


原文: Learn Clustering in Python – A Machine Learning Engineering Handbook
您是否想学习如何发现与分析数据中隐藏的模式呢?聚类,作为一项基本的无监督机器学习技术,能够助力您揭示极具价值的洞察,进而从根本上转变您对复杂数据集的认知。
在这本全面的手册中,我们将深入探讨一些必须掌握的聚类算法和技术,并辅以相关理论作为支撑。随后,您将通过大量实例、Python 实现方法和其可视化效果来知晓其工作原理。
无论您是刚入门的初学者,或者是富有经验的数据科学家,这本手册都是熟悉掌握聚类技术的宝贵资源。您也能够在此下载这本手册。
倘若您同样喜欢通过听来学习,这里还有个 15 分钟的播客,在其中我们更详细地讨论了聚类。在这一期里,我们探索了聚类的基本理念,从而帮助您更深入地了解如何将这些技术应用于现实世界的数据。
以下是我们将要涵盖的内容:
在通过本手册的学习探索后,你将具备以下技能:
-
理解无监督学习基础原理 – 您将掌握监督学习与无监督学习的关键差异,并知晓聚类怎样融入更广泛的机器学习范畴.
-
精通聚类相关的重要术语 – 您将熟悉数据点、簇中心、距离度量和聚类评估方法等关键概念.
-
数据预处理以适用于聚类 – 您将会学习怎样处理缺失值、对数据集进行规范化、去除异常值,以及应用像 PCA 和 t-SNE 这类降维技术。
-
深入领会聚类技术 – 您将探索各种各样的聚类方法, 包括 K 均值算法、层次聚类和 DBSCAN,并了解何时使用每种方法。
-
在 Python 中实现 K-均值聚类 – 您将学习如何使用 Python 应用 K-均值算法,同时使用肘部法则优化聚类数量,并有效地可视化聚类结果。
-
应用层次聚类 – 您将理解聚合聚类和分裂聚类,学习如何构建树状图,并使用 Python 实现层次聚类。
-
使用 DBSCAN 进行基于密度的聚类 – 您将掌握 DBSCAN 的聚类方法,包括其识别噪声点和任意形状聚类的能力。
-
可视化聚类结果 – 您将能够使用 Matplotlib、Seaborn 和 t-SNE 等库为聚类结果生成有意义的可视化效果,从而有效地分析和解释数据。
-
评估聚类性能 – 您将学习如何使用轮廓分数、戴维森堡丁指数和方差比准则等技术评估聚类质量。
-
使用真实世界的数据集来进行工作 – 您将获得在真实世界的数据集上应用聚类技术的实践经验,包括客户细分、异常检测和模式识别。
-
扩展您在聚类之外的知识 – 您将接触到其他无监督学习技术,例如混合模型和主题建模,从而拓宽您在机器学习方面的专业知识。
通过学习本手册,您将在聚类和无监督学习方面打下坚实的基础,这将使您能够自信地分析复杂数据集并发现其隐藏的模式!
前提条件
在深入研读这本关于聚类和无监督学习的手册之前,您应当对机器学习概念、数据预处理技术以及基础的 Python 编程技能有扎实的了解。这些前提条件将有助于您理解本书中涵盖的理论基础和实际应用。
首先也是最重要的是,要熟悉 机器学习的基础知识。您应当了解有监督学习和无监督学习之间的区别,以及聚类技术背后的核心原理。
诸如数据点、特征、距离度量(欧几里得距离、曼哈顿距离), 以及相似性度量等概念在聚类算法中的重要作用. 而掌握概率、统计学和线性代数的基础知识也将对帮助您理解有所帮助,因为这些数学概念构成了许多机器学习模型的基础。
接下来,数据预处理技术 对于处理真实世界的数据集起到至关重要的作用。由于聚类算法严重依赖于结构良好的数据,您需要了解如何处理缺失值、对数值特征进行归一化或标准化以及去除可能扭曲聚类结果的异常值。
诸如特征缩放(最小 - 最大归一化、标准化)和降维(PCA, t-SNE)之类的技术能够提高聚类的准确性和效率,让您更易于解读结果。
最后,要跟上本手册中的实践操作,需要具备 熟练的Python 编程和掌握数据科学库能力。您应当能够熟悉使用诸如 NumPy 和 Pandas 等库来进行数据处理,使用 Matplotlib 和 Seaborn 进行数据可视化,以及使用 Scikit-learn 实现机器学习算法。
由于您将应用诸如 K-均值算法、层次聚类和 DBSCAN 等聚类技术,熟悉使用 Jupyter Notebooks 编写和执行 Python 脚本以及解读聚类结果,将有助于提升您的学习体验
在这些领域打下坚实的基础后,您将能够充分发挥聚类的优势,从数据中获取更深入的洞察。
无监督学习导论
无监督学习是机器学习中的一项强大技术,它能够在没有预定义标签或目标变量的情况下揭示数据中的隐藏模式和结构。不同于依赖标签数据进行训练的监督学习,无监督学习使我们能够探索和理解无标签数据集的内在结构。
无监督学习的一个重要应用是聚类。聚类是一种根据数据点的内在特征和相似性将其分组的过程。通过识别数据集中的模式和关系,聚类能够帮助我们提取有价值的见解,并理解复杂数据的结构。
聚类在多个领域具有重要应用,包括客户分群、异常检测、图像识别和推荐系统。它能够识别数据中的不同群组,将数据分类为有意义的类别,并揭示数据集背后的潜在趋势。
在后续章节里,我们将深入探讨不同的聚类算法,包括 K-Means、层次聚类 和 DBSCAN, 分析其理论基础、实现方法与可视化呈现。在本手册结束时,您将全面掌握无监督学习的相关知识,能够熟练运用各类聚类技术到自己的数据分析工作中,具备相应的知识与技能。
请记住,聚类只是无监督学习的一个方面,它还包含许多其他技术和应用。让我们深入探索无监督学习的精彩世界,挖掘它在从无标签数据中提取洞察方面的强大能力!
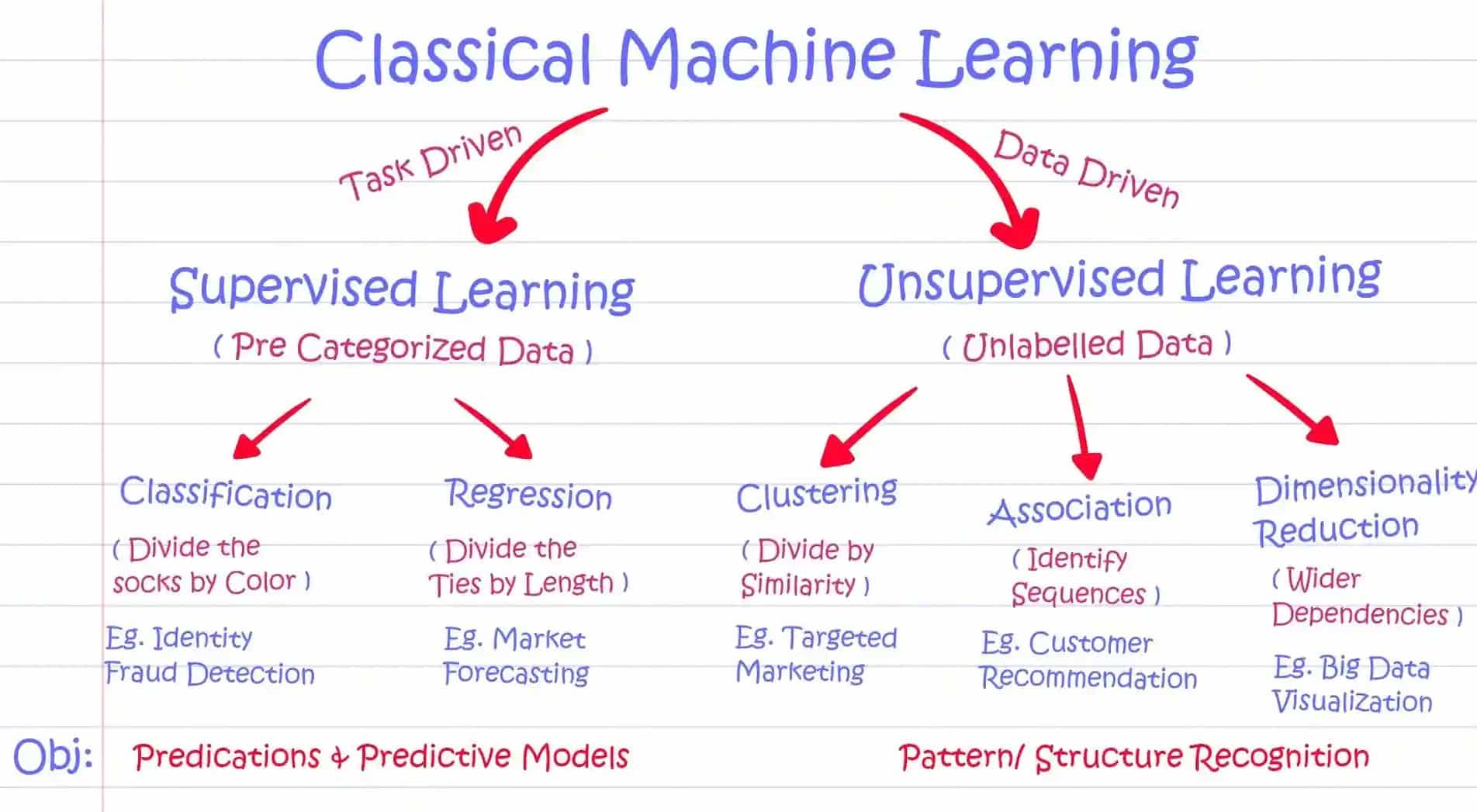
监督学习 vs. 无监督学习
谈到机器学习,主要有两种方法:有监督学习和无监督学习。理解这两种方法之间的差异对于根据您的数据分析需求选择合适的技术至关重要。
监督学习,顾名思义,是指在有标签的数据上训练机器学习模型。在这种方法中,输入数据包含特征(也称为属性或变量)以及相应的目标值或标签。模型从这些有标签的数据中学习,并根据新的、未见过的数据进行预测或分类。
而另一方面,无监督学习完全是关于探索未标记的数据。在无监督学习中,数据没有预定义的标签或目标值。相反,算法自行在数据中寻找模式、结构和关系。其目标是发现隐藏的见解,并更深入地了解数据的潜在结构。
值得一提的是,无监督学习的一个关键优势是能够发现此前未知的模式和关系。因为由于不受标签数据的限制,无监督算法可以揭示其他分析方法可能难以察觉的有价值信息。这使得无监督学习在探索性数据分析、异常检测和聚类等领域尤为有用。
在监督学习中,目标变量起到引导作用,使模型能够进行准确的预测或分类。然而,这种对标签数据的依赖也会限制模型的能力,因为它可能难以处理训练数据中未出现的全新模式或未被充分表示的数据。
相比之下,无监督学习提供了一种更灵活和自适应的方法。即使没有明确的标签,它仍能捕捉数据的内在结构和关系。通过利用聚类算法和降维技术,无监督学习为解析复杂数据集提供了强大的工具。
总而言之,监督学习适用于有标签数据的任务,目标是进行精准的预测或分类。而无监督学习在探索数据中的隐藏模式和关系时尤为重要,特别是在标签数据稀缺或不存在的情况下。
通过理解这两种方法之间的差异,您可以有效地选择正确的技术,从而充分发挥数据分析工作的潜力。
关键术语
想要全面理解无监督学习和聚类,熟悉与这些概念相关的关键术语至关重要。以下是一些您应该了解的重要术语:
1. 数据点
数据点指的是数据集中单个的观测值或实例。每个数据点包含描述特定对象或事件的各种特征或属性。
2. 聚类数量
聚类的数量代表了在聚类过程中,数据将被划分成不同组别的期望数量或估计数量。这是一个关键参数,它决定了最终聚类的结构。
3. 无监督算法
无监督算法是一种数学方法,用于在没有标记或预分类示例的情况下识别数据中的模式或关系。这些算法能够探索数据集的内在结构,挖掘隐藏的规律。
理解并运用这些术语,将为您的无监督学习和聚类之旅奠定坚实的基础。而在接下来的部分中,我们将更深入地探讨如何在 Python 中实现聚类技术的实际应用。
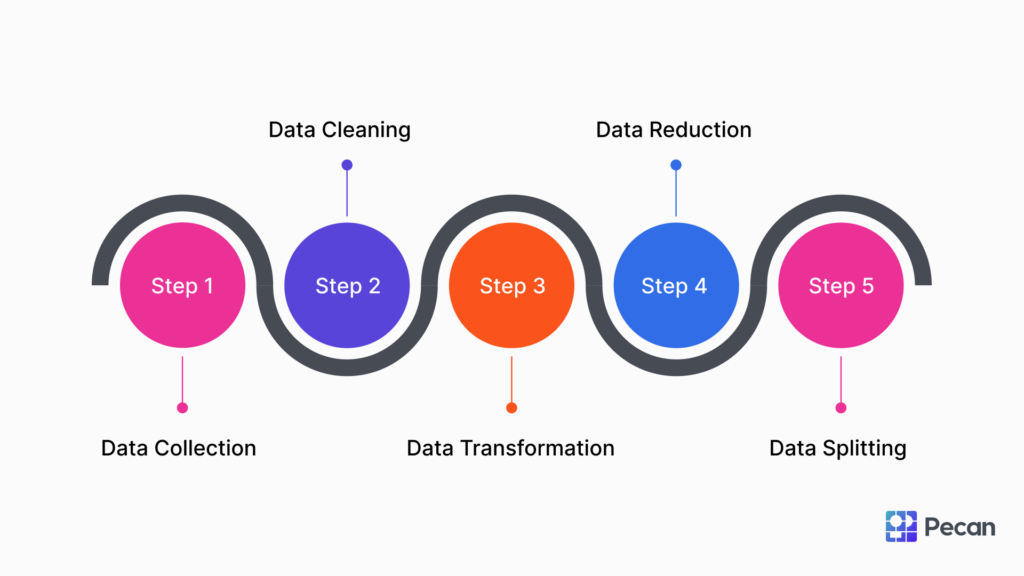
如何为无监督学习做数据预处理
在实施无监督学习算法之前,确保数据已经过适当的预处理至关重要。这包括采取某些步骤来优化输入数据,使其适合使用聚类技术进行分析。以下是为无监督学习准备数据时的重要考虑因素:
数据归一化
数据准备的一个关键方面是归一化,即把所有特征都缩放到一致的范围。这是必要的,因为数据集中的变量可能具有不同的单位或量级。
