
原文:Introduction to Algorithms – with JavaScript Examples,作者:Germán Cocca
大家好!在这篇文章中,我们将研究算法,这是计算机科学和软件开发的一个关键话题。
算法是一个花哨的词,有时令人生畏,而且经常被误解。算法听起来像是一件非常困难和复杂的事情,但实际上它只不过是为了实现某个目标而必须采取的一系列步骤。
我认为关于算法的基本知识主要包括两点:
- 渐进符号(用来比较两种算法之间的性能)
- 常见任务涉及的经典算法的基本知识,如:搜索、排序和遍历
这篇文章的内容差不多就是这些。😉
让我们开始吧!
目录
什么是算法
如前所述,算法只是为了实现某个目标而需要采取的一系列步骤。
我发现当人们第一次听到算法这个词时,他们会想象出这样的情景:

但实际上以下图片更加准确:

算法就像一本菜谱,它会指出实现目标所需遵循的必要步骤。
制作面包的菜谱如下:
1- Mix flower, salt, water and yeast //混合面粉、盐和酵母
2- Let the dough rise //发面
3- Put in the oven for 30' //在烤箱里烤30分钟
4- Let chill and enjoy //放松享受面包
题外话:希望你既能从这篇免费教程中学会如何编写代码,也能学会如何烤面包。😜
识别单词是否为“回文”(palindrome)的算法可以写成:
function isPalindrome(word) {
// 第一步:在单词的两端分别放置两个指针
// 第二步:指针向字符串中心方向遍历
// 第三步:每一次遍历都检查两个指针所在位置的值是否一致
// 一旦不满足这个条件,该单词就不是回文
let left = 0
let right = word.length-1
while (left < right) {
if (word[left] !== word[right]) return false
left++
right--
}
return true
}
isPalindrome("neuquen") // true
isPalindrome("Buenos Aires") // false
这个算法就和菜谱类似,设定一个目标,并将目标拆分成不同步骤,这些步骤以给定的顺序执行,以达到我们想要的结果。
维基百科对算法的定义如下:
算法是明确定义的一连串有序的指令,通常用于解决一类特定问题或者执行计算。
算法复杂度
现在我们知道了什么是算法,让我们来学习如何比较不同的算法。
假设我们遇到下面的问题:
写一个函数,这个函数包含两个参数:一个是非空数组,这个数组中的元素是不重复的整数;另一个是一个整数,值为目标总和。如果数组中任意两个整数加起来等于目标整数,函数返回包含这两个整数的数组,如果没有任何两个数的总和是目标整数,函数返回空数组。
以下是一种解法:
function twoNumberSum(array, targetSum) {
let result = []
// 我们使用嵌套循环来测试数组中每一个可能的数字组合
for (let i = 0; i < array.length; i++) {
for (let j = i+1; j < array.length; j++) {
// 如果我们找到合适的组合,就把值推入结果数组,并返回
if (array[i] + array[j] === targetSum) {
result.push(array[i])
result.push(array[j])
return result
}
}
}
// 返回结果数组
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
以下是另一个种解法:
function twoNumberSum(array, targetSum) {
// 从小到大排列数组,并在两个边界分别放一个指针,向数组中间方向遍历
// 每一次遍历都查看两个指针所在位置的值之和是否等于目标值
// 如果大于目标值,将右指针向左移
// 如果小于目标值,将左指针向右移
let sortedArray = array.sort((a,b) => a-b)
let leftLimit = 0
let rightLimit = sortedArray.length-1
while (leftLimit < rightLimit) {
const currentSum = sortedArray[leftLimit] + sortedArray[rightLimit]
if (currentSum === targetSum) return [sortedArray[leftLimit], sortedArray[rightLimit]]
else currentSum < targetSum ? leftLimit++ : rightLimit--
}
return []
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
还有一种解法:
function twoNumberSum(array, targetSum) {
// 仅遍历一次数组
// 在每次遍历中检查指针所在当前值与目标值的差值是否存在于数组
// 如果存在,则返回指针所在位置的值和差值
let result = []
for (let i = 0; i < array.length; i++) {
let desiredNumber = targetSum - array[i]
if (array.indexOf(desiredNumber) !== -1 && array.indexOf(desiredNumber) !== i) {
result.push(array[i])
result.push(array[array.indexOf(desiredNumber)])
break
}
}
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
这三种都完成了目标,但我们可以对比哪一个解法更好吗?
