
原文:Data Structures in JavaScript – With Code Examples,作者:Germán Cocca
大家好,在这篇文章中,我们将看一看计算机科学和软件开发中的一个重要话题:数据结构。
数据结构是任何一个软件开发从业人员必须知道的内容,但当你刚开始学习的时候,可能觉得这个话题难以理解,甚至有些吓人。
在这篇文章中,我会简单介绍什么是数据结构,它们在什么时候有用,以及如何用 JavaScript 来实现这些数据结构。
让我们开始吧!
目录
什么是数据结构
在计算机科学中,数据结构是一种组织、管理和存储数据的形式,这种形式方便数据访问和修改。
准确来讲,数据结构是数据值的合集、数据间的关系,以及可以应用到数据的函数和操作。
这些概念乍一听有些抽象费解,但值得你去思考。如果你已经编写过一段时间代码,你肯定使用过数据结构。
你使用过数组或者对象吗?它们就是数据结构。它们都是相互关联值的合集,并且可供你操作。😉
// 值 1、2、3 的合集
const arr = [1, 2, 3]
// 每一个值都是彼此相关联的,因为每一个值都在数组中具备自己的索引序号
const indexOfTwo = arr.indexOf(2)
console.log(arr[indexOfTwo-1]) // 1
console.log(arr[indexOfTwo+1]) // 3
// 我们可以对数组进行很多操作,例如给数组添加一个新的值
arr.push(4)
console.log(arr) // [1,2,3,4]
JavaScript 包含原始(内置) 和 非原始(非内置) 两种数据结构。
原始数据结构是编程语言默认的、可以拿来就用(如数组和对象)的;而非原始数据结构不是默认的、如果需要使用的话,你必须先编写出来。
不同的数据结构对应不同的操作场景。你或许可以使用内置数据结构处理大部分编程任务,但当遇到特殊任务的时候,非原始数据机构可以派上用场。
让我们一起来看一看最流行的数据结构,它们是怎么运行的,在哪些场合适用,以及如何使用 JavaScript 编写这些数据结构。
数组
数组是存储在连续内存位置的项目合集。
数组内的每一个元素都可以通过其索引(位置)访问。数组的索引通常从 0 开始,所以在一个包含 4 个元素的数组中,第三个元素的索引为 2。
const arr = ['a', 'b', 'c', 'd']
console.log(arr[2]) // c
数组的长度属性定义了数组包含的元素数量。如果一个数组包含 4 个元素,我们就可以说这个数组的长度为 4。
const arr = ['a', 'b', 'c', 'd']
console.log(arr.length) // 4
在一些编程语言中,一个数组中只能存储同一种数据类型的元素,在数组被创建的时候就必须定义数组的长度,并且不可以修改。
但 JavaScript 的数组并不是这样,在 JavaScript 中,同一数组可以存储任何数据类型的元素,数组长度是动态的(也就是说可以按需更改数组长度)。
const arr = ['store', 1, 'whatever', 2, 'you want', 3]
JavaScript 数组可以存储任何数据类型的值,也就意味着可以存储数组。一个包含其他数组的数组被称为多维数组。
const arr = [
[1,2,3],
[4,5,6],
[7,8,9],
]
JavaScript 数组有许多内置的属性和方法,可以针对不同目的来使用,如从数组添加或者删除元素、给数组排序、过滤数组,以及我们知道的数组长度等,数组的完全属性和方法列表可以在这里找到。😉
在数组中每一个元素都对应一个索引,索引跟元素位于数组位置相关。如果我们在数组末尾添加一个新的元素,则这个元素的索引为之前数组最后一位索引加一。
但当我们想要在数组的开头或者中间添加或者删除元素的话,添加或删除的这个元素之后的所有元素的索引都会变化。这样会增加计算成本,也是这种数据结构的缺点之一。
当需要存储独立值以及在数据结构末尾添加和删除值的时候,数组十分有效。但当需要在结构中添加删除元素,其他数据结构会更有效。(我们会在后文提到)
对象(哈希表)
在 JavaScript 中,对象是键值对的集合。在其他编程语言中,这种数据结构也被称作映射、字典和哈希表。
一个典型的 JS 对象如下:
const obj = {
prop1: "I'm",
prop2: "an",
prop3: "object"
}
我们使用花括号声明对象,在每一个键之后紧跟一个冒号和对应的值。
需要注意的是,在同一个对象中所有的键都是独一无二的,不可以出现两个命名相同的键。
对象可以存储值和函数。在对象的语境中,我们将值叫作属性,将函数叫作方法。
const obj = {
prop1: "Hello!",
prop3: function() {console.log("I'm a property dude!")