归一化有助于在聚类过程中避免对任何特定特征产生偏向。常见的归一化方法包括最小 - 最大缩放和标准化。
处理缺失值
处理缺失值是数据预处理中的关键步骤。在应用聚类算法之前,必须识别并解决数据集中存在的缺失值。
处理缺失值的方法多种多样,其中一种常见技术是插值,即使用统计方法或算法估算缺失值并进行填充。
异常值检测与处理
异常值可能会显著影响聚类结果,因为它们可能会干扰簇边界的确定。因此,及时检测和处理异常值至关重要。常见的方法包括 Z-score 分析和四分位距(IQR)分析,用于识别并处理异常值。
降维
在某些情况下,数据集可能具有很高的维度,这意味着它包含大量的特征。高维数据可能难以有效地可视化和分析。可以采用诸如主成分分析(PCA)之类的降维技术来减少特征的数量,同时保留数据中最具信息量的部分。
通过仔细准备数据、标准化变量、处理缺失值、解决异常值以及在必要时降低维度,您可以优化无监督学习算法的输入数据质量。这能确保聚类结果准确且有意义,从而在数据中发现有价值的见解和模式。
请记住,数据准备是无监督学习过程中至关重要的步骤,它为成功的聚类分析奠定基础。

聚类解析
聚类是无监督学习中的一项基本技术,在揭示数据中的隐藏模式方面发挥着关键作用。它通过基于数据点的相似性对其进行分组,使我们能够识别数据集中的不同子集或簇。通过分析这些簇的结构,我们可以获得有价值的见解并做出基于数据的决策。
聚类的概念
从本质上讲,聚类旨在找出数据点之间的相似性或关系,而无需任何预定义的标签或目标变量。其目标是在每个聚类内部最大化相似性,同时在不同聚类之间最大化差异性。这一过程使我们能够识别数据中的模式和内在结构。
聚类可以通过多种因素来定义,例如距离、连通性或密度。聚类中的每个数据点与其他同一聚类中的点的相似度高于与其他聚类中的点的相似度。这种分组方式使我们能够对数据进行细分,这在诸如客户细分、异常检测和图像识别等各种领域中都具有极大的用处。
聚类算法的类型
有几种聚类算法可供选择,每种算法都有其自身将数据划分成簇的方法。一些流行的算法包括 K 均值聚类、层次聚类和 DBSCAN(基于密度的空间聚类算法,用于处理噪声和离群点)。
1. K-均值聚类
K 均值聚类是一种被广泛使用的算法,旨在将数据划分成 K 个不同的簇。它通过迭代地将每个数据点分配给最近的簇中心,然后重新计算簇中心来实现这一目标。这个过程会一直持续到收敛,从而形成定义明确的簇。
2. 层次聚类
层次聚类通过基于特定标准递归地划分或合并聚类来创建聚类的层次结构。这种方法可以用树状图来表示,树状图能为聚类的层次结构以及聚类之间的关系提供有价值的见解。
3. DBSCAN 聚类
DBSCAN 是一种基于密度的算法,它根据数据点的密度和连通性对其进行分组。该算法特别适用于识别任意形状的簇以及处理噪声数据。
这些只是聚类算法的几个例子,每种算法都有其自身的优势和适用于特定场景的情况。根据数据特征和问题领域选择最合适的算法是很重要的。
在接下来的部分中,我们将更深入地探讨这些聚类算法的理论、实现和可视化,以便为您提供对其工作原理以及何时使用它们的全面理解。
需要谨记的是,聚类是一种强大的技术,它能让我们挖掘出数据中隐藏的结构,从而获得宝贵的见解并做出明智的决策。所以就让我们一起走进聚类的世界,探索它所蕴含的潜力。

K-均值聚类
K 均值聚类是一种常见的无监督学习算法,基于数据点之间的相似性将其划分到不同的簇中。在本节中,我们将深入探讨 K 均值聚类的理论原理,并使用 scikit-learn 库在 Python 中实现该算法。
在数据科学和数据分析领域,我们常常希望将观察结果归类到一系列的 分段 或者 簇 以满足不同的分析需求。例如,一家公司可能希望根据客户的交易历史或购买频率,将客户分为 3 到 5 组。这通常是一种 无监督 学习 方法,因为这些标签(组别/分段/簇)在分析前是未知的。
将观测值聚类分组的最流行方法之一是无监督聚类算法K-均值. 以下是 K 均值聚类的条件:
-
需要提前指定聚类的数量:K
-
每个观察结果都需要至少属于一个类别
-
每个观测值都必须只属于一个类别(类别之间不能有重叠)
-
任何观测值都不应属于超过一个类别。
K 均值算法背后的理念在于 最小化簇内方差,并最大化簇间方差 因此,K 均值算法将观测值划分成 K 个簇,使得所有 K 个簇的总簇内方差尽可能小。
其背后的动机是将观测值进行聚类,使得聚类到同一组的观测值尽可能相似,而来自不同组的观测值尽可能不同。
从数学角度而言,簇内变异的定义取决于您自行选择的距离度量方式。例如,您可以选用欧几里得距离、曼哈顿距离等作为距离度量方式。
K 均值聚类在簇内变异最小的情况下是最优的 簇 C_k 的簇内差异量度 W(C_k) 反映了同一簇内观测点之间的差异程度。因此,需要解决以下优化问题:
$$\min_{C_1, \dots, C_K} \sum_{k=1}^{K} W(C_k)$$
其中,基于欧几里得距离的簇内差异可以表示如下:
$$W(C_k) = \frac{1}{|C_k|} \sum_{i,i' \in C_k} \sum_{j=1}^{p} (x_{ij} - x_{i'j})^2$$
第 k 个聚类中的观测值数量用 |C_k | 表示。因此,K 均值的优化问题可以描述如下:
$$\min_{C_1, \dots, C_K} \left\{ \sum_{k=1}^{K} \frac{1}{|C_k|} \sum_{i,i' \in C_k} \sum_{j=1}^{p} (x_{ij} - x_{i'j})^2 \right\}$$
K-均值算法
K 均值算法的伪代码可描述如下:

K 均值算法是一种非确定性方法,其随机性体现在第一步,即所有观测值都被随机分配到 K 个类别中的一个。
在第二步中,对于每个聚类,通过计算该聚类中所有数据点的平均值来计算聚类质心。第 Kth 个聚类的质心是一个长度为 p 的向量,其中包含第 kth 个聚类中所有观测值的变量均值,而 p 为变量的数量。
然后,在下一步中,对观测值的簇进行更新,使得每个观测值都被分配到其质心最近的簇中,通过迭代最小化 总簇内平方和 来实现。也就是说,我们反复执行步骤 2 和 3,直到簇的质心不再变化或者达到最大迭代次数为止。
K 均值聚类:Python 的实现方法
让我们来看一个将观测值分类为 4 类的例子。原始数据如下所示:
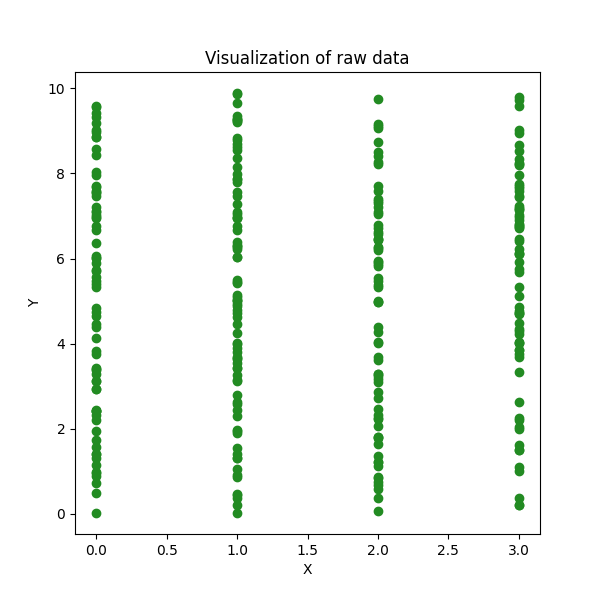
# 导入项目所需要的库
# KMeans 是 scikit-learn 提供的聚类算法
from sklearn.cluster import KMeans
# Metrics 模块用于评估聚类性能
from sklearn import metrics
# 用于数值计算和数组操作
import numpy as np
# Pandas 用于以结构化 DataFrame 格式处理数据
import pandas as pd
# 生成用于 K-Means 聚类的合成数据
# 创建一个 100×2 的数组,元素为 0 到 9 之间的随机整数
df = np.random.randint(0, 10, size=[100, 2])
# 生成一个 300×1 的数组,元素为 0 到 3 之间的随机整数
X1 = np.random.randint(0, 4, size=[300, 1])
# 生成一个 300×1 的数组,元素为 0 到 10 之间的随机浮点数
X2 = np.random.uniform(0, 10, size=[300, 1])
# 沿第二个轴(列方向)合并 X1 和 X2,形成具有两个特征的数据集
df = np.append(X1, X2, axis=1)
# 在生成的数据集上应用 K-Means 聚类算法
# 调用 KMeans_Algorithm 函数,并设置簇数 K=4
Clustered_df = KMeans_Algorithm(df=df, K=4)
# 将聚类后的数据转换为 Pandas DataFrame
df = pd.DataFrame(Clustered_df)
# 执行 K-Means 聚类的函数
def KMeans_Algorithm(df, K):
"""
在给定数据集上执行 K-Means 聚类。
参数:
df (array-like): 待聚类的输入数据集。
K (int): 聚类的簇数.
