


原文: Learn Solidity – A Handbook for Smart Contract Development
当我在 2018 年从律师转行到软件工程师时,我从未想过我会像现在这样喜欢做开发工作。我也从没想过我最终会为谷歌和 Chainlink Labs 优秀的公司工作。
在从事法律和其他工作 15 年之后,我经历了许多工作、国家、公司和职业道路。它们都无法与我从编码工作中获得的快乐和兴奋相提并论。
不足之处?掌握新的编码技能可能会令人困惑、沮丧且耗时。而且很容易忘记一些微小但重要的细节。
所以我写了这本手册。它旨在让您尽快开始编写 Solidity 代码。它遵循帕累托法则(又名 80/20 法则),手册将会专注于 20% 的信息,而这 20% 的信息将满足你 80% 需求。
作为我在 Chainlink Labs 工作的一部分,我在学习 Solidity 时就开始了解这些概念,并且把它们总结在一起。我在 38 岁的时候转为程序员,这次我也使用了许多当时的自学方法。
这个手册是我经常会用到的参考文件。它旨在为初学者和中级开发人员提供参考,以便快速解答在你深入学习该语言时的问题。
我会不断更新这本手册,但我真的需要你的帮助!如果我需要更新这本手册,请发推给我 @ZubinPratap 告诉我。
我要感谢我出色的同事 Kevin Ryu、Andrej Rakic、Patrick Collins 和 Richard Gottleiber,他们为本手册提供了宝贵的指导和意见。
(译者注:感谢 luojiyin 参与翻译本手册,并提供详细的校对建议。)
目录
- 这本手册是为谁而写的
- 必要的前置知识
- 什么是 Solidity
- 什么是智能合约
- 怎样在 Solidity 中声明变量和函数
- 智能合约中的变量作用域
- 如何使用可见性标识符(visibility specifier)
- 什么是构造函数
- 接口和抽象合约
- 智能合约案例 #2
- 什么是合约状态
- 状态可变性关键字(修饰符:modifier)
- 数据存储类型 – storage/memory/stack
- 数据类型原理
- Solidity 数据类型
- Solidity 中数组如何声明和初始化数组
- 函数修饰符(function modifier)是什么
- Solidity 中的异常处理 - require/assert/revert
- Solidity 中的继承
- 继承与构造函数参数
- Solidity 中的类型转换
- Solidity 中如何使用浮点数
- 哈希、ABI 编码(encoding)和解码(decoding)
- 如何调用合约并且使用 fallback 函数
- 如何发送和接收 Ether
- Solidity 库(library)
- Solidity 中的事件(events)和日志(logs)
- Solidity 中的时间逻辑
- 总结和更多资源
这本手册是为谁而写的
本手册适用于有兴趣探索 “Web3”背后的愿景,并希望学习相应的技能以实现该愿景所需的人。
不要死记硬背!阅读它,然后将其用作“参考文件”。当你学习任何一门新语言时,你会发现概念、习语和用法会变得有些混乱,或者你的记忆会随着时间的推移而消失。没关系!这就是本手册旨在帮助你随时查阅到所需的知识。
随着时间的推移,我可能会为此添加一些更高阶的内容,或者创建一个单独的教程。但就目前而言,这本手册将为你提供所需的大部分知识,以开始创建几个 Solidity DApp。
本手册假定你至少有几个月的编程经验,我的意思是至少你用 JavaScript 或 Python 或一些编译语言写过程序(HTML 和 CSS 实际上不是“编程”语言,所以只知道它们是不够的)。
唯一的其他要求是你要有好奇心、坚定不移,不要给自己限定任何的停止学习的时间点。
只要你有一台笔记本电脑和一个可以连接互联网的浏览器,你就可以运行 Solidity 代码。您可以在浏览器中使用 Remix 来编写本手册中的代码。不需要其他 IDE!
必要的前置知识
我还假设你了解区块链技术的基础知识,尤其是以太坊的基础知识以及什么是智能合约,提示:智能合约是在区块链上运行的程序,因此具备信任最小化(Trust-minimized)的优势!
虽然你不太可能需要它们来理解本手册,但实际上,拥有像 Metamask 这样的浏览器钱包并了解以太坊合约账户和外部账户(EOA 账户)之间的区别将帮助你充分利用这本手册。
什么是 Solidity
现在,让我们开始了解什么是 Solidity。 Solidity 是一种受 C++、JavaScript 和 Python 影响的面向对象的编程语言。
Solidity 旨在编译(从人类可读代码转换为机器可读代码)以太坊虚拟机 (EVM) 上运行的字节码。这是 Solidity 代码的运行时环境,就像你的浏览器是 JavaScript 代码的运行时环境一样。
所以,你通过 Solidity 编写智能合约,编译器将其转换为字节码。然后该字节码被部署并存储在以太坊(以及其他 EVM 兼容的区块链)上。
你可以在我制作的这个视频 中找到对 EVM 和字节码的基本介绍。
什么是智能合约
这是一个开箱即用的简单智能合约。它可能看起来没什么用,但你将从中了解很多 Solidity 知识!
请先连同每条评论一起阅读,以了解合约在做什么,然后继续学习一些关键知识。
现在,从上面的例子中学习七个关键知识:
-
第一个注释是机器可读行 (// SPDX-License-Identifier: MIT),它指定了所包含的代码的许可。
强烈建议使用 SPDX 许可证标识符,尽管你的代码在没有它的情况下也能编译。在这里阅读更多。此外,你也可以添加注释或“注释掉”任何一行,方法是在其前面加上两个正斜杠“//”。
-
任意一个 Solidity 文件中,
pragma指令必须是在代码的第一行。 Pragma 是一个指令,它告诉编译器应该使用哪个编译器版本将人类可读的 Solidity 代码转换为机器可读的字节码。Solidity 是一门新语言,更新频率很高,所以不同版本的编译器在编译代码时会产生不同的结果。当使用较新的编译器版本编译时,一些较旧的 solidity 文件会抛出错误或警告。
在较大的项目中,当你使用像 Hardhat 这样的工具时,可能需要指定多个编译器版本,因为导入的 solidity 文件或你依赖的库是为旧版本的 solidity 编写的。在此处阅读有关 Solidity 的 pragma 指令的更多信息。
-
pragma指令遵循语义化版本控制 (SemVer),SemVer 是一个系统,其中每个数字表示该版本中包含的更改的类型和范围。如果你想要 SemVer 的实际操作解释,请查看本教程,SemVer 非常有助于理解,并且如今在开发(尤其是 Web 开发)中得到广泛使用。 -
分号在 Solidity 中是必不可少的。即使缺少一个,编译器也会失败。Remix 会提醒你!
-
关键字
contract告诉编译器你正在声明一个智能合约。如果你熟悉面向对象编程,那么你可以将契约视为类。如果你不熟悉 OOP,那么可以将合约视为保存数据的对象——包括变量和函数。你可以通过智能合约为区块链应用程序提供所需的功能。
-
函数是封装单个想法、特定功能、任务等的可执行代码单元。通常我们希望函数一次只做一件事。
尽管函数可以在智能合约代码块之外的文件中声明,当时它们通常还是出现在智能合约中。函数可以接受 0 个或多个参数,也可以返回 0 个或多个值。输入和输出是静态类型的,这是你将在本手册稍后部分了解的概念。
-
在上面的例子中,变量
qtyCups被称为“状态变量”。它保存了合约的状态——这里的状态指的是程序需要跟踪运行的数据。与其他程序不同,智能合约应用程序即使在程序未运行时也会保持其状态。数据与应用程序一起存储在区块链中,这意味着区块链网络中的每个节点都在本地副本维护和同步数据和智能合约。
状态变量就像传统应用程序中的数据库“存储”,但由于区块链需要在网络中的所有节点之间同步状态,因此使用存储可能非常昂贵!稍后会详细介绍。
怎样在 Solidity 中声明变量和函数
让我们分解一下 HotFudgeSauce 智能合约,以便我们更多地了解这个合约中的内容。
在 Solidity 中定义事物的基本结构/语法类似于其他静态类型语言。函数和变量都有名字。
但是在类型化语言中,我们还需要为创建、输入或输出返回的数据指定数据类型。如果你需要了解什么是类型化数据,可以跳到本手册的类型化数据部分。
下面,我们将看到如何声明“状态变量”。还可以看到如何声明函数。
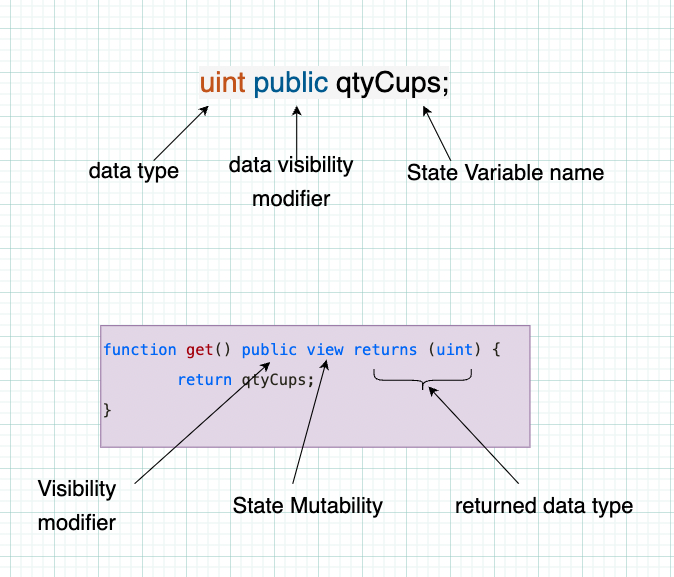
第一个部分声明了一个名为 qtyCups 的状态变量(我很快会解释这是什么)。这只能存储 uint 类型的值,这意味着无符号整数。 “整数”是指零以下(负)和零以上(正)的所有整数。
由于这些数字附有 + 或 - 符号,所以称为有符号整数。无符号整数始终是正整数(包括零)。
在第二个片段中,我们在声明函数时也看到了一个熟悉的结构。最重要的是,我们看到在函数中,必须为其返回的值指定数据类型。
在这个例子中,由于 get() 返回我们刚刚创建的存储变量的值,我们可以看到返回值必须是一个 uint。
public 是可见性标识符。稍后会详细介绍。 view 是一个状态可变性修饰符,也会在后面的内容中介绍。
这里值得注意的是,状态变量也可以是其他类型——constant 和 immutable。它们是这样的:
因此,如果我们将 qtyCups 状态变量设为 constant 或 immutable,我们将无法再对其调用 increment() 或 decrement() 函数(事实上,调用的话代码将无法编译!)。
constant 的值必须在代码本身中硬编码(hardcode),而immutable 变量可以将它们的值设置一次,通常是通过构造函数中的赋值(我们很快就会讨论构造函数)。你可以在此处的文档中阅读更多内容。
智能合约中的变量作用域
智能合约中的变量有 3 个作用域:
- 状态变量:通过将值记录在区块链上,在智能合约中存储永久数据(称为持久状态)。
- 局部变量:这些是“暂时性”数据,在运行计算时会在短时间内保存信息。这些值不会永久存储在区块链上。
- 全局变量:这些变量和函数由 Solidity“注入”到您的代码中,无需专门创建或从任何地方导入它们即可使用。这些提供了代码运行时的区块链环境信息,还包括程序中会用到的功能性函数。
你可以按如下方式区分变量作用域:
- 状态变量通常位于智能合约内部,但位于函数外部。
- 局部变量位于函数内部,不能从该函数之外访问。
- 全局变量不是由你声明的,当时它们“神奇地”可供你使用。
这是我们的 HotFudgeSauce 示例,稍作修改以显示不同类型的变量。我们给 qtyCups 一个初始值,然后给除了我以外的每个人分一杯 Fudge Sauce(因为我正在节食)。

如何使用可见性标识符(visibility specifier)
“可见性”这个词的使用有点令人困惑,因为在公共区块链上,几乎所有东西都是“可见的”,因为透明度是一个关键特征。这里的可见性意味着一段代码可以被另一段代码看到和访问的能力。
可见性指定变量、函数或智能合约可以从定义它的代码所在的区域之外访问的程度。可以根据整个系统中的哪些部分需要访问它来调整其可见范围。
