

This tutorial will give you a broad overview of basic concepts of the C programming language.
We'll go over the history of the language, why and where it is used, the compilation process, and some very basic programming concepts that are common in most popular programming languages.
This is not a complete guide to the language, but will rather give you a high level understanding of important C concepts and ideas as an absolute beginner to coding.
Each language has its own syntax and specific ways of doing things, but the concepts covered here are common and applied to all programming languages.
Having an understanding of how things work and these universal concepts can take you a long way in your coding journey. It makes learning a new technology easier in the long run.
This tutorial takes heavy inspiration from the material covered in the first couple of weeks of the course CS50: Introduction To Computer Science which I highly recommend to anyone wanting to dive deeper into computer science and programming no matter their level of experience.
Table of Contents
- The History behind the origins of C - An Overview
- Language Characteristics and why to consider learning C
- Where Is C used?
- Compilation process: Write-Compile-Run
- Hello world
- Variables and assignment
- Operators
- Extra Reading
The History of the C Programming Language
The history of the C programming language is closely tied to the history of the development of the Unix Operating System.
If we look back to understand what led to the development of the operating system that changed the world of computing, we'll see the steps that led to the development of C.
Simply put, C was derived from the need to initially find and eventually create a language to apply on the Unix Operating system.
Project MAC and MULTICS
It all started in 1965 when the experimental project MAC was completed at MIT – the first system of its kind. This was the beginning of the MULTICS era. It used something called CTSS, or the Compatible Time Sharing System.
This was a key innovation at that time. Up to this point, we were in the early mainframe era, where massive, powerful, and extremely costly computers used to take up entire rooms.
To get tasks done, programmers would write code by hand. Then they'd punch a deck of paper tape cards that were encoded with the program written by hand.
They did this by handing the sheets of paper the program was written on to operators who used a key punch machine that would punch the card's holes and represent the data and instructions on the card.
Then they'd feed the punched cards to a punch card reader connected to the mainframe computer. It then converted the sequences in the cards holes to digital information. Simple tasks took a long time using this method and only one person could use each machine at a time.
The idea of time sharing changed everything. Instead of using cards, it attached multiple consoles (which at the time were mechanical terminals called teletypes) to a main computer. This allowed many people to use the same computer simultaneously.
Over 100 typewriter terminals spread around MIT's campus could be attached to one main big computer. This system supported up to 30 remote users at the same time, each using one of those terminals.
The operating system of the main computer multitasked and circled around the people who wanted to perform computing tasks from their connected terminals and gave a few seconds to each one.
It provided what seemed like a continuous service, appearing to be loading and running many programs simultaneously. But in reality it just went through each user's program very quickly. This gave the illusion that one person had the whole computer to themselves.
This system proved to be extremely efficient, effective, and productive, saving time and in the long run money, since those computers were extremely expensive.
Something that might have taken days to complete now took much less time. And this started enabling greater access to computing.
Following the success of the CTSS, MIT decided it was time to build upon this system and take the next step. This next step would be to create a more advanced time sharing system.
But they imagined a more ambitious endeavor than that: they wanted to build a system that would serve as a computing utility for programers that would be capable of supporting hundreds of users accessing the mainframe at the same time. And it would share of data and resources between them.
This would require more resources, so they joined forces with General Electric and Bell Labs.
This new project was named MULTICS, which stood for 'Multiplexed Information and Computing Service' and was implemented on one of General Electric's mainframes, the GE 635.
This team worked on MULTICS for a number of years. But in 1969 Bell Labs left the project because it was taking too long and was too expensive.
Bell Labs: The Innovation Hub
Bell Labs pulling out of the MULTICS project left some employees frustrated and looking for alternatives.
While working on MULTICS, the team created an unparalleled computing environment. They were used to working with time sharing systems and had seen their effectiveness. These programmers had a vast knowledge of operating systems, and the innovations from that project made them want to expand more.
A group led mainly by Ken Thompson and Dennis Ritchie wanted to use communal computing and create a file system that they could share. It would have the innovative characteristics they liked from MULTICS but they'd implement it in a simple, smaller, and less expensive way.
They shared their ideas and started to iterate.
 _Ken Thompson and Dennis Ritchie, Image source from Wikipedia_
_Ken Thompson and Dennis Ritchie, Image source from Wikipedia_
Bell Labs fostered an open and supportive environment that allowed creative expression and innovative ideas to bloom. It was research heavy, and they encouraged independent thinking problem solving to help them improve upon their initial solutions.
Through lots of discussion and experimentation they made the biggest breakthroughs and wrote history.
While still working on MULTICS, Ken Thompson had created a game called Space Travel. He initially wrote it on MULTICS, on the GE 635, but when Bell Labs pulled out he adapted the gamae to a Fortran program to run on the GECOS operating system that ran on the GE 635.
There were many problems with the game – it did not work as well on GECOS as it did on MULTICS and he needed a different and less expensive machine to run it on.
Ken Thompson faced rejection when asking for funding to create a different operating system, since Bell labs had pulled out from such a project already. But he did end up finding an old and little-used DEC PDP-7 minicomputer that he could try out – it was the only system available.
 A DEC PDP-7, Image source from Wikipedia
A DEC PDP-7, Image source from Wikipedia
He started to write his game on that simple system but was limited by the software on the computer. So while he was working on it, he ended up implementing the bare bones of the file system his team had been envisioning.
He started with a hierarchical file system, a command line interpreter, and other utility programs. Within a month he had created an operating system with an assembler, editor, and shell. They were smaller and simpler features of MULTICS. This operating system was the first version of Unix.
The Early Days of Unix with Assembly language
At the beginning of the project, Ken Thompson could not program on the DEC PDP-7 computer. DEC PDP-7 programs had to be compiled and translated on the more powerful GE 635 mainframe and then the output was physically transferred to the PDP-7 by paper tape.
The DEC PDP-7 had very little memory, just 8KB. To deal with this restriction, the filesystem, the first version of the Unix kernel, and practically everything else in the project were coded in Assembly. Using Assembly allowed Thompson to directly manipulate and control each part of the memory on that computer.
Assembly language is a low level programming language which uses symbolic code and is close to the machine's native language, binary. The instructions in the code and each statement in the language closely corresponds to machine instructions specific to the computer's architecture.
It's machine dependent and machine specific, meaning one set of instructions has very different results from one machine to another. Programs written in Assembly language are written for a specific type of processor – so a program written in Assembly will not work on a variety of processors.
It was common to write operating systems using Assembly language back then. And when they first started working on Unix, they did not have portability in mind.
They didn't care if the operating system worked on different machine systems and architectures. That was a thought that came later. Their main priority was the efficiency of the software.
While working on MULTICS, they used high level programming languages, like PL/I in the beginning and later BCPL. Programmers had gotten used to using high level languages for writing operating system kind of software, utilities, and tools because of the advantages they offered (they were relatively easy to use and understand).
