
Artículo original: How I investigated memory leaks in Go using pprof on a large codebase
He estado trabajando con Go durante la mejor parte de este año, implementando una infraestructura de blockchain escalable en Orbs, y ha sido un año estupendo. En el curso de 2018, investigué qué lenguaje elegir para nuestra implementación de blockchain. Esto nos llevó elegir Go porque, a nuestro entender, tiene una buena comunidad y un conjunto de herramientas maravilloso.
En las semanas recientes estamos entrando en las etapas finales de integración de nuestro sistema. Como en cualquier sistema grande, las etapas siguientes los cuales incluyen problemas de rendimiento, más específico fugas de memoria, podrían ocurrir. Mientras estábamos integrando el sistema, nos dimos cuenta de que encontramos uno. En este artículo tocaré los detalles de cómo investigar una fuga de memoria en Go, detallando los pasos tomados para encontrar, entender y resolverlo.
El conjunto de herramientas ofrecido por Go(lang) es excepcional, pero tiene sus limitaciones. Tocando estos primeros, el más grande es la habilidad limitada de investigar volcados de memoria completos. Un volcado de memoria completo sería la imagen de la memoria (o memoria de usuario) tomado por el proceso que ejecuta el programa.
Podemos imaginar el mapeo de memoria como un árbol, y atravesar ese árbol nos tomaría a través de distintas asignaciones de objetos y las relaciones. Esto significa que cualquier cosa que esté en la raíz es la razón para 'sostener' la memoria y que no sea tomado por el Recolector de Basura. Ya que en Go no hay una manera sencilla de analizar el volcado de memoria completo, ir a las raíces de un objeto que no pasa por el Recolector de Basura es difícil.
Al momento de escribir, fuimos incapaz de encontrar alguna herramienta en línea que nos pueda asistir con eso. Ya que existe un formato de volcado de memoria y una sencilla manera suficiente de exportarlo desde el paquete de depuración, podría ser que haya usado uno en Google. Buscando en línea parece que está en la tubería de Go(lang), creando un visualizador de volcado de memoria como tal, pero parece que nadie está trabajando en él. Habiendo dicho eso, inclusive sin acceso a tal solución, con las herramientas existentes podemos usualmente llegar a la raíz de la causa.
Fugas de Memoria
Las fugas de memoria, o presión de memoria, pueden venir en varias formas a través de todo el sistema. Usualmente, podemos abarcarlos como errores, pero a veces su causa raíz podría ser en decisiones de diseño.
A medida que construimos nuestro sistema bajo principios de diseño emergentes, tales consideraciones no se toman como de importancia y eso está bien. Es más importante construir el sistema de una manera que evita las optimizaciones prematuras y te permita ejecutarlos luego a medida que el código madure, más que sobredimensionarlo desde el principio. Aún, algunos ejemplos comunes de ver problemas de presión de memoria materializarse son:
- Demasiadas asignaciones, representación de datos incorrectos
- Uso intenso de reflexión o de cadenas
- Usar globales
- Huérfanos, rutinas de go interminables
En Go, la manera más sencilla de crear una fuga de memoria es definir una variable global, un arreglo, y adjuntar datos a ese arreglo.
Entonces, ¿por qué estoy escribiendo este post? Cuando estaba investigando este caso encontré muchos recursos sobre fugas de memoria. Aunque, en realidad los sistemas tienen más de 50 líneas de código y un solo struct. En tales casos, encontrar el recurso de un problema de memoria es mucho más complejo de lo que ese ejemplo describe.
Go(lang) nos da una herramienta maravillosa llamada pprof. Esta herramienta, cuando se lo domina, puede ayudar en investigar y muy probablemente encontrar cualquier problema de memoria. Otro propósito que tiene es para investigar problemas de CPU, pero no iré en nada relacionado al CPU en este post.
Herramienta de go pprof
Cubrir todo lo que esta herramienta hace requerirá más que un post de blog. Una cosa que tomó tiempo fue encontrar cómo usar esta herramienta para tener algo procesable. Me concentraré en este post en su característica relacionada a memoria.