如果你是 JavaScript 或 NodeJS 开发人员,那么你已经熟悉可见性——你导出一个对象的时,就是为了使它在声明它的文件之外可见。
可见度类型
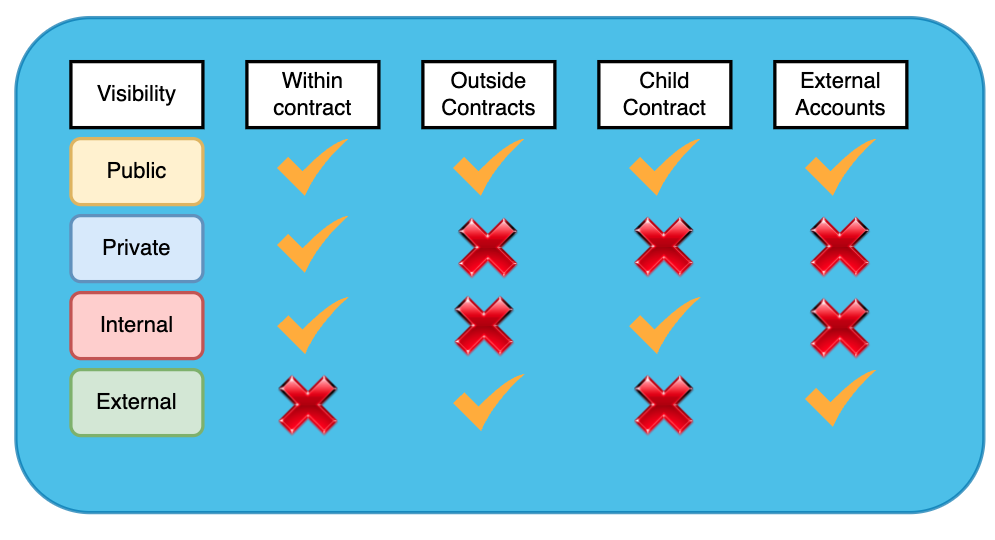
在 Solidity 中有 4 种不同类型的可见性:public、external、internal 和 private。
Public 函数和变量可以在合约内部、外部、其他智能合约和外部账户(你 Metamask 钱包中的那种)访问——几乎可以从任何地方访问。这是最广泛、最宽松的可见性级别。
当一个存储变量被赋予 public 可见度时,Solidity 会自动为该变量的值创建一个隐性的 getter 函数。
所以在我们的 HotFudgeSauce 智能合约中,我们不需要 get() 方法,因为 Solidity 会隐式地为我们提供完全一样的功能,只需给 qtyCups 一个 public 可见度修饰符。
Private 函数和变量只能在声明它们的智能合约中访问。但是它们不能在包含它们的智能合约之外访问。 private 是四个可见性说明符中限制性最强的。
Internal 可见性类似于 private 可见性,因为内部函数和变量只能从声明它们的合约中访问。但是标记为 internal 的函数和变量也可以从派生合约(即从声明合约继承的子合约)访问,但不能从合约外部访问。稍后我们将讨论继承(和派生/子合约)。
状态变量的默认可见度就是 internal。
4 种可见度标识符的表格
external 可见性说明符不适用于变量 - 只有函数可以指定为 external。
external 函数不能从声明合约或继承自声明合约的合约的内部调用。因此,它们只能从该合约之外调用。
这就是它们与公共函数的不同之处——公共函数也可以从声明它们的合约内部调用,而外部函数则不能。
什么是构造函数
构造函数是一种特殊类型的函数。在 Solidity 中,它是可选的,仅在合约创建时执行一次。
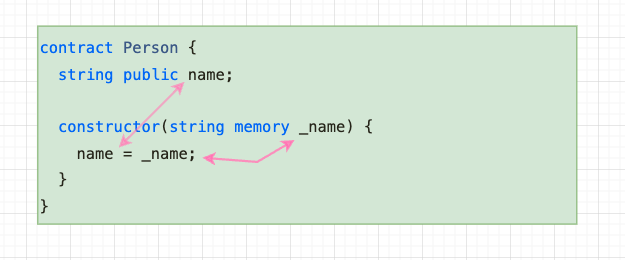
在下面的示例中,我们有一个显式构造函数,它接受一些数据作为参数。你必须在创建智能合约时将此构造函数参数注入到这个智能合约中。
有入参的 Solidity 构造函数
要了解构造函数何时被调用,先了解智能合约创建的几个阶段:
- 它被编译成字节码(你可以在这里阅读更多关于字节码的信息)。这个阶段称为“编译时间”。
- 它被创建(构造) - 这是构造函数开始运行的时候。这可以称为“构造时间”。
- 然后字节码被部署到区块链。这就是“部署”。
- 部署的智能合约字节码在区块链上运行(执行)。这可以被认为是“运行时”。
在 Solidity 中,与其他语言不同,程序(智能合约)仅在构造函数完成其创建智能合约的工作后才会部署。
有趣的是,在 Solidity 中,最终部署的字节码并不包含构造函数代码。这是因为在 Solidity 中,构造函数代码是创建代码(构造时间)的一部分,而不是运行时代码的一部分。它在创建智能合约时用完了,因为它只会调用一次,在这个阶段过去后,就不需要被调用了,所以不回在最终部署的字节码中。
因此,在我们的示例中,构造函数创建(构造)Person 智能合约的一个实例。我们的构造函数希望我们将一个名为 _name 的字符串值传递给它。
当构建智能合约时,_name 的值将存储在名为 name 的状态变量中(这通常也是将配置信息和其他数据传递到智能合约的方式)。然后当实际部署合约时,状态变量 name 将保存我们传递给构造函数的任何字符串值。
理解为什么这样设计构造函数
你可能想知道为什么我们费心将值注入构造函数。为什么不把它们写进合约呢?
这是因为我们希望合约是可配置的或“参数化的”。我们想要的不是将一个值硬编码(把值写死),而是在需要时注入合适的数据,这样才能给合约带来的灵活性和可重用性。
在我们的示例中,假设 _name 指的是将要部署合约的以太坊网络的名称(如 Rinkeby、Goerli、Kovan、Mainnet 等)。
我们如何将这些信息提供给智能合约?将所有这些值都放入其中会很浪费。这也意味着我们需要添加额外的代码来确定合约在哪个区块链上运行。然后我们必须从我们存储在合约中的硬编码列表中选择正确的网络名称,这将会在部署时使用更多的 gas。
相反,我们可以在将智能合约部署到相关区块链网络时将其注入构造函数。这样,我们就可以编写一个可以使用任意数值作为参数的合约。
另一个常见的用例是当你的智能合约继承自另一个智能合约,并且你需要在创建合约时将值传递给父智能合约。但是继承是我们后面要讨论的。
我提到构造函数是可选的。在 HotFudgeSauce 中,虽然我们没有编写显式构造函数,但是 Solidity 支持隐式构造函数。因此,如果我们不在智能合约中包含构造函数,Solidity 将假定一个默认构造函数,看起来像 constructor() {}。
如果你评估一下它的作用,你会发现它其实什么都不做,这就是为什么它可以被隐藏(被隐式创建)并且让编译器使用默认构造函数。
接口和抽象合约
solidity 中的接口是一个需要理解的基本概念。以太坊上的智能合约是公开可见的,因此你可以通过它们的函数与它们进行交互(在可见度标识符允许的范围内!)。
这就是使智能合约“可组合”的原因,也是为什么如此多的 Defi 协议被称为“金钱乐高”——你可以编写与其他智能合约交互的智能合约,这些智能合约又与其他智能合约交互等等……现在你明白它的意思了。
当你想让智能合约 A 与智能合约 B 进行交互时,你需要 B 的接口。接口为你提供了各种函数的索引,你可以使用这些函数调用某个的智能合约。
接口的一个重要特征是它们不能对定义的任何函数有任何实现(代码逻辑)。接口只是函数名称及其预期参数和返回类型的集合。它们并不是 Solidity 独有的概念。
因此,我们的 HotFudgeSauce 智能合约的接口看起来像这样(请注意,按照惯例,solidity 接口的命名方式是在智能合约的名称前加上“I”前缀((就变成了 IHotFudgeSauce)):
就是这样!由于 HotFudgeSauce 只有三个函数,因此界面仅显示这些函数。
但这里有一个值得注意的点:接口并不需要包含智能合约中可调用的所有函数,所以你可以删掉一些不必要的函数,让接口包含打算调用的函数的定义就可以!
因此,如果你只想在 HotFudgeSauce 上使用 decrement() 方法,那么你完全可以从接口中删除 get() 和 increment() - 但你也将无法调用合约中的这两个函数。
那么到底发生了什么?好吧,接口只是让你的智能合约知道在你的目标智能合约中可以调用哪些函数,这些函数接受哪些参数(及其数据类型),以及你可以期望返回什么类型的数据。在 Solidity 中,这就是你与另一个智能合约交互所需的全部信息。
在某些情况下,你可以拥有一个类似于但又不同于接口的概念 -- 抽象合约(abstract contract)。
抽象合约是使用 abstract 关键字声明的,合约中声明了一个或多个函数但未实现的函数。或者使用另一种定义,至少有一个函数已声明但未实现。
反过来说,抽象合约可以有其实现的函数(不像接口不能有函数实现),但只要有一个函数未实现,合约就必须标记为抽象的:
你可能(合理地)想知道这有什么意义。好吧,抽象合约不能直接实例化(创建)。它们只能被继承,继承它的合约可以使用它的函数。
因此,抽象合约通常被用作其他智能合约可以“继承”的模板或“基础合约”,从而迫使继承的智能合约实现抽象(父)合约声明的某些函数。这是在很多情况下的一种很有用的设计模式,即在相关合约之间强制统一结构。
当我们稍后讨论继承时,你会对继承相关的知识更清晰。现在,请记住,你可以声明一个不实现其所有函数的抽象智能合约——但如果你这样做,你将无法实例化它,而未来继承它的智能合约必须完成实现那些未实现函数。
接口和抽象合约之间的一些重要区别是:
- 接口中不能有实现的函数,而抽象合约可以有任意数量的函数实现,但是至少有一个函数是“抽象的”(即未实现)。
- 接口中的所有函数都必须标记为 “external”,因为它们只能由实现该接口的其他合约调用。
- 接口不能有构造函数,而抽象合约可以有。
- 接口不能有状态变量,抽象合约可以有。
智能合约实例#2
对于接下来的几个 Solidity 概念,我们将使用下面的智能合约。因为这个例子包含了一个在现实世界中实际使用的智能合约,我选择它也是因为我对 Chainlink Labs 有明显的偏好,因为我在那里工作 (😆) 而且 Chainlink Labs 是一家很棒的公司。但这也是我学到很多 Solidity 的地方,除此以外,通过真实世界的例子学习会更好。
因此,请先阅读下面的代码和评论。如果你仔细阅读,你已经了解了理解下面合约所需的 99%。然后我们继续从这份合约中学关键知识。
该智能合约从实时运行 Chainlink 价格馈送预言机(参见 etherscan 上的预言机)获取 1 ETH 最新的美元价格。该示例使用 Goerli 网络,因此你不会在以太坊主网上花费真钱。
现在,你需要了解 6 个基本的 Solidity 概念:
-
在
pragma语句之后我们有一个 import 语句。这会将现有代码导入我们的智能合约。这非常有用,因为这是我们重用他人编写的代码并从中受益的方式。你可以查看在此 GitHub 链接上导入的代码。
实际上,当我们编译我们的智能合约时,这个导入的代码会被拉入并与它一起编译成字节码。我们马上就会明白为什么我们需要它……
-
单行注释是用
//标记的。现在你正在学习多行注释。它们可能跨越一行或多行并使用/*和*/开始和结束注释。 -
我们声明了一个名为
priceFeed的变量,它的数据类型为AggregatorV3Interface。但是这种奇怪的类型是从哪里来的呢?从导入语句中导入的代码中——我们能够使用AggregatorV3Interface类型,因为 Chainlink 定义了它。如果你查看 Github 链接,你会看到该类型定义了一个接口(我们刚刚讨论完接口)。所以
priceFeed是对AggregatorV3Interface类型的某个对象的引用。 -
看一下构造函数。这个构造函数不接受参数,但我们可以很容易地将 ETH/USD 喂价(price feed)的 oracle 智能合约的地址
0xD4a33860578De61DBAbDc8BFdb98FD742fA7028e作为地址类型的参数传递给它。相反,我们在构造函数中对地址进行硬编码。但我们也正在创建对 Price Feed Aggregator 智能合约的引用(使用称为
AggregatorV3Interface的接口)。现在我们可以调用
AggregatorV3Interface上可用的所有方法,因为priceFeed变量引用该智能合约。事实上,我们接下来要做的是…… -
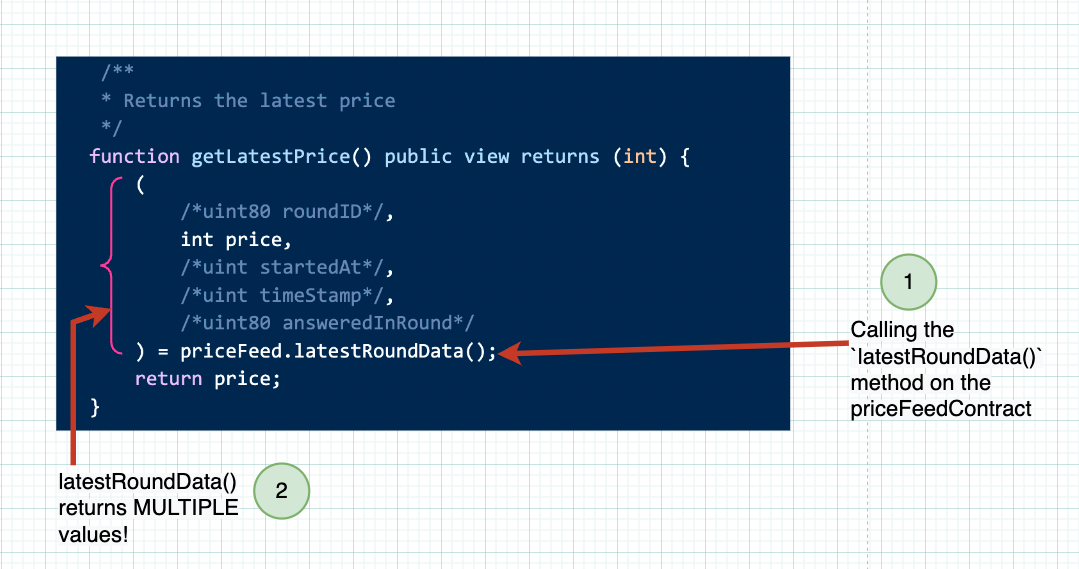
让我们跳转到函数
getLatestPrice()。你可以从我们在HotFudgeSauce中的讨论中认出它的结构,这个函数正在做一些有趣的事情。在这个
getLatestPrice()函数中,我们调用了存在于AggregatorV3Interface接口中的latestRoundData()函数。如果你查看此方法的源代码,你会注意到此latestRoundData()函数返回 5 种不同类型的整数!
