

When I changed careers from lawyer to software engineer in 2018, I never imagined that I’d enjoy being a developer as much as I do. I also never thought I'd end up working for amazing organizations like Google and Chainlink labs.
After 15 years in law and other roles, I’d experienced a number of jobs, countries, companies, and career paths. None of them compared to the joy and thrill I get from coding.
The downside? Picking up new coding skills can be confusing, frustrating, and time consuming. And it’s easy to forget some of the minute but important details.
So I wrote this handbook. It's intended to get you started on coding Solidity ASAP. It follows the Pareto Principle (aka the 80/20 rule) by focusing on the 20% of the info that will cover 80% of your needs.
I started assembling these concepts when I was learning Solidity, as part of my role at Chainlink Labs. I applied many of the self-learning techniques that I learned when transitioning to coder at the age of 38.
This is the resource I wish I had. It is designed to give beginner and intermediate developers solid mental models to stack as you get deeper into the language (mental models massively accelerate effective learning).
I will keep this handbook updated, but I could really use your help! Just tweet me @ZubinPratap to let me know if I need to update this handbook.
I’d like to acknowledge my amazing colleagues Kevin Ryu, Andrej Rakic, Patrick Collins, and Richard Gottleber for the invaluable guidance and input on this handbook.
Table of Contents
Who Is This Handbook For?
This handbook is for people who are interested in exploring the vision behind “Web3”, and who wish to acquire in-demand skills that are essential to realizing that vision.
Do not memorize it! Read it and then use it as a “desktop reference” companion. As you learn any new language, you will find that concepts, idioms, and usage can get a bit confusing or your memory fades with time. That’s ok! That’s what this handbook is designed to help you with.
Over time I may add some more advanced topics to this, or create a separate tutorial. But for now this handbook will get you most of the outcomes you require to build your first several Solidity dApps.
This handbook assumes you have at least a few months of experience with programming. By programming I mean at the very least you’ve written in JavaScript or Python or some compiled language (since HTML and CSS aren't actually "programming" languages, it won't be enough to know only them).
The only other requirements are that you are curious, committed, and not putting arbitrary deadlines on yourself.
As long as you have a laptop, and a browser with an internet connection, you’ll be able to run the Solidity code. You can use Remix in your browser to write the code in this handbook. No other IDE required!
Essential Prior Knowledge
I have also assumed that you know the basics of blockchain technology, and in particular you understand the basics of Ethereum and what smart contracts are (hint: they’re programs that run on blockchains and hence provide special trust-minimized benefits!).
You are unlikely to need them to understand this handbook. But practically speaking, having a browser wallet like Metamask and understanding the difference between Ethereum contract accounts and externally owned accounts will help you get the most out of this handbook.
What is Solidity?
Now, let’s start with understanding what Solidity is. Solidity is an object-oriented programming language influenced by C++, JavaScript and Python.
Solidity is designed to be compiled (converted from human readable to machine readable code) into bytecode that runs on the Ethereum Virtual Machine (EVM). This is the runtime environment for Solidity code, just like your browser is a runtime environment for JavaScript code.
So, you write Smart Contract code in Solidity, and the compiler converts it into bytecode. Then that bytecode gets deployed and stored on Ethereum (and other EVM-compatible blockchains).
You can get a basic introduction to the EVM and bytecode in this video I made.
What is a Smart Contract?
Here is a simple smart contract that works out of the box. It may not look useful, but you’re going to understand a lot of Solidity from just this!
Read it along with each comment to get a sense of what’s going on, and then move on to some key learnings.
// SPDX-License-Identifier: MIT |
We will get to some of the details like what public and view mean shortly.
For now, take seven key learnings from the above example:
- The first comment is a machine readable line (
// SPDX-License-Identifier: MIT) that specifies the licensing that covers the code.
SPDX license identifiers are strongly recommended, though your code will compile without it. Read more here. Also, you can add a comment or “comment out” (suppress) any line by prefixing it with two forward slashes "// ".
- The
pragmadirective must be the first line of code in any Solidity file. Pragma is a directive that tells the compiler which compiler version it should use to convert the human-readable Solidity code to machine readable bytecode.
Solidity is a new language and is frequently updated, so different versions of the compiler produce different results when compiling code. Some older solidity files will throw errors or warnings when compiled with a newer compiler version.
In larger projects, when you use tools like Hardhat, you may need to specify multiple compiler versions because imported solidity files or libraries that you depend on were written for older versions of solidity. Read more on Solidity’s pragma directive here.
The
pragmadirective follows Semantic Versioning (SemVer) - a system where each of the numbers signifies the type and extent of changes contained in that version. If you want a hands-on explanation of SemVer is check out this tutorial - it is very useful to understand and it’s used widely in development (especially web dev) these days.Semicolons are essential in Solidity. The compiler will fail if even a single one is missing. Remix will alert you!
The keyword
contracttells the compiler that you’re declaring a Smart Contract. If you’re familiar with Object Oriented Programming, then you can think of Contracts as being like Classes.
If you’re not familiar with OOP then think of contracts as being objects that hold data - both variables and functions. You can combine smart contracts to give your blockchain app the functionality it needs.
- Functions are executable units of code that encapsulate single ideas, specific functionality, tasks, and so on. In general we want functions to do one thing at a time.
Functions are most often seen inside smart contracts, though they can be declared in the file outside the smart contract’s block of code. Functions may take 0 or more arguments and they may return 0 or more values. Inputs and outputs are statically typed, which is a concept you will learn about later in this handbook.
- In the above example the variable
qtyCupsis called a “state variable”. It holds the contract’s state - which is the technical term for data that the program needs to keep track of to operate.
Unlike other programs, smart contract applications keep their state even when the program is not running. The data is stored in the blockchain, along with the application, which means that each node in the blockchain network maintains and synchronizes a local copy of the data and smart contracts on the blockchain.
State variables are like database “storage” in a traditional application, but since blockchains need to synchronize state across all nodes in the network, using storage can be quite expensive! More on that later.
How to Declare Variables and Functions in Solidity
Let’s break down that HotFudgeSauce Smart Contract so we understand more about each little piece.
The basic structure/syntax to defining things in Solidity is similar to other statically typed languages. We give functions and variables a name.
But in typed languages we also need to specify the type of the data that is created, passed as input or returned as output. You can jump down to the Typing Data section in this handbook if you need to understand what typed data is.
Below, we see what declaring a “State Variable” looks like. We also see what declaring a function looks like.
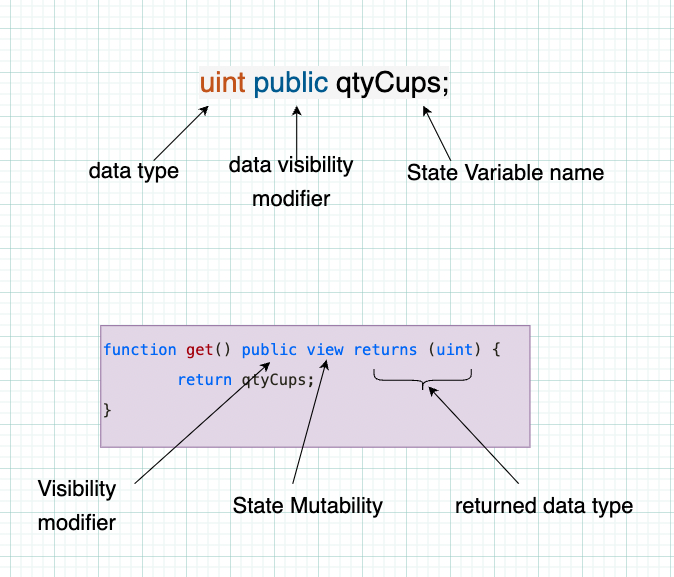
The first snippet declares a State Variable (I’ll explain what this is soon, I promise) called qtyCups. This can only store values that are of type uint which means unsigned integers. “Integer” refers to all whole numbers below zero (negative) and above zero (positive).
Since these numbers have a + or - sign attached, they’re called signed integers. An unsigned integer is therefore always a positive integer (including zero).
In the second snippet, we see a familiar structure when we declare functions too. Most importantly, we see that the functions have to specify a data type for the value that the function returns.
In this example, since get() returns the value of the storage variable we just created, we can see that the returned value must be a uint.
public is a visibility specifier. More on that later. view is a State-Mutability modifier. More on that below too!
It’s worth noting here that state variables can also be of other types - constant and immutable. They look like this:
string constant TEXT = "abc"; |
Constants and immutable variables have their values assigned once, and only once. They cannot be given another value after their first value is assigned.
So if we made the qtyCups state variable either constant or immutable, we would not be able to call the increment() or decrement() functions on it anymore (in fact, the code wouldn’t compile!).
Constants must have their values hardcoded in the code itself, whereas immutable variables can have their values set once, generally by assignment in the constructor function (we’ll talk about constructor functions very soon, I promise). You can read more in the docs here.
Variable Scope in Smart Contracts
There are three scopes of variables that Smart Contracts have access to:
State Variables: store permanent data in the smart contract (referred to as persistent state) by recording the values on the blockchain.
Local Variables: these are “transient” pieces of data that hold information for short periods of time while running computations. These values are not stored permanently on the blockchain.
Global variables: these variables and functions are “injected” into your code by Solidity, and made available without the need to specifically create or import them from anywhere. These provide information about the blockchain environment the code is running on and also include utility functions for general use in the program.
You can tell the difference between the scopes as follows:
state variables are generally found inside the smart contract but outside of a function.
local variables are found inside functions and cannot be accessed from outside that function’s scope.
Global variables aren’t declared by you - they are “magically” available for you to use.
Here is our HotFudgeSauce example, slightly modified to show the different types of variables. We give qtyCups a starting value and we dispense cups of fudge sauce to everyone except me (because I’m on a diet).

How Visibility Specifiers Work
The use of the word “visibility” is a bit confusing because on a public blockchain, pretty much everything is “visible” because transparency is a key feature. But visibility, in this context, means the ability for one piece of code to be seen and accessed by another piece of code.
Visibility specifies the extent to which a variable, function, or contract can be accessed from outside the region of code where it was defined. The scope of visibility can be adjusted depending on which portions of the software system need to access it.
If you’re a JavaScript or NodeJS developer, you’re already familiar with visibility – any time you export an object you’re making it visible outside the file where it is declared.
Types of Visibility
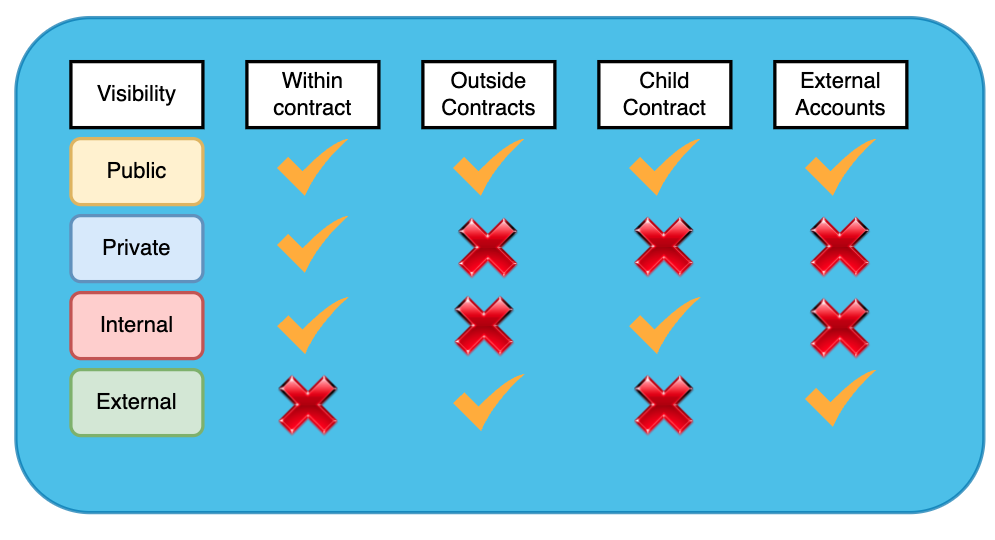
In Solidity there are 4 different types of visibility: public, external, internal and private.
