

Artículo original escrito por Milap Neupane
Artículo original How to work optimally with relational databases
Traducido y adaptado por Gemma Fuster
Las bases de datos relacionales manejan los datos sin problemas, ya sea trabajando con volúmenes pequeños o procesando millones de filas. Veremos cómo podemos utilizar las bases de datos relacionales de acuerdo con nuestras necesidades y sacarles el máximo partido.
MySQL ha sido una opción popular para empresas grandes y pequeñas debido a su capacidad de escalabilidad. De manera similar, PostgreSQL también ha experimentado un aumento en popularidad.
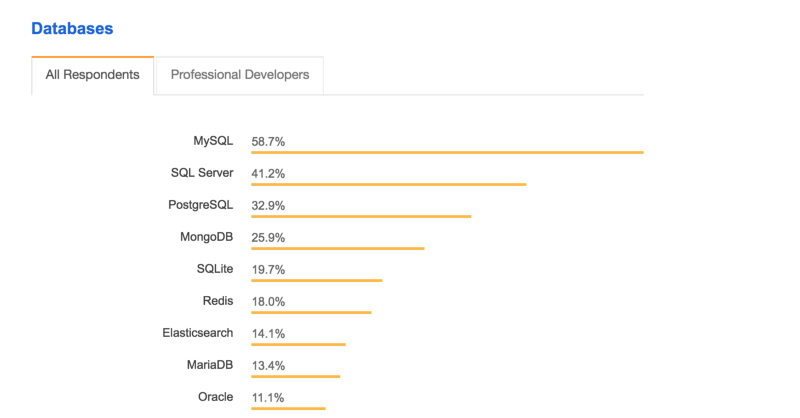
Según la encuesta de Stack Overflow 2018, MySQL es la base de datos más popular entre todos los usuarios.
Los ejemplos descritos anteriormente utilizan InnoDB como motor de almacenamiento para MySQL. No son solamente relevantes en MySQL sino también en otras bases de datos relacionales como PostgreSQL. Todas las comparativas se realizan en una computadora con 8GB de RAM y con un procesador i5 a 2.7 GHz.
Comencemos con los conceptos básicos de cómo la base de datos relacional almacena los datos.
Entendiendo las bases de datos relacionales
Almacenamiento
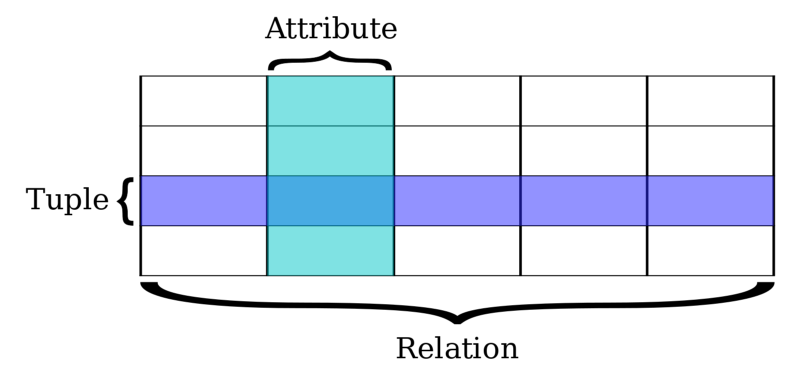
MySQL es una base de datos relacional donde los datos (data) estan representados en tuplas o lista de registros (tuples), agrupadas en relaciones (relations). Un tupla se representa por sus atributos (attributes).
Supongamos que tenemos una aplicación en la que las personas pueden prestar libros. Necesitaremos almacenar todas las transacciones de préstamo de libros. Para almacenarlos, hemos diseñado una tabla relacional simple con el siguiente comando:
> CREATE TABLE libro_transacciones ( id INTEGER NOT NULL AUTO_INCREMENT, libro_id INTEGER, prestatario_id INTEGER, prestador_id INTEGER, retorno_fecha DATE, PRIMARY KEY (id));La tabla es:
libro_transacciones
------------------------------------------------
id prestatario_id prestador_id libro_id retorno_fechaEl id es la clave principal y prestatario_id, prestador_id, libro_id son las claves foráneas. Después de lanzar nuestra aplicación, hay registradas pocas transacciones:
libro_transacciones
----------------------------------------------------------
id prestatario_id prestador_id libro_id retorno_fecha
----------------------------------------------------------
1 1 1 1 2018-01-13
2 2 3 2 2018-01-13
3 1 2 1 2018-01-13Obteniendo los datos
Tenemos una página de tablero para cada usuario donde pueden ver las transacciones de sus libros prestados. Busquemos las transacciones de libros para un usuario:
> SELECT * FROM libro_transacciones WHERE prestatario_id = 1;
libro_transacciones
---------------------------------------------------------
id prestatario_id prestador_id libro_id retorno_fecha
---------------------------------------------------------
1 1 1 1 2018-01-13
2 1 2 1 2018-01-13Esto escanea la relación secuencialmente y nos da los datos para el usuario. Esto es muy rápido, ya que hay muy pocos datos en la relación. Para ver la hora exacta de ejecución de la consulta, configura profiling a true (verdadero) ejecutando lo siguiente:
> set profiling=1;Una vez que profiling está configurado, ejecuta la misma consulta nuevamente y luego ejecuta esto para ver el tiempo de ejecución:
> show profiles;Esto devolverá la duración de la consulta que hemos ejecutado.
