

Uno de los aspectos más importantes al trabajar con datos, consiste en el pre-procesamiento de estos.
La limpieza de datos es un paso necesario antes de realizar cualquier tarea relevante en análisis/ciencia de datos, desde elaborar un simple análisis gráfico, hasta implementar un modelo de aprendizaje automático.
En la práctica es probablemente la tarea que más tiempo te tomará hacer. Pero no todo el proceso es incertidumbre y vicisitud. Entre las ventajas de Python, está su facilidad (tanto de comprensión como de ejecución) a la hora sumergirnos en este proceso. En este artículo tendremos una primera mirada a esta tarea.
Introducción
¿Qué es Limpieza de Datos?
Denominado en Inglés Data Cleaning o Data Cleansing, este proceso involucra detectar, eliminar,corregir o transformar cualquier anomalía, perturbación o irrelevancia de los datos.
Razones para efectuar Limpieza de Datos
Este proceso ayuda a obtener resultados confiables, un error peligroso a la hora de realizar un análisis es abstraerse en exceso en el modelo a implementar, y no empezar por lo más simple. Tu fuente de información y su tratamiento. Los datos en el mundo real rara vez son homogéneos y directamente intuitivos. Asimismo, realizar este proceso puede reducir posibles sesgos en el análisis. He aquí varias de las razones más comunes:
Remover Outliers: Por outlier nos referimos a cualquier dato que difiere significativamente del promedio o rango observado del resto de nuestros datos. Aunque los outliers son mucho más fáciles de apreciar gráficamente, también pueden detectarse a primera vista en un conjunto de datos, por ejemplo, encontrar la variable edad de una persona en 480. Inmediatamente nos indica que es un error de entrada de datos, conocido en inglés como "data entry error", probablemente la edad sea 48.
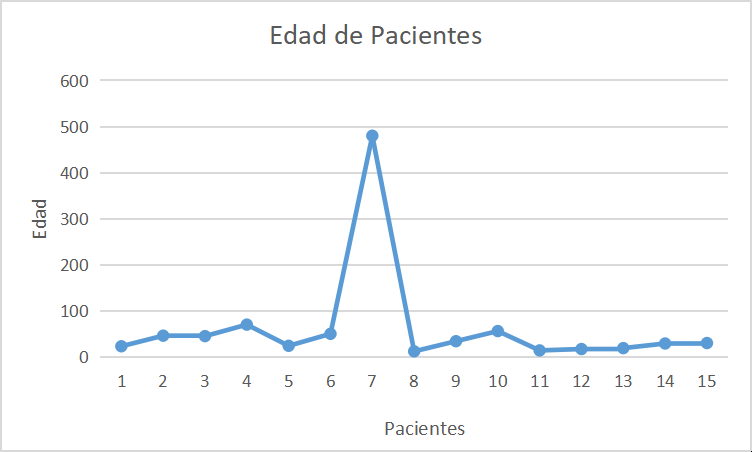
Trabajar datos Nulos: No se ha introducido información alguna en alguno de los elementos de la variable. Estos pueden deberse a falta de información o bien a no haber podido estimar la variable,un error de entrada, o bien hubo un fenómeno externo que impidió la recolección de datos. Cualquiera sea la razón es importante estar consciente de esta situación, puesto que conociendo la localización y el tipo de datos que se encuentran nulos, podremos extrapolarlos, efectuar una transformación o bien, al menos conocer las limitaciones de nuestra información. Este fenómeno también puede ser conocido como "Missing Data".

Eliminar o transformar datos erróneos e irrelevantes: Estos representan información fuera de contexto en nuestra base de datos, por ejemplo tener la variable precio de venta en números negativos.

Limpieza de Datos con Pandas
Pandas nos ofrece una variedad de opciones para resolver problemas de este tipo.
Sin mayores preámbulos, veamos el proceso.
import pandas as pd
datos=pd.read_csv("C:Downloads\SP.csv")
datosAhora veamos nuestros datos.
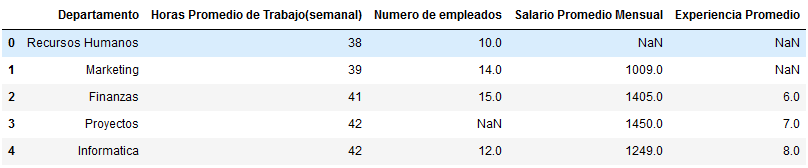
Como se aprecia, tenemos un resumen de la plantilla de cierta empresa ficticia. Se detalla el departamento,empleados, así como los valores promedio de las horas de trabajo, salario y experiencia. El problema radica no solo en la presencia de datos nulos, sino en que estos se encuentran dispersos en distintas variables o "columnas".
Detección de datos nulos
En este ejemplo pueda que dichos datos sean de fácil advertencia, pero... ¿Qué haríamos si nuestro archivo csv hubiese tenido 100 filas y 20 columnas?
Isnull
Isnull nos permite detectar datos nulos, simplificando este proceso independientemente de la dimensión de nuestra base de datos.
#agregamos la función isnull.
datos.isnull()
#Si lo prefieres puedes usar:
datos.notnull()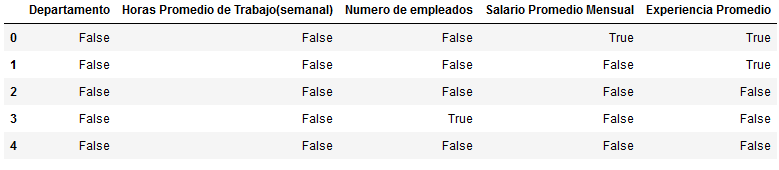
Notnull
Una alternativa menos conocida es Notnull. Es la indicación lógica contraria, y la forma de llamar a la función es similar.

Como vez, los resultados son opuestos, puedes usar la que prefieras siempre y cuando recuerdes el criterio lógico.
Limpieza de Datos
Ahora que sabemos localizar los datos nulos. Veamos como trabajar con ellos. A partir de este punto estaremos modificando datos.
Dropna
dropna() elimina las filas que contienen datos nulos, por tanto es muy útil para eliminar filas con varias datos nulos a la vez, ya que dichas filas no aportarían información significativa más que para unas cuantas variables.

La desventaja al usar dropna() es que puede eliminar información importante, como se muestra en el ejemplo, incluso las filas que solo tenían un solo dato nulo fueron eliminadas.
Fillna
fillna() rellena los valores nulos con un valor predeterminado. Es importante destacar que existen distintos métodos a la hora de trabajar con fillna.
Esta función es muy útil cuando solo necesitas corregir un número mínimo de datos nulos.
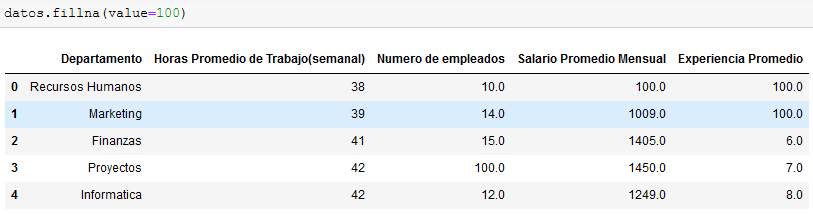
En el ejemplo rellenamos los datos nulos con fillna(value=100) asignándole el valor de 100 a todos los datos nulos.
¿Desventaja? Como habrás notado la asignación de dicho valor puede llegar a ser arbitraria.
Veamos otro método de fillna() más rápido y efectivo.
bfill
Este método rellena los datos nulos, en base al valor de la siguiente fila.
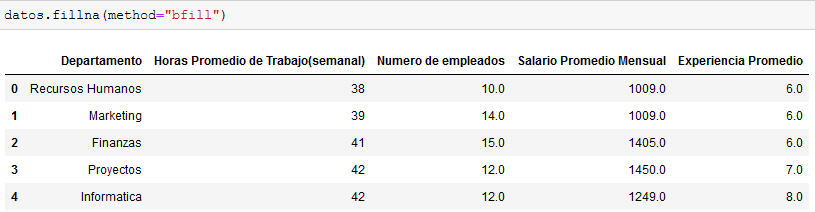
Ventajas: Sin duda es mucho mejor que asignar un valor arbitrario a los datos, además garantiza que los datos se mantengan dentro de un rango específico. Es especialmente útil en bases de datos de gran extensión y con poca proporción de datos nulos.
Desventajas:Sin embargo, debes asegurarte que el número de datos nulos NO sea significativo, para que el coeficiente de variación y otras medidas de dispersión no sufran de un sesgo muy grande. Por otra parte no involucra ninguna estimación en pleno sentido.
¿Y los Outliers?
Habíamos mencionado la posibilidad de detectar los outliers. Existen varias formas de hacerlo, tales como el método interquartil, o el método de boxplot, entre otros.
Sin embargo también podemos lograr buenos resultados de forma visual.
Usando describe.