通过我们的智能合约调用其他智能合约的方法
在我们的智能合约中,我们注释掉了 4 个不需要的值。所以这意味着 Solidity 函数可以返回多个值(在这个例子中我们返回了 5 个值),所以我们可以挑选需要的。
另一种使用调用 latestRoundData() 的结果的方法是:( ,int price, , ,) = priceFeed.latestRoundData(),对于 5 个返回值中的 4 个,我们不给它们变量名以忽略它们。
当我们将变量名分配给一个函数返回的一个或多个值时,我们称之为“解构赋值(destructuring assignment)”,因为我们解构返回值(将每个值分开)并在解构时对它们赋值,就像我们对上面的 price 所做的那样。
由于你已经了解了接口,我建议你查看 Chainlink Labs 的 GitHub repo 以检查 Aggregator 合约中已实现的 latestRoundData() 函数以及 AggregatorV3Interface 如何提供与 Aggregator 合约交互的接口。
什么是合约状态
在我们继续之前,重要的是要确保你理解将经常要看到的术语。
计算机科学中的“状态(state)”具有明确的含义。虽然它会变得非常混乱,但状态的关键在于它指的是程序在运行时“记住”的所有信息。此信息可以改变、更新、删除、创建等。而且,如果你在不同时间为其快照,信息将处于不同的“状态”。
所以状态只是程序的当前快照,在其执行期间的某个时间点 - 它的变量持有什么值,它们在做什么,已经创建或删除了哪些对象,等等。
我们之前已经研究了三种类型的变量——状态变量、局部变量和全局变量。状态变量以及全局变量为我们提供了智能合约在任何给定时间点的状态。因此,智能合约的状态是对以下内容的描述:
- 它的状态变量持有什么值,
- 区块链相关的全局变量在那个时刻有什么值,以及
- 智能合约账户余额(如果有的话)。
状态可变性关键字(修饰符:modifier)
现在我们已经讨论了状态、状态变量和函数,让我们了解一些 Solidity 关键字,这些 Solidity 关键字指定了我们可以对状态执行的操作。
这些关键字称为修饰符。但并非所有这些都允许你修改状态。事实上,其中许多修饰符明确禁止你修改状态。
以下是你将在真正的智能合约中看到的 Solidity 修饰符:
请注意,不是存储变量的变量(即在给定函数范围内声明和使用的局部变量)不需要状态修饰符。这是因为它们实际上并不是智能合约状态的一部分。它们只是该函数内部局部状态的一部分。那么根据定义,它们是可修改的,不需要对其可修改性进行控制。
数据存储类型 – storage/memory/stack
在以太坊和基于 EVM 的链上,系统内的数据可以在多个“数据位置”存储以被访问。
数据存储位置是 EVM 基本设计和架构的一部分。当你看到 “memory”、“storage” 和 “stack” 等词时,你应该开始思考“数据存储位置”——即数据可以存储(写入)和从中检索(读取)的位置。
数据位置会影响代码在运行时的执行方式。除此以外,它对智能合约在部署和运行期间使用的 gas 数量也有非常重要的影响。
gas 的使用需要对 EVM 和称为操作码(opcode)的东西有更深入的了解——我们可以暂时搁置这个讨论。虽然有用,但并不是你了解数据存储位置的充分条件。
虽然到目前为止我已经提到了 3 个 数据位置 ,但还有 2 种其他方式可以在智能合约中存储和访问数据:“calldata” 和 “code”。但这些不是 EVM 设计中的数据位置。它们只是提到过的 3 个数据位置的子集。
让我们从 storage 开始。在 EVM 的设计中,需要永久存储在区块链上的数据被放置在相关智能合约的“storage”区域。这包括任何合约“状态变量”。
由于存储将数据永久保存在区块链上,因此所有数据都需要在网络中的所有节点之间同步,这就是节点必须就数据状态达成共识的原因。这种共识使存储使用起来很昂贵。
你已经看到了存储变量(也称为合约状态变量)的示例,但这里是取自 Chainlink VRF(可验证随机数)的 consumer 智能合约的示例

Storage 数据。将数据放入合约的存储布局中。
创建和部署上述合约时,传递给合约构造函数的任何地址都会永久存储在智能合约的 storage 中,并且可以使用变量 vrfCoodinator 访问。由于此状态变量被标记为immutable,因此在此之后无法更改。
回忆一下上一节关于关键字,我们在上一节讨论了 immutable 变量和 constant 变量,这些值没有放在 storage 里面。在构造合约时,它们成为代码本身的一部分,因此这些值不会像 storage 变量那样消耗那么多的 gas。
现在让我们看 memory。这表示临时存储,你可以在其中读取和写入智能合约运行期间所需的数据。一旦使用该数据的函数执行完毕,该数据将被擦除。
memory 位置空间就像一个临时记事本,每次触发函数时都会在智能合约中提供一个新的,执行完成后,该临时记事本将被删除。
在理解 storage 和 memory 的区别时,您可以将 storage 视为传统计算世界中的一种硬盘,因为它具有“持久”存储数据的意义。但 memory 在传统计算中更接近 RAM。
堆栈(stack)是执行大部分 EVM 计算的数据区域。 EVM 遵循基于 stack 的计算模型,而不是基于寄存器的计算模型,这意味着要执行的每个操作都需要使用stack 数据结构进行存储和访问。
stack 的深度——即它可以容纳的项目总数——是 1024,stack 中的每个项目可以是 256 位(32 字节)长。这与存储数据位置中每个键和值的大小相同。
你可以在此处详细了解 EVM 如何控制对 stack 数据存储区域的访问。
接下来说说 calldata。我假设你对以太坊智能合约消息和交易有基本的了解。如果你没有,请先阅读这些链接。
消息和交易是调用智能合约函数的方式,它们包含执行这些函数所需的各种数据。此消息数据存储在 calldata 中,calldata 是 memory 只读部分,其中包含函数名称和参数等内容。
这与外部可调用函数相关,因为 internal 函数和 private 函数不使用 calldata。calldata 仅存储要被“传入”函数执行的数据和函数参数。
请记住,calldata 是内存,只是 calldata 是只读的。你不能向其中写入数据。
最后,代码(code)不属于以上的任何一个存储类型,而是指智能合约的编译字节码,它被永久部署和存储在区块链上。该字节码存储在不可变的 ROM(只读存储器)中,其中加载了要执行的智能合约的字节码。
还记得我们如何讨论 Solidity 中 immutable 变量和 constant 变量之间的区别吗?immutable 值被赋值一次(通常在构造函数中),constant 变量的值被硬编码到智能合约代码中。因为它们是硬编码的,常量值按字面编译并直接嵌入到智能合约的字节码中,并存储在这个代码/ROM 中。
和 calldata 一样,code也是只读的——如果你理解了上一段,你就会明白为什么!
数据类型原理
类型是编程中一个非常重要的概念,因为它是我们为数据提供结构的方式。从该结构中,我们可以以安全、一致和可预测的方式对数据运行操作。
当一种语言具有严格类型时,这意味着该语言严格定义了每条数据的类型,并且不能为具有类型的变量赋予另一种类型。
换句话说,在严格类型语言中:
但是在没有类型的 JavaScript 中,b=a 也成立——这使得 JavaScript 成为“动态类型”。
同样,在静态类型的语言中,你不能将整数传递给需要字符串的函数。但是在 JavaScript 中,我们可以将任何东西传递给函数,程序仍然可以编译,但在执行程序时可能会抛出错误。
例如这个函数:
可以想象,这会产生一些很难发现的错误。尽管它会产生意想不到的结果,但是代码编译甚至可以执行都不会失败。
但是强类型语言永远不会让你传递字符串“2”,因为函数会坚持它接受的类型。
让我们看看这个函数是如何用像 Go 这样的强类型语言编写的。

通过 go 语言来说明数据类型的工作原理
如果传递一个 string(即使它代表一个数字),就会阻止程序编译(构建)。你会看到这样的错误:
./prog.go:13:19: cannot use "2" (untyped string constant) as int value in argument to add
Go build failed.
所以类型很重要,因为对于人类来说似乎相同的数据可能会被计算机以非常不同的方式获得。这可能会导致一些非常奇怪的错误,程序崩溃,甚至是严重的安全漏洞。
类型还使开发人员能够创建自己的自定义类型,然后可以使用自定义属性和操作对其进行编程。
有了类型系统,人类便可以通过询问“此数据的类型是什么,它应该能够做什么?”这样的问题来推理数据,并且机器可以完全按照预期进行操作。
这是另一个例子,说明在你我看来相同的数据可能如何被处理器以截然不同的方式解释。取二进制数字序列(即数字只能有 0 或 1 的值,这是处理器使用的二进制系统)1100001010100011。
对于人类来说,使用十进制系统看起来是一个非常大的数字——也许是 11 gazillion 之类的。
但是对于二进制的计算机来说,它不是 11 gazillion 之类的东西。计算机将其视为一个 16 位序列(二进制数字的缩写),在二进制中这可能意味着正数(无符号整数)49,827 或带符号整数 -15,709 或英镑符号 £ 的 UTF-8 表示或其他不同的东西!
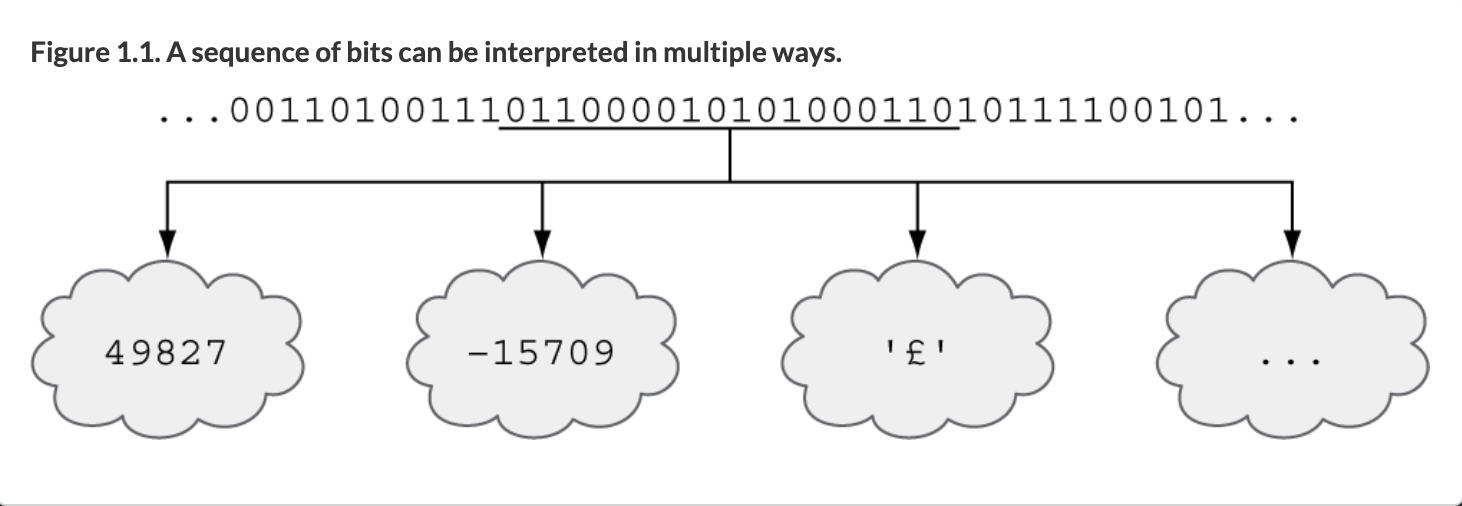
计算机可以将一系列的二进制位解释为很多不同的含义(来源)
所以所有这些解释都是在说类型很重要,并且类型可以“内置”到一种语言中,即使该语言不严格强制类型,如 JavaScript。
JavaScript 具有内置类型,如数字(numbers)、字符串(strings)、布尔值(booleans),对象(objects)和数组(arrays)。但正如我们所看到的,JavaScript 并不像 Go 这样的静态类型语言一样对于数据类型严格。
现在回到 Solidity。 Solidity 在很大程度上是一种静态类型的语言。声明变量时,还必须声明其类型。更进一步,如果你尝试将字符串传递给需要整数的函数,Solidity 将直接拒绝编译。
事实上,Solidity 对类型非常严格。例如,不同类型的整数也可能无法编译,如下例所示,其中函数 add() 需要一个无符号整数(正),并且只会与该数字相加,因此始终返回一个正整数。但是返回类型指定为 int,这意味着它可以是正数或负数!
