

Este manual de comandos de Linux cubrirá 60 comandos básicos de Bash que necesitarás como desarrollador. Cada comando incluye código de ejemplo y consejos sobre cuándo usarlo.
Este Manual de Comandos de Linux sigue la regla 80/20: aprenderás el 80% de un tema en alrededor del 20% del tiempo que pases estudiándolo.
Encuentro que este enfoque te da una buena visión general sobre el tema.
Este manual no intenta cubrir todo lo relacionado con Linux y sus comandos. Se centra en los pequeños comandos clave que usarás el 80% o 90% del tiempo, e intenta simplificar el uso de los más complejos.
Todos estos comandos funcionan en Linux, macOS, WSL, y en cualquier lugar donde tengas un entorno UNIX.
Espero que el contenido de este manual te ayude a conseguir lo que quieres: sentirte cómodo con Linux.
Puedes guardar esta página en favoritos de tu navegador para poder consultar este manual en el futuro.
Y puedes descargar este manual en formato PDF / ePUB / Mobi de forma gratuita (en inglés).
¡Disfrútalo!
Índice
- Introduccion a Linux y los shells
- El comando
mande Linux - El comando
lsde Linux - El comando
cdde Linux - El comando
pwdde Linux - El comando
mkdirde Linux - El comando
rmdirde Linux - El comando
mvde Linux - El comando
cpde Linux - El comando
opende Linux - El comando
touchde Linux - El comando
findde Linux - El comando
lnde Linux - El comando
gzipde Linux - El comando
gunzipde Linux - El comando
tarde Linux - El comando
aliasde Linux - El comando
catde Linux - El comando
lessde Linux - El comando
tailde Linux - El comando
wcde Linux - El comando
grepde Linux - El comando
sortde Linux - El comando
uniqde Linux - El comando
diffde Linux - El comando
echode Linux - El comando
chownde Linux - El comando
chmodde Linux - El comando
umaskde Linux - El comando
dude Linux - El comando
dfde Linux - El comando
basenamede Linux - El comando
dirnamede Linux - El comando
psde Linux - El comando
topde Linux - El comando
killde Linux - El comando
killallde Linux - El comando
jobsde Linux - El comando
bgde Linux - El comando
fgde Linux - El comando
typede Linux - El comando
whichde Linux - El comando
nohupde Linux - El comando
xargsde Linux - El comando
vimdel editor de Linux - El comando
emacsdel editor de Linux - El comando
nanodel editor de Linux - El comando
whoamide Linux - El comando
whode Linux - El comando
sude Linux - El comando
sudode Linux - El comando
passwdde Linux - El comando
pingde Linux - El comando
traceroutede Linux - El comando
clearde Linux - El comando
historyde Linux - El comando
exportde Linux - El comando
crontabde Linux - El comando
unamede Linux - El comando
envde Linux - El comando
printenvde Linuxw - Conclusión
Introduccion a Linux y los shells
¿Qué es Linux?
Linux es un sistema operativo, como macOS o Windows.
También es el sistema operativo de código abierto más popular, y te da mucha libertad.
Alimenta a la gran mayoría de los servidores que componen Internet. Es la base sobre la que se construye todo. Pero no sólo eso. Android está basado en (una versión modificada de) Linux.
El "núcleo" de Linux (llamado kernel) nació en 1991 en Finlandia, y ha recorrido un largo camino desde sus humildes comienzos. Se convirtió en el núcleo del sistema operativo GNU, creando el dúo GNU/Linux.
Hay una cosa acerca de Linux que las corporaciones como Microsoft, Apple y Google nunca podrán ofrecer: la libertad de hacer lo que uno quiera con su computadora.
En realidad van en dirección contraria, construyendo jardines amurallados, especialmente en el lado móvil.
Linux es la libertad definitiva.
Es desarrollado por voluntarios, algunos pagados por empresas que dependen de él, algunos de forma independiente. Pero no hay una sola compañía comercial que pueda dictar lo que va a ir en Linux, o las prioridades del proyecto.
También puedes usar Linux como tu computadora del día a día. Uso macOS porque realmente disfruto de las aplicaciones y el diseño (y también solía ser un desarrollador de aplicaciones para iOS y Mac). Pero antes de usar macOS usaba Linux como sistema operativo de mi computadora principal.
Nadie puede dictar qué aplicaciones puedes ejecutar, o "llamar a casa" con aplicaciones que te rastrean, tu posición y más.
Linux también es especial porque no hay "un solo Linux", como es el caso de Windows o macOS. En su lugar, tenemos distribuciones.
Una "distro" es hecha por una compañía u organización y empaqueta el núcleo de Linux con programas y herramientas adicionales.
Por ejemplo, tenemos Debian, Red Hat y Ubuntu, probablemente las distribuciones más populares.
Pero existen muchas, muchas más. También puedes crear tu propia distribución. Pero lo más probable es que uses una popular que tenga muchos usuarios y una comunidad a su alrededor. Esto te permite hacer lo que necesitas hacer sin perder demasiado tiempo reinventando la rueda y encontrando respuestas a problemas comunes.
Algunas computadoras de escritorio y laptops vienen con Linux preinstalado. O puedes instalarlo en tu computadora con Windows o en Mac.
Pero no es necesario interrumpir tu computadora sólo para tener una idea de cómo funciona Linux.
No tengo una computadora con Linux.
Si usas una Mac, sólo necesitas saber que debajo de macOS hay un sistema operativo UNIX. Comparte muchas de las mismas ideas y software que usa un sistema GNU/Linux, porque GNU/Linux es una alternativa libre a UNIX.
Unix es un término paraguas que agrupa muchos sistemas operativos utilizados en las grandes corporaciones e instituciones, a partir de los años 70.
La terminal de macOS te da acceso a los mismos comandos exactos que describiré en el resto de este manual.
Microsoft tiene un subsistema oficial de Windows para Linux (Windows Subsystem for Linux) que puedes (¡y deberías!) instalar en Windows. Esto te dará la posibilidad de ejecutar Linux de una manera muy fácil en tu PC.
Pero la gran mayoría de las veces ejecutarás una computadora Linux en la nube a través de un VPS (Virtual Private Server, o Servidor Privado Virtual) como DigitalOcean.
¿Qué es un shell de Linux?
Un shell es un intérprete de comandos que expone una interfaz para que el usuario trabaje con el sistema operativo subyacente.
Permite ejecutar operaciones usando texto y comandos, y proporciona a los usuarios características avanzadas como la posibilidad de crear scripts.
Esto es importante: los shells te permiten realizar cosas de una manera más optimizada de lo que una GUI (Graphical User Interface o Interfaz Gráfica de Usuario) podría permitirte hacer. Las herramientas de línea de comandos pueden ofrecer muchas opciones de configuración diferentes sin ser demasiado complejas de usar.
Hay muchos tipos diferentes de shells. Este post se centra en los shells de Unix, los que se encuentran comúnmente en computadoras Linux y macOS.
Muchos tipos diferentes de shells fueron creados para estos sistemas a lo largo del tiempo, y algunos de ellos dominan el espacio: Bash, Csh, Zsh, Fish, ¡y muchos más!
Todos los shells se originan del Bourne Shell, llamado sh. "Bourne" porque su creador fue Steve Bourne.
Bash significa Bourne-again shell. sh era propietario y no de código abierto, y Bash fue creado en 1989 para crear una alternativa libre para el proyecto GNU y la Free Software Foundation. Como los proyectos tenían que pagar para usar el Bourne shell, Bash se hizo muy popular.
Si usas una Mac, intenta abrir tu terminal de Mac. Por defecto funciona con ZSH (o, pre-Catalina, Bash).
Puedes configurar tu sistema para ejecutar cualquier tipo de shell — por ejemplo, yo uso el Fish shell.
Cada shell tiene sus propias características y uso avanzado, pero todos comparten una funcionalidad común: pueden permitirte ejecutar programas, y pueden ser programadas.
En el resto de este manual veremos a detalle los comandos más comunes que usarás.
El comando man de Linux
El primer comando que presentaré te ayudará a entender todos los demás comandos.
Cada vez que no sé cómo usar un comando, escribo man <command> para obtener el manual:
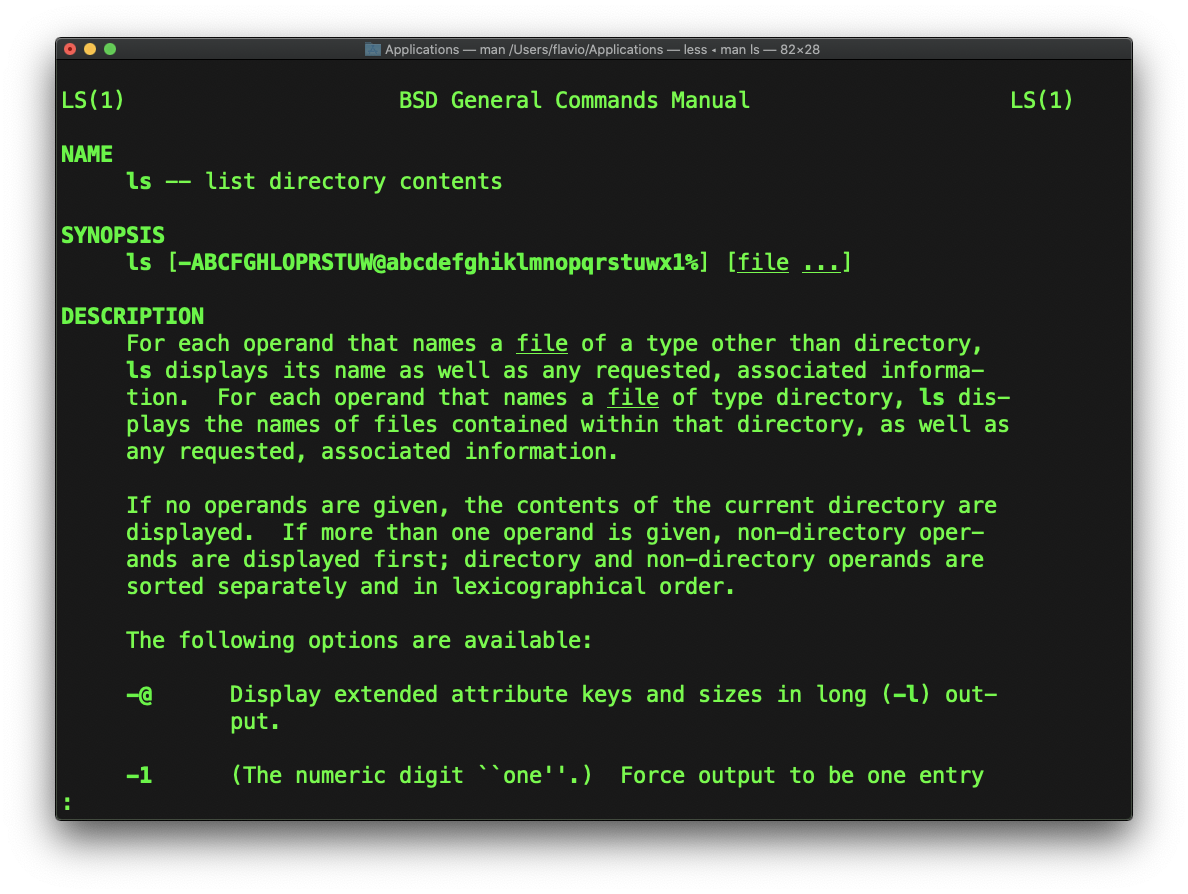
Este es un página man (del_manual_). Las páginas de man son una herramienta esencial para aprender como desarrollador. Contienen tanta información que a veces es casi demasiado.
La captura de pantalla anterior es sólo 1 de las 14 pantallas de explicación del comando ls.
La mayoría de las veces cuando necesito aprender un comando rápidamente utilizo este sitio llamado páginas tldr: https://tldr.sh. Es un comando que puedes instalar, que luego puedes ejecutar así: tldr <command>. Te da una visión general muy rápida de un comando, con algunos ejemplos prácticos de escenarios de uso común:
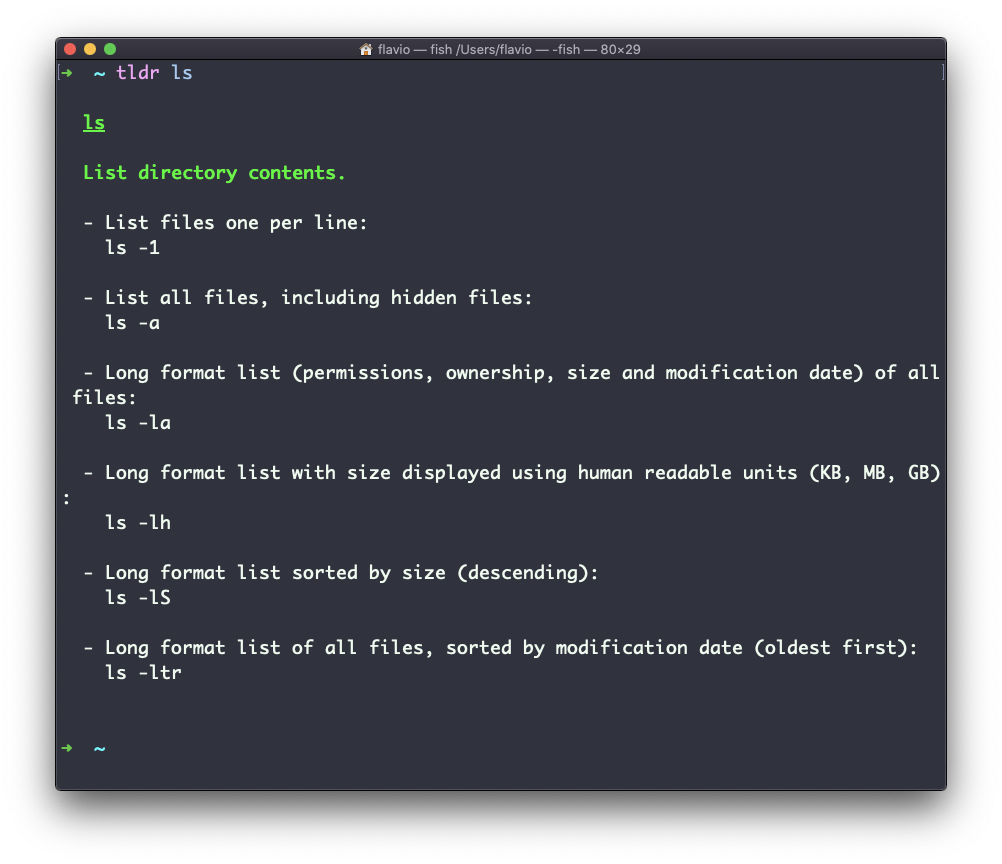
Esto no es un sustituto de man, sino una herramienta útil para evitar perderse en la enorme cantidad de información presente en una página de man. Entonces puedes usar la página de man para explorar todas las diferentes opciones y parámetros que puedes usar en un comando.
El comando ls de Linux
Dentro de una carpeta puedes enlistar todos los archivos que contiene la carpeta usando el comando ls:
lsSi agregas un nombre de una carpeta o una ruta, se imprimirá el contenido de esa carpeta:
ls /bin
ls acepta muchas opciones. Una de mis combinaciones favoritas es -al. Pruébalo:
ls -al /bin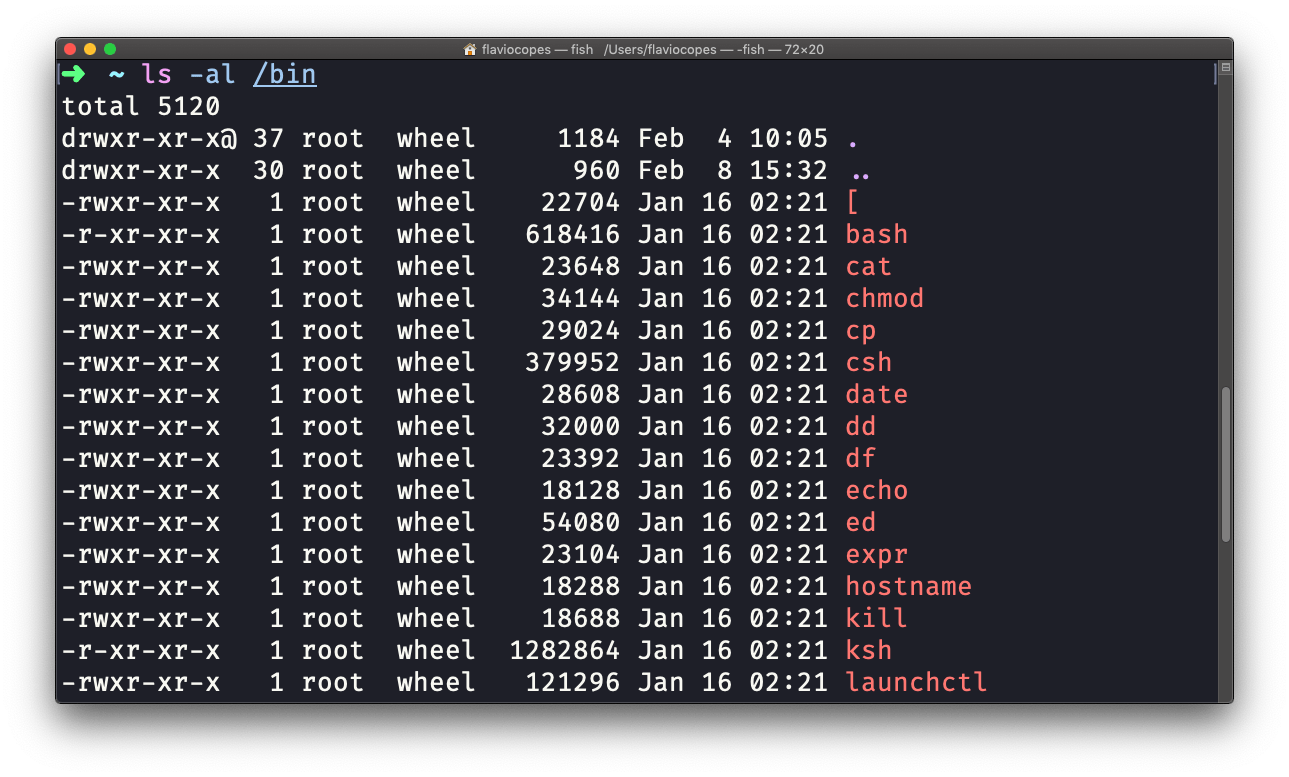
Comparado con el comando de ls puro, esto devuelve mucha más información:
Tienes, de izquierda a derecha:
- los permisos de los archivos (y si tu sistema soporta ACLs, también obtienes una bandera ACL)
- el número de enlaces a ese archivo
- el propietario del archivo
- el grupo del archivo
- el tamaño del archivo en bytes
- la fecha y hora de la última modificación del archivo
- el nombre el archivo
Este conjunto de datos es generado por la opción l. La opción a, en cambio, también muestra los archivos ocultos.
Los archivos ocultos con archivos que comienzan con un punto (.).
El comando cd de Linux
Una vez que tienes una carpeta, te puedes mover a ella usando el comando cd. cd significa change directory (o cambio de directorio). Se invoca especificando la carpeta a la que te vas a mover. Puedes especificar un nombre de carpeta o una ruta de acceso completa.
Por ejemplo:
mkdir fruits
cd fruitsAhora estás en la carpeta fruits.
Puedes usar la ruta especial .. para indicar la carpeta padre:
cd .. #devuelta a la carpeta homeEl caracter # indica el comienzo de un comentario, que dura toda la línea después de ser encontrado.
Puedes usarlo para formar una ruta:
mkdir fruits
mkdir cars
cd fruits
cd ../carsHay otro indicador de ruta espacial que es ., e indica la carpeta actual.
También puedes utilizar rutas absolutas, que empiezan en la carpeta raíz /:
cd /etcEl comando pwd de Linux
Cuando te sientas perdido en el sistema de archivos, llama al comando pwd para saber dónde estás:
pwdImprimirá la ruta de la carpeta actual.
El comando mkdir de Linux
Puedes crear carpetas usando el comando mkdir:
mkdir fruitsPuedes crear múltiples carpetas con un solo comando:
mkdir dogs carsTambién puedes crear múltiples carpetas anidadas al agregar la opción -p:
mkdir -p fruits/applesLas opciones de los comandos UNIX suelen adoptar estar forma. Las agregas justo después del nombre del comando y cambian el comportamiento del mismo. A menudo también puedes combinar varias opciones.
Puedes encontrar qué opciones soporta un comando escribiendo man <command>. Inténtalo ahora con man mkdir por ejemplo (presiona la tecla q para salir de la página de man). Las páginas de manual son la increíble ayuda incorporada para UNIX.
El comando rmdir de Linux
Así como puedes crear una carpeta usando mkdir, puedes eliminar una carpeta usando rmdir:
mkdir fruits
rmdir fruitsPuedes borrar múltiples carpetas a la vez:
mkdir fruits cars
rmdir fruits carsLa carpeta que borres debe de estar vacía.
Para borrar carpetas con archivos dentro, usaremos el comando genérico rm el cual borrar archivos y carpetas, usando la opción -rf:
rm -rf fruits carsTen cuidado, ya que este comando no pide confirmación e inmediatamente eliminará todo lo que le pidas que elimine.
No hay papelera cuando se eliminan archivos desde la línea de comandos, y recuperar archivos perdidos puede ser difícil.
El comando mv de Linux
Una vez que tienes un archivo, puedes moverlo usando el comando mv. Especificas la ruta actual del archivo, y su nueva ruta:
touch pear
mv pear new_pearEl archivo pear se ha movido a new_pear. Así es como se renombran los archivos y las carpetas.
Si el último parámetro es una carpeta, el archivo ubicado en la ruta del primer parámetro se moverá a esa carpeta. En este caso, puedes especificar una lista de archivos y todos ellos se moverán en la ruta de la carpeta identificada por el último parámetro:
touch pear
touch apple
mkdir fruits
mv pear apple fruits # pear y apple se movieron a la carpeta fruitsEl comando cp de Linux
Puedes copiar un archivo usando el comando cp:
touch apple
cp apple another_applePara copiar carpetas hay que agregar la opción -r para copiar recursivamente todo el contenido de la carpeta:
mkdir fruits
cp -r fruits carsEl comando open de Linux
El comando open te permite abrir un archivo usan esta sintaxis:
open <filename>También puedes abrir un directorio, el cual en macOS abre la aplicación Finder con el directorio actual abierto:
open <directory name>Lo uso todo el tiempo para abrir el directorio actual:
open .El símbolo especial.apunta al directorio actual, así como..apunta al directorio padre
El mismo comando puede ser usado para correr una aplicación:
open <application name>El comando touch de Linux
Puedes crear un archivo vacío usando el comando touch:
touch appleSi el archivo ya existe, es abierto en modo de escritura, y se actualiza la marca de tiempo (timestamp) del archivo.
El comando find de Linux
El comando find puede utilizarse para encontrar archivos o carpetas que coincidan con un patrón de búsqueda determinado. Busca de forma recursiva.
Aprendamos a usarla con un ejemplo.
Busca todos los archivos del árbol actual que tengan la extensión .js e imprime la ruta relativa de cada archivo que coincida:
find . -name '*.js'Es importante usar comillas alrededor de los caracteres especiales como * para evitar que el shell los interprete.
Encuentra directorios bajo el árbol actual que coincidan con el nombre "src":
find . -type d -name srcUsa -type f para buscar sólo archivos, o -type l para buscar sólo enlaces simbólicos.
-name es sensible a mayúsculas y minúsculas. Usar -iname para realizar una búsqueda insensible a mayúsculas y minúsculas.
Puedes buscar en múltiples árboles raíz:
find folder1 folder2 -name filename.txtEncuentra directorio bajo el árbol actual que coincida con el nombre "node_modules" o "public":
find . -type d -name node_modules -or -name publicTambién puedes excluir la ruta usando -not -path:
find . -type d -name '*.md' -not -path 'node_modules/*'Puedes buscar archivos con más de 100 caracteres (bytes) en ellos:
find . -type f -size +100cBuscar archivos mayores a 100kB pero menores a 1MB:
find . -type f -size +100k -size -1MBuscar archivos editados no hace más de 3 días:
find . -type f -mtime +3Buscar archivos editados en las últimas 24 horas:
find . -type f -mtime -1Puedes borrar todos los archivos que coinciden con una búsqueda al agregar la opción -delete. Esto borra todos los archivos editados en las últimas 24 horas:
find . -type f -mtime -1 -deletePuede ejecutar un comando en cada resultado de la búsqueda. En este ejemplo ejecutamos cat para imprimir el contenido del archivo:
find . -type f -exec cat {} \;Fíjate en la terminación \;. {} se llena con el nombre del archivo en el momento de la ejecución.
El comando ln de Linux
El comando ln es parte de los comandos del sistema de archivos de Linux.
Se usa para crear enlaces. ¿Qué es un enlace? Es como un puntero a otro archivo, o un archivo que apunta a otro archivo. Puede que estés familiarizado con los atajos de Windows. Son similares.
Tenemos dos tipos de enlaces: hard links y soft links.