除了有效性 (是否达成目标)以外, 我们还会根据 效率来衡量算法, 即是否在 时间上 (处理时间)和 空间上 (内存的使用)占用最少的资源。
这很容易马上想到对策——“就去测量算法运行了多长时间不就好了吗?”,这样做确实有效。
但问题是由于计算机硬件和配置的不同,同一个算法在不同的计算机上运行时长也会不同;即便是在同一个台计算机上,后台的运行任务不同也会影响算法的时长。
需要一个客观且不会发生变化的方式来计算算法的性能,渐进符号就派上用场了。
渐进符号(又称大O符号)是用来 分析和比较当输入增加时算法的性能变化的一种系统。
大O是分析和比较不同算法复杂度(时间和空间上)的一种标准方法,因为复杂度的计算的是输入发生变化时,算法运行的次数的变化,无论环境发生什么改变,两者之间的关系不变。
有各种各样复杂度的算法,但是最常用的几个如下:
- 常数 — O(1): 指对运行次数和空间的需求永远独立于输入,保持不变的时候。比如向一个函数输入一个数字,返回这个数字减去10的结果。不论你输入的是100还是1000000,函数始终都运行单个运算(减去10),所以复杂度是常数O(1)。
- 对数 — O(log n): 指随着输入的增加,所需的运行次数和空间需求的增长逐渐放缓。这种类型的复杂性通常出现在分治算法或查找算法中。经典的例子是二分查找,通过不断将数据集拆分成两部分,得到最终结果。
- 线性 — O(n): 指所需的运行次数和空间需求与输入同速率增长时。以打印数组每一个值的循环为例,运行的次数会随着数组的长度而增长,所以复杂度是线性的 O(n)。
- 平方 — O(n²): 指所需运行次数和空间需求以输入的平方增长时。嵌套循环是这个的经典例子。假设我们有一个遍历整个数字数组的循环,并且在该循环中有另一个循环再次遍历整个数组。这样数组中的每个值都被遍历了两次,因此复杂度是平方 O(n²)。

请注意在讨论时间和空间复杂度时使用相同的符号。例如,一个函数无论它接收到什么输入,它总是创建一个具有单个值的数组,那么空间复杂度将是常数 O(1),以此类推其他复杂度类型。
为了更好地理解,让我们回到之前的问题,并分析解决方案的复杂度。
示例1:
function twoNumberSum(array, targetSum) {
let result = []
// 我们使用嵌套循环来测试数组中每一个可能的数字组合
for (let i = 0; i < array.length; i++) {
for (let j = i+1; j < array.length; j++) {
// 如果我们找到合适的组合,就把值推入结果数组,并返回
if (array[i] + array[j] === targetSum) {
result.push(array[i])
result.push(array[j])
return result
}
}
}
// 返回结果数组
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
在这个例子中,我们遍历参数数组,对于数组中的每个值,我们再次遍历整个数组,寻找一个和这个值加起来为目标总和的数字。
每一次遍历为一个任务:
- 如果数组中有3个数字,那么每一个数字都需要遍历三遍一共9遍(三乘以数组里的三个数字),这个任务总共要执行12次。
- 如果数组中有4个数字,那么每一个数字都需要遍历4遍一共16遍(四乘以数组里的三个数字),这个任务总共要执行20次。
- 如果数组中有5个数字,那么每一个数字都需要遍历5遍一共25遍(五乘以数组里的三个数字),这个任务总共要执行30次。
可以看到,与输入相比该算法中的任务数量如何呈指数增长且不成比例。该算法的复杂度是平方 – O(n²)。
