

Articolo originale: An in-depth look at Database Indexing
Le prestazioni sono estremamente importanti per molti prodotti come e-commerce, sistemi di pagamento, giochi, applicazioni relative ai trasporti e così via. Sebbene i database siano ottimizzati internamente attraverso molteplici meccanismi per soddisfare i requisiti di prestazione nel mondo di oggi, molto dipende anche dallo sviluppatore dell'applicazione – dopo tutto è colui che sa quali query deve eseguire l'applicazione.
Gli sviluppatori che hanno a che fare con database relazionali hanno usato o almeno sentito parlare dell'indicizzazione, ed è un concetto molto comune nell'ambito dei database. Tuttavia la parte più importante da capire è cosa indicizzare e come l'indicizzazione andrà a migliorare i tempi di risposta delle query. Per fare questo devi capire come andrai a interrogare le tabelle del tuo database. Un'indicizzazione adeguata può essere creata solo se sai esattamente quali sono i modelli della tua query e dell'accesso ai dati.
In termini semplici, un indice mappa le chiavi di ricerca ai corrispondenti dati su disco usando diverse strutture dati in memoria e su disco. L'indice viene usato per velocizzare la ricerca riducendo il numero di record da cercare.
Generalmente un indice viene creato sulle colonne specificate dalla clausola WHERE di una query, visto che il database recupera e filtra dati dalle tabelle in base a queste colonne. Se non crei un indice il database cerca su tutte le righe, filtra quelle che corrispondono e restituisce il risultato. Con milioni di record, questa operazione di ricerca potrebbe impiegare molti secondi e questi alti tempi di risposta rendono le API e le applicazioni più lente o addirittura non utilizzabili. Vediamo un esempio.
Useremo MySQL con un motore di database InnoDB predefinito, tuttavia i concetti spiegati in questo articolo sono più o meno gli stessi anche per altri server di database come Oracle, MSSQL ecc.
Crea una tabella chiamata index_demo con lo schema seguente:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Come verifichiamo che stiamo utilizzando il motore InnoDB?
Esegui il seguente comando:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;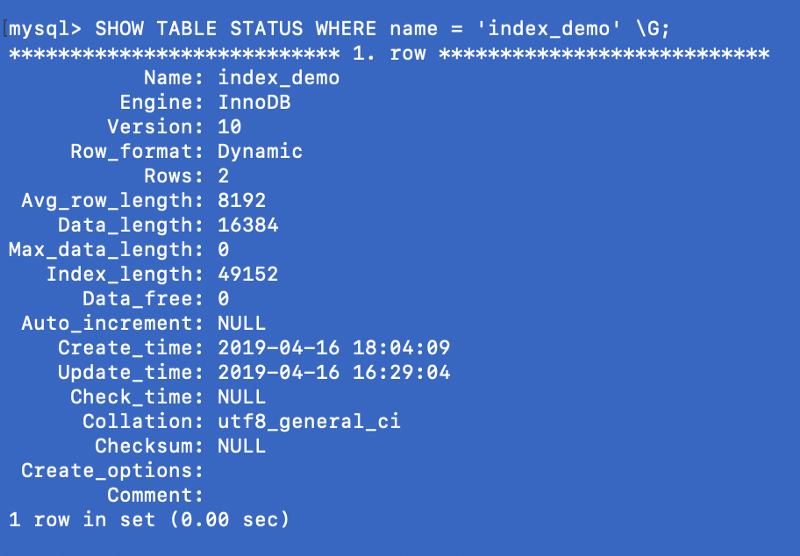
La voce Engine nella videata qui sopra rappresenta il motore usato per creare la tabella. In questo caso è InnoDB.
Ora inserisci qualche dato casuale nella tabella, la mia tabella ha 5 righe tipo queste:
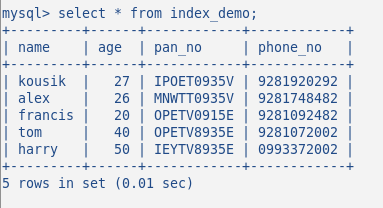
Non ho ancora creato alcun indice su questa tabella. Verifichiamolo con il comando: SHOW INDEX. Dovrebbe restituire 0 come risultato.

Al momento, se eseguiamo una semplice query con SELECT, visto che non c'è un indice definito dall'utente, la query scorrerà l'intera tabella per restituire il risultato:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN mostra come il motore della query pianifica l'esecuzione della stessa. Nella videata qui sopra, puoi vedere che la colonna rows restituisce 5 e la colonna possible_keys (chiavi possibili) restituisce null. possible_keys rappresenta tutti gli indici disponibili che si possono utilizzare per questa query. La colonna key indica quale indice verrà effettivamente usato tra tutti quelli possibili per questa query.