Query_ID | Duration | Query
1 | 0.00254000 | SELECT * FROM libro_transacciones ...La ejecución parece muy buena (rápida).
Poco a poco, la tabla libro_transacciones se empieza a llenar de datos, a medida que aumentan las transacciones.
El problema
Esto incrementa el número de tuplas de la relación. Con esto, el tiempo que lleva recuperar las transacciones del libro para el usuario comenzará a tomar más y más tiempo. MySQL necesita pasar por todas las tuplas para encontrar el resultado.
Para insertar muchos datos en la tabla, he escrito el siguiente procedimiento almacenado:
DELIMITER //
CREATE PROCEDURE insertarMuchos()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= 100000) DO
INSERT INTO libro_transacciones (prestatario_id, prestador_id, libro_id, retorno_fecha) VALUES ((FLOOR(1 + RAND() * 60)), (FLOOR(1 + RAND() * 60)), (FLOOR(1 + RAND() * 60)), CURDATE());
SET i = i+1;
END WHILE;
END //
DELIMITER ;
* Ha tardado 7 minutos en insertar 1.5 millines de datosEsto inserta 100,000 registros aleatorios en la tabla libro_transacciones. Al ejecutar esto, el profiler muestra un ligero aumento en el tiempo de ejecución:
Query_ID | Duration | Query
1 | 0.07151000 | SELECT * FROM libro_transacciones ...Agreguemos algunos datos más ejecutando el procedimiento anterior y veamos qué sucede. Con más y más datos agregados, la duración de la consulta aumenta. Con 1,5 millones de datos insertados en la tabla, ahora el tiempo de respuesta aumenta.
Query_ID | Duration | Query
1 | 0.36795200 | SELECT * FROM libro_transacciones ...Esta es solamente una consulta simple con un valor integer (entero).
Con más consultas compuestas, consultas ordenadas y consultas con recuento, el tiempo de ejecución empeora aún más.
Esto no parece ser mucho tiempo para una consulta, pero cuando tenemos miles o incluso millones de consultas ejecutándose cada minuto, esto hace una gran diferencia.
Habrá mucho más tiempo de espera y esto obstaculizará el rendimiento general de la aplicación. El tiempo de ejecución para la misma consulta aumentó de 2 ms a 370 ms.
Recuperando la velocidad
Index
MySQL, y otras bases de datos proporcionan indexación, una estructura de datos que ayuda a recuperar datos más rápido.
Hay diferentes tipos de indexación en MySQL:
- Clave primaria — Index agregado a la clave primaria. Por defecto, las claves primarias siempre están indexadas. Esto también asegura que las dos filas no tengan el mismo valor de clave principal.
- Unique — El index (índice) de Unique key index asegura que no haya dos filas en una relación que tengan el mismo valor. Se pueden almacenar varios valores nulos con un index de Unique Key .
- Index — Adición a cualquier otro campo que no sea la clave principal.
- Full Text — el index de Full text ayuda a las consultas de datos basados en caracteres.
Hay dos formas principales de almacenar un índice:
Hash — esto se usa principalmente para una coincidencia exacta (=), y no funciona con comparaciones (≥, ≤)
B-Tree — Esta es la forma más común en la que se almacenan los tipos de índices (indexes) mencionados anteriormente.
MySQL utiliza un B-Tree como formato de indexación por defecto. Los datos se almacenan en un árbol binario(binary tree) lo que hace que la recuperación de datos sea rápida.