}}
访问属性有两种语法,object.property和object["property"]。访问方法可以调用object.method()。
console.log(obj.prop1) // "Hello!"
console.log(obj["prop1"]) // "Hello!"
obj.prop3() // "I'm a property dude!"
赋值的语法也类似:
obj.prop4 = 125
obj["prop5"] = "The new prop on the block"
obj.prop6 = () => console.log("yet another example")
console.log(obj.prop4) // 125
console.log(obj["prop5"]) // "The new prop on the block"
obj.prop6() // "yet another example"
和数组一样,JavaScript 对象也有内置的方法供我们进行不同的操作,或者获取特定对象的信息,完整内容可以查看这里。
对象是将有相同之处或者相互关联的数据放在一起的好办法。同时,因为对象的属性是独一无二的,当想要根据特定条件来区分数据的时候,对象可以派上用场。
可以使用对象来记录有多少人喜欢不同的食物:
const obj = {
pizzaLovers: 1000,
pastaLovers: 750,
argentinianAsadoLovers: 12312312312313123
}
栈
栈是一种以列表的方式来存储信息的数据结构,添加和删除栈的元素遵循 LIFO 模式(后进先出)。在栈中,不允许按照元素顺序来添加或删除元素,只能遵循 LIFO 模式。
你可以想象桌面有一叠纸,来思考栈是如何运作的。你只能在这叠纸上方添加更多纸张,也只能在最上方取出纸张。这就是 LIFO,后进先出。 😉

只要确认元素遵循 LIFO模式,那么栈结构就可以派上用场。下面是栈的使用场景:
- JavaScript 的调用栈
- 在各种编程语言中管理函数调用
- 许多程序提供的撤销/重做功能
有不止一种实现栈的方法,但是最简单的或许是在数组中使用 push 和 pop 方法。如果你仅通过 pop 和 push 的方法来添加和删除元素,你就遵循了 LIFO 模式,用栈的方法操作了数组。
另一个方法是列表,实现如下:
// 为栈的每一个节点创建一个类
class Node {
// 每一个节点包含两个属性,其值以及一个指向下一个节点的指针
constructor(value){
this.value = value
this.next = null
}
}
// 为栈创建一个类
class Stack {
// 栈有三个属性,第一个节点,最后一个节点,以及栈的大小
constructor(){
this.first = null
this.last = null
this.size = 0
}
// push 方法接受一个值,并将其添加到栈的“顶端”
push(val){
var newNode = new Node(val)
if(!this.first){
this.first = newNode
this.last = newNode
} else {
var temp = this.first
this.first = newNode
this.first.next = temp
}
return ++this.size
}
// pop 方法删除栈“顶端”的值,并返回这个值
pop(){
if(!this.first) return null
var temp = this.first
if(this.first === this.last){
this.last = null
}
this.first = this.first.next
this.size--
return temp.value
}
}
const stck = new Stack
stck.push("value1")
stck.push("value2")
stck.push("value3")
console.log(stck.first) /*
Node {
value: 'value3',
next: Node { value: 'value2', next: Node { value: 'value1', next: null } }
}
*/
console.log(stck.last) // Node { value: 'value1', next: null }
console.log(stck.size) // 3
stck.push("value4")
console.log(stck.pop()) // value4
栈方法的大 O 表示法为:
- 插入 - O(1)
- 删除 - O(1)
- 查找 - O(n)
- 访问 - O(n)
队列
