

原文: What Happens When You Visit a Website? How the Web Works Explained
在这篇文章中,我将引导你了解使用浏览器访问网站时发生的整个过程。
无论你是刚接触 web 开发还是已经有一些经验,这篇文章都将帮助你更好地理解网络及其核心技术的工作原理。
目录
在深入介绍过程中的每个步骤细节之前,让我们先回顾一下将会涉及的基本概念。
互联网是一个由相互连接的计算机组成的庞大网络。万维网(又称 web)建立在这项技术之上,还有电子邮件、聊天系统或文件共享等其他服务。
连接到互联网的计算机分为:
-
客户端,web 用户的设备和这些设备用来访问 web 的软件。
-
服务器,存储网页、网站或应用程序以及在用户的 web 浏览器或设备中显示所需文件的计算机。
资源定位:URL
每个存储在服务器上的资源都可以通过其对应的 URL 被客户端定位。以下是一个有效 URL 的示例:

你可能已经知道 URL 是什么,但让我们详细看看它的每个组成部分:
-
协议类型: URL 的第一部分表明应该使用哪种协议来获取资源。网站可以使用 HTTP 和 HTTPS 协议,我们稍后会详细介绍。协议类型后面的
:用来分隔 URL 的下一部分。 -
授权: 这部分由域名和端口号组成,用冒号分隔。只有当 web 服务器不使用 HTTP 协议的标准端口(HTTP 用 80,HTTPS 用 443)时,端口才是必需的。域名前的
//表示授权的开始。 -
资源路径: 这是 web 服务器上资源的抽象或物理路径。
-
参数: 一组键/值对,为返回请求的资源添加额外选项。它们用
&分隔,每个 web 服务器都有自己处理参数的方式。这部分以?开始。 -
锚点: 如果存在,以
#开始,由浏览器处理以显示返回文档的特定部分。例如,它可以指向 HTML 文档中的特定部分。
当你在浏览器地址栏中输入 URL 时,会发生一些让你能够访问网站并与其内容交互的事情。让我们详细了解每一个过程。
匹配 IP 和 URL:DNS 解析
虽然作为人类我们更喜欢由单词组成的域名,但计算机之间使用 IP 地址进行通信。IP 地址由数字组成,对人类来说更难记忆。域名系统(DNS)就是将域名和 IP 地址关联起来的系统。
当你输入 URL 时,浏览器首先会查看本地缓存,检查是否已存储 DNS 查询结果。然后,它还会检查操作系统缓存。
如果没有存储结果,浏览器将调用 DNS 解析器来尝试找到域名对应的 IP 地址。
什么是 DNS 解析器?
解析器通常由你的互联网提供商的 DNS 定义。尽管这是大多数人使用的默认设置,但你可以将其更改为 Google、Cloudflare 或其他任何你想要的服务。
同样,提供商的 DNS 可能在其缓存中存储了域名的结果,如果没有,它会询问根 DNS 服务器。
什么是根 DNS 服务器?
根 DNS 服务器是实际驱动整个互联网的系统。它由分布在全球的十三个服务器组成。它会用请求域名的相关顶级域服务器来响应解析器的查询。