每当我们遇到嵌套遍历,我们的反应链应该是平方复杂度 => 不妙 => 可能有更好的解决办法。
示例2:
function twoNumberSum(array, targetSum) {
// 从小到大排列数组,并在两个边界分别放一个指针,向数组中间方向遍历
// 每一次遍历都查看两个指针所在位置的值之和是否等于目标值
// 如果大于目标值,将右指针向左移
// 如果小于目标值,将左指针向右移
let sortedArray = array.sort((a,b) => a-b)
let leftLimit = 0
let rightLimit = sortedArray.length-1
while (leftLimit < rightLimit) {
const currentSum = sortedArray[leftLimit] + sortedArray[rightLimit]
if (currentSum === targetSum) return [sortedArray[leftLimit], sortedArray[rightLimit]]
else currentSum < targetSum ? leftLimit++ : rightLimit--
}
return []
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
在这个例子中,我们在遍历前对数组进行了排序,通过边界的两个指针向内遍历使得我们仅遍历了一次数组。
因为我们仅遍历了一次数组,所以这个解法比上个好。但是我们对数组进行了排序(通常是对数复杂度)然后再遍历(线性复杂度)。这个解法的复杂度为 O(n log(n))。
示例3:
function twoNumberSum(array, targetSum) {
// 仅遍历一次数组
// 在每次遍历中检查指针所在当前值与目标值的差值是否存在于数组
// 如果存在,则返回指针所在位置的值和差值
let result = []
for (let i = 0; i < array.length; i++) {
let desiredNumber = targetSum - array[i]
if (array.indexOf(desiredNumber) !== -1 && array.indexOf(desiredNumber) !== i) {
result.push(array[i])
result.push(array[array.indexOf(desiredNumber)])
break
}
}
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []
在这个例子中,我们仅遍历了一次,并且在遍历之前没有做任何操作。因为了任务数量为三个里面最少的,所以这是最优解。这种情况的复杂度为 – O(n)。
复杂度就是 算法背后最重要的概念。了解如何比较不同的实现,哪一种方式更为有效十分有必要,因此如果你对这个概念尚不清晰,我鼓励你再看一遍上面的例子,或者查阅其他的资料。你还可以 观看这个超级棒的freeCodeCamp 视频教学。
查找算法
在了解了算法复杂度之后,我们来看看用于解决常见程序任务的常用算法。让我们从查找算法开始。
若想要在一个数据结构中查找一个值,可以采用不同种类的方法。我们将展开讲讲并对比两个最常见的方法。
线性查找
线性查找是通过遍历整个数据结构,每次查找一个值,看是否与目标值匹配。 这或许是最符合直觉的查找方式,如果查找是未被排序的数据结构,这是最好的方式。
假设有一个数字数组,我们需要为这个数组编写一个函数,这个函数以单个数字为输入,如果这个数字在数组内则返回这个数字的索引,如果不在,则返回-1.一个可能的解法如下:
const arr = [1,2,3,4,5,6,7,8,9,10]
