

Articolo originale: https://www.freecodecamp.org/news/an-introduction-to-software-architecture-patterns/
In questo manuale, scoprirai il vasto e intricato mondo dell'architettura del software.
È un campo che ho trovato disorientante e complicato, quando ho iniziato il mio viaggio nella programmazione. Quindi proverò a risparmiarti la confusione.
In questo manuale, tenterò di darti un'introduzione generale, semplice e facile da capire di cos'è l'architettura del software.
Parleremo di cos'è l'architettura all'interno del mondo del software, di alcuni dei concetti che dovresti capire e di alcuni dei modelli architettonici maggiormente usati oggigiorno.
Per ogni argomento, ti darò una breve introduzione teorica, fornendo poi degli esempi di codice per rendere più chiare le idee sul loro funzionamento. Iniziamo!
Sommario
- Cos'è l'architettura del software?
- Concetti importanti di architettura del software da conoscere
- Cos'è il modello client-server?
- Cosa sono le API?
- Cos'è la modularità?
- Organizzazione delle infrastrutture
- Architettura monolitica
- Architettura di microservizi
- Cos'è il back-end per front-end?
- Come usare i bilanciatori di carico e scalare orizzontalmente
- Dove risiedono le infrastrutture
- Hosting on-premise
- Fornitori di server tradizionali
- Hosting sul cloud
- Tradizionale
- Elastico
- Serverless
- Molti altri servizi
- Diverse strutture di cartelle da conoscere
- Tutto nello stesso posto
- Struttura di cartelle a livelli
- Struttura di cartelle MVC
- Conclusione
Cos'è l'architettura del software?
Secondo questa fonte:
L'architettura del software è un sistema che rappresenta le decisioni progettuali correlate alla struttura e al comportamento complessivi di un sistema.
Piuttosto generico, non è vero? Ed è esattamente ciò che mi ha confuso così tanto, ogni volta che facevo ricerche sull'architettura del software. È un argomento che comprende un sacco di termini usati per parlare di cose molto diverse.
Il modo più semplice di spiegarlo è che l'architettura del software si riferisce all'organizzazione degli elementi nel processo di creazione del software. E qui, "elementi" può fare riferimento a:
- Dettagli di implementazione (ovvero, la struttura di cartelle del tuo repository)
- Decisioni di implementazione del design (utilizzi il rendering lato server o lato client? Database relazionali o non relazionali?)
- Le tecnologie che scegli (utilizzi REST o GraphQl per la tua API? Python con Django o Node con Express per il back end?)
- Decisioni di design di sistema (il tuo sistema è un monolite o è diviso in microservizi?)
- Decisioni infrastrutturali (il tuo software è ospitato on premise o su un provider cloud?)
Ci sono un sacco di scelte e possibilità diverse. E ciò che complica ancora di più il tutto è che all'interno di queste 5 suddivisioni, i vari modelli possono essere combinati. Ciò vuol dire che possiamo avere una API monolitica che utilizza REST o GraphQL, una app basata su microservizi ospitata on premise o sul cloud e così via.
Per spiegare meglio questo caos, esporrò prima alcuni concetti di base. Poi affronteremo alcune di queste sezioni, spiegando i modelli o le scelte di architettoniche più comuni usate per creare app al giorno d'oggi.
Concetti importanti di architettura del software da conoscere
Cos'è il modello client-server?
Client-server è un modello che struttura le attività o i carichi di lavoro di una applicazione tra una risorsa o fornitore di servizi (server) e un servizio o richiedente della risorsa (client).
In poche parole, il client è l'applicazione che richiede qualche tipo di informazione o svolge delle azioni, e il server è il programma che invia le informazioni o svolge delle azioni a seconda di cosa fa il client.
I client sono normalmente rappresentati dalle applicazioni front-end che vengono eseguite sul web o sulle app mobile (sebbene esistano anche altre piattaforme e le applicazioni back-end possano agire anch'esse da client). I server, di solito, sono le applicazioni back-end.
Per illustrarlo con un esempio, immagina di entrare sul tuo social network preferito. Quando inserisci l'URL sul tuo browser e premi invio, il browser agisce come app client, mandando una richiesta al server del social network, il quale risponde inviandoti il contenuto del sito web.
La maggior parte delle applicazioni odierne utilizza il modello client-server. Il concetto più importante da ricordare è che il client richiede risorse o servizi che il server svolge.
Un altro concetto importante da sapere è che i client e i server fanno parte dello stesso sistema, ma ognuno costituisce una applicazione/programma a sé stante. Ciò vuol dire che possono essere sviluppati, ospitati ed eseguiti separatamente.
Se non hai familiarità con le differenze tra front-end e back-end, ecco un bell'articolo che le illustra. E qui c'è un altro articolo che amplia il concetto di client-server.
Cosa sono le API?
Abbiamo appena menzionato che i client e i server sono delle entità che comunicano tra loro facendo richieste e inviando delle risposte. Il modo in cui queste parti comunicano di solito è attraverso una API (application programming interface).
Una API non è nient'altro che un insieme di regole definite che stabilisce come le applicazioni dovrebbero comunicare tra loro. È come un contratto tra due parti che dice "Se invii A, risponderò sempre B. Se invii C, risponderò sempre D..." e così via.
Avendo questo insieme di regole, il client sa esattamente cosa deve richiedere per poter completare una certa azione, e il server sa esattamente cosa richiederà il client quando viene eseguita una certa azione.
