

Artículo original: An introduction to Q-Learning: reinforcement learning
Q-learning es un algoritmo de aprendizaje basado en valores en el aprendizaje por refuerzo. En este artículo, aprenderemos sobre Q-Learning y sus detalles:
- ¿Qué es Q-Learning?
- Matemáticas detrás de Q-Learning
Q-Learning — Una visión general simplificada
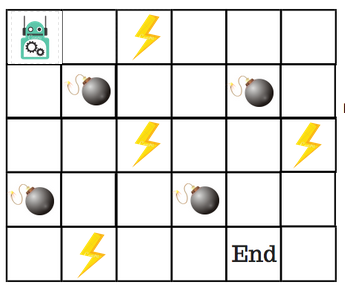
Digamos que un robot tiene que cruzar un laberinto y llegar al punto final. Hay minas, y el robot sólo puede moverse una casilla a la vez. Si el robot pisa una mina, el robot muere. El robot tiene que llegar al punto final en el menor tiempo posible.
El sistema de puntuación/recompensa es el siguiente:
- El robot pierde 1 punto en cada paso. Esto se hace para que el robot tome el camino más corto y llegue a la meta lo más rápido posible.
- Si el robot pisa una mina, la pérdida de puntos es de 100 y el juego termina.
- Si el robot obtiene poder ⚡️, gana 1 punto.
- Si el robot alcanza la meta, el robot obtiene 100 puntos.
Ahora, la pregunta obvia es: ¿Cómo entrenamos a un robot para llegar a la meta final con el camino más corto sin pisar una mina?
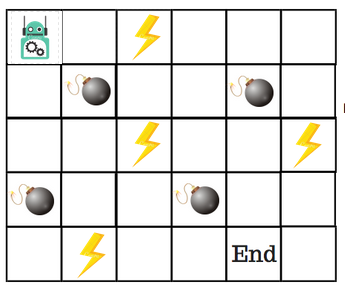
Entonces, ¿cómo resolvemos esto?
Introducción a Q-Table
Q-Table es sólo un nombre elegante para una simple tabla de búsqueda donde calculamos las máximas recompensas futuras esperadas por acción en cada estado. Básicamente, esta tabla nos guiará a la mejor acción en cada estado.
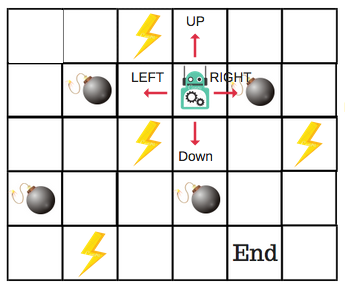
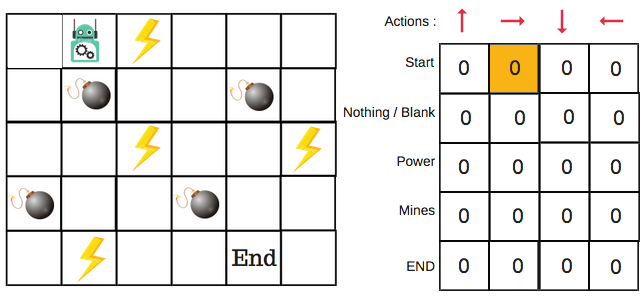
Habrá cuatro números de acciones en cada mosaico sin bordes. Cuando un robot está en un estado puede moverse hacia arriba, hacia abajo, hacia la derecha o la izquierda.
Por lo tanto, modelemos este entorno en nuestra Q-Table.
En la Q-Table, las columnas son las acciones y las filas son los estados.
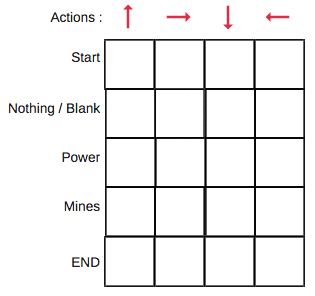
Cada puntuación de la Q-Table será la máxima recompensa futura esperada que el robot recibirá si toma esa acción en ese estado. Se trata de un proceso iterativo, ya que necesitamos mejorar la Q-Table en cada iteración.
Pero las preguntas son:
- ¿Cómo calculamos los valores de la Q-Table?
- ¿Los valores están disponibles o predefinidos?
Para aprender cada valor de la Q-Table, utilizamos el algoritmo Q-Learning.
Matemáticas: el algoritmo Q-Learning
Q-function
La Q-function utiliza la ecuación de Bellman y toma dos entradas: estado (s) y acción (a).
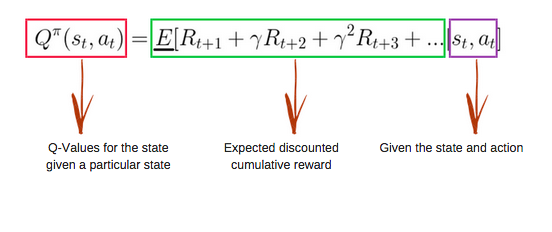
Usando la función anterior, obtenemos los valores de Q para las celdas de la tabla.
Cuando empezamos, todos los valores de la Q-Table son ceros.
Hay un proceso iterativo de actualización de los valores. A medida que comenzamos a explorar el entorno, la Q-function nos da mejores y mejores aproximaciones, actualizando continuamente los Q-values de la tabla.
Ahora, vamos a entender cómo se lleva a cabo la actualización.
Introducción al proceso del algoritmo Q-Learning
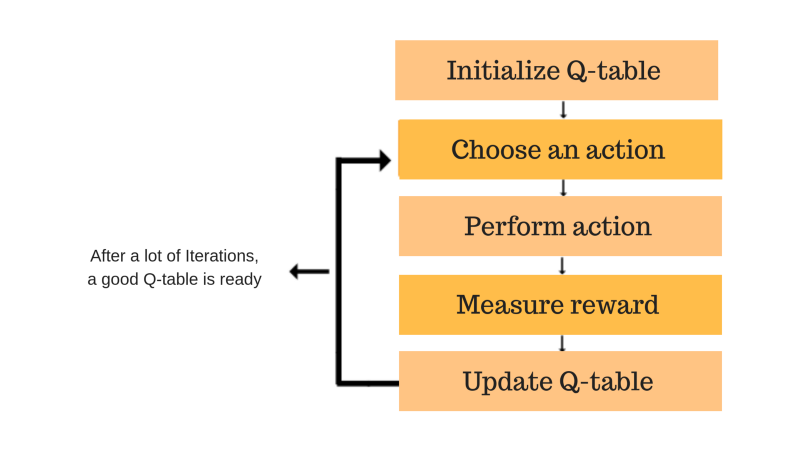
Cada una de las cajas de colores es un paso. Vamos a entender cada uno de estos pasos en detalle.