Public functions and variables can be accessed inside the contract, outside it, from other smart contracts, and from external accounts (the kind that sit in your Metamask wallet) - pretty much from anywhere. It’s the broadest, most permissive visibility level.
When a storage variable is given public visibility, Solidity automatically creates an implicit getter function for that variable’s value.
So in our HotFudgeSauce smart contract, we don’t really need to have the get() method, because Solidity will implicitly provide us identical functionality, just by giving qtyCups a public visibility modifier.
Private functions and variables are only accessible within the smart contract that declares them. But they cannot be accessed outside of the Smart Contract that encloses them. private is the most restrictive of the four visibility specifiers.
Internal visibility is similar to private visibility, in that internal functions and variables can only be accessed from within the contract that declares them. But functions and variables marked internal can also be accessed from derived contracts (that is, child contracts that inherit from the declaring contract) but not from outside the contract. We will talk about inheritance (and derived/child contracts) later on.
internal is the default visibility for storage variables.
The 4 Solidity Visibility specifiers and where they can be accessed from
The external visibility specifier does not apply to variables - only functions can be specified as external.
External functions cannot be called from inside the declaring contract or contracts that inherit from the declaring contract. Thus, they can only be called from outside the enclosing contract.
And that’s how they’re different from public functions – public functions can also be called from inside the contract that declare them, whereas an external function cannot.
What are Constructors?
A constructor is a special type of function. In Solidity, it is optional and is executed once only on contract creation.
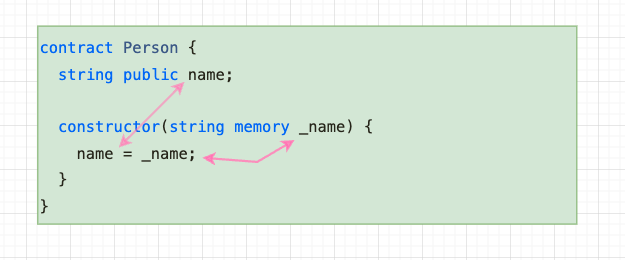
In the following example we have an explicit constructor and it accepts some data as a parameter. This constructor parameter must be injected by you into your smart contract at the time you create it.
Solidity constructor function with input parameter
To understand when the constructor function gets called, it’s helpful to remember that a Smart Contract is created over a few phases:
it is compiled down to bytecode (you can read more about bytecode here). This phase is called “compile time”.
it gets created (constructed) - this is when the constructor kicks into action. This can be referred to as “construction time”.
Bytecode then gets deployed to the blockchain. This is “deployment”.
The deployed smart contract bytecode gets run (executed) on the blockchain. This can be considered “runtime”.
In Solidity, unlike other languages, the program (smart contract) is deployed only after the constructor has done its work of creating the smart contract.
Interestingly, in Solidity, the finally deployed bytecode does not include the constructor code. This is because in Solidity, the constructor code is part of the creation code (construction time) and not part of the runtime code. It is used up when creating the smart contract, and since it’s only ever called once it is not needed past this phase, and is excluded in the finally deployed bytecode.
So in our example, the constructor creates (constructs) one instance of the Person smart contract. Our constructor expects us to pass a string value which is called _name to it.
When the smart contract is being constructed, that value of _name will get stored in the state variable called name (this is often how we pass configuration and other data into the smart contract). Then when the contract is actually deployed, the state variable name will hold whatever string value we passed into our constructor.
Understanding the Why
You might wonder why we bother with injecting values into the constructor. Why not just write them into the contract?
This is because we want contracts to be configurable or “parameterized”. Rather than hard code values, we want the flexibility and reusability that comes with injecting data as and when we need.
In our example, let’s say that _name referred to the name of a given Ethereum network on which the contract is going to be deployed (like Rinkeby, Goerli, Kovan, Mainnet, and so on).
How could we give that information to our smart contract? Putting all those values in it would be wasteful. It would also mean we need to add extra code to work out which blockchain the contract is running on. Then we'd have to pick the right network name from a hard-coded list which we store in the contract, which takes up gas on deployment.
Instead, we can just inject it into the constructor, at the time we are deploying the smart contract to the relevant blockchain network. This is how we write one contract that can work with any number of parameter values.
Another common use case is when your smart contract inherits from another smart contract and you need to pass values to the parent smart contract when your contract is being created. But inheritance is something we will discuss later.
I mentioned that constructors are optional. In HotFudgeSauce, we didn’t write an explicit constructor function. But Solidity supports implicit constructor functions. So if we don’t include a constructor function in our smart contract, Solidity will assume a default constructor which looks like constructor() {}.
If you evaluate this in your head you’ll see it does nothing and that’s why it can be excluded (made implicit) and the compiler will use the default constructor.
Interfaces and Abstract Contracts
An interface in solidity is an essential concept to understand. Smart Contracts on Ethereum are publicly viewable and therefore you can interact with them via their functions (to the extent the Visibility Specifiers allow you to do so!).
This is what makes smart contracts “composable” and why so many Defi protocols are referred to as “money Legos” - you can write smart contracts that interact with other smart contracts that interact with other smart contracts and so on…you get the idea.
So when you want your smart contract A to interact with another smart contract B, you need B’s interface. An interface gives you an index or menu of the various functions available for you to call on a given Smart Contract.
An important feature of Interfaces is that they must not have any implementation (code logic) for any of the functions defined. Interfaces are just a collection of function names and their expected arguments and return types. They’re not unique to Solidity.
So an interface for our HotFudgeSauce Smart Contract would look like this (note that by convention, solidity interfaces are named by prefixing the smart contract’s name with an “I”:
// SPDX-License-Identifier: MIT |
That’s it! Since HotFudgeSauce had only three functions, the interface shows only those.
But there is an important and subtle point here: an interface does not need to include all the functions available to call in a smart contract. An interface can be shortened to include the function definitions for the functions that you intend to call!
So if you only wanted to use the decrement() method on HotFudgeSauce then you could absolutely remove get() and increment() from your interface - but you would not be able to call those two functions from your contract.
So what’s actually going on? Well, interfaces just give your smart contract a way of knowing what functions can be called in your target smart contract, what parameters those functions accept (and their data type), and what type of return data you can expect. In Solidity, that’s all you need to interact with another smart contract.
In some situations, you can have an abstract contract which is similar to but different from an interface.
An abstract contract is declared using the abstract keyword and is one where one or more of its functions are declared but not implemented. This is another way of saying that at least one function is declared but not implemented.
Flipping that around, an abstract contract can have implementations of its functions (unlike interfaces which can have zero implemented functions), but as long as at least one function is unimplemented, the contract must be marked as abstract:
// SPDX-License-Identifier: MIT |
You may (legitimately) wonder what the point of this is. Well, abstract contracts cannot be instantiated (created) directly. They can only be used by other contracts that inherit from them.
So abstract contracts are often used as a template or a “base contract” from which other smart contracts can “inherit” so that the inheriting smart contracts are forced to implement certain functions declared by the abstract (parent) contract. This enforces a defined structure across related contracts which is often a useful design pattern.
This inheritance stuff will become a little clearer when we discuss Inheritance later. For now, just remember that you can declare an abstract smart contract that does not implement all its functions - but if you do, you cannot instantiate it, and future smart contracts that inherit it must do the work of implementing those unimplemented functions.
Some of the important differences between interfaces and abstract contracts are that:
Interfaces can have zero implementations, whereas abstract contracts can have any number of implementations as long as at least one function is “abstract” (that is, not implemented).
All functions in an interface must be marked as “external” because they can only be called by other contracts that implement that interface.
Interfaces cannot have constructors, whereas abstract contracts may.
Interfaces cannot have state variables where abstract contracts may.
Smart Contract Example #2
For the next few Solidity concepts we’ll use the below smart contract. This is partly because this example contains a smart contract that is actually used in the real world. I've also chosen it because I have a clear bias to Chainlink Labs since I work there (😆) and it’s awesome. But it’s also where I learned a lot of Solidity, and it’s always better to learn with real-world examples.
So start by reading the code and the comments below. You’ve already learned 99% of what you need to understand the contract below, provided you read it carefully. Then move on to key learnings from this contract.
// SPDX-License-Identifier: MIT |
This smart contract gets the latest USD price of 1 Eth, from a live Chainlink price feed oracle (see the oracle on etherscan). The example uses the Goerli network so you don’t end up spending real money on the Ethereum mainnet.
Now to the 6 essential Solidity concepts you need to absorb:
- Right after the
pragmastatement we have an import statement. This imports existing code into our smart contract.
This is super cool because this is how we reuse and benefit from code that others have written. You can check out the code that is imported on this GitHub link.
In effect, when we compile our smart contract, this imported code gets pulled in and compiled into bytecode along with it. We will see why we need it in a second…
Previously you saw that single-line comments were marked with
//. Now you're learning about multiline comments. They may span one or more lines and use/*and*/to start and end the comments.We declare a variable called
priceFeedand it has a typeAggregatorV3Interface. But where does this strange type come from? From our imported code in the import statement - we get to use theAggregatorV3Interfacetype because Chainlink defined it.
If you looked at that Github link, you’d see that the type defines an interface (we just finished talking about interfaces). So priceFeed is a reference to some object that is of type AggregatorV3Interface.
- Take a look at the constructor function. This one doesn’t accept parameters, but we could have just as easily passed the ETH/USD Price Feed’s oracle smart contract’s address
0xD4a33860578De61DBAbDc8BFdb98FD742fA7028eto it as a parameter of typeaddress. Instead, we are hard-coding the address inside the constructor.
But we are also creating a reference to the Price Feed Aggregator smart contract (using the interface called AggregatorV3Interface).
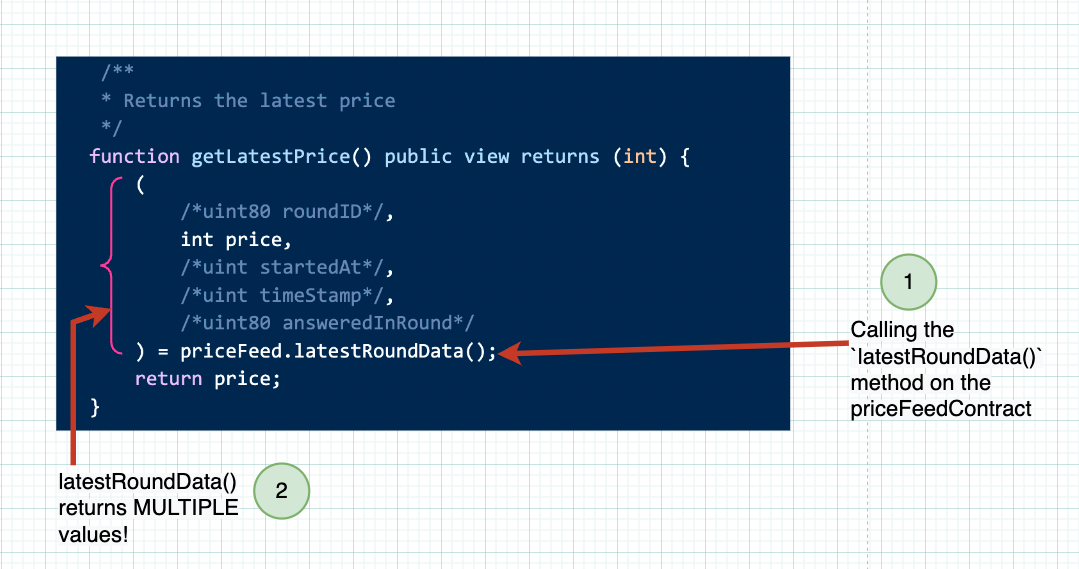
Now we can call all the methods available on the AggregatorV3Interface because the priceFeed variable refers to that Smart Contract. In fact, we do that next… 5. Let's jump to the function getLatestPrice(). You’ll recognize its structure from our discussion in HotFudgeSauce, but it’s doing some interesting things.