因此,尽管输入和输出都是 256 位整数,但函数只接收无符号整数这一事实,就会使编译器抱怨无符号整数类型不能隐式转换为有符号整数类型。
以上对类型的控制相当严格!开发人员可以通过将 return 语句重写为 return int256(a + 10) 来强制转换(称为类型转换)。但是这种行动需要考虑一些问题,这超出了我们在这里讨论的范围。
现在,请记住 Solidity 是静态类型的,这意味着在代码中声明每个变量时必须明确指定它们的类型。你可以组合类型以形成更复杂的复合类型。接下来,我们讨论一些内置类型。
Solidity 数据类型
内置于语言中并且可以“开箱即用”的类型通常被称为“原语(primitive)”。它们是语言固有的。你可以组合 primitive 数据类型以形成更复杂的数据结构,这些数据结构成为“自定义(custom)”数据类型。
例如,在 JavaScript 中,primitive不是 JS 对象并且也没有方法或属性的数据。 JavaScript 中有 7 种基本数据类型:string、number、bigint、boolean、undefined、symbol 和 null。
Solidity 也有自己的 primitive 数据类型。有趣的是,Solidity 没有“undefined”或“null”。相反,当你声明一个变量及其类型,但不为其分配值时,Solidity 将为该类型分配一个默认值。该默认值究竟是什么,取决于数据类型。
Solidity 的许多 primitive 数据类型都是相同“基本”类型的变体。例如,int 类型本身具有子类型,而子类型就基于 integer 可以存储的二进制位。
如果这让你有点困惑,请不要担心 - 如果你不熟悉位和字节,这并不容易,我将很快介绍整数。
在我们探索 Solidity 类型之前,你必须了解另一个非常重要的概念 - 它是编程语言中许多错误和“意外陷阱”的来源。
这就是值类型(value type)和引用类型(reference type)之间的区别,以及程序中数据“按值传递(pass by value)”与“按引用传递(pass by reference)”之间的区别。我将在下面进行快速总结,但你还可以在继续之前观看这段简短的视频。
按引用传递 vs 按值传递
在操作系统级别,当程序运行时,程序在执行期间使用的所有数据都存储在计算机 RAM(内存)中的位置。当你声明一个变量时,操作系统会分配一些内存空间来保存该变量的数据,这些存储空间会分配给或最终分配给该变量的值。
还有一种数据,就是常说的“指针”。该指针指向可以找到该变量及其值的内存位置(计算机 RAM 中的“地址”)。因此,指针实际上包含了对计算机内存中数据所在位置的引用。
因此,当你在程序中传递数据时(例如,当你将值分配给新变量名称时,或者当你将输入(参数)传递给函数或方法时,语言的编译器可以通过两种方式实现这一点。它可以通过指向计算机内存中数据位置的指针,或者它可以复制数据本身,并传递实际值。
第一种方法是“通过引用传递”。第二种方法是“按值传递”。
Solidity 的数据类型基元分为两类——它们要么是值类型(value type),要么是引用类型(reference type)。
换句话说,在 Solidity 中,当你传递数据时,数据的类型将决定你传递的是值的副本还是对值在计算机内存中位置的引用。
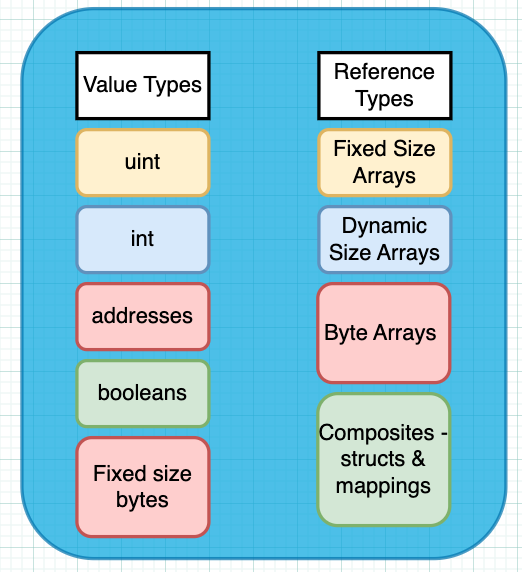
Solidity 中值类型(Value Types)和引用类型(Reference Types)
在 Solidity 的“值类型”中,整数分为两类——uint 是无符号的(只有正整数,所以它们没有正负号)和 int 是有符号的(可以是正数也可以是负数,如果你把它们写下来,它们有加号或减号)。
整数类型还可以指定它们有多少位长 - 或者有多少位用于表示 integer。
uint8 是由 8 个二进制数字(位)表示的整数,最多可以存储 256 个不同的值 (2^8=256)。由于 uint 用于无符号(正)整数,这意味着它可以存储从 0 到 255(不包括 1 到 256)的值。
但是,当你使用带符号的整数(如 int8)时,其中一位将用于表示它是正数还是负数。这意味着我们只剩下 7 位,因此我们最多只能表示 2^7 (128) 个不同的值,包括 0。因此 int8 可以表示从 -127 到 +127 的任何值。
通过扩展,int256 的长度为 256 位,可以存储 +/- (2^255) 值。
位长度是 8 的倍数(因为 8 位构成一个字节),因此你可以使用 int8、int16、int24 等一直到 256(32 字节)。
地址指的是以太坊账户类型——智能合约账户或外部拥有账户(又名“EOA”。你的 Metamask 钱包代表一个 EOA)。所以地址也是 Solidity 中的一种类型。
地址的默认值(如果你声明一个类型地址的变量但不分配任何值,则将具有的值)为0x00000000000000000000000000000000000000000000000000,这也是此表达式所代表的值:address(0)。
布尔值表示真值还是假值。最后,我们有固定大小的字节数组,如 bytes1、bytes2 … bytes32。这些是包含字节的固定长度数组。所有这些类型的值在代码中传递时都会被复制。
对于“引用类型”,我们有数组,它们可以在声明时指定固定大小,或者动态大小的数组。虽然它们声明时大小是固定的,但其大小可以“调整”,因为数组中元素的数量会增加。
字节是一种底层数据类型,指的是编码为二进制格式的数据。编译器最终将所有数据还原为二进制形式,以便 EVM(或者在传统计算中,处理器)可以使用它。
与其他更易读的数据类型相比,存储和使用字节通常更快、更高效。
你可能想知道为什么我没有在上图中的任何一种数据类型中引用字符串。那是因为在 Solidity 中,字符串实际上是动态大小的数组,数组存储以 UTF-8 编码格式编码的字节序列(只是二进制数)。
它们不是 Solidity 中的原语(primitive)。在 JavaScript 中,它们是原语,但即使在 JavaScript 中,字符串也类似于(但不相同)数组,并且是一系列以 UTF-16 编码的整数值。
在智能合约中将 string 存储为 bytes 类型通常更高效,因为 string 和 bytes 之间的转换非常容易。因此,将 string 存储为 bytes 但在函数中将它们作为 string 返回是很有用的。你可以在下面看到一个示例:
除了 Solidity 字符串,bytes 数据类型是一个动态大小的字节数组。此外,与其他固定大小字节数组不同,它是一种引用类型。 Solidity 中的 bytes 类型是“array of bytes”的简写,在程序中可以写成 bytes 或 byte[]。
如果你对字节和字节数组感到困惑……我表示同情。
字符串和字节数组的底层细节与本手册不太相关。现在的重点是一些数据类型通过引用传递,而另一些数据类型通过复制它们的值来传递。
可以认为没有指定大小的 Solidity 字符串和字节是引用类型,因为它们都是动态大小的数组。
最后,在 Solidity 的原语中,我们有结构体(structure)和映射(mapping)。有时这些被称为“复合”数据类型,因为它们是由其他原语组成的。
struct 将一段数据定义为具有一个或多个属性,并指定每个属性的数据类型和名称。结构使你能够定义自己的自定义类型,以便你可以将数据片段组织和收集到一个更大的数据类型中。
例如,你可以拥有定义 Person 的结构,如下所示:
你也可以通过下面的方法初始化 Person 结构体:
映射(mapping)类似于哈希表(hashtable)、字典(dictionary)或 JavaScript 对象(object)和映射(map),但功能少一些。
mapping 也是一个键值对,但是键的数据类型有限制,你可以在这里查看。与映射键关联的数据类型可以是任何原语、结构,甚至其他映射。
以下是映射的声明、初始化、写入和读取方式——以下示例来自 Chainlink Link Token 智能合约源代码。
在 Solidity 中声明和使用映射

如果你尝试使用映射中不存在的键访问一个值,它将返回存储在映射中的类型的默认值。
在上面的例子中,balances 映射中所有值的类型都是 uint256,它的默认值为 0。所以如果我们调用 balanceOf() 并传入一个没有任何 LINK 通证的地址,我们将会得到 0 值。
在这个例子中这一设置是合理的,但是当我们想要找出一个键是否存在于映射中时,它可能有点棘手。
目前没有办法枚举映射中存在哪些键(也就是说,没有与 JavaScript 的 Object.keys() 方法等效的方法)。使用键检索只会返回与数据类型关联的默认值,这并不能清楚地告诉我们该键是否实际存在。
映射有一个有趣的“陷阱”。与你可以将键值数据结构作为参数传递给函数的其他语言不同,Solidity 不支持将映射作为参数传递给函数,除非函数可见性被标记为 internal。因此,你无法编写接受键值对作为参数的外部或公共可调用函数。
如何在 Solidity 中声明和初始化数组
Solidity 有两种类型的数组,因此了解声明和初始化它们的不同方式是很有必要的。
Solidity 中的两种主要数组类型是固定大小数组和动态大小数组。
为了强化你的记忆,请回忆前几节内容。固定大小的数组按值传递(在代码中传递时复制),动态大小的数组按引用传递(指向内存地址的指针在代码中传递)。
它们的语法和容量(大小)也不同,这决定了我们何时使用其中一个与另一个。
这是固定大小的数组在声明和初始化时的样子。它的固定容量为 6 个元素,一旦声明就不能更改。 6 个元素的数组的内存空间已分配且无法更改。
也可以通过使用以下语法声明一个固定大小的数组,声明中包含变量名,数组的大小及其元素的类型:
与其不同,按如下方式声明和初始化的动态大小数组,它的容量是不确定的,这样你就可以使用 push() 方法添加元素:
你还可以在同一行代码中声明和初始化数组的值。
这些数组是在 storage 中存储的。但是,如果你只需要函数内的临时数组(存储在 memory)怎么办?在这种情况下,有两条规则:只允许使用固定大小的数组,并且必须使用 new 关键字。
显然,有几种方法可以声明和初始化数组。当你想要对 gas 和计算进行优化时,你需要仔细考虑需要哪种类型的数组、它们的容量是多少,以及它们是否可能在没有上限的情况下增长。
这也会影响你的代码设计并受其影响——你是需要数组存储在 storage 还是 memory 中。
函数修饰符(function modifier)是什么
在编写函数时,我们通常会收到一些输入,我们需要在处理其余“业务”逻辑之前对这些输入进行某种验证、检查或运行其他逻辑。
例如,如果你使用纯 JavaScript 编写,你可能想要检查您的函数接收的是整数而不是字符串。如果它在后端,你可能需要检查 POST 请求是否包含正确的身份验证标头和密码。
在 Solidity 中,我们可以通过声明一个称为修饰符(modifier)来执行这些类型的验证步骤,修饰符是是一个类似函数的代码块。
修饰符是一段代码,可以在运行主函数(即应用了修饰符的函数)之前或之后自动运行。
修饰符也可以从父合约继承。它是避免重复代码的一种方法,方法是提取通用功能放入修饰符中,而修饰符可以在整个代码库中重用。
修饰符看起来很像函数。观察修饰符的关键是 _(下划线)出现的位置。该下划线就像一个“占位符”,指示主函数何时运行,可以认为是在当前下划线所在的位置插入了主函数。
因此,在下面的修饰符代码中,我们运行条件检查以确保消息发送者是合约的所有者(owner),然后我们运行调用此修饰符的函数的其余部分。请注意,单个修饰符可以由任意数量的函数使用。

函数修饰符怎么写,以及下划线符号的作用
在此示例中,require() 语句在下划线 (changeOwner()) 之前运行,通常来说,可以通过这样的方式来确保只有当前所有者(owner)才能更改谁拥有合约。
如果你切换修饰符的顺序并且 require() 语句排在第二位,那么 changeOwner() 中的代码将首先运行。在那之后 require() 语句才会运行,那将是一个错误!
