

El mundo de las bases de datos relacionales o bases de datos SQL es maravilloso, sólo que a veces nos puede resultar complejo, por no tener conocimiento de todas las herramientas que tenemos a disposición.
Hagamos un repaso rápido de que es una base de datos y sus tipos. Una base de datos es una herramienta que nos permite almacenar datos de forma permanente. Existen 2 tipos de bases de datos que difieren en su forma de almacenar y recuperar los datos pero cumplen el objetivo anteriormente descrito, veamos un poco en detalle esto.
Tipos de bases de datos:
- Relacionales o SQL. Los datos se almacenan en tablas y campos, donde una tabla puede tener múltiples campos y estos campos almacenan un dato, que puede ser cadena de caracteres, textos (cadenas con más de 255 caracteres), números (enteros y decimales), fecha, fecha y hora, datos binarios. Cada herramientas de gestión de base de datos SQL puede tener algunos tipos de campos adicionales.
- NoSQL o no solo SQL. Los datos se van a almacenar de acuerdo a como la herramienta lo implemente, siendo las más usadas: colecciones y documentos, par registros de la forma llave-valor, columnas anchas (donde se generan tablas y campos pero con la ventaja de cada registro puede tener diferentes campos), grafos.
De acuerdo la necesidad que se tenga, se selecciona el tipo de base de datos a utilizar. Nuestro foco en este artículo es el de las bases de datos relacionales o SQL. Para ello vamos a partir de un ejemplo que tenemos pre-construido, donde la base de datos posee 3 tablas, relacionadas entre sí, de acuerdo con el siguiente módelo: entidad-relación (es el modelo usado por excelencia para representar bases de datos SQL):
Base de datos de ejemplo:
En nuestro caso partimos de una base de datos que simula un sistema de gestión de tickets o turnos, que está compuesto de 3 tablas, que representan las 3 entidades envueltas:
- users, es la tabla que nos permite representar los usuarios o clientes que van a solicitar turnos o tickets.
- stores, almacena los datos de las tiendas o comercios que ofrecen los servicios y que desean tener control de los turnos o tickets de sus clientes.
- tickets, tabla que almacena los turnos o tickets de los clientes en las tiendas o comercios.
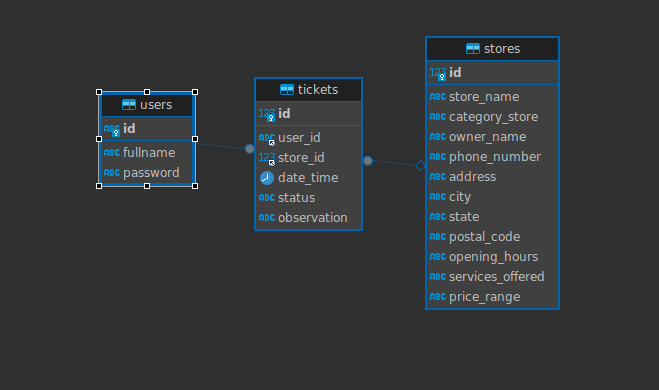
De acuerdo al modelo anterior, podemos entender que un usuario (registro en la tabla users) puede tener n turnos, en este caso hablamos de una relación 1 -> N, luego podemos observar que una tienda (registro en la tabla stores) va a disponer o habilitar n turnos, entonces la relación será de la misma forma: 1 -> N. Luego es posible observar que un usuario va a n turnos en n tiendas, por lo tanto la relación de usuarios con tiendas será N -> M.