El paquete pprof crea un archivo de volcado de muestra de pila, el cual puedes analizar / visualizar luego para darte un mapeo de ambos:
- Asignaciones de memoria Actuales
- Asignaciones de memoria Totales (acumulativas)
La herramienta tiene la habilidad de comparar tomas de imágenes instantáneas. Esto te permite comparar en una pantalla la diferencia de tiempo de lo que pasó ahora mismo y 30 segundos atrás, por ejemplo. Para escenarios de estrés, esto puede ser útil para asistir en asignar áreas problemáticas de tu código.
Perfiles de pprof
La forma en que pprof funciona es usando perfiles.
Un Perfil es una colección de rastros de pila mostrando las secuencias de llamada que llevó a las instancias de un evento particular, tales como asignación.
El archivo runtime/pprof/pprof.go contiene la información detallada y la implementación de los perfiles.
Go tiene varias incorporaciones en perfiles para nosotros para usarlos en casos comunes:
- goroutine — rastros de pila de todas las rutinas de go actuales
- heap — un muestreo de asignaciones de memoria de objetos vivos
- allocs — un muestreo de todas las asignaciones de memoria anteriores
- threadcreate — rastros de pila que llevó a la creación de nuevos hilos del OS
- block — rastros de pila que llevó a bloquear las primitivas de sincronización
- mutex — rastros de pila de poseedores de mutexes disputados
Cuando miremos a los problemas de memoria, nos concentraremos en el perfil de pila. El perfil de asignaciones es idéntico en lo referido a la colección de datos que hace. La diferencia entre los dos es en la manera en que la herramienta pprof lee allí al mismo tiempo. El perfil de asignaciones comenzará pprof en un modo el cual muestra el número total de bytes asignados desde que el programa comenzó (incluyendo los bytes recogidos como basura). Usualmente, usaremos ese modo cuando intentemos hacer nuestro código más eficiente.
La pila
En resumen, aquí es donde el OS (Sistema Operativo) almacena los objetos de memoria que nuestro código utiliza. Esta es la memoria el cual luego queda 'coleccionado como basura', o liberado manualmente en lenguajes no coleccionados como basura.
La pila no es el único lugar donde las asignaciones de memoria ocurren, alguna memoria también es asignado en el Stack. El propósito del stack es de corto plazo. En go el stack es usualmente usado para asignaciones que ocurren dentro del cierre de una función. Otro lugar donde Go usa el stack es donde el compilador 'sabe' cuánto de memoria necesita ser reservada antes del tiempo de ejecución (por ej. arreglos de tamaño fijos). Hay una manera de ejecutar el compilador de Go de manera que mostrará una análisis de dónde las asignaciones 'escapan' del stack a la pila, pero no tocaré eso en este post.
Mientras que los datos de la pila necesitan ser 'liberados' y pasar por gc, los datos del stack no lo necesitan. Esto significa que es más eficiente usar el stack donde fuera posible.
Esto es un resumen de las distintas localizaciones donde la asignación de memoria ocurre. Hay un montón más de esto pero estará fuera del alcance para este post.
Obtener datos de la pila con pprof
Hay dos manera generales de obtener los datos para esta herramienta. El primero será usualmente parte de esta prueba o una rama e incluye importar runtime/pprof y después llamar a pprof.WriteHeapProfile(algun_archivo) para escribir la información del heap.
Nota que WriteHeapProfile es sintaxis legible para ejecutar :
// lookup toma un perfil namepprof.Lookup("heap").WriteTo(algun_archivo, 0)De acuerdo con la documentación, WriteHeapProfile existe para retrocompatibilidad. El resto de los perfiles no tienen tales atajos y debes usar la función Lookup() para obtener sus datos de perfil.
