


Articolo originale: What is The C Programming Language? A Tutorial for Beginners
Questo tutorial ti fornirà un'ampia panoramica dei concetti di base del linguaggio di programmazione C.
Parleremo della storia del linguaggio, di dove e perché viene utilizzato, del processo di compilazione e di altri fondamentali concetti di programmazione, comuni alla maggior parte dei linguaggi di programmazione più popolari.
Questa non è una guida completa al linguaggio, ma piuttosto ti permetterà di raggiungere una buona comprensione dei concetti importanti di C partendo dal livello di un principiante assoluto.
Ogni linguaggio possiede la propria sintassi e dei modi specifici di fare le cose, ma i concetti che tratteremo qui sono comuni e applicati a tutti i linguaggi di programmazione.
Comprendere il funzionamento delle cose e questi concetti generali può richiedere molta della strada del tuo viaggio nella programmazione, ma sul lungo termine ti renderà più semplice capire nuove tecnologie.
Sommario
- Storia del linguaggio
- Caratteristiche di C e perché dovresti impararlo
- Dove viene utilizzato C?
- Processo di compilazione
- Hello world
- File di intestazione
- Programma main
- Commenti
- Ottenere un output sulla console
- Variabili
- Assegnazione
- Dichiarazione e inizializzazione
- Nomenclatura delle variabili
- Visibilità delle variabili
- Tipi di dati
- Specificatori di formato
- Operatori
- Operatori aritmetici
- Operatore di assegnazione
- Operatori logici
- Operatori di confronto
- Funzioni
- Argomenti
- Output
- Metodi
- Chiamare una funzione
- Espressioni booleane
- Istruzioni condizionali
- Loop
Storia del linguaggio di programmazione C
La storia del linguaggio di programmazione C è strettamente legata alla storia dello sviluppo del sistema operativo Unix.
Se proviamo a capire cosa ha portato allo sviluppo del sistema operativo che ha cambiato il mondo della programmazione, sapremo quali sono stati gli step che hanno determinato lo sviluppo di C.
In breve, C è nato dalla necessità di trovare un linguaggio da applicare al sistema operativo Unix.
Progetto MAC e MULTICS
Iniziò tutto nel 1965, quando il progetto sperimentale MAC fu completato al MIT – il primo sistema del suo genere, che ha segnato l'inizio dell'era MULTICS. Utilizzava una tecnologia chiamata CTSS (Compatible Time Sharing System).
Per l'epoca fu un'innovazione fondamentale. In quel momento, si era all'inizio dell'era mainframe, dove computer enormi, potenti ed estremamente costosi occupavano stanze intere.
Per svolgere delle attività, i programmatori dovevano scrivere il codice a mano, per poi perforare delle schede di carta che codificavano il programma appena scritto.
Lo facevano consegnando i fogli di carta su cui era scritto il programma a degli operatori che utilizzavano una macchina perforatrice per creare dei buchi nelle schede, che rappresentavano dati e istruzioni.
Poi utilizzavano un lettore di schede perforate connesso al computer mainframe per leggere le schede. In seguito, la sequenza dei buchi nella scheda veniva convertita in informazione digitale. Semplici operazioni necessitavano di tempi lunghi a causa di questo metodo e ogni macchina poteva essere usata soltanto da una persona alla volta.
L'idea del time sharing ha cambiato ogni cosa. Invece di usare le schede, delle console multiple (che al tempo erano costituite da terminali meccanici detti telescriventi) venivano attaccate al computer principale. Ciò ha permesso a molte persone di usare lo stesso computer simultaneamente.
Più di 100 terminali telescriventi distribuiti attorno al campus del MIT erano collegati al grande computer centrale. Il sistema supportava fino a 30 utenti, ognuno dei quali usava quei terminali in remoto allo stesso tempo.
Il sistema operativo del computer centrale svolgeva più compiti contemporaneamente, passando tra le persone che volevano eseguire attività computazionali dai terminali connessi e dando pochi secondi a ognuno di loro.
Forniva ciò che può assomigliare a un servizio continuo, con molti programmi in esecuzione simultanea. In realtà, passava molto velocemente da un programma di un utente all'altro, dando alla persona l'illusione di avere l'intero computer per sé.
Questo sistema si è dimostrato estremamente efficiente, efficace e produttivo, permettendo di risparmiare tempo e denaro sul lungo termine, dato che quei computer erano estremamente costosi.
Ciò che avrebbe richiesto giorni interi per essere completato, ora era fattibile in molto meno tempo, favorendo l'accesso all'utilizzo dei computer.
Seguendo il successo del CTSS, il MIT decise che era tempo di basarsi su questo sistema e portarlo allo step successivo, creando un sistema più avanzato di time sharing.
Ma immaginavano un progetto ben più ambizioso: volevano costruire un sistema da usare come risorsa informatica per i programmatori, capace di supportare contemporaneamente centinaia di accessi di utenti al mainframe. E gli utenti sarebbero stati in grado di condividere dati e risorse tra di loro.
Questo progetto richiedeva più risorse, così si unirono alla General Electric e ai Bell Labs.
Il nuovo progetto, chiamato MULTICS (da Multiplexed Information and Computing Service), fu implementato nel mainframe della General Electric, il GE 635.
Il team lavorò su MULTICS per svariati anni, ma nel 1969 il progetto fu abbandonato dai Bell Labs perché stava richiedendo troppo tempo ed era troppo costoso.
Bell Labs: il centro dell'innovazione
L'abbandono del progetto MULTICS da parte dei Bell Labs lasciò molti impiegati frustrati e in cerca di alternative.
Mentre stava lavorando su MULTICS, il team creò un ambiente informatico senza precedenti. Lavoravano con sistemi basati sul time sharing e conoscevano la sua efficacia. Questi programmatori avevano una vasta conoscenza dei sistemi operativi e volevano espandere le innovazioni partite da quel progetto.
Un gruppo guidato da Ken Thompson e Dennis Ritchie voleva utilizzare un ambiente comune e creare un file system da poter condividere. Avrebbe avuto le caratteristiche innovative che apprezzavano del progetto MULTICS ma un'implementazione più semplice e meno costosa.
Condivisero le loro idee e iniziarono tentare.

{kind=link}
I Bell Labs crearono un ambiente aperto e collaborativo che permise all'espressione creativa e all'innovazione di sbocciare. Facevano molta ricerca e incoraggiavano il pensiero indipendente nella risoluzione dei problemi per migliorare le loro soluzioni iniziali.
Attraverso tanti confronti e sperimentazione hanno realizzarono un cambiamento epocale scrivendo la storia.
Mentre stava ancora lavorando su MULTICS, Ken Thompson creò un gioco chiamato Space Travel. Lo aveva inizialmente scritto per MULTICS, sul GE 635, ma quando i Bell Lab si chiamarono fuori, adattò il gioco in un programma Fortran da eseguire sul sistema operativo GECOS del GE 635.
Il gioco aveva molti problemi – su GECOS non funzionava così bene come faceva su MULTICS e aveva bisogno di una macchina diversa e meno costosa su cui girare.
A Ken Thompson furono negati i fondi richiesti per creare un diverso sistema operativo, dato che i Bell Labs si erano chiamati già fuori dal progetto. Alla fine, riuscì a trovare un vecchio minicomputer DEC PDP-7 poco usato con cui fare un tentativo – era l'unico sistema disponibile.

{kind=link}
Iniziò a scrivere il suo gioco su quel semplice sistema ma era limitato dal software del computer. Così, mentre ci stava lavorando su, finì a implementare lo scheletro del file system che il suo team aveva ideato.
Partì con un file system gerarchico, un interprete della riga di comando e altri programmi di utilità. In un mese, riuscì a creare un sistema operativo con un assembler, un editor e uno shell, con funzionalità ridotte e più semplici rispetto a MULTICS: era nata la prima versione di Unix.
Gli albori di Unix e del linguaggio assembly
All'inizio del progetto, Ken Thompson non poteva programmare sul computer DEC PDP-7. I suoi programmi dovevano essere compilati e tradotti sul più potente mainframe GE 635 e poi l'output doveva essere fisicamente trasferito sulla scheda del PDP-7.
Il DEC PDP-7 aveva una memoria molto ridotta di soli 8 KB. Per far fronte a questa limitazione, il file system, la prima versione del kernel di Unix e praticamente ogni altra cosa nel progetto era programmata in assembly. L'uso di assembly permetteva a Thompson di manipolare direttamente e controllare ogni parte della memoria di quel computer.
Il linguaggio assembly è un linguaggio di programmazione di basso livello che utilizza del codice simbolico ed è vicino al linguaggio macchina, il codice binario. Le istruzioni del codice e ogni istruzione nel linguaggio corrispondono strettamente alle istruzioni-macchina specifiche per l'architettura del computer.
È dipendente dalla macchina e specifico, così che un'insieme di istruzioni ha risultati molto differenti a seconda della macchina su cui viene eseguito. I programmi scritti in linguaggio assembly sono pensati per uno specifico tipo di processore – quindi un programma scritto in assembly non si adatta a processori diversi.
A quel tempo, era comune scrivere sistemi operativi usando il linguaggio assembly e quando iniziarono a lavorare su Unix, non avevano in mente di renderlo portabile.
A loro non interessava che il sistema operativo fosse in grado di operare su sistemi e architetture macchina diversi. Questa idea arrivò più tardi. La loro priorità era l'efficienza del software.
Mentre lavoravano su MULTICS, usavano linguaggi di programmazione ad alto livello (PL/I all'inizio e poi BCPL). I programmatori si erano abituati a utilizzare linguaggi di programmazione ad alto livello per scrivere software come sistemi operativi, utilità e strumenti, per via dei vantaggi che offrivano (erano relativamente facili da usare e da capire).
Nell'uso di un linguaggio di programmazione di alto livello, c'è un'astrazione tra l'architettura del computer e svariati altri dettagli oscuri. Questo significa che il linguaggio si trova sopra il livello della macchina e non c'è manipolazione diretta della memoria dell'hardware.
