

Artículo original escrito por David Clinton
Artículo original How to Use Python and Pandas to Map Major Storms, Pessimism, and Hard Data
Traducido y adaptado por Luis Ignacio Cabezas
A veces puede ser reconfortante, de algún modo, reflexionar sobre lo mucho peor que está todo ahora, de lo que solía estar en los viejos tiempos.
"Los niños no respetan."
"Todo es demasiado caro."
"Los funcionarios públicos no inspiran confianza."
"¿Y qué pasa con el clima? Nunca habíamos tenido tantos huracanes devastadores, ¿O sí?"
Bueno, soy lo suficientemente mayor como para haber dado unas cuantas vueltas a la manzana y no estoy seguro. De niño no era precisamente angelical, las cosas siempre costaban más de lo que queríamos y los funcionarios públicos nunca fueron las criaturas más queridas del planeta. ¿Pero las grandes tormentas? No tengo ni idea.
Resulta que hay muchos datos excelentes sobre tormentas, así que no hay razón para no buscar al menos algunas pistas. Y mis intentos de añadir la analítica de datos a mi actual stock de herramientas profesionales podrían ayudar, aquí.
Sin embargo, primero debemos definir cuidadosamente algunos términos y antecedentes.
¿Qué es una gran tormenta?
Huracanes - o, más precisamente, ciclones tropicales - son "tropicales" en el sentido de que se forman sobre oceanos en regiones tropicales. El término "tropicales" se refiere al área de la superficie terrestre que se encuentra dentro de los 23 grados (más o menos) del ecuador, tanto al norte como al sur.
Las tormentas se llaman "ciclones" porque el movimiento de sus vientos es cíclico (en el sentido de las agujas del reloj en el hemisferio sur y en sentido contrario en el hemisferio norte).
Los ciclones se alimentan del agua oceánica evaporada y dejan a su paso tormentas torrenciales y a menudo violentas, sobre todo después de pasar por zonas terrestres habitadas.
En términos generales, una tormenta que produce vientos sostenidos de entre 34 y 63 nudos (o entre 39 y 72 millas por hora) se considera una tormenta tropical. Las tormentas con vientos superiores a 64 nudos (73 millas por hora) son huracanes (o, en los océanos Pacífico Occidental o Índico Norte, son tifones).
Los huracanes se miden por categorías entre uno y cinco, siendo los de categoría cinco los más violentos y peligrosos.
¿De dónde provienen los datos de las grandes tormentas?
Existen datos históricos de tormentas fiables y en gran medida consistentes, al menos en Estados Unidos, para el último siglo y medio. Pero para entender correctamente el contexto de esos datos es necesario conocer cómo se han realizado esas observaciones a lo largo de los años.
Hasta la década de 1940, la mayor parte de las observaciones fueron realizadas por las tripulaciones de los buques oceánicos. Pero las tripulaciones de los barcos solo pueden observar e informar de lo que ven, y lo que ven estará determinado por el lugar al que vayan.
Antes de la apertura del Canal de Panamá en 1914, los barcos que viajaban entre Europa y el océano Pacífico seguían una ruta alrededor del extremo sur de Sudamérica que en gran medida no llegaba a las zonas costeras de Estados Unidos. Como resultado, es probable que un porcentaje significativo de los fenómenos meteorológicos simplemente no fueran notados.
Del mismo modo, la llegada de los aviones de reconocimiento en la década de 1940 habría permitido a los científicos captar más fenómenos que antes se habrían perdido. Y el uso de satélites meteorológicos a partir de los años sesenta ha permitido captar casi toda la actividad oceánica.
Estos cambios, y su impacto en los datos de las tormentas, se resumen claramente en esta página del sitio de la Administración Nacional Oceánica y Atmosférica (NOAA) del gobierno estadounidense, basada en un estudio de análisis de datos realizado para el Laboratorio de Dinámica de Fluidos Geofísicos (GFDL).
¿Qué muestra el registro histórico?
Después de todos estos antecedentes, ¿qué dicen realmente los datos? ¿Son los huracanes graves más frecuentes ahora que en el pasado? Bueno, según el sitio web de la NOAA, la respuesta es: "No". Esto es lo que dicen:
"Las tormentas tropicales del Atlántico de más de dos días de duración no han aumentado en número. Las tormentas que duran menos de dos días han aumentado considerablemente, pero esto se debe probablemente a la mejora de las observaciones... No conocemos una señal de cambio climático que dé lugar a un aumento solo de las tormentas de menor duración, mientras que dicho aumento es cualitativamente coherente con lo que cabría esperar de las mejoras con las prácticas de observación."
La historia completa, incluyendo una buena explicación de las opciones de manipulación de datos que hicieron, la obtendrás leyendo el propio estudio. De hecho, te animo a que leas ese estudio, porque es un gran ejemplo de cómo los profesionales abordan los problemas de datos.
A partir de aquí, sin embargo, te quedarás con mis intentos amateurs y simplificados de visualizar el registro de datos en bruto y sin ajustar.
Datos de huracanes de Estados Unidos: 1851-2019
Nuestra fuente de datos de "Impactos/caídas de huracanes en los Estados Unidos continentales" es esta página web de la NOAA
Para descargar los datos, simplemente los copié haciendo clic con el ratón en la parte superior izquierda (el campo de encabezamiento "Año") y arrastrando todo el camino hasta la parte inferior derecha. A continuación, lo pegué en un editor de texto plano en mi ordenador local y lo guardé en un archivo con la extensión .csv.
Cómo limpiar los datos de los huracanes
Si echas un vistazo a la página web, verás que hay que limpiar el formato. Cada década se introduce con una sola fila que no contiene nada más que una cadena parecida a esto:1850s. Querremos eliminar esas filas. Los años sin eventos contienen la cadena none en la segunda columna. Esas también se tendrán que ir.
Hay algunos eventos que aparentemente no tienen datos para sus velocidades máximas de viento (Max Wind). En lugar de un número (medido en nudos), los valores de velocidad de esos eventos se representan con cinco guiones (-----). Tendremos que convertirlo en algo con lo que podamos trabajar.
Y, por último, aunque los meses suelen representarse con abreviaturas de tres letras, hubo un par de eventos que se extendieron a lo largo de dos meses. Para que podamos procesarlos adecuadamente, convertiréSp-Oc y Jl-Au a Sep y Jul respectivamente.
El hecho es que en realidad no vamos a utilizar la columna del mes, por lo que esto no supondrá ninguna diferencia. Pero es una buena herramienta para conocer.
Así es como configuramos las cosas en Jupyter:
import pandas as pd
import matplotlib as plt
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('data-huracanes-noaa.csv')
Veamos los tipos de datos de cada columna. Podemos ignorar las cadenas de la columna Estados (States) y Nombre (Name) - no nos interesan de todos modos. Pero tendremos que hacer algo con las columnas de Fecha y Viento Máximo - no nos servirán comoobject.
df.dtypes
Year object
Month object
States Affected and Category by States object
Highest\nSaffir-\nSimpson\nU.S. Category float64
Central Pressure\n(mb) float64
Max Wind\n(kt) object
Name object
dtype: object
Así que voy a filtrar todas las filas en la columna Año (Year) para la letra s y simplemente las eliminaré (== False). Eso se encargará de todas las cabeceras de las décadas (es decir, las filas que contienen una s como parte de algo como 1850s).
Del mismo modo, eliminaré las filas que contengan la cadena None en la columna Mes (Month) para eliminar los años sin tormentas.
Aunque los años tranquilos podrían tener algún impacto en nuestras visualizaciones, sospecho que incluirlos con algún tipo de valor nulo probablemente sesgaría las cosas aún más en la dirección contraria. También complicarían mucho nuestras visualizaciones.
Por último, reemplazaré esas dos filas de varios meses.
df = df[(df.Year.str.contains("s")) == False]
df = df[(df.Month.str.contains("None")) == False]
df = df.replace('Sp-Oc','Sep')
df = df.replace('Jl-Au','Jul')
A continuación, utilizaré el práctico método de Pandas to-datetime para convertir las abreviaturas de tres letras del mes en números entre el 1 y el 12. El código de formato %b es una de las designaciones legales de Python relacionadas con la fecha y le indica a Python que estamos trabajando con una abreviatura de tres letras. Para ver la lista completa, consulte esta página.
df.Month = pd.to_datetime(df.Month, format='%b').dt.month
Me gustaría ajustar un poco las cabeceras para que sean un poco más fáciles de leer y de referenciar en nuestro código. df.columns cambiará todos los valores de las cabeceras de las columnas a la lista que especifique aquí:
df.columns =['Año', 'Mes', 'Estados', 'Categoría',
'Presión', 'VientoMáximo', 'Nombre']
Tendré que convertir los datos de Año de objetos de cadena a enteros, o Python no sabrá cómo trabajar con ellos adecuadamente. Eso se hace usando astype.