Chiave Primaria:
La query qui sopra è altamente inefficiente. Ottimizziamola: renderemo la colonna phone_no (numero telefonico) una chiave primaria (PRIMARY KEY) assumendo che non possano esistere nel nostro sistema più utenti con lo stesso numero di telefono. Considera quanto segue quando crei una chiave primaria:
- Una chiave primaria dovrebbe essere parte di molte delle query vitali per la tua applicazione.
- La chiave primaria è un vincolo che identifica univocamente ciascuna riga in una tabella. Se più colonne fanno parte di una chiave primaria, dovrebbe essere univoca la combinazione dei valori che rappresentano per ogni riga.
- La chiave primaria non dovrebbe avere valori null. Mai rendere una colonna che può avere valori null una chiave primaria. Secondo lo standard ANSI SQL le chiavi primarie dovrebbero essere confrontabili tra loro, e dovresti sicuramente essere in grado di determinare se il valore di una colonna con chiave primaria sia maggiore, minore o uguale al valore della stessa colonna in un'altra riga. Visto che
NULLsignifica per gli standard SQL un valore non definito, non lo si può deterministicamente confrontare con qualsiasi altro valore, pertanto logicamenteNULLnon è consentito. - Il tipo ideale per una chiave primaria dovrebbe essere un numero come
INToBIGINTin quanto il confronto tra gli interi è più veloce, quindi percorrere gli indici sarà molto veloce.
Spesso definiamo nelle tabelle un campo id come AUTO INCREMENT (auto incrementale) e lo usiamo come chiave primaria, ma la scelta della chiave primaria dipende dagli sviluppatori.
Cosa succede se non si crea esplicitamente una chiave primaria?
Non è obbligatorio creare una chiave primaria esplicitamente. Se non hai definito alcuna chiave primaria, InnoDB ne crea una implicitamente al tuo posto in quanto InnoDB è concepito per avere una chiave primaria in ogni tabella. Pertanto quando crei successivamente una chiave primaria per una certa tabella InnoDB elimina quella che aveva precedentemente auto definito.
Visto che attualmente non abbiamo alcuna chiave primaria, vediamo cosa ha creato per noi InnoDB di default:
SHOW EXTENDED INDEX FROM index_demo;
Con la clausola EXTENDED vengono mostrati tutti gli indici che non sono utilizzabili dall'utente ma gestiti interamente da MySQL.
Qui vediamo che MySQL ha definito un indice composto (parleremo più tardi degli indici composti) su DB_ROW_ID, DB_TRX_ID, DB_ROLL_PTR e tutte le colonne definite nella tabella. In mancanza di una chiave primaria definita dall'utente, questo indice è usato per trovare univocamente i record.
Che differenza c'è tra chiave e indice?
Sebbene i termini chiave (key) e indice (index) siano usati intercambiabilmente, key significa un vincolo impostato sul comportamento della colonna. In questo caso il vincolo è che la chiave primaria sia un campo che non possa contenere NULL e che identifichi univocamente ciascuna riga. D'altra parte, index è una struttura dati speciale che facilita la ricerca dei dati nella tabella.
Creiamo ora l'indice primario su phone_no ed esaminiamo l'indice creato:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;Nota che CREATE INDEX non può essere usato per creare un indice primario, ma viene usato ALTER TABLE.

Nella videata qui sopra vediamo che è stato creato un indice primario sulla colonna phone_no. Descriviamo cosa rappresentano le intestazioni delle colonne nella videata qui sopra:
Table: la tabella nella quale è stato creato l'indice.
Non_unique: se il valore è 1, l'indice non è univoco, se il valore è 0 l'indice è univoco.
Key_name: il nome dell'indice creato. Il nome dell'indice primario è sempre PRIMARY in MySQL, a prescindere da un eventuale nome di indice che tu possa avere fornito o meno nella creazione dell'indice.
Seq_in_index: il numero sequenziale della colonna nell'indice. Se l'indice è costituito da colonne multiple, il numero di sequenza assegnato sarà in base a come le colonne saranno ordinate in fase di creazione dell'indice. Il numero di sequenza inizia da 1.
Collation: il modo nel quale la colonna viene ordinata nell'indice. A significa ascendente, D discendente, NULL significa non ordinata.
Cardinality: il numero stimato di valori univoci nell'indice. Più una cardinalità è elevata, maggiori saranno le possibilità che l'ottimizzatore di query scelga quell'indice per le query.
Sub_part: il prefisso dell'indice. È NULL se l'intera colonna è indicizzata. Altrimenti mostra il numero di byte indicizzati nel caso che la colonna sia parzialmente indicizzata. Esamineremo gli indici parziali successivamente.