Puedes obtener la base de datos de ejemplo para práctica en el siguiente link:
https://github.com/ljcl79/practica-joins
Como realizar consultas sobre una base de datos SQL
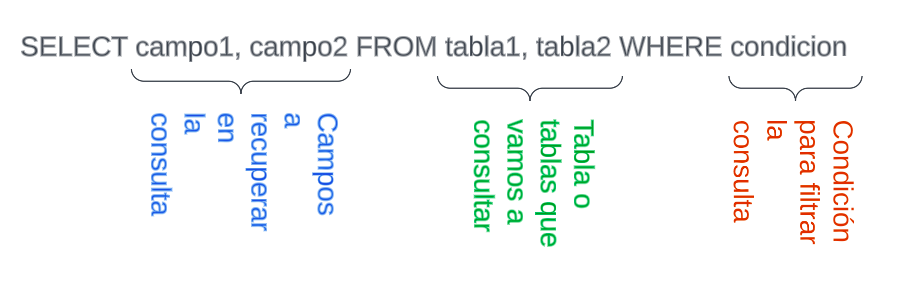
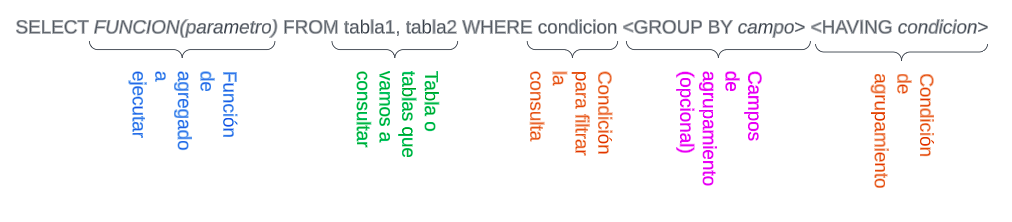
Para realizar una consulta sobre una base de datos SQL, recordemos que usamos el comando SELECT, el cual nos retorna los campos de los registros que cumplan la condición de búsqueda. La anatomía de un SELECT sigue a continuación:
En este video podrás encontrar un mejor detalle de como realizar consultas básicas, hacemos uso de la misma base de datos del documento actual.
Con el contexto anterior, podemos avanzar un nivel en cuanto a consultas de base de datos SQL, es el uso de JOINs. Los JOINs nos permites relacionar tablas por campos, que generalmente corresponden a campos que identifican registros en la tabla principal y referencia a un campo en la tabla destino.
Por ejemplo en el modelo que estamos usando como ejemplo, tenemos las relaciones indicadas anteriormente:
- Tabla
userspor el campoidestá relacionado con la tablaticketspor el campouser_id. - Tabla
storespor el campoidestá relacionado con la tablaticketspor el campostore_id
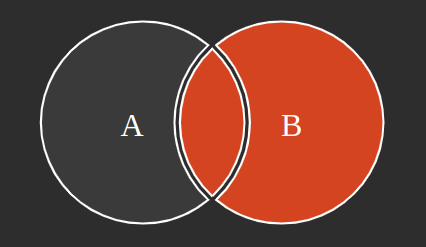
Ahora pensemos en como hacer una consulta que relacione las tablas, ejemplo, saber que usuarios tienen turnos, ya sea realizados o agendados. Para ello podemos aplicar el uso de JOIN, en este caso veamos la siguiente figura:
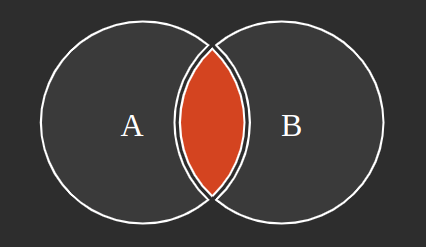
En el caso anterior la tabla A será la tabla users y la tabla B será la tabla tickets, la consulta a ejecutar para obtener que usuarios tienen turnos, como indicamos anteriormente será:
SELECT * FROM users A INNER JOIN tickets B ON A.id = B.user_id;Observando la gráfica podemos obtener los distintos tipos de JOINs que SQL permite realizar:
INNER JOIN
LEFT JOIN
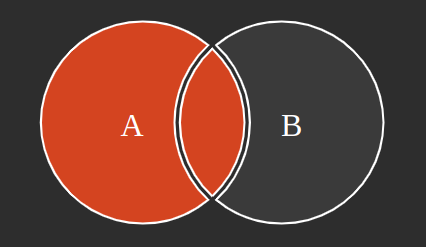
RIGHT JOIN
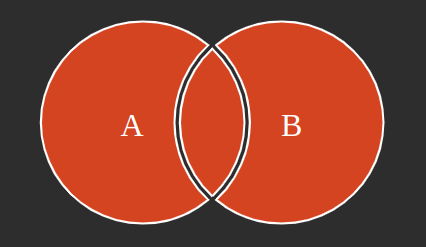
FULL JOIN
Para profundizar sobre el tema de JOINs puedes acceder a este artículo de freeCodeCamp.org en español: https://www.freecodecamp.org/espanol/news/tutorial-de-uniones-en-sql/.
