

Los algoritmos basados en árboles son métodos populares de aprendizaje automático que se utilizan para resolver problemas de aprendizaje supervisado. Estos algoritmos son flexibles y pueden resolver cualquier tipo de problema (clasificación o regresión).
Los algoritmos basados en árboles tienden a usar la media para características (features) continuas o el modo para características categóricas cuando hacen predicciones sobre muestras de entrenamiento en las regiones a las que pertenecen. También producen predicciones con alta precisión, estabilidad y facilidad de interpretación.
Ejemplos de algoritmos basados en árboles
Hay diferentes algoritmos basados en árboles que puedes usar, como por ejemplo
- Árboles de Decisiones (Decision Trees)
- Bosques Aleatorios (Random Forest)
- Aumento de Gradiente (Gradient Boosting)
- Bagging (Agregación Bootstrap "Bootstrap Aggregation")
Por lo tanto, todo científico de datos debería aprender estos algoritmos y usarlos en sus proyectos de aprendizaje automático.
En este artículo, aprenderás sobre el algoritmo de bosques aleatorios (random forest). Después de completar este artículo, podrás dominar el uso del algoritmo de bosque aleatorio para resolver y crear modelos predictivos para problemas de clasificación con scikit-learn.
¿Qué es el algoritmo de bosques aleatorios?
Bosque aleatorio es uno de los algoritmos de aprendizaje supervisado basados en árboles más populares. También es el más flexible y fácil de usar.
El algoritmo se puede utilizar para resolver problemas de clasificación y regresión. El bosque aleatorio tiende a combinar cientos de árboles de decisión y luego entrena cada árbol de decisión en una muestra diferente de las observaciones.
Las predicciones finales del bosque aleatorio se realizan promediando las predicciones de cada árbol individual.
Los beneficios son numerosos. Los árboles de decisión individuales tienden a sobre ajustarse (overfit) a los datos de entrenamiento, pero el bosque aleatorio puede mitigar ese problema al promediar los resultados de predicción de diferentes árboles. Esto le da al algoritmo de bosques aleatorios una mayor precisión predictiva que un solo árbol de decisión.
El algoritmo de bosque aleatorio también puede ayudarte a encontrar características que son importantes en tu conjunto de datos. Esto se debe al algoritmo de Boruta, que selecciona características importantes en un conjunto de datos.
El bosque aleatorio se ha utilizado en una variedad de aplicaciones, por ejemplo, para proporcionar recomendaciones de diferentes productos a los clientes en el comercio electrónico.
En medicina, el algoritmo puede ser utilizado para identificar la enfermedad del paciente a través del análisis de su historial médico.
También en el sector bancario, puede ser utilizado para determinar fácilmente si el cliente es fraudulento o legítimo.
¿Cómo funciona el algoritmo de bosques aleatorios?
El algoritmo funciona completando los siguientes pasos:
Paso 1: El algoritmo selecciona muestras en forma aleatoria de la base de datos proporcionada.
Paso 2: El algoritmo creará un árbol de decisión para cada muestra seleccionada. Luego obtendrá un resultado de predicción de cada árbol creado.
Paso 3: A continuación, se realizará la votación para cada resultado previsto. Para un problema de clasificación, usará la moda, y para un problema de regresión, usará la media.
Paso 4: Y finalmente, el algoritmo seleccionará el resultado de predicción más votado como predicción final.
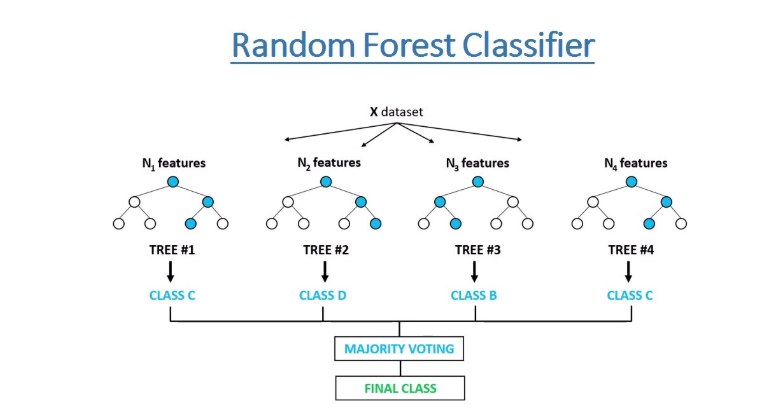
Algoritmo de bosques aleatorios en la práctica
Ahora que conoces el funcionamiento del algoritmo de bosque aleatorio, creemos un clasificador.