队列和栈的运作方式类似,但是元素遵循另一个添加和删除的模式。队列值遵循 FIFO 先进先出模式。在队列中,元素不按照顺序添加或删除,仅遵循 FIFO 模式。
下面这张排队购买食物的图可以帮助你思考这个概念。这里的逻辑是如果你先加入到队伍中,你就会先被服务。如果你是队伍的第一个,你就第一个离开队伍。FIFO。😉

队列的使用场景:
- 后台任务
- 打印/任务处理
和栈一样,有不止一种实现队列的方式。但是最简单的是在数组中使用 push 和 shift 方法。
如果我们仅使用 push 和 shift 方法来添加和删除元素,我们就在数组中遵循了 FIFO 模式,将数组按照队列来操作。
另一个实现办法是列表,如下:
// 为队列每一个节点的类
class Node {
//每一个节点包含两个属性,其值以及一个指向下一个节点的指针
constructor(value){
this.value = value
this.next = null
}
}
// 为队列创建类
class Queue {
// 队列包含三个属性:第一个节点、最后一个节点、队列的大小
constructor(){
this.first = null
this.last = null
this.size = 0
}
// enqueue 方法接受一个值并将其添加到队列的末端
enqueue(val){
var newNode = new Node(val)
if(!this.first){
this.first = newNode
this.last = newNode
} else {
this.last.next = newNode
this.last = newNode
}
return ++this.size
}
// dequeue 方法删除队列“最前端”的元素,并返回
dequeue(){
if(!this.first) return null
var temp = this.first
if(this.first === this.last) {
this.last = null
}
this.first = this.first.next
this.size--
return temp.value
}
}
const quickQueue = new Queue
quickQueue.enqueue("value1")
quickQueue.enqueue("value2")
quickQueue.enqueue("value3")
console.log(quickQueue.first) /*
Node {
value: 'value1',
next: Node { value: 'value2', next: Node { value: 'value3', next: null } }
}
*/
console.log(quickQueue.last) // Node { value: 'value3, next: null }
console.log(quickQueue.size) // 3
quickQueue.enqueue("value4")
console.log(quickQueue.dequeue()) // value1
队列方法的大 O 表示法:
- 插入 - O(1)
- 删除 - O(1)
- 查询 - O(n)
- 访问 - O(n)
链表
链表是一种以列表存储值的数据结构,在列表中每一个值都被当作为一个节点,每一个节点都通过指针与列表的下一个值关联(若该节点是列表最后一个元素则下一个值为 null)。
有两种链表:单链表和双链表。两种链表的运作方式类似,但是在单链表中每一个节点有单指针指向下一个节点,在双链表中,每一个节点有双指针,一个指向下一个节点,一个指向上一个节点。
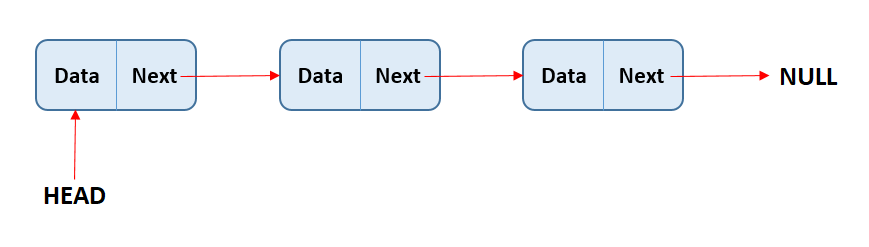
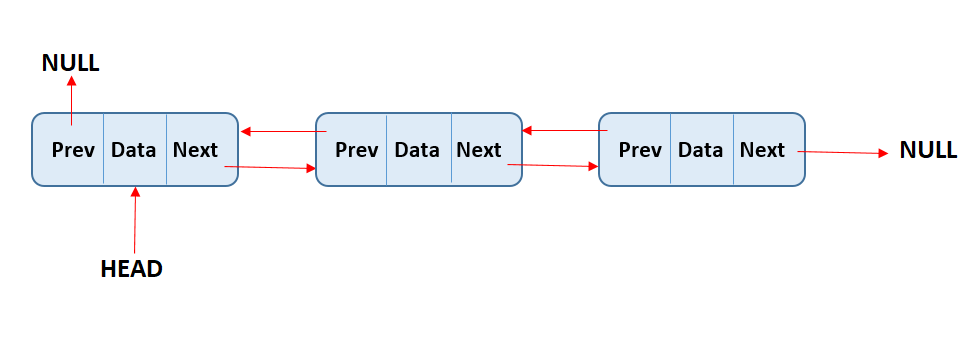
列表的第一个元素被当作头,列表的最后一个元素被当作尾。和数组一样,列表的长度由列表中的元素个数决定。
列表和数组主要不同包括:
- 列表没有索引,列表中的每一个值仅“知道”其通过指针连接到的值。
- 因为列表没有索引,所以我们不能随机访问列表中的元素。当我们想要访问一个值,必须通过从头到尾遍历整个列表的方法。
- 没有索引的好处是添加或删除列表中任意部分比在数组中更高效。我们只需要重新分配指针指向的“相邻”值,但是在数组中,我们需要重新分配余下所有值的索引。
和其他所有数据结构一样,可以采用不同的方法来操作以链表存储的数据。通常会使用:push(在尾部添加)、pop(在尾部删除)、unshift(在头部添加)、shift(在头部删除)、get(获取)、set(设置)、remove(删除)和 reverse(反转)。
我们先来看看如何实现单链表,再来看看如何实现双链表。
单链表
完全实现单链表的代码如下:
// 为列表中的每一个节点创建一个类
class Node{
// 每一个节点有两个属性:其值和指向下一个值的指针
constructor(val){