Packed: indica in che modo la chiave è compressa; NULL se non lo è.
Null: YES se la colonna può contenere valori NULL, vuoto altrimenti.
Index_type: indica quale struttura dati di indicizzazione viene usata per quell'indice. Alcune possibili scelte sono BTREE, HASH, RTREE o FULLTEXT.
Comment: informazioni circa l'indice che non sono descritte in colonne specifiche.
Index_comment: il commento per l'indice specificato quando è stato creato l'indice usando l'attributo COMMENT.
Ora vediamo se questo indice riduce il numero di righe che dovrebbero essere scorse per trovare corrispondenza con un valore per il campo phone_no passato nelle clausola WHERE della query.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Nella videata qui sopra, nota che il valore restituito dalla colonna rows è solo 1 e sia possible_keys che key ritornano PRIMARY. Questo vuole dire in pratica che usando l'indice primario chiamato PRIMARY (il nome è stato auto assegnato quando hai creato la chiave primaria) l'ottimizzatore di query è andato direttamente verso quel record e lo ha recuperato. È molto efficiente. Questo dimostra esattamente a cosa serve un indice: per ridurre al minimo l'ambito di ricerca a scapito dello spazio extra.
Indice clustered:
Un indice clustered (clustered index) è collocato con i dati nello stesso spazio della tabella oppure del file su disco. Puoi considerare che un indice clustered come un indice di tipo B-Tree i cui nodi foglia sono gli effettivi blocchi di dati sul disco, visto che indice e dati risiedono assieme. Questo tipo di indice organizza fisicamente i dati su disco secondo l'ordine logico della chiave dell'indice.
Cosa significa organizzazione fisica dei dati?
Fisicamente, i dati sono organizzati su disco in migliaia o milioni di dischi/blocchi di dati. Per un indice clustered, non è obbligatorio che tutti i blocchi di dati siano conservati in modo contiguo. I blocchi dati fisici sono spostati costantemente qua e là dal sistema operativo quando necessario. Un sistema di database non ha alcun controllo assoluto sulla gestione dello spazio fisico per i dati, ma all'interno di un blocco dati i record possono essere conservati o gestiti in ordine logico dalla chiave dell'indice. Il diagramma semplificato che segue lo spiega:
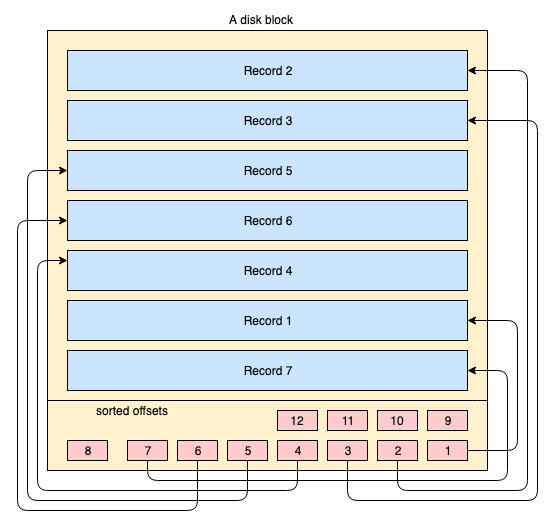
- Il riquadro con sfondo giallo rappresenta un blocco di disco/blocco di dati
- I rettangoli blu rappresentano i dati conservati come righe (record) all'interno di quel blocco
- L'area in basso rappresenta l'indice del blocco dove i piccoli rettangoli a sfondo rosso si trovano ordinati secondo una data chiave. Questi piccoli blocchi non sono altro che una sorta di puntatori agli offset dei record.
I record sono conservati nel blocco di disco in un qualsiasi ordine arbitrario. Ogniqualvolta vengono aggiunti nuovi record, vengono sistemati nel primo spazio libero disponibile. Quando un record esistente viene aggiornato, il sistema operativo decide se quel record possa ancora rimanere nella stessa posizione o se sia necessario allocarlo in una nuova posizione.
Quindi la posizione dei record è completamente gestita dal sistema operativo e non esiste alcuna relazione definita tra l'ordine di due record qualsiasi. Al fine di recuperare i record nell'ordine logico della chiave, le pagine del disco contengono una sezione indice, l'indice contiene un elenco di puntatori di offset (i riquadri rossi della videata qui sopra) ordinati in base alla chiave. Ogni volta che un record viene modificato o creato, l'indice viene regolato.
In questo modo, in realtà non è necessario preoccuparsi dell'effettiva organizzazione fisica dei record in un certo ordine, viceversa viene mantenuta una piccola sezione indice in quell'ordine e recuperare o mantenere i record diventa piuttosto facile.