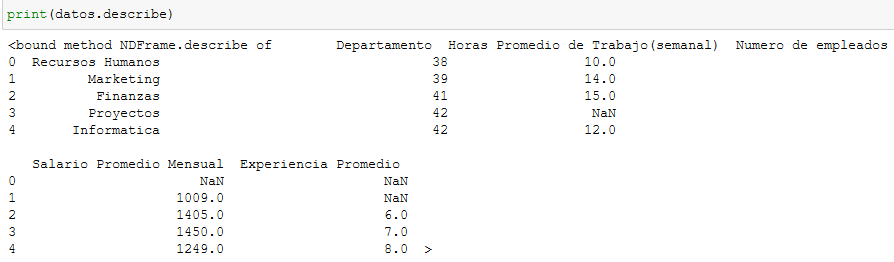
En este caso podemos observar detalladamente los diferentes valores que existen en nuestro conjunto de datos, y detectar anomalías a primera vista.
Usando un Histograma
Probemos ahora con el histograma. simplemente empleamos datos.hist() en este caso se ajustó el tamaño del mismo por motivos de presentación. Sin embargo, si lo buscas es solo una mirada rápida a tus datos no suele ser necesario.
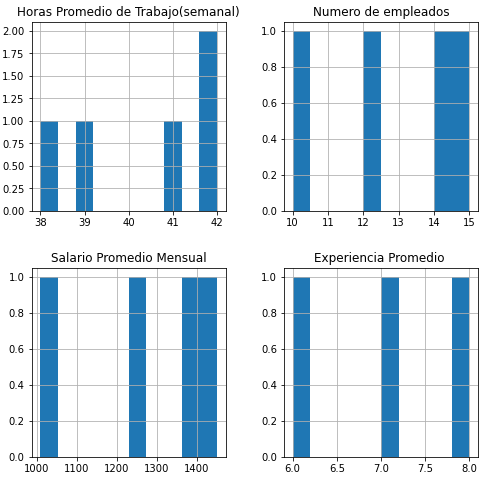
Ambos métodos son extremadamente rápidos y simples, puesto que involucran una sola llamada a la función, en adición, pueden ahorrarte mucho tiempo y energía.
¡Bonus!
Otros problemas: Datos erróneos e irrelevantes.
No es posible abarcar la amalgama de problemas que pueden presentarse a la hora de limpiar datos, sin embargo, habrá un último ejemplo, que puede ser de utilidad con errores de entrada de datos. Este ejemplo es adicional puesto que implica la creación de un DataFrame, así como una pequeña iteración, y por tanto involucra un poco más de programación. Vamos a ello.
Nuestro ejemplo consiste en la organización de nuestro sistema de inventarios de una empresa ficticia. Este sistema de inventarios contiene como información cuantitativa, el precio, y el tiempo en existencias medido en días. Como variables cualitativas, está la revisión de calidad, con el 1 representando Sí, y el 0 No. Por último está la clasificación predeterminada de estos inventarios de acuerdo al Método ABC.
Sin embargo nuestra información tiene errores con respecto a los días en inventarios, la persona a cargo de llevar la cuenta ignoró 3 de los inventarios y al final, se excusó colocando ## en lugar del valor adecuado (también pudo hacer colocado "n.d", "no sé", o cualquier palabra, en todo caso, la situación no cambia).
Usted como persona a cargo del análisis de datos, decide estimar los días de estos tres inventarios restantes en base al promedio del total de días en inventario.
El quid del asunto es; ¿Cómo hacemos esto en Python?
El proceso viene a continuación.
#Primero ordenaremos la información creando un DataFrame
inventario = pd.DataFrame({"Dias en Inventario": ["23", "24", "##", "14", "12", "10", "35","##","40","##"],
"Precio Promedio": ["23", "24", "18", "14", "46", "44", "35","41","15","9"],
"Tipo de Inventario": ["A", "B", "C","B", "C", "C", "A","A","B","C"],
"Revision Calidad": [1, 1, 0, 1, 0, 0, 1, 1, 0, 0]})
print(inventario)Como resultado tenemos lo siguiente:
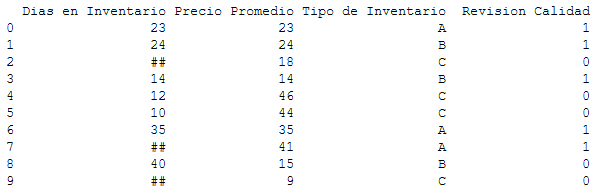
En este caso, a diferencia del anterior, solo es una columna la que presenta problemas en los datos. Pese a esta aparente "facilidad", estos no deben tratarse como datos nulos.
