

Dentro del Aprendizaje Supervisado se encuentran los algoritmos de Regresión y Clasificación, los cuales nos permiten hacer predicciones y clasificar variables.
La Regresión Logística es un caso excelente puesto aplicarse a ambas tareas.
Primero que nada. ¿Por qué el aprendizaje es supervisado?
En este contexto, el calificativo supervisado nos indica simplemente que el conjunto de datos a trabajar contendrán una etiqueta.
El aprendizaje supervisado, a diferencia del no supervisado, se caracteriza por el uso de conjuntos de datos etiquetados.
Estos datos etiquetados son la esencia del proceso, ya que con ellos se implementará un algoritmo que permitirá realizar las siguientes tareas:
Predicción: Cuando escuchamos acerca de predecir una variable, puede que lleguemos a pensar en los modelos de regresión; desde el más simple cómo la Regresión Lineal, hasta otros más complejos como la Regresión Polinomial. Una observación importante es que para realizar una tarea de predicción no es indispensable que la variable sea numérica. Podemos realizar una predicción con variables categóricas, como sucede en la Regresión Logística.
Clasificación: Como su nombre lo indica, este tipo de tareas se centran en la clasificación de información. Son muy útiles para clasificar categorías en los datos. Dicha tarea se elabora con algoritmos que son ideales para variables categóricas (también llamados algoritmos de clasificación).
Pese a existir una amplia gama de algoritmos, aprender acerca de la Regresión Logística es un muy buen comienzo.
Por otra parte es importante no confundir las tareas de predicción y clasificación con los problemas de regresión y clasificación. Estos problemas hacen referencia más a la naturaleza intrínseca del algoritmo, mientras que las tareas están más relacionadas con su implementación práctica. La verdad es que casi cualquier modelo de aprendizaje supervisado, tendrá por uso final predecir o clasificar. Por ejemplo usar un modelo de regresión para predecir una variable.
Habiendo aclarado esta confusión, este artículo explicará la regresión logística y tomando en cuenta su capacidad para realizar ambas tareas (predicción y clasificación).
Regresión Logística, Introducción.
A veces denominado modelo logit en los textos de estadística. Puede emplearse tanto para clasificación como para predicción. En el caso de clasificación su comprensión es simple, busca clasificar dos clases diferentes. En caso de la predicción, la curva realiza una predicción binaria entre dos categorías.
Pero... ¿Cómo funciona?
Para predecir la probabilidad de que nuestra variable y = 1 (o bien, la probabilidad que nuestro evento sea verdadero), usamos una Función de Respuesta Logística. Mucha de esta información fue tomada del MIT OCW páginas 11-13.
Pasos Función de Respuesta Logística.
1.Denominamos la variable dependiente como y
2.Establecemos la probabilidad máxima de variable como P (y = 1)
3.Entonces tendremos que el caso negativo tiene una probabilidad de:
P (y = 0) que es lo mismo que: 1 -P (y = 1)
4.Podemos añadir variables independientes x1,x2,...,xk
5.Usamos la Función de Respuesta Logística
6.Gracias a esa transformación tenemos:
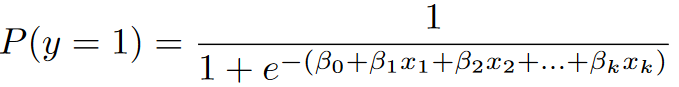
- ¡Listo! Hemos obtenido una transformación no lineal de la ecuación, por tanto todos nuestros valores estarán entre 0 y 1
Esta función posee valores entre 0 y 1, basándose en este margen, la regresión permitirá hacer una decisión entre dos categorías, por ejemplo, Positivo y Negativo, en esta dualidad, todo valor cercano a uno representará la categoría positivo, mientras que todo valor cercano a cero, representará negativo.
Pero... ¿Y los valores cercanos a ambos?
¡Excelente observación! Existe la necesidad de Umbral de Decisión o "Threshold". Por norma general, y en el contexto del ejemplo, se usará, 0.5 cómo el Umbral para nuestra Predicción. Por tanto, cualquier valor superior al umbral será tomado cómo Positivo. Mientras que cualquier valor inferior al umbral, será tomado como negativo.
Representación.
Las categorías en el umbral pueden representar la suscripción o no a un servicio, la llamada o no a una entrevista de empleo, si una persona tiene alguna enfermedad o no, entre muchas otras. Si la transformación anterior te pareció muy extensa, esta puede abreviarse de la siguiente manera:
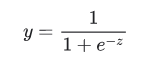

Tal como se aprecia en la imagen, el umbral de decisión representa el 0.5. Vemos también cómo la función toma valores cada vez más evidentes hacia la izquierda o derecha del eje X en base al valor de la probabilidad. O si lo prefieres, la función dará un valor negativo para probabilidades por debajo del umbral, y positivo para probabilidades mayores al valor del umbral.
Además, gracias a la transformación no lineal efectuada, la función no puede tomar valores fuera de los extremos de 0 y 1. Y por tanto, matemáticamente la probabilidad dependerá de las variables de predicción asignadas como exponentes de e. Es decir del valor -z que se encuentra en el denominador de la función.
Reflexión. Predicción y Clasificación, dos caras del mismo... ¿Dado?
Ejemplo mental.