Hard links
Los hard links se usan raramente. Tienen algunas limitaciones: no se pueden enlazar a directorios, y no se pueden enlazar a sistemas de archivos externos (discos).
Un hard link se crea usando la siguiente sintaxis:
ln <original> <link>Por ejemplo, digamos que tienes un archivo llamado recipes.txt. Puedes crear un hard link hacia él usando:
ln recipes.txt newrecipes.txtEl nuevo hard link que creaste es indistinguible de un archivo regular:
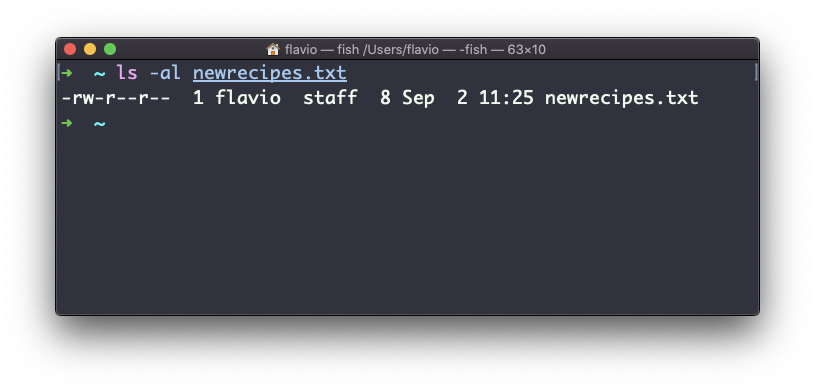
Ahora cada vez que edites cualquiera de esos archivos, el contenido se actualizará para ambos.
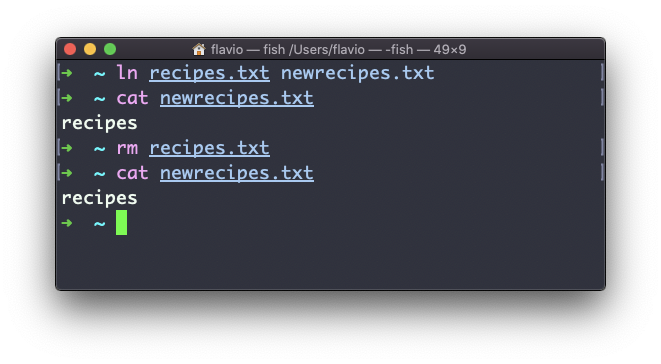
Si eliminas el archivo original, el enlace seguirá almacenando el contenido del archivo original, ya que no se eliminará hasta que haya un enlace duro que apunte a él.
Soft links
Los soft links son diferentes. Son más poderosos ya que pueden enlazar a otros sistemas de archivos y a directorios. Pero ten en cuenta que cuando se elimina el original, el enlace se rompe.
Puedes crear soft links usando la opción -s de ln:
ln -s <original> <link>Por ejemplo, digamos que tienes un archivo llamado recipes.txt. Puedes crear un soft link hacia él usando:
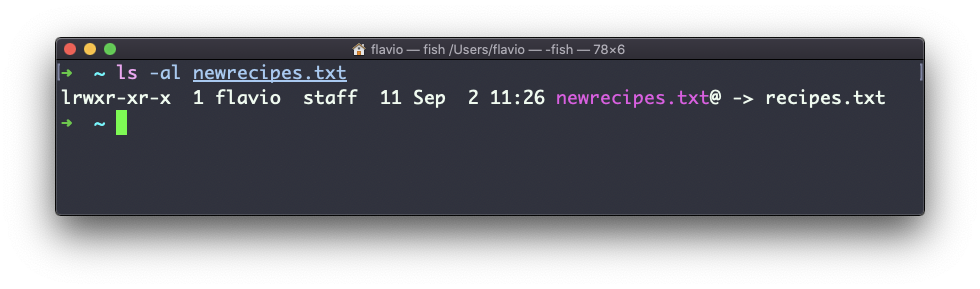
ln -s recipes.txt newrecipes.txtEn este caso, puedes ver que hay una bandera especial l cuando enumeras el archivo usando ls -al. El nombre del archivo tiene un @ al final, y también tiene un color diferente si tienes los colores activados:
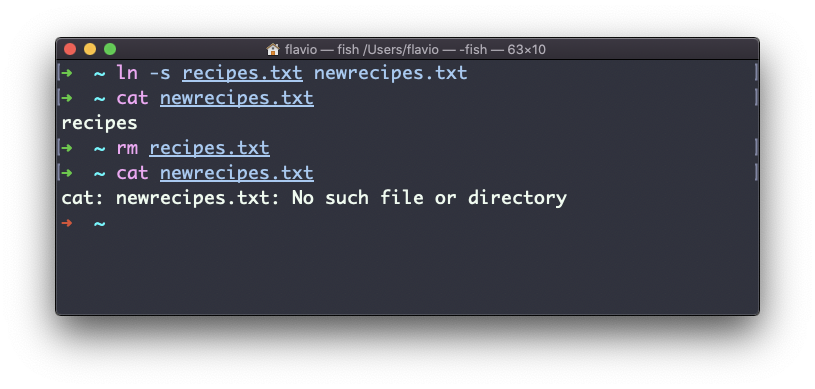
Ahora bien, si borrar el archivo original, los enlaces se romperán, y el shell te dirá "No existe tal archivo o directorio" si intentas acceder a él:
El comando gzip de Linux
Puedes comprimir un archivo usando el protocolo de compresión llamado LZ77 usando el comando gzip.
Este es el uso más simple:
gzip filenameEsto comprimirá el archivo, y le añadirá una extensión .gz. El archivo original es eliminado.
Para evitar esto último, puedes utilizar la opción -c y usar la redirección de salida para escribir el archivo filename.gz:
gzip -c filename > filename.gzLa opción -c especifica que la salida irá al flujo de salida estándar, dejando el archivo original intacto.O puedes usar la opción -k:
gzip -k filenameHay varios niveles de compresión. Cuanto mayor sea la compresión, más tiempo llevará comprimir (y descomprimir). Los niveles van de 1 (la compresión más rápida y peor) a 9 (la compresión más lenta y mejor), el valor predeterminado es 6.
Puedes elegir un nivel específico con la opción -<NUMBER>:
gzip -1 filenamePuedes comprimir múltiples archivos al enlistarlos:
gzip filename1 filename2Puedes comprimir todos los archivos en un directorio, recursivamente, usando la opción -r:
gzip -r a_folderLa opción -v imprime la información del porcentaje de compresión. Aquí está un ejemplo siendo usado con la opción -k (keep o mantener):
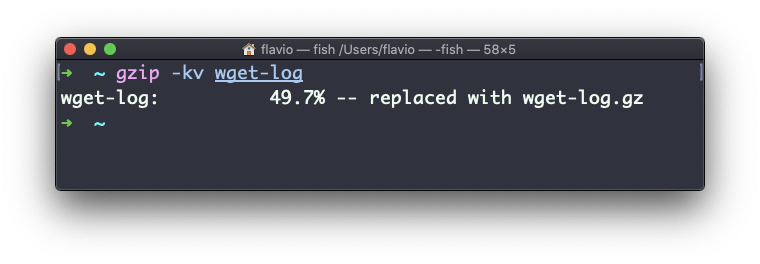
gzip también puede ser usado para descomprimir un archivo, usando la opción -d:
gzip -d filename.gzEl comando gunzip de Linux
El comando gunzip es básicamente equivalente al comando gzip, excepto que la opción -d siempre está activado por defecto.
El comando puede ser invocado de la siguiente manera:
gunzip filename.gzEsto hará que se ejecute gunzip y eliminará la extensión .gz, poniendo el resultado en el archivo "filename". Si ese archivo existe, lo sobreescribirá.
Puedes extraer a un archivo diferente usando la redirección de salida utilizando la opción -c:
gunzip -c filename.gz > anotherfilenameEl comando tar de Linux
El comando tar es usado para crear un archivo, agrupando múltiples archivos en uno solo.
Su nombre viene del pasado y significa archivo de cintas (o tape archive en inglés, cuando los archivos se almacenaban en cintas).
Este comando crea un archivo llamado archive.tar con el contenido del file1 y file2:
tar -cf archive.tar file1 file2La opcióncsignifica crear. La opciónfes usada para escribir el archivo y archivar al mismo.
Para extraer archivos de otro de la carpeta actual, usa:
tar -xf archive.tarla opción x representa extracciónY para extraerlos a un directorio en específico, usa:
tar -xf archive.tar -C directoryTambién puedes solo enlistar los archivos que se contienen en un archivo tar:
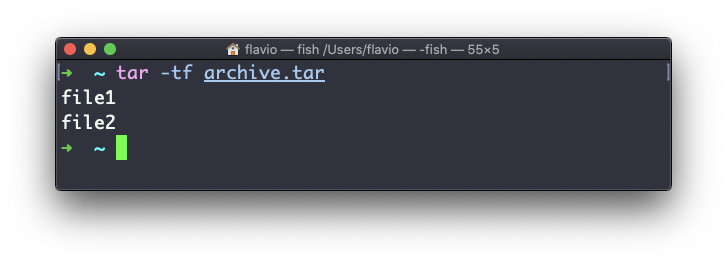
tar se usa a menudo para crear un archivo comprimido.
Esto se hace usando la opción z:
tar -czf archive.tar.gz file1 file2Esto es como crear un archivo tar, y después aplicar gzip en el mismo.
Para desarchivar un archivo comprimido, puedes usar gunzip, o gzip -d, y después desarchivarlo. Pero tar -xf lo reconocerá como un archivo comprimido y lo hará por ti.
tar -xf archive.tar.gzEl comando alias de Linux
Es común que siempre se ejecute un programa con un conjunto de opciones que te gusta usar.
Por ejemplo, toma el comando ls. Por defecto, imprime muy poca información:
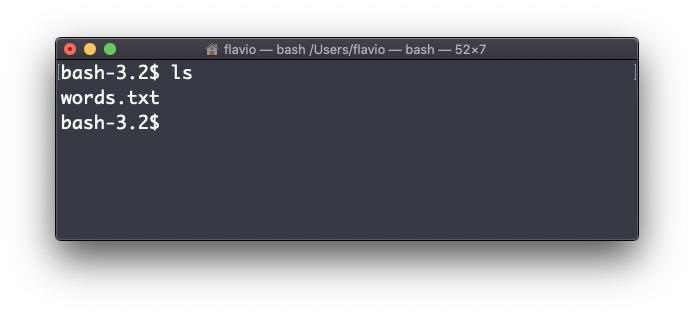
Pero si usas las opción -al imprimirá algo más útil, incluyendo la fecha de modificación del archivo, el tamaño, el propietario y los permisos. También enlistará los archivos ocultos (archivos que empiezan con un .):
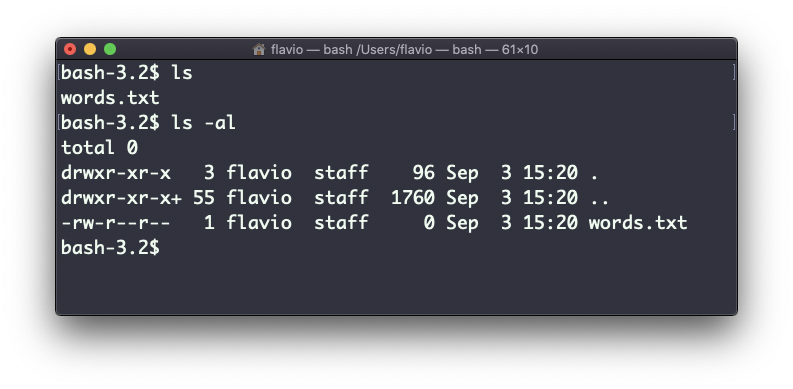
Puedes crear un nuevo comando, por ejemplo, me gusta llamarlo ll, que es un alias de ls -al.
Lo haces así:
alias ll='ls -al'Una vez que lo hagas, puedes llamar a ll como si fuer un comando regular de UNIX:
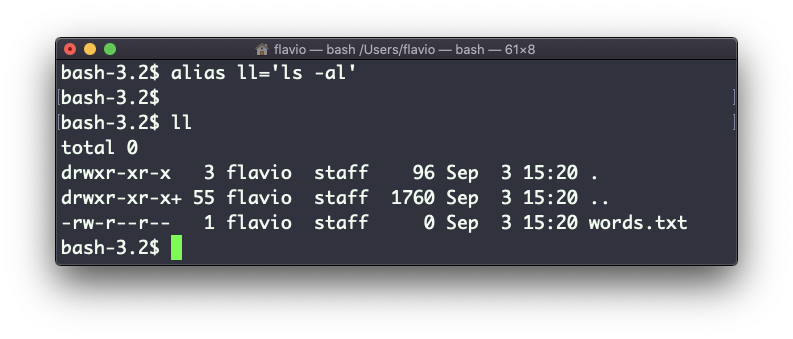
Ahora llamando alias sin ninguna opción enlistará los aliases definidos:
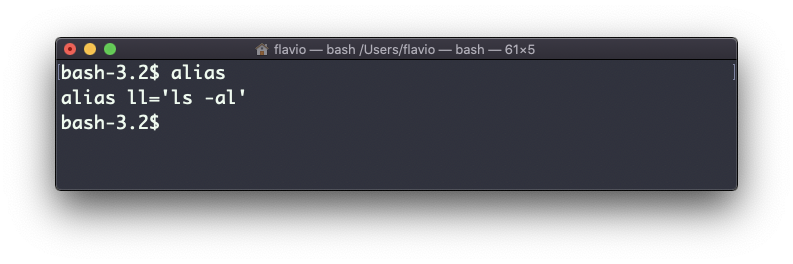
El alias funcionará hasta que se cierre la sesión de la terminal.
Para hacerlo permanente,. necesitas agregarlo a la configuración del shell. Esto podría ser ~/.bashrc o ~/.profile o ~/.bash_profile si usas un shell Bash, dependiendo del caso de uso.
Ten cuidado con las comillas si tienes variables en el comando: si usas comillas dobles, la variable se resuelve en el momento de definición. Si usas comillas simples, se resuelve en el momento de la invocación. Esas 2 son diferentes:
alias lsthis="ls $PWD"
alias lscurrent='ls $PWD'$PWD se refiere a la carpeta actual en la que se encuentra el shell. Si ahora navegas a una nueva carpeta, lscurrent enlista los archivos en la nueva carpeta, mientras que lsthis todavía enlista los archivos en la carpeta donde estaba cuando definió el alias.
El comando cat de Linux
Similar a tail en algunos aspectos, tenemos cat. Excepto que cat también puedes agregar contenido a un archivo, y esto lo hacer súper poderoso.
En su uso más simple, cat imprime el contenido de un archivo a la salida estándar:
cat filePuedes imprimir el contenido de múltiples archivos:
cat file1 file2y usando el operador de redirección de salida > puedes concatenar el contenido de múltiples archivo a un nuevo archivo:
cat file1 file2 > file3Usando >> puedes anexar el contenido de múltiples archivo en un nuevo archivo, creándolo si este no existiera:
cat file1 file2 >> file3Cuando miras archivos con código fuente, es útil poder ver el número de líneas. Puedes hacer que cat los imprima usando la opción -n:
cat -n file1Sólo puedes agregar un número a las líneas no vacías usando -b, o también puedes eliminar todas la múltiples líneas vacías usando -s.
cat se usa a menudo en combinación con el operador pipe | para alimentar el contenido de un archivo como entrada de otro comando: cat file1 | otro comando.
El comando less de Linux
El comando less es uno que uso mucho. Te muestra el contenido almacenado dentro de un archivo, en una agradable e interactiva interfaz de usuario.
Uso: less <filename>
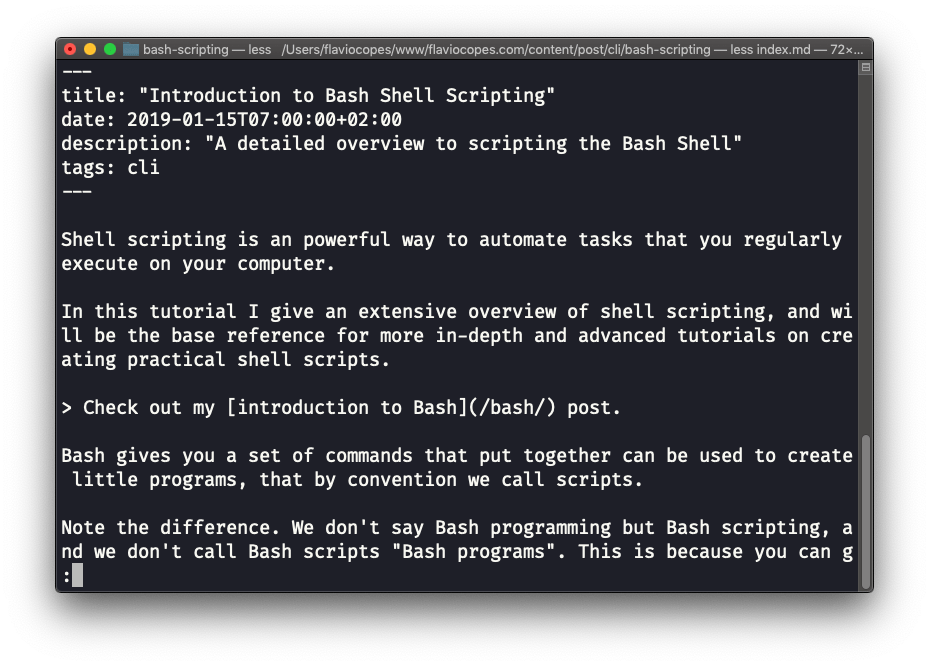
Una vez que estás dentro de una sesión less, puedes salir presionando q.
Puedes navegar el contenido del archivo usando las teclas de arriba u abajo, o usando la barra espaciadora y b para navegar página por página. También puedes saltar al final de un archivo presionando G y saltar devuelta al inicio presionando g.
Puedes buscar contenido dentro del archivo presionando / y escribiendo la palabra a buscar. Esto busca hacia delante. Puedes buscar hacia atrás usando el signo ? y escribiendo una palabra.
Este comando sólo visualiza el contenido de un archivo. Puedes abrir directamente un editor de texto presionando v. Esto usará el editor del sistema, que en la mayoría de casos es vim.
Presionando la tecla F entramos a modo de seguimiento, o modo de observación (follow mode, o watch mode en inglés, respectivamente). Cuando el archivo es cambiado por alguien más, como desde otro programa, puedes ver los cambios en vivo.
Esto no pasa por defecto, y sólo ves la versión del archivo en el momento de abrirlo. Necesitar presionar ctrl-C pata salir de este modo. En este caso el comportamiento es similar a ejecutar el comando tail -f <filename>.
Puedes abrir múltiples archivos y navegar a través de ellos usando :n (para ir al siguiente archivo) y :p (para ir al anterior).
El comando tail de Linux
El mejor caso de uso de tail en mi opinión es cuando se llama con la opción -f. Abre el archivo al final, y observa los cambios de archivo.
Cada vez que hay un nuevo contenido en el archivo, se imprime en la ventana. Esto es genial para ver los archivos de registro, por ejemplo:
tail -f /var/log/system.logPara salir, presiona ctrl-C.
Puedes imprimir las últimas 10 líneas de un archivo:
tail -n 10 <filename>Puedes imprimir todo el contenido del archivo a partir de una línea específica usando + antes del número de línea:
tail -n +10 <filename>tail puede hacer mucho más y como siempre mi consejo es revisar man tail.
El comando wc de Linux
El comando wc nos brinda información útil sobre un archivo o entrada que se recibe via "pipes".
echo test >> test.txt
wc text.txt
1 1 5 test.txtEjemplo usando pipes, contamos la salida de la corrida del comando ls -al:
ls -al | wc
6 47 284La primera columna regresa el número de líneas. La segunda es el número de palabras. La tercera es el número de bytes.
Podemos decirle que sólo cuente las líneas:
wc -l test.txto sólo las palabras:
wc -w test.txto sólo los bytes:
wc -c test.txtLos bytes en los juegos de caracteres (charsets) ASCII equivalen a caracteres. Pero con los charsets que no son ASCII, el numero de caracteres pueden diferir porque algunos caracteres pueden tomar múltiples bytes (por ejemplo, esto sucede en Unicode).
En este caso la bandera -m te ayudará a obtener el valor correcto:
wc -m test.txtEl comando grep de Linux
El comando grep es una herramienta muy útil. Cuando lo domines, te ayudará enormemente en tu trabajo diario como programador.
Si te lo preguntas, grep significa impresión de expresión regular global (global regular expression print en inglés).
Puedes usar grep para buscar en archivos, o combinarlo con pipes para filtrar la salida de otro comando.
Por ejemplo, así es como podemos encontrar las ocurrencias de la línea document.getElementById en el archivo index.md:
grep document.getElementById index.md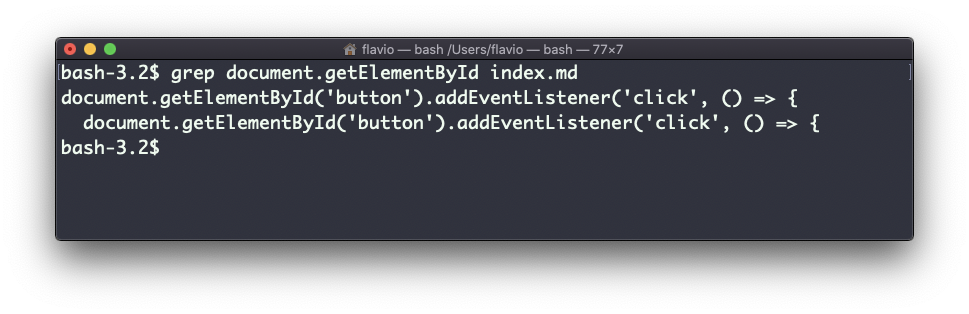
Usando la opción -n mostrará el número de líneas:
grep -n document.getElementById index.md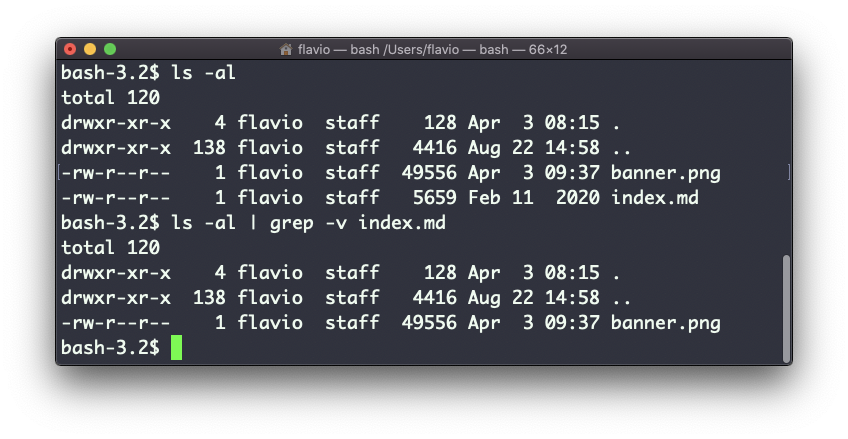
Una cosa muy útil es decirle a grep que imprima 2 líneas antes y 2 líneas después de la línea emparejada para darle más contexto. Eso se hace usando la opción -C, que acepta un número de líneas:
grep -nC 2 document.getElementById index.md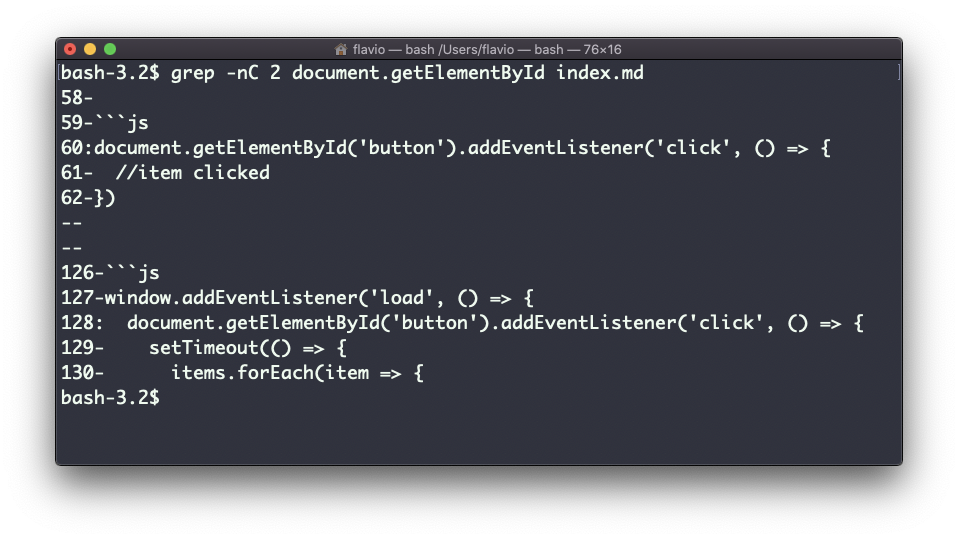
La búsqueda es sensible a mayúsculas y minúsculas por defecto. Usa la bandera -i para hacerla insensible.
