
原文:How to Detect Outliers in Machine Learning – 4 Methods for Outlier Detection,作者:Bala Priya C
你是否使用过现实数据来对机器学习模型进行过训练?如果答案是肯定的,你很可能遇到过_异常点_。
异常点通常_明显_地不同于数据集中其他数据。异常点的存在会扭曲数据集的数据分布,提高数据的不连贯性或使观测产生错误。
为了使训练模型在进行测试时有更好的泛用性,发现并删除异常点非常重要。
在本文中,我们将介绍几个常用来发现并去除异常点的统计学工具。
为什么需要发现异常点
在机器学习流程中_数据清洗_和_数据预处理_是两个关键步骤,它们能帮助你更好地理解你所面对的数据。这些步骤中包括处理丢失值,发现异常值等操作。
过高或过低的异常值常常会扭曲数据集的统计分析结果。这会使得训练出来的模型低效甚至完全无效。
处理异常值需要一定的专业性,在_不清楚_所面对的数据和消除异常值工具适用环境的情况下不应冒然使用。
举例来说,如果你在房价数据集中发现_少量_房价处于150万美金并显著高于所有房价中位数时,这些150万美金的房价很可能是异常值。但是,当数据集包含有大量100万美金以上的房价时,房价呈现上涨趋势。此时将150万美金的房价将视为异常值是_不合适_的。在此情境下,数据分析者需要一定的房地产知识以便正确处理异常值。
发现异常值的目的是为了去除_真正的异常值_以便构建一个泛用的,即使面对未知数据依旧能表现良好的模型。我们将几个有助于发现异常值的统计工具。
如何通过标准差发现异常值
如果一组数据,或数据集中某些特征符合正态分布时,可以考虑使用正态分布及等效的Z-分数(z-score)来发现异常值。
在统计学中,标准差(standard deviation)反映了_数据点和均值(mean)之间的关系+,一言以蔽之,标准差衡量的是数据点离数据的算数平均有多远。
对于正态分布的数据来说,约68.2%的数据在均值的一倍标准差之内。约有95.4%和99.7%的数据点在均值的两倍和三倍标准差以内。
我们约定标准差为σ,算术平均为μ。
一个发现异常值的方法是将_阈值下限_设为均值减去三倍标准差 (μ - 3*σ) ,_阈值上限_设为均值加上三倍标准差 (μ + 3*σ) 。所有在阈值之外的数据点都被视为异常值。
因为99.7%的数据点会在均值的±三倍标准差以内,此方法将会发现并标记0.3%的数据点为异常值。
使用标准差检测异常点的代码
我们通过构造一个正态分布的学生分数数据集,用以解释发现异常点的过程。
第一步,载入必须的python库。
import numpy as np
import pandas as pd
import seaborn as sns
第二步,定义名为generate_scores()的函数,这个函数会生成一个有包含有200个数据的正态分布的分数数据集。我们会使用这个函数生成数据集并存储到变量scores_data中。
def generate_scores(mean=60,std_dev=12,num_samples=200):
np.random.seed(27)
scores = np.random.normal(loc=mean,scale=std_dev,size=num_samples)
scores = np.round(scores, decimals=0)
return scores
scores_data = generate_scores()
你可以使用Seaborn的displot()函数来生成数据集分布图像。通过下图可以看出,这个数据集服从正态分布。
sns.set_theme()
sns.displot(data=scores_data).set(title="Distribution of Scores", xlabel="Scores")

图表1:正态分布
接下来,我们可以把该数据集导入Pandas dataframe 以便进一步分析。
df_scores = pd.DataFrame(scores_data,columns=['score'])
你可以使用.mean()和.std()方法来获取数据集df_scores的均值和标准差。
df_scores.mean()
# Output
score 61.005
dtype: float64
df_scores.std()
# Output
score 11.854434
dtype: float64
像之前说的一样,阈值下限(lower_limit)设为算数平均减去三倍标准差,阈值上限(upper_limit)设为算术平均加上三倍标准差。
lower_limit = df_scores.mean() - 3*df_scores.std()
upper_limit = df_scores.mean() + 3*df_scores.std()
print(lower_limit)
print(upper_limit)
# Output
25.530716709142666
96.47928329085734
通过上一步我们定义了阈值的上下限,我们可以使用这个阈值[lower_limit, upper_limit]来筛选数据集df_score中处于这个阈值的数据点,代码如下。
df_scores_filtered=df_scores[(df_scores['score']>lower_limit)&(df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[198 rows x 1 columns]
通过上面的输出,我们发现这个方法移除了两个数据点,数据集df_scores_filtered包含有198个数据点。
如何用过z-score检测异常值
接下来我们尝试使用z-score检测异常值的方法。对于均值为μ标准差为σ的正态分数来说,数据点x的z-score可以这么计算:
z = (x - μ)/σ
通过上述公式,我们可以推导出以下条件:
- 当 x = μ 时,z-score 为 0
- 当 x = μ ± 1, μ ± 2, 或 μ ± 3 时,z-score 为 ± 1, ± 2, 或 ± 3
我们可以发现,通过z-score检测异常值的方法其实等价于我们之前尝试过的通过标准差检测异常值的方法。通过对数据点进行标准化(z = (x - μ)/σ),所有低于标准差方法中低阈((μ - 3*σ)的数据点将等价于z-score小于-3的数据点。