Vamos a ver un ejemplo de probabilidades para entender intuitivamente la clasificación y predicción en la Regresión Logística.
La alegoría de los dados, aunque no directamente relacionada, puede llegar a ser realmente esclarecedora; por una parte un dado posee seis caras, lo cual desde el punto de vista de la predicción equivale a lo siguiente:
Supongamos que lanzamos un solo dado una sola vez. La probabilidad de cada cara en un solo lanzamiento equivaldría a un sexto (16.67%). Por tanto, la predicción de y=1 en la cara 3 equivaldría a 16.67%. Mientras que la de y=0 equivaldría a 0.83%. Cómo estamos en un solo lanzamiento, y la predicción es sí o no. ¿Qué es más probable? ¿Qué salga la cara 3 o que no?
Por otra parte, desde el punto de vista de clasificación, nos centraríamos en la tipología de estos, por ejemplo, ¿Es el resultado un número par o impar? Sí o no. Par e Impar han pasado a representar categorías. ¿Puedo medir Par o Impar como cantidades? La respuesta es NO, pero sí podemos clasificar ambas como variables categóricas. Esta es la esencia de la clasificación.
De esta forma hemos visto tanto el aspecto cuantitativo cómo cualitativo de un solo elemento, en este ejemplo, los dados. Por tanto, aunque la predicción y la clasificación sean dos tareas muy diferentes, tienes que tener en cuenta que la elección de una u otra depende de la variable y del contexto que quieres inferir. Es aquí donde entrará tu rol en ciencia de datos.
Como ejemplo adicional, supón que trabajas con una cartera de clientes. Tu interés está en clasificar datos preexistentes de un grupo de clientes basado en sus compras previas y preferencias de navegación, entonces empleas un modelo de clasificación.
Si usas ese modelo de clasificación para predecir la próxima compra de tu cliente, habrás hecho tanto la tarea de clasificación como de predicción.
Reflexiones finales. Regresión Logística Características Principales
¿Qué hace a especial a la Regresión Logística? A continuación te comento tres de las distinciones (e intuiciones) principales de la Regresión Logística:
1. La Regresión Logística puede emplearse tanto para predicción como clasificación. A diferencia de otros modelos cómo la Regresión Lineal que solo puede emplearse en predicción.
2. El resultado final en Regresión Logística. Su naturaleza es binaria. De allí el Sí o No de la predicción o clasificación. En niveles más avanzados puede ser Multinomial(tres o más categorías sin orden natural de las etiquetas) u Ordinal(tres o más categorías con un orden natural de las etiquetas). En cualquier caso, la respuesta que se busca es similar.

3. La Regresión Logística NO asume una relación lineal entre las variables dependientes e independientes. Como consecuencia, tampoco asume un resultado con tendencia continua a medida se incrementan los valores de la variable como en la regresión lineal.
y=mx+b
Basada en la ecuación de la recta, la regresión lineal está basada en una tendencia constante.
Si tienes problemas en este concepto de la regresión lineal, puedes encontrar una explicación muy detallada en este artículo.
Conclusión:
En este artículo habrás aprendido qué es el Aprendizaje Supervisado así como sus tareas más importantes de Predicción y Clasificación.
Una vez reconocido este contexto, habrás aprendido el modelo de Regresión Logística de forma matemática, gráfica e intuitiva en un nivel introductorio.
Esta fue una introducción a la Regresión Logística y sus aplicaciones de predicción y clasificación en el contexto del Aprendizaje Automático Supervisado. A lo largo del artículo se intentó evitar el mayor número de terminología posible, así como explicaciones técnicas y extensión que podrían dar lugar a confusión (como la regularización, la función de pérdida, entre otras).
Siguiendo ese mismo propósito, el artículo hizo énfasis en la interpretación conceptual del modelo y la explicación de su utilidad en la vida real con un lenguaje simple.
Si llegaste hasta aquí ¡Muchas Gracias y Felicidades!
Ánimos en tus estudios, gracias por leer y...
¡Feliz aprendizaje!