this.val = val
this.next = null
}
}
//为列表创建一个类
class SinglyLinkedList{
// 列表有三个属性,头、尾和列表大小
constructor(){
this.head = null
this.tail = null
this.length = 0
}
// 向 push 方法传入一个值作为参数,并将其赋值给队列的尾
push(val) {
const newNode = new Node(val)
if (!this.head){
this.head = newNode
this.tail = this.head
} else {
this.tail.next = newNode
this.tail = newNode
}
this.length++
return this
}
// pop 方法删除队列尾
pop() {
if (!this.head) return undefined
const current = this.head
const newTail = current
while (current.next) {
newTail = current
current = current.next
}
this.tail = newTail
this.tail.next = null
this.length--
if (this.length === 0) {
this.head = null
this.tail = null
}
return current
}
// shift 方法删除队列头
shift() {
if (!this.head) return undefined
var currentHead = this.head
this.head = currentHead.next
this.length--
if (this.length === 0) {
this.tail = null
}
return currentHead
}
// unshift 方法将一个值作为参数并赋值给队列的头
unshift(val) {
const newNode = new Node(val)
if (!this.head) {
this.head = newNode
this.tail = this.head
}
newNode.next = this.head
this.head = newNode
this.length++
return this
}
// get 方法将一个索引作为参数,并返回此索引所在节点的值
get(index) {
if(index < 0 || index >= this.length) return null
const counter = 0
const current = this.head
while(counter !== index) {
current = current.next
counter++
}
return current
}
// set 方法将索引和值作为参数,修改队列中索引所在的节点值为传入的参数值
set(index, val) {
const foundNode = this.get(index)
if (foundNode) {
foundNode.val = val
return true
}
return false
}
// insert 方法将索引和值作为参数,在队列索引位置插入传入的值
insert(index, val) {
if (index < 0 || index > this.length) return false
if (index === this.length) return !!this.push(val)
if (index === 0) return !!this.unshift(val)
const newNode = new Node(val)
const prev = this.get(index - 1)
const temp = prev.next
prev.next = newNode
newNode.next = temp
this.length++
return true
}
// remove 方法将索引作为参数,在队列中删除索引所在的值
remove(index) {
if(index < 0 || index >= this.length) return undefined
if(index === 0) return this.shift()
if(index === this.length - 1) return this.pop()
const previousNode = this.get(index - 1)
const removed = previousNode.next
previousNode.next = removed.next
this.length--
return removed
}