I linguaggi di alto livello sono più facili da leggere, imparare, comprendere e gestire. Ciò fa sì che siano una scelta più facile per lavorare in gruppo. I comandi hanno una sintassi che ricorda l'inglese e i termini e le istruzioni sono più familiari e a misura d'uomo rispetto al formato simbolico di assembly.
Usare linguaggi di alto livello significa anche scrivere meno codice per compiere delle operazioni, mentre i programmi in assembly sono estremamente lunghi.
Fin dal principio, Thompson voleva usare un linguaggio di alto livello per Unix, ma era limitato dal DEC PDP-7.
Con il progredire del progetto e l'aggiunta di altre persone al gruppo, l'uso di assembly non era ideale. Thompson decise che Unix aveva bisogno di un linguaggio di programmazione di alto livello.
Nel 1970 ottenne i fondi per il più grande e potente DEC PDP-11, che sostanzialmente aveva più memoria.
Con un linguaggio di programmazione di alto livello, più veloce, strutturato ed efficiente in grado di sostituire assembly, tutti avrebbero potuto capire il codice e i compilatori sarebbero stati disponibili per macchine diverse.
Iniziarono ad esplorare linguaggi differenti per scrivere sistemi software da usare per implementare Unix.
Da B a C: il bisogno di un nuovo linguaggio
L'obiettivo era creare utilità – programmi che aggiungono funzionalità – da eseguire su Unix. Thompson tentò inizialmente di creare un compilatore FORTRAN ma poi optò per un linguaggio che aveva già utilizzato, BCPL (Basic Combined Programming Language).
BCPL era stato progettato e sviluppato alla fine degli anni '60 da Martin Richards. Il suo utilizzo principale era per scrivere compilatori e sistemi software.
Questo linguaggio era lento e aveva molte limitazioni, così quando Thompson iniziò a usarlo nel 1970 per il progetto Unix sul DEC PDP-7, fece degli aggiustamenti e delle modifiche e finì per scrivere un linguaggio tutto suo, chiamato B.
B aveva molte delle funzionalità di BCPL ma era un linguaggio più snello, con meno sintassi verbose e uno stile più semplice. Era ancora lento e non abbastanza potente per supportare le utilità di Unix, inoltre, non poteva trarre vantaggio dalle potenti funzionalità del PDP-11.
Dennis Ritchie decise di migliorare i due linguaggi precedenti, BCPL e B. Prese funzionalità e caratteristiche da entrambi e aggiunse altri concetti. Creò un linguaggio più potente ed efficiente – C – tanto quanto assembly. Questo nuovo linguaggio superò le limitazioni dei linguaggi precedenti, permettendo anche di sfruttare efficientemente le potenzialità della macchina.
Così, nel 1972, nacque C, con il primo compilatore C scritto e implementato per la prima volta sul DEC PDP-11.

_and_Dennis_Ritchie_at_PDP-11_(2876612463).jpg){kind=link}
Il linguaggio di programmazione C
Nel 1973, Dennis Ritchie riscrisse il codice sorgente di Unix e la maggior parte dei programmi e delle applicazioni usando il linguaggio di programmazione C, che divenne il linguaggio di implementazione standard del sistema operativo.
Reimplementò il kernel di Unix in C scrivendo quasi tutto il sistema operativo (ben oltre il 90%) in questo linguaggio di alto livello. C unisce sia le caratteristiche di leggibilità del linguaggio di alto livello con le funzionalità di basso livello, rendendolo la scelta perfetta per scrivere un sistema operativo.
Verso la fine degli anni '70, la popolarità di C iniziò a crescere e il linguaggio a diventare più ampiamente supportato e sviluppato. Fino a quel punto, C era ancora soltanto disponibile per i sistemi Unix e i compilatori non erano disponibili fuori dai Bell Labs.
L'aumento della popolarità derivò non solo dalle potenzialità date da C alla macchina, ma anche al programmatore. Fu d'aiuto anche il fatto che il sistema operativo Unix stesse diventando più diffuso a un ritmo addirittura maggiore.
Unix si distingueva da tutto ciò che era conosciuto per via della sua portabilità e della possibilità di essere eseguito su una varietà di macchine, sistemi e ambienti differenti.
C ha reso possibile la portabilità e dal momento in cui venne utilizzato come linguaggio del sistema Unix, ha guadagnato molta notorietà – sempre più programmatori hanno voluto provarlo.
Nel 1978, Brian Kernighan e Dennis Ritchie scrissero in collaborazione e pubblicarono la prima edizione del libro 'Il linguaggio di programmazione C', conosciuto nella comunità dei programmatori anche con il nome di 'K&R'. Per molti anni, questo è stato il testo di riferimento per la descrizione e definizione del linguaggio C.

Negli anni '80, la popolarità di C salì alle stelle dato che diversi compilatori furono creati e commercializzati. Molti gruppi e aziende che non erano state coinvolte nella progettazione di C iniziarono a produrre compilatori per ogni sistema operativo e architettura di computer, rendendo C disponibile su tutte le piattaforme.
Dato che queste società creavano i compilatori per conto proprio, iniziarono a cambiare le caratteristiche del linguaggio per adattare il compilatore a ogni piattaforma per cui era stato scritto.
Esistevano varie versioni di C con piccole differenze tra di loro. Mentre scrivevano i compilatori, questi gruppi svilupparono le proprie interpretazioni di alcuni aspetti del linguaggio, basate sulla prima edizione del libro 'Il linguaggio di programmazione C'.
Dopo tutte le prove e gli aggiustamenti, il libro non descriveva più il linguaggio originario, e i cambiamenti iniziarono a causare dei problemi.
Il mondo aveva bisogno di una versione comune di C, uno standard per il linguaggio.
Lo standard C
Nel 1983, l'ANSI (American National Standards Institute) formò una commissione per far sì che la definizione del linguaggio fosse standardizzata e indipendente dalla macchina. La commissione, chiamata X3J11, aveva il compito di fornire una definizione e una standardizzazione di C chiara ed esaustiva.
Dopo pochi anni, nel 1989, la commissione terminò il suo lavoro e lo rese ufficiale. Avevano definito uno standard commerciale per il linguaggio. Quella versione del linguaggio è conosciuta come 'ANSI C' o C89.
C venne utilizzato in tutto il mondo e un anno dopo, nel 1990, lo standard fu approvato e adottato dall'ISO (International Standards Organization). La prima versione, C90, fu chiamata ISO/IEC 9899:1990.
Da allora, ci sono state molte revisioni del linguaggio.
Nel 1999, fu pubblicata C99, la seconda versione dello standard (denominata ISO/IEC 9899:1999), che introdusse nuove funzionalità addizionali nel linguaggio. La terza versione, C11, fu pubblicata nel 2011. La più recente è la quarta, C17, denominata ISO/IEC 9899:2018.
La continuazione di C
C ha tracciato il sentiero per la creazione di un gran numero di linguaggi di programmazione diversi. Molti dei moderni linguaggi di programmazione di alto livello che usiamo e amiamo sono basati su C.
E molti dei linguaggi creati dopo C dovevano ovviare ai problemi che C non poteva risolvere, o superare alcune delle sue limitazioni. Ad esempio, il discendente più popolare di C è la sua estensione orientata agli oggetti C++, ma anche Go, Java e JavaScript si ispirano a C.
Le caratteristiche di C e perché dovresti impararlo
C è un linguaggio vecchio, ma attualmente è ancora popolare, anche dopo tutti questi anni.
Deve la sua popolarità all'ascesa e al successo di Unix, ma è andato ben oltre l'essere il linguaggio 'originario' di Unix. Attualmente è alla base della maggior parte, se non di tutti i server e sistemi nel mondo.
I linguaggi di programmazione sono strumenti che utilizziamo per risolvere specifici problemi informatici che ci influenzano su larga scala.
Non hai bisogno di conoscere C per creare pagine e applicazioni web, ma torna utile quando vuoi scrivere un sistema operativo, un programma che controlla altri programmi, un'utilità di programmazione per lo sviluppo del kernel o quando vuoi programmare dispositivi integrati in qualsiasi applicazione di sistema. C eccelle in tutte queste attività, quindi vediamo insieme alcune ragioni per apprendere questo linguaggio.
C aiuta a capire come funziona un computer
Nonostante C sia un linguaggio di programmazione general purpose, è principalmente usato per interagire con le funzioni macchina di basso livello. A parte le ragioni pratiche dietro all'apprendimento del linguaggio, conoscere C può aiutarti a capire come funziona effettivamente un computer, cosa accade dietro le quinte e come i programmi vengono realmente eseguiti sulle macchine.
Dato che C è considerato la base di altri linguaggi di programmazione, se sei in grado di comprendere i concetti su cui si basa, in seguito, ti sarà molto più facile imparare altri linguaggi.
Scrivere del codice C ci fa comprendere i processi nascosti che si verificano nei nostri computer, permettendoci ci avvicinarci all'hardware senza confonderci con il linguaggio assembly. Ci dà anche accesso a una moltitudine di azioni di basso livello restando leggibile come i linguaggi di alto livello.
C è veloce ed efficiente
Allo stesso tempo, non perdiamo la funzionalità, l'efficienza e il controllo di basso livello sull'esecuzione del codice che fornisce assembly.
Ricorda che ogni processore nell'hardware di un qualsiasi dispositivo possiede il proprio codice assembly, che è unico per quel processore e non è affatto compatibile con tutti i processori di altri dispositivi.
Usare C ci garantisce un approccio più veloce, facile e complessivamente meno macchinoso, nei confronti dell'interazione con il computer nel suo livello più basso. Infatti, è una commistione di funzionalità sia di alto che di basso livello e ci aiuta a svolgere un compito senza i problemi e le scocciature del lungo e spesso poco comprensibile codice assembly.
Dunque, C è quanto più vicino tu possa arrivare all'hardware del computer e costituisce un ottimo rimpiazzo per assembly (il vecchio standard per scrivere sistemi operativi) quando stai lavorando sull'implementazione di un software di sistema.
C è potente e flessibile
La stretta vicinanza all'hardware implica che il codice C debba essere scritto in modo esplicito e preciso. Ti dà una chiara immagine di un modello mentale per capire come il codice interagisce con il computer.