Como ya se ha mencionado, puedes usar grep para filtrar la salida de otro comando. Podemos replicar la misma funcionalidad de arriba usando:
less index.md | grep -n document.getElementById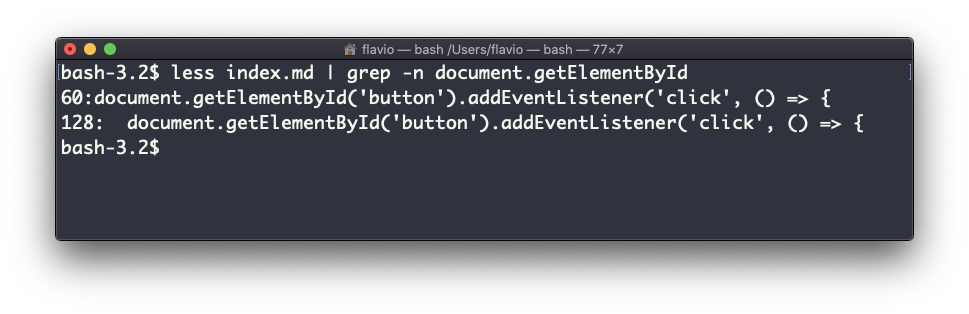
La cadena de búsqueda puede ser una expresión regular, y esto hace que grep sea muy poderoso.
Otra cosa que puede ser muy útil es invertir el resultado, excluyendo las líneas que coinciden con una cadena particular, usando la opción -v:
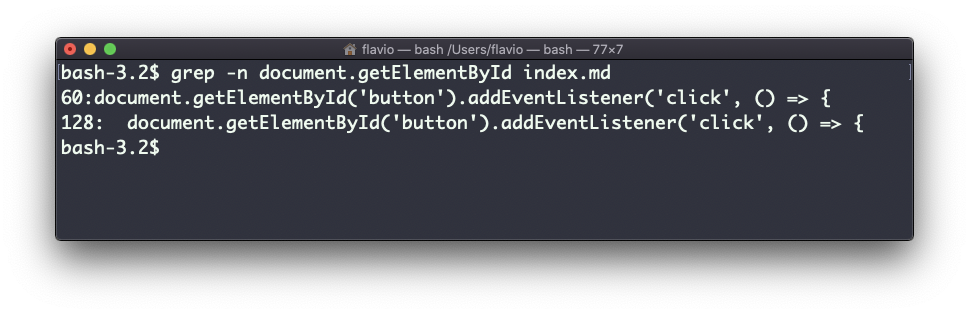
El comando sort de Linux
Supongamos que tienes un archivo de text que contiene nombres de perros:
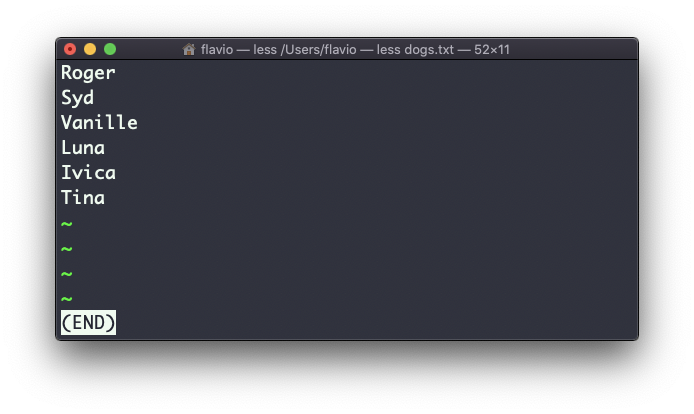
Esta lista está desordenada.
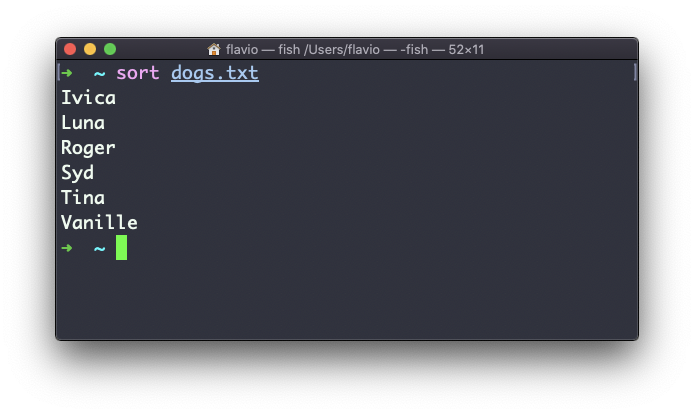
El comando sort ayudar a ordenarlos por nombre:
Puedes usar la opción -r para invertir el orden:
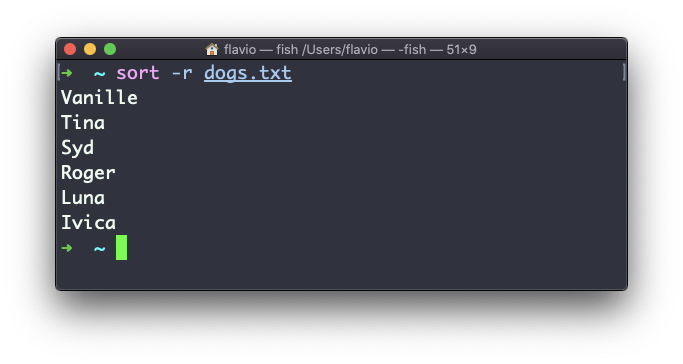
El ordenamiento por defecto es sensible a mayúsculas y minúsculas, y alfabético. Usa la opción --ignore-case para ordenar ignorando la sensibilidad a mayúsculas y minúsculas, y la opción -n para ordenarlas de manera numérica.
Si el archivo contiene líneas duplicadas:
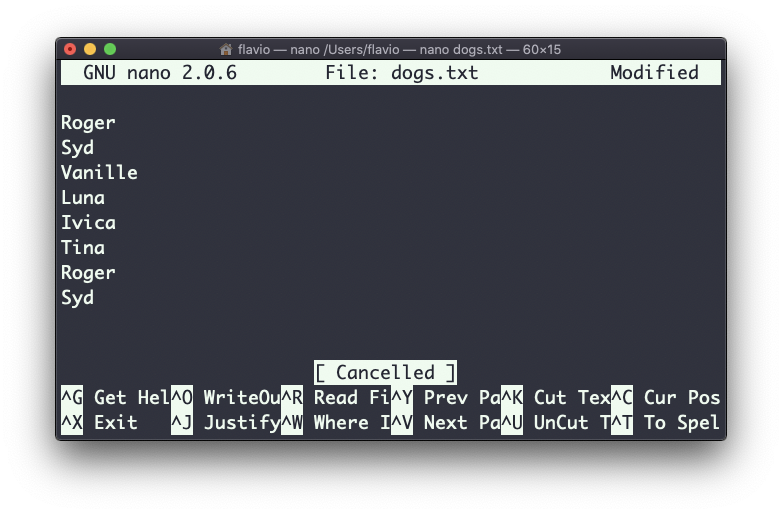
Puedes usar la opción -u para eliminarlos:
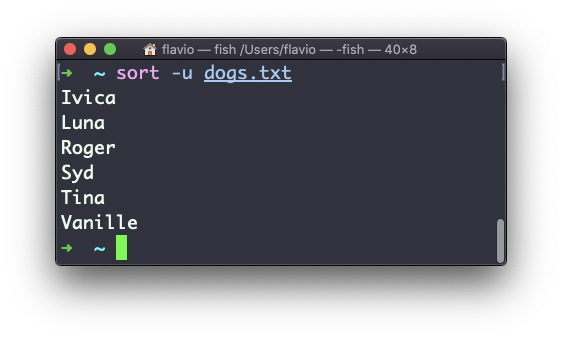
sort no sólo funciona en los archivos, como muchos comandos de UNIX — sino que también funciona con pipes. Así que puedes usarlo en la salida de otro comando. Por ejemplo, puedes ordenar los archivos devueltos por ls con:
ls | sortsort es muy poderoso y tiene muchas opciones, los cuáles puedes explorar al llamar man sort.
El comando uniq de Linux
uniq es un comando que te ayuda a ordenar las líneas de texto.
Puedes obtener esas líneas de un archivo, o usando pipes de la salida de otro comando:
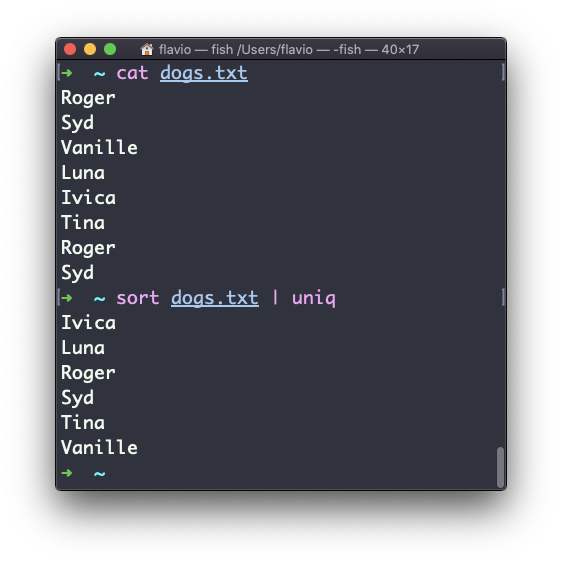
uniq dogs.txt
ls | uniqDebes considerar esta clave: uniq sólo detectará las líneas duplicadas adyacentes.
Esto implica que lo más probable es que lo utilices junto con sort:
sort dogs.txt | uniqEl comando sort tiene su propia manera de remover duplicar con la opción -u (unique). Pero uniq tiene más poder.
Por defecto remueve líneas duplicadas:
Puedes decirle que sólo muestre líneas duplicadas, por ejemplo, con la opción -d:
sort dogs.txt | uniq -d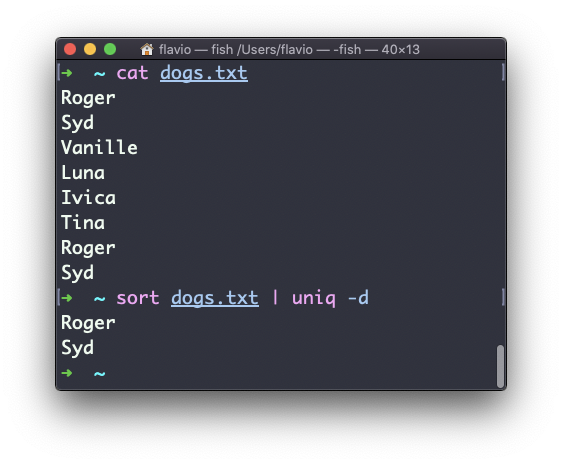
Puedes usar la opción -u para sólo mostrar líneas no duplicadas:
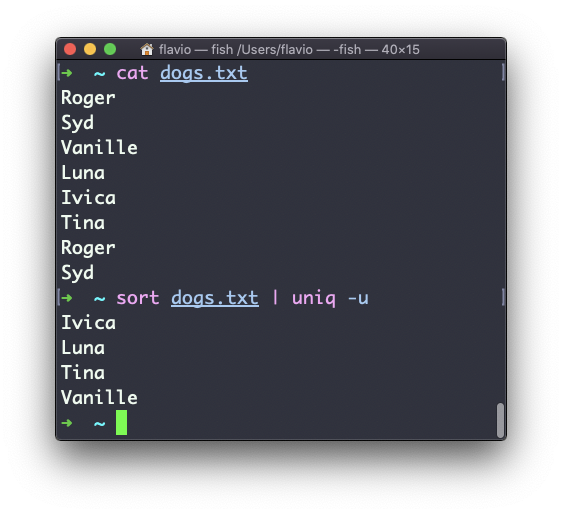
Puedes contar las ocurrencias de cada línea con la opción -c:
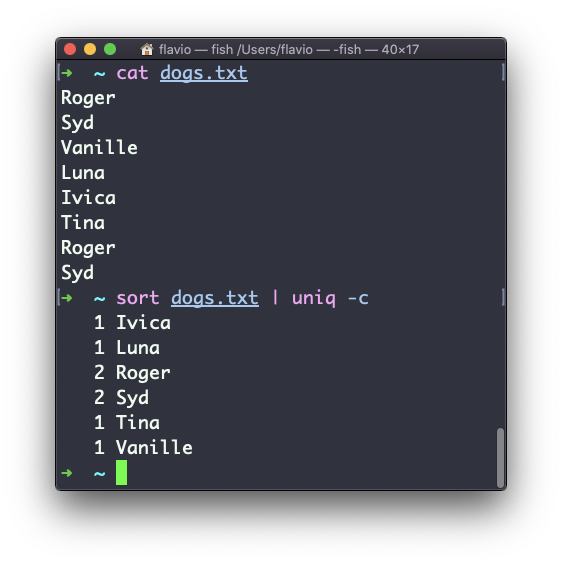
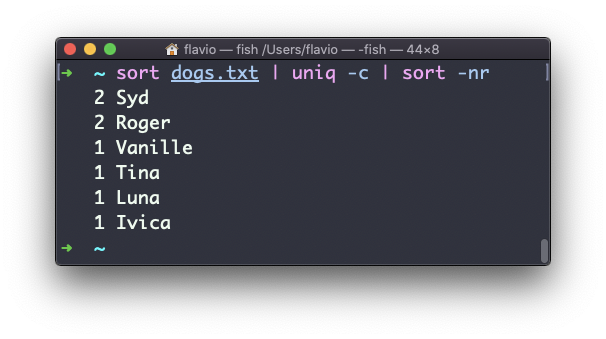
Puedes usar la combinación especial:
sort dogs.txt | uniq -c | sort -nrpara luego ordenar esas líneas por su mayor frecuencia:
El comando diff de Linux
diff es un comando útil. Supongamos que tienes 2 archivos, que contienen casi la misma información, pero que no puedes encontrar la diferencia entre ellos.
diff procesará los archivo y te dirá la diferencia.
Supongamos que tienes 2 archivos: dogs.txt y moredogs.txt. La diferencia es que moredogs.txt contiene un nombre de perro más:
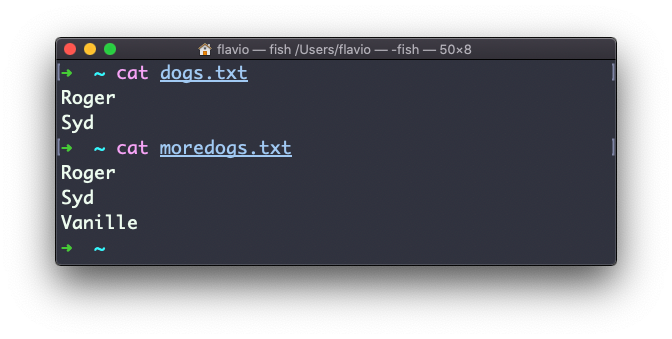
diff dogs.txt moredogs.txt te dirá que el segundo archivo tiene una línea más, línea 3 con la línea Vanille:
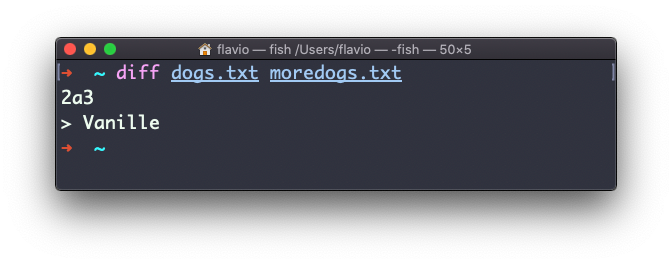
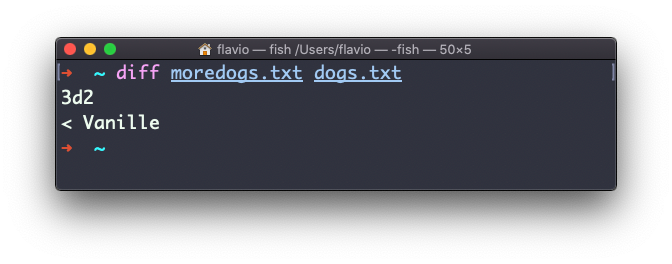
Si inviertes el orden de los archivos, te dirá que el segundo archivo le falta la línea 3, cuyo contenido es Vanille:
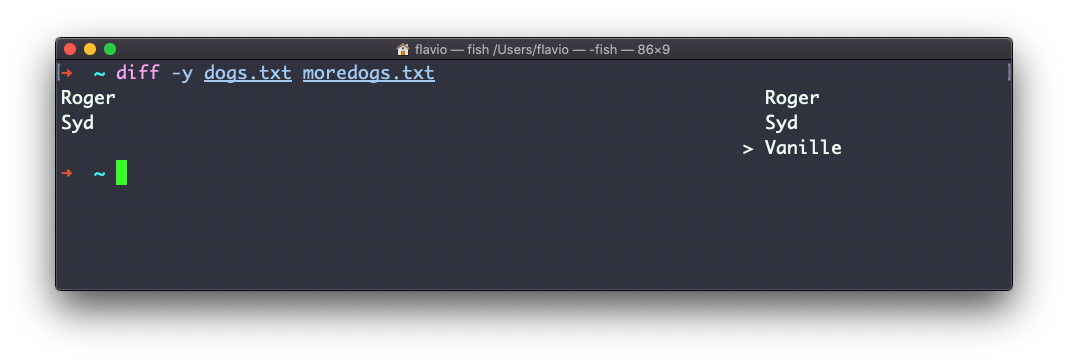
Usa la opción -y que comparará los 2 archivos línea por línea:
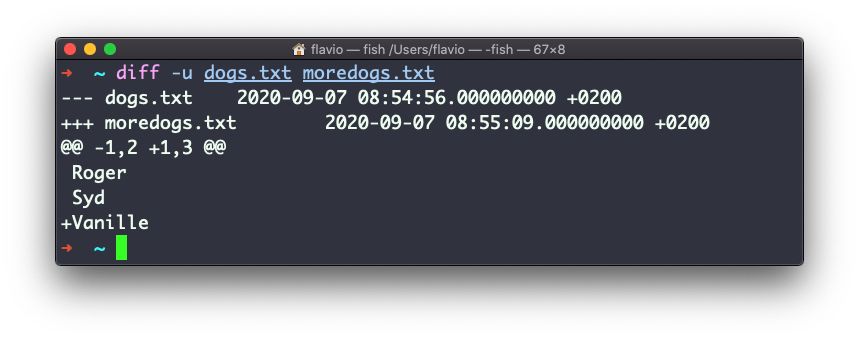
La opción -u, sin embargo, te resultará familiar, porque es la misma que utiliza el sistema de control de versiones de Git para mostrar las diferencias entre versiones:
Comparar directorios funciona de la misma manera. Debes usar la opción -r para comparar de forma recursiva (yendo a subdirectorios):
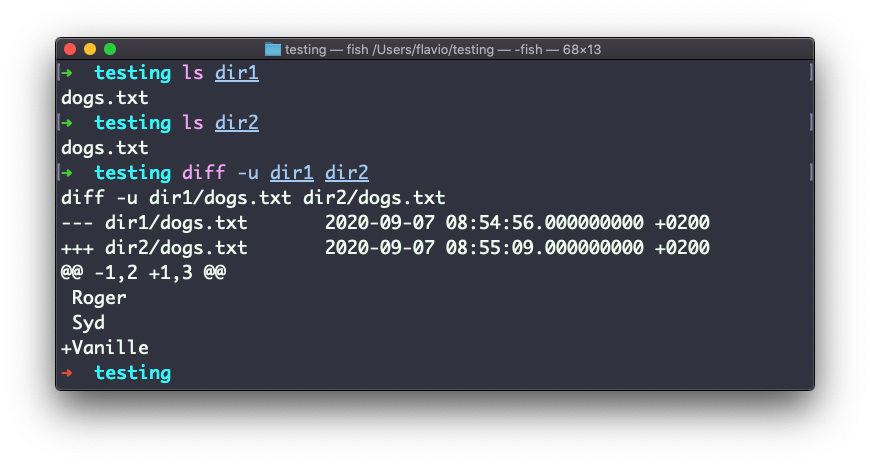
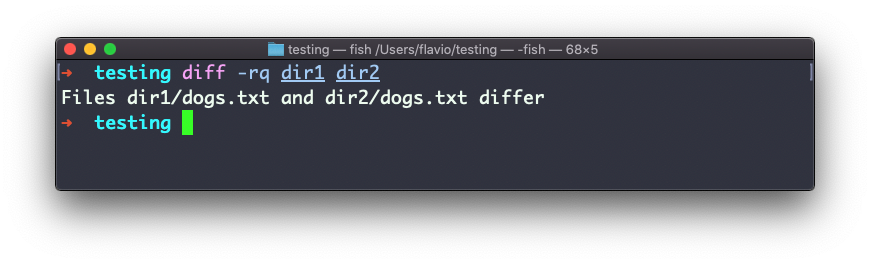
En caso de que estés interesado en saber qué archivos difieren, más que el contenido, utiliza las opciones r y q:
Hay muchas más opciones que puedes explorar en la página de manual al correr man diff:
El comando echo de Linux
El comando echo hace un simple trabajo: imprime en la salida el argumento que se le ha pasado.
Este ejemplo:
echo "hello"imprimirá hello en la terminal.
Podemos anexar la salida a un archivo:
echo "hello" >> output.txtPodemos interpolar variable de ambiente:
echo "The path variable is $PATH"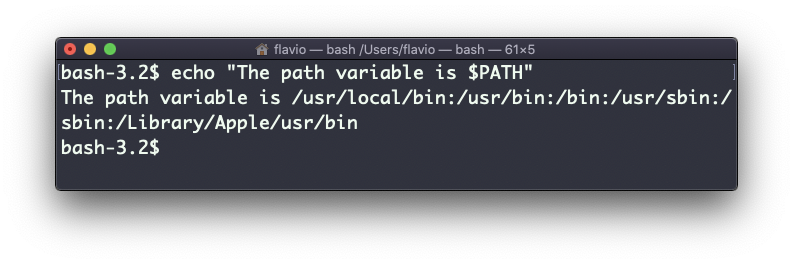
Tenga cuidado con los caracteres especiales que deben ser escapados con una barra invertida \. $ por ejemplo:
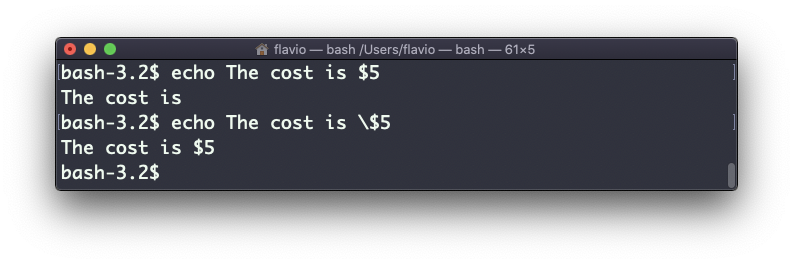
Esto es solo el comienzo. Podemos hacer buenas cosas cuando se trata de interactuar con las características del shell.
Podemos realizar echo a los archivos en la carpeta actual:
echo *Podemos realizar echo a los archivos en la carpeta actual que inician con la letra o:
echo o*Cualquier comando Bash (o de cualquier shell que estés usando) y característica pueden ser usados aquí.