Como se anunció, también convertiré los valores null en VientoMáximo a NaN - que NumPy leerá como "no es un número". Luego convertiré los datos en VientoMáximo de object a float.
df = df.astype({'Año': 'int'})
df = df.replace('-----',np.NaN)
df = df.astype({'VientoMáximo': 'float'})
Veamos cómo queda todo eso ahora:
df.dtypes
Año int64
Mes int64
Estados object
Categoría float64
Presión float64
Viento Maximo float64
Nombre object
dtype: object
Mucho mejor.
Cómo presentar los datos de los huracanes
Ahora, mirando nuestros datos, voy a sugerir que separemos las tres métricas: categoría de huracán, presión barométrica y velocidad máxima del viento.
Mi opinión es que no se gana mucho con la complicación añadida al agruparlas, y corremos el riesgo de perder de vista las importantes diferencias entre los incidentes de las tormentas más ligeras y las más graves.
Por supuesto, siempre puedo aislar las métricas individuales para ver cómo serían sus distribuciones. Utilizando value_counts contra la columna de categoría, por ejemplo, me muestra que los huracanes más ligeros de categoría 1 y 2 son mucho más frecuentes que los eventos más peligrosos.
df['Categoría'].value_counts()
1.0 124
2.0 85
3.0 62
4.0 26
5.0 4
Name: Categoria, dtype: int64
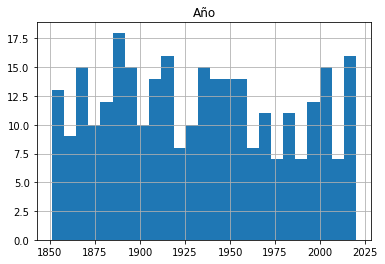
El histograma del conjunto de datos nos da una visión general del número de eventos (representados en el eje Y) a lo largo de la historia, pero es posible que perdamos algunos detalles.
A partir de este histograma, es obvio que no ha habido ningún cambio notable en la frecuencia de las tormentas a lo largo del tiempo. Para estar seguro de que mi elección del número de intervalos que utilizamos no está ocultando involuntariamente tendencias importantes, experimente con otros valores además de 25.
df.hist(column='Año', bins=25)
Pero para poder centrarnos en cada métrica, trazaré tres gráficos distintos. Para ello, crearé tres nuevos marcos de datos y rellenaré cada uno de ellos con el contenido de la columna Año y la respectiva columna de datos.
df_categoria = df[['Año','Categoría']]
df_viento = df[['Año','VientoMáximo']]
df_presion = df[['Año','Presión']]
Enviar cada uno de esos marcos de datos (dataframes) directamente a un gráfico no servirá de nada, porque no distinguirá entre la gravedad de las tormentas. Así que le mostraré cómo podemos desglosar los datos por categoría (1-5). Este bucle for iterará a través de los números 1-6 (que es la manera de Python para devolver los números entre 1 y 5) y utiliza cada uno de esos números a su vez para buscar huracanes de esa categoría.
Las filas cuya categoría coincida con el número se escribirán en un nuevo marco de datos (temporal) llamado df1 que, a su vez, se utilizará para trazar un histograma. La línea plt.title aplica un título para el gráfico impreso que incluirá el número de categoría (el valor actual de num_convertido).
El bucle trabajará a través del proceso cinco veces, cada vez escribiendo el número de eventos de la categoría actual en df1. Los cinco histogramas se imprimirán, uno tras otro.
for x in range(1, 6):
num_cat = x
num_convertido = str(num_cat)
dfcat = df_categoria['Categoría']==(x)
df1 = df_categoria[dfcat]
df1.hist(column='Año', bins=20)
plt.title("Eventos Totales de la Categoría " + (num_convertido))
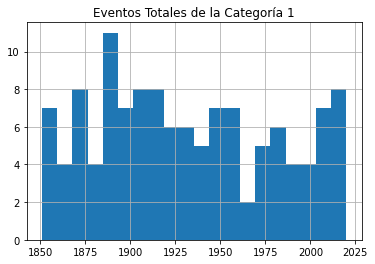
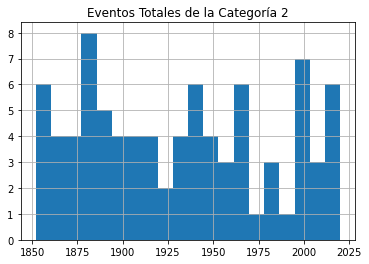
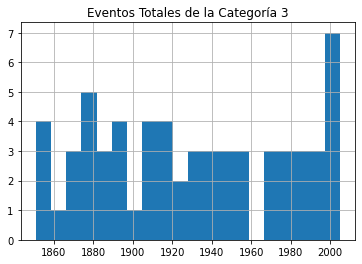
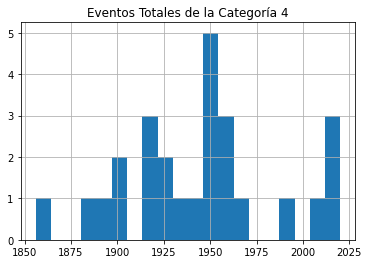
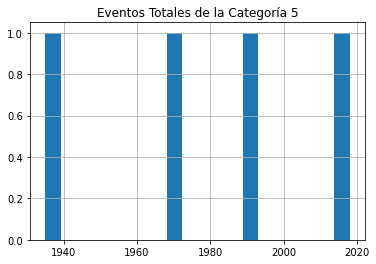
Como se puede ver, no hay pruebas notables de un aumento significativo de la frecuencia de las tormentas a lo largo del tiempo.
Como siempre, analice sus datos (utilizando herramientas como value_counts()) para confirmar que los gráficos tienen sentido en el mundo real.
Datos de tormentas tropicales de Estados Unidos: 1851-1965, 1983-2019
Los huracanes (o ciclones) son, por supuesto, solo una parte de la historia. Un aumento de la frecuencia de las tormentas tropicales destructivas también sería motivo de preocupación.
Afortunadamente, la NOAA pone a disposición los datos pertinentes en un formato muy similar al de sus datos sobre huracanes. Aquí está la página web donde encontrarás el gráfico. Copia los datos en un archivo .csv de la misma manera que antes.
Sin embargo, observe que no hay datos para los años 1966-1982. No me pregunten por qué. Simplemente no hay. Es curioso el clima.
Yo crearía un nuevo Jupyter notebook para esta parte del proyecto, ya que no hay nada que vayamos a necesitar de la versión de huracanes. Por lo tanto, se configurarán las cosas como siempre:
import pandas as pd
import matplotlib as plt
import numpy as np
df = pd.read_csv('tormentas-tropicales-usa-noaa.csv')
Limpiemos Los Datos De Las Tormentas Tropicales
Las filas que representan años sin eventos deberían, de nuevo, ser eliminadas:
df = df[(df.Date.str.contains("None")) == False]
La columna Fecha (Date) de este conjunto de datos tiene caracteres que apuntan a cinco notas a pie de página: $, *, #, % y &. Las notas a pie de página contienen información importante, pero esos caracteres nos darán problemas si no los eliminamos.
Estos comandos lo conseguirán, sustituyendo todas esas cadenas en la columna Fecha por nada:
df['Date'] = df.Date.str.replace('\$', '')
df['Date'] = df.Date.str.replace('\*', '')
df['Date'] = df.Date.str.replace('\#', '')
df['Date'] = df.Date.str.replace('\%', '')
df['Date'] = df.Date.str.replace('\&', '')
A continuación, voy a restablecer los encabezados de las columnas. En primer lugar, porque será más fácil trabajar con nombres bonitos y cortos. Pero principalmente porque, como administrador de sistemas de Linux, encuentro los espacios en los nombres de archivos o en los encabezados moralmente ofensivos.