// reverse 方法反转队列和所有指针,让队列的头尾对调
reverse(){
const node = this.head
this.head = this.tail
this.tail = node
let next
const prev = null
for(let i = 0; i < this.length; i++) {
next = node.next
node.next = prev
prev = node
node = next
}
return this
}
}
单链表的复杂度为:
- 插入 - O(1)
- 删除 - O(n)
- 查找 - O(n)
- 访问 - O(n)
双链表
如上文所述,双链表和单链表的区别在于双链表的前后两个节点之间由双指针相互连接,而单链表只有一个指向下一个值的指针。
双指针使得在特定场景下双链表比单链表的表现更好,但是也增加了存储空间的成本(存储双指针比单指针更占位置)。
完全实现双链表的代码类似于:
// 创建列表节点的类
class Node{
// 每一个节点包含三个属性,其值,一个指向上一个节点的指针,一个指向下一个节点的指针
constructor(val){
this.val = val;
this.next = null;
this.prev = null;
}
}
// 创建一个列表的类
class DoublyLinkedList {
// 列表有三个属性,头,尾和列表的大小
constructor(){
this.head = null
this.tail = null
this.length = 0
}
// push 方法将值作为参数并赋值给队列尾
push(val){
const newNode = new Node(val)
if(this.length === 0){
this.head = newNode
this.tail = newNode
} else {
this.tail.next = newNode
newNode.prev = this.tail
this.tail = newNode
}
this.length++
return this
}
// pop 方法删除队列尾
pop(){
if(!this.head) return undefined
const poppedNode = this.tail
if(this.length === 1){
this.head = null
this.tail = null
} else {
this.tail = poppedNode.prev
this.tail.next = null
poppedNode.prev = null
}
this.length--
return poppedNode
}
// shift 方法删除队列头
shift(){
if(this.length === 0) return undefined
const oldHead = this.head
if(this.length === 1){
this.head = null
this.tail = null
} else{
this.head = oldHead.next
this.head.prev = null
oldHead.next = null
}
this.length--
return oldHead
}
// unshift 方法将值作为参数并赋值给队列头
unshift(val){
const newNode = new Node(val)
if(this.length === 0) {
this.head = newNode
this.tail = newNode
} else {
this.head.prev = newNode
newNode.next = this.head
this.head = newNode
}
this.length++
return this
}
// get 方法将索引作为参数并返回队列对应索引的值
get(index){
if(index < 0 || index >= this.length) return null
let count, current
if(index <= this.length/2){
count = 0
current = this.head
while(count !== index){
current = current.next
count++
}
} else {
count = this.length - 1
current = this.tail
while(count !== index){
current = current.prev
count--
}
}
return current
}
// set 方法将索引和值作为参数,修改队列中索引所在的节点值为传入的参数值
set(index, val){
var foundNode = this.get(index)
if(foundNode != null){
foundNode.val = val
