


Articolo originale: Introduction to Linux
Sommario
- Capitolo 1: Le Famiglie di Distribuzioni Linux
- Capitolo 2: Filosofia e Concetti di Linux
- Capitolo 3: Le Basi di Linux e l'Avvio del Sistema
- Capitolo 4: Interfaccia grafica
- Capitolo 5: Configurazione del Sistema dall'Interfaccia Grafica
- Capitolo 6: Applicazioni Comuni
- Capitolo 7: Operazioni dalla riga di comando
- Capitolo 8: Trovare la Documentazione Linux
- Capitolo 9: Processi
- Capitolo 10: Operazioni sui File
- Capitolo 11: Editor di Testo
- Capitolo 12: Ambiente dell'Utente
- Capitolo 13: Manipolare i File
- Capitolo 14: Operazioni di Rete
- Capitolo 15: La Shell Bash e lo Scripting di Base
- Capitolo 16: Altro sullo Scripting di Shell Bash
- Capitolo 17: Stampare
Se sei alle prime armi con Linux, questo corso è per te.
In questo corso completo, imparerai molti sugli strumenti utilizzati ogni giorno sia dagli amministratori di sistema di Linux che dai milioni di persone che eseguono distribuzioni Linux come Ubuntu sui loro PC. Questo corso ti insegnerà come spostarti nelle Interfacce Grafiche Utente di Linux e nel potente ecosistema dello strumento di riga di comando.
Il contenuto di questo corso è stato sviluppato dalla Linux Foundation (lo chiamano LFS101x). Ho seguito il loro corso principalmente basato su testo e l'ho trasformato in un corso basato su video.
Puoi leggere la versione di testo del corso proprio qui o puoi guardare la versione video (in lingua inglese) del corso sul canale YouTube di freecodecamp.org (durata di 6 ore).
Questo tutorial rientra nella licenza Creative Commons 4.0.
Quindi, se vuoi seguire la versione scritta del corso, continua a leggere!
Capitolo 1: Le Famiglie di Distribuzioni Linux
Entro la fine di questo capitolo, dovresti essere in grado di:
- Descrivere l'ambiente software richiesto per questo corso.
- Descrivere le tre principali famiglie di distribuzione Linux.
Requisiti del corso
Per beneficiare pienamente di questo corso, dovrai installare almeno una distribuzione Linux (se non hai già familiarità con il termine distribuzione, in quanto si riferisce a Linux, presto l'avrai!).
Stai per imparare alcuni dettagli sulle molte distribuzioni Linux disponibili. Poiché ci sono letteralmente centinaia di distribuzioni, non le tratterò tutte in questo corso. Viceversa mi concentrerò sulle tre principali famiglie di distribuzione.
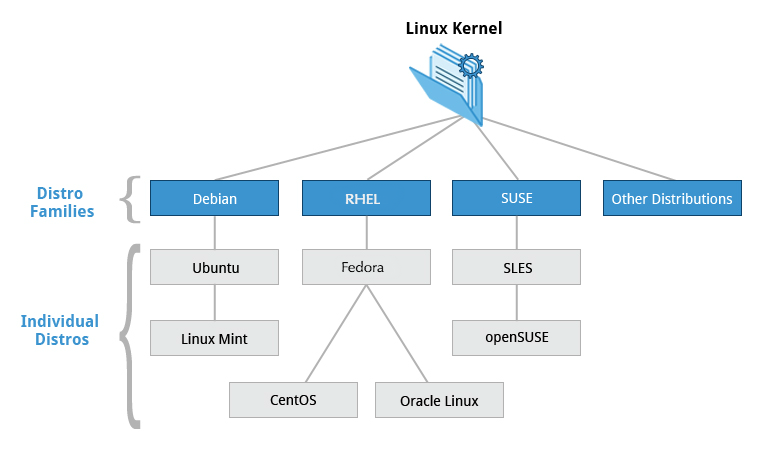
Le famiglie e le distribuzioni che le rappresentano che prenderemo in esame sono:
- Famiglia di Sistemi Red Hat (tra cui CentOS e Fedora)
- Famiglia di Sistemi SUSE (incluso openSUSE)
- Famiglia di Sistemi Debian (inclusi Ubuntu e Linux Mint).
Focus sulle su tre principali famiglie di distribuzione Linux
Sto per dirti qualcosa di più su Red Hat, SUSE e Debian. Mentre questo corso si concentra su queste tre principali famiglie di distribuzione Linux, fintanto che ci sono collaboratori di talento, le famiglie di distribuzioni e le distribuzioni all'interno di queste famiglie continueranno a cambiare e crescere. Le persone vedono un bisogno e sviluppano configurazioni e utility per rispondere a tale necessità. A volte quello sforzo crea una distribuzione completamente nuova di Linux. A volte, sfrutta una distribuzione esistente per espandere i membri di una famiglia esistente.
La famiglia Red Hat
Red Hat Enterprise Linux (o RHEL [pronunciato "rel"]) capeggia la famiglia che include CentOS, CentOS Stream, Fedora e Oracle Linux.
Fedora ha una stretta relazione con RHEL e contiene significativamente più software rispetto alla versione Enterprise (aziendale) di Red Hat. Uno dei motivi è che una comunità diversificata è coinvolta nella costruzione di Fedora, con molti collaboratori che non lavorano per Red Hat. Inoltre, viene utilizzato come piattaforma di test per future versioni RHEL.
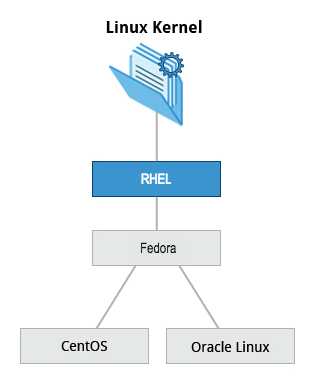
In questo corso, useremo principalmente CentOS Stream dalla famiglia Red Hat.
La versione di base di CentOS è anche praticamente identica a RHEL, la distribuzione Linux più popolare negli ambienti aziendali. Tuttavia, CentOS 8 non ha più aggiornamenti programmati. Al suo posto c'è CentOS 8 Stream.
Fatti chiave sulla famiglia Red Hat
Alcuni dei fatti chiave sulla famiglia di distribuzione Red Hat sono:
- Fedora funge da piattaforma di test a monte per RHEL.
- CentOS è un clone stretto di RHEL, mentre Oracle Linux è principalmente una copia con alcune modifiche.
- Supporta piattaforme hardware come Intel X86, ARM, Itanium, PowerPC e IBM System Z.
- Utilizza i gestori di pacchetti basati su RMP yum e dnf (discussi più avanti) per installare, aggiornare e rimuovere i pacchetti nel sistema.
- RHEL è ampiamente utilizzato dalle aziende che ospitano i propri sistemi.
La famiglia Suse
La relazione tra SUSE (SUSE Linux Enterprise Server o SLES) e openSUSE è simile a quella descritta tra RHEL, CentOS e Fedora.
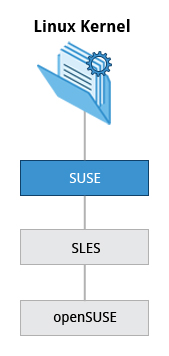
Usiamo openSUSE come distribuzione di riferimento per la famiglia SUSE, in quanto è disponibile per gli utenti finali gratuitamente. Poiché i due prodotti sono estremamente simili, il materiale che copre openSUSE può in genere essere applicato a SLES con pochi problemi.
Fatti chiave sulla famiglia SUSE
Alcuni dei fatti chiave sulla famiglia SUSE sono elencati di seguito:
- SUSE Linux Enterprise Server (SLES) si basa sulla distribuzione openSUSE.
- Utilizza il gestore pacchetti zypper basato su RPM (lo tratteremo in dettaglio in seguito) per installare, aggiornare e rimuovere i pacchetti nel sistema.
- Include l'applicazione YaST (Yet Another Setup Tool) per scopi di amministrazione di sistema.
- SLES è ampiamente utilizzata nella vendita al dettaglio e in molti altri settori.
La famiglia Debian
La distribuzione di Debian è la distribuzione base per diverse altre distribuzioni, tra cui Ubuntu. A sua volta, Ubuntu è la distribuzione base per Linux Mint e una serie di altre distribuzioni. È comunemente usato sia su computer server che desktop. Debian è un progetto puramente della comunità open source (non di proprietà di nessuna società) e ha una forte attenzione alla stabilità.
Debian fornisce di gran lunga il repository di software più grande e completo ai suoi utenti di qualsiasi distribuzione Linux.
Ubuntu mira a fornire un buon compromesso tra stabilità a lungo termine e facilità d'uso. Poiché Ubuntu ottiene la maggior parte dei suoi pacchetti dal ramo stabile di Debian, ha anche accesso a un repository di software molto grande. Per questi motivi, useremo Ubuntu LTS (Supporto a Lungo Termine) come riferimento alle distribuzioni della famiglia Debian per questo corso.
Fatti chiave sulla famiglia Debian
Alcuni fatti chiave sulla famiglia Debian sono elencati di seguito:
- La famiglia Debian è la distribuzione di base per Ubuntu e Ubuntu è la distribuzione di base per Linux Mint e altri.
- Utilizza il gestore di pacchetti APT basato su DPKG (utilizzando apt, apt-get, apt-cache, ecc., che tratteremo in dettaglio in seguito) per installare, aggiornare e rimuovere i pacchetti nel sistema.
- Ubuntu è stato ampiamente utilizzato per la distribuzione su cloud.
- Mentre Ubuntu è derivato da una distribuzione Debian ed è basato su GNOME sotto il cofano, differisce visivamente dall'interfaccia su Debian standard e altre distribuzioni.
Riassunto capitolo
- Esistono tre principali famiglie di distribuzioni all'interno di Linux: Red Hat, Suse e Debian. In questo corso, lavoreremo con membri rappresentativi di tutte queste famiglie.
Capitolo 2: Filosofia e Concetti di Linux
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Definire i termini comuni associati a Linux.
- Discutere i componenti di una distribuzione Linux.
La potenza di Linux
Introduzione
Affinché tu possa ottenere il massimo da questo corso, ti consigliamo di avere Linux installato su una macchina che puoi utilizzare durante questo corso. È possibile seguire questa breve guida di installazione in lingua inglese "Preparazione del computer per la formazione su Linux". Ti aiuterà a selezionare una distribuzione Linux per l'installazione, decidere se desideri creare una macchina Linux pura autonoma o una a doppio boot, se fare un'installazione fisica o virtuale, ecc.. Poi ti guiderà attraverso i passi da compiere. Tratterò presto anche l'installazione.
Non abbiamo esaminato tutto in dettaglio, ma tieni presente che la maggior parte della documentazione di Linux è già sul tuo sistema sotto forma di pagine di manuale, delle quali discuteremo in modo molto dettagliato in seguito. Ogni volta che non capisci qualcosa o vuoi saperne di più circa un comando, un programma, un argomento o un'utility, puoi semplicemente digitare man <argomento> dalla riga di comando. Supporremo che tu stia pensando in questo modo e non ripeteremo costantemente "Per ulteriori informazioni, consulta la pagina di manuale per <argomento>".
Come nota correlata, durante il corso utilizziamo un'abbreviazione diffusa nella comunità open source. Quando ci si riferisce ai casi in cui l'utente deve fare una scelta su cosa digitare (ad esempio il nome di un programma o file), utilizziamo l'abbreviazione "foo" che sta per <digita il nome del file qui>. Quindi attenzione, in realtà non stiamo suggerendo di manipolare file o di installare servizi chiamati "foo"!
Il modo migliore per imparare Linux è provare a usarlo. Quindi assicurati di provare le cose tu stesso mentre segui.
Dovrai avere un sistema Linux attivo e in esecuzione che può essere un sistema Linux nativo sul tuo hardware, una distribuzione live lanciata da una chiave USB o da un CD o una macchina virtuale in esecuzione tramite hypervisor.
Ti mostreremo tutti questi metodi, quindi andiamo avanti.
Video: Terminologia Linux
Distribuzioni Linux
Supponiamo che ti sia stato assegnato un progetto che costruisce un prodotto per una piattaforma Linux. I requisiti del progetto includono l'assicurarsi che il progetto funzioni correttamente sulle distribuzioni Linux più utilizzate. Per raggiungere questo obiettivo, è necessario conoscere i diversi componenti, servizi e configurazioni associati a ciascuna distribuzione. Stiamo per vedere esattamente come farlo.
Quindi, cos'è una distribuzione Linux e qual è la relazione con il kernel Linux?
Il kernel Linux è il nucleo del sistema operativo. Una distribuzione completa di Linux è costituita dal kernel più una serie di altri strumenti software per operazioni relative ai file, gestione degli utenti e gestione dei pacchetti software. Ognuno di questi strumenti fornisce una parte del sistema completo. Ogni strumento ha spesso un progetto a sé stante, con i propri sviluppatori che lavorano per perfezionare quel pezzo del sistema.
Mentre il kernel Linux più recente (e le versioni precedenti) è sempre disponibile negli archivi del kernel Linux, le distribuzioni Linux possono essere basate su diverse versioni del kernel. Ad esempio, la distribuzione RHEL 8 molto popolare si basa sul kernel 4.18, che non è nuovo, ma è estremamente stabile. Altre distribuzioni possono muoversi più rapidamente nell'adottare le ultime versioni del kernel. È importante notare che il kernel non è un monolite e può essere aggiornato/integrato anche parzialmente, ad esempio, Rhel/CentOS hanno incorporato molti dei più recenti miglioramenti del kernel nelle loro versioni precedenti, così come Ubuntu, openSUSE, SLES, ecc.
Esempi di altri strumenti e ingredienti essenziali forniti dalle distribuzioni includono i compilatori C/C++ e Clang, il debugger gdb, le applicazioni di librerie di sistema core che devono collegate per l'esecuzione, l'interfaccia di basso livello per disegnare grafica sullo schermo, così come l'ambiente desktop di livello superiore e il sistema per l'installazione e l'aggiornamento dei vari componenti, incluso il kernel stesso. Tutte le distribuzioni sono dotate di una suite piuttosto completa di applicazioni già installate.
Servizi associati alle distribuzioni
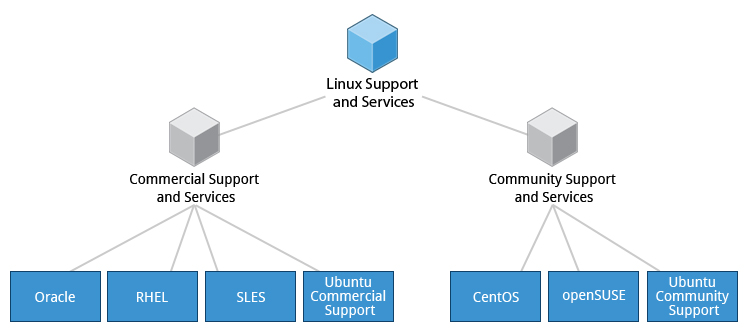
La vasta varietà di distribuzioni Linux è progettata per soddisfare un pubblico molto vario, organizzazioni incluse, con esigenze e gusti specifici. Tuttavia, le grandi organizzazioni, come aziende e istituzioni governative e altri enti, tendono a scegliere le principali distribuzioni supportate dal punto di vista commerciale da Red Hat, SUSE e Canonical (Ubuntu).
CentOS e CentOS Stream sono popolari alternative gratuite (vale a dire con nessun costo) a Red Hat Enterprise Linux (RHEL) e sono spesso utilizzate da organizzazioni che si sentono a proprio agio nell'operare senza supporto tecnico a pagamento. Ubuntu e Fedora sono ampiamente utilizzate dagli sviluppatori e sono anche popolari in ambito educativo. Scientific Linux è favorita dalla comunità di ricerca scientifica per la sua compatibilità con pacchetti software scientifici e matematici. Entrambe le varianti CentOS sono compatibili dal punto di vista binario con RHEL; vale a dire che nella maggior parte dei casi, i pacchetti software binari si installeranno correttamente su diverse distribuzioni.
Nota che CentOS dalla fine del 2021 è stata abbandonata a favore di CentOS Stream. Tuttavia, ci sono almeno due nuovi sostituti derivati da RHEL: Alma Linux e Rocky Linux che stanno stabilendo un punto d'appoggio.
Molti distributori commerciali, tra cui Red Hat, Ubuntu, SUSE e Oracle, forniscono un supporto a pagamento a lungo termine basato sulle loro distribuzioni, nonché la certificazione hardware e software. Tutti i principali distributori forniscono servizi di aggiornamento per mantenere il sistema aggiornato con le ultime correzioni di sicurezza e bug e miglioramenti delle prestazioni, oltre a fornire risorse di supporto online.
Capitolo 2 - Riepilogo
Hai completato il capitolo 2. Riassumiamo i concetti chiave coperti:
- Linux si ispira fortemente al sistema operativo UNIX, del quale i suoi creatori erano esperti.
- Linux accede a molte funzionalità e servizi tramite file e oggetti simili a file.
- Linux è un sistema operativo multi-tasking, multi-utente, con processi di rete e di servizio integrati noti come demoni.
- Linux è sviluppato da una confederazione libera di sviluppatori da tutto il mondo, che collaborano su Internet, con Linus Torvalds in testa. La competenza tecnica e il desiderio di contribuire sono gli unici requisiti per la partecipazione.
- La comunità Linux è un ecosistema di vasta portata di sviluppatori, fornitori e utenti che supporta e fa avanzare il sistema operativo Linux.
- Alcuni dei termini comuni utilizzati in Linux sono: kernel, distribuzione, boot loader, servizio, filesystem, sistema X Window, ambiente desktop e riga di comando.
- Una distribuzione completa di Linux è costituita dal kernel più una serie di altri strumenti software per operazioni relative ai file, gestione degli utenti e gestione dei pacchetti software.
Capitolo 3: Le Basi di Linux e l'Avvio del Sistema
Entro la fine di questo capitolo, dovresti essere in grado di:
- Identificare i filesystem Linux.
- Identificare le differenze tra partizioni e filesystem.
- Descrivere il processo di avvio.
- Installare Linux su un computer.
Il processo di avvio
Il processo di avvio di Linux è la procedura per l'inizializzazione del sistema. Consiste in tutto ciò che accade da quando il computer viene acceso per la prima volta fino a quando l'interfaccia utente è completamente operativa.
Avere una buona comprensione dei passaggi nel processo di avvio può aiutarti nella risoluzione dei problemi, nonché ad adattare le prestazioni del computer alle tue esigenze.
D'altra parte, il processo di avvio può essere piuttosto tecnico e puoi iniziare a utilizzare Linux senza conoscere tutti i dettagli.

BIOS - I Primi Passi
L'avvio di un sistema Linux basato su architettura x86 prevede una serie di passaggi. Quando il computer viene acceso, il BIOS (Basic Input/Output System) inizializza l'hardware, incluso lo schermo e la tastiera, ed esegue test sulla memoria principale. Questo processo è anche chiamato POST (Power On Self Test).
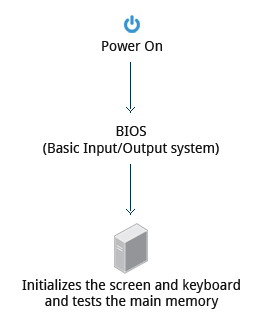
Il software BIOS è conservato su un chip ROM (sola lettura) sulla scheda madre. Successivamente, il resto del processo di avvio è controllato dal sistema operativo (OS).
Master Boot Record (MBR) e Boot Loader
Una volta completate le operazioni di POST, il controllo del sistema passa dal BIOS al boot loader. Il boot loader viene generalmente memorizzato su uno dei dischi rigidi del sistema, sia nel settore di avvio (per i sistemi BIOS/MBR tradizionali) o nella partizione EFI (Interfaccia del Firmware Estensibile) o nei sistemi più recenti EFI/UEFI (Interfaccia Unificata del Firmware Estensibile). Fino a questa fase, la macchina non accede ad alcun supporto di archiviazione di massa. Successivamente, le informazioni su data, ora e le periferiche più importanti vengono caricate dai valori CMOS (una tecnologia utilizzata per la conservazione di memoria alimentato a batteria che consente al sistema di tenere traccia della data e dell'ora anche quando è spento).
Esistono numerosi boot loader per Linux; quelli più comuni sono GRUB (Grand Unified Boot Loader), ISOLINUX (per l'avvio da supporti rimovibili) e DAS U-Boot (per l'avvio su dispositivi/apparecchi incorporati). La maggior parte dei boot loader Linux può presentare un'interfaccia utente per la scelta di opzioni alternative per l'avvio di Linux e persino altri sistemi operativi che potrebbero essere installati. Quando si avvia Linux, il boot loader è responsabile del caricamento dell'immagine del kernel e del disco RAM iniziale o filesystem (che contiene alcuni file critici e driver di dispositivo necessari per avviare il sistema) in memoria.

Boot Loader in azione
Il boot loader ha due fasi distinte:
Per i sistemi che utilizzano il metodo BIOS/MBR, il boot loader risiede nel primo settore del disco rigido, noto anche come MBR - Master Boot Record. La dimensione del MBR è di soli 512 byte. In questa fase, il boot loader esamina la tabella delle partizioni e trova una partizione avviabile. Una volta che trova una partizione avviabile, cerca il boot loader del secondo stadio, ad esempio GRUB, e lo carica nella RAM. Per i sistemi che utilizzano il metodo EFI/UEFI, il firmware UEFI legge i dati del suo Boot Manager per determinare quale applicazione UEFI deve essere lanciata e da dove (cioè da quale disco e partizione è possibile trovare la partizione EFI). Il firmware lancia quindi l'applicazione UEFI, ad esempio GRUB, come definito nella voce di avvio nel Boot Manager del firmware. Questa procedura è più complicata, ma più versatile dei vecchi metodi MBR.
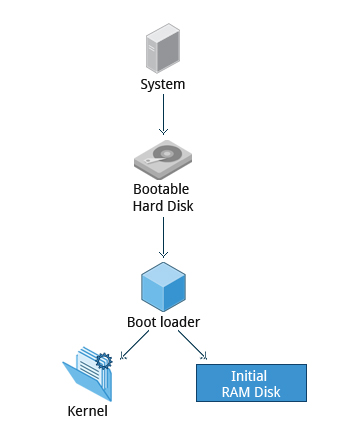
Il boot loader del secondo stadio risiede sotto /boot. Viene visualizzato uno splash screen, che ci consente di scegliere quale sistema operativo (OS) avviare. Dopo aver scelto il sistema operativo, il boot loader carica il kernel del sistema operativo selezionato in RAM e passa il controllo a esso. I kernel sono quasi sempre compressi, quindi il suo primo lavoro è quello di decomprimere sé stesso. Successivamente, controllerà e analizzerà l'hardware di sistema e inizializzerà qualsiasi driver di dispositivi hardware sia integrato nel kernel.
Disco RAM iniziale
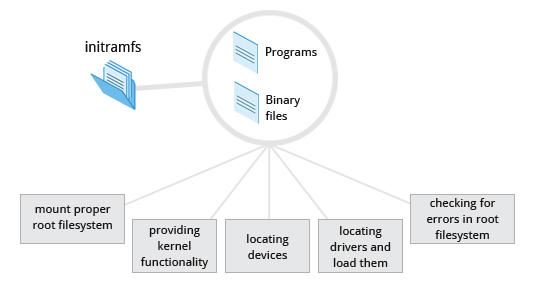
L'immagine del filesystem initramfs contiene programmi e file binari che eseguono tutte le azioni necessarie per montare il filesystem di root corretto, come fornire funzionalità del kernel per i driver di filesystem e dispositivi necessari per i controller di archiviazione di massa con una funzione chiamata udev, che è responsabile per capire quali dispositivi sono presenti, individuare i driver del dispositivo che devono funzionare correttamente e caricarli. Dopo che il filesystem root è stato trovato, viene controllato per errori e montato.
Il programma mount indica al sistema operativo che un filesystem è pronto per l'uso e lo associa a un punto particolare nella gerarchia complessiva del filesystem (il punto di montaggio). Se ciò ha esito positivo, initramfs viene scaricato dalla RAM e il programma di inizializzazione sul filesystem root (/sbin/init) viene eseguito.
init gestisce il montaggio attaccandolo al filesystem root finale. Se sono necessari driver hardware speciali prima di accedere all'archiviazione di massa, devono essere nell'immagine initramfs.
Accesso in modalità testo
Verso la fine del processo di avvio, init avvia una serie di istruzioni di accesso in modalità testo. Queste ti consentono di digitare il tuo username, seguito dalla tua password e di ottenere una shell di comandi. Tuttavia, se stai eseguendo un sistema con un'interfaccia di accesso grafico, all'inizio non li vedrai.
Come imparerai nel Capitolo 7: Operazioni della riga di comando, i terminali che eseguono le shell di comando possono essere accessibili utilizzando il tasto ALT più un tasto funzione. La maggior parte delle distribuzioni avvia sei terminali di testo e un terminale grafico a partire da F1 o F2. All'interno di un ambiente grafico, il passaggio a una console di testo richiede di digitare CTRL-ALT più il tasto funzione appropriato (con F7 o F1 che porta alla GUI).
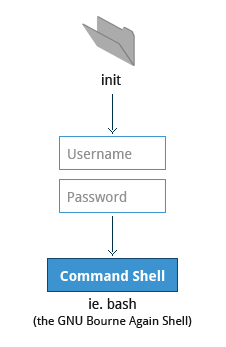
Di solito, la shell di comando predefinita è bash - GNU Bourne Again Shell, ma sono disponibili diverse altre shell di comando avanzate. La shell stampa un prompt di testo, indicando che è pronta ad accettare i comandi; dopo che l'utente digita il comando e preme Invio, il comando viene eseguito e un altro prompt viene visualizzato dopo aver eseguito il comando.
Il kernel Linux
Il boot loader carica sia il kernel che un file system iniziale a base di RAM (initramfs) in memoria, quindi può essere utilizzato direttamente dal kernel.
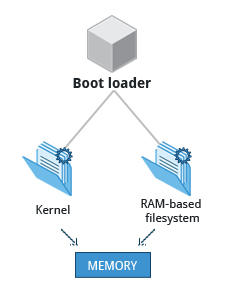
Quando il kernel viene caricato in RAM, inizializza e configura immediatamente la memoria del computer e configura anche tutto l'hardware collegato al sistema. Ciò include tutti i processori, i sottosistemi I/O, i dispositivi di archiviazione, ecc. Il kernel carica anche alcune applicazioni nello spazio utente necessarie.
/sbin/init e servizi
Una volta che il kernel ha impostato tutto il suo hardware e montato il filesystem root, il kernel esegue /sbin/init. Questo diventa quindi il processo iniziale, che a sua volta avvia altri processi per far funzionare il sistema. La maggior parte degli altri processi sul sistema traccia la propria origine da init; le eccezioni includono i cosiddetti processi del kernel. Questi vengono avviati direttamente dal kernel e il loro compito è gestire i dettagli interni del sistema operativo.
Oltre ad avviare il sistema, init è responsabile del mantenimento in esecuzione del sistema e di chiuderlo in modo pulito. Una delle sue responsabilità è quella di agire quando necessario come gestore per tutti i processi non kernel; pulisce dopo il loro completamento, e riavvia i servizi di accesso utente secondo necessità quando gli utenti accedono ed escono, e fa lo stesso per altri servizi di sistema in background.
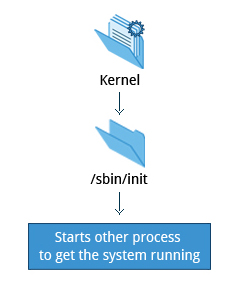
Tradizionalmente, questa inizializzazione del processo veniva effettuata utilizzando convenzioni che risalgono agli anni '80 e alla varietà System V di Unix. Questo processo seriale faceva passare il sistema attraverso una sequenza di livelli di esecuzione (runlevel) che contenengono un insieme di script che avviavano e fermavano i servizi. Ogni runlevel supportava una diversa modalità di esecuzione del sistema. All'interno di ogni runlevel, i singoli servizi potrebbero essere impostati per essere eseguiti o per essere chiusi se in esecuzione.
Tuttavia, tutte le principali distribuzioni si sono allontanate da questo metodo sequenziale di inizializzazione del sistema tramite runlevel, sebbene di solito emulino molte utility di System V per scopi di compatibilità. Successivamente, tratteremo dei nuovi metodi, tra i quali systemd è diventato dominante.
Alternative di avvio
SysVinit considerava le cose come un processo seriale, diviso in una serie di stadi sequenziali. Ogni fase richiedeva il completamento prima che la prossima potesse procedere. Pertanto, l'avvio non ha potuto facilmente sfruttare l'elaborazione parallela che potrebbe essere eseguita su più processori o core.
Inoltre, l'arresto e il riavvio erano visti come un evento relativamente raro; quanto tempo impiegava esattamente non è stato considerato importante. Questo non è più vero, specialmente con dispositivi mobili e sistemi Linux incorporati. Alcuni metodi moderni, come l'uso di contenitori, possono richiedere tempi di avvio quasi istantanei. Pertanto, i sistemi ora richiedono metodi con capacità più veloci e migliorate. Infine, i metodi più vecchi richiedevano script di avvio piuttosto complicati, che erano difficili da mantenere universali attraverso versioni di distribuzione, versioni del kernel, architetture e tipi di sistemi. Le due principali alternative sviluppate erano:
Upstart
- Sviluppato da Ubuntu e incluso per la prima volta nel 2006
- Adottato in Fedora 9 (nel 2008) e in RHEL 6 e i suoi cloni
SystemD
- Adottato da Fedora per la prima volta (nel 2011)
- Adottato da RHEL 7 e SUSE
- Sostituisce Upstart in Ubuntu 16.04
Sebbene la migrazione verso systemd sia stata piuttosto controversa, è stata adottata da tutte le principali distribuzioni e quindi non discuteremo dei metodi più vecchi Syistem V o Upstart, che sono diventati un vicolo cieco. Indipendentemente da come ci si schieri rispetto alla controversia o ai metodi tecnici di systemd, l'adozione quasi universale ha reso più semplice apprendere come lavorare sui sistemi Linux, poiché ci sono meno differenze tra le distribuzioni. In seguito elenchiamo le funzionalità di sistema.
Funzionalità systemd
I sistemi con systemd si avviano più velocemente di quelli con i metodi init meno recenti. Ciò è in gran parte dovuto al fatto che sostituisce un insieme serializzato di passaggi con tecniche di parallelizzazione aggressive, che consente di avviare più servizi contemporaneamente.
I complicati script di shell di avvio vengono sostituiti con file di configurazione più semplici, che elencano ciò che deve essere fatto prima che venga avviato un servizio, su come eseguire l'avvio del servizio e quali condizioni il servizio dovrebbe identificare come da completarsi al termine dell'avvio. Una cosa da notare è che /sbin/init ora punta a /lib/systemd/systemd; cioè systemd assume il controllo del processo init.
Un comando systemd (systemctl) viene utilizzato per la maggior parte delle attività di base. Anche se non abbiamo ancora parlato di come lavorare alla riga di comando, ecco un breve elenco dei suoi utilizzi:
- Avvio, arresto, riavvio di un servizio (utilizzando httpd, il server Web Apache, ad esempio) su un sistema attualmente in esecuzione:
$ sudo systemctl start | stop | restart httpd.service - Abilitare o disabilitare un servizio di sistema dall'avvio del sistema di boot:
$ sudo systemctl enable | disable httpd.service
Nella maggior parte dei casi, l'estensione .service può essere omessa. Ci sono molte differenze tecniche con i metodi più vecchi che vanno oltre lo scopo della nostra discussione.