const search = num => {
for (let i = 0; i < arr.length; i++) {
if (num === arr[i]) return i
}
return -1
}
console.log(search(6)) // 5
console.log(search(11)) // -1
因为数组未被排序,所以我们并不知道每个值的大概位置,最好的办法就是一次检查一个值。这种算法的复杂度是 线性- O(n),因为最坏的情况是我们遍历了整个数组才找到我们需要的值。
线性查找被很多JavaScript内置方法采用,如 indexOf、 includes和findIndex。
二分查找
当数据是被排序过的时候,我们可以使用更有效率的办法:二分查找。二分查找的步骤如下:
- 选择数据结构的中间值后“提问”:这是我们需要的值吗?
- 如果不是,“提问”:这个值是比我们需要的值大还是小?
- 如果更大,则“丢弃”掉比中间值小的那一半数据,如果更小,则“丢弃”比中间值大的那一半数据。
- 不断重复上述操作,直找到我们需要的值,或者剩下的“部分”已经不能被平分了。
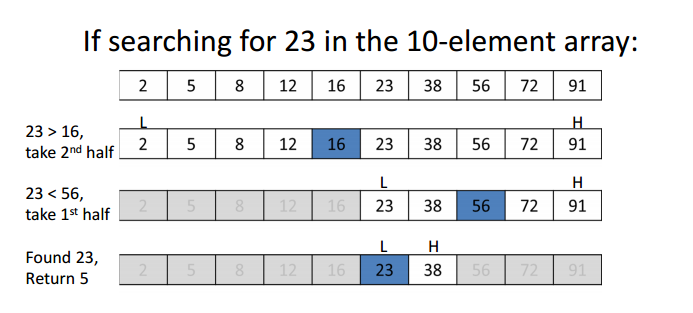
二分查找最棒的地方在于每一次遍历我们几乎都丢弃掉了一半数据。这使得查找更加快速高效。 👌
假设针对同一组数组(排过序)我们需要编写一样的函数,输入一个数字,返回这个数字在数组中的索引,或者如果数字不存在数组中,返回-1。使用二分查找的写法如下:
const arr = [1,2,3,4,5,6,7,8,9,10]
const search = num => {
//我们将使用三个指针
//一个位于左边界,一个位于右边界,一个位于数组的中间
let start = 0
let end = arr.length-1
let middle = Math.floor((start+end)/2)
// 当我们并没有找到目标值,并且开始值小于等于结束值的时候
while (arr[middle] !== num && start <= end) {
// 如果目标值比中间值要小,丢弃掉数值更大的一半数组
if (num < arr[middle]) end = middle - 1
// 如果目标值比中间值大,丢弃掉数值更小的一半数组
else start = middle + 1
// 重新计算中间值
middle = Math.floor((start+end)/2)
}
// 如果找到目标值或者数组不能再被对半分的情况下,跳出循环
return arr[middle] === num ? middle : -1
}
console.log(search(6)) // 5
console.log(search(11)) // -1
这种方法看上去写了“更多代码”,但可能发生的遍历去比线性查找要少了很多,因为我们每一次遍历都丢弃了一半的数组。这种算法的复杂度为 对数的 – O(log n)。
排序算法
我们可以采取不同的方法对数据结构排序,让我们来看看一些最常用的排序方法以及它们之间的区别。
冒泡排序
冒泡排序遍历整个数据结构,一次对比一对值。如果这对值的顺序不对,则交换位置来调整顺序,遍历一直持续到所有数据的顺序正确。这个算法将更大的值“冒泡”至数组的末尾。
因为每一个值都要和剩下的所有值做一次对比,这种算法的复杂度是 平方 – O(n²)。
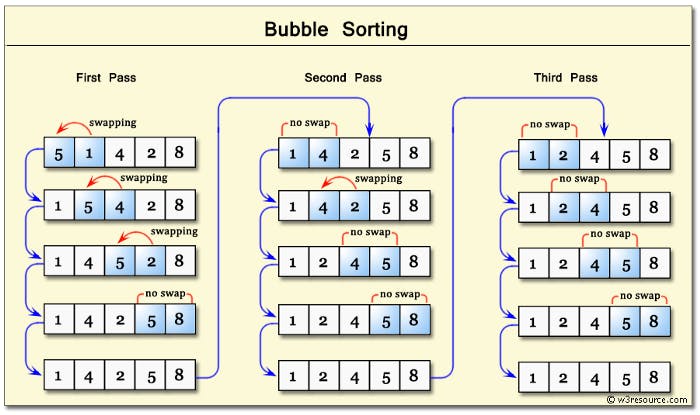
以下是一种实现方式:
const arr = [3,2,1,4,6,5,7,9,8,10]
const bubbleSort = arr => {
// 设置一个标记变量