return true
}
return false
}
// insert 方法将索引和值作为参数,将值插入队列响应索引位置
insert(index, val){
if(index < 0 || index > this.length) return false
if(index === 0) return !!this.unshift(val)
if(index === this.length) return !!this.push(val)
var newNode = new Node(val)
var beforeNode = this.get(index-1)
var afterNode = beforeNode.next
beforeNode.next = newNode, newNode.prev = beforeNode
newNode.next = afterNode, afterNode.prev = newNode
this.length++
return true
}
}
双链表的大 O 表示法为:
- 插入 - O(1)
- 删除 - O(1)
- 搜索 - O(n)
- 访问 - O(n)
树
树是一种以父子关系相连的节点之间的数据结构,也就是说节点之间相互依赖。

树由根节点(树的第一个节点)开始,其他所有由根发展出来的节点被称作子节点。树结构最底部的节点没有“后代”,被称为叶节点。树的高度由父子节点相连的层数决定。
和链表及数组不同的地方是,树是非线性的,程序可以在数据结构内选择不同的方向遍历数据,从而得出不同的值。
而在链表或者数组中,程序由一个端点开始遍历到另一端点,每一次都重复同样的路径。
构成树结构一个重要的要素是仅从父到子连接的节点是合法的。“亲属”之间或者由子向父节点是我连接都不被允许(这样的连接会形成图表,是另一种数据结构),另一个重要的要素是树只能有一个根节点。
程序中使用树的场景有:
- DOM 模型
- 人工智能中的情景分析
- 操作系统中的文件夹
有不同类型的树,每一种类型的树的值都遵从不同的模式而组织起来,这样也就适用于不同的解决问题的场景。最常见的两种树是二叉树和堆。
二叉树
二叉树是每个节点最多只有两个节点的树结构。
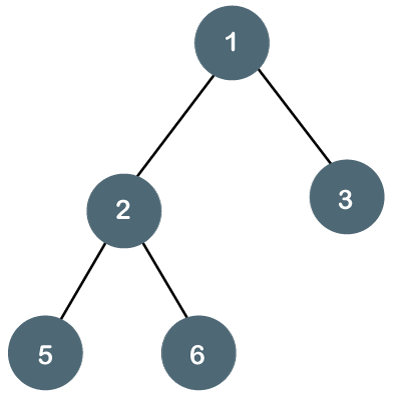
二叉树的一个重要使用场景是搜索。用于搜索的二叉树被称为二叉查找树(BST)。
BST 和普通二叉树类似,只是内部的数据结构被排列成易于搜索的结构。
在 BST 中的值是排过序的,所有节点的左子节点的值要小于父节点,所有节点的右子节点的值要大于父节点。

这样给值排过序的数据结构非常适合做搜索,因为树的每一层都可以对比是比父节点大还是小,在对比的过程中,我们可以逐步舍弃掉一半的数据得到最终我们需要的值。
当插入或者删除值的时候,我们的算法会进行如下步骤:
- 检查是否存在根节点
- 如果存在根节点,检查这个需要添加或删除的值是比根节点大还是小
- 如果比根节点小,则检查左边是否有节点,并重复上面的步骤;如果左边没有节点,则将这个节点在当下位置添加或者删除
- 如果比根节点大,则检查右边有没有节点,并重复上述步骤;如果有变没有节点,则将这个节点在当下位置添加或者删除
在 BST 中查找与上述方法类似,但是没有添加或者删除值,取而代之的是与节点比较我们搜寻的值的大小。
树的大 o 复杂度呈对数(log(n))。但是需要注意的是,想要实现这样的时间复杂度,必须保证树结构的每一步都是左右对称的,这样我们才可以在搜索的过程中“丢弃”一半的数据。如果在任意一边存储的值更多,树结构的搜索效率就会打折扣。
实现 BST 的方法如下:
// 我们创建树的节点
class Node{
// 每一个节点有三个属性:其值,以及指向左节点的指针和指向右节点的指针
constructor(value){
this.value = value
this.left = null
this.right = null
}
}
// 创建BST的类
class BinarySearchTree {
// 这个树只有一个属性即根节点
constructor(){
this.root = null
}
// insert 方法将一个值作为参数,并将值插入树对应的位置
insert(value){
const newNode = new Node(value)
if(this.root === null){
this.root = newNode
return this
}
let current = this.root
while(true){
if(value === current.value) return undefined
if(value < current.value){
if(current.left === null){
current.left = newNode
return this
}
current = current.left
} else {
if(current.right === null){