C non nasconde la complessità con cui una macchina opera. Ti dà potere e flessibilità, come l'abilità di assegnare, manipolare e scrivere direttamente nella memoria.
Il programmatore svolge un sacco di duro lavoro e il linguaggio permette di gestire e strutturare la memoria in un modo efficiente per la macchina, garantendo performance elevate, ottimizzazione e velocità. C permette al programmatore di fare ciò di cui ha bisogno.
C è portabile, prestante e indipendente dalla macchina
C è anche altamente portabile e indipendente dalla macchina. Anche se è vicino alla macchina e ha accesso alle sue funzioni di basso livello, possiede un'astrazione da quelle componenti, tale da rendere possibile la portabilità.
Dato che le istruzioni assembly sono specifiche per ogni macchina, i programmi non sono portabili. Un programma scritto su una macchina dovrebbe essere riscritto per essere eseguito su un'altra, ed è complicato gestire tutto ciò considerando l'architettura di ogni computer.
C è universale e i programmi scritti in C possono essere compilati ed eseguiti su un gran numero di piattaforme, architetture e una varietà di macchine senza perdite in termini di prestazioni. Questo è ciò che fa di C un'ottima scelta per la creazione di sistemi e programmi in cui la performance è cruciale.
C ha ispirato la creazione di molti linguaggi di programmazione
Molti linguaggi oggi comunemente usati, come Python, Ruby, PHP e Java, traggono ispirazione da C. Questi linguaggi moderni si basano su C per operare efficientemente. Anche le loro librerie, i loro compilatori e interpreti sono costruiti in C.
Questi linguaggi nascondono la maggior parte dei dettagli sul funzionamento reale di un programma e, utilizzandoli, non devi aver a che fare con l'assegnazione della memoria, bit e byte, in quanto ci sono più livelli di astrazione. Non hai bisogno di un simile controllo dettagliato con applicazioni di alto livello dove ogni interazione con la memoria può determinare degli errori.
Ma quando stai implementando una parte di un sistema operativo e di un dispositivo integrato, conoscere quei dettagli di basso livello e di manipolazione diretta può aiutarti a scrivere un codice più pulito.
C è un linguaggio compatto
Nonostante C possa essere piuttosto criptico e difficile da comprendere per i principianti, è in realtà un linguaggio ragionevolmente ridotto e compatto con una sintassi e un insieme di parole chiave e di funzioni integrate minimale. Quindi, puoi sperare di imparare e utilizzare le sue funzionalità basilari, già esplorandone il funzionamento.
Anche se non sei interessato a imparare come programmare un sistema operativo o un'applicazione di sistema, conoscere le basi di C e il modo in cui interagisce con il computer ti darà delle buone basi di concetti e principi informatici.
Inoltre, capire come funziona ed è organizzata una memoria è un concetto di programmazione fondamentale. Quindi, comprendere il funzionamento di un computer a un livello più profondo e i processi che avvengono al suo interno, può davvero aiutarti a imparare e utilizzare altri linguaggi.
Dove viene utilizzato C?
C'è tantissimo codice C nei dispositivi, prodotti e strumenti che che utilizziamo nelle nostre vite quotidiane. Questo codice è alla base di tutto, dai supercomputer ai gadget più piccoli.
Il codice C fa funzionare i sistemi integrati e i dispositivi smart di tutti i tipi. Alcuni esempi sono le applicazioni domestiche come frigoriferi, TV, macchine da caffè, lettori DVD e videocamere digitali.
Il tuo fitness tracker e il tuo smart watch? Basati su C. Il sistema di rilevamento GPS della tua automobile e i semafori? Hai indovinato – C. E ci sono molti altri esempi di sistemi integrati che si basano sul codice C usati nell'industria medicale, robotica e automobilistica.
Un'altra area in cui C è ampiamente usato è nello sviluppo di sistemi operativi e kernel. A parte Unix, per cui il linguaggio è stato creato, altri importanti e popolari sistemi operativi, in una certa misura, sono programmati in C.
Il kernel di Microsoft Windows è scriptato principalmente in C, così come il kernel di Linux. La maggior parte dei supercomputer e anche dei server di Intenet si basa su Linux. Ciò significa che C è alla base di un'ampia porzione di internet.
Linux alimenta anche i dispositivi Android, quindi il codice C fa funzionare non solo i supercomputer, ma anche i computer personali e gli smartphone. Perfino OSX è parzialmente programmato in C, facendo sì che anche i computer Mac si basino su C.
C è anche diffuso per lo sviluppo di applicazioni desktop e di interfacce grafiche (GUI). La gran parte delle applicazioni Adobe che utilizziamo per l'editing di foto e video e per la progettazione grafica (come Photoshop, Adobe illustrator e Adobe Premiere) è programmata con C o il suo successore, C++.
I compilatori, gli interpreti e gli assembler per una varietà di linguaggi sono progettati e costruiti con C – infatti, questi sono alcuni degli utilizzi più comuni del linguaggio.
Molti dei browser e delle loro estensioni sono realizzati con C, come Google Chromium e il file system di Google. Gli sviluppatori usano spesso C anche nella progettazione di database (MySQL e Oracle sono due dei sistemi di database più famosi realizzati in C) e per la grafica avanzata di molti videogiochi.
Da questa panoramica, possiamo vedere che C e il suo derivato C++ gestiscono la gran parte di internet e del mondo in generale. Molti degli apparecchi e delle tecnologie che usiamo nelle nostre vite quotidiane sono scritte o dipendono da C.
Il processo di compilazione di C: scrivi-compila-esegui
Cos'è un programma in C?
Un programma per computer scritto in C è un insieme ordinato di istruzioni comprensibili ed eseguibili da un computer. Punta a fornire una soluzione per uno specifico problema informatico e dice al computer di svolgere una determinata azione tramite una sequenza di istruzioni da seguire.
Essenzialmente, tutti i programmi sono soltanto semplici file di testo memorizzati nell'hard drive del computer, che utilizzano una sintassi speciale, definita dal linguaggio di programmazione che stai usando.
Ogni linguaggio ha le proprie regole che determinano cosa puoi scrivere e cosa è considerato valido e cosa no.
Un programma possiede delle parole chiave, ovvero delle parole specifiche che sono riservate e fanno parte del linguaggio. Contiene anche pezzi letterali di dati come stringhe e numeri. Ha parole specifiche che seguono le regole del linguaggio, che definiamo e introduciamo (come variabili e metodi).
Cos'è un compilatore?
I programmi sono scritti da noi e per noi. Sono fatti per essere compresi dalle persone.
Quando scriviamo programmi in forma leggibile, possiamo capirli – ma il computer potrebbe non esserne in grado. I computer non capiscono direttamente i linguaggi di programmazione, ma soltanto il binario. Quindi i programmi devono essere tradotti così che il computer possa realmente capire le istruzioni del programma.
I programmi scritti in linguaggi di alto livello possono essere compilati o interpretati. Fanno uso di parti speciali di software chiamati rispettivamente compilatori e interpreti.
Qual è la differenza tra un compilatore e un interprete?
Sia i compilatori che gli interpreti sono programmi, ma di una complessità di gran lunga superiore a quelli usuali e agiscono come traduttori. Prendono un programma così com'è scritto e lo trasformano in una forma comprensibile per il computer. E rendono possibile l'esecuzione di programmi su sistemi differenti.
I programmi compilati vengono prima convertiti in una forma comprensibile dal computer, ovvero vengono tradotti in linguaggio macchina prima di essere eseguiti. Il codice macchina è un linguaggio numerico – istruzioni binarie composte da una sequenza di 0 e 1.
La compilazione produce un programma eseguibile, che è un file contenente il codice in linguaggio macchina, che la CPU (Central Processing Unit) sarà in grado di leggere, capire ed eseguire direttamente.
Dopodiché, il programma può girare e il computer fa quello che il programma gli dice di fare. I programmi compilati hanno una corrispondenza più forte con l'hardware e possono manipolare più facilmente la CPU e la memoria del computer.
I programmi interpretati, d'altro canto, non sono eseguiti direttamente dalla macchina né hanno bisogno di essere tradotti in un programma in linguaggio macchina. Invece, utilizzano un interprete che traduce automaticamente e direttamente, ed esegue ogni dichiarazione o istruzione del codice riga per riga durante il run time.
C è un linguaggio di programmazione compilato. Ciò significa che usa un compilatore per analizzare il codice sorgente scritto in C che viene poi convertito in un file binario che l'hardware del computer può eseguire direttamente. Tutto ciò è specifico per ogni macchina.
Come utilizzare il compilatore GCC con esempi
Unix e altri sistemi simili hanno già un compilatore C integrato e installato. Questo vuol dire che Linux e MacOS hanno un compilatore integrato molto popolare, chiamato compilatore GCC (o GNU Compiler Collection).
Nel resto di questa sezione, vedremo alcuni esempi relativi a questo compilatore. Ho basato questi esempi su sistemi Unix o simili, quindi se hai un sistema Windows, assicurati di abilitare il sottosistema Windows per Linux.
Prima di tutto, assicurati di avere il compilatore GCC installato. Puoi verificarlo aprendo il terminale e scrivendo gcc --version nel prompt, tipicamente dopo il carattere $.
Se stai usando MacOS e non hai installato gli strumenti per sviluppatori da riga di comando, visualizzerai una finestra di dialogo che ti chiederà di installarli – quindi se la vedi, prosegui pure.
Una volta aver proceduto con l'installazione, apri un nuovo terminale e riscrivi il comando gcc --version. Se hai già installato gli strumenti da riga di comando, dovresti ottenere l'output qui sotto:

Il solo termine compilazione è un'astrazione e una semplificazione, dato che in realtà ci sono molti step che avvengono in dietro le quinte. Sono i dettagli di basso livello più sottili che avvengono tra il momento in cui scriviamo, la compilazione e l'esecuzione del programma in C, la cui maggior parte, avviene automaticamente senza che ce ne rendiamo conto.
Come scrivere il codice sorgente C
Per sviluppare dei programmi in C, abbiamo bisogno di un qualche tipo di editor di testo. Un editor di testo è un programma che usiamo per scrivere il nostro codice (chiamato codice sorgente) in un file di testo.
Per questo, abbiamo bisogno di un editor di testo da riga di comando come nano o Vim.
Puoi anche utilizzare un IDE (Integrated Development Environment) o un editor di testo con caratteristiche di IDE (un terminale integrato, la possibilità di scrivere, fare debug, eseguire i nostri programmi in solo posto senza lasciare l'editor, e molto altro).
Visual Studio Code è un editor con queste caratteristiche, e ha un'estensione C/C++. Per tutto il resto di questo tutorial useremo VSCode.
Tornando al nostro terminale, prosegui e scrivi i comandi qui sotto per creare un file in cui il nostro codice C prenderà vita.
`cd` # Ci porta alla directory principale, se non ci siamo già
`mkdir cprogram` # Crea una directory chiamata cprogram
`cd cprogram` # Ci porta alla directory cprogram appena creata
`touch hello.c` # Crea un file chiamato hello
`code .` # Apre VSCODE nella directory attuale
Abbiamo appena creato un semplice file di testo, hello.c. Questo file conterrà il codice scritto in linguaggio C, ovvero sarà un programma in C, come indicato dall'estensione convenzionale .c.
Al suo interno possiamo scrivere qualsiasi programma in C desideriamo, partendo da uno estremamente semplice che dà come output 'Hello world'.

Per vedere cosa fa effettivamente il nostro codice, dobbiamo eseguire il programma che abbiamo appena scritto. Prima di farlo, però, dobbiamo compilarlo, scrivendo il comando nel terminale.
Possiamo continuare a usare la riga di comando sul nostro computer oppure possiamo usare il terminale integrato di VSCode (premendo insieme i tasti control ~ si aprirà una nuova finestra terminale).
Possiamo vedere che sul pannello di sinistra c'è solo un file nella cartella cprogram, hello.c, che contiene il nostro codice C.
La "compilazione del codice C" non avviene in un solo passaggio e include alcune azioni minori che si verificano automaticamente.
Quando ci riferiamo alla compilazione, intendiamo tipicamente che il compilatore prende il codebase come input (il codice che abbiamo scritto in C, che ha una sintassi simile all'inglese) e lo traduce per produrre delle istruzioni in linguaggio macchina come output.
Questo codice macchina corrisponde direttamente alle istruzioni del nostro codice sorgente, ma è scritto in un modo comprensibile dalla CPU, così che questa possa prendere le istruzioni ed eseguirle.
Come il codice sorgente in C viene trasformato in binario
Abbiamo descritto l'idea generale – ma nel processo sono coinvolti 4 passaggi minori. Quando compiliamo il nostro codice, in realtà lo stiamo precompilando, compilando, assemblando e collegando.
Questi step iniziano ad accadere quando scriviamo nel terminale il comando gcc hello.c, contenente il nome del compilatore e del file con il codice sorgente, rispettivamente.
Volendo, avremmo potuto personalizzare il comando scrivendone uno più specifico come gcc -o hello hello.c, dove:
-osta per 'output'helloè il nome che specifichiamo per il file eseguibile del programma di cui vogliamo che sia creato l'outputhello.cè il file che il compilatoregccprenderà come input (il file che contiene il nostro codice sorgente e che vogliamo compilare).
Un altro programma che è parte del compilatore svolge questo primo step – il preprocessore. Il preprocessore fa molte cose – ad esempio, agisce come uno strumento "trova e sostituisci", scansionando il codice sorgente in cerca di istruzioni particolari e righe che iniziano con #.
Le righe che iniziano con un #, come #include, vengono chiamate direttive di precompilazione. Ogni riga che inizia con un # indica al preprocessore che va fatto qualcosa. In particolare, comunica che la riga dovrebbe essere automaticamente sostituita con qualcos'altro. Non vediamo questo processo, ma accade dietro le quinte.
Ad esempio, quando il preprocessore trova la riga #include <stdio.h> nel programma hello world, #include dice letteralmente al preprocessore di inserire, con un copia e incolla, tutto il codice del file di intestazione (che è una libreria esterna, stdio.h) al posto di questa istruzione nel nostro codice sorgente. Quindi sostituisce la riga #include <stdio.h> con il contenuto del file stdio.h.
Nella libreria stdio.h ci sono prototipi di funzioni e definizioni o suggerimenti. In questo modo, tutte le funzioni sono definite in modo che il computer le riconosca durante il tempo di compilazione e che noi possiamo usarle nel nostro programma.
Ad esempio, all'interno di <stdio.h>, la funzione printf(); è definita come int printf(const char *format,…);. Gli stessi passaggi si verificano per gli altri file di intestazione (i file con l'estensione .h).
Durante la precompilazione, i commenti nel nostro codice vengono rimossi e le macro vengono espanse e rimpiazzate dai loro valori. Una macro è un frammento di codice a cui è stato dato un nome.
In questo stadio, se non ci sono errori nel nostro codice, non dovrebbe esserci un output nel terminale, il che è un buon segno.
Non vediamo nessun output, ma è stato creato un nuovo file con l'estensione .i, che è ancora in codice sorgente C. Questo file include l'output della precompilazione, quindi viene chiamato codice sorgente precompilato. In questo caso, è stato generato un nuovo file hello.i, ma non sarà visibile nel nostro editor.
Se eseguiamo il comando gcc -E hello.c:

Saremo in grado di vedere tutto il contenuto di questo file (che è piuttosto grande), la cui fine dovrebbe essere simile a:
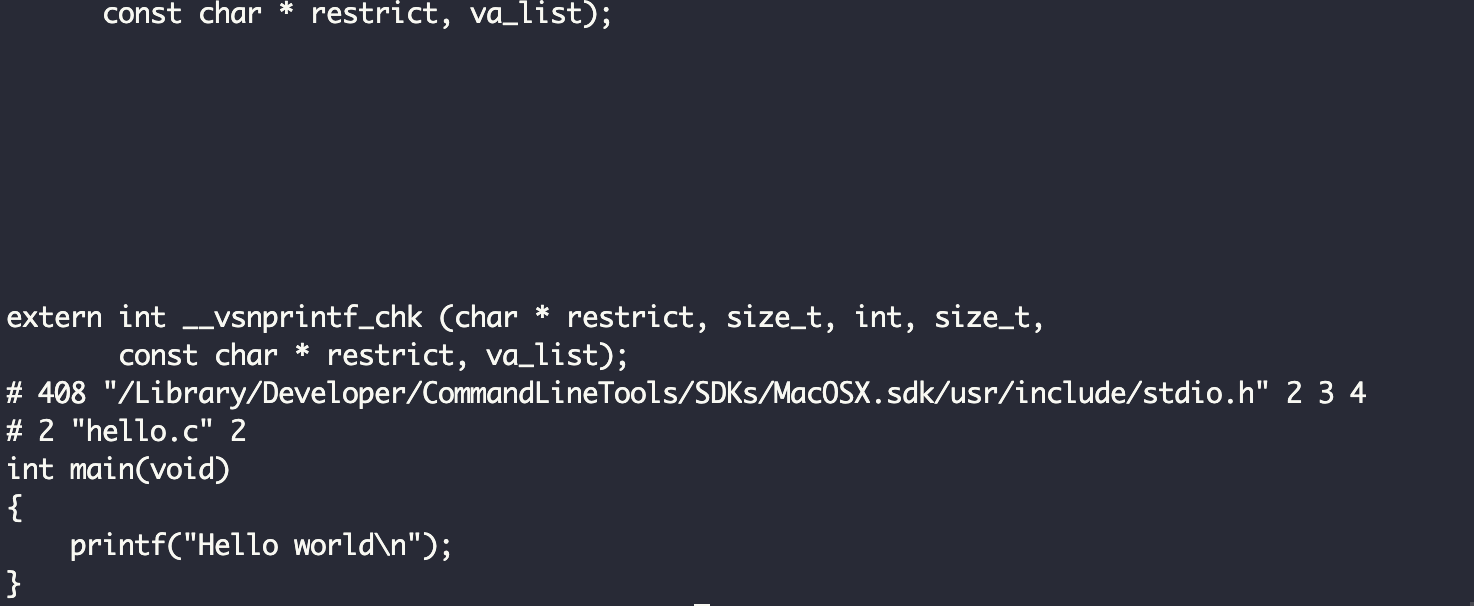
Se ci sono degli errori che inficiano la correttezza del nostro codice o non stiamo seguendo la semantica del linguaggio, vedremo dei messaggi di errore e la compilazione si bloccherà. Dovremo correggere gli errori e far ripartire il processo dall'inizio.
La compilazione in C
Dopo la precompilazione, che produce il codice sorgente C precompilato, avviene la compilazione. Questo processo consiste nel prendere il codice (che è ancora codice sorgente in C) e modificarlo in un'altra forma intermedia. Questo passaggio viene svolto da un compilatore.
Per rinfrescarci la memoria, un compilatore è un programma che prende il codice sorgente come input e lo traduce in una forma più vicina al linguaggio nativo dei computer.
Riferendoci alla compilazione, possiamo intendere sia l'intero processo di traduzione del codice sorgente in un codice oggetto (codice macchina) o soltanto uno step specifico dell'intero processo di compilazione.
Il passaggio di cui stiamo discutendo adesso riguarda la conversione, da parte del compilatore, di ogni istruzione del codice sorgente C preprocessato in un linguaggio più familiare e più vicino al binario, il linguaggio che un computer può capire direttamente.
Questo linguaggio intermedio è codice assembly, un linguaggio di programmazione di basso livello usato per controllare la CPU e manipolarla per svolgere operazioni specifiche e avere accesso alla memoria del computer. Ricordi il codice assembly di cui abbiamo parlato nella sezione sulla storia di C?
Ogni CPU – il cervello del computer – ha le proprie istruzioni. Il codice assembly sfrutta delle istruzioni e dei comandi direttamente correlati con le istruzioni e le operazioni di basso livello che vengono svolte da una CPU.
In questo step del processo di compilazione, ogni istruzione del codice sorgente C preprocessato nel file hello.i è tradotta dal compilatore nell'istruzione equivalente in linguaggio assembly, a un livello più basso.