Puedes imprimir la ruta de la carpeta home:
echo ~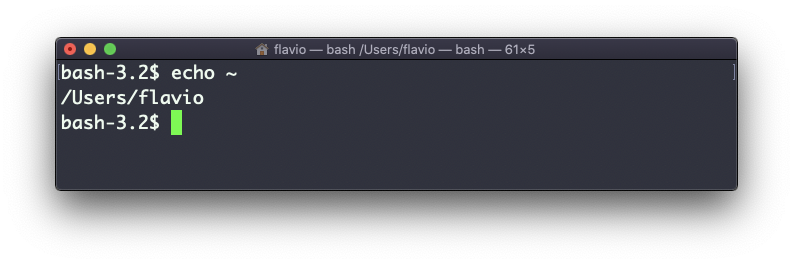
También puedes ejecutar comandos, e imprimir el resultado como salida estándar (o a un archivo, como veas):
echo $(ls -al)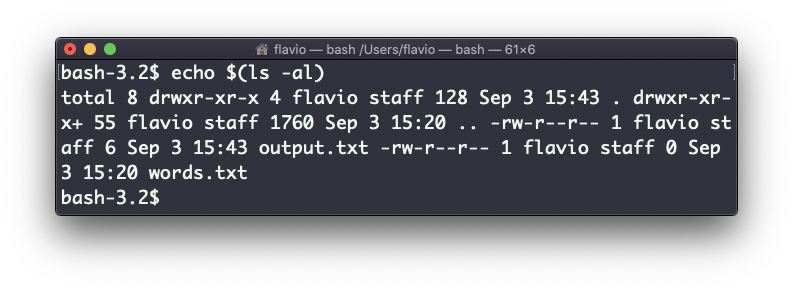
Ten en cuenta que los espacios en blanco no se conservan por defecto. Necesitas envolver el comando entre comillas para hacerlo:
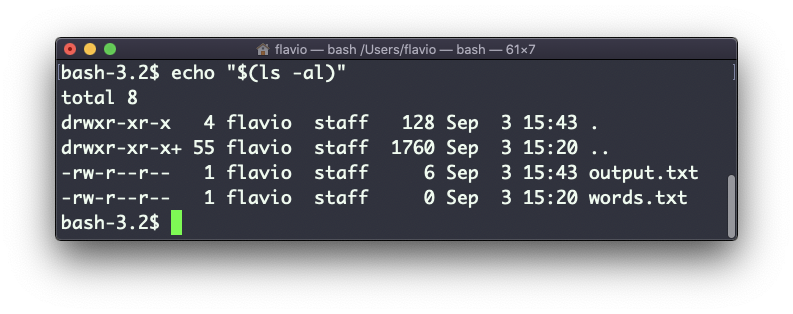
Puedes generar una lista de cadenas, por ejemplo rangos:
echo {1..5}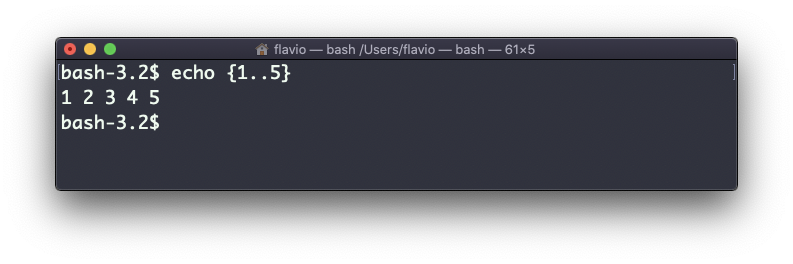
El comando chown de Linux
Cada archivo/directorio en un sistema operativo como Linux o macOS (y cada sistema UNIX en general) tiene un propietario.
El propietario de un archivo puede hacer todo con él. Puede decidir el destino de ese archivo.
El propietario (y el usuario root) puede cambiar el propietario a otro usuario, también, usando el comando chown:
chown <owner> <file>Así:
chown flavio test.txtPor ejemplo, si tienes un archivo que es propiedad de root, no puedes escribir en él como otro usuario:
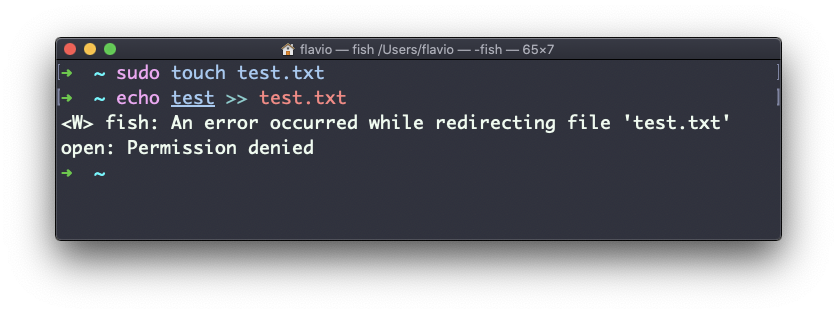
Puedes usar chown para transferirte la propiedad:
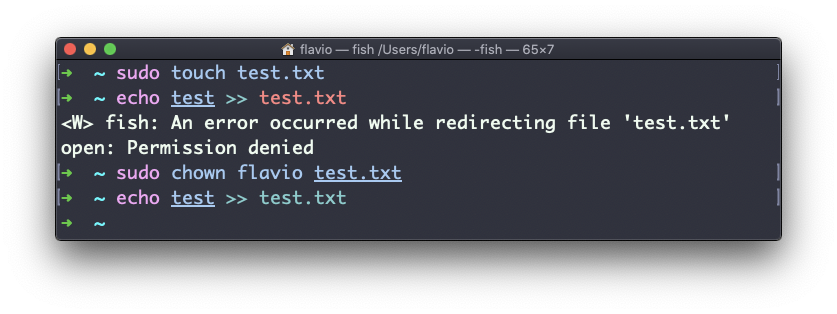
Es bastante común la necesidad de cambiar la propiedad de un directorio, y recursivamente todos los archivos dentro, además de todos los subdirectorios y los archivos contenidos en ellos también.
Puedes hacer esto usando la bandera -R:
chown -R <owner> <file>Los archivos/directorios no sólo tienen un propietario, también tienen un grupo. A través de este comando puedes cambiar eso simultáneamente mientras cambias el propietario:
chown <owner>:<group> <file>Por ejemplo:
chown flavio:users test.txtTambién puedes cambiar el grupo de un archivo usando el comando chgrp:
chgrp <group> <filename>El comando chmod de Linux
Cada archivo en los sistemas operativos Linux / macOS ( y en los sistemas UNIX en general) tiene 3 permisos: leer, escribir y ejecutar.
Ve a una carpeta, y corre el comando ls -al:
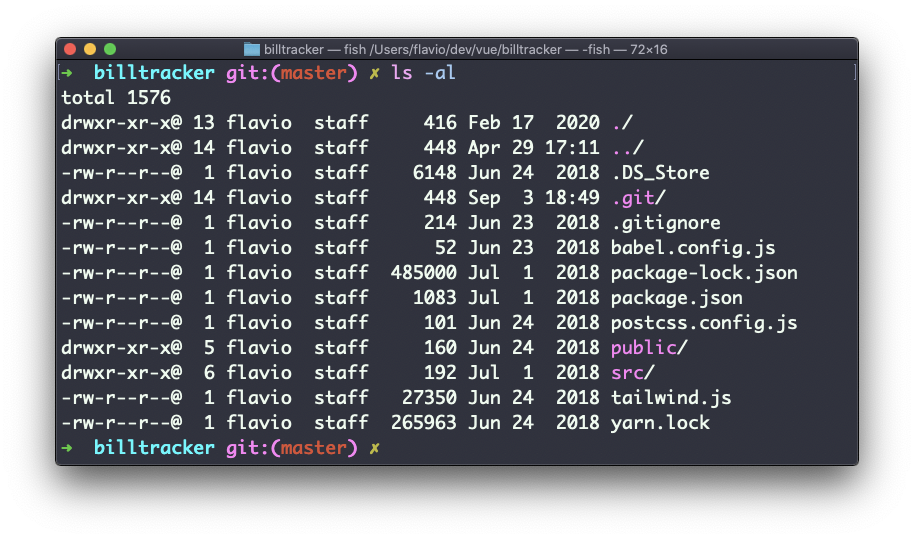
Las extrañas cadenas que ves en cada línea del archivo, como drwxr-xr-x, definen los permisos del archivo o carpeta.
Vamos a diseccionarlo.
La primera letra indica el tipo de archivo:
-significa que es un archivo normaldsignifica que es un directoriolsignifica que es un enlace
Luego tienes 3 conjuntos de valores:
- El primer conjunto representa los permisos del propietario del archivo
- El segundo conjunto representa los permisos de los miembros del grupo al que el archivo está asociado
- El tercer conjunto representa los permisos de todos los demás
Esos conjuntos se componen de 3 valores. rwx significa que una persona específica tiene acceso de lectura, escritura y ejecución. Todo lo que se elimina se intercambia con un -, que permite formar varias combinaciones de valores y permisos relativos: rw-, r--, r-x, y así sucesivamente.
Puedes cambiar los permisos dados a un archivo usando el comando chmod.
chmod puede ser usado de dos maneras. La primera es usando argumento simbólicos, la segunda es usando argumentos numéricos. Empecemos con los símbolos primero, lo cual es más intuitivo.
Escribes chmod seguido de un espacio y una letra:
asignifica todosusignificar usuariogsignifica grupoosignifica otros
Luego escribes + o - para agregar permiso, o para eliminarlo. Después ingresass uno o más símbolos de permiso (r, w, x).
Todo seguido por el nombre del archivo o la carpeta.
Aquí hay algunos ejemplos:
chmod a+r filename # todos pueden leerlo
chmod a+rw filename # todos puende leerlo y escribirlo
chmod o-rwx filename # otros (no el propietario, no en el mismo grupo del archivo) no pueden leer, escribir o ejecutar el archivoPuedes aplicar los mismos permisos a múltiples personas al agregar múltiples letras antes de +/-:
chmod og-r filename # otros y el grupo no pueden leer el archivoEn caso de que estés editando una carpeta, puedes aplicar los permisos a cada archivo dentro de esa carpeta usando la bandera -r (recursiva).
Los argumentos numéricos son más rápidos, pero cuesta recordarlos cuando no los usas día a día. Usas un dígito que representa los permisos de la persona. Este valor numérico puede ser un máximo de 7, y se calcula de esta manera:
1si tiene permiso de ejecución2si tiene permiso de escritura4si tiene permiso de lectura
Esto nos da 4 combinaciones:
0no tiene permisos1puede ejecutar2puede leer3puede escribir, ejecutar4puede leer5puede leer, ejecutar6puede leer, escribir7puede leer, escribir y ejecutar
Los usamos en pares de 3, para establecer los permisos de los 3 grupos en conjunto:
chmod 777 filename
chmod 755 filename
chmod 644 filenameEl comando umask de Linux
Cuando creas un archivo, no tienes que decidir los permisos por adelantado. Los permisos tienen valores por defecto.
Esos valores por defecto pueden ser controlados y modificados usando el comando umask.
Escribir umask sin argumentos te mostrará el umask actual, en este caso 0022:
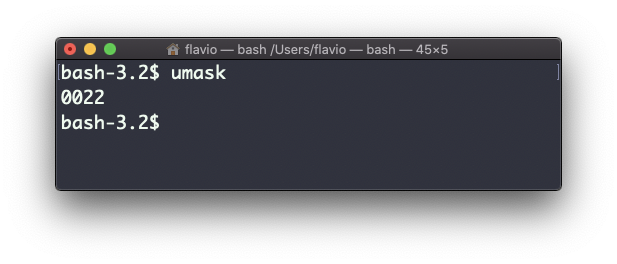
¿Qué significa 0222? Es un valor octal que representa los permisos.
Otro valor común es 0002.
Usa umask -S para ver una notación legible por los humanos:
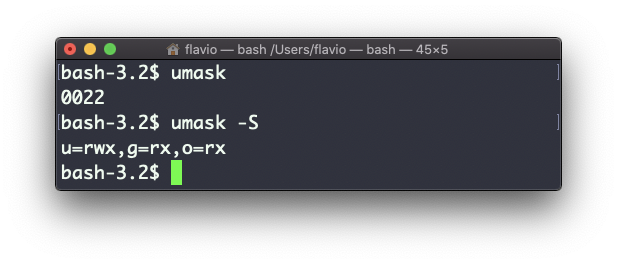
En este caso, el usuario (u), propietario del archivo, tiene permisos de lectura, escritura y ejecución en los archivos.
Otros usuarios pertenecientes al mismo grupo (g) tienen permiso de lectura y ejecución, al igual que todos los demás usuarios (o).
En la notación numérica, normalmente cambiamos los últimos 3 dígitos.
Aquí hay una lista que da un significado al número:
0lectura, escritura y ejecución1lectura y escritura2lectura y ejecución3sólo lectura4escritura y ejecución5sólo escritura6sólo ejecución7sin permisos
Nota que esta notación numérica difiere de la que usamos en chmod.
Podemos establecer un nuevo valor para la máscara fijando el valor en formato numérico:
umask 002o puedes cambiar el permiso de un rol específico:
umask g+rEl comando du de Linux
El comando du calculará el tamaño de un directorio en su conjunto:
du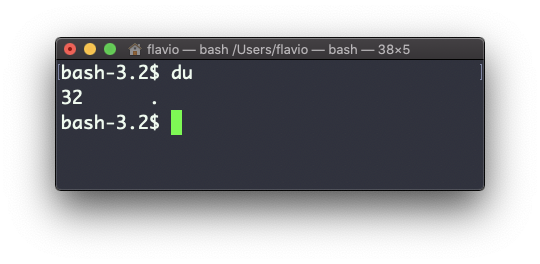
El número 32 aquí es un valor expresado en bytes.
Al correr du * calculará el tamaño de cada archivo individualmente:
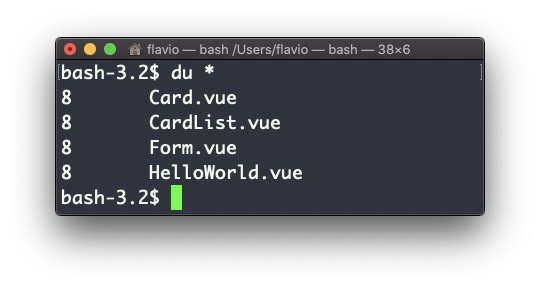
Puedes configurar du para que muestre los valores en MegaBytes usando du -m, y GigaBytes usando du -g.
La opción -h mostrará una notación legible por los humanos para los tamaños, adaptándose al tamaño:
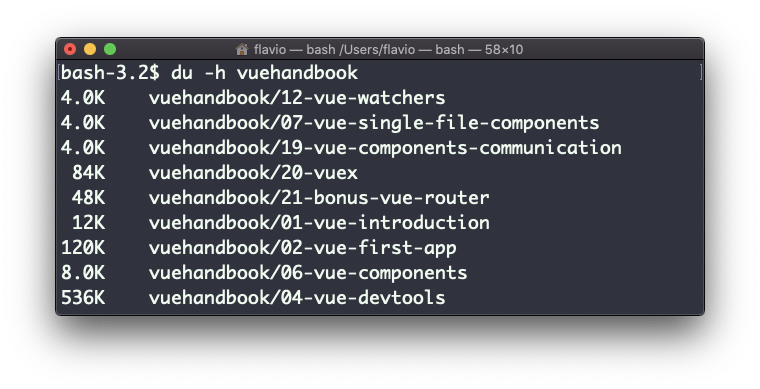
Agregando la opción -a también imprimirá el tamaño de cada uno de los archivos en los directorios:
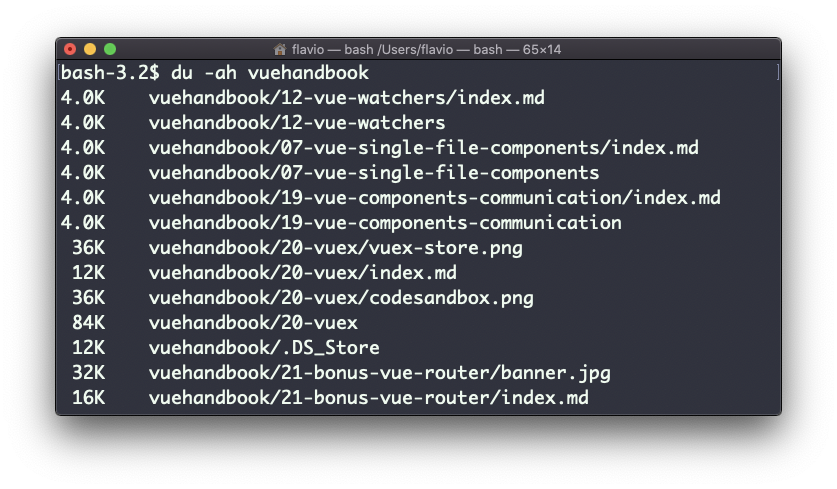
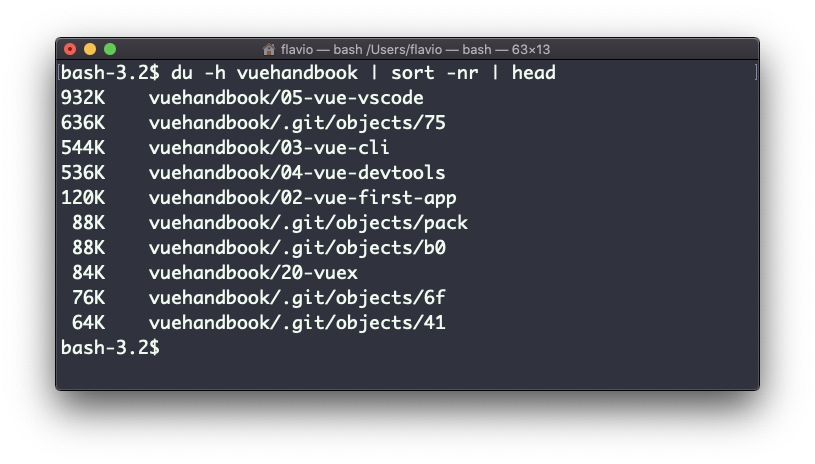
Una cosa útil es clasificar los directorios por tamaño:
du -h <directory> | sort -nry luego agregar un pipe a head para sólo obtener los primeros 10 resultados:
El comando df de Linux
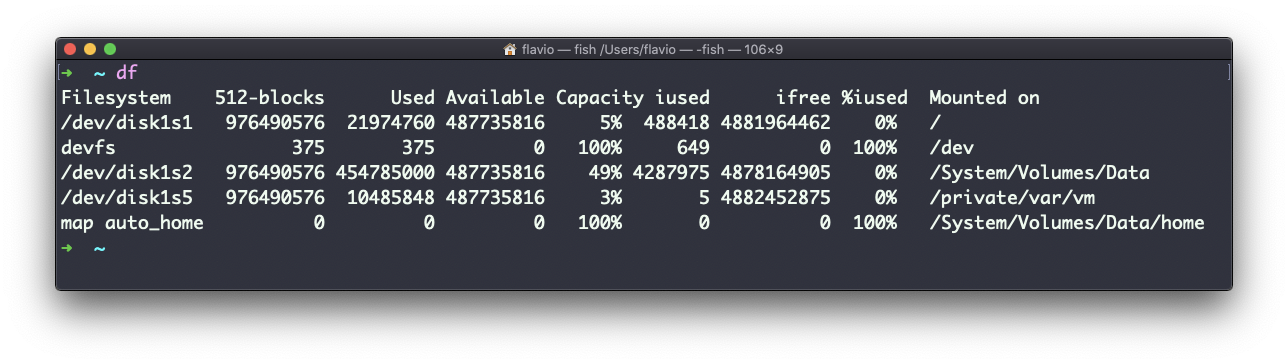
El comando df se usa para obtener información sobre el uso del disco.
Su forma básica imprimirá información sobre los volúmenes montados:
Usando la opción -h (df -h) mostrará los valores en un formato legible para los humanos:
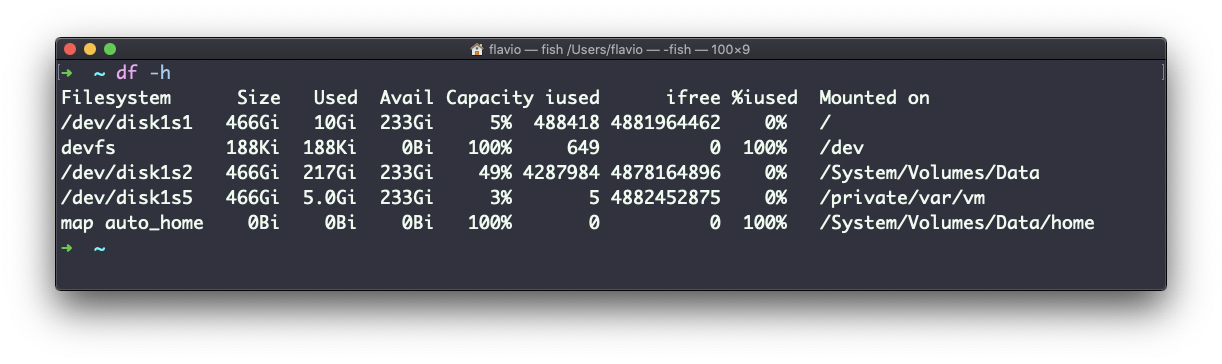
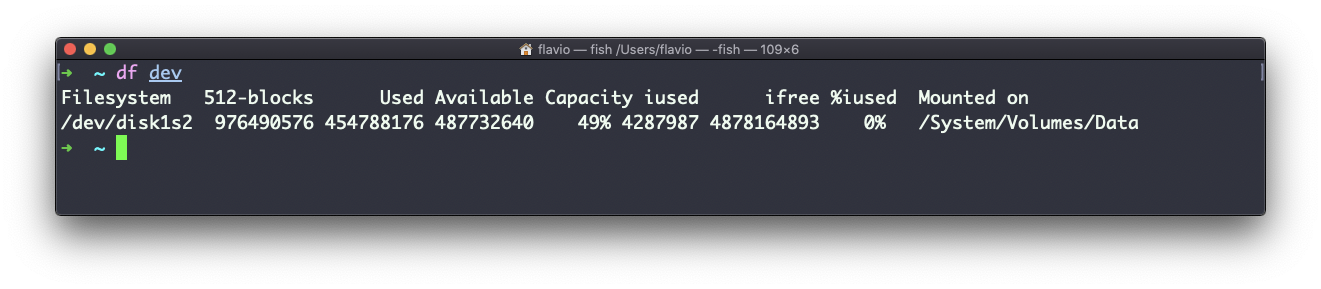
También puedes especificar el nombre de un archivo o directorio para obtener información sobre el volumen específico del que vive:
El comando basename de Linux
Supongamos que tienes una ruta a un archivo, por ejemplo Users/flavio/test.txt.
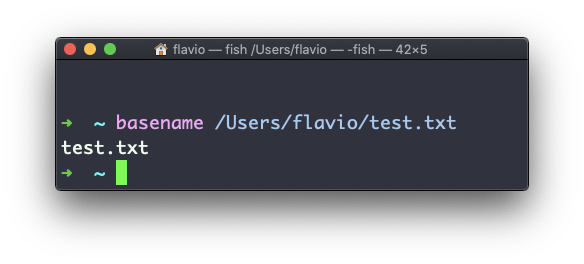
Al ejecutar
basename /Users/flavio/test.txtretornará la cadena text.txt:
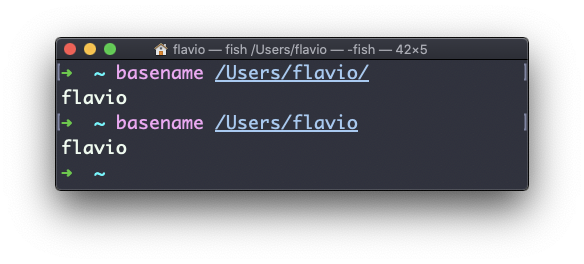
Si ejecutas basename en una cadena de rutas que apunta a un directorio, obtendrás el último segmento de la ruta. En este ejemplo, Users/flavio es un directorio:
El comando dirname de Linux
Supongamos que tienes una ruta a un archivo, por ejemplo Users/flavio/test.txt.
Al ejecutar
dirname /Users/flavio/test.txtretornará la cadena /Users/flavio:
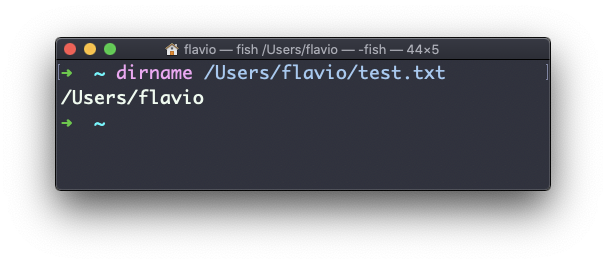
El comando ps de Linux
Tu computadora ejecuta un montón de diferentes procesos todo el tiempo.
Puedes inspeccionarlos a todos usando el comando ps:
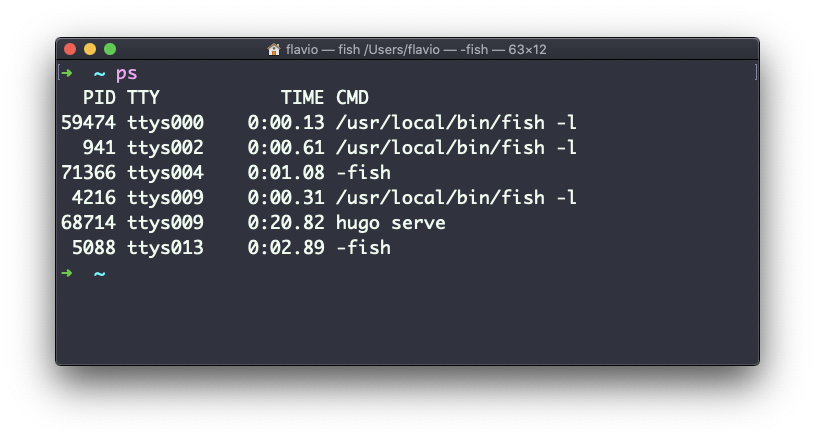
Esta es la lista de procesos iniciados por el usuario que se están ejecutando actualmente en la sesión en curso.
Aquí tengo algunas instancias del shell fish, la mayoría abiertas por VS Code dentro del editor, y una instancia de Hugo ejecutando la vista previa de desarrollo de un sitio.
Esos son sólo los comandos asignados al usuario actual. Para enlistar todos los procesos necesitamos pasarle algunas opciones a ps.