current.right = newNode
return this
}
current = current.right
}
}
}
// find 方法将值作为参数,遍历树寻找对应的值
// 如果找到了,返回找到的值,如果没有找到,返回undefined
find(value){
if(this.root === null) return false
let current = this.root,
found = false
while(current && !found){
if(value < current.value){
current = current.left
} else if(value > current.value){
current = current.right
} else {
found = true
}
}
if(!found) return undefined
return current
}
// contain 方法将值作为参数,如果找到树中对应的值返回 true,如果没有找到则返回 false
contains(value){
if(this.root === null) return false
let current = this.root,
found = false
while(current && !found){
if(value < current.value){
current = current.left
} else if(value > current.value){
current = current.right
} else {
return true
}
}
return false
}
}
堆
堆是有特殊规则的树结构。主要有两种形式的堆:最大堆和最小堆。在最大堆中,父节点的值必须比子节点大;在最小堆中,父节点的值必须比子节点小。
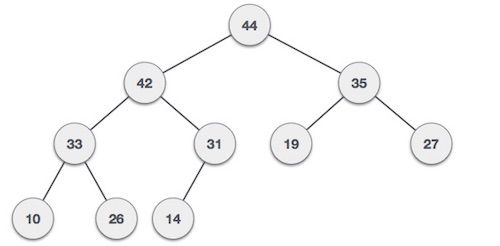
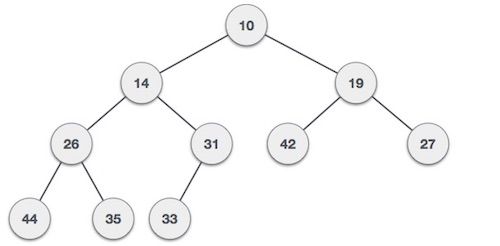
堆结构的规则不适用于相邻的两个节点,也就是说在同一层的节点除了必须比自己的父节点大或者小,不需要遵循其他规则。
另外,堆越紧凑越好,也就是每一层都尽可能填满空位,新的节点首先添加到左边。
堆,特别是二进制堆,通常被用来解决优先队列问题,也被运用到知名的算法问题——戴克斯特拉算法。
优先队列是一种数据结构,在这种结构中,每一个元素都被关联了优先级,优先级高的元素优先展示出来。
图
图是一种有一组节点相互连接的数据结构。和树不一样的是,图并没有根或者叶节点,也没有“头”或者“尾”。不同的节点随机关联在一起,之间并没有父子关系。
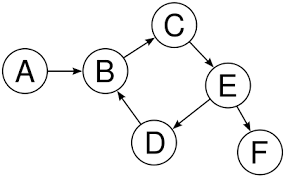
图经常被应用于:
- 社交网络
- 地理定位
- 推荐系统
根据节点之间关联的特征,可以把图分成不同的类别:
有向图和无向图
如果节点之间没有的关联没有定义方向,我们就称这个图为无向图。
在下图中我们可以看到节点 2 和节点 3 之间的关联没有方向性,我们可以从节点 2 到节点 3,也可以从节点 3 到节点 2。无定向意味着节点间的连接是双向的。

你可能已经猜出来了,有向图就是完全相反的。让我们再次使用上面的图,这时节点之间的连接是有固定方向的。
在这幅图中,你可以由节点 A 到节点 B,但是不能从节点 B 到节点 A。
加权图和非加权图
如果节点之间的连接被分配了权重,我们就称其为加权图。权重仅分配给了节点之间的连接,仅和连接相关,不和节点相关。
在下面的例子中我们可以看到,节点 0 和节点 4 之间连接的权重是 7;而节点 3 和节点 1 之间的权重是 4。

想要了解加权图,可以想象你需要向用户展现一个标注了不同地点的地图,你需要告诉用户从一个地方到另一个地方需要花多长时间。
加权图就可以用来表现这个场景,你可以使用节点来存储地点的信息,节点之间的连接就是两个地点之间的道路,连接的权重代表从一个地点到另一个地点的物理距离。
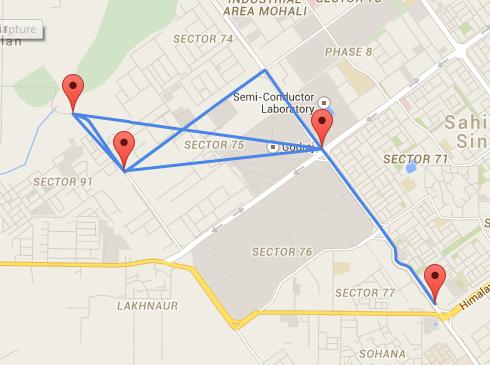
你应该已经猜到了,无加权图即节点之间的连接没有被分配权重,所以节点间的连接没有额外的信息,只表达节点间的关系。
如何表达图
在编码图的时候,主要可以使用两种方法:邻接矩阵和邻接列表。让我们分别看看这两种方法的优缺点。
邻接矩阵是一个二维结构代表图的节点和节点之间的连接。
如果我们使用这个的例子:
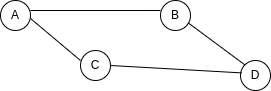
我们的邻接矩阵会是这个样子:
矩阵可以用表格来表示,列和行来代表图里的节点,单元格内的值表示节点之间连接,如果单元格的值为 1,则表示该位置的行和列是相关联的,如果是 0,则表示没有联系。
这个表格可以用简单的二维数组来表示:
[
[0, 1, 1, 0]
[1, 0, 0, 1]
[1, 0, 0, 1]
[0, 1, 1, 0]
]
邻接列表可以使用键值对结构来表示,键代表节点而值代表对应节点的连接。
上面的例子,用邻接列表可以表达为:
{
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "D"],
D: ["B", "C"],
}
每一个节点为一个键,对应的值是与节点相连接的节点组成的数组。
这就是邻接矩阵和列表的所有区别吗?除此之外,当我们需要添加或者删除节点的时候,列表会更加方便;而当我们需要查询某个节点之间的关联的话,矩阵更方便。
假设要在我们的图里添加一个新的节点:
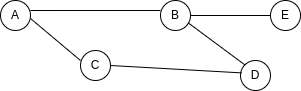
如果要用矩阵来表达的话,我们需要添加一个全新的列和行:
但是在列表中,我们只需要在 B 的连接数组中添加一个值,以及再添加一个代表 E 的键值对就够了:
{
A: ["B", "C"],
B: ["A", "D", "E"],
C: ["A", "D"],
D: ["B", "C"],
E: ["B"],
}
现在假设我们需要验证 B 和 E 之间是否存在连接,在矩阵中检查就非常简单,因为我们知道节点间关联的位置位于哪个单元格。
但如果是在列表中,我们不能马上得出结论,必须先遍历所有和 B 的连接相关的数组,来查看是否有 E。通过这个例子你就了解了两种形式的优劣了。
邻接列表的完全实现如下,我们把图限定在无向和无权重,来简化代码:
// 为图创建一个类
class Graph{
// 图仅有一个属性,即邻接列表
constructor() {
this.adjacencyList = {}
}
// addNode 将节点值作为参数,如果邻接列表没有键的话,就把节点值传入邻接链表作为键
addNode(node) {
if (!this.adjacencyList[node]) this.adjacencyList[node] = []
}
// addConnection 将两个节点作为参数,并添加到每一个节点键对应的值的数组中
addConnection(node1,node2) {
this.adjacencyList[node1].push(node2)
this.adjacencyList[node2].push(node1)
}
// removeConnection 方法将两个节点作为参数,并删除掉非自己节点对应数组里的值
removeConnection(node1,node2) {
this.adjacencyList[node1] = this.adjacencyList[node1].filter(v => v !== node2)
this.adjacencyList[node2] = this.adjacencyList[node2].filter(v => v !== node1)
}
// removeNode 方法将节点作为参数,删除该节点所有的连接,并且删除列表中该节点相关的键
removeNode(node){
while(this.adjacencyList[node].length) {
const adjacentNode = this.adjacencyList[node].pop()
this.removeConnection(node, adjacentNode)
}
delete this.adjacencyList[node]
}
}
const Argentina = new Graph()
Argentina.addNode("Buenos Aires")
Argentina.addNode("Santa fe")
Argentina.addNode("Córdoba")
Argentina.addNode("Mendoza")
Argentina.addConnection("Buenos Aires", "Córdoba")
Argentina.addConnection("Buenos Aires", "Mendoza")
Argentina.addConnection("Santa fe", "Córdoba")
console.log(Argentina)
// Graph {
// adjacencyList: {
// 'Buenos Aires': [ 'Córdoba', 'Mendoza' ],
// 'Santa fe': [ 'Córdoba' ],
// 'Córdoba': [ 'Buenos Aires', 'Santa fe' ],
// Mendoza: [ 'Buenos Aires' ]
// }
// }
总结
以上就是全部内容。在这篇文章中我们介绍了计算机科学和软件开发中的主要数据结构。这些数据结构是许多程序的基础,所以学习这些知识非常有用。
虽然刚开始接触这个话题的时候,你会觉得非常抽象甚至有些害怕,但是我相信当你把这些数据结构当作解决日常任务的一种方式的时候,你会更理解它们。
希望你享受阅读这篇文章,并且从中受益。你可以在 LinkedIn 或者 Twitter 上关注我。
我们下篇文章见!
