
Articolo originale: https://www.freecodecamp.org/news/a-quick-and-simple-guide-to-javascript-regular-expressions-48b46a68df29/
Vuoi imparare JavaScript? Scarica il mio ebook su jshandbook.com
Introduzione alle espressioni regolari
Un'espressione regolare (anche detta regex) è un modo rapido per lavorare con le stringhe di testo.
Creando un'espressione regolare con una sintassi speciale puoi:
- cercare un testo in una stringa
- sostituire del testo in una stringa
- ed estrarre informazioni da una stringa
Quasi ogni linguaggio di programmazione presenta una qualche implementazione delle espressioni regolari. Esistono piccole differenze tra ogni implementazione, ma i concetti generali si applicano quasi ovunque.
Le espressioni regolari risalgono agli anni '50 del Novecento, quando vennero formalizzate come modello di ricerca concettuale per gli algoritmi di elaborazione di stringhe.
Implementate in strumenti UNIX come grep, sed e in editor di testo comuni, le espressioni regolari crebbero in popolarità. Vennero introdotte nel linguaggio di programmazione Perl e, successivamente, anche in altri linguaggi.
JavaScript, insieme a Perl, è uno dei linguaggi di programmazione che comprende il supporto per le espressioni regolari direttamente integrato nel linguaggio.
Difficili ma utili
Se non si impiega il tempo necessario per comprenderle, le espressioni regolari possono sembrare totalmente insensate per un principiante e, molte volte, anche per uno sviluppatore professionista.
Espressioni regolari criptiche sono difficili da scrivere, difficili da leggere e difficili da modificare/manutenere.
Ma delle volte un'espressione regolare è il solo modo sensato per manipolare delle stringhe, quindi è uno strumento di grande valore in tuo possesso.
Questo tutorial mira a introdurti alle espressioni regolari in JavaScript in un modo semplice e a darti tutte le informazioni per leggere e creare espressioni regolari.
La regola generale è che più semplici sono le espressioni regolari e più è semplice leggerle e scriverle, mentre le espressioni regolari complesse possono diventare velocemente un pasticcio se non afferri appieno le basi.
Che aspetto ha un'espressione regolare?
In JavaScript, un'espressione regolare è un oggetto che può essere definito in due modi.
Il primo è istanziare un nuovo oggetto usando il costruttore RegEx:
const re1 = new RegExp('hey')Il secondo è usare un'espressione regolare letterale:
const re1 = /hey/Sai che JavaScript ha oggetti e array letterali? Ha anche espressioni regolari letterali.
Nell'esempio precedente, hey è detto pattern. Nella forma letterale è delimitato da barre oblique, mentre non lo è all'interno del costruttore.
Questa è la prima importante differenza tra le due forme, ma ne vedremo altre in seguito.
Come funziona?
L'espressione regolare che abbiamo precedentemente definito come re1 è molto semplice. Cerca la stringa hey, senza alcuna limitazione. La stringa può contenere molto testo e hey nel mezzo e l'espressione è soddisfatta. Può anche contenere solo hey e anche in questo caso l'espressione è soddisfatta.
Piuttosto semplice.
Puoi testare un'espressione regolare usando RegExp.test(String), che restituisce un booleano:
re1.test('hey') //✅
re1.test('blablabla hey blablabla') //✅
re1.test('he') //❌
re1.test('blablabla') //❌Nell'esempio qui sopra, abbiamo verificato se "hey" soddisfa il pattern dell'espressione regolare memorizzata in re1.
Questo è il caso più semplice, ma adesso conosci già molti concetti sulle espressioni regolari.
Ancoraggi
/hey/indica hey in qualsiasi posizione di una stringa.
Se vuoi trovare stringhe che iniziano con hey, usa l'operatore ^:
/^hey/.test('hey') //✅
/^hey/.test('bla hey') //❌Se vuoi trovare stringhe che finiscono con hey, usa l'operatore $:
/hey$/.test('hey') //✅
/hey$/.test('bla hey') //✅
/hey$/.test('hey you') //❌Se combini i due, troverai esattamente e soltanto la stringa hey:
/^hey$/.test('hey') //✅Per trovare una stringa che inizia con una sottostringa e finisce con un'altra, puoi usare .*, che indica qualsiasi carattere ripetuto 0 o più volte:
/^hey.*joe$/.test('hey joe') //✅
/^hey.*joe$/.test('heyjoe') //✅
/^hey.*joe$/.test('hey how are you joe') //✅
/^hey.*joe$/.test('hey joe!') //❌Intervalli
Invece di trovare una particolare stringa, puoi scegliere di trovare qualsiasi carattere in un intervallo, ad esempio:
/[a-z]/ //a, b, c, ... , x, y, z
/[A-Z]/ //A, B, C, ... , X, Y, Z
/[a-c]/ //a, b, c
/[0-9]/ //0, 1, 2, 3, ... , 8, 9Queste espressioni regolari indicano stringhe che contengono almeno uno dei caratteri compresi negli intevalli:
/[a-z]/.test('a') //✅
/[a-z]/.test('1') //❌
/[a-z]/.test('A') //❌
/[a-c]/.test('d') //❌
/[a-c]/.test('dc') //✅Gli intervalli possono essere combinati:
/[A-Za-z0-9]/
/[A-Za-z0-9]/.test('a') // ✅
/[A-Za-z0-9]/.test('1') // ✅
/[A-Za-z0-9]/.test('A') // ✅Intervalli con elementi multipli
Puoi verificare se una stringa contiene uno e soltanto un carattere nell'intervallo usando il carattere -:
/^[A-Za-z0-9]$/
/^[A-Za-z0-9]$/.test('A') // ✅
/^[A-Za-z0-9]$/.test('Ab') // ❌Pattern negati
Il carattere ^ all'inizio di un pattern lo ancora all'inizio della stringa.
Se usato in un intervallo, nega i suoi elementi:
/[^A-Za-z0-9]/.test('a') //❌
/[^A-Za-z0-9]/.test('1') //❌
/[^A-Za-z0-9]/.test('A') //❌
/[^A-Za-z0-9]/.test('@') //✅\dcorrisponde a qualsiasi cifra, equivalente a[0-9]\Dcorrisponde a qualsiasi carattere che non è una cifra, equivalente a[^0-9]\wcorrisponde a qualsiasi carattere alfanumerico, equivalente a[A-Za-z0-9]\Wcorrisponde a qualsiasi carattere non alfanumerico, equivalente a[^A-Za-z0-9]\scorrisponde a qualsiasi carattere di spazio: spazio, tab, nuova riga e spazi Unicode\Scorrisponde a qualsiasi carattere che non è uno spazio\0corrisponde a null\ncorrisponde al carattere nuova riga\tcorrisponde al carattere tab\uXXXXcorrisponde al carattere Unicode con codice XXXX (richiede il flagu).corrisponde a qualsiasi carattere che non è una nuova riga (e.g.\n) (a meno che non usi il flags, spiegato in seguito)[^]corrisponde a qualsiasi carattere, incluso il carattere nuova riga. Utile su stringhe multi-riga.
Scelte nelle espressioni regolari
Se vuoi cercare una stringa oppure un'altra, usa l'operatore |.
/hey|ho/.test('hey') //✅
/hey|ho/.test('ho') //✅Quantificatori
Supponiamo di avere questa espressione regolare che verifica se una stringa ha una cifra al suo interno e nient'altro:
/^\d$/Puoi usare il quantificatore ? per renderla opzionale (presente 0 o 1 volta):
/^\d?$/Ma se volessi trovare più cifre?
Puoi farlo in 4 modi, usando +, *, {n} e {n,m}. Vediamo queste opzioni una alla volta.
+
indica 1 o più (>=1) elementi
/^\d+$/
/^\d+$/.test('12') // ✅
/^\d+$/.test('14') // ✅
/^\d+$/.test('144343') // ✅
/^\d+$/.test('') // ❌
/^\d+$/.test('1a') // ❌*
indica 0 o più (>= 0) elementi
/^\d+$/
/^\d*$/.test('12') // ✅
/^\d*$/.test('14') // ✅
/^\d*$/.test('144343') // ✅
/^\d*$/.test('') // ✅
/^\d*$/.test('1a') // ❌{n}
indica esattamente n elementi
/^\d{3}$/
/^\d{3}$/.test('123') // ✅
/^\d{3}$/.test('12') // ❌
/^\d{3}$/.test('1234') // ❌
/^[A-Za-z0-9]{3}$/.test('Abc') // ✅{n,m}
indica elementi tra n e m volte:
/^\d{3,5}$/
/^\d{3,5}$/.test('123') // ✅
/^\d{3,5}$/.test('1234') // ✅
/^\d{3,5}$/.test('12345') // ✅
/^\d{3,5}$/.test('123456') // ❌m può essere omesso per un intervallo aperto, così da avere almeno n elementi:
/^\d{3,}$/
/^\d{3,}$/.test('12') // ❌
/^\d{3,}$/.test('123') // ✅
/^\d{3,}$/.test('12345') // ✅
/^\d{3,}$/.test('123456789') // ✅Elementi opzionali
Apporre un ? dopo un elemento lo rende opzionale:
/^\d{3}\w?$/
/^\d{3}\w?$/.test('123') // ✅
/^\d{3}\w?$/.test('123a') // ✅
/^\d{3}\w?$/.test('123ab') // ❌Gruppi
Usando le parentesi puoi creare gruppi di caratteri: (...)
Questo esempio indica esattamente 3 cifre seguite da uno o più caratteri alfanumerici:
/^(\d{3})(\w+)$/
/^(\d{3})(\w+)$/.test('123') // ❌
/^(\d{3})(\w+)$/.test('123s') // ✅
/^(\d{3})(\w+)$/.test('123something') // ✅
/^(\d{3})(\w+)$/.test('1234') // ✅I caratteri di ripetizione posti dopo la parentesi di chiusura di un gruppo fanno riferimento all'intero gruppo:
/^(\d{2})+$/
/^(\d{2})+$/.test('12') //✅
/^(\d{2})+$/.test('123') //❌
/^(\d{2})+$/.test('1234') //✅Gruppi di acquisizione
Finora, abbiamo visto come testare delle stringhe e verificare se contengono un certo pattern.
Una funzionalità molto bella delle espressioni regolari è la possibilità di acquisire parti di una stringa e inserirle in un array.
Puoi farlo usando i gruppi e in particolare i gruppi di acquisizione (capturing group).
Di default, un gruppo è un gruppo di acquisizione. Adesso, invece di usare RegExp.test(String), che restituisce un booleano se il pattern è soddisfatto, useremo String.match(RegExp) o RegExp.exec(String).
Funzionano esattamente allo stesso modo e restituiscono un array con l'intera stringa trovata come primo elemento, seguita dal contenuto dei gruppi.
Se non c'è corrispondenza, restituiscono null:
'123s'.match(/^(\d{3})(\w+)$/)
// Array [ "123s", "123", "s" ]
/^(\d{3})(\w+)$/.exec('123s')
// Array [ "123s", "123", "s" ]
'hey'.match(/(hey|ho)/)
// Array [ "hey", "hey" ]
/(hey|ho)/.exec('hey')
// Array [ "hey", "hey" ]
/(hey|ho)/.exec('ha!')
// nullQuando un gruppo viene trovato più volte, solo l'ultima corrispondenza viene inserita nell'array:
'123456789'.match(/(\d)+/) //Array [ "123456789", "9" ]Gruppi opzionali
Un gruppo di acquisizione può essere reso opzionale usando (...)?. Se non viene trovato, la posizione corrispondente nell'array conterrà undefined:
/^(\d{3})(\s)?(\w+)$/.exec('123 s')
// Array [ "123 s", "123", " ", "s" ]
/^(\d{3})(\s)?(\w+)$/.exec('123s')
// Array [ "123s", "123", undefined, "s" ]Riferimenti dei gruppi trovati
A ogni gruppo che viene trovato viene assegnato un numero. $1 si riferisce al primo, $2 al secondo e via dicendo. Questo sarà utile quando parleremo più avanti di sostituire parti di una stringa.
Gruppi di acquisizione con nome
Questa è una nuova funzionalità di ES2018.
A un gruppo può essere assegnato un nome piuttosto che uno slot nell'array dei risultati:
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/
const result = re.exec('2015-01-02')
// result.groups.year === '2015';
// result.groups.month === '01';
// result.groups.day === '02';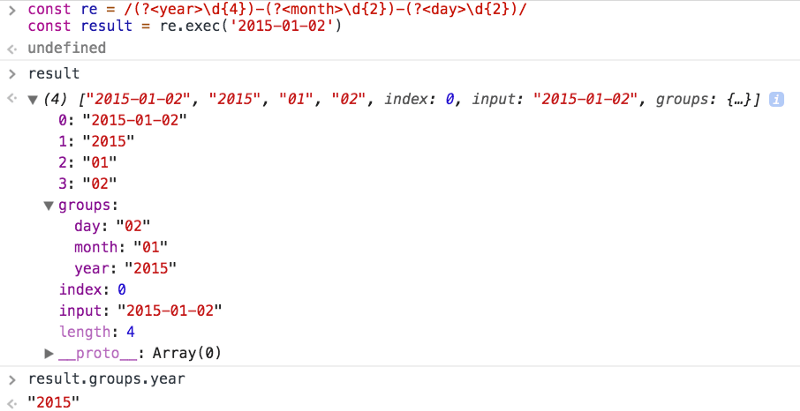
Usare match ed exec senza gruppi
Esiste una differenza nell'uso di match e exec senza gruppi: il primo elemento dell'array non è l'intera stringa trovata, ma direttamente la corrispondenza:
/hey|ho/.exec('hey')
// [ "hey" ]
/(hey).(ho)/.exec('hey ho')
// [ "hey ho", "hey", "ho" ]Gruppi non acquisiti
Dato che i gruppi sono per impostazione predefinita gruppi di acquisizione, ti serve un modo per ignorare alcuni gruppi nell'array dei risultati. Questo è possibile usando i cosiddetti non-capturing group, che iniziano con (?:...):
'123s'.match(/^(\d{3})(?:\s)(\w+)$/)
// null
'123 s'.match(/^(\d{3})(?:\s)(\w+)$/)
// Array [ "123 s", "123", "s" ]Flag
Puoi usare i seguenti flag su qualsiasi espressione regolare:
g: trova il pattern più voltei: rende la regex indifferente a maiuscole/minuscolem: abilita la modalità multi-riga. In questa modalità,^e$indicano l'inizio e la fine dell'intera stringa. Senza questo flag con stringhe multi-riga indicano l'inizio e la fine di ogni riga.u: consente il supporto Unicode (introdotto in ES6/ES2015)s: (nuovo in ES2018) abbreviazione per single line (riga singola), fa sì che il.trovi anche il carattere nuova riga.
I flag possono essere combinati e sono aggiunti alla fine dell'espressione regolare letterale:
/hey/ig.test('HEy') //✅o come secondo parametro nel costruttore RegEx:
new RegExp('hey', 'ig').test('HEy') //✅Analizzare un'espressione regolare
Data un'espressione regolare, puoi consultare le seguenti proprietà:
sourceè il patternmultilineè true con il flagmglobalè true con il flaggignoreCaseè true con il flagilastIndex
/^(\w{3})$/i.source //"^(\\d{3})(\\w+)$" /^(\w{3})$/i.multiline //false /^(\w{3})$/i.lastIndex //0 /^(\w{3})$/i.ignoreCase //true /^(\w{3})$/i.global //falseEscaping
Questi caratteri sono speciali:
\/[ ]( ){ }?+*|.^$
Sono speciali perché sono caratteri di controllo che hanno un significato nel pattern dell'espressione regolare. Se vuoi usarli all'interno del pattern come caratteri da ricercare, devi eseguirne l'escape anteponendo loro una barra rovesciata:
/^\\$/ /^\^$/ // /^\^$/.test('^') ✅ /^\$$/ // /^\$$/.test('$') ✅Confini di stringa
\b e \B ti consentono di verificare se una stringa si trovi all'inizio o alla fine di una parola:
\bindica un insieme di caratteri all'inizio o alla fine di una parola\Bindica un insieme di caratteri che non si trovano all'inizio o alla fine di una parola
Esempio:
'I saw a bear'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear/) //Array ["bear"]
'I saw a beard'.match(/\bbear\b/) //null
'cool_bear'.match(/\bbear\b/) //nullSostituire usando le espressioni regolari
Abbiamo già visto come verificare se una stringa contiene un pattern.
Abbiamo anche visto come estrarre parte di una stringa in un array, tramite la corrispondenza con un pattern.
Ora vediamo come sostituire parti di una stringa sulla base di un pattern.
L'oggetto String in JavaScript ha un metodo replace() che può essere usato senza espressioni regolari per eseguire una singola sostituzione in una stringa:
"Hello world!".replace('world', 'dog')
// Hello dog!
"My dog is a good dog!".replace('dog', 'cat')
// My cat is a good dog!Questo metodo accetta anche un'espressione regolare come argomento:
"Hello world!".replace(/world/, 'dog') //Hello dog!Usare il flag g è l'unico modo per sostituire più occorrenze in una stringa in JavaScript:
"My dog is a good dog!".replace(/dog/g, 'cat') //My cat is a good cat!I gruppi ci consentono di fare cose più complesse, come muovere parti di una stringa:
"Hello, world!".replace(/(\w+), (\w+)!/, '$2: $1!!!') // "world: Hello!!!"Invece di usare una stringa, puoi usare una funzione per fare cose ancora più complesse. Potrà ricevere diversi argomenti come quelli restituiti da String.match(RegExp) o RegExp.exec(String), con il numero di argomenti che dipende dal numero di gruppi:
"Hello, world!".replace(/(\w+), (\w+)!/, (matchedString, first, second) => {
console.log(first);
console.log(second);
return `${second.toUpperCase()}: ${first}!!!`
})
// "WORLD: Hello!!!"Avidità
Le espressioni regolari di default mostrano un comportamento per cui sono dette greedy.
Cosa vuol dire?
Prendiamo questa regex:
/\$(.+)\s?/Ci aspettiamo che estragga una somma di dollari da una stringa:
/\$(.+)\s?/.exec('This costs $100')[1] //100Ma se abbiamo altre parole dopo il numero, dà di matto:
/\$(.+)\s?/.exec('This costs $100 and it is less than $200')[1] //100 and it is less than $200Questo accade perché l'espressione regolare, dopo il segno $, cerca qualsiasi carattere con .+ e non si fermerà finché non viene raggiunta la fine della stringa. Poi termina perché \s? rende lo spazio finale opzionale.
Per sistemare questo aspetto, dobbiamo dire alla regex di essere pigra (lazy) e trovare la minor corrispondenza possibile. Possiamo farlo usando il simbolo ? dopo il quantificatore:
/\$(.+?)\s/.exec('This costs $100 and it is less than $200')[1] //100Ho rimosso?dopo\s. Altrimenti avrebbe trovato soltanto la prima cifra, dato che lo spazio era opzionale.
Quindi ? ha diversi significati in base alla sua posizione, perché può essere sia un quantificatore che un indicatore della modalità lazy.
Lookahead: trovare una stringa in base a cosa c'è dopo
Usa ?= per trova una stringa che è seguita da una specifica sottostringa:
/Roger(?=Waters)/
/Roger(?= Waters)/.test('Roger is my dog') // false
/Roger(?= Waters)/.test('Roger is my dog and Roger Waters is a famous musician')
// true?! svolge l'operazione inversa, cercando una stringa che non è seguita da una specifica sottostringa:
/Roger(?!Waters)/
/Roger(?! Waters)/.test('Roger is my dog') // true
/Roger(?! Waters)/.test('Roger Waters is a famous musician')
// falseLookbehind: trovare una stringa in base a cosa c'è prima
Questa è una funzionalità di ES2018.
I lookahead utilizzano il simbolo ?= symbol. I lookbehind usano ?<=:
/(?<=Roger) Waters/
/(?<=Roger) Waters/.test('Pink Waters is my dog')
// false
/(?<=Roger) Waters/.test('Roger is my dog and Roger Waters is a famous musician')
// trueUn lookbehind viene negato usando ?<!:
/(?<!Roger) Waters/
/(?<!Roger) Waters/.test('Pink Waters is my dog')
// true
/(?<!Roger) Waters/.test('Roger is my dog and Roger Waters is a famous musician')
// falseEspressioni regolari e Unicode
Il flag u è obbligatorio per lavorare con le stringhe Unicode. Ciò è particolarmente vero quando hai bisogno di gestire caratteri non inclusi tra i primi 1600 caratteri Unicode.
Le emoji sono un buon esempio, ma non sono l'unico.
Se non aggiungi il flag, questa semplice regex che dovrebbe trovare un carattere non funzionerà perché per JavaScript quella emoji è rappresentata internamente da 2 caratteri (vedi Unicode in JavaScript):
/^.$/.test('a') // ✅
/^.$/.test('🐶') // ❌
/^.$/u.test('🐶') // ✅
Quindi usa sempre il flag u.
Unicode, proprio come i normali caratteri, accetta gli intervalli:
/[a-z]/.test('a') // ✅
/[1-9]/.test('1') // ✅
/[🐶-🦊]/u.test('🐺') // ✅
/[🐶-🦊]/u.test('🐛') // ❌
JavaScript verifica la rappresentazione interna del codice, quindi 🐶 < 🐺 < 🦊 perché \u1F436 < \u1F43A < \u1F98A. Dai un'occhiata alla lista completa delle emoji per vedere i codici e scoprire l'ordine (suggerimento: il selettore di emoji macOS ha alcune emoji in diverso ordine, quindi non farci affidamento).
Proprietà Unicode
Come abbiamo visto prima, nel pattern di un'espressione regolare puoi usare \d per indicare qualsiasi cifra, \s per indicare qualsiasi carattere di spazio, \w per indicare qualsiasi carattere alfanumerico e così via.
Le proprietà Unicode costituiscono una funzionalità di ES2018 che estende questo concetto a tutti caratteri Unicode grazie a \p{} e alla sua negazione \P{}.
Ogni carattere Unicode ha una serie di proprietà. Ad esempio Script determina la famiglia della lingua, ASCII è un booleano che è true per ogni carattere ASCII e così via. Puoi inserire una proprietà tra parentesi graffe e l'espressione regolare controllerà se è vera:
/^\p{ASCII}+$/u.test('abc') // ✅
/^\p{ASCII}+$/u.test('ABC@') // ✅
/^\p{ASCII}+$/u.test('ABC🙃') // ❌
ASCII_Hex_Digit è un'altra proprietà booleana che verifica se la stringa contiene solo cifre esadecimali valide:
/^\p{ASCII_Hex_Digit}+$/u.test('0123456789ABCDEF') // ✅
/^\p{ASCII_Hex_Digit}+$/u.test('h') // ❌
Esistono molte altre proprietà booleane che puoi controllare aggiungendone il nome tra parentesi graffe. Tra queste Uppercase, Lowercase, White_Space, Alphabetic, Emoji e altre:
/^\p{Lowercase}$/u.test('h') // ✅
/^\p{Uppercase}$/u.test('H') // ✅
/^\p{Emoji}+$/u.test('H') // ❌
/^\p{Emoji}+$/u.test('🙃🙃') // ✅
In aggiunta a queste proprietà binarie, puoi verificare se le proprietà corrispondono a un valore specifico. In questo esempio, verifico se la stringa è scritta in alfabeto greco o latino:
/^\p{Script=Greek}+$/u.test('ελληνικά') // ✅
/^\p{Script=Latin}+$/u.test('hey') // ✅
Se vuoi sapere altro sulle proprietà che puoi usare consulta direttamente la proposta.
Esempi
Supponendo che una stringa contenga solo un numero che hai bisogno di estrarre, /\d+/ dovrebbe andare bene:
'Test 123123329'.match(/\d+/)
// Array [ "123123329" ]Trovare un indirizzo email
Un approccio semplicistico è verificare i caratteri che non sono spazi prima e dopo il segno @, usando \S:
/(\S+)@(\S+)\.(\S+)/
/(\S+)@(\S+)\.(\S+)/.exec('copesc@gmail.com')
// ["copesc@gmail.com", "copesc", "gmail", "com"]
Tuttavia, questo è un esempio riduttivo, dato che molti indirizzi email non validi soddisfano comunque questa regex.
Acquisire il testo tra virgolette doppie
Supponi di avere una stringa che contiene qualcosa tra virgolette doppie e di voler estrarre quel contenuto.
Il modo migliore per farlo è usare un gruppo di acquisizione, in quanto sappiamo che la parte di interesse inizia e termina con ", e possiamo facilmente selezionarla, ma vogliamo anche rimuovere le virgolette dal risultato.
Troveremo ciò che ci serve in result[1]:
const hello = 'Hello "nice flower"'
const result = /"([^']*)"/.exec(hello)
// Array [ "\"nice flower\"", "nice flower" ]Ottenere il contenuto di un tag HTML
Per esempio, possiamo ottenere il contenuto di un tag span, consentendo qualsiasi numero di argomenti nel tag:
/<span\b[^>]*>(.*?)<\/span>/
/<span\b[^>]*>(.*?)<\/span>/.exec('test')
// null
/<span\b[^>]*>(.*?)<\/span>/.exec('<span>test</span>')
// ["<span>test</span>", "test"]
/<span\b[^>]*>(.*?)<\/span>/.exec('<span class="x">test</span>')
// ["<span class="x">test</span>", "test"]
Vuoi imparare JavaScript? Scarica il mio JavaScript Handbook.