let noSwaps
//我们需要一个嵌套循环
// 一个从右至左遍历的指针
for (let i = arr.length; i > 0; i--) {
noSwaps = true
// 和一个从右至左遍历的指针
for (let j = 0; j < i-1; j++) {
//比较两个指针
if (arr[j] > arr[j+1]) {
let temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
noSwaps = false
}
}
if (noSwaps) break
}
}
bubbleSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]
选择排序
选择排序和冒泡排序类似,差别在于选择排序不是将更大的值放在数据结构的末尾,而是将更小的值放在数据结构的开始。具体步骤如下:
- 将数据的第一个元素存储为最小值
- 遍历整个数据结构,将每一个值与最小值做对比,如果找到比最小值更小的值,就将其设置为新的最小值
- 如果最小值不是数据结构的第一个值,则将最小值的位置与第一个值的位置交换。
- 重复上述操作直至数组排序正确
这种算法的复杂度为平方 – O(n²)。
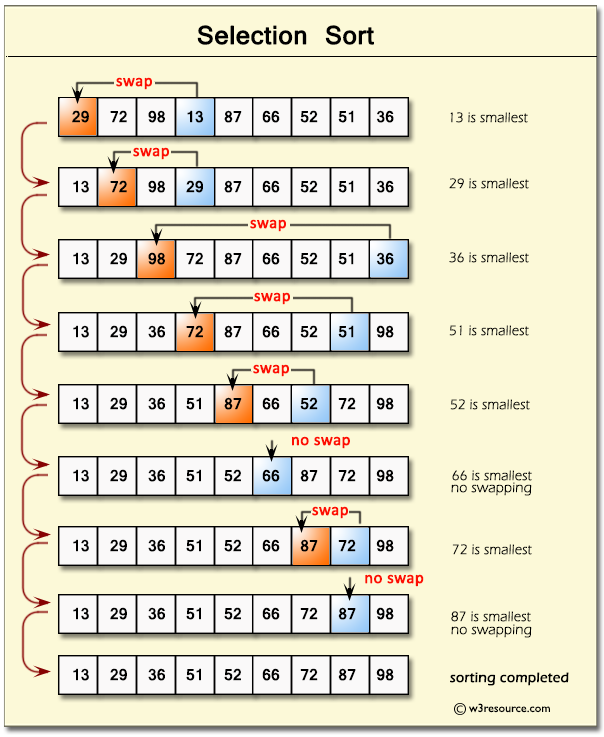
一个可能的实现办法如下:
const arr = [3,2,1,4,6,5,7,9,8,10]
const selectionSort = arr => {
for (let i = 0; i < arr.length; i++) {
let lowest = i
for (let j = i+1; j < arr.length; j++) {
if (arr[j] < arr[lowest]) {
lowest = j
}
}
if (i !== lowest) {
let temp = arr[i]
arr[i] = arr[lowest]
arr[lowest] = temp
}
}
}
selectionSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]
插入排序
插入排序是创建一个“有序的一半”来对数据结构进行排序,遍历整个数据结构,将每一个元素插入到“有序一半”的正确位置。
具体步骤如下:
- 首先挑选数据结构中的第二个元素
- 将其与前一个元素进行比较,必要时进行位置交换
- 继续进入到下一个元素,如果这个元素不在正确的位置,就遍历“有序的一半”找到正确的位置,并且将这个元素插入进去
- 重复上述步骤直至数据结构顺序正确
这个算法的复杂度为平方(O(n²))。
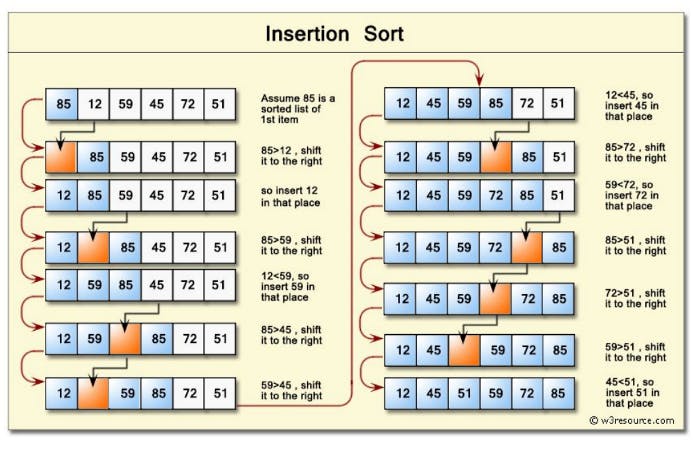
一个可能的实现方案如下:
const arr = [3,2,1,4,6,5,7,9,8,10]
const insertionSort = arr => {
let currentVal
for (let i = 1; i < arr.length; i++) {
currentVal = arr[i]
for (var j = i-1; j >= 0 && arr[j] > currentVal; j--) {
arr[j+1] = arr[j]
}
arr[j+1] = currentVal
}
return arr
}
insertionSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]
冒泡排序、选择排序和插入排序的问题在于并不好扩展。
当我们处理大数据集时,有更好的选择:其中包括归并排序、快速排序和基数排序。那么让我们现在来看看这些吧!