此时,DNS 解析器会缓存该顶级域服务器的 IP,这样就不必再次向根 DNS 服务器询问。
什么是顶级域名服务器?
顶级域(TLD)服务器存储用户所查找域名的权威域名服务器的 IP 地址。
在 URL www.exampleurl.com 中,顶级域是 .com。有不同类型的顶级域,如通用顶级域(.com 或 .org)、通常由两个字母 ISO 国家代码表示的国家代码顶级域等。
TLD 返回请求域名的权威域名服务器。DNS 解析器会再次缓存结果,这样以后就不必再回来请求。
权威域名服务器
此服务器包含将域名映射到 IP 地址的 DNS 记录。每个域名都有多个域名服务器。
此时不涉及缓存,因为权威域名服务器是最高权威机构,也是 DNS 解析链的最后一环。
如果 IP 地址可用,权威域名服务器会用域名的 IP 地址响应 DNS 解析器查询。如果不可用,则会返回错误。然后,DNS 解析器存储 IP 并将其发送回客户端浏览器。
一旦 DNS 查询完成且浏览器获得 IP 地址,它就可以尝试与服务器建立连接。
建立连接:TCP/IP 模型
客户端和服务器之间的连接使用传输控制协议(TCP)和互联网协议(IP)建立。这些协议是万维网和其他互联网技术(如电子邮件)背后的主要协议,它们决定了数据如何在网络上传输。
TCP/IP 模型是一个用于组织互联网和其他网络通信中不同协议的框架。TCP/IP 的主要责任是将数据分成数据包并将其发送到最终目的地,确保数据包可以在通信的另一端重新组装。
这个过程遵循四层模型,数据在一个方向上传输,到达目的地后再反向传输:
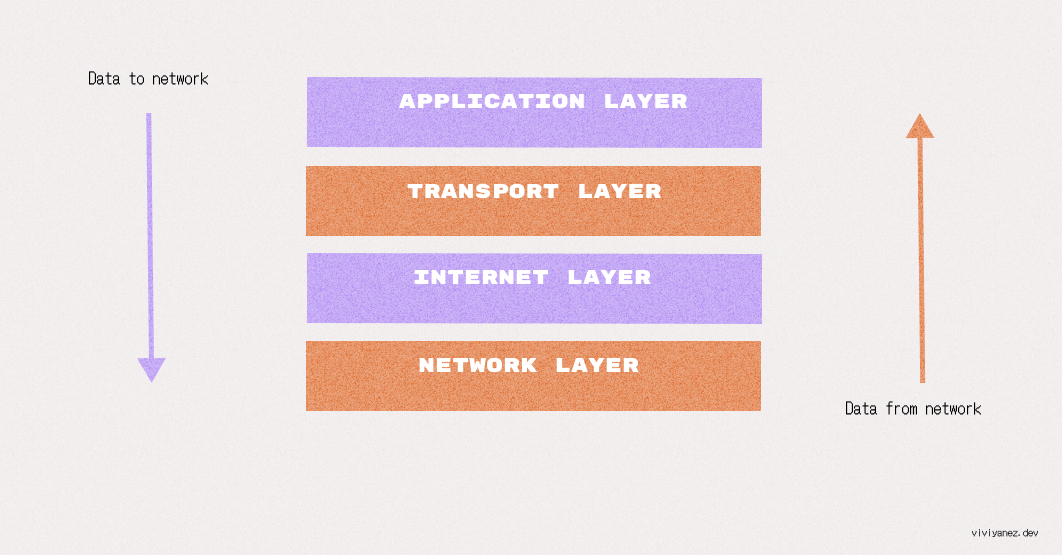
传输层确保应用程序可以通过建立数据通道来交换数据。它还建立了网络端口的概念,这是一个为应用程序需要的特定通信通道分配的编号数据通道系统。
TCP/IP 模型的传输层包括互联网上最常用的两个协议:TCP 和用户数据报协议(UDP)。
TCP 包含一些功能,使其在大多数基于互联网的应用程序中普遍存在,所以我们重点讨论它。
TCP 连接如何工作?
TCP 允许数据可靠且有序地传输到目的地。它是一个面向连接的协议,这意味着发送者和接收者必须在实际建立连接之前就连接参数达成一致。这个过程被称为握手程序。
TCP 三次握手
握手是客户端和服务器建立安全连接并确保双方同步和准备好开始交换消息的方式。
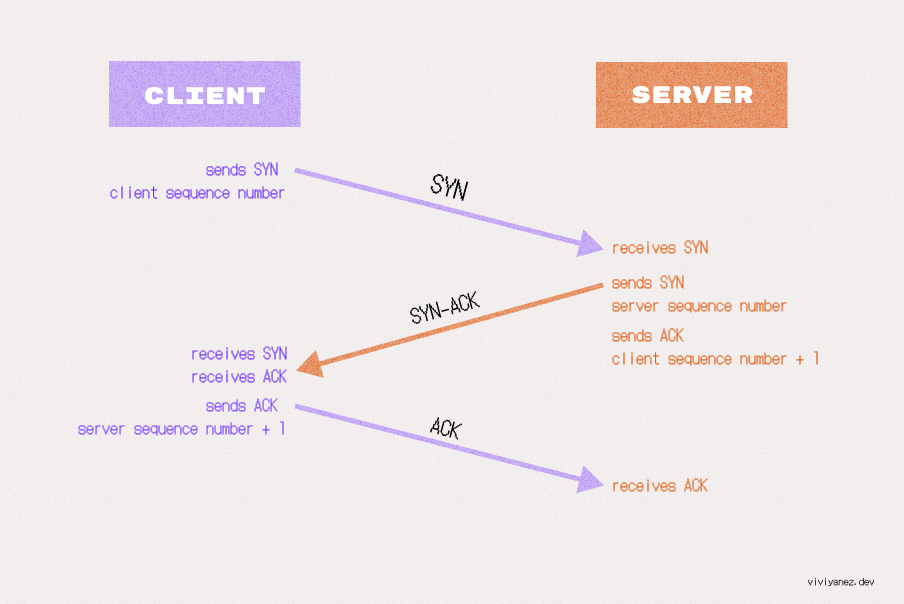
TCP 握手包括三个步骤:
-
客户端通过发送 SYN(同步)数据包通知服务器它想建立连接。这个数据包指定后续段将开始的序列号。
-
服务器收到 SYN 并用 SYN-ACK(同步-确认)段响应。它包括服务器的序列号和对客户端序列号的确认(加一)。
-
客户端用 ACK 消息响应,确认服务器的序列号。此时,连接已建立。
开始交换:客户端-服务器通信
一旦建立 TCP 连接,客户端和服务器就可以使用 HTTP 协议开始交换消息。
什么是 HTTP 协议?
