

原文: How to Improve AWS Performance Without Spending More Money
识别性能问题一直是工程的圣杯。你希望成为能够诊断和解决生产中出现的性能问题的软件工程师。这确实为你的工程能力增加口碑。
最近我们在工作中遇到了一个问题,我觉得写这个问题很有意思。我将深入探讨我们如何去尝试找到问题的根源(这通常是问题的 90%),然后我们如何修复它。
问题开始的地方
问题是从 AWS 开始的。该应用程序已经顺利地运行了一段时间,没有任何问题。我们决定运行一个负载测试,以了解一个特定的 API 是否能够处理我们预期的负载。
我们下载了 JMeter,试图弄清楚如何使用它,然后放弃了。一天后,我们又回到了这里,终于对如何启动和运行它有了一些想法。
我们把它指向在 AWS 上运行的测试服务器,并启动 25 个线程循环运行 8 次,很快就看到约 25% 的请求失败。请求的平均时间是 45 秒。不瞒你说,这是很可怕的。
这让我们很害怕,因为这意味着我们的路由是如此可笑的低效,以至于它只能产生大约 1.2 个请求/秒的吞吐量。但我们预计它可以处理大约 4-8 个请求/秒的负载。
好吧,那到底发生了什么?为什么这条路线的效率如此之低?
节流(Throttling)CPU
我们立即做出的假设是将问题指向公司内部的 ERP 系统,我们依靠该系统进行验证。当然,这必须是 ERP,因为这意味着我们不需要承担任何责任,因为它是一个不同的供应商。
好吧,在将 JMeter 指向本地机器并运行相同的负载测试后,我们很容易达到了我们想要的吞吐量。事实上,我们超过了它(想要的吞吐量)相当多的数量。如果是内部 ERP 系统造成的问题,为什么不能在本地机器上重现?
我联系了在 AWS 工作的人寻求帮助,并被告知 AWS 节省服务器费用的方向,因为我们的 CPU 负载在 EC2 测试实例上从未超过 10%。
那么,当你在 AWS 上运行你的应用程序时,到底发生了什么?说实话,我并不真正了解内部情况,现在也不完全了解。
你从 AWS 购买计算时间。我以为这意味着他们在服务器上运行我们的应用程序,我们为服务器时间付费。但是,这并不十分准确。
AWS 有一个 EC2 计算单元(ECU)的概念,这是他们抽象出的,不必考虑你的应用程序实际运行在什么服务器上。如果你能从 ECU 的角度考虑问题,你就根本不必担心实际的物理基础设施。
AWS 后来将 ECU 改为虚拟 CPU(vCPU),但你仍然可以在网上找到很多关于 ECU 的参考资料。
因此,vCPU 是他们描述各种实例的计算能力的方式。我们为我们的测试服务器使用一个 t2.micro EC2 实例,并为我们的生产服务器运行其中两个实例。我们的应用程序主要是读取繁重的 OLTP 工作负载。
由于 AWS 在由管理程序分隔的单个服务器上运行多个应用程序,因此它们会根据你选择的实例为你的应用程序分配特定数量的计算带宽、网络带宽和存储。
AWS 如何为 t2 类实例管理这一点是通过被称为 Burst Credits 的东西。
我如何因突发积分而 CPU 被限制?
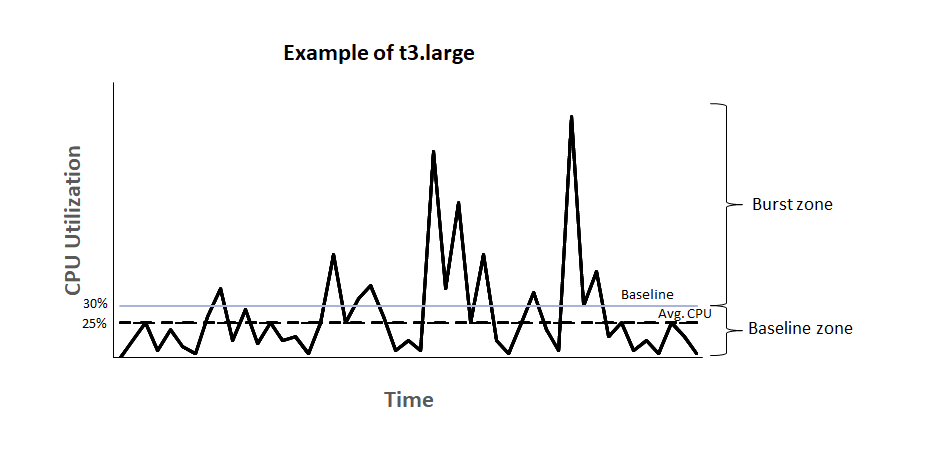
上面的图表确切地解释了 AWS 突发积分对 EC2 实例的作用。该图片的来源是该 AWS 文档。
这是 AWS 为你提供了一个基准 CPU 利用率,超出该基准你需要为所消耗的 CPU 时间付费。
以 EC2 t2.micro 实例为例,其基准 CPU 利用率设置为 10%。该实例根据其拥有的 vCPU 数量不断获得积分。
获得积分的计算方法是:
1vCPU * 10% 基线 * 60 分钟 = 每小时 6 个积分
如果你使用的是 15%,则消费积分的计算是:
1vCPU * 15% CPU * 60 分钟 = 每小时 9 个积分
因此,如果你一直以 15% 的速度运行,你的实例每小时就会损失 9 个积分。一个 t2.micro 实例总共只能积累 144 个积分。一旦这些信用额度用完,你的 CPU 使用率将被节制在 10%,这是基准利用率。
因此,虽然你可能不会在实例上严格地付钱,但你是在损失的 CPU 周期中为此付出代价。
另一种确认你因节流而丢失 CPU 周期的方法是登录你的 EC2 实例并运行 top 命令来检查等待 CPU 的时间百分比(steal time)。如果您尝试对服务器进行负载测试并且 CPU 受到限制,那么你可以实时观察等待 CPU 的时间百分比(steal time) 的增加,以防止你的进程占用任何额外的 CPU 时间。
数据库故障
好吧,如果问题是 EC2 实例的节流,移除节流应该可以解决问题,对吗?好吧,我们检查了我们的生产实例,发现它们也有故障,即使它们没有被节流。