Vantaggio dell'indice clustered
Questo ordinamento o co-locazione dei dati correlati rende effettivamente un indice clustered più veloce. Quando i dati vengono recuperati dal disco, l'intero blocco che contiene i dati è letto dal sistema, visto che il sistema di lettura/scrittura su disco del sistema operativo legge e scrive dati in blocchi. Quindi in caso di query che recuperano un intervallo di dati, è abbastanza probabile che i dati siano presenti nel buffer di memoria. Ipotizziamo di lanciare la seguente query:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'Un blocco dati viene caricato in memoria quando viene eseguita la query. Diciamo che il blocco dati contiene valori in phone_no da 9010000000 fino a 9030000000. Quindi qualunque intervallo dati sia stato richiesto nella query è solo uno sottoinsieme dei dati presenti nel blocco. Se successivamente lanci una query per ottenere tutti i numeri di telefono (campo phone_no) che vanno da 9015000000 fino a 9019000000, non devi recuperare altri blocchi dal disco. I dati completi possono essere trovati nel blocco dati corrente, pertanto un indice clustered riduce il numero di letture da disco collocando quanti più dati dati correlati possano esserci nello stesso blocco dati. Questo riduce gli accessi al disco e genera miglioramenti di prestazione.
Quindi se hai ben determinato la tua chiave primaria e le tue ricerche sono basate su di essa, le prestazioni saranno super veloci.
Vincoli degli indici clustered:
Visto che un indice clustered impatta sull'organizzazione fisica dei dati, può esistere solo un indice clustered per tabella.
Relazione tra chiave primaria e indice clustered:
Usando InnoDB in MySQL non è possibile creare manualmente un indice clustered. È MySQL che lo sceglie per te. Ma in che modo? Secondo questo estratto dalla documentazione di MySQL:
Quando si definisce una chiave primaria in una tabella,InnoDBla usa come indice clustered. Definisci una chiave primaria per ogni tabella che crei. Se non c'è una colonna o un insieme di colonne che contengono valori logicamente univoci e non contengono valori null, aggiunge una nuova colonna auto-incrementale, i cui valori saranno valorizzati automaticamente.
Se non definisci una chiave primaria (PRIMARY KEY) per una tabella, MySQL cerca il primo indice univoco (UNIQUE) dove tutte le colonne sono non nulle (NOT NULL) eInnoDBlo usa come indice clustered.
Se la tabella non ha una chiave primaria (PRIMARY KEY) oppure un indice che possa essere univoco (UNIQUE),InnoDBgenera internamente un indice clustered nascosto chiamatoGEN_CLUST_INDEXsu una colonna di sintesi che contiene i valori di ID delle righe. Le righe sono ordinate per l'ID cheInnoDBassegna alle righe nella suddetta tabella. L'ID della riga è un campo di 6 byte che cresce monotonicamente mano a mano che si aggiungono nuove righe. Pertanto le righe ordinate per il loro ID sono fisicamente nell'ordine di inserimento.
In breve, il motore InnoDB di MySQL gestisce in realtà l'indice primario come indice clustered per migliorare le prestazioni, in modo che la chiave primaria e l'effettivo record su disco siano raggruppati insieme.
Struttura dell'indice (clustered) della chiave primaria:
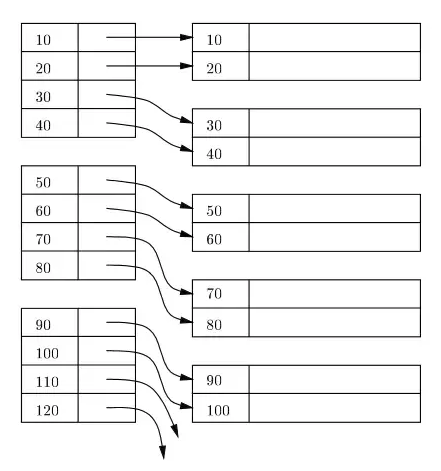
In genere un indice viene conservato come B+Tree su disco e in memoria, e qualsiasi indice viene conservato in blocchi su disco. Questi blocchi sono chiamati blocchi indice. Gli elementi nel blocco indice sono sempre ordinati sulla chiave dell'indice/ricerca. La foglia del blocco indice contiene un localizzatore di riga. Per l'indice primario, il localizzatore di riga fa riferimento all'indirizzo virtuale della corrispondente posizione fisica dei blocchi dati sul disco dove risiedono le righe in base alla chiave indice.
Nel diagramma seguente, i rettangoli di sinistra rappresentano il livello foglia dei blocchi indice, e i rettangoli nella parte destra rappresentano i blocchi dati. Logicamente i blocchi dati sembra siano allineati secondo un ordinamento, ma, come descritto in precedenza, le effettive posizioni fisiche potrebbero essere sparse qui e là.
È possibile creare un indice primario su una chiave non primaria?
In MySQL, un indice primario viene creato automaticamente, e abbiamo già descritto in che modo MySQL sceglie l'indice primario. Ma nel mondo dei database, in realtà non è necessario creare un indice sulla colonna della chiave primaria – l'indice primario può anche essere creato su colonne con chiavi non primarie. Tuttavia, quando creato sulla chiave primaria, tutte le voci sono univoche nell'indice, mentre nell'altro caso l'indice primario potrebbe avere anche chiavi duplicate.
È possibile eliminare una chiave primaria?
È possibile eliminare una chiave primaria. Quando si elimina una chiave primaria anche l'indice clustered collegato, così come la proprietà univoca di quella colonna viene perduto.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- Se la chiave primaria non esiste, si ottiene l'errore seguente:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"
- ERRORE 1091 (42000): Non posso eliminare 'PRIMARY', verifica che quella colonna/chiave esista"Vantaggi dell'indice primario:
- Le query per ottenere intervalli di dati basati sull'indice primario sono molto efficienti. Potrebbe esserci la possibilità che il blocco disco dal quale il database ha letto da disco contenga tutti i dati che appartengono alla query, visto che l'indice primario è clustered e i record sono ordinati anche fisicamente. Quindi la prossimità dei dati può essere fornita dall'indice primario.
- Qualsiasi query che tragga vantaggio dalla chiave primaria è molto veloce.
Svantaggi dell'indice primario:
- Visto che l'indice primario contiene un riferimento diretto all'indirizzo del blocco dati tramite l'indirizzo di spazio virtuale e i blocchi disco sono organizzati fisicamente nell'ordine dell'indice, ogni volta che il sistema operativo esegue qualche divisione di una pagina di disco a causa di operazioni
DML(Linguaggio di Manipolazione Dati) comeINSERT/UPDATE/DELETE(inserimento/aggiornamento/cancellazione) deve essere aggiornato anche l'indice primario. Quindi le operazioniDMLmettono sotto una certa pressione le prestazioni dell'indice primario.
Indice secondario:
Qualsiasi indice diverso da un indice clustered viene detto secondario. A differenza degli indici primari, gli indici secondari non hanno impatto sulla posizione di archiviazione fisica.
Quando serve un indice secondario?
Potresti avere parecchi casi d'uso nella tua applicazione dove non interroghi il database con una chiave primaria. Nel nostro esempio phone_no è la chiave primaria ma potremmo voler interrogare il database per i campi pan_no o name. In questi casi ti serve un indice secondario su queste colonne se la frequenza di queste query è molto alta.
Come creare un indice secondario in MySQL?
Il comando seguente crea un indice secondario per la colonna name nella tabella index_demo.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Struttura di un indice secondario:
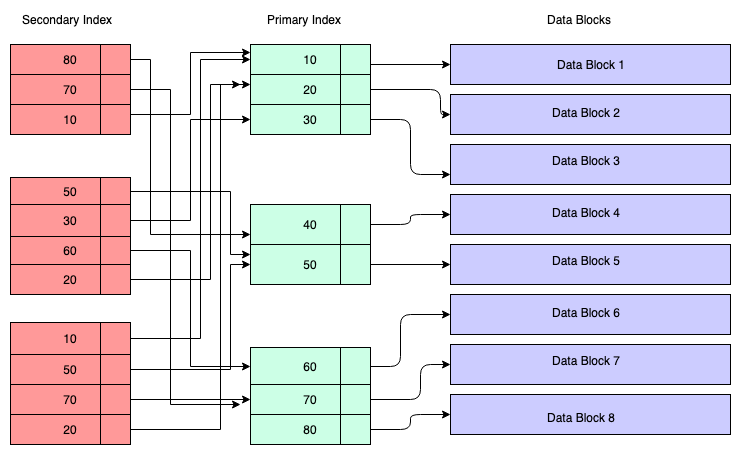
Nel diagramma qui sotto i rettangoli a sfondo rosso rappresentano blocchi di indice secondario. Anche l'indice secondario è conservato in un B+Tree ed è ordinato in base alla chiave sulla quale è stato creato l'indice. I nodi foglia contengono una copia della chiave dei dati corrispondenti nell'indice primario.
Tanto per capirci, puoi assumere che l'indice secondario abbia riferimenti all'indirizzo della chiave primaria, anche se non è il caso. Recuperare dati tramite l'indice secondario significa che devi attraversare due B+tree – uno dell'indice secondario stesso e l'altro dell'indice primario
Vantaggi di un indice secondario:
In teoria puoi creare tanti indici secondari quanti ne desideri. Ma in realtà per stabilire quanti indici siano veramente necessari serve un accurato processo di analisi visto che ciascun indice ha la sua propria penalità.
Svantaggi di un indice secondario:
Con operazioni DML come DELETE / INSERT, anche l'indice secondario deve essere aggiornato in modo che la copia della colonna dalla chiave primaria possa essere cancellata/inserita. In questi casi l'esistenza di molti indici secondari può causare problemi.
Inoltre, se una chiave primaria è molto grande come un URL, visto che l'indice secondario contiene una copia del valore della colonna della chiave primaria, può essere inefficiente dal punto di vista dell'archiviazione. Più indici secondari significa avare un numero maggiore di duplicati del valore della colonna della chiave primaria, quindi un aumentato spazio di conservazione se la chiave primaria è di grandi dimensioni. Inoltre la chiave primaria stessa conserva le chiavi, quindi la ripercussione dell'effetto combinato sullo spazio di conservazione può essere molto alto.
Considerazioni prima di eliminare un indice primario:
In MySQL, puoi eliminare un indice primario eliminando la chiave primaria. Abbiamo già visto che un indice secondario dipende da un indice primario. Pertanto se elimini un indice primario, tutti gli indici secondari devono essere aggiornati in modo che contengano una copia del nuovo indice della chiave primaria; operazione che MySQL esegue in autonomia.
Se ci sono parecchi indici secondari il processo è costoso. Anche altre tabelle potrebbero avere una chiave esterna che fa riferimento alla chiave primaria, quindi devi anche eliminare i riferimenti di quelle chiavi esterne prima di eliminare la chiave primaria.
Quando viene eliminata una chiave primaria, MySQL crea internamente un'altra chiave primaria ed è una operazione costosa.
Indice con chiave univoca (clausola UNIQUE):
Come le chiavi primarie, anche le chiavi univoche possono identificare i record univocamente con una differenza: la colonna della chiave univoca può contenere valori null .
Al contrario di altri server di database, in MySQL una colonna con chiave univoca può avere tanti valori null quanti ne sono possibili. Pertanto se MySQL deve contenere solo un valore null in una colonna con chiave univoca, deve assumere che tutti i valori null sono uguali.
Tuttavia logicamente questo non è corretto visto che null significa indefinito, e i valori indefiniti non possono essere confrontati tra loro, è la natura di null. Visto che MySQL non può asserire che tutti i valori null abbiano lo stesso significato, consente valori null nella colonna.
Il seguente comando mostra come creare un indice univoco in MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Indice composto:
MySQL ti consente di definire indici su colonne multiple, fino a 16. Questo indice è chiamato indice multi colonna/composito/composto.
Supponiamo di avere un indice definito su quattro colonne: col1, col2, col3, col4. Con un indice composto, abbiamo capacità di ricerca su col1, (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4). Quindi possiamo usare qualsiasi prefisso per il valore della parte sinistra delle colonne indicizzate, ma non possiamo omettere un colonna nel mezzo e usarla in questo modo: (col1, col3) o (col1, col2, col4) o col3 o col4 ecc. Queste combinazioni non sono valide.
I comandi seguenti creano due indici composti nella nostra tabella:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);Se hai delle query che contengono una clausola WHERE su colonne multiple, scrivi la clausola nell'ordine delle colonne dell'indice composto. La query trarrà beneficio dall'indice. In effetti, nel processo di determinazione delle colonne che devono far parte di un indice composto, puoi analizzare diversi casi d'uso del tuo sistema e provare a determinare l'ordine delle colonne con il quale trarrai il maggior beneficio nella maggior parte dei tuoi casi di uso.
Gli indici composti possono aiutarti anche nelle query con JOIN & SELECT. Esempio: nella query SELECT * che segue, viene usato l'indice composite_index_2.

Quando sono definiti parecchi indici, l'ottimizzatore di query di MySQL sceglie quell'indice che gli consente di eliminare il maggior numero di righe o di scorrere il minor numero di righe possibile per migliorare l'efficienza.
Perché usiamo gli indici composti? Perché non definire indici secondari multipli sulle colonne alle quali siamo interessati?
MySQL usa solo un indice per tabella per le query, eccetto le UNION (In una UNION – unione – ciascuna query logica viene eseguita separatamente, e i risultati sono poi combinati). Pertanto definire molteplici indici su molteplici colonne non garantisce che questi indici siano usati anche se le colonne fanno parte della query.
MySQL mantiene qualcosa chiamato statistiche di indice che lo aiuta a dedurre l'aspetto dei dati nel sistema. Le statistiche di indice sono una generalizzazione, tuttavia sulla base di questi metadati, MySQL decide quale indice sia appropriato per la query corrente.
Come funzionano gli indici composti?
Le colonne usate negli indici composti sono concatenate assieme e quelle chiavi concatenate sono conservate in ordine usando un B+ Tree. Quando esegui una ricerca, viene cercata una corrispondenza tra la concatenazione delle tue chiavi di ricerca e quelle dell'indice composto. Quindi, se c'è una mancata corrispondenza tra l'ordinamento delle chiavi di ricerca e l'ordinamento delle colonne di indice composto, l'indice non può essere utilizzato.
Nel nostro esempio per il record seguente, è stato formato un indice composto concatenando i campi pan_no, name, age : HJKXS9086Wkousik28.
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Come capire se serve un indice composto:
- Analizza prima le tue query in base ai casi d'uso. Se vedi che alcuni campi appaiono insieme in molte query, potresti prendere in considerazione la creazione di un indice composto.
- Se stai creando un indice in
col1e un indice composto in (col1,col2), allora dovrebbe essere sufficiente l'indice composto.col1da sola può essere servita dall'indice composto stesso visto che è la parte sinistra del prefisso dell'indice. - Considera la cardinalità. Se le colonne utilizzate nell'indice composto finiscono con un'alta cardinalità insieme, sono dei buoni candidati per l'indice composto.
Indice di copertura:
Un indice di copertura (covering index) è un tipo di indice composto speciale dove tutte le colonne specificate nella query esistono da qualche parte nell'indice. Quindi l'ottimizzatore di query non deve accedere al database per ottenere i dati, viceversa può recuperare il risultato dall'indice stesso. Esempio: abbiamo già definito un indice composto su (pan_no, name, age), quindi ora considera la query seguente:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'Le colonne indicate nelle clausole SELECT e WHERE fanno parte dell'indice composto. Quindi in questo caso possiamo in effetti ottenere il valore della colonna age dall'indice composto stesso. Vediamo cosa mostra il comando EXPLAIN per questa query:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';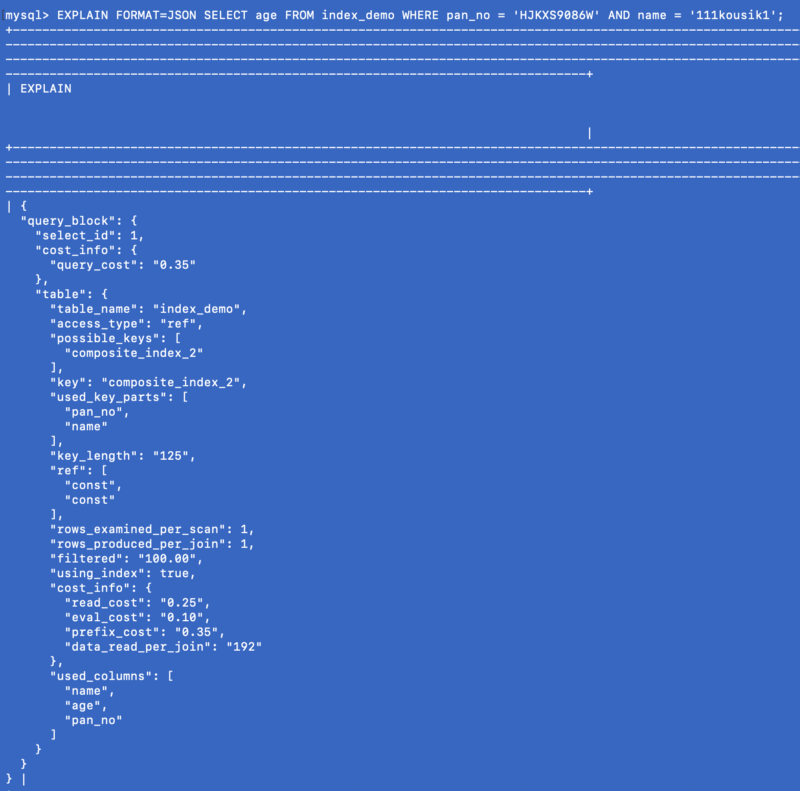
Nella risposta qui sopra, nota che c'è una chiave, using_index, impostata su true, il che vuol dire che l'indice di copertura è stato usato per rispondere alla query.
Non so quanto gli indici di copertura possano essere apprezzati in ambienti di produzione, ma apparentemente sembra che siano una buona ottimizzazione nel caso che la query sia quella giusta.