超文本传输协议(HTTP)是 TCP/IP 套件中最广泛使用的应用层协议,但它被认为是不安全的,导致向 HTTPS 转变,HTTPS 在 TCP 之上使用 TLS 进行数据加密。稍后你会看到更多相关细节。
浏览器将首先向服务器发送 HTTP 请求消息,请求以 HTML 文件形式获取网站的副本。HTTP 协议可以传输 HTML、CSS、JS、SVG 等文件。
HTTP 请求/响应
HTTP 消息有两种类型:
-
请求:由客户端发送到服务器以触发操作。
-
响应:由服务器发送到客户端作为对先前请求的答复。
消息是纯文本文档,按照通信协议(在本例中是 HTTP)确定的精确方式构建。
HTTP 请求包含三个部分:
-
请求行: 包括请求方法,这是定义要执行的操作的动词。在我们这篇博文中讨论的情况下,浏览器将发出 GET 请求从服务器获取页面。请求行还将包括资源位置(在本例中是 URL)和使用的协议版本。
-
请求头: 一组键值对。其中两个是必需的。
Host表示目标域名,Connection除非必须保持打开,否则总是设置为 close。请求头总是以空行结束。 -
请求正文: 是一个可选字段,允许向服务器发送数据。
服务器将用 HTTP 响应回复请求。响应包括有关请求状态的信息,可能包括请求的资源或数据。
HTTP 响应的结构包括以下部分:
-
状态行: 包括使用的协议版本、状态代码和状态文本,以及状态代码的人类可读描述。
-
响应头: 一组键值对,可以是应用于整个消息的通用标头、提供服务器状态附加信息的响应标头或描述消息数据格式和编码(如果存在)的表示标头。
-
响应正文: 包含请求的数据或资源。如果客户端不期望数据或资源,响应通常不会包含主体。
当服务器批准网页请求时,响应将包含 200 OK 消息。其他现有的 HTTP 响应代码包括:
- 404 未找到
- 403 禁止
- 301 永久移动
- 500 内部服务器错误
- 304 未修改
- 401 未授权
响应还将包含 HTTP 标头列表和响应主体,包括请求页面对应的 HTML 代码。
HTTPS
超文本传输协议安全版(HTTPS)并不是一个不同的协议,而是 HTTP 的扩展。它通常被称为基于传输层安全(TLS)的 HTTP。让我们看看这具体是什么意思。
HTTP 是浏览器和服务器之间大多数通信使用的协议,但它缺乏安全性。通过 HTTP 发送的任何数据都可能被网络上的任何人看到。当连接涉及敏感数据时,这尤其危险,比如登录凭证、财务信息、健康信息等。