El segundo, el cual es el más interesante, es habilitarlo sobre HTTP (puntos finales basados en web). Esto te permite extraer el adhoc de los datos, desde un contenedor en ejecución en tu entorno e2e / prueba o inclusive desde 'producción'. Este es un lugar mas donde el tiempo de ejecución y el conjunto de herramientas de Go sobresale. La documentación del paquete entero lo encuentras aquí, pero el TL;DR es que necesitarás agregarlo a tu código así:
import ( "net/http" _ "net/http/pprof")
...
func main() { ... http.ListenAndServe("localhost:8080", nil)}El 'efecto secundario' de importar net/http/pprof es el registro de los puntos finales de pprof en la raíz del servidor web en /debug/pprof. Ahora usando curl podemos obtener los archivos de información del heap para investigar:
curl -sK -v http://localhost:8080/debug/pprof/heap > heap.outAgregando el http.ListenAndServe() arriba es requerido solamente si tu programa no tenía un oyente de http antes. Si lo tienes lo enganchará y no hay necesidad de escuchar otra vez. Hay formas también de configurarlo usando ServeMux.HandleFun() el cual tendría más sentido para un programa habilitado para http más complejo.
Usando pprof
Así que hemos recogidos datos, ¿ahora qué? Como mencionamos arriba, hay dos estrategias de análisis de memorias principales con pprof. Una es mirar las asignaciones actuales (cuenta de bytes u objeto), llamado inuse. El otro es mirar todos los bytes asignados o cuenta de objeto a lo largo del tiempo de ejecución del programa, llamado alloc. Esto significa que a sin importar si fue a través de gc, una suma de todo lo muestreado.
Este es un buen lugar para reiterar que el perfil de la pila es un sampleo de las asignaciones de memoria. pprof en detrás de escena está usando la función runtime.MemProfile, el cual por defecto recolecta información de asignación en cada 512KB de los bytes asignados. Es posible cambiar MemProfile para recoger información de todos los objetos. Nota que muy probablemente, esto ralentizará tu aplicación.
Esto significa que por defecto, hay alguna chance de que un problema pueda ocurrir con objetos más pequeños que pasará inadvertido del radar de pprof. Para una base de código grande / programa de larga duración, esto no es un problema.
Una vez que recogimos el archivo del perfil, es tiempo de cargarlo en la consola interactiva que pprof ofrece. Hazlo así corriendo:
> go tool pprof heap.outObservemos la información que se muestra
Type: inuse_spaceTime: Jan 22, 2019 at 1:08pm (IST)Entering interactive mode (type "help" for commands, "o" for options)(pprof)Lo importante a notar aquí es el Type: inuse_space. Esto significa que estamos mirando a los datos de asignación de un momento específico (cuando capturamos el perfil). El tipo es el valor de configuración de sample_index, y los valores posibles son:
- inuse_space — cantidad de memoria asignada y no liberada todavía
- inuse_object s— cantidad de objetos asignados y no liberados todavía
- alloc_space — cantidad total de memoria asignada (sin importar of released)
- alloc_objects — cantidad total de objetos asignados (sin importar de released)
Ahora escribe top en el interactivo, la salida serán los consumidores máximos de memoria
Podemos ver una línea diciéndonos sobre Droppped Nodes, esto significa que son filtrados. Un nodo es una entrada de objeto, o un 'nodo' en el árbol. Discontinuar nodos es una buena idea para reducir algo de ruido, pero a veces podría ocultar la causa raíz de un problema de memoria. Veremos un ejemplo de eso mientras continuamos con nuestra investigación.
Si quieres incluir todos los datos del perfil, agrega la opción -nodefraction=0 cuando ejecutes pprof o escribe nodefraction=0 en la consola interactiva.
En la lista expuesta podemos ver dos valores, flat y cum.
- flat significa que la memoria es asignada por esta función y retenida por esa función
- cum significa que la memoria fue asignada por esta función o una función que llamó al stack
Esta sola información puede a veces ayudarnos en entender si hay un problema. Toma por ejemplo un caso en donde la función es responsable de asignar mucha memoria pero no lo está reteniendo. Esto significaría que algún otro objeto está apuntando a esa memoria y manteniéndola asignada, lo que significa que tendríamos un problema de diseño de sistema o un error.
Otro truco elegante sobre top en la ventana interactiva es que en realidad está ejecutando top10. El comando top soportar el formato topN donde N es el número de entradas que quieres ver. En el caso pegado arriba, ejecutar top70 por ejemplo, imprimiría todos los nodos.
Visualizaciones
Mientras que el topN da una lista textual, hay varias opciones de visualizaciones muy útiles que vienen con pprof. Es posible escribir png o gif y muchos más (mira go tool pprof -help para una lista completa).
En nuestro sistema, la salida visual por defecto se ve algo así:
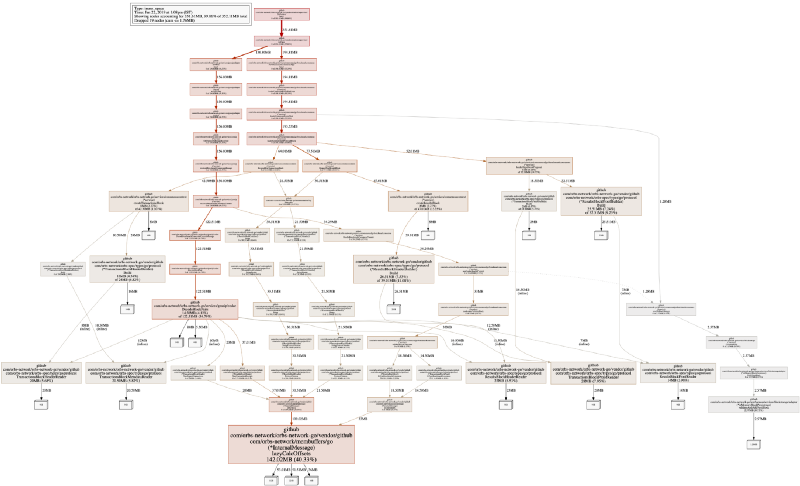
Esto podría ser intimidante al principio, pero es la visualización de los flujos de asignación de memoria (según los rastros del stack) en un programa. Leer el gráfico no es tan complicado como parece. Un cuadrado en blanco con un número muestra espacio asignado (y lo acumulativo de cuánta memoria está tomando ahora mismo en el borde del gráfico), y cada rectángulo más ancho muestra la función de asignación.
Nota que en la imagen de arriba, tomé un png de un modo de ejecución inuse_space. Muchas veces deberías ver también a inuse_objects, ya que puede ayudar en encontrar problemas de asignación.
Indagando más profundo, encontrando una cause raíz
Hasta ahora, fuimos capaz de entender qué es asignar memoria en nuestra aplicación durante el tiempo de ejecución. Esto nos ayuda a tener una sensación de cómo nuestro programa se comporta (o se malcomporta).
En nuestro caso, podríamos ver que la memoria es retenida por membuffers, el cual es nuestra librería de serialización de datos. Esto no significa que tenemos una fuga de memoria en ese segmento de código, sino que la memoria está siendo retenida por esa función. Es importante entender cómo leer el gráfico, y la salida de pprof en general. En este caso, entender que cuando serializamos los datos, lo que quiere decir que asignamos memoria a objetos structs y primitivos (int, string), nunca es liberado.