When using a higher level programming language, there is an abstraction between the computer's architecture and various obscure details. This means that it is above the level of the machine and there is no direct manipulation of the hardware's memory.
High level languages are easier to read, learn, understand, and maintain which makes them an easier choice when working on a team. Commands have an English like syntax, and terms and instructions look more familiar and human-friendly compared to the symbolic format of Assembly.
Using high level languages also means writing less code to achieve something, whereas assembly programs were extremely long.
Thompson wanted to use a higher level language for Unix from the very start, but was limited by the DEC PDP-7.
As the project progressed and as more people started working working on it, using Assembly was not ideal. Thompson decided that Unix needed a high level system programming language.
In 1970 they managed to get funding for the bigger and more powerful DEC PDP-11 that had substantially more memory.
With a fast, structured, and more efficient high level programming language that could replace Assembly, everyone could understand the code and compilers could be made available to different machines.
They started exploring different languages for writing system software that they could use to implement Unix.
From B to C: The Need for a New Language
The aim was to create utilities – programs that add functionality – to run on Unix. Thompson initially attempted to create a FORTRAN compiler but then turned to a language he used before, BCPL (Basic Combined Programming Language).
BCPL was designed and developed in the late 1960's by Martin Richards. Its main purpose was for writing compilers and system software.
This language was slow and had many restrictions, so when Thompson started using it in 1970 for the Unix project on the DEC PDP-7, he made adjustments and modifications and ended up writing his own language, called B.
B had many of the features of BCPL but it was a smaller language, with a less verbose syntax and simpler style. It was still slow and not powerful enough to support Unix utilities, however, and couldn't take advantage of the powerful features of the PDP-11.
Dennis Ritchie decided to improve upon these two previous languages, BCPL and B. He took features and characteristics from each and added additional concepts. He created a more powerful language – C – just as powerful and efficient as Assembly. This new language overcame the limitations of its predecessors and could use the power of the machine in an effective way.
So in 1972 C was born, and the first C compiler was written and implemented for the first time on the DEC PDP-11 machine.
 _The famous picture of Thompson and Ritchie working on a PDP-11, Image source Wikipedia_
_The famous picture of Thompson and Ritchie working on a PDP-11, Image source Wikipedia_
The C Programming Language
In 1973 Dennis Ritchie rewrote the Unix source code and most Unix programs and applications using the C programming language. This made it the standard implementation language of the operating system.
He reimplemented the Unix kernel in C, and almost all of the operating system (well over 90%) is written in this high level language. It mixes both high level readability features and the low level functionality, making it the perfect choice for writing an operating system.
Towards the late 1970's, C's popularity started to rise and the language started getting more widespread support and use. Up until that point, C was still only available for Unix systems and compilers were not available outside of Bell labs.
This increase in popularity came from not only the power C gave to the machine but also to the programmer. It also helped that the Unix operating system was gaining the same popularity at an even faster rate.
Unix stood out from what came before because of its portability and its ability to run on a variety of different machines, systems, and environments.
C made that portability possible and since it was the language of the Unix system, it gained more notariety – so more and more programmers wanted to try it out.
In 1978 Brian Kernighan and Dennis Ritchie co-wrote and published the first edition of 'the C programming language' book, also known in the programming community as 'K&R'. For many years this text was the go-to for C language description, definition, and reference.
 [Front page cover of the book,image source Wikipedia](https://en.wikipedia.org/wiki/C(programminglanguage)#History)
[Front page cover of the book,image source Wikipedia](https://en.wikipedia.org/wiki/C(programminglanguage)#History)
In the 1980's, C's popularity skyrocketed as different compilers were created and comercialized. Many groups and organisations that were not involved in C's design started making compilers for every operating system and computer architecture structure. C was now available on all platforms.
As these organisations created compilers of their own, they started to change characteristics of the language to adapt to each platform the compiler was being written for.
There were various versions of C that had slight differences between them. While writing the compilers, these groups came up with their own interpretations of some aspects of the language, which were based on the first edition of the book 'C programming language'.
With all the iterations and adjustments, though, this book no longer described the language as it was, and the changes to the language started to cause problems.
The world needed a common version of C, a standard for the language.
The C Standard
To make sure there was a standard, machine independent definition of the language, ANSI (the American National Standards Institute) formed a committee in 1983. This committee was named the X3J11 committee, and their mission was to provide a clear, comprehensive definition and standardization of C.
After a few years, in 1989, the committee's work was done and made official. They defined a commercial standard for the language. That version of the language is known as 'ANSI C' or C89.
C was used all around the world, so a year later in 1990 the standard was approved and adopted by ISO, the International Standards Organization. The first version, C90, was called ISO/IEC 9899:1990.
Since then, many revisions to the language have taken place.
The second version of the standard, C99, was published in 1999 called ISO/IEC 9899:1999 and introduced new language additional features. The third version, C11, was published in 2011. The most recent version is the forth, C17, and is called ISO/IEC 9899:2018.
The Continuation of C
C forged a path for the creation of many different programming languages. Many of the modern high level programming languages that we use and love today are based on C.
Many of the languages created after C wanted to solve problems that C couldn't, or overcome some of the issues that limit C. For example, the most popular child of C is its Object Oriented extension C++ – but Go, Java, and JavaScript were also inspired by C.
C Language Characteristics and Why You Should Consider Learning C
C is an old language, but it still remains popular to this day, even after all these years.
It owes its popularity to the rise and success of Unix, but nowadays it has gone far beyond just being the 'native' language of Unix. It now powers most, if not all, of the world's servers and systems.
Programming languages are tools we use to solve specific computing problems that affect us on a large scale.
You don't need to know C to create web pages and web applications. But it comes in handy when you want to write an operating system, a program that controls other programs, or a programming utility for kernel development, or when you want to program embedded devices or any systems application. C excells at all these tasks. So let's look at some reasons to learn C.
It helps you understand how your computer works
Despite the fact that C is a general purpose programming language, it is mainly used to interact with low level machine functions. Besides the practical reasons behind learning the language, knowing C can help you understand how the computer actually works, what is happening underneath the hood, and how programs actually run and execute on machines.
Since C is considered the base of other programming languages, if you can learn the concepts used in this language it will be easier to understand other languages too later on.
Writing C code lets us understand the hidden processes happening in our machines. It allows us to get closer to the underlying hardware of the computer without messing with Assembly language. It also lets us get a handle on a multitude of low level tasks while staying readable like high level languages.
C is fast and efficient
At the same time, we don't lose the functionality, efficiency, and low level control of how code executes that Assembly provides.
Rememeber that each processor in every device's hardware has its own Assembly code that is unique to that processor. It's not at all compatible with any other processor on any other device.
Using C gives us a faster, easier, and overall less cumbersome approach to interacting with the computer at its lowest level. In fact, it has a mixture of both high and low level features. And it helps us get the job done without the hassle and fuss of long incomprehensible Assembly code.