HTTPS 的主要目的是确保数据隐私、完整性和身份识别。这意味着确保数据只能被预期的接收者访问,不能被中间人截获或修改。同时,发送者和接收者都可以通过合法的权威机构确认其身份。
在 HTTPS 中,通信使用 TLS 协议加密,该协议依赖于非对称公钥基础设施。它结合了两个密钥:一个公钥和一个私钥。服务器共享其公钥,客户端可以用它加密消息,而这些消息只能用服务器的私钥解密。
为建立加密通信,客户端和服务器必须启动另一次握手。在握手期间,它们就使用的 TLS 版本以及在连接期间如何加密数据和相互认证达成一致,这一组规则被称为密码套件。
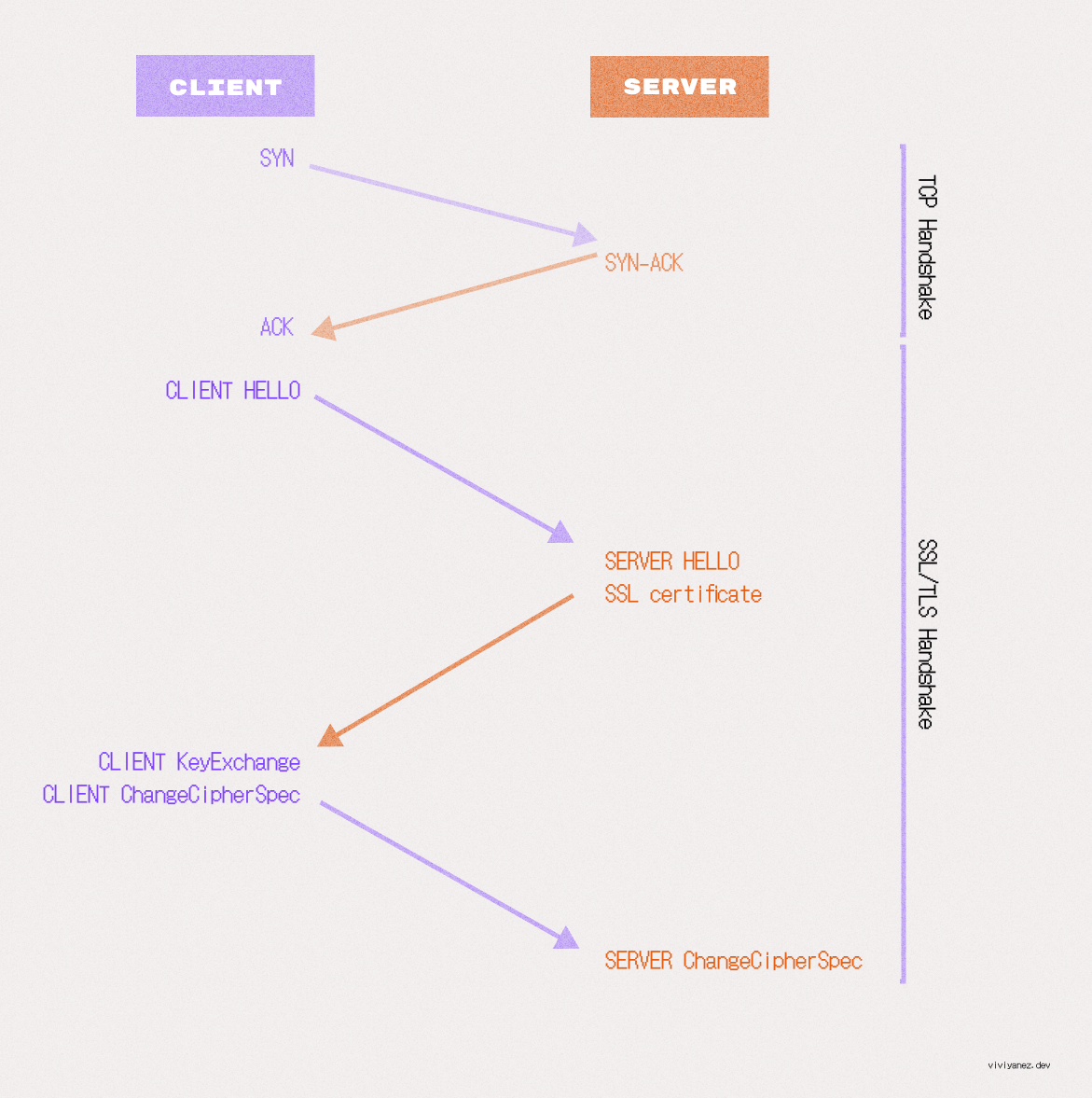
这个握手或 TLS 协商在建立 TCP 连接后开始,包括以下步骤:
-
客户端问候: 浏览器发送一个包含所有支持的 TLS 版本和密码套件的问候消息。
-
服务器问候: 服务器回应选定的密码套件和 TLS 版本,以及包含服务器公钥的 SSL 证书。
-
认证和预主密钥: 客户端通过相应的可信机构验证服务器的 SSL 证书,然后使用服务器的公钥(之前在证书中共享)创建预主密钥并与服务器共享。
-
预主密钥解密: 预主密钥只能使用服务器的私钥解密。如果服务器能够解密它,客户端和服务器就可以就会话使用的共享主密钥达成一致。
-
客户端更改密码规范: 客户端使用共享主密钥创建会话密钥,并向服务器发送所有先前交换的记录,这次使用会话密钥加密。
-
服务器更改密码规范: 如果服务器生成正确的会话密钥,它就能解密消息并验证收到的记录。然后服务器发送记录以确认客户端也有正确的密钥。
-
安全连接建立: 握手完成。
一旦握手完成,客户端和服务器之间的所有通信都由会话密钥进行对称加密保护,浏览器就可以发出网站的第一个 HTTP GET 请求。
第一字节时间
一旦浏览器的请求被批准,服务器将发送 200 OK 消息以及响应头和请求的内容。因为是网站,内容很可能是 HTML 文档。
数据在客户端和服务器之间传输时被分成一系列小数据块,称为数据包。这使得在需要时很容易替换损坏的数据块,也允许数据往返于不同位置,使多个用户能够更快且同时访问数据。
当客户端发出第一个请求时,作为响应到达的第一个数据包标志着第一字节时间(TTFB),它表示从请求发起到接收到第一块数据作为响应所经过的时间。这包括 DNS 查询、建立连接的 TCP 握手,以及如果请求通过 HTTPS 发送则包括 TLS 握手所需的时间。
从数据到像素:关键渲染路径