La más común que uso es ps ax:
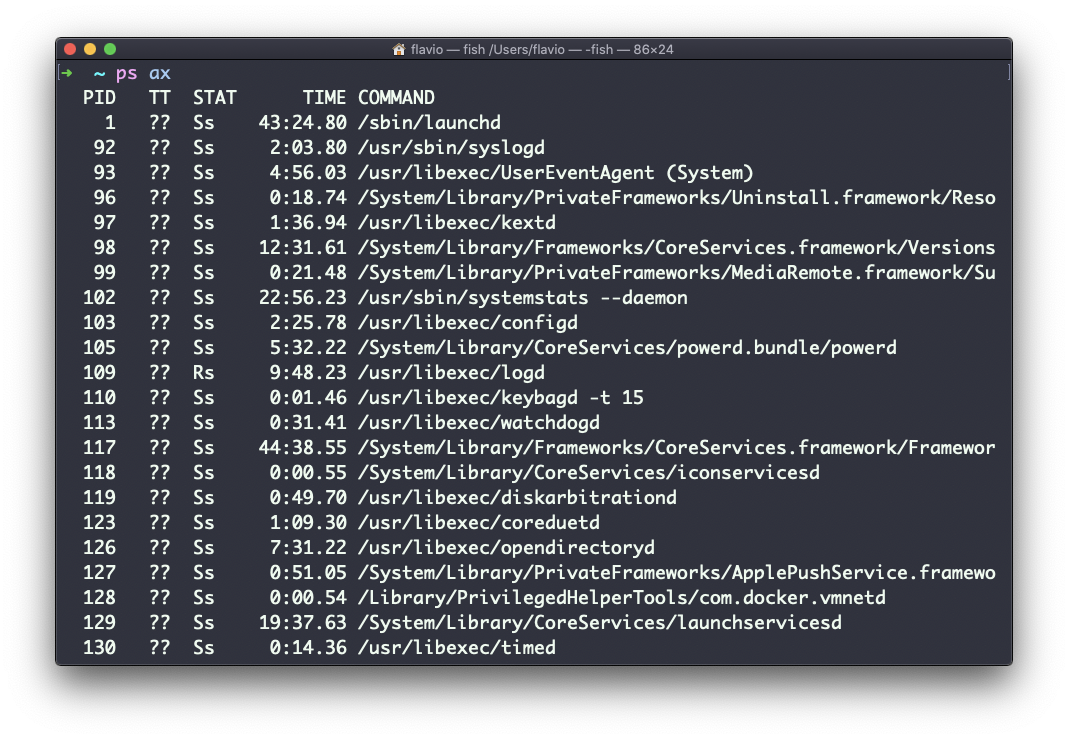
La opciónase utiliza para enumerar también los procesos de otros usuarios, no sólo los suyos propios.xmuestra los procesos no vinculados a una terminal (no iniciados por los usuarios a través de una terminal).
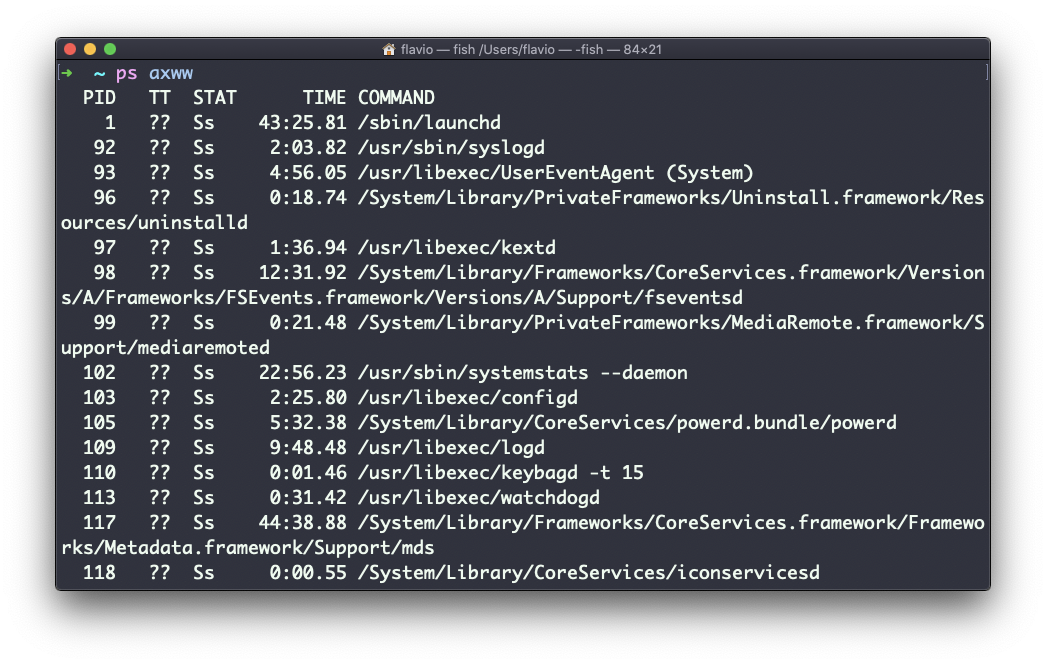
Como puedes ver, los comandos más largos se cortan. Usa el comando ps axww para continuar el listado de comando en una nueva línea en lugar de cortarlo:
Necesitamos especificar w 2 veces para aplicar este ajuste (no es un error tipográfico).Puedes buscar un proceso específico que combine el comando grep con un pipe, como este:
ps axww | grep "Visual Studio Code"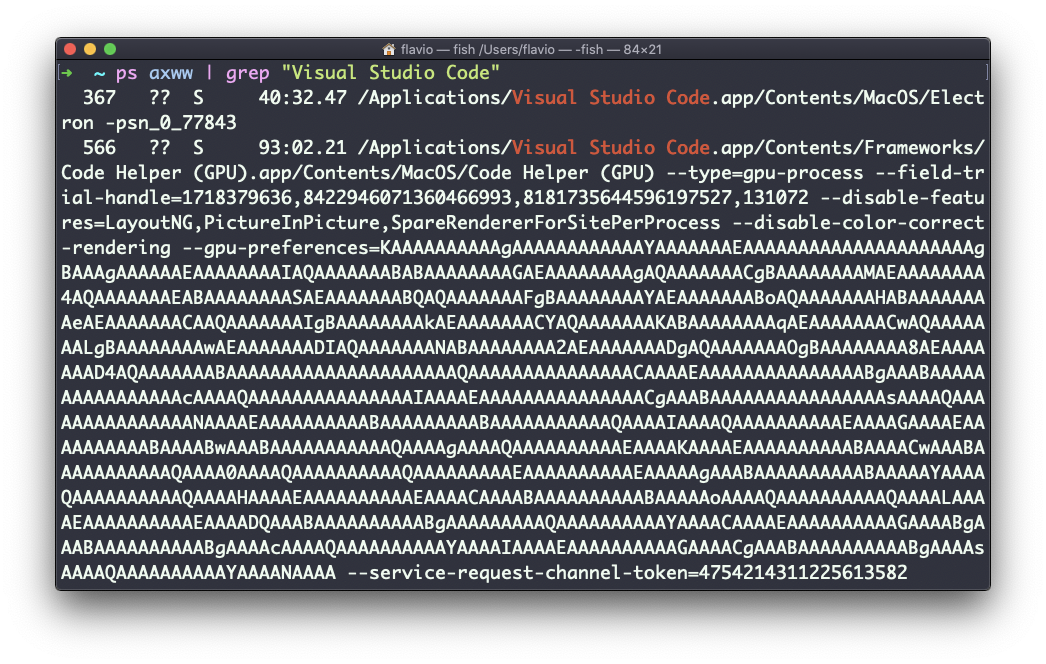
Las columnas devueltas por ps representan alguna información clave.
La primera información es PID, la identificación del proceso (process ID en inglés). Esta es la clave cuando se quiere hacer referencia a este proceso en otro comando, por ejemplo, matarlo.
Luego tenemos TT que nos dice el ID de la terminal utilizada.
Después STAT nos dice el estado del proceso:
I un proceso que está inactivo (dormido durante más de 20 segundos)R un proceso ejecutableS un proceso que duerme por menos de 20 segundosT un proceso detenidoU un proceso en espera ininterrumpidaZ un proceso muerto (un zombi)
Si tienes más de una letra, la segunda representa más información, que puede ser muy técnica.
Es común tener el + que indica que el proceso está en primer plano en su terminal. La s significa que el proceso es un líder de sesión.
TIME nos dice cuánto tiempo ha estado funcionando el proceso.
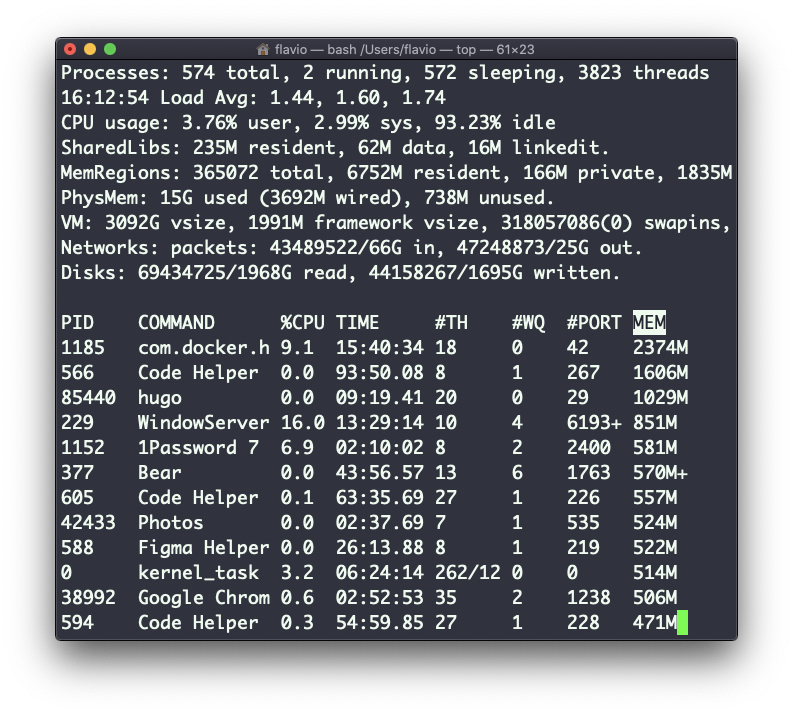
El comando top de Linux
El comando top se utiliza para mostrar información dinámica en tiempo real sobre los procesos en ejecución en el sistema.
Es muy útil para entender lo que está pasando.
Su uso es simple — sólo tienes que escribir top, y la terminal estará completamente inmersa en esta nueva vista:
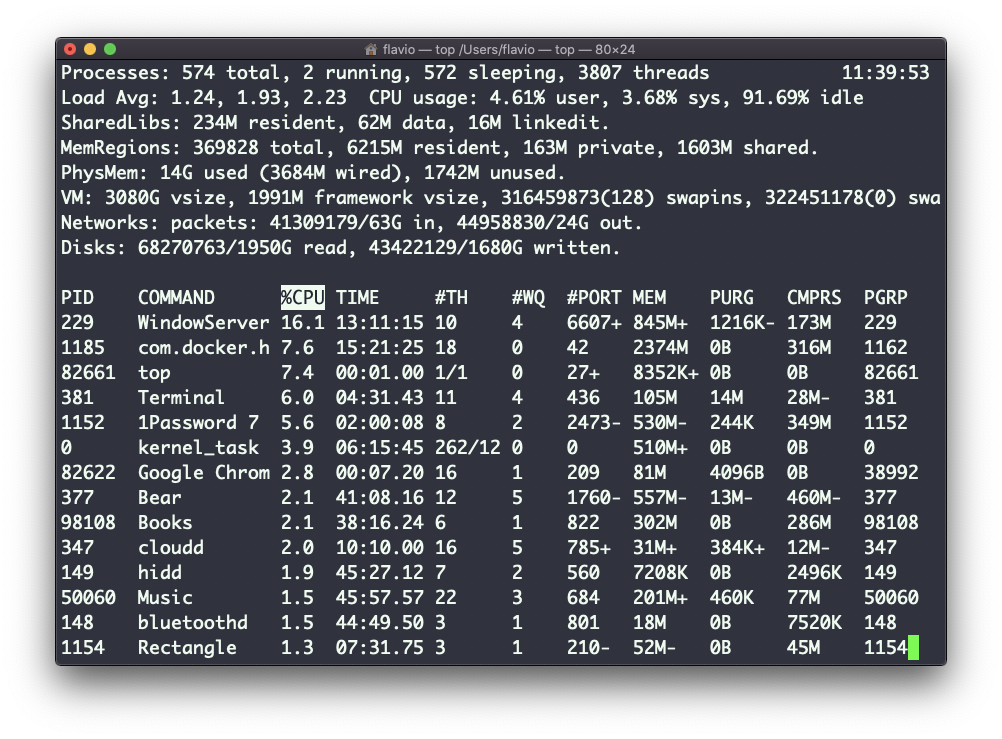
El proceso está corriendo continuamente. Para salir, puedes escribir la letra q o ctrl-C.
Se nos da mucha información: el número de procesos, cuántos están corriendo o durmiendo, la carga del sistema, el uso de la CPU, y mucho más.
A continuación, la lista de los procesos que más memoria y CPU consumen se actualiza constantemente.
Por defecto, como se puede ver en la columna %CPU resaltada, están ordenados por la CPU utilizada.
Puedes agregar una bandera para ordenar los procesos por la memoria utilizada:
top -o memEl comando kill de Linux
Los procesos de Linux pueden recibir señales y reaccionar a ellas.
Esa es una forma en la que podemos interactuar con los programas en ejecución.
El programa kill puede enviar una variedad de señales a un programa.
No sólo se usa para terminar un programa, como el nombre lo sugiere, sino que es su principal trabajo. Lo usamos de esta manera:
kill <PID>Por defecto, este manda una señal TERM al identificador de proceso indicado.
Podemos usar banderas para mandar otras señales, incluyendo:
kill -HUP <PID>
kill -INT <PID>
kill -KILL <PID>
kill -TERM <PID>
kill -CONT <PID>
kill -STOP <PID>HUP significa colgar (hang up en inglés). Se envía automáticamente cuando una ventana de terminal que inició un proceso se cierra antes de terminar el proceso.
INT significa interrumpir (interrupt en inglés), y envía la misma señal que se usa cuando pulsamos ctrl-C en la terminal, que normalmente terminal el proceso.
KILL no se envía al proceso, sino al núcleo del sistema operativo, que inmediatamente se detiene y termina el proceso.
TERM significa terminar (terminate en inglés). El proceso lo recibirá y terminará por sí mismo. Es la señal por defecto enviada por kill.
CONT significa continuar (continue en inglés). Se puede usar para reanudar un proceso detenido.
STOP no se envía al proceso, sino al núcleo del sistema operativo, que inmediatamente detiene (pero no termina) el proceso.
Podrías ver números usados en su lugar, como kill -1 <PID>. En este caso,
1 corresponde a HUP.2 corresponde a INT.9 corresponde a KILL.15 corresponde a TERM.18 corresponde a CONT.15 corresponde a STOP.
El comando killall de Linux
Similar al comando kill, killall enviará la señal a múltiples procesos a la vez en lugar de enviar una señal a un identificador de proceso específico.
Su sintaxis es:
killall <name>donde name es el nombre del programa. Por ejemplo, puedes tener múltiples instancias del programa top en ejecución, y killall top terminará con todos ellos.
Puedes especificar la señal, como con kill (y consulta el tutorial de kill para leer más sobre los tipos específicos de señales que podemos enviar), por ejemplo:
killall -HUP topEl comando jobs de Linux
Cuando ejecutamos un comando en Linux / macOS, podemos configurarlo para que se ejecute en segundo plano, usando el símbolo & después del comando.
Por ejemplo, podemos ejecutar top en el fondo:
top &Esto es muy útil para los programas de larga duración.
Podemos volver a ese programa usando el comando fg. Esto funciona bien si sólo tenemos un trabajo en el fondo, de lo contrario necesitamos usar el número de trabajo: fg 1, fg 2 y así sucesivamente.
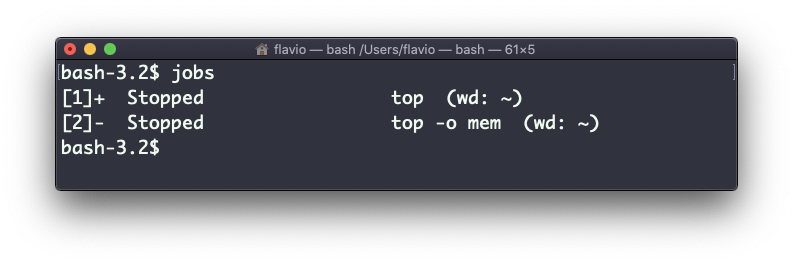
Para obtener el número de trabajo, usamos el comando jobs.
Digamos que ejecutamos top & y luego top -o mem &, entonces tenemos 2 instancias top en ejecución. jobs nos dirá esto:
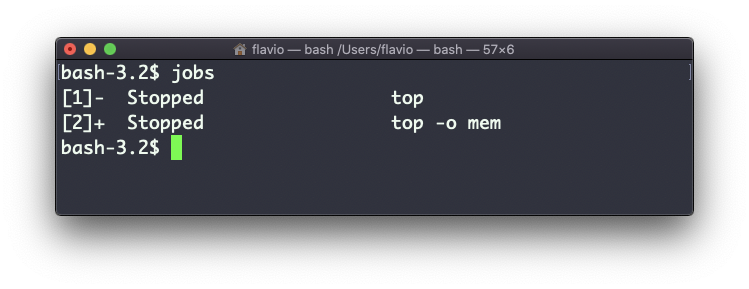
Ahora podemos volver a uno de esos usando fg <jobid>. Para detener el programa de nuevo, podemos pulsar ctrl-Z.
Ejecutando jobs -l también imprimirá el identificador de proceso de cada trabajo.
El comando bg de Linux
Cuando un comando se está ejecutando puedes suspenderlo usando ctrl-Z.
El comando se detendrá inmediatamente, y volverás al shell de la terminal.
Puedes reanudar la ejecución del comando en segundo plano, así que seguirá ejecutándose pero no te impedirá hacer otro trabajo en la terminal.
En este ejemplo tengo 2 comandos detenidos:
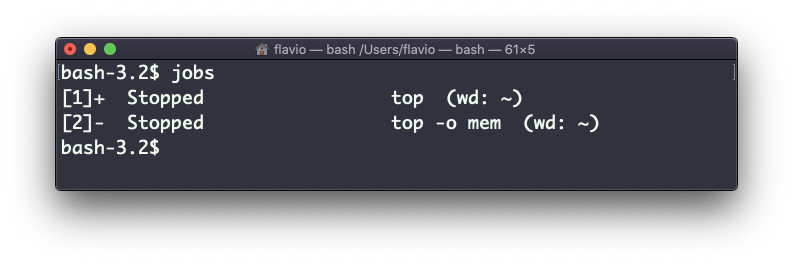
Puedo ejecutar bg 1 para reanudar en segundo plano la ejecución del trabajo #1.
También podría haber dicho bg sin ninguna opción, ya que por defecto es elegir el trabajo #1 de la lista.
El comando fg de Linux
Cuando un comando se ejecuta en segundo plano, porque lo iniciaste con & al final (ejemplo: top & o porque lo pusiste en segundo plano con el comando bg), puedes ponerlo en primer plano usando fg.
Ejecutando
fgreanudará en primer plano el último trabajo que fue suspendido.
También puedes especificar qué trabajo quieres retomar en primer plano pasando el número de trabajo, que puedes obtener usando el comando jobs.
Ejecutando fg 2 reanudará el trabajo #2:
El comando type de Linux
Un comando puede ser uno de 4 tipos:
- un ejecutable
- un programa incorporado en shell
- una función shell
- un alias
El comando type puede ayudar a resolver esto, en caso de que queramos saberlo o simplemente tengamos curiosidad. Te dirá cómo será interpretado el comando.
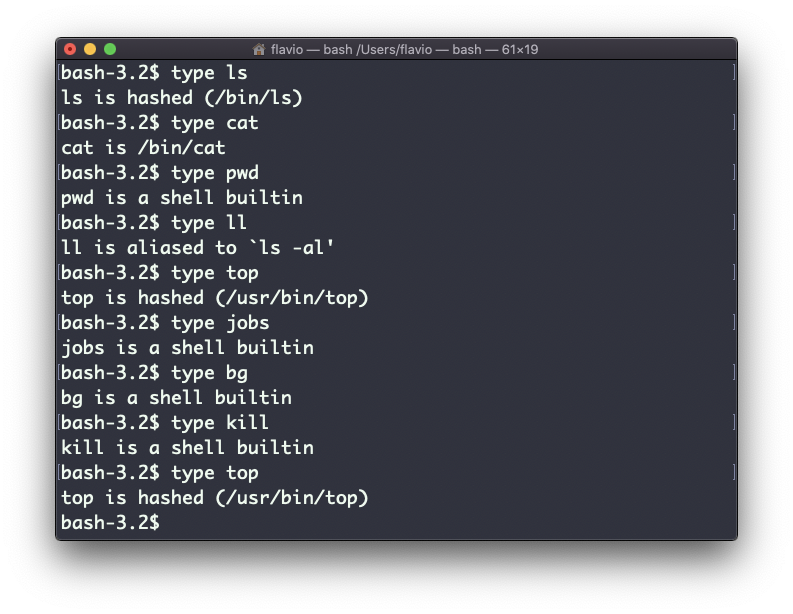
La salida dependerá del shell utilizado. Este es Bash:
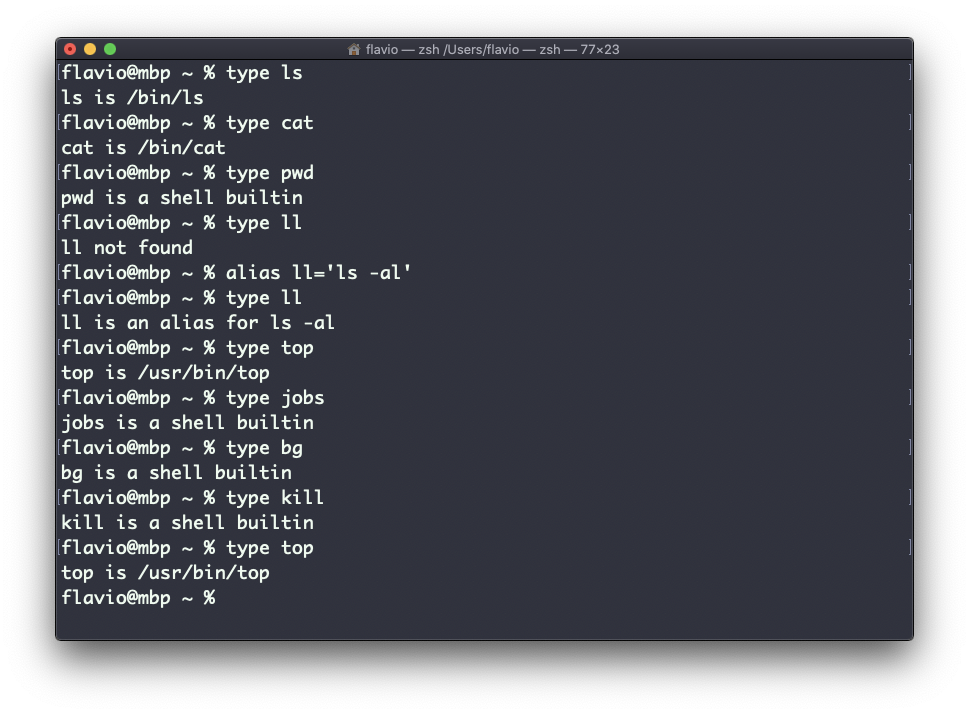
Este es Zsh:
Este es Fish:
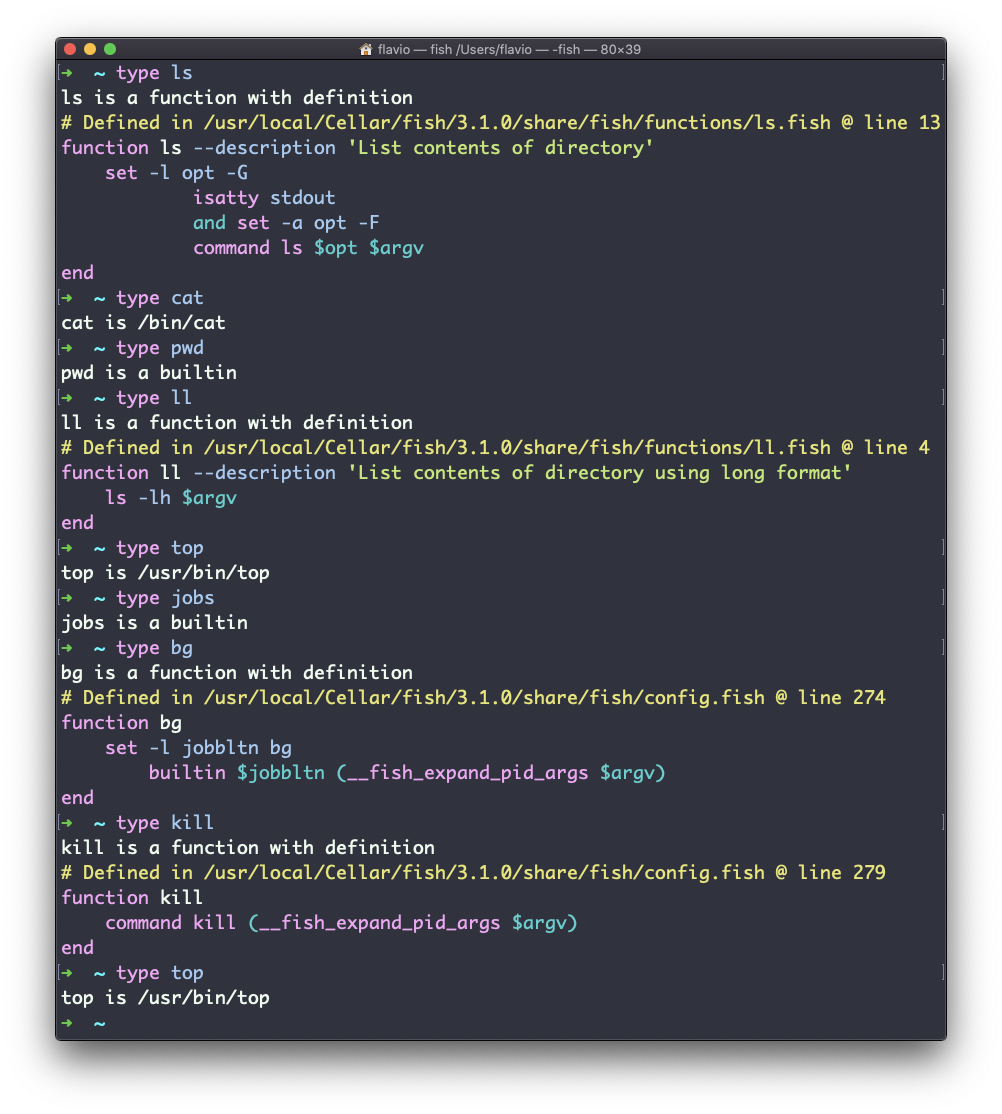
Una de las cosas más interesantes aquí es que para los aliases te dirá a qué se está aliando. Puedes ver el alias ll, en el caso de Bash y Zsh, pero Fish lo proporciona por defecto, así que te dirá que es una función de shell incorporada.