返回:
df (DataFrame): 原始数据集,新增一列用于存储聚类标签。
"""
# 使用指定参数初始化 K-Means 模型
# 将聚类数量设置为 K
# 使用 k-means++ 初始化以提高收敛速度
# 将最大迭代次数设置为 300
# 设置固定的随机种子以确保结果可复现
KMeans_model = KMeans(
n_clusters=K,
init='k-means++',
max_iter=300,
random_state=2021
)
# 在数据集上拟合 K-Means 模型
KMeans_model.fit(df)
# 提取聚类质心(每个簇的中心点)。
centroids = KMeans_model.cluster_centers_
# 将质心转换为 DataFrame,并设置列名为 "X" 和 "Y"
centroids_df = pd.DataFrame(centroids, columns=["X", "Y"])
# 获取分配给每个数据点的聚类标签
labels = KMeans_model.labels_
# 将输入数据转换为 Pandas DataFrame(如果尚未转换)
df = pd.DataFrame(df)
# 添加新列以存储分配的聚类标签
df["labels"] = labels
# 返回包含聚类标签的更新后的 DataFrame
return d

此脚本旨在生成合成数据,应用 K-Means 聚类,并为每个数据点分配聚类标签。K-Means 聚类算法是一种无监督机器学习方法,它根据特征空间中数据点的接近程度将相似的数据点分组到不同的簇中。以下是该脚本的工作原理的逐步分解。
第一步是导入必要的库。 该脚本使用sklearn.cluster 中的 KMeans 来实现 K-均值聚类算法。虽然 metrics 模块在 sklearn 已经存在, 但是在本脚本中未被使用, 不过它对于评估聚类质量非常有用. NumPy 负责数值计算和数组操作,而 Pandas用于将数据组织成 DataFrame,以便更方便地操作和处理。
接下来,脚本生成合成数值数据。创建一个 NumPy 数组 df,其维度为 100×2,包含 0 到 9 之间的随机整数。此外,还分别生成两个额外的数组 X1 and X2。其中 X1 为 300×1 的数组,包含 0 到 3 之间的随机整数,而 X2 为 300×1 的数组,包含 0 到 10 之间的随机浮点数。随后,这两个数组沿第二个轴(列方向)合并,形成一个具有两个特征的数据集,使其可以用于聚类分析。
在合成数据准备完成后,脚本应用 K-Means 聚类算法。调用 KMeans_Algorithm 函数,并设置 K=4, 即算法将数据分为四个簇。该函数返回聚类后的数据集,并将其转换为 Pandas DataFrame 进行进一步处理。
KMeans_Algorithm 函数接受两个参数:数据集 df 和簇的数量 K. 在该函数内部,使用 KMeans() 初始化 K-均值模型. 簇的数量设为 K, 同时 init='k-means++' 参数用于优化初始化,以加快收敛速度。max_iter=300 限制最大迭代次数,以防止计算时间过长,而 random_state=2021 用于确保结果的可复现性。
初始化后,使用KMeans_model.fit(df) 在数据集上拟合 K-均值模型。这一步骤处理数据集,识别聚类中心,并将数据点归入相应的簇。训练完成后,通过 KMeans_model.cluster_centers_提取聚类质心,并将其存储在一个 Pandas DataFrame 中,列名设为 "X" and "Y",以便更直观地解析聚类结果。
每个数据点都会被分配一个聚类标签,该标签可通过 KMeans_model.labels_获取。 脚本随后确保数据集被存储为 Pandas DataFrame(如果尚未转换),并添加一个新的 "labels"列来存储分配的聚类标签。最终,返回包含原始特征及聚类结果的更新数据集。
该脚本的输出是一个 Pandas DataFrame,包含三列:两列数值特征列表示生成的数据点,另一列 "labels" 列指示每个数据点所属的聚类。 例如,简化的输出可能如下所示:一个数据点 [2.0, 7.4] 被分配到簇 0,而另一个数据点 [1.0, 3.2] 归属于簇 1.
该脚本成功创建了一个结构化数据集,将数据划分为四个不同的簇,并为每个数据点分配了相应的聚类标签。 结果可以通过散点图等可视化技术进一步分析,以更直观地理解聚类分布。未来的优化方向可能包括使用 轮廓系数评估聚类质量,或尝试不同的簇数量,以找到最优的聚类方案。
K 均值聚类:可视化的实现方法
K-均值的关键优势之一在于其处理大型数据集时的简单性和高效性。它是一种在众多领域广泛使用的聚类算法,包括客户细分、图像压缩、异常检测和模式识别。
尽管K-均值算法简单,但它在发现数据中固有的群组结构方面非常有效,使其成为无监督学习中的重要工具。但和任何算法一样,它也有局限性,比如对初始质心选择的敏感性以及难以检测非球形簇。了解这些优缺点有助于在将K-均值应用于实际数据集时做出明智的决策。
在本节中,我们将探讨如何在 Python 中实现 K-均值聚类并可视化结果。通过逐步的代码实现,您将看到数据点是如何被分组到各个簇中的,以及算法是如何迭代地优化其簇分配的。我们还将讨论选择最优簇数的最佳实践以及如何评估聚类质量。
洞悉K-均值算法
在深入探讨实现方法之前,让我们先简要了解一下K-均值算法的工作原理。该算法遵循以下步骤:
-
步骤 1:初始化 – 随机选择 K 个质心,其中 K 表示期望的聚类数量。
-
步骤 2:分配任务 – 根据欧几里得距离,将每个数据点分配给最近的质心。
-
步骤 3: 更新 – 通过取分配给每个聚类的所有数据点的平均值来重新计算质心
-
步骤 4: 重复 – 重复步骤 2 和 3,直至满足收敛标准(例如,质心移动极小)。
fig, ax = plt.subplots(figsize=(6, 6))
# 针对具有不同标签的观测数据,使用第 1 列和第 2 列进行可视化。
plt.scatter(df[df["labels"] == 0][0], df[df["labels"] == 0][1],
c='black', label='cluster 1')
plt.scatter(df[df["labels"] == 1][0], df[df["labels"] == 1][1],
c='green', label='cluster 2')
plt.scatter(df[df["labels"] == 2][0], df[df["labels"] == 2][1],
c='red', label='cluster 3')
plt.scatter(df[df["labels"] == 3][0], df[df["labels"] == 3][1],
c='y', label='cluster 4')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='*', s=300, c='black', label='centroid')
plt.legend()
plt.xlim([-2, 6])
plt.ylim([0, 10])
plt.xlabel('X')
plt.ylabel('Y')
plt.title('聚类数据的可视化')
ax.set_aspect('equal')
plt.show()

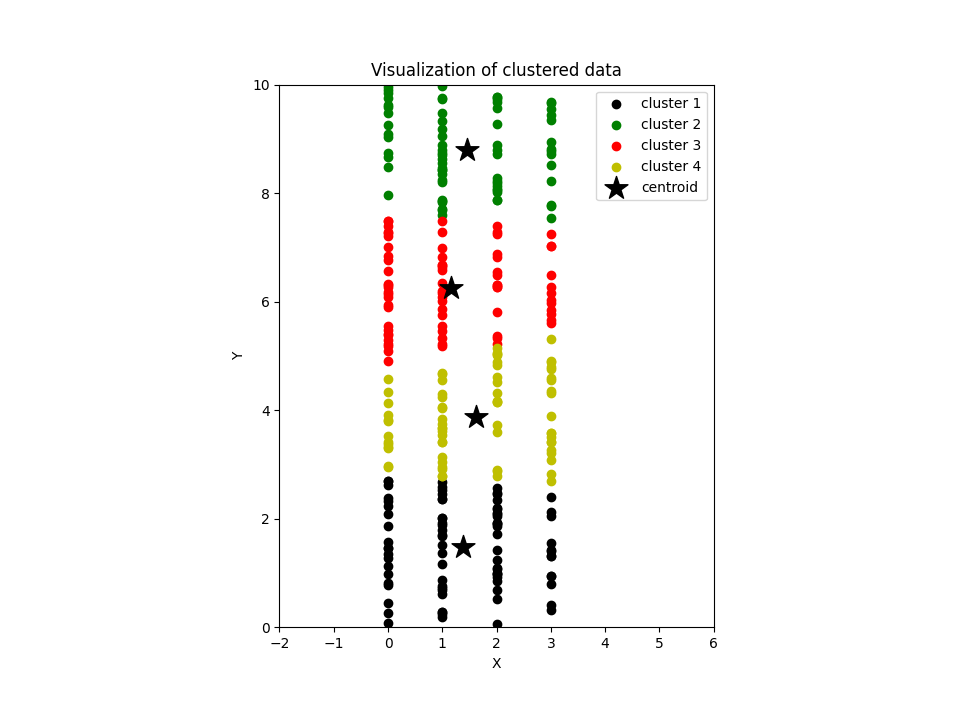
在上图中,K 均值算法已将这些观测值聚类为 4 组。从可视化效果来看,这些观测值的聚类方式甚至从图表上看也显得很自然,而且合乎情理。
肘部法则确定最优聚类数(K)
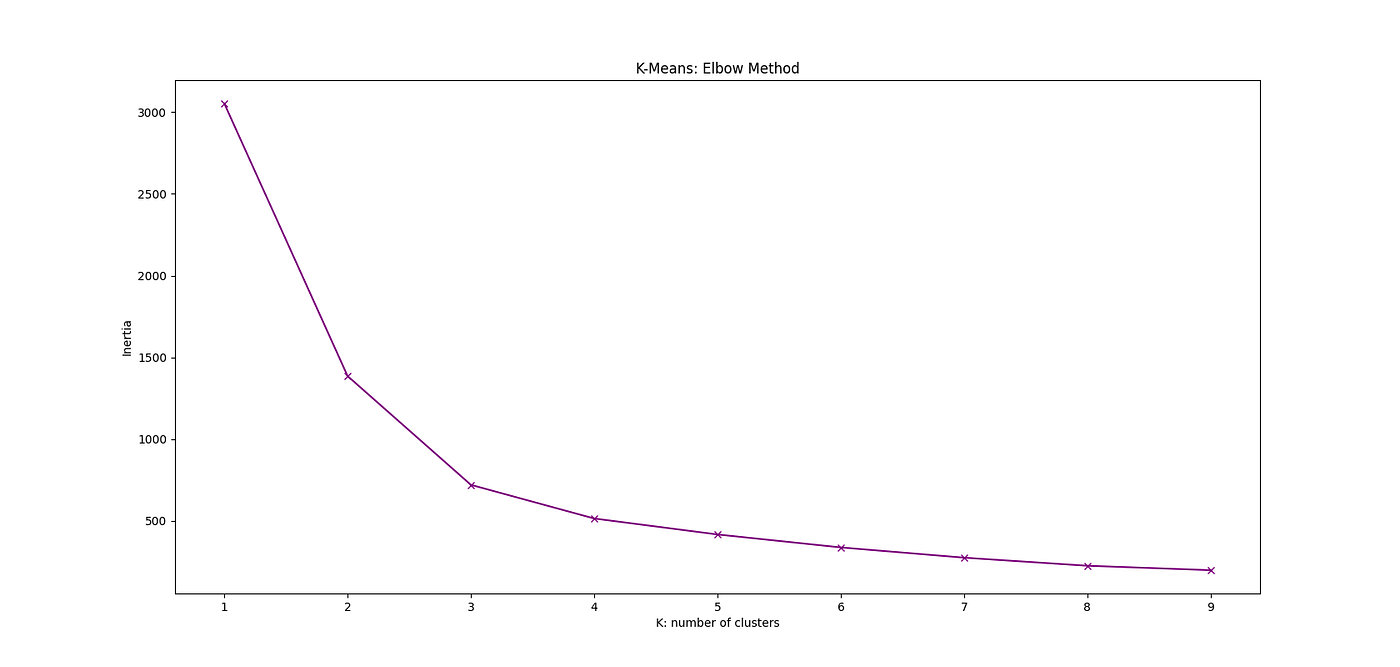