Indice parziale:
Già sappiamo che gli indici velocizzano le nostre query a scapito dello spazio. Più indici hai, maggiore è lo spazio di conservazione richiesto. Abbiamo già creato un indice chiamato secondary_idx_1 sulla colonna name. La colonna name può contenere valori di qualunque lunghezza. Inoltre nell'indice i localizzatori di riga o metadati dei puntatori di riga hanno una loro propria dimensione. Quindi, nel complesso, un indice può richiedere un elevato spazio di conservazione e carico di memoria.
In MySQL, è possibile creare un indice anche sui primi byte di dati. Esempio: il seguente comando crea un indice sui primi 4 byte della colonna name. Sebbene questo metodo riduca i sovraccarichi di memoria di un certo ammontare, l'indice non può eliminare molte righe, poiché in questo esempio i primi 4 byte possono essere comuni in molti nomi. In genere questo tipo di indicizzazione di prefissi è supportata per i tipi di colonna CHAR ,VARCHAR, BINARY e VARBINARY.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Cosa succede sotto il cofano quando definiamo un indice?
Eseguiamo nuovamente il comando SHOW EXTENDED:
SHOW EXTENDED INDEXES FROM index_demo;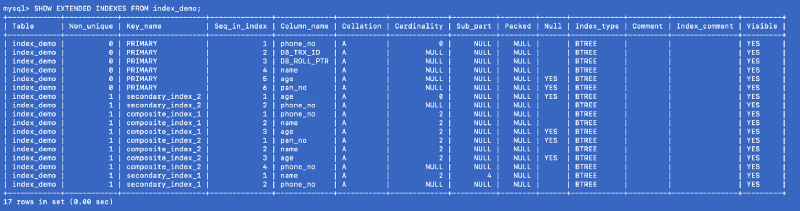
Definiamo secondary_index_1 su name, ma MySQL ha creato un indice composto su (name, phone_no) dove phone_no è la colonna della chiave primaria. Abbiamo creatosecondary_index_2 su age e MySQL ha creato un indice composto su (age, phone_no). Abbiamo creato composite_index_2 su (pan_no, name, age) e MySQL ha creato un indice composto su (pan_no, name, age, phone_no). L'indice composto composite_index_1 ha già incluso phone_no come parte di esso.
Quindi, qualunque indice creiamo, MySQL crea dietro le quinte un indice composto di supporto che a sua volta punta alla chiave primaria. Ciò significa che la chiave primaria è un cittadino di prima classe nel mondo dell'indicizzazione MySQL. Dimostra inoltre che tutti gli indici sono supportati da una copia dell'indice primario, ma non sono sicuro che una singola copia dell'indice primario sia condivisa o che siano utilizzate copie diverse per indici diversi.
Ci sono molti altri indici offerti da MySQL come gli indici spaziali (Spatial index) e a ricerca full text (Full Text Search index). Non ho ancora fatto esperimenti con questi indici pertanto non li tratterò in questo post.
Linee guida generali sull'indicizzazione:
- Poiché gli indici consumano memoria extra, decidi attentamente quanti e quali tipi di indice saranno sufficienti per le tue necessità.
- Con le operazioni
DML, gli indici vengono aggiornati, quindi le operazioni di scrittura sono abbastanza costose con gli indici. Più indici hai, maggiore è il costo. Gli indici vengono utilizzati per rendere le operazioni di lettura più veloci. Quindi, se hai un sistema che necessita di molte scritture su disco ma poche letture da disco, valuta attentamente se davvero hai bisogno di un indice o meno. - La cardinalità è importante: la cardinalità corrisponde al numero di valori distinti in una colonna. Se si crea un indice in una colonna che ha una bassa cardinalità, ciò non sarà utile poiché l'indice dovrebbe ridurre lo spazio di ricerca. La bassa cardinalità non riduce in modo significativo lo spazio di ricerca. Esempio: se si crea un indice su una colonna di tipo booleano (solo
int1o0), l'indice sarà molto distorto poiché la cardinalità è inferiore (la cardinalità è 2 qui). Ma se questo campo booleano può essere combinato con altre colonne per produrre un'alta cardinalità, scegli quell'indice quando necessario. - Gli indici potrebbero richiedere anche una certa manutenzione se i vecchi dati rimangono ancora nell'indice. Devono essere eliminati altrimenti la memoria verrà soffocata, quindi cerca di avere un piano di monitoraggio per i tuoi indici.
Ricapitolando, è estremamente importante comprendere i diversi aspetti dell'indicizzazione del database. Aiuterà durante la progettazione a basso livello del sistema. Molte ottimizzazioni della vita reale delle nostre applicazioni dipendono dalla conoscenza di questi dettagli intricati. Un indice scelto con cura ti aiuterà sicuramente ad aumentare le prestazioni dell'applicazione.
Se ti è piaciuto questo articolo, condividilo con i tuoi amici e sui social :)
Riferimenti:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- http://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html