Construiremos un clasificador utilizando el conjunto de datos de diabetes de los indios Pima. El conjunto de datos de diabetes de los indios Pima implica predecir la aparición de la diabetes en un plazo de 5 años según los detalles médicos proporcionados. Este es un problema de clasificación binaria.
Nuestro objetivo es analizar y crear un modelo sobre aquel conjunto de datos para predecir si un paciente en particular tiene riesgo de desarrollar diabetes, dados otros factores independientes.
Comenzaremos importando paquetes importantes que usaremos para cargar el conjunto de datos y crear un clasificador de bosque aleatorio. Usaremos la biblioteca scikit-learn para cargar y usar el algoritmo de bosque aleatorio.
# importar paquetes importantes
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas_profiling
from matplotlib import rcParams
import warnings
warnings.filterwarnings("ignore")
# tamaño de la figura en pulgadas
rcParams["figure.figsize"] = 10, 6
np.random.seed(42)Conjunto de datos
Luego, carga el conjunto de datos desde el directorio de datos:
# Cargar conjunto de datos
data = pd.read_csv("../data/pima_indians_diabetes.csv")Ahora podemos observar la muestra del conjunto de datos.
# mostrar muestra del conjunto de datos
data.sample(5)
Como puedes ver, en nuestro conjunto de datos tenemos deferentes características con valores numéricos.
Entendamos la lista de características que tenemos en este conjunto de datos.
# mostrar columnas
data.columns
En este conjunto de datos, hay 8 características de entrada y 1 característica de salida / destino. Se cree que los valores que faltan están codificados con valor cero. El significado de los nombres de las características es el siguiente (desde la primera hasta la última):
- Número de embarazos.
- Concentración de glucosa en plasma a 2 horas en una prueba oral de tolerancia a la glucosa.
- Presión arterial diastólica (mm Hg).
- Espesor del pliegue cutáneo del tríceps (mm).
- Insulina sérica de 2 horas (mu U / ml).
- Índice de masa corporal (peso en kg / (altura en m) ^ 2).
- Función del pedigrí de la diabetes.
- Edad (años).
- Variable de clase (0 o 1).
Luego, dividimos el conjunto de datos en características independientes y característica de destino. Nuestra característica de destino para este conjunto de datos se llama class.
# dividir los datos en características de entrada y de destino
X = data.drop("class", axis=1)
y = data["class"]Preprocesamiento del Conjunto de Datos
Antes de crear un modelo, necesitamos estandarizar nuestras características independientes usando el método standardScaler de scikit-learn.
# estandarizar el conjunto de datos
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)Dividiendo el conjunto de datos en datos de entrenamiento y prueba
Ahora dividimos nuestro conjunto de datos procesados en datos de prueba y entrenamiento. Los datos de prueba serán el 10% de todo el conjunto de datos procesados.
# dividir en conjunto de entrenamiento (train) y
#conjunto de prueba (test)
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, stratify=y, test_size=0.10, random_state=42
)Construyendo el Clasificador de bosque aleatorio
Ahora es el momento de crear nuestro clasificador de bosque aleatorio y luego entrenarlo en el conjunto de entrenamiento. También pasaremos el número de árboles (100) del bosque que queremos usar mediante el parámetro llamado n_estimators.
# crear el clasificador
classifier = RandomForestClassifier(n_estimators=100)
# Entrenar el modelo usando el conjunto de entranamiento
classifier.fit(X_train, y_train)
El resultado anterior muestra diferentes valores de parámetros del clasificador de bosque aleatorio utilizado durante el proceso de entrenamiento en los datos de entrenamiento.
Después del entrenamiento, podemos realizar predicciones sobre los datos de la prueba.
# predicción en el conjunto de prueba
y_pred = classifier.predict(X_test)Luego, verificamos la precisión utilizando los valores reales y los predichos de los datos de prueba.
# Calcular la precisión del modelo
print("Precisión:", accuracy_score(y_test, y_pred))Precisión: 0.8051948051948052
Nuestra precisión es de alrededor del 80,5%, lo cual es bueno. Pero siempre podemos hacerlo mejor.
Identificar características importantes
Como dije antes, también podemos verificar las características importantes usando la variable feature_importances_ del algoritmo de bosque aleatorio en scikit-learn.