Esistono modi diversi in cui una API può essere implementata. Quelli usati più di frequente sono REST, SOAP e GraphQL.
Per quanto riguardo il modo in cui le API comunicano, viene quasi sempre usato il protocollo HTTP e il contenuto è scambiato in formato JSON o XML. Ma sono anche possibili altri protocolli e formati.
Se vuoi approfondire questo argomento, ecco un bell'articolo che puoi leggere.
Cos'è la modularità?
Quando parliamo di "modularità" in architettura del software, facciamo riferimento alla pratica di dividere le cose in parti più piccole. Questa pratica viene svolta per semplificare le applicazioni grandi o i codebase molto estesi.
La modularità ha i seguenti vantaggi:
- È ottima per dividere attività e funzionalità, migliorando la visualizzazione, la comprensione e l'organizzazione di un progetto.
- Il progetto tende a essere più facile da gestire e meno predisposto a errori e bug quando è chiaramente organizzato e suddiviso.
- Se un progetto è suddiviso in molti pezzi diversi, ognuno può funzionare ed essere modificato separatamente e indipendentemente, il che risulta molto utile.
So che sembra tutto piuttosto generico, ma la modularità o la pratica di suddividere le cose è una parte molto importante dell'architettura del software. Quindi tieni a mente questo concetto – diventerà più chiaro ed evidente man mano che faremo degli esempi. ;)
Se vuoi approfondire questo argomento, ho recentemente scritto un articolo sull'uso dei moduli in JS che potresti trovare utile.
Organizzazione delle infrastrutture
Ok, adesso passiamo alle cose interessanti. Inizieremo a parlare dei diversi modi in cui puoi organizzare una applicazione software, partendo da come organizzare le infrastrutture dietro al tuo progetto.
Per rendere il tutto meno astratto, useremo un'ipotetica app che chiameremo Notflix.🤔🤫🥸
Nota: tieni a mente che questo esempio potrebbe non essere il più realistico e che forzerò delle situazioni per presentare alcuni concetti. L'idea è di aiutarti a capire i concetti chiave di architettura attraverso degli esempi, non di svolgere un'analisi realistica.
Architettura monolitica
Quindi Notflix sarà una tipica applicazione di streaming video, in cui l'utente sarà in grado di guardare film, serie, documentari e via dicendo. L'utente potrà usare l'app nel browser, una app mobile o una app per TV.
I servizi principali inclusi nella nostra app saranno l'autenticazione (per permettere alle persone di creare un account, fare il login e così via), il pagamento (per potersi abbonare e accedere ai contenuti... Non pensavi mica che fossi gratis, vero? 😑) e naturalmente lo streaming (per consentire alle persone di vedere ciò per cui stanno pagando).
La nostra architettura potrebbe essere come nel seguente diagramma:

Alla sinistra ci sono tre diverse app front-end che agiscono come client in questo sistema. Potrebbero essere sviluppate con React e React-native, per esempio.
Abbiamo un singolo server che riceve le richieste da tutte e tre le app client, comunica con il database quando necessario e risponde a ogni front-end di conseguenza. Il back-end potrebbe essere sviluppato con Node e Express, tanto per dire.
Questo tipo di architettura è chiamato monolitico perché c'è una singola applicazione server responsabile per tutte le funzionalità del sistema. Nel nostro caso, se un utente vuole autenticarsi, pagare o guardare un film, tutte le richieste saranno inviate alla stessa applicazione server.
Il maggior vantaggio di un design monolitico è la semplicità. Il suo funzionamento e la configurazione richiesta sono semplici e facili da seguire. Ed ecco perché la gran parte della applicazioni inizia in questo modo.
Architettura di microservizi
Quindi si scopre che Notflix sta andando alla grande. Abbiamo appena rilasciato l'ultima stagione di "Stranger thugs", che è una fantastica science fiction su dei rapper teenager, e il film "Agent 404" (su un agente segreto che si infiltra in una azienda facendo finta di essere un programmatore esperto ma in realtà non sa nulla di programmazione) sta battendo tutti i record...
Stiamo ottenendo decine di migliaia di nuovi utenti da tutto il mondo ogni mese, che è ottimo per i nostri affari, ma non molto per la nostra app monolitica.
Ultimamente abbiamo notato dei ritardi nei tempi di risposta del server e anche se abbiamo scalato verticalmente il server (aggiunto più RAM e GPU), il poveretto non sembra più in grado di tenere botta con questo carico.
Inoltre, abbiamo continuato a sviluppare nuove funzionalità per il nostro sistema (come uno strumento per consigliare all'utente dei contenuti che corrispondono alle sue preferenze) e il nostro codebase sta iniziando a essere enorme e molto complesso per lavorarci su.
Analizzando a fondo il problema, abbiamo scoperto che la funzionalità che prende più risorse è lo streaming, mentre gli altri servizi, come l'autenticazione e il pagamento non rappresentano un grosso carico.
Per risolvere il problema, implementeremo un'architettura di microservizi che avrà questo aspetto:

Se tutto ciò ti è nuovo, probabilmente stai pensando "cosa diamine è un microservizio?". Potremmo definirlo come il concetto di dividere le funzionalità lato server in piccoli server che sono responsabili solo per una o poche funzionalità specifiche.
Seguendo il nostro esempio, prima avevamo un singolo server responsabile per tutte le funzionalità (architettura monolitica). Dopo aver implementato i microservizi, avremo un server responsabile dell'autenticazione, uno per i pagamenti, uno per lo streaming e l'ultimo per i consigli.