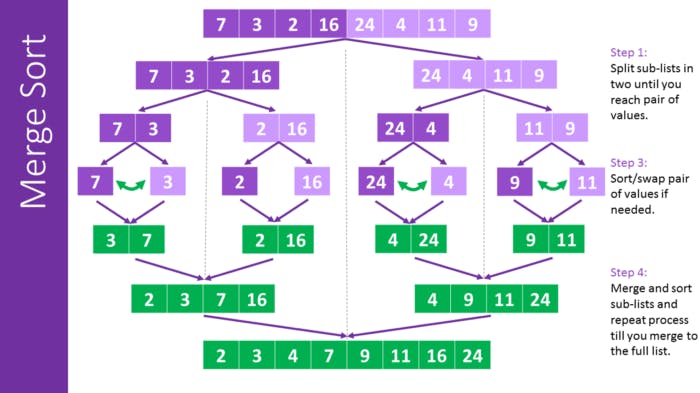
归并排序
归并排序是一种算法,它重复将数据结构分解为单个值,然后按照顺序地组合它。
具体步骤如下:
- 递归地将数据平分两半直至每一个“一半”仅有一个值
- 再递归地将各个“一半”排序直至合并成原数组长度的数组
这个算法的复杂度为 O(n log n), 因为拆解数组的复杂度为log n,而对比大小的复杂度为n。
一个可能的实现方法如下:
const arr = [3,2,1,4,6,5,7,9,8,10]
// 归并函数
const merge = (arr1, arr2) => {
const results = []
let i = 0
let j = 0
while (i < arr1.length && j < arr2.length) {
if (arr2[j] > arr1[i]) {
results.push(arr1[i])
i++
} else {
results.push(arr2[j])
j++
}
}
while (i < arr1.length) {
results.push(arr1[i])
i++
}
while (j < arr2.length) {
results.push(arr2[j])
j++
}
return results
}
const mergeSort = arr => {
if (arr.length <= 1) return arr
let mid = Math.floor(arr.length/2)
let left = mergeSort(arr.slice(0,mid))
let right = mergeSort(arr.slice(mid))
return merge(left, right)
}
console.log(mergeSort(arr)) // [1,2,3,4,5,6,7,8,9,10]
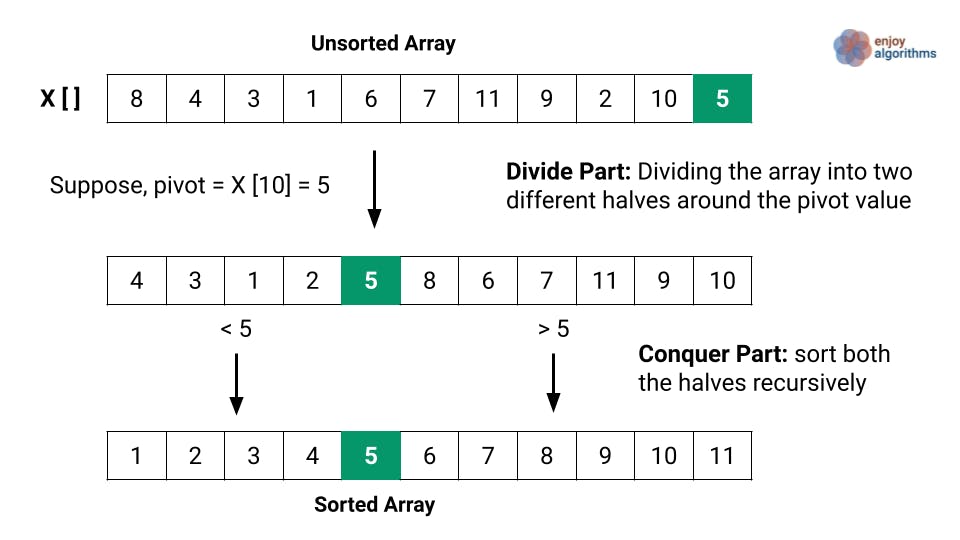
快速排序
快速排序通过选择一个元素(称为“基准”),并最终确定基准应在在一个排好序的数组里的索引位置。
快速排序的运行时间部分取决于选择基准的方式。理想情况下,它应该是被排序后的数据集的中间值。
具体步骤如下:
- 识别基准值,并放置在应该放置的索引位置
- 递归地沿用上述方式对数据结构每一个“一半”进行操作。
这个算法的复杂度是O(n log n)。
一种可能的实现方式如下:
const arr = [3,2,1,4,6,5,7,9,8,10]
const pivot = (arr, start = 0, end = arr.length - 1) => {
const swap = (arr, idx1, idx2) => [arr[idx1], arr[idx2]] = [arr[idx2], arr[idx1]]
let pivot = arr[start]
let swapIdx = start
for (let i = start+1; i <= end; i++) {
if (pivot > arr[i]) {
swapIdx++
swap(arr, swapIdx, i)
}
}
swap(arr, start, swapIdx)
return swapIdx
}
const quickSort = (arr, left = 0, right = arr.length - 1) => {
if (left < right) {
let pivotIndex = pivot(arr, left, right)
quickSort(arr, left, pivotIndex-1)
quickSort(arr, pivotIndex+1, right)