修饰符也可以接受输入——你只需将输入的数据类型和名称传递给修饰符。
修饰符是一个很方便的封装逻辑片段的方式,这些逻辑片段可以在你的 dApp 中的各种智能合约中重复使用。重用逻辑会使你的代码更易于阅读、维护和推理——因此遵循 DRY(Don't Repeat Yourself 不要重复自己)原则。
Solidity 中的异常处理 - require/assert/revert
Solidity 中的错误处理可以通过几个不同的关键字和操作来实现。
当出现错误时,EVM 将恢复对区块链状态的所有更改。换句话说,当抛出异常并且未在 try-catch 块中捕获时,该异常将在被调用的方法的堆栈中“冒泡”, 并返回给用户。当前调用(及其子调用)中对区块链状态所做的所有更改都将被撤销。
在诸如 delegatecall、send、call 等底层函数中有一些例外,其中错误会将布尔值 false 返回给调用者,而不是冒出一个错误。
作为开发人员,你可以采用三种方法来处理和抛出错误:require()、assert() 或 revert()。
require 语句检查你指定的布尔条件,如果为假,它将抛出带有你提供的字符串或没有说明(如果没有指定)的错误:
在继续我们的代码逻辑之前,我们使用 require() 来验证输入、验证返回值和检查其他条件。
在此示例中,如果函数的调用者未发送至少 1 个 ETH,该函数将恢复并抛出一条错误消息:“你必须至少支付 1 个 ETH!”。
你想要返回的错误字符串是 require() 函数的第二个参数,但它是可选的。没有它,你的代码将抛出一个没有数据的错误——如果没有数据的话,就不会很有帮助。
require() 的好处是它会返回未使用的 gas,但在 require() 语句之前使用的 gas 将丢失。这就是我们应该尽早使用 require() 的原因。
assert() 函数与 require() 非常相似,只是它抛出类型为 Panic(uint256) 而不是 Error(string) 的错误。
assert 也用于略有不同的情况——这些情况下需要不同类型的保护。
大多数情况下,你使用 assert 来检查“invariant(不变)”的数据片段。在软件开发中,不变量是一个或多个数据,其值在程序执行时永远不会改变。
上面的代码示例是一个微型合约,并不是为了接收或存储任何 ETH 而设计的。它的设计旨在确保它的合约余额始终为零,这就是我们使用 assert 测试的不变量。
assert() 调用也用在 internal 函数中。它们可以测试本地状态不包含或不可能的值,但由于合约状态变得“脏”,这些值可能已经改变。
正如 require(), assert() 也会回退所有更改。但是在 Solidity 的 v0.8 之前,assert() 用于耗尽所有剩余的 gas,这一点与 require() 不同。
通常,你可能会更多地使用 require() 而不是 assert()。
第三种方法是使用 revert() 调用。这通常用于与 require() 相同的情况,但使用 revert()的场景中,一般条件逻辑会更复杂。
此外,你可以在使用 revert() 时抛出自定义错误。就 gas 消耗而言,使用自定义错误通常可以更便宜,并且从代码和错误可读性的角度来看,自定义错误通常可以提供更多信息。
请注意我是如何通过在自定义错误名称前加上合约名称,从而提高其可读性和可追溯性的,通过这种方式我们可以知道是哪个合约引发了错误。
在上面的示例中,我们使用了一次 revert 和一个带有两个特定参数的自定义错误,然后我们再次使用 revert 且仅包含一个字符串错误数据。在任何一种情况下,区块链状态都会 revert,未使用的 gas 将返回给调用者。
Solidity 中的继承
继承是面向对象编程 (OOP) 中的一个非常重要的概念。我们不会在这里详细介绍 OOP 是什么。但是,可以将继承理解为,一段代码通过导入和嵌入另一段代码来“继承”数据和函数。
Solidity 中的继承还允许开发人员访问、使用和修改继承自合约的属性(数据)和函数(行为)。
接收这种继承材料的合约称为派生合约、子合约或子类。其代码可用于一个或多个派生合约的合约称为父合约。
继承让代码的重用变得更加方便——想象一下继承链,应用程序代码从其他代码继承,而被继承代码又从其他代码继承,等等。与其写出整个继承层次结构,我们可以只使用几个关键词来“扩展”继承链中所有应用程序代码获得的函数和数据。通过这样的方式,合约就可以从其层次结构中的所有父合约中受益,就像每一代都继承下来的基因一样。
与 Java 等某些编程语言不同,Solidity 允许多重继承。多重继承是指派生合约能够从多个父合约继承数据和方法。换句话说,一个子合约可以有多个父合约。
你可以通过查找 is 关键字来发现子合同并识别其父合同。
如果你使用浏览器内的 Remix IDE 仅部署合约 B,你会注意到合约 B 可以访问 getName() 方法,即使它从未写在合约 B 中。当你调用该函数时,它返回“A”,这是在合约 A 中实现的逻辑数据,而不是合约 B。合约 B 可以访问存储变量 A_NAME 和 B_NAME,以及合约 A 中的所有函数。
这就是继承的工作原理。这就是合约 B 如何重用合约 A 中已经编写的代码,这些代码可能是由其他人编写的。
Solidity 允许开发人员更改父合约中的函数在派生合约中的实现方式。修改或替换继承代码的函数称为“重写(overriding)”。为了理解它,让我们探讨一下当合约 B 尝试实现自己的 getName() 函数时会发生什么。
通过向合约 B 添加 getName() 来修改代码。确保函数名称和签名与合约 A 中的相同。子合约在 getName() 函数中的逻辑实现可能与它在父合约中的实现方式完全不同,尽管函数名称及其签名是一模一样的。
编译器会给出两个错误:
- 在合约A中,会提示你“trying to override non-virtual function(试图覆盖非虚函数)”,提示你是否忘记添加
virtual关键字。 - 在合约 B 中,它会抱怨
getName()函数缺少标识符override。
这意味着你在合约 B 中的新 getName 试图重写父合约中同名的函数,但父合约的函数未标记为 virtual - 这意味着它无法被重写。
你可以更改合约 A 的功能并添加 virtual 关键字,如下所示:
添加关键字 virtual 不会改变函数在合约 A 中的运行方式。并且它不要求继承合约必须重新实现它。它只是意味着如果开发人员选择,此功能可能会被任何派生合约重写。
添加 virtual 修复了编译器对合约 A 的提出的问题,但对合约 B 没有。这是因为合约 B 中的 getName 还需要添加 override 关键字,如下所示:
我们还为合约 B 的 getName() 添加了 pure 关键字,因为这个函数不会改变区块链的状态,并且只读取 constant(constant,你会记得,在编译时被硬编码到字节码中,不在存储数据位置)。
请记住,只有在父合约和子合约中,函数的名称和签名相同时,你才需要重写它。
但是对于名称相同但参数不同的函数会发生什么情况呢?当这种情况发生时,它不是重写,而是重载。并且没有冲突,因为这些函数有不同的参数,所以它们的签名可以向编译器表明它们是不同的。
例如,在合约 B 中,我们可以有另一个带有参数的 getName() 函数。与父合约 A 的 getName() 实现相比,不同的参数会使得函数的“签名”不同。重载函数不需要任何特殊关键字:
不要担心 abi.encodepacked() 方法调用。稍后当我们谈论编码和解码时,我会解释这一点。现在只需了解 encodepacked() 将字符串编码为字节,然后将它们连接起来,并返回一个字节数组。
我们在本手册的前一节(在类型那一节)讨论了 Solidity 字符串和字节之间的关系。
此外,由于你已经了解了函数修饰符,这恰是可以添加修饰符也是可继承的地方。以下是你的操作方式:
你可能想知道如果继承链中存在具有相同名称和签名的函数,将调用哪个版本的函数。
例如,假设有一个合约继承的链条,如 A → B → C → D → E,它们都有一个 getName() 且都重写了前一个父合约中的 getName() 。
哪个 getName() 被调用?答案是最后一个——这个合约继承结构中的“最后派生”的函数实现。
子合约中的状态变量不能与其父合约具有相同的名称和类型。
例如,下面的合约 B 将无法编译,因为它的状态变量“隐藏”了父合约 A 的状态变量。但请注意合约 C 如何正确处理此问题:
值得注意的是,通过将新值传递给合约 C 的构造函数中的变量 author,我们实际上覆盖了合约 A 中的值。然后调用继承方法 C.getAuthor() 将返回 'Hemingway' 而不是 'Zubin' !