Le app lato client comunicheranno con il server di autenticazione quando l'utente vuole accedere, con il server dei pagamenti quando vuole pagare, e con il server di streaming quando desidera guardare qualcosa.
Tutta questa comunicazione avviene tramite API, proprio come con un normale server monolitico (o attraverso altri sistemi di comunicazione come Kafka o RabbitMQ). L'unica differenza è che ci sono più server responsabili per diverse azioni invece di un singolo server che fa tutto.
Sembra un po' più complesso e in effetti lo è, ma i microservizi offrono alcuni vantaggi:
- È possibile scalare un particolare servizio secondo necessità, invece di scalare l'intero back-end. Seguendo il nostro esempio, quando abbiamo iniziato a riscontrare dei problemi di prestazione, abbiamo scalato verticalmente l'intero server – ma la funzionalità che richiedeva più risorse era soltanto lo streaming. Ora che abbiamo la funzionalità di streaming separata in un server a parte, possiamo scalare soltanto questo e lasciare il resto invariato finché funziona bene.
- Le funzionalità sono più "slegate" (caratterizzate da loose coupling), che vuol dire che saremo in grado di svilupparle e distribuirle indipendentemente.
- Il codebase per ogni server sarà più ridotto e più semplice, che è ottimo per gli sviluppatori che lavorano su un progetto dall'inizio, così come per risulta più semplice e veloce da capire per i nuovi sviluppatori.
I microservizi costituiscono un tipo di architettura più complessa da impostare e gestire, ed è per questo che ha senso solo per progetti molto grandi. La maggior parte dei progetti inizia con un'architettura monolitica e per poi passare ai microservizi solo quando risulta necessario per motivi di prestazione.
Se vuoi sapere di più sui microservizi, ecco un'ottima spiegazione (risorsa in inglese).
Cos'è il back-end per front-end?
Un problema che viene fuori implementando dei microservizi è che la comunicazione con le app front-end diventa più complicata. Avendo più server responsabili per cose diverse, ogni app front-end ha bisogno di tenere traccia di queste informazioni per sapere a chi fare le richieste.
Di norma, questo problema viene risolto implementando un livello che funge da intermediario tra le app front-end e i microservizi. Questo livello riceverà tutte le richieste font-end, reindirizzandole al microservizio corrispondente, e riceverà le risposte del microservizio, reindirizzandole all'app front-end corrispondente.
Il vantaggio del modello back-end per front-end è che otteniamo i benefici dell'architettura di microservizi senza complicare la comunicazione con le app front-end.
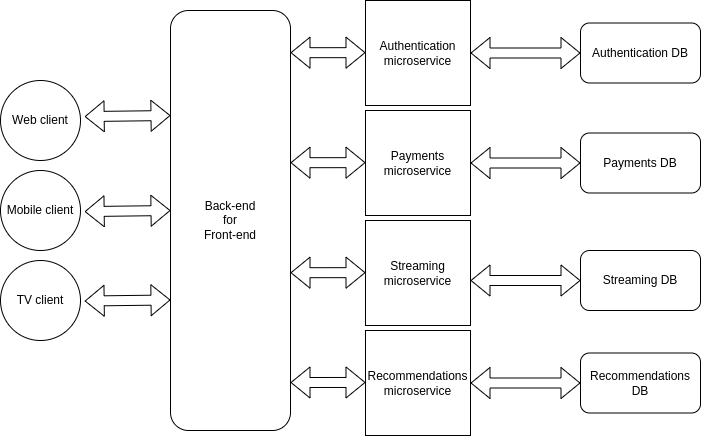
Ecco un video che spiega il modello back end per front end (risorsa in inglese), nel caso volessi saperne di più.
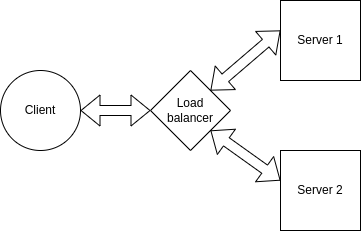
Come usare i bilanciatori di carico e scalare orizzontalmente
La nostra app continua a crescere a un ritmo esponenziale. Abbiamo milioni di utenti in tutto il mondo che guardano film h24 e stiamo iniziando ad avere di nuovo problemi di prestazioni prima del previsto.
Ancora una volta abbiamo riscontrato che il servizio di streaming è quello più sollecitato e abbiamo scalato verticalmente quel server per quanto possibile. Un'ulteriore suddivisione in altri microservizi non avrebbe senso, quindi abbiamo deciso di scalare orizzontalmente il servizio.
Prima abbiamo menzionato che scalare verticalmente significa aggiungere più risorse (RAM, spazio sul disco, GPU e via dicendo) a un singolo server/computer. D'altro canto, scalare orizzontalmente significa allestire più server per svolgere la stessa funzione.
Invece di avere un solo server responsabile per lo streaming, adesso ne avremo tre. Quindi le richieste eseguite dai client saranno bilanciate tra i tre server, in modo che tutti gestiscano un carico accettabile.
Questa distribuzione di richieste è normalmente svolta un elemento chiamato bilanciatore di carico, che agisce come un reverse proxy per i nostri server, intercettando le richieste del client prima che arrivino al server e reindirizzandole al server corrispondente.