}
return arr
}
console.log(quickSort(arr)) // [1,2,3,4,5,6,7,8,9,10]
基数排序
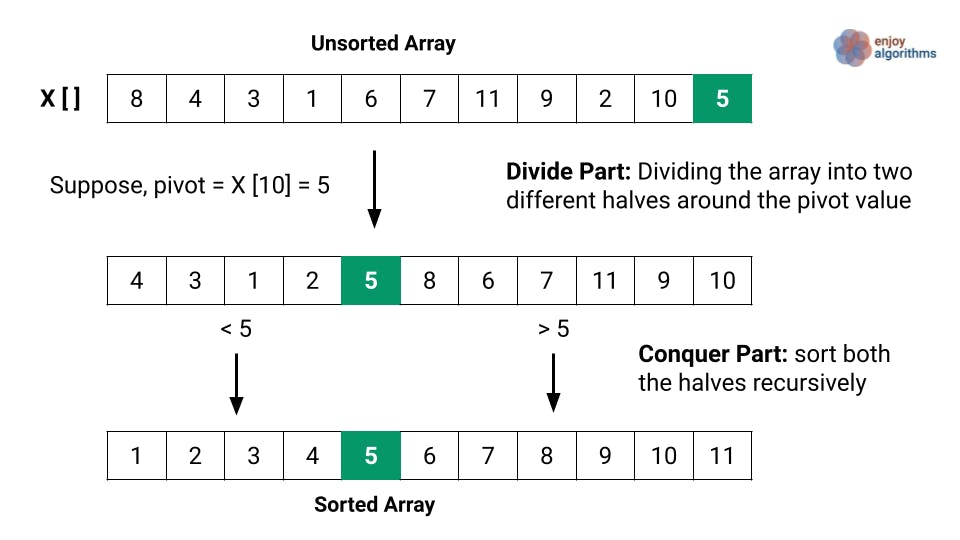
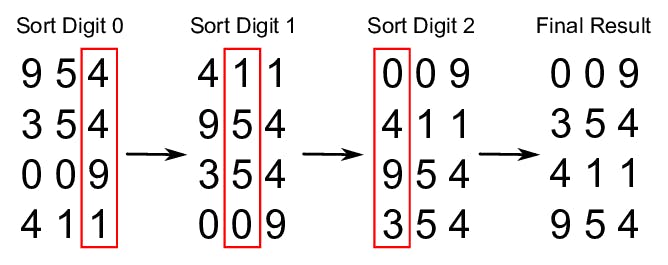
基数算法和前面我们看到的这些算法的运行方式不太一样,因为基数算法并不对比值。基数算法根据数字位数来判断数字大小(位数越多数字越大),从而给数组进行排序。
基数算法是按照位数来给数字排序。它首先按第一个位数对所有值进行排序,然后再按第二个位数,然后按第三个位数……这个过程重复的次数与列表中最大数字的位数一样多。在这个过程结束时,算法返回完全排序后的列表。
具体步骤如下:
- 计算出最大的数字有多少位数
- 循环遍历列表直到最大位数。在每次迭代中:
- 为每个位数(从 0 到 9)创建“桶”,并根据评估将每个值放入其对应的桶中。
- 将现有列表替换为在桶中排序的值,从 0 开始到 9。
这个算法的复杂度为 O(n*k),k是最大数的位数。因为没有相互比较大小,所以这个算法的运行速度比其他的要快,但是这个方法只对数字列表奏效。
如果想要使用一个与数据无关的排序算法,可以使用我们之前讨论的方法。
一种可能的实现方式如下:
const arr = [3,2,1,4,6,5,7,9,8,10]
const getDigit = (num, i) => Math.floor(Math.abs(num) / Math.pow(10, i)) % 10
const digitCount = num => {
if (num === 0) return 1
return Math.floor(Math.log10(Math.abs(num))) + 1
}
const mostDigits = nums => {
let maxDigits = 0
for (let i = 0; i < nums.length; i++) maxDigits = Math.max(maxDigits, digitCount(nums[i]))
return maxDigits
}
const radixSort = nums => {
let maxDigitCount = mostDigits(nums)
for (let k = 0; k < maxDigitCount; k++) {
let digitBuckets = Array.from({ length: 10 }, () => [])
for (let i = 0; i < nums.length; i++) {
let digit = getDigit(nums[i], k)
digitBuckets[digit].push(nums[i])
}
nums = [].concat(...digitBuckets)
}
return nums
}
console.log(radixSort(arr)) // [1,2,3,4,5,6,7,8,9,10]
遍历算法
我们要讨论的最后一种算法是遍历算法,这种算法使用不同方法遍历整个数据结构(主要是树结构和图)。
当我们遍历树结构的时候,我们可以从广度和深度两个方向给数据结构进行优先级排序。
如果我们以深度优先,我们会顺着分支往下遍历整个树,从树首到每一个分支的叶子。

如果我们优先对广度进行搜索,我们就横向地遍历树的每一个节点,然后再遍历到下一个层次。

选取哪一种方式主要取决于我们要遍历的是什么以及数据结构是怎么构建的。
广度优先(BFS)
让我们首先来分析BFS。正如我们介绍过的,BFS会首先横向遍历数组。在下面的图示中,数值将以这个顺序被遍历: [10, 6, 15, 3, 8, 20].