Inside this getLatestPrice() function we call the latestRoundData() function which exists on the AggregatorV3Interface type. If you look at the source code of this method you’ll notice that this latestRoundData() function returns 5 different types of integers!
Calling methods on another smart contract from our smart contract
In our smart contract, we are commenting out all 4 values that we don’t need. So this means that Solidity functions can return multiple values (in this example we are returned 5 values), and we can pick and choose which ones we want.
Another way of consuming the results of calling latestRoundData() would be:( ,int price, , ,) = priceFeed.latestRoundData() where we ignore 4 out of 5 returned values by not giving them a variable name.
When we assign variable names to one or more values returned by a function, we call it “destructuring assignment” because we destructure the returned values (separate each one out) and assign them at the time of destructuring, like we do with price above.
Since you’ve learned about interfaces, I recommend you take a look at Chainlink Labs’ GitHub repo to examine the implemented latestRoundData() function in the Aggregator contract and how the AggregatorV3Interface provides the interface to interact with the Aggregator contract.
What is Contract State?
Before we proceed any further, it’s important to make sure that the terminology that we’re going to see a lot is comprehensible to you.
“State” in computer science has a well-defined meaning. While it can get very confusing, the crux of state is that it refers to all the information that is “remembered” by a program as it runs. This information can change, update, be removed, created and so on. And if you were to take a snapshot of it at various times, the information will be in different “states”.
So the state is just the current snapshot of the program, at a point in time during its execution - what values do its variables hold, what are they doing, what objects have been created or removed, and so on.
We have previously examined the three types of variables - State Variables, Local Variables, and Global variables. State variables, along with Global variables give us the state of the smart contract at any given point in time. Thus, the state of a smart contract is a description of:
what values its state variables hold,
what values the blockchain-related global variables have at that moment in time, and
the balance (if any) lying in the smart contract account.
State Mutability Keywords (Modifiers)
Now that we have discussed state, state variables, and functions, let’s understand the Solidity keywords that specify what we are allowed to do with state.
These keywords are referred to as modifiers. But not all of them permit you to modify state. In fact many of them expressly disallow modifications.
Here are Solidity modifiers you will see any real-world smart contract:
| Modifier Keyword | Applies to… | Purpose |
| constant | State variables | Declared and given a value once, at the same time. Hard coded into code. Its given value can never be changed. |
| immutable | State variables | These are declared at the top of smart contracts, but given their value (only once!) at construction time - i.e. via the constructor function. Once they receive their value, they are (effectively) constants. And their values are actually stored in the code itself rather than in a storage slot (storage will be explained later). |
| view | functions | You’ll generally see this right after the visibility specifier. A view modifier means that the function can only “view” (read from) contract state, but cannot change it (cannot “write” to contract state). This is effectively a read-only modifier. If the function needs to use any value that is in the contract’s state, but not modify that value, it will be a view function. |
| pure | functions | Functions that are pure are not allowed to write to (modify) contract state, nor are they allowed to even read from it! They do things that do not, in any way, interact with blockchain state. Often these can be helper functions that do some calculation or convert an input of one data type into another data type etc. |
| payable | functions | This keyword enables a function to receive Eth. Without this keyword you cannot send Eth while calling a function. |
Note that in Solidity version 0.8.17, there were breaking changes that enabled the use of payable as a data type. Specifically we now allowed to convert the address data type to a payable address type by doing a type conversion that looks like payable(0xdCad3a6d3569DF655070DEd06cb7A1b2Ccd1D3AF).
What this does is makes a given ethereum address payable, after which we can send Eth to that address.
Note that this use of payable is a type conversion, and not the same as the function modifier, though the same keyword is used. We will cover the address type later, but you can read about this here. | | virtual | functions | This is a slightly more advanced topic and is covered in detail in the section on Inheritance. This modifier allows the function to be “overridden” in a child contract that inherits from it. In other words, a function with the keyword virtual can be “rewritten” with different internal logic in another contract that inherits from this one. | | override | functions | This is the flip side to the virtual modifier. When a child contract “rewrites” a function that was declared in a base contract (parent contract) from which it inherits, it marks that rewritten function with override to signal that its implementation overrides the one given in the parent contract. If a parent’s virtual function is not overridden by the child, the parent's implementation will apply to the child. | | indexed | events | We will cover events later in this handbook. They are small bundles of data “emitted” by a smart contract typically in response to noteworthy events happening. The indexed keyword indicates that one of the pieces of data contained in an event should be stored in the blockchain for retrieval and filtering later. This will make more sense once we cover Events and Logging later in this handbook. | | anonymous | events | The docs say “Does not store event signature as topic” which probably doesn’t mean a lot to you just yet. But the keyword does indicate that it’s making some part of the event “anonymous”. So this will make sense once we understand events and topics later in this handbook. |
Note that variables that are not storage variables ( i.e. local variables declared and used inside the scope of a given function) do not need state modifiers. This is because they’re not actually part of the smart contract’s state. They’re just part of the local state inside that function. By definition then, they’re modifiable and don’t need controls on their modifiability.
Data Locations – Storage, Memory, and Stack
On Ethereum and EVM-based chains, data inside the system can be placed and accessed in more than one “data location”.
Data locations are part of the fundamental design and architecture of the EVM. When you see the words “memory”, “storage” and “stack”, you should start thinking “data locations” - that is, where can data be stored (written) to and retrieved (read) from.
Data location has an impact on how the code executes at run time. But it also has very important impacts on how much gas gets used during deployment and running of the smart contract.
The use of gas requires a deeper understanding of the EVM and something called opcodes - we can park that discussion for now. While useful, it is not strictly necessary for you to understand data locations.
Though I’ve mentioned 3 data locations so far, there are 2 other ways in which data can be stored and accessed in Smart Contracts: “calldata”, and “code”. But these are not data locations in the EVM’s design. They’re just subsets of the 3 data locations.
Let’s start with storage. In the EVM’s design, data that needs to be stored permanently on the blockchain is placed in the relevant smart contract’s “storage” area. This includes any contract “state variables”.
Once a contract is deployed and has its specific address, it also gets its own storage area, which you can think of as a key-value store (like a hash table) where both the keys and the values are 256 bit (32 byte) data “words”. And “words” has a specific meaning in computer architecture.
Because storage persists data on the blockchain permanently, all data needs to be synchronized across all the nodes in the network, which is why nodes have to achieve consensus on data state. This consensus makes storage expensive to use.
You’ve already seen examples of storage variables (aka contract state variables) but here is an example taken from the Chainlink Verifiable Random Number Consumer smart contract

Storage data location. Putting data in the contract's storage layout.
When the above contract is created and deployed, whatever address that is passed into the contract’s constructor becomes permanently stored in the smart contract’s storage, and is accessible using the variable vrfCoodinator. Since this state variable is marked as immutable, it cannot be changed after this.
To refresh your memory from the previous section on keywords, where we last discussed immutable and constant variables, these values are not put in storage. They become part of the code itself when the contract is constructed, so these values don’t consume as much gas as storage variables.
Now let’s move to memory. This is temporary storage where you can read and write data needed during the running of the smart contract. This data is erased once the functions that use the data are done executing.
The memory location space is like a temporary notepad, and a new one is made available in the smart contract each time a function is triggered. That notepad is thrown away after the execution completes.
When understanding the difference between storage and memory, you can think of storage as a kind of hard disk in the traditional computing world, in the sense that it has “persistent” storage of data. But memory is closer to RAM in traditional computing.
The stack is the data area where most of the EVM’s computations are performed. The EVM follows a stack based computation model and not a register based computation model, which means each operation to be carried out needs to be stored and accessed using a stack data structure.
The stack’s depth - that is the total number of items it can hold - is 1024, and each item in the stack can be 256 bits (32 bytes) long. This is the same as the size of each key and value in the storage data location.
You can read more about how the EVM controls access to the stack data storage area here.
Next, let's talk about calldata. I have assumed that you have a basic understanding about Ethereum smart contract messages and transactions. If you don’t, you should first read those links.
Messages and transactions are how smart contract functions are invoked, and they contain a variety of data necessary for the execution of those functions. This message data is stored in a read-only section of the memory called calldata, which holds things like the function name and parameters.
This is relevant for externally callable functions, as internal and private functions don’t use calldata. Only “incoming” function execution data and function parameters are stored in this location.
Remember, calldata is memory except that calldata is read-only. You cannot write data to it.
And finally, code is not a data location but instead refers to the smart contract's compiled bytecode that is deployed and stored permanently on the blockchain. This bytecode is stored in an immutable ROM (Read Only Memory), that is loaded with the bytecode of the smart contract to be executed.
Remember how we discussed the difference between immutable and constant variables in Solidity? Immutable values get assigned their value once (usually in the constructor) and constant variables have their values hard-coded into the smart contract code. Because they’re hardcoded, constant values are compiled literally and embedded directly into the smart contract’s bytecode, and stored in this code / ROM data location.
Like calldata, code is also read-only - if you understood the previous paragraph you’ll understand why!
How Typing Works
Typing is a very important concept in programming because it is how we give structure to data. From that structure we can run operations on the data in a safe, consistent and predictable way.
When a language has strict typing, it means that the language strictly defines what each piece of data’s type is, and a variable that has a type cannot be given another type.
In other words, in strictly typed languages:
int a =1 // 1 here is of the integer type |
But in JavaScript, which is not typed, b=a would totally work - this makes JavaScript “dynamically typed”.
Similarly, in statically typed languages you cannot pass an integer into a function that expects a string. But in JavaScript we can pass anything to a function and the program will still compile but it may throw an error when you execute the program.
For example take this function:
function add(a,b){ |
As you can imagine, this can produce some pretty hard-to-find bugs. The code compiles and can even execute without failing, though it produces unexpected results.
But a strongly typed language would never let you pass the string “2” because the function would insist on the types that it accepts.
Let’s take a look at how this function would be written in a strongly typed language like Go.

How typing works in syntax, using Golang for illustration purposes
Trying to pass a string (even if it represents a number) will prevent the program from even compiling (building). You will see an error like this:
./prog.go:13:19: cannot use "2" (untyped string constant) as int value in argument to add
Go build failed.
So types are important because data that seems the same to a human can be perceived very differently by a computer. This can cause some pretty weird bugs, errors, program crashes and even big security vulnerabilities.
Types also give developers the ability to create their own custom types, which can then be programmed with custom properties (attributes) and operations (behaviors).
Type systems exist so that humans can reason about the data by asking the question “what is this data’s type, and what should it be able to do?” and the machines can do exactly what is intended.