Mentre una tipica connessione client-server ha questo aspetto:

Usando un bilanciatore di carico possiamo distribuire le richieste dei client tra più server:
Dovresti sapere che è possibile scalare orizzontalmente anche i database, proprio come i server. Un modo per implementare tutto ciò è tramite un modello sorgente-replica, in cui un particolare database sorgente riceverà tutte le query di scrittura e copierà i suoi dati in uno o più database replica. I database replica riceveranno e risponderanno a tutte le query di lettura.
I vantaggi della replicazione di DB sono:
- Prestazioni migliori – questo modello consente l'elaborazione in parallelo di più query.
- Affidabilità e disponibilità – se uno dei server database viene distrutto o è inaccessibile per qualsiasi ragione, i dati vengono conservati negli altri database.
Dopo aver implementato il bilanciamento di carico, scalato orizzontalmente e replicato il database, la nostra architettura ha questo aspetto:
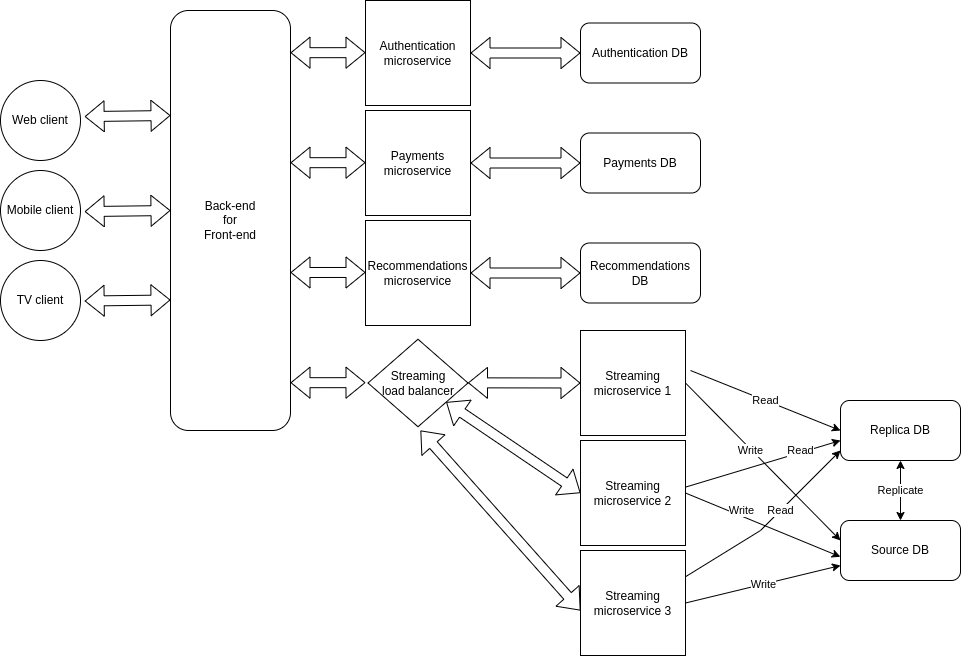
Se sei interessato a saperne di più, ecco una fantastica spiegazione sui bilanciatori di carico (risorsa in inglese).
Nota: quando parliamo di microservizi, bilanciamento di carico e scalabilità, si tratta con tutta probabilità di app back-end. Le app front-end sono per lo più sviluppate in modo monolitico, anche se esiste una cosa strana e interessante chiamata micro-front-end (risorsa in inglese).🧐
Dove risiedono le infrastrutture
Ora che hai un'idea di base di come possono essere organizzate le infrastrutture fondamentali di un'applicazione, la prossima cosa a cui pensare è dove andremo a mettere tutta questa roba.
Come vedremo, ci sono fondamentalmente tre opzioni quando occorre decidere dove e come ospitare un'applicazione: on premise, su fornitori di server tradizionali o sul cloud.
Hosting on-premise
On premise vuol dire che possiedi l'hardware in cui l'app viene eseguita. Nel passato, questo era il modo più comune di ospitare un'applicazione. Le aziende avevano delle apposite stanze in cui avere i server e gruppi dedicati per la configurazione e la manutenzione dell'hardware.
La cosa positiva di questa opzione è che l'azienda ha il totale controllo sull'hardware. La cosa negativa è che richiede spazio, tempo e denaro.
Immagina di voler scalare orizzontalmente un certo server, il che vuol dire comprare più attrezzatura, montarla, supervisionarla costantemente, riparare quello che si rompe... E se poi hai bisogno di ridimensionare il server, beh, di solito non è possibile restituire tutte queste cose una volta che le hai comprate. 🥲
Per la maggior parte delle aziende, avere dei server on premise significa dedicare molte risorse a un'attività non direttamente collegata ai propri obiettivi.


Una situazione in cui i server on premise hanno ancora senso è nel caso in cui si ha a che fare con informazioni molto delicate o private. Pensa al software che gestisce una centrale elettrica o alle informazioni private di una banca, ad esempio. Molte di queste organizzazioni decidono di avere dei server on premise come modo per avere un controllo completo sul software e sull'hardware.
Fornitori di server tradizionali
Un'opzione più comoda per la maggior parte delle aziende è costituita dai tradizionali fornitori o provider di server. Si tratta di società che possiedono dei server propri e li affittano. Puoi decidere di che tipo di hardware hai bisogno per il tuo progetto e pagare una quota mensile (o sulla base di altre condizioni).
Il grande vantaggio di questa opzione è che non devi più preoccuparti di nulla che sia correlato all'hardware. Se ne occupa il fornitore, mentre l'azienda può focalizzarsi sul suo obiettivo principale, il software.
Un'altra cosa interessante è che scalare in entrambi i sensi è semplice e non ha rischi. Se hai bisogno di più hardware, paghi. Se non ti serve più, smetti di farlo.
Un esempio un server provider molto conosciuto è hostinger.
Hosting sul cloud
Se ti interessi di tecnologia, probabilmente hai sentito la parola "cloud" più di una volta. All'inizio sembra qualcosa di astratto e in qualche modo magico, ma in realtà quello che c'è dietro non è niente di più di un gigantesco centro dati di proprietà di società come Amazon, Google e Microsoft.
A un certo punto, queste società hanno realizzato di avere un enorme potenza computazionale che non stavano utilizzando di continuo. E dato che l'hardware rappresenta un costo, che lo si usi o meno, la cosa più intelligente da fare è vendere quella potenza computazionale ad altri.
Ed ecco cos'è il cloud. Usando diversi servizi come AWS (Amazon web services), Google Cloud o Microsoft Azure, siamo in grado di ospitare le nostre applicazioni nei centri dati di queste società e trarre vantaggio da tutta la loro potenza di calcolo.

Approcciandosi ai servizi cloud, è importante notare che esistono molti modi diversi in cui possiamo usarli:
Tradizionale
Il primo modo di utilizzarli è simile a quello in cui faresti uso di un fornitore di server tradizionale. Selezioni il tipo di hardware che desideri e paghi di conseguenza mensilmente.
Elastico
Il secondo modo è trarre vantaggio delle risorse "elastiche" fornite dalla maggior parte dei provider. "Elastico" vuol dire che la capacità dell'hardware della tua applicazione si adatta automaticamente a seconda dell'utilizzo dell'app.
Ad esempio, potresti iniziare con un server che ha 8 GB di RAM e 500 GB di spazio sul disco. Se il server inizia ad avere sempre più richieste e questa capacità non è più sufficiente per garantire una buona prestazione, il sistema può essere scalato automaticamente in modo verticale o orizzontale.
Uno degli aspetti migliori di ciò è che puoi configurare il tutto preventivamente e non devi preoccupartene in seguito. Nel momento in cui le risorse dedicate ai server si ridimensionano automaticamente, pagherai solo per quelle consumate.
Serverless
Un altro modo in cui puoi fare uso del cloud computing è con un'architettura serverless (senza server).
Seguendo questo modello, non avrai un server che riceve tutte le richieste e vi risponde. Invece, avrai delle singole funzioni corrispondenti a un punto di accesso (simile all'endpoint di una API).
Queste funzioni saranno eseguite ogni volta che riceveranno una richiesta e svolgeranno qualsiasi azione per cui siano state programmate (connessione a un database, esecuzione di operazioni CRUD o qualsiasi altra cosa potrebbero fare in un normale server).
Un aspetto molto bello dell'architettura serverless è che non occorre pensare alla manutenzione del server e alle questioni di scalabilità. Ci sono solo funzioni che vengono eseguite quando c'è bisogno e ogni funzione viene scalata in su o in giù automaticamente quando necessario.
Come cliente, paghi soltanto la quantità di tempo in cui la funzione viene eseguita e la durata del tempo di elaborazione per ogni esecuzione.
Se vuoi saperne di più, ecco una spiegazione del modello serverless (risorsa in inglese).
Molti altri servizi
Probabilmente hai capito quanto i servizi elastici e senza server costituiscano delle alternative semplici e convenienti per realizzare l'infrastruttura di un software.
Oltra a tutti i servizi legati ai server, i fornitori cloud offrono molte altre soluzioni come database relazionali e non relazionali, servizi di archiviazione file, servizi di caching, servizi di autenticazione, machine learning ed elaborazione dati, monitoraggio e analisi delle prestazioni e altro. E tutto è ospitato sul cloud.
Attraverso strumenti come Terraform o AWS Cloud formation possiamo addirittura impostare la nostra infrastruttura come codice. Ciò vuol dire che possiamo scrivere uno script che imposta un server, un database e qualsiasi altra cosa di cui potremmo avere bisogno sul cloud nel giro di pochi minuti.
Da un punto di vista ingegneristico è strabiliante, ed è molto conveniente per noi sviluppatori. Oggigiorno, il cloud computing offre un insieme molto completo di soluzioni che possono adattarsi facilmente sia a progetti piccoli che ai prodotti digitali più grandi al mondo. Ecco perché sempre più progetti software scelgono di ospitare le loro infrastrutture sul cloud.
Come detto in precedenza, i fornitori cloud più usati e conosciuti sono AWS, Google Cloud e Azure. Ma ci sono anche altre opzioni come IBM, DigitalOcean e Oracle.
La maggior parte di questi provider offre lo stesso tipo di servizio, anche se potrebbero avere dei nomi diversi. Ad esempio, le funzioni serverless sono chiamate "lambda" su AWS e "funzioni cloud" su Google cloud.
Diverse strutture di cartelle da conoscere
Finora abbiamo visto come l'architettura può fare riferimento all'organizzazione delle infrastrutture e all'hosting. Adesso vedremo un po' di codice e come l'architettura può riferirsi alla struttura delle cartelle e alla modularità del codice.
Tutto nello stesso posto
Per illustrare perché le strutture delle cartelle sono importanti, facciamo un esempio banale su una API. Avremo un database mock di conigli 🐰🐰 e l'API svolgerà su di esso delle azioni CRUD. Realizzeremo il tutto con Node ed Express.