Le Basi del Filesystem Linux
Pensa a un frigorifero che ha più ripiani che possono essere utilizzati per conservare vari alimenti. Questi ripiani ti aiutano a organizzare gli alimenti per forma, dimensioni, tipo, ecc.. Lo stesso concetto si applica a un filesystem, che è l'incarnazione di un metodo di memorizzazione e organizzazione di raccolte arbitrarie di dati in una forma utilizzabile dall'uomo.
Diversi tipi di filesystem supportati da Linux:
- Filesystem del disco convenzionali: EXT3, EXT4, XFS, BTRFS, JFS, NTFS, VFAT, EXFAT ecc.
- Filesystem di conservazione flash: Ubifs, JFFS2, Yaffs, ecc.
- Filesystem di database
- Filesystem a scopo speciale: Procfs, SYSFS, TMPFS, SquashFS, Debugfs, Fuse ecc.
Questa sezione descriverà la disposizione del filesystem standard condiviso dalla maggior parte delle distribuzioni Linux.
Partizioni e filesystem
Una partizione è una sezione fisicamente contigua di un disco o appare come tale in alcune configurazioni avanzate.
Un filesystem è un metodo per archiviare/trovare file su un disco rigido (di solito in una partizione).
Si può pensare a una partizione come a un contenitore in cui risiede un filesystem, sebbene in alcune circostanze un filesystem può trovarsi su più di una partizione se si utilizzano collegamenti simbolici, di cui discuteremo molto più tardi.
Un confronto tra filesystem in Windows e Linux è riportato nella tabella seguente:
| Windows | Linux | |
|---|---|---|
| PARTIZIONE | Disco1 | /dev(sda1 |
| Tipo Filesystem | NTFS/VFAT | EXT3/EXT4/XFS/BTRFS... |
| Parametri Montaggio | LetteraDrive | PuntoMontaggio |
| Cartella Base (dove è salvato il Sistema Operativo) | C:\; |
/ |
La Gerarchia del Filesystem Standard
I sistemi Linux archiviano i loro file importanti secondo una disposizione standard chiamata Filesystem Hierarchy Standard (FHS), che è stata a lungo mantenuta dalla Fondazione Linux. Per ulteriori informazioni, dai un'occhiata al seguente documento in lingua inglese: "Gerarchia del Filesystem Standard" creato dal gruppo di lavoro LSB. Avere uno standard garantisce che utenti, amministratori e sviluppatori possano spostarsi tra le distribuzioni senza dover nuovamente imparare come è organizzato il sistema.
Linux utilizza il carattere / per separare i percorsi (a differenza di Windows, che utilizza \) e non ha lettere per identificare i drive. I vari driver e/o partizioni sono montati come directory nel singolo filesystem. I media rimovibili come unità USB, CD e DVD appariranno come montate su /run/media/username/etichettadisco per i sistemi Linux recenti o sotto /media per distribuzioni più vecchie. Ad esempio, se il tuo nome utente è studente, una chiave USB etichettata come FEDORA potrebbe essere montata in /run/media/studente/FEDORA e un file README.txt su quel disco sarebbe accessibile a /run/media/studente/FEDORA/README.txt`.
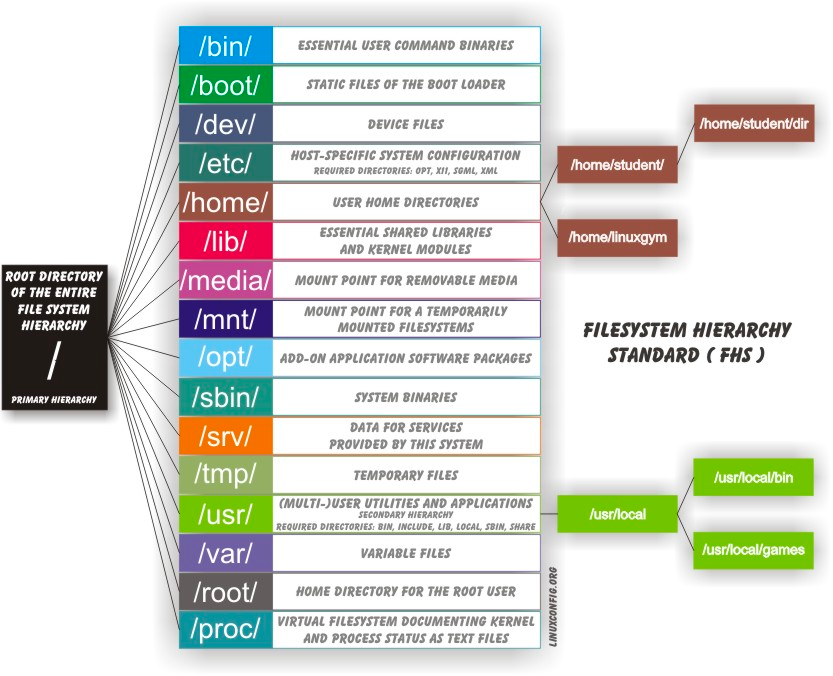
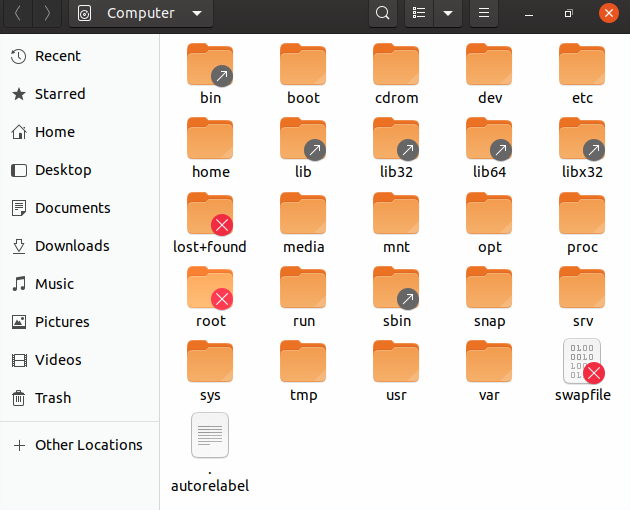
Tutti i nomi nel filesystem Linux distinguono tra maiuscole e minuscole quindi /boot, /Boot e /BOOT rappresentano tre diverse directory (o cartelle). Molte distribuzioni distinguono tra le utility di base necessarie per il corretto funzionamento del sistema e altri programmi e posizionano questi ultimi nelle directory sotto /usr (pensa a utente). Per avere un'idea di come sono organizzati gli altri programmi, trova la directory /usr nel diagramma qui sopra e confronta le sottodirectory con quelle che esistono direttamente sotto la directory di root del sistema (/).
Video: Visualizzare la Gerarchia del Filesystem dall'Interfaccia Grafica in Ubuntu
Video: Visualizzare la Gerarchia del Filesystem dall'Interfaccia Grafica in openSUSE
Installazione di una Distribuzione Linux
Supponiamo che tu intenda acquistare una nuova auto. Quali fattori devi considerare per fare una scelta adeguata? I requisiti che devono essere presi in considerazione includono le dimensioni necessarie per le esigenze della tua famiglia, il tipo di di motore e di carburante utilizzato, il budget previsto e le opzioni di finanziamento disponibili, l'affidabilità e i servizi post-vendita, ecc.
Allo stesso modo, anche determinare quale distribuzione installare richiede una pianificazione. La figura seguente mostra alcune, ma non tutte le scelte. Si noti che molti sistemi Linux incorporati utilizzano contenuti realizzati su misura, piuttosto che Android o Yocto.
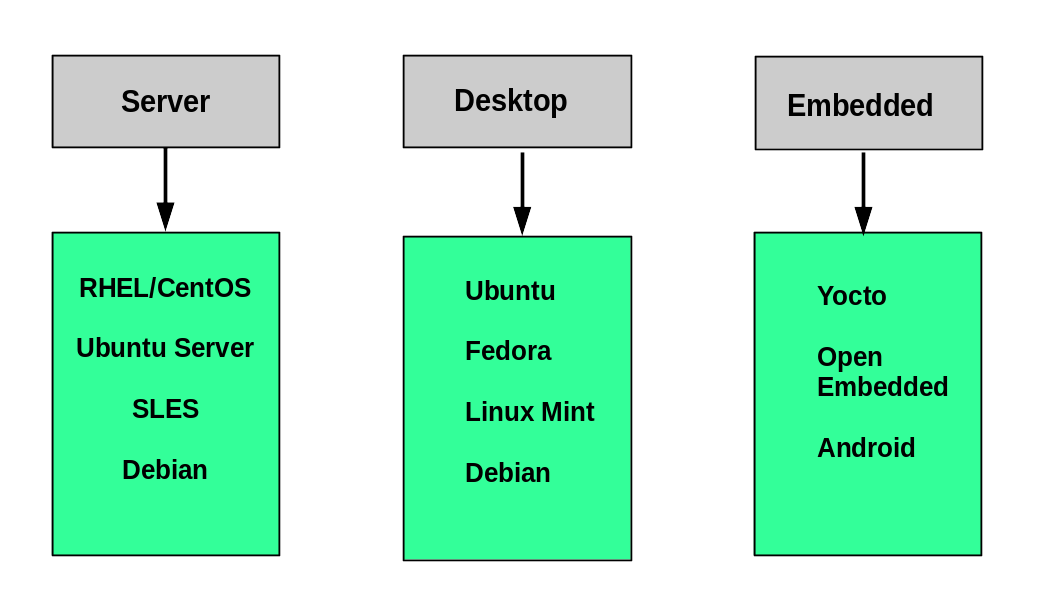
Domande da Porsi Quando si Sceglie una Distribuzione
Alcune domande che vale la pena di porsi prima di orientarsi verso una distribuzione includono:
- Qual è la funzione principale del sistema (server o desktop)?
- Quali tipi di pacchetti sono importanti per l'utilizzo? Ad esempio, server Web, elaborazione testi, ecc.
- Quanto spazio su disco rigido è richiesto e quanto è disponibile? Ad esempio, quando si installa Linux su un dispositivo incorporato, lo spazio è generalmente ristretto.
- Quante volte vengono aggiornati i pacchetti?
- Quanto dura il ciclo di supporto per ogni versione? Ad esempio, le versioni LTS hanno un supporto a lungo termine.
- Hai bisogno di personalizzazione del kernel dal venditore o da una terza parte?
- Su quale hardware installerai la distribuzione? Ad esempio, potrebbe essere X86, ARM, PPC, ecc.
- Hai bisogno di stabilità a lungo termine? Puoi accettare (o aver bisogno di) un sistema all'avanguardia più instabile che esegua l'ultimo software?
Installazione di Linux: Pianificazione
La disposizione della partizione deve essere decisa al momento dell'installazione; può essere difficile cambiare in seguito. Sebbeme i sistemi Linux gestiscano più partizioni montandole in punti specifici nel filesystem, e sia sempre modificare la disposizione in seguito, è sempre più facile cercare di farlo bene subito.
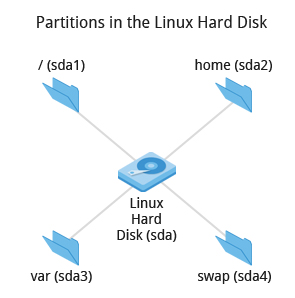
Quasi tutti gli installer forniscono una disposizione predefinita ragionevole, con tutto lo spazio dedicato ai file normali su una grande partizione e una partizione di swap più piccola o con partizioni separate per alcune aree sensibili in relazione allo spazio come /home e /var. Potrebbe essere necessario sovrascrivere le impostazioni predefinite e fare qualcosa di diverso se hai esigenze speciali o se desideri utilizzare più di un disco.
Installazione di Linux: Scelte Software
Tutte le installazioni includono il software minimo indispensabile per l'esecuzione di una distribuzione Linux.
La maggior parte degli installer fornisce anche opzioni per l'aggiunta di categorie di software. Applicazioni comuni (come il web browser Firefox e la suite LibreOffice), strumenti per sviluppatori (come gli editor di testo vi ed emacs, che esploreremo più avanti in questo corso) e altri servizi popolari (come gli strumenti di Apache Web Server o il database MySQL) di solito sono inclusi. Inoltre, per qualsiasi sistema con un desktop grafico, un desktop scelto (come GNOME o KDE) è installato come predefinito.
Tutti gli installer hanno alcune funzionalità di sicurezza iniziali configurate sul nuovo sistema. Un passaggio di base consiste nell'impostazione della password per il superutente (root) e nell'impostazione di un utente iniziale. In alcuni casi (come Ubuntu), viene impostato solo un utente iniziale; l'accesso a root diretto non è configurato e l'accesso a root richiede prima l'accesso come utente normale, quindi utilizzando sudo, come descriveremo in seguito. Alcune distribuzioni installeranno anche framework di sicurezza più avanzati, come SElinux o AppArmor. Ad esempio, tutti i sistemi basati su Red Hat, inclusi Fedora e CentOS, usano sempre SElinux per impostazione predefinita e Ubuntu viene fornito con AppArmor attivo e funzionante.
Installazione di Linux: Sorgente d'Installazione
Come altri sistemi operativi, le distribuzioni Linux sono fornite su media rimovibili come unità USB e CD o DVD. La maggior parte delle distribuzioni Linux supporta anche l'avvio di una piccola immagine e il download del resto del sistema sulla rete. Queste piccole immagini sono utilizzabili sui supporti o come immagini di avvio di rete, nel qual caso è possibile eseguire un'installazione senza utilizzare alcun supporto locale.
Molti installer possono eseguire un'installazione completamente automatica, utilizzando un file di configurazione con le specifiche delle opzioni di installazione. Questo file è chiamato file Kickstart per i sistemi basati su Red Hat, profilo AutoYAST per sistemi basati su SUSE e file Preseed per i sistemi basati su Debian.
Ogni distribuzione fornisce la propria documentazione e strumenti per la creazione e la gestione di questi file.
Installazione di Linux: Il Processo
Il processo di installazione effettivo è abbastanza simile per tutte le distribuzioni.
Dopo aver avviato dal supporto di installazione, l'installer inizia e pone domande su come impostare il sistema. Queste domande vengono saltate se viene fornito un file di installazione automatica. Successivamente, viene eseguita l'installazione.
Infine, il computer si riavvia nel sistema appena installato. Su alcune distribuzioni, vengono poste ulteriori domande dopo il riavvio del sistema.
La maggior parte degli installer ha la possibilità di scaricare e installare aggiornamenti come parte del processo di installazione; ciò richiede l'accesso a Internet. In caso contrario, il sistema utilizza il suo normale meccanismo di aggiornamento per recuperare tali aggiornamenti dopo la fine dell'installazione.
Installazione di Linux: Avvertimento
Le dimostrazioni mostrano come installare Linux direttamente sulla tua macchina, cancellando tutto ciò che era lì. Mentre le dimostrazioni non modificheranno il tuo computer, seguendo queste procedure nella vita reale cancellerà tutti i dati attuali.
La Fondazione Linux ha un documento in lingua inglese: "Preparing Your Computer for Linux Training" che descrive metodi alternativi per installare Linux senza sovrascrivere dati esistenti. Potresti consultarlo, se è necessario preservare le informazioni sul disco rigido.
Questi metodi alternativi sono:
- Ri-partizionamento del disco rigido per liberare abbastanza spazio per consentire l'installazione dual boot di Linux, insieme al sistema operativo attuale.
- Utilizzo di un programma Host Machine Hypervisor (come i prodotti VMware oppure Oracle Virtual Box) per installare una macchina virtuale Linux client.
- Avvio da e utilizzo di un CD o chiave USB e non scrivere nulla sul disco rigido.
Il primo metodo talvolta è complicato e dovrebbe essere adottato se hai dimestichezza con l'argomento e comprendi i passi da compiere. Il secondo e il terzo metodo sono piuttosto sicuri e rendono difficile danneggiare il sistema.
Video: Passaggi per Installare Ubuntu
Video: Passaggi per Installare CentoOS
Video: Passaggi per Installare openSUSE
Capitolo 3 - Riepilogo
Hai completato il capitolo 3. Riassumiamo i concetti chiave trattati:
- Una partizione è una parte logica del disco.
- Un filesystem è un metodo per archiviare/trovare file su un disco rigido.
- Dividendo il disco rigido in partizioni, i dati possono essere raggruppati e separati secondo necessità. Quando si verifica un fallimento o un errore, solo i dati nella partizione interessata saranno danneggiati, mentre i dati sulle altre partizioni probabilmente sopravviveranno.
- Il processo di avvio ha più passaggi, a partire dal BIOS, che innesca il boot loader per avviare il kernel Linux. Da lì, viene invocato il filesystem
initramfs, che innesca il programmainitper completare il processo di avvio. - Determinare la distribuzione appropriata da installare richiede di scegliere la distribuzione le cui caratteristiche meglio si abbinano alle necessità del sistema specifico.

Capitolo 4: Interfaccia grafica
Obiettivi formativi
Alla fine di questo capitolo, dovresti essere in grado di:
- Gestire sessioni di interfaccia grafica.
- Eseguire le operazioni di base utilizzando l'interfaccia grafica.
- Modificare il desktop grafico in base alle tue esigenze.
Desktop grafico
È possibile utilizzare un'Interfaccia da Linea di Comando (CLI) o un'Interfaccia Grafica Utente (GUI) quando si utilizza Linux. Per lavorare con la CLI, devi ricordare quali programmi e comandi vengono utilizzati per eseguire attività e come ottenere in modo rapido e accurato maggiori informazioni sul loro uso e opzioni. D'altra parte, l'utilizzo della GUI è spesso veloce e facile. Ti consente di interagire con il tuo sistema tramite icone e schermate grafiche. Per compiti ripetitivi, la CLI è spesso più efficiente, mentre con la GUI è più facile spostarsi se non ricordi tutti i dettagli o fai qualcosa solo raramente.
Impareremo come gestire le sessioni usando la GUI per le tre famiglie di distribuzione Linux che trattiamo di più in questo corso: Red Hat (CentOS, Fedora), SUSE (openSUSE) e Debian (Ubuntu, Mint). Dal momento che stiamo usando la variante basata su GNOME di openSUSE anziché quella basata su KDE, tutte sono in realtà abbastanza simili. Se stai usando KDE (o altri desktop Linux come XFCE), la tua esperienza varierà in qualche modo rispetto a quanto mostrato, ma non in modo intrinsecamente difficile, poiché le interfacce utente hanno adottato determinati comportamenti comuni sui moderni sistemi operativi. Nelle sezioni successive di questo corso ci concentreremo in modo molto dettagliato sull'interfaccia della riga di comando, che è praticamente la stessa su tutte le distribuzioni.
Il Sistema Window X
In generale, in un sistema desktop Linux, il sistema Window X viene caricato come uno dei passaggi finali nel processo di avvio. È spesso solo chiamato X.
Un servizio chiamato Display Manager tiene traccia dei display forniti e carica il server X (cosiddetto, perché fornisce servizi grafici alle applicazioni, a volte chiamate client X).Il Display Manager gestisce anche gli accessi grafici e avvia l'ambiente desktop appropriato dopo che un utente accede.
X è un software piuttosto vecchio; risale a metà degli anni '80 e, in quanto tale, ha alcune carenze sui sistemi moderni (ad esempio, la sicurezza), poiché è stato spinto piuttosto lontano dai suoi scopi originali. Un sistema più recente, noto come Wayland, lo sta gradualmente superando ed è il sistema di visualizzazione predefinito per Fedora, RHEL 8 e altre recenti distribuzioni. Per la maggior parte, sembra proprio X per l'utente, sebbene sotto il cofano sia abbastanza diverso.
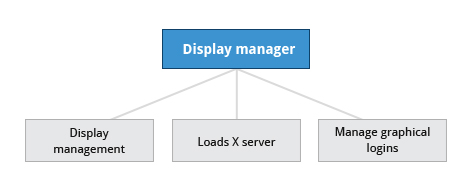
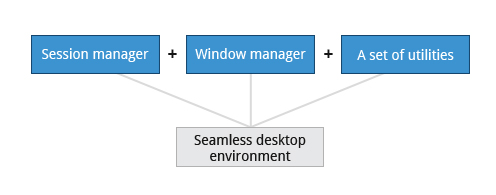
Un ambiente desktop è costituito da un gestore di sessione, che avvia e mantiene i componenti della sessione grafica, e il gestore delle finestre, che controlla il posizionamento e il movimento delle finestre, le barre dei titoli della finestra e i controlli.
Sebbene questi possano essere combinati, generalmente un insieme di utility, un gestore di sessione e un gestore di finestre vengono utilizzati insieme come unità e insieme forniscono un ambiente desktop senza soluzione di continuità.
Se il Display Manager non viene avviato per impostazione predefinita nel runlevel predefinito, è possibile avviare il desktop grafico in modo diverso, dopo l'accesso a una console in modalità testo, eseguendo startx dalla riga di comando. Oppure, è possibile avviare manualmente il Display Manager (GDM, LightDM, KDM, XDM, ecc.) dalla riga di comando. Ciò differisce dall'esecuzione di startx poiché i display manager proietteranno un segnale allo schermo. Ne discutiamo dopo.
Avvio della GUI
Quando si installa un ambiente desktop, il Display Manager X parte alla fine del processo di avvio. È responsabile dell'avvio del sistema grafico, di fornire l'accesso all'utente e dell'avvio dell'ambiente desktop dell'utente. È spesso possibile selezionare da una serie di ambienti desktop quando si accede al sistema.

Il Display Manager predefinito per GNOME si chiama gdm. Altri gestori di display popolari includono lightdm (utilizzato su Ubuntu prima della versione 18.04 LTS) e kdm (associato a KDE).
Ambiente Desktop GNOME
GNOME è un ambiente desktop popolare con un'interfaccia utente grafica di facile utilizzo. È fornito come ambiente desktop predefinito per la maggior parte delle distribuzioni Linux, tra cui Red Hat Enterprise Linux (RHEL), Fedora, CentOS, SUSE Linux Enterprise, Ubuntu e Debian. GNOME ha una navigazione basata sui menu ed è talvolta una transizione facile da compiere per gli utenti di Windows. Tuttavia, come vedrai, il look and feel, vale a dire le caratteristiche dell'interfaccia grafica, può essere abbastanza diverso tra le distribuzioni, anche se tutte usano GNOME.
Un altro ambiente desktop comune molto importante nella storia di Linux e anche ampiamente utilizzato è KDE, che è stato spesso usato in combinazione con SUSE e openSUSE. Altre alternative per un ambiente desktop includono Unity (presente su versioni Ubuntu più vecchie, ma ancora basato su GNOME), XFCE e LXDE. Come accennato in precedenza, la maggior parte degli ambienti desktop seguono una struttura simile a GNOME e ci limiteremo principalmente a esso per mantenere le cose meno complesse.
Video: Avvio del Sistema, Accesso e Uscita
Sfondo del Desktop Grafico
Ogni distribuzione Linux viene fornita con la propria collezione di sfondi desktop. È possibile modificare il valore predefinito scegliendo un nuovo sfondo o selezionando un'immagine personalizzata da impostare come sfondo del desktop. Se non si desidera utilizzare un'immagine come sfondo, è possibile selezionare un colore da visualizzare sul desktop.
Inoltre, puoi anche cambiare il tema del desktop, che cambia l'aspetto del sistema Linux. Il tema definisce anche l'aspetto delle finestre dell'applicazione.
Impareremo come cambiare lo sfondo e il tema desktop.
Personalizzare lo sfondo del desktop
Per modificare lo sfondo, è possibile fare clic con il tasto destro ovunque sul desktop e scegliere "Cambia sfondo".
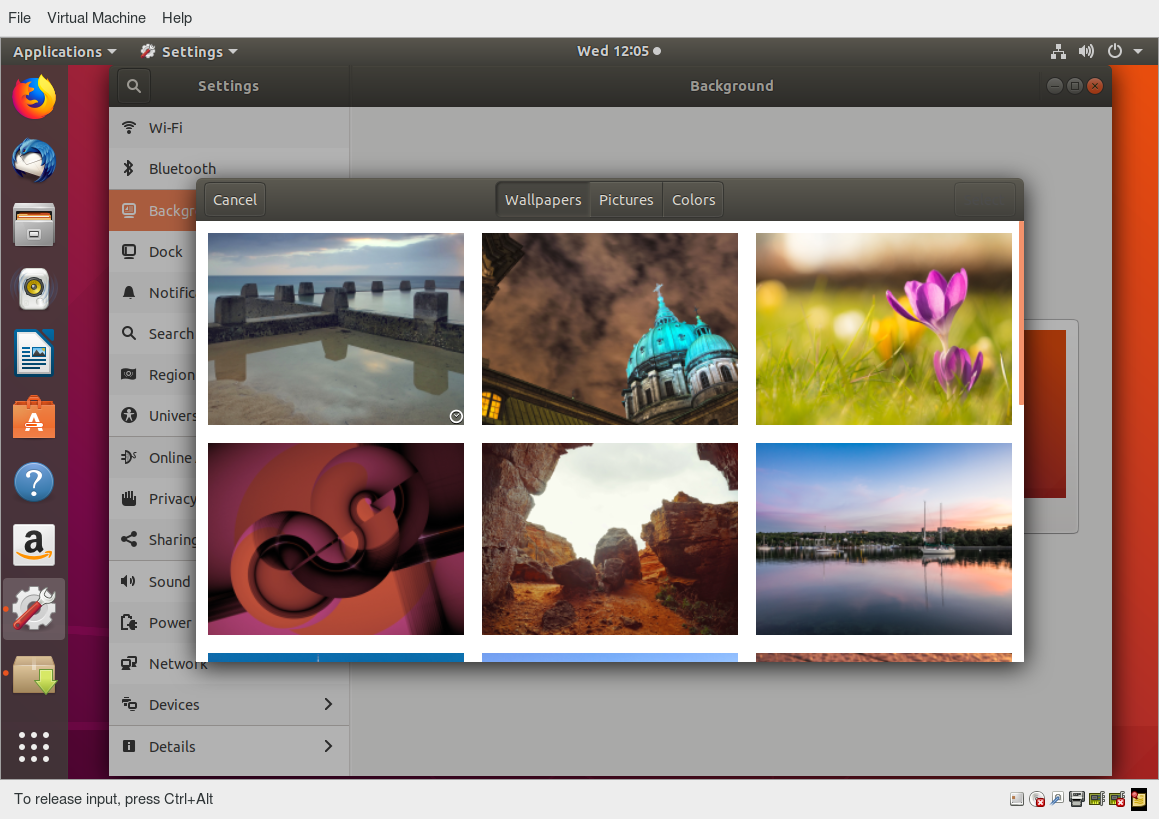
Video: Come Cambiare le Sfondo del Desktop
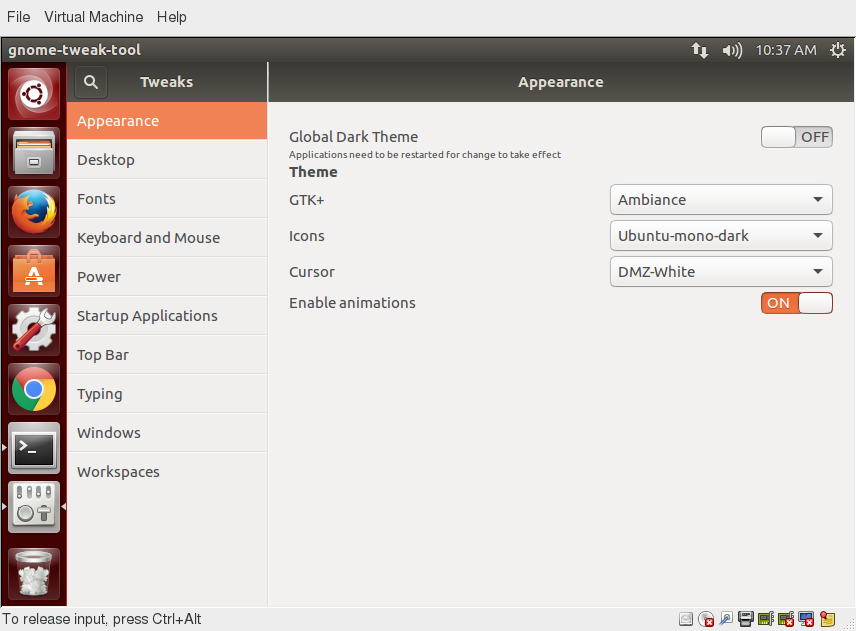
gnome-tweaks
Le impostazioni più comuni, sia personali che a livello di sistema, si trovano facendo clic nell'angolo in alto a destra, su un'icona che rappresenta un ingranaggio o un'altra icona che potrebbe rappresentare delle impostazioni, a seconda della tua distribuzione Linux.
Tuttavia, ci sono molte impostazioni che molti utenti vorrebbero modificare che non sono accessibili con il metodo sopra descritto; l'utility delle impostazioni predefinita è purtroppo piuttosto limitata nelle moderne distribuzioni basate su GNOME. Sfortunatamente, la ricerca di semplicità ha effettivamente reso difficile adattare il tuo sistema ai tuoi gusti e bisogni.
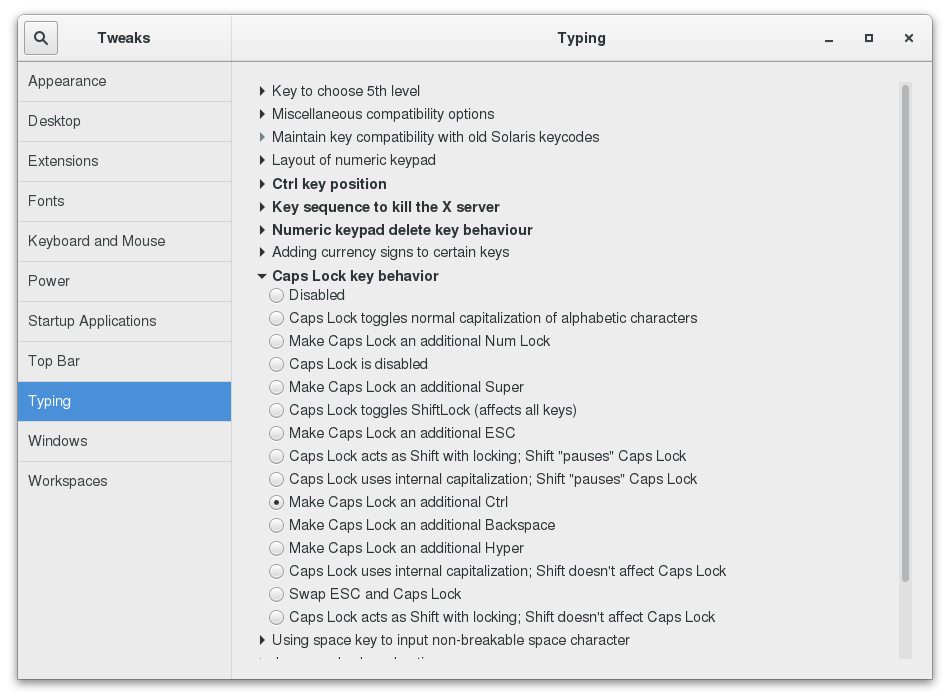
Fortunatamente, esiste un'utility standard, gnome-tweaks, che espone molte più opzioni di impostazione. Ti consente inoltre di installare facilmente le estensioni di terze parti. Non tutte le distribuzioni Linux installano questo strumento nella modalità predefinita, ma è sempre disponibile (le distribuzioni più vecchie hanno utilizzato il nome gnome-tweak-tool). Potrebbe essere necessario eseguirlo digitando Alt-F2, poi digitando il nome. Potresti voler aggiungerlo alla tua lista dei Preferiti come discuteremo.
Come verrà trattato nel prossimo capitolo, alcune recenti distribuzioni hanno eliminato la maggior parte delle funzionalità da questo strumento e la hanno messe in una nuova, chiamata gnome-extensions-app.
Nella videata seguente, la mappatura della tastiera viene regolata in modo che il tasto Capslock altrimenti inutile possa essere utilizzato come tasto Ctrl aggiuntivo; ciò risparmia agli utenti che usano molto il tasto Ctrl (come gli appassionati di emacs) lo stiramento del dito mignolo.
Cambiare il Tema
L'aspetto visivo delle applicazioni (i pulsanti, le barre di scorrimento, i widget e altri componenti grafici) sono controllati da un tema. GNOME è provvisto di una serie di temi diversi che possono cambiare l'aspetto delle tue applicazioni.
Il metodo esatto per modificare il tema può dipendere dalla tua distribuzione. Per le vecchie distribuzioni basate su GNOME, puoi semplicemente eseguire gnome-tweaks, come mostrato nello videata da Ubuntu. Tuttavia, come accennato in precedenza, se non lo trovi lì, dovrai utilizzare gnome-extensions-app, che ora può configurare i temi. Ciò richiede l'installazione di ancora più software e di andare su siti web esterni, quindi è improbabile che sia visto come un miglioramento da parte di molti utenti.
Ci sono altre opzioni per ottenere ulteriori temi oltre alla selezione predefinita. Puoi scaricare e installare temi dal sito Wiki di GNOME.
Gestione della Sessione
Accedere e uscire
Il video successivo mostra una dimostrazione per l'accesso e l'uscita sulle principali famiglie di distribuzione Linux su cui ci concentriamo in questo corso. Nota che l'evoluzione ci ha portato a una fase in cui ha poca importanza la distribuzione che scegli, poiché sono tutte piuttosto simili.

Accesso e Uscita usando la GUI in Ubuntu, openSUSE e CentOS
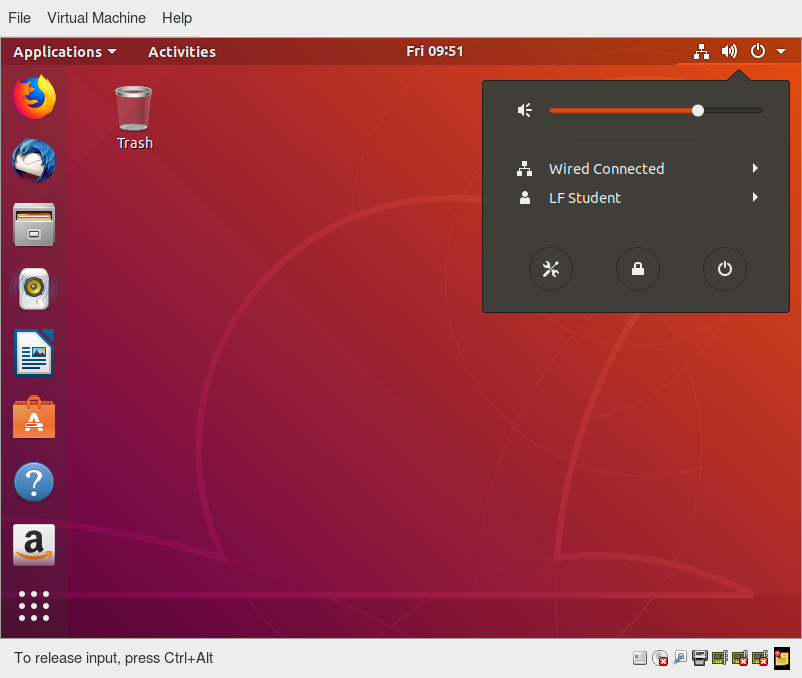
Bloccare lo schermo
Spesso è una buona idea bloccare lo schermo per impedire ad altre persone di accedere alla tua sessione mentre sei lontano dal tuo computer.
Nota: questo non sospende il computer; tutte le applicazioni e i processi continuano a funzionare mentre lo schermo è bloccato.
Esistono due modi per bloccare lo schermo:
- Utilizzando l'interfaccia grafica.
Facendo clic nell'angolo in alto a destra del desktop, quindi facendo clic sull'icona del lucchetto. - Utilizzando il collegamento per tastiera
SUPER-L
(Il tasto SUPER è anche conosciuto come il tasto Windows).
La scorciatoia da tastiera per il blocco dello schermo può essere modificata cambiando le impostazioni della tastiera, la combinazione esatta varia in base alla distribuzione, ma non è difficile da verificare.
Per rientrare nella sessione desktop devi solo fornire di nuovo la tua password.
La videata qui sotto mostra come bloccare lo schermo per Ubuntu. I dettagli variano poco nelle distribuzioni moderne.
Video: Maggiori Dettagli su Bloccare e Sbloccare lo Schermo
Cambiare Utente
Linux è un vero sistema operativo multiutente, che consente a più di un utente di essere connesso contemporaneamente. Se più di una persona utilizza il sistema, è meglio che ogni persona abbia il proprio account utente e la password. Ciò consente impostazioni personalizzate, directory home e altri file. Gli utenti possono fare a turno utilizzando la macchina, mantenendo in vita le sessioni di tutti o addirittura effettuare l'accesso simultaneamente attraverso la rete.
Video: Cambiare Utente in Linux
Spegnere e riavviare
Oltre al normale avvio e arresto giornaliero del computer, potrebbe essere richiesto un riavvio del sistema come parte di alcuni importanti aggiornamenti del sistema, generalmente solo quelli che coinvolgono l'installazione di un nuovo kernel Linux.

L'avvio del processo di spegnimento dal desktop grafico è piuttosto banale su tutte le distribuzioni Linux attuali, con pochissime variazioni. Discuteremo più tardi come farlo dalla riga di comando, usando il comando shutdown.
In tutti i casi, fai clic sull'icona delle impostazioni (l'ingranaggio) o sull'icona di alimentazione e segui le istruzioni.
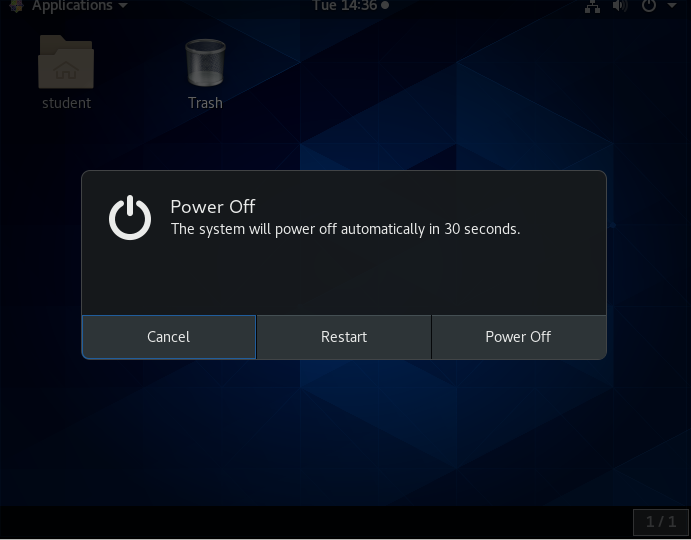
Spegnere e riavviare su GNOME
Per spegnere il computer in qualsiasi recente distribuzione Linux basata su GNOME, eseguire i seguenti passaggi:
- Fai clic sull'icona dell'alimenzione o dell'ingranaggio nell'angolo in alto a destra dello schermo.
- Fai clic su Spegni, oppure Riavvia, oppure Annulla. Se non fai nulla, il sistema si spegne in 60 secondi.
Le operazioni di spegnimento, riavvio e disconnessione chiederanno conferma prima di andare avanti. Questo perché molte applicazioni non salveranno correttamente i loro dati quando terminate in questo modo.
Salva sempre i documenti e i dati prima di riavviare, chiudere o disconnetterti.
Sospensione
Tutti i computer moderni supportano la modalità di sospensione, quando si desidera smettere di utilizzare il proprio computer per un po'. La modalità di sospensione consente di salvare lo stato attuale del sistema e consente di riprendere la tua sessione più rapidamente, il sistema, pur rimanendo acceso, utilizza pochissima potenza nello stato di sospensione. Funziona mantenendo le applicazioni del sistema, il desktop e così via, nella RAM del sistema, ma spegnendo tutto l'altro hardware. Ciò riduce il tempo per un avvio a sistema completo e conserva l'energia della batteria. Si dovrebbe notare che le moderne distribuzioni Linux si avviano così in fretta che la quantità di tempo risparmiata è spesso poco significativa
Per sospendere il sistema, la procedura si avvia come quella per l'arresto o il blocco dello schermo.
Il metodo è abbastanza semplice e universale nelle distribuzioni basate su GNOME più recenti. Se fai clic sull'icona di alimentazione e lo mantieni per un breve periodo, poi rilasci, otterrai l'icona visualizzata di seguito, che puoi cliccare per sospendere il sistema. Alcune distribuzioni, incluso Ubuntu, possono ancora mostrare un'icona di sospensione separata invece di usare il metodo sopra indicato.

