一个Animal对象dog,这是编译时,但是在运行时dog.eat()打印dog eating ...
Python运算符重载
运算符重载是一种先进的技术,我们可以用来使类具有可比性,并使它们与Python运算符一起工作。
让我们来创建一个类Dog:
class Dog:
# the Dog class
def __init__(self, name, age):
self.name = name
self.age = age
创建两个Dog对象:
roger = Dog('Roger', 8)
syd = Dog('Syd', 7)
我们可以使用运算符重载添加一种基于age属性的方法来比较这两个对象:
class Dog:
# the Dog class
def __init__(self, name, age):
self.name = name
self.age = age
def __gt__(self, other):
return True if self.age > other.age else False
现在如果您尝试运行print(roger > syd),将得到结果True。
与我们定义__gt__()(大于)的方式相同,我们可以定义以下方法:
__eq__()检查是否相等__lt__()使用<操作符检查一个对象是否被认为低于另一个对象__le__()表示小于或等于 (<=)__ge__()表示大于或等于 (>=)__ne__()表示不相等 (!=)
然后还有使用算术运算符操作的方法:
__add__()响应+运算符__sub__()响应-运算符__mul__()响应*运算符__truediv__()响应/运算符__floordiv__()响应//运算符__mod__()响应%运算符__pow__()响应**运算符__rshift__()响应>>运算符__lshift__()响应<<运算符__and__()响应&运算符__or__()响应|运算符__xor__()响应^运算符
还有其它几种方法可以与运算符一起使用,但您应该明白了(这种思想)。
Python虚拟环境
在您的系统上运行多个Python应用程序是很常见的。
当应用程序需要相同的模块时,有时您会遇到一个棘手的情况,即一个应用程序需要一个版本模块,而另一个应用程序需要该模块的不同版本。
您可以使用虚拟环境解决这个问题。
我们将使用venv。其它工具的工作方式类似,例如pipenv。
如下创建虚拟环境
python -m venv .venv
(该命令)在您要开始的项目的文件夹或者现有项目的文件夹(的根目录下运行)。
译者:项目的根目录即其本身,例如一个项目fCC在/Users/abc/projects/fCC,那么该项目的根目录就是/Users/abc/projects/fCC/
然后运行
source .venv/bin/activate
(如果是)在Fish shell上,使用
source .venv/bin/activate.fish
执行这个命令将激活Python虚拟环境。根据您的配置,可能还会看到终端提示发生变化。
我的从
➜ folder
变成
(.venv) ➜ folder
现在运行pip将使用这个虚拟环境而不是全局环境。
总结
非常感谢您阅读本书。
我希望它能鼓励您更多去地了解 Python。
有关Python和一般编程教程的更多信息,请查看我的博客 flaviocopes.com。
在mailto:flavio@flaviocopes.com 发送任何反馈、勘误或意见,您可以在Twitter@flaviocopes 上与我联系 .
请注意:您可以获取此Python手册的PDF、ePub和Mobi版本