Paso 1: Inicializar la Q-Table
Primero construiremos una Q-Table. Hay n columnas, donde n= número de acciones. Hay m filas, donde m= número de estados. Inicializaremos los valores en 0.
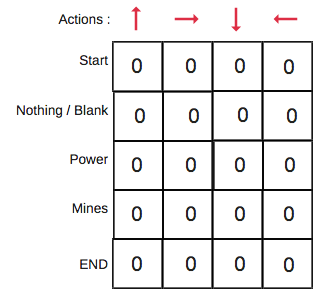
En nuestro ejemplo de robot, tenemos cuatro acciones (a=4) y cinco estados (s=5). Así que vamos a construir una tabla con cuatro columnas y cinco filas.
Pasos 2 y 3: elegir y realizar una acción
Esta combinación de pasos se realiza por un tiempo indefinido. Esto significa que este paso se ejecuta hasta el momento en que detenemos el entrenamiento, o el bucle de entrenamiento se detiene como se define en el código.
Elegiremos una acción (a) en el estado (s) basado en la Q-Table. Pero, como se mencionó anteriormente, cuando el episodio comienza inicialmente, cada valor de Q es 0.
Así que ahora entra en juego el concepto de compensación de exploración y explotación.
Vamos a utilizar algo llamado la estrategia codiciosa de Épsilon.
Al principio, las tasas de épsilon serán más altas. El robot explorará el entorno y elegirá acciones al azar. La lógica detrás de esto es que el robot no sabe nada sobre el medio ambiente.
A medida que el robot explora el entorno, la velocidad de épsilon disminuye y el robot comienza a explotar el entorno.
Durante el proceso de exploración, el robot adquiere progresivamente más confianza en la estimación de los Q-values.
Para el ejemplo del robot, hay cuatro acciones para elegir: arriba, abajo, izquierda y derecha. Comenzamos el entrenamiento ahora — nuestro robot no sabe nada sobre el medio ambiente. Así que el robot elige una acción al azar, la derecha.
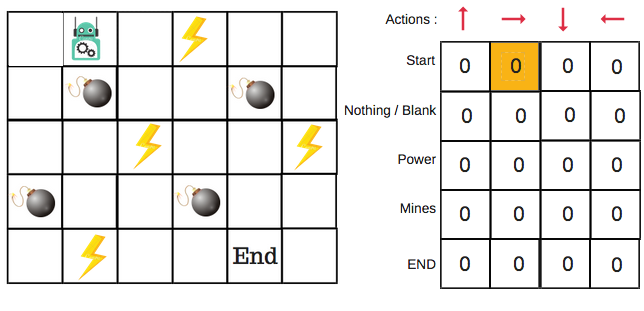
Ahora podemos actualizar los Q-values para estar en el comienzo y mover a la derecha usando la ecuación de Bellman.
Pasos 4 y 5: evaluar
Ahora hemos tomado una acción y observado un resultado y recompensa.Necesitamos actualizar la función Q(s,a).

En el caso del juego del robot, para reiterar la estructura de puntuación/recompensa es:
- power = +1
- mine = -100
- end = +100

Repetiremos esto una y otra vez hasta que el aprendizaje se detenga. De esta manera se actualizará la Q-Table.
Vamos a recapitular
- Q-Learning es un algoritmo de aprendizaje por refuerzo basado en valores que se utiliza para encontrar la política óptima de selección de acciones utilizando una función Q.
- Nuestro objetivo es maximizar la función de valor Q.
- La Q-Table nos ayuda a encontrar la mejor acción para cada estado.
- Ayuda a maximizar la recompensa esperada seleccionando la mejor de todas las acciones posibles.
- Q(estado, acción) devuelve la recompensa futura esperada de esa acción en ese estado.
- Esta función se puede estimar usando Q-Learning, que actualiza iterativamente Q(s,a) usando la ecuación de Bellman.
- Inicialmente, exploramos el entorno y actualizamos la Q-Table. Cuando la Q-Table esté lista, el agente comenzará a explotar el entorno y comenzará a tomar mejores medidas.
Si usted tiene alguna pregunta, por favor hágamelo saber en un comentario en Twitter.