Operazioni di base
Anche gli utenti esperti possono dimenticare il comando preciso che lancia un'applicazione o esattamente quali opzioni e argomenti richiede. Fortunatamente, Linux consente di aprire rapidamente applicazioni utilizzando l'interfaccia grafica.
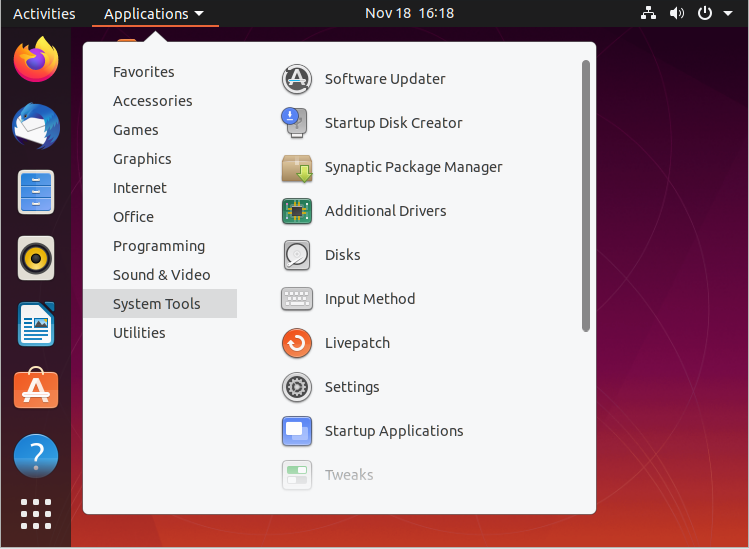
Le applicazioni si trovano in diverse posizioni in Linux (e all'interno di GNOME):
- Dal menu delle Applicazioni nell'angolo in alto a sinistra.
- Dal menu delle Attività nell'angolo in alto a sinistra.
- In alcune versioni di Ubuntu, dal pulsante Dash (il pulsante con il simbolo di Ubuntu) nell'angolo in alto a sinistra.
- Per KDE e alcuni altri ambienti, le applicazioni possono essere aperte dal pulsante nell'angolo in basso a sinistra.
Nelle pagine seguenti imparerai come eseguire operazioni di base in Linux usando l'interfaccia grafica.
Individuare le applicazioni
A differenza di altri sistemi operativi, l'installazione iniziale di Linux di solito viene fornita con una vasta gamma di applicazioni e archivi software che contengono migliaia di programmi che consentono di svolgere una vasta gamma di attività con il tuo computer. Per la maggior parte delle attività principali, di solito è già installata un'applicazione predefinita. Tuttavia, puoi sempre installare più applicazioni e provare diverse opzioni.
Ad esempio, Firefox è popolare poiché è il browser predefinito in molte distribuzioni Linux, mentre Epiphany, Konqueror e Chromium (la base open source per Google Chrome) sono generalmente disponibili per l'installazione dai repository del software. Sono disponibili anche browser Web proprietari, come Opera e Chrome.
La localizzazione delle applicazioni dai menu GNOME e KDE è facile, in quanto sono ordinatamente organizzate in sottomenu per categorie.
Applicazioni predefinite
Sono disponibili più applicazioni per svolgere varie attività e aprire un file di un determinato tipo. Ad esempio, è possibile fare clic su un indirizzo web durante la lettura di una e-mail e avviare un browser come Firefox o Chrome.
Per impostare le applicazioni predefinite, aprire il menu Impostazioni (su tutte le distribuzioni di Linux recenti), quindi fare clic su Applicazioni predefinite o Dettagli > Applicazioni predefinite. L'elenco esatto varierà da quanto mostrato qui nella videata di Ubuntu in base a ciò che è effettivamente installato e disponibile sul tuo sistema.
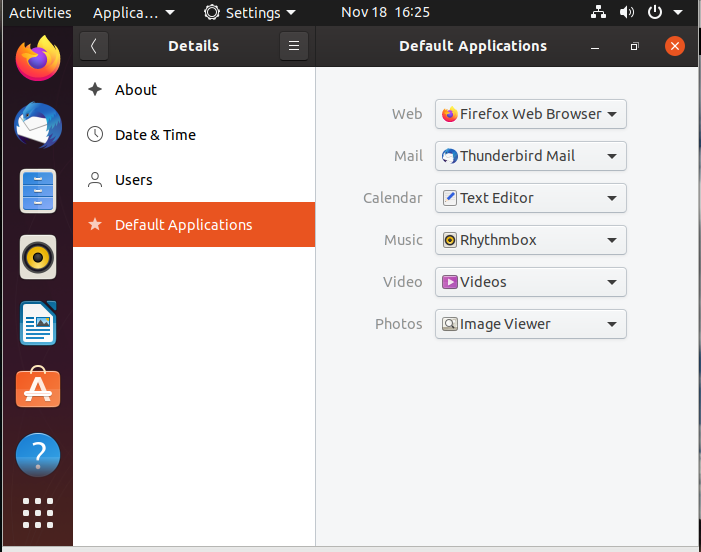
Video: Impostazione delle Applicazioni Predefinite
File Manager
Ogni distribuzione implementa il File Manager Nautilus, che viene utilizzato per navigare nel file system. Può individuare i file e, quando su un file viene fatto clic, lo eseguirà se si tratta di un programma o verrà lanciata un'applicazione associata utilizzando il file come dati. Questo comportamento è del tutto familiare a chiunque abbia utilizzato altri sistemi operativi.
Per avviare il file manager dovrai fare clic sulla sua icona (un cassetto) che si trova facilmente, di solito sotto i preferiti o gli accessori. Avrà il nome File.
Verrà aperta una finestra che visualizza la tua directory Home. Il pannello sinistro della finestra del File Manager contiene un elenco di directory comunemente usate, come Desktop, Documenti, Download e Immagini.
È possibile fare clic sull'icona della lente d'ingrandimento in alto a destra per cercare file o directory (cartelle).
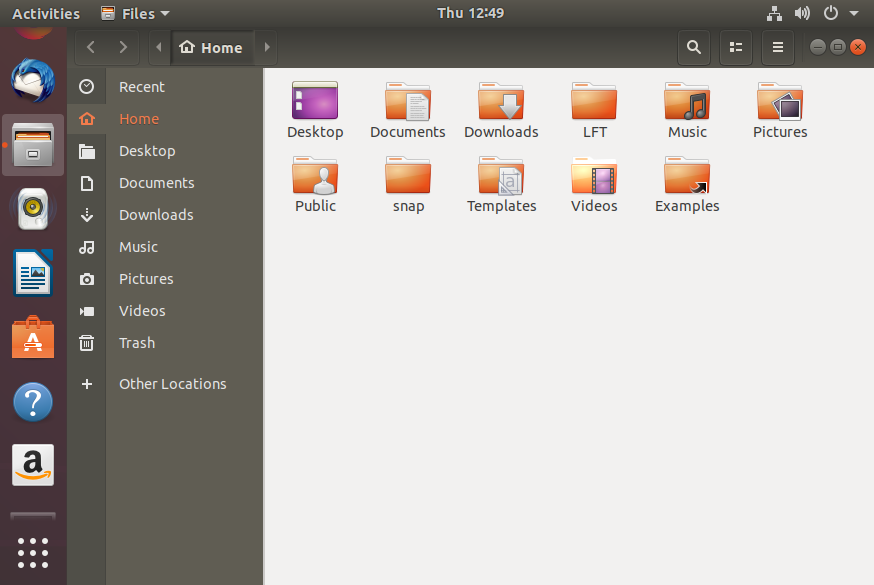
Le Directory nella Home
Il File Manager consente di accedere a diverse posizioni sul tuo computer e sulla rete, tra cui la directory Home, Desktop, Documenti, Immagini e Altre posizioni.
Ogni utente con un account sul sistema avrà una directory home, di solito creata sotto /home, e in genere denominata con il nome utente, ad esempio /home/studente.
Per impostazione predefinita, i file salvati dall'utente verranno inseriti in un albero di directory che inizia da lì. La creazione dell'account, durante l'installazione del sistema o in un secondo momento, quando viene aggiunto un nuovo utente, crea anche le directory predefinite, situate sotto la directory home dell'utente, come Documenti, Desktop e Download.
Nella videata mostrata per Ubuntu, abbiamo scelto il formato di visualizzazione a elenco e stiamo anche mostrando i file nascosti (quelli che iniziano con un punto). Vedi se puoi fare lo stesso sulla tua distribuzione.
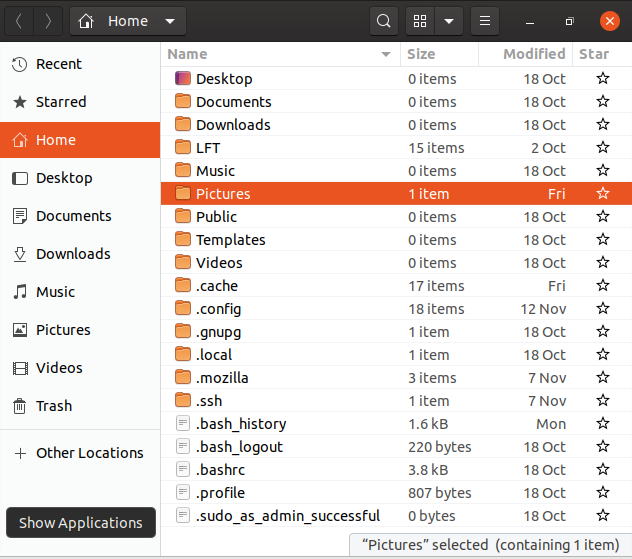
Visualizzare file
Il File Manager consente di visualizzare file e directory in più di un modo.
È possibile passare tra la visualizzazione a icone e quella a elenco, facendo clic sulle icone relative nella barra superiore, oppure è possibile premere rispettivamente Ctrl-1 o Ctrl-2.
Inoltre, è inoltre possibile disporre i file e le directory per nome, dimensione, tipo o data di modifica per un ulteriore ordinamento. Per fare ciò, fai clic su Visualizza e seleziona Disponi elementi.
Un'altra opzione utile è quella di mostrare i file nascosti (chiamati a volte impropriamente file di sistema), che di solito sono file di configurazione nascosti per impostazione predefinita e il cui nome inizia con un punto. Per mostrare i file nascosti, selezionare Mostra file nascosti dal menu oppure premere Ctrl-H.
Il file browser fornisce diversi modi per personalizzare la vista della finestra per facilitare le operazioni di drag and drop (trascina e rilascia). È inoltre possibile modificare le dimensioni delle icone selezionando Zoom In e Zoom Out nel menu Visualizza.
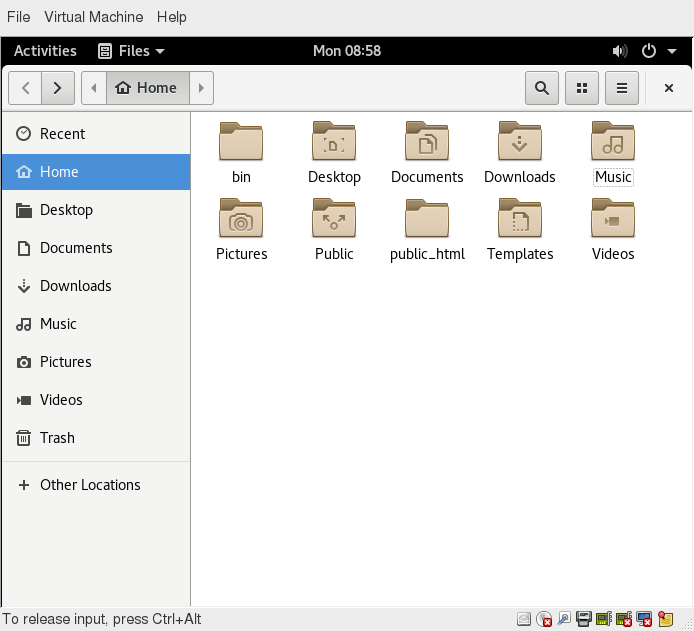
Cercare i File
Il File Manager include un ottimo strumento di ricerca all'interno della finestra del file browser.
- Fai clic su Cerca nella barra degli strumenti (per visualizzare una casella di testo).
- Digita la parola chiave nella casella di testo. Ciò fa sì che il sistema esegua una ricerca ricorsiva dalla directory corrente per qualsiasi file o directory che contiene una parte di questa parola chiave.
Per aprire il File Manager dalla riga di comando, sulla maggior parte dei sistemi digita semplicemente nautilus.

La scorciatoia da tastiera per accedere alla casella di testo di ricerca è Ctrl-F. È possibile uscire dalla visualizzazione della casella di testo di ricerca facendo nuovamente clic sul pulsante di ricerca oppure con Ctrl-F nuovamente.
Un altro modo rapido per accedere a una directory specifica è premere Ctrl-L, che ti mostrerà una casella di testo di Posizione (location) per digitare un percorso verso una directory.
Maggiori Informazioni sulla Ricerca di File
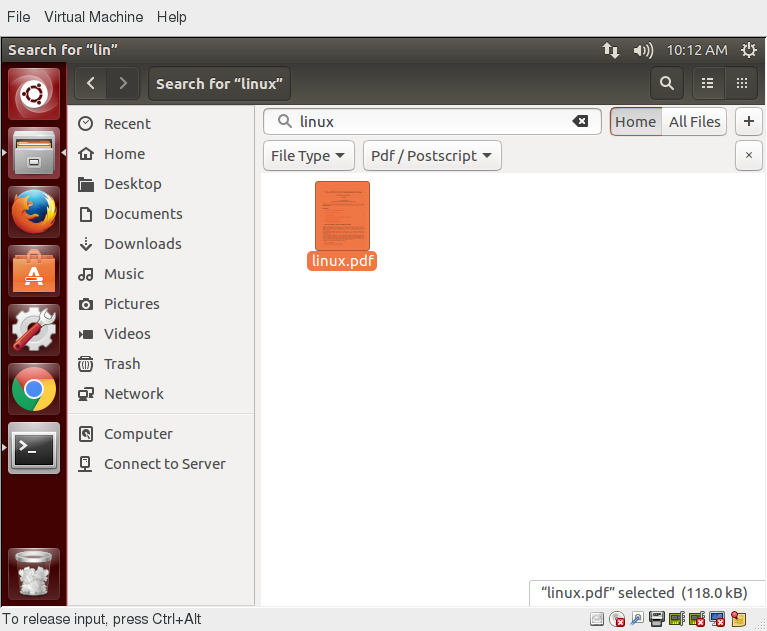
Puoi perfezionare la tua ricerca oltre alla parola chiave iniziale utilizzando un menu a discesa per filtrare ulteriormente la ricerca.
- In base alla Posizione o al Tipo di File, seleziona criteri aggiuntivi dal menu a discesa.
- Per ripetere la ricerca, fai clic sul pulsante Ricarica.
- Per aggiungere più criteri di ricerca, fai clic sul pulsante
+e seleziona Criteri di ricerca aggiuntivi.
Ad esempio, se desideri trovare un file PDF contenente la parola Linux nella directory home, vai alla tua directory home e cerca la parola "Linux". Dovresti vedere che il criterio di ricerca predefinito limita già la ricerca alla tua directory home. Infine, fai clic sul pulsante + per aggiungere un altro criterio di ricerca, seleziona Tipo di file per il tipo e seleziona PDF nel menu a discesa del Tipo di File.
Modificare un File
La modifica di qualsiasi file di testo tramite l'interfaccia grafica è facile nell'ambiente desktop GNOME. Basta fare doppio clic sul file sul desktop o nella finestra del file browser Nautilus per aprire il file con l'editor di testo predefinito.
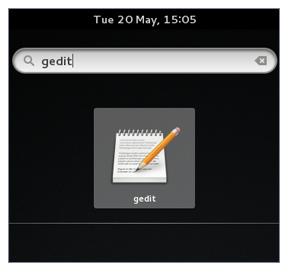
L'editor di testo predefinito in GNOME è gedit. È semplice ma potente, ideale per la modifica dei documenti, per aggiungere note rapide e programmare. Sebbene gedit sia concepito come editor di testo per uso generale, offre ulteriori funzionalità per il controllo ortografico, l'evidenziazione, gli elenchi di file e le statistiche.
Imparerai molto di più sull'uso degli editor di testo in un capitolo successivo.
Rimuovere un file
L'eliminazione di un file in Nautilus sposterà automaticamente i file eliminati nella directory .local/share/Trash/files/ (una specie di cestino) sotto la directory home dell'utente. Esistono diversi modi per eliminare file e directory usando Nautilus.
- Seleziona tutti i file e le directory che desideri eliminare.
- Premi
Ctrl-Cancsulla tastiera o fai clic con il pulsante destro del mouse sul file. - Seleziona Sposta nel Cestino
Nota che è possibile avere un'opzione Elimina in modo permanente che bypassa la cartella del cestino e che questa opzione può essere visibile tutto il tempo o solo nella visualizzazione in modalità elenco (anziché in modalità icona).

Per eliminare permanentemente un file:
- Sul pannello sinistro all'interno di una finestra del file browser Nautilus, fai clic con il pulsante destro del mouse sulla directory del cestino.
- Seleziona Svuota Cestino.
In alternativa, seleziona il file o la directory che si desidera eliminare in modo permanente e premi Shift-Canc.
Per precauzione, non dovresti mai eliminare la tua directory Home, poiché molto probabilmente cancellerà tutti i file di configurazione GNOME ed eventualmente ti impedirà di accedere. Molte configurazioni di sistema personali e di programmi sono conservate nella tua directory home.
Video: Individuare le Applicazioni Predefinite ed Esplorare i Filesystem in OpenSUSE
Capitolo 4 - Riepilogo
Hai completato il capitolo 4. Riassumiamo i concetti chiave trattati:
- GNOME è un popolare ambiente desktop e interfaccia utente grafica che funziona sopra il sistema operativo Linux.
- Il Display Manager predefinito per GNOME si chiama gdm.
- Il Display Manager gdm presenta all'utente la schermata di accesso, che richiede il nome utente e la password di accesso.
- La disconnessione tramite l'ambiente desktop ferma i processi nella tua sessione X corrente e ritorna alla schermata di accesso.
- Linux consente agli utenti di passare tra più sessioni di accesso.
- La sospensione mette il computer in modalità sospensione.
- Per ogni attività principale, esiste generalmente un'applicazione predefinita installata.
- Ogni utente creato nel sistema avrà una directory home.
- Il menu Posizioni contiene voci che consentono di accedere a diverse parti del computer e della rete.
- Nautilus fornisce tre formati per visualizzare i file.
- La maggior parte degli editor di testo si trova nel sottomenu Accessori.
- Ogni distribuzione Linux viene fornita con il proprio insieme di sfondi desktop.
- GNOME è provvisto di una serie di temi diversi che possono cambiare il modo in cui le tue applicazioni appaiono.
Capitolo 5: Configurazione del Sistema dall'Interfaccia Grafica
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Applicare le impostazioni di sistema, visualizzazione, e data e ora, utilizzando il pannello Impostazioni.
- Tenere traccia delle impostazioni di rete e gestire connessioni utilizzando Network Manager in Linux.
- Installare e aggiornare il software in Linux da un'interfaccia grafica.
Nota: rivisiteremo tutte queste attività in seguito, quando discuteremo di come realizzarle dall'interfaccia della riga di comando.
Impostazioni di sistema, visualizzazione, data e ora
Il pannello delle Impostazioni di sistema consente di controllare la maggior parte delle opzioni di configurazione di base e le impostazioni del desktop, come specificare la risoluzione dello schermo, la gestione delle connessioni di rete o la modifica della data e dell'ora del sistema.
Per il Desktop Manager GNOME, si fa clic sull'angolo in alto a destra e quindi si seleziona Impostazioni (l'icona di un ingranaggio). A seconda della distribuzione, potresti trovare anche altri modi per entrare nella configurazione delle impostazioni. Troverai anche la variazione nella disposizione del menu tra distribuzioni e versioni Linux, quindi potresti dover cercare dove trovare le impostazioni necessarie da esaminare o modificare.

Menu Impostazioni di Sistema
Per approfondire la configurazione, è possibile configurare elementi come lo schermo, la tastiera, le stampanti, ecc.
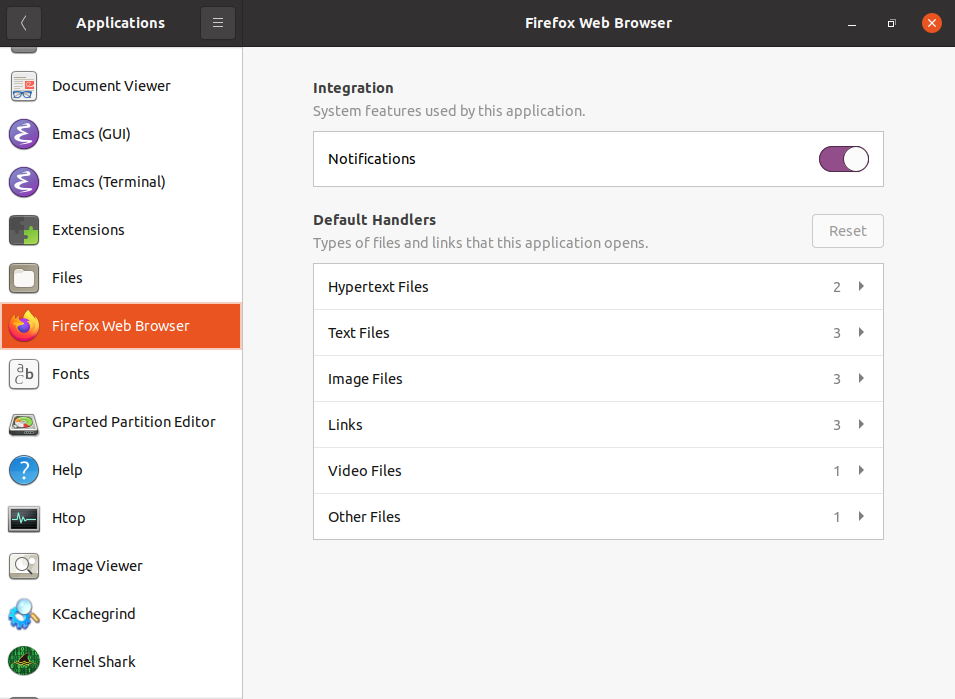
Si può anche fare clic sull'icona Utenti (che può essere sotto Dettagli) per impostare i valori per gli utenti di sistema, come la loro immagine di accesso, password, ecc.
gnome-tweaks
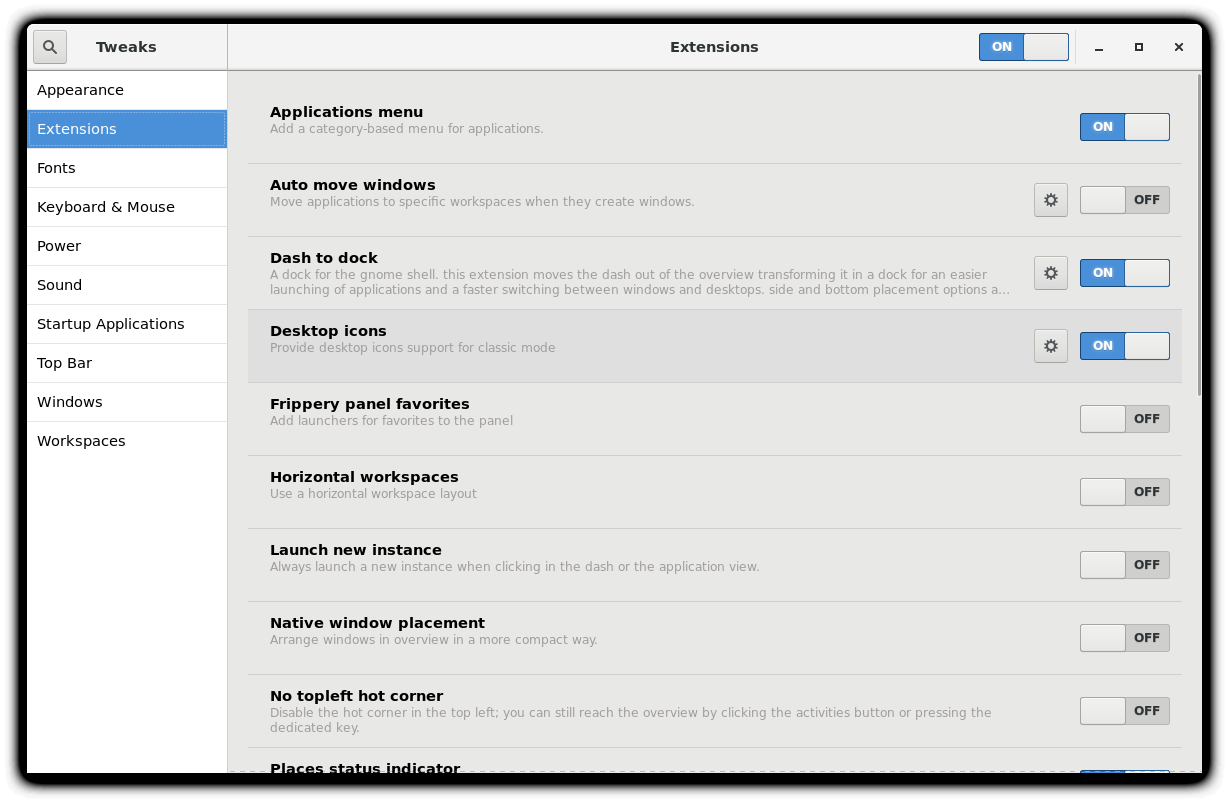
Molte impostazioni di configurazione personalizzate non compaiono nei menu delle impostazioni. Invece, è necessario lanciare uno strumento chiamato gnome-tweaks (o gnome-tweak-tool su vecchie distribuzioni Linux). Non abbiamo ancora discusso come lavorare alla riga di comando, ma puoi sempre lanciare un programma come questo digitando Alt-F2 e inserendo il comando. Alcune distribuzioni hanno un collegamento ai menu delle modifiche nelle impostazioni, ma per qualche ragione misteriosa, molti nascondono questo strumento e diventa difficile scoprire come modificare anche attributi e comportamenti desktop anche piuttosto di base.
Le cose importanti che puoi fare con questo strumento includono la selezione di un tema, la configurazione di estensioni che puoi ottenere dalla distribuzione o il download da Internet, i caratteri di controllo, modificare il layout della tastiera e impostare quali programmi si avviano quando si accede.
Le versioni GNOME più recenti hanno rimosso gran parte della funzionalità di gnome-tweaks; le estensioni ora devono essere configurate utilizzando una nuova app chiamata gnome-extensions-app. Il ragionamento dietro questa scelta è oscuro.
La videata qui proviene da un sistema Red Hat con alcune estensioni installate, ma non tutte utilizzate.
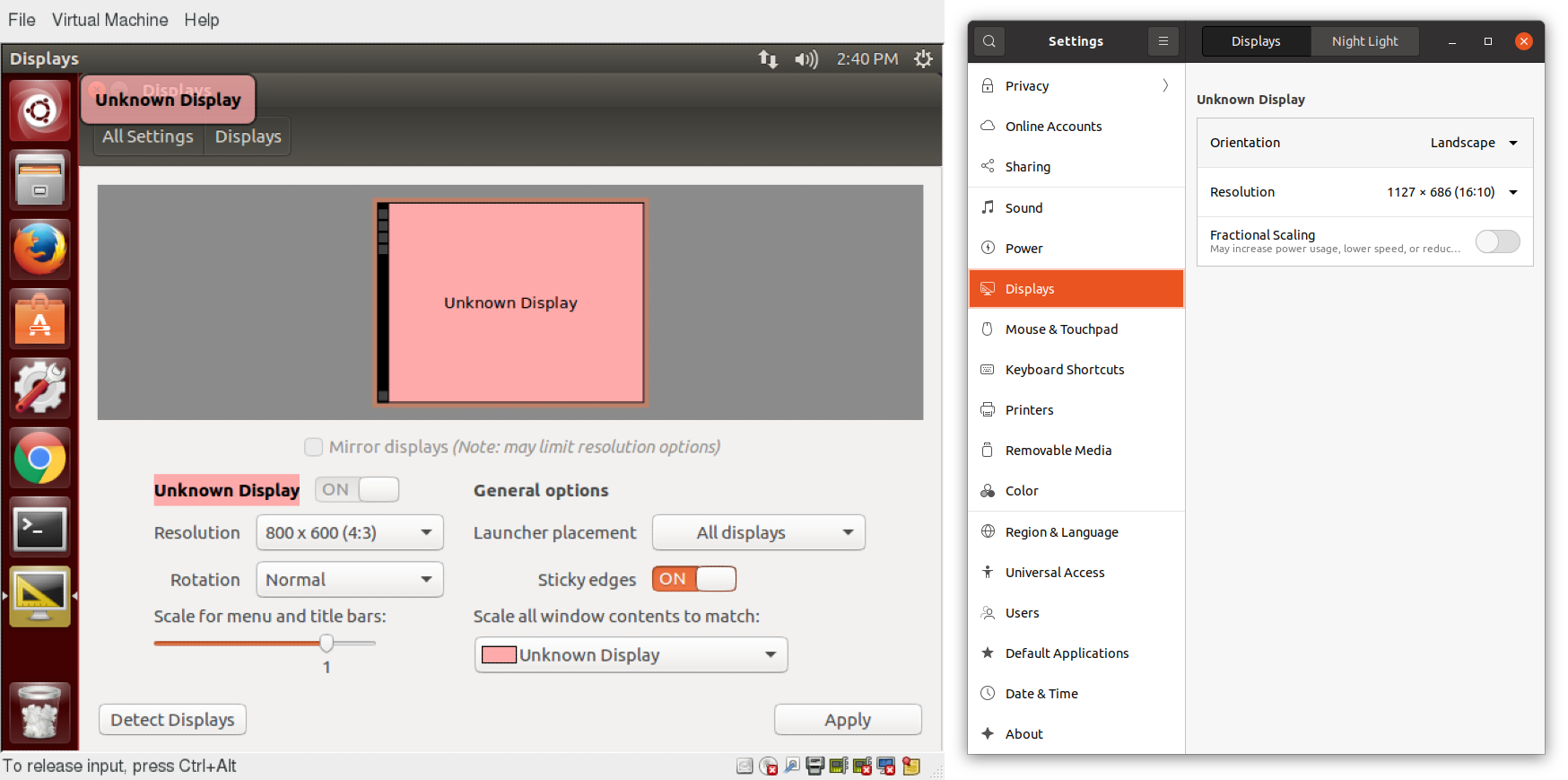
Impostazione dello Schermo
Facendo click su Impostazioni > Schermi (o Impostazioni > Dispositivi > Schermi) verranno visualizzate le impostazioni più comuni per gestire i dispositivi di visualizzazione. Queste impostazioni funzionano indipendentemente dai driver di visualizzazione specifici che stai eseguendo. L'aspetto esatto dipenderà enormemente da quanti monitor hai e altri fattori, come la distribuzione di Linux e la versione particolare.
Se il sistema utilizza un driver di scheda video proprietario (di solito da nVidia o AMD), probabilmente avrai un programma di configurazione separato per quel driver. Questo programma può offrire più opzioni di configurazione, ma può anche essere più complicato e potrebbe richiedere l'accesso a sysadmin (root). Se possibile, è necessario configurare le impostazioni nel pannello di visualizzazione anziché con il programma proprietario.
Il server X, che in realtà fornisce la GUI, utilizza /etc/x11/xorg.conf come file di configurazione se esiste; nelle moderne distribuzioni Linux, questo file è generalmente presente solo in circostanze insolite, come quando sono in uso alcuni driver grafici meno comuni. La modifica diretta di questo file di configurazione è di solito per utenti più avanzati.
Impostazione della Risoluzione e Configurazione di più Schermate
Mentre il tuo sistema di solito scoprirà automaticamente la migliore risoluzione per lo schermo, potrebbe sbagliare in alcuni casi o potresti voler cambiare la risoluzione per soddisfare le tue esigenze.
Puoi farlo usando il pannello Schermi. Il passaggio alla nuova risoluzione sarà efficace quando si fa clic su Applica e quindi conferma che la risoluzione funziona. Nel caso in cui la risoluzione selezionata non funzioni o non sei contento dell'aspetto, il sistema tornerà alla risoluzione originale dopo un breve timeout. Ancora una volta, l'aspetto esatto della schermata di configurazione varierà molto tra distribuzioni e versioni, ma di solito è piuttosto intuitivo e facile, una volta che si trova il menu di configurazione.
Nella maggior parte dei casi, la configurazione per più schermi viene impostata automaticamente come un grande schermo che copre tutti i monitor, usando una supposizione ragionevole per la loro disposizione. Se la disposizione degli schermi non è come desiderato, una casella di controllo può attivare la modalità specchio, in cui lo stesso schermo è visualizzato su tutti i monitor. Facendo clic su una particolare immagine di monitor è possibile configurare la risoluzione di ciascuno e realizzare un grande schermo o emulare lo stesso schermo, ecc.
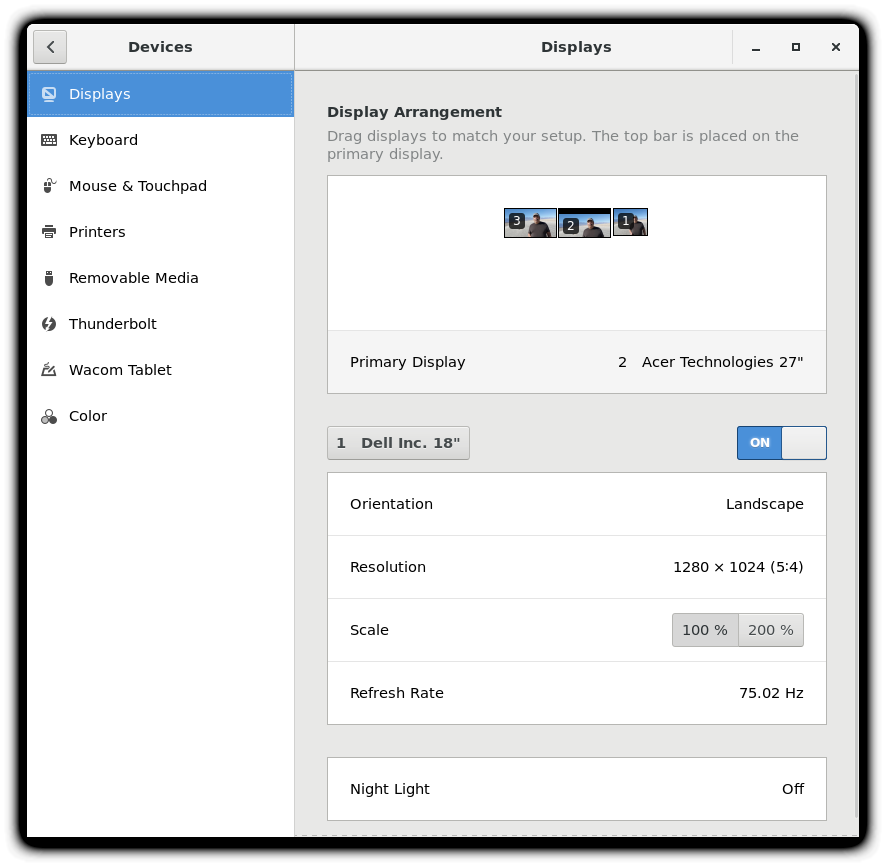
Video: Configurazione Impostazioni dello Schermo
Impostazioni di Data e Ora
Per impostazione predefinita, Linux utilizza sempre il tempo universale coordinato (UTC) per la gestione interna del tempo. I valori di tempo visualizzati o archiviati si basano sull'impostazione del fuso orario di sistema per ottenere il tempo corretto. UTC è simile, ma più accurato del Greenwich Mean Time (GMT).
Se fai clic sul tempo visualizzato sul pannello superiore, puoi regolare il formato con cui viene visualizzata la data e l'ora; su alcune distribuzioni, puoi anche alterare i valori.
Le impostazioni di data e ora più dettagliate possono essere selezionate dalla finestra Data e ora nel menu Impostazioni di sistema.
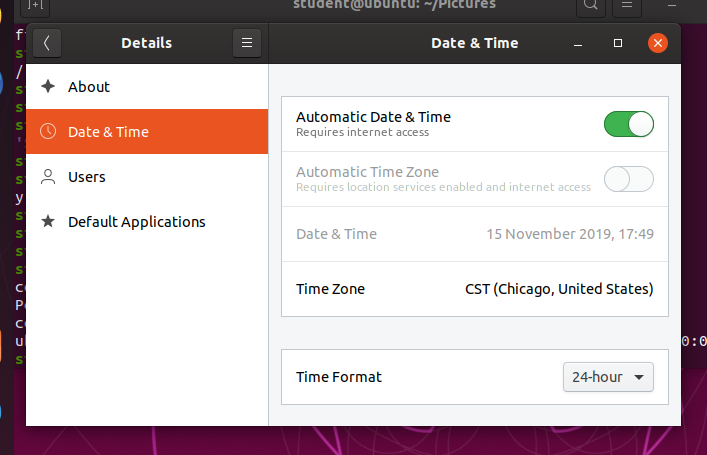
Le impostazioni "automatiche" si riferiscono all'uso del protocollo temporale di rete (NTP), di cui discutiamo in seguito.
Protocollo Temporale di rete
Il Network Time Protocol (NTP) è il protocollo più popolare e affidabile per impostare l'ora locale consultando server Internet dedicati. Le distribuzioni Linux sono sempre provviste di una configurazione NTP funzionante, che si riferisce a specifici server dedicati eseguiti o chiamati dalla distribuzione. Ciò significa che nessuna configurazione, oltre "acceso" o "spento", è generalmente richiesta per la sincronizzazione del tempo di rete.

Configurazione della rete
Tutte le distribuzioni Linux dispongono di file di configurazione di rete, ma i formati e le posizioni dei file possono differire da una distribuzione all'altra. La modifica a mano di questi file può gestire configurazioni piuttosto complicate, ma non è molto dinamica o facile da imparare e usare. L'app di configurazione di rete Network Manager è stata sviluppata per rendere le cose più semplici e più uniformi tra le distribuzioni. Può elencare tutte le reti disponibili (sia cablate che wireless), consentire la scelta di una rete cablata, wireless o mobile a banda larga, gestire password e impostare le reti private virtuali (VPN). Ad eccezione di situazioni insolite, è generalmente meglio consentire a Network Manager di stabilire le connessioni e tenere traccia delle tue impostazioni.
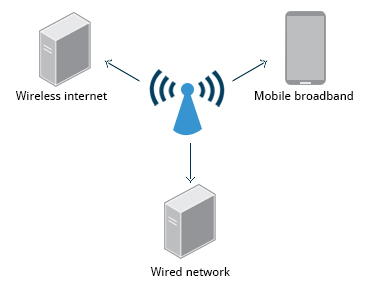
In questa sezione, imparerai come gestire le connessioni di rete, tra cui connessioni cablate e wireless e connessioni mobili a banda larga e VPN.
Connessioni cablate e wireless
Le connessioni cablate di solito non richiedono una configurazione complicata o manuale. L'interfaccia hardware e la presenza del segnale vengono rilevati automaticamente, quindi Network Manager configura le impostazioni di rete effettive tramite il protocollo di configurazione IP dinamica (DHCP).
Per configurazioni statiche che non utilizzano DHCP, la configurazione manuale può anche essere eseguita facilmente tramite Network Manager. È inoltre possibile modificare l'indirizzo MAC (Ethernet Media Access Control) se l'hardware lo supporta. L'indirizzo MAC è un numero esadecimale univoco della tua scheda di rete.
Le reti wireless di solito non sono collegate per impostazione predefinita. È possibile visualizzare l'elenco delle reti wireless disponibili e vedere a quale (se presente) sei attualmente connesso utilizzando Network Manager. È quindi possibile aggiungere, modificare o rimuovere reti wireless note e anche specificare quali si desidera connettere per impostazione predefinita quando presenti.
Configurazione di connessioni wireless
Per configurare una rete wireless in qualsiasi recente distribuzione basata su GNOME:
Fai clic sull'angolo in alto a destra, che apre una finestra di impostazioni e/o rete. Mentre l'aspetto esatto dipenderà dalla distribuzione e dalla versione Linux, sarà sempre possibile fare clic su un sottomenu Wi-Fi, purché sia presente l'hardware. Ecco un esempio di un sistema RHEL 8:
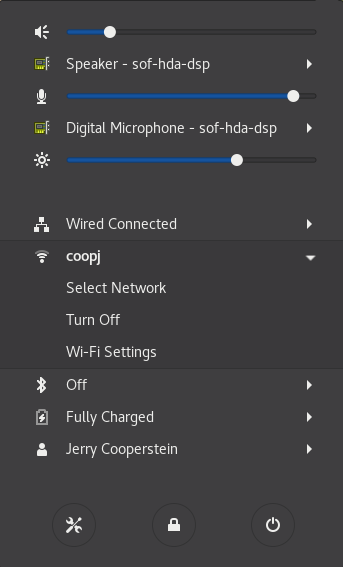
Seleziona la rete wireless a cui desideri connetterti. Se si tratta di una rete sicura, la prima volta ti richiederà di inserire la password appropriata. Per impostazione predefinita, la password verrà salvata per connessioni successive.
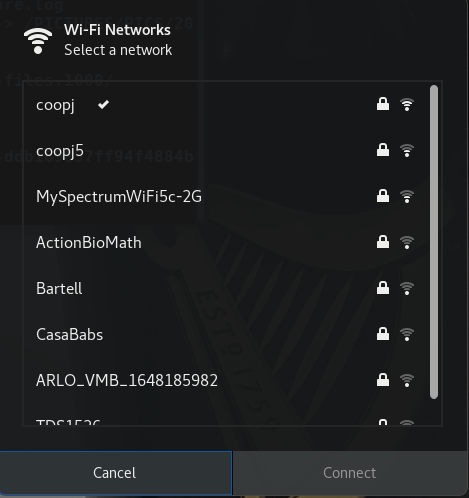
Se fai click su Impostazioni Wi-Fi, comparirà la terza schermata. Se fai clic sull'icona dell'ingranaggio per qualsiasi connessione, è possibile configurarla in modo più dettagliato.
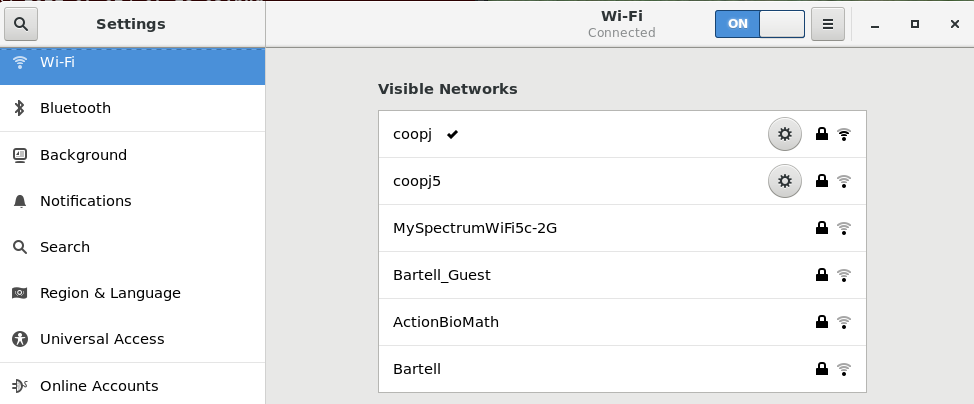
Le distribuzioni più vecchie e altre distribuzioni Linux possono apparire un poco diverse nei dettagli, ma i passaggi e le scelte sono essenzialmente identici, in quanto tutte eseguono Network Manager con aspetti un po' diversi.
Video: Gestione delle Impostazioni di Rete
Connessioni mobili a banda larga e VPN
È possibile impostare una connessione mobile a banda larga con Network Manager, che avvia una procedura guidata per impostare i dettagli della connessione per ciascuna connessione.
Una volta terminata la configurazione, la rete è configurata automaticamente ogni volta che la rete a banda larga è collegata.
Network Manager può anche gestire le tue connessioni VPN.
Supporta molte tecnologie VPN, come quelle native IPSEC, Cisco OpenConnect (tramite il client Cisco o un client open source nativo), Microsoft PPTP e OpenVPN.
Potresti ottenere supporto per VPN come pacchetto separato dal tuo distributore. È necessario installare questo pacchetto se la tua VPN preferita non è supportata.
Installazione e aggiornamento del software
Ogni pacchetto in una distribuzione Linux fornisce un pezzo del sistema, come il kernel Linux, il compilatore C, le utility per manipolare il testo o la configurazione della rete oppure i tuoi browser web e client di posta elettronica preferiti.
I pacchetti dipendono spesso l'uno dall'altro. Ad esempio, poiché il tuo client e-mail può comunicare utilizzando SSL/TLS, dipenderà da un pacchetto che fornisce la possibilità di crittografare e decrittografare la comunicazione SSL e TLS e non si installerà a meno che quel pacchetto non sia installato contemporaneamente.