使用 K 均值算法时面临的最大挑战之一是聚类数目的选择。有时这是业务决策,但大多数时候我们希望选择一个最优且合理的 K 值(即聚类数量)。确定这个最优 K 值(或聚类数量)最常用的方法之一是 肘部法则。
要使用这种方法,您需要了解什么是 惯性。惯性是样本到其最近聚类中心的平方距离之和。因此,惯性或 聚类内平方和 值可以表明不同聚类的连贯性或纯度如何。惯性可以这样描述:
$$\sum_{i=1}^{N} (x_i - C_k)^2$$
其中 N 是数据集中的样本数量,C 是一个聚类的中心,k 是聚类的索引。因此,惯性只是计算每个聚类中样本到其聚类中心的平方距离,并将它们相加。
然后我们可以计算不同聚类数量 K 的惯性。我们可以像下面的图一样绘制出来,其中我们考虑 K = 1, 2, ..., 10。然后从图中我们可以选择肘部出现时对应的 K 值。在这种情况下,肘部出现在 K = 3 时。
def Elbow_Method(df):
inertia = []
# 考虑 K = 1, 2,..., 10 作为 K
K = range(1, 10)
for k in K:
KMeans_Model = KMeans(n_clusters=k, random_state = 2022)
KMeans_Model.fit(df)
inertia.append(KMeans_Model.inertia_)
return(inertia)
K = range(1, 10)
inertia = Elbow_Method(df)
plt.figure(figsize = (17,8))
plt.plot(K, inertia, 'bx-')
plt.xlabel("K: 聚类数量")
plt.ylabel("惯性")
plt.title("K 均值:肘部法则")
plt.show()

K 均值算法是一种非确定性方法,其随机性体现在第一步,即所有观测值都被随机分配到 K 个类别中的一个。
正如您所见,K 均值聚类提供了一种基于相似性对数据点进行分组的高效且有效的方法。通过在 Python 中实现 K 均值算法,您可以轻松地将此技术应用于自己的数据集,并从数据中获得有价值的见解。
Python 提供了强大的工具来实现和可视化 K-Means 聚类。借助 scikit-learn 库和 matplotlib,您可以轻松地将 K-Means 应用于您的数据集,并从生成的聚类中获得很多有用的信息。

层次聚类理论
另一种常见的聚类技术是层次聚类。 这是一种无监督学习方法,可用于将观测数据聚类成不同的分组。但与 K-Means 不同,层次聚类最初将每个观测数据视为一个独立的簇。
凝聚层次聚类 vs. 分裂层次聚类
层次聚类主要有两种类型:凝聚层次聚类和分裂层次聚类。
凝聚聚类首先将每个数据点分配到其自身的簇中。然后,它基于选定的距离度量标准,迭代地合并最相似的簇,直到形成一个包含所有数据点的单个簇。
这种自下而上的方法会生成一种类似二叉树的结构,也称为树状图,其中每个节点的高度代表正在合并的簇之间的差异程度。
另一方面,分裂聚类从包含所有数据点的一个单一簇开始。然后,它递归地将簇划分为更小的子簇,直到每个数据点都在自己的簇中。这种自上而下的方法生成了一个树状图,提供了有关簇层次结构的见解。
层次聚类的距离度量
要确定聚类或数据点之间的相似性,您可以使用多种距离度量方法。常用的度量方法包括欧几里得距离、曼哈顿距离和余弦相似度。这些度量方法量化了成对数据点之间的差异或相似性,并指导聚类过程。
在这种技术中,最初每个数据点都被视为一个单独的簇。在每次迭代中,最相似或差异最小的簇合并为一个簇,此过程一直持续到只剩下一个簇为止。因此,该算法反复执行以下步骤:
-
1: 找出距离最近的两个聚类。
-
2: 合并两个最相似的簇。
-
然后它继续这种迭代过程,直到所有的簇都合并在一起。
两个簇之间的相异性或相似性计算取决于所选择的链接(Linkage)方式。常见的五种链接方法包括:
-
完全链接: 计算两个簇(K1 和 K2)之间的最大簇间差异性。具体而言,需要计算 K1 中所有观测点与 K2 中所有观测点之间的成对差异性,并选择其中最大的值作为簇间距离。
-
单链接: 计算两个簇(K1 和 K2)之间的最小簇间差异性。具体而言,需要计算 K1 中所有观测点与 K2 中所有观测点之间的成对差异性,并选择其中最小的值作为簇间距离。
-
平均链接: 计算两个簇(K1 和 K2)之间的平均簇间差异性。具体而言,需要计算 K1 中所有观测点与 K2 中所有观测点之间的成对差异性,并取这些差异值的平均值作为簇间距离。
-
质心链接: 计算簇 K1 的质心与簇 K2 的质心之间的差异性。(这种链接方式通常较少被使用,因为它可能导致较多的簇重叠。)
-
沃德法: 通过最小化每个观测点与簇内平均观测点之间的平方和距离,来决定如何合并簇。该方法倾向于生成大小相近的簇,并在层次聚类中常用于优化聚类结果。
层次聚类:Python 的实现方法
层次聚类是一种强大的无监督学习技术,可根据数据点之间的相似性将其分组为不同的簇。 在本节中,我们将探讨如何在 Python 中实现层次聚类。
以下是在 Python 中实现层次聚类的示例:
import scipy.cluster.hierarchy as HieraarchicalClustering
from sklearn.cluster import AgglomerativeClustering
import numpy as np
import pandas as pd
# 生成层次聚类的数据
df = np.random.randint(0,10,size = [100,2])
X1 = np.random.randint(0,4,size = [300,1])
X2 = np.random.uniform(0,10,size = [300,1])
df = np.append(X1,X2,axis = 1)
hierCl = HieraarchicalClustering.linkage(df, method='ward')
Hcl= AgglomerativeClustering(n_clusters = 7, affinity = 'euclidean', linkage ='ward')
Hcl_fitted = Hcl.fit_predict(df)
df = pd.DataFrame(df)
df["labels"] = Hcl_fitted

这段代码使用了 Scipy 的层次聚类模块和 Scikit-learn 的凝聚聚类算法来实现层次聚类。该脚本的目的是生成一个合成数据集,应用层次聚类,并为数据点分配聚类标签。
脚本的第一部分导入了所需的库。导入了 Scipy 的层次聚类模块 (scipy.cluster.hierarchy) 并将其命名为 HieraarchicalClustering,用于执行基于链接的聚类。还导入了 Scikit-learn 的 AgglomerativeClustering 类来实现一种特定类型的层次聚类。此外,NumPy 用于数值运算和生成随机数据,而 Pandas 则用于将数据结构化为 DataFrame。
接下来,脚本生成合成的数值数据。创建一个 100×2 的矩阵 (df),其中包含 0 到 9 之间的随机整数。然后分别创建两个额外的数据集 X1 and X2。X1 包含 300 个 0 到 3 之间的随机整数,而X2 包含 300 个 0 到 10 之间的随机浮点数。然后使用 np.append()沿着第二轴将这两个数据集合并,形成一个具有两个特征的数据集,该数据集将用于聚类。
一旦数据集准备就绪,便使用 Ward 连接法进行层次聚类,该方法可使合并后的聚类之间的方差最小化。通过 HieraarchicalClustering.linkage(df, method='ward') 创建链接矩阵 hierCl,该函数用于计算层次聚类的解决方案。