De igual forma, en el siguiente video podrás entrar en detalle de como realizar consultas usando JOINs.
Consultas a realizar
Con el modelo anterior indicado, pensemos en algunas consultas que serán interesantes realizar:
- Cantidad de usuarios con ticket por día en un periodo
- Promedio de turnos por día en un periodo
- Cantidad de turnos mayor o menor por dia.
- Cantidad de turnos ejecutados mayor o menor por dia.
- Cantidad de turnos por Tienda por día en un periodo
- Top 10 de las tiendas con mayor cantidad de turnos ejecutados.
Todas las consultas anteriores tienen un elemento en común, es que necesitan agruparse para poder hacer las operaciones de cálculo, para ello, SQL tiene un palabra reservada que podemos ejecutar en nuestras queries: GROUP BY, que adicionalmente se puede filtrar usando la palabra reserva HAVING.
Además de ello, de las consultas podemos entender que debemos conseguir el valor mayor, el valor menor, el promedio por ejemplo, todo lo anterior se denomina, funciones de agregado, veamos esto en detalle.
Agrupando los resultados por campos
Cuando realizamos una consulta, podemos definir que los resultados se agrupen por los valores de un campo, de esta forma, luego podemos obtener valores como conteo, suma o promedio de valores, incluso obtener el mayor o el menor valor de un campo . Adicionalmente cuando agrupamos podemos filtrar esos resultados agrupados aplicando los criterios anteriomente indicados (conteo, suma, etc);
Anatamía de un GROUP BY con HAVING:

Ordenando los resultados
Al momento de realizar consultas, es posible querer que estas se ordenen por algun campo, siendo los criterios disponibles: de forma ascendente y de forma descendente. Esto nos permite obtener los datos con una visual definida de tal forma que sea facil ubicar los datos y también poder comparar sus valores.
Para ordenar una consulta simplemente agregamos al final de ella, las palabras reservadas ORDER BY y luego el o los campos los cuales deseamos ordenar, siendo posible ordenar por multiples campos y cada campo tenga su criterio (ascendente o descendente).
Limitando los resultados
En alguna oportunidades queremos solo obtener el primer registro de la consulta (aunque sea haya retornado una cantidad mayor de registros), o por ejemplo queremos obtener el top 10 de registros con cierta condición, para ello usamos cada herramienta de base de datos posee una palabra reservada, en nuestro caso, usando MySQL o PostgreSQL, la palabra reservada será LIMIT.
Más adelante usaremos tanto el orden como la limitación para ajustar nuestras consultas.
Funciones de agregado
Estas son funciones de SQL (Si SQL así como un lenguaje de programación tienen funciones, lo que lo haces aún más poderoso 😎), que realizan un calculo, en base a un campo o expresión de campos, sobre un conjunto de datos y retornan un resultado.
Tomando en cuenta lo indicado en punto anterior, las funciones de agregado generalmente van acompañadas de las palabras reservadas GROUP BY y en algunos casos de la palabra HAVING (estas trabajan en conjunto se mencionó anteriormente), pero esto no es regla, es decir no es necesario ello. Entendido esto, podemos obtener una única fila como resultado de una consulta con una función de agregado, o una fila por cada grupo generado en la query (usando GROUP BY)
Anatomía de las funciones de agregado
Las consultas o SELECT usando funciones de agregado van a seguir la siguiente forma:
Ejemplo de consultas que retornarian un único resultado:
- Día del primer turno registrado
- Día del último turno registrado
- Cantidad de turnos procesados por el sistema
- Si le agregamos a la tabla de tickets, los minutos de cada turno ejecutado, podemos obtener la suma de tiempo ejecutado.
Estos 4 ejemplos nos van a retornar una fila de resultado solamente, porque no estamos agrupando por ningún elemento.
Ahora bien, veamos cuales son esas funciones de agregado:
COUNT
Nos permite hacer el conteo, o contar cuantos registros o filas que cumplen la condición de la consulta. Su sintaxis es muy simple: ]
SELECT COUNT(campo o *) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> Ahora vemos la siguiente consulta:
SELECT COUNT(campo o *) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> GROUP BY <campo1>SUM
Nos permite hacer la suma de los valores del campo de los registros o filas que cumplen la condición de la consulta. Tiene sentido cuando el campo es numérico. Su sintaxis sigue a continuación:
SELECT SUM(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> Agrupando por algún campo queda:
SELECT SUM(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> GROUP BY <campo1>AVG
Esta función calcula el promedio de los valores del campo de los registros o filas que cumplen la condición de la consulta, se entiende como el promedio a la suma de los valores dividido entre la cantidad de registros, sería algo como SUM/COUNT. Sólo funciona si el campo es numérico. La sintaxis es:
SELECT AVG(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> Agrupando por algún campo queda:
SELECT AVG(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> GROUP BY <campo1>MAX
La función MAX, nos permite calcular el máximo o mayor valor de un conjunto de registros o filas que cumplen la condición de la consulta (siempre comento esto porque estas funciones se pueden o no combinar con condiciones de consulta). A diferencia de las anteriores, es posible usarla en cualquier tipo de dato que sea ordenable, por ejemplo, textos y números. La usamos de la siguiente forma es:
SELECT MAX(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> Agrupando por algún campo queda:
SELECT MAX(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> GROUP BY <campo1>MIN
La función MIN, nos permite calcular el menor valor o el valor mínimo de un conjunto de registros o filas devueltos a realizar una consulta, esta puede tener o no condiciones. Como su antecesora (MAX), es posible usarla en cualquier tipo de dato que sea ordenable, caso más usado: textos y números. Para ejecutarla, lo indicamos de la siguiente forma:
SELECT MIN(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> Agrupando por algún campo queda:
SELECT MIN(campo) FROM tabla1 INNER JOIN tabla2 ON (tabla1.key = tabla2.key) WHERE <condicion> GROUP BY <campo1>Implementando las consultas solicitadas en SQL
Vamos a realizar el código SQL para cada una de las consultas planteadas anteriormente, para ello vamos a usar lo que hemos aprendido: Funciones de agregado, agrupamiento y relacionamiento.
- Cantidad de usuarios con ticket por día en un periodo. Definamos ese periodo para el ejemplo como el mes de julio de 2023.
En este caso, lo que requerimos es cantidad de registros, es contar por lo tanto la función de agregado que vamos a usar es COUNT, adicionalmente nos piden que ese conteo, sea realizado por día, es decir debemos agrupar los datos por el día del turno.
Con lo anterior la consulta a construir será:
SELECT COUNT(*) FROM users INNER JOIN tickets ON (users.id = tickets.user_id) WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY date_time La consulta está correcta de sintaxis, pero el campo date_time es de tipo fecha y hora, por lo tanto, esta agrupando siempre que el ticket fuese realizado en el mismo día y a la misma hora, lo cual no es lo solicitado, para ello vamos a hacer uso de una función especial que nos retorne la fecha solamente en el caso de un campo de tipo datetime, en ese caso la función es DATE, luego es necesario que ademas del conteo, mostremos el día, por lo que la consulta queda:
SELECT DATE(date_time), COUNT(*) FROM users INNER JOIN tickets ON (users.id = tickets.user_id) WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY DATE(date_time)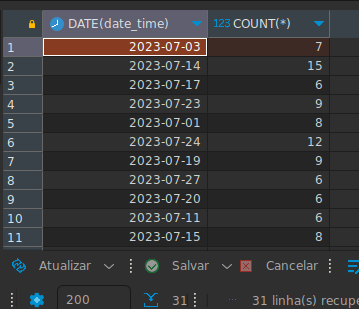
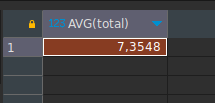
- Promedio de turnos por día en un periodo
Para esta consulta debemos hacer uso de la función AVG, ya que lo nos piden es el promedio de turnos por dia, en un periodo, en ese caso, tomamos la consulta anterior, y sobre esa consulta aplicamos un concepto que se denomina SUBSELECT. Cuando hacemos uso de SUBSELECT debemos encerrar entre () la consulta original y luego le damos un nombre, observa como queda la consulta:
SELECT AVG(total) FROM
(SELECT DATE(date_time), COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id) WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY DATE(date_time)) as t1El texto as t1 es el que nos permite indicarle a SQL que ese SUBSELECT que está entre parentesis: (SELECT DATE(date_time), COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id) WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY DATE(date_time))
Otro punto interesante es que le dimos un nombre al valor de conteo, para poder luego obtener su promedio, eso lo hicimos de esta forma: COUNT(*) as total
- Cantidad de turnos mayor o menor por dia.
En este caso debemos usar las funciones de MAX y MIN, vamos a realizar 2 consultas para ello. Para obtener el día con mayor cantidad de turnos esperados (es decir sin importar su status), hacemos la siguiente consulta:
SELECT MAX(t1.total) FROM
(
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY DATE(date_time)
) as t1;La consulta anterior nos devuelve la cantidad máximas de turnos, pero no obtenemos el día, lo cual sería importante, por lo que en ese caso podemos hacer uso de otra herramienta que no es función de agregado, pero que es básica para cualquier consulta, el ordenar, luego si solo queremos un registro, nos apoyamos en otra herramientas disponible que es la de limitar como vimos anteriormente.
Como queda nuestra consulta para obtener el día com mayor cantidad de turnos, usando orden y limitación:
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01'
GROUP BY DATE(date_time)
ORDER BY 2 DESC LIMIT 1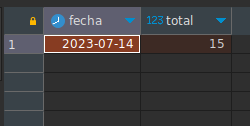
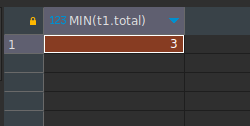
Para obtener la cantidad menor de turnos en un día usamos las mismas consultas, sólo ajustando las funciones de agregado o el criterio de orden.
SELECT MIN(t1.total) FROM
(
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY DATE(date_time)
) as t1;Observa que en este caso cambiamos MAX por MIN.
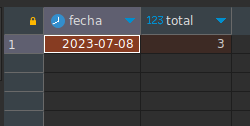
Ahora usando orden y limitación:
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01'
GROUP BY DATE(date_time)
ORDER BY 2 ASC LIMIT 1Para este caso solo cambiamos es DESC por ASC.
- Día con mayor o menor cantidad de turnos ejecutados
Esta consulta es similar a la anterior, solo que en este caso vamos a agregar una condición del valor del campo status, que sea igual a realizado, observa como quedan las consultas:
Primero veamos el día con mayor cantidad de turnos realizados o ejecutados:
SELECT MAX(t1.total) FROM
(
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' AND status = 'Realizado' GROUP BY DATE(date_time)
) as t1;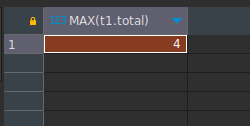
Recordando que si queremos la fecha, usamos orden y limitación:
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' AND status = 'Realizado'
GROUP BY DATE(date_time)
ORDER BY 2 DESC LIMIT 1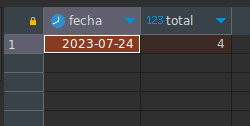
Ahora veamos el día con menor cantidad de turnos realizados o ejecutados:
SELECT MIN(t1.total) FROM
(
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' AND status = 'Realizado' GROUP BY DATE(date_time)
) as t1;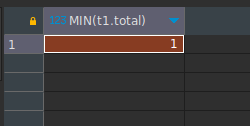
Usando orden y limitación, obtenemos tanto la cantidad como la fecha que sucedió:
SELECT DATE(date_time) as fecha, COUNT(*) as total FROM users INNER JOIN tickets ON (users.id = tickets.user_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' AND status = 'Realizado'
GROUP BY DATE(date_time)
ORDER BY 2 ASC LIMIT 1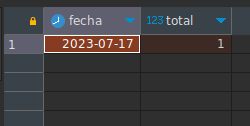
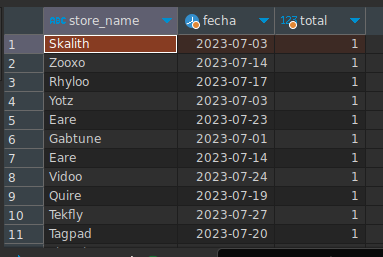
- Cantidad de turnos por Tienda por día en un periodo
Veamos ahora este ejemplo, donde la función de agregado es la de conteo, pero debemos agrupar por 2 campos, en este será la fecha del turno y el nombre de la tienda, los campos están en 2 tablas diferentes pero esto no será problema para nuestra consulta. Veamos como queda:
SELECT store_name, DATE(date_time) as fecha, COUNT(*) as total FROM stores INNER JOIN tickets ON (stores.id = tickets.store_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY store_name, DATE(date_time)
En la consulta apreciamos que el agrupamiento se realizó por el nombre de la tienda y la fecha del turno: GROUP BY store_name, DATE(date_time)
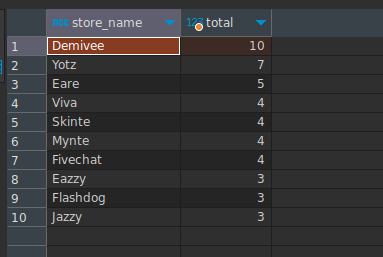
- Top 10 de las tiendas con mayor cantidad de turnos ejecutados.
En este caso, analicemos la consulta, vamos a necesitar contar los turnos, función COUNT, luego debemos agruparlos por cada tienda, de esta forma obtenemos la cantidad por tienda, luego aplicamos un criterio de orden descendente, para que las primeras sean las tiendas de mayor cantidad de turnos y luego lo limitamos a 10. Excelente!, veamos la query.
SELECT store_name, COUNT(*) as total FROM stores INNER JOIN tickets ON (stores.id = tickets.store_id)
WHERE date_time >= '2023-07-01' AND date_time < '2023-08-01' GROUP BY store_name ORDER BY total DESC LIMIT 10
Resultando lo siguiente:
Veamos aquellas consultas que sabemos que no tienen agrupamiento:
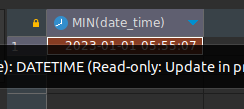
- Día del primer turno registrado
SELECT MIN(date_time) FROM tickets t De forma rápida apreciamos que usando la función MIN, obtemos el valor mínimo de ese campo.
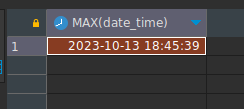
- Día del último turno registrado
SELECT MAX(date_time) FROM tickets tAcá apreciamos que logramos obtener el valor máximo del campo fecha del turno.
- Cantidad de turnos procesados por el sistema
Consulta básica:
SELECT COUNT(*) FROM tickets WHERE status = 'Realizado'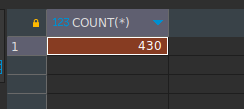
- Si le agregamos a la tabla de tickets, los minutos de cada turno ejecutado, podemos obtener la suma de tiempo ejecutado.
SELECT SUM(tiempo) FROM tickets WHERE status = 'Realizado'Recuerden que para poder ejecutar la consulta anterior debe agregarse la columna tiempo en la tabla tickets.
Todo lo realizado hasta aquí lo puedes ver en la práctica en el siguiente video: