

Articolo originale: JVM Tutorial - Java Virtual Machine Architecture Explained for Beginners
Che tu sia solito sviluppare programmi in Java oppure no, a un certo punto potresti aver sentito parlare di Java Virtual Machine (JVM).
La JVM è il fulcro dell'ecosistema Java e rende possibile per i programmi basati su Java di seguire l'approccio "write once, run anywhere" (ovvero scrivi una volta ed esegui ovunque). Puoi scrivere del codice Java su una macchina ed eseguirlo su qualsiasi altra macchina che utilizza la JVM.
La JVM è stata inizialmente progettata per supportare soltanto Java. Tuttavia, nel tempo, altri linguaggi come Scala, Kotlin e Groovy sono stati adottati sulla piattaforma Java. Tutti questi linguaggi sono collettivamente conosciuti come linguaggi JVM.
In questo articolo, impareremo di più a riguardo della JVM, il suo funzionamento e i vari componenti di cui è costituita.
Cos'è una macchina virtuale?
Prima di passare alla JVM, esaminiamo il concetto di macchina virtuale (virtual machine, VM).
Una macchina virtuale è una rappresentazione virtuale di un computer fisico. La macchina virtuale può essere chiamata macchina guest, e il computer fisico su cui gira la macchina virtuale può essere detto macchina host.
N.d.T.
Dall'inglese host, chi offre ospitalità, e guest, chi ne usufruisce.
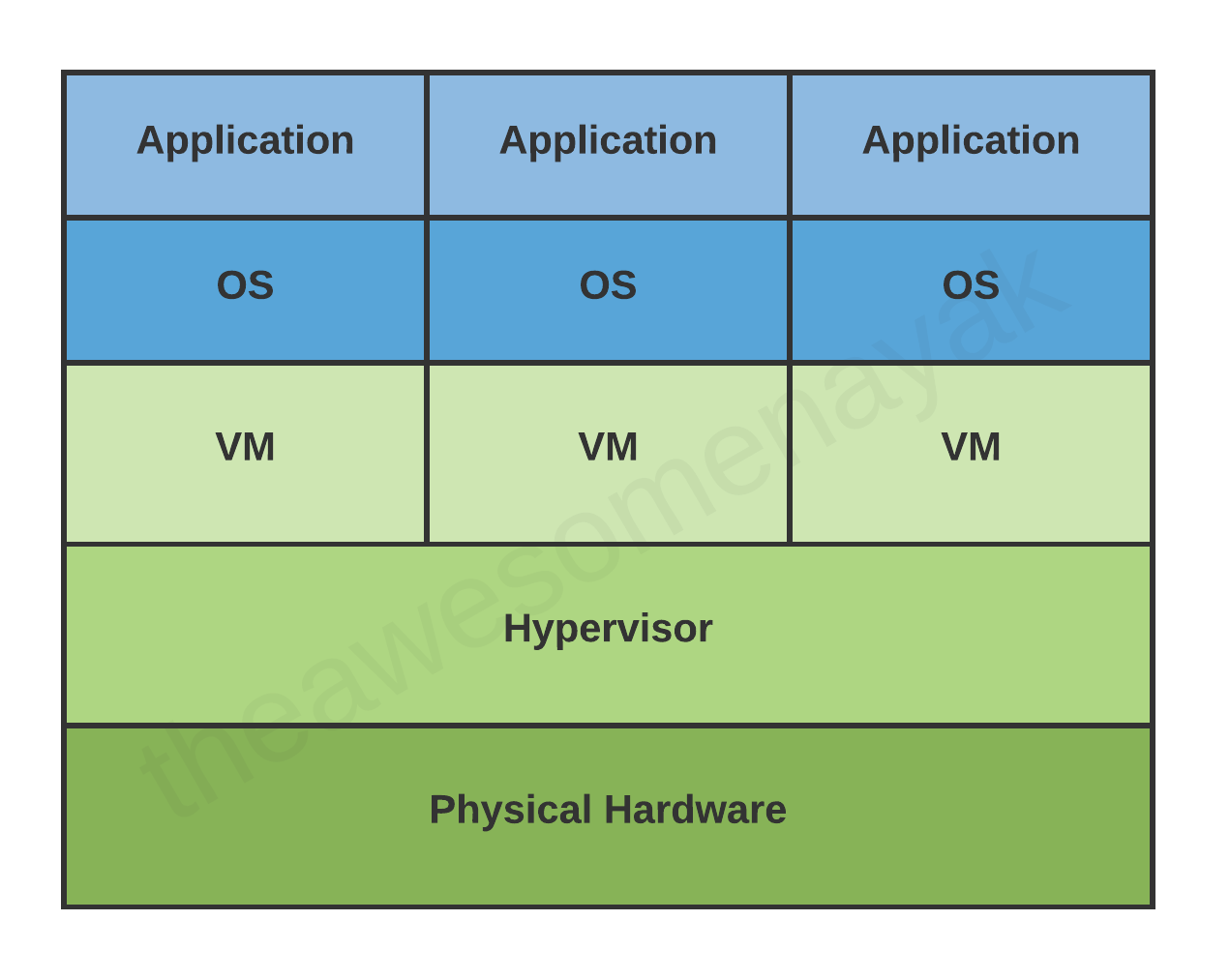
Una singola macchina fisica può ospitare più macchine virtuali, ognuna con il proprio sistema operativo e le proprie applicazioni, e ognuna isolata dalle altre.
Cos'è la Java Virtual Machine?
Nei linguaggi di programmazione come C e C++, il codice viene prima compilato in codice macchina specifico per una piattaforma. Questi linguaggi sono detti compilati.
D'altro canto, nei linguaggi come JavaScript e Python, il computer esegue le istruzioni direttamente senza doverli compilare. Questi linguaggi sono detti interpretati.
Java utilizza una combinazione di entrambe le tecniche. Il codice Java viene prima compilato in bytecode per generare un file class, che viene poi interpretato dalla Java Virtual Machine per la piattaforma sottostante. Lo stesso file class può essere eseguito su qualsiasi versione della JVM in esecuzione su su qualsiasi piattaforma e sistema operativo.
Come le macchine virtuali, la JVM crea uno spazio isolato su una macchina host. Questo spazio può essere usato per eseguire i programmi Java indipendentemente dalla piattaforma o dal sistema operativo della macchina.
Architettura della Java Virtual Machine
La JVM consiste di tre componenti distinti:
- Class Loader
- Memoria di runtime/area dati
- Execution Engine
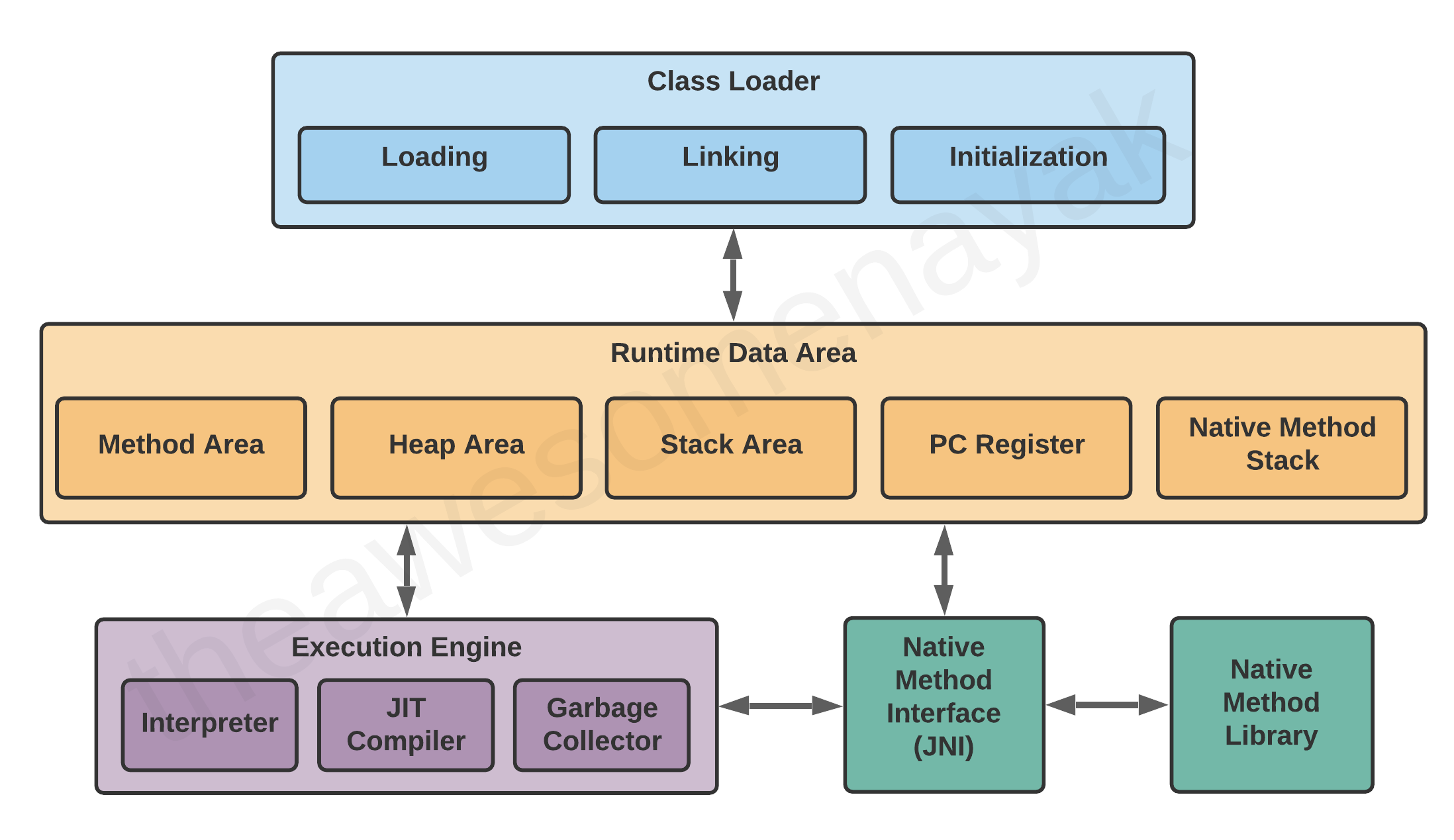
Diamo un'occhiata a ognuno di loro più nel dettaglio.
Class Loader
Quando compili un file sorgente .java, questo viene convertito in bytecode come un file .class. Quando provi a utilizzare questa classe in un programma, il class loader la carica nella memoria principale.
La prima classe ad essere caricata nella memoria è solitamente la classe che contiene il metodo main().
Esistono tre fasi nel processo di caricamento della classe: caricamento (loading), collegamento (linking) e inizializzazione (initialization).
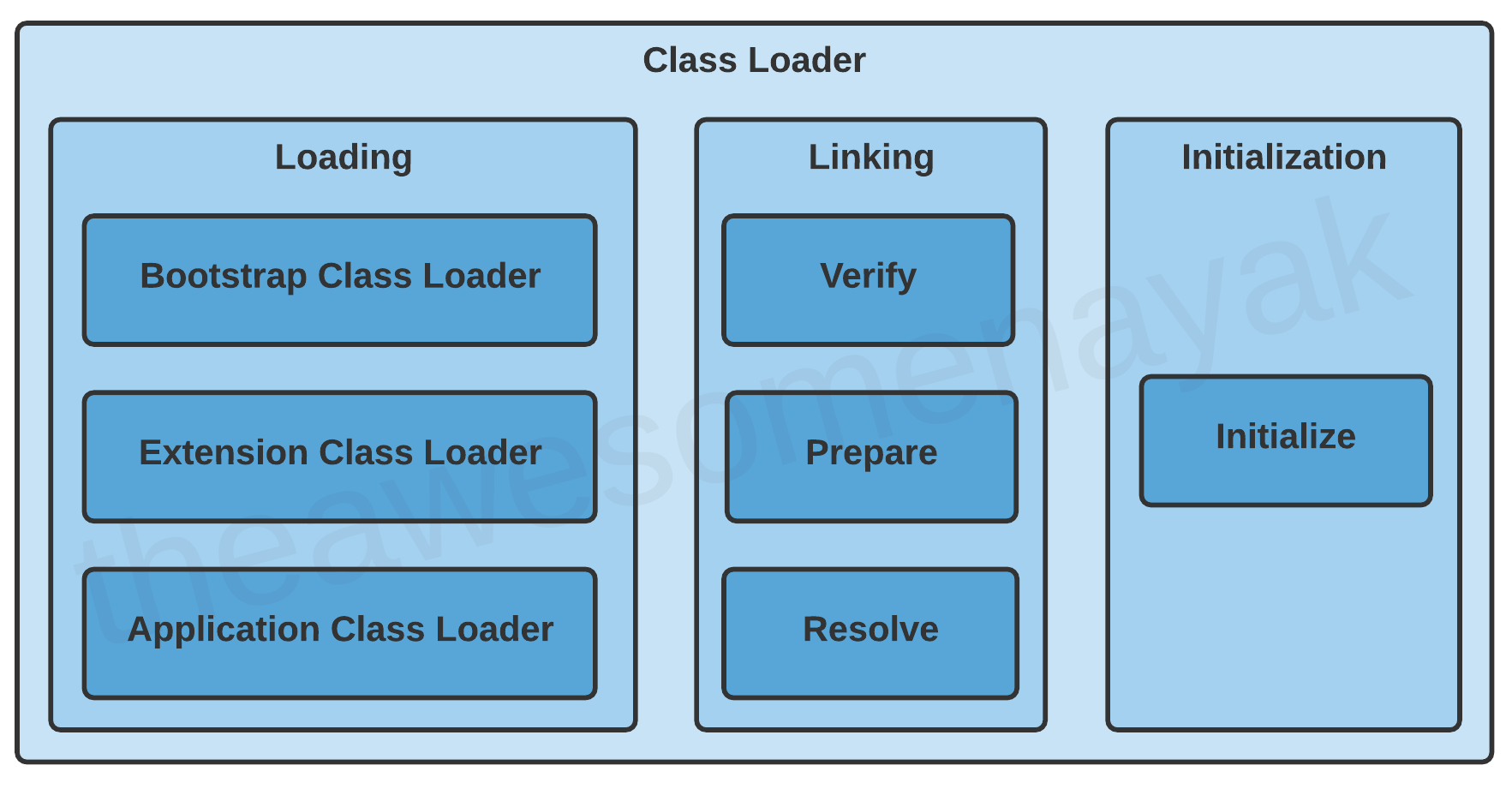
Caricamento
Il processo di caricamento comporta prendere la rappresentazione binaria (bytecode) di una classe o interfaccia con un particolare nome, e da essa generare la classe originaria o interfaccia.
Esistono tre class loader integrati disponibili in Java:
- Bootstrap Class Loader - Questo è il class loader radice. Si tratta di una superclasse dell'Extension Class Loader e carica i pacchetti standard Java come
java.lang,java.net,java.util,java.ioe via dicendo. Questi pacchetti sono presenti all'interno del filert.jare altre librerie di base presenti nella cartella$JAVA_HOME/jre/lib. - Extension Class Loader - È una sottoclasse del Bootstrap Class Loader e superclasse dell'Application Class Loader. Si occupa del caricamento delle librerie standard Java che sono presenti nella cartella
$JAVA_HOME/jre/lib/ext. - Application Class Loader - È l'ultimo class loader e sottoclasse dell'Extension Class Loader. Carica i file presenti nel classpath. Per impostazione predefinita, il classpath è regolato sulla cartella corrente dell'applicazione. Il classpath può anche essere modificato aggiungendo le opzioni da riga di comando
-classpatho-cp.
La JVM utilizza il metodo ClassLoader.loadClass() per caricare la classe nella memoria. Tenta di caricare la classe sulla base di un nome pienamente abilitato.
Se il class loader genitore non è in grado di trovare una classe, delega il lavoro al class loader figlio. Se l'ultimo class loader figlio non è in grado di caricare la classe restituisce NoClassDefFoundError o ClassNotFoundException.
Collegamento
Dopo che una classe viene caricata in memoria, viene sottoposta al processo di collegamento. Collegare una classe o un'interfaccia implica collegare insieme i diversi elementi e dipendenze del programma.
Il collegamento comprende i seguenti passaggi:
Verifica: questa fase controlla la correttezza strutturale del file .class facendo un confronto con un insieme di vincoli o regole. Se la verifica fallisce per qualche ragione, otteniamo VerifyException.
Ad esempio, se il codice è stato creato usando Java 11, ma viene eseguito su un sistema che ha installato Java 8, la fase di verifica fallirà.
Preparazione: in questa fase, la JVM alloca la memoria per i campi statici di una classe o un'interfaccia e li inizializza con dei valori predefiniti.
Ad esempio, supponi di aver già dichiarato la seguente variabile nella tua classe:
private static final boolean enabled = true;Durante la fase di preparazione, la JVM alloca memoria per la variabile enabled e imposta il suo valore su quello predefinito per un booleano, ovvero false.
Risoluzione: in questa fase, i riferimenti simbolici vengono sostituiti con riferimenti diretti al constant pool nel runtime.
Ad esempio, se ci sono riferimenti ad altre classi o variabili costanti presenti in altre classe, sono risolti durante questa fase e rimpiazzati con i riferimenti attuali.
Inizializzazione
L'inizializzazione comporta l'esecuzione del metodo di inizializzazione della classe o dell'interfaccia (conosciuto come <clinit>). Ciò può comprendere la chiamata del costruttore della classe, eseguendo il blocco statico e assegnando i valori a tutti le variabili statiche. Questo è il passaggio finale del caricamento di una classe.
Ad esempio, prima, quando abbiamo dichiarato il seguente codice:
private static final boolean enabled = true;La variabile enabled era impostata al suo valore predefinito, false, durante la fase di preparazione. Nella fase di inizializzazione, alla variabile è assegnato il suo valore reale, true.
Nota: la JVM è multi-thread. Può capitare che più thread tentino di inizializzare la stessa classe allo stesso tempo. Ciò può portare a problemi di concorrenza. Occorre gestire la sicurezza del thread per assicurare che il programma funzioni in modo appropriato in un ambiente multi-thread.
Area dati di runtime
Esistono cinque componenti all'interno dell'area dati di runtime:

Analizziamoli individualmente.
Area dei metodi
Tutti i dati di livello classe come i dati di constant pool, campo e metodo, e il codice per metodi e costruttori sono conservati qui.
Se la memoria disponibile nell'area dei metodi non è sufficiente per l'avvio del programma, la JVM restituisce OutOfMemoryError.
Ad esempio, supponi di avere la seguente definizione di classe:
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
}In questo codice di esempio, il dato al livello del campo come name e age e i dettagli del costruttore sono caricati nell'area dei metodi.
L'area dei metodi è creata all'avvio della macchina virtuale e ce n'è una sola per JVM.
Area di heap
Tutti gli oggetti e le loro corrispondenti variabili di istanza sono memorizzati qui. Questa è l'area di dati di run-time dalla quale è allocata la memoria per tutte le istanze di classe e array.
Ad esempio, supponi di dichiarare la seguente istanza:
Employee employee = new Employee();In questo esempio di codice, viene creata un'istanza di Employee e caricata nell'area heap.
L'area di heap è creata all'avvio della macchina virtuale e ce n'è una sola per JVM.
Nota: dato che l'area dei metodi e l'heap condividono la stessa memoria per thread multipli, i dati memorizzati qui non sono thread-safe.
Stack
Ogniqualvolta un nuovo thread viene creato nella JVM, viene creato contemporaneamente uno stack di runtime separato. Tutte le variabili locali, le chiamate di metodi e i risultati parziali sono memorizzati nell'area di stack.
Se l'elaborazione fatta in un thread richiede una dimensione di stack maggiore di quella disponibile, la JVM restituisce StackOverflowError.
Per ogni chiamata di un metodo, viene creata un'entrata nella memoria di stack, chiamata frame dello stack. Quando la chiamata del metodo è completa, il frame dello stack viene eliminato.
Un frame dello stack è diviso in tre sottoparti:
- Variabili locali – Ogni frame contiene un array di variabili conosciuto come variabili locali. Tutte le variabili locali e i loro valori sono memorizzati qui. La lunghezza di questo array è determinata al tempo di compilazione.
- Stack degli operandi – Ogni frame contiene uno stack LIFO (last-in-first-out) conosciuto come stack degli operandi. Agisce come spazio di lavoro di runtime per svolgere qualsiasi operazione intermedia. La massima profondità di questo stack è determinata al tempo di compilazione.
- Frame Data – Tutti i simboli corrispondenti ai metodi sono memorizzati qui. Contiene anche le informazioni sui blocchi catch in caso di eccezioni.
Ad esempio, supponi di avere il seguente codice:
double calculateNormalisedScore(List<Answer> answers) {
double score = getScore(answers);
return normalizeScore(score);
}
double normalizeScore(double score) {
return (score – minScore) / (maxScore – minScore);
}
In questo esempio di codice, le variabili come answers e score sono posizionate nell'array delle variabili locali. Lo stack degli operandi contiene le variabili e gli operatori richiesti per svolgere i calcoli matematici di sottrazione e divisione.

Nota: dato che l'area di stack non è condivisa, è totalmente thread-safe.
Registri Program Counter (PC)
La JVM supporta più thread allo stesso tempo. Ogni thread ha il suo registro PC per contenere l'indirizzo dell'istruzione JVM attualmente in esecuzione. Una volta che l'istruzione è eseguita, il registro PC viene aggiornato con l'istruzione successiva.
Stack dei metodi nativi
La JVM contiene degli stack che supportano metodi nativi. Questi metodi sono scritti in altri linguaggio diverso da Java, come C e C++. Per ogni nuovo thread, viene allocato uno stack separato per un metodo nativo.
Execution Engine
Una volta che il bytecode è stato caricato nella memoria principale e i dettagli sono disponibili nell'area dati di runtime, il passo successivo è eseguire il programma. L'execution engine si occupa di eseguire il codice presente in ogni classe.
Tuttavia, prima di eseguire il programma, il bytecode deve essere convertito in istruzioni in linguaggio macchina. La JVM può usare un interprete o un compilatore JIT per l'execution engine.
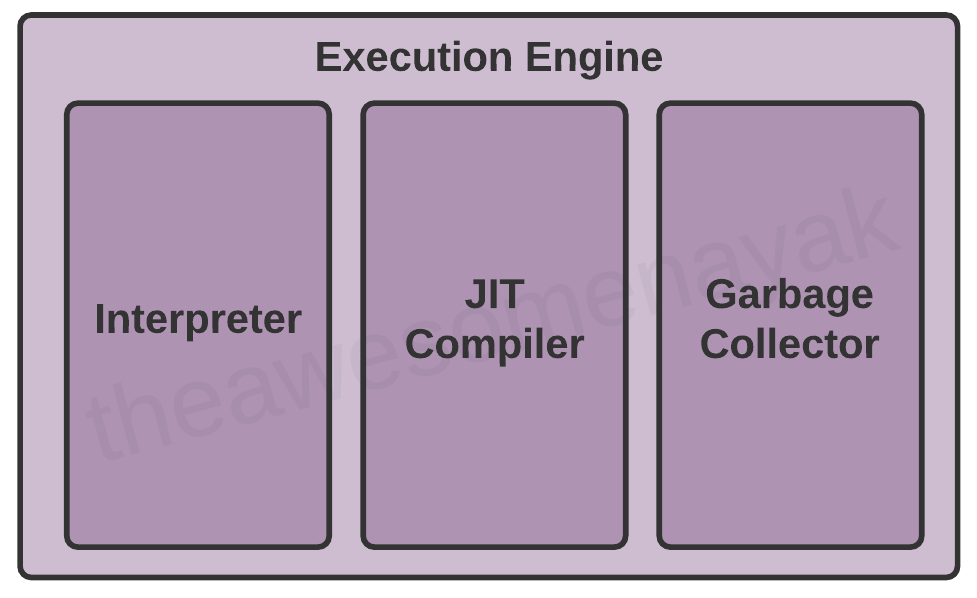
Interprete
L'interprete legge ed esegue le istruzioni del bytecode riga per riga. A causa dell'esecuzione riga per riga, l'interprete è relativamente più lento.
Un altro svantaggio dell'interprete è che quando un metodo viene chiamato più volte, è necessaria una nuova interpretazione ogni volta.
Compilatore JIT
Il compilatore JIT rimedia allo svantaggio dell'interprete. L'execution engine utilizza prima l'interprete per eseguire il bytecode, ma quando trova del codice ripetuto, utilizza il compilatore JIT.
Il compilatore JIT poi compila l'intero bytecode e lo modifica in codice macchina nativo, che viene usato direttamente per chiamate di metodi ripetute, che migliorano le prestazioni del sistema.
Il compilatore JIT ha i seguenti componenti:
- Intermediate Code Generator - genera il codice intermedio
- Code Optimizer - ottimizza il codice intermedio per ottenere delle prestazioni migliori
- Target Code Generator - converte il codice intermedio in codice macchina nativo
- Profiler - trova gli hotspot (codice che viene eseguito ripetutamente)
Per capire meglio la differenza tra l'interprete e in compilatore JIT, supponi di avere il seguente codice:
int sum = 10;
for(int i = 0 ; i <= 10; i++) {
sum += i;
}
System.out.println(sum);Un interprete recupera dalla memoria il valore di sum per ogni iterazione del loop, gli aggiunge il valore di i e scrive nella memoria. Si tratta di un'operazione dispendiosa, in quanto accede alla memoria ogni volta che entra nel loop.
Tuttavia, il compilatore JIT riconosce che questo codice ha un hot spot ed esegue delle ottimizzazioni. Conserva una copia locale di sum nel registro PC per il thread e continua ad aggiungervi il valore di i nel loop. Una volta che il loop è completato, scrive il valore di sum in memoria.
Nota: un compilatore JIT impiega più tempo a compilare il codice rispetto a quello necessario all'interprete per interpretare il codice riga per riga. Se ti occorre eseguire un programma solo una volta, è meglio usare l'interprete.
Garbage Collector
Il Garbage Collector (GC) raccoglie e rimuove gli oggetti non referenziati dall'area di heap. Si tratta del processo di recuperare la memoria di runtime inutilizzata, eliminandoli.
Questo processo rende efficiente la memoria di Java, perché rimuove gli oggetti non referenziati dalla memoria heap e crea spazio per nuovi oggetti. Consta di due fasi:
- Mark - in questo passaggio, il GC identifica gli oggetti inutilizzati in memoria
- Sweep - in questo passaggio, il GC rimuove gli oggetti identificati durante la fase precedente
Il processo di raccolta è svolto automaticamente dalla JVM a intervalli regolari e non necessita di essere gestito separatamente. Può essere anche innescato dalla chiamata System.gc(), ma l'esecuzione non è garantita.