L'output di quest'azione crea un file con estensione .s (nel nostro caso hello.s) che contiene le istruzioni in assembly.
Con il comando gcc -S hello.c possiamo vedere il contenuto e i comandi in assembly piuttosto incomprensibili del file hello.s, creato dal compilatore (ma non visibile scrivendo semplicemente gcc hello.c).
Guardando con attenzione, vedremo un paio di parole chiave e istruzioni familiari, usate nel nostro codice sorgente C. Ad esempio, main e printf:
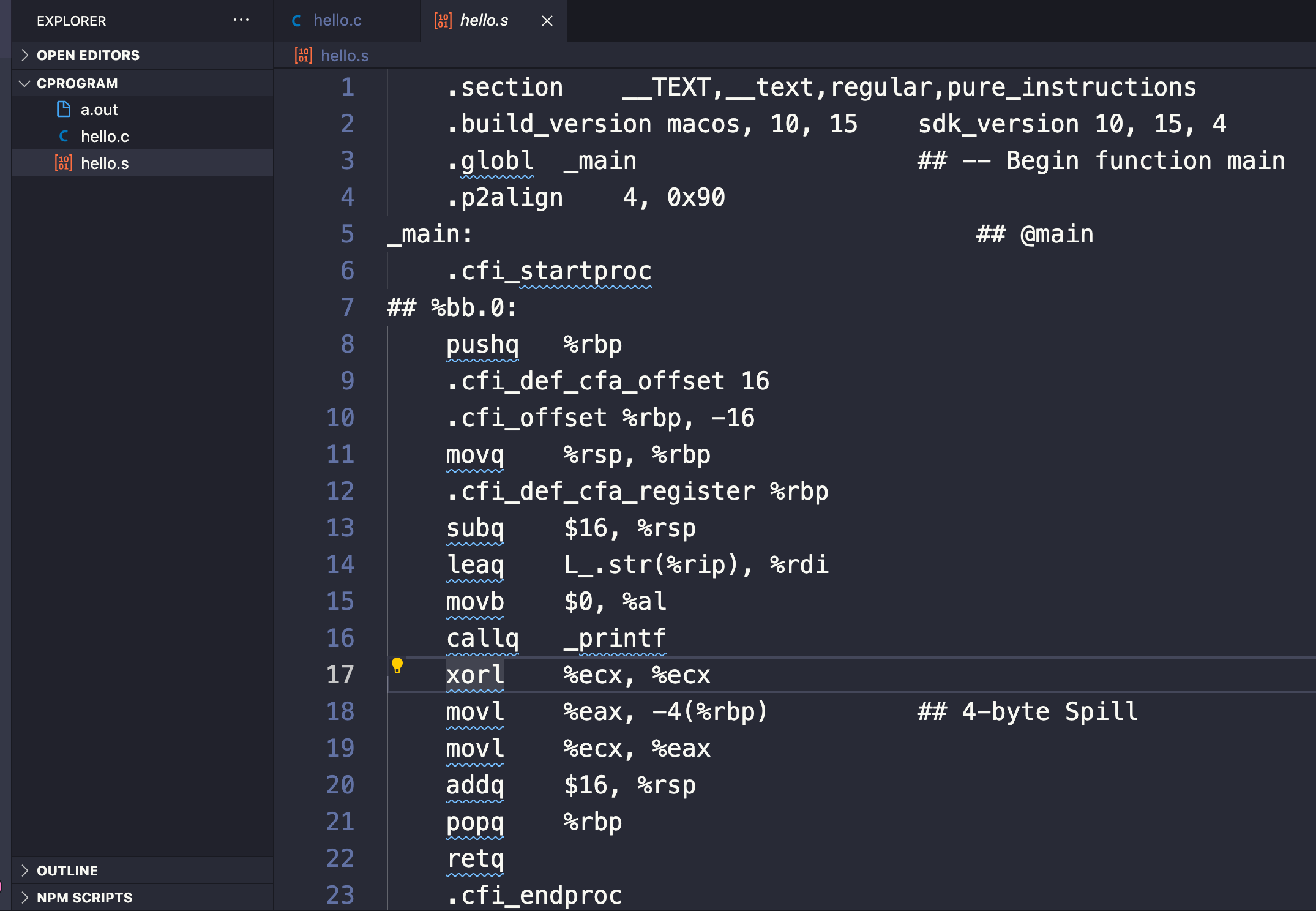
L'assemblaggio in C
L'assemblaggio consiste nel prendere come input il file hello.s contenente il codice assembly e, con l'aiuto di un altro programma che viene eseguito automaticamente nel processo di compilazione, assemblarlo in istruzioni in codice macchina. Questo vuol dire avere un output di istruzioni in formato binario, composto di una serie di 0 e 1.
Questo passaggio avviene in background e genera le istruzioni nel linguaggio finale, tradotte a partire dal nostro codice sorgente. Adesso il computer è finalmente in grado di capire le istruzioni.
Ogni comando che abbiamo scritto nel codice sorgente C è stato trasformato in istruzioni in linguaggio assembly e, infine, nelle istruzioni equivalenti in binario. Tutto ciò è accaduto con il comando gcc. Wow!
Il codice che abbiamo adesso è detto codice oggetto e può essere compreso da una specifica CPU. Il linguaggio è incomprensibile per noi umani.
Le persone programmavano in linguaggio macchina, ma era un procedimento tedioso. È difficile raccapezzarsi con tutti i simboli che non fanno parte del codice macchina (cioè tutto ciò che non è 0 o 1). Programmare in questo modo rende estremamente facile commettere degli errori.
In questo stadio, viene creato un altro file con un'estensione .o (che sta per oggetto) – hello.o nel nostro caso.
Possiamo vedere il contenuto del file oggetto contenente le istruzioni al livello macchina con il comando gcc -c hello.c. Se lo facciamo, in hello.o vedremo del contenuto non comprensibile da una persona:
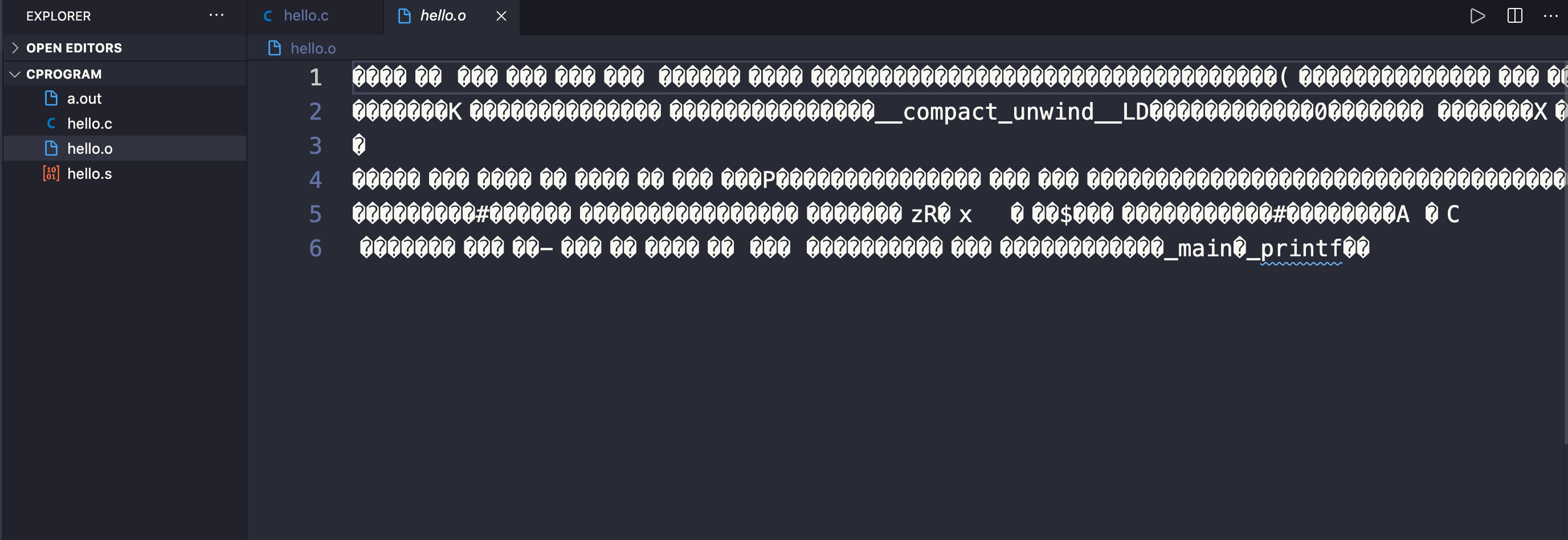
Il collegamento in C
Nell'immagine qui sopra, potresti aver notato un file a.out nella nostra cartella.
Il file viene creato durante uno step di default quando digitiamo il comando del compilatore e il nome del file, gcc hello.c nel nostro caso.
Se usiamo il comando precedentemente menzionato gcc -o hello hello.c, vedremo un programma eseguibile con il nome personalizzato hello al posto di a.out.
a.out sta per assembly output. Se scriviamo ls sul terminale per vedere l'elenco dei file nella nostra cartella, vedremo che a.out ha anche un aspetto diverso dagli altri:

Il collegamento è il passaggio finale del processo di compilazione in cui il file finale in binario hello.o viene collegato con l'altro codice oggetto nel nostro progetto.
Quindi se ci sono altri file contenenti codice sorgente C (come file inclusi nel nostro programma che implementano librerie C già processate e compilate, o un altro file che abbiamo scritto oltre a hello.c, chiamato, ad esempio, nomefile.c), questo è il momento in cui il file oggetto nomefile.o verrà combinato con hello.o e gli altri codici oggetto, e risulteranno collegati tutti insieme.
Il risultato è un grande file eseguibile con il codice macchina combinato, a.out o hello, che rappresenta il nostro programma.
Dato che abbiamo finalmente terminato il processo di compilazione, il programma è nella sua forma finale e possiamo eseguire il file sulla nostra macchina scrivendo ./a.out. Questo vuol dire 'eseguire il file a.out che è nella cartella di lavoro attuale', dato che ./ rappresenta la cartella in cui ci troviamo. Poi vedremo l'output del nostro programma sul terminale:

Ogni volta che apportiamo dei cambiamenti al nostro file con il codice sorgente, dobbiamo ripetere il processo di compilazione dall'inizio per poter vedere le modifiche quando eseguiamo di nuovo il codice.
Come scrivere Hello World in C
Hello world è un programma estremamente semplice, ma scriverlo è una tradizione quando stai imparando a programmare in un nuovo linguaggio.
Se esegui con successo il tuo programma Hello world, sai che il tuo sistema è configurato correttamente.

{kind=link}
Un programma Hello world contiene la sintassi di base del linguaggio:
#include<stdio.h>
int main(void)
{
// stampa hello world sullo schermo
printf("Hello world\n");
}
Nelle prossime sezioni analizzeremo le varie parti che lo compongono.
I File di intestazione in C
I file di intestazione sono librerie esterne, ovvero del codice già scritto da sviluppatori ad uso di altri sviluppatori.
Forniscono funzionalità che non sono incluse nel nucleo del linguaggio C. Aggiungendo i file di intestazione al codice, otteniamo funzionalità aggiuntive da utilizzare nei nostri programmi.
I file di intestazione come include <stdio.h> terminano con l'estensione .h. In particolare, un file di intestazione come stdio.h è già integrato nel compilatore.
La riga include <stdio.h> è un'istruzione per le funzioni contenute nella libreria stdio.h, che dice al computer di accedervi e includerle nel nostro programma.
stdio.h ci dà le funzionalità standard input e standard output, grazie alle quali saremo in grado di ottenere input e fornire output agli utenti. Quindi, dovremmo imparare a usare funzioni di input/output come printf.
Se non includi il file stdio.h all'inizio del codice, il computer non comprenderà cos'è la funzione printf.
Il programma main in C
Ecco il codice:
int main(void)
{
}
Questa è la funzione principale di partenza in C. Le parentesi graffe ({}) sono il corpo che contiene tutto il codice che dovrebbe essere nel nostro programma.
Questa riga agisce come modello e punto di partenza per tutti i programmi in C. Fa sapere al computer dove iniziare a leggere il codice durante l'esecuzione dei programmi.
Commenti in C
Tutto ciò che scriviamo dopo // non influenzerà l'esecuzione del nostro codice e non sarà preso in considerazione dal computer durante il tempo di compilazione ed esecuzione.
Le due sbarre indicano la presenza di un commento, ovvero una nota per noi e i nostri collaboratori. I commenti possono aiutarci a ricordare cosa fa una specifica riga di codice o perché si trova in quella posizione. Ci ricorda anche lo scopo preciso di una parte di codice quando torniamo a lavorarci su dopo un giorno o addirittura dopo alcuni mesi.
Ottenere un output sulla console in C
printf("Hello world/n"); stampa la frase 'Hello world' sulla console. Utilizziamo printf quando vogliamo scrivere qualcosa e vedere un output sullo schermo. I caratteri che fanno parte dell'output devono essere compresi tra virgolette doppie "" e parentesi ().
/n è un carattere di escape, che crea una nuova riga e comunica al cursore di muoversi a capo quando viene incontrato.
; indica la fine della frase e la fine della riga di codice.
Variabili in C
Ecco come definiamo una variabile in C:
Un elemento di dati che può assumere uno o più valori durante il runtime di un programma.
In termini più semplici, puoi pensare a una variabile come una scatola con un nome. Una scatola che agisce come posto per immagazzinare diverse informazioni e il cui contenuto può variare.
Ogni scatola ha un nome unico, che ha la funzione di etichetta identificativa che ci informa sul contenuto della scatola. Il contenuto è il valore della variabile.
Le variabili contengono e puntano a un valore, a qualche dato utile. Agiscono come riferimento o astrazione per dati letterali. Questi dati sono conservati nella memoria del computer e occupano un certo spazio. Si trovano lì, così che possiamo recuperarli per usarli quando ne abbiamo bisogno più avanti nei nostri programmi.
Come suggerisce il nome, ciò a cui fa riferimento una variabile può variare. Le variabili sono in grado di assumere valori diversi nel tempo, in base alle informazioni che cambiano durante la vita del programma.
Assegnazione delle variabili in C
Il processo di dare un nome a una variabile si chiama assegnazione. Ciò avviene tramite l'uso dell'operatore di assegnazione =, impostando un valore specifico per un nome specifico, rispettivamente alla destra e alla sinistra dell'operatore.
Come già detto, puoi cambiare il valore della variabile, quindi puoi assegnare e riassegnare variabili. Quando riassegni un valore, il nuovo valore punta al nome della variabile. Quindi, il valore può cambiare, ma il nome della variabile resta invariato.
Come dichiarare e inizializzare una variabile in C
A differenza di molti altri moderni linguaggi di programmazione, l'assegnazione dei tipi delle variabili in C segue una tipizzazione statica forte.
Nei linguaggi tipizzati staticamente, devi dichiarare esplicitamente il tipo di dato di una variabile. In questo modo, durante il tempo di compilazione, il compilatore conosce se una variabile è in grado di eseguire l'azione stabilita e richiesta.
Nei linguaggi tipizzati dinamicamente, una variabile può passare tra differenti tipi di dati senza bisogno di una definizione esplicita del tipo di dato.
Dunque, quando dichiariamo una nuova variabile in C, dobbiamo definire e specificare il tipo della variabile, ovvero il tipo del valore che contiene.
In questo modo, il programma e poi il compilatore conoscono la natura dell'informazione memorizzata.
Per dichiarare una variabile, devi specificare il tipo di dato e dare un nome alla variabile. Uno step opzionale è impostare un valore iniziale. Non dimenticare il punto e virgola alla fine, per terminare l'istruzione!
#include <stdio.h>
int main(void)
{
int n = 27;
// int è il tipo di dato
// n è il nome
// n può contenere valori interi
// numeri interi positivi/negativi o 0
// = è l'operatore di assegnazione
// 27 è il valore
}
Qual è la differenza tra inizializzare e dichiarare una variabile?
In sostanza:
int n; // dichiarazione: crea una variabile chiamata n in grado di contenere valori interi
int n = 27; // inizializzazione: crea una variabile chiamata n e assegna un valore, memorizzando il numero nella variabile
int n; è la dichiarazione della variabile. Dichiarare vuol dire definire un nome per la variabile e specificarne il tipo.
Non dobbiamo necessariamente specificare un valore per la variabile, basta questo. Infatti, la dichiarazione comunica al computer che vogliamo che la variabile esista e abbiamo bisogno di assegnarle dello spazio in memoria. Il valore sarà immagazzinato in un secondo momento.
In seguito, quando assegniamo il valore alla variabile, non c'è bisogno di specificare di nuovo il tipo di dato. Possiamo anche dichiarare più variabili in un colpo solo.
int nome, età;
Se dichiariamo una variabile e le assegniamo contemporaneamente un valore, stiamo inizializzando la variabile.
int n = 27; è l'inizializzazione della variabile. Vuol dire assegnare un valore iniziale che in seguito può essere cambiato.
Se il nuovo valore è dello stesso tipo di dato, non dobbiamo specificarlo. Se invece il tipo di dato è differente, otterremo un errore.
#include<stdio.h>
int main(void)
{
int age = 27;
age = 37;
// il nuovo valore di age è 37
}
Nomenclatura delle variabili in C
- I nomi delle variabili devono iniziare con una lettera o con un trattino basso. Ad esempio
agee_agesono dei nomi validi. - Il nome di una variabile può contenere lettere (maiuscole o minuscole), numeri o un trattino basso.
- Non possono esserci altri caratteri speciali oltre il trattino basso.
- I nomi delle variabili sono case sensitive, quindi
ageè diversoAge.
Visibilità di una variabile in C
La visibilità (scope) di una variabile fa riferimento a dove è possibile avere accesso alla variabile. È essenzialmente lo spazio in cui la variabile si trova ed è valida, e il modo in cui è vista dal resto del programma.
Visibilità locale
Se una variabile viene dichiarata all'interno di un set di parentesi graffe, {}, come una specifica funzione, avrà una visibilità locale (local scope) e non sarà possibile avere accesso alla variabile nel resto del programma al di fuori delle parentesi. Il resto del programma non saprà che esiste.
Perciò, può non essere una buona idea dichiarare variabili in questo modo, in quanto la visibilità e l'utilizzo limitati possono generare degli errori.
Visibilità globale
Se le variabili vengono dichiarate al di fuori delle funzioni, hanno una visibilità globale (global scope). Avere una visibilità globale vuol dire che vi si può accedere da ogni parte del programma.
Ma tieni a mente che può essere difficile tenerne traccia. Ogni cambiamento che facciamo strada facendo può confondere, dato che può avvenire in qualsiasi parte del programma.
Tipi di dati in C
I tipi di dati specificano in che forma possiamo rappresentare e immagazzinare un'informazione nel nostro programma in C. Ci permettono di conoscere come potrà essere utilizzata quell'informazione e le operazione che vi potranno essere eseguite.
I tipi di dati determinano anche quale può essere il contenuto di una variabile, dato che ogni variabile in C ha bisogno di una dichiarazione esplicita del tipo di dato.
Ci sono 6 tipi di dati integrati nel linguaggio, ma è possibile convertire tipi diversi. Ciò fa sì che il linguaggio non sia così fortemente tipizzato.
Ogni tipo di dato richiede una diversa assegnazione di memoria e può avere degli intervalli di valori validi differenti.
Aggiungere parole chiave prima del nome di un tipo di dato lo modifica. Queste parole chiave possono essere unsigned o signed.
La parola chiave unsigned sta a significare che il tipo può essere soltanto positivo e non negativo, mentre signed permette di avere un numero negativo o positivo.
Diamo un'occhiata più dettagliata a questi tipi di dati.
Il tipo di dato char in C
Il tipo di dato più semplice in C è char. Si utilizza per caratteri singoli come quelli della tabella ASCII come 'a', 'Z', o '!" (nota l'uso delle virgolette singole per circondare il carattere – non puoi utilizzare le virgolette doppie in questo caso).
char ti permette anche di memorizzare i numeri da -128 a 127 e in entrambi i casi utilizza 1 byte di memoria.
Un unsigned char può assumere i valori da 0 a 255.
Il tipo di dato int in C
int è un numero intero che può contenere un valore positivo o negativo o 0 senza decimali.
È un valore con un numero di bit limitato. Quando dichiari un int, il computer gli assegna 4 byte di memoria (più specificamente utilizza almeno 2 byte, ma di solito ne usa 4). 4 byte di memoria equivalgono a 32 bit (dato che 1 byte = 8 bit). Quindi un int ha 232 possibili valori – più di 4 miliardi di interi possibili.
L'intervallo va da -231 a 231-1, più precisamente da -2,147,483,648 a 2,147,483,647.
- Un unsigned int ha ancora la stessa dimensione in memoria di un intero (4 bytes) ma non include i numeri negativi nell'intervallo dei valori possibili, che quindi va da 0 a 232-1, più precisamente da 0 a 4,294,969,295
- Uno short int ha un valore più piccolo di un int e occupa 2 byte di memoria. È compreso nell'intervallo da -32,768 a 32,767
- Un unsigned short int occupa 2 byte di memoria e è compreso tra 0 e 65,535
- Un long int è destinato a numeri grandi. Occupa almeno 4 byte di memoria, ma solitamente occupa 8 byte ed è compreso tra -2,147,483,648 e 2,147,483,647
- Un unsigned long int occupa almeno 4 byte di memoria ed è compreso tra 0 e 4,294,967,295
- Un long long int è un intero con più bit che è in grado di contenere numeri più grandi di un int o un long int. Occupa 8 byte (64 bit) invece di 4. Questo permette un intervallo più ampio, da -263 a 263-1, più precisamente da -9,223,372,036,854,775,808 a 9,223,372,036,854,775,807
- Un unsigned long long utilizza 8 bytes e va da 0 a 18,446,744,073,709,551,615
Il tipo di dato float in C
I float sono numeri con una parte decimale (anche detti numeri reali), con precisione singola, e occupano 4 byte di memoria.
Il tipo di dato double in C
Un double è un numero decimale con un valore maggiore di un float. Occupa più memoria rispetto a un float – 8 bytes – e ha precisione doppia.
- Un long double è di dimensione maggiore in confronto a un float e un double e occupa almeno 10 byte di memoria, fino a un massimo di 12 o 16 byte.
Infine, il tipo di dato void significa essenzialmente nessun valore.
Specificatori di formato in C
Gli specificatori di formato vengono utilizzati per gli input e gli output in C.
Sono un modo per comunicare al compilatore che tipo di dato accetta una variabile come input e quale tipo di dato produce come output utilizzando la funzione printf(). La f in printf() sta per formattato.
Agiscono come un segnaposto per un formato di codice e sostituiscono le variabili. Fanno sapere in anticipo al compilatore di che tipo sono quando il valore dell'output standard (ovvero ciò che vogliamo stampare) non è ancora conosciuto.
La sintassi che usiamo è % specificatore di formato per il tipo di dato:
#include<stdio.h>
int main(void)
{
int age = 27;
printf("My age is %i/n", age)
// stampa 27
// age è la variabile che vogliamo usare
// %i è lo specificatore di formato, un segnaposto per un valore intero
// separiamo ogni argomento con una virgola
// nell'output %i viene sostituito con il valore di age
}
Ci sono diversi specificatori di formato per ogni tipo di dato di cui abbiamo parlato precedentemente. Eccone alcuni:
| FORMAT SPECIFIER | DATA TYPE |
|---|---|
%c | char |
%c | unsigned char |
%i or &d | int |
%u | unsigned int |
%hi or %hd | short int |
%hu | unsigned short int |
%li or %ld | long int |
%lu | unsigned long int |
%lli or %lld | long long int |
%llu | unsigned long long int |
%f | float |
%lf | double |
%Lf | long double |
Operatori in C
Operatori aritmetici in C
Gli operatori aritmetici sono operatori matematici che eseguono funzioni matematiche su dei numeri. Le operazioni includono l'addizione, la sottrazione, la moltiplicazione e la divisione.
Gli operatori utilizzati più di frequente sono:
+per l'addizione-per la sottrazione*per la moltiplicazione/per la divisione%per la divisione con modulo (restituisce il resto della divisione)
Operatore di assegnazione in C
L'operatore di assegnazione = assegna un valore a una variabile. In altre parole, imposta qualsiasi cosa si trovi sul lato destro di = come valore della variabile sul lato sinistro di =.
Esistono specifici operatori di assegnazione per aggiornare una variabile modificandone il valore.
In C, ci sono diversi modi per aggiornare il valore delle variabili. Ad esempio, se vogliamo incrementare il valore della variabile di 1, abbiamo tre modi possibili per farlo.
Prima di tutto, vale la pena precisare che incrementare vuol dire prendere il valore attuale della variabile, qualsiasi valore sia sulla destra, e aggiungervi 1. Il nuovo valore viene memorizzato nella variabile e aggiornato automaticamente.
Consideriamo di voler incrementare o aggiornare una variabile chiamata x con un valore iniziale di 5:
x=5.
Per aggiungere 1 alla variabile x, scriviamo x = x + 1 che vuol dire x = 5 + 1.
Il nuovo valore di x adesso è 6, x=6.
Esiste una scorciatoia per questa operazione, utilizzando una sintassi particolare che incrementa le variabili.
Invece di scrivere x = x +1 scriviamo x += 1.
Un modo ancora più corto è utilizzare l'operatore di incremento, che segue la sintassi nome_variabile ++, quindi nel nostro caso x ++.
La stessa cosa vale per diminuire, ovvero decrementare, una variabile di 1.
I tre modi per farlo sono rispettivamente:
x = x-1, x -= 1, x -- (usando l'operatore di decremento).
Questi sono i modi per incrementare e decrementare una variabile di 1 in C. Siamo in grado di aggiornare una variabile prendendo il suo valore e aggiungendo, sottraendo, moltiplicando e dividendo quel valore per un altro numero, e poi impostando il risultato dell'operazione come nuovo valore. Queste operazioni sono rispettivamente +=, -=, *= e /=.
Quindi con x = x * 5 oppure con la scorciatoia x *= 5 il valore della variabile x sarà moltiplicato per 5 e poi memorizzato in x.
Operatori logici in C
In C, utilizziamo gli operatori logici per prendere decisioni. Il risultato di questo tipo di operazioni può essere vero (true) o falso (false).
L'operatore logico && (and) necessita che gli operandi posti sia al lato sinistro che al destro di && siano veri affinché la condizione sia verificata.
L'operatore logico || (or) necessita che almeno uno degli operandi sul lato destro e sinistro di || sia vero affinché la condizione sia verificata.
Infine, l'operatore logico ! (not) inverte il valore dell'operando. Se un operando è true, allora l'operatore ! rende la condizione false e vice versa.
Operatori di confronto in C
Gli operatori di confronto sono:
- Maggiore di
> - Maggiore di o uguale a
>= - Minore di
< - Minore di o uguale a
=<
Esiste anche l'operatore di uguaglianza, ==, da non confondere con =, l'operatore di assegnazione.
Usiamo == per confrontare due valori e testare che siano uguali oppure no. Questo operatore pone la domanda 'Questi due elementi sono uguali?', mentre = assegna un valore a una variabile.
Utilizzando l'operatore di uguaglianza (che pone la domanda qui sopra) c'è sempre un valore di ritorno che può essere true o false. Questi ultimi sono conosciuti nel mondo della programmazione come valori booleani.
Infine, abbiamo l'operatore di disuguaglianza, !=, utilizzato per verificare se due valori non sono uguali.
Funzioni in C
Le funzioni sono parti di codice che svolgono piccole azioni. Eseguono un compito specifico.
Incorporano una parte di un processo che è pensato per essere ripetuto più volte. Lo scopo delle funzioni è di avere un certo procedimento scritto soltanto una volta, così da poterlo riutilizzare all'occorrenza, più volte e in posti differenti all'interno di un programma. In questo modo, il codice diventa più semplice e meglio organizzato.
Le funzioni hanno uno scopo particolare, esistono per eseguire un compito ed essere riutilizzate, accettando degli input per restituire degli output.
Argomenti di funzioni in C
Gli input che una funzione accetta sono detti argomenti. Una funzione può avere uno o più argomenti.
Una funzione comune nel linguaggio C è printf();, che stampa qualcosa sullo schermo. È una funzione usata per dire qualcosa.
Le parentesi () accolgono l'input della funzione. Al loro interno vanno gli argomenti – ovvero, ciò che vogliamo effettivamente dire e stampare sullo schermo, quindi quello che si trova tra le parentesi viene stampato.
In printf("Hello world!");, Hello world! è l'input della funzione printf. Qui, stiamo chiamando la funzione chiamata printf e le stiamo dando come argomento una stringa, dicendo specificatamente di stampare sullo schermo 'Hello world!'.
Output di funzioni in C
Esistono due tipi di output di funzioni:
- I primi sono output visuali, con un effetto immediato, qualcosa che viene stampato velocemente sullo schermo.
Non puoi fare altro con questi output in seguito al loro effetto. Come nel caso diprintf("Hello world!");, la stringa di output "Hello world!" viene stampata sullo schermo, e fine. Non puoi usare quella stringa in un altro modo, perchéprintfnon ha un valore di ritorno.
Questi tipi di funzioni sono conosciuti come effetti collaterali, nel senso che hanno un effetto osservabile immediato senza restituire un valore.
Inoltre, una funzione comeprintfè un'invocazione di funzione e nella libreriastdioè definita comeint printf(const char *format,...);. - I secondi sono riutilizzabili, in quanto sono dei valori di ritorno. Un valore di ritorno è un valore restituito al programmatore e conservato in una variabile per essere utilizzato in un secondo momento.
In questo caso, l'effetto non è immediato – non viene stampato nulla sullo schermo. L'output ci viene restituito, conservato come informazione e salvato in una variabile.
Come definire un metodo in C
Ci sono tre cose che hai bisogno di avere nella prima riga, la riga di dichiarazione, quando definisci una funzione.
- Il tipo del valore di ritorno
Questa è la prima parola chiave utilizzata e appena la funzione inizia indica il valore di ritorno.
Ad esempio, in una funzione comevoid say_something(void), il primo void vuol dire che la funzione non ha valore di ritorno.
In un altro esempio con una funzione diversa,int main(void), specifichiamo e definiamo il tipo del valore di ritorno comeint. L'output della funzione sarà un dato di tipointe sarà restituito quando la funzione è invocata. - Il nome della funzione
Il nome può essere qualsiasi cosa, tuttavia è una buona pratica chiamare i metodi con dei nomi pertinenti alle azioni che svolgono. - Nessuno, uno o più argomenti
Sono gli input della funzione e il tipo di dati degli input.
Invoid say_something(void), ilvoidtra parentesi è una parola chiave per l'argomento e un segnaposto per "niente". Significa che la funzione non accetta input. In casi come questo, l'argomento è anche detto parametro.
I parametri sono essenzialmente variabili dichiarate nella funzione, all'interno delle parentesi come la parola chiavevoid. Agiscono come segnaposto per accedere ai dati di input della funzione, gli argomenti.
I parametri fanno riferimento al valore che viene passato al metodo. Ciò vuol dire che quando chiamiamo la funzione in un secondo momento, le passiamo il valore reale, ovvero l'argomento.
Come chiamare una funzione in C
Possiamo chiamare una funzione come:
void say_hi(void)
{
printf("hello");
}
scrivendo il nome della funzione seguito dagli argomenti tra parentesi e un punto e virgola, come say_hi();. La funzione say_hi non accetta input e non ha un valore di ritorno. La invochiamo solo per stampare 'hello' sullo schermo.
Un'altra funzione come:
int square(int n)
{
return n * n
}
viene chiamata nello stesso modo dell'esempio precedente. In questo caso, la funzione square accetta un input e ha un valore di ritorno (sono entrambi int). L'input che prende è il parametro chiamato n, che restituisce un int quando la funzione è invocata.
La parola return specifica quello che sarà restituito, l'input n moltiplicato per sé stesso.
Ad esempio, quando la funzione è chiamata con square(3);, n agisce come una variabile che punta al parametro che è stato passato alla funzione, cioè 3. È come se avessimo impostato n = 3, e il valore restituito è 9.
Le funzioni sono pensate per essere riutilizzate, quindi la possiamo usare ogni volta che vogliamo il quadrato di un numero:
#include <stdio.h>
int square(int x)
{
return x * x;
}
int main(void)
{
printf("%i\n", square(2));
printf("%i\n", square(4));
printf("%i\n", square(8));
}
Come usare le espressioni booleane in C
Un'espressione booleana è un'espressione il cui valore può essere true o false. Queste espressioni prendono il loro nome dal matematico, filosofo e logico George Boole.
{kind=link}
Usiamo le espressioni booleane per confrontare due valori, e sono particolarmente utili nelle strutture di controllo.
Ogni valore diverso da 0 è true e 0 è false.
Possiamo combinare espressioni booleane con l'uso di operatori logici differenti, come && (and), || (or) e ! (not) di cui abbiamo parlato precedentemente.
Combinazioni differenti di valori e operatori portano a diversi risultati di output, che possono essere riassunti in una tabella della verità, una tabella matematica usata per rappresentare equazioni logiche il cui risultato è 1 o 0, o il loro equivalente true o false.
Quando confrontiamo due valori booleani usando l'operatore && (and), entrambi i valori devono essere veri affinché lo sia anche l'espressione combinata.
Ad esempio, se qualcuno ci chiede "Vuoi una pizza e dell'insalata?", l'unico modo per cui l'espressione sia vera è che noi vogliamo entrambi i cibi (quindi che la nostra risposta sia sì per tutti e due). Se la risposta per uno dei due non è valutata come true, allora l'espressione combinata è false.
Tabella della verità per &&
| VALUE A | VALUE B | RESULT |
|---|---|---|
| true | false | false |
| false | true | false |
| false | false | false |
| true | true | true |
A differenza di &&, l'operatore || non è esclusivo e l'espressione combinata viene valutata come vera se una o entrambe le espressioni sono vere.
Considerando la precedente domanda di esempio "Vuoi una pizza e dell'insalata?", se cambiamo l'operatore AND con OR, non significa che vogliamo entrambi i cibi. Possiamo volerne uno o l'altro e non necessariamente entrambi.
Tabella della verità per ||
| VALUE A | VALUE B | RESULT |
|---|---|---|
| true | false | true |
| false | true | true |
| false | false | false |
| true | true | true |
Infine, l'operatore ! (not) viene usato per le negazioni. Ciò vuol dire che cambia true in false e false in true.
!true is false
!false is true
Come usare le istruzioni condizionali in C
Le istruzioni condizionali svolgono un'azione specifica in base al risultato di un'operazione di confronto. Sono dette strutture di controllo, poiché sono dei costrutti che governano il flusso di esecuzione, definendo lo svolgimento di un'azione nel caso una condizione sia vera, ed eventualmente un'azione differente nel caso sia falsa.
Alcune parti di un programma possono non essere eseguite a seconda di un risultato o di un certo input dell'utente. L'utente può percorrere diverse strade con varie biforcazioni durante la vita del programma.
I programmi con istruzioni condizionali sfruttano principalmente dei blocchi if. I blocchi if usano espressioni booleane che possono essere true o false, e "prendono decisioni" a seconda dei valori risultanti. Denotiamo il blocco di un'istruzione if usando le parentesi graffe, {}, e indentando il codice come segue.
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 3;
if (x < y)
// x < y è un'espressione booleana, può essere solo true o false.
// Se tutto ciò che è nelle parentesi è true
// -in questo caso x è effettivamente minore di y-
// viene eseguito il seguente codice
{
printf("x è minore di y");
// Poiché x < y è true, la frase verrà stampata sulla console
}
}
Un'istruzione if da sola non è particolarmente utile, soprattutto se il programma cresce sempre di più. In questo caso, l'istruzione if è accompagnata dall'istruzione else.
Il codice qui sotto si comporta in questo modo: se la condizione di if è true viene eseguito il blocco corrispondente, altrimenti viene eseguito il blocco else. La parola chiave else è la soluzione per il caso in cui la condizione di if è falsa e quindi il codice correlato non viene eseguito.
int main(void)
{
int x = 1;
int y = 2;
if ( x > y)
{
printf("x è maggiore di y");
}
else
{
printf("x è minore di y");
// Poiché x > y è false ,
// Questo blocco di codice viene eseguito
// e viene stampata sullo schermo la frase del ramo else
}
}
Se desideriamo scegliere tra più di due opzioni e vogliamo una varietà maggiore di istruzioni e azioni, possiamo introdurre una condizione else if.
Il codice qui sotto si comporta in questo modo: se la condizione è true viene eseguito il primo corrispondente, in caso contrario viene valutata la condizione del blocco else if. Se è true il blocco viene eseguito, altrimenti viene eseguito il blocco else.
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 2;
if(x < y)
// Se la condizione è true esegui questo blocco
{
printf("x è minore di y");
}
else if(x > y)
// Se invece questa condizione è true esegui questo blocco
{
printf("x è maggiore di y");
}
else
// Se questo blocco di codice viene eseguito
// è perché x < y è false
// e anche x > y è false
// il che vuol dire che x == y
{
printf("x è uguale a y");
}
}
Come usare i loop in C
Un loop è un insieme specifico di istruzioni che sono ripetute un certo numero di volte, fino a che una certa condizione viene raggiunta. Si tratta di una stessa azione, uno stesso codice ripetuto ancora e ancora.
Loop while in C
Prima di eseguire qualsiasi codice, i loop while devono valutare una condizione. Se la condizione è verificata, il codice viene eseguito. In caso contrario, il codice non partecipa all'azione. Quindi, l'esecuzione del codice non è garantita neanche una volta se la condizione non si verifica.
Esistono diversi tipi di loop while, e uno di questi è il loop infinito.
#include <stdio.h>
int main(void)
{
while(true)
{
printf("Hello world");
}
}
La parola chiave while è usata insieme all'espressione booleana, in questo caso true (che resta sempre true).
Dopo aver stampato la riga di codice all'interno delle parentesi graffe, la condizione viene rivalutata per sapere se eseguire ancora il corpo del loop. La risposta è sempre sì (dato che la condizione resta true ogni volta), così che l'esecuzione del loop continua indefinitamente.
In quest'esempio, l'unico modo per fermare il programma e uscire da questo loop senza fine è con il comando Ctrl + C dal terminale.
Se invece la condizione fosse stata false, il codice all'interno delle parentesi graffe non sarebbe mai stato eseguito.
Un altro loop, è quello che ripete qualcosa un certo numero di volte.
#include <stdio.h>
int main(void)
{
int i = 0;
while(i < 10)
{
// Quando i è minore di 10 esegui questo codice
printf("Hello world");
// e poi incrementa i
i++
// valuta la condizione ogni volta
// una volta eseguito il codice tra le parentesi graffe, valuta se i è ancora minore di 10.
// In questo caso esegui il codice, incrementa e poi valuta ancora
// Il loop terminerà quando i eguaglia 10
}
}
Loop do-while
#include <stdio.h>
int main(void)
{
int i = 10;
do {
printf("the value of i: %i\n", i);
i++;
}
while( i < 20 );
}
In confronto a un loop while, l'esecuzione di un loop do- while è garantita almeno una volta.
Compie prima un'azione e poi valuta la condizione. Può essere utile se vogliamo ripetere qualcosa per un certo numero di volte, e almeno una volta.
Nel nostro esempio, il codice viene eseguito almeno una volta e la frase viene stampata almeno una volta. Poi, il valore viene incrementato e viene valutato che sia minore di 20. In tal caso, il codice è eseguito nuovamente. Il loop termina una volta che il valore incrementato ogni volta non è più minore di 20.
Conclusione
Siamo arrivati alla fine di questa introduzione al linguaggio di programmazione C! Spero di averti dato l'infarinatura necessaria a comprendere i fondamenti di C e per iniziare a scrivere dei programmi di base in questo linguaggio.
Grazie per aver letto questo articolo.
Buona programmazione!