


Artículo original: Gradient Descent – Machine Learning Algorithm Example
¿Qué es el algoritmo de descenso de gradiente?
El descenso de gradiente es probablemente el algoritmo de aprendizaje automático más popular. En esencia, el algoritmo existe para minimizar los errores tanto como sea posible.
El objetivo del descenso de gradiente como algoritmo es minimizar la función de costo de un modelo. Podemos decir esto por los significados de las palabras 'Gradiente' y 'Descenso'.
Mientras que gradiente significa la brecha entre dos puntos definidos (esa es la función de costo en este contexto), el descenso se refiere al movimiento hacia abajo en general (es decir, minimizar la función de costo en este contexto).
Entonces, en el contexto del aprendizaje automático, Descenso de Gradiente (Gradient Descent en inglés) se refiere al intento iterativo de minimizar el error de predicción de un modelo de aprendizaje automático ajustando sus parámetros para producir el menor error posible.
Este error se conoce como la Función de Costo. La función de costo es un gráfico de la respuesta a la pregunta "¿En cuánto difiere el valor predicho del valor real?". Si bien la forma de evaluar las funciones de costo a menudo difiere para diferentes modelos de aprendizaje automático, en un modelo de regresión lineal simple, generalmente se refiere al error cuadrático medio del modelo.
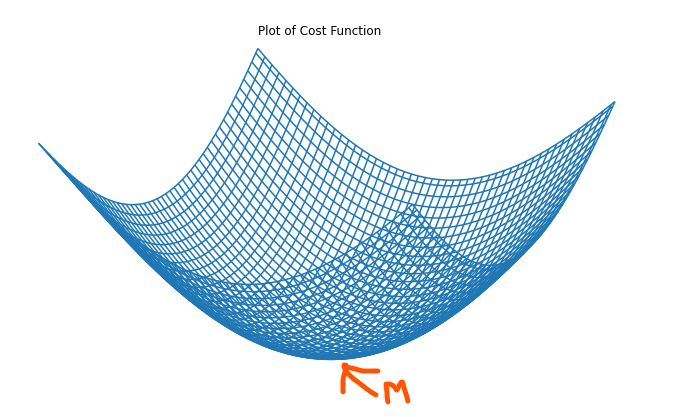
Es importante tener en cuenta que para los modelos más simples como la regresión lineal, un gráfico de la función de costo suele tener forma de arco, lo que facilita determinar el punto mínimo.
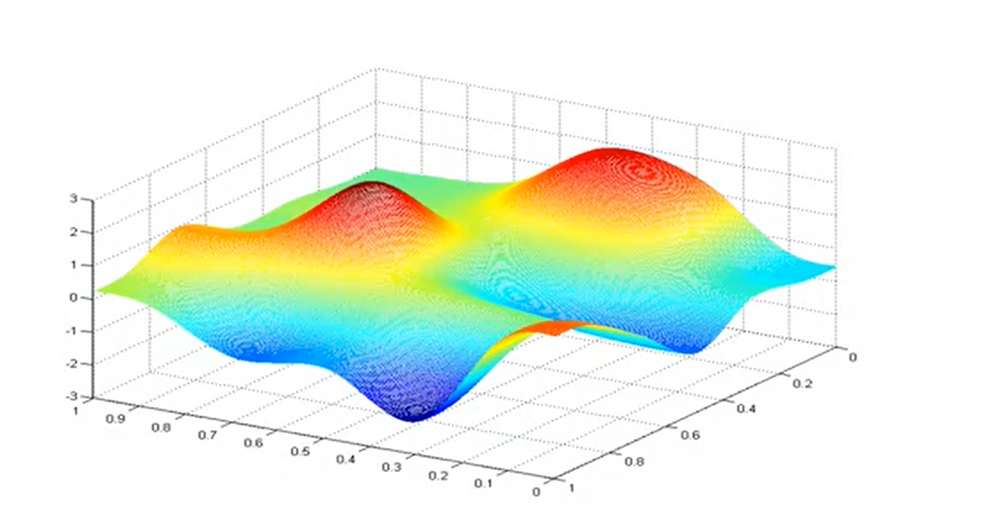
Sin embargo, este no es siempre el caso. Para modelos más complejos (por ejemplo, redes neuronales), es posible que el gráfico no tenga forma de arco. Es posible que la función de costo tenga múltiples puntos mínimos como se muestra en la imagen a continuación.
¿Cómo funciona el descenso de gradiente?
En primer lugar, es importante tener en cuenta que, como la mayoría de los procesos de aprendizaje automático, el algoritmo de descenso de gradiente es un proceso iterativo.
Suponiendo que tiene la función de costo para un modelo de regresión lineal simple como j(w,b) donde j es una función de w y b, el algoritmo de descenso de gradiente funciona de tal manera que comienza con una conjetura aleatoria inicial para w y b. El algoritmo seguirá modificando los parámetros w y b en un intento de optimizar la función de costo, j.
En la regresión lineal, la elección de los valores iniciales no importa mucho. Una opción común es cero.
La analogía perfecta para el algoritmo de descenso de gradiente que minimiza la función de costo j(w, b) y alcanza su mínimo local ajustando los parámetros w y b es caminar hasta el pie de una montaña o colina (como se muestra en la gráfica 3D de la función de costo de un modelo de regresión lineal simple mostrado anteriormente).
O bien, podemos imaginar que estamos tratando de llegar al punto más bajo de un campo de golf. En cualquier caso, darán pasos cortos, repetitivos hasta llegar al pie de la montaña o colina.
La fórmula de descenso de gradiente
Aquí está la fórmula para el descenso de gradiente: b = a - γ Δ f(a)
La ecuación anterior describe el accionar del algoritmo de descenso de gradiente.
Es decir, b es la siguiente posición del excursionista, mientras que representa la posición actual. El signo menos es para la parte de minimización del algoritmo de descenso de gradiente, ya que el objetivo es minimizar el error tanto como sea posible. γ en el medio es un factor conocido como tasa de aprendizaje, y el término Δf(a) es un término de gradiente que define la dirección del punto mínimo.
Como tal, esta fórmula indica la siguiente posición para el excursionista/la persona en el campo de golf (esa es la dirección del descenso más empinado).
Es importante notar que el término γΔ f(a) se resta de a porque el objetivo es moverse contra el gradiente, hacia el mínimo local.
¿Qué es la tasa de aprendizaje?
La tasa de aprendizaje es el determinante de cuán grandes son los pasos que toma el descenso del gradiente en la dirección del mínimo local. Determina la velocidad con la que el algoritmo se mueve hacia los valores óptimos de la función de coste.
Debido a esto, la elección de la tasa de aprendizaje, γ, es importante y tiene un impacto significativo en la efectividad del algoritmo.
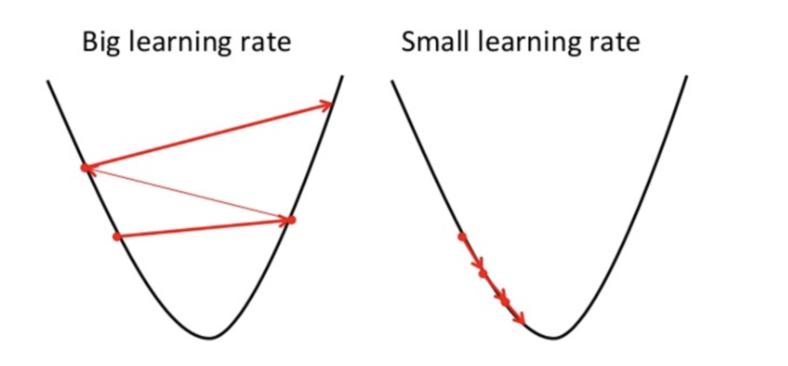
Si la tasa de aprendizaje es demasiado grande como se muestra arriba, en un intento por encontrar el punto óptimo, se mueve desde el punto de la izquierda hasta el punto de la derecha (como la tasa de aprendizaje es muy grande, los "saltos" también lo son, por lo que es muy difícil que el algoritmo acierte en el punto óptimo).En ese caso, vemos que la función de costo ha empeorado.
Por otro lado, si la tasa de aprendizaje es demasiado pequeña, los descensos de gradiente funcionarán, aunque muy lentamente. Es decir, como los pasos son muy pequeños, es muy probable que el algoritmo acierte, aunque la optimización irá muy despacio.
Es por ello, importante elegir cuidadosamente la tasa de aprendizaje.
Cómo implementar el descenso de gradiente en la regresión lineal
import numpy as np
import matplotlib.pyplot as plt
class Linear_Regression:
def __init__(self, X, Y):
self.X = X
self.Y = Y
self.b = [0, 0]
def update_coeffs(self, learning_rate):
Y_pred = self.predict()
Y = self.Y
m = len(Y)
self.b[0] = self.b[0] - (learning_rate * ((1/m) * np.sum(Y_pred - Y)))
self.b[1] = self.b[1] - (learning_rate * ((1/m) * np.sum((Y_pred - Y) * self.X)))
def predict(self, X=[]):
Y_pred = np.array([])
if not X: X = self.X
b = self.b
for x in X:
Y_pred = np.append(Y_pred, b[0] + (b[1] * x))
return Y_pred
def get_current_accuracy(self, Y_pred):
p, e = Y_pred, self.Y
n = len(Y_pred)
return 1-sum(
[
abs(p[i]-e[i])/e[i]
for i in range(n)
if e[i] != 0]
)/n
#def predict(self, b, yi):
def compute_cost(self, Y_pred):
m = len(self.Y)
J = (1 / 2*m) * (np.sum(Y_pred - self.Y)**2)
return J
def plot_best_fit(self, Y_pred, fig):
f = plt.figure(fig)
plt.scatter(self.X, self.Y, color='b')
plt.plot(self.X, Y_pred, color='g')
f.show()
def main():
X = np.array([i for i in range(11)])
Y = np.array([2*i for i in range(11)])
regressor = Linear_Regression(X, Y)
iterations = 0
steps = 100
learning_rate = 0.01
costs = []
#original best-fit line
Y_pred = regressor.predict()
regressor.plot_best_fit(Y_pred, 'Initial Best Fit Line')
while 1:
Y_pred = regressor.predict()
cost = regressor.compute_cost(Y_pred)
costs.append(cost)
regressor.update_coeffs(learning_rate)
iterations += 1
if iterations % steps == 0:
print(iterations, "epochs elapsed")
print("Current accuracy is :",
regressor.get_current_accuracy(Y_pred))
stop = input("Do you want to stop (y/*)??")
if stop == "y":
break
#final best-fit line
regressor.plot_best_fit(Y_pred, 'Final Best Fit Line')
#plot to verify cost function decreases
h = plt.figure('Verification')
plt.plot(range(iterations), costs, color='b')
h.show()
# if user wants to predict using the regressor:
regressor.predict([i for i in range(10)])
if __name__ == '__main__':
main()
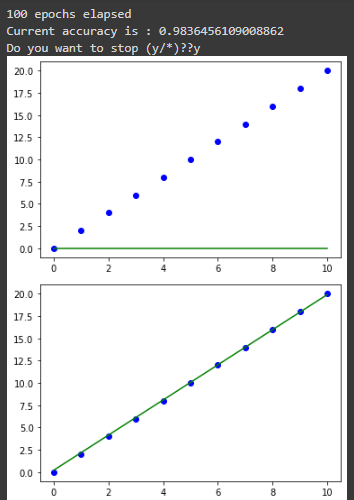
En esencia, puedes ver que el bloque de código entrena un algoritmo de descenso de gradiente para un modelo de aprendizaje automático de regresión lineal usando 0.01 como tasa de aprendizaje, basándose en 100 pasos.
Al ejecutar el código, tenemos lo siguiente:

Conclusión
En conclusión, es importante tener en cuenta que el algoritmo de descenso de gradiente es especialmente importante en los dominios de inteligencia artificial y aprendizaje automático, ya que los modelos deben optimizarse para la precisión.
En este artículo, aprendimos qué es el algoritmo de descenso de gradiente, cómo funciona, su fórmula, qué tasa de aprendizaje es y la importancia de elegir la tasa de aprendizaje correcta. También vimos una ilustración de código de cómo funciona Gradient Descent.
Finalmente, compartí mis escritos sobre inteligencia artificial, aprendizaje automático y Microsoft Azure en Twitter si disfrutaste este artículo y quieres ver más.