


Articolo originale: A Visual Guide to Git Internals — Objects, Branches, and How to Create a Repo From Scratch
Molti di noi usano git quotidianamente. Ma quanti di noi sanno cosa succede dietro le quinte?
Per esempio, cosa succede quando usiamo git commit? Cosa viene conservato dopo ogni commit? Sono solo le differenze tra il commit attuale e quello precedente? In questo caso come sono codificate le differenze? Oppure viene salvata un'istantanea del repository ogni volta? Cosa succede veramente quando usiamo git init?
Molti di coloro che usano git non conoscono le risposte alle domande poste qui sopra. Ma ha davvero importanza?
Innanzitutto, come professionisti, dovremmo impegnarci a capire gli strumenti che usiamo, specialmente così di frequente, come git.
Ma soprattutto, ho scoperto che capire come funziona effettivamente git è utile in molte situazioni, sia che si tratti di risolvere conflitti di merge, che si cerchi di eseguire un rebase interessante, o anche solo quando qualcosa va leggermente storto.
Potrai trarre vantaggio da questo post se hai già abbastanza esperienza con git per sentirti a tuo agio con comandi come git pull ,git push ,git add oppure git commit.
Ciononostante, inizieremo con uno sguardo d'insieme per essere sicuri di essere tutti allo stesso livello per quanto riguarda la conoscenza dei meccanismi di git, e in particolare con i termini che verranno usati in questo post.
Ho anche caricato su YouTube una serie che tratta degli argomenti trattati in questo post e che ti invito a guardare qui.
Cosa aspettarsi da questo tutorial
Avremo una approfondita comprensione di ciò che accade dietro le quinte durante le operazioni che facciamo quasi quotidianamente con git.
Inizieremo trattando gli oggetti — blob, tree (alberi) e commit. Discuteremo quindi brevemente dei branch e di come vengono implementati. Analizzeremo i dettagli della directory di lavoro, dell'area di stage e del repository.
Ci assicureremo anche di capire come questi termini si relazionano rispetto ai comandi git che conosciamo e utilizziamo per creare un nuovo repository.
Successivamente, creeremo un repository da zero , senza usare git init, git add o git commit. Questo ci consentirà di approfondire la nostra comprensione di ciò che avviene dietro le quinte quando lavoriamo con git.
Creeremo anche nuovi branch, ci sposteremo tra di essi e creeremo ulteriori commit, tutto senza usare git branch o git checkout.
Alla fine di questo post, ti sentirai di aver capito git. Sei pronto per farlo?😎
Oggetti Git: blob, alberi (tree) e commit
È molto utile pensare a git come alla gestione di un file system, e in particolare a "istantanee" di un file system in un dato momento.
Un file system inizia con una directory radice (root directory), nei sistemi basati su Unix, /, che in genere contiene altre directory (per esempio /usr o /bin). Queste directory possono contenere altre directory e/o file (per esempio /usr/1.txt).
In git, il contenuto dei file viene conservato in oggetti chiamati blob (binary large objects – grandi oggetti binari).
La differenza tra blob e file è che i file contengono anche metadati. Per esempio un file "ricorda" quando è stato creato, quindi se lo sposti in un'altra directory, la sua data di creazione rimane la stessa.
I blob, diversamente, hanno solo contenuto, flussi binari di dati. Un blob non registra la sua data di creazione, il suo nome o qualsiasi altra cosa diversa dal suo contenuto.
Ogni blob in git viene identificato dal suo hash SHA-1. Gli hash SHA-1 sono di 20 byte e rappresentano in genere 40 caratteri in formato esadecimale. In questo post talvolta mostreremo solo i primi caratteri di questo hash.

In git, l'equivalente di una directory è un albero (tree). Un albero in pratica è un elenco del contenuto di una directory, che può essere costituito da dei blob così come da altri alberi.
Anche gli alberi sono identificati dal loro hash SHA-1. Per riferirsi a questi oggetti, siano blob o alberi, si usa il loro hash SHA-1.

Osserva l'albero CAFE7 che contiene il blob F92A0 che rappresenta pic.png. In un altro albero, quello stesso blob potrebbe avere un altro nome.

Il diagramma qui sopra equivale a un file system con una directory radice che ha un file, /test.js, e una directory chiamata /docs nella quale ci sono due file: /docs/pic.png e /docs/1.txt.
Ora è tempo di prendere un'istantanea di quel file system e conservare tutti i file al momento esistenti, assieme al loro contenuto.
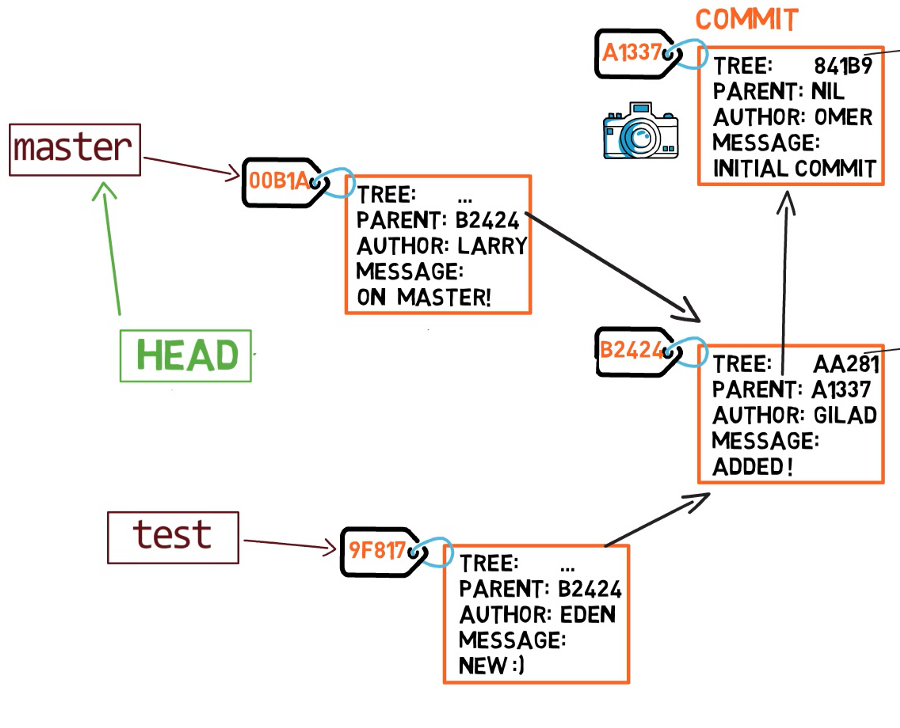
In git, un'istantanea è un commit. Un oggetto commit include un puntatore all'albero principale (la directory radice), e anche altri metadati come il l'esecutore del commit (committer), un messaggio di commit, e la marca temporale del commit.
In molti casi, un commit ha anche uno o più commit genitori, vale a dire le istantanee precedenti. Naturalmente anche gli oggetti commit sono identificati dal loro hash SHA-1. Questi sono gli hash mostrati quando usiamo git log.

Ogni commit contiene l'intera istantanea, non solo le differenze rispetto ai commit precedenti.
Come può funzionare? Non significa che dovremo conservare un gran volume di dati ad ogni commit?
Esaminiamo cosa succede se modifichiamo il contenuto di un file. Diciamo che vogliamo modificare 1.txt, aggiungendo un punto esclamativo, cioè modifichiamo il contenuto da HELLO WORLD a HELLO WORLD!.
Bene, questa modifica significa avere un nuovo blob, con un nuovo hash SHA-1. Ha senso, visto che sha1("HELLO WORLD") è diverso da sha1("HELLO WORLD!").

Poiché abbiamo un nuovo hash, allora anche il contenuto dell'albero dovrebbe cambiare, dopo tutto il nostro albero non punta più al blob 73D8A, ma al blob 62E7A . Quando modifichiamo il contenuto di un albero cambiamo anche il suo hash.

Ora, visto che l'hash dell'albero è diverso, dobbiamo cambiare anche l'albero genitore, visto che non punta più all'albero CAFE7, ma all'albero 24601. Ne consegue che anche l'albero genitore avrà un nuovo hash.

Siamo quasi pronti per creare un nuovo oggetto commit, e sembra che andremo a salvare un gran volume di dati, l'intero file system, ancora una volta! È davvero necessario?
In realtà, alcuni oggetti, blob nello specifico, non sono cambiati rispetto al commit precedente, il blob F92A0 è rimasto invariato, e anche il blob F00D1.
Ecco il trucco, fintanto che un oggetto non cambia, non lo salviamo nuovamente. In questo caso non dobbiamo salvare nuovamente i blob F92A0 e blob F00D1. Dobbiamo solo riferirci a essi usando i loro valori di hash. Quindi possiamo creare il nostro oggetto commit.
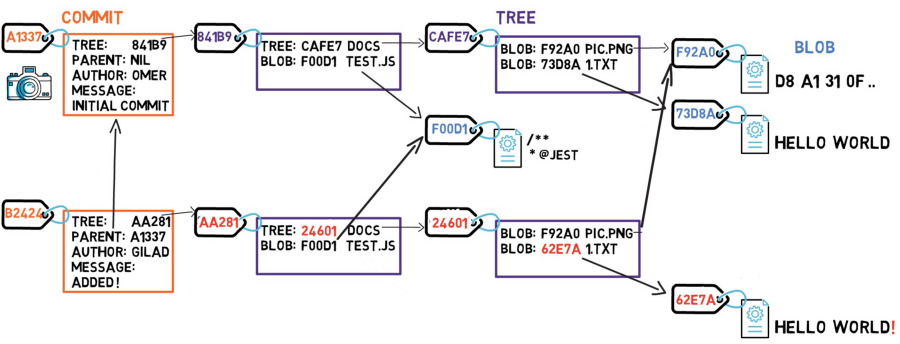
Visto che questo commit non è il primo commit, ha un genitore, il commit A1337.
Per ricapitolare, abbiamo introdotto tre oggetti git:
- blob — il contenuto di un file.
- tree (albero) — il contenuto di una directory (di blob e alberi).
- commit — un'istantanea dell'albero di lavoro.
Prendiamo un attimo in considerazione gli hash di questi oggetti. Supponiamo che io abbia scritto la stringa git is awesome! e da essa abbia creato un blob. Tu hai fatto lo stesso sul tuo sistema. Avremo lo stesso hash?
La risposta è sì. Visto che i blob contengono gli stessi dati, avranno gli stessi valori di hash SHA-1.
Cosa succede se io creo un albero che fa riferimento al blob git is awesome!, e gli do nome e metadati specifici, e tu fai esattamente la stessa cosa sul tuo sistema. Avremo lo stesso hash?
Ancora una volta la risposta è sì. Visto che gli oggetti alberi sono uguali, avranno lo stesso hash.
Se creo un commit di quell'albero con il messaggio di commit Hello, e tu fai lo stesso nel tuo file system. Avremo gli stessi hash?
In questo caso la risposta è negativa. Anche se i nostri oggetti commit fanno riferimento allo stesso albero, hanno dettagli di commit diversi, la marca temporale, l'esecutore del commit, e così via.
Branch in Git
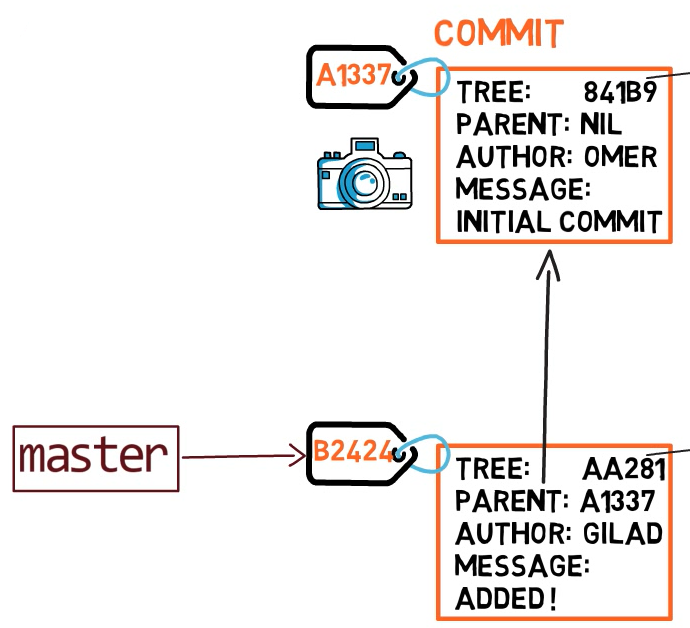
Un branch (ramo) è semplicemente un riferimento nominativo a un commit.
Possiamo sempre fare riferimento a un commit in git tramite il suo hash SHA-1, ma noi umani in genere preferiamo altri modi per denominare gli oggetti. Un branch è un modo di referenziare un commit, ma è semplicemente questo.
Nella maggior parte dei repository, la linea principale di sviluppo viene implementata in un branch chiamato master. È semplicemente un nome, creato quando usiamo git init, pertanto largamente usato. Tuttavia non riveste un significato particolare, e si potrebbe usare un qualsiasi altro nome ci vada a genio.
Tipicamente, il branch punta all'ultimo commit nella linea di sviluppo sulla quale stiamo attualmente lavorando.
Per creare un altro branch, in genere usiamo il comando git branch. Facendo questo creiamo in realtà un altro puntatore. Quindi se creiamo un branch chiamato test, usando il comando git branch test, stiamo in realtà creando un altro puntatore direzionato verso lo stesso commit del branch nel quale ci troviamo attualmente.
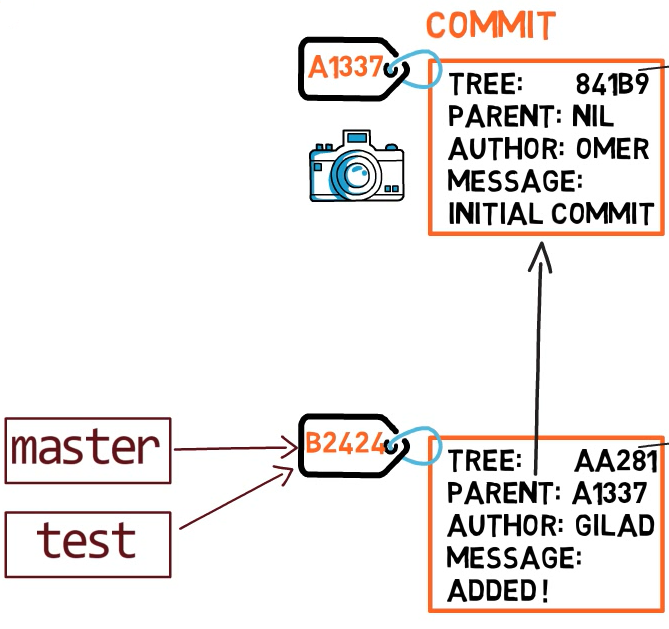
git branch si crea un altro puntatoreCome fa git a sapere su quale branch ci troviamo attualmente? Mantiene un puntatore speciale, detto HEAD. In genere HEAD punta a un branch, che a sua volta punta a un commit. In alcuni casi, HEAD può anche puntare direttamente a un commit, ma non ci focalizzeremo su questo.

HEAD punta al branch nel quale ci troviamo attualmente.Per rendere attivo il branch test, possiamo usare il comando git checkout test. Possiamo già indovinare cosa fa questo comando in realtà: cambia semplicemente il puntamento di HEAD verso test.

git checkout test modfiica il puntamento di HEADPossiamo anche usare git checkout -b test prima di creare il branch test, che equivale a eseguire git checkout test, per far puntare HEAD al nuovo branch.
Cosa succede se eseguiamo qualche modifica e creiamo un nuovo commit con git commit? A quale branch verrà aggiunto il nuovo commit?
La risposta è il branch test, visto che è il branch attivo (quello su cui punta HEAD). Successivamente, il puntatore di test verrà spostato verso il nuovo commit aggiunto. Nota che HEAD punta ancora a test.
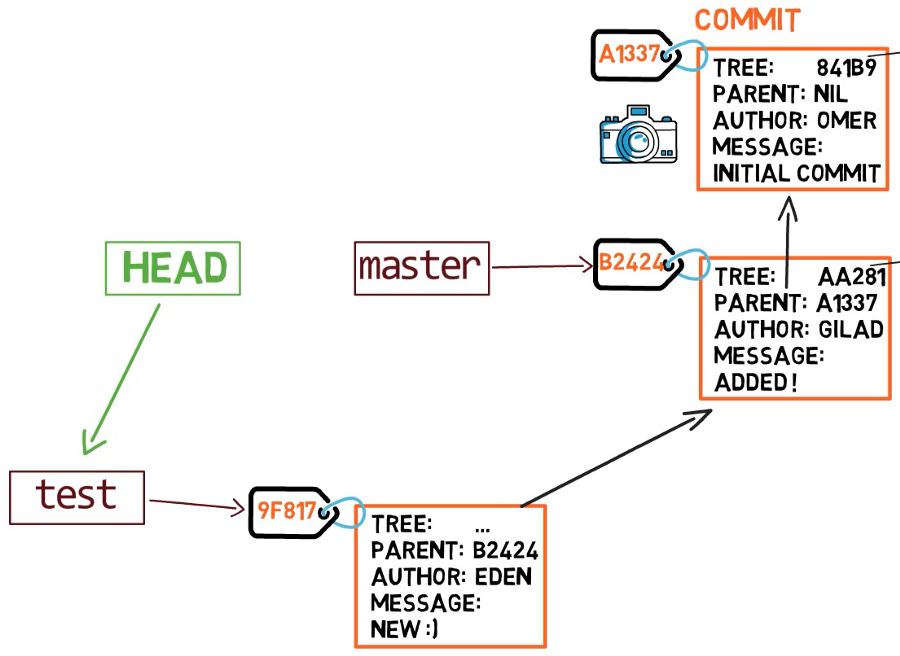
git commit, il puntatore del branch si sposta verso il nuovo commit creato.Quindi se riattiviamo master eseguendo git checkout master, facciamo in modo che HEAD punti nuovamente a master .

Ora se creiamo un altro commit, verrà aggiunto al branch master (e il suo genitore sarà il commit B2424).
Come registrare le modifiche in Git
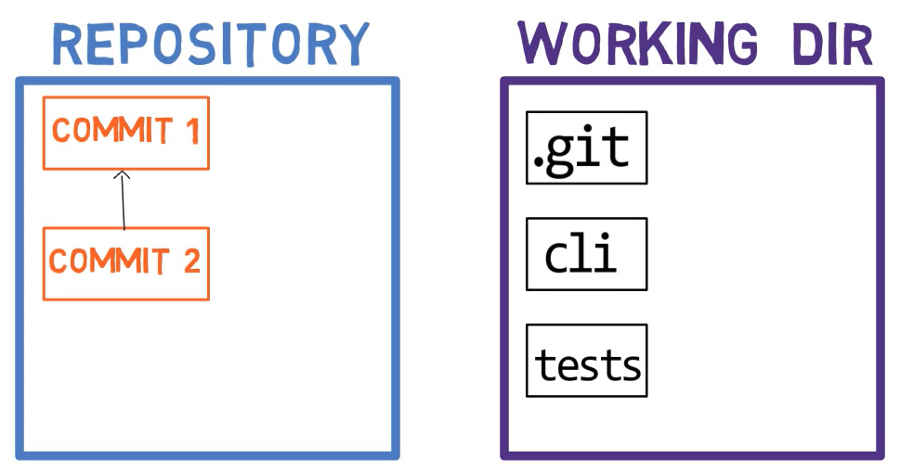
In genere, quando lavoriamo sul nostro codice, lo facciamo da una directory di lavoro (working dir). Una directory di lavoro o albero di lavoro, è una qualsiasi directory nel nostro file system che ha un repository associato. Contiene le cartelle e i file del nostro progetto, e una directory chiamata .git, che esamineremo più approfonditamente in seguito.
Dopo aver fatto alcune modifiche, vogliamo registrarle nel nostro repository. Un repository (repo in breve) è una collezione di commit, ciascuno dei quali rappresenta un archivio di quello che era l'albero di lavoro in una data precedente, sia sulla nostra macchina che su quella di qualcun altro.
Un repository include anche altre cose oltre ai nostri file che contengono il codice, come HEAD, branch, e così via.
A differenza di altri strumenti simili che potresti avere usato, git non inserisce le modifiche effettuate dall'albero di lavoro direttamente nel repository. Viceversa le modifiche sono prima registrate in qualcosa chiamato indice (index) o area di stage (staging area).
Entrambi questi termini fanno riferimento alla stessa cosa e sono spesso usati nella documentazione di git. Useremo questi termini in modo intercambiabile all'interno di questo post.
Quando attiviamo (checkout) un branch, git popola l'indice con tutti i contenuti dei file che erano presenti l'ultima volta nella nostra directory di lavoro e come apparivano quando sono stati originariamente verificati. Quando usiamo git commit, il commit viene creato in base allo stato dell'indice.
L'uso dell'indice ci consente di preparare con cura ogni commit. Per esempio potremmo avere due file con modifiche rispetto al nostro ultimo commit nella nostra directory di lavoro. Potremmo volere aggiungere solo uno di essi all'indice (usando git add), quindi usare git commit per registrare solo quelle modifiche.

I file nella nostra directory di lavoro possono trovarsi in uno di due stati: tracciato (tracked) o non tracciato (untracked).
I file tracciati sono quelli che git conosce. Potrebbero trovarsi nell'ultima istantanea (commit) oppure essere stati portati nell'area di stage adesso.
I file non tracciati, sono tutto il resto, qualunque file o directory nella nostra directory di lavoro che non compariva nella nostra ultima istantanea (commit) e che non si trova attualmente nell'area di stage.
Come creare un repository nel modo convenzionale
Assicuriamoci di capire in che modo i termini che abbiamo introdotto si riferiscono al procedimento di creazione di un repository. Questa è solo una rapida panoramica di alto livello, prima di immergerci molto più a fondo in questo processo.
Nota: la maggior parte delle videate con i comandi di shell mostra i comandi UNIX. Fornirò comandi sia per Windows che per UNIX, con schermate da Windows, per coprire i sistemi operativi più diffusi. Quando i comandi saranno esattamente gli stessi, li fornirò solo una volta.
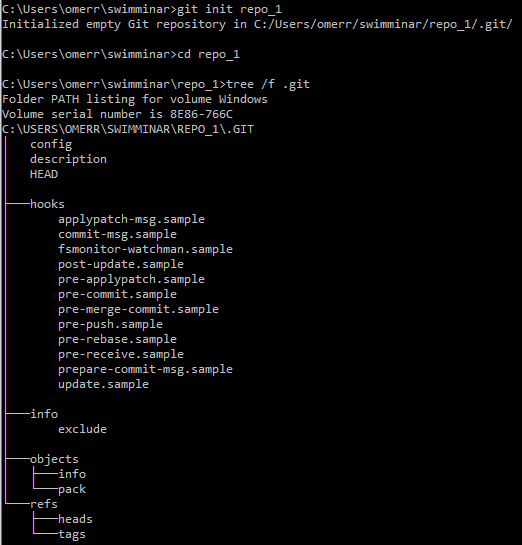
Inizializzeremo un nuovo repository usando git init repo_1, quindi ci sposteremo nella directory di quel repository usando cd repo_1. Digitando tree /f .git possiamo vedere che l'esecuzione di git init ha prodotto parecchie sottodirectory all'interno di .git. (L'opzione del comando tree /f include anche i file nel risultato dell'esecuzione del comando).
Creiamo un file all'interno della directory repo_1 (versione Windows):

Sui sistemi Linux e macOS:

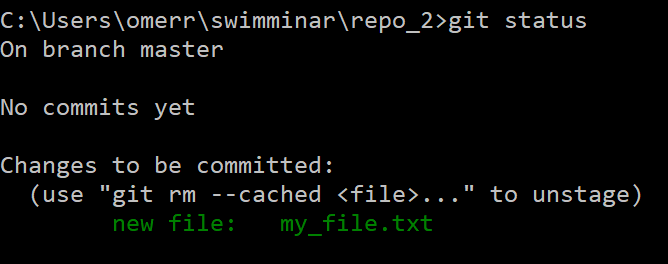
Questo file si trova all'interno della nostra directory di lavoro. Tuttavia, visto che non è ancora stato inserito nell'area di stage, attualmente risulta non tracciato (untracked). Verifichiamolo con il comando git status:

Ora possiamo aggiungere questo file all'area di stage con il comando git add new_file.txt. Possiamo verificare che il file si trova nell'area di stage eseguendo git status:

Ora possiamo creare un commit con git commit:

È cambiato qualcosa nella directory .git? Eseguiamo tree /f .git per verificare:

.gitSembra che siano cambiate parecchie cose. È ora di esaminare approfonditamente la struttura di .git e capire cosa succede dietro le quinte quando eseguiamo git init, git add oppure git commit.
Ora di andare alle fondamenta
Fino ad ora abbiamo trattato alcuni degli aspetti base di Git, ora siamo pronti per andare davvero a fondo.
Per capire a fondo come funziona git, dovremo creare un repository, questa volta però lo faremo partendo da zero.
Non useremo git init, git add o git commit, il che ci consentirà di ottenere una migliore comprensione pratica del procedimento.
Come impostare .git
Creiamo una nuova directory, portiamoci all'interno di essa ed eseguiamo git status:

Va bene, git non sembra contento visto che non ha trovato nessuna cartella .git. La cosa naturale da fare sarebbe semplicemente crearla, poi rieseguire git status:

Apparentemente, non è sufficiente creare una cartella .git . Ci serve qualche cosa da immettere in quella directory.
Un repository git ha due componenti principali:
- Una collezione di oggetti — blob, alberi, e commit.
- Un sistema di denominazione di quegli oggetti, o riferimenti (references).
Un repository potrebbe anche contenere altre cose, come gli hook di git, ma come minimo deve includere oggetti e riferimenti.
Creiamo quindi una directory per gli oggetti, .git\objects e una per i riferimenti, .git\refs (sui sistemi UNIX .git/objects e .git/refs, rispettivamente).

Un tipo di riferimento sono i branch. Internamente, git chiama i branch con il nome head. Quindi andremo a creare una directory apposita, .git\refs\heads.

Lo stato non cambia ancora eseguendo git status:

Come fa git a sapere dove iniziare a cercare un commit nel repository? Come spiegato in precedenza, cerca HEAD, che punta al branch attivo corrente (o commit in taluni casi).
Quindi dobbiamo creare HEAD, che è semplicemente un file che si trova in ./git/HEAD. Per farlo eseguiamo:
Su Windows: > echo ref: refs/heads/master > .git\HEAD
Su sistemi UNIX: $ echo "ref: refs/heads/master" > .git/HEAD
⭐ Adesso sappiamo come viene implementato HEAD, è semplicemente un file e il suo contenuto descrive verso quale oggetto puntare.
Dopo l'esecuzione dei comandi qui sopra, git status sembra cambiare idea:

Ora git crede che siamo nel branch chiamato master, anche se non abbiamo creato questo branch. Come detto prima, master è solo un nome. Avremmo potuto far credere a git di essere su un branch chiamato banana se avessimo voluto:

Per il resto di questo post torneremo a master, semplicemente per conformarci alla normale convenzione.
Ora che la nostra directory .git è pronta, possiamo iniziare le operazioni per creare un commit (come già detto, senza usare git add oppure git commit).
I comandi in Git, idraulica vs. ceramica
A questo punto sarebbe utile fare una distinzione tra due tipi di comando in git: idraulici e in ceramica. La definizione è presa in prestito da termini usati dagli idraulici quando si parla di tazza (già, questa — 🚽), che tradizionalmente è fatta di ceramica mentre l'infrastruttura (tubi e scarichi) costituisce l'idraulica.
Mantenendo l'analogia, possiamo dire che la ceramica fornisce all'utente un'interfaccia amichevole per accedere a tubature e scarichi. La maggior parte delle persone ha a che fare con la ceramica. Tuttavia, quando succede qualcosa di veramente brutto, e qualcuno vuole capirne il motivo, deve rimboccarsi le maniche e controllare le tubature e gli scarichi. (Nota: questi termini non sono miei, sono usati in modo estensivo in git).
git usa questa terminologia come analogia per distinguere i comandi di basso livello che in genere gli utenti non usano direttamente (i comandi idraulici che agiscono su tubi e scarichi) dai comandi di alto livello più amichevoli per gli utenti (comandi in ceramica).
Fino a ora abbiamo avuto a che fare con i comandi in ceramica, git init, git add o git commit. Di seguito passeremo ai comandi idraulici.
Come creare oggetti in Git
Partiamo creando un oggetto e scrivendolo nel database degli oggetti di git, che si trova in .git\objects. Troveremo un valore di hash SHA-1 per un blob usando il nostro primo comando di basso livello (idraulico), git hash-object, in questo modo:
Su Windows:
> echo git is awesome | git hash-object --stdin
Su sistemi UNIX:
$ echo "git is awesome" | git hash-object --stdin
Usando --stdin diciamo a git hash-object di prendere i suoi dati dallo standard input. Questo ci fornirà il relativo valore hash valido.
Per scrivere effettivamente quel blob nel database degli oggetti di git possiamo semplicemente aggiungere l'opzione -w a git hash-object. Successivamente possiamo verificare il contenuto della cartella .git e vedere cosa è cambiato.

Adesso possiamo vedere che l'hash del nostro blob è 54f6...36. Possiamo anche vedere che è stata creata una sottodirectory in .git\objects chiamata 54, il file è stato chiamato f6...36.
Quindi git in realtà prende i primi due caratteri dell'hash SHA-1 e li usa come nome di una directory. I restanti caratteri dell'hash vengono usati come nome del file che contiene il blob.
Come mai? Immagina un repository piuttosto grande, uno che abbia 300.000 oggetti (blob, alberi, e commit) nel suo database. Può servire molto tempo per cercare un hash in una lista di 300.000 elementi. Per questo git divide semplicemente il problema per 256.
Per cercare l'hash qui sopra, git per prima cosa cerca una directory chiamata 54 all'interno di .git\objects, che potrebbe avere fino a 256 directory (da 00 a FF). Poi cerca in quella directory, restringendo la ricerca mano a mano che la stessa progredisce.
Torniamo al nostro procedimento per generare un commit. Ora che abbiamo creato un oggetto, di che tipo è? Possiamo usare un altro comando di basso livello, git cat-file -t (-t sta per “tipo”), per verificarlo:

Non c'è da sorprendersi, questo oggetto è un blob. Possiamo anche usare git cat-file -p (-p sta per “pretty-print” - bella stampa) per vederne il contenuto:

Il procedimento di creazione di un blob in genere si verifica quando aggiungiamo qualcosa nell'area di stage, vale a dire quando usiamo git add.
Ricorda che git crea un blob dell'intero file portato in area di stage. Anche se viene modificato un solo carattere (come nell'esempio di prima quando abbiamo aggiunto un !), il file avrà un nuovo blob con un nuovo hash.
Vedremo modifiche se verifichiamo lo stato del repository usando git status?

Apparentemente no. Aggiungere un oggetto blob al database interno di git non modifica lo stato, visto che git non sa in questa fase quali file siano tracciati o meno.
Dobbiamo tracciare questo file, aggiungendolo all'area di stage. A questo scopo possiamo usare il comando di basso livello git update-index, così: git update-index --add --cacheinfo 100644 <blob-hash> <nomefile>.
Nota: cacheinfo è un file in modalità 16-bit conservato da git, seguendo le direttive di tipi e modalità POSIX. Questo va oltre lo scopo di questo post.
Eseguendo il comando qui sopra otterremo una modifica nel contenuto di .git:

Riesci a identificare le modifiche? È stato creato un nuovo file chiamato index . Eccolo, il famoso indice (o area di stage), è praticamente un file che si trova nella directory .git.
Adesso che il nostro blob è stato aggiunto all'indice, ci aspettiamo che il risultato di git status sia diverso, come questo:

Interessante! Sono successe due cose.
La prima, possiamo vedere che my_file.txt è visualizzato in verde nella sezione Changes to be committed (modifiche da portare in commit). Questo perché l'indice ora contiene my_file.txt, in attesa di essere portato in un commit.
La seconda, osserviamo che my_file.txt viene visualizzato in rosso, poiché git crede che my_file.txt sia stato eliminato e il fatto che il file sia stato eliminato non è stato registrato in area di stage.
Questo succede in quanto abbiamo aggiunto un blob con il contenuto git is awesome al database degli oggetti, e abbiamo detto all'indice che my_file.txt ha il contenuto di quel blob, ma in realtà non abbiamo mai veramente creato quel file.
Possiamo facilmente risolvere prendendo il contenuto del blob e scrivendolo nel nostro file system, in un file chiamato my_file.txt:

Ne consegue che my_file.txt non appare più in rosso nel risultato di git status:
È ora di creare un oggetto commit dalla nostra area di stage. Come spiegato sopra, un oggetto commit ha un riferimento a un albero, quindi dobbiamo crearlo.
Lo possiamo fare con il comando git write-tree, che registra il contenuto dell'indice in un oggetto albero. Naturalmente possiamo usare git cat-file -t per verificare che in effetti si tratti di un albero:

Possiamo usare git cat-file -p per vedere il contenuto:

Grande, abbiamo creato un albero, e ora ci serve creare un oggetto commit che faccia riferimento a questo albero. Per farlo possiamo usare git commit-tree <hash-albero> -m <messaggio_di_commit>:

Ora dovresti essere a tuo agio con i comandi usati per verificare il tipo di oggetto creato, e per stamparne il contenuto:

Osserva che questo commit non ha un genitore, visto che è il primo commit. Quando aggiungeremo un altro commit, dovremo dichiarare il suo genitore, lo faremo più tardi.
L'ultimo hash che abbiamo ottenuto, 80e...8f è l'hash di un commit. Questi hash ci devono essere piuttosto familiari, ci abbiamo a che fare tutte le volte. Nota che un commit detiene un oggetto albero, con un proprio hash, che raramente specifichiamo esplicitamente.
Qualcosa è cambiato nel risultato di git status?

Niente 🤔.
Come mai? Bene, per sapere che il nostro file è stato portato in commit, a git serve conoscere il nostro ultimo commit. Come ci riesce? Legge HEAD:

HEAD su Windows
HEAD su sistemi UNIXHEAD punta a master, ma cos'è master? Non l'abbiamo ancora creato.
Come spiegato in precedenza, un branch è semplicemente un riferimento nominativo a un commit. In questo caso, vorremmo che master facesse riferimento al commit con hash 80e8ed4fb0bfc3e7ba88ec417ecf2f6e6324998f.
Possiamo farlo creando semplicemente un file master in \refs\heads, con questo hash come contenuto, così:

⭐ Alla fine, un branch è semplicemente un file all'interno di .git\refs\heads, che contiene un hash del commit al quale si riferisce.
Ora, finalmente, git status e git log sembrano apprezzare i nostri sforzi:

Abbiamo creato con successo un commit senza usare i comandi di alto livello (quelli in ceramica)! Forte, non è vero? 🎉
Come lavorare con i branch in Git: dietro le quinte
Proprio come abbiamo creato un repository e un commit senza usare git init, git add o git commit, ora possiamo creare e spostarci tra i branch senza usare i comandi di primo livello (quelli in ceramica), git branch o git checkout.
È perfettamente legittimo che tu sia eccitato, lo sono anche io 🙂
Iniziamo:
Finora abbiamo solo un branch, che si chiama master. Per crearne un altro che chiameremo test (l'equivalente di git branch test), dobbiamo semplicemente creare un file chiamato test all'interno di .git\refs\heads, e il contenuto di quel file sarà lo stesso hash del commit al quale master punta.

Se usiamo git log, possiamo vedere che questo è in effetti il caso, sia master che test puntano a questo commit:

Ora spostiamoci nel nostro branch appena creato (l'equivalente di git checkout test). A questo scopo, dovremo modificare HEAD per farlo puntare al nostro nuovo branch:
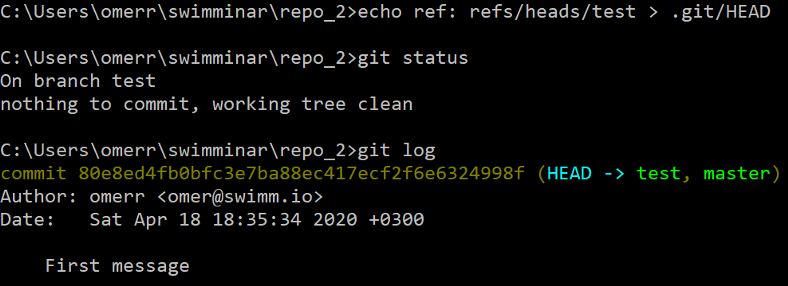
test modificando HEADCome possiamo vedere, sia git status che git log confermano che HEAD ora punta a test, che è, di conseguenza, il branch attivo.
Ora possiamo avvalerci dei comandi già usati per creare un altro file e aggiungerlo all'indice:

Con i comandi qui sopra, abbiamo creato un file chiamato test.txt, che contiene la parola Testing, creato il blob corrispondente, e lo abbiamo aggiunto all'indice. Abbiamo anche creato un albero che rappresenta l'indice.
Adesso creiamo un commit che fa riferimento a questo albero. Questa volta, dovremmo anche specificare il genitore di questo commit, che sarà il commit precedente. Specifichiamo il genitore usando l'opzione -p per git commit-tree:

Abbiamo appena creato un commit, con albero e un genitore, come possiamo vedere:

Il risultato di git log ci mostrerà il nuovo commit?

git log non ci mostra nulla di nuovo, come puoi vedere. Perché?🤔 Ricorda che git log traccia i branch per trovare commit rilevanti da mostrare. Adesso ci mostra test e il commit a cui punta, e ci mostra anche master, che punta allo stesso commit.
Esatto, dobbiamo modificare test per farlo puntare al nostro nuovo commit. Lo facciamo modificando semplicemente il contenuto di .git\refs\heads\test:

Ha funzionato! 🎉🥂
git log passa per HEAD, che gli dice di andare al branch test, che a sua volta punta al commit 465...5e, il quale fa riferimento nuovamente al suo commit genitore 80e...8f.
Meraviglioso, non è vero? 😊
Riepilogo
Questo post ti ha introdotto ai meccanismi interni di git. Abbiamo iniziato trattando gli oggetti di base, blob, alberi e commit.
Abbiamo appreso che un blob conserva il contenuto di un file. Un albero è un elenco di directory contenente blob e/o sottoalberi. Un blob è un'istantanea della nostra directory di lavoro, con alcuni metadati come la marca temporale e il messaggio di commit.
Abbiamo quindi discusso dei branch e spiegato che non sono altro che un riferimento nominativo a un commit.
Abbiamo continuato descrivendo la directory di lavoro, una directory a cui è associato un repository, l'area di stage (indice) che contiene l'albero per il commit successivo e il repository, che è una raccolta di commit.
Abbiamo chiarito come questi termini si relazionano ai comandi git che conosciamo creando un nuovo repository ed eseguendo il commit di un file utilizzando i ben noti comandi git init, git add e git commit.
Quindi ci siamo immersi senza paura in git. Abbiamo smesso di usare comandi di alto livello (in ceramica) e siamo passati a comandi di basso livello (idraulici).
Usando echo e comandi di basso livello come git hash-object, siamo stati in grado di creare un blob, aggiungerlo all'indice, creare un albero dell'indice e creare un oggetto commit che punta a quell'albero.
Siamo stati anche in grado di creare e passare da un branch all'altro. Complimenti a quelli di voi che l'hanno provato da soli!👏
Spero che dopo aver seguito questo post sentirai di aver approfondito la tua conoscenza di ciò che accade dietro le quinte quando lavori con git.
Grazie per aver letto! Se ti è piaciuto questo articolo, puoi leggere di più su questo argomento sul blog swimm.io.
Omer Rosenbaum, Chief Technology Officer per Swimm. Esperto di cyber training e fondatore di Checkpoint Security Academy. Autore di Computer Networks (in Ebraico).
Visita il mio Canale YouTube
Risorse addizionali
Molto è stato scritto e detto su git. In particolare, ho trovato utili queste risorse (in lingua inglese - n.d.t.):