Here is another example of how data that looks the same to you and me may be interpreted in hugely different ways by a processor. Take the sequence of binary digits (that is the digits can only have a value of 0 or 1, which is the binary system that processors work with) 1100001010100011.
To a human, using the decimal system that looks like a very large number - perhaps 11 gazillion or something.
But to a computer that is binary, so it’s not 11 anything. The computer sees this as a sequence 16 bits (short for binary digits) and in binary this could mean the positive number (unsigned integer) 49,827 or the signed integer -15,709 or the UTF-8 representation of the British Pound symbol £ or something different!
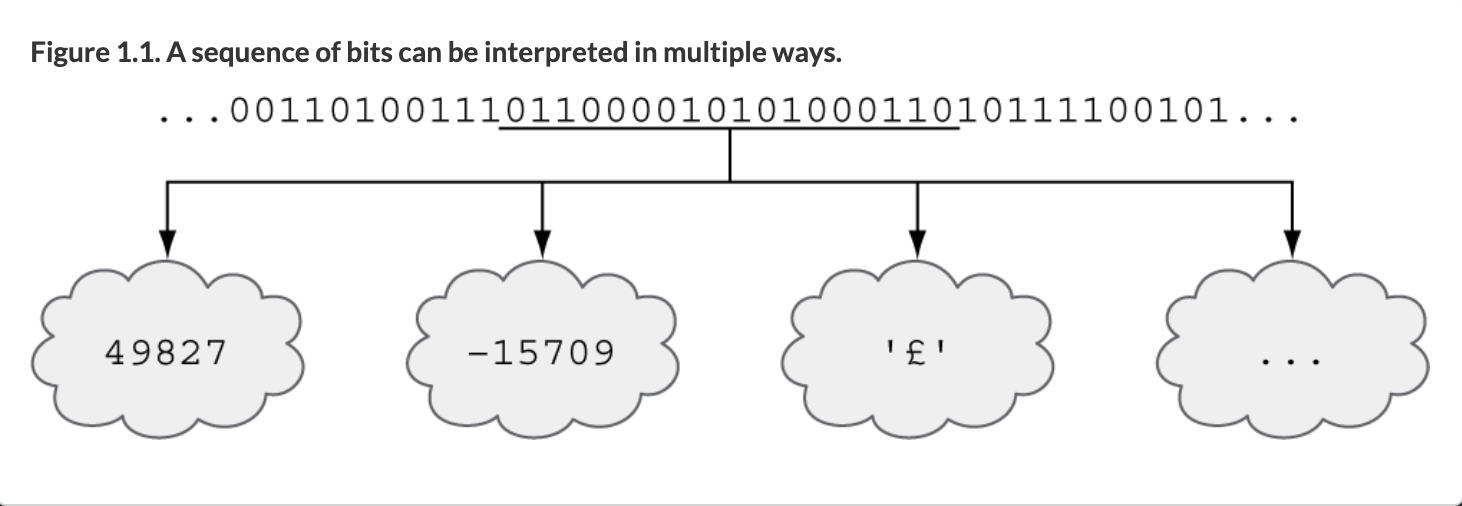
A sequence of bits can be interpreted by a computer to have very different meanings (source)
So all this explanation is to say that types are important, and that types can be “inbuilt” into a language even if the language does not strictly enforce types, like JavaScript.
JavaScript already has inbuilt types like numbers, strings, booleans, objects, and arrays. But as we saw, JavaScript does not insist on types being stuck to the way a statically typed language like Go does.
Now back to Solidity. Solidity is very much a statically typed language. When you declare a variable you must also declare its type. Going further, Solidity will simply refuse to compile if you try to pass a string into a function that expects an integer.
In fact Solidity is very strict with types. For example, different types of integers may also fail compilation like the following example where the function add() expects an unsigned integer (positive) and will only add to that number thus always returning a positive integer. But the return type is specified as an int which means it could be positive or negative!
function add(uint256 a) public pure returns (int256){ |
So even though the input and output are 256-bit integers, the fact that the function only receives unsigned integers makes the compiler complain that the unsigned integer type is not implicitly convertible to the signed integer type.
That’s pretty strict! The developer can force the conversion (called type casting) by rewriting the return statement as return int256(a + 10). But there are issues to consider with that sort of action, and that’s out of scope for what we’re talking about here.
For now, just remember that Solidity is statically typed, which means that the type of each variable must be expressly specified when declaring them in the code. You can combine types to form more complex, composite types. Next, we can discuss some of these inbuilt types.
Solidity Data Types
Types that are built into the language and come with it “out of the box” are often referred to as “primitives”. They’re intrinsic to the language. You can combine primitive types to form more complex data structures that become “custom” data types.
In JavaScript, for example, primitives are data that is not a JS object and has no methods or properties. There are 7 primitive data types in JavaScript: string, number, bigint, boolean, undefined, symbol, and null.
Solidity also has its own primitive data types. Interestingly, Solidity does not have “undefined” or “null”. Instead, when you declare a variable and its type, but do not assign a value to it, Solidity will assign a Default Value to that type. What exactly that default value is depends on the data type .
Many of Solidity’s primitive data types are variations of the same ‘base’ type. For example the int type itself has subtypes based on the number of binary digits that the integer type can hold.
If that confuses you a bit, don’t worry - it isn’t easy if you’re not familiar with bits and bytes, and I’ll cover integers a bit more shortly.
Before we explore Solidity types, there is another very important concept that you must understand - it is the source of many bugs, and “unexpected gotchas” in programming languages.
This is the difference between a value type and reference type, and the resulting distinction between data in programs being “passed by value” vs “passed by reference”. I’ll go into a quick summary below but you may also find it useful to watch this short video to strengthen your mental model before proceeding.
Pass by reference vs pass by value
At an operating system level, when a program is running, all data used by the program during its execution is stored in locations in the computer’s RAM (memory). When you declare a variable, some memory space is allocated to hold data about that variable and the value that is, or eventually will be, assigned to that variable.
There is also a piece of data that is often called a “pointer”. This pointer points to the memory location (an “address” in the computer’s RAM) where that variable and its value can be found. So the pointer effectively contains a reference to where the data can be found in the computer’s memory.
So when you pass data around in a program (for example when you assign a value to a new variable name, or when you pass inputs (parameters) into a function or method, the language’s compiler can achieve this in two ways. It can pass a pointer to the data’s location in the computer’s memory, or it can make a copy of the data itself, and pass the actual value.
The first approach is “pass by reference”. The second approach is “pass by value”.
Solidity’s data type primitives fall into two buckets - they’re either value types, or they’re reference types.
In other words, in Solidity, when you pass data around, the type of the data will decide whether you’re passing copies of the value or a reference to the value’s location in the computer’s memory.
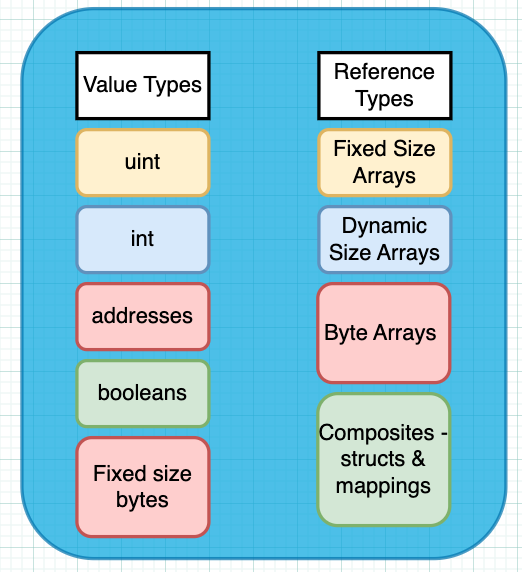
Value Types and Reference Types in Solidity
In Solidity’s “value types”, integers are of two categories - uint is unsigned (positive integers only, so they have no plus or minus signs) and int is signed (could be positive or negative, and if you wrote them down, they’d have a plus or minus sign).
Integer types can also specify how many bits long they are - or how many bits are used to represent the integer.
An uint8 is an integer represented by 8 binary digits (bits) and can store up to 256 different values (2^8=256). Since uint is for unsigned (positive) integers, this means it can store values from 0 to 255 (not including 1 to 256).
However when you have signed integers, like an int8, then one of the bits is used up to represent whether it's a positive or negative number. That means we have only 7 bits left, and so we can only represent up to 2^7 (128) different values, including 0. So an int8 can represent anything from -127 to +127.
By extension, an int256 is 256 bits long and can store +/- (2^255) values.
The bit lengths are multiples of 8 (because 8 bits makes a byte) so you can have int8, int16, int24 etc all the way to 256 (32 bytes).
Addresses refer to the Ethereum account types - either a smart contract account or an externally owned account (aka “EOA”. Your Metamask wallet represents an EOA). So an address is also a type in Solidity.
The default value of an address (that is the value it will have if you declare a variable of type address but don’t assign it any value) is 0x0000000000000000000000000000000000000000 which is also the result of this expression: address(0).
Booleans represent either true or false values. Finally, we have fixed size byte arrays like bytes1, bytes2 … bytes32. These are arrays of fixed length that contain bytes. All these types of values are copied when they’re passed around in the code.
For “reference types”, we have arrays, which can have a fixed size specified when they’re declared, or dynamically sized arrays, which start off with a fixed size, but can be “resized” as the number of data elements in the array grows.
Bytes are a low-level data type that refer to the data that is encoded into binary format. All data is eventually reduced to binary form by the compiler so that the EVM (or, in traditional computing, the processor) can work with it.
Storing and working with bytes is often faster and more efficient compared to other data types that are more human readable.
You may be wondering why I’ve not referred to strings in either types of data in the picture above. That’s because in Solidity, strings are actually dynamically-sized arrays, and the arrays store a sequence of bytes (just binary numbers) that are encoded in the UTF-8 encoding format.
They’re not a primitive in Solidity. In JavaScript they’re referred to as primitives, but even in JavaScript strings are similar (but not the same as) to arrays and are a sequence of integer values, encoded in UTF-16.
It is often more efficient to store a string as a bytes type in a smart contract, as converting between strings and bytes is quite easy. It is therefore useful to store strings as bytes but return them in functions as strings. You can see an example below:
// SPDX-License-Identifier: MIT |
Other than Solidity strings, the bytes data type is a dynamically sized byte array. Also, unlike its fixed-size byte array cousin, it's a reference type. The bytes type in Solidity is a shorthand for “array of bytes” and can be written in the program as bytes or byte[].
If you’re confused by bytes and byte arrays…I sympathise.
The underlying gory details of strings and byte arrays are not too relevant for this handbook. The important point for now is that some data types are passed by reference and others are passed by copying their values.
Suffice it to say that Solidity strings and bytes without a size specified are reference types because they’re both dynamically sized arrays.
Finally, among Solidity’s primitives, we have structs and mappings. Sometimes these are referred to as “composite” data types because they’re composed from other primitives.
A struct will define a piece of data as having one or more properties or attributes, and specifying each property’s data type and name. Structs give you the ability to define your own custom type so that you can organize and collect pieces of data into one larger data type.
For example you could have struct that defines a Person as follows:
struct Person { |
You can instantiate or initialize a Person struct in the following ways:
// dot notation updating. Job struct is uninitialized |
Mappings are similar to hashtables, dictionaries or JavaScript objects and maps, but with a little less functionality.
A mapping is also a key-value pair, and there are restrictions on the kinds of data types you can have as keys, which you can read about here. The data types associated with a mapping’s keys can be any of primitives, structs, and even other mappings.
