

Artículo original: JVM Tutorial - Java Virtual Machine Architecture Explained for Beginners
Tanto si has programado en Java como si no, seguramente habrás escuchado hablar de la Máquina Virtual de Java (en inglés Java Virtual Machine, JVM) en algún momento.
JVM es el núcleo del ecosistema Java, permitiendo al software basado en esta tecnología seguir el enfoque "escríbelo (tu programa) una sola vez, ejecútalo en cualquier parte (write once, run anywhere)". Puedes escribir código Java en un tipo de máquina concreto, y ejecutarlo en cualquier otro tipo de máquina usando la JVM.
Inicialmente, la JVM fue diseñada para admitir Java solamente. Pero, con el paso de los años, muchos otros lenguajes como Scala, Kotlin y Groovy fueron adoptados por la plataforma Java. El conjunto de estos lenguajes se conoce como lenguajes JVM.
En este artículo aprenderemos las esencias de la JVM, cómo funciona y los componentes en que se divide.
¿Qué es una máquina virtual?
Antes de entrar de lleno en la JVM, revisemos el concepto de máquina virtual (VM).
Una máquina virtual es la representación virtual de un ordenador físico. Normalmente, se llama huésped (guest) a la máquina virtual, mientras que al ordenador físico en que se ejecuta, se le suele llamar anfitrión (host).
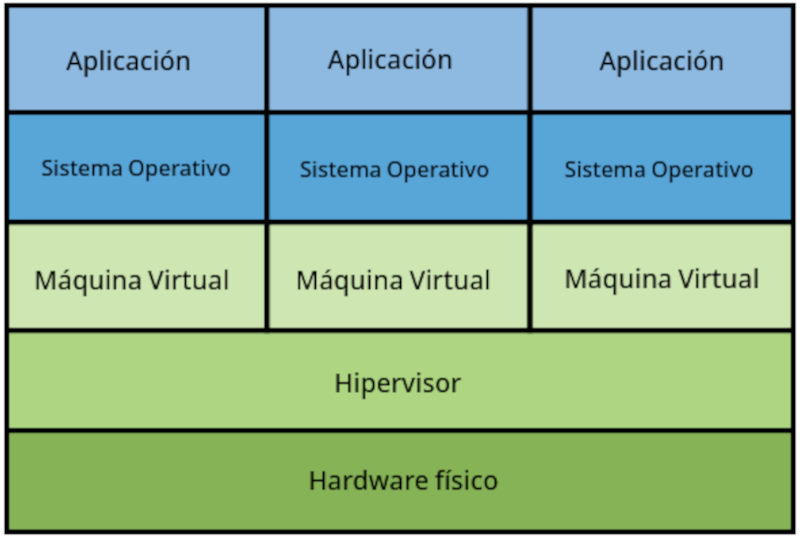
Una sola máquina física puede ejecutar varias máquinas virtuales, cada una con su propio sistema operativo y aplicaciones a nivel de usuario; están aisladas unas de otras.
¿Qué es la Máquina Virtual de Java?
En lenguajes de programación como C o C++, el código es compilado al código máquina específico de esa platoforma en concreto: son lenguajes compilados.
Por otro lado, en lenguajes como JavaScript o Python, el ordenador ejecuta las instrucciones directamente sin tener que compilarlas: son lenguajes interpretados.
Java usa una combinación de ambas técnicas. El código es compilado a bytecode (un formato binario independiente del hardware y del sistema operativo, que representa instrucciones de la JVM) generando un fichero con formato class. Este fichero class es interpretado por la JVM en la plataforma anfitriona. Un mismo fichero class puede ser ejecutado por la JVM en cualquier plataforma y sistema operativo.
De manera similar a las máquinas virtuales, la JVM crea un espacio aislado en la máquina anfitriona. Este espacio se usa para ejecutar programas Java sea cual sea la plataforma o el sistema operativo de dicha máquina.
Arquitectura de la Máquina Virtual de Java
La JVM consta de tres componentes:
- Cargador de clases (Class Loader)
- Área de datos/memoria en tiempo de ejecución (Runtime Memory/Data Area)
- Motor de ejecución (Execution Engine)
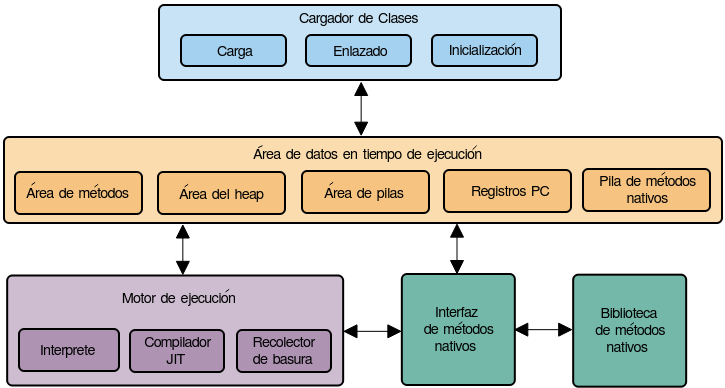
Echemos un vistazo a cada uno de ellos.
Cargador de clases
Como resultado de la compilación del código fuente almacenado en un fichero.java, se obtiene bytecode almacenado en un fichero .class . Si en un programa se va a hacer uso de esta clase, será cargado en memoria principal por el cargador de clases.
La primera clase en ser cargada en memoria es, normalmente, aquella que contiene el método main() .
El proceso de carga de clases consta de tres fases: carga (loading), enlazado (linking), e inicialización (initialization).
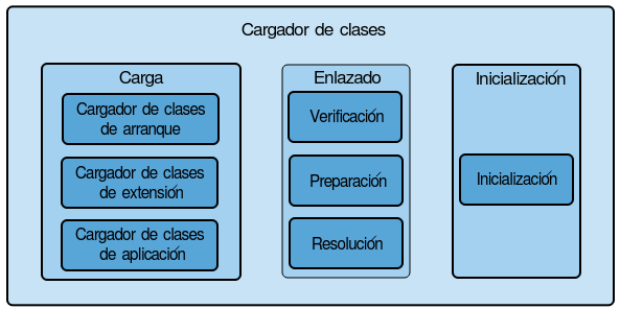
Carga (loading)
La fase de carga consiste en encontrar la representación binaria (bytecode) de una clase o interfaz con un nombre concreto, y crear una clase o interfaz a partir de dicha representación (crear una clase o interfaz c es construir una representación interna, específica de esa implementación de la JVM, de c).
Hay tres cargadores de clases incorporados:
- Cargador de clases de arranque (Bootstrap Class Loader) - raíz de la jerarquía de cargadores de clases, superclase de Extension Class Loader. Carga los paquetes estándar de Java como
java.lang,java.net,java.util,java.io, etc. localizados en el ficherort.jary otras bibliotecas fundamentales presentes en el directorio$JAVA_HOME/jre/lib. - Cargador de clases de extensión (Extension Class Loader) - subclase de Bootstrap Class Loader y superclase de Application Class Loader. Carga las extensiones de las bibliotecas estándar de Java presentes en el directorio
$JAVA_HOME/jre/lib/ext. - Cargador de clases de aplicación (Application Class Loader) - es el cargador de clases en el nivel más bajo de la jerarquía, subclase de Extension Class Loader. Carga los ficheros indicados en el classpath (variable de entorno que almacena la ruta a las clases creadas por el usuario). Por defecto, la variable classpath es establecida al directorio actual de la aplicación; puede ser modificada desde la línea de comandos con la opción
-classpatho-cp(al ejecutarjavaojavac, por ejemplo).
La JVM usa el método ClassLoader.loadClass() para cargar una clase en memoria, haciendo uso del nombre binario de la clase.
Si un cargador de clases es incapaz de encontrar una clase, delega el trabajo en el cargador de una subclase suya. Si el último cargador de la jerarquía tampoco es capaz de encontrar la clase en cuestión, se producirá NoClassDefFoundError o ClassNotFoundException.
Enlazado (linking)
Después de que una clase haya sido cargada en memoria, se somete al proceso de enlazado. Enlazar una clase o una interfaz supone resolver las referencias externas y dependencias, integrando la clase en el conjunto del programa que hace uso de ella.
El enlazado incluye los siguientes pasos:
Verificación: esta fase verifica la corrección estructural del archivo.class contrastándolo frente a un conjunto de restricciones o reglas. Si la verificación falla, se produce VerifyException.
Por ejemplo, si el código se ha construído con Java 11, pero se va a ejecutar en un sistema con Java 8, la fase de verificación fallará.
Preparación: en esta fase, la JVM asigna memoria para los campos estáticos de una clase o interfaz, inicializándolos con valores por defecto.
Supón, como ejemplo, que has declarado en una clase la siguiente variable:
private static final boolean activado = true;Durante la fase de preparación, la JVM asigna memoria para la variable activado y le asigna el valor por defecto para un booleano, que es false.