在生产实例上,我们意识到一些请求需要超过 10 秒,一旦到了下午 2 点就会超时。
为什么下午 2 点是相关的?
因为 AWS 限制了你在 EC2 服务器上可以使用的 CPU 率,他们也限制了你的 RDS 实例的 IOPS 数量。
AWS 将你的 IOPS 限制为 3(分配给你的 EBS 卷的存储)。实例化 RDS 实例时,还需要为其分配一些磁盘存储。AWS 如何在不影响任何数据的情况下升级你的 RDS 实例,将这两者相互分离。
我们一开始在 GP2 存储中使用 20GB,这为我们提供了 60IOPS。但是,AWS 提供至少 100 IOPS。
但是,每次你的 RDS 实例超过 100 IOPS 时,你都会消耗特定于数据库实例积分,不同于 EC2 实例的 CPU 突发积分。
用户在每天下午 2 点左右面临速度变慢的原因是因为我们的 IOPS 全天超过 100,这将消耗突发信用,然后在下午 2 点用完,我们被限制为 100 IOPS。
这导致了我们的用户面临的所有超时!我们认为解决此问题的最简单和最便宜的方法是增加 EBS 卷的存储容量。我们将其增加到 100GB,这为我们提供了 300 IOPS 的基准。我们认为这已经足够了,因为我们一天中的平均 IOPS 波动很大,但似乎平均在这个数字附近。
我们升级了 EBS 卷并等待第二天下午,但是完全相同的问题再次出现!
在查看我们的平均 IOPS 时,我选择了 1 分钟的间隔,因为它显示了很多尖峰,所以并不能公平地反映平均值。 选择 1 小时间隔显示平均 600 IOPS 明显更高!
在深入研究 IOPS 问题后,我发现读取 IOPS 占总 IOPS 的大部分负载。
作为最后的手段,我们决定在 AWS 控制台上为我们的 RDS 实例启用 Performance Insights,以便我们可以查看哪些查询占用了大部分 IOPS 并修复该特定查询。
当我们尝试启用 Performance Insights 时,我们发现它只适用于 db.t3.medium,这迫使我们升级到具有 4GB RAM 的数据库实例。
我们升级了实例,然后重新启动了数据库服务器并等待。我密切关注 IOPS 指标,但它似乎没有超出 0-10 IOPS,我认为这意味着没有人使用该应用程序。
我反复检查并被告知,人们正在使用该应用程序,它的工作完全正常,但我就是不明白发生了什么。为什么它在工作?它不应该工作,几乎没有任何 IOPS 发生。
请记住为什么内存很重要
好吧,我没有意识到的一件事是 RAM 如何影响数据库发生的 IOPS。
AWS 将 IOPS 测量为对硬盘本身的读取和写入。它不会将其测量为对 MySQL 中的 innoDB 引擎维护的缓冲池的读/写。
问题是我们之前使用的数据库实例(db.t2.micro)只有 1BG 的 RAM,这意味着缓冲池大小约为 250MB。在具有 4GB RAM 的新实例上,这意味着缓冲池有 2GB 可供使用。
导致大量 IOPS 的有问题的查询是查询大小约为 210 MB 的表。由于它正在执行表扫描,它几乎将整个表加载到缓冲池中,然后在上面运行它需要进行的任何操作。
由于缓冲池只有 250 MB 左右,一旦加载大表,它会不断删除所有其他数据,然后必须返回磁盘获取它们,从而导致更高的 IOPS。
有问题的查询
这个难题仍然缺少一块。每次运行时都会将 210MB 的数据加载到内存中的查询是什么?当然,我们通过增加 RAM 解决了这个问题,但是这里显然出了点问题。该表会增加大小,并且不断增加 RAM 并不是一个好的解决方法。
以下是导致所有问题的查询:
EXPLAIN ANALYZE
SELECT `oc`.`oc_number` AS `ocNumber` , `roll`.`po_number` AS `poNumber` ,
`item`.`item_code` AS `itemCode` , `roll`.`roll_length` AS `rollLength` ,
`roll`.`roll_utilized` AS `rollUtilized`
FROM `fabric_barcode_rolls` AS `roll`
INNER JOIN `fabric_barcode_oc` AS `oc` ON `oc`.`oc_unique_id` = `roll` . `oc_unique_id`
INNER JOIN `fabric_barcode_items` AS `item` ON `item`.`item_unique_id` = `roll`.`item_unique_id_fk`
WHERE BINARY `roll`.`roll_number` = 'dZkzHJ_je8'
在其上运行 EXPLAIN ANALYZE 后,MySQL 提供了以下分析(query plan):