df.columns =['Tormenta#', 'Fecha', 'Tiempo', 'Lat', 'Lon',
'VientoMáximo', 'EstadoTierra', 'NombreTormenta']
Los tipos de datos de las columnas van a necesitar algo de trabajo:
df.dtypes
Tormenta# object
Fecha object
Tiempo object
Lat object
Lon object
VientoMáximo float64
EstadoTierra object
NombreTormenta object
dtype: object
Veamos cómo se ven nuestros datos:
df.head()
Tormenta# Fecha Tiempo Lat Lon VientoMáximo EstadoTierra NombreTormenta
1 6 10/19/1851 1500Z 41.1N 71.7W 50.0 NY NaN
6 3 8/19/1856 1100Z 34.8 76.4 50.0 NC NaN
7 4 9/30/1857 1000Z 25.8 97 50.0 TX NaN
8 3 9/14/1858 1500Z 27.6 82.7 60.0 FL NaN
9 3 9/16/1858 0300Z 35.2 75.2 50.0 NC NaN
La verdad es que no estoy seguro de lo que significan esos valores de Tormenta#, pero no hacen daño a nadie. Las fechas tienen un formato mucho mejor que el de los datos de los huracanes. Pero tendré que convertirlas a un nuevo formato. Hagámoslo bien y vayamos con datetime.
df.Fecha = pd.to_datetime(df.Fecha)
Cómo presentar los datos de la tormenta tropical
Para nuestros propósitos, la única columna de datos que realmente importa es VientoMáximo - ya que es lo que define la intensidad de la tormenta. Este comando creará un nuevo marco de datos compuesto por las columnas Fecha y VientoMáximo:
df1 = df[['Fecha','VientoMáximo']]
No hay razón para aplazar esto: también podemos disparar un histograma de inmediato. Verás inmediatamente la brecha alrededor de 1970, donde no había datos. También verás que, de nuevo, no parece haber mucha tendencia al alza.
df1['Fecha'].hist()
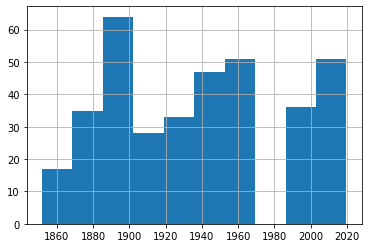
Pero realmente deberíamos profundizar un poco más aquí. Después de todo, estos datos sólo mezclan tormentas de 30 nudos con otras de 75 nudos. Definitivamente querremos saber si están ocurriendo o no a ritmos similares.
Averigüemos cuántas filas de datos tenemos. shape nos dice que tenemos 362 eventos en total.
print(df1.shape)
(362, 2)
La impresión de nuestro marco de datos nos muestra que los valores de VientoMáximo son todos múltiplos de 5. Si escaneas los datos por ti mismo, verás que oscilan entre 30 y 70 más o menos.
df1
Fecha VientoMaximo
1 1851-10-19 50.0
6 1856-08-19 50.0
7 1857-09-30 50.0
8 1858-09-14 60.0
9 1858-09-16 50.0
... ... ...
391 2017-09-27 45.0
392 2018-05-28 40.0
393 2018-09-03 45.0
394 2018-09-03 45.0
395 2019-09-17 40.0
362 rows × 2 columns
Así que dividamos nuestros datos en cuatro conjuntos más pequeños, como aproximaciones razonables a tormentas de distintos niveles de intensidad. He creado cuatro marcos de datos y los he rellenado con eventos que caen en sus rangos más estrechos (es decir, entre 30 y 39 nudos, 40 y 49, 50 y 59, y 60 y 79). Esto debería darnos un marco de referencia razonable para nuestros eventos.
df_30 = df1[df1['VientoMáximo'].between(30, 39)]
df_40 = df1[df1['VientoMáximo'].between(40, 49)]
df_50 = df1[df1['VientoMáximo'].between(50, 59)]
df_60 = df1[df1['VientoMáximo'].between(60, 79)]
Confirmemos que los puntos de corte que hemos elegido tienen sentido. Este código imprimirá de forma atractiva el número de filas en el índice de cada uno de nuestros cuatro formularios de datos.
st1 = len(df_30.index)
print('El número de tormentas entre 30 y 39: ', st1)
st2 = len(df_40.index)
print('El número de tormentas entre 40 y 49: ', st2)
st3 = len(df_50.index)
print('El número de tormentas entre 50 y 59: ', st3)
st4 = len(df_60.index)
print('El número de tormentas entre 60 y 79: ', st4)
El número de tormentas entre 30 y 39: 51
El número de tormentas entre 40 y 49: 113
El número de tormentas entre 50 y 59: 142
El número de tormentas entre 60 y 79: 56
Probablemente haya una forma elegante de combinar esos cuatro comandos en uno solo. Pero mi filosofía es que la sintaxis que me llevaría una hora averiguar nunca superará la simplicidad de cinco segundos de cortar y pegar. Nunca.