El comando which de Linux
Supongamos que tienes un comando que puedes ejecutar, porque está en la ruta del shell, pero quieres saber dónde se encuentra.
Puedes hacerlo usando which. El comando devolverá la ruta al comando especificado:
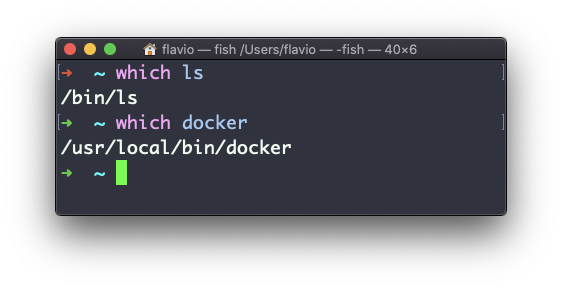
which sólo funcionará con ejecutables almacenados en disco, no aliases o funciones de shell incorporadas.
El comando nohup de Linux
A veces hay que ejecutar un proceso de larga duración en una máquina remota, y luego hay que desconectarse.
O simplemente quieres evitar que el comando se detenga si hay algún problema de red entre tú y el servidor.
La forma de hacer que un comando se ejecute incluso después de cerrar la sesión o la sesión con un servidor es usar el comando nohup.
Usa nohup <command> para que el proceso continúe funcionando incluso después de cerrar la sesión.
El comando xargs de Linux
El comando xargs se utiliza en un shell de UNIX para convertir la entrada de una entrada estándar en argumentos para un comando.
En otras palabras, mediante el uso de xargs la salida de un comando se utiliza como la entrada de otro comando.
Aquí está la sintaxis que utilizarás:
command1 | xargs command2Usamos un pipe (|) para pasar la salida a xargs. Eso se encargará de ejecutar el comando command2, usando la salida del command1 como su(s) argumento(s).
Hagamos un ejemplo sencillo. Quieres remover algunos archivos específicos de un directorio. Esos archivos están enlistados dentro de un archivo de texto.
Tenemos 3 archivos: file1, file2, file3.
En todelete.txt tenemos una lista de archivos que queremos borrar, en este ejemplo, file1 y file3:
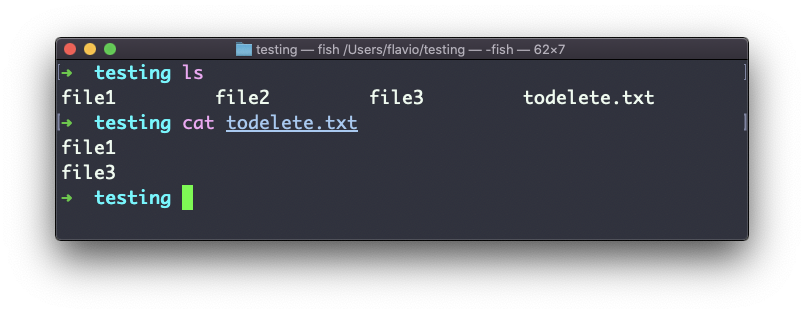
Canalizaremos la salida de cat todelete.txt al comando rm, a través de xargs.
De este manera:
cat todelete.txt | xargs rmEse es el resultado, los archivos que hemos enumerado se han eliminado:
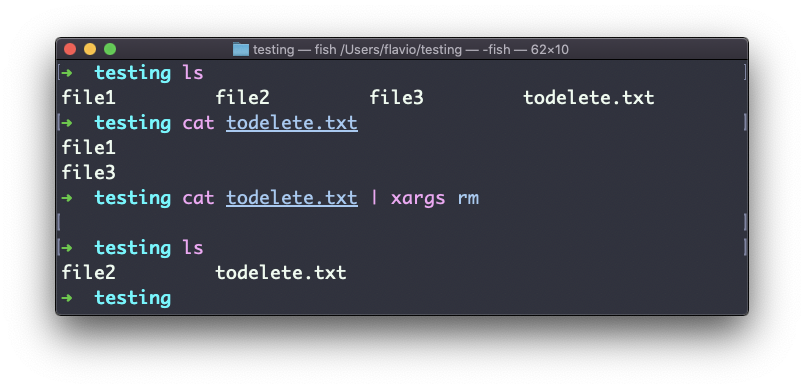
La forma en que funciona es que xargs ejecutará rm dos veces, una por cada línea devuelta por cat.
Este es el uso más simple de xargs. Hay varias opciones que podemos usar.
Una de las más útiles, en mi opinión (especialmente cuando se empieza a aprender xargs), es -p. Usar esta opción hará que xargs imprima un aviso de confirmación con la acción que va a realizar:
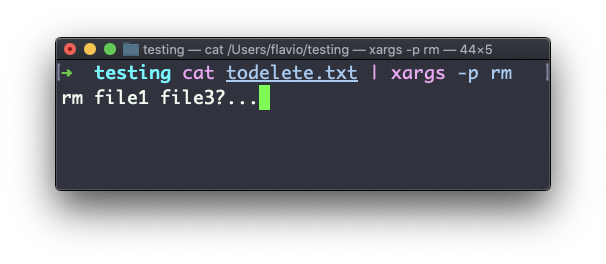
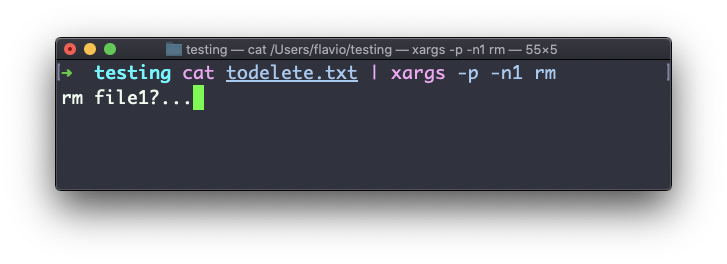
La opción -n te permite decirle a xargs que realice una iteración a la vez, para que puedas confirmarlos individualmente con -p. Aquí le decimos a xargs que realice una iteración a la vez con -n1:
La opción -I es otra muy utilizada. Te permite obtener la salida de un marcador, y entonces puedes hacer varias cosas.
Una de ellas es ejecutar múltiples comandos:
command1 | xargs -I % /bin/bash -c 'command2 %; command3 %'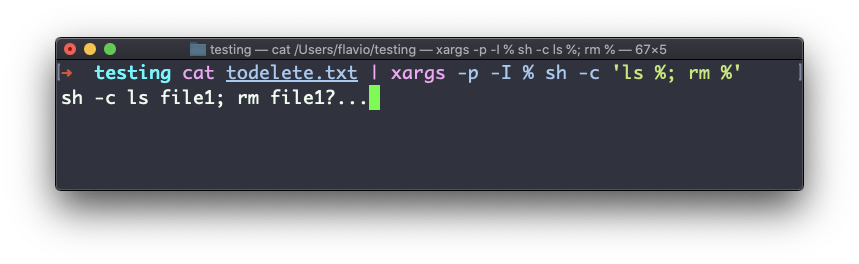
Puedes cambiar el símbolo % que usé arriba por cualquier otra cosa — es una variable.El comando vim del editor de Linux
vim es un editor de archivos muy popular, especialmente entre los programadores. Es desarrollado activamente y se actualiza con frecuencia, y hay una gran comunidad a su alrededor. ¡Incluso hay una conferencia de Vim!
vi en los sistema s modernos es sólo un alias para vim, lo que significa vi improved.
Se inicia ejecutando vi en la línea de comandos.
Puedes especificar un nombre de archivo en el momento de la invocación para editar ese archivo específico:
vi test.txt
Debes saber que Vim tiene 2 modos principales:
- modo de comando (command en inglés) también llamado normal
- modo de inserción (insert en inglés)
Cuando inicias el editor, estás en modo de comando, No puedes introducir texto como esperas de un editor basado en una interfaz gráfica de usuario. Tienes que entrar en el modo de inserción.
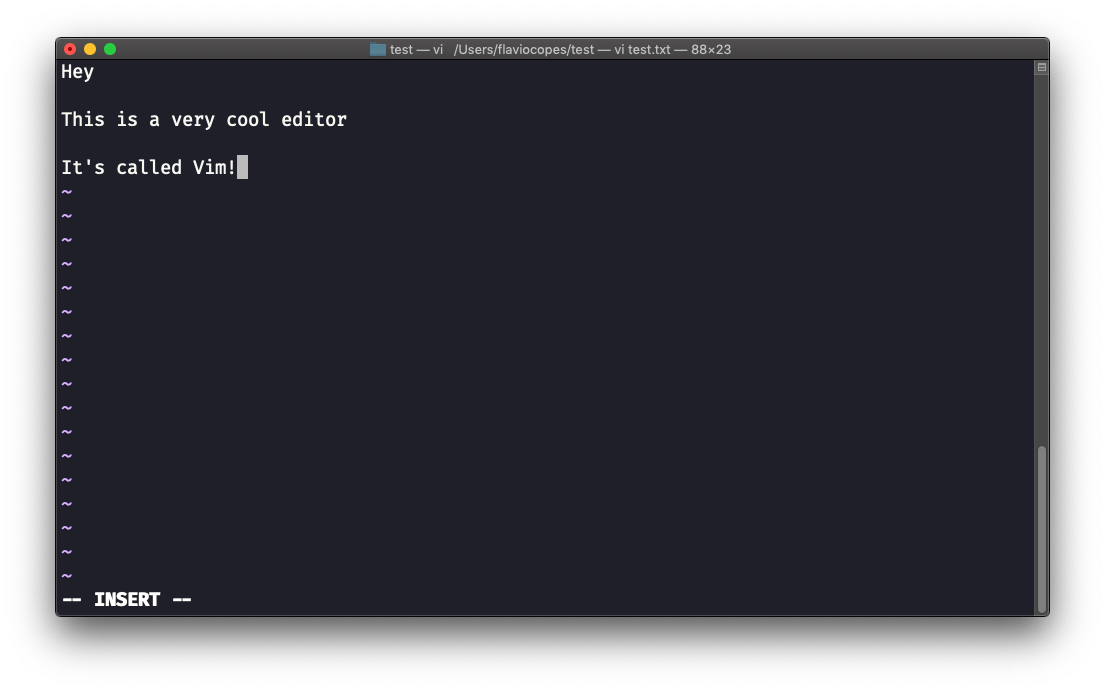
Puedes hacerlo pulsando la tecla i. Una vez que lo hagas, la palabra -- INSERT -- aparece en la parte inferior del editor.

Ahora puedes empezar a escribir y llenar la pantalla con el contenido del archivo:
Puedes moverte por el archivo con las teclas de flechas, o usando las teclas h - j - k - l. h-l para izquierda-derecha, j-k para abajo-arriba.
Una vez que hayas terminado de editar puedes pulsar la tecla esc para salir del modo de inserción y volver al modo de comando.
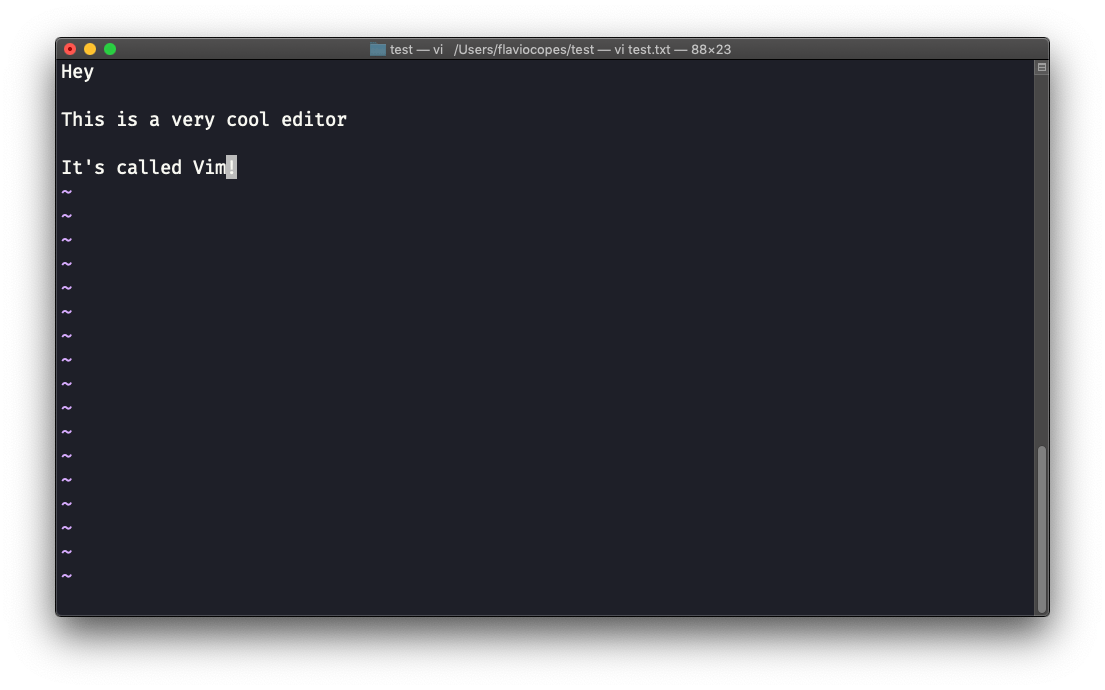
En este punto puedes navegar por el archivo, pero no puedes agregarle contenido (y ten cuidado con las teclas que pulses, ya que pueden ser comandos).
Una cosa que quizá quieras hacer ahora es guardar el archivo. Puedes hacerlo pulsando : (dos puntos), luego w.
Puedes guardar y salir presionando : luego w y q: :wq
Puedes salir sin guardar presionando : luego q y !: :q!
Puedes deshacer y editar yendo al modo de comando y presionando u. Puedes rehacer (cancelar un deshacer) presionando ctrl-r.
Esos son los fundamentos de trabajar con Vim. A partir de aquí comienza el "cuento sin fin" en el cual no podemos entrar en esta pequeña introducción.
Sólo mencionaré los comandos que te permitirán empezar a editar con Vim:
- pulsando la tecla
xborra el caracter actualmente resaltado - pulsando
Ate dirige el cursor al final de la línea actualmente seleccionada y entras a modo de inserción - pulsando
0te dirige al comienzo de la línea - ve al primer caracter de una palabra y pulsa
dseguido dewpara borrar una palabra. Si la sigues con unaeen lugar dew, el espacio en blanco antes de la siguiente palabra se conserva. - usar un número entre
dywpara borrar más de una palabra, por ejemplo, usard3wpara borrar 3 palabras hacia adelante. - pulsando
dseguido dedpara borrar una línea entera. Pulsadseguido de$para borrar toda la línea desde donde está el cursor hasta el final
Para saber más sobre Vim, puedo recomendar el Vim FAQ. También puedes ejecutar el comando vimtutor, que ya debería estar instalado en tu sistema y te ayudará enormemente a comenzar tu exploración de vim.
El comando emacs del editor de Linux
emacs es un editor impresionante y es históricamente considerado como el editor de los sistemas UNIX. Famosamente, las guerras y acaloradas discusiones de vi vs emacs han causado muchas horas improductivas para los desarrolladores de todo el mundo.
emacs es muy poderoso. Algunas personas lo usan todo el día como una especie de sistema operativo (https://news.ycombinator.com/item?id=19127258). Hablaremos de lo básico aquí.
Puedes abrir una nueva sesión de emacs simplemente invocando a emacs:
Usuarios de macOS, paren un segundo ahora. Si estás en Linux, no hay problema, pero macOS no es cargado con aplicaciones usando GPLv3, y cada comando UNIX incorporado que ha sido actualizado GPLv3 no ha sido actualizado.
Aunque hay un pequeño problema con los comandos que he enumerado hasta ahora, en este caso usar una versión de emacs de 2007 no es exactamente lo mismo que usar una versión con 12 años de mejoras y cambios.
Esto no es un problema con Vim, que está actualizado. Para arreglar esto, ejecutabrew install emacsy ejecutandoemacsusarás la nueva versión de Homebrew (asegúrate de tener Homebrew instalado).
También puedes editar un archivo existente llamando a emacs <filename>:
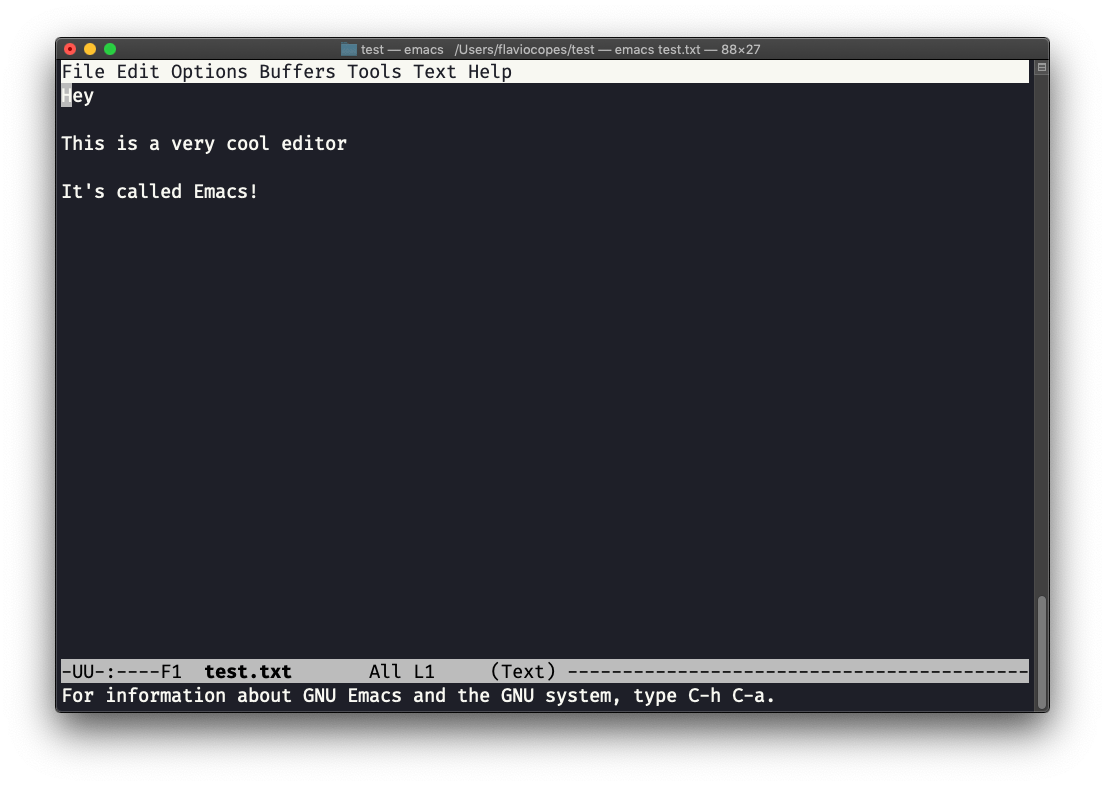
Ya puedes empezar a editar. Una vez que hayas terminado, presiona ctrl-x seguido de ctrl-w. Confirma la carpeta:
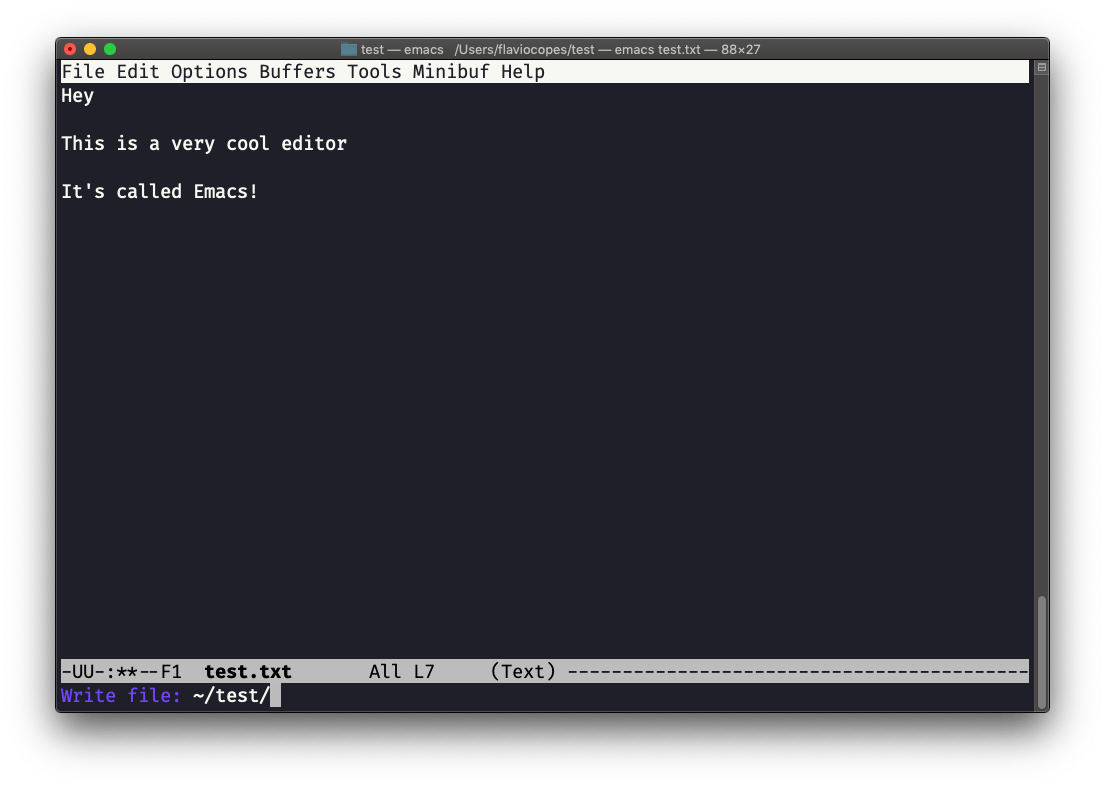
e Emacs te dice que el archivo existe, preguntándote si debería sobrescribirlo:
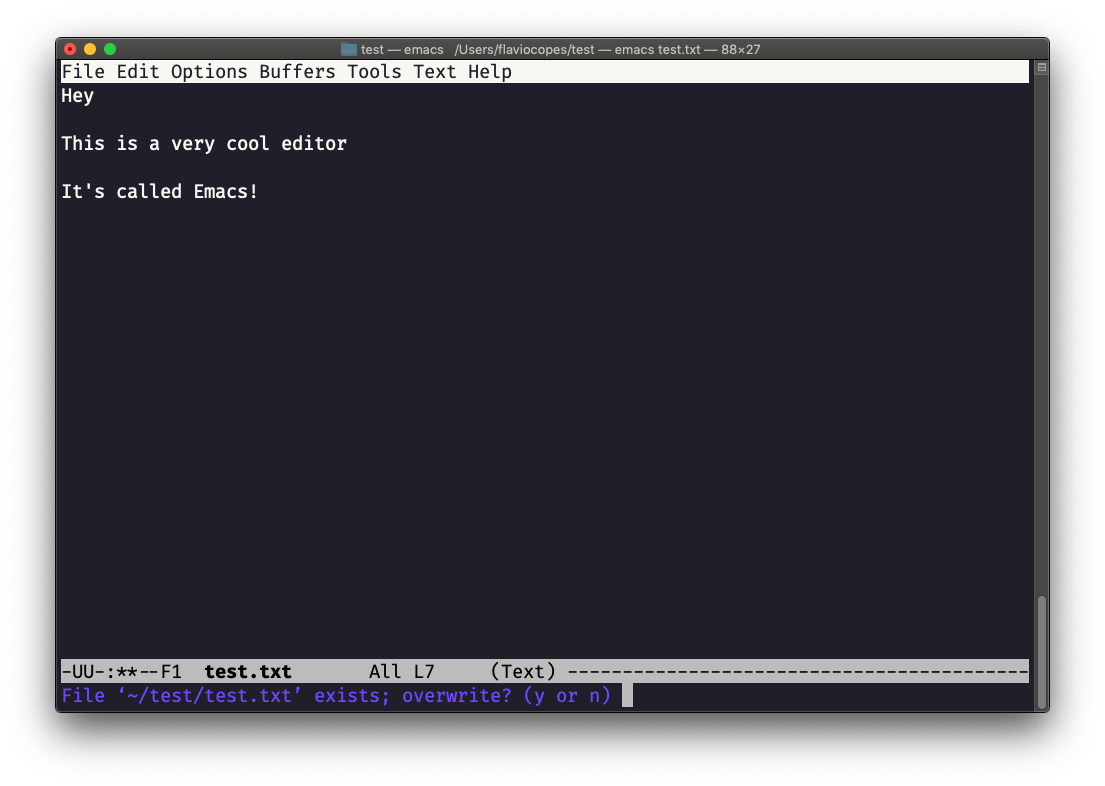
Responde y, y tendrás una confirmación de éxito:
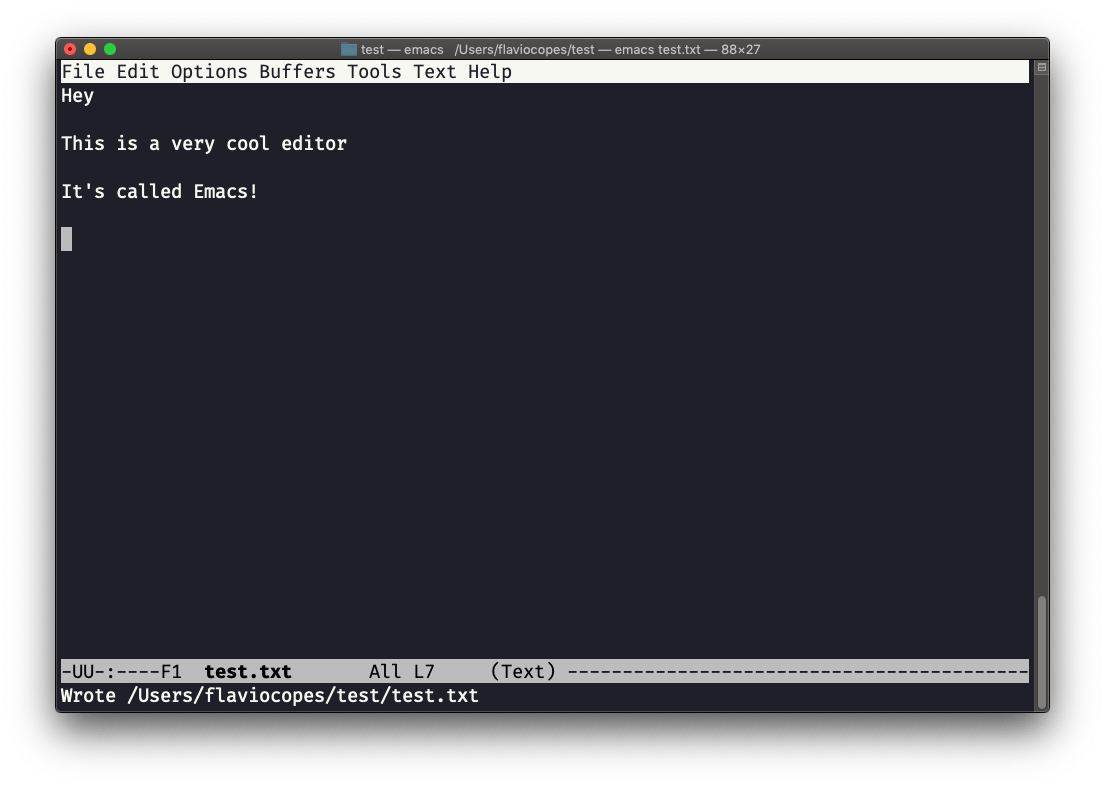
Puedes salir de Emacs presionando ctrl-x seguido de ctrl-c. O ctrl-x seguido de c (mantén presionado ctrl ).