Ecco il nostro primo approccio, senza una struttura di cartelle. Il nostro repository sarà composto dalla cartella node modules e dai file app.js, package-lock.json e package.json.

All'interno del file app.js ci sarà il nostro piccolo server, il DB mock e due endpoint:
// App.js
const express = require('express');
const app = express()
const port = 7070
// Mock DB
const db = [
{ id: 1, name: 'John' },
{ id: 2, name: 'Jane' },
{ id: 3, name: 'Joe' },
{ id: 4, name: 'Jack' },
{ id: 5, name: 'Jill' },
{ id: 6, name: 'Jak' },
{ id: 7, name: 'Jana' },
{ id: 8, name: 'Jan' },
{ id: 9, name: 'Jas' },
{ id: 10, name: 'Jasmine' },
]
/* Routes */
app.get('/rabbits', (req, res) => {
res.json(db)
})
app.get('/rabbits/:idx', (req, res) => {
res.json(db[req.params.idx])
})
app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
Se testiamo gli endpoint, vedremo che funzionano alla perfezione:
http://localhost:7070/rabbits
# [
# {
# "id": 1,
# "name": "John"
# },
# {
# "id": 2,
# "name": "Jane"
# },
# {
# "id": 3,
# "name": "Joe"
# },
# ....
# ]
###
http://localhost:7070/rabbits/1
# {
# "id": 2,
# "name": "Jane"
# }
Quindi? Qual è il problema? In realtà, nessuno, funziona tutto bene. Ci saranno dei problemi soltanto quando il codebase diventerà più grande e complesso e inizieremo ad aggiungere funzionalità nuove alla nostra API.
In modo simile a quanto detto prima a riguardo delle architetture monolitiche, avere tutto in un solo posto è bello e semplice all'inizio. Ma quando le cose iniziano a diventare più grandi e complesse, si tratta di un approccio che crea confusione e risulta difficile da seguire.
Seguendo il principio di modularità, è meglio avere diverse cartelle e file per le varie responsabilità e azioni da svolgere.
Per spiegarlo meglio, aggiungiamo delle nuove funzionalità alla nostra API e vediamo come possiamo intraprendere un approccio modulare con l'aiuto di un'architettura a livelli.
Struttura di cartelle a livelli
L'architettura a livelli fa riferimento alla suddivisione di attività e responsabilità in diverse cartelle e file, permettendo una comunicazione diretta solo tra alcune cartelle e file.
Quanti livelli dovrebbe avere un progetto, i nomi dei livelli e le azioni di cui dovrebbero occuparsi rientrano nell'oggetto della discussione. Quindi vediamo quello che ritengo sia un buon approccio per il nostro esempio.
La nostra applicazione avrà cinque diversi livelli, che saranno ordinati in questo modo:
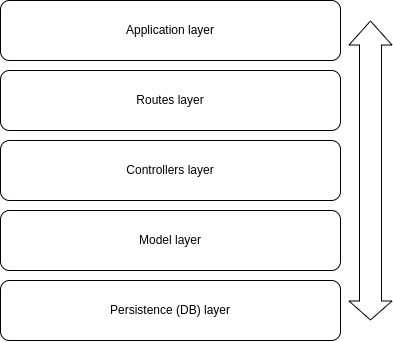
- Il livello dell'applicazione conterrà le impostazioni di base del server e della connessione alle nostre rotte (il livello successivo)
- Il livello delle rotte conterrà la definizione di tutte le rotte e la connessione ai controller (il livello successivo)
- Il livello dei controller conterrà la logica che vogliamo eseguire in ognuno degli endpoint e la connessione al livello dei modelli (il livello successivo, ormai hai capito...)
- Il livello dei modelli conterrà la logica per interagire con il database mock.
- Infine, il livello di persistenza conterrà il database.
Come puoi vedere, questo approccio è molto più strutturato e possiede una chiara divisione delle attività. Può avere l'aspetto di un sacco di boilerplate, ma dopo aver impostato questa architettura, saremo in grado di sapere chiaramente dove si trova ogni cosa e quali cartelle e quali file sono responsabili per ogni azione che viene eseguita dalla nostra applicazione.
Una cosa importante da tenere a mente è che in questo tipo di architettura esiste un flusso di comunicazione definito tra i livelli che deve essere seguito affinché il tutto abbia senso.
Ciò vuol dire che una richiesta deve prima passare per il primo livello, poi il secondo, il terzo e via dicendo. Nessuna richiesta dovrebbe saltare dei livelli perché manderebbe a monte la logica dell'architettura e i vantaggi dell'organizzazione e della modularità che fornisce.

E ora vediamo un po' di codice. Usando l'architettura a livelli, la nostra struttura di cartelle potrebbe avere questo aspetto:

- Abbiamo una nuova cartella chiamata
dbche conterrà il file del database. - E un'altra cartella chiamata
rabbitsche conterrà le rotte, i controller e i modelli collegati a questa entità. app.jsimposta il server e la connessione alle rotte.
// App.js
const express = require('express');
const rabbitRoutes = require('./rabbits/routes/rabbits.routes')
const app = express()
const port = 7070
/* Routes */
app.use('/rabbits', rabbitRoutes)
app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
rabbits.routes.jscontiene ognuno degli endpoint correlati a questa entità e li collega al corrispondente controller (la funzione che vogliamo eseguire quando la richiesta giunge all'endpoint).
// rabbits.routes.js
const express = require('express')
const bodyParser = require('body-parser')
const jsonParser = bodyParser.json()
const { listRabbits, getRabbit, editRabbit, addRabbit, deleteRabbit } = require('../controllers/rabbits.controllers')
const router = express.Router()
router.get('/', listRabbits)
router.get('/:id', getRabbit)
router.put('/:id', jsonParser, editRabbit)
router.post('/', jsonParser, addRabbit)
router.delete('/:id', deleteRabbit)
module.exports = router
rabbits.controllers.jscontiene la logica corrispondente a ogni endpoint. È qui che che programmiamo quello che la funzione dovrebbe prendere come input, quale processo dovrebbe essere svolto e cosa dovrebbe restituire. 😉 Inoltre, ogni controller si collega alla corrispondente funzione modello (che eseguirà delle operazioni riguardanti il database).
// rabbits.controllers.js
const { getAllItems, getItem, editItem, addItem, deleteItem } = require('../models/rabbits.models')
const listRabbits = (req, res) => {
try {
const resp = getAllItems()
res.status(200).send(resp)
} catch (err) {
res.status(500).send(err)
}
}
const getRabbit = (req, res) => {
try {
const resp = getItem(parseInt(req.params.id))
res.status(200).send(resp)
} catch (err) {
res.status(500).send(err)
}
}
const editRabbit = (req, res) => {
try {
const resp = editItem(req.params.id, req.body.item)
res.status(200).send(resp)
} catch (err) {
res.status(500).send(err)
}
}
const addRabbit = (req, res) => {
try {
console.log( req.body.item )
const resp = addItem(req.body.item)
res.status(200).send(resp)
} catch (err) {
res.status(500).send(err)
}
}
const deleteRabbit = (req, res) => {
try {
const resp = deleteItem(req.params.idx)
res.status(200).send(resp)
} catch (err) {
res.status(500).send(err)
}
}
module.exports = { listRabbits, getRabbit, editRabbit, addRabbit, deleteRabbit }
rabbits.models.jsè dove definiamo le funzioni che svolgeranno le azioni CRUD nel database. Ogni funzione rappresenta un tipo di azione differente (leggere un elemento, leggere tutto, modificare, eliminare e così via). Questo file è quello che si connette al DB.
// rabbits.models.js
const db = require('../../db/db')
const getAllItems = () => {
try {
return db
} catch (err) {
console.error("getAllItems error", err)
}
}
const getItem = id => {
try {
return db.filter(item => item.id === id)[0]
} catch (err) {
console.error("getItem error", err)
}
}
const editItem = (id, item) => {
try {
const index = db.findIndex(item => item.id === id)
db[index] = item
return db[index]
} catch (err) {
console.error("editItem error", err)
}
}
const addItem = item => {
try {
db.push(item)
return db
} catch (err) {
console.error("addItem error", err)
}
}
const deleteItem = id => {
try {
const index = db.findIndex(item => item.id === id)
db.splice(index, 1)
return db
return db
} catch (err) {
console.error("deleteItem error", err)
}
}
module.exports = { getAllItems, getItem, editItem, addItem, deleteItem }
- Infine,
db.jsospita il database mock. In un progetto reale, è qui che potrebbe risiedere la connessione al database.
// db.js
const db = [
{ id: 1, name: 'John' },
{ id: 2, name: 'Jane' },
{ id: 3, name: 'Joe' },
{ id: 4, name: 'Jack' },
{ id: 5, name: 'Jill' },
{ id: 6, name: 'Jak' },
{ id: 7, name: 'Jana' },
{ id: 8, name: 'Jan' },
{ id: 9, name: 'Jas' },
{ id: 10, name: 'Jasmine' },
]
module.exports = db
Come puoi vedere, ci sono molte più cartelle e file in questa architettura. Ma come conseguenza il nostro codebase è molto più strutturato e organizzato chiaramente. Ogni cosa ha il suo posto e la comunicazione tra diversi file è chiaramente definita.
Questo tipo di organizzazione facilita grandemente l'aggiunta di nuove funzionalità, le modifiche del codice e la risoluzione di bug.
Una volta che acquisisci familiarità con la struttura delle cartelle e sai dove trovare ogni cosa, vedrai che è molto conveniente lavorare con questi file più corti e piccoli invece di dover scorrere attraverso uno o due file enormi in cui viene messo tutto insieme.
Sono anche favorevole ad avere una cartella per ognuna delle entità principali di una app (conigli nel nostro caso). Ciò permette di avere una comprensione addirittura più chiara delle relazioni di ogni file.
Diciamo che vuoi aggiungere nuove funzionalità per aggiungere/modificare/eliminare anche gatti e cani. Potremmo creare nuove cartelle per ognuna di esse, ognuna con i propri file di rotte, controller e modelli. L'idea è di separare i problemi e avere ogni cosa al proprio posto. 👌👌
Struttura di cartelle MVC
Il modello di architettura MVC sta per Model View Controller. Possiamo dire che l'architettura MVC è come una semplificazione dell'architettura a livelli, e incorpora anche il lato front-end (UI) dell'applicazione.
Sotto questa architettura abbiamo tre livelli principali:
- Il livello view sarà responsabile del rendering dell'interfaccia utente.
- Il livello controller sarà responsabile della definizione delle rotte e della logica di ognuna di esse.
- Il livello model sarà responsabile dell'interazione con il database.