关键渲染路径(CRP)是浏览器执行的一系列步骤,用于将从服务器接收回来的数据转换为屏幕上的像素。它包括创建文档对象模型(DOM)和 CSS 对象模型(CSSOM、渲染树和布局。
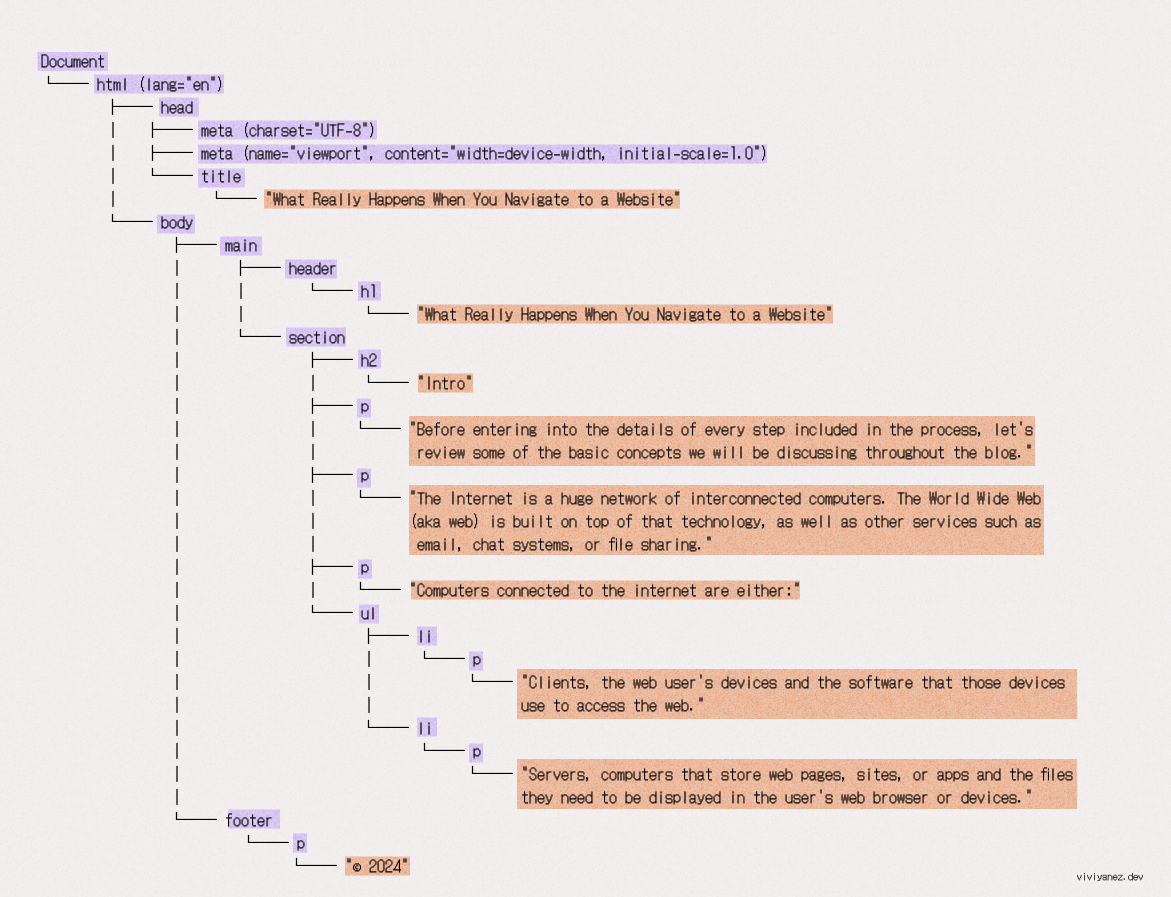
构建 DOM 树
当第一块数据到达时,浏览器开始解析 HTML。解析意味着分析并将一段输入代码转换为特定运行时可以解释的语法和表示。在这种情况下,浏览器组装接收到的数据包并解析 HTML,构建文档的节点树表示,称为 DOM 树。
文档中的每个 HTML 标签都在 DOM 树中表示为一个节点。节点根据它们在文档中的层次位置连接到 DOM 树,每个节点的表示包含关于该标签的所有相关信息。
对于以下 HTML 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>What Really Happens When You Navigate to a Website</title>
</head>
<body>
<main>
<header>
<h1>What Really Happens When You Navigate to a Website</h1>
</header>
<section>
<h2>Intro</h2>
<p>
Before entering into the details of every step included in the process let's review some of the basic concepts we will be discussing throughout the blog.
</p>
<p>
The Internet is a huge network of interconnected computers. The World Wide Web (aka web) is built on top of that technology, as well as other services such as email, chat systems, or file sharing.
</p>
<p>Computers connected to the internet are either:</p>
<ul>
<li>
<p>Clients, the web user's devices and the software that those devices use to access the web.</p>