Hay mucho que saber sobre Emacs, ciertamente más de lo que soy capaz de escribir en esta pequeña introducción. Te invito a abrir Emacs y a pulsar ctrl-h r para abrir el manual incorporado y ctrl-h t para abrir el tutorial oficial.
El comando nano del editor de Linux
nano es un editor amigable para principiantes.
Ejecútalo usando nano <filename>.
Puedes escribir directamente los caracteres en el archivo sin preocuparte por los modos.
Puedes salir sin editar usando ctrl-X. Si has editado el búfer del archivo, el editor te pedirá confirmación y podrás guardar las ediciones o descartarlas.
La ayuda de la parte inferior muestra los comandos del teclado que te permiten trabajar con el archivo:
pico es más o menos lo mismo, aunque nano es la versión GNU de pico que en algún momento de la historia no era de código abierto. El clon nano fue hecho para satisfacer los requisitos de la licencia del sistema operativo GNU.
El comando whoami de Linux
Escribe whoami para imprimir el nombre de usuario que está conectado a la sesión de la terminal:
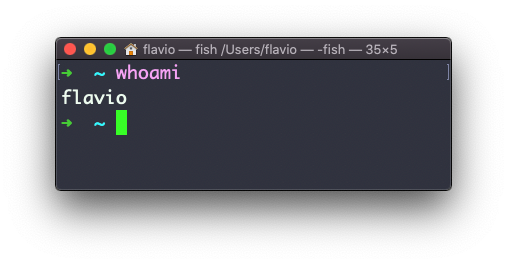
Nota: esto es diferente del comando who am i, el cual imprime más informaciónEl comando who de Linux
El comando who muestra los usuarios conectados al sistema.
A menos que estés usando un servidor al que varias personas tienen acceso, lo más probable es que seas el único usuario conectado, varias veces:
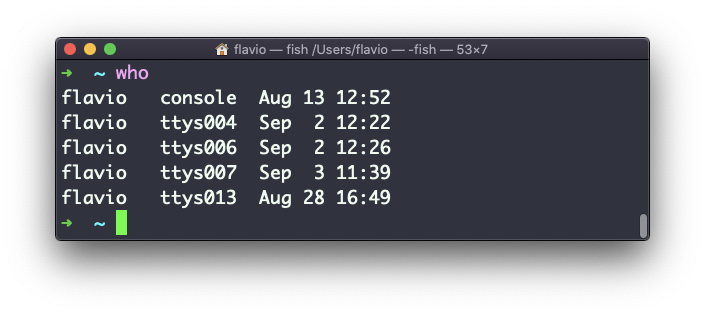
¿Por qué varias veces? Porque cada shell abierto cuando como un acceso.
Puedes ver el nombre de la termina utilizada, y la hora/día en que se inició la sesión.
Las banderas -aH le dirán a who a mostrar más información, incluyendo el tiempo de inactividad y el identificador del proceso de la terminal:
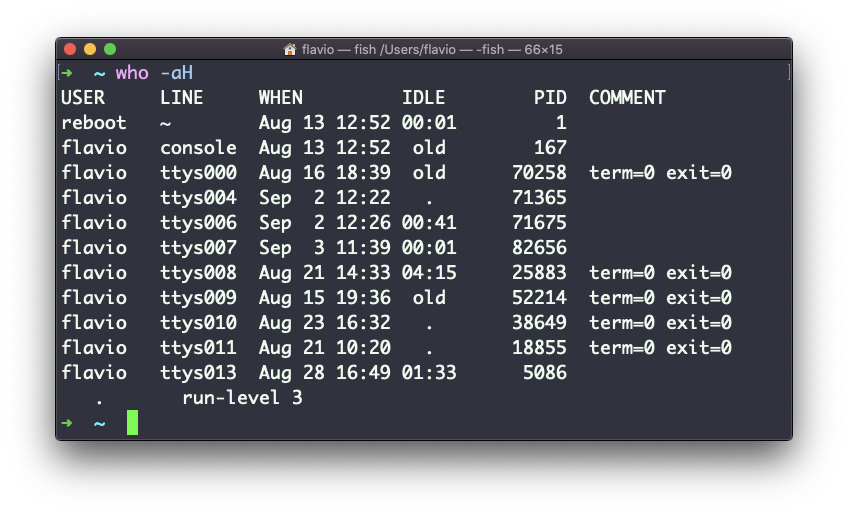
El comando especial who am i enlistará los detalles de la sesión de terminal actual:
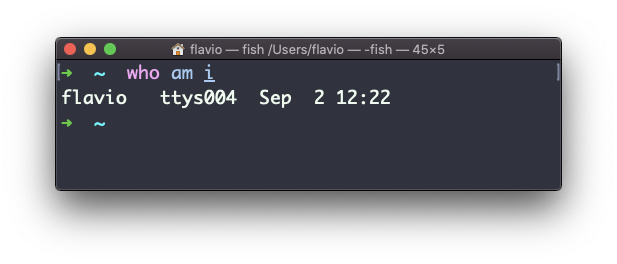
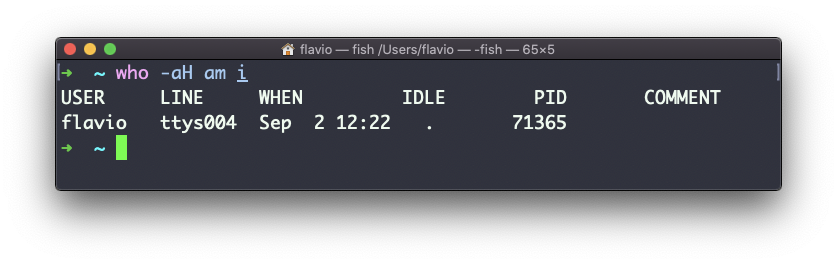
El comando su de Linux
Mientras estás conectado a la terminal con un usuario, puede que tengas que cambiar a otro usuario.
Por ejemplo, estás conectar como root para realizar algo de mantenimiento, pero luego quieres cambiar a una cuenta de usuario.
Puedes hacerlo con el comando su:
su <username>Por ejemplo: su flavio.
Si has iniciado sesión como usuario, al ejecutar su sin nada más te pedirá que introduzcas la contraseña del usuario root, ya que es el comportamiento predeterminado.
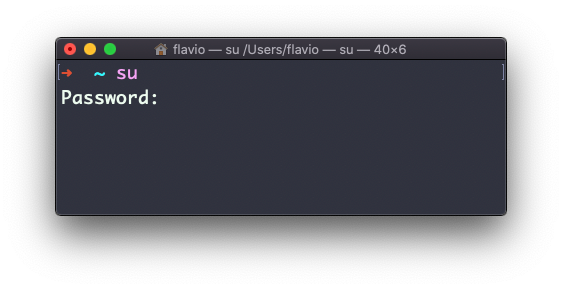
su iniciará un nuevo shell como otro usuario.
Cuando termines, al escribir exit en el shell cerrará el mismo, y te devolverá al shell del usuario actual.
El comando sudo de Linux
sudo se usa comúnmente para ejecutar un comando como root.
Debes estar habilitado para usar sudo, y una vez que lo estés, puedes ejecutar comandos como root introduciendo la contraseña de tu usuario (no la contraseña del usuario root).
Los permisos son altamente configurables, lo que es estupendo especialmente en un entorno de servidor multiusuario. A algunos usuarios se les puede conceder acceso a la ejecución de comandos específicos a través de sudo.
Por ejemplo, se puede editar un archivo de configuración del sistema:
sudo nano /etc/hostsque de otra manera no se salvaría ya que no tienes los permisos para ello.
Puedes ejecutar sudo -i para iniciar un shell como root:
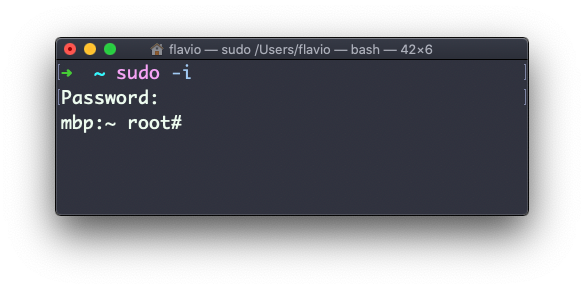
Puedes usar sudo para ejecutar comandos como cualquier usuario. root es el predeterminado, pero usa la opción -u para especificar otro usuario:
sudo -u flavio ls /Users/flavioEl comando passwd de Linux
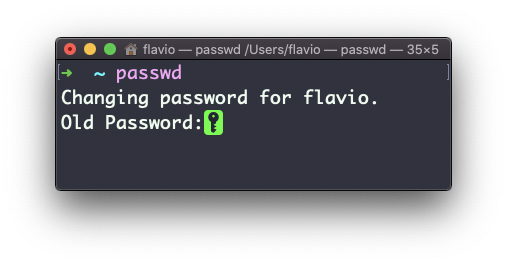
Los usuarios en Linux tienen una contraseña asignada. Puedes cambiar la contraseña usando el comando passwd.
Hay dos situaciones aquí.
La primera es cuando quieres cambiar tu contraseña. En este caso escribes:
passwdy un aviso interactivo te pedirá la contraseña anterior, y luego te pedirá la nueva:
Cuando eres root (o tienes privilegios de superusuario) puedes establecer el nombre de usuario ara el que quieres cambiar la contraseña:
passwd <username> <new password>En este caso no necesitas introducir la contraseña anterior.
El comando ping de Linux
El comando ping hace un ping de un host de red específico, en la red local o en Internet.
Lo usas con la sintaxis ping <host> donde <host> podría ser un nombre de dominio, o una dirección IP.
Aquí hay un ejemplo de "pinging" a google.com:
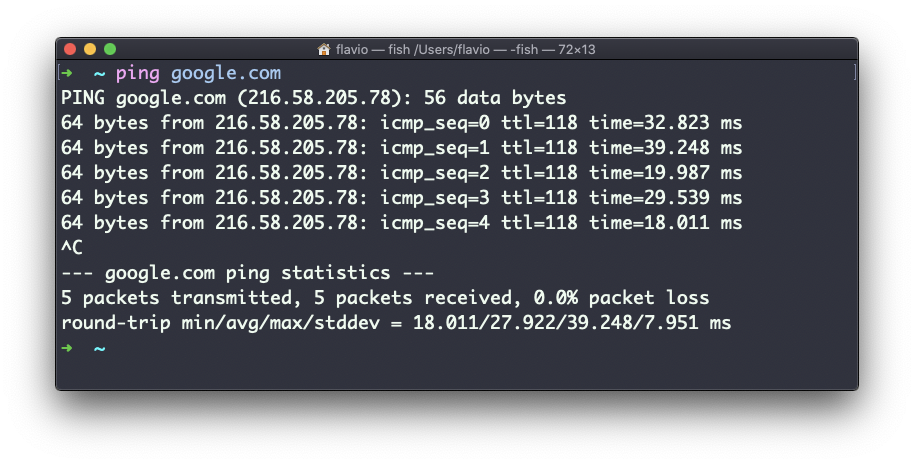
ping sigue enviando la solicitud cada segundo por defecto. Seguirá funcionando hasta que lo detengas con ctrl-C, a menos que pases el número de veces que quieras intentarlo con la opción -c: ping -c 2 google.com.
Una vez que se detenga el ping, imprimirá algunas estadísticas sobre los resultados: el porcentaje de paquetes perdidos, y estadísticas sobre el rendimiento de la red.
Como puedes ver, la pantalla imprime la dirección IP del host, y el tiempo que tardó en obtener la respuesta.
No todos los servidores soportan hacerles un ping, en este caso la solicitud se agota:
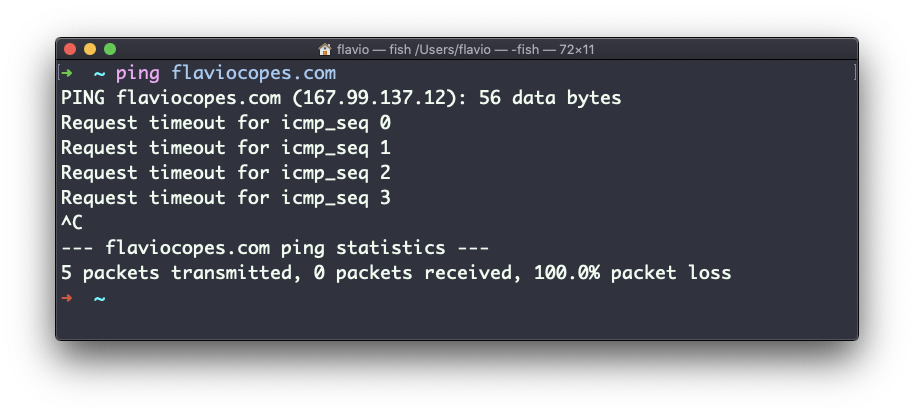
A veces esto se hace a propósito, para "esconder" el servidor, o sólo para reducir la carga. Los paquetes de ping también pueden ser filtrados por los cortafuegos.
ping funciona usando el protocolo ICMP (Internet Control Message Protocol), un protocolo de capa de red como el TCP o el UDP.
La solicitud envía un paquete al servidor con el mensaje ECHO_REQUEST, y el servidor devuelve un mensaje ECHO_REPLY. No entraré en detalles, pero este es el concepto básico.
Hacer ping a un host es útil para saber si el host es alcanzable (suponiendo que implemente ping), y cuán distante está en términos de cuánto tiempo le lleva volver a ti.
Normalmente cuanto más cerca esté el servidor geográficamente, menos timepo tardaré en volver a ti. Leyes físicas simples hacen que una mayor distancia introduzca más retraso en los cables.
El comando traceroute de Linux
Cuando intentas contactar con un host en Internet, lo haces a través del router de tu casa. Luego llegas a la red de tu ISP (proveedor de Internet), que a su vez pasa por su propio enrutador de red ascendente, y así sucesivamente, hasta que finalmente llegas al host.
¿Alguna vez has querido saber qué pasos siguen tus paquetes para hacer eso?
El comando traceroute está hecho para esto.
Lo invocas
traceroute <host>y recogerá (lentamente) toda la información mientras el paquete viaja.
En este ejemplo, intenté buscar mi blog con traceroute flaviocopes.com:
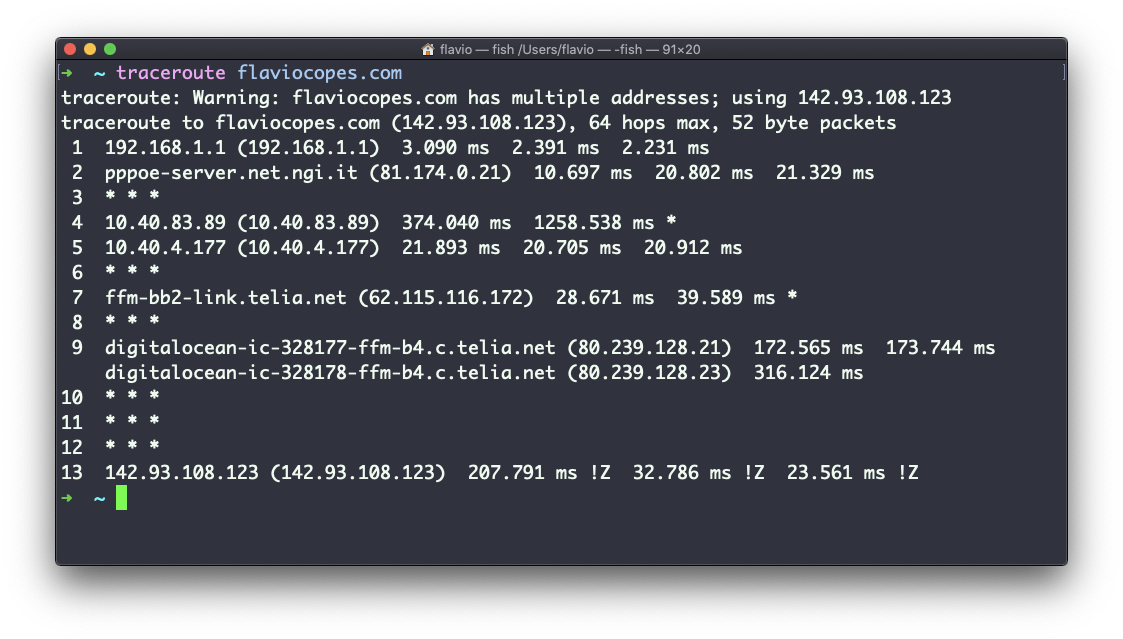
No todos los routers que viajan nos devuelven información. En este caso, traceroute imprime * * *. De lo contrario, podemos ver el nombre del host, la dirección IP y algún indicador de rendimiento.
Por cada router podemos ver 3 muestras, lo que significa que traceroute intenta por defecto 3 veces para conseguir una buena indicación del tiempo necesario para alcanzarlo.
Por esto se tarda tanto en ejecutar traceroute en comparación con simplemente hacer un ping a ese host.
Puedes personalizar este número con la opción -q:
traceroute -q 1 flaviocopes.com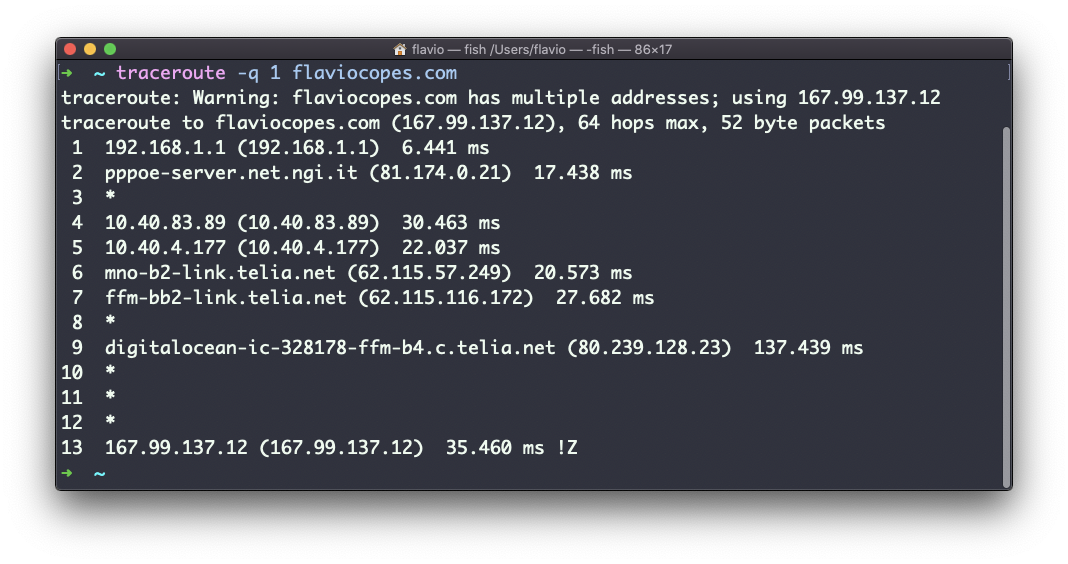
El comando clear de Linux
Escribe clear para borrar todos los comandos anteriores que se ejecutaron en la terminal actual.
La pantalla se borrará y sólo verás el aviso en la parte superior:
Nota: este comando tiene un atajo práctico: ctrl-LUna vez que lo hagas, perderás el acceso al desplazamiento para ver la salida de los comandos anteriormente introducidos.
Así que tal vez quieras usar clear -x en su lugar, que sigue despejando la pantalla, pero te permite volver a ver el trabajo anterior desplazándote hacia arriba.
El comando history de Linux
Cada vez que ejecutas un comando, se memoriza en el historial.