类似的,通过标准化,大于上阈值(μ + 3*σ)的数据点等价于z-score大于3的数据点。所以上下阈值[lower_limit, upper_limit]可以理解为[-3, 3]。
接下来我们将使用z-score方法来检测数据集df_scores中的异常点。
使用z-score检测异常点方法的代码
第一步,我们计算所有数据点的z-score,并把z_score作为新的一列添加进数据集df_scores中。
df_scores['z_score']=(df_scores['score'] - df_scores['score'].mean())/df_scores['score'].std()
df_scores.head()
# Output
score z_score
0 75.0 1.180571
1 56.0 -0.422205
2 67.0 0.505718
3 65.0 0.337005
4 63.0 0.168291
第二步,我们用阈值[-3, 3]来过滤掉数据集df_scores中z-score不在范围内的数据点。由于此方法等价与之前解释过的标准差方法,过滤后的数据集包含有198个数据点。
以上两种方法(通过标准差检测异常值和通过z-score来检测异常值)只适用于服从正态分布的数据。
接下来,我们将研究两种对数据分布_没有要求_的检测异常值的方法。
通过四分位距(IQR)检测异常值的方法
统计学上,四分位距(IQR)反映了给定数据集中第一和第三分位数之间的距离。
- 第一份位数又称为四分之一分位数或25%分位数
- 我们约定
q25为第一分位数,这意味这数据集中有25%的数据点小于q25 - 第三份位数又称为四分之三分位数或75%分位数
- 我们约定
q75为第三分位数,这意味这数据集中有75%的数据点大于q75 - 使用上述表述方法,
IQR = q75 - q25
通过四分位距(IQR)检测异常值方法的代码
我们可以使用箱型图或者箱线图来图形化数据集中的异常值。明显位于箱线图之外的数据点可以被视为异常值。
我们可以使用Seaborn中的boxplot函数生成箱型图。
sns.boxplot(data=scores_data).set(title="Box Plot of Scores")
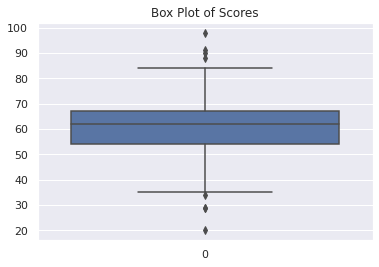
图表2:箱型图
现在,我们调用.describe()函数检测数据集df_scores。
df_scores.describe()
# Output
score
count 200.000000
mean 61.005000
std 11.854434
min 20.000000
25% 54.000000
50% 62.000000
75% 67.000000
max 98.000000
我们使用25%和75%分位数来计算四分位距(IQR),并使用它们(25%分位数到75%分位数)作为阈值。
IQR = 67-54
lower_limit = 54 - 1.5*IQR
upper_limit = 67 + 1.5*IQR
print(upper_limit)
print(lower_limit)
# Output
86.5
34.5
下一步,利用四分位距(IQR)对数据集df_scores进行筛选。
df_scores_filtered = df_scores[(df_scores['score']>lower_limit) & (df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[192 rows x 1 columns]
从以上结果可以看出,四分位距方法把八个数据点标记为异常值,筛选后的数据集包含有192个数据点。
我们除了可以使用.describe()来计算分位数,还可以使用NumPy库中的.percentile()函数来计算分位数。
以下代码展示了如何使用.percentile()函数计算第一和第三分位数。
q25,q75 = np.percentile(a = df_scores,q=[25,75])
IQR = q75 - q25
print(IQR)
# Output
13.0
利用百分位数方法检测异常值
上一小节中我们探讨了四分位距和利用它进行异常值检测的方法。四分位距可以认为是百分位数的一个特例,所以我们也可以用百分位数来检测异常值。
上一节中的四分位距方法使用[q25 - 1.5*IQR, q75 + 1.5*IQR]作为阈值,不在此范围内的数据点被标记为异常值。四分位距方法适用于数据点分布较分散的数据集,这种方法倾向于过多的标记异常值。
为了更好地标记异常值,我们可能需要使用除第一和第三分位数之外的其他分位数。接下来我们将通过百分位数方法再次检测scores数据集中的异常值。
使用百分位数检测异常值方法的代码
第一步,我们首先找到0.5百分位数和99.5百分位数的范围。我们可以利用.percentile()函数带入q = [0.5, 99.5]来计算这个范围,代码如下:
lower_limit, upper_limit = np.percentile(a=df_scores,q=[0.5,99.5])
print(upper_limit)
print(lower_limit)
# Output
91.035
28.955
下一步,我们可以使用之前计算的阈值对数据集进行检测。
df_scores_filtered = df_scores[(df_scores['score']>lower_limit) & (df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[198 rows x 1 columns]
通过以上代码的结果我们可以看出有两个数据点被标记为异常值,过滤后的数据集包含有198个数据点。
结语
本文介绍了什么是异常值,我们为什么需要检测异常值,及我们如何检测异常值。本文介绍了四种最常见的检测异常值的方法。
总结如下:
- 如果要研究的数据或特征符合正态分布,我们可以使用标准差或z-score来标记异常值。通常我们标记超出均值正负三倍标准差的数据点为异常值。
- 如果要研究的数据不服从正态分布是,我们可以使用四分位距或者百分位数来检测异常值。
此外我们还介绍了检测异常值的一些特殊情况。当数据集中有大量数据被标记为异常值时要慎重,因为造成这种情况的原因可能是因为我们手头的数据集属于一个更大更完备的数据集,被标记的异常值可能描述了更大的数据集的分布情况。
除此之外,在检测异常值的过程中要根据数据集的特征适时调整用来筛选检测异常值的阈值。