Here is how mappings are declared, initialized, written to and read from - the below example is from the Chainlink Link Token Smart Contract source code.

Declaring and using the Mappings type in Solidity
If you try to access a value using a key that doesn’t exist in the mapping, it will return the default value of the type that is stored in the mapping.
In the above example, the type of all values in the balances mapping is uint256, which has a default value of 0. So if we called balanceOf() and passed in an address that does not have any LINK tokens issued to it, we’d get a value of 0 back.
This is reasonable in this example, but it can be a bit tricky when we want to find out whether or not a key exists in a mapping.
Currently there is no way to enumerate what keys exist in a mapping (that is, there is nothing equivalent to JavaScript’s Object.keys() method). Retrieving using a key will only return the default value associated with the data type, which does not clearly tell us whether or not the key actually exists.
There is an interesting “gotcha” with mappings. Unlike other languages where you can pass key-value data structures as an argument to function, Solidity does not support passing mappings as arguments to functions except where the functions visibility is marked as internal. So you could not write an externally or publicly callable function that would accept key-value pairs as an argument.
How to Declare and Initialize Arrays in Solidity
Solidity comes with two flavors of arrays, so it is useful to understand the different ways in which they can be declared and initialized.
The two main types of arrays in Solidity are the fixed-size array and the dynamic-sized array.
To refresh your memory, fixed-size arrays are passed by value (copied when passed around in the code) and dynamic-sized arrays are passed by reference (a pointer to the memory address is passed around in the code).
They’re also different in their syntax and their capacity (size), which then dictates when we would use one versus the other.
Here’s what a fixed-size array looks like when declared and initialized. It has a fixed capacity of 6 elements, and this cannot be changed once declared. The memory space for an array of 6 elements is allocated and cannot change.
string[6] fixedArray; // Max capacity is 6 elements. |
A fixed-size array can also be declared by just declaring a variable and the size of the array and the type of its elements with the following syntax:
// datatype arrayName[arraySize]; |
Contrast that with a dynamically-sized array that is declared and initialized as follows. Its capacity is unspecific and you can add elements using the push() method:
uint[] dynamicArray; |
You can also declare and initialize the value of an array in the same line of code.
string[3] fixedArray = ["a", "b", "c"]; // Fixed sized string array |
These arrays are available in storage. But what if you needed only temporary in-memory arrays inside a function? In that case there are two rules: only fixed size arrays are allowed, and you must use the new keyword.
function inMemArray(string memory firstName, string memory lastName) |
Clearly, there are several ways to declare and initialize arrays. When you’re wanting to optimize for gas and computations you want to carefully consider which type of arrays are required, what their capacity is, and if they’re likely to grow without an upper bound.
This also influences and is influenced by the design of your code - whether you need arrays in storage or whether you need them only in memory.
What are Function Modifiers?
When writing functions, we often receive inputs that need some sort of validation, checking, or other logic run on those inputs before we go ahead with the rest of the “business” logic.
For example, if you’re writing in pure JavaScript, you may want to check that your function receives integers and not strings. If it’s on the backend you may want to check that the POST request contained the right authentication headers and secrets.
In Solidity, we can perform these sort of validation steps by declaring a function-like block of code called a modifier.
A modifier is a snippet of code that can run automatically before or after you run the main function (that is, the function that has the modifier applied to it).
Modifiers can be inherited from parent contracts too. It is generally used as a way to avoid repeating your code, by extracting common functionality and putting it in a modifier that can be reused throughout the codebase.
A modifier looks a lot like a function. The key thing to observe about a modifier is where the _ (underscore) shows up. That underscore is like a “placeholder” to indicate when the main function will run. It reads as if we inserted the main function where the underscore is currently.
So in the modifier snippet below, we run the conditional check to make sure that the message sender is the owner of the contract, and then we run the rest of the function that called this modifier. Note that a single modifier can be used by any number of functions.

How function modifiers are written, and the role of the underscore symbol
In this example, the require() statement runs before the underscore (changeOwner()) and that’s the correct way to ensure that only the current owner can change who owns the contract.
If you switched the modifier’s lines and the require() statement came second, then the code in changeOwner() would run first. Only after that would the require() statement run, and that would be a pretty unfortunate bug!
Modifiers can take inputs too - you’d just pass the type and name of the input into a modifier.
modifier validAddress(address addr) { |
Modifiers are a great way to package up snippets of logic that can be reused in various smart contracts that together power your dApp. Reusing logic makes your code easier to read, maintain and reason about – hence the principle DRY (Don’t Repeat Yourself).
Error Handling in Solidity - Require, Assert, Revert
Error handling in Solidity can be achieved through a few different keywords and operations.
The EVM will revert all changes to the blockchain’s state when there is an error In other words, when an exception is thrown, and it’s not caught in a try-catch block, the exception will “bubble up” the stack of methods that were called, and be returned to the user. All changes made to the blockchain state in the current call (and its sub-calls) get reversed.
There are some exceptions, in low-level functions like delegatecall, send, call, and so on, where an error will return the boolean false back to the caller, rather than bubble up an error.
As a developer there are three approaches you can take to handle and throw errors. You can use require(), assert() or revert().
A require statement evaluates a boolean condition you specify, and if false, it will throw an error with no data, or with a string that you provide:
function requireExample() public pure { |
We use require() to validate inputs, validate return values, and check other conditions before we proceed with our code logic.
In this example, if the function’s caller does not send at least 1 ether, the function will revert and throw an error with a string message: “you must pay me at least 1 ether!”.
The error string that you want returned is the second argument to the require() function, but it is optional. Without it, your code will throw an error with no data - which is not terribly helpful.
The good thing about a require() is that it will return gas that has not been used, but gas that was used before the require() statement will be lost. That’s why we use require() as early as possible.
An assert() function is quite similar to require() except that it throws an error with type Panic(uint256) rather than Error(string).
contract ThrowMe { |
An assert is also used in slightly different situations– where a different type of guarding is required.
Most often you use an assert to check an “invariant” piece of data. In software development, an invariant is one or more pieces of data whose value never changes while the program is executing.
In the above code example, the contract is a tiny contract, and is not designed to receive or store any ether. Its design is meant to ensure that it always has a contract balance of zero, which is the invariant we test for with an assert.
Assert() calls are also used in internal functions. They test that local state does not hold unexpected or impossible values, but which may have changed due to the contract state becoming “dirty”.
Just as require() does, an assert() will also revert all changes. Prior to Solidity’s v0.8, assert() used to use up all remaining gas, which was different from require().
In general, you’d likely use require() more than assert().
A third approach is to use a revert() call. This is generally used in the same situation as a require() but where your conditional logic is much more complex.
In addition, you can throw custom-defined errors when using revert(). Using custom errors can often be cheaper in terms of gas used, and are generally more informative from a code and error readability point of view.
Note how I improve the readability and traceability of my error by prefixing my custom error’s name with the Contract name, so we know which contract threw the error.
contract ThrowMe { |
In the above example, we use revert once with a custom error that takes two specific arguments, and then we use revert another time with only a string error data. In either case, the blockchain state is reverted and unused gas will be returned to the caller.
Inheritance in Solidity
Inheritance is a powerful concept in Object Oriented Programming (OOP). We won't go into the details of what OOP is here. But the best way to reason about inheritance in programming is to think of it as a way by which pieces of code “inherit” data and functions from other pieces of code by importing and embedding them.
Inheritance in Solidity also allows a developer to access, use and modify the properties (data) and functions (behaviour) of contracts that are inherited from.
The contract that receives this inherited material is called the derived contract, child contract or the subclass. The contract whose material is made available to one or more derived contracts is called a parent contract.
Inheritance facilitates convenient and extensive code reuse – imagine a chain of application code that inherits from other code, and those in turn inherit from others and so on. Rather than typing out the entire hierarchy of inheritance, we can just use a a few key words to “extend” the functions and data captured by all the application code in the inheritance chain. That way child contract gets the benefit of all parent contracts in its hierarchy, like genes that get inherited down each generation.
Unlike some programming languages like Java, Solidity allows for multiple inheritance. Multiple inheritance refers to the ability of a derived contract to inherit data and methods from more than one parent contract. In other words, one child contract can have multiple parents.
You can spot a child contract and identify its parent contract by looking for the is keyword.
contract A { |
If you were to deploy only Contract B using the in-browser Remix IDE you’d note that Contract B has access to the getName() method even though it was not ever written as part of Contract B. When you call that function, it returns “A” , which is data that is implemented in Contract A, not contract B. Contract B has access to both storage variables A_NAME and B_NAME, and all functions in Contract A.
This is how inheritance works. This is how Contract B reuses code already written in Contract A, which could have been written by someone else.
Solidity lets developers change how a function in the parent contract is implemented in the derived contract. Modifying or replacing the functionality of inherited code is referred to as “overriding”. To understand it, let’s explore what happens when Contract B tries to implement its own getName() function.
Modify the code by adding a getName() to Contract B. Make sure the function name and signature is identical to what is in Contract A. A child contract’s implementation of logic in the getName() function can be totally different from how it’s done in the parent contract, as long as the function name and its signature are identical.
contract A { |
The compiler will give you two errors:
In Contract A, it will indicate that you are “trying to override non-virtual function” and prompt you by asking if you forgot to add the
virtualkeyword.In Contract B, it will complain that the
getName()function is missing theoverridespecifier.
This means that your new getName in Contract B is attempting to override a function by the same name in the parent contract, but the parent’s function is not marked as virtual – which means that it cannot be overridden.
You could change Contract A’s function and add virtual as follows:
function getName() public virtual returns (string memory) { |
Adding the keyword virtual does not change how the function operates in Contract A. And it does not require that inheriting contracts must re-implement or override it. It simply means that this function may be overridden by any derived contracts if the developer chooses.
Adding virtual fixes the compiler’s complaint for Contract A, but not for Contract B. This is because getName in Contract B needs to also add the override keyword as follows:
function getName() public pure override returns (string memory) { |
We also add the pure keyword for Contract B’s getName() as this function does not change the state of the blockchain, and reads from a constant (constants, you’ll remember, are hardcoded into the bytecode at compile time and are not in the storage data location).
Keep in mind that you only need to override a function if the name and the signature are identical.
But what happens with functions that have identical names but different arguments? When this happens it’s not an override, but an overload. And there is no conflict because the methods have different arguments, and so there is enough information in their signatures to show the compiler that they're different.
For example, in contract B we could have another getName() function that takes an argument, which effectively gives the function a different “signature” compared to the parent Contract A’s getName() implementation. Overloaded functions do not need any special keywords:
// getName() now accepts a string argument. |
Don’t worry about the abi.encodepacked() method call. I’ll explain that later when we talk about encoding and decoding. For now just understand that encodepacked() encodes the strings into bytes and then concatenates them, and returns a bytes array.
We discussed the relationship between Solidity strings and bytes in a previous section of this handbook (under Typing).
Also, since you’ve already learned about function modifiers, this is a good place to add that modifiers are also inheritable. Here’s how you’d do it:
contract A { |
You might wonder which version of a function will be called if a function by the same name and signature exists in a chain of inheritance.
For example, let's say there is a chain of inherited contracts like A → B → C → D → E and all of them have a getName() that overrides a getName() in the previous parent contract.
Which getName() gets called? The answer is the last one – the “most derived” implementation in the contract hierarchy.
State variables in child contracts cannot have the same name and type as their parent contracts.
For example, Contract B below will not compile because its state variable “shadows” that of the parent Contract A. But note how Contract C correctly handles this:
contract A { |
It’s important to note that by passing a new value to the variable author in Contract C’s constructor, we are effectively overriding the value in Contract A. And then calling the inherited method C.getAuthor() will return ‘Hemingway’ and not ‘Zubin’!
It is also worth noting that when a contract inherits from one or more parent contract, only one single (combined) contract is created on the blockchain. The compiler effectively compiles all the other contracts and their parent contracts and so on up the entire hierarchy all into a single compiled contract (which is referred to as a “flattened” contract).
Inheritance with Constructor Parameters
Some constructors specify input parameters and so they need you to pass arguments to them when instantiating the smart contract.
If that smart contract is a parent contract, then its derived contracts must also pass arguments to instantiate the parent contracts.
There are two ways to pass arguments to parent contracts - either in the statement that lists the parent contracts, or directly in the constructor functions for each parent contract. You can see both approaches below:
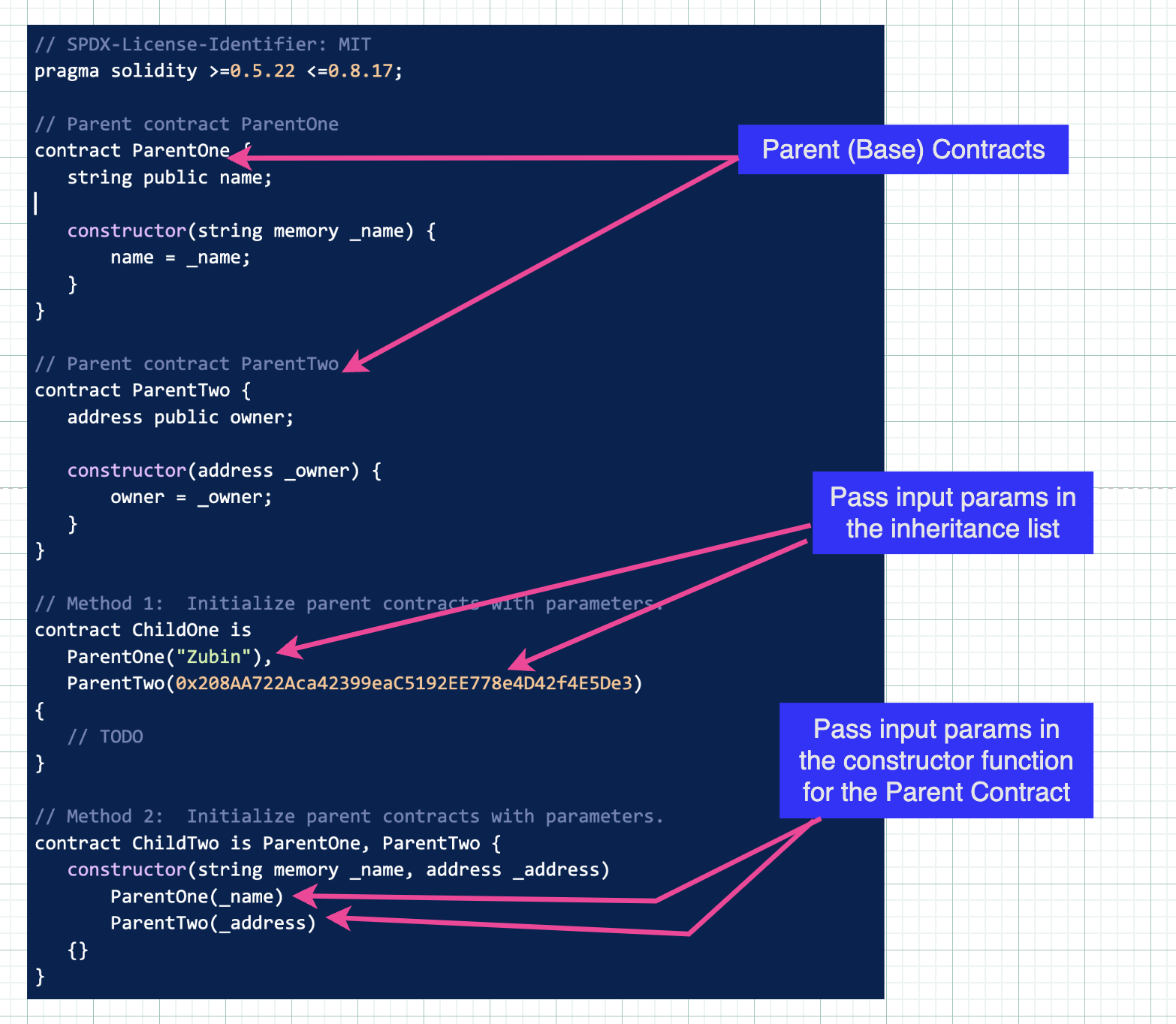
In Method 2 in the ChildTwo contract, you’ll note that the arguments passed to the parent contracts are first supplied to the child contract and then just passed up the inheritance chain.
This is not necessary, but is a very common pattern. The key point is that where parent contract constructor functions expect data to be passed to them, we need to provide them when we instantiate the child contract.
Type Conversion and Type Casting in Solidity
Sometimes we need to convert one data type to another. When we do so we need to be very careful when converting data and how the converted data is understood by the computer.
As we saw in our discussion on typed data, JavaScript can sometimes do strange things to data because it is dynamically typed. But that’s also why it’s useful to introduce the concept of type casting and type conversions generally.
Take the following JavaScript code:
var a = "1" |
There are two ways of converting the variable a into an integer. The first, called type casting, is done explicitly by the programmer and usually involves a constructor-like operator that uses ().
a = Number(a) // Type casting the string to number is explicit. |
var b = a + 9 // 10. A number. More intuitive! |
Now let's reset a to a string and do an implicit conversion, also known as a type conversion. This is implicitly done by the compiler when the program is executed.
a = '1' |
In Solidity, type casting (explicit conversion) is permissible between some types, and would look like this:
uint256 a = 2022; |
In this example we converted an integer with a size of 256 bits (since 8 bits makes 1 byte, this is 32 bytes) into a bytes array of size 32.
Since both the integer value of 2022 and the bytes value are of length 32 bytes, there was no “loss” of information in the conversion.
But what would happen if you tried to convert 256 bits into 8 bits (1 byte)? Try running the following in your browser-based Remix IDE:
contract Conversions { |
Why does the integer 2022 get converted to 230? That’s clearly an undesirable and unexpected change in the value. A bug, right?
The reason is that an unsigned integer of size 256 bits will hold 256 binary digits (either 0 or 1). So a holds the integer value ‘2022’ and that value, in bits, will have 256 digits, of which most will be 0, except for the last 11 digits which will be... (see for yourself by converting 2022 from decimal system to binary here).
The value of b on the other hand will have only 8 bits or digits, being 11100110. This binary number, when converted to decimal (you can use the same converter - just fill in the other box!) is 230. Not 2022.
Oopsie.
So what happened? When we dropped the integer’s size from 256 bits to 8 bits we ended up shaving the first three digits of data (11111100110) which totally changed the value in binary!
This, folks, is information loss.
So when you’re explicitly casting, the compiler will let you do it in some cases. But you could lose data, and the compiler will assume you know what you’re doing because you’re explicitly asking to do it. This can be the source of many bugs, so make sure you test your code properly for expected results and be careful when explicitly casting data to smaller sizes.
Casting up to larger sizes does not result in data lost. Since 2022 needs only 11 bits to be represented, you could declare the variable a as type uint16 and then up-cast it to a variable b of type uint256 without data loss.
The other kind of casting that is problematic is when you’re casting from unsigned integers to signed integers. Play around with the following example:
contract Conversions { |
Note that a , being a signed integer of size 16 bits holds -2022 as a (negative integer) value. If we explicitly type cast it to an unsigned integer (only positive) values, the compiler will let us do it.
But if you run the code, you’ll see that b is not -2022 but 63,514! Because uint cannot hold information regarding the minus sign, it has lost that data, and the resulting binary gets converted to a massive decimal (base 10) number - clearly undesirable, and a bug.
If you go further, and un-comment the line that assigns the value of c, you’ll see the compiler complain with 'Explicit type conversion not allowed from "int16" to "uint256"'. Even though we are up-casting to a larger number of bits in uint256, because c is an unsigned integer, it cannot hold minus sign information.
So when explicitly casting, be sure to think through what the value will evaluate to after you’ve forced the compiler to change the type of the data. It is the source of many bugs and code errors.
There is more to Solidity type conversions and type casting and you can go deep into some of the nitty gritty in this article.
How to Work with Floating Point Numbers in Solidity
Solidity doesn’t handle decimal points. That may change in the future, but currently you cannot really work with fixed (floating) point numbers like 93.6. In fact typing int256 floating = 93.6; in your Remix IDE will throw an error like : Error: Type rational_const 468 / 5 is not implicitly convertible to expected type int256.
What’s going on here? 468 divided by 5 is 93.6, which seems a weird error, but that’s basically the compiler saying it cannot handle floating point numbers.
Follow the suggestions of the error, and declare the variable’s type to be fixed or ufixed16x1.
fixed floating = 93.6; |
You’ll get an “UnimplementedFeatureError: Not yet implemented - FixedPointType” error.
So in Solidity, we get around this by converting the floating point number to a whole number (no decimal points) by multiplying by 10 raised to the exponent of the number of decimal places to the right of the decimal point.
In this case we multiply 93.6 by 10 to get 936 and we have to keep track of our factor (10) in a variable somewhere. If the number was 93.2355 we would multiply it by 10 to the power 4 as we need to shift the decimal 4 places to the right to make the number whole.
When working with ERC tokens we will note that the decimal places are often 10, 12, or 18.
For example, 1 Ether is 1*(10^18) wei, which is 1 followed by 18 zeros. If we wanted that expressed with a floating point, we would need to divide 1000000000000000000 by 10^18 (which will give us 1), but if it was 1500000000000000000 wei, then dividing by 10^18 will throw a compiler error in Solidity, because it cannot handle the return value of 1.5.
In scientific notation, 10^18 is also expressed as 1e18, where 1e represents 10 and the number after that represents the exponent that 1e is raised to.
So the following code will produce a compiler error: “Return argument type rational_const 3 / 2 is not implicitly convertible to expected type…int256”:
function divideBy1e18()public pure returns (int) { |
The result of the above division operation is 1.5, but that has a decimal point which Solidity does not currently support. Thus Solidity smart contracts return very big numbers, often up to 18 decimal places, which is more than JavaScript can handle. So you'll need to handle that appropriately in your front end using JavaScript libraries like Ethersjs that implement helper functions for the BigNumber type.
Hashing, ABI Encoding and Decoding
As you work more with Solidity, you’ll see some strange-sounding terms like hashing, ABI encoding, and ABI decoding.
While these can take some effort to wrap your head around, they’re quite fundamental to working with cryptographic technology, and Ethereum in particular. They’re not complex in principle, but can be a bit hard to grasp at first.
Let’s start with hashing. Using cryptographic math, you can convert any data into a (very large) unique integer. This operation is called hashing. There are some key properties to hashing algorithms:
They’re deterministic - identical inputs will always produce an identical output, each time and every time. But the chance of producing the same output using different inputs is extremely unlikely.
It is not possible (or computationally infeasible) to reverse engineer the input if you only have the output. It is a one-way process.
The output’s size (length) is fixed - the algorithm will produce fixed-size outputs for all inputs, regardless of the input size. In other words the outputs of a hashing algorithm will always have a fixed number of bits, depending on the algorithm.
There are many algorithms that are industry-standard for hashing but you’ll likely see SHA256 and Keccak256 most commonly. These are very similar. And the 256 refers to the size - the number of bits in the hash that is produced.