Puedes mostrar todo el historial usando:
historyEsto muestra la historia con números:
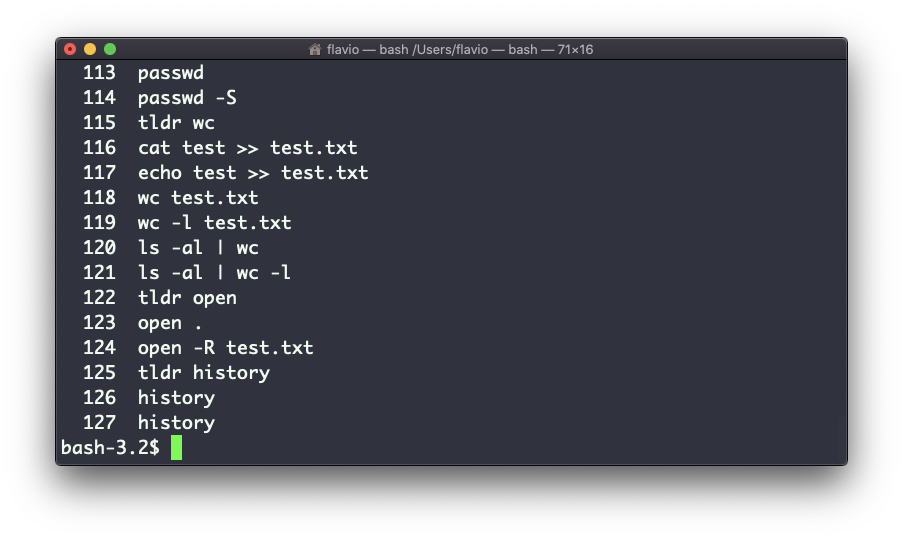
Puedes usar la sintaxis !<command number> para repetir un comando almacenado en el historial. En el ejemplo anterior, escribiendo !121 se repetirá el comando ls -al | wc -l.
Normalmente los últimos 500 comandos se almacenan en el historial.
Puedes combinar esto con grep para encontrar un comando que hayas ejecutado:
history | grep docker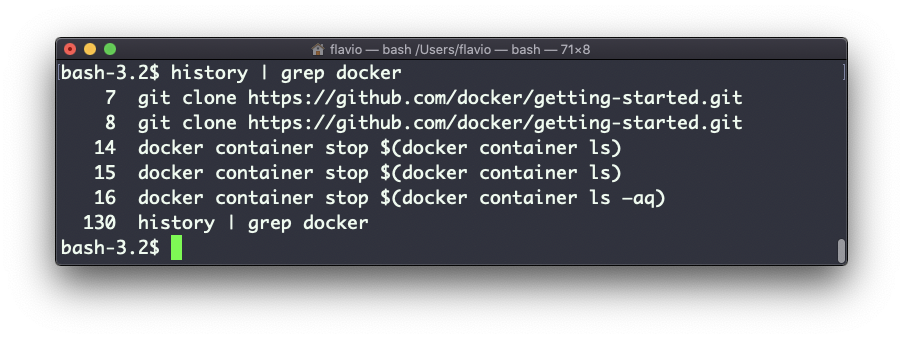
Para borrar el historial, ejecuta history -c.
El comando export de Linux
El comando export se utiliza para exportar variables a procesos hijos.
¿Qué significa esto?
Supongamos que tienes una variable TEST definida de esta manera:
TEST="test"Puedes imprimir su valor usando echo $TEST:
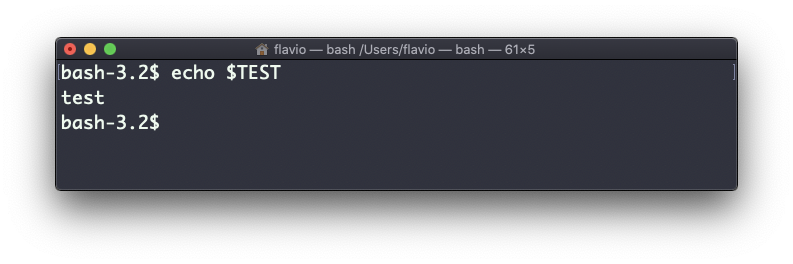
Pero si intentas definir un script Bash en un archivo script.sh con el comando anterior:
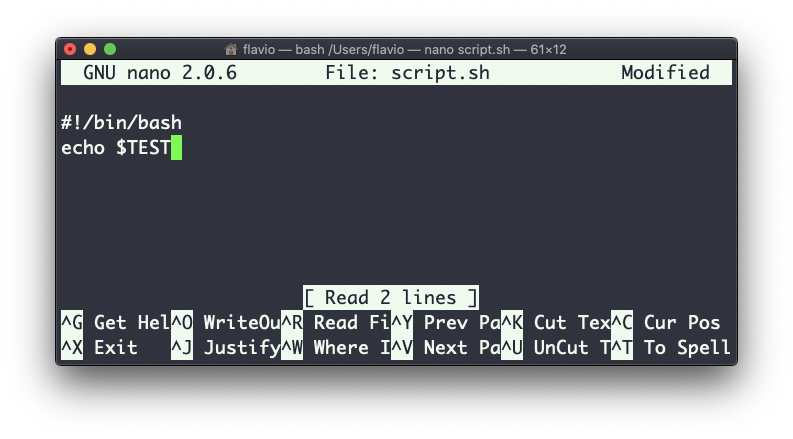
Entonces cuando pones chmod u+x script.sh y ejecutas este script con ./script.sh, ¡la línea echo $TEST no imprimirá nada!
Esto se debe a que en Bash la variable TEST se definió local al shell. Cuando se ejecuta un script de shell u otro comando, se lanza un subshell para ejecutarlo, que no contiene la variables locales actuales del shell.
Para que la variable esté disponible allí, necesitamos no definir TEST de esta manera:
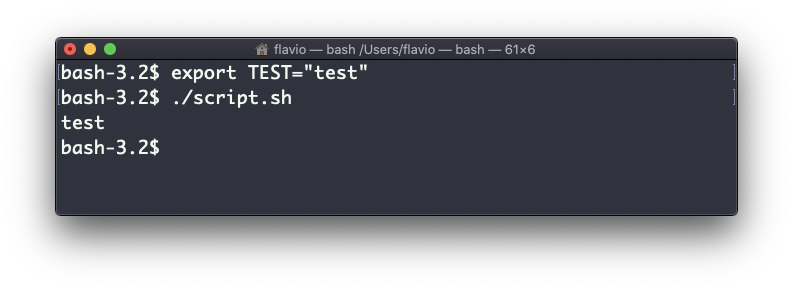
TEST="test"pero de esta:
export TEST="test"Inténtalo, y ejecutando ./script.sh ahora debería imprimir "test":
A veces hay que agregar algo a una variable. A menudo se hace con la variable PATH. Se utiliza esta sintaxis:
export PATH=$PATH:/new/pathEs común usar export cuando se crean nuevas variables de esta manera. Pero también puedes usarlo cuando creas variables en los archivos de configuración .bash_profile o .bashrc con Bash, o en .zshenv con Zsh.
Para remover una variable, usa la opción -n:
export -n TESTSi se llama a export sin ninguna opción, se enlistarán todas las variables exportadas.
El comando crontab de Linux
Los trabajos "cron" son trabajos que están programados para ejecutarse a intervalos específicos. Puedes que tengas un comando que realice algo cada hora, o cada día, o cada 2 semanas. O los fines de semana.
Son muy poderosos, especialmente cuando se usan en servidores para realizar mantenimiento y automatizaciones.
El comando crontab es el punto de entrada para trabajar con trabajos cron.
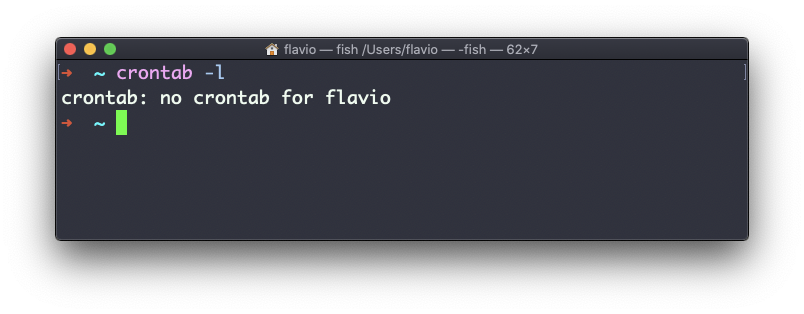
Lo primero que puedes hacer es explorar qué trabajos cron son definidos por ti:
crontab -lPuede que no tengas ninguno, como yo:
Ejecuta
crontab -epara editar los trabajos cron, y agregar otros nuevos.
Por defecto, esto se abre con el editor predeterminado, que suele ser vim. Me gusta más nano. Puedes usar esta línea para usar un editor diferente:
EDITOR=nano crontab -eAhora puedes agregar una línea por cada trabajo cron.
La sintaxis para definir los trabajos cron es un poco aterradora. Por eso suelo utilizar un sitio web que me ayuda a generarlo sin errores: https://crontab-generator.org/
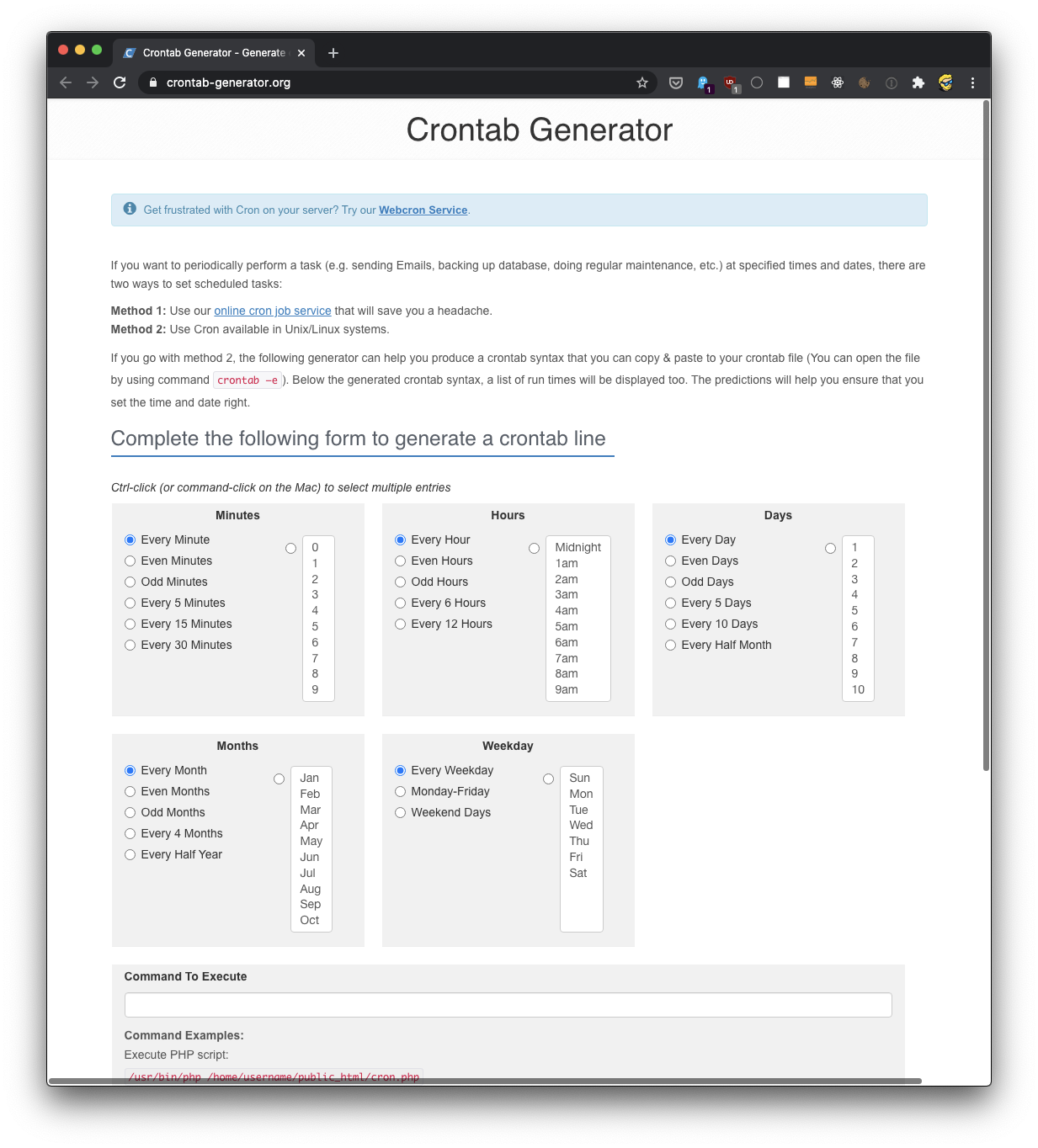
Escoge un intervalo de tiempo para el trabajo cron, y escribe el comando a ejecutar.
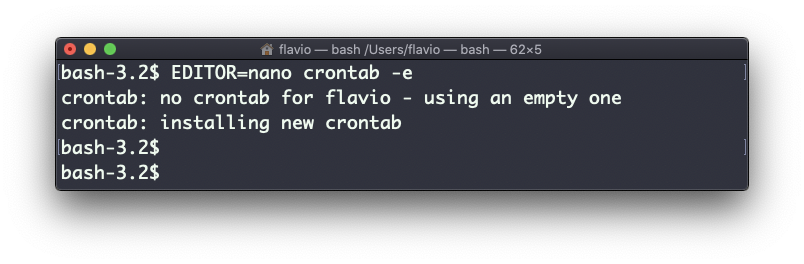
Elegí ejecutar un script localizado en /Users/flavio/test.sh cada 12 horas. Esta es la línea de crontab que necesito ejecutar:
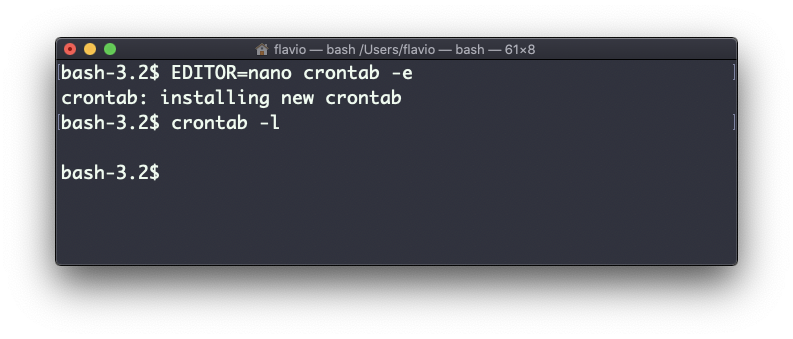
* */12 * * * /Users/flavio/test.sh >/dev/null 2>&1Ejecuto crontab -e:
EDITOR=nano crontab -ey agrego esa línea, luego pulso ctrl-X y presiono y para salvar.
Si todo va bien, el trabajo cron está listo:
Una vez hecho esto, puedes ver la lista de trabajos cron activos ejecutándose:
crontab -l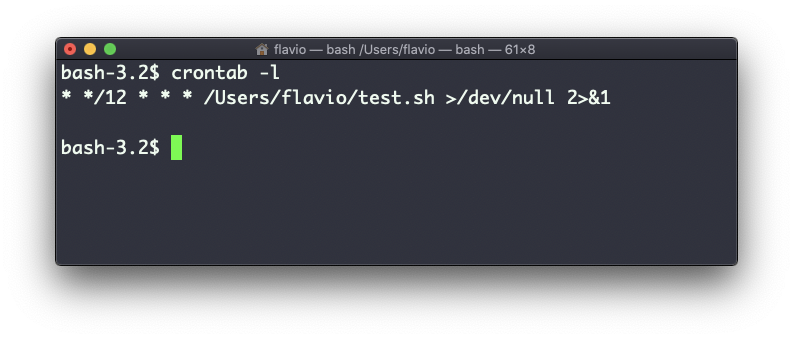
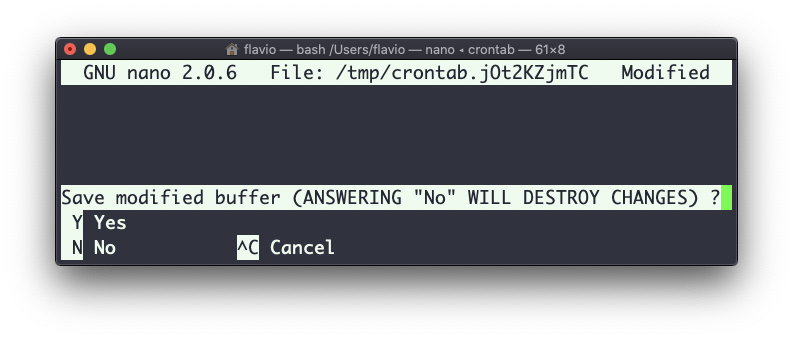
Puedes eliminar un trabajo cron ejecutando crontab -e de nuevo, eliminando la línea y saliendo del editor:
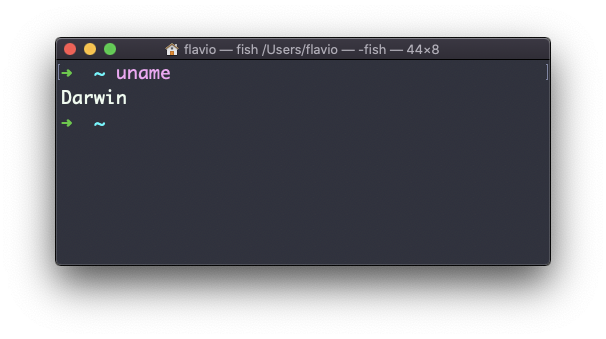
El comando uname de Linux
Llamar a uname sin opciones devolverá el nombre en clave del Sistema Operativo:
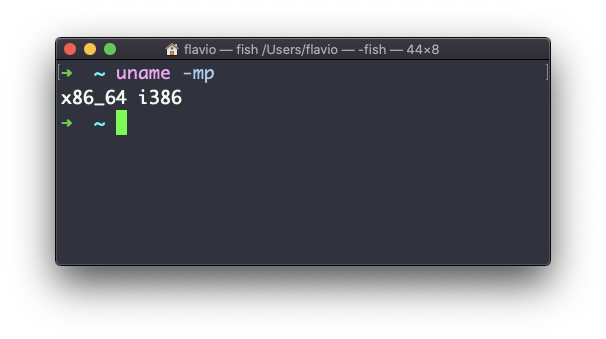
La opción m muestra el nombre del hardware (x86_64 en este ejemplo) y la opción p imprime el nombre de la arquitectura del procesador (i386 en este ejemplo):
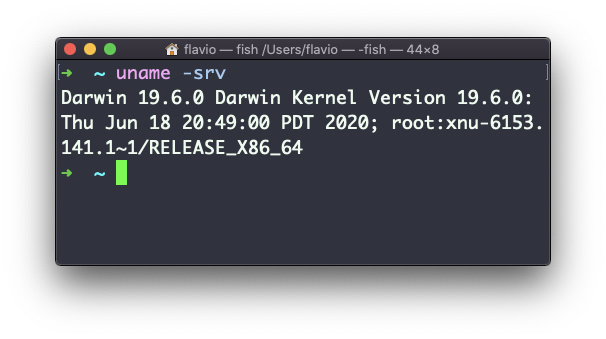
La opción s imprime el nombre del Sistema Operativo. r imprime el último lanzamiento (release) y v imprime la versión:
La opción n imprime el nombre de la red de nodos:
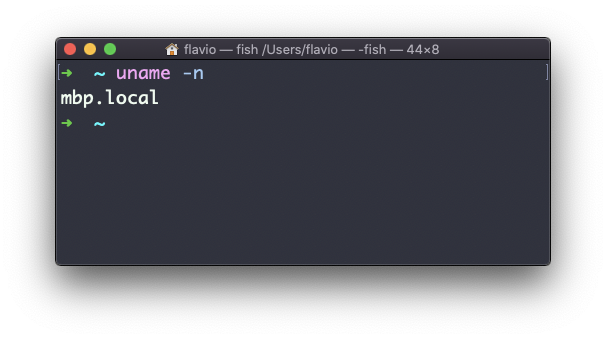
La opción a imprime toda la información disponible:
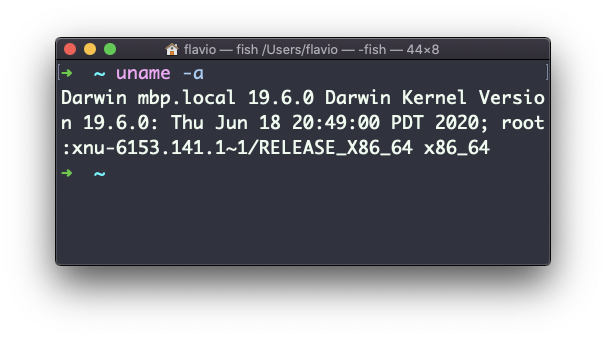
En macOS también puedes usar al comando sw_vers para imprimir más información sobre el Sistema Operativo de macOS. Ten en cuenta que esto difiere de la versión de Darwin (el Kernel), que arriba muestra que es 19.6.0.
Darwin es el nombre del kernel de macOS. El kernel es el "núcleo" del Sistema Operativo, mientras que el Sistema Operativo en conjunto se llama macOS. En Linux, Linux es el kernel, y GNU/Linux sería el nombre del Sistema Operativo (aunque todos nos referimos a él como "Linux").
El comando env de Linux
El comando env puede ser usado para pasar variables de entorno sin configurarlas en el entorno exterior (el shell actual).
Supongamos que quieres ejecutar una aplicación de Node.js y establecer la variable USER en ella.
Puedes ejecutar
env USER=flavio node app.jsy la variable de entorno USER será accesible desde la aplicación Node.js a través de la interfaz de Node process.env.
También puedes ejecutar el comando que borra todas las variables de entorno ya establecidas, usando la opción -i:
env -i node app.jsEn este caso obtendrás un error diciendo env: node: No such file or directory porque el comando node no es alcanzable, ya que la variable PATH usada por el shell para buscar comandos en las rutas comunes no está establecida.
Así que tienes que pasar la ruta completa al programa de node:
env -i /usr/local/bin/node app.jsInténtalo con un simple archivo app.js con este contenido:
console.log(process.env.NAME)
console.log(process.env.PATH)Verás la salida como
undefined
undefinedPuedes pasar una variable env:
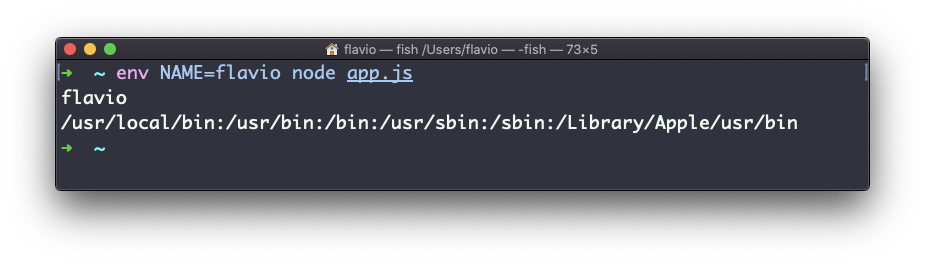
env -i NAME=flavio node app.jsy la salida será
flavio
undefinedEliminado la opción -i hará que PATH esté disponible de nuevo dentro del programa:
El comando env también puede ser usado para imprimir todas las variables de entorno. Si se ejecuta sin opciones:
envdevolverá una lista de las variables de entorno establecidas, por ejemplo:
HOME=/Users/flavio
LOGNAME=flavio
PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Library/Apple/usr/bin
PWD=/Users/flavio
SHELL=/usr/local/bin/fishTambién puedes hacer que una variable sea inaccesible dentro del programa que ejecutas, usando la opción -u. Por ejemplo, este código elimina la variable HOME del entorno de comandos:
env -u HOME node app.jsEl comando printenv de Linux
Aquí está una guía rápida del comando printenv, usado para imprimir los valores de las variables de entorno.
En cualquier shell hay un buen número de variables de entorno, establecidas ya sea por el sistema, o por tus propios scripts de shell y configuración.
Puedes imprimirlas todas a la terminal usando el comando printenv. La salida será algo como esto:
HOME=/Users/flavio
LOGNAME=flavio
PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Library/Apple/usr/bin
PWD=/Users/flavio
SHELL=/usr/local/bin/fishcon unas pocas líneas más, por lo general.
Puedes agregar un nombre de variable como parámetro, para mostrar solo el valor de la variable:
printenv PATH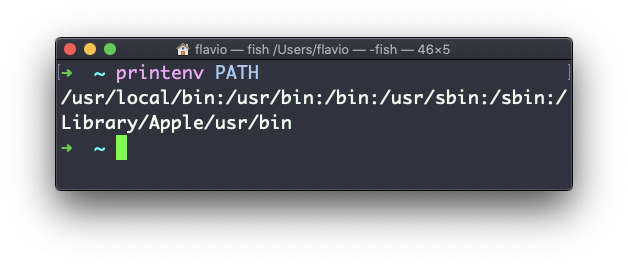
Conclusión
Muchas gracias por leer este manual.
Espero que te inspire para aprender más sobre Linux y sus capacidades. Es un conocimiento perdurable que no quedará desactualizado pronto.
¡Recuerda que puedes descargar este manual en formato PDF / ePUB / Mobi si así lo deseas!
Publico tutoriales de programación todos los días en mi sitio web flaviocopes.com si quieres ver más contenido genial como este.
Puedes contactarme en Twitter @flaviocopes.
Traducido del artículo de Flavio Copes' The Linux Command Handbook