生成层次聚类链接矩阵后,应用凝聚聚类将数据分为七个簇(n_clusters=7)。 affinity='euclidean' 参数指定使用欧几里得距离作为度量点之间相似性的距离度量。linkage='ward' 参数确保使用 Ward 方法合并簇,以最小化方差。然后使用 Hcl.fit_predict(df) 将模型拟合到数据集,为每个数据点分配一个簇标签。
最后,数据集被转换为一个 Pandas 数据框,并添加了一个新列“labels”来存储分配的聚类标签。生成的数据框现在既包含原始数据点,也包含其对应的聚类分配,从而便于进一步分析或可视化。
总之,此脚本生成随机数据,使用 Scipy 的 linkage 方法和 Scikit-learn 的 Agglomerative Clustering 进行层次聚类,并为每个数据点分配聚类标签。最终的数据集可用于分析聚类结构、可视化结果或验证聚类效果。
层次聚类: 可视化的实现方法
层次聚类的一个关键优势在于其能够创建聚类的层次结构,这能够为数据点之间的关系提供有价值的见解。
在 Python 中可视化层次聚类,我们可以使用诸如 Scikit-learn、SciPy 和 Matplotlib 等多种库。这些库提供了易于使用的函数和工具,从而简化了可视化过程。
因此,在执行层次聚类之后,通常很有帮助的是将聚类结果可视化。我们可以使用各种可视化技术,例如树状图或热图。
正如我们上面所讨论的,树状图是一种树形图,用于展示聚类之间的层次关系。它可以通过 Python 中的 Scipy 库生成。
以下是一个在 Python 中可视化树状图和聚类点的示例:
# 生成一个树状图以帮助确定最佳聚类数量
# 树状图展示了层次聚类如何逐步合并数据点。
dendrogram = HieraarchicalClustering.dendrogram(hierCl)
# 设置树状图的标题
plt.title('树状图')
# 在 x 轴上标注以表明观测值(数据点)
plt.xlabel("观察结果")
# 在 y 轴上标注出各聚类之间的欧几里得距离
plt.ylabel('欧几里得距离')
# 显示树状图
plt.show()
# 使用散点图可视化聚类数据
# 每种颜色代表一个不同的类别。
# 将属于聚类 1 的所有点用黑色绘制出来
plt.scatter(df[df["labels"] == 0][0], df[df["labels"] == 0][1],
c='black', label='cluster 1')
# 将属于第 2 类的所有点都用绿色标出。
plt.scatter(df[df["labels"] == 1][0], df[df["labels"] == 1][1],
c='green', label='cluster 2')
# 将属于第 3 类的所有点都用红色标出。
plt.scatter(df[df["labels"] == 2][0], df[df["labels"] == 2][1],
c='red', label='cluster 3')
# 将属于第 4 类的所有点用洋红色绘制出来
plt.scatter(df[df["labels"] == 3][0], df[df["labels"] == 3][1],
c='magenta', label='cluster 4')
# 将属于第 5 类的所有点都用紫色标出。
plt.scatter(df[df["labels"] == 4][0], df[df["labels"] == 4][1],
c='purple', label='cluster 5')
# 将属于第 6 类的所有点用黄色标出
plt.scatter(df[df["labels"] == 5][0], df[df["labels"] == 5][1],
c='y', label='cluster 6')
# 将属于第 7 类的所有点用黑色标出
plt.scatter(df[df["labels"] == 6][0], df[df["labels"] == 6][1],
c='black', label='cluster 7')
# 在图中显示图例以标注每个聚类
plt.legend()
# 将代表特征 1(第一维度)的 x 轴标注出来
plt.xlabel('X')
# 将代表特征 2(第二维度)的 y 轴标注出来
plt.ylabel('Y')
# 设置散点图的标题
plt.title('层级聚类')
# 显示聚类散点图
plt.show()

以下是在 Python 中可视化层次聚类的分步指南:
步骤 1:预处理数据
在进行层次聚类的可视化之前,对数据进行预处理(如缩放或标准化)是很重要的。这能确保所有特征具有相似的范围,并防止对特定特征产生任何偏见。
步骤 2: 执行层次聚类
接下来,我们使用选定的算法,例如 Scikit-learn 中的 AgglomerativeClustering 执行层次聚类。该算法计算数据点之间的相似度,并根据特定的链接准则将它们合并为簇。
步骤 3: 创建一个树状图
我们可以使用 SciPy 库中的树状图函数来创建这种可视化效果。树状图能够让我们直观地看到各个聚类之间的距离和关系。
步骤 4: 绘制聚类图
最后,我们可以使用散点图或其他合适的可视化技术来绘制聚类。这有助于我们直观地看到每个聚类中的数据点,并深入了解每个聚类的特征。
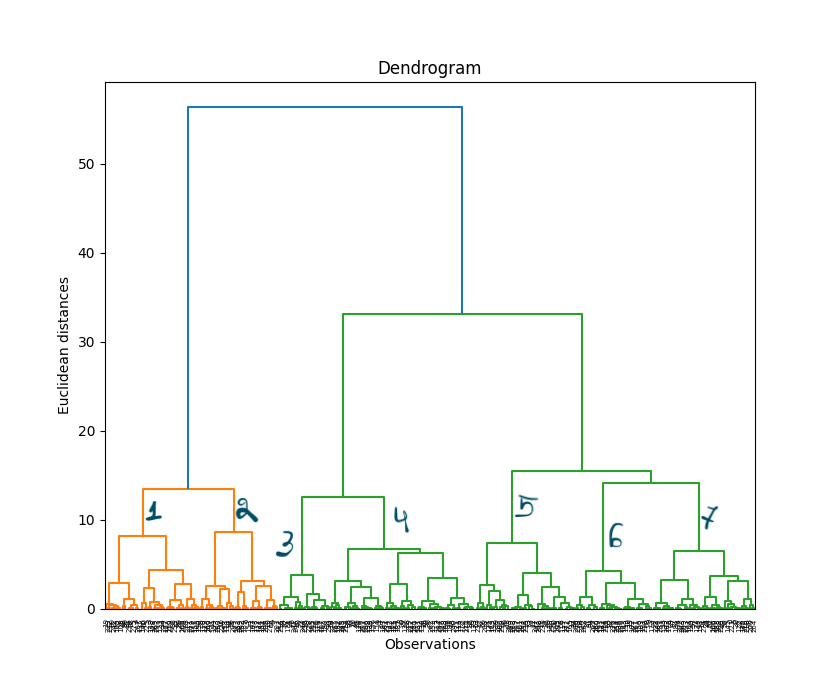
此树状图随后可帮助我们确定更优的聚类数量。如您所见,在这种情况下,我们似乎应该使用 7 个聚类。
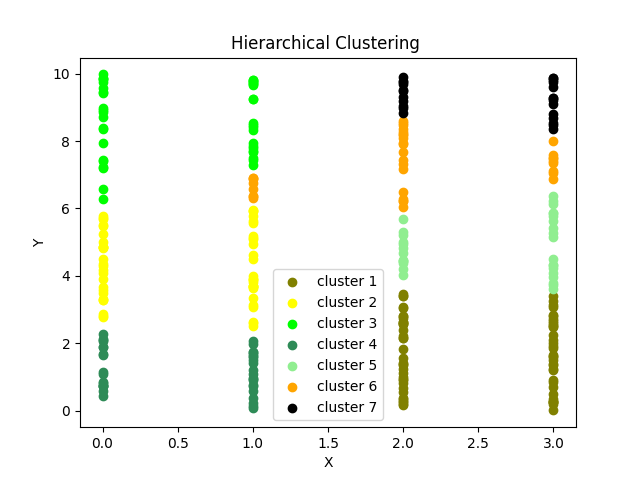
通过在 Python 中对层次聚类进行可视化,我们可以更好地理解数据内部的结构和关系。这种可视化技术在处理复杂数据集时特别有用,并且有助于决策过程和模式发现。
请记得根据您的数据集和目标调整具体的参数和设置。尝试不同的可视化方法和技术能够让您对数据有更深入的了解。
DBSCAN 聚类理论
DBSCAN (基于密度的空间聚类算法,用于处理噪声数据)是一种用于聚类分析的无监督学习算法。它特别擅长识别任意形状的聚类,并能处理噪声数据。
与 K-均值 或层次聚类不同,DBSCAN 不需要预先指定聚类的数量。相反,它根据数据中的密度和连通性来定义聚类。
DBSCAN 工作原理:
基于密度的聚类: DBSCAN 会将彼此距离较近且具有足够数量近邻的数据点归为一组。它将数据点密集的区域识别为聚类,并将稀疏区域视为噪声。
核心点、边界点和噪声点: DBSCAN 将数据点分为三种类型:核心点、边界点和噪声点。
-
核心要点: 在指定距离(由
eps参数定义)内具有最少数量邻近点(由min_samples参数定义)的数据点。 -
边界点: 位于核心点的
eps距离内但相邻点数量不足,而不能被视为核心点的数据点。 -
噪声点:既非核心点也非边界点的数据点。
可达性与连通性: DBSCAN 通过可达性和连通性的概念来定义簇。如果一个数据点可以通过一条由核心点(Core Points)连接的路径到达另一个数据点,则认为该数据点是可达的(reachable)。如果两个数据点是可达的,它们属于同一个簇。
簇扩展: DBSCAN 从一个任意数据点开始,通过检查其邻居及其邻居的邻居,不断扩展簇,从而形成一个连通的数据点群。
** DBSCAN 聚类的核心优势:**
-
检测复杂结构的能力: DBSCAN 能够发现各种形状和大小的簇,使其非常适合处理具有非线性关系或不规则模式的数据集。
-
抗噪声能力强: DBSCAN 能够有效地处理含噪声的数据,通过将噪声点与聚类点区分开来。
-
自动确定聚类数量: DBSCAN 算法无需预先指定聚类的数量,这使其更方便且能更好地适应不同的数据集。
-
适用于大规模数据集: 与某些其他聚类算法相比,DBSCAN 的时间复杂度相对较低,这使其能够很好地扩展到大规模数据集。