一般来说,BFS分为以下几个步骤:
- 创建一个队列和变量来存储”被访问过“的节点
- 将根节点放置在队列
- 只要队列中有元素,就循环下去
- 将节点移出队列,并保存在存储被访问过节点的变量中
- 如果被移除的节点对象有左侧属性,则添加到队列
- 如果被移除的节点对象有右侧属性,则添加到队列
一个可行的实现方法如下:
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BinarySearchTree {
constructor(){ this.root = null; }
insert(value){
let newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
let current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
BFS(){
let node = this.root,
data = [],
queue = [];
queue.push(node);
while(queue.length){
node = queue.shift();
data.push(node.value);
if(node.left) queue.push(node.left);
if(node.right) queue.push(node.right);
}
return data;
}
}
const tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.BFS()) // [ 10, 6, 15, 3, 8, 20 ]
深度优先(DFS)
DFS会首先横向遍历数组。在上面的图示中,数值将以这个顺序被遍历:[10, 6, 3, 8, 15, 20].
这种DFS又称作“先序遍历”,DFS主要分为三种,这三种的区别在于节点被遍历的顺序。
- 先序: 先访问当前节点,然后左边的节点,然后右边的节点
- 后序: 先访问所有左手边的子节点,再访问所有右手边的子节点,最后访问当前节点
- 中序: 想访问所有左手边的节点,再访问当前节点,最后访问所有右手边节点
现在听上去可能有些让人困惑,不过没关系,看了后面的例子你就会明白了。
先序DFS
在先序DFS中,我们将进行以下步骤:
- 创建一个存储所有被访问过的节点
- 在变量中存储树的根节点
- 编写一个辅助函数接受节点作为参数
- 将节点的值推入存储值的变量中
- 如果节点对象有左属性,则将左节点作为参数调用辅助函数
- 如果节点对象有左属性,则将右节点作为参数调用辅助函数
一个可行的实现如下:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSPreOrder(){
var data = [];
function traverse(node){
data.push(node.value);
if(node.left) traverse(node.left);
if(node.right) traverse(node.right);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSPreOrder()) // [ 10, 6, 3, 8, 15, 20 ]
后续DFS
后续DFS算法的执行步骤如下:
- 创建一个变量存储访问过的节点
- 在变量中存储树的根节点
- 编写一个辅助函数接受节点作为参数
- 如果节点对象有左属性,则参入左节点作为参数调用辅助函数
- 如果节点对象有右属性,则参入右节点作为参数调用辅助函数
- 用当前节点作为参数调用辅助函数
一个可行的执行如下:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSPostOrder(){
var data = [];
function traverse(node){
if(node.left) traverse(node.left);
if(node.right) traverse(node.right);
data.push(node.value);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSPostOrder()) // [ 3, 8, 6, 20, 15, 10 ]
中序DFS
中序DFS算法的执行步骤如下:
- 创建一个变量存储被访问过的节点
- 在变量中存储树结构的根节点
- 编写一个以节点作为参数的辅助函数
- 如果这个节点对象有左属性,将所有左节点作为参数调用辅助函数
- 将节点的值推入存储的值的变量中
- 如果这个节点对象有左属性,将所有右节点作为参数调用辅助函数
- 将当前节点作为参数调用辅助函数
一个可行的实现如:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSInOrder(){
var data = [];
function traverse(node){
if(node.left) traverse(node.left);
data.push(node.value);
if(node.right) traverse(node.right);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSInOrder()) // [ 3, 6, 8, 10, 15, 20 ]
你可能已经注意到,先序、后序和中序的实现非常类似,仅改变了遍历节点的顺序。但其实这三种实现得到的结果大相径庭,有时其中一种方法可能比其他的要有用得多。
何时使用BFS或者DFS取决于数据结构是如何组织的
一般来说如果你有一个结构非常宽的树或者图(意味着在同一水平线上有很多后代节点),就应该采用深度优先。如果是处理分支很长的大型树或者图,就应该使用广度优先。
两种算法的时间复杂度是一样的,因为我们始终遍历了所有节点一次。但是空间复杂度取决于有多少节点被存储在内存中,所以不相同。因此记录越少的节点越好。
总结
希望享受阅读这篇文章,并且从中有所收获。你可以在LinkedIn或者Twitter上关注我。
下篇文章见!