</li>
<li>
<p>Servers, computers that store web pages, sites, or apps and the files they need to be displayed in the user's web browser or devices.</p>
</li>
</ul>
</section>
</main>
<footer>
<p>© 2024</p>
</footer>
</body>
</html>
生成的 DOM 树如下所示:
在解析 HTML 时,浏览器会对遇到的资源发出额外请求。CSS 文件和图片是非阻塞资源,这意味着解析器会在等待请求资源的同时继续其任务。但如果遇到 <script> 标签,HTML 解析将暂停,这会影响首次渲染时间。
构建 CSSOM 树
DOM 包含页面内容及其层次结构的所有信息,而 CSSOM 包含如何设置页面样式的信息。
在 CSSOM 中,每个 HTML 元素都与其对应的 CSS 样式匹配。结果是一个树,它不包含有关元素内容的信息,而是包含它们应该如何显示的信息。
给定以下 CSS 代码:
* {
box-sizing: border-box;
}
body {
font-family: Arial, sans-serif;
background-color: #f4f4f9;
color: #333;
}
main {
padding: 20px;
max-width: 800px;
margin: 0 auto;
}
header {
background-color: #005bbb;
color: #ffffff;
padding: 10px;
text-align: center;
}
h1 {
font-size: 24px;
}
section {
margin-top: 20px;
}
h2 {
font-size: 20px;
color: #005bbb;
display: none;
}
p {
margin-bottom: 10px;
}
ul {
margin-left: 20px;
list-style-type: disc;
}
footer {
margin-top: 40px;
text-align: center;
font-size: 14px;
color: #555;
}
当浏览器处理它时,生成的 CSSOM 会如下所示:
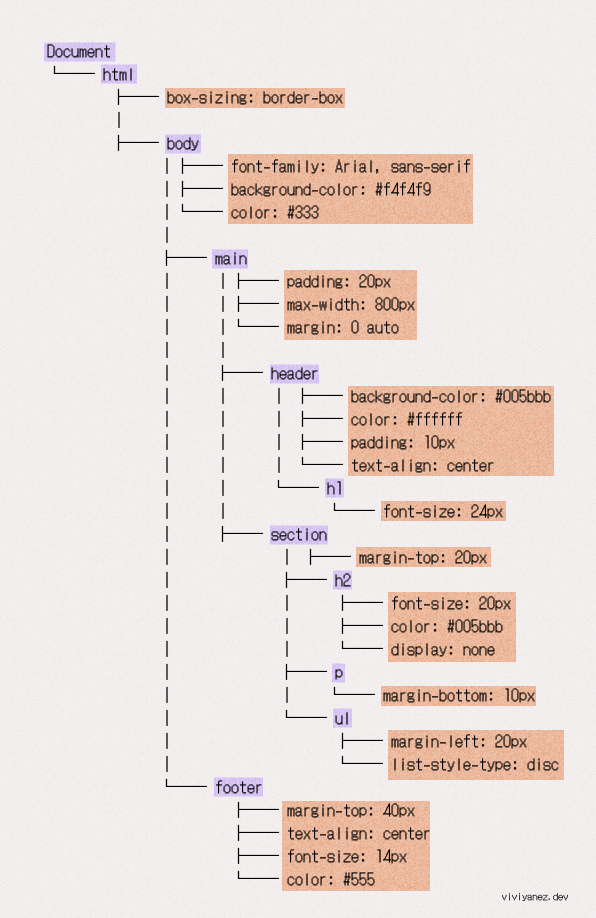
它的创建不是增量式的,这意味着浏览器会停止渲染页面,直到处理完所有 CSS。
之所以这样工作是因为,顾名思义,层叠样式表(CSS)从上到下应用样式,这意味着后面定义的类会覆盖文档开头的类。CSS 文档需要在屏幕上渲染任何内容之前完全处理,因为可能有类会改变。
JavaScript 编译和执行
在创建 CSSOM 时,渲染被阻塞,但浏览器会继续下载它遇到的任何 JavaScript 文件。
JavaScript 也由浏览器解析、编译和解释,但如前所述,它在默认情况下是一个解析器阻塞资源。这意味着当浏览器遇到 <script> 标签时,它会停止 HTML 解析并在继续之前执行该文件。可以使用 async 或 defer 属性来避免这种行为,允许在获取资源时继续解析。
一旦浏览器完成解析并执行所有可能修改 DOM 和 CSSOM 的 JavaScript 文件,下一步就是构建渲染树。但在详细了解这一步之前,让我们先关注一下无障碍树。
构建可访问性树
基于 DOM 树创建的站点结构,浏览器还创建了一个可访问性树。
可访问性树是网站内容的另一种表示形式,专门设计用于通过辅助技术进行网站导航。
在可访问性树中,每个 DOM 元素都表示为一个可访问对象,包含以下信息:
-
名称: 用于引用元素的标识符。
-
描述: 关于元素的附加信息。
-
角色: 它是什么类型的元素,与其预期用途有关。
-
状态和其他属性: 如果元素可能发生变化,它可能包含其当前状态。它还可以包含指定其他功能的其他属性。
在主要的网络浏览器中,你可以通过在 DOM 树查看器中选择一个节点并导航到"无障碍"选项卡来访问可访问对象及其信息。
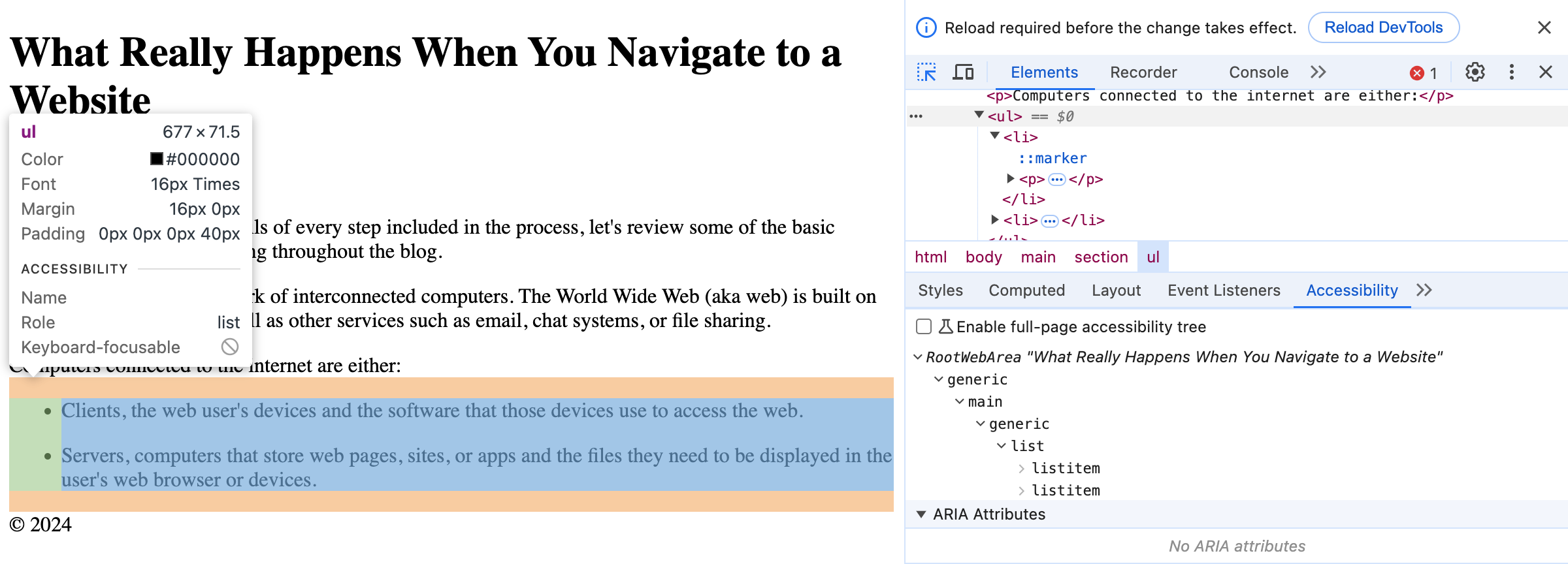
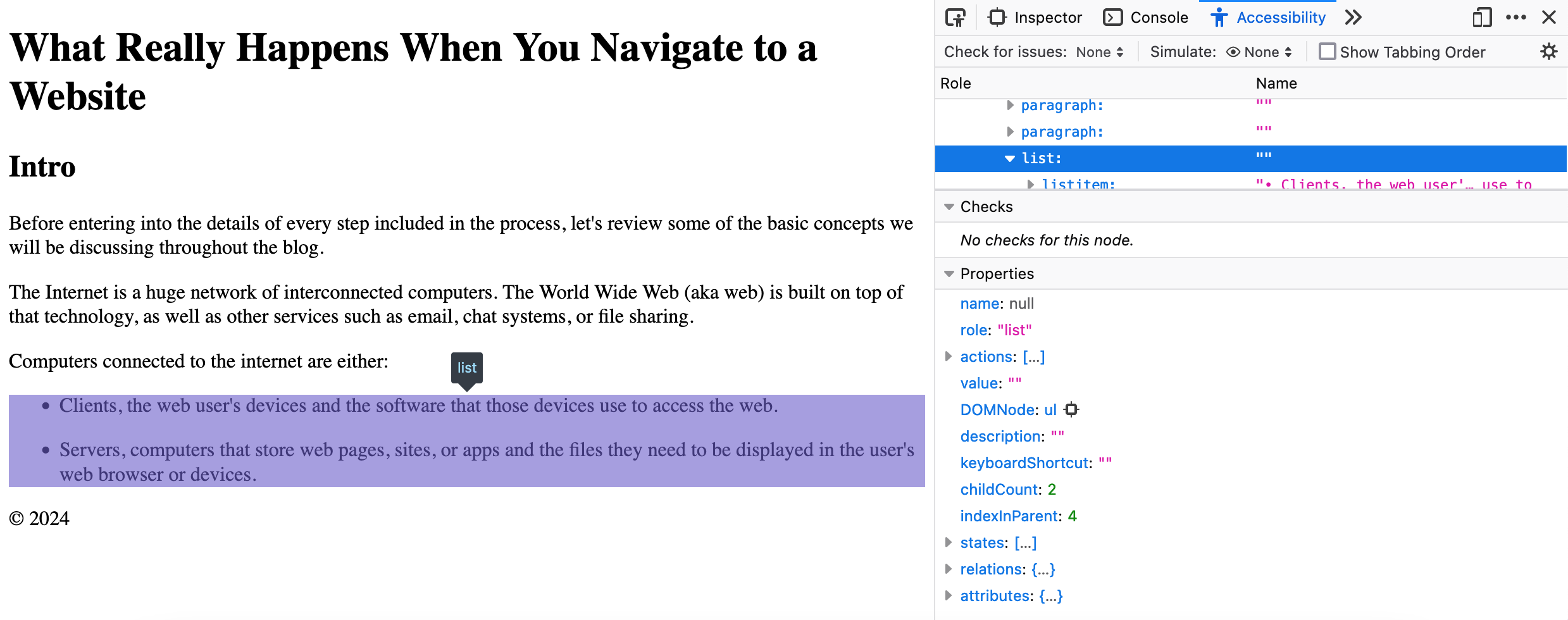
拥有一个结构良好的可访问性树,是决定网站能否通过辅助技术进行导航的关键,这直接关系到网站是具有包容性还是排他性。
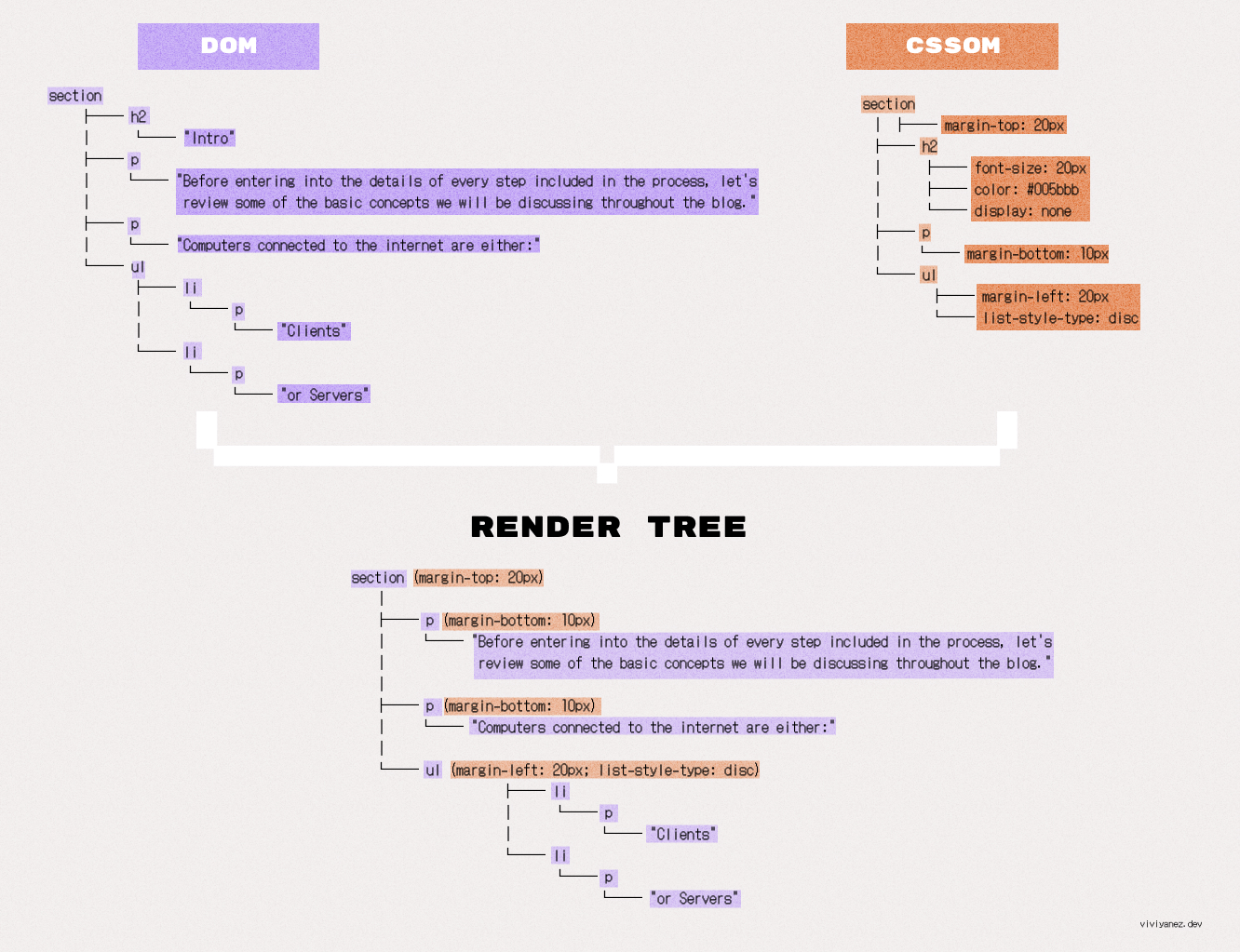
渲染树
在构建完 DOM、CSSOM 和无障碍树之后,浏览器构建渲染树。
这个树是 DOM 和 CSSOM 树的组合。浏览器处理所有节点并只保留可见的节点。然后,它将它们与对应的 CSSOM 规则组合。结果是所有可见元素与其计算样式的集合。