还值得注意的是,当一个合约继承自一个或多个父合约时,区块链上只会创建一个(组合)合约。编译器有效地将所有其他合约及其父合约(parent contract)等编译成一个单一的编译合约(称为“扁平化(flatten)”合约)。
继承与构造函数参数
一些构造函数指定输入参数,因此它们需要你在实例化智能合约时将参数传递给它们。
如果该智能合约是父合约,则其派生合约也必须传递参数以实例化父合约。
有两种方法可以将参数传递给父合约——在列出父合约的语句中,或者直接在每个父合约的构造函数中。你可以在下面看到这两种方法:
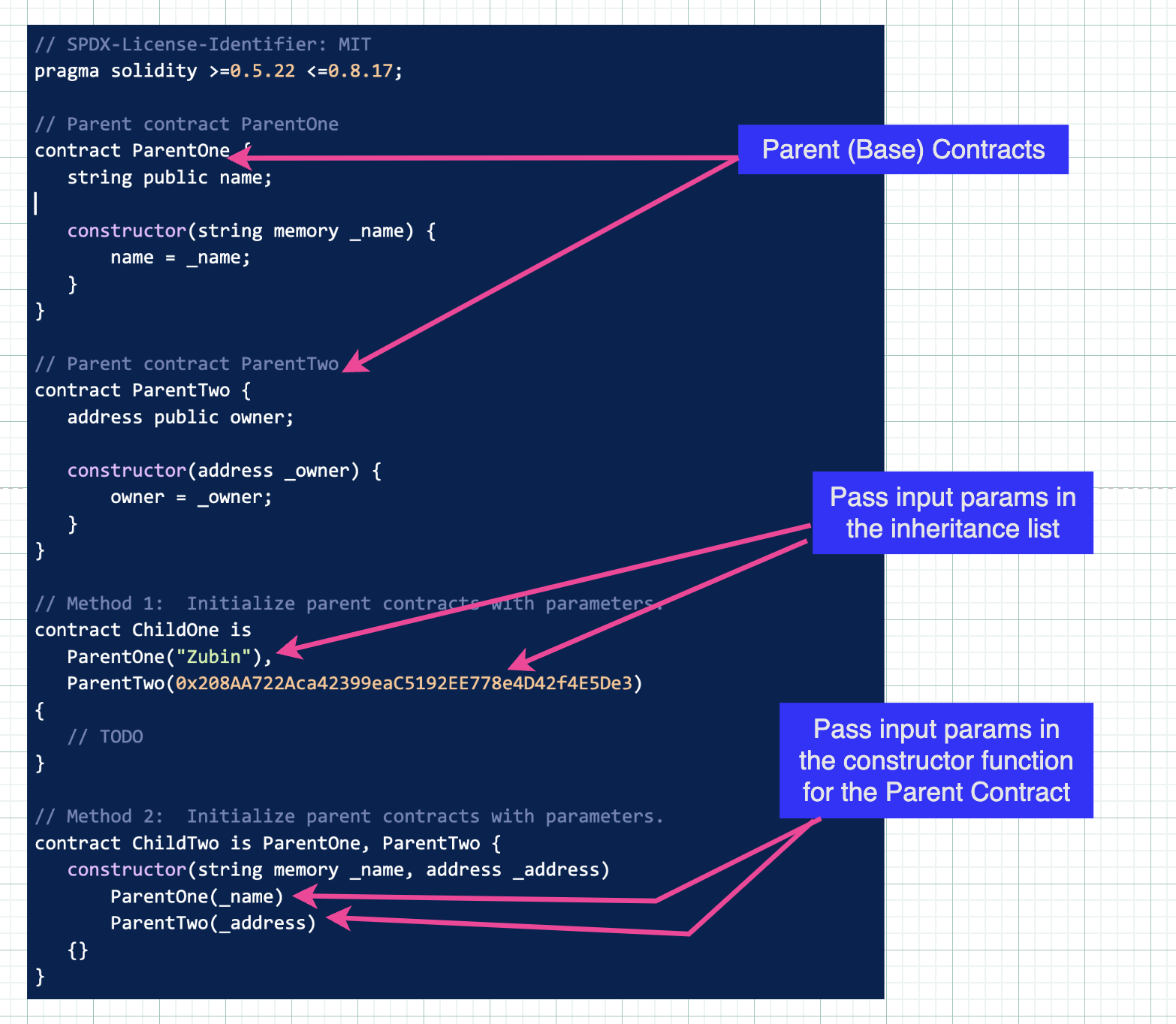
在 ChildTwo 合约的方法 2 中,你会注意到传递给父合约的参数首先提供给子合约,然后沿着继承链向上传递。
这不是必需的,但却是一种非常常见的模式。关键是父合约构造函数期望输入参数,而我们需要在实例化子合约时提供它们。
Solidity 中的类型转换
有时我们需要将一种数据类型转换为另一种数据类型。当我们这样做时,我们需要非常小心地转换数据,同时考虑计算机会如何理解转换后的数据。
正如我们在关于类型化数据的讨论中看到的那样,JavaScript 有时会对数据做一些奇怪的事情,因为它是动态类型的语言。但这也是为什么一般地介绍类型转换和类型转换的概念是有用的。
采用以下 JavaScript 代码:
有两种方法可以将变量 a 转换为整数。第一个称为类型转换,由程序员显式完成,通常涉及使用 () 的类似构造函数的操作符。
现在让我们将 a 重置为字符串并进行隐式转换,也称为类型转换。这是编译器在执行程序时隐式完成的。
在 Solidity 中,类型转换(显式转换)在某些类型之间是允许的,代码类似于下面这样:
在此示例中,我们将大小为 256 位的整数(因为 8 位构成 1 个字节,所以这是 32 个字节)转换为大小为 32 的字节数组。
由于 2022 的整数值和字节值的长度均为 32 字节,因此在转换过程中没有“丢失”信息。
但是,如果您尝试将 256 位转换为 8 位(1 字节),会发生什么情况?尝试在基于浏览器的 Remix IDE 中运行以下代码:
为什么整数 2022 会转换为 230?这显然不是我们预想的结果。明显是一个错误,对吧?
原因是大小为 256 位的无符号整数将包含 256 个二进制数字(0 或 1)。所以 a 保存整数值 '2022' 并且该值(以位为单位)将有 256 位数字,其中大部分将为 0,除了最后 11 位数字将是......(通过将 2022 从十进制系统到二进制 此处)。
另一方面,b 的值只有 8 位或数字,即 11100110。这个二进制数转换为十进制时(你可以使用相同的转换器 - 只需再另一个框中填写!)是 230。不是 2022 .
哎呀。
所以发生了什么事?当我们将整数的大小从 256 位减少到 8 位时,我们最终去掉了数据的前三位数字 (11111100110),这完全改变了二进制值!
朋友们,这就是信息丢失。
所以当你显式转换时,编译器在某些情况下会允许你这样做,但是你可能会丢失数据。因为你明确要求这样做,所以编译器会假设你知道自己在做什么。这可能是许多错误的根源,因此请确保正确测试代码以获得预期结果,并在将数据显式转换为较小尺寸时要小心。
投射到更大的尺寸不会导致数据丢失。由于 2022 只需要 11 位来表示,您可以将变量 a 声明为 uint16 类型,然后将其向上转换为 uint256 类型的变量 b,而不会丢失数据。
另一种有问题的转换是从无符号整数转换为有符号整数。尝试以下示例:
请注意,作为 16 位大小的带符号整数的 a 将 -2022 作为(负整数)值保存。如果我们想要将它类型转换为一个 unsigned 整数(只有正数)值,编译器也会允许我们这样做。
但是如果你运行代码,你会看到 b 不是 -2022 而是 63,514!因为 uint 无法保存有关减号的信息,它丢失了该数据,并且生成的二进制被转换为大量十进制(以 10 为基数)数字 - 显然这和预期不一样,是一个 bug。
如果你更进一步,取消注释给 c 赋值的那一行,你会看到编译器报错 “不允许从 “int16” 到 “uint256” 的显式类型转换”。即使我们在 uint256 中向上转换为更多的位,因为 c 是一个无符号整数,它不能包含负号信息。
因此,在显式强制转换时,请务必考虑,在强制编译器更改数据类型后,该值的计算结果会是什么。这会是许多错误和代码错误的根源。
Solidity 类型转换和类型转换还有更多内容,你可以在这个文章 中深入了解一些细节。
Solidity 中如何使用浮点数
Solidity 不处理小数点。这在未来可能会改变,但目前你无法真正使用浮点数,如 93.6。事实上,在您的 Remix IDE 中键入 int256 floating = 93.6; 会抛出如下错误:Error: Type rational_const 468 / 5 is not implicitly convertible to expected type int256.
这里发生了什么? 468 除以 5 是 93.6,这似乎是一个奇怪的错误,但这基本上是编译器说它不能处理浮点数。
按照错误的提示,将变量的类型声明为 fixed 或 ufixed16x1
你会收到“UnimplementedFeatureError:Not yet implemented - FixedPointType”错误。
因此,在 Solidity 中,我们通过将浮点数乘以 10 的指数,将浮点数转换为整数(无小数点)来解决这个问题,指数大小为小数点右边的小数位数。
在这种情况下,我们将 93.6 乘以 10 得到 936,我们必须在某处的变量中跟踪我们的因子 (10)。如果数字是 93.2355,我们会将其乘以 10 的 4 次方,因为我们需要将小数点右移 4 位以使数字完整。
使用 ERC 代币时,我们会注意到小数位通常为 10、12 或 18。
例如,1 Ether 是 1*(10^18) wei,即 1 后接 18 个零。如果我们想用浮点数表示,我们需要将 1000000000000000000 除以 10^18(这将得到 1),但如果它是 1500000000000000000 wei,那么除以 10^18 将在 Solidity 中抛出编译器错误,因为它无法处理 1.5 的返回值。
在科学计数法中,10^18 也表示为 1e18,其中 1e 表示 10,后面的数字表示 1e 的指数。
所以下面的代码会产生一个编译器错误:“Return argument type rational_const 3 / 2 is not implicitly convertible to expected type…int256”:
上述除法运算的结果是 1.5,但是有小数点,Solidity 目前不支持。因此 Solidity 智能合约返回非常大的数字,通常最多 18 位小数,这超出了 JavaScript 的处理能力。因此,你需要在前端使用 Ethersjs 等 JavaScript 库处理这个问题,这些库为 BigNumber 实现辅助函数/v5/api/utils/bignumber/) 类型。
哈希、ABI 编码(encoding)和解码(decoding)
随着你使用 Solidity 越来越多,你会看到一些听起来很奇怪的术语,例如哈希、ABI 编码和 ABI 解码。
虽然这些可能需要一些学习才可以理解,但它们对于使用密码技术(尤其是以太坊)来说是非常基础的。它们原则上并不复杂,只是一开始可能有点难以掌握。
让我们从哈希开始。使用加密数学,你可以将任何数据转换为(非常大的)唯一整数。此操作称为哈希算法。哈希算法有一些重要的特点:
- 它们是确定性的——相同的输入将总是产生相同的输出,每次都是如此。但是使用不同的输入产生相同输出的概率极小。
- 如果只有输出,基本不可能(或计算上不可行)对输入进行逆向工程。这是一个单向过程。
- 输出的大小(长度)是固定的——无论输入大小如何,算法都会为所有输入生成固定大小的输出。换句话说,哈希算法的输出将始终具有固定的位数,具体取决于算法
哈希算法有许多行业标准,但你可能会最常见地看到 SHA256 和 Keccak256。这些非常相似。256 指的是大小——生成的哈希中的位数。
例如,请进入此网站 并将“FreeCodeCamp”复制并粘贴到文本输入中。使用 Keccak256 算法,输出将(始终)为“796457686bfec5f60e84447d256aba53edb09fb2015bea86eb27f76e9102b67a”。
这是一个 64 字符的十六进制字符串,由于十六进制字符串中的每个字符代表 4 位,因此该十六进制字符串为 256 位(32 字节长)。
现在,删除文本输入框中除“F”之外的所有内容。结果是一个完全不同的十六进制字符串,但它仍然有 64 个字符。这是 Keccak265 哈希算法的“固定大小”性质。
现在粘贴回“FreeCodeCamp”并更改任意字符。你可以把“F”变成小写。或者加一个空格。对于你所做的每个单独更改,哈希十六进制字符串输出都会发生很大变化,但长度不变。
这是哈希算法的一个重要特性。最细微的变化都会大大改变散列。这意味着你始终可以通过比较它们的哈希来测试两个事物是否相同(或根本没有被篡改)。
在 Solidity 中,比较哈希比比较原始数据类型要高效得多。
例如,比较两个字符串通常是通过比较它们的 ABI 编码(字节)形式的哈希值来完成的。在 Solidity 中比较两个字符串的常见辅助函数如下所示:
稍后我们将讨论 ABI 编码是什么,但请注意 encodePacked() 的结果是一个 bytes 数组,然后使用 keccak256 算法(这是 Solidity 使用的哈希算法)对其进行哈希处理。比较输出的哈希值(256 位整数)是否相等。
现在让我们转向 ABI 编码。首先,我们记得 ABI(Application Binary Interface:应用程序二进制接口)是指定如何与部署的智能合约进行交互的接口。 ABI 编码是将给定元素从 ABI 转换为字节以便 EVM 可以处理它的过程。
EVM 在位和字节上运行计算。所以编码是将结构化输入数据转换为字节的过程,使得计算机可以运行它。解码是将字节转换回结构化数据的逆过程。有时,编码也称为“序列化”。
你可以在 此处。编码数据的方法将它们转换为字节数组(“bytes”数据类型)。相反,解码其输入的方法期望字节数据类型作为输入,然后将其转换为已编码的数据类型。
你可以在以下代码片段中观察到这一过程:
我在 Remix 中运行了上面的代码,并为 encode() 使用了以下输入:1981, 0x3C44CdDdB6a900fa2b585dd299e03d12FA4293BC, [1,2,3,4]。
我返回的字节以十六进制形式表示为:
0x00000000000000000000000000000000000000000000000000000000000007bd0000000000000000000000003c44cdddb6a900fa2b585dd299e03d12fa4293bc000000000000000000000000000000000000000000000000000000000000006000000000000000000000000000000000000000000000000000000000000000040000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000030000000000000000000000000000000000000000000000000000000000000004.