For example, go to this site and copy and paste “FreeCodeCamp” into the text input. Using the Keccak256 algorithm, the output will (always) be 796457686bfec5f60e84447d256aba53edb09fb2015bea86eb27f76e9102b67a.
This is a 64 character hexadecimal string, and since each character in a hex string represents 4 bits, this hexadecimal string is 256 bits (32 bytes long).
Now, delete everything in the text input box except the “F”. The result is a totally different hex string, but it still has 64 characters. This is the “fixed-size” nature of the Keccak265 hashing algorithm.
Now paste back the “FreeCodeCamp” and change any character at all. You could make the “F” lowercase. Or add a space. For each individual change you make, the hash hex string output changes a lot, but the size is constant.
This is an important benefit from hashing algorithms. The slightest change changes the hash substantially. Which means you can always test whether two things are identical (or have not been tampered with at all) by comparing their hashes.
In Solidity, comparing hashes is much more efficient than comparing the primitive data types.
For example, comparing two strings is often done by comparing the hashes of their ABI-encoded (bytes) form. A common helper function to compare two strings in Solidity would look like this:
function compareStrings(string memory str1, string memory str2) |
We’ll address what ABI encoding is in a moment, but note how the result of encodePacked() is a bytes array which is then hashed using the keccak256 algorithm (this is the native hashing algorithm used by Solidity). The hashed outputs (256 bit integers) are compared for equality.
Now let's turn to ABI encoding. First, we recall that ABI (Application Binary Interface) is the interface that specifies how to interact with a deployed smart contract. ABI-encoding is the process of converting a given element from the ABI into bytes so that the EVM can process it.
The EVM runs computation on bits and bytes. So encoding is the process of converting structured input data into bytes so that a computer can operate on it. Decoding is the reverse process of converting bytes back into structured data. Sometimes, encoding is also referred to as “serializing”.
You can read more about the solidity built-in methods provided with the global variable abi that do different types of encoding and decoding here. Methods that encode data convert them to byte arrays (bytes data type). In reverse, methods that decode their inputs expect the bytes data type as input and then convert that into the data types that were encoded.
You can observe this in the following snippet:
// SPDX-License-Identifier: MIT |
I ran the above in Remix, and used the following inputs for encode(): 1981, 0x3C44CdDdB6a900fa2b585dd299e03d12FA4293BC, [1,2,3,4].
And the bytes I got returned were represented in hexadecimal form as the following:
0x00000000000000000000000000000000000000000000000000000000000007bd0000000000000000000000003c44cdddb6a900fa2b585dd299e03d12fa4293bc000000000000000000000000000000000000000000000000000000000000006000000000000000000000000000000000000000000000000000000000000000040000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000030000000000000000000000000000000000000000000000000000000000000004
I fed this as my input into the decode() function and got my original three arguments back.
Thus, the purpose of encoding is to convert data into the bytes data type that the EVM needs to process data. And decoding brings it back into the human readable structured data that we developers can work with.
How to Call Contracts and Use the Fallback Function
Depending on the design of the smart contract and the visibility specifiers present in it, the contract can be interacted with by other smart contracts or by externally owned accounts.
Calling from your wallet via Remix is an example of the latter, as is using Metamask. You can also interact with smart contracts programmatically via libraries like EthersJS and Web3JS, the Hardhat and Truffle toolchains, and so on.
For the purposes of this Solidity handbook, we will use Solidity to interact with another contract.
There are two ways for a smart contract to call other smart contracts. The first way calls the target contract directly, by using interfaces (which we discussed previously). Or, if the Target contract is imported into the scope of the calling contract, it directly calls it.
This approach is illustrated below:
contract Target { |
In Remix you can deploy Target first, and call count() to see that the default value for the count variable is 0, as expected. This value will be decremented by 1 if you call the decrement() method.
Then you can deploy TargetCaller and there are two methods you can call, both of which will decrement the value of count in Target.
Note that each of these two methods access the Target contract using a slightly different syntax. When interacting by using the ITarget interface, the first method takes in Target’s address whereas the second method treats Target as a custom type.
This second approach is only possible when the Target contract is declared in, or imported into, the same file as the TargetCaller. Most often, you will interact with smart contracts deployed by third parties, for which they publish ABI interfaces.
Each time you call these methods, the value of count in Target will decrease by 1. This is a very common way to interact with other smart contracts.
The second way to do it is by using the “low level” call syntax that Solidity provides. You use this when you also want to send some ether (value) to the target contract. Will talk about sending value in the next section, but for now just replace the code in Remix with the following:
contract Target { |
You’ll note that decrement() now takes an argument, and the interface and the Target contract are updated with this new input data.
Next note that TargetCaller implements a new function that calls decrement() with a new syntax, explained below.
In the next section we will see examples of these low level ways of calling a target smart contract to send Ether to it.
But what happens when you call a contract and it doesn’t actually have the function you tried to call?
This can happen maliciously to exploit how Solidity works on the EVM. Or, more commonly, it can happen accidentally. This occurs when, for example, there is an error in the Interface and the compiler cannot match the function and parameters you sent with any that are actually contained in the contract. What happens then?
For these situations, many contracts employ a special function called the fallback function. The function looks like a normal function but it doesn’t need the function keyword. If you want it to also handle situations where your contract is sent some ether, you must also mark it payable. But this is not the recommended way to enable your contract to receive payments.
Let’s take a look by repurposing our previous Target, ITarget and TargetCaller and adding a fallback function as follows:
contract Target { |
Once we deploy a fresh instance of Target, we can call count() and see that it is set to the default value of zero.
Next we can deploy TargetCaller and call the callFallback() method which internally calls nonExistentFunction().
It’s worth noting that the interface says that nonExistentFunction() is available but the actual Target contract does not have any such function. This is why the Target fallback function gets triggered and the value of count is now incremented by 1.
The purpose of the fallback function is to handle calls to the contract where no other function is available to handle it. And if the fallback is marked payable, the fallback function will also enable the smart contract to receive Ether (though that is not the recommended use for fallback). We will cover this in the next section.
How to Send and Receive Ether
To send Ether to a target contract from your smart contract, you need to call the target contract using one of the following three in-built Solidity methods: transfer, send or call.
transfer will throw an exception when it fails, and send and call will return a boolean that you must check before proceeding. Of these three, transfer and send are no longer recommended for security reasons, though you can still use them and they'll work.
Smart Contracts cannot receive Ether except in the following scenarios:
They implement a
payablefallback orpayablereceive special function, orForcibly when the calling contract calls
selfdestructand forces a target contract to accept all its remaining ether. The calling contract is then deleted from the blockchain. This is a separate topic and is often used maliciously by exploiters.
It is generally recommended that you use a receive() function if you want your smart contract to receive Ether. You can get away by just making your fallback function payable, but recommended practice is to use a receive() function instead.
If you rely only on the fallback function, your compiler will grumble at you with the following message: “Warning: This contract has a payable fallback function, but no receive ether function. Consider adding a receive ether function.”
If you have both receive and fallback, you may legitimately wonder how Solidity decides which function to receive Ether with. This design decision also tells you what these functions are designed to do.
Receive is meant to receive ether. And fallback is meant to handle situations where the contract has been called but, as we discussed in the previous section, there is no matching method in the contract that can handle the call.
Solidity matches the method that was intended to be called by checking the msg.data field in the transaction sent by the caller. If that field is a non-empty value, and that value does not match any other function declared in the called contract, then the fallback method is triggered.
If msg.data is empty, then it will check if there is a receive function that has been implemented. If so, it will use that to accept the Ether. If no receive exists, it will default to the fallback function. The fallback is therefore the...fallback (default) method when nothing else makes sense.
The receive function is the better way to enable your contract to receive Ether. You can use the fallback function for any scenario where your smart contract is called but there is nothing to “handle” that call.
Here is a super handy logic tree that shows what receive and fallback are intended to handle.
Which function is called, fallback() or receive()? |
(credit: Solidity By Example)
Going back to our example where we explored the fallback function, we can add a receive function to Target as follows:
contract Target { |
We already saw how callFallback will change the count value in Target. But if we deploy a fresh instance of Target, we can now send it 10 wei, as shown below, because it now has a payable receive function. Prior to sending 10 wei (or any other amount) Target has a balance of zero, as shown below.
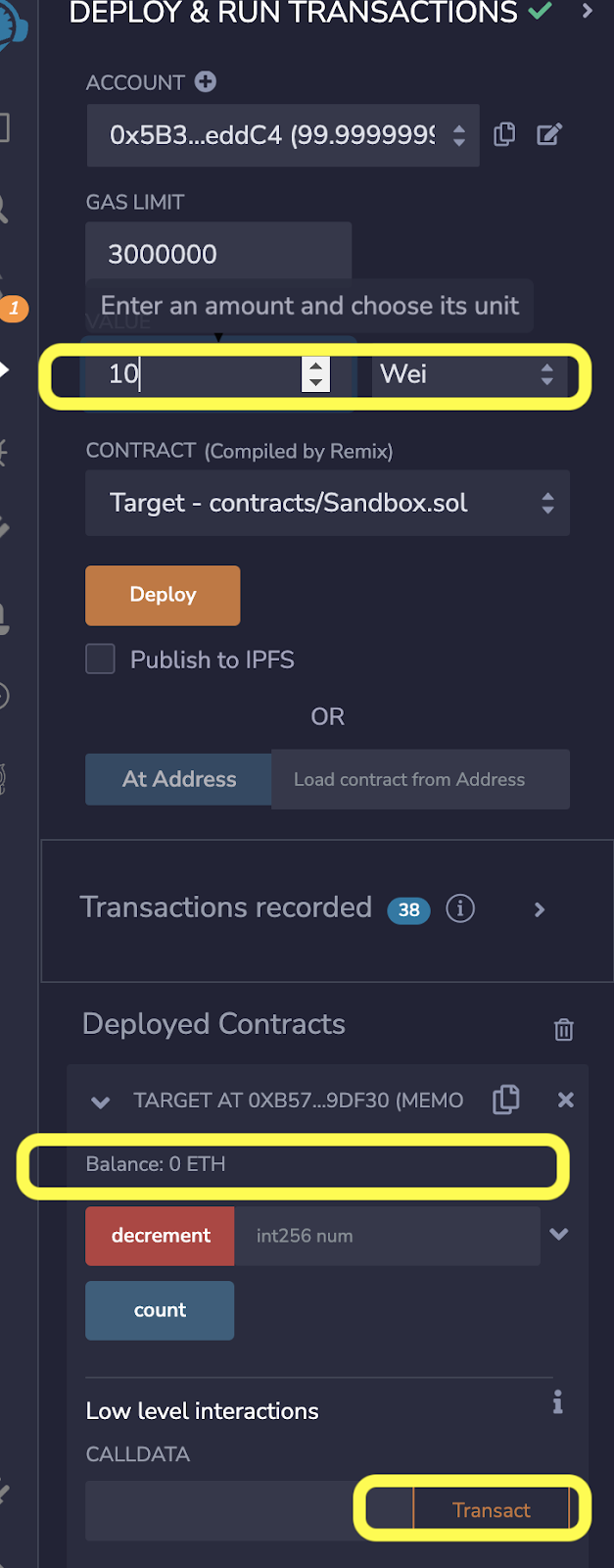
Hitting the Transact button with empty calldata (msg.data) will change the balance as shown in the image below. We can check count to see that it is incremented by 5, which is the logic in the receive function.