Si aplicamos isnull() a inventario, obtendremos:
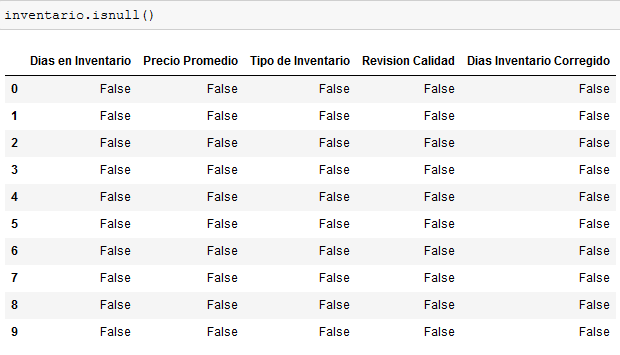
Vemos pues, que isnull NO funcionará siempre y cuando exista al menos un caracter en cada elemento.
Pasemos a resolver el problema mediante el reemplazo de datos, por medio de una iteración reemplazando ## por 22, es decir, por el valor promedio de días en inventario.
#Creamos una nueva columna con los valores ya reemplazados.
for dias in inventario.iterrows():
index_value, column_values=dias
arreglo=int(column_values['Dias en Inventario'].replace('##','22'))
inventario.at[index_value,'Dias Inventario Corregido']=arregloVeamos el resultado:
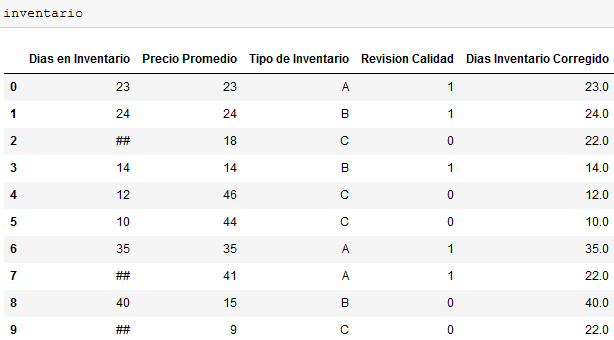
Se ha creado la nueva columna reemplazando los datos erróneos con el promedio 22.
Pero antes de cantar victoria, eliminemos la columna antigua.
#Eliminamos Dias en Inventario.
inventario.drop(axis=1, columns='Dias en Inventario')Y... tenemos:
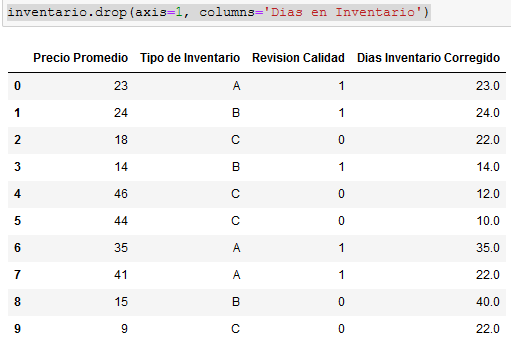
Hemos garantizado (o al menos mejorado), la integridad de todos nuestros datos. Los valores de ## han sido reemplazados por el valor más cercano a la media; 22. Puedes confirmar que el valor de la media es 22.4 usando inventario['Dias Inventario Corregido'].mean().
Conclusión.
En este artículo vimos los aspectos esenciales de la limpieza de datos, desde un aspecto práctico.
Durante la primera parte del artículo estudiamos la definición de limpieza de datos, así como su importancia en el mundo real. Asimismo fueron mencionados varios de los problemas más aquejantes a la hora de efectuar dicho proceso.
Póstumamente, en la segunda parte; procedimos a ver las principales funcionalidades de Pandas a la hora de limpiar nuestros datos. En esta fase se presenció como detectar, eliminar, rellenar y modificar datos empleando funciones simples y métodos específicos.
Finalmente, tratamos con otros problemas relacionados con la detección rápida de outliers, de forma tanto descriptiva como gráfica.
Como punto de cierre, se presentó un ejemplo adicional, el cuál incluyó la iteración de los valores en las columnas para efectuar una sustitución de valores erróneos (##), por un valor numérico estadísticamente coherente.
El primer ejemplo estuvo relacionado a la gestión de información de una empresa, mientras que el segundo, al análisis de inventarios. Pese a ser meros ejemplos, fueron hechos con intención práctica. Gracias a que las funciones de pandas presentadas son universales, pueden realizarse con bases de datos de mayor realidad y calibre.
Reflexión Final.
Python posee múltiples funcionalidades y facilita en gran medida el análisis y limpieza de datos. Si te interesa estudiar Python a profundidad, Freecodecamp tiene una certificación gratuita de Python.
Espero hayas aprendido con este artículo. Si llegaste hasta aquí, gracias y felicidades. Espero pronto puedas mejorar tus habilidades en Python.
Muchas Gracias por leer y...
¡Feliz aprendizaje!