我将其作为我的输入,输入到 decode() 函数中,并取回了我原来的三个参数。
因此,编码的目的是将数据转换成 EVM 处理数据所需的字节数据类型。解码将其转换为开发人员可以使用的人类可读结构化数据。
如何调用合约并且使用 fallback 函数
根据智能合约的设计和其中存在的可见度标识符,合约可以与其他智能合约或外部拥有的账户(EOA)进行交互。
通过你的钱包在 remix 中调用是后者的一个例子,就像使用 Metamask 一样。你还可以通过 EthersJS 和 Web3JS 这些库,以及 Hardhat 和 Truffle 工具链以可编程方式与智能合约进行交互。
出于本 Solidity 手册的目的,我们将使用 Solidity 与另一个合约进行交互。
一个智能合约调用其他智能合约有两种方式。第一种方式通过使用接口(我们之前讨论过)直接调用目标合约。或者,如果将 Target 合约引入到调用合约的范围内,然后直接调用它。
这种方法如下所示:
在 Remix 中,你可以先部署 Target,然后调用 count() 以查看 count 变量的默认值为 0,正如预期的那样。如果你调用 decrement() 方法,该值将减 1。
然后你可以部署TargetCaller,有两个方法可以调用,这两个方法都会将 Target 中 count 的值减 1。
请注意,这两种方法中的每一种都使用略有不同的语法访问 Target 合约。当使用 ITarget 接口进行交互时,第一个方法接受 Target 的地址,而第二个方法将 Target 视为自定义类型。
只有当 Target 合约在与 TargetCaller 文件中声明或导入时,第二种方法才可用。大多数情况下,你将与第三方部署的智能合约进行交互,为了能够交易,第三方一般都会发布了 ABI 接口。
每调用一次这些方法,Target 中的 count 值就会减 1。这是与其他智能合约交互的一种非常常见的方式。
第二种方法是使用 Solidity 提供的“底层”调用语法。当你还想向目标合约发送一些 ETH 时,你可以使用它。将在下一节讨论发送 ETH,但现在只需将 Remix 中的代码替换为以下内容:
你会注意到 decrement() 现在接受一个参数,并且接口和 Target 合约会使用这个新的输入数据进行更新。
接下来请注意,TargetCaller 实现了一个使用新语法调用 decrement() 的新函数,如下所述。
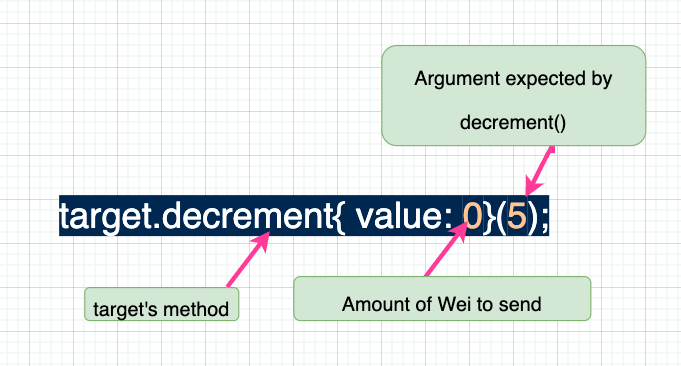
在下一节中,我们将看到示例,展示如何通过底层方法调用目标智能合约以向其发送 Ether。
但是当你调用一个合约,而这个合约实际上并没有你想要调用的函数时会发生什么?
利用 Solidity 在 EVM 上的运行机制,这一点可能会被人利用以进行恶意攻击。或者,更常见的是,它可能会意外发生。例如,当接口中存在错误,并且编译器无法将你发送的函数和参数与合约中实际包含的任何内容相匹配时,就会发生这种情况。那么会发生什么?
对于这些情况,许多合约采用了一种称为回退(fallback)函数的特殊函数。该函数看起来像一个普通函数,但它不需要 function 关键字。如果你想让它也处理你的合约被发送一些以太币的情况,你还必须将它标记为 payable。但不推荐你通过方式来接受收款。
让我们通过重新调整我们之前的 Target、ITarget 和 TargetCaller 并添加一个 fallback 函数来看一下回发生什么,代码如下所示:
我们部署了一个新的 Target 实例以后,就可以调用 count() 并看到它被设置为默认值零。
接下来我们可以部署 TargetCaller 并调用 callFallback() 方法,该方法在内部调用 nonExistentFunction()。
值得注意的是,该接口表示 nonExistentFunction() 可用,但实际的 Target 合约没有这样的函数。这就是触发 Target 的 fallback 函数并且计数值现在增加 1 的原因。
fallback 函数的目的是在没有其他函数可用于处理情况下,处理外部对合约的调用。如果 fallback 被标记为 payable,fallback 函数还将使智能合约能够接收 Ether(尽管不推荐这样使用 fallback)。我们将在下一节中介绍这一点。
如何发送和接收 Ether
如果你想要从你的智能合约向目标合约发送以太币,需要使用以下三种内置的 Solidity 方法之一,来调用目标合约:transfer、send 或 call。
transfer 失败时会抛出异常,而 send 和 call 将返回一个布尔值,所以你需要在继续运行下面的代码之前检查该值。在这三个中,出于安全原因不再推荐使用 transfer 和 send,但你仍然可以使用它们并且它们会起作用。
除以下情况外,智能合约无法接收 Ether:
- 它们实现了一个
payable的 fallback 函数或payable的特殊接收函数,或者 - 当调用合约调用
selfdestruct并强制目标合约接受其所有剩余的 ether。然后调用合约从区块链中删除。这是另一个话题,经常被开发者恶意使用。
如果你希望智能合约接收 ETH,通常建议您使用 receive() 函数。当然你也可以通过将 fallback 函数设置为 payable 来实现,但推荐的做法还是使用 receive() 函数。
如果你只依赖 fallback 函数,你的编译器会向你发出以下消息:“警告:这个合约有 payable fallback 函数,但没有 receive ether 的函数。考虑添加 receive ether 的函数。”
如果你同时拥有 receive 和 fallback,你可能想知道 Solidity 如何决定使用哪个函数接收 Ether。该设计会告诉你这些函数的设计初衷是什么。
receive 是用来接收 ether 的。而 fallback 函数,正如我们在上一节中讨论的那样,是在合约在被调用时,被调用的函数不存在的时使被使用的。
Solidity 通过检查调用者发送的交易中的 msg.data 字段来匹配要调用的方法。如果该字段是一个非空值,并且该值与被调用合约中声明的任何其他函数都不匹配,则会触发 fallback 方法。
如果 msg.data 为空,那么它将检查是否有已实现的 receive 函数。如果有,这个 receive 函数将会被调用以接受 ETH。如果不存在 receive 函数,它将默认使用 fallback 函数。
在你的合约中,使用 receive 函数来接受 ETH 更好。对于 fallback 函数,你可以在没有任何函数能够“处理”某个函数调用时去使用它。
这是一个超级方便的逻辑树,显示了 receive 和 fallback 应该的使用方式。
(感谢: Solidity By Example)
回到我们探索 fallback 函数的示例,我们可以向 Target 添加一个 receive 函数,如下所示:
我们已经看到 callFallback 将如何更改 Target 合约中的变量 count 的值。但是,如果我们部署一个新的 Target 实例,我们现在可以向它发送 10 wei,如下所示,因为它现在具有“payable”和“receive”功能。在发送 10 wei(或任何其他金额)之前,Target 的余额为零,如下所示。
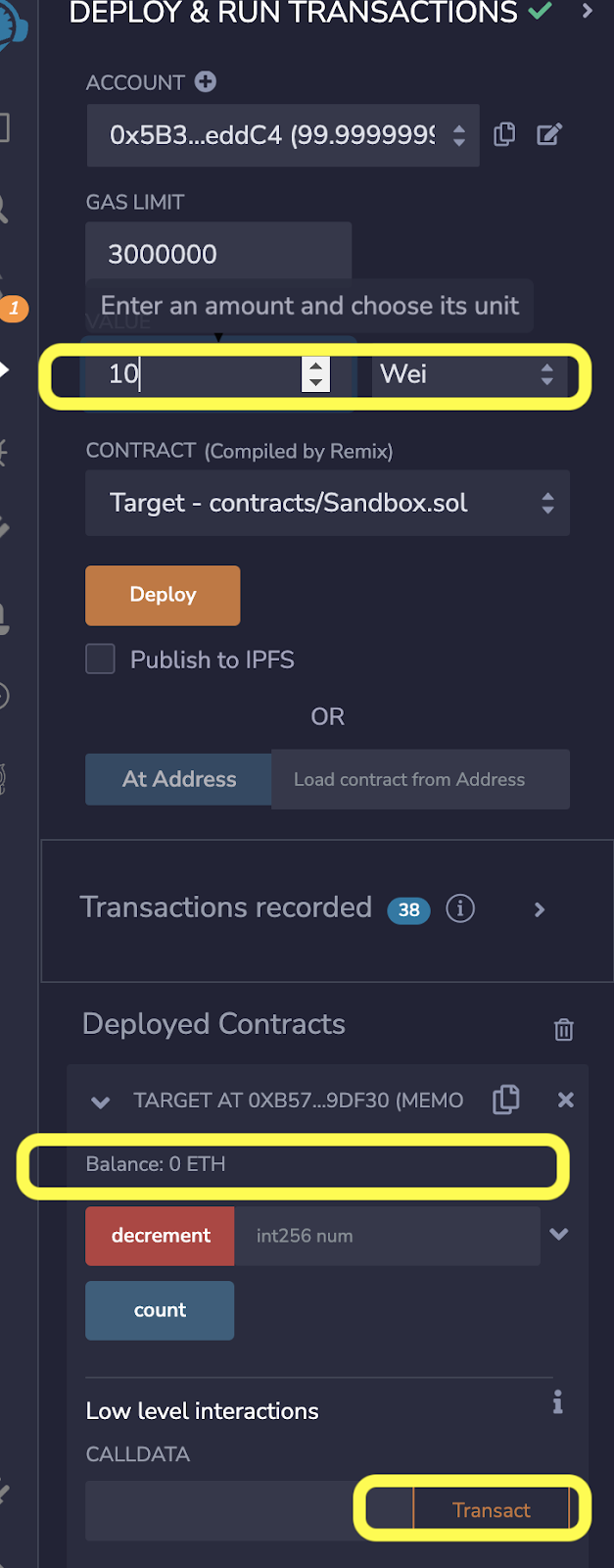
使用空的 calldata(msg.data)点击交易按钮将改变余额,如下图所示。我们可以检查 count 以查看它增加了 5,因为这是 receive 函数中的逻辑。
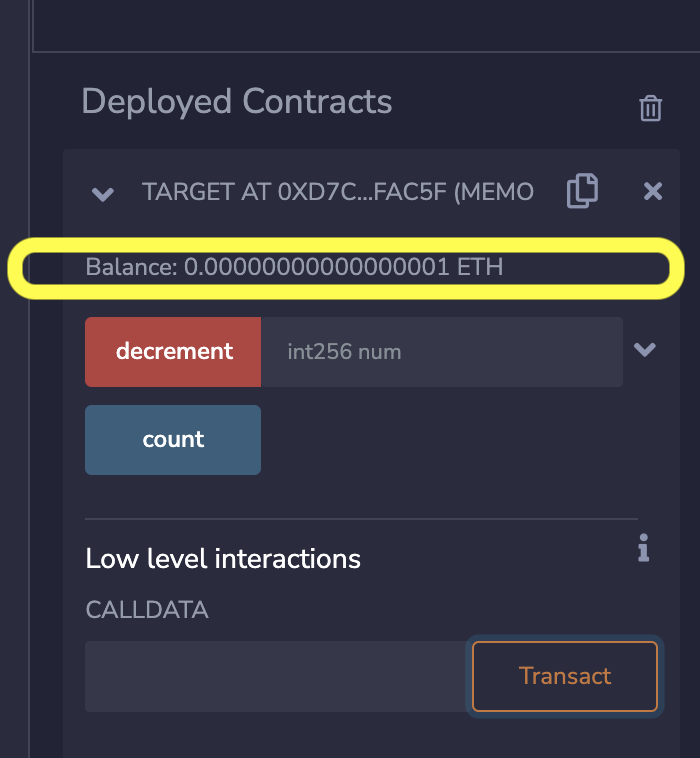
将 Wei 发送到 Target 合约并观察更新后的余额
如果我们调用 callFallback 并给它新的 Target 实例的地址,我们会注意到它只递增 1。如果我们包含一些 wei,那也会增加 Target 的余额。
因此,任何将 ETH 转移到智能合约的转账,都需要接收 ETH 的智能合约具有可以接收 ETH 的 payable 函数。至少,接收 ETH 的智能合约需要一个 payable fallback 函数,尽管 payable receive 函数是接收 ETH 转账的更好方法。
Solidity 库(library)
在任何编程语言中,库都是指辅助和功能型函数的集合,这些函数旨在被多个代码文件重用。这些函数解决了特定的、重复出现的编程问题。
在 Solidity 中,库也是做同样的事情,但有一些特殊的属性。
首先,它们是无状态的——也就是说,它们不存储数据(常量除外,因为它们不会改变区块链的状态)。它们也不能接收 value(这意味着它们不能有 payable receive 或 fallback 函数)。
它们也不能从其他合约或库继承,库也不能有子(派生)合约。
库中声明的所有函数都不能是抽象的——也就是说,它们必须都有具体的实现。
由于 Solidity 库是无状态的,因此其中的任何方法都不能修改区块链的状态。这意味着库中的所有方法都是 pure 或 view 函数。
Solidity 库的另一个有趣属性是它们不需要导入到你的智能合约中。它们可以作为独立合约部署,然后在所有使用智能合约中通过它们的接口调用——就像传统工程世界中的 API 服务一样。
但是,库必须包含公共或外部方法,才有意义。同时,该库可以作为独立合约部署,从而具有自己的以太坊地址的,并可被所有使用智能合约调用。