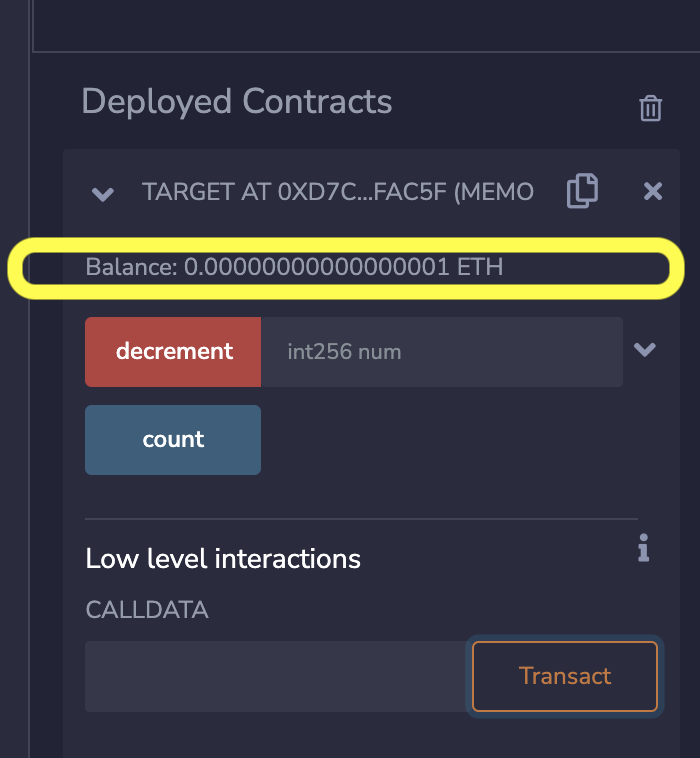
Sending Wei to the Target Contract and observing the updated balance
If we call callFallback and give it the address of the new Target instance, we will note that it increments only by 1. If we include some wei, that will increase the balance of Target as well.
So any transfer of Ether to a smart contract would require the receiving smart contract to have payable functions that can receive it. At the very minimum, the receiving smart contract would need a payable fallback function, though a payable receive function is the better approach for receiving Ether payments.
Solidity Libraries
In any programming language, a library refers to a collection of helper and utility functions that are designed to be reusable across multiple code bases. These functions solve specific, recurring programming problems.
In Solidity, libraries serve the same purpose, but have some special attributes.
First, they are stateless - that is, they don't store data (other than constants because these do not change the blockchain’s state). They also can't receive value (which means they cannot have payable receive or fallback functions).
They also cannot inherit from other contracts or libraries, nor can libraries have child (derived) contracts.
All functions declared in a library must not be abstract - that is, they must all have concrete implementations.
Since Solidity libraries are stateless, none of the methods in them can modify the blockchain’s state. This means all methods inside libraries are pure or view functions.
Another interesting attribute of Solidity libraries is that they don't need to be imported into your smart contract. They can be deployed as standalone contracts and then called via their interface in all consuming smart contracts - just as you would an API service in the traditional engineering world.
However, this is true only where the library contains public or external methods. Then that library can be deployed as a standalone contract with its own Ethereum address, and becomes callable to all consuming smart contracts.
If the libraries contain only internal methods, then the EVM simply “embeds” the library code into the smart contract that uses the library (because internal functions cannot be accessed from other smart contracts).
Libraries in Solidity have advantages that go beyond code reuse. Deploying a library one time on the blockchain can save on future gas costs by avoiding repeated deployment or importing of the library's code.
Let's look at a simple library and then dissect the code to understand how to use the library’s code.
library WeirdMath { |
This library has two methods that operate on the int data type. The first argument is called self for reasons that will become clear shortly. One method takes a number and then multiplies it by a constant value that is stored in the library’s code. The second method takes in two numbers and adds them.
Now let’s see how we can use this in a consuming smart contract.
// SPDX-License-Identifier: MIT |
The first thing to note is that there are two ways of using the WeirdMath library.
You can use it by either:
Invoking the library’s name followed by the function you want to call, or
calling the function directly on the data type you want the function to operate on. This data type must be identical to the type of the
selfparameter in the library’s function.
The first approach is demonstrated by method 1 in the code snippet where we invoke the library with WeirdMath.add(num1, num2);.
The second approach uses the Solidity using keyword. The expression return num1.add(num2); applies the WeirdMath library’s add function to the num1 variable. This is the same as passing it in as self, which is the first argument to the add function.
Events and Logs in Solidity
Smart Contracts can emit events. The events contain pieces of data that you the developer specify.
Events cannot be consumed by other smart contracts. Instead, they are stored on the blockchain as logs, and can be retrieved via the APIs that read from the blockchain.
This means that your application (most commonly your front end application) can “read” logs that contain the event’s data from the blockchain. In this way your user interface can respond to events on the blockchain.
This is how application user interfaces are updated to respond to on-chain events. Since these logs on the blockchain can be queried, logs are a cheap form of storage, as discussed previously in the discussion on storage areas.
Events emitted by a Smart Contract can be inspected using the relevant blockchain explorer, because everything on a public blockchain is publicly viewable. But if the smart contract’s bytecode has not been verified, the event data may not be human readable (it will be encoded). The events of verified smart contracts will be human readable.
Nodes and other blockchain clients can listen for (subscribe to) specific events. At the heart of it, this is how Chainlink Oracles work - decentralized oracle nodes listen to events from smart contracts, and then respond accordingly. They can even pull data off from events, run complex and resource-intensive computations off-chain, and then submit cryptographically verifiable computation results back onto the blockchain.
Other network APIs and indexing services like subgraphs are made possible because of the ability to query blockchain data via the events emitted by smart contracts.
Here is what an Event looks like in Solidity:
// SPDX-License-Identifier: MIT |
An event is first declared, and its arguments and their data types are specified. Any piece of data that has the indexed keyword is indexed by the EVM so that queries on blockchain logs can use the indexed param as a filter. This makes retrieving logs faster.
An event can store up to 4 indexed parameters - depending on whether it is anonymous or non-anonymous. Indexed event parameters are also referred to as “Topics” in the Solidity world.
Most events are non-anonymous, meaning that they include data on the name and arguments of the Event.
Non-anonymous events allow the developer to specify only 3 topics because the first topic is reserved to specify the Event signature in ABI-encoded hexadecimal form. You can read more about anonymous and non-anonymous topics here.
You can also explore Events on the relevant blockchain explorer (like etherscan.io).
You can approach this from one of two entry points. You can look at the contract’s address directly and then go to the Events Tab (which will show you events emitted by that contract only). Or you can go to a transaction hash and examine all the events emitted by all contracts that were touched by that transaction.
For example, below is a screenshot of the Chainlink VRF Coordinator smart contract’s events on Ethereum mainnet.

Inspecting the Chainlink VRF Coordinator Contract's events on etherscan
The contract tab has a green tick mark which means the contract is verified, and so the Event name and arguments are human readable. Take a moment to study this image as it contains a lot of information! If you’d like to study it directly on etherscan, click here.
This Chainlink VRF Coordinator contract responds to requests for cryptographically verifiable random numbers, and supplies the asking smart contract with random numbers (referred to as “random words”).
If you want to learn what the computer science meaning of “word” is, check out my colleague and I addressing this question in this Chainlink 2022 Hackathon video).
When the VRF Coordinator contract fulfills the request for random numbers, it emits a RandomWordsFulfilled event. That event contains 4 pieces of data, of which the first one, requestID, is indexed.
Solidity events contain three categories of data:
The address of the contract that emitted the event.
The topics (indexed event parameters used for filtering queries of the logs).
Non-indexed parameters, referred to as “data”, and they are ABI-encoded and represented in hexadecimal. This data needs to be ABI-decoded, in the way described in the section on ABI encoding and decoding.
When working in Remix you can also inspect the Events in the console as shown below:
Inspecting Event data in the Remix Browser IDE
You can also programmatically access the events using the contract receipts object in EthersJS. Using the code snippet we used above in the SimpleStorage contract, we can access the events using EthersJS and Hardhat using the following JavaScript:
const transactionResponse = await simpleStorage.store(1981) |
You can also use libraries such as the EtherJs library in your front end application to listen to events and filter historical events. Both of these are useful when your application needs to respond to events on the blockchain.
Time Logic in Solidity
Time in Solidity is specified in relation to each block that gets added to the blockchain.
The global variable block.timestamp refers to the time, in milliseconds, when the block was generated and added to the blockchain. The milliseconds count refers to the number of milliseconds that have passed since the beginning of the Unix Epoch (in computing, this is 1 January 1970).
Unlike Web2 references to timestamps in milliseconds, the value may not increment with every millisecond.
A block often contains several transactions, and since block.timestamp refers to the time at which the block was mined, all transactions in a mined block will have the same timestamp value. So the timestamp really refers to the block’s time, and not so much as to when the caller may have initiated the transaction.
Solidity supports directly referring to the following units of time: seconds, minutes, hours, days, and weeks.
So we could do something like uint lastWeek = block.timestamp - 1 weeks; to calculate the timestamp of exactly 1 week before this current block was mined, down to milliseconds. That value would be the same as block.timestamp - 7 days;.
You can also use this to calculate future expiry dates, where, for example, you may want an operation to be possible between now and next week. You could do this with uint registrationDeadline = block.timestamp + 1 weeks; and then we could use the registrationDeadline as a validation or guard in a function as follows:
function registerVoter(address voter) public view { |
In this function we register the voter only if the current block’s timestamp is not past the registration deadline.
This logic is used extensively when we want to make sure certain operations are performed at the right time, or within an interval.
This is also one of the ways in which Chainlink Automation, a decentralized way to automate the execution of your smart contract, can be configured. The Chainlink decentralized oracle network can be configured to automatically trigger your smart contracts, and you can run a wide variety of automations by checking conditions, including time related conditions. These are used extensively for airdrops, promotions, special rewards, earn-outs and so on.
Conclusion and Further Resources
Congrats! You made it through this epic journey. If you’ve invested the time digesting this handbook, and run some of the code in the Remix IDE, you are now trained in Solidity.
From here on, it’s a question of practice, repetition and experience. As you go about building your next awesome decentralized application, remember to revisit the basics and focus on security. Security is especially important in the Web3 space.
You can get good information on best practices from OpenZeppelin’s blogs and the Trail of Bits resources, amongst others.
You can also get more practical hands on experience by doing the full end-to-end full-stack blockchain developer course that my colleague Patrick Collins published on freeCodeCamp (it’s free!).
There are other resources like blockchain.education and freeCodeCamp’s own upcoming Web3 curriculum that can consolidate your learnings.
In any event, this handbook can be your “desktop companion” for that quick refresh on basic concepts, regardless of what level of experience you’re at.
The important thing to remember is that Web3 technology is always evolving. There is a crying need for developers willing to tackle complex challenges, learn new skills, and solve important problems that come with decentralized architecture.
That could (and should) be you! So just follow your curiosity and don’t be afraid to struggle along the way.
And once again, I intend to keep this handbook updated. So if you see anything that’s not quite right, is outdated, or unclear, just mention it in a tweet and tag me and freeCodeCamp - a big shout out to you all for being part of keeping this handbook fresh.
Now…go be awesome!
Post Script
If you are serious about a career change to code, you can learn more about my journey from lawyer to software engineer. Check out episode 53 of the freeCodeCamp podcast and also Episode 207 of "Lessons from a Quitter". These provide the blueprint for my career change.
If you are interested in changing your career and becoming a professional coder, please reach out here. You can also check out my free webinar on Career Change to Code if that is what you're dreaming of.