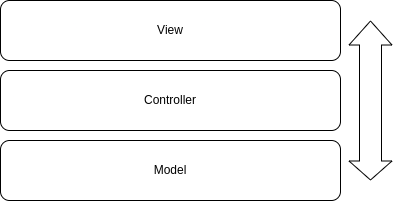
Come prima, ogni livello interagirà solo con il successivo in modo da avere un flusso di comunicazione definito.
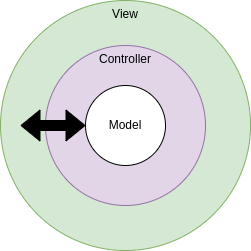
Esistono molti framework che consentono di implementare un'architettura MVC pronta all'uso (come Django o Ruby on Rails ad esempio). Per farlo con Node ed Express avremo bisogno di un template engine come EJS.
Se non hai familiarità con i template engine, si tratta di un modo per renderizzare facilmente l'HTML traendo vantaggio di funzionalità programmatiche come variabili, loop, condizionali e via dicendo (molto simile a quanto avremmo fatto col JSX in React).
Come vedremo tra un attimo, creeremo dei file EJS per ogni tipo di pagina che vorremmo renderizzare, e da ogni controller andremo a renderizzare questi file come risposta, passando le risposte corrispondenti come variabili.
La nostra struttura di cartelle avrà questo aspetto:

- Ci siamo sbarazzati di molte delle cartelle che avevamo prima, tenendo le cartelle
db,controllersemodels. - Abbiamo aggiunto una cartella
viewsche corrisponde a ognuna delle pagine/risposte che vogliamo renderizzare. - I file
db.jsemodels.jsrestano uguali. app.jsdovrebbe avere questo aspetto:
// app.js
const express = require("express");
var path = require('path');
const rabbitControllers = require("./rabbits/controllers/rabbits.controllers")
const app = express()
const port = 7070
// Ejs config
app.set("view engine", "ejs")
app.set('views', path.join(__dirname, './rabbits/views'))
/* Controllers */
app.use("/rabbits", rabbitControllers)
app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
rabbits.controllers.jscambia per definire le rotte, connettersi alle corrispondenti funzioni modello e renderizzare la vista corrispondente per ogni richiesta. Osserva che nei metodi render stiamo passando la risposta alla richiesta come parametro della vista. 😉
// rabbits.controllers.js
const express = require('express')
const bodyParser = require('body-parser')
const jsonParser = bodyParser.json()
const { getAllItems, getItem, editItem, addItem, deleteItem } = require('../models/rabbits.models')
const router = express.Router()
router.get('/', (req, res) => {
try {
const resp = getAllItems()
res.render('rabbits', { rabbits: resp })
} catch (err) {
res.status(500).send(err)
}
})
router.get('/:id', (req, res) => {
try {
const resp = getItem(parseInt(req.params.id))
res.render('rabbit', { rabbit: resp })
} catch (err) {
res.status(500).send(err)
}
})
router.put('/:id', jsonParser, (req, res) => {
try {
const resp = editItem(req.params.id, req.body.item)
res.render('editRabbit', { rabbit: resp })
} catch (err) {
res.status(500).send(err)
}
})
router.post('/', jsonParser, (req, res) => {
try {
const resp = addItem(req.body.item)
res.render('addRabbit', { rabbits: resp })
} catch (err) {
res.status(500).send(err)
}
})
router.delete('/:id', (req, res) => {
try {
const resp = deleteItem(req.params.idx)
res.render('deleteRabbit', { rabbits: resp })
} catch (err) {
res.status(500).send(err)
}
})
module.exports = router- Infine, nei file view prendiamo la variabile ricevuta come parametro e la renderizziamo come HTML.
<!-- Rabbits view -->
<!DOCTYPE html>
<html lang="en">
<body>
<header>All rabbits</header>
<main>
<ul>
<% rabbits.forEach(function(rabbit) { %>
<li>
Id: <%= rabbit.id %>
Name: <%= rabbit.name %>
</li>
<% }) %>
</ul>
</main>
</body>
</html><!-- Rabbit view -->
<!DOCTYPE html>
<html lang="en">
<body>
<header>Rabbit view</header>
<main>
<p>
Id: <%= rabbit.id %>
Name: <%= rabbit.name %>
</p>
</main>
</body>
</html>Ora possiamo andare sul nostro browser, su http://localhost:7070/rabbits per ottenere:

O http://localhost:7070/rabbits/2 e ottenere:

Questa è l'MVC!

Conclusione
Spero che questi esempi ti abbiano aiutato a fare chiarezza su cosa si intende quando si parla di "architettura" nel mondo del software.
Come ho detto all'inizio, si tratta di un argomento vasto e complesso che spesso racchiude molte cose diverse.
Qui abbiamo introdotto i modelli di infrastrutture e sistemi, le opzioni di hosting e provider cloud e, infine, alcune comuni e utili strutture di cartelle che puoi usare nei tuoi progetti.
Abbiamo imparato cosa vuol dire scalare verticalmente e orizzontalmente, cosa sono le applicazioni monolitiche e i microservizi, e il cloud computing elastico e senza server... Un sacco di cose. Ma questa è solo la punta dell'iceberg! Quindi continua a imparare e fare ricerche per conto tuo. 💪💪
Come sempre, spero ti sia piaciuto questo manuale e che tu abbia imparato qualcosa di nuovo. Se vuoi, puoi seguirmi su LinkedIn o Twitter.
Ed ecco una piccola canzone per salutarti... Perché no? 🤷♂️

A presto, ci vediamo alla prossima! ✌️