También podemos profundizar un poco más en los datos utilizando nuestro viejo amigo, value_counts(). Esto nos mostrará que hubo 71 eventos de 40 nudos y 42 eventos de 45 nudos a lo largo de nuestro rango de tiempo.
df_40['VientoMáximo'].value_counts()
40.0 71
45.0 42
Name: VientoMáximo, dtype: int64
Podemos trazar un único gráfico de líneas para mostrar los cuatro subconjuntos juntos. Este gráfico añade etiquetas en los ejes y en el gráfico y una leyenda para facilitar la comprensión de los datos. El valor subplot(111) controla el tamaño de la figura.
fig = plt.figure()
ax = plt.subplot(111)
df_30['VientoMáximo'].plot(ax=ax, label='df_30')
df_40['VientoMáximo'].plot(ax=ax, label='df_40')
df_50['VientoMáximo'].plot(ax=ax, label='df_50')
df_60['VientoMáximo'].plot(ax=ax, label='df_60')
ax.set_ylabel('Velocidad del Viento en Nudos')
ax.set_xlabel('Tiempo Entre 1851 y 2019')
plt.title('Tormentas Tropicales por Velocidad del Viento Máximo (nudos)')
ax.legend()
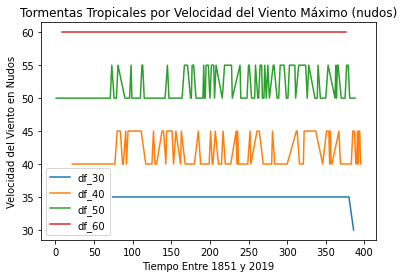
Esto puede ser útil para confirmar que no estamos desordenando los datos. La comprobación visual mostrará, por ejemplo, que en nuestro conjunto de datos sólo hubo un único evento de 30 nudos y que tuvo lugar hacia el final de nuestro marco temporal en 2016. Pero no es una buena manera de mostrarnos los cambios en la frecuencia de los eventos.
Para ello, miraremos los datos que contiene cada uno de nuestros marcos de datos.
df_30['Fecha'].hist(bins=20)
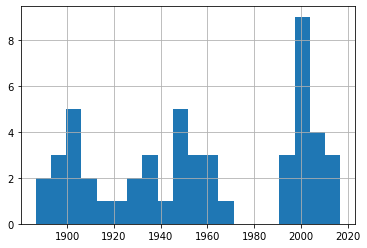
df_40['Fecha'].hist(bins=20)
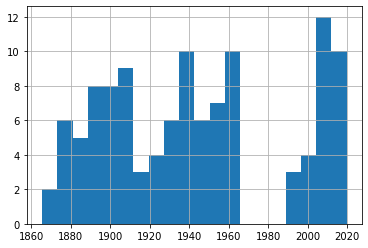
df_50['Fecha'].hist(bins=20)
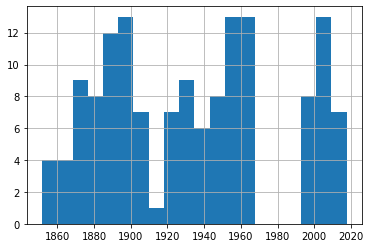
df_60['Fecha'].hist(bins=20)
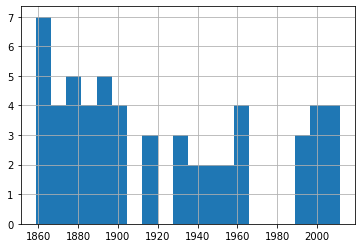
Un rápido vistazo a estos cuatro gráficos nos muestra una frecuencia de eventos bastante consistente a lo largo de los 150 años de nuestros datos. De nuevo, pruébalo tú mismo utilizando diferentes números de intervalos para asegurarte de que no estamos pasando por alto algunas tendencias importantes.