Saltando a conclusiones o malinterpretando el gráfico, podríamos haber asumido que uno de los nodos en el camino a serialización es responsable de retener la memoria, por ejemplo:
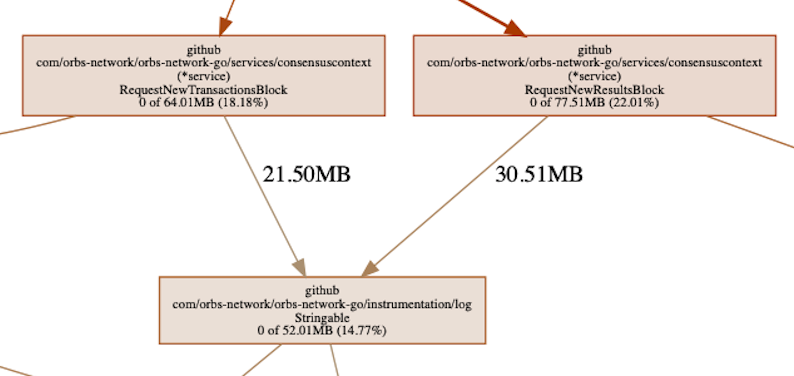
En algún lugar en la cadena podemos ver nuestra librería de registro, responsable de >50Mb de memoria asignada. Esto es memoria la cual es asignada por funciones llamadas por nuestro registrador. Pensándolo bien, en realidad es lo que se espera. El registrador ocasiona asignaciones de memoria ya que necesita serializar datos para imprimirlos al registro y así causa asignaciones de memoria en el proceso.
También podemos ver el camino de asignación, la memoria es retenida solamente por serialización y nada más. Adicionalmente, la cantidad de memoria retenida por el registrador es de 30% del total. Lo de arriba nos dice que, muy probablemente, el problema no es con el registrador. Si fuera 100%, o algo cerca a eso, entonces deberíamos haber estado mirando allí – pero no. Lo que podría significar es que algo está siendo registrado que no debería, pero no es una fuga de memoria por el registrador.
Este es un buen tiempo para introducir otro comando de pprof llamado list. Acepta una expresión regular el cual será un filtro de qué listar. La 'lista' es en realidad el código fuente anotado relacionado a la asignación. En el contexto del registrador el cual estamos viendo, ejecutaremos list RequestNew ya que nos gustaría ver llamadas hechas al registrador. Estas llamadas están viniendo de dos funciones los cuales vienen a empezar con el mismo prefijo.
Podemos ver que las asignaciones están en la columna cum, lo que significa que la memoria asignada es retenida al stack de llamada. Esto se correlaciona a lo que el gráfico también muestra. En este punto es fácil ver que la razón de que el registrador estaba asignando la memoria es porque le enviamos el objeto 'bloque' entero. Necesitaba serializar algunas partes de éste a lo menos (nuestros objetos son objetos de membuffer, lo cuales siempre implementan algunas función String()). ¿Es un mensaje de registro útil, o una buena práctica? Probablemente no, pero no es una fuga de memoria, no al final del registrador o del código el cual llamó el registrador.
list puede encontrar el código fuente al buscarlo en tu entorno GOPATH. En casos donde la raíz que se busca no coincide, el cual depende en tu máquina de construcción, puedes usar la opción -trim_path. Esto te ayudará para arregrarlo y te permite ver el código de fuente anotado. Recuerda poner tu git al commit correcto el cual se estaba ejecutando cuando el perfil heap fue capturado.
Entonces, ¿por qué la memoria es retenida?
El trasfondo de esta investigación fue la sospecha de que tenemos un problema – una fuga de memoria. Llegamos a esa noción mientras vimos que el consumo de memoria fue más alto de lo que esperaríamos que el sistema necesitara. Encima de eso, lo vimos incrementar, lo cual fue otro fuerte indicador de que 'hay un problema aquí'.
En este punto, en el caso de Java o .Net, abriríamos algún análisis 'gc roots' o el perfilador y llegar al objeto actual el cual está referenciando a ese dato, y está creando la fuga. Como se explicó, esto no es exactamente posible con Go, ambos por un error de herramienta pero también por la representación baja de memoria de Go.
Sin ir en detalles, no pensamos que Go tiene noción de qué objeto es almacenado en tal dirección (excepto por los punteros tal vez). Esto significa que en realidad, entender qué dirección de memoria representa tal miembro de tu objeto (struct) requerirá algún tipo de mapeo a la salida de un perfil de pila. Hablando de teoría, esto podría significar que antes de tomar un volcado de memoria completo, uno debería también tomar un perfil de pila, de esa manera las direcciones pueden ser mapeados a la línea de asignación y archivo y así el objeto representado en la memoria.