So, C is as close as you can get to the computer's underlying hardware and is a great replacement for Assembly (the old standard for writing operating systems) when you're working with and implementing system software.
C is powerful and flexible
This close proximity to the hardware means that C code is written explicitly and precisely. It gives you a clear picture and mental model of how your code is interacting with the computer.
C does not hide the complexity with which a machine operates. It gives you a lot of power and flexibility, like the ability to manually allocate, manipulate, and write directly to memory.
The programmer does a lot of the heavy work and the language lets you manage and structure memory in an efficient way for the machine delivering high performance, optimisation, and speed. C lets the programmer do what needs to get done.
C is portable, performant, and machine-independent
C is also highly portabile and machine independent. Even though it is close to the machine and has access to its low level functions, it has enough abstraction from these parts to make code portability possible.
As Assembly instructions are machine specific, programs are not portable. One program written on one machine would have to be re-written to run on another. And that is hard to maintain for every computer architecture.
C is universal and programs written in it can be compiled and run across many platforms, architectures, and a variety of machines without losing any performance. This makes C a great choice for creating systems and programs where performance really matters.
C inspired the creation of many other programming languages
Many languages that are commonly used today, like Python, Ruby, PHP and Java, were inspired by C. These modern languages rely on C to work and be efficient. Also, their libraries, compilers, and interpreters are built in C.
These languages hide most of the details about how programs actually work underneath the hood. Using these languages, you don't have to deal with memory allocation and bits and bytes since there are more levels of abstraction. And you don't need this level of granular control with higher level applications where interaction with memory is error-prone.
But when you're implementing part of an operating system or embedded device, knowing those lower-level details and direct handling can help you write cleaner code.
C is a fairly compact language
Although C can be quite cryptic and hard to learn for beginners, it is actually a fairly small and compact language with a minimal set of keywords, syntax, and built-in functions. So you can expect to learn and use all of the features of the language when exploring how it works.
Even if you're not interested in learning how to program an operating system or a systems application, knowing C basics and how it interacts with the computer will give you a good foundation of computer science concepts and principals.
Also, understanding how memory works and is laid out is a fundamental programming concept. So understanding how the computer behaves on a deeper level and the processes that are happening can really help you learn and work with any other language.
Where Is C used?
There is a lot of C code in the devices, products, and tools that billions of us use in our everyday lives. This code powers everything from the world's supercomputers to the smallest gadgets.
C code makes embedded systems and smart devices of all kinds work. Some examples are household appliances like fridges, TVs, coffee makers, DVD players, and digital cameras.
Your fitness tracker and smart watch? Powered by C. The GPS tracking system in your car, and even traffic light controllers? You guessed it – C. And there are many examples of embedded systems used in the industrial, medical, robotics, and automobile industries that run on C code.
Another area where C is widely used is Operating Systems and kernel development. Besides Unix, for which the language was created, other major and popular Operating Systems are coded to some extent in C.
The Microsoft Windows kernel is scripted mostly in C, and so is the Linux kernel. Most supercomputers are powered by Linux, and so are most Internet servers. This means that C powers a large section of the Internet.
Linux also powers Android devices, so C code not only makes supercomputers and personal computers work, but smartphones too. Even OSX is coded to some extent in C, which makes Mac computers run on C, too.
C is also popular for developing desktop applications and GUIs (Graphical User Interfaces). Most Abode Applications we use for video and photo editing and graphic design (like Photoshop, Adobe illustrator, and Adobe Premiere) are coded with C or its successor, C++.
Compilers, interpreters, and assemblers for a variety of languages are designed and built with C – in fact these are some of the most common usages of the language.
Many browsers and their extensions are built with C, like Google Chromium and the Google file system. Developers also use C often in database design (MySql and Oracle are two of the most popular database systems built in C), and it powers advanced graphics in many computer games.
From this general overview, we can see that C and it's derivative C++ run a large part of the internet and the world at large. Many of the devices and technologies we use in our daily lives are written in or depend on C.
C Compilation Process: Write-Compile-Run
What is a program in C?
A computer program written in C is a human readable and ordered set of instructions that a computer executes. It aims to provide a solution to a specific computing problem and tell the computer to perform a certain task with a sequence of instructions that it needs to follow.
Essentially all programs are just plain text files stored on your computer’s hard drive that use a special syntax which is defined by the programming language you're using.
Each language has its own rules that dictate what you can write and what's considered valid, and what is not.
A program has keywords, which are specific words that are reserved and are part of the language. It also has literal pieces of data like strings and numbers. And it has words that follow the language’s rules, which we define and introduce to the language that don’t already exist (like variables or methods).
What is a compiler?
Programs are written by us and for us. They are meant to be understood by humans.
When we write programs in human readable form, we can understand them – but the computer may not be able to. Computers don’t directly understand programming languages, they only understand binary. So programs need to be translated into this other form so the computer can actually understand our program's instructions.
Programs in high level languages can be either compiled or interpreted. They use special pieces of software called compilers and interpreters, respectively.
What's the difference between an compiler and an interpreter?
Both compilers and interpreters are programs, but they're far more complex ones, and they act as translators. They take a program that's written in a human readable form and turn it into something that computers can make sense of. And they make it possible to run and execute programs on different computer systems.
Compiled programs are first converted into machine-readable form which means they are translated into machine code before they run. Machine code is a numerical language – binary instructions composed of sequences of 0s and 1s.
This compliation produces an executable program, that is a file containing the code in the machine language that the CPU (Central Processing Unit) will be able to read, understand, and execute directly.
After this, the program can run and the computer does what the program tells it to do. Compiled programs have a stronger correspondence with the underlying hardware and can more easily manipulate the computer's CPU and memory.
Interpreted programs, on the other hand, are not directly executed by the machine nor do they need to be translated into a machine language program. Instead, they use an interpreter that automatically and directly translates and executes each statement and instruction in the code line by line during run time.
C is a compiled programming language. This means that it uses a compiler to analyse the source code written in C and then turns it into a binary file that the computer's hardware can directly execute. This will be specific for each particular machine.
How to use the GCC Compiler with examples
Unix and Unix-like systems already have a C compiler built in and installed. This means that Linux and MacOS have a popular compiler built in, called the GCC Compiler (or GNU Compiler Collection).
In the rest of this section we'll see examples using this compiler and I've based these examples on a Unix or Unix-like system. So if you have a Windows system, make sure to enable the Windows Subsystem for Linux.
First, make sure you have the GCC compiler installed. You can check by opening your terminal and typing gcc --version in the prompt which is typically after the $ character.
If you're using MacOS and have not installed the command line developer tools, you will get a dialog box pop up asking you to install them – so if you see that, go ahead and do so.
Once you have those installed, open a new terminal session and re-type the gcc --version command. If you have already installed the command line tools, you should get the output below:

The term compiling alone is an abstraction and simplification, though, since in reality there are many steps happening behind the scenes. These are the finer lower level details that happen between us writing, compiling, and then running our C program. Most even happen automatically, without us even realising it.
How to write C source code
In order to develop C programs, we first need to have some type of text editor. A text editor is a program we can use to write our code (called our source code) in a text file.
For this you can use a command-line text editor like nano or Vim if you are comfortable with those.
You can also use an IDE (Integrated Development Environment), or text editor with IDE-like features (an integrated terminal, the ability to write, debug, run and execute our programs all in one place without leaving the editor, and much more).
One editor with these capabilities is Visual Studio Code, using the C/C++ extension. Throughout the rest of this tutorial we'll use VSCode.
Back in your terminal, go ahead and type the commands below to create a file where our C code will live.
`cd` # Takes us to our home directory,if not there already
`mkdir cprogram` # Creates a directory named cprogram
`cd cprogram` #navigates us into the cprogram directory we just created
`touch hello.c` #creates a file named hello
`code .` #opens VSCODE in the current directory
So we have just created a plain text file, hello.c. This file will have code written in the C language meaning it will be a C program. This is indicated by the .c file extension which is a convention.
Inside it we can write any C program we like, starting from a very basic one like a program that outputs 'hello world' to the screen.

In order to see what our code does, we have to run the program we have just written. Before running it, though, we have to first compile it by typing some commands in the terminal.
We can continue using the command line on our computer or we can use the integrated terminal in VSCode (by holding the control ~ keys at the same time a new terminal window opens).
So far we can see on the left panel that there is only one file in our cprogram directory, hello.c, which contains our C code.
The term 'compiling our C code' doesn't just happen in one step. It also involves some smaller actions that occur automatically for us.
As a reminder, when we refer to compiling, we typically mean that the compiler takes our source code as input (the code we wrote in C which has English like syntax), and translates it to produce machine code statements as output.
This machine code corresponds directly to our source code instructions, but it's written in a way the CPU can understand so it can carry out the instructions and execute them.
How C source code gets transformed into binary code
This is the general idea – but there are 4 smaller steps involved that happen in between. When we compile our code we are actually preprocessing, compiling, assembling, and linking it.
These steps start happening when we type the command gcc hello.c in the terminal which is the name of the compiler and the source code file, respectively.
If we wanted, we could alternate and customise that command by typing a more specific one like gcc -o hello hello.c, where:
-ostands for 'output this file'hellois the name we ourselves specify for the executable program file we want to output that will be created, andhello.cis the file thegcccompiler will take as input (which is the file where our source code lives and we want to compile).
Preprocessing in C
Another program that is part of the compiler conducts this first step – the preprocessor. The preprocessor does many things – for example, it acts as a ‘find and replace tool’ as it scans through our source code looking for special statements and searches for lines starting with a #.
Lines starting with a # ,like #include, are called preprocessor directives. Any line starting with a # indicates to the preprocessor that it must do something. In particular, it tells that it should substitute that line with something else automatically. We don't see this process, but it's happening behind the scenes.
For example, when the preprocessor finds the line #include <stdio.h> in our hello world program from earlier, the #include literally tells the preprocessor to include, by copying and pasting, all the code from that header file (which is an external library, stdio.h) in the place of that statement in our own source code. So it replaces the #include <stdio.h> line with the actual contents of the stdio.h file.
Inside the <stdio.h> library there are function prototypes and definitions or hints. This way all the functions are defined so the computer recognizes them during compilation time, and we can use them in our program.
For example, the function printf(); is defined as int printf(const char *format,…); inside <stdio.h>. The same steps happen for other header files, that is files with a .h extension.
During the preprocessing step, our comments in our code are also removed and macros are expanded and replaced with their values. A macro is a fragment of code which has been given a name.
At this stage if there are no errors in our code, there should be no output in the terminal, which is a good sign.
We see no output, but a new file has been created with a .i extension which is still C source code. This file includes the output from the preprocessing, so it is called preprocessed source code. In this case a new file, hello.i, is generated but it won't be visible in our editor.
If we run the command gcc -E hello.c:

We will be able to see all the contents of this file (which is a lot) and the ending looks something like this:
If there are any mistakes with the correctness of our code or we're not following the semantics of the language, we'll see some errors and the compilation will end. We would have to correct the mistakes and start the process from the beginning.
Compiling in C
After the preprocessing step which produces preprocessed C source code, next we have to compile the code. This involves taking the code that is still source code and changing it into another intermediate form. We use a compiler for this step.
To review, a compiler is a program which takes as input the source code and translates it into something closer to the native language of computers.
When we refer to compiling we can either mean the entire process of translating source code to object code (machine code) or just a specific step in the whole compilation process.
The step we're discussing now is when compiling converts every statement of the preprocessed C source code program to a more computer friendly language. This language is closer to binary which the computer can actually directly understand.
This intermediate language is assembly code, a low level programming language used to control the CPU and manipulate it to perform specific tasks and get close access to the computer's memory. Remember assembly code from the history section?
Every CPU – the brains of the computer – has its own set of instructions. Assembly code uses specific statements and commands that directly correlate to those instructions and low level operations that a CPU performs and carries out.
So in this step of the compilation process, each statement in the preprocessed C source code in the file hello.i is translated by the compiler to the equivalent statement in assembly language at a lower level.
The output of this action creates a file ending in .s (so hello.s behind the scenes) that contains instructions in assembly.
By typing the command gcc -S hello.c we can view the contents and the somewhat incomprehensible assembly commands of the hello.s file that the compiler created (but that was not visible to us when we typed gcc hello.c alone).
If we look closely we'll see a couple familiar keywords and statements used in our C source code like main and printf:
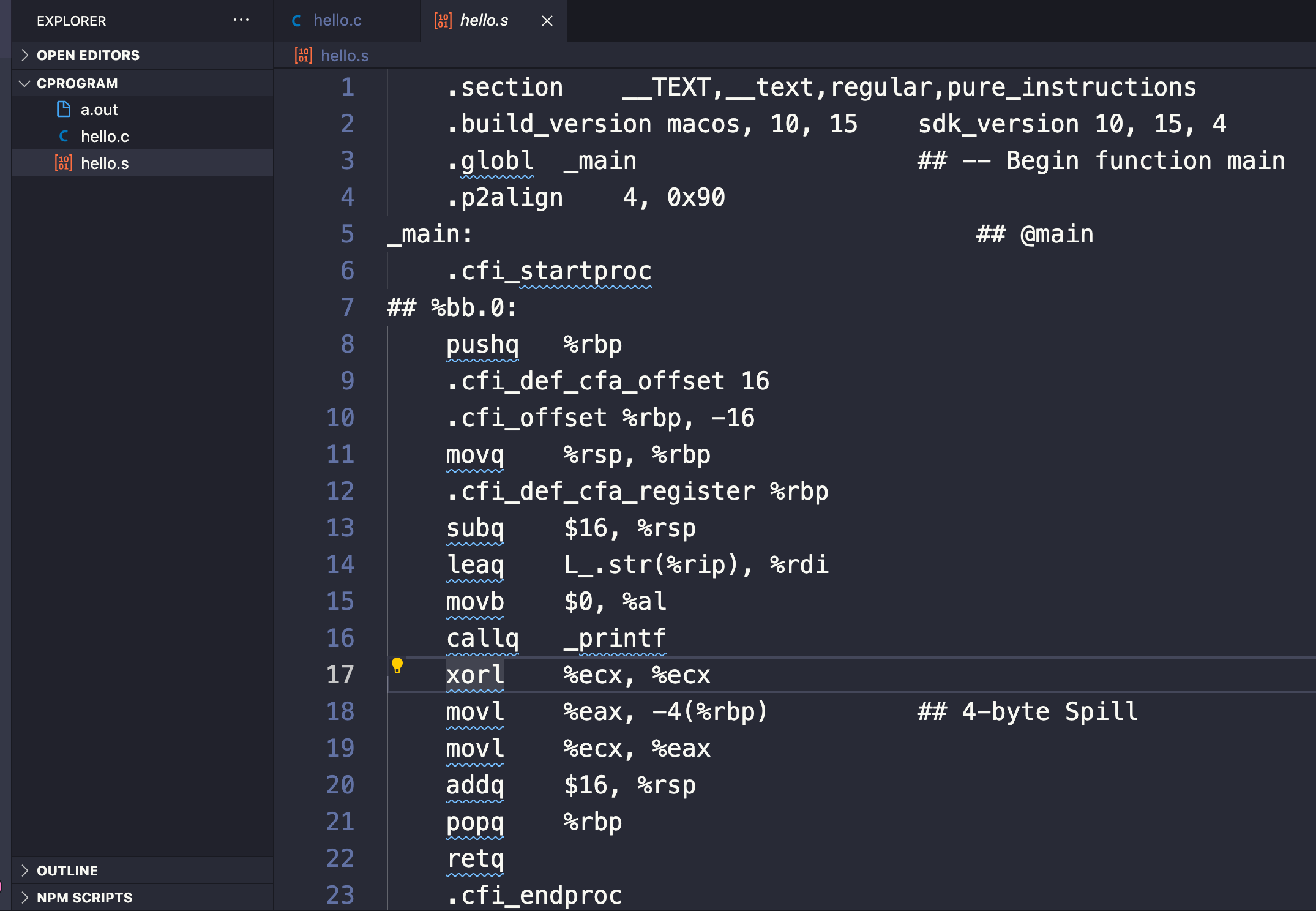
Assembling in C
Assembling means taking the hello.s file containing assembly code statements as input and, with the help of another program that is executed automatically in the compilation process, assembling it to machine code instructions. This means it will have as output actual 0s and 1s, or binary format statements.
This step also happens behind the scenes, and it results in the final language the instructions in our source code are translated to. And now the computer can finally understand those instructions.
Each of the commands we wrote in our C source code were transformed to assembly language statements and finally into the equivalent binary instructions. All this happened just with the command gcc. Whew!
The code we wrote is now called object code, which a specific computer's CPU can understand. The language is incomprehensible to us humans.
People used to code in machine language, but it was a very tedious process. Any symbols that are non-machine code symbols (that is, anything that's not 0s and 1s) are hard to make sense of. Coding in such a language directly is extremely error-prone.
At this stage, another file is created with a .o extension (for object) – so in our case it'll be hello.o.
We can see the actual contents of the object file containing the machine level instructions with the command gcc -c hello.c. If we do this, we'll see the not human readable contents of hello.o:
Linking in C
In the images above, you might have noticed an a.out file in our directory.
This is the default step and file that gets created when we type the compiler command and our filename, gcc hello.c in our case.
If we had used the command gcc -o hello hello.c mentioned earlier, we would have seen a custom named hello executable program in place of a.out.
The a.out stands for assembly output. If we type ls in the terminal to list the files in our directory, we see that a.out even looks different from the rest:

Linking is the final stage of the compilation process where the final binary file hello.o is linked with all the other object code in our project.
So if there are other files containing C source code (like files included in our program that implement C libraries which are already processed and compiled, or another file we have written named, for example, filename.cbesides hello.c), this is when the object file filename.o will be combined with hello.o and the other object codes, linking them all together.
This forms one big executable file with the combined machine code, a.out or hello, which represents our program.
Since we're finally done compiling, the program is in its final form. And now we can execute and run the file on our machine by typing ./a.out. This means 'run the a.out file that is in the current directory', since ./ represents the folder we are in. We then see the output of our program in the terminal:

Whenever we make changes to our source code file, we have to repeat the process of compiling from the beginning in order to see the changes when we run the code again.
How to Write Hello World in C
A hello world program is a very simple one, but it's a tradition that also acts as a test message when you're first starting to learn how to code in a new programming language.
If you execute your "Hello World" program successfully, this lets you know that your system is correctly configured.
 _'Hello world' devised by Brian Kernighan from Artsy's Algorythm Auction based on a 1974 Bell Laboratories internal memorandum, "Programming in C: A Tutorial," which contains the first known version. It was reprinted in the popular 1978 book, The C Programming Language. Image and description source from Wikipedia_
_'Hello world' devised by Brian Kernighan from Artsy's Algorythm Auction based on a 1974 Bell Laboratories internal memorandum, "Programming in C: A Tutorial," which contains the first known version. It was reprinted in the popular 1978 book, The C Programming Language. Image and description source from Wikipedia_
A 'hello world' program contains the basic syntax for the language and we can break it down into smaller parts:
#include<stdio.h>
int main(void)
{
// print hello world to the screen
printf("Hello world\n");
}
Header files in C
Header files are external libraries. This means they are a set of code already written by some developers for other developers to use.
They provide features that are not included at the core of the C language. By adding header files to our code, we in return get additional functionality that we can use in our programs.
Header files like include <stdio.h> end in the extension .h. In particular, a header file like stdio.h comes already built into the compiler.
The line include <stdio.h> is an instruction for the pre-written functions in the stdio.h library file which tells the computer to access and include them in our program.
stdio.h gives us the functionality standard input and standard output, which means we'll be able to get input and output from the user. We therefore get to use input/output functions like printf.
If you don't include the stdio.h file at the top of your code, the computer will not understand what the printf function is.
The main program in C
Here's the code:
int main(void)
{
}
This is the main starting function of a C program. The curly braces ({}) are the body which wraps all the code that should be in our program.
This line acts as a boilerplate and starting point for all C programs. It lets the computer know where to begin reading the code when it executes our programs.
Comments in C
Whatever we write after the // will not affect how our code runs and the computer will not take it into account during compilation and execution time.
Those two lines indicate that you're adding comments, which are notes to our future selves and to our coworkers. Comments can help us remember and remind others what a certain line of code does or why we wrote that code in the first place. It also reminds us what exactly is the purpose of that code when we come back to it the next day of even months later.
Output or printing to the console in C
printf("Hello world/n"); prints the phrase 'Hello world' to the console. We use printf when we want to say something and to see the output on the screen. The characters we want to output need to be surrounded by double quotes "" and parentheses ().
The /n is an escape character, which means that it creates a newline and tells the cursor to move to the next line when it sees it.
The ; indicates the end of of sentence and the end of that line of code.
Variables in C
Here's how we define a variable in C:
A data item that may take on more than one value during the runtime of a program.
In the simplest terms, you can think of variables as a named box. A box that acts as a storage place and location for holding different information that can vary in content.
Each box has a unique name which acts like a label put on the outside that is a unique identifier, and the information/content lives on the inside. The content is the variable's value.
Variables hold and point to a value, to some useful data. They act as a reference or abstraction to literal data. That data is stored in the computer's memory, and takes up an certain amount of space. It lives there so we can retrieve it later and use it in our programs when we need to.
As the name suggests, what variables point to can vary. They are able to take different values over time as information changes during the life of the program.
Variable Assignment in C
The process of naming a variable is called assignment. You set a specific value that is on the right, to a specific variable name that is on the left. You use the = or the assignment operator to do this.
As I mentioned, you can change a variable's value, so you can assign and reassign variables. When you reassign a value, the new value points to the variable name. So the value can be a new one, but the variable name stays the same.
How to declare vs initialise a variable in C
The C programming language is a strongly statically typed language, unlike many other modern programming languages.
In statically typed languages, you need to explicitly declare your variables to be of a certain data type. That way the compiler knows during compilation time if the variable is able to perform the actions it was set out and requested to do.
In dynamically typed languages, a variable can change between different data types without the need to explicitly define that data type.
So, when declaring a new variable in the C language, you need to define and specify what type it is, and what type of data its value holds.
A variable's type is the type of the value it holds. This lets the program and later the compiler know what kind of information it's storing.
To declare a variable, you specify the data type, and give a name to the variable. An optional step is to set an initial value. Do not forget the semicolon at the end, which ends the statement!
#include <stdio.h>
int main(void)
{
int n = 27;
// int is the data type
// n is the name
// n is capable of holding integer values
// positive/negative whole numbers or 0
// = is the assignment operator
// 27 is the value
}
What is the difference between initialising and declaring a variable?
In summary:
int n; // declaration, create a variable called n capable of holding integer values
int n = 27; // initialisation, creating a variable called n and assigning a value, storing a number in that variable
int n; is declaring a variable. Declaring means we define a name for the variable and specify its type.
We don't necessarily need to specify a value for the variable just yet. This is enough, as declaring a variable tells the computer we want a variable to exist and we need to allocate some space in memory for it. The value can and will be stored at a later time.
When we do assign the variable a value later, there is no need to specify the data type again. We can also declare multiple variables at once.
int name, age;
If we declare a variable and assign it a value at once, this is called initialising the variable.
int n = 27; is initialising the variable. It refers to assigning an initial value which we can change later.
If the new value is the same data type, we don't need to include the data type, just the new value. If the data type is different, we will get an error.
#include<stdio.h>
int main(void)
{
int age = 27;
age = 37;
// the new value of age is 37
}
Rules for naming variables in C
- Variable names must begin either with a letter or an underscore, for example
ageand_ageare valid. - A variable name can contain letters (uppercase or lowercase), numbers, or an underscore.
- There can be no other special symbols besides an underscore.
- Variable names are case sensitive, for example
ageis different fromAge.
The scope of a variable in C
The scope of a variable refers to where the variable can be referenced and accessed from. It is essentially where the variable lives and is valid and how visible it is to the rest of the program.
Local scope
If a variable is declared within a set of culry braces, {}, like for example a specific function, that will be its scope and we can't access it and use it outside those braces in the rest of the program. The rest of the program won't know it exists.
Therefore it is not a good idea to declare variables that way since their scope and use is so limited which can lead to errors. This scope is called local scope.
Global scope
If variables are declared outside of functions, they have global scope. Having a global scope means they are visible within the whole program and can be accessed from anywhere.
But keep in mind that it can be difficult to keep track of them. Also, any changes we make to them along the way can get confusing since they can happen in any part and location of the program.
Data Types in C
Data types specify in what form we can represent and store information in our C programs. They let us know how that information will be used and what operations can be performed on it.
Data types also determine what type of data our variables can hold, as each variable in C needs to declare what data type it represents.
There are 6 data types built into the language. But you can convert between different types which makes it not as strongly typed.
Each of the data types requires a different allocation of memory and each data type can have different ranges up to which they can store values.
Adding keywords in front of a type name modifies and makes changes to the type. These keywords can be either unsigned or signed.
An unsigned keyword means that the type can only be positive and not negative, so the range of numbers start from 0. A signed keyword lets you make a number negative or positive.
Let's look at these data types in more detail.
The char data type in C
The most basic data type in C is char. You use it to store a single character such as letters of the ASCII chart like 'a', 'Z', or '!". (Notice how I used single quotation marks surrounding the single character – you can't use double quotes in this case.)
char also lets you store numbers ranging from [-128 to 127] and in both cases uses 1 byte of memory.
An unsigned char can take a range of numbers form [0-255]
The int data type in C
int is a an integer, a whole number, that can hold a positive or negative value or 0 but that has no decimal.
It is a value up to a certain number of bits. When you declare an int, it the computer allocates 4 bytes of memory for it. More specifically it uses at least 2 bytes but usually 4. 4 bytes of memory means it allocates 32 bits (since 1 byte = 8 bits). So an int has 232 possible values – more than 4 billion possible integers.
The range is of a -231 to 231-1,specifically from [-2,147,483,648 to 2,147,483,647].
- An unsigned int has still the same size as an int (4 bytes) but that doesn't include the negative numbers in the range of possible values. So the range is from 0 to 232-1, more specifically [0 to 4,294,969,295]
- A short int has smaller values than an int and allocates 2 bytes of memory. It allows for numbers in a range of [-32,768 to 32,767]
- An unsigned short int uses again 2 bytes of memory and has a range of numbers from [0 to 65,535]
- A long int is for when we need to use a larger number. It uses at least 4 bytes of memory, but usually 8 bytes with values from [-2,147,483,648 to 2,147,483,647]
- An unsigned long int has at least 4 bytes of memory with a range from [0 to 4,294,967,295]
- A long long int is an integer with more bits that's able to count to higher and larger numbers compared to ints and long ints. They use 8 bytes instead of 4 and so use 64 bits. This allows for a range from -263 to 263-1 ,so for numbers from [-9,223,372,036,854,775,808 to 9,223,372,036,854,775,807]
- An unsigned long long uses 8 bytes and has a range of numbers from [0 to 18,446,744,073,709,551,615]
The float data type in C
Floats are a floating point value which is a number with a decimal (also called a real number), with single precision. It allocates 4 bytes of memory.
The double data type in C
A double is a floating point value which has bigger values than that of a float. It can hold more memory – 8 bytes – compared to a float, and is double precision.
- A long double is the largest size compared to floats and doubles, holding at least 10 bytes of memory, but can even hold up to 12 or 16 bytes.
And lastly, the void type essentially means nothing or no value.
Format Codes in C
Format codes or format specifiers are used for input and output in C.
These are a way to tell the compiler what type of data it takes in as input with a variable, and what type of data it produces as output when using the printf() function. The f in printf() stands for formated.
They act as a format code placeholder and substitute for variables. They let the compiler know in advance what type they are when the value of the standard output (that is, what we want to print) is not already known.
The syntax we use is % format specifier for data type:
#include<stdio.h>
int main(void)
{
int age = 27;
printf("My age is %i/n", age)
// prints 27
// age is the variable we want to use
// %i is the format specifier,a placeholder for an integer value
// we separate each argument with a comma
// in the output %i is replaced with the value of age
}
There are different format specifiers for each data type we discussed earlier. Here are some of them:
| Format Specifier | Data type |
%c | char |
%c | unsigned char |
%i or &d | int |
%u | unsigned int |
%hi or %hd | short int |
%hu | unsigned short int |
%li or %ld | long int |
%lu | unsigned long int |
%lli or %lld | long long int |
%llu | unsigned long long int |
%f | float |
%lf | double |
%Lf | long double |
Operators in C
Arithmetic operators in C
Arithmetic operators are mathematical operators that perform mathematical functions on numbers. Operations can include addition, subtraction, multiplication, and division.
The most commonly used operators are:
+for addition-for subtraction*for multiplication/for division%for modulo division (calculating the remainder of the division)
Assignment operator in C
The assignment operator, =, assigns a value to a variable. It 'puts' a value into a variable.
In other words, it sets whatever is on the right side of the = to be the value of the variable on the left side of the =.
There are specific assignment operators for updating a variable by modifying the value.
In C, there are various ways we can update the values of variables. For example, if we want to increment the variable by 1 there are three possible ways to do so.
It is worth mentioning first that incrementing means to take the existing value of a variable, whatever value is on the right, and add 1 to it. The new value is then stored back to the variable and automatically updated.
The simplest way to increment or update is to have a variable called x with an initial value of 5, so:
x=5.
To add 1 to the variable x, we do x = x + 1 which means x = 5 + 1.
The new value of x is now 6, x=6.
There is a shorthand for this operation, using a special syntax that increments variables.
Instead of writing x = x +1 we can write x += 1.
An even shorter way is to use the increment operator, which looks like variable_name ++, so in our case x++.
The same goes for decreasing, that is decrementing, a variable by 1.
The three ways to do so are:
x = x-1, x -= 1, x -- (using the decrement operator) respectively.
Those are the ways to increment and decrement a variable by 1 in C. We are able to update a variable by taking its value and adding, subtracting, multiplying, and dividing that value by any other number and setting the result of that operation as the new value. Those operations would be +=, -=, *=, and /= respectively.
So x = x * 5 or the shorthand x *= 5 will take the value of the variable x and multiply it by 5 and store it back to x.
Logical Operators in C
We use logical operators to make decisions in C. The result of an operation can be either true or false.
There is the logical AND operator, &&. Operands on both the left and right sides of && need to be true for the condition to be true.
There is also the logical OR operator, ||. At least one or both of the operands on the right and left sides of || need to be true for the condition to be true.
Lastly, there is the logical NOT. This inverts the value of the operand. If an operand is true, then the NOT operator makes the condition false and vice versa.
Comparison operators in C
Comparison operators are:
- Greater than
> - Greater than or equal to
>= - Less than
< - Less than or equal to
=<
There is also an equality comparisson operator, ==. Don't confuse this with =, the assignment operator.
We use the == to compare two values and test to see if they are equal or not. This operator asks the question 'Are these two equal?', whereas = assigns a value to a variable.
When using the equality comparisson operator and asking the above question, there is always a return value that can either be true or false, otherwsie knokn as a Boolean value in the context of computer programming.
Lastly, there is the inequality operator, !=, that we use to test whether two values are NOT equal.
Functions in C
Functions are verbs, that is, small actions. They do something. They perform a particular, specific task.
They encapsulate a piece of behaviour that is meant to be used again and again. The purpose of functions is to have that behaviour written out just once somewhere so you can reuse it whenever you need to, at different times and in different places throughout a program. This makes your code simpler and better organised.
Functions exist to perform one task, serve a particular purpose, and be reused. And they can take in inputs and produce outputs.
Function arguments in C
The inputs that functions take in are called arguments. A function can have one or more arguments.
A common function in the C programming language is printf();. This prints something to the screen. It's a function used to say something.
The parentheses () are the inputs to the function, where the arguments go in – that is, what we actually want to say and print to the screen. What is between the parentheses gets printed out.
In printf("Hello world!"); , Hello world! is the input to the printf function. Here, we are calling a function called printf and we are giving it an argument that is a string. This says literally, print 'Hello world! 'to the screen.
Function outputs in C
There are two types of function output:
First, outputs can just be something visual, an immediate visual effect, something quickly printed to the screen.
You can't do anything more with that output after the effect. Like in the case of printf("Hello world!");, the output is the string "Hello world!" printed to the screen, and that's it. You can't use that string in some other way, because printf has no return value.
These types of functions are known as side effects, meaning they have an immediate observable effect without returning a value.
Also, a function like printf is a function invocation and in the stdio library is defined as int printf(const char *format,...);.
Second, the output can be reusable, and has a return value. A return value is a value passed back to the programmer and stored in a variable for later use.
In such cases, there is no immediate effect – nothing gets printed to the screen. The output is instead return to us, stored as information and saved in a variable.
How to Define a Method in C
There are three things you need to have in the first line, the decelerating line, when defining a function.
1) The return type
This is the very first keyword used, and how a function starts indicates the return value.
For example in a function like: void say_something(void), the first void means that the function has no return value.
In another example with a different function, int main(void), we specify and define its return data type, in this case an int. The function's output will be an int data type and will be returned to where the function is called.
2) The function name
The name can be anything we want, although it is best practice to name the methods after what they intend to do.
3) None or one or more arguments
These are the function's inputs, and the data type of those inputs.
In void say_something(void), the void inside the parentheses is a keyword for the argument and a placeholder for 'nothing'. It means it takes In no inputs. In cases like this, the argument is also called a parameter.
Parameters are essentially variables declared in the function, inside the parentheses like the void keyword. They act as a placeholder to access the function input data, the arguments.
Parameters refer to the value being passed in to the method. This means that when we later call the function, we pass the actual values to it, the arguments to the function.
How to Call a Function in C
We can call a function like:
void say_hi(void)
{
printf("hello");
}
By writing the function's name, followed by any arguments in parentheses and a semicolon like say_hi();. The say_hi function takes in no inputs and has no return value. When called it just prints 'hello' to the screen.
Another function like:
int square(int n)
{
return n * n
}
is called in the same way as the previous example. In this case, the square function take in an input and has a return value (both are ints). The input it takes in is the parameter called n, that returns an int when the function is called.
The word return specifies that what will get returned, the input n multiplied by itself.
For example, when the function is called square(3);, n acts as a variable that points to the parameter that has been passed in to the function, like 3. It is like we have set n = 3. The value that gets returned is 9.
Functions are meant to be reused, so we can use it anytime we wish to square a number:
#include <stdio.h>
int square(int x)
{
return x * x;
}
int main(void)
{
printf("%i\n", square(2));
printf("%i\n", square(4));
printf("%i\n", square(8));
}
How to Use Boolean Expressions in C
A boolean expression is an expression that evaluates to one of two values, true or false. They get their name after the mathematician, philosopher, and logician George Boole.
 _George Boole Image Source Wikimedia_
_George Boole Image Source Wikimedia_
We use boolean expressions to compare two values and they are particularly helpful in control flow.
Every non-zero value is true and 0 is false.
We can combine boolean expressions with the use of the different logical operators, like && (and), || (or) and ! (not) mentioned earlier in the article.
Different combinations of values and operators lead to different output results, which can be expressed in a truth table, a mathematical table used to represent logical equations wich result to 1 or 0 or their equivalent true or false.
When comparing two boolean values using the && (and) operator, both values have to equate to true for the combined experssion to be true.
For example if someone asks us "Do you want a pizza and a salad?", the only way for the expression to be true is for us to want both a pizza and a salad (so our answer is yes to both). If the answer to one of them is not true then the whole expression is false.
Truth Table for &&
| Value A | Value B | Result |
| true | false | false |
| false | true | false |
| false | false | false |
| true | true | true |
Unlike &&, the || operator lets us take action if one or both values are true. So this operator is not exclusive, either one of the comparissons has to be true for the experssion to evaluate to true or even both.
This is quite unique to computing, since in our example question used earlier, if instead of AND we changed it to OR, the statement 'Do you want pizza or a salad?' does not mean that you want both. You want one or the other, not necessarily both together.
Truth table for ||
| Value A | Value B | Result |
| true | false | true |
| false | true | true |
| false | false | false |
| true | true | true |
Lastly, the ! (not) operator is used for negation, meaning it turns true to false and false to true.
!true is false
!false is true
How to Use Conditional Statements in C
Conditional statements take a specific action based on the result of a comparisson that takes place. The act of doing one thing if a particular condition is true and possibly a different thing if that particular condition turns out to be false is called control flow.
Certain parts of the program may not run depending on the results or depending on certain user input. The user can go down different paths depending on the various forks in the road that come up during a program's life.
Programs with conditional statements use if blocks primaraly. The if blocks use boolean expressions that can only be true or false and they make decisions depending on those resulting values. We denote an if block statement by using curly braces, {}, and indendation of the code that follows.
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 3;
if (x < y)
// x < y is a boolean expression,it can only be true or false.
// If whatever is in the parentheses is true
//-in this case is x is actually less than y-
//run the code that follows
{
printf("x is less than y");
// Because x < y is true that statement will be printed
}
}
An if statement on its own is not that helpful especially as the programs grow larger and larger. So in that case the if statement is accompanied by an else statement.
These mean that 'if this condition is true do the following, else do this instead'. The else keyword is the solution for when the if condition is false and therefore doesn't run.
int main(void)
{
int x = 1;
int y = 2;
if ( x > y)
{
printf("x is larger than y");
}
else
{
printf("x is less than y");
// Because x > y is false ,
// this block of code will be executed
// resulting in printing the statement of the else branch
}
}
If we wish to chose between more than just two options and want to have a greater variety in statement and actions, then we can introduce an else if condition.
This means that 'If this condition is true, do this. If it is not, do this thing instead. However, if none of the above is true, finally do this instead.'
#include <stdio.h>
int main(void)
{
int x = 2;
int y = 2;
if(x < y)
// if this condition is true run this block
{
printf("x is less than y");
}
else if(x > y)
/ / if the above statement was true run this block instead
{
printf("x is greater than y");
}
else
// if this block of code runs
//it runs because x < y was false
//and so was x > y
//so it means x == y
{
printf("x is equal to y");
}
}
How to Use Loops in C
A loop is an isolated behavior or a specific set of instructions that are repeated a certain number of times, over and over again, until a condition is met. It is the same action, the same code, being repeated again and again.
While loops in C
Before they run any code, while loops have to check a condition. If it is met, the code runs. If not, the code doesn't take any action. So, code is not guaranteed to run even at least one time if a condition is not met.
There are different types of while loops. One of them is an infinite loop.
#include <stdio.h>
int main(void)
{
while(true)
{
printf("Hello world");
}
}
The while keyword is used along with a required boolean expression, true in this case (which always stays true).
After printing the line of code inside the curly braces, it continuously checks wether it should run the code again. As the answer is always yes (since the condition it needs to check is always true each and every time), it runs the code again and again and again.
In this example the only way to stop the program and escape from the endless loop is running Ctrl + C in the terminal.
If the condition was false, it would never run the code inside the curly braces.
Another loop, is a loop that repeats something a certain number of times.
#include <stdio.h>
int main(void)
{
int i = 0;
while(i < 10)
{
//while i is less than 10 run this code
printf("Hello world");
// and then increment
i++
//check the condition everytime
//once the code in the curly braces is run, check if i is still less than 10.
// If so run code + increment again and check again
//loop will eventually end when i reaches 10
}
}
Do-while loops
#include <stdio.h>
int main(void)
{
int i = 10;
do {
printf("the value of i: %i\n", i);
i++;
}
while( i < 20 );
}
Compared to the while loop, the do- while loop is guaranteed to run at least once and execute the code inside the curly braces at least one time.
It first does something and then checks a condition. This is useful when we want to repeat something at least once but for an unknown number of times.
In our example, the code will run at least one time and the statement will be printed at least once. Next, the value is incremented. It then checks if the value is less than 20, and if so, it runs the code again. It will stop running the code once the value being incremented each time is no longer less than 20.
Resources to continue learning C
This marks the end of this intoduction to the C programming language! Nice work for making it through to the end.
I hope this gave you an insight into the 'whys' and the 'hows' of the language and the fundamentals you need to know to start writing basic programs in C.
If you want to go more in depth, build some projects, and problem solve using C, give CS50 Introduction To Computer Science a go.
If you enjoy learning by reading books, I recommend the ones below:
If you enjoy learning by watching videos and coding along,check out the C Programming Tutorial for Beginners video on freeCodeCamp's YouTube channel.
Thanks for reading and happy coding!