在下一节中,我们将深入探讨如何在 Python 中实现 DBSCAN 算法,并提供分步指导和示例。
DBSCAN 聚类: Python 的实现方法
在本节中,我将指导您如何使用 Python 实现 DBSCAN。
DBSCAN 聚类的关键步骤
-
数据预处理: 在应用 DBSCAN 之前,对数据进行预处理非常重要。这包括处理缺失值、对特征进行标准化以及选择合适的距离度量。
-
定义参数: DBSCAN 需要两个主要参数 epsilon (eps) 和最小点数 (MinPts). Epsilon 决定了将两点视为邻点的最大距离,而 MinPts 则指定了形成密集区域所需的最少点数。
-
执行基于密度的聚类: DBSCAN 算法首先随机选取一个数据点,并找出其在指定的 epsilon 距离内的邻点。如果邻点数量超过 MinPts 阈值,则形成一个新的聚类。该算法通过迭代添加新点来扩展这个聚类,直到无法再添加新的点为止。
-
执行噪声检测: 不属于任何聚类的点被视为噪声或异常值。这些点未被分配到任何聚类中,对于识别数据中的异常情况至关重要。
要在 Python 中执行 DBSCAN 聚类,我们可以使用 scikit-learn 库。首先,需要导入所需的库并加载要聚类的数据集。然后,可以创建 DBSCAN 类的一个实例,并设置 epsilon (eps) 和最小样本数 (min_samples) 参数。
以下是一个示例代码片段,可帮助您入门:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
# 生成示例数据
X, _ = make_moons(n_samples=500, noise=0.05, random_state=0)
# 应用 DBSCAN 聚类
db = DBSCAN(eps=0.3, min_samples=5, metric='euclidean')
y_db = db.fit_predict(X)

请记得将 X 替换为您的实际数据集。您可以调整 eps 和 min_samples 参数以获得不同的聚类结果。eps 参数是将一个样本视为另一个样本邻域内的最大距离。min_samples 是将一个点视为核心点的邻域中的样本数或总权重。
DBSCAN 相较于其他聚类算法具有诸多优势,比如无需预先设定聚类的数量。这使得它适用于聚类数量未知的数据集。DBSCAN 还能够识别出形状和大小各异的聚类,使其在捕捉复杂结构方面更具灵活性。
但是 DBSCAN 在处理数据集中的不同密度时可能会遇到困难,并且对 epsilon (eps)和最小点数参数的选择较为敏感。要获得最佳的聚类结果,必须对这些参数进行精细调整。
通过在 Python 中实现 DBSCAN,您可以利用这一强大的聚类算法来发现数据中具有意义的模式和结构。
在我们探讨 DBSCAN 与其他聚类技术之间的差异之前,让我们更仔细地研究一下影响 DBSCAN 性能和结果的关键参数。
理解 DBSCAN 的关键参数
eps (epsilon) 参数定义了两个数据点之间的最大距离,使其中一个点被视为另一个点的邻居。这意味着,在核心点 eps 半径范围内的所有点都属于同一个簇。选择合适的 eps 值至关重要,因为 eps 过小可能会导致簇数量过多且规模较小,而 eps 过大可能会将原本独立的簇合并为一个簇。
min_samples 参数决定形成高密度区域所需的最小数据点数. 如果一个点在 eps 半径范围内至少有 min_samples 个邻居,则被分类为 核心点 。如果一个点落在某个核心点的 eps 半径内,但自身不满足 min_samples 要求,则被分类为 边界点. 任何既不是核心点也不是边界点的数据点都会被标记为噪声或异常值。
DBSCAN 如何对数据点进行分组
DBSCAN 通过识别核心点并围绕它们扩展簇来运行。它根据密度将紧密分布的点(即簇)归为一组,并将低密度点标记为异常值(或噪声)。其过程如下:
-
选择一个未访问的数据点 并检查其
eps半径范围内是否至少有min_samples个邻居。 -
如果满足条件,该点被标记为核心点,并以其为中心形成一个新的簇。
-
扩展簇 将所有
eps范围内直接可达的点加入簇中。如果这些点也是核心点,则将其邻居点一并加入。 -
继续扩展 直到没有更多数据点满足密度准则。
-
移动到下一个未访问的数据点 ,并重复该过程。
-
对剩余数据点进行分类。 将剩余数据点分类为边界点(属于某个簇但不是核心点)或噪声点(不属于任何簇的异常值)。
DBSCAN 示例实现
在该实现中:
-
eps=0.3: 定义数据点之间的最大距离,决定它们是否被视为邻居。 -
min_samples=5: 设置形成高密度区域所需的最小数据点数 -
fit_predict(X): 为每个数据点分配一个聚类标签。
应用 DBSCAN 算法后,数据点会被分配标签。如果两个点属于同一个聚类,它们在 y_db中将具有相同的标签。 被识别为离群点的数据点将被标记为-1 并且不被聚类。
生成的散点图直观地展示了 DBSCAN 如何识别出两个新月形的簇。与假定簇为球形的 K-均值不同,DBSCAN 能够有效地检测出任意形状的簇。
plt.scatter(X[y_db == 0, 0], X[y_db == 0, 1],
c='lightblue', marker='o', s=40,
edgecolor='black',
label='cluster 1')
plt.scatter(X[y_db == 1, 0], X[y_db == 1, 1],
c='red', marker='s', s=40,
edgecolor='black',
label='cluster 2')
plt.legend()
plt.show()

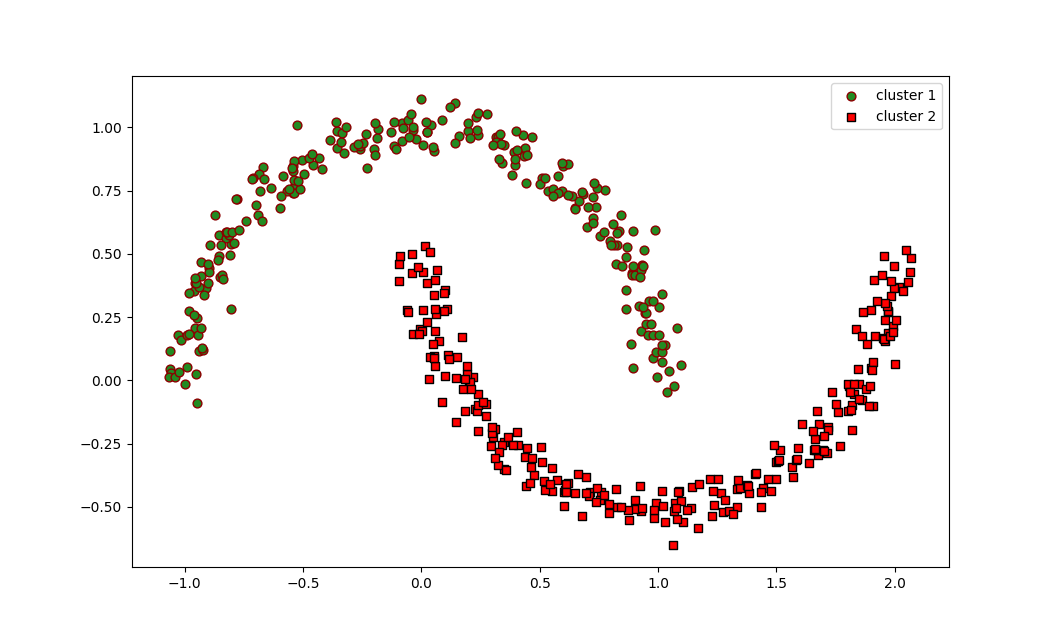
生成的图表将显示两个呈月牙状的簇,分别以绿色和红色呈现,这表明 DBSCAN 成功地识别并分离了这两个相互交织的半圆。
如何评估聚类算法的性能
评估聚类模型的性能可能颇具挑战性,因为在无监督学习中没有可用的真实标签。不过,有几种评估指标可以为聚类结果的质量提供见解。
-
轮廓系数: 衡量每个数据点与其所属聚类的契合程度,同时与其他聚类进行比较。轮廓系数越高,表明聚类效果越好。
-
戴维森堡丁指数: 该指标衡量每个聚类与其最相似聚类之间的平均相似度,同时考虑聚类之间的分离度。值越低表示聚类效果越好。
-
方差比准则: 评估簇间离散度与簇内离散度的比值,较高的值表示聚类效果更清晰。
-
可视化评估: 检查聚类结果的可视化表示,例如散点图或树状图,也能为聚类的质量和意义提供有价值的见解。
我建议您结合使用评估指标和视觉评估,以全面评估聚类模型的性能。
K 均值聚类、层次聚类和 DBSCAN 之间的区别
K 均值、层次聚类和 DBSCAN 是三种广泛使用的聚类算法,每种算法都有其独特的数据分组方法。理解它们之间的差异对于根据数据特征和分析目标选择最合适的算法至关重要。
K-均值聚类
K 均值聚类是一种基于质心的算法,它根据相似性将数据划分为 K 个簇。该算法首先随机初始化 K 个质心,然后迭代地将每个数据点分配给最近的质心。一旦所有数据点都被分配,就根据每个簇内点的均值重新计算质心。这个过程会一直持续到达到收敛为止。
K-均值聚类的核心优势:
-
对于大型数据集而言,高效且可扩展。
-
当聚类呈球形且分布均匀时效果良好。
-
与层次聚类相比,计算速度更快。
-
易于实施和理解。
K-均值聚类的局限性:
-
需要提前指定聚类(K)的数量。
-
对初始质心位置敏感,导致结果不同。
-
假定各聚类大小相等且呈球形,但实际情况并非总是如此。
-
在处理异常值和非线性形状的聚类时遇到的难题。
层次聚类
层次聚类创建了一个嵌套的聚类层次结构,无需预先定义聚类的数量。它从将每个数据点视为单独的聚类开始,然后根据相似性逐步合并或拆分聚类。其结果通常用树状图来可视化,这有助于确定最佳的聚类数量。