En este punto, porque estamos familiarizado con nuestro sistema, fue fácil entender que ya no es un error. Fue (casi) por diseño. Pero continuemos explorando en cómo obtener la información de las herramientas (pprof) para el encontrar la causa raíz.
Cuando ponemos nodefraction=0 llegaremos a ver el mapeo entero de los objetos asignados, incluyendo los más pequeños. Miremos la salida:
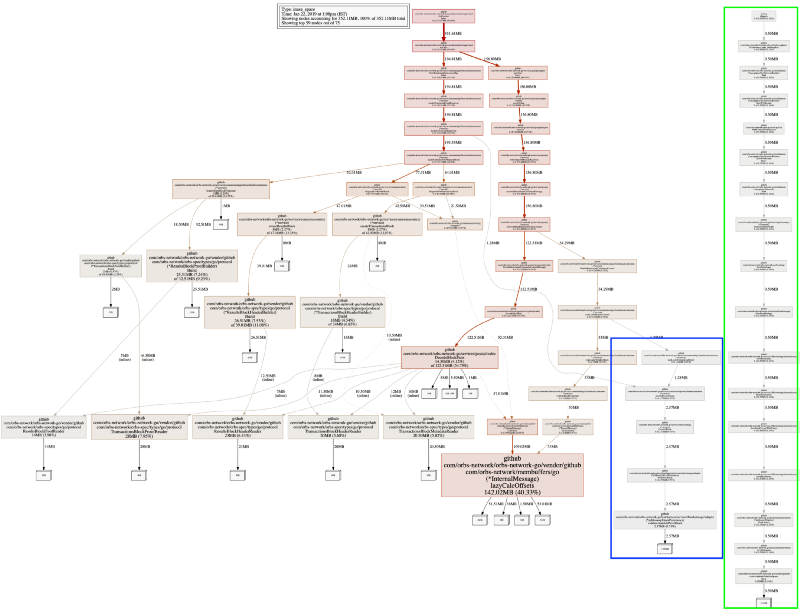
Tenemos dos subárboles nuevos. Recordando otra vez, el perfil de pila de pprof está muestreando asignaciones de memoria. Para nuestro sistema eso funciona – no estamos perdiendo ninguna información importante. El nuevo árbol más largo, en verde, el cual está completamente desconectado del resto del sistema es el ejecutador de pruebas, no es interesante.
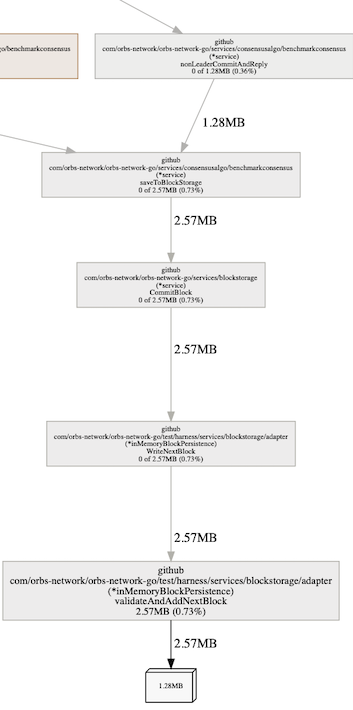
El más corto, en azul, el cual tiene una esquina conectándolo al sistema entero es inMemoryBlockPersistance. Ese nombre también explica la 'fuga' que imaginamos que tenemos. Este es el backend de los datos, el cual está ordenando todos los datos en memoria y no persiste en el disco. Lo que es lindo de notar es que podríamos ver inmediatamente que está reteniendo dos objetos grandes. ¿Por qué dos? Porque podemos ver que el objeto es del tamaño de 1.28MB y la función está reteniendo 2.57MB, lo que significa dos de ellos.
El problema está bien entendido en este punto. Podríamos haber usado delve (el depurador) para ver que este es el arreglo reteniendo todos los bloques para el controlador de persistencia en memoria que tenemos.
Así que, ¿qué podríamos arreglar?
Bueno, eso apesta, fue un error humano. Mientras el proceso fue educativo (y compartir es cuidar), no mejoramos, ¿o sí?
Hubo una cosa que todavía 'olía' sobre esta información de la pila. Los datos deserializados estaban tomando demasiada memoria, ¿por qué 142MB para algo que debería estar tomando sustancialmente menos?... pprof puede responder eso – en realidad, existe una manera de responder a tales preguntas exactamente.
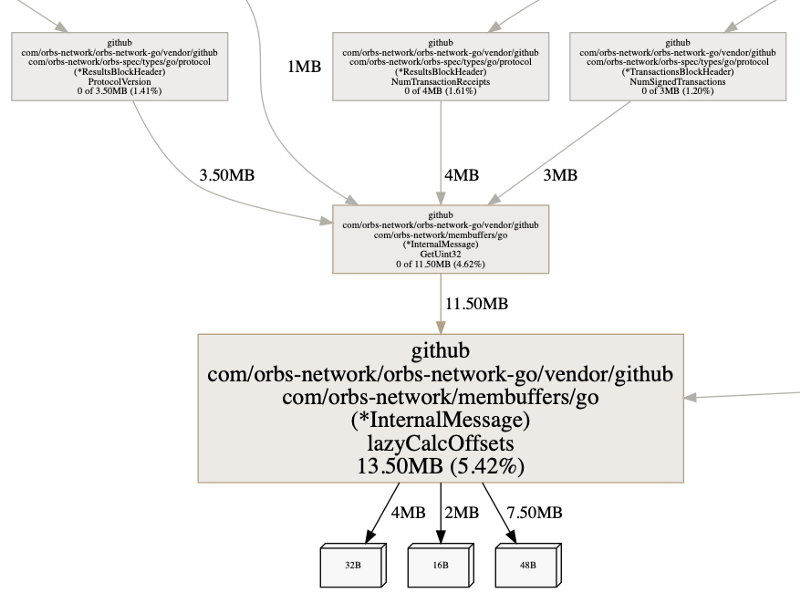
Para buscar el código fuente anotado de la función, ejecutaremos list lazy. Usamos lazy, ya que el nombre de la función que estamos buscando es lazyCalcOffsets(), y no sabemos de otra funciones en nuestro código que comiencen con lazy. Escribir list lazyCalcOffsets funcionaría también por supuesto.
Podemos ver dos pedazos interesantes de información. De nuevo, recuerda que el perfil de pila de pprof muestrea la información sobre las asignaciones. Podemos ver que ambos números flat y cum son los mismos. Esto indica que la memoria asignada también es retenida por estos puntos de asignación.
Luego, podemos ver que el make() está tomando algo de memoria. Tiene sentido, es el puntero a la estructura de datos. Aunque también vemos la asignación en la línea 43 está tomando memoria, lo que significa que crea una asignación.
Esto nos enseñó sobre mapeos, donde una asignación a un mapeo no es una asignación de variable directa. Este artículo va en gran detalle sobre cómo el mapeo funciona. En pocas palabras, un mapeo tiene una sobrecarga, y cuanto más elementos, más grande esta sobrecarga va a 'costar' cuando comparamos a un slice.
Lo siguiente debería ser tomado como un granito de sal: Estaría bien decir que usar un map[int]T, cuando los datos no están esparcidos o pueden ser convertidos a índices sequenciales, usualmente deberían ser probados con una implementación de corte si el consumo de memoria es una consideración relevante. Aunque, un corte grande, cuando se expanda, podría ralentizar una operación, siendo que en un mapeo esta ralentización será despreciable. No hay una fórmula mágica para las optimizaciones.
En el código de arriba, después de chequear cómo usamos ese mapeo, nos dimos cuenta que mientras nos imaginábamos que es un arreglo esparcido, no llegó a ser tan esparcido. Esto coincide con el argumento de arriba y podríamos ver inmediatamente que una refactorización pequeña de cambiar el mapeo a un corte es en realidad posible, y podría hacer ese código más eficiente para la memoria. Así que lo cambiamos a:
Tan simple como eso, en vez de usar un mapeo ahora estamos usando un corte. Debido a la manera en que recibimos los datos los cuales son cargados de manera perezoza dentro del corte, y cómo después accedemos a esos datos, aparte de esas dos líneas y la estructura reteniendo esos datos, ningún otro cambio de código fue requerido. ¿Qué le hizo al consumo de memoria?
Miremos a benchcmp durante un par de pruebas.
Las pruebas de lectura inicializan la estructura de datos, los cuales crean las asignaciones. Podemos ver que el tiempo de ejecución mejoró con un ~30%, las asignaciones han bajado en un 50% y el consumo de memoria con un >90%(!).
Ya que el mapeo, ahora corte, nunca fue llenado con muchos items, los números más o menos muestran que veremos en producción. Depende en la entropía de los datos, pero podría haber casos donde las asignaciones y las mejoras de consumo de memoria hubieran sido aún más grandes.
Viendo a pprof otra vez, y tomando un perfil de pila de la misma prueba, veremos que ahora el consumo de memoria es de hecho por debajo del ~90%.
El punto será que para los conjuntos de datos más pequeños, no deberías usar mapeos donde los cortes bastarían, ya que los mapeos tienen una sobrecarga grande.
Volcado de memoria completo
Como se mencionó, aquí es donde vemos la limitación más grande con las herramientas ahora mismo. Cuando estábamos investigando este problema, nos obsesionamos con ser capaz de llegar al objeto raíz, sin mucho éxito. Go evoluciona con el tiempo a un gran ritmo, pero esa evolución viene con un precio en el caso del volcado de memoria o la representación de memoria. El formato del volcado de la pila completa, ya que cambia, no es retrocompatible. Para la última versión descrito aquí y escribir un volcado de pila completa, puedes usar debug.WriteHeapDump().
Aunque ahora mismo, no nos encontramos 'estancados' porque no hay una buena solución para explorar volcados completos. pprof contestó todas nuestras preguntas hasta ahora.
Toma nota, la internet recuerda un montón de información que ya no es más relevante. Aquí hay algunas cosas que deberías ignorar si vas a intentar y abrir un volcado completo tu mismo, a partir de go1.11:
- No hay manera de abrir y depurar un volcado de memoria completo en MacOS, solamente en Linux.
- Las herramientas en https://github.com/randall77/hprof son para Go1.3, existe un fork para 1.7+ pero no funciona apropiadamente tampoco (incompleto).
- viewcore at https://github.com/golang/debug/tree/master/cmd/viewcore no compila realmente. Es bastante fácil arreglar (los paquetes en lo interno están apuntando a golang.org y no a github.com), pero, tampoco funciona, no en MacOS, tal vez en Linux.
- https://github.com/randall77/corelib también falla en MacOS
pprof UI
Un último detalle a tener en mente cuando se trata de pprof, es su característica UI. Puede salvar mucho tiempo cuando se empieza una investigación en cualquier problema relacionando a un perfil tomado con pprof.
go tool pprof -http=:8080 heap.outA este punto debería abrir el navegador web. Si no lo hace entonces busca en el puerto en el que lo configuraste. Te permite cambiar las opciones y tener retroalimentación visual más rápido de lo que puedes con una línea de comando. Una manera muy útil de consumir la información.
La UI en realidad me hizo familiarizar con los gráficos de llama, los cuales exponen áreas culpables del código muy rápidamente.
Conclusión
Go es un lenguaje emocionante con un muy rico conjunto de herramientas, hay mucho más de lo que puedes hacer con pprof. Este post no toca perfilado de CPU en absoluto, por ejemplo.