Resolución: es el proceso de resolver dinámicamente las referencias simbólicas presentes en el almacén de constantes de tiempo de ejecución (runtime constant pool, una estructura de datos del fichero .class).
Las referencias (simbólicas) que dentro de una clase se hacen a otras clases o a constantes presentes en otras clases, son resueltas en esta etapa asignándoles los valores reales.
Inicialización (initialization)
La inicialización consiste en ejecutar <clinit>, el método de inicialización de una clase o interfaz. En esta etapa se ejecutan los bloques de inicialización estáticos y se asignan los valores a las variables estáticas. Es el paso final del proceso de carga de clases.
Por ejemplo, cuando anteriormente hemos declarado el siguiente código:
private static final boolean activado = true;La variable activado fue establecida con su valor por defecto, false , durante la fase de preparación. Ahora, en la fase de inicialización, se le asigna el valor real que queríamos darle, true.
Nota: la JVM es multihilo. Cabe la posibilidad de que múltiples hilos intenten inicializar la misma clase al mismo tiempo, provocando problemas de concurrencia. Hay que gestionar cada hilo de forma segura para garantizar que el programa funcione adecuadamente en un entorno multihilo.
Área de datos en tiempo de ejecución
El área de datos en tiempo de ejecución está formado por cinco componentes:
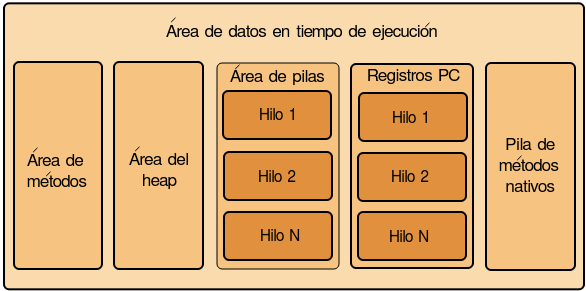
Veamos cada componente por separado.
Área de métodos
Todos los datos a nivel de clase, como el runtime constant pool, datos de los campos y los métodos, así como el código de los métodos y constructores, son almacenados en esta área.
Si la memoria disponible en el área de métodos no puede satisfacer una petición de asignación de memoria por parte de un proceso, la JVM emite un OutOfMemoryError.
Supongamos que has definido la siguiente clase:
public class Empleado {
private String nombre;
private int edad;
public Empleado(String nombre, int edad) {
this.nombre = nombre;
this.edad = edad;
}
}Los datos de los campos nombre y edad y el código del constructor son guardados en el área de métodos.
El área de métodos se crea al arrancar la JVM y es compartida por todos los hilos de ejecución.
Area del montículo (heap)
Todos los objetos y sus correspondientes variables de instancia son almacenados en esta zona. El montículo es el área de datos de tiempo de ejecución en la que se aloja la memoria asignada a los arrelgos e instancias de clases.
Supongamos que se ha declarado la siguiente instancia:
Employee empleado = new Empleado();En este ejemplo, se crea una instancia de la clase Empleado , que será cargada en memoria en el área del montículo.
Al igual que el área de métodos, el área del montículo es creada al arrancar la JVM, y se comparte por todos los hilos.
Nota: como las áreas del montículo y de métodos comparten la misma memoria para los diferentes hilos, habrá que gestionar cada hilo de forma segura para asegurar la integridad de los datos, como ya comentábamos en el apartado de inicialización de clases.
Area de pilas (stack)
A cada hilo creado en la JVM le corresponde en exclusiva una pila, creada al mismo tiempo que el propio hilo. Las variables locales, resultados parciales y llamadas a métodos se almacenan en esta zona de memoria conocida como pila.
Si el procesamiento que se está llevando a cabo en un hilo requiere un tamaño de pila mayor del permitido, la JVM emite un StackOverflowError.
Para cualquier llamada a método, se genera en la memoria de pila una entrada llamada marco de pila (stack frame). Cuando se completa la llamada al método, el marco de pila es destruido.
El marco de pila se divide en tres partes:
- Variables locales – cada marco contiene un arreglo donde se almacenan las variables locales y sus valores. La longitud de este arreglo se establece en tiempo de compilación.
- Pila de operandos (operand stack) – esta estructura de tipo pila es utilizada para llevar a cabo las operaciones intermedias durante la llamada al método en cuestión. La profundidad máxima de esta pila se determina también en tiempo de compilación.
- Marco de datos (frame data) – aquí se guardan todos los símbolos del método invocado, así como la información del bloque catch en caso de que se produzca alguna excepción.
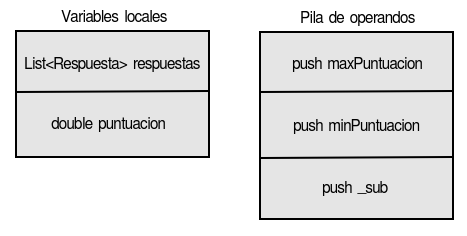
Supongamos el siguiente código:
double calcularPuntuacionNormalizada(List<Respuesta> respuestas) {
double puntuacion = getPuntuacion(respuestas);
normalizarPuntuacion(puntuacion);
}
normalizarPuntuacion(double puntuacion) {
return (puntuacion – minPuntuacion) / (maxPuntuacion – minPuntuacion);
}
En este ejemplo, el arreglo de variables locales contendrá las variables respuestas y puntuacion. La pila de operandos contiene las variables y operadores necesarios para realizar las operaciones de sustracción y división.
Nota: como cada pila es exclusiva de un hilo, esta área de memoria es inherentemente segura en ambiente multihilo.
Registros de contador de programa (PC, program counter)
La JVM admite múltiples hilos simultáneamente. Cada hilo tiene su propio registro contador de programa (PC) para guardar la dirección de la instrucción de la JVM ejecutándose en ese momento. Una vez ejecutada dicha instrucción, el registro PC es actualizado con la dirección de la próxima instrucción.
Pilas para métodos nativos
La JVM puede hacer uso de pilas que soporten métodos nativos, métodos escritos en lenguajes diferentes a Java, como C o C++. Cada hilo posee su propia pila de métodos nativos.
Motor de ejecución
Una vez que el bytecode se ha cargado en memoria y la información necesaria está disponible en el área de datos de tiempo de ejecución, el siguiente paso es ejecutar el programa. El motor de ejecución gestiona este proceso ejecutando el código de cada clase.
Sin embargo, antes de ejecutar el programa, hay que traducir el bytecode a instrucciones del lenguaje máquina, usando un intérprete o un compilador JIT.
Intérprete
El intérprete lee y ejecuta las instrucciones del bytecode línea a línea. Debido a esta ejecución línea por línea, el intérprete es comparativamente más lento.
Otra desventaja es la reinterpretación de un método cada vez que es llamado.
Compilador JIT
El compilador JIT salva las desventajas del intérprete. En primera instancia, el motor de ejecución usa el intérprete para ejecutar el bytecode, entrando en acción el compilador JIT cuando se encuentra código repetido.
El compilador JIT compila el bytecode traduciéndolo a código máquina nativo, que es usado directamente en las reiteradas llamadas a métodos, mejorando así el rendimiento del sistema.
El compilador JIT se divide en los siguientes componentes:
- Generador de código intermedio
- Optimizador de código - optimiza el código intermedio para un mejor desempeño
- Generador de código objetivo - traduce el código intermedio en código máquina nativo
- Perfilador (profiler) - encuentra los HotSpots (código que es ejecutado repetidamente)
Veamos el siguiente código para ilustrar la diferencia entre el intérprete y el compilador JIT:
int sum = 10;
for(int i = 0 ; i <= 10; i++) {
sum += i;
}
System.out.println(sum);Un intérprete busca en memoria el valor de sum en cada iteración del bucle, le suma el valor dei, y lo vuelve a almacenar en la memoria. Es una operación costosa, ya que se está accediendo a memoria en cada iteración.
Sin embargo, el compilador JIT reconoce que este código tiene un HotSpot, y realizará optimizaciones sobre él. Creará una copia local de sum en el registro PC del hilo, sumándole el valor de i en cada vuelta del bucle y, una vez concluído, llevará el nuevo valor de sum a la memoria.
Nota: un compilador JIT tarda más en compilar el código que un intérprete en interpretarlo línea por línea. Si se va a ejecutar el programa solo una vez, es mejor usar el intérprete.
Recolector de basura (GC, garbage collector)
El recolector de basura detecta y elimina objetos no referenciados en el área del heap. Es el proceso de recuperar automáticamente, en tiempo de ejecución, la memoria ocupada por objetos que ya no van a ser utilizados, mediante la destrucción de tales objetos.
La recolección de basura hace que Java sea eficiente desde el punto de vista de la gestión de memoria, ya que libera memoria del área heap eliminando objetos no referenciados, creándose así espacio para nuevos objetos. Este proceso implica dos fases:
- Marcado - identificación de objetos no referenciados
- Barrido - destrucción de los objetos identificados en el paso anterior
La JVM realiza automáticamente la recolección de basura a intervalos regulares, no siendo necesaria su gestión separadamente. Puede ser disparada invocando System.gc(), aunque la ejecución no está garantizada.
La JVM tiene tres tipos de recolectores de basura:
- En serie - es la implementación más simple, diseñada para pequeñas aplicaciones ejecutándose en entornos monohilo. Usando un solo hilo, produce un evento de tipo "parar el mundo" en el que todos los hilos de aplicación son detenidos hasta que la operación se complete. El argumento de la JVM para usar recolección de basura en serie es
-XX:+UseSerialGC - En paralelo - es la implementación por defecto en la JVM, conocido como recolector de rendimiento (throughput collector). Uitiliza múltiples hilos, pero aún necesita parar los hilos de aplicación. El argumento de la JVM es
-XX:+UseParallelGC. - Garbage First (G1) GC - G1GC fue diseñado para aplicaciones multihilo con gran cantidad disponible de heap (más de 4GB). Particiona el heap en un conjunto de regiones de igual tamaño, utilizando múltiples hilos para explorarlas. G1GC identifica las regiones con el máximo de basura y realiza la limpieza prioritaria de esas regiones. El argumento de la JVM para G1GC es
-XX:+UseG1GC
Nota: hay otro tipo de colector de basura llamado Barrido de Marcas Concurrente (Concurrent Mark Sweep (CMS) GC). Sin embargo, fue declarado obsoleto en Java 9 y completamente eliminado en Java 14 en favor de G1GC.
Interfaz nativa de Java (JNI)
En ocasiones, es necesario utilizar código nativo en lugar de Java (por ejemplo, C/C++). Esas ocasiones pueden ser cuando necesitamos interactuar con el hardware, o salvar las restricciones de Java en cuanto a gestión de memoria y rendimiento. Java admite la ejecución de código nativo a través de la Interfaz Nativa de Java (JNI).
JNI hace de puente permitiendo el uso de paquetes de apoyo para otros lenguajes, como C, C++, etc. Esto resulta de mucha ayuda en casos en que se necesita escribir código que no esté enteramente admitido por Java, como ciertas características específicas de la plataforma subyacente que solo pueden ser escritas en C.
La palabra reservada native indica que la implementación del método será proporcionada por una biblioteca nativa. Es necesario invocar System.loadLibrary() para cargar en memoria dicha biblioteca nativa compartida y tener su funcionalidad disponible en Java.
Bibliotecas de métodos nativos
Las bibliotecas de métodos nativos son bibliotecas escritas en otros lenguajes, como C, C++ y ensamblador, normalmente en archivos de extensión .dll o .so. Pueden ser cargadas a través de JNI.
Errores habituales de la JVM
- ClassNotFoundException - ocurre cuando el cargador de clases intenta cargar clases mediante
Class.forName(),ClassLoader.loadClass()oClassLoader.findSystemClass()pero no se encuentra la definición de la clase con el nombre especificado. - NoClassDefFoundError - se produce cuando la compilación de la clase ha tenido éxito, pero el cargador de clases no es capaz de encontrar el fichero tipo class en tiempo de ejecución.
- OutOfMemoryError - la JVM no puede asignar memoria para un objeto, ya que no hay suficiente y el recolector de basura no es capaz de proporcionar más memoria.
- StackOverflowError - la JVM se queda sin espacio al crear nuevos marcos de pila.
Conclusión
En este artículo hemos discutido la arquitectura de la Máquina Virtual de Java y sus diversos componentes. Lo habitual es no preocuparse demasiado de su mecánica interna ni de su funcionamiento mientras nuestro código se ejecuta con normalidad.
Solo cuando algo va mal, y necesitamos ajustar la JVM o corregir un fallo de memoria, intentamos comprender su funcionamiento interno.
Es una cuestión muy popular en entrevistas de trabajo, tanto a nivel junior como senior para perfiles backend. Tener amplios conocimientos de la JVM te ayudará a producir mejor código y evitar trampas que conduzcan a errores de pila o de memoria.
Gracias por acompañarme hasta tan lejos. Espero que te haya gustado el artículo. Puedes encontrarme en LinkedIn, donde normalmente hablo sobre tecnología y sobre la vida. Echa también un vistazo a mis otros artículos y a mi canal de YouTube. Que disfrutes de la lectura. ?