非可见节点,如 <script> 或 <meta> 标签,以及使用 display: none CSS 属性隐藏的元素,不会包含在这个树中。
布局
一旦计算出渲染树,浏览器就会运行布局。在这个过程中,浏览器计算每个元素在页面中将占用的确切位置和大小。
这些计算基于视口大小,即实际显示网站内容的浏览器区域。视口的大小根据设备屏幕大小、浏览器窗口大小、系统设置等条件而变化。
布局输出是一个盒模型,它捕获渲染树中每个元素和对象对应的大小和位置。浏览器通常从 <body> 标签开始处理文档,然后遍历其所有后代。
布局计算之后,文档中一个或多个元素的大小或位置的任何变化都会触发新的计算。这些后续计算称为重排。
绘制
现在,最后一步是在用户屏幕上显示布局输出。在绘制或栅格化阶段,浏览器将每个布局盒子元素转换为屏幕上对应的像素。
整个页面的可视化表示最初在屏幕上渲染,然后只重新渲染受更改影响的区域。
许多因素会影响浏览器执行这一步骤所需的时间,有一些工具可以帮助开发者测量和优化这个时间。
绘制之后,在用户开始与网站交互之前,浏览器可能会执行任何使用 defer 或 async 属性延迟的 JavaScript,以避免阻塞初始 HTML 解析。
关于 JavaScript 水合的说明
上面描述的步骤展示了在浏览器中渲染所有网站的 HTML、CSS 和 JavaScript 代码的过程。这被称为客户端渲染(CSR)。你可能也听说过服务器端渲染(SSR)。
SSR 包括在每个请求上渲染网站内容,并将其作为可在浏览器中显示的 HTML 交付给客户端。
当使用 CSR 渲染网站时,所有 JavaScript 在页面渲染之前执行。在 SSR 中,服务器渲染的 HTML 在浏览器中快速加载和显示,但仍需要将 JavaScript 发送到客户端以启用用户交互。
JavaScript 水合是将 JavaScript 添加到服务器渲染的 HTML 页面以使其交互的过程。一旦初始 HTML 被提供并在浏览器中显示,JavaScript 就会"水合"静态内容,附加事件监听器并启用交互功能。
结论
通过本文,你加深了对从在浏览器地址栏输入网址到访问所需网站内容这整个过程的理解。
你了解了 URL 以及浏览器执行的 DNS 查询以查找网站的 IP 地址。你还了解了浏览器和服务器之间如何建立连接以及它们如何通信。
最后,你探索了从服务器接收第一块数据到网站在屏幕上显示之间发生的事情,以及无障碍树和 JavaScript 水合过程等关键概念。
希望你觉得这个指南有用。感谢阅读!