如果库仅包含 internal 方法,那么 EVM 只是将库代码“嵌入”到使用该库的智能合约中(因为无法从其他智能合约访问 internal 函数)。
除了代码重用以外,Solidity 中的库还具有其他的优势。在区块链上一次性部署一个库可以避免重复部署或导入库的代码,从而节省未来的 gas 成本。
让我们看一个简单的库,然后剖析代码以了解如何使用库。
该库有两种对 int 数据类型进行操作的方法。第一个参数称为 self。第一种方法接受一个数字,然后将其乘以存储在库代码中的常量值。第二种方法接受两个数字并将它们相加。
现在让我们看看如何在用户智能合约中使用它。
首先要注意的是,有两种使用 WeirdMath 库的方法。
你可以通过以下任一方式使用它:
- 调用库的名称后跟要调用的函数,或者
- 直接在你希望函数操作的数据类型上调用函数。此数据类型必须与库函数中
self参数的类型相同。
第一种方法由代码片段中的方法 1 演示,我们使用 WeirdMath.add(num1, num2); 调用库。
第二种方法使用 Solidity 的 using 关键字。表达式 return num1.add(num2); 将 WeirdMath 库的 add 函数应用到 num1 变量上。这与将其作为 self 传入效果相同,self 是 add 函数的第一个参数。
Solidity 中的事件(events)和日志(logs)
智能合约可以发出事件。这些事件包含开发人员指定的一些数据。
事件不能被其他智能合约调用使用。相反,它们作为日志存储在区块链上,并且可以通过从区块链读取的 API 进行检索。
这意味着你的应用程序(通常是你的前端应用程序)可以从区块链“读取”包含事件数据的日志。通过这种方式,你的用户界面可以对区块链上的事件做出响应。
这就是更新应用程序用户界面以响应链上事件的方式。由于可以查询区块链上的这些日志,因此日志是一种廉价的存储形式,正如前面关于存储区域的讨论中所讨论的那样。
可以使用相关的区块链浏览器来获取智能合约发出的事件,因为公共区块链上的所有内容都是公开可见的。但是如果智能合约的字节码没有经过验证,事件数据可能不是人类可读的(它将被编码),只有经过验证的智能合约的事件才是人类可读的。
节点和其他区块链客户端可以监听(订阅)特定事件。这也是 Chainlink 预言机 的工作原理——去中心化的预言机节点监听来自智能合约的事件,然后做出相应的响应。它们甚至可以从事件中提取数据,在链下运行复杂且消耗很多计算资源的计算,然后将可加密验证的计算结果提交回区块链。
其他网络 API 和索引服务 如 subgraph 之所以成为可能,是因为能够通过智能合约发出的事件查询区块链数据。
这是 Solidity 中事件的样子:
首先声明一个事件,并指定其参数及其数据类型。任何具有 indexed 关键字的数据都由 EVM 索引,使得对区块链日志的查询可以使用索引参数作为过滤器,会让日志的检索速度更快。
一个事件最多可以存储 4 个索引参数——取决于它是匿名的还是非匿名的。索引事件参数在 Solidity 世界中也称为“Topics”。
大多数事件都是非匿名的,这意味着它们包含有关事件名称和参数的数据。
非匿名事件只允许开发人员指定 3 个主题,因为第一个主题保留用于指定 ABI 编码的十六进制形式的事件签名。你可以在 此处 阅读有关匿名和非匿名 topics 的更多信息。
你还可以在相关的区块链浏览器(例如 etherscan.io)上探索事件。
你可以从两个点进行了解。你可以直接查看合约的地址,然后转到“事件”选项卡(它将仅显示该合约发出的事件)。或者可以转到交易哈希并检查由该交易交互的所有合约发出的所有事件。
例如,下面是以太坊主网上的 Chainlink VRF Coordinator 智能合约的 事件的屏幕截图。

在 etherscan 上查看 Chainlink VRF Coordinator 合约的事件
合约的选项卡有一个绿色的勾号,这意味着合同已经过验证,因此事件名称和参数是人类可读的。花点时间研究这张图片,因为它包含很多信息!如果你想直接在 etherscan 上研究它,单击此处。
该 Chainlink VRF Coordinator 合约响应对加密可验证随机数的请求,并为请求智能合约提供随机数(称为“随机词:random words”)。
如果您想了解“word”在计算机科学中的含义,请查看我和我的同事在 Chainlink 2022 黑客马拉松视频 中解决这个问题的方法。
当 VRF Coordinator 合约满足随机数请求时,它会发出一个 RandomWordsFulfilled 事件。该事件包含 4 条数据,其中第一个 requestID 可以被用作索引。
Solidity 事件包含三类数据:
- 发出事件的合约地址。
- 主题(用于过滤日志查询的索引事件参数)。
- 非索引参数,简称“数据”,采用ABI编码,以十六进制表示。此数据需要按照 ABI 编码和解码部分中描述的方式进行 ABI 解码。
在 Remix 中工作时,你还可以在控制台中检查事件,如下所示:
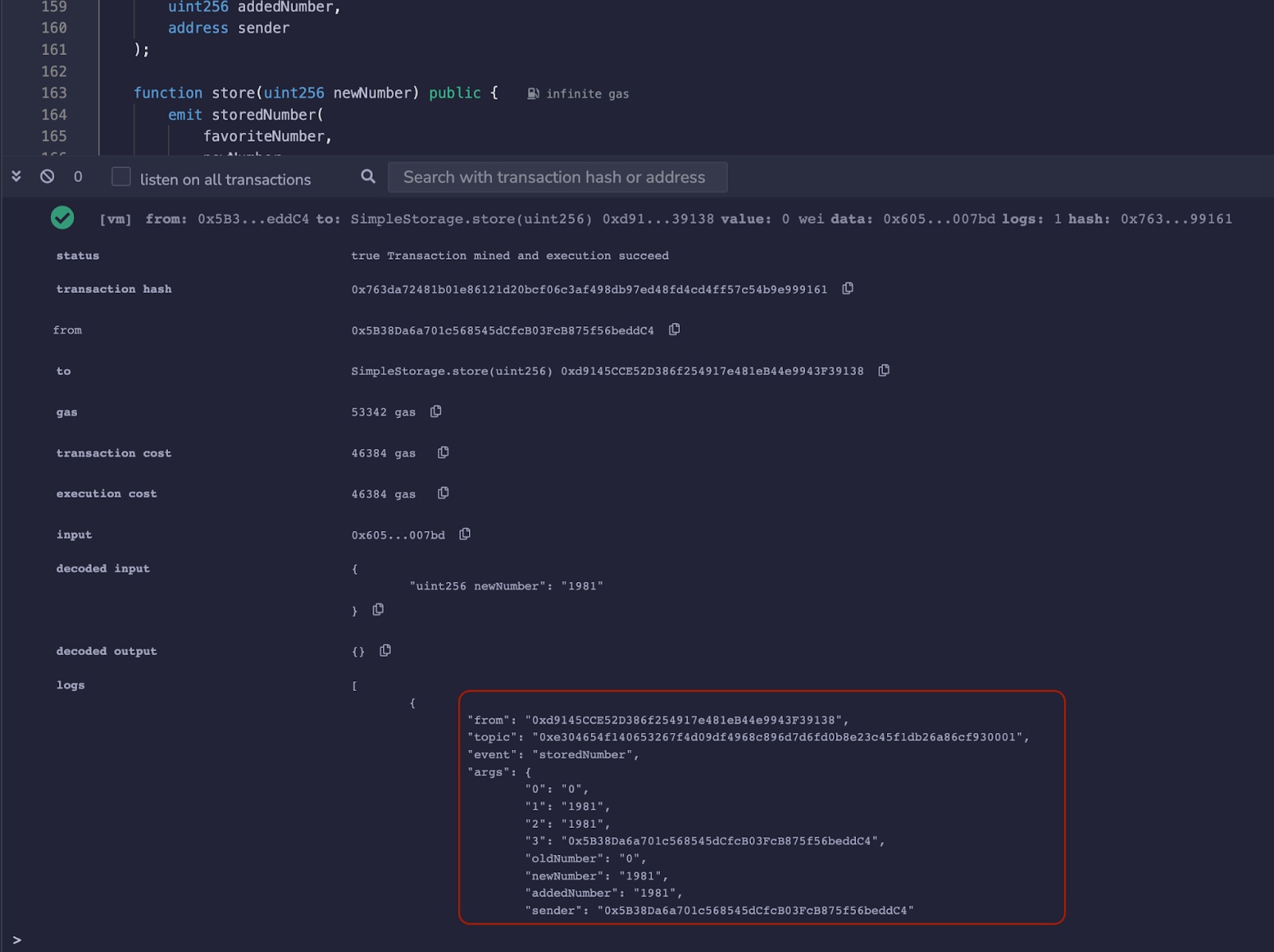
在 Remix Browser IDE 中查看事件数据
你还可以在 EthersJS 中以编程方式访问事件 使用合同收据对象。使用我们上面在 SimpleStorage 合约中使用的代码片段,我们可以通过以下 JavaScript 代码来使用 EthersJS 和 Hardhat 访问事件:
你还可以在前端应用程序中使用像是 EtherJs 这样的库来监听事件 和过滤历史事件。当你的应用程序需要响应区块链上的事件时,这两者都很有用。
Solidity 中的时间逻辑
Solidity 中的时间是根据添加到区块链的每个区块决定的。
全局变量 block.timestamp 指的是块生成并添加到区块链的时间,以毫秒为单位。毫秒计数是指自 Unix 纪元开始以来经过的毫秒数(在计算中,这是 1970 年 1 月 1 日)。
与 Web2 以毫秒为单位引用时间戳不同,该值可能不会每毫秒增加一次。
一个区块通常包含多个交易,并且由于 block.timestamp 指的是区块被开采的时间,所以一个区块中的所有交易都将具有相同的时间戳值。所以时间戳实际上指的是区块的时间,而不是调用者发起交易的时间。
Solidity 支持直接引用以下时间单位:秒、分钟、小时、天和周。
所以我们可以通过类似 uint lastWeek = block.timestamp - 1 weeks; 这样的代码来计算当前区块被开采前 1 周的时间戳,精确到毫秒。该值与 block.timestamp - 7 days; 相同。
你还可以使用它来计算未来的到期日期,例如,你可能希望在现在和下周之间可以进行操作。你可以使用 uint registrationDeadline = block.timestamp + 1 weeks; 来执行此操作,然后我们可以使用 registrationDeadline 作为函数中的验证或保护,如下所示:
在此函数中,我们仅在当前区块的时间戳未超过注册截止日期时才注册 voter。
当我们想要确保某些操作在正确的时间或在一定时间间隔内执行时,都可以使用此逻辑。
这也是可以配置 Chainlink Automation 的一种方式,这是一种自动执行智能合约的去中心化方式。 Chainlink 去中心化预言机网络可以配置为自动触发您的智能合约,你可以通过检查条件(包括与时间相关的条件)来运行各种自动化。这些被广泛用于空投、促销、特殊奖励、赚取收益等。
总结和更多资源
恭喜!你完成了这段史诗般的旅程。如果你花时间消化了本手册,并在 Remix IDE 中运行了一些代码,那么你现在已经接受了 Solidity 的培训。
从这里开始,这是一个练习、重复和经验的问题。当你着手构建下一个出色的去中心化应用程序时,请记住重新审视基础知识并关注安全性。安全性在 Web3 空间中尤为重要。
你可以从 OpenZeppelin 的博客 和 Trail of Bits 资源等获取有关最佳实践的更多信息。
你还可以通过完成我的同事 Patrick Collins 发布在 freeCodeCamp 上 端到端全栈区块链开发人员课程(免费!) 获得更多实践经验。
还有其他资源,例如 blockchain.education 和 freeCodeCamp 自己即将推出的 Web3 课程,可以巩固你的学习。
无论如何,无论你的经验水平如何,本手册都可以成为你快速复习基本概念的“桌面伴侣”。
要记住的重要一点是 Web3 技术总是在不断发展。迫切需要愿意应对复杂挑战、学习新技能并解决分散式架构带来的重要问题的开发人员。
那可能(也应该)是你!所以只要跟随你的好奇心,不要害怕一路上的挣扎。
再一次,我打算不断更新这本手册。因此,如果你发现任何不太正确、过时或不清楚的内容,只需在推文中提及并标记我 和 freeCodeCamp - 感谢所有人为了保持本手册不过时所做出的努力。
现在……变得很棒!
写在最后
如果你真的想转行做代码,你可以了解更多关于我从律师到软件工程师的旅程。查看 freeCodeCamp 播客 的 第 53 集 和还有“Lessons from a Quitter”第 207 集。这些为我的职业转变提供了蓝图。
如果你有兴趣改变职业并成为一名专业开发者,请联系此处。如果你想的话,你还可以查看我的 免费网络研讨会 Career Change to Code。