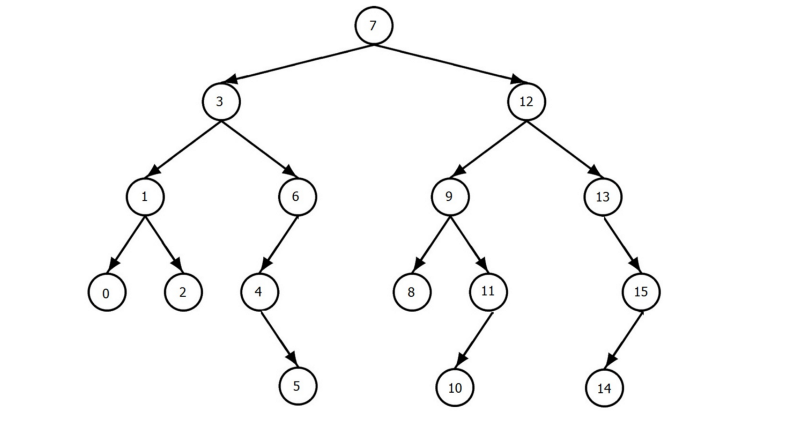
La organización de datos realizada por el B-tree ayuda a omitir el escaneo completo de la tabla en todas las tuplas de nuestra relación.
Hay un total de 16 nodos en el árbol (B-Tree) anterior. Si necesitamos encontrar el número 6, solamente necesitamos hacer un número total de 3 escaneos para obtenerlo. Esto ayuda a mejorar el rendimiento de la búsqueda.
Para mejorar el rendimiento en libro_transacciones, agreguemos el index en el campo prestador_id.
> CREATE INDEX prestadorId ON libro_transaccciones(prestador_id)
----------------------------------------------------
* Ha tardado unos 6.18secEl comando anterior agrega un index al campo prestador_id. Veamos cómo esto afecta el rendimiento de los 1,5 millones de datos que tenemos al ejecutar la misma consulta nuevamente.
> SELECT * FROM libro_transacciones WHERE prestador_id = 1;
Query_ID | Duration | Query
1 | 0.00787600 | SELECT * FROM libro_transacciones ...Woohoo! Ya hemos vuelto.
Es tan rápido como cuando solo había 3 registros en nuestra relación. Con el índice (index) correcto agregado, podemos ver una mejora dramática en la duración.
Índice compuesto y único
El índice que hemos agregado es un índice de campo único. Los índices también se pueden agregar a un campo compuesto.
Si nuestra consulta involucrara varios campos, un índice compuesto nos ayudaría. Podemos agregar un índice compuesto de la siguiente forma:
> CREATE INDEX prestadorRetornoFecha ON libro_transacciones(pretador_id, retorno_fecha);Otro uso para los índices
Las consultas no son para lo único que sirven los índices. Además se puedan usar para la cláusula ORDER BY. Ordenemos los registros en base a prestador_id.
> SELECT * FROM libro_transacciones ORDER BY prestador_id;
1517185 rows in set (4.08 sec)4.08 sec, ¡es mucho! ¿qué ha pasado? Tenemos el índice. Profundicemos en cómo se ejecuta la consulta con la ayuda de la cláusula EXPLAIN.
Usando Explain
Podemos agregar una cláusula explain para ver cómo se ejecutará la consulta en nuestro conjunto de datos actual.
> EXPLAIN SELECT * FROM libro_transacciones ORDER BY prestador_id;
El resultado es:

Hay varios campos que explican las devoluciones. Veamos la tabla anterior e identifiquemos el problema.
rows (filas): Número total de filas que se analizarán
filtered (filtrado): El porcentaje de fila que se escaneará para obtener los datos.
type (tipo): Se da si se está utilizando el índice. ALL significa que no está usando index.
possible_keys, key, key_len son NULL, lo que significa que no se está utilizando ningún índice.
Entonces, ¿por qué la consulta no usa el índice?
Es porque tenemos select * en la consulta, lo que significa que estamos seleccionando todos los campos de nuestra relación.
El índice solo tiene información sobre los campos que están indexados y no sobre otros campos. Esto significa que MySQL deberá ir a la tabla principal para recuperar datos nuevamente.
Entonces, ¿cómo deberíamos escribir la consulta?
Selecciona solo el campo requerido
Para eliminar la necesidad de ir a la tabla principal para la consulta, necesitamos seleccionar solo el valor que está presente en la tabla de índice. Así que cambiemos la consulta a:
> SELECT prestador_id FROM libro_transacciones ORDER BY prestador_id;
Esto devolverá el resultado en 0,46 segundos, que es mucho más rápido. Pero todavía hay margen de mejora.