La JVM contiene 3 tipi differenti di garbage collector:
- Serial GC - Questa è l'implementazione più semplice di GC ed è progettata per piccole applicazioni in esecuzione su ambienti mono-thread. Utilizza un solo thread per raccolta. Quando viene eseguito, porta a un evento "stop the world", in cui l'intera applicazione viene messa in pausa. L'argomento JVM per usare il Serial Garbage Collector è
-XX:+UseSerialGC - Parallel GC - Questa è l'implementazione predefinita di GC nella JVM, conosciuta anche come Throughput Collector. Utilizza più thread per raccolta, ma mette comunque in pausa l'applicazione quando viene eseguito. L'argomento JVM per usare il Parallel Garbage Collector è
-XX:+UseParallelGC. - Garbage First (G1) GC - G1GC è stato progettato per applicazioni multi-thread che hanno disponibili una grande dimensione dell'heap (più di 4 GB). Ripartisce l'heap in un set di regioni di uguale dimensione e usa thread multipli per scansionarle. G1GC identifica le regioni più ricche di elementi non più referenziati e inizia da queste a svolgere la raccolta. L'argomento JVM per usare G1GC è
-XX:+UseG1GC
Nota: esiste un altro tipo di garbage collector chiamato Concurrent Mark Sweep (CMS) GC. Tuttavia, è obsoleto fin da Java 9 e completamente rimosso in Java 14 in favore di G1GC.
Java Native Interface (JNI)
Delle volte, è necessario usare del codice nativo (non Java), ad esempio C/C++. Potrebbe essere nel caso in cui dobbiamo interagire con l'hardware, oppure per ovviare ai vincoli di Java sulla gestione della memoria e le prestazioni. Java supporta l'esecuzione del codice nativo tramite la Java Native Interface (JNI).
La JNI agisce come un ponte per consentire il supporto di pacchetti per altri linguaggi di programmazione come C, C++ e via dicendo. Ciò è particolarmente utile nei casi in cui ti occorre scrivere del codice non interamente supportato da Java, come delle specifiche funzionalità di alcune piattaforme che possono essere scritte solo in C.
Puoi usare la parola chiave native per indicare che l'implementazione del metodo sarà fornita in una libreria nativa. Avrai anche bisogno di invocare System.loadLibrary() per caricare in memoria la libreria nativa condivisa e rendere le sue funzioni disponibili in Java.
Librerie di metodi nativi
Le librerie di metodi nativi sono librerie scritte in altri linguaggi di programmazione, come C, C++ e assembly. Queste librerie sono solitamente presenti in forma di file .dll o .so, e possono essere caricateattraverso il JNI.
Errori comuni JVM
- ClassNotFoundExcecption - Si verifica quando il class loader sta cercando di caricare delle classi usando
Class.forName(),ClassLoader.loadClass()oClassLoader.findSystemClass()ma non viene trovata nessuna definizione per il nome della classe specificato. - NoClassDefFoundError - Si verifica quando un compilatore compila con successo la classe, ma il class loader non è in grado di individuare il file class durante il runtime.
- OutOfMemoryError - Si verifica quando la JVM non può allocare un oggetto perché non c'è memoria, e non è possibile liberare altra memoria tramite il garbage collector.
- StackOverflowError - Si verifica quando la JVM esaurisce la memoria creando un nuovo frame dello stack processando un thread.
Conclusione
In questo articolo, abbiamo discusso l'architettura della Java Virtual Machine e i suoi diversi componenti. Spesso non scaviamo a fondo nella meccanica interna della JVM o non ci interessiamo a come funziona mentre il nostro codice è all'opera.
È soltanto quando qualcosa va storto e abbiamo bisogno di ottimizzare la JVM o sistemare un problema di memoria che proviamo a capire la sua meccanica interna.
Questa è anche una domanda molto comune durante i colloqui di lavoro, sia al livello junior che senior per le posizioni backend. Una conoscenza approfondita della JVM ti aiuta a scrivere del codice migliore e a evitare le insidie collegate agli errori di stack e di memoria.
Grazie per essere rimasto con me fino a questo punto. Spero che questo articolo ti sia piaciuto. Puoi connetterti con me su LinkedIn, dove discuto abitualmente di vita e tecnologia. Dai anche un'occhiata ai miei altri articoli e al mio canale YouTube (risorse in lingua originale inglese). Buona lettura. 🙂