层次聚类的核心优势:
-
无需 预先指定聚类数量。
-
捕捉集群之间的层级关系。
-
能够处理不同类型的数据,包括数值型和分类型。
-
对于探索性分析很有用,带有树状图以提高可解释性。
层次聚类的局限性:
-
计算成本高,在大规模数据集上效率低(O(n²)时间复杂度)。
-
由于内存限制,难以扩展到大规模数据集。
-
确定树状图的合适截断点较具挑战性。
-
对噪声和异常值敏感,可能导致层次结构失真。
DBSCAN(基于密度的应用空间聚类算法)
DBSCAN 是一种基于密度的聚类算法,它根据数据点之间的接近程度和密度来对数据点进行分组,而不是基于预先定义的聚类。与 K-Means 和层次聚类不同,DBSCAN 不需要指定聚类的数量。相反,它使用两个关键参数:eps (两个点被视为邻居的最大距离) 和 min_samples (形成高密度簇所需的最小点数)。不满足这些条件的点会被标记为噪声。
DBSCAN 的核心优势:
-
无需预先指定聚类的数量。
-
能够检测任意形状的簇,这与假定簇为球形的 K-均值 算法不同。
-
能够有效地处理异常值,将其标记为噪声,而不是强行将其归入某个聚类。
-
适用于密度不均或具有非线性结构的数据集,在复杂数据分布下表现良好。
DBSCAN 的局限性:
-
难以处理不同密度的聚类,因为单一的 eps 值可能无法适用于所有簇。
-
对参数调整敏感 (eps 和 min_samples),参数选择会影响聚类性能。
-
不适用于高维数据,因为在高维空间中,欧几里得距离的区分度会降低。
-
在超大规模数据集上可能表现欠佳,尽管其可扩展性优于层次聚类。
选择合适的聚类算法
| 特征 | K-均值 | 层次聚类 | DBSCAN |
|---|---|---|---|
| 簇形 | 假设聚类为球形 | 适用于层次结构 | 适用于任意形状的聚类 |
| 可扩展性 | 高度可扩展(适用于大规模数据集,计算速度快) | 不具备良好扩展性 (时间复杂度 O(n²)) | 度可扩展(处理超大规模数据集可能存在挑战) |
| 簇的数量 | 必须预定义 | 无需指定 | 无需指定 |
| 处理异常值 | 较差 | 对噪声敏感 | 良好,可检测异常值作为噪声 |
| 计算复杂度 | O(n) 至 O(n log n) | O(n²) | O(n log n) |
| 可解释性 | 结果输出易于理解 | 树状图提供良好的可视化解析 | 直观性较低,需要调整参数 |
每种聚类算法都有其优缺点。 K-均值 在处理大型数据集以及簇呈球形且彼此分离时效果最佳。层次聚类 在存在层次关系或簇的数量未知时很有用。DBSCAN 在检测任意形状的簇和处理噪声方面表现出色,但需要仔细调整参数。
通过了解每种算法的特点,您可以做出明智的决定,选择最适合您数据分析需求的聚类方法。
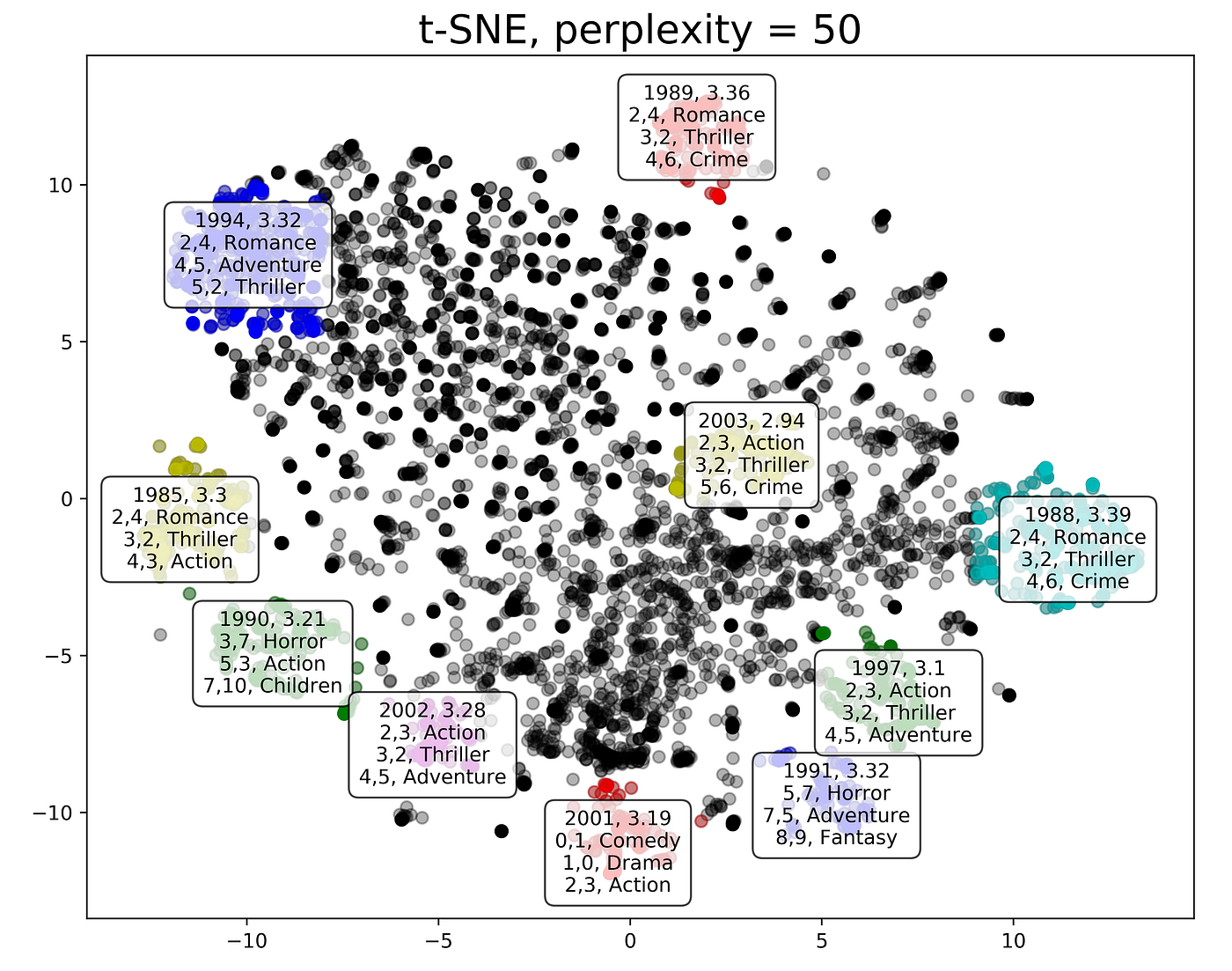
如何使用 t-SNE 在 Python 中可视化聚类
在应用 K-Means、层次聚类和 DBSCAN 等聚类算法后,通常需要对聚类结果进行可视化,以更好地理解数据的内在结构。
而对于二维或三维数据集,散点图可以很好地展示聚类结果。然而,在实际应用中,数据通常具有高维特征,直接可视化是较为困难的。
为应对这一挑战,您可以使用诸如t-SNE (t-Distributed Stochastic Neighbor Embedding) 之类的降维技术将高维数据投影到低维空间,同时保留其结构。这使您能够更有效地可视化聚类,并识别出在原始数据中可能不那么明显的隐藏模式。
在本节中,我们将探讨 t-SNE 的理论基础及其在 Python 中的实现。
深入解析 t-SNE
t-SNE 由 Laurens van der Maaten 和 Geoffrey Hinton 于 2008 年提出,作为一种用于可视化复杂数据结构的方法。其目标是在低维空间中表示高维数据点,同时保留数据点之间的局部结构和成对相似性。
t-SNE 通过在高维空间和低维空间中建模数据点之间的相似性来实现这一目标。
t-SNE 算法
t-SNE 算法的执行步骤如下:
-
计算高维空间中数据点的两两相似度。通常使用高斯核函数(Gaussian kernel),基于欧几里得距离( Euclidean distances)来衡量数据点之间的相似性。
-
随机初始化低维嵌入。
-
定义一个成本函数,用于衡量高维空间与低维空间中数据点相似性的匹配程度。
-
使用梯度下降优化成本函数,以最小化高维空间与低维空间相似性之间的差异。
-
重复执行步骤 3 和 4,直至成本函数收敛。
借助 scikit-learn 等库,用 Python 实现 t-SNE 相对简单。scikit-learn 库为将 t-SNE 应用于您的数据提供了用户友好的 API。通过遵循 scikit-learn 的文档和示例,您可以轻松地将 t-SNE 集成到您的机器学习流程中。
二维 t-SNE 可视化
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
# 加载数据集
digits = datasets.load_digits()
X, y = digits.data, digits.target
# 应用 t-SNE 算法
tsne = TSNE(n_components=2, random_state=0)
X_tsne = tsne.fit_transform(X)
# 在二维平面上可视化结果
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, edgecolor='none', alpha=0.7, cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(scatter)
plt.title("数字数据集的 t-SNE 可视化")
plt.show()

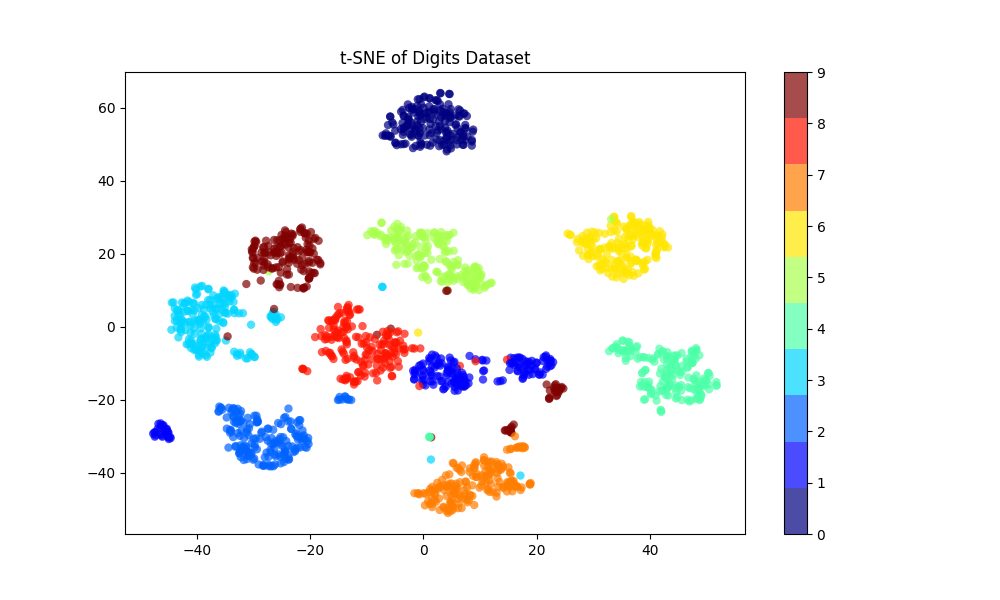
在这个例子中:
-
我们将加载
digits数据集. -
我们应用 t-SNE 将数据从 64 维(因为每张图像为 8×8)降维至 2 维。
-
然后我们绘制转换后的数据,根据每个点的真实数字标签为其着色。
生成的可视化结果将展示出若干簇,每个簇对应一个数字(从 0 到 9)。这有助于了解不同数字在原始高维空间中的分离程度。
高维数据可视化
t-SNE 的主要优势之一在于其能够将高维数据在低维空间中进行可视化。通过降低数据的维度,t-SNE 使我们能够识别出在原始高维空间中可能不明显的聚类和模式。由此产生的可视化结果能够为数据的结构提供有价值的见解,从而有助于人们的决策过程。
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
from mpl_toolkits.mplot3d import Axes3D
# 加载数据集
digits = datasets.load_digits()
X, y = digits.data, digits.target
# 应用 t-SNE 算法
tsne = TSNE(n_components=3, random_state=0)
X_tsne = tsne.fit_transform(X)
# 在三维平面上实现可视化结果
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(X_tsne[:, 0], X_tsne[:, 1], X_tsne[:, 2], c=y, edgecolor='none', alpha=0.7, cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(scatter)
plt.title("数字数据集的三维 t-SNE 分析图")
plt.show()

在这段修订后的代码中:
-
我们将 t-SNE 的
n_components=3设置为 3,以获得三维变换。 -
我们使用
mpl_toolkits.mplot3d.Axes3D来创建一个三维散点图。
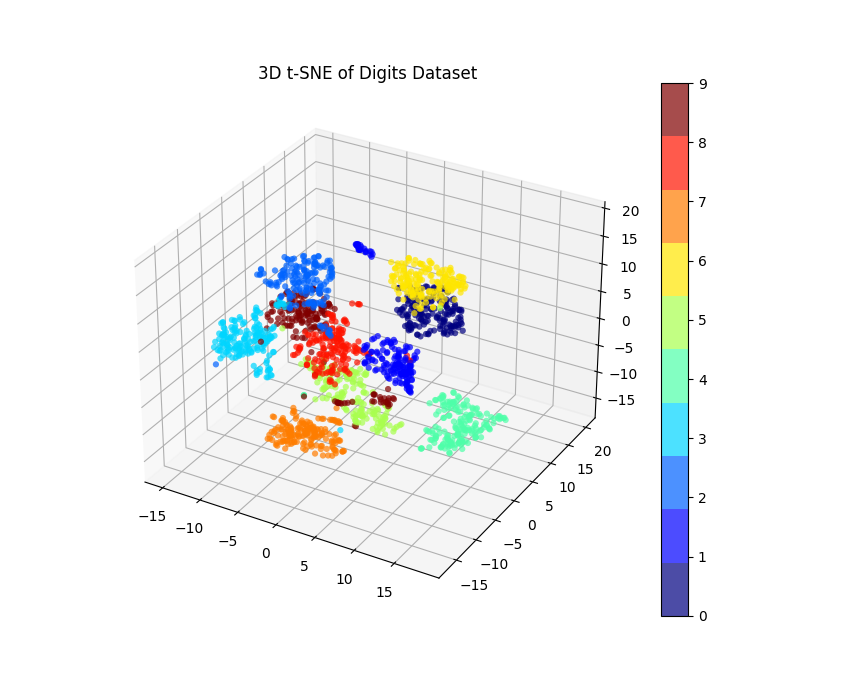
执行此代码后,您将看到一个 3D 散点图,其中的点根据其 t-SNE 坐标进行定位,并根据其真实的数字标签进行着色。
而旋转三维可视化图像,会有助于我们更好地理解数据点的空间分布情况。
t-SNE 是一种强大的降维和高维数据可视化工具。通过利用其功能,您可以更深入地了解复杂的数据集,并发现那些并非一目了然的隐藏模式。而凭借其 Python 实现方法和易用性,t-SNE 对于任何数据科学家或机器学习从业者来说都是一项宝贵的资源。
有关更多的无监督学习技术
除了我们在此讨论的聚类技术之外,还有一些重要的无监督学习技术值得探索。虽然我们在此不会进行详细的探讨,但让我们简要提及其中两种技术:混合模型和主题建模。
混合模型
混合模型是一类概率模型,用于建模复杂的数据分布。它假设整体数据集可以表示为多个潜在子群或成分的组合,每个成分由其自身的概率分布描述。
混合模型在数据点不属于明确的独立聚类且可能存在重叠特征的情况下特别有用。
主题建模
主题建模是一种用于从文档集合中提取潜在主题的方法,它可以帮助探索和发现文本数据中的隐含语义模式。
通过分析单词在不同文档中的共现情况并识别常见主题,主题建模能够实现大规模文本数据的自动分类和摘要生成。该技术广泛应用于自然语言处理(NLP)、信息检索和内容推荐系统等领域。
尽管这些技术的深入研究超出了本手册的范围,但是值得进一步探索,因为它们是很有价值的工具,从而有助于挖掘和洞察隐藏的模式从您的数据中,从而帮助您获得见解。
请一定要牢记,掌握无监督学习是需要持续的学习和实践。在熟悉上述不同技术后,您将能够更好地应对各种数据分析挑战,并在多个领域内灵活运用这些方法。
常见问题解答
小问答: 请问监督学习和无监督学习之间的区别是什么?
首先,监督学习会是在带有标签的数据上训练模型,其中输入与对应的输出配对,目标是预测新数据的输出结果。
而相比之下,无监督学习处理的是无标签数据,旨在发现数据中的模式、结构或聚类,而无需来预定义其输出结果。
所以在本质上,监督学习的目标是学习一个映射函数,而无监督学习则侧重于发现数据中的隐藏关系或分组结构。
小问答: 如何知道哪种聚类算法最适合我的数据类型?
聚类算法的适用性取决于多种因素,例如数据的性质、期望的聚类数量以及您试图解决的具体问题。
在本手册中,我们将讨论三种常用的聚类算法:
-
K-均值 是一种常用的聚类算法,旨在将数据划分为 K 个簇,并将每个数据点分配给最临近的质心。该算法适用于分布均匀、接近球形的聚类,但需要预先指定簇的数量。
-
层次聚类 通过迭代合并或拆分数据点来构建聚类层次结构。它提供树状图来可视化聚类过程,并能够处理不同形状和规模的聚类。
-
DBSCAN 是一种基于密度的聚类算法,它将相互接近的数据点归为一类,并识别并分离异常值。该算法能够发现任意形状的聚类,并且无需预先指定聚类数量。
要确定最适合您用例的算法,我建议您尝试不同的技术,并根据诸如聚类质量、计算效率和可解释性等指标来评估其性能。
小问答: 请问无监督学习可以用于预测分析吗?
尽管无监督学习主要关注在没有特定输出标签的情况下发现数据中的模式和关系,但它也可以间接支持预测分析。通过来揭示数据中的隐藏结构和聚类,无监督学习能够提供有价值的洞察,从而优化特征工程、异常检测或数据分群,这些都能进一步提升预测模型的性能。
最明显的一个例子是,聚类等无监督学习技术可以帮助识别数据中的不同群组或模式,这些信息可作为预测模型的输入特征,或者用于生成新的预测变量。因此,无监督学习在预测分析中发挥着重要作用,它能够加深对数据的理解,并提升预测模型的准确性和有效性。
数据科学与人工智能资源
想要更详细的了解有关数据科学、机器学习和人工智能方面的职业,或者学习如何获得一份数据科学的工作吗?您可以下载这本 免费的数据科学与人工智能职业手册.
想从零开始学习机器学习,或者想巩固已有知识吗? 下载这本 免费的机器学习基础手册 一次性获取所有与 Python 示例相结合的机器学习基础知识。
关于作者
Tatev Aslanyan 是一位高级机器学习和人工智能工程师,以及 LunarTech的首席执行官兼联合创始人。其领导的 LunarTech 是一家致力于让数据科学和人工智能在全球普及的深度技术创新初创公司。Tatev 在人工智能工程和数据科学领域拥有超过 6 年的工作经验,曾在美国、英国、加拿大和荷兰工作过,她将自己的专业知识应用于推进不同行业的人工智能解决方案。
Tatev 本人不仅拥有顶尖荷兰大学的[硕士]计量经济学和[本科]运筹学学位51,还曾发表了多篇科学学术文章有关于自然语言处理(NLP)、机器学习和推荐系统在美国权威的学术期刊上。
作为顶级开源项目的贡献者, Tatev 共同参与撰写了多门课程和书籍, 其中包括 2024 年的 freeCodeCamp 项目, 并且还在LunarTech 项目中发挥了关键作用,帮助了来自于 144 个国家的 30,000 多名学习者。
LunarTech 作为一家深度技术创新公司,其不断研发人工智能驱动的产品,并同时提供教育工具来帮助企业和个人推动创新,从而实现让其能降低运营成本并提升盈利能力。
联系我们
-
订阅 LunarTech Newsletter 或者 LENS - 我们的资讯频道。
想要更全面了解数据科学、机器学习和人工智能的职业发展,并学习如何成功获得数据科学岗位吗?那就立即下载这本免费的数据科学与人工智能职业手册。
感谢您选择本手册作为您的学习伙伴。在您继续探索广阔的人工智能领域时,我希望您能够保持自信、精准思考,并怀揣创新精神!
由 LunarTech 打造的人工智能工程师训练营
如果您坚定地想成为一名人工智能工程师,并寻找一门既涵盖深层理论又注重实践的全方位训练营, 那么一定要看看专注于生成式人工智能的LunarTech 人工智能工程师训练营. 这虽然不是在有关人工智能工程上最全面和最高级的项目, 但是该训练营将为您提供在最具竞争力的人工智能领域和行业中脱颖而出的全部技能和知识。
在 3 至 6 个月内,你可以选择自定进度或参与小组学习,掌握生成式人工智能及其基础模型,如 变分自编码器、生成式对抗网络、Transformers 和大型语言模型。深入学习数学、统计学、模型架构,以及使用 PyTorch 和 TensorFlow 等行业标准框架训练这些模型的技术细节。
该课程涵盖大型模型的预训练、微调、提示工程、量化和大模型优化,以及诸如检索增强生成(RAGs)等前沿技术。
本次训练营将帮助您弥合研究与实际应用之间的差距,赋能您能够设计出有影响力的解决方案, 并同时打造出包含前沿项目的优秀作品集。
该课程还同时考虑人工智能伦理,帮助您构建可持续并且合乎道德规范的人工智能模型,与负责任的人工智能原则相契合。这不单单是一门课程 —— 它还将是一段全面的旅程,旨在让您成为人工智能革命中的领军人物 立即浏览课程详情。
由于名额有限,我们对于人工智能工程师的需求比以往任何时候都更高。所以请不要犹豫,您的人工智能工程师之路,将从现在开始!您可以报名参加。
“让我们一起共创未来!“ - Tatev Aslanyan, LunarTech 的首席执行官兼联合创始人
数据科学与人工智能电子期刊 | Tatev Karen | Substack
如果想从零开始学习机器学习,或者想要巩固已有知识? 可下载免费的机器学习基础手册
如果还想全面了解数据科学、机器学习和人工智能行业,并学习如何进入数据科学领域?可下载免费的数据科学与人工智能职业手册。
感谢您选择本手册作为您的学习伙伴。在您继续探索广阔的机器学习领域时,希望您充满信心、严谨细致,并秉持创新精神。祝您未来一切顺利!