Tutti i sistemi hanno un'utilità di basso livello che gestisce i dettagli di decomprimere un pacchetto e sistemare le varie parti nei posti giusti. Il più delle volte, lavorerai con un'utilità di livello superiore che sa come scaricare i pacchetti da Internet e può gestire dipendenze e gruppi per te.
In questa sezione, imparerai come installare e aggiornare il software in Linux utilizzando il sistema di gestione di pacchetti Debian (utilizzato anche da sistemi come Ubuntu) e sistemi di gestione di pacchetti RPM (che vengono utilizzati dalle famiglie di sistemi Red Hat e SUSE). Questi sono i principali in uso sebbene ci siano altri che funzionano bene per altre distribuzioni che sono meno utilizzate.
Sistema di Gestione di Pacchetti Debian
Diamo un'occhiata alla gestione dei pacchetti per il sistema della famiglia Debian.
dpkg è il gestore dei pacchetti basilare per questi sistemi. Può installare, rimuovere e creare pacchetti. A differenza dei sistemi di gestione dei pacchetti di livello superiore, non scarica e installa automaticamente i pacchetti e soddisfa le loro dipendenze.
Per i sistemi basati su Debian, il sistema di gestione dei pacchetti di livello superiore è il sistema di utility APT (Advanced Package Tool). In generale, mentre ogni distribuzione all'interno della famiglia Debian utilizza APT, crea la propria interfaccia utente sopra di esso (ad esempio, apt e apt-get, synaptic, gnome-software, Ubuntu Software Center, ecc.). Sebbene i repository apt siano generalmente compatibili tra loro, il software che contengono generalmente non lo è. Pertanto, la maggior parte dei repository mira a una particolare distribuzione (come Ubuntu) e spesso i distributori di software gestiscono più repository per supportare più distribuzioni. Le dimostrazioni sono mostrate più avanti in questa sezione.
Sistema di Gestione di Pacchetti Red Hat (RPM)
Red Hat Package Manager (RPM) è l'altro sistema di gestione dei pacchetti popolare sulle distribuzioni Linux. È stato sviluppato da Red Hat e adottato da una serie di altre distribuzioni, tra cui SUSE/OpenSUSE, Mageia, CentOS, Oracle Linux e altri.
Il gestore dei pacchetti di livello superiore differisce tra le distribuzioni. Quelle della famiglia Red Hat RHEL/CentOS utilizzano storicamente RPM mentre Fedora usa dnf, pur mantenendo una buona retrocompatibilità con il vecchio programma Yum. Anche le distribuzioni della famiglia SUSE come OpenSUSE si appoggiano a RPM, ma usano l'interfaccia Zypper.
Gestione del software YAST di OpenSuse
Il software Yet another Setup Tool (YAST) è simile ad altri gestori di pacchetti grafici. È un'applicazione basata su RPM. È possibile aggiungere, rimuovere o aggiornare i pacchetti utilizzando questa applicazione molto facilmente. Per accedere al gestore del software YAST:
- Fai clic su Attività
- Nella casella di ricerca, digita yast
- Fai clic sull'icona YaST
- Fai clic su Gestione del software
Puoi anche trovare YAST facendo clic su Applicazioni > Altro-Yast, un posto un po' strano dove trovarlo.
L'applicazione di gestione del software YAST di OpenSuse è simile ai gestori di pacchetti grafici in altre distribuzioni. Una dimostrazione del gestore del software YAST è mostrata più avanti in questa sezione.
Video: Installazione e Aggiornamento Software in openSUSE
Video: Installazione e Aggiornamento Software in Ubuntu
Capitolo 5 - Riepilogo
Hai completato il capitolo 5. Riassumiamo i concetti chiave trattati:
- Puoi controllare le opzioni di configurazione di base e le impostazioni del desktop tramite il pannello Impostazioni di sistema.
- Linux utilizza sempre il tempo universale coordinato (UTC) per il proprio tempo interno. È possibile configurare le impostazioni della data e dell'ora dalla finestra Impostazioni di sistema.
- Il protocollo temporale di rete (NTP) è il protocollo più popolare e affidabile per l'impostazione dell'ora locale tramite server Internet.
- Il pannello Schermi consente di modificare la risoluzione dello schermo e configurare più monitor.
- Network Manager può presentare reti wireless disponibili, consentire la scelta di una rete a banda larga wireless o mobile, gestire le password e impostare VPN.
- dpkg e RPM sono i sistemi di gestione dei pacchetti più popolari utilizzati sulle distribuzioni Linux.
- Le distribuzioni Debian utilizzano utility basate su dpkg e apt per la gestione dei pacchetti.
- RPM è stato sviluppato da Red Hat e adottato da una serie di altre distribuzioni, tra cui Opensuse, Mandriva, CentOS, Oracle Linux e altre.

Capitolo 6: Applicazioni Comuni
Entro la fine di questo capitolo, dovresti avere familiarità con le comuni applicazioni Linux, tra cui:
- Applicazioni Internet come browser e programmi di posta elettronica.
- Suite di produttività d'ufficio come LibreOffice.
- Strumenti per sviluppatori, come compilatori, debugger, ecc.
- Applicazioni multimediali, come quelle per audio e video.
- Editor grafici come GIMP e altre utilità grafiche.
Applicazioni Internet
Internet è una rete globale che consente agli utenti di tutto il mondo di eseguire più attività, come la ricerca di dati, la comunicazione tramite e-mail e lo shopping online. Ovviamente, è necessario utilizzare applicazioni consapevoli della rete per sfruttare Internet. Queste includono:
- Browser Web
- Client e-mail
- Applicazioni di Riproduzione Multimediale in Streaming
- Internet Relay Chat (IRC)
- Software di conferenza
Browser Web
Come discusso nel capitolo sulle Interfacce grafiche, Linux offre un'ampia varietà di browser web, basati sia su grafica che testo, tra cui:
- Firefox
- Google Chrome
- Chromium
- Epiphany (ora Web)
- Konqueror
- linx, lynx, w3m
- Opera

Applicazioni Email
Le applicazioni email consentono l'invio, la ricezione e la lettura di messaggi su Internet. I sistemi Linux offrono un ampio numero di client di posta elettronica, sia grafici che basati sul testo. Inoltre, molti utenti utilizzano semplicemente i loro browser per accedere ai propri account email.
La maggior parte dei client di posta elettronica utilizza il Protocollo di Accesso dei Messaggi Internet (IMAP) o il Protocollo Post Office (POP) per accedere alle email memorizzate su un server di posta remoto. La maggior parte delle applicazioni email visualizzano anche email in formato HTML (HyperText Markup Language) che visualizza oggetti, come immagini e collegamenti ipertestuali. Le funzionalità delle applicazioni email avanzate includono la possibilità di importare elenchi di indirizzi/contatti, informazioni di configurazione ed email da altre applicazioni email.
Linux supporta i seguenti tipi di applicazioni email:
- Client di posta elettronica grafica, come Thunderbird, Evolution e Claws Mail.
- Client email in modalità di testo, come Mutt e Mail.
- Tutti i client basati su browser Web, come Gmail, Yahoo Mail e Office 365.
Altre Applicazioni Internet
I sistemi Linux forniscono molte altre applicazioni per l'esecuzione di attività relative a Internet. Queste includono:
| Applicazione | Utilizzo |
|---|---|
FileZilla |
Client FTP intuitivo che supporta FTP, Secure File Transfer Protocol (SFTP), e FTP Secured (FTPS). Usati per trasferire file da/per server (FTP). |
Pidgin |
Per accedere a GTalk, AIM, ICQ, MSN, IRC e altre reti di messaggistica. |
Ekiga |
Per connettersi a reti Voice over Internet Protocol (VoIP). |
Hexchat |
Per accedere alle reti Internet RelayChat (IRC). |



Applicazioni per Ufficio
La maggior parte dei sistemi informatici odierni dispone di applicazioni di produttività (a volte chiamate suite di ufficio) disponibili o installate. Ogni suite è una raccolta di programmi strettamente connessi utilizzati per creare e modificare diversi tipi di file come:
- Testo (articoli, libri, report, ecc.)
- Fogli di calcolo
- Presentazioni
- Oggetti grafici.
La maggior parte delle distribuzioni Linux offre LibreOffice, una suite di ufficio open source resa disponibile nel 2010, che si è evoluta da OpenOffice. Mentre sono disponibili altre suite per ufficio, LibreOffice è la più matura, ampiamente usata e sviluppata intensamente.
Inoltre, gli utenti di Linux hanno pieno accesso alle suite di ufficio basate su Internet come Google Docs e Microsoft Office 365.
Componenti di LibreOffice
Le applicazioni incluse in LibreOffice sono:
- Writer: elaborazione testi
- Calc: fogli di calcolo
- Impress: presentazioni
- Draw: creazione e modifica di grafica e diagrammi.
Le applicazioni LibreOffice possono leggere e scrivere formati di documenti non nativi, come quelli utilizzati da Microsoft Office. Di solito, la fedeltà viene mantenuta abbastanza bene, ma documenti complicati potrebbero avere alcune conversioni imperfette.
Applicazioni per lo Sviluppo
Le distribuzioni Linux sono dotate di un insieme completo di applicazioni e strumenti necessari a chi sviluppa sia le applicazioni utente che il kernel stesso o si occupa della manutenzione.
Questi strumenti sono strettamente integrati e includono:
- Editor avanzati personalizzati per le esigenze dei programmatori, come vi ed emacs.
- Compilatori (come gcc e clang per programmi in C e C++) per ogni linguaggio di computer che sia mai esistito, compresi quelli nuovi molto popolari come Golang e Rust.
- Debugger come gdb, vari front end grafici e molti altri strumenti di debug (come Valgrind).
- Programmi di misurazione e monitoraggio delle prestazioni, alcuni con interfacce grafiche facili da usare, altri più arcani e pensati per essere utilizzati solo da ingegneri informatici esperti.
- Ambienti di sviluppo integrati (IDE) completi come Eclipse e Visual Studio Code che mettono insieme tutti questi strumenti.
Su altri sistemi operativi, questi strumenti devono essere ottenuti e installati separatamente, spesso a un costo elevato, mentre su Linux sono tutti disponibili senza alcun costo attraverso i sistemi di installazione standard dei pacchetti.


Lettori Audio
Le applicazioni multimediali vengono utilizzate per ascoltare musica, guardare video, ecc., nonché per presentare e visualizzare testo e grafica. I sistemi Linux offrono una serie di applicazioni di lettori audio, tra cui:
| Applicazione | Uso |
|---|---|
| Amarok | lettore MP3 maturo con interfaccia grafica, che riproduce file audio e video e file audio in streaming). Ti consente di creare una playlist che contiene un gruppo di brani, e usa un database per conservare le informazioni riguardo alla collezione musicale. |
| Audacity | Usato per registrare e modificare suoni. Può essere installato velocemente tramite un gestore di pacchetti. Audacity ha una semplice interfaccia per iniziare. |
| Rhythmbox | Supporta un'ampia varietà di sorgenti di musica digitale, compreso lo streaming audio da Internet e i podcast. L'applicazione consente anche di cercare un certo brano in una libreria. Supporta le playlist intelligenti con una funzionalità di aggiornamento automatico, con la quale puoi aggiornare playlist in base a criteri di selezione specificati. |
Naturalmente, un sistema Linux può anche connettersi con servizi di streaming di musica online commerciale, come Pandora e Spotify tramite browser web.

Lettori Video
I lettori video possono riprodurre input da molte fonti diverse, dalla macchina locale o su Internet.

I sistemi Linux offrono un certo numero di queste applicazioni, tra cui:
- VLC
- MPlayer
- Xine
- Totem
Editor Video
Gli editor video sono usati per modificare video e film. I sistemi Linux offrono diversi editor video, tra i quali:
| Applicazione | Uso |
|---|---|
| Cinepaint | Ritocco fotogramma-per-fotogramma. Cinepaint è usato per editare immagini in un video. |
| Blender | Crea animazioni e progetti 3D. Blender è uno strumento professionale che usa la modellazione come punto di partenza. Ci sono strumenti complessi e potenti per cattura della fotocamera, registrazione, editing, creazione e ritocco video, ognuno ha un proprio focus. |
| Cinelerra | Cattura, compone e modifica audio/video. |
| FFmpeg | Registra, converte ed esegue streaming di audio/video. FFmpeg è un convertitore di formato, tra le altre cose, e ha altri strumenti come ffplay e ffserver. |


GIMP (Programma di Manipolazione Immagini)
Gli editor grafici consentono di creare, modificare, visualizzare e organizzare immagini di vari formati, come JPEG (o JPG), Portable Network Graphics (PNG), Graphics Interchange Format (GIF) e TIFF.
Il Programma di Manipolazione delle Immagini GNU (GIMP) è uno strumento di ritocco e modifica dell'immagine ricco di funzionalità simile ad Adobe Photoshop ed è disponibile su tutte le distribuzioni Linux. Alcune caratteristiche di GIMP sono:
- La gestione di qualsiasi formato di file di immagine.
- Disponibilità di molti plugin e filtri a scopo speciale.
- Esposizione di ampie informazioni sull'immagine, come livelli, canali e istogrammi.
Utilità grafiche
Oltre a GIMP, ci sono altre utilità grafiche che aiutano a eseguire varie attività relative all'immagine, tra cui:
| Utilità Grafica | Utilizzo |
|---|---|
| eog | Eye of Gnome (eog) è un visualizzatore di immagini che fornisce funzionalità di presentazione e alcuni strumenti di editing di immagini, come rotazione e ridimensionamento. Può anche scorrere le immagini in una directory con solo un clic. |
| Inkscape | Inkscape è un editor di immagini con molte funzionalità di editing. Funziona con strati e trasformazioni dell'immagine. A volte è paragonato ad Adobe Illustrator. |
| convert | convert è uno strumento da riga di comando (parte dell'insieme di applicazioni ImageMagick) che può modificare i file di immagine in molti modi. Le opzioni includono la conversione del formato file e numerose opzioni di modifica dell'immagine, come sfocatura, ridimensionamento, smacchiatura ecc. |
| Scribus | Scribus viene utilizzato per la creazione di documenti utilizzati per la pubblicazione e fornisce un ambiente Wysiwyg (quello che vedi è ciò che ottieni). Fornisce anche numerosi strumenti di editing. |

Capitolo 6 - Riepilogo
Hai completato il capitolo 6. Riassumiamo i concetti chiave trattati:
- Linux offre un'ampia varietà di applicazioni Internet, come browser web, client di posta elettronica, applicazioni per riproduzione media online e altre.
- I browser web supportati da Linux possono essere grafici o basati sul testo, come Firefox, Google Chrome, Epiphany, w3m, Lynx e altri.
- Linux supporta client di posta elettronica grafica, come Thunderbird, Evolution e Claws Mail e client di posta elettronica in modalità di testo, come Mutt e Mail.
- I sistemi Linux forniscono molte altre applicazioni per l'esecuzione di attività relative a Internet, come Filezilla, XChat, Pidgin e altri.
- La maggior parte delle distribuzioni Linux offre LibreOffice per creare e modificare diversi tipi di documenti.
- I sistemi Linux offrono intere suite di applicazioni e strumenti di sviluppo, inclusi compilatori e debugger.
- I sistemi Linux offrono una serie di lettori audio tra cui Amarok, Audacity e Rhythmbox.
- I sistemi Linux offrono svariati lettori video, tra cui VLC, Mplayer, Xine e Totem.
- I sistemi Linux offrono diversi editor video, tra cui Kino, Cinepaint e Blender.
- L'utilità GIMP (GNU Image Manipulation Program) è uno strumento di ritocco e modifica dell'immagine ricco di funzionalità disponibile su tutte le distribuzioni Linux.
- Altre utility grafiche che aiutano ad eseguire diverse attività legate alle immagini sono eog, Inkscape, convert, e Scribus.

Capitolo 7: Operazioni dalla riga di comando
Obiettivi formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Utilizzare la riga di comando per eseguire operazioni in Linux.
- Cercare file.
- Creare e gestire i file.
- Installare e aggiornare il software.
Introduzione alla riga di comando
Gli amministratori di sistema Linux trascorrono una parte significativa del loro tempo utilizzando il prompt della riga di comando. Spesso automatizzano attività e risolvono problemi in questo ambiente di testo. C'è un detto: Le interfacce utente grafiche semplificano le attività facili, mentre le interfacce della riga di comando rendono possibili attività difficili". Linux si basa fortemente sull'abbondanza di strumenti di riga di comando. L'interfaccia della riga di comando offre i seguenti vantaggi:
- Non vi è alcun sovraccarico dovuto alla GUI.
- Praticamente qualsiasi compito può essere svolto dalla riga di comando.
- È possibile implementare script per attività spesso usate (o facili da dimenticare) e serie di procedure.
- È possibile accedere a macchine remote ovunque su Internet.
- È possibile avviare applicazioni grafiche direttamente dalla riga di comando invece di cercarle all'interno dei menu.
- Mentre gli strumenti grafici possono variare tra le distribuzioni Linux, l'interfaccia della riga di comando no.

Utilizzare un Terminale di Testo sul Desktop Grafico
Un emulatore del terminale emula (simula) un terminale a sé stante all'interno di una finestra sul desktop. Con questo intendiamo che si comporta essenzialmente come se tu stessi accedendo alla macchina in un terminale di testo puro senza interfaccia grafica in esecuzione. La maggior parte dei programmi di emulatore terminale supporta più sessioni di terminale aprendo ulteriori schede o finestre.
Per impostazione predefinita, sugli ambienti desktop GNOME, l'applicazione gnome-terminal viene utilizzata per emulare un terminale in modalità testo in una finestra. Altri programmi di terminale disponibili includono:
- xterm
- konsole (predefinito in KDE)
- terminator
$ ls -aAvviare Finestre del Terminale
Per aprire un terminale su qualsiasi sistema che utilizza un recente desktop GNOME fai clic su Applicazioni > Strumenti di sistema > Terminale oppure Applicazioni > Utilità > Terminale. Se non disponi del menu Applicazioni, dovrai installare il pacchetto gnome-shell-extensions e attivarlo con gnome-tweaks.
Su quasi tutte le più recenti distribuzioni basate su GNOME, puoi sempre aprire un terminale facendo clic con il pulsante destro del mouse ovunque sullo sfondo del desktop e selezionare Apri in terminale. Se questo non funziona, dovrai ancora una volta installare e attivare il pacchetto gnome-shell-extensions appropriato.
Puoi anche premere Alt-F2, poi digitare gnome-terminal oppure konsole, a seconda di quale sia appropriato.
Poiché le distribuzioni tendono a nascondere l'apertura di un terminale di riga di comando, e la posizione nei menu può variare nella GUI, è una buona idea capire come "attaccare" l'icona del terminale al pannello, il che potrebbe significare aggiungerlo al gruppo dei Preferiti sui sistemi GNOME.
Alcune Utility di Base
Esistono alcune utility di base della riga di comando che vengono costantemente utilizzate e sarebbe impossibile procedere ulteriormente senza usarne alcune in forma semplice prima di discuterne in modo più dettagliato. Un breve elenco deve includere:
- cat: usato per stampare un file (o per unire file).
- head: usato per mostrare le prime righe di un file.
- tail: usato per mostrare le ultime righe di un file.
- man: usato per consultare la documentazione.
La videata qui sotto mostra utilizzi elementari di questi programmi. Nota che il simbolo pipe (|) è usato per fare in modo che un programma riceva come input il risultato di un altro programma.
Per la maggior parte delle volte, useremo queste utility solo nelle videate che mostrano varie attività, prima di discuterne in dettaglio.
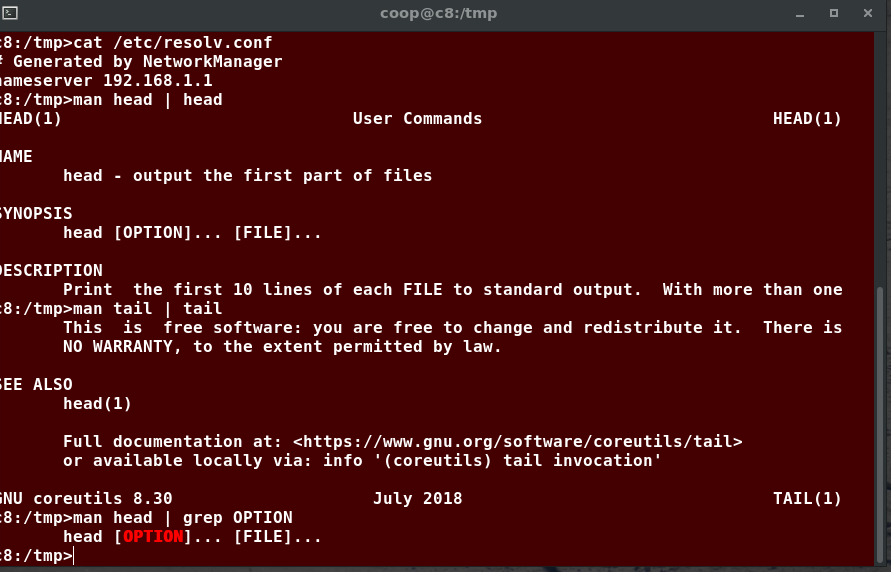
La riga di comando
La maggior parte delle righe di input digitate al prompt della shell ha tre elementi di base:
- Comando
- Opzioni
- Argomenti
Il comando è il nome del programma che stai eseguendo. Può essere seguito da una o più opzioni (o switch) che modificano ciò che il comando può fare. Le opzioni di solito iniziano con uno o due trattini, ad esempio -p o --print, al fine di differenziarle dagli argomenti, che rappresentano quello su cui sta operando il comando.
Tuttavia, molti comandi non hanno opzioni, o argomenti, o nessuno dei due. Inoltre, altri elementi (come l'impostazione delle variabili di ambiente) possono anche apparire sulla riga di comando durante l'avvio di un'attività.
sudo
Tutte le dimostrazioni create hanno un utente configurato con funzionalità sudo per fornire all'utente i privilegi amministrativi (admin) quando richiesto. sudo consente agli utenti di eseguire programmi utilizzando i privilegi di sicurezza di un altro utente, generalmente root (superutente).
Sui tuoi sistemi, potrebbe essere necessario impostare e abilitare sudo affinché funzioni correttamente. Per fare ciò, devi seguire alcuni passaggi che non spiegheremo molto dettagliatamente ora, ma imparerai più avanti in questo corso. Quando si esegue su Ubuntu e alcune altre distribuzioni recenti, sudo è già impostato per te durante l'installazione. Su altre distribuzioni Linux, probabilmente dovrai impostare sudo in modo che funzioni correttamente dopo l'installazione iniziale.
Qui sotto, imparerai i passaggi per impostare ed eseguire sudo sul tuo sistema.
$ sudo ls -la /rootPassaggi per l'Impostazione e l'Esecuzione di sudo
Se il tuo sistema non ha già sudo impostato e abilitato, devi seguire i seguenti passaggi:
Devi eseguire modifiche come utente amministrativo, o superutente, root. Mentre sudo diventerà il metodo preferito per farlo, non lo abbiamo ancora impostato, quindi useremo su (di cui discuteremo più avanti in dettaglio). Al prompt della riga di comando, digita su e premi Invio. Ti verrà quindi richiesta la password di root, immettila e premi Invio. Noterai che nulla viene stampato; questo è concepito in modo che nessuno possa vedere la password sullo schermo. Dovresti ottenere un prompt dall'aspetto diverso, che spesso finisce con "#". Per esempio:$ su Password:#
Ora, è necessario creare un file di configurazione per consentire al tuo account utente di utilizzare sudo. In genere, questo file viene creato nella directory /etc/sudoers.d/ con il nome del file che coincide con il tuo username. Ad esempio, per questa demo, supponiamo che il tuo username sia student. Dopo il passaggio 1, poi dovresti creare il file di configurazione per student in questo modo:# echo "student ALL=(ALL) ALL" > /etc/sudoers.d/student
Per ultimo, alcune distribuzioni Linux potrebbero richiedere anche di cambiare i permessi del file, che farai digitando:# chmod 440 /etc/sudoers.d/student
Dovrebbe essere tutto. Per il resto di questo corso, sudo dovrebbe essere impostato correttamente. Quando si utilizza sudo, per impostazione predefinita ti verrà richiesto di fornire una password (la tua password utente) almeno la prima volta che lo fai entro un intervallo di tempo specificato. È possibile (anche se molto insicuro) configurare sudo per non richiedere una password o modificare la finestra temporale in cui la password non deve essere ripetuta con ogni comando sudo.

Sandwich
(Ottenuta da XKCD, fornita con la licenza Creative Commons Attribution-NonCommercial 2.5)
Spostarsi tra GUI e Riga di Comando
La natura personalizzabile di Linux consente di abbandonare l'interfaccia grafica (temporaneamente o permanentemente) o di avviarla dopo che il sistema è in esecuzione.
La maggior parte delle distribuzioni Linux offre un'opzione durante l'installazione (o ha più di una versione del supporto di installazione) di scelta tra desktop (con un desktop grafico) e server (di solito senza).
I server di produzione Linux sono generalmente installati senza GUI e anche se è installata, di solito non viene lanciata durante l'avvio del sistema. La rimozione dell'interfaccia grafica da un server di produzione può essere molto utile per mantenere un sistema snello, che può essere più facile da supportare e mantenere al sicuro.
Terminali Virtuali
I Terminali Virtuali (VT) sono sessioni di console che utilizzano l'intero schermo e la tastiera al di fuori di un ambiente grafico. Tali terminali sono considerati "virtuali" perché, sebbene possano esserci più terminali attivi, un solo terminale alla volta rimane visibile. Un VT non è esattamente uguale alla riga di comando di una finestra del terminale; puoi avere molti di questi visibili contemporaneamente su un desktop grafico.
Un terminale virtuale (di solito numero uno o sette) è riservato all'ambiente grafico e gli accessi in modalità testo sono abilitati sui VT non utilizzati. Ubuntu usa VT 7, ma CentOS/RHEL e OpenSuse utilizzano VT 1 per il display grafico.
Un esempio di situazione in cui l'utilizzo di VT è utile è quando si incontrano problemi con il desktop grafico. In questa situazione, puoi passare a uno dei VT di testo e risolvere i problemi.
Per passare a un VT, premi CTRL-ALT-tasto_funzione per il VT. Ad esempio, premi CTRL-ALT-F6 per VT6. In realtà, devi solo premere la combinazione di tasti Alt-F6 se sei già in un VT e desideri passare a un altro VT.
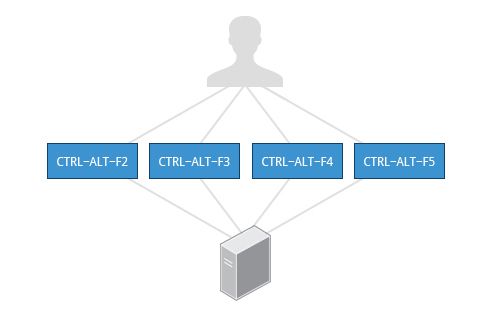
Fermare il Desktop Grafico
Le distribuzioni Linux possono avviare e fermare il desktop grafico in vari modi. Il metodo esatto differisce tra le distribuzioni e tra le versioni di distribuzione. Per le nuove distribuzioni basate su systemd, il display manager viene eseguito come servizio, pertanto è possibile fermare il desktop GUI con l'utilità systemctl e per la maggior parte delle distribuzioni funzionerà anche con il comando telinit, in questo modo:
per fermare il Desktop: $ sudo systemctl stop gdm (oppure sudo telinit 3)
per farlo ripartire (dopo esserti connesso alla console): $ sudo systemctl start gdm (oppure sudo telinit 5)
Nelle versioni Ubuntu precedenti la 18.04 LTS, sostituisci lightdm al posto di gdm.
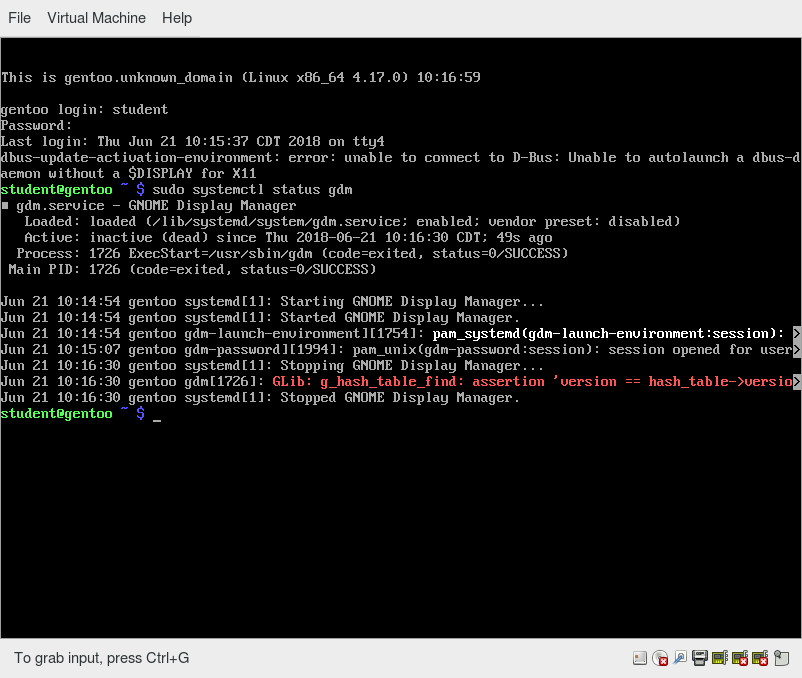
Operazioni di Base
In questa sezione, discuteremo di come realizzare le operazioni di base dalla riga di comando. Queste includono come accedere e disconnettersi dal sistema, riavviare o chiudere il sistema, individuare le applicazioni, accedere alle directory, identificare percorsi assoluti e relativi ed esplorare il filesystem.
Accedere e Uscire
Un terminale di testo disponibile richiederà uno username (con la stringa Login: ) e la password. Quando si digita la password, non viene visualizzato nulla sul terminale (nemmeno un * per indicare che hai digitato qualcosa), per impedire agli altri di vedere la tua password. Dopo aver effettuato l'accesso al sistema, è possibile eseguire operazioni di base.
Una volta avviata la sessione (accedendo a un terminale di testo o tramite un programma di terminale grafico), è anche possibile connettersi e accedere a sistemi remoti utilizzando Secure Shell (SSH). Ad esempio, digitando ssh student@server.remoto.com, SSH si connette in modalità sicura alla macchina remota server.remoto.com fornendo all'utente student una finestra di terminale di riga di comando, richiedendo una password (come per gli accessi normali) o una chiave crittografica per accedere senza fornire una password per verificare l'identità.
Riavviare e Spegnere
Il metodo preferito per spegnere o riavviare il sistema è utilizzare il comando shutdown. Questo invia un messaggio di avvertimento, quindi impedisce a ulteriori utenti di accedere. Il processo init controllerà quindi la chiusura o il riavvio del sistema. È importante chiudere sempre correttamente; in caso contrario, si possono causare danni al sistema e/o perdita di dati.
I comandi halt e poweroff eseguono shutdown-h per fermare il sistema; reboot esegue shutdown-r e fa riavviare la macchina invece di chiuderla. Sia il riavvio che la chiusura dalla riga di comando richiedono l'accesso superutente (root).
Se amministri un sistema multiutente, hai la possibilità di avvisare tutti gli utenti prima dell'arresto, in questo modo:
$ sudo shutdown -h 10:00 "Spegnimento per operazioni di manutenzione."
NOTA: sulle recenti distribuzioni Linux basate su Wayland i messaggi trasmessi non vengono visualizzati nelle sessioni di emulazione del terminale in esecuzione sul desktop; appaiono solo sui display della console VT.