-> Nested loop inner join (cost=468792.05 rows=582836) (actual time=0.092..288.104 rows=1 loops=1)
-> Nested loop inner join (cost=264799.45 rows=582836) (actual time=0.067..288.079 rows=1 loops=1)
-> Filter: (cast(roll.roll_number as char charset binary) = 'dZkzHJ_je8') (cost=60806.85 rows=582836) (actual time=0.053..288.064 rows=1 loops=1)
-> Table scan on roll (cost=60806.85 rows=582836) (actual time=0.048..230.675 rows=600367 loops=1)
-> Single-row index lookup on oc using PRIMARY (oc_unique_id=roll.oc_unique_id) (cost=0.25 rows=1) (actual time=0.014..0.014 rows=1 loops=1)
-> Single-row index lookup on item using PRIMARY (item_unique_id=roll.item_unique_id_fk) (cost=0.25 rows=1) (actual time=0.024..0.024 rows=1 loops=1)
查看查询计划(query plan),奇怪的是每次查询运行时都会对 roll 表进行全表扫描。它每次查看 582,000 行,这是性能问题的来源。
这似乎是索引不佳的问题。因此,我浏览了数据表(tables)并查看了每个表的索引,并确保它们是准确的。在运行其余查询之前,我尝试重写查询以过滤 roll 表,但性能更差。
最后,一时兴起,我删除了查询中的 BINARY 函数调用,以确保不区分大小写。由此产生的查询执行计划令人震惊:
-> Rows fetched before execution (cost=0.00 rows=1) (actual time=0.000..0.000 rows=1 loops=1)
只是一个函数调用浪费了荒谬的执行时间。那么,为什么一个函数调用会导致所有这些问题呢?
我想了想,做了每个有自尊的软件工程师在遇到他们无法解决的问题时所做的事情。我在 Stack Overflow 上发布了这个问题。
这是问题的链接。答案是它与列排序规则有关。
由于我将 roll 表中的 roll_number 列中的每个值转换为二进制值,因此 MySQL 不能使用索引,除非在 DDL 中的列上定义了特定的排序规则。
由于索引没用,它正在执行全表扫描并通过嵌套的内连接检查每一行的值。
删除 BINARY 函数调用是解决问题的最简单方法。但是将列排序规则更改为使用拉丁字符集并区分大小写,因此索引是区分大小写的,确保我们不会遇到条形码冲突发生的问题。
AWS 带来的挑战
毫无疑问,AWS 在从数百万软件工程师手中抽象,把硬件方面做得非常出色。但它同时让定价变得如此难以理解,以至于没有人真正知道他们支付了多少,直到为时已晚。
我们不能把 EBS 卷从 100GB 降级到 20GB,因为 AWS 不允许这样做。我们不需要额外的存储空间,而且拥有它也没有意义,但我们只能这样做了。
我们也不能从 db.t3.medium 降级到 db.t3.micro,因为我们无法使用性能洞察(Performance Insights)。当然,我们可以重新创建 Performance Insights,因为它本质上是建立在 Performance Schema 之上的,而 Performance Schema 是 MySQL 的原生功能,但这需要大量的工程时间,对我们的最终客户没有任何价值。
结语
我爱 AWS,我爱它使数百万的开发者能够轻松地使用硬件。但是,我不禁对围绕着 AWS 的糟糕的文档感到沮丧,而且除非你愿意不断地掏钱,否则很容易让自己吃亏。
我知道了解硬件是如何被使用的,是软件工程师的必修课。但是,当你需要花这么多时间去理解 AWS 的抽象时,感觉就像一个双重打击,因为它应该消除对底层硬件的担忧。
AWS 有一个 Aurora DB,似乎是一个管理数据库,可以防止这类问题的发生。但有时感觉更容易,就像 Oxide Computer 鼓励人们做的那样,运行自己的硬件。
注:你可以在我的博客这里找到这篇文章和其他文章。