Como esta consulta se realiza en todos los 1,5 millones de registros que tenemos, está tomando un poco más de tiempo, ya que necesita cargar datos en la memoria.
Usa Limit
Es posible que no necesitemos todos los 1,5 millones de datos al mismo tiempo. Entonces, en lugar de obtener todos los datos, usar LIMIT y obtener datos en lotes es una manera mejor de hacerlo.
> SELECT prestador_id
FROM libro_transacciones
ORDER BY prestador_id LIMIT 1000;Con un límite establecido, el tiempo de respuesta mejora drásticamente y se ejecuta en 0,0025 segundos. Ahora podemos buscar el siguiente lote con OFFSET.
> SELECT prestador_id
FROM libro_transacciones
ORDER BY prestador_id LIMIT 1000 OFFSET 1000;Esto buscará el siguiente lote de 1000 filas. Con esto podemos aumentar el desplazamiento y el límite para obtener todos los datos. ¡Pero hay un "te pillé"! Con un aumento en la compensación, el rendimiento de la consulta disminuye.
Esto se debe a que MySQL escaneará todos los datos para alcanzar el punto de compensación. Por lo tanto, es mejor no utilizar un desplazamiento más alto.
¿Qué pasa con la consulta Count (recuento)?
El motor InnoDB tiene la capacidad de escribir simultáneamente. Esto lo hace altamente escalable y mejora el rendimiento por segundo.
Pero esto tiene un precio. InnoDB no puede agregar un contador de caché para el número de registros en ninguna tabla. Por lo tanto, el recuento debe realizarse en tiempo real escaneando todos los datos filtrados. Esto hace que la consulta COUNT sea lenta.
Por lo tanto, se recomienda calcular los datos de recuento resumidos en la lógica de la aplicación cuando se trata de una gran cantidad de datos.
¿Por qué no agregar un índice a todos los campos?
Agregar índice ayuda a mejorar mucho el rendimiento, pero también tiene un precio. Debe utilizarse de forma eficaz. Agregar un índice a más campos tiene los siguientes problemas:
- Necesita mucha memoria, una computadora más grande
- Cuando eliminamos, hay una reindexación (eliminaciones intensivas de CPU y más lentas)
- Cuando agregamos algo, hay reindexación (inserciones intensivas de CPU y más lentas)
- Los cambios a un registro no reindexan por completo, por lo que la actualización es más rápida y eficiente en la CPU.
Ahora tenemos claro que agregar un índice ayuda mucho. Pero no podemos seleccionar todos los datos, excepto los que están indexados para un rendimiento rápido.
¿cómo podemos seleccionar todos los atributos y seguir obteniendo un rendimiento rápido?
Particionamiento (partitioning)
Cuando creamos índices, solamente tenemos información sobre el campo que está indexado. Pero no tenemos datos de los campos que no están presentes en el índice.
Entonces, como dijimos anteriormente, MySQL necesita mirar hacia atrás en la tabla principal para obtener los datos de otros campos. Esto puede ralentizar el tiempo de ejecución.
La forma en que podemos resolver esto es mediante particiones.
El particionamiento es una técnica en la que MySQL divide los datos de una tabla en varias tablas, pero los administra como una sola tabla.
Al realizar cualquier tipo de operación en la tabla, necesitamos especificar qué partición se está utilizando. Con los datos desglosados, MySQL tiene un conjunto de datos más pequeño para consultar. Determinar la partición correcta de acuerdo con las necesidades es clave para un alto rendimiento.
Pero si seguimos usando la misma máquina, ¿escalará?
Fragmentación (Sharding)
Con un gran conjunto de datos, almacenar todos sus datos en la misma máquina puede resultar problemático.
Una partición específica puede ser muy grande y necesitar más consultas, mientras que otras menos. Entonces uno afectará a otro. No pueden escalarse por separado.
Supongamos que los datos de los últimos tres meses son los más utilizados, mientras que los más antiguos se utilizan menos. Quizás los datos recientes en su mayoría se actualizan / crean, mientras que los datos antiguos en su mayoría solo se leen.
Para resolver este problema, podemos mover la partición de los últimos tres meses a otra máquina. La fragmentación es una forma en la que dividimos un gran conjunto de datos en fragmentos más pequeños y lo pasamos a RDBMS separados. En otras palabras, la fragmentación también se puede llamar "partición horizontal".
Las bases de datos relacionales tienen la capacidad de escalar a medida que crece la aplicación. Es necesario encontrar el índice correcto y ajustar la infraestructura según las necesidades.