Trovare Applicazioni
A seconda delle specifiche particolari della tua distribuzione, i programmi e i pacchetti software possono essere installati in varie directory. In generale, programmi eseguibili e script dovrebbero risiedere nelle directory /bin, /usr/bin, /sbin, /usr/sbin o talvolta in /opt. Possono anche trovarsi in /usr/local/bin e /usr/local/sbin, oppure in una directory all'interno dello spazio dell'account dell'utente, come /home/student/bin.
Un modo per individuare i programmi è impiegare l'utility which. Ad esempio, per scoprire esattamente dove risiede il programma diff sul filesystem:
$ which diff/usr/bin/diff
Se which non trova il programma, whereis è una buona alternativa perché cerca pacchetti in una gamma più ampia di directory di sistema:
$ whereis diffdiff: /usr/bin/diff /usr/share/man/man1/diff.1.gz /usr/share/man/man1p/diff.1p.gz
oltre a cercare il codice sogente e i file man (le pagine di manuale) distribuiti assieme al programma.
which e whereisAccedere alle Directory
Quando accedi per la prima volta a un sistema o apri un terminale, la directory predefinita dovrebbe essere la tua directory home. Puoi stamparne il percorso esatto digitando echo $ home. Molte distribuzioni Linux in realtà aprono nuovi terminali grafici in $ home/Desktop. I seguenti comandi sono utili per la spostarrsi tra le directory:
| Comando | Risultato |
|---|---|
pwd |
Visualizza la directory corrente |
cd ~ oppure cd |
Vai alla tua directory home (il cui nome abbreviato è il carattere tilde (~)) |
cd .. |
Vai alla directory superiore (..) |
cd - |
Vai alla directory precedente (- (meno)) |
Video: Accedere alle Directory
Comprendere i Percorsi Assoluti e Relativi
Esistono due modi per identificare i percorsi:
- Nome percorso assoluto
Un nome di percorso assoluto inizia con la directory radice (root) e segue l'albero del filesystem, ramo per ramo, fino a raggiungere la directory o il file desiderati. I percorsi assoluti iniziano sempre con/. - Nome percorso relativo
Un percorso relativo parte dalla directory corrente di lavoro. I percorsi relativi non iniziano mai con/.
Più barre (/) tra le directory e i file sono consentite, ma sono tutte ignorate dal sistema a parte una. ////usr//bin è un percorso valido ma viene visto come /usr/bin dal sistema.
Il più delle volte, è più conveniente utilizzare percorsi relativi, che richiedono meno digitazione. Di solito, sfrutti le scorciatoie che rappresentano: . (directory corrente), .. (directory superiore) e ~ (la tua directory home).
Ad esempio, supponiamo che tu stia attualmente lavorando nella tua home directory e desideri passare alla directory /usr/bin. I seguenti due modi ti porteranno alla stessa directory partendo dalla tua home:
- Con il percorso assoluto
$ cd /usr/bin - Con il percorso relativo
$ cd ../../usr/bin
In questo caso, usare il metodo del percorso assoluto richiede di scrivere meno.
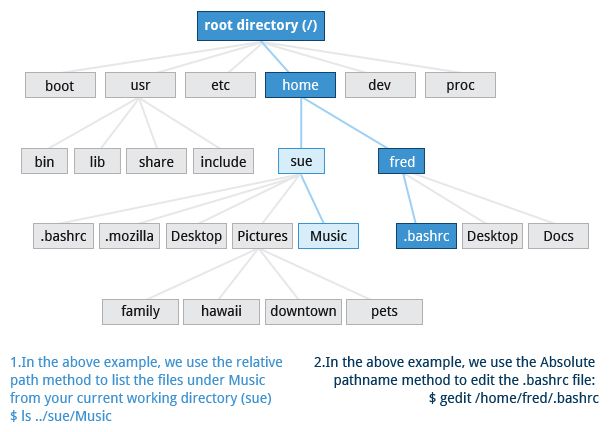
Esplorare il Filesystem
Attraversare su e giù l'alberatura del filesystem può diventare noioso. Il comando tree è un buon modo per ottenere una vista dall'alto dell'albero del filesystem. Usa tree -d per visualizzare solo le directory e l'elenco dei nomi dei file.
I seguenti comandi ti possono aiutare a esplorare il filesystem:
| Comando | Utilizzo |
|---|---|
cd / |
Va dalla directory corrente alla radice del filesystem (root) / (o al percorso che digiti) |
ls |
Elenca il contenuto della directory di lavoro corrente |
ls –a |
Elenca tutti i file, compreso directory e file nascosti (quelli che iniziano con . ) |
tree |
Visualizza una vista ad albero del filesystem |
Hard Link
L'utility ln viene usata per creare hard link (collegamenti fisici) e, con l'opzione -s, soft link (collegamenti simbolici), anche noti come symlink. Questi due tipi di link sono molto utili nei sistemi operativi basati su UNIX.
Supponi che il file file1 esista già. Un hard link, chiamato file2, viene creato con il comando:
$ ln file1 file2
Nota che ora sembrano esistere due file. Tuttavia, un esame più accurato dell'elenco dei file mostra che questo non è del tutto vero.
$ ls -li file1 file2
L'opzione -i del comando ls stampa nella prima colonna il numero di inode, che è un valore univoco per ciascun oggetto file. Il valore di questo campo è lo stesso per entrambi i file; ciò che sta realmente accadendo qui è che c'è solo un file, ma ha più di un nome associato a esso, come indicato dal 2 che appare nel risultato del comando ls. Pertanto, c'era già un altro oggetto collegato a file1 prima che il comando fosse eseguito.
Gli hard link sono molto utili e risparmiano spazio, ma devi stare attento al loro uso. Per prima cosa, se rimuovi file1 o file2 nell'esempio, l'oggetto inode (e il nome del file non cancellato) rimarrà, il che potrebbe essere indesiderabile, in quanto può portare a errori subdoli in seguito, se ricrei un file con quel nome.
Se modifichi uno dei file, ciò che accade nello specifico dipende dal tuo editor; la maggior parte degli editor, tra cui vi e gedit, manterrà il collegamento per impostazione predefinita, ma è possibile che la modifica di uno dei nomi possa rompere il collegamento e comportare la creazione di due oggetti.
Soft Link (Link Simbolici)
Sono creati con l'opzione -s, in questo modo:
$ ln -s file1 file3$ ls -li file1 file3
Nota che file3 non risulta più essere un file normale, e chiaramente punta a file1 e ha un numero inode diverso.
I link simbolici non richiedono spazio extra nel filesystem (a meno che i loro nomi siano veramente lunghi). Sono estremamente convenienti, visto che possono essere facilmente modificati per indicare posizioni diverse. Un modo semplice per creare un collegamento dalla tua directory home verso file con nomi di percorso lunghi è creare un collegamento simbolico.
A differenza degli hard link, i collegamenti simbolici possono indicare oggetti anche su diversi filesystem, partizioni e/o dischi e altri media, che possono o meno essere attualmente disponibili o addirittura esistere. Nel caso in cui il collegamento non indichi un oggetto attualmente disponibile o esistente, otterrai un collegamento pendente.
Spostarsi nella Cronologia delle Directory
Il comando cd ricorda la tua posizione precedente, e ti consente di ritornarvi con cd -. Per ricordare qualcosa di più oltre all'ultima directory visitata, usa pushd per cambiare directory invece che cd; questo immette la tua directory di partenza in una lista. Usando popd potrai tornare a quelle directory, in ordine inverso (la directory più recente sarà la prima recuperata con popd). L'elenco delle directory nella lista viene visualizzato con il comando dirs.
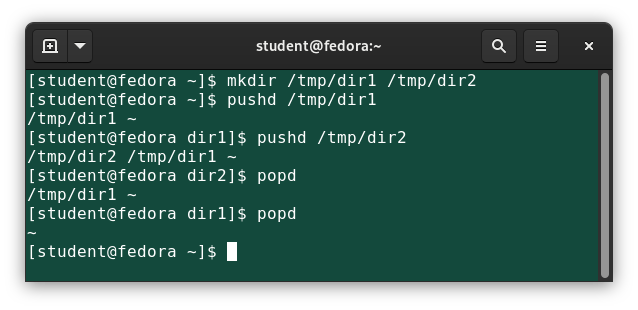
Lavorare con i File
Linux fornisce molti comandi che ti aiutano a visualizzare il contenuto di un file, creare un nuovo file o un file vuoto, modificare la marca temporale (timestamp) di un file e spostare, rimuovere e rinominare un file o una directory. Questi comandi ti aiutano a gestire i tuoi dati e file garantendo che i dati corretti siano disponibili nella posizione corretta.

Visualizzare i File
È possibile utilizzare le seguenti utility della riga di comando per visualizzare i file:
| Comando | Utilizzo |
|---|---|
cat |
Usato per visualizzare file di piccole dimensioni; non fornisce alcuna possibiltà di scorrimento a ritroso. |
tac |
Usato per visualizzare un file all'indietro, partendo dall'ultima riga. |
less |
Usato per visualizzare file di dimensioni maggiori in quanto è un programma di scorrimento di schermate. Si mette in pausa a ogni schermata riempita di testo, fornisce capacità di scorrimento a ritroso, e ti consente di cercare e spostarti all'interno del file NOTA: Usa / per effettuare la ricerca di un pattern in avanti e ? per una ricerca all'indietro. Un vecchio programma chiamato more è ancora usato, ma ha meno funzionalità. |
tail |
Usato per stampare le ultime 10 righe di un file nella modalità predefinita. Puoi modificare il numero di righe con l'opzione -n <numero_righe> oppure solo -<numero_righe>; se ad esempio vuoi visualizzare le ultime 15 righe di un file usa -n 15 oppure -15. |
head |
L'opposto del comando tail; nella modalità predefinita stampa le prime 10 righe di un file. |
Video: Altre Informazioni sulla Visualizzazione File
touch
Il comando touch viene spesso utilizzato per impostare o aggiornare la data e l'ora di ultima modifica e/o di ultimo accesso dei file. Per impostazione predefinita, ripristina la marca temporale di un file portandola all'ora corrente.
Tuttavia, puoi anche creare un file vuoto utilizzando touch:
$ touch <nome_file>
Questo viene normalmente fatto per creare un file vuoto come segnaposto per uno scopo successivo.
touch fornisce diverse opzioni utili. Ad esempio, l'opzione -t consente di impostare la data e la marca temporale del file su un valore specifico, ad esempio:
$ touch -t 16001209 myfile
Questo imposta la marca temporale di myfile alle 16 (1600) del 9 dicembre (09 12).
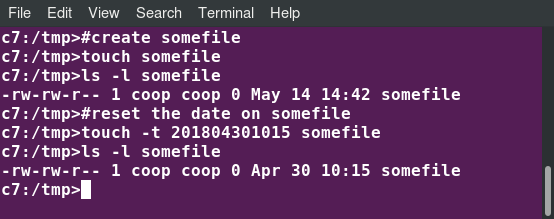
mkdir e rmdir
mkdir è usato per creare una directory:
mkdir sampdir
Crea una directory di esempio chiamatasampdirsotto la directory corrente.mkdir /usr/sampdir
Crea una directory di esempio chiamatasampdirsotto/usr.
La rimozione di una directory viene eseguita con rmdir. La directory deve essere vuota o il comando fallirà. Per rimuovere una directory e tutti il suo contenuto devi eseguire rm -rf.
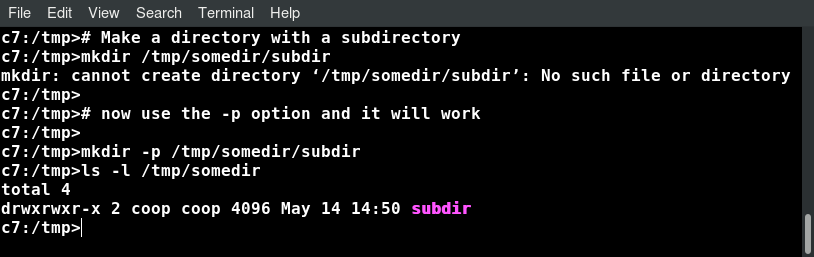
Spostare, Rinominare o Rimuovere un File
Nota che il comando mv esegue due compiti, visto che può:
- Rinominare semplicemente un file
- Spostare un file in un'altra posizione, cambiando il suo nome allo stesso tempo.
Se non sei sicuro di rimuovere i file che corrispondono a uno schema fornito, è sempre bene eseguire rm in modo interattivo (rm –i) che richiede una conferma prima di ogni rimozione.
| Comando | Utilizzo |
|---|---|
mv |
Rinomina un file |
rm |
Rimuove un file |
rm –f |
Forza la rimozione di un file |
rm –i |
Rimuove un file in modalità interattiva |
Rinominare o Rimuovere una Directory
rmdir funziona solo su directory vuote; altrimenti si ottiene un errore.
Sebbene il comando rm –rf sia un modo semplice per rimuovere un'intero pezzo di alberatura dal filesystem in modo ricorsivo, è estremamente pericoloso e dovrebbe essere usato con la massima cura, specialmente se usato dalla radice - root - (ricorda che ricorsivo significa percorrere tutte le sotto-directory, fino in fondo all'ultimo ramo).
| Comando | Utilizzo |
|---|---|
mv |
Rinomina una directory |
rmdir |
Rimuove una directory vuota |
rm -rf |
Forza la rimozione di una directory ricorsivamente |
Modificare il Prompt della Riga di Comando
La variabile PS1 è la stringa di caratteri visualizzata come prompt nella riga di comando. La maggior parte delle distribuzioni imposta PS1 su un valore predefinito noto, che è adeguato nella maggior parte dei casi. Tuttavia, gli utenti potrebbero desiderare informazioni personalizzate da mostrare nella riga di comando. Ad esempio, alcuni amministratori di sistema richiedono che l'utente e il nome del sistema host vengano visualizzati sulla riga di comando in questo modo:
student@c8 $
Questo potrebbe rivelarsi utile se lavori in più ruoli e vuoi che venga sempre visualizzato il tuo username e su quale macchina ti trovi. Il prompt qui sopra potrebbe essere implementato impostando la variabile PS1 su: \u@\h\$.
Per esempio:
$ echo $PS1\$$ PS1="\u@\h \$ "student@c8 $ echo $PS1\u@\h \$student@c8 $
Per convenzione, la maggior parte dei sistemi viene impostata in modo che l'utente di root abbia il simbolo del cancelletto (#) come prompt.

Video: Lavorare con File e Directory al Prompt dei Comandi
Flussi Standard dei File
Quando vengono eseguiti i comandi, in modalità predefinita ci sono tre flussi di file (o descrittori) sempre aperti per l'uso: standard input (standard in oppure stdin), standard output (standard out oppure stdout) e standard error (oppure stderr).
| Nome | Nome Simbolico | Valore | Esempio |
|---|---|---|---|
| standard input | stdin |
0 | tastiera |
| standard output | stdout |
1 | terminale |
| standard error | stderr |
2 | file di log |
Di solito, stdin è la tua tastiera e stdout e stderr sono stampati sul tuo terminale. stderr viene spesso reindirizzato a un file di registrazione degli errori, mentre stdin viene alimentato dirigendo l'input che proviene da un file o dall'output di un comando precedente attraverso una pipe, stdout viene spesso reindirizzato in un file. Poiché stderr è dove vengono scritti i messaggi di errore, di solito nulla andrà lì.
In Linux, tutti i file aperti sono rappresentati internamente da quelli che vengono chiamati descrittori di file. In poche parole, questi sono rappresentati da numeri a partire da zero. stdin è il descrittore di file 0, stdout è il descrittore di file 1, e stderr è 2. In genere, se altri file vengono aperti oltre a questi tre, che sono aperti per impostazione predefinita, inizieranno da un descrittore di file 3 e il valore del descrittore aumenterà da lì.
Nella sezione successiva e nei capitoli a venire, vedrai esempi che alterano dove un comando in esecuzione ottiene il suo input, dove scrive il suo output o dove stampa i messaggi diagnostici (di errore).
Reindirizzare Input e Output (I/O)
Attraverso la shell di comando, possiamo reindirizzare i tre flussi di file standard in modo da poter ottenere l'input da un file o da un altro comando, anziché dalla nostra tastiera, e possiamo scrivere risultati ed errori su file o usarli per fornire input per i comandi successivi.
Ad esempio, se abbiamo un programma chiamato fa_qualcosa che legge da stdin e scrive verso stdout e stderr, possiamo cambiare la sua fonte di input usando il segno di minore (<) seguito dal nome del file dal quale si devono ottenere i dati in input:
$ fa_qualcosa < input-file
Se vuoi inviare il risultato a un file, usa il segno di maggiore (>) in questo modo:$ fa_qualcosa > output-file
Nell'esempio qui sopra, visto che stderr non è uguale a stdout, i messaggi di errore saranno comunque visibili nella finestra del terminale.
Se vuoi reindirizzare stderr a un file separato, usa il numero del descrittore di file di stderr (2), il segno di maggiore (>), seguito dal nome del file nel quale vuoi scrivere tutto quanto viene generato dal comando che scrive verso stderr:
$ fa_qualcosa 2> error-file
NOTA: con la stessa logica, fa_qualcosa 1> output-file è uguale a fa_qualcosa > output-file
Una speciale notazione scorciatoia può inviare qualunque cosa venga scritta verso il descrittore di file 2 (stderr) nella stessa destinazione del descrittore di file 1 (stdout): 2>&1.
$ fa_qualcosa > all-output-file 2>&1
Bash consente una sintassi più semplice per quanto sopra:
$ fa_qualcosa >& all-output-file
Pipe
La filosofia UNIX/Linux è quella di far cooperare insieme molti programmi (o comandi) semplici e brevi per produrre risultati piuttosto complessi, invece che avere un programma complesso con molte possibili opzioni e modalità operative. Per raggiungere questo obiettivo, viene fatto un ampio uso delle pipe. È possibile convogliare il risultato di un comando o programma verso un altro comando/programma come input.
Per fare ciò, inseriamo tra i comandi la barra verticale, il simbolo pipe, (|), così:
$ comando1 | comando2 | comando3
Quanto sopra rappresenta ciò che spesso chiamiamo una pipeline (conduttura) e consente a Linux di combinare le azioni di diversi comandi in uno. Questo è straordinariamente efficiente perché comando2 e comando3 non devono attendere che i precedenti comandi della pipeline siano completati prima che possano iniziare a elaborare i dati nei loro flussi di input; su sistemi con più CPU o core, la potenza di calcolo disponibile è molto meglio utilizzata e le cose vengono fatte più rapidamente.
Inoltre, non è necessario salvare l'output in file (temporanei) tra le fasi della pipeline, il che fa risparmiare spazio su disco e riduce le operazioni di lettura e scrittura dal disco, che sono spesso il collo di bottiglia più lento per elaborare qualcosa.
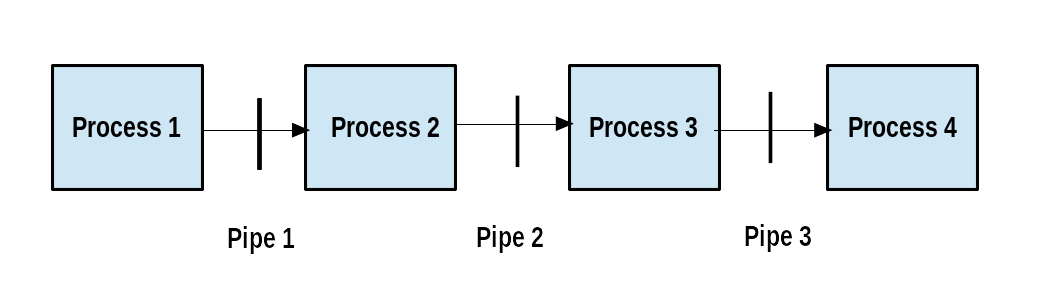
Cercare File
Essere in grado di trovare rapidamente i file che stai cercando ti farà risparmiare tempo e migliorare la produttività. È possibile cercare file sia all'interno della directory di home, sia in qualsiasi altra directory o posizione sul sistema.

Gli strumenti principali per farlo sono le utility locate e find. Mostreremo anche come usare i caratteri jolly (wildcard) in bash, al fine di trovare qualsiasi file che corrisponda a una determinata richiesta generalizzata.
locate
L'utility locate esegue una ricerca sfruttando un database di file e directory precedentemente costruito sul sistema. Cerca corrispondenza con tutte le voci che contengono una stringa di caratteri specificata. Questo a volte può provocare un elenco molto lungo.
Per ottenere un elenco più breve (e forse più rilevante), possiamo usare il programma grep come filtro. grep stamperà solo le righe che contengono una o più stringhe specificate, ad esempio:
$ locate zip | grep bin
elencherà tutti i file e le directory che hanno zip e bin nel loro nome. Esamineremo grep in modo molto più dettagliato in seguito. Nota l'uso del pipe | per collegare i due comandi insieme.
locate utilizza un database creato da un'utilità correlata, updatedb. La maggior parte dei sistemi Linux la esegue automaticamente una volta al giorno. Tuttavia, puoi eseguire un aggiornamento in qualsiasi momento semplicemente digitando updatedb dalla riga di comando come utente root.
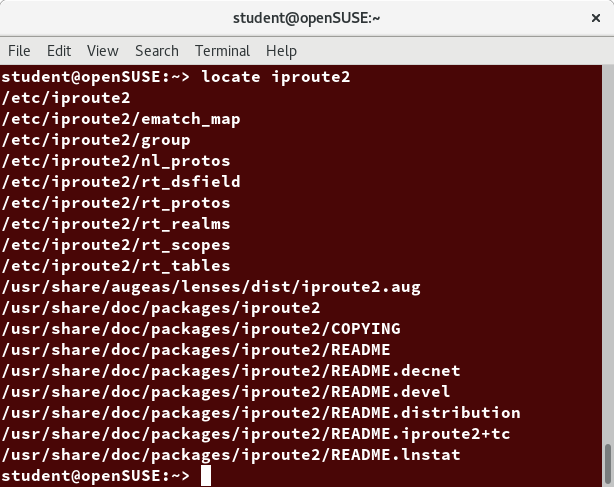
Caratteri Jolly e Corrispondenza con i Nomi di File
È possibile cercare un nome di file contenente caratteri specifici usando i caratteri jolly.
| Carattere Jolly | Risultato |
|---|---|
? |
Trova corrispondenza con qualsiasi carattere singolo |
* |
Trova corrispondenza con qualsiasi stringa di caratteri |
[insieme] |
Trova corrispondenza con qualsiasi carattere dell'insieme di caratteri, per esempio [adf] trova corrispondenza con tutte le occorrenze di a,d, o f |
[!insieme] |
Trova corrispondenza con qualsiasi carattere non compreso nell'insieme di caratteri |
Per cercare file utilizzando il carattere jolly ?, sostituisci ogni carattere sconosciuto con ?. Ad esempio, se sai solo che le prime due lettere di un nome file di tre lettere con un'estensione di .out sono "ba", digita ls ba?.out.
Per cercare file usando il carattere jolly *, sostituisci la stringa sconosciuta con *. Per esempio se ricordi solo che l'estensione era .out, digita ls *.out.
Video: Cercare File
Video: Usare i Caratteri Jolly per Cercare i File
Il Programma find
find è un programma estremamente utile e spesso utilizzato nella vita quotidiana di un amministratore di sistema Linux. Attraversa ricorsivamente l'albero del filesystem partendo da una qualunque specifica directory (o insieme di directory) e individua i file che corrispondono alle condizioni specificate. Il percorso predefinito è sempre la directory di lavoro corrente.
Ad esempio, gli amministratori a volte scansionano file di base potenzialmente grandi (che contengono informazioni diagnostiche dopo che un programma va in errore) che hanno data più vecchia di diverse settimane per rimuoverli.
È inoltre comune rimuovere i file non essenziali o obsoleti che si trovano in /tmp (e altre directory volatili, come quelle contenenti file memorizzati nella cache) a cui non si è acceduto di recente. Molte distribuzioni Linux utilizzano script di shell che sono eseguiti periodicamente (tramite cron di solito) per eseguire tale pulizia del sistema.
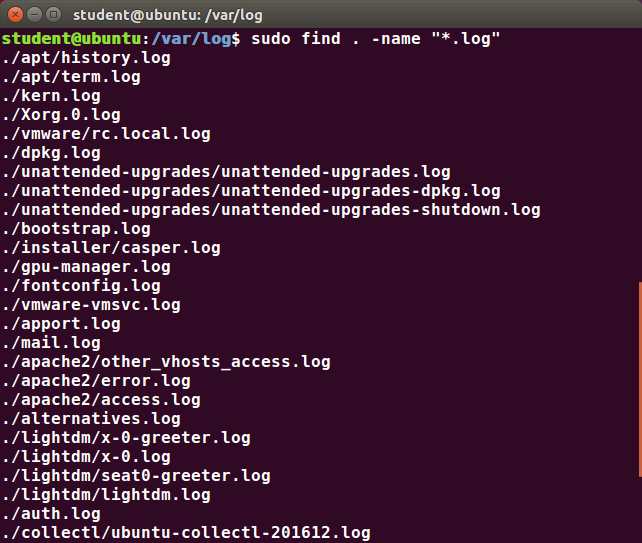
Usare find
Quando non vengono forniti argomenti, find elenca tutti i file nella directory corrente e tutte le sue sottodirectory. Le opzioni comunemente usate per abbreviare l'elenco includono -name (elenca solo i file con un determinato modello nel loro nome), -iname (non distingue tra minuscole e maiuscole nei nomi dei file) e -type (che limiterà i risultati a file di un determinato tipo specificato, come d per le directory, l per i collegamenti simbolici o f per un file normale, ecc.).
Cerca file e directory che si chiamano gcc:
$ find /usr -name gcc
Cerca solo le directory che si chiamano gcc:
$ find /usr -type d -name gcc
Cerca solo i file normali che si chiamano gcc:
$ find /usr -type f -name gcc
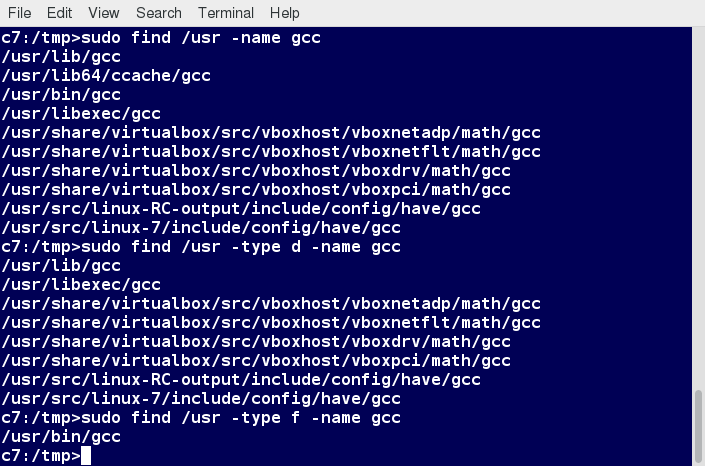
Usare Opzioni Avanzate di find
Un altro buon uso di find è eseguire comandi sui file che corrispondono ai criteri di ricerca. L'opzione -exec viene utilizzata per questo scopo.
Per cercare ed eliminare tutti i file che finiscono per .swp:
$ find -name "*.swp" -exec rm {} ’;’
Le parentesi graffe {} sono un segnaposto che verrà riempito con tutti i nomi di file che corrispondono al criterio di ricerca specificato, e il comando che precede verrà eseguito su ciascun file individualmente.
Nota che devi terminare il comando con ‘;’ (compresi i singoli apici)
oppure "\;". Entrambi i formati vanno bene.
Si può anche usare l'opzione -ok, che si comporta come -exec, tranne che find ti chiederà l'autorizzazione prima di eseguire il comando. Questo lo rende un buon modo per testare i risultati prima di eseguire ciecamente eventuali comandi potenzialmente pericolosi.
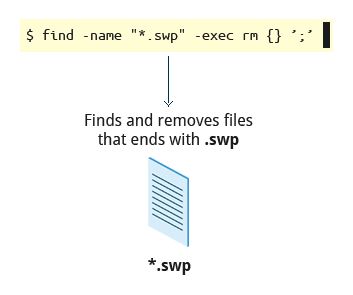
Trovare File in Base a Data e Dimensione
A volte desideri trovare file secondo alcuni attributi, ad esempio quando sono stati creati, usati per l'ultima volta, ecc.. Oppure in base alle loro dimensioni. È facile eseguire tali ricerche.
Per trovare file in base alla data:
$ find / -ctime 3
Qui, -ctime si riferisce a quando i metadati dell'inode (vale a dire la proprietà del file, i permessi, ecc.) sono cambiati l'ultima volta; spesso, ma non necessariamente, quando il file è stato creato per la prima volta. Puoi anche cercare per ultima data di accesso/lettura (-atime) oppure ultima data di modifiche/scrittura (-mtime). Il numero è il numero di giorni e può essere espresso sia come un numero (n) che significa esattamente quel valore , +n, che significa maggiore di quel numero, oppure -n, che significa minore di quel numero. Ci sono opzioni simili anche per i minuti (-cmin, -amin, e -mmin).
Per trovare file in base alla loro dimensione:
$ find / -size 0
Nota che la dimensione qui è in blocchi da 512 byte, nella modalità predefinita, puoi anche specificare byte (c), kilobyte (k), megabyte (M), gigabyte (G), ecc.. Così come i numeri relativi al tempo qui sopra, anche le dimensioni possono essere numeri esatti (n), oppure +n o -n. Per i dettagli, consulta la pagina di manuale per find.
Ad esempio, per trovare file di dimensioni superiori a 10 Mb ed eseguire un comando su quei file:
$ find / -size +10M -exec command {} ’;’
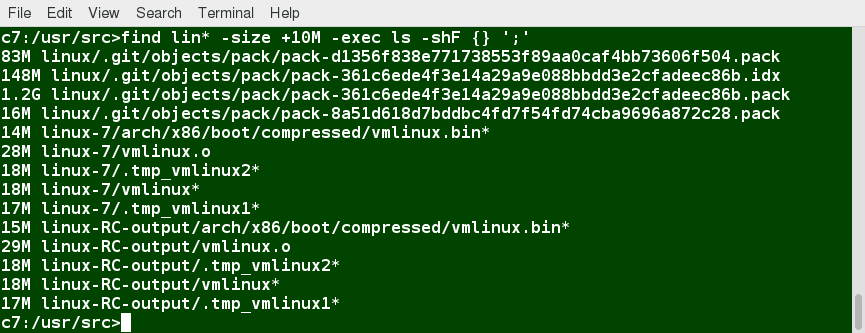
Video: Trovare File in una Directory
Sistemi di Gestione di Pacchetti in Linux
Le parti fondamentali di una distribuzione Linux e la maggior parte del suo software aggiuntivo sono installate tramite il Sistema di Gestione dei Pacchetti. Ogni pacchetto contiene i file e le altre istruzioni necessarie per far funzionare bene un componente software e collaborare con gli altri componenti che comprendono l'intero sistema. I pacchetti possono dipendere l'uno dall'altro. Ad esempio, un pacchetto per un'applicazione web scritta in linguaggio PHP può dipendere dal pacchetto PHP.

Esistono due ampie famiglie di gestori di pacchetti: quelli basati su Debian e quelli che utilizzano RPM come gestore di pacchetti di basso livello. I due sistemi sono incompatibili, ma in generale, forniscono le stesse caratteristiche e soddisfano le stesse esigenze. Esistono altri sistemi utilizzati da distribuzioni Linux più specializzate.
In questa sezione, imparerai come installare, rimuovere o cercare pacchetti dalla riga di comando utilizzando questi due sistemi di gestione dei pacchetti.
Gestori di Pacchetti: Due Livelli
Entrambi i sistemi di gestione dei pacchetti operano su due livelli distinti: uno strumento di basso livello (come dpkg o rpm) si occupa dei dettagli della decompressione dei singoli pacchetti, di eseguire script e di installare il software correttamente, mentre uno strumento di alto livello (come apt-get, dnf, yum, o zypper) funziona con gruppi di pacchetti, scarica pacchetti dal fornitore e gestisce le dipendenze.
Il più delle volte gli utenti devono lavorare solo con lo strumento di alto livello, che si occuperà di chiamare lo strumento di basso livello secondo necessità. La risoluzione delle dipendenze è una caratteristica particolarmente importante dello strumento di alto livello, in quanto gestisce i dettagli di ricerca e installazione di ogni dipendenza per te. Fai attenzione, tuttavia, poiché l'installazione di un singolo pacchetto potrebbe comportare l'installazione di molte dozzine o addirittura centinaia di pacchetti dipendenti.
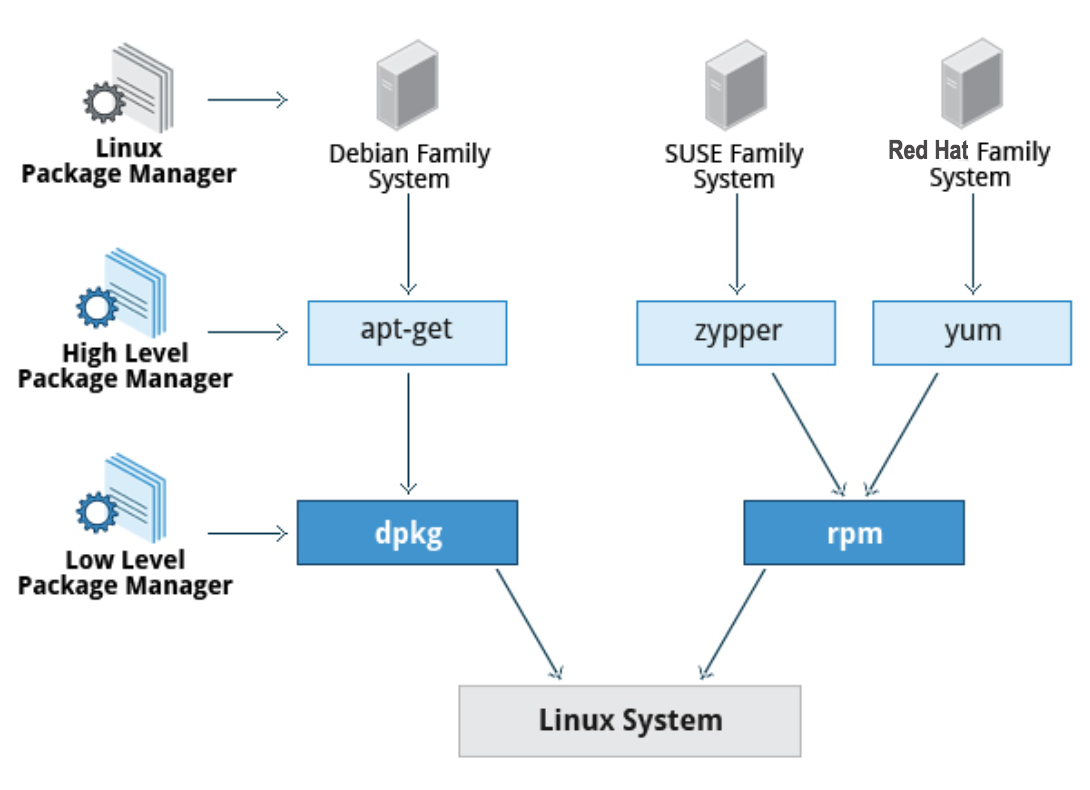
Lavorare con Due Diversi Sistemi di Gestione Pacchetti
apt (Advanced Packaging Tool) è il sistema di gestione dei pacchetti sottostante che gestisce il software sui sistemi basati su Debian. Mentre costituisce il backend per i gestori di pacchetti grafici, come Ubuntu Software Center e Synaptic, la sua interfaccia utente nativa è sulla riga di comando, con programmi che includono apt (o apt-get) e apt-cache.
dnf è l'utilità open source di gestione dei pacchetti da riga di comando per i sistemi Linux compatibili con RPM che appartengono alla famiglia Red Hat. dnf ha un'interfaccia sia da riga di comando che grafica. Fedora e RHEL 8 hanno sostituito l'utilità più vecchia yum con dnf, eliminando così un sacco di zavorra storica, oltre a introdurre molte nuove belle capacità. dnf è praticamente retrocompatibile con yum per i comandi quotidiani.
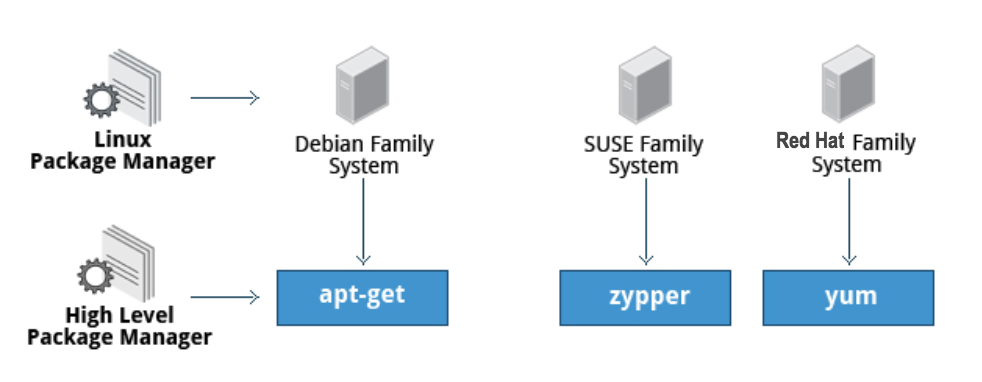
zypper è il sistema di gestione dei pacchetti per la famiglia SUSE/OpenSuse, anch'esso basato su RPM. zypper ti consente anche di gestire repository da riga di comando. zypper è abbastanza semplice da usare e assomiglia parecchio a dnf/yum.
Per imparare i comandi base dei gestori di pacchetti, dai un'occhiata a questi comandi:
| Operazione | rpm | deb |
|---|---|---|
| Installare un pacchetto | rpm -i foo.rpm |
dpkg --install foo.deb |
| Installare un pacchetto e le sue dipendenze | dnf install foo |
apt-get install foo |
| Eliminare un pacchetto | rpm -e foo.rpm |
dpkg --remove foo.deb |
| Eliminare un pacchetto e le sue dipendenze | dnf remove foo |
apt-get autoremove foo |
| Aggiornare un pacchetto | rpm -U foo.rpm |
dpkg --install foo.deb |
| Aggiornare un pacchetto e le sue dipendenze | dnf update foo |
apt-get install foo |
| Aggiornare l'intero sistema | dnf update |
apt-get dist-upgrade |
| Mostrare tutti i pacchetti installati | rpm -qa oppure dnf list installed |
dpkg --list |
| Ottenere informazioni su un pacchetto | rpm -qil foo |
dpkg --listfiles foo |
Cerca i pacchetti che si chiamano foo |
dnf list "foo" |
apt-cache search foo |
| Mostrare tutti i pacchetti disponibili | dnf list |
apt-cache dumpavail foo |
Di quale pacchetto fa parte un file? |
rpm -qf file |
dpkg --search file |
Video: Gestione Pacchetti Debian a Basso Livello con dpkg
Video: Gestione Pacchetti RPM a Basso Livello con rpm
Video: Gestione Pacchetti ad Alto Livello con dnf
Video: Gestione Pacchetti ad Alto Livello con zypper su openSUSE
Video: Gestione Pacchetti ad Alto Livello con apt su Ubuntu
Riepilogo del Capitolo
Hai completato il capitolo 7. riassumiamo i concetti chiave che abbiamo trattato:
- I terminali virtuali (VT) in Linux sono console o terminali della riga di comando che utilizzano il monitor e la tastiera connessi.
- Diverse distribuzioni Linux avviano e arrestano il desktop grafico in modi diversi.
- Un programma di emulatore del terminale sul desktop grafico funziona emulando un terminale all'interno di una finestra sul desktop.
- Il sistema Linux consente di accedere tramite terminale di testo o in remoto tramite la console.
- Quando si digita la password, nulla viene stampato sul terminale, nemmeno un simbolo generico per indicare che hai digitato.
- Il metodo preferito per chiudere o riavviare il sistema è utilizzare il comando shutdown.
- Esistono due tipi di nomi di percorso: assoluto e relativo.
- Un nome di percorso assoluto inizia con la directory radice e segue l'alberatura, ramo per ramo, fino a raggiungere la directory o il file desiderati.
- Un percorso relativo inizia dalla directory di lavoro corrente.
- L'uso di hard link e soft link (simbolici) è estremamente utile in Linux.
- cd ricorda la tua ultima posizione e ti riporta lì con
cd -. - locate esegue una ricerca in un database per trovare tutti i nomi di file dato un modello specificato.
- find trova i file ricorsivamente da una data directory o insieme di directory.
- find è in grado di eseguire comandi sui file che trova, se usato con l'opzione -exec .
- touch è usato per impostare data e ora di accesso o di modifica dei file, e per creare file vuoti.
- Il sistema di gestione di pacchetti apt (The Advanced Packaging Tool) è usato per gestire il software installato sui sistemi basati su Debian.
- Puoi usare l'utility da riga di comando per la gestione dei pacchetti dnf per le distribuzioni della famiglia Red Hat basate su RPM.
- Il sistema di gestione di pacchetti zypper è basato su RMP ed è usato dalla distribuzione openSUSE.

Capitolo 8: Trovare la Documentazione di Linux
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Utilizzare diverse fonti di documentazione.
- Usare le pagine del manuale.
- Accedere al Sistema Informativo GNU.
- Usare il comando help e l'opzione --help.
- Utilizzare altre fonti di documentazione.
Fonti di Documentazione di Linux
Che tu sia un utente inesperto o un veterano, non sempre saprai (né ricorderai) l'uso corretto di vari programmi e utility Linux, qual è il comando da digitare, quali opzioni impiega, ecc. Dovrai consultare la documentazione di aiuto regolarmente. Poiché i sistemi basati su Linux attingono da una grande varietà di fonti, ci sono numerose sorgenti di documentazione e modi per ottenere aiuto. I distributori consolidano questo materiale e lo presentano in modo completo e facile da usare.
Sorgenti di Documentazione Linux
Importanti fonti di documentazione Linux includono:
- Le pagine di manuale (man)
- GNU Info
- Il comando help e l'opzione --help
- Altre fonti di documentazione, ad esempio Il manuale di Gentoo e la Documentazione Ubuntu (in lingua inglese).
Le Pagine di Manuale
Le pagine di Manuale (man pages) sono la fonte più spesso usata della documentazione di Linux. Forniscono una documentazione approfondita su molti programmi e utility, nonché altri argomenti, inclusi file di configurazione e API di programmazione per chiamate di sistema, routine di libreria e il kernel. Sono presenti su tutte le distribuzioni Linux e sono sempre a portata di mano.
L'infrastruttura delle pagine di manuale è stata introdotta per la prima volta nelle prime versioni UNIX, all'inizio degli anni '70. Il nome man è solo un'abbreviazione per manual.

Digitando man con un nome come argomento si ottengono le informazioni conservate nelle pagine di manuale dell'argomento.
Le pagine di manuale vengono spesso convertite in altri formati, come documenti PDF e pagine web. Per saperne di più, dai un'occhiata alle pagine di manuale Linux online (in lingua inglese). Molte pagine web hanno un'interfaccia grafica per gli elementi di aiuto, che possono includere pagine di manuale.
Esiste anche una versione italiana delle pagine di manuale online curata dal progetto PLUTO - n.d.t.
Altre fonti di documentazione includono libri pubblicati e molti siti Internet.
man
Il programma man ricerca, formatta e visualizza le informazioni contenute nel sistema di pagine di manuale. Poiché molti argomenti hanno abbondanti quantità di informazioni pertinenti, il risultato viene convogliato attraverso un programma di paginazione (come less) per visualizzare una pagina alla volta. Allo stesso tempo, le informazioni sono formattate per un buon aspetto visivo.
Un determinato argomento può avere più pagine a esso associate ed esiste un ordine predefinito che determina quale viene visualizzata quando non viene specificata alcuna opzione o numero di sezione. Per elencare tutte le pagine sull'argomento, utilizzare l'opzione -f. Per elencare tutte le pagine che trattano di un argomento specifico (anche se il soggetto specificato non è presente nel nome), utilizzare l'opzione -k.
man –fequivale a digitarewhatis.man –kequivale a digitareapropos.
L'ordine predefinito è specificato in /etc/man_db.conf ed è approssimativamente (ma non esattamente) in ordine numerico ascendente per sezione.
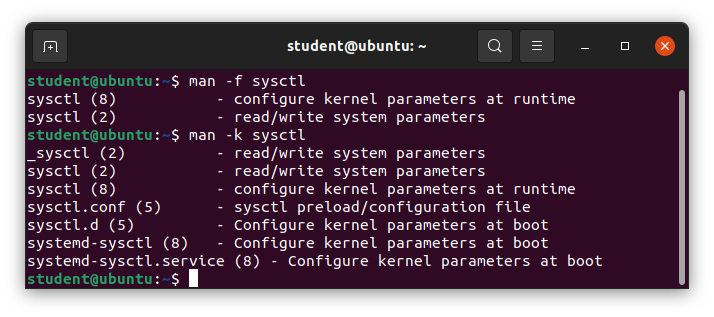
Capitoli del Manuale
Le pagine di manuale sono divise in capitoli numerati da 1 a 9. In alcuni casi, una lettera viene aggiunta al numero del capitolo per identificare un argomento specifico. Ad esempio, molte pagine che descrivono parte dell'API di X Window sono nel capitolo 3X.
Il numero del capitolo può essere usato per forzare il programma a visualizzare la pagina da un particolare capitolo. È comune avere più pagine su più capitoli con lo stesso nome, in particolare per i nomi delle funzioni della libreria o delle chiamate di sistema.
Con il parametro -a, man visualizzerà tutte le pagine con il nome specificato in tutti i capitoli, uno dopo l'altro, in questo modo:
$ man -a socket
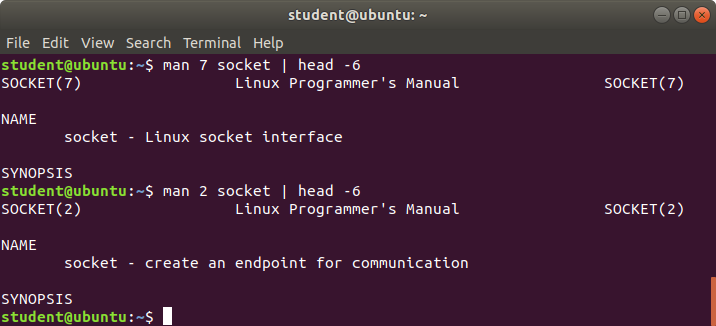
Video: Usare man
Il Sistema di Informazione GNU
La prossima fonte di documentazione di Linux è il Sistema di Informazione GNU (GNU Info System).
Questo è il formato di documentazione standard del progetto GNU, preferito come alternativa a man. Il sistema informativo è sostanzialmente in forma libera e supporta sottosezioni collegate.
Dal punto di vista funzionale, info assomiglia a man in molti modi. Tuttavia, gli argomenti sono connessi utilizzando link (anche se la sua progettazione precede il World Wide Web). Le informazioni possono essere visualizzate tramite un'interfaccia della riga di comando, un'utilità di aiuto grafico, stampate o visualizzate online.
Usare info dalla Riga di Comando
Digitando info senza argomenti in una finestra di terminale viene mostrato un indice di argomenti disponibili. È possibile sfogliare l'elenco degli argomenti usando i normali tasti di movimento: le frecce, PaginaSu e PaginaGiu.
Puoi visualizzare l'aiuto per un argomento particolare digitando info . Il sistema quindi cerca l'argomento in tutti i file info disponibili.
Alcuni tasti utili sono: q per uscire, h per aiuto, e Invio per selezionare una voce di menu.
Struttura di una Pagina info
L'argomento che visualizzi in una pagina di informazioni è chiamato nodo. La tabella elenca i tasti di base per lo spostamento tra i nodi.
I nodi sono essenzialmente sezioni e sottosezioni nella documentazione. È possibile spostarsi tra i nodi o visualizzare ciascun nodo in sequenza. Ogni nodo può contenere menu e sotto argomenti collegati, o elementi.
Gli elementi funzionano come i collegamenti del browser e sono identificati da un asterisco (*) all'inizio del nome dell'elemento. Gli elementi denominati (al di fuori di un menu) sono identificati con due simboli di due punti affiancati (::) alla fine del nome dell'elemento. Gli elementi possono fare riferimento ad altri nodi all'interno del file o ad altri file.
| Tasto | Funzione |
|---|---|
n |
Va al nodo successivo |
p |
Va al nodo precedente |
u |
Si sposta al nodo superiore nell'indice |
Video: Usare info
L'Opzione --help
Un'altra importante fonte di documentazione di Linux è l'uso dell'opzione --help.
La maggior parte dei comandi ha una descrizione breve disponibile che può essere visualizzata utilizzando l'opzione --help oppure -h assieme al comando o applicazione. Per esempio, per saperne di più circa il comando man puoi digitare:
$ man --help
L'opzione --help è utile come riferimento rapido e visualizza le informazioni più velocemente rispetto a man oppure info.
Il Comando Help
Quando eseguiti all'interno di una shell di comando bash, alcuni popolari comandi (come echo e cd) in realtà sono eseguiti con una versione specificamente integrata nelle versioni bash dei comandi, rispetto ai normali programmi binari trovati nel filesystem, diciamo sotto /bin o /usr/bin. È più efficiente fare in questo modo poiché l'esecuzione è più veloce perché vengono utilizzate meno risorse (discuteremo in seguito delle shell di comando). Si dovrebbe notare che ci possono essere alcune differenze (di solito piccole) nelle due versioni del comando.
Per visualizzare una sinossi di questi comandi integrati, puoi semplicemente digitare help come mostrato nella videata.
Per questi comandi integrati, help ha lo stesso effetto degli argomenti -h e --help per i programmi a sé stanti.
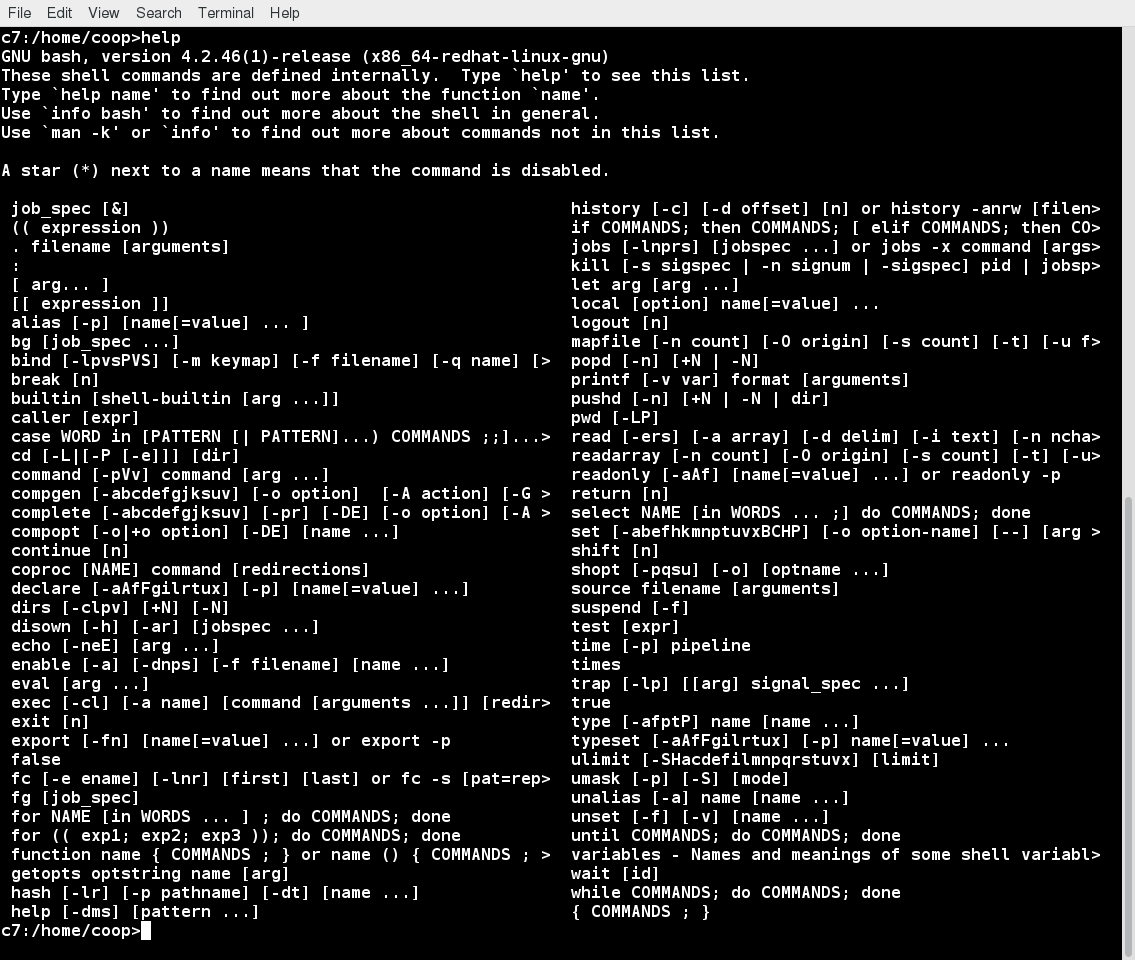
Altre Fonti di Documentazione
Oltre alle pagine di manuale, il sistema di informazione GNU e il comando help, ci sono altre fonti di documentazione Linux, tra le quali:
- Il sistema di help del Desktop
- La documentazione dei pacchetti
- Le risorse online
I sistemi di Aiuto Grafico
Tutti i sistemi desktop Linux hanno un'applicazione di aiuto grafico. Questa applicazione viene generalmente visualizzata come un'icona che rappresenta un punto interrogativo o un'immagine di un salvagente e può essere trovata anche all'interno del sistema di menu. Questi programmi di solito contengono un aiuto personalizzato per il desktop stesso e alcune delle sue applicazioni e talvolta includono anche versioni grafiche di info e delle pagine di manuale.
Se non si desidera dedicare del tempo a cercare l'icona o la voce di menu giusta per avviare l'applicazione di aiuto, è anche possibile avviare il sistema di aiuto grafico da una finestra del terminale o da un prompt dei comandi utilizzando uno dei seguenti programmi di utilità:
- GNOME: gnome-help o yelp
- KDE: khelpcenter
Documentazione dei Pacchetti
La documentazione di Linux è disponibile anche come parte del sistema di gestione dei pacchetti. Di solito, questa documentazione viene estratta direttamente dal codice sorgente a monte, ma può anche contenere informazioni su come la distribuzione è confezionata e sull'impostazione del software.
Tali informazioni sono posizionate nella directory /usr/share/doc, raggruppate in sottodirectory che prendono il nome da ciascun pacchetto, talvolta includendo il numero di versione nel nome.
Risorse Online
Ci sono molti luoghi per accedere alla documentazione di Linux online e con un po' di ricerca rimarrai facilmente sepolto dalle risorse.
Il seguente libro ha avuto buone recensioni da altri utenti di questo corso. È un compendio della riga di comando gratuito e scaricabile sotto una licenza Creative Commons: "The Linux Command Line" (in lingua inglese) di William Shotts.
Puoi anche trovare una documentazione molto utile per ogni distribuzione. Ogni distribuzione ha i suoi forum creati dagli utenti e sezioni wiki. Ecco solo alcuni collegamenti a tali fonti (in lingua inglese):
- Documentazione Ubuntu
- Documentazione CentoS
- Documentazione openSUSE
- Documentazione Gentoo
- Documentazione Fedora.
Inoltre, puoi utilizzare siti di ricerca online per individuare risorse utili da Internet, inclusi post di blog, forum e mailing list, articoli di notizie e così via.
Riepilogo del Capitolo
Hai completato il capitolo 8. riassumiamo i concetti chiave trattati:
- Le sorgenti principali della documentazione Linux sono le pagine di manuale, il Sistema di Informazione GNU, l'opzione --help, il comando help e una ricca varietà di fonti di documentazione online.
- L'utility man cerca, formatta e visualizza pagine di manuale.
- Le pagine di manuale forniscono una documentazione approfondita sui programmi e altri argomenti circa il sistema, compresi i file di configurazione, le chiamate di sistema, le routine di libreria e il kernel.
- Il sistema di Informazione GNU (GNU Info System) fu creato dal progetto GNU come sua documentazione standard. È robusto e accessibile da riga di comando, web e strumenti grafici usando il programma info.
- Brevi descrizioni dei comandi sono in genere visualizzate con l'argomento -h oppure --help .
- Puoi digitare help alla riga di comando per visualizzare una sinossi dei comandi integrati.
- Ci sono molte altre risorse di aiuto sia sul tuo sistema che su Internet.

Capitolo 9: Processi
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Descrivere cosa è un processo e distinguere tra tipi di processi.
- Elencare gli attributi di processo.
- Gestire i processi utilizzando ps e top.
- Comprendere l'uso di medie di carico e altre metriche di processo.
- Manipolare i processi mettendoli in background e ripristinandoli in primo piano.
- Usare at, cron e sleep per pianificare processi nel futuro o metterli in pausa.
Cos'è un Processo?
Un processo è semplicemente un'istanza di una o più attività correlate (thread) in esecuzione sul tuo computer. Non è lo stesso di un programma o di un comando. Un singolo comando può in effetti avviare diversi processi contemporaneamente. Alcuni processi sono indipendenti l'uno dall'altro e altri sono correlati. Un fallimento di un processo può o meno influire sugli altri processi in esecuzione sul sistema.
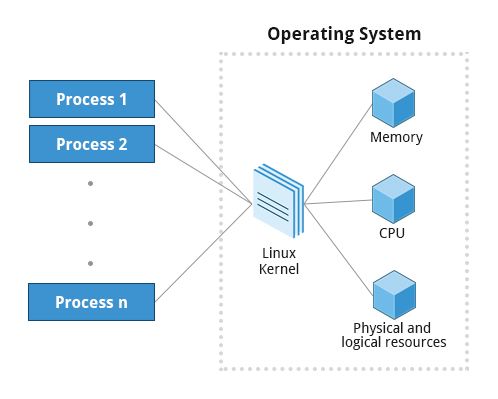
I processi utilizzano molte risorse di sistema, come memoria, cicli CPU (unità di elaborazione centrale) e dispositivi periferici, come schede di rete, dischi rigidi, stampanti e monitor. Il sistema operativo (in particolare il kernel) è responsabile dell'allocazione di una quota adeguata di queste risorse a ciascun processo e di garantire l'utilizzo ottimizzato generale del sistema.
Tipi di processo
Una finestra di un terminale (un tipo di shell di comando) è un processo che funziona finché è necessario. Consente agli utenti di eseguire programmi e accedere alle risorse in un ambiente interattivo. Puoi anche eseguire programmi in background, il che significa che vengono distaccati dalla shell.
I processi possono essere di diversi tipi in base all'attività che viene eseguita. Ecco alcuni diversi tipi di processo, insieme alle loro descrizioni ed esempi:
| Tipo Processo | Descrizione | Esempio |
|---|---|---|
| Processi Interattivi | Devono essere avviati da un utente, sia da riga di comando che da un'interfaccia grafica come un'icona o la selezione da un menu. | bash, firefox, top |
| Processi Batch | Processi automatici che sono pianificati da terminale, poi da esso staccati. Queste attività sono accodate e lavorano su un sistema a base FIFO(First-In,First-Out). | updatedb, ldconfig |
| Demoni | Processi server che sono sempre in esecuzione. Molti sono lanciati durante l'avvio del sistema, per poi attendere che un utente o il sistema gli indichi che il loro servizio è richiesto. | httpd, sshd, libvirtd |
| Thread | Processi leggeri. Queste sono attività in esecuzione sotto il controllo di un processo principale, condividendo memoria e altre risorse, ma sono pianificate ed eseguite dal sistema su base individuale. Un thread singolo può terminare senza che l'intero processo sia terminato, e un processo può creare nuovi thread in qualunque momento. Molti programmi non semplici sono multi-thread. | firefox, gnome-terminal-server |
| Thread del Kernel | Le attività del kernel per le quali gli utenti hanno poco controllo e non possono né avviare né fermare. Queste potrebbero eseguire azioni come spostare un thread da una CPU a un'altra, oppure assicurarsi che le operazioni di input/output da/verso disco siano completate. | kthreadd, migration, ksoftirqd |
Pianificazione e Stati di un Processo
Una funzione di kernel critica chiamata scheduler sposta costantemente i processi dentro e fuori la CPU, condividendo il tempo in base alla priorità relativa, quanto tempo è necessario e quanto è già stato concesso a un'attività.
Quando un processo si trova in un cosiddetto stato di esecuzione (running), significa che sta attualmente eseguendo le istruzioni su una CPU, o sta aspettando che gli venga concessa una quota di tempo in modo da poterle eseguire. Tutti i processi in questo stato risiedono in quella che viene chiamata coda di esecuzione e su un computer con più CPU o core, c'è una coda di esecuzione ciascuna.
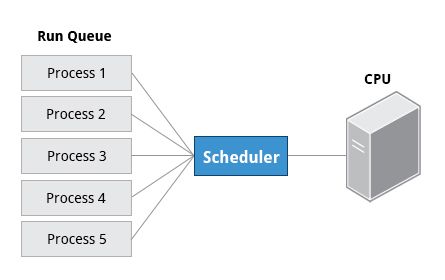
Tuttavia, a volte i processi vanno in quello che viene chiamato stato di sonno (sleep), in generale quando aspettano che accada qualcosa prima che possano riprendere, ad esempio che l'utente digiti qualcosa. In questa condizione, si dice che un processo si trova in una coda di attesa.
Esistono altri stati di processo meno frequenti, soprattutto quando un processo sta terminando. A volte viene completato un processo figlio, ma il suo processo genitore non ha chiesto del suo stato. In modo divertente, si dice che un tale processo sia in uno stato zombie; non è davvero vivo, ma si presenta ancora nell'elenco dei processi del sistema.
Processi e IDentificativi del Thread
In qualsiasi momento, ci sono sempre diversi processi in esecuzione. Il sistema operativo ne tiene traccia assegnando a ciascun un numero identificativo di processo univoco (PID). Il PID viene utilizzato per tracciare lo stato del processo, l'utilizzo della CPU, l'uso della memoria, il punto preciso nella memoria dove le risorse si trovano e altre caratteristiche.
I nuovi PID sono generalmente assegnati in ordine crescente man mano che nascono i processi. Pertanto, il PID 1 indica il processo init (processo di inizializzazione) e ai processi successivi vengono gradualmente assegnati numeri più elevati.
La tabella spiega i tipi PID e le loro descrizioni:
| Tipo ID | Descrizione |
|---|---|
| ID di Processo (PID) | Numero ID di Processo univoco |
| ID di Processo Genitore (PPID) | Il processo (genitore) che ha fatto partire questo processo. Se il genitore muore, il PPID viene fatto puntare verso un genitore adottivo; sui kernel recenti, questo è il kthreadd che ha PPID=2. |
| ID del Thread (TID) | Numero di ID del thread. È lo stesso del PID per un processo a thread singolo. Per processi multi thread, ciascun thread condivide lo stesso PID, ma ha un TID univoco. |
Terminare un Processo
Ad un certo punto, una delle tue applicazioni potrebbe smettere di funzionare correttamente. Come la elimini?
Per interrompere un processo, è possibile digitare kill -SIGKILL <pid> oppure kill -9 <pid>.
Nota, tuttavia, puoi solo uccidere i tuoi processi; quelli appartenenti a un altro utente sono vietati, a meno che tu non sia root.
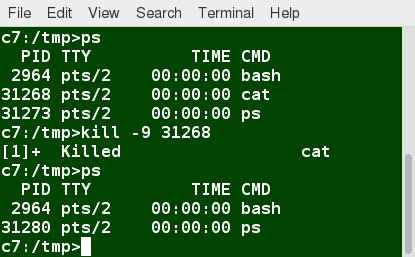
IDentificativi di Utenti e Gruppi
Molti utenti possono accedere a un sistema contemporaneamente e ogni utente può eseguire più processi. Il sistema operativo identifica l'utente che avvia il processo tramite l'ID Utente Reale - Real User ID (RUID) - assegnato all'utente.
L'utente che determina i diritti di accesso per gli utenti è identificato dall'UID effettivo (EUID). L'EUID può o meno essere uguale al RUID.
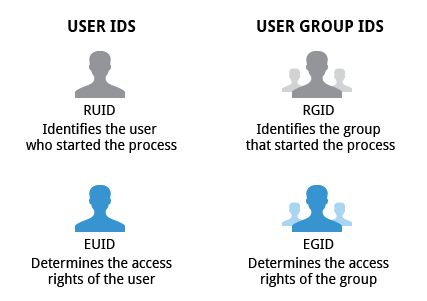
Gli utenti possono essere classificati in vari gruppi. Ogni gruppo è identificato dall'ID Gruppo Reale - Real Group ID (RGID). I diritti di accesso del gruppo sono determinati dall'ID Gruppo Effettivo (EGID). Ogni utente può essere membro di uno o più gruppi.
Il più delle volte ignoriamo questi dettagli e parliamo semplicemente dell'ID utente (UID) e dell'ID del Gruppo (GID).
Maggiori Informazioni sulle Priorità
In un dato momento, molti processi sono in esecuzione (cioè nella coda di esecuzione) sul sistema. Tuttavia, una CPU può effettivamente ospitare solo un'attività alla volta, proprio come un'auto può avere un solo guidatore alla volta. Alcuni processi sono più importanti di altri, quindi Linux consente di impostare e manipolare la priorità del processo. Processi con priorità più elevata ottengono un accesso preferenziale alla CPU.
La priorità per un processo può essere impostata specificando un valore (nice value o niceness) per il processo. Più basso è il valore, maggiore è la priorità. I valori bassi sono assegnati a processi importanti, mentre i valori alti sono assegnati a processi che possono attendere più a lungo. Un processo con un valore elevato consente semplicemente che vengano eseguiti prima altri processi. In Linux, un valore di -20 rappresenta la priorità più alta e +19 rappresenta la più bassa. Sebbene ciò possa sembrare controintuitivo, questa convenzione (valore del processo più alto, minore priorità) risale ai primi giorni di Unix.

Puoi anche assegnare una cosiddetta priorità in tempo reale ad attività che richiedono urgenza, come il controllo delle macchine attraverso un computer o la raccolta di dati in arrivo. Questa è solo una priorità molto alta e non deve essere confusa con ciò che viene chiamato "hard real time", che è concettualmente diverso e ha più a che fare con l'assicurarsi che un lavoro venga completato in una finestra temporale molto ben definita.
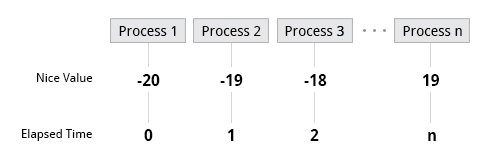
Video: Usare renice per Impostare Priorità
Medie di Carico
La media di carico (load average) è la media del valore di carico per un determinato periodo di tempo. Tiene conto dei processi che sono:
- Attivamente in esecuzione su una CPU.
- Considerati eseguibili (runnable), ma in attesa che una CPU sia disponibile.
- Dormienti: cioè in attesa che sia disponibile una sorta di risorsa (in genere, I/O).
NOTA: Linux differisce da altri sistemi operativi simili a Unix in quanto include i processi dormienti. Inoltre, include solo i cosiddetti dormienti ininterrotti, quelli che non possono essere risvegliati facilmente.
La media di carico può essere visualizzata eseguendo w, top oppure uptime. Spiegheremo i numeri nella sezione successiva.
Interpretare le Medie di Carico
La media di carico è visualizzata usando tre numeri (0.45, 0.17 e 0.12) nella videata seguente. Ipotizzando che il nostro sistema sia a CPU singola, i tre numeri della media di carico sono da interpretare come segue:
- 0.45: Durante l'ultimo minuto, il sistema è stato utilizzato in media per il 45%.
- 0.17: Durante gli ultimi 5 minuti l'utilizzo è stato del 17%.
- 0.12: Durante gli ultimi 15 minuti l'utilizzo è stato del 12%.
Se vedessimo un valore di 1,00 nella seconda posizione, ciò implicherebbe che il sistema a CPU singola è stato utilizzato al 100%, in media, negli ultimi 5 minuti; questo va bene se vogliamo utilizzare completamente un sistema. Un valore superiore a 1,00 per un sistema a CPU singola implica che il sistema è stato sovrautilizzato: c'erano più processi che necessitavano di CPU rispetto alla sua disponibilità.
Se avessimo più di una CPU, ad esempio un sistema con quattro CPU, divideremmo i numeri medi di carico per il numero di CPU. In questo caso, ad esempio, vedere una media di carico per 1 minuto di 4,00 implica che il sistema nel suo insieme è stato utilizzato al 100% (4,00/4) durante l'ultimo minuto.
Gli aumenti a breve termine di solito non sono un problema. Un picco elevato che vedi è probabilmente un aumento improvviso delle attività, non un nuovo livello. Ad esempio, all'avvio, molti processi partono, poi l'attività si stabilizza. Se si osserva un picco elevato nelle medie di carico a 5 e 15 minuti, potrebbe essere motivo di preoccupazione.
Processi in Primo Piano e in Background
Linux supporta l'elaborazione di attività (job) in background e in primo piano. Un attività in questo contesto è solo un comando lanciato da una finestra del terminale. Le attività in primo piano sono eseguite direttamente dalla shell e quando un'attività in primo piano è in esecuzione, altre attività devono attendere per accedere alla shell (almeno in quella finestra del terminale se si utilizza la GUI), fino al completamento. Questo va bene quando le attività si completano rapidamente. Ma questo può avere un effetto negativo se l'attuale attività richiederà molto tempo (anche diverse ore) per essere completata.
In tali casi, è possibile eseguire l'attività in background e liberare la shell per altri compiti. L'attività in background verrà eseguita con una priorità inferiore, che, a sua volta, consentirà un'esecuzione regolare delle attività interattive e potrai digitare altri comandi nella finestra del terminale mentre l'attività in background è in esecuzione. Per impostazione predefinita, tutte le attività vengono eseguite in primo piano. Puoi mettere un attività in background aggiungendo & al comando, per esempio: updatedb &.
Puoi utilizzare sia CTRL-Z per sospendere un'attività in primo piano oppure CTRL-C per terminare un'attività in primo piano, e puoi sempre usare i comandi bg e fg per eseguire un processo in background o in primo piano rispettivamente.
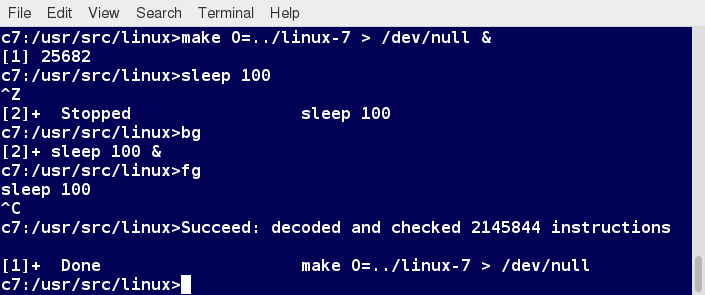
Gestire le Attività
L'utility jobs visualizza tutte le attività in esecuzione in background. Viene visualizzato l'ID dell'attività, lo stato e il nome del comando, come mostrato nella videata qui sotto.
jobs -l fornisce le stesse informazioni di jobs, e aggiunge il PID delle attività in background.
Le attività in background sono connesse alla finestra del terminale, quindi se ti disconnetti, l'utility jobs non mostrerà le attività avviate in quella finestra.
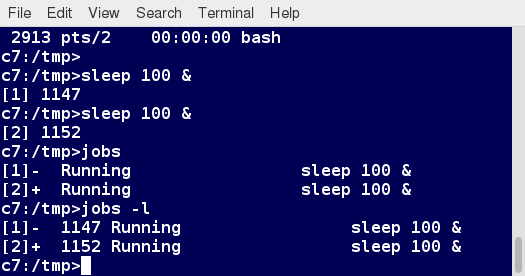
Il Comando ps (Stile System V)
ps fornisce informazioni sui processi attualmente in esecuzione identificati dal PID. Se desideri un aggiornamento ripetitivo di questo stato, puoi usare top o altre varianti comunemente installate (come htop oppure atop) dalla riga di comando, oppure lanciare l'applicazione grafica di monitoraggio del sistema della tua distribuzione.
ps ha molte opzioni per specificare esattamente quali attività esaminare, quali informazioni visualizzare su di esse ed esattamente quale formato di output dovrebbe essere utilizzato.
Senza opzioni, ps visualizzerà tutti i processi in esecuzione nella shell corrente. Puoi usare l'opzione -u per visualizzare le informazioni sui processi per un specifico username. Il comando ps -ef visualizza tutti i processi nel sistema in dettaglio. Il comando ps -eLf compie un passo ulteriore e visualizza una riga di informazione per ciascun thread (ricorda, un processo può contenere più thread).
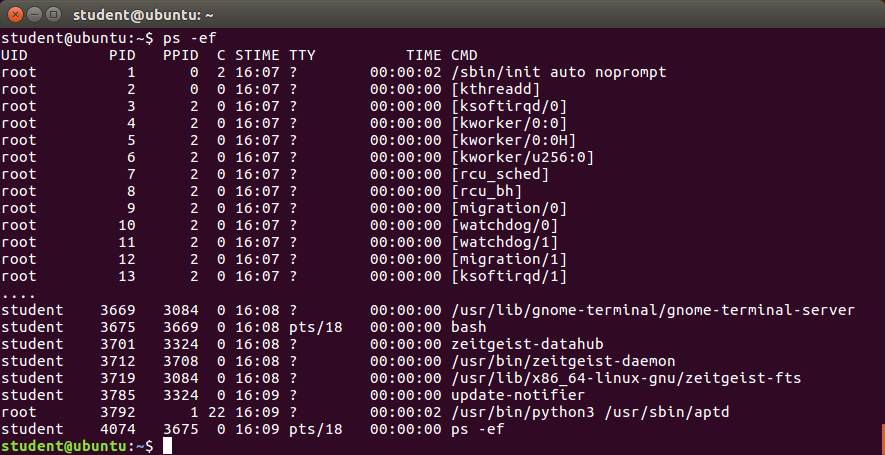
Il Comando ps (Stile BSD)
ps ha un altro stile per specificare delle opzioni, che deriva dalla varietà BSD di UNIX, in cui le opzioni sono specificate senza trattini che le precedono. Ad esempio, il comando ps aux visualizza tutti i processi di tutti gli utenti. Il comando ps axo consente di specificare quali attributi si desidera visualizzare.
La videata mostra una visualizzazione campione di ps con le opzioni aux e axo.
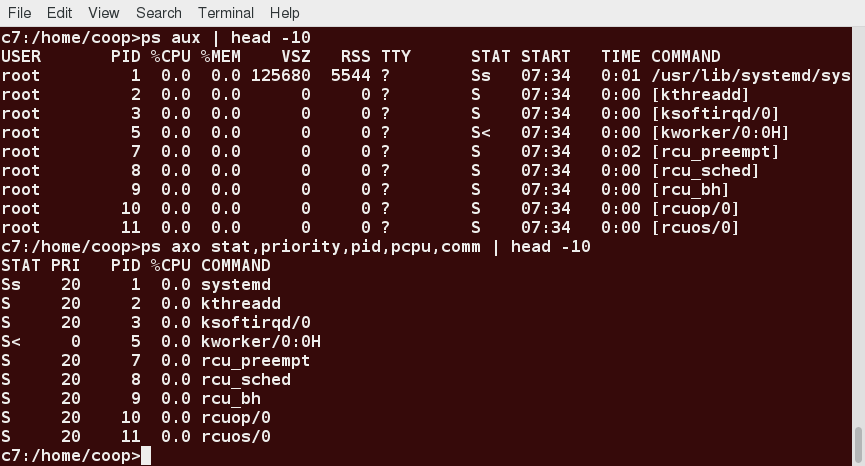
Video: Usare ps
L'albero dei Processi
pstree visualizza i processi in esecuzione sul sistema sotto forma di un diagramma ad albero che mostra la relazione tra un processo e il suo processo genitore e qualsiasi altro processo che ha creato. Le voci ripetute di un processo non vengono visualizzate e i thread vengono visualizzati tra parentesi graffe.
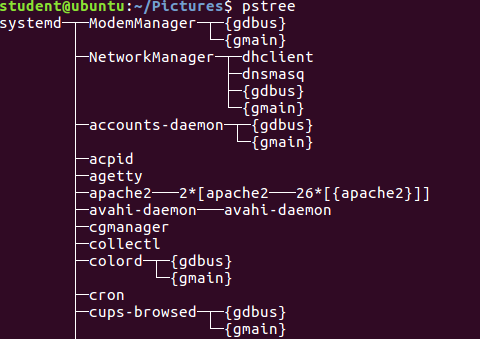
top
Mentre è utile una visione statica di ciò che il sistema sta facendo, è importante anche monitorare le prestazioni del sistema nel tempo. Un'opzione sarebbe quella di eseguire ps a intervalli regolari, diciamo ogni pochi secondi. Un'alternativa migliore è utilizzare il comando top per ottenere aggiornamenti costanti in tempo reale (ogni due secondi per impostazione predefinita), fino a quando non si esce digitando q. top evidenzia chiaramente quali processi stanno consumando il maggior numero di cicli CPU e memoria (usando gli appropriati comandi all'interno di top).
Prima Riga dell'Output di top
La prima riga dell'output di top mostra un breve riepilogo di ciò che sta accadendo nel sistema, tra cui:
- Da quanto tempo il sistema è in esecuzione
- Quanti utenti sono attualmente connessi
- Quale è la media di carico
La media di carico determina quanto sia occupato il sistema. Una media di carico di 1,00 per CPU indica un sistema completamente occupato, ma non in sovraccarico. Se la media del carico supera questo valore, indica che i processi sono in competizione per il tempo della CPU. Se la media del carico è molto elevata, potrebbe indicare che il sistema ha un problema, come un processo "runaway" (fuggitivo - un processo in uno stato non rispondente).
Seconda Riga dell'Output di top
La seconda riga dell'output di top visualizza il numero totale di processi, il numero di processi in esecuzione, dormienti, fermati e zombie. Il confronto del numero di processi di esecuzione con la media di carico aiuta a determinare se il sistema ha raggiunto la sua capacità o forse un determinato utente sta eseguendo troppi processi. I processi fermati dovrebbero essere esaminati per vedere se tutto è correttamente in esecuzione.
Terza Riga dell'Output di top
La terza riga dell'output di top indica come il tempo della CPU viene diviso tra gli utenti (us) e il kernel (sy) visualizzando la percentuale di tempo della CPU utilizzata per ciascuno.
Viene quindi elencata la percentuale di attività utente in esecuzione con una priorità inferiore (niceness - ni). La modalità inattiva (id) deve essere bassa se la media di carico è alta e viceversa. È elencata la percentuale di attività in attesa (wa) per I/O. Gli interrupt includono la percentuale di hardware (hi) rispetto agli interrupt software (si). Il tempo rubato (st) è generalmente utilizzato con le macchine virtuali, che hanno parte del loro tempo di inattività della CPU occupato per altri usi.
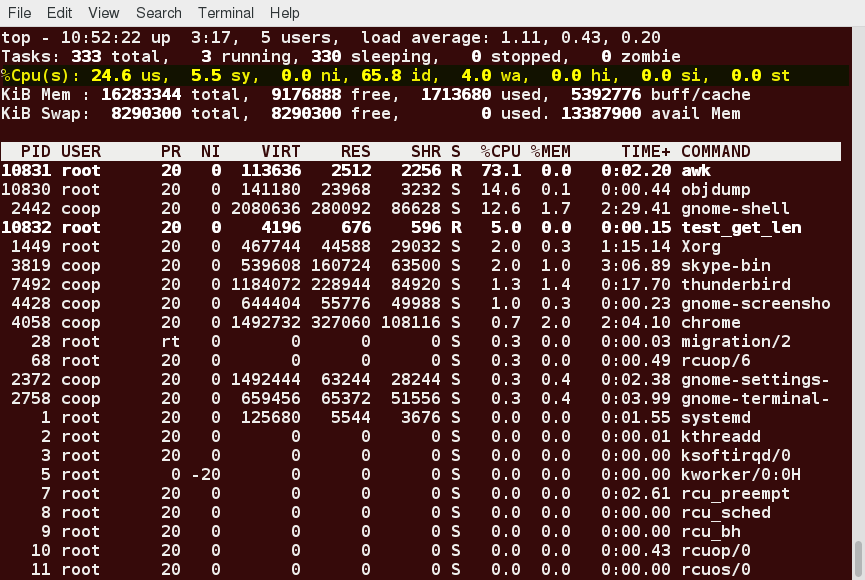
Quarta e Quinta Riga dell'Output di top
La quarta e la quinta riga dell'output di top indicano l'utilizzo della memoria, che è diviso in due categorie:
- Memoria fisica (RAM) - visualizzata sulla riga 4.
- Spazio di swap - visualizzato sulla riga 5.
Entrambe le categorie visualizzano la memoria totale, la memoria utilizzata e lo spazio libero.
È necessario monitorare l'utilizzo della memoria con molta attenzione per garantire buone prestazioni del sistema. Una volta esaurita la memoria fisica, il sistema inizia utilizzando lo spazio di swap (spazio di archiviazione temporaneo sul disco rigido) come un pool di memoria esteso e poiché l'accesso al disco è molto più lento dell'accesso alla memoria, ciò influenzerà negativamente le prestazioni del sistema.
Se il sistema inizia a utilizzare spesso lo swap, è possibile aggiungere più spazio di swap. Tuttavia, dovrebbe essere considerata anche l'aggiunta di più memoria fisica.
Elenco dei Processi nell'Output di top
Ogni riga nell'elenco dei processi dell'output di top visualizza informazioni su un processo. Per impostazione predefinita, i processi sono ordinati per maggiore utilizzo della CPU. Vengono visualizzate le seguenti informazioni su ciascun processo:
- Numero di identificazione del processo (PID)
- Proprietario del processo (USER)
- Priorità (PR) e valori nice (NI)
- Memoria virtuale (VIRT), fisica (RES) e condivisa (SHR)
- Stato (S)
- Percentuale di CPU (%CPU) e memoria (%MEM) usata
- Tempo in escuzione (TIME+)
- Comando (COMMAND).
Tasti Interattivi con top
Oltre a visualizzare informazioni, top può essere utilizzato in modo interattivo per il monitoraggio e il controllo dei processi. Mentre top è in esecuzione in una finestra del terminale, è possibile inserire comandi costituiti da una singola lettera per modificarne il comportamento. Ad esempio, è possibile visualizzare i processi di livello più alto in base all'utilizzo della CPU o della memoria. Se necessario, è possibile modificare le priorità dell'esecuzione dei processi oppure è possibile fermare/uccidere un processo.
La tabella elenca cosa succede quando si premono vari tasti quando si esegue top:
| Commndo | Risultato |
|---|---|
t |
Visualizza o nasconde informazioni di riepilogo (righe 2 e 3) |
m |
Visualizza o nasconde informazioni sulla memoria (righe 4 e 5) |
A |
Ordina l'elenco dei processi rispetto al maggior consumo di risorse |
r |
Esegue il comando renice (modifica la priorità) di un processo specifico |
k |
Uccide un processo specifico |
f |
Entra nella schermata di configurazione di top |
o |
Seleziona interattivamente un nuovo ordinamento dell'elenco dei processi |
Video: Uso di top
Video: Uso del Sistema di Monitoraggio
Pianificare Processi Futuri Usando at
Supponi di dover svolgere un'attività in un giorno specifico in futuro. Tuttavia, sai che sarai lontano dalla macchina in quel giorno. Come eseguirai l'attività? È possibile utilizzare il programma di utilità at per eseguire qualsiasi comando non interattivo in un momento specificato, come illustrato nella seguente videata:
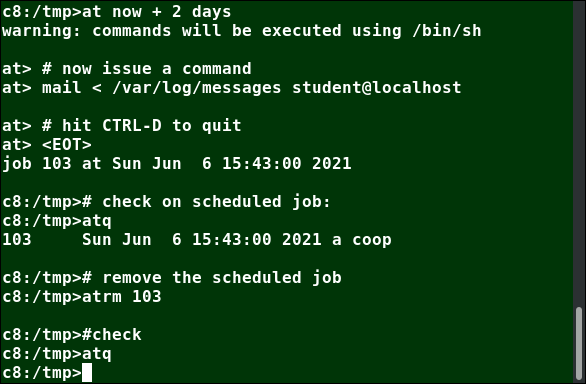
cron
cron è un programma di utilità di pianificazione temporale. Può lanciare lavori di routine in background in momenti specifici e/o giorni su base continuativa. cron è guidato da un file di configurazione chiamato /etc/crontab (tabella cron), che contiene i vari comandi di shell che devono essere eseguiti nei tempi adguatamente programmati. Ci sono file crontab sia a livello di sistema che per utente. Ogni riga di un file crontab rappresenta un'attività (job), ed è composto dalla cosiddetta espressione CRON, seguita dal comando di shell da eseguire.
Digitando crontab -e verrà aperto l'editor di crontab per modificare attività esistenti oppure per crearne di nuove. Ciascuna riga nel file crontab conterrà sei campi:
| Campo | Descrizione | Valori |
|---|---|---|
| MIN | Minuti | da 0 a 59 |
| HOUR | Ore | da 0 a 23 |
| DOM | Giorno del Mese | 1-31 |
| MON | Numero del Mese | 1-12 |
| DOW | Giorno della Settimana | 0-6 (0 = Domenica) |
| CMD | Comando | Qualunque comando da eseguire |
Esempi:
- La voce
* * * * * /usr/local/bin/execute/this/script.shpianificherà l'attività di esecuzione discript.shogni minuto di ogni ora di ogni giorno del mese, per ogni mese e per ogni giorno della settimana. - La voce
30 08 10 06 * /home/sysadmin/full-backuppianificherà una copia di salvataggio completa (full-backup) alle 8.30 della mattina del 10 giugno, a prescindere dal giorno della settimana.
sleep
A volte, un comando o un'attività devono essere ritardati o sospesi. Supponi, ad esempio, che un'applicazione abbia letto ed elaborato il contenuto di un file di dati e quindi debba salvare un rapporto su un sistema di backup. Se il sistema di backup è attualmente occupato o non disponibile, l'applicazione può essere messa a "dormire" (messa in attesa) fino a quando non può completare il suo lavoro. Tale ritardo potrebbe essere quello di montare il dispositivo di backup e prepararlo per la scrittura.
sleep sospende l'esecuzione per almeno il periodo di tempo specificato, che può essere fornito come numero di secondi (il valore predefinito), minuti, ore o giorni. Dopo che è passato quel tempo (o è stato ricevuto un segnale di interruzione), l'esecuzione riprenderà.
La sintassi è:
sleep NUMERO[SUFFISSO]...
dove SUFFISSO potrebbe essere:
sper i secondi (predefinito)mper i minutihper le oredper i giorni.
sleep e at sono abbastanza diversi; sleep ritarda l'esecuzione per un dato periodo, mentre at inizia l'esecuzione in un tempo futuro.
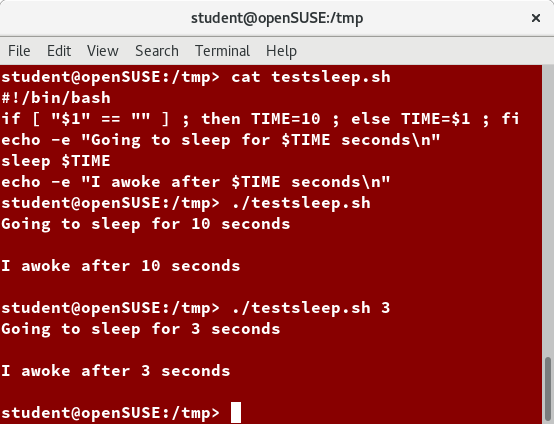
Riepilogo del Capitolo
Hai completato il capitolo 9. Riassumiamo i concetti chiave trattati:
- I processi vengono utilizzati per eseguire varie attività sul sistema.
- I processi possono essere a thread singolo o multi-thread.
- I processi possono essere di diversi tipi, come interattivi e non interattivi.
- Ogni processo ha un identificatore univoco (PID) per consentire al sistema operativo di tenerne traccia.
- Il valore "nice", o "niceness", può essere utilizzato per stabilire la priorità.
- ps fornisce informazioni sui processi attualmente in esecuzione.
- Puoi utilizzare top per ottenere aggiornamenti costanti in tempo reale sulle prestazioni complessive del sistema, nonché informazioni sui processi in esecuzione sul sistema.
- La media di carico indica la quantità di utilizzo del sistema durante un certo lasso di tempo.
- Linux supporta l'elaborazione in background e in primo piano per un'attività.
- at esegue qualsiasi comando non interattivo a un orario specificato.
- cron viene utilizzato per pianificare le attività che devono essere eseguite a intervalli regolari.

Capitolo 10: Operazioni sui File
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Esplorare il filesystem e la sua gerarchia.
- Spiegare l'architettura del filesystem.
- Confrontare i file e identificare diversi tipi di file.
- Eseguire il backup e comprimere i dati.
Introduzione al Filesystem
In Linux (e tutti i sistemi operativi simili a UNIX) si dice spesso "tutto è un file", o almeno è trattato come tale. Ciò significa che quando lavori con file di dati e documenti normali oppure con dispositivi come schede audio e stampanti, interagisci con loro attraverso lo stesso tipo di operazioni di input/output (I/O). Questo semplifica le cose: apri un "file" ed esegui operazioni normali come leggerlo e scrivere su di esso (che è uno dei motivi per cui gli editor di testo, che imparerai in una prossima sezione, sono così importanti).
Su molti sistemi (incluso Linux), il filesystem è strutturato come un albero. L'albero è di solito ritratto rovesciato e inizia da quella che viene generalmente chiamata directory root, che segna l'inizio della gerarchia del filesystem e talvolta viene anche detta tronco, o semplicemente indicata da '/'. La directory root non è lo stessa cosa dell'utente root. La gerarchia del filesystem contiene anche altri elementi nel percorso (nomi delle directory), che sono separati da barre oblique (/), come in /usr/bin/emacs, dove l'ultimo elemento è il nome effettivo del file.
In questa sezione, imparerai alcuni concetti di base, tra cui la gerarchia del filesystem, nonché le partizioni del disco.
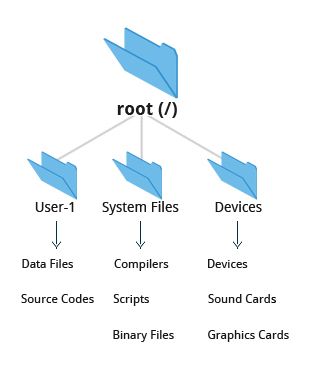
Varietà di Filesystem
Linux supporta una serie di tipi di filesystem nativi, espressamente creati dagli sviluppatori Linux, come:
- ext3
- ext4
- squashfs
- btrfs
Offre anche implementazioni di filesystem utilizzati su altri sistemi operativi non nativi, come quelli di:
- Windows (ntfs, vfat)
- SGI (xfs)
- IBM (jfs)
- MacOS (hfs, hfs+)
Sono supportati anche molti filesystem più vecchi e legacy, come FAT.
Spesso è vero che più di un tipo di filesystem viene utilizzato su una macchina, in base a considerazioni come la dimensione dei file, quanto spesso sono modificati, su quale tipo di hardware risiedono, quale tipo di velocità di accesso è necessaria, ecc. I tipi più avanzati di filesystem di uso comune sono le varietà journaling: ext4, xfs, btrfs e jfs. Questi hanno molte caratteristiche all'avanguardia e alte prestazioni e sono molto difficili da corrompere accidentalmente.
Partizioni Linux
Ogni filesystem su un sistema Linux occupa una partizione di disco. Le partizioni aiutano a organizzare il contenuto dei dischi in base al tipo e all'uso dei dati contenuti. Ad esempio, programmi importanti richiesti per eseguire il sistema vengono spesso mantenuti su una partizione separata (nota come root o /) rispetto a quella che contiene file di proprietà di utenti normali di quel sistema (/home). Inoltre, i file temporanei creati e distrutti durante il normale funzionamento di Linux possono essere posizionati su partizioni dedicate. Un vantaggio di questo tipo di isolamento per tipo e variabilità è che quando tutto lo spazio disponibile su una particolare partizione è esaurito, il sistema può ancora funzionare normalmente.
L'immagine mostra l'uso dell'utilità gparted, che visualizza la disposizione delle partizioni su un sistema che ha quattro sistemi operativi: RHEL 8, CentOS 7, Ubuntu e Windows.
Punti di Montaggio
Prima di poter iniziare a utilizzare un filesystem, devi montarlo sull'albero del filesystem in un punto di montaggio. Questo è semplicemente una directory (che può o meno essere vuota) nella quale il filesystem deve essere innestato. A volte, potrebbe essere necessario creare la directory se non esiste già.
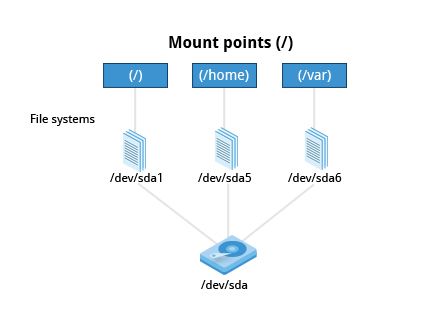
AVVERTIMENTO: se si monta un filesystem su una directory non vuota, il contenuto precedente di tale directory è coperto e non é accessibile fino a quando il filesystem non viene smontato. Pertanto, i punti di montaggio sono generalmente directory vuote.
Montare e Smontare
Il comando mount viene utilizzato per innestare un filesystem (che può essere locale al computer o su una rete) da qualche parte all'interno dell'albero del filesystem. Gli argomenti di base sono il device node (nodo di dispositivo) e il punto di montaggio. Per esempio,
$ sudo mount /dev/sda5 /home
innesterà il filesystem contenuto nella partizione di disco associato al nodo di dispositivo /dev/sda5 nell'albero del filesystem nel punto di montaggio /home. Esistono altri modi per specificare la partizione oltre che dal nodo di dispositivo, come usare l'etichetta del disco o dell'UUID.
Per smentare la partizione, il comando sarà:
$ sudo umount /home
Nota che il comando è umount, non unmount! Solo un utente di root (connesso come root o usando sudo) ha il privilegio di eseguire questi comandi, a meno che il sistema non sia stato configurato altrimenti.
Se vuoi che sia automaticamente disponibile ogni volta che il sistema si avvia, devi modificare di conseguenza il file /etc/fstab (il nome è l'abbreviazione di filesystem table - tabella del filesystem). Se visualizzi questo file ti mostrerà la configurazione di tutti i filesystem preconfigurati. man fstab ti mostrerà come viene utilizzato questo file e come configurarlo.
L'esecuzione di mount senza alcun argomento mostrerà tutti i filesystem attualmente montati.
Il comando df -Th (disk-free - spazio libero su disco) visualizzerà informazioni sui filesystem montati, incluso il tipo di filesystem e le statistiche di utilizzo sullo spazio attualmente utilizzato e di quello disponibile.
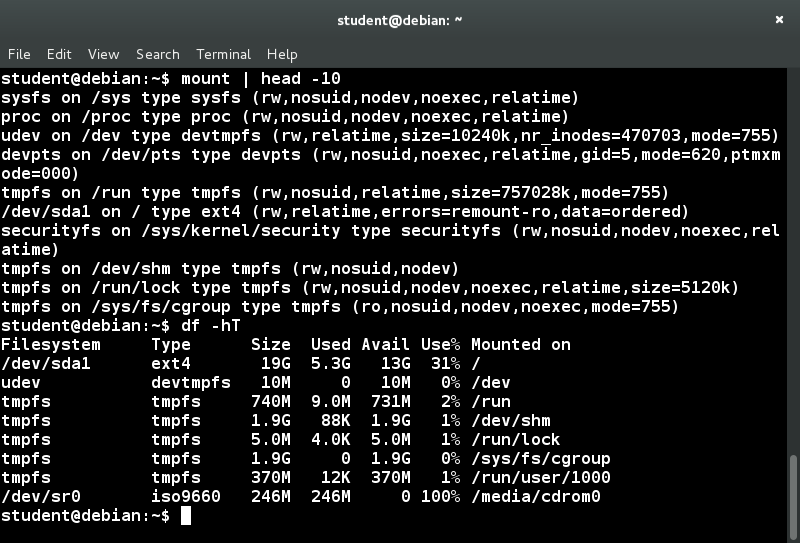
I filesystem NFS e di Rete
È spesso necessario condividere i dati tra sistemi fisici che possono essere nella stessa posizione o ovunque possano essere raggiunti da Internet. Un filesystem di rete (a volte detto anche distribuito) può avere tutti i suoi dati su una macchina o diffonderlo su più di un nodo di rete. Una varietà di filesystem diversi può essere utilizzata localmente sulle singole macchine; un filesystem di rete può essere pensato come un raggruppamento di filesystem di basso livello di vari tipi.
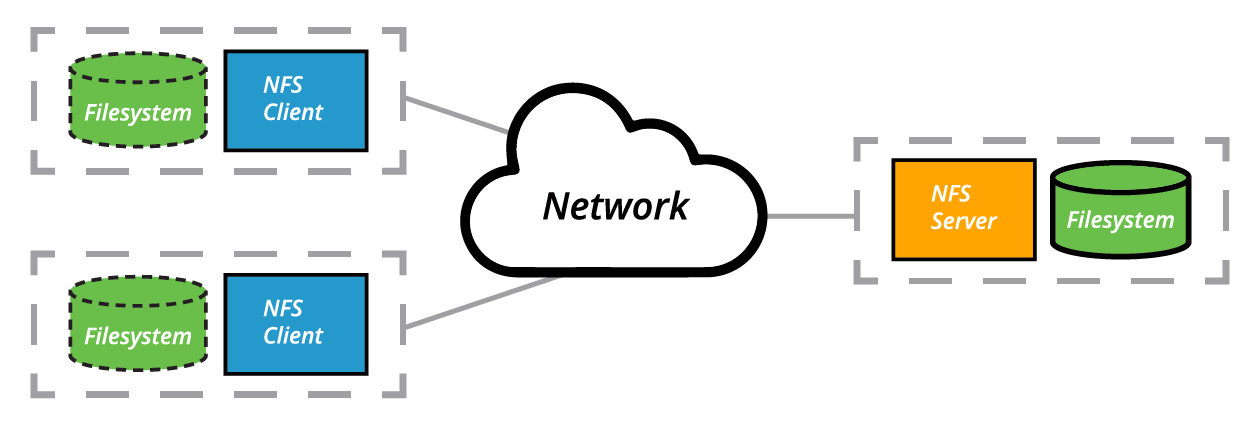
Molti amministratori di sistema montano le directory home degli utenti remoti su un server per consentire loro di accedere agli stessi file e file di configurazione su più sistemi client. Ciò consente agli utenti di accedere da computer diversi, pur avendo ancora accesso agli stessi file e risorse.
Il più comune di questi filesystem è chiamato semplicemente NFS (Network File System). Ha una storia molto lunga ed è stato sviluppato per la prima volta da Sun Microsystems. Un'altra implementazione comune è CIFS (anche chiamato SAMBA), che ha radici Microsoft. Limiteremo la nostra attenzione nelle sezioni seguenti a NFS.
NFS sul Server
Ora esamineremo in dettaglio come utilizzare NFS sul server.
Sulla macchina server, NFS utilizza demoni (processi integrati di rete e servizio in Linux) e altri server di sistema che vengono avviati nella riga di comando digitando:
$ sudo systemctl start nfs
NOTA: Su RHEL/CentOS 8 il servizio è chiamato nfs-server, non nfs.
Il file di testo /etc/exports contiene le directory e le autorizzazioni che un host desidera condividere con altri sistemi su NFS. Una voce molto semplice in questo file potrebbe essere la seguente:
/projects *.example.com(rw)
Questa voce consente alla directory /projects di essere montata usando NFS con permessi di letttura e scrittura (rw) e condivisa con altri host nel dominio example.com. Come descriveremo in dettaglio nel prossimo capitolo, ogni file in Linux ha tre possibili permessi: lettura (r), scrittura (w) ed esecuzione (x).
Dopo la modifica del file /etc/exports puoi digitare exportfs -av per avvisare Linux delle directory che si consente che siano montate in remoto usando NFS. Puoi anche riavviare NFS con sudo systemctl restart nfs, ma questo è più pesante, in quanto interrompe NFS per un po' prima di riavviarlo. Per assicurarsi che il servizio NFS sia attivato ogni volta che il sistema viene avviato, esegui sudo systemctl enable nfs.
NFS sul Client
Sulla macchina client, se si desidera che il filesystem remoto venga montato automaticamente al momento dell'avvio del sistema, occorre modificare /etc/fstab per raggiungere questo obiettivo. Ad esempio, una voce nel client del file /etc/fstab potrebbe essere come la seguente:
nomeserver:/projects /mnt/nfs/projects nfs defaults 0 0
È inoltre possibile montare il filesystem remoto senza un riavvio o come supporto una tantum utilizzando direttamente il comando mount:
$ sudo mount nomeserver:/projects /mnt/nfs/projects
Ricorda, se /etc/fstab non è modificato, il montaggio di questo supporto remoto non avverrà la prossima volta che sarà riavviato il sistema. Inoltre, potresti voler usare l'opzione nofail in fstab Nel caso in cui il server NFS non sia disponibile all'avvio.
Panoramica delle Directory nella Home Utente
In questa sezione, imparerai a identificare e distinguere tra le directory più importanti che si trovano in Linux. Iniziamo con lo spazio della directory home degli utenti ordinari.
Ogni utente ha una directory home, di solito posizionata sotto /home. La directory /root sui moderni sistemi Linux non è altro che la directory home dell'utente root (o superutente o account amministratore di sistema).
Sui sistemi multiutente, l'infrastruttura della directory /home è spesso montata come filesystem separato nella sua propria partizione, oppure esportata (condivisa) in remoto su una rete tramite NFS.
A volte, puoi raggruppare gli utenti in base al loro settore o funzione. È quindi possibile creare sotto-directory nella directory /home per ciascuno di questi gruppi. Per esempio una scuola potrebbe organizzare la directory /home in questo modo:
/home/faculty//home/staff//home/students/
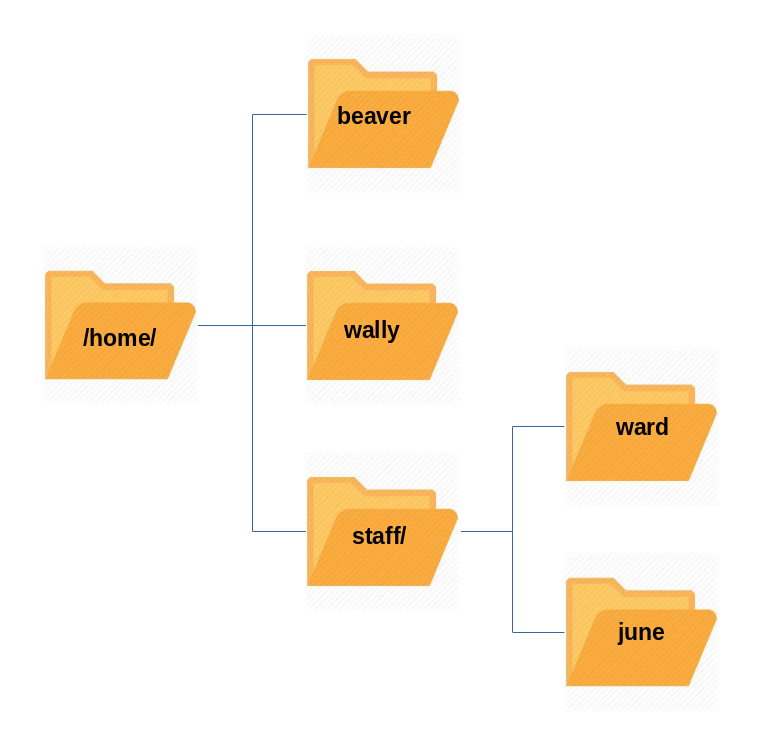
Le Directory /bin e /sbin
La directory /bin contiene binari eseguibili, comandi essenziali utilizzati per avviare il sistema o in modalità utente singolo e comandi essenziali richiesti da tutti gli utenti del sistema, come cat, cp, ls, mv, ps, e rm.
Alla stessa stregua, la directory /sbin è destinata a binari essenziali relativi all'amministrazione del sistema, come fsck e ip. Per visualizzare un elenco di questi programmi, digita:
$ ls /bin /sbin
I comandi non essenziali (teoricamente) per l'avvio del sistema o che operino in modalità utente singolo sono posizionati nelle directory /usr/bin e /usr/sbin. Storicamente, questo è stato fatto in modo che /usr possa essere montata come filesystem separato, eventualmente in una fase successiva all'avvio del sistema o anche su una rete. Tuttavia, al giorno d'oggi la maggioranza trova questa distinzione obsoleta. In effetti, è stato scoperto che molte distribuzioni sono incapaci di avviarsi con questa separazione, poiché questa modalità non era stata utilizzata o testata per molto tempo.
Quindi, su alcune delle più recenti distribuzioni Linux /usr/bin e /bin sono in realtà unite insieme con link simbolici, così come /usr/sbin e /sbin.
Il Filesystem /proc
Alcuni filesystem, come quello montato su /proc, sono chiamati pseudo-filesystem perché non hanno una presenza permanente da nessuna parte sul disco.
Il filesystem /proc contiene file virtuali (file che esistono solo in memoria) che consentono di visualizzare la modifica dei dati del kernel in costante evoluzione. /proc contiene file e directory che imitano le strutture del kernel e le informazioni di configurazione. Non contiene file reali, ma informazioni sul sistema in esecuzione, ad esempio memoria di sistema, dispositivi montati, configurazione hardware, e così via. Alcune voci importanti in /proc sono:
/proc/cpuinfo/proc/interrupts/proc/meminfo/proc/mounts/proc/partitions/proc/version
Anche /proc ha delle sotto-directory, tra le quali:
/proc/<Process-ID-#>/proc/sys
La videata qui sotto mostra che esiste una directory per ogni processo in esecuzione sul sistema, che contiene informazioni vitali al riguardo. Inoltre mostra una directory virtuale che contiene molte informazioni sull'intero sistema, in particolare il suo hardware e la sua configurazione. Il filesystem /proc è molto utile perché le informazioni che riporta sono raccolte solo se necessario e non ha mai bisogno di spazio di archiviazione sul disco.
La Directory /dev
La directory /dev contiene i nodi di dispositivo, un tipo di pseudo-file utilizzato dalla maggior parte dei dispositivi hardware e software, ad eccezione dei dispositivi di rete. Questa directory è:
- Vuota sulla partizione del disco quando non è montata
- Contiene voci che sono create dal sistema udev, che crea e gestisce i nodi di dispositivo su Linux, creandoli dinamicamente quando i dispositivi vengono trovati. La directory
/devcontiene elementi come:
/dev/sda1(prima partizione sul primo disco rigido)/dev/lp1(seconda stampante)/dev/random(una fonte di numeri casuali).
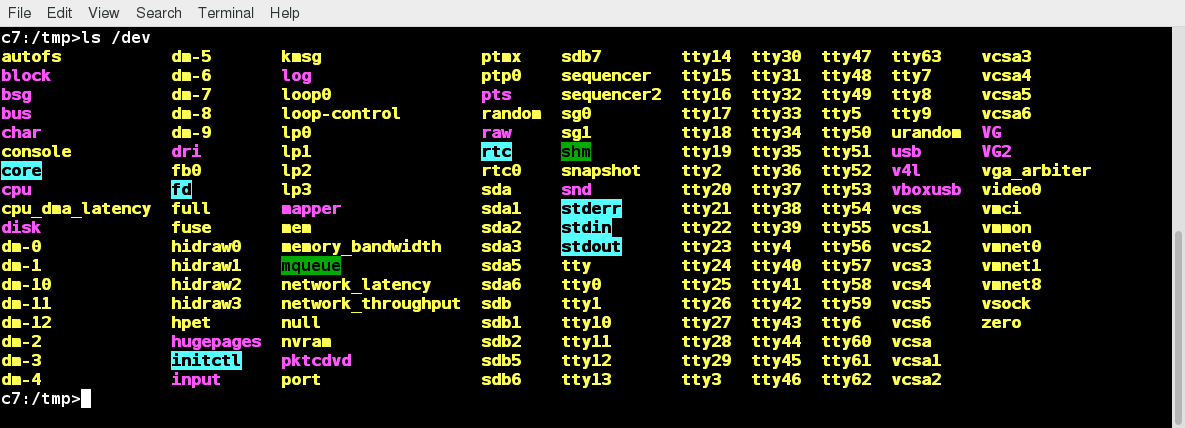
La Directory /var
La Directory /var contiene file che ci si attende cambino in dimensioni e contenuti man mano che il sistema è in esecuzione (var sta per variabile), come le voci nelle seguenti directory:
- File di log di sistema:
/var/log - File di pacchetti e database:
/var/lib - Code di stampa:
/var/spool - File temporanei:
/var/tmp.
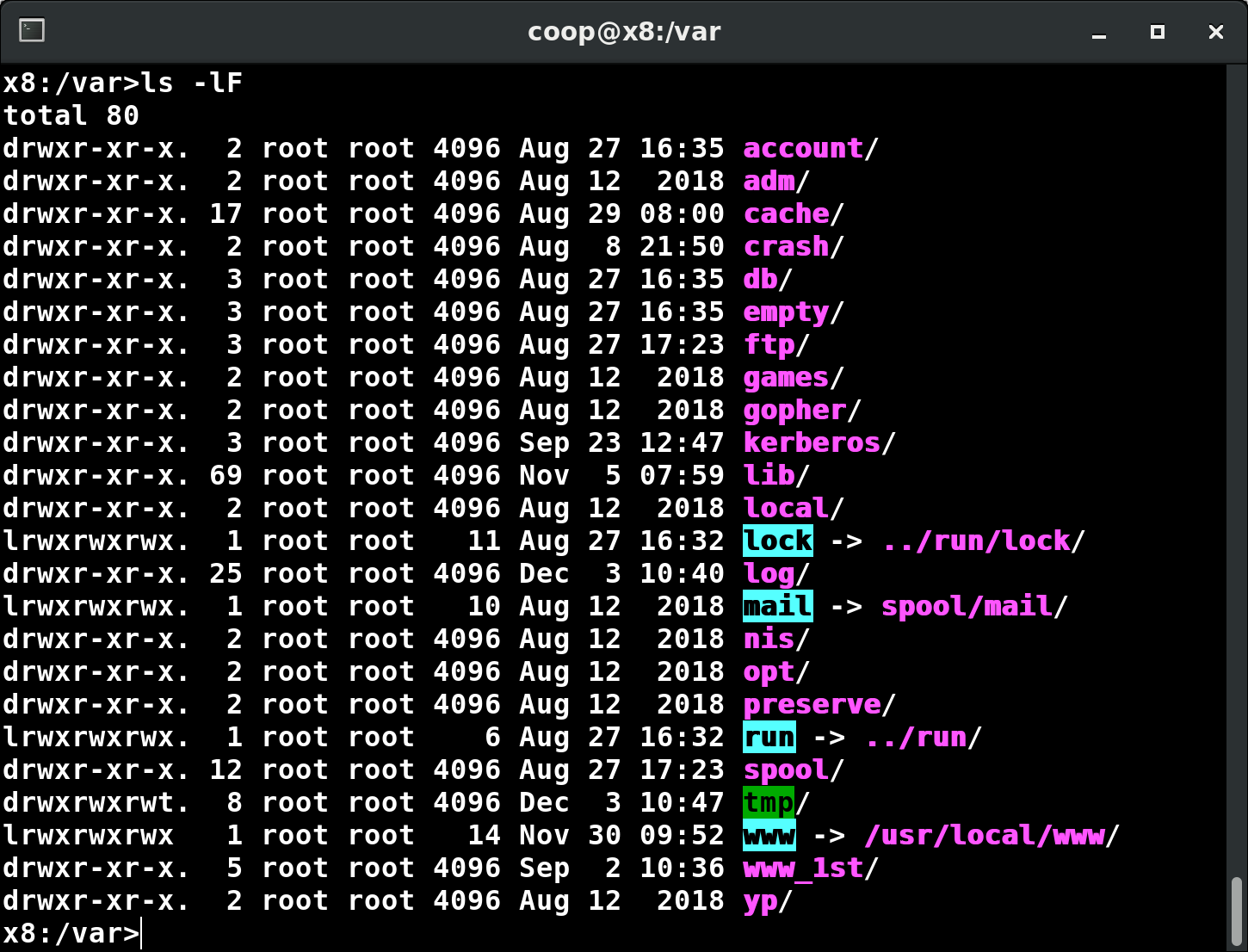
La Directory /var può essere inserita sul proprio filesystem in modo che la crescita dei file possa essere adattata e qualsiasi dimensione e che nessun forte aumento improvviso della dimensione dei file influisca fatalmente nel sistema. Anche le directory dei servizi di rete come /var/ftp (il servizio FTP) e /var/www (il servizio web HTTP) si trovano in /var.
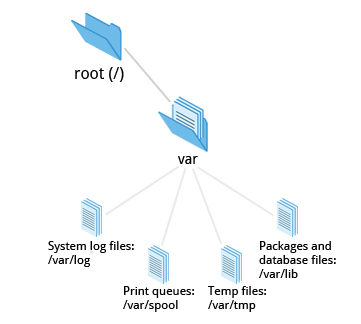
La Directory /etc
La Directory /etc è la home per i file di configurazione del sistema. Non contiene programmi binari, sebbene ci siano alcuni script eseguibili. Per esempio, /etc/resolv.conf dice al sistema dove andare sulla rete per ottenere il nome host dalla mappatura degli indirizzi IP (DNS). File come passwd, shadow e group per gestire gli account utenti si trovano nella directory /etc. Mentre alcune distribuzioni hanno storicamente avuto un'ampia infrastruttura propria sotto /etc (per esempio, Red Hat e SUSE hanno usato /etc/sysconfig), con l'avvento di systemd c'è molta più uniformità tra le distribuzioni oggi.
Nota che /etc è per i file di configurazione a livello di sistema e solo il superutente può modificare i file lì. I file di configurazione specifici dell'utente si trovano sempre nella sua home directory.
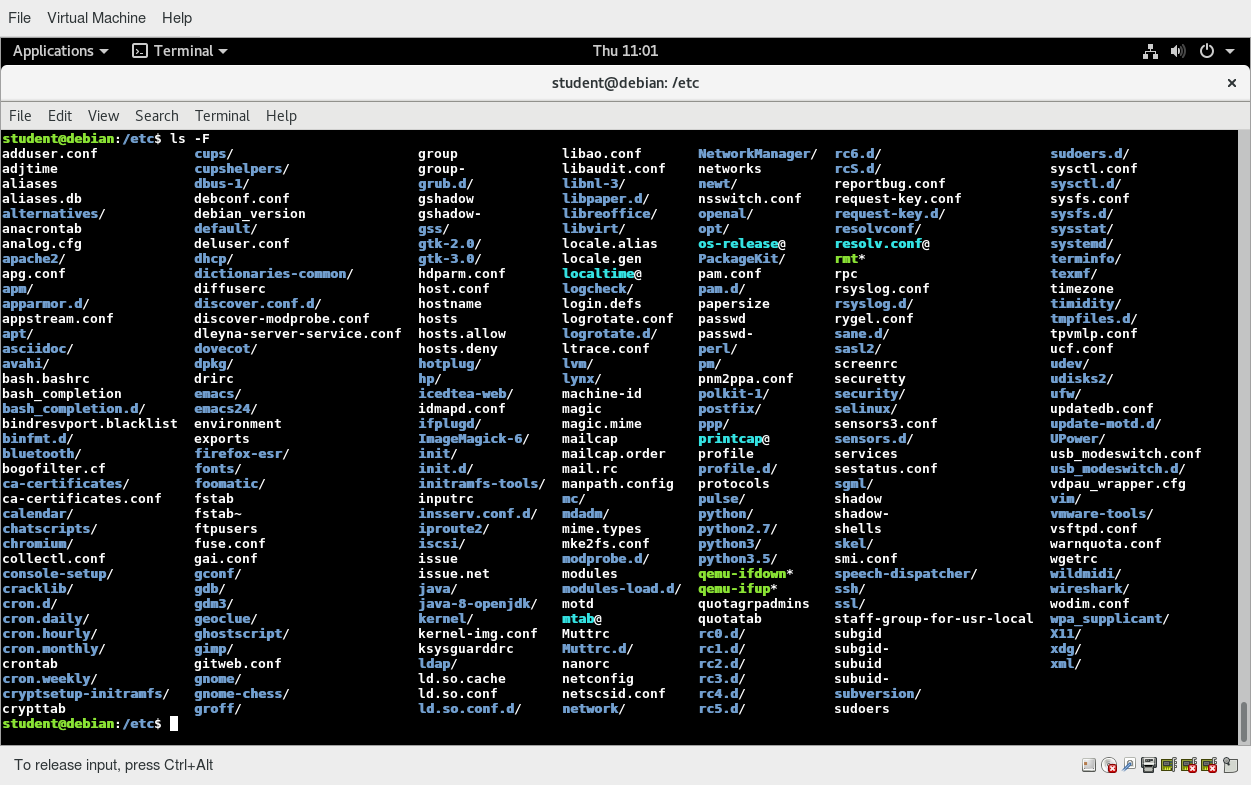
La Directory /boot
La directory /boot contiene i pochi file essenziali necessari per avviare il sistema. Per ogni kernel alternativo installato sul sistema ci sono quattro file:
vmlinuz
Il kernel Linux compresso, richiesto per l'avvio.initramfs
Il filesystem ram iniziale, richiesto per l'avvio, talvolta chiamatoinitrd, noninitramfs.config
Il file di configurazione del kernel, usato solo per debug e tracciatura.System.map
Tabella dei simboli del kernel, usata solo per debug.
Ognuno di questi file ha una versione del kernel aggiunta al suo nome.
Anche i file di GRUB (Grand Unified Bootloader) come /boot/grub/grub.conf o /boot/grub2/grub2.cfg si trovano nella directory /boot.
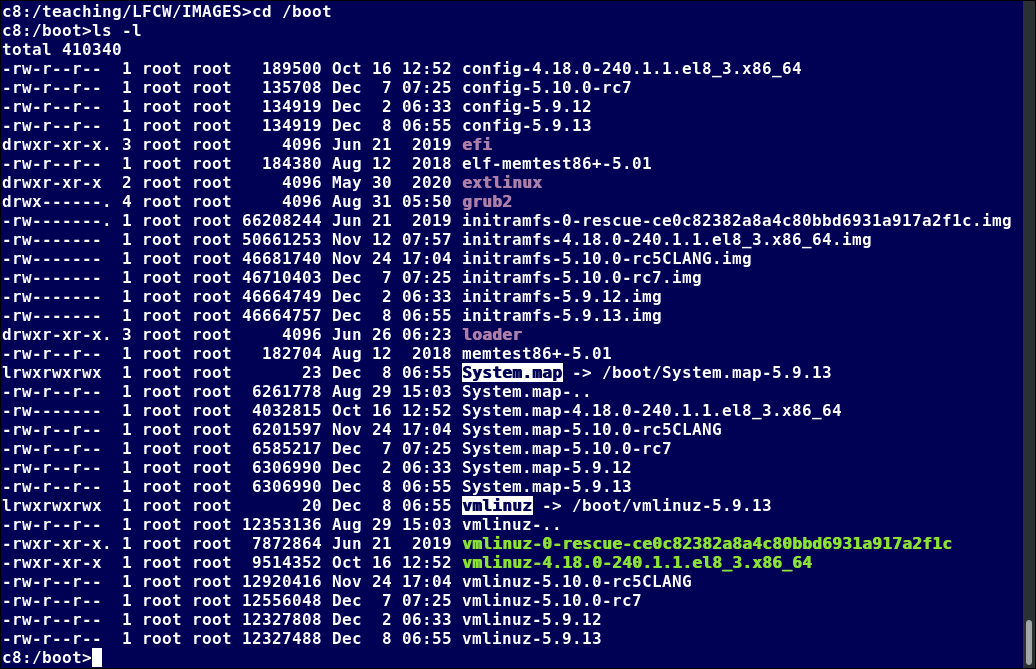
Questa videata mostra un esempio del contenuto della directory /boot, preso da un sistema RHEL che ha più kernel installati. I nomi cambiano e le cose tendono a essere leggermente diverse in base alla distribuzione.
Le Directory /lib e /lib64
/lib contiene librerie (codice comune condiviso dalle applicazioni e necessario per la loro esecuzione) per i programmi essenziali in /bin e /sbin. Questi nomi di file di libreria iniziano per ld o lib. Per esempio, /lib/libncurses.so.5.9.
La maggior parte di questi sono ciò che è noto come librerie caricate dinamicamente (dette anche librerie condivise o oggetti condivisi - SO - shared objects). Su alcune distribuzioni Linux esiste una directory /lib64 contenente librerie a 64 bit, mentre /lib contiene versioni a 32 bit.
Su recenti distribuzioni Linux, si possono trovare:

cioè, proprio come per /bin e /sbin, le directory puntano solo a quelle sotto /usr.
I moduli del kernel (codice kernel, spesso driver di dispositivi, che possono essere caricati e scaricati senza riavviare il sistema) si trovano in /lib/modules/<numero-versione-kernel>.
Media rimuovibili: le Directory /media, /run e /mnt
Si utilizzano spesso media rimovibili, come unità USB, CD e DVD. Per rendere il materiale accessibile tramite il normale filesystem, devono essere montati in una posizione comoda. La maggior parte dei sistemi Linux sono configurati in modo che qualsiasi supporto rimovibile venga montato automaticamente quando il sistema rileva che qualcosa è stato collegato.
Sebbene storicamente questo sia stato fatto sotto la directory /media, le moderne distribuzioni Linux collocano questi punti di montaggio sotto la directory /run. Per esempio una chiave USB con etichetta myusbdrive per un utente con username student sarebbe montata sotto /run/media/student/myusbdrive.