# verificar características importantes
feature_importances_df = pd.DataFrame(
{"feature": list(X.columns), "importance": classifier.feature_importances_}
).sort_values("importance", ascending=False)
# Mostrar
feature_importances_df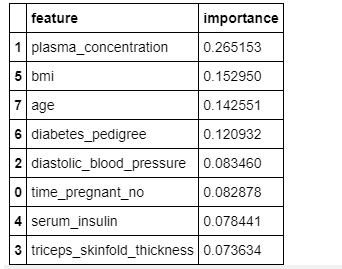
La figura anterior muestra la importancia relativa de las características y su contribución al modelo. También podemos visualizar estas características y sus puntuaciones utilizando las bibliotecas seaborn y matplotlib.
# visualizarcaracterísticas importantes
# Crear un diagrama de barras
sns.barplot(x=feature_importances_df.feature, y=feature_importances_df.importance)
# agregar estiquestas
plt.xlabel("Feature Importance Score")
plt.ylabel("Features")
plt.title("Visualizing Important Features")
plt.xticks(
rotation=45, horizontalalignment="right", fontweight="light", fontsize="x-large"
)
plt.show()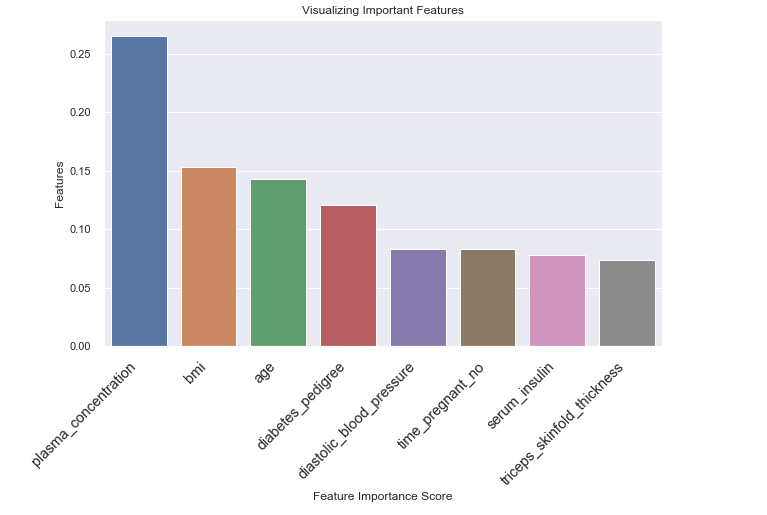
En la figura anterior, puedes ver que la variable triceps_skinfold_thickness tiene poca importancia y no contribuye mucho a la predicción.
Esto significa que podemos eliminar esta variable y entrenar nuestro clasificador nuevamente y luego ver si puede mejorar su rendimiento en los datos de prueba.
# cargar datos con características seleccionadas
X = data.drop(["class", "triceps_skinfold_thickness"], axis=1)
y = data["class"]
# estandarizar el conjunto de datos
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# dividir en conjunto de entrenamiento y de prueba
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, stratify=y, test_size=0.10, random_state=42
)Entrenaremos el algoritmo con las características procesadas seleccionadas de nuestro conjunto de datos, realizaremos predicciones y luego calcularemos la precisión del modelo.
# crear clasificador
clf = RandomForestClassifier(n_estimators=100)
# Entrenar el modelo usando el conjunto de entrenamiento
clf.fit(X_train, y_train)
# predicción en el conjunto de prueba
y_pred = clf.predict(X_test)
# Calcular la precisión del modelo,
print("Precisión:", accuracy_score(y_test, y_pred))Precisión: 0.8181818181818182
Ahora, la precisión del modelo ha aumentado del 80,5% al 81,8% después de que eliminamos la característica menos importante llamada triceps_skinfold_thickness.
Esto sugiere que es muy importante verificar las características importantes y ver si puedes eliminar las menos importantes para aumentar el rendimiento de su modelo.
En resumen
Los algoritmos basados en árboles son realmente importantes para que los aprenda todo científico de datos. En este artículo, has aprendido los conceptos básicos de los algoritmos basados en árboles y cómo crear un modelo de clasificación utilizando el algoritmo de bosque aleatorio.
¡Felicitaciones, has llegado al final de este artículo!
Si aprendiste algo nuevo o disfrutaste leyendo este artículo, compártelo para que otros puedan verlo. Hasta entonces, ¡nos vemos en el próximo post! También me pueden contactar en Twitter @Davis_McDavid
Traducido del artículo de Davis David - Random Forest Classifier Tutorial: How to Use Tree-Based Algorithms for Machine Learning