La directory /mnt è stata utilizzata sin dai primi giorni di UNIX per il montaggio temporaneo di filesystem. Possono essere quelli su media rimovibili, ma più spesso potrebbero essere filesystem di rete, che normalmente non sono montati. Oppure possono essere partizioni temporanee, o cosiddetti filesystem di loopback, che sono file che fingono di essere partizioni.
Ulteriori Directory sotto /
Ci sono alcune directory aggiuntive che si trovano nella directory radice:
| Nome Directory | Utilizzo |
|---|---|
/opt |
Pacchetti software di appilicazioni opzionali |
/sys |
Peudo-filesystem virtuali che forniscono informazioni sul sistema e l'hardware Possono essere usati per alterare i parametri di sistema per scopi di debug |
/srv |
Dati specifici al sito serviti dal sistema Raramente usata |
/tmp |
File temporanei; su alcune distribuzioni vengono eliminati durante i riavvi e/oppure potrebbe in realtà essere un disco ram in memoria |
/usr |
Applicazioni multi utente, utility e dati |
L'Albero di Directory /usr
L'albero di directory /usr contiene programmi e script teoricamente non essenziali (nel senso che non dovrebbero essere necessari per avviare inizialmente il sistema) e ha almeno le seguenti sotto-directory:
| Nome Directory | Utilizzo |
|---|---|
/usr/include |
File di intestazione usati per compilare le applicazioni |
/usr/lib |
Librerie per programmi in /usr/bin e /usr/sbin |
/usr/lib64 |
Librerie a 64-bit per programmi a 64-bit in /usr/bin e /usr/sbin |
/usr/sbin |
Binari non essenziali al sistema, come i demoni di sistema |
/usr/share |
Dati condivisi usati dalle applicazioni, generalmente indipendenti dall'architettura |
/usr/src |
Codice sorgente, in genere per il kernel Linux |
/usr/local |
Dati e programmi specifici alla macchina locale; le sotto directory includono bin, sbin, lib, share, include, ecc. |
/usr/bin |
Questa è la directory principale per i comandi eseguibili sul sistema |
Confrontare File con diff
Ora che conosci il filesystem e la sua struttura, apprendiamo come gestire file e directory.
diff viene utilizzato per confrontare file e directory. Questa utility usata frequentemente ha molte opzioni utili (vedi: man diff) tra cui:
| Opzione diff | Utilizzo |
|---|---|
| -c | Fornisce un elenco di differenze che includono tre righe di contesto prima e dopo le righe che differiscono nel contenuto |
| -r | Utilizzato per confrontare ricorsivamente le sotto-directory, nonché la directory corrente |
| -i | Ignora differenze tra lettere maiuscole/minuscole |
| -w | Ignora differenze tra spazi e tabulazioni |
| -q | Modalità silenziosa: segnala solo se i file sono diversi senza elencare le differenze |
Per confrontare due file, al prompt dei comandi, digita diff [opzioni] <nomefile1> <nomefile>. diff è pensata per essere utilizzata per i file di testo; per i file binari, si può usare cmp.
In questa sezione, imparerai metodi aggiuntivi per confrontare e come applicare patch ai file.
Usare diff3 e patch
Puoi confrontare tre file contemporaneamente utilizzando diff3, che utilizza un file come base di riferimento per gli altri due. Ad esempio, supponiamo che tu e un collega abbiate entrambi apportato modifiche allo stesso file contemporaneamente in modo indipendente. diff3 può mostrare le differenze in base al file comune dal quale entrambi avete iniziato. La sintassi per diff3 è la seguente:
$ diff3 mio-file file-comune altro-file
La videata mostra l'uso di diff3.
Molte modifiche al codice sorgente e ai file di configurazione sono distribuite utilizzando patch, che vengono applicate, non sorprendentemente, con il programma patch. Un file patch contiene il delta (le modifiche) richieste per aggiornare una vecchia versione di un file con una nuova. I file patch sono effettivamente prodotti eseguendo diff con le opzioni corrette, in questo modo:
$ diff -Nur fileoriginale nuovofile > filepatch
Distribuire solo il file patch è più conciso ed efficiente della distribuzione dell'intero file. Ad esempio, se è necessario cambiare solo una riga in un file che contiene 1000 righe, il file patch conterrà solo poche righe.
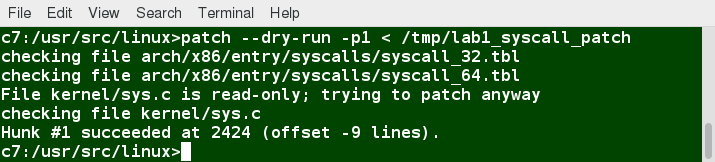
Per applicare patch, puoi semplicemente utilizzare uno dei due metodi di seguito:
$ patch -p1 < filepatch$ patch fileoriginale filepatch
Il primo utilizzo è il più comune, in quanto viene spesso adottato per applicare le modifiche a un intero albero di directory, piuttosto che un solo file, come nel secondo esempio. Per capire l'uso dell'opzione -p1 e molte altre, consulta la pagina di manuale per patch.
Usare l'Utility file
In Linux, l'estensione di un file spesso non lo classifica come potrebbe in altri sistemi operativi. Non si può presumere che un file denominato file.txt sia un file di testo e non un programma eseguibile. In Linux, un nome file è generalmente più significativo per l'utente del sistema rispetto al sistema stesso. In effetti, la maggior parte delle applicazioni esamina direttamente il contenuto di un file per vedere che tipo di oggetto è piuttosto che fare affidamento su un'estensione. Questo è molto diverso dal modo in cui Windows gestisce i nomi file, in cui un nome di file che termina con .exe, ad esempio, rappresenta un file binario eseguibile.
La vera natura di un file può essere accertata usando l'utility file. Per i nomi dei file forniti come argomenti, esamina il contenuto e alcune caratteristiche per determinare se i file sono testo normale, librerie condivise, programmi eseguibili, script o qualcos'altro.
Effettuare Backup (Copie) dei Dati
Esistono molti modi in cui è possibile eseguire il backup dei dati o persino dell'intero sistema. I modi di base per farlo includono l'uso di una semplice copia con cp e l'uso del più robusto rsync.
Entrambi possono essere usati per sincronizzare interi alberi di directory. Tuttavia, rsync è più efficiente, perché controlla se il file che viene copiato esiste già. Se il file esiste e non vi è alcuna modifica delle dimensioni o del tempo di modifica, rsync eviterà una copia non necessaria e risparmierà tempo. Inoltre, poiché rsync copia solo le parti dei file che sono effettivamente cambiate, può essere molto veloce.
cp può copiare solo file da e verso destinazioni sulla macchina locale (a meno che non si stia copiando da o verso un filesystem montato utilizzando NFS), ma rsync Può anche essere utilizzato per copiare i file da una macchina all'altra. Le posizioni sono indicate nel formato destinazione:percorso, dove destinazione può essere sotto forma di qualcuno@host. La parte qualcuno@ è facoltativa e utilizzata se l'utente remoto è diverso dall'utente locale.
rsync è molto efficiente quando si copia ricorsivamente un albero di directory su un altro, perché solo le differenze vengono trasmesse sulla rete. Spesso si sincronizza l'albero della directory di destinazione con l'origine, usando l'opzione -r per scorrere in modo ricorsivo l'albero della directory copiando tutti i file e le directory sotto quello elencato come sorgente.

Per usare rsync al prompt dei comandi, digita rsync filesorgente filedestinazione, dove ognuno dei due file può essere sulla macchina locale o su una macchina in rete; il contenuto di filesorgente sarà copiato in filedestinazione.
Di seguito una buona combinazione di opzioni:
$ rsync --progress -avrxH --delete directorysorgente directorydestinazione
I dati dei file vengono spesso compressi per salvare lo spazio su disco e ridurre il tempo necessario per trasmettere file su reti.
Linux utilizza una serie di metodi per eseguire questa compressione, tra cui:
| Comando | Utilizzo |
|---|---|
gzip |
L'utility Linux di compressione usata più di frequente |
bzip2 |
Genera file significativamente più piccoli di quelli generati da gzip |
xz |
L'utility di compressione più efficace per quanto riguarda lo spazio usata in Linux |
zip |
Spesso richiesto per esaminare e decomprimere archivi da altri sistemi operativi |
Queste tecniche variano nell'efficienza della compressione (quanto spazio viene salvato) e in quanto tempo impiegano per comprimere i dati; in generale, le tecniche più efficienti richiedono più tempo. Il tempo di decompressione non varia tanto tra i diversi metodi.
Inoltre, l'utility tar viene spesso utilizzata per raggruppare i file in un archivio e quindi comprimere contemporaneamente l'intero archivio.
Comprimere Dati Usando gzip
gzip è l'utilità di compressione Linux più spesso utilizzata. Comprime molto bene ed è molto veloce. La tabella seguente fornisce alcuni esempi di utilizzo:
| Comando | Utilizzo |
|---|---|
gzip * |
Comprime tutti i file nella directory corrente; ogni file è compresso e rinominato con un estensione .gz. |
gzip -r projectX |
Comprime tutti i file nella directory projectX, insieme a tutti i file in tutte le directory sotto projectX. |
gunzip foo |
Decomprime foo che si trova nel file foo.gz. Sotto il cofano, il comando gunzip equivale a digitare gzip –d. |
Comprimere Dati Usando xz
xz è l'utility di compressione più efficiente per quanto riguarda lo spazio usata in Linux e viene utilizzata per conservare gli archivi dei kernel Linux (risorsa in inglese). Ancora una volta, scambia una velocità di compressione più lenta per un rapporto di compressione ancora più elevato.
Alcuni esempi di utilizzo:
| Comando | Utilizzo |
|---|---|
xz * |
Comprime tutti i file nella directory corrente e sostituisce ciascun file con uno con un'estensione .xz. |
xz foo |
Comprime foo in foo.xz utilizzando il livello di compressione predefinito (-6),e rimuove foo se la compressione ha successo. |
xz -dk bar.xz |
Decomprime bar.xz in bar e non elimina bar.xz anche se la decompressione ha successo. |
xz -dcf a.txt b.txt.xz > abcd.txt |
Decomprime un misto di file compressi e decompressi verso l'output standard, usando un singolo comando. |
xz -d *.xz |
Decomprime i file compressi usando xz. |
I file compressi sono salvati con una estensione .xz.
Gestire File Usando zip
Il programma zip non viene spesso usato per comprimere i file in Linux, ma spesso è necessario esaminare e decomprimere gli archivi da altri sistemi operativi. Viene utilizzato in Linux solo quando si ottiene un file compresso con estensione .zip da un utente di Windows. È un programma legacy.
| Comando | Utilizzo |
|---|---|
zip backup * |
Comprime tutti i file nella directory corrente e li colloca in backup.zip. |
zip -r backup.zip ~ |
Archivia la tua directory home (~) e tutti i file e directory sotto di essa in backup.zip. |
unzip backup.zip |
Estrae tutti i file in backup.zip e li piazza nella directory corrente. |
Archiviare e Comprimere Dati Usando tar
Storicamente, tar, che sta per "tape archive" (archivio su nastro), era usato per archiviare i file su un nastro magnetico. Ti consente di creare o estrarre file da un file di archivio, spesso chiamato tarball. Allo stesso tempo, è possibile comprimere facoltativamente mentre crei l'archivio e decomprimerlo mentre ne estrai il contenuto.
Ecco alcuni esempi dell'uso di tar:
| Comando | Utilizzo |
|---|---|
tar xvf mydir.tar |
Estrae tutti i file in mydir.tar nella directory mydir. |
tar zcvf mydir.tar.gz mydir |
Crea l'archivio e lo comprime con gzip. |
tar jcvf mydir.tar.bz2 mydir |
Crea l'archivio e lo comprime con bz2. |
tar Jcvf mydir.tar.xz mydir |
Crea l'archivio e lo comprime con xz. |
tar xvf mydir.tar.gz |
Estrae tutti i file in mydir.tar.gz nella directory mydir.NOTA: Non devi dire a tar che è in formato gzip. |
Puoi separare le fasi di archiviazione e compressione, ad esempio:
$ tar cvf mydir.tar mydir ; gzip mydir.tar$ gunzip mydir.tar.gz ; tar xvf mydir.tar
tuttavia questo è più lento e spreca spazio creando un file .tar intermedio non necessario.
Tempi e Dimensioni di Compressione Relativi
Per dimostrare la diversa efficienza di gzip, bzip2, e xz, la seguente videata mostra i risultati della compressione di un albero di una directory di file di testo puri (la directory include dalle sorgenti del kernel) usando i tre metodi.
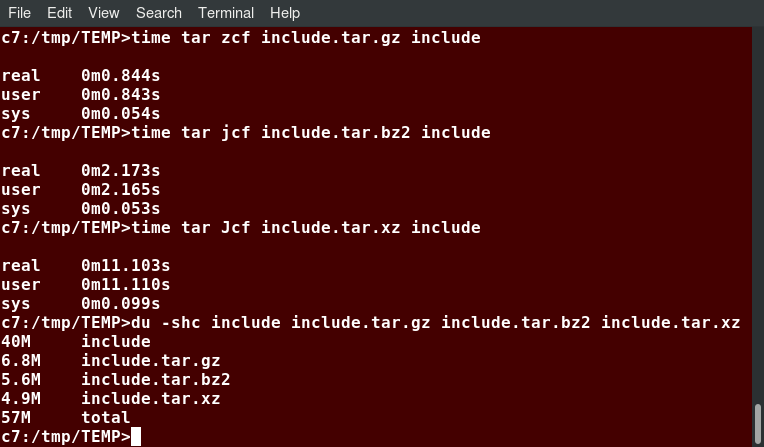
Ciò dimostra che quando i fattori di compressione aumentano, anche il tempo della CPU aumenta (ovvero la produzione di archivi più piccoli richiede più tempo).
Copia da Disco a Disco (dd)
Il programma dd è molto utile per creare copie di spazio grezzo del disco. Per esempio, per fare una copia del tuo Master Boot Record (MBR) (il primo settore di 512 byte sul disco che contiene una tabella che descrive la partizione su quel disco) dovresti digitare:
dd if=/dev/sda of=sda.mbr bs=512 count=1
ATTENZIONE!
Il comando:
dd if=/dev/sda of=/dev/sdb
per fare una copia di un disco in un altro, eliminerà qualsiasi cosa sia precedentemente esistita sul secondo disco.
Una copia esatta del primo dispositivo disco viene creata sul secondo dispositivo disco.
Non sperimentare questo comando come scritto sopra, in quanto può cancellare un disco rigido!
Cosa significhi esattamente dd è un argomento spesso dibattuto. La frase "data definition" (definizione dati) è la teoria più popolare, e ha radici nella storia recente di IBM. Spesso la gente scherzando, dice che significa "disk destroyer" (distruttore di disco) oppure altre varianti come "delete data" (cancella dati)!

Riepilogo del Capitolo
Hai completato il capitolo 10. Riassumiamo i concetti chiave trattati:
- L'albero del filesystem inizia da quella che viene spesso chiamata directory di root (o tronco o
/). - La Gerarchia Standard del Filesystem (FHS) fornisce agli sviluppatori e agli amministratori di sistema Linux una struttura di directory standard per il filesystem.
- Le partizioni aiutano a separare i file in base all'utilizzo, alla proprietà e al tipo.
- I filesystem possono essere montati ovunque sull'albero principale del filesystem in un punto di montaggio. Il montaggio automatico del filesystem può essere impostato mediante modifica di
/etc/fstab. - NFS (Network File System) è un metodo utile per condividere file e dati attraverso sistemi di rete.
- Filesystem come
/procsono chiamati pseudo-filesystem perché esistono solo in memoria. /root(slash-root) è la directory home per l'utente root./varpotrebbe essere inserita nel suo proprio filesystem in modo che la crescita dei file all'interno possa essere contenuta e non influisca fatalmente al sistema./bootcontiene i file di base necessari per avviare il sistema.- patch è uno strumento molto utile in Linux. Molte modifiche al codice sorgente e ai file di configurazione sono distribuite con file di patch, poiché contengono i delta, o modifiche, per passare da una vecchia versione di un file alla nuova versione.
- Le estensioni dei file in Linux non significano necessariamente che un file sia di un certo tipo.
- cp viene utilizzato per copiare i file sulla macchina locale, mentre rsync può anche essere utilizzato per copiare i file da una macchina all'altra, nonché sincronizzare i contenuti.
- gzip, bzip2, xz e zip vengono utilizzati per comprimere i file.
- tar ti consente di creare o estrarre file da un archivio, spesso chiamato tarball. È possibile comprimere facoltativamente l'archivio durante la creazione e decomprimerlo durante l'estrazione del suo contenuto.
- dd può essere usato per realizzare copie esatte di grandi dimensioni, anche di intere partizioni di disco, in modo efficiente.

Capitolo 11: Editor di Testo
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti avere familiarità con:
- La creazione e la modifica dei file utilizzando gli Editor Linux disponibili.
- nano, un semplice editor basato sul testo.
- gedit, un semplice editor grafico.
- vi ed emacs, due editor avanzati con interfacce sia basate sul testo che grafiche.
Panoramica degli Editor di Testo in Linux
A un certo punto, dovrai modificare manualmente i file di testo. Potresti dover scrivere una email senza connessione a Internet, scrivere uno script da utilizzare per bash o altri interpreti di comando, modificare un file di configurazione di sistema o applicazione, oppure sviluppare codice sorgente per un linguaggio di programmazione come C, Python o Java.
Gli amministratori di Linux possono evitare l'uso di un editor di testo, impiegando invece utilità grafiche per la creazione e la modifica dei file di configurazione del sistema. Tuttavia, questo può essere più laborioso che usare direttamente un editor di testo e più limitante. Nota che le applicazioni di elaborazione testi (comprese quelle che fanno parte delle suite di ufficio) non sono realmente editor di testo di base; aggiungono molte informazioni di formattazione extra (solitamente invisibili) che probabilmente renderebbero i file di configurazione di amministrazione del sistema inutilizzabili per il loro scopo previsto. Quindi, sapere come utilizzare con sicurezza uno o più editor di testo è davvero un'abilità essenziale da avere per Linux.
Ormai, hai sicuramente capito che Linux è pieno di alternative; quando si tratta di editor di testo, ci sono molte scelte, da abbastanza semplici a molto complesse, tra cui:
- nano
- gedit
- vi
- emacs
In questa sezione, impariamo prima gli editor nano e gedit, che sono relativamente semplici e facili da apprendere, successivamente passeremo alle scelte più complicate, vi ed emacs. Prima di iniziare, diamo un'occhiata ad alcuni casi in cui un editor non è necessario.
Creare File Senza Usare un Editor
A volte, potresti voler creare un file breve e non vuoi dover lanciare un editor di testo completo. Inoltre, farlo in questo modo può essere abbastanza utile se utilizzato all'interno degli script, anche quando si creano file più lunghi. Senza dubbio ti ritroverai a usare questo metodo quando inizierai nei capitoli successivi a lavorare con gli script di shell!
Se si desidera creare un file senza utilizzare un editor, ci sono due modi standard per farlo dalla riga di comando e riempirlo di contenuto.
Il primo è usare echo ripetutamente:
$ echo line one > myfile
$ echo line two >> myfile
$ echo line three >> myfile
Nota che un singolo carattere di maggiore (>) invia il risultato di un comando a un file, due caratteri (>>) aggiungono nuovo contenuto a un file esistente.
Il secondo modo è usare cat combinato con il reindirizzamento:
$ cat << EOF > myfile> line one> line two> line three> EOF$
Entrambe le tecniche producono un file con le seguenti righe:
line one
line two
line three
e sono estremamente utili se impiegati con gli script.
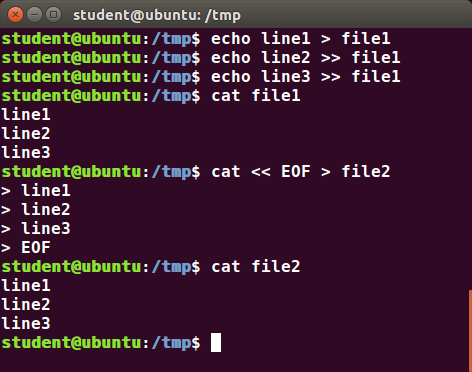
nano e gedit
Ci sono alcuni editor di testo che sono abbastanza facili; per imparare a usarli non necessitano di un'esperienza particolare e in realtà sono abbastanza performanti e anche robusti. Uno particolarmente facile da usare è l'editor basato sul terminale di testo nano. Basta eseguire nano dando un nome file come argomento. Tutto l'aiuto di cui hai bisogno viene visualizzato nella parte inferiore dello schermo e dovresti essere in grado di procedere senza alcun problema.
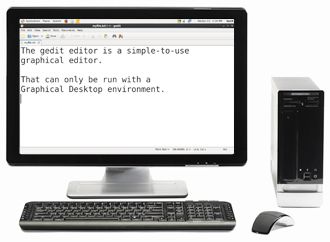
Come editor grafico, gedit fa parte del sistema desktop GNOME (kwrite è associato a KDE). Gli editor gedit e kwrite sono molto facili da usare e sono estremamente validi. Sono anche molto configurabili. Assomigliano molto al blocco note di Windows. Altre varianti come kate sono anche supportate da KDE.
nano
Nano è facile da usare e per imparare a usarlo serve pochissimo sforzo. Per aprire un file, digita nano <nomefile> poi Invio. Se il file non esiste, verrà creato.
nano fornisce una barra di scelta rapida di due righe nella parte inferiore dello schermo che elenca i comandi disponibili. Alcuni di questi comandi sono:
CTRL-G
Visualizza la schermata di aiuto.CTRL-O
Scrive un file.CTRL-X
Esce da un file (e dall'editor).CTRL-R
Inserisce i contenuti da un altro file al buffer corrente.CTRL-C
Mostra la posizione del cursore.
gedit
gedit (pronunciato 'g-edit') è un editor grafico semplice da usare che può essere eseguito solo all'interno di un ambiente desktop grafico. È visivamente abbastanza simile all'editor di testo Blocco Note in Windows, ma in realtà è molto più capace e molto configurabile e ha una vasta gamma di plugin disponibili per estendere ulteriormente le sue capacità.
Per aprire un nuovo file trova il programma nel sistema di menu del desktop o dalla riga di comando digita gedit <nomefile>. Se il file non esiste, verrà creato.
L'uso di gedit è piuttosto semplice e non richiede molto allenamento. La sua interfaccia è composta da elementi abbastanza familiari.
vi ed emacs
Gli sviluppatori e gli amministratori esperti che lavorano su sistemi tipo UNIX, usano quasi sempre una delle due venerabili opzioni di editing: vi ed emacs. Entrambi sono presenti o facilmente disponibili su tutte le distribuzioni e sono completamente compatibili con le versioni disponibili su altri sistemi operativi.
Sia vi che emacs hanno una forma di base puramente basata sul testo che può funzionare in un ambiente non grafico. Hanno anche una o più forme di interfaccia grafica con capacità estese; queste possono essere più amichevoli per un utente meno esperto. Mentre vi ed emacs possono avere curve di apprendimento significativamente ripide per i nuovi utenti, sono estremamente efficienti una volta imparato a usarli.
Devi essere consapevole del fatto che ci sono diatribe tra gli utenti esperti su quale editor sia meglio che possono essere abbastanza intense e sono spesso descritte come una guerra santa.
Introduzione a vi
Di solito, il programma effettivo installato sul sistema è vim, che sta per VI Migliorato.
Anche se non si desidera utilizzare vi, è bene acquisire un po' di familiarità con esso; è uno strumento standard installato praticamente su tutte le distribuzioni Linux. In effetti, potrebbero esserci momenti in cui non vi è altro editor disponibile sul sistema.
GNOME estende vi con un'interfaccia grafica nota come gvim e KDE offre kvim. Ognuno di questi potrebbe essere più facile da usare all'inizio.
Quando si utilizza vi, tutti i comandi vengono inseriti tramite la tastiera. Non è necessario continuare a muovere le mani per utilizzare un dispositivo di puntamento come un mouse o un touchpad, a meno che tu non lo voglia fare se utilizzi una delle versioni grafiche dell'editor.
vimtutor
Digitando vimtutor si lancia un tutorial breve ma molto completo per coloro che vogliono imparare i loro primi comandi vi. Anche se fornisce solo un'introduzione e solo sette lezioni, ha abbastanza materiale per renderti un utente vi molto abile, perché tratta un gran numero di comandi. Dopo aver appreso quelli di base, puoi cercare nuovi trucchi da includere nel tuo elenco di comandi vi perché ci sono sempre modi più ottimali per fare le cose in vi digitando di meno.
Modalità di vi
| Modalità | Funzionalità |
|---|---|
| Command | - Predefinita, vi parte in modalità Command (Comando). - Ogni tasto è un comando dell'editor. - I tasti digitati sono interpretati come comandi che possono modificare i contenuti del file. |
| Insert | - Digita i per passare alla modalità Insert (Inserimento) dalla modalità Command.- La modalità Insert viene utilizzata per immettere (inserire) il testo in un file. - La modalità Insert è contrassegnata da un indicatore “ ? INSERT ? " nella parte inferiore dello schermo.- Digita Esc per uscire dalla modalità Insert e tornare alla modalità Command. |
| Line | - Digita : per passare alla modalità Line (riga) dalla modalità Command. Ogni tasto è un comando esterno, comprese operazioni come la scrittura del contenuto del file su disco o l'uscita.- Utilizza i comandi di modifica della riga ereditati dagli editor di riga più vecchi. La maggior parte di questi comandi in realtà non è più utilizzata. Alcuni comandi di modifica della riga sono molto potenti. - Digita Esc per uscire dalla modalità Line e tornare alla modalità Command. |
vi Fornisce tre modalità, come descritto nella tabella qui sopra. È fondamentale non perdere traccia della modalità in cui ti trovi. Molti tasti e comandi si comportano in modo molto diverso in diverse modalità.
Lavorare con i File in vi
La tabella descrive i comandi più importanti utilizzati per aprire, uscire, leggere e scrivere file in vi. Il tasto Invio deve essere premuto dopo tutti questi comandi.
| Comando | Utilizzo |
|---|---|
vi myfile |
Lancia l'editor e apre myfile |
vi -r myfile |
Lancia l'editor e apre myfile in modalità di ripristino da un crash di sistema |
:r file2 |
Legge file2 e inserisce il contenuto nella posizione corrente |
:w |
Scrive il file aperto nell'editor |
:w myfile |
Scrive il file myfile |
:w! file2 |
Sovrascrive il file file2 |
:x oppure :wq |
Esce e scrive il file modificato |
:q |
Esce |
:q! |
Esce abbandonando modifiche non salvate in precedenza |
Cambiare la Posizione del Cursore in vi
La tabella descrive i tasti più importanti utilizzati per spostare il cursore in vi. I comandi in modalità Line (quelli che seguono : ) richiedono che il tasto Invio sia premuto dopo che il comando è stato digitato.
| Key | Utilizzo |
|---|---|
| tasti freccia | Per spostarsi su, già, sinistra, destra |
j oppure <ret> |
Per spostarsi alla riga successiva |
k |
Per spostarsi alla riga precedente |
h oppure Backspace |
Per sposarsi di un carattere a sinistra |
l oppure Barra Spazio |
Per spostarsi di un carattere a destra |
0 |
Per spostarsi all'inizio della riga |
$ |
Per spostarsi alla fine della riga |
w |
Per spostarsi all'inizio della parola successiva |
:0 oppure 1G |
Per spostarsi all'inizio del file |
:n oppure nG |
Per spostarsi alla riga n |
:$ oppure G |
Per spostarsi all'ultima riga del file |
CTRL-F oppure PaginaGiu |
Per spostarsi alla schemata successiva |
CTRL-B oppure PaginaSu |
Per spostarsi alla schemata precedente |
zz |
Per aggiornare e centrare il cursore sulla schermata |
Video: Uso delle Modalità e dei Movimenti Cursore in vi
Cercare Testo in vi
La tabella descrive i più importanti comandi usati per cercare testo in vi. Il tasto Invio dovrebbe essere premuto dopo la digitazione del modello di testo da cercare.
| Comando | Utilizzo |
|---|---|
/modello |
Ricerca in avanti del modello |
?modello |
Ricerca a ritroso del modello |
La tabella descrive i più importanti tasti usati per cercare testo in vi.
| Tasto | Utilizzo |
|---|---|
n |
Si sposta all'occorrenza successiva del modello di ricerca |
N |
Si sposta all'occorrenza precedente del modello di ricerca |
Lavorare con il Testo in vi
La tabella descrive le più importanti combinazioni di tasti usati per modificare, aggiungere e cancellare testo in vi.
| Tasto | Utilizzo |
|---|---|
a |
Aggiunge testo dopo il cursore; si interrompe con il tasto Esc |
A |
Aggiunge testo alla fine della riga corrente; si interrompe con il tasto Esc |
i |
Inserisce testo prima del cursore; si interrompe con il tasto Esc |
I |
Inserisce testo all'inizio della riga corrente; si interrompe con il tasto Esc |
o |
Inizia una nuova riga sotto la riga corrente, e inserisce lì il testo; si interrompe con il tasto Esc |
O |
Inizia una nuova riga sopra la riga corrente, e inserisce lì il testo; si interrompe con il tasto Esc |
r |
Sostituisce il carattere alla posizione corrente |
R |
Sostituisce il testo che inizia dalla posizione corrente; si interrompe con il tasto Esc |
x |
Elimina il carattere alla posizione corrente |
Nx |
Elimina N caratteri, a partire dalla alla posizione corrente |
dw |
Elimina la parola alla posizione corrente |
D |
Elimina il resto della riga dalla posizione corrente |
dd |
Elimina la riga corrente |
Ndd oppure dNd |
Elimina N righe |
u |
Annulla l'operazione precedente |
yy |
Copia (yank) la riga corrente e la inserisce nel buffer |
Nyy oppure yNy |
Copia (yank) N righe e le inserisce nel buffer |
p |
Copia alla posizione corrente la riga o le righe inserite nel buffer |
Ecco un PDF consolidato con un elenco di comandi per vi.
Usare Comandi Esterni in vi
Digitando il comando sh si apre una shell di comando esterna. Quando esci dalla shell, riprendi la tua sessione di editing corrente.
Digitando ! esegui un comando dall'interno di vi. Il comando segue il punto esclamativo. Questa tecnica è più adatta per i comandi non interattivi, come : ! wc %, che esegue il comando wc (conteggio parole - word count) in un file; il carattere % rappresenta il file attualmente in fase di modifica.
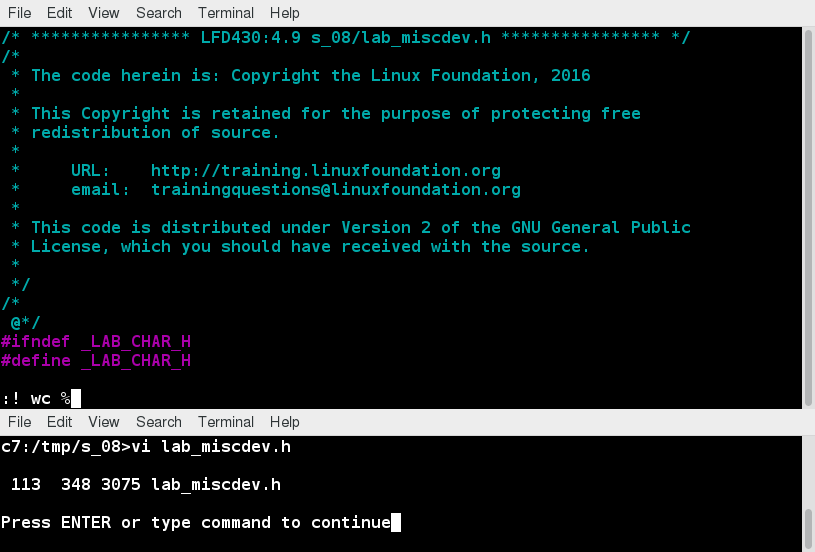
Video: Usare Comandi Esterni, Salvare e Chiudere nell'Editor vi
Introduzione a emacs
L'editor emacs è un popolare concorrente di vi. A differenza di vi, non funziona con le modalità. emacs è altamente personalizzabile e include un gran numero di funzionalità. Inizialmente è stato progettato per l'uso su una console, ma è stato presto adattato per lavorare anche con una GUI. emacs ha molte altre funzionalità diverse dal semplice editing di testo. Ad esempio, può essere utilizzato per e-mail, debug, ecc.
Invece di avere diverse modalità per comandi e inserimento, come vi, emacs usa i tasti CTRL e Meta (Alt oppure Esc) per comandi speciali.
Lavorare con emacs
La tabella elenca alcune delle combinazioni di tasti più importanti che vengono utilizzate quando si aprono, chiudono, leggono e scrivono file in emacs.
| Tasto | Utilizzo |
|---|---|
emacs myfile |
Avvia emacs e modifica myfile |
CTRL-x i |
Richiede l'inserimento di un file alla posizione corrente |
CTRL-x s |
Salva tutti i file |
CTRL-x CTRL-w |
Scrive il file dandogli un nuovo nome (da inserire al prompt) |
CTRL-x CTRL-s |
Salva il file corrente |
CTRL-x CTRL-c |
Esce dopo la richiesta di salvataggio di qualsiasi file modificato |
Il tutorial di emacs è un buon posto per iniziare a imparare i comandi di base. È disponibile in qualsiasi momento all'interno di emacs digitando semplicemente CTRL-h (per help) quindi la lettera t per tutorial.
Cambiare la Posizione del Cursore in emacs
La tabella elenca alcuni dei tasti e delle combinazioni di tasti utilizzate per spostare il cursore in emacs.
| Tasto | Utilizzo |
|---|---|
| tasti freccia | Usa i tasti freccia per spostarsi su, giù, sinistra e destra |
CTRL-n |
Una riga giù |
CTRL-p |
Una riga su |
CTRL-f |
Un carattere avanti/destra |
CTRL-b |
Un carattere indietro/sinistra |
CTRL-a |
Si sposta all'inizio della riga |
CTRL-e |
Si sposta alla fine della riga |
Meta-f |
Si sposta all'inizio della parola successiva |
Meta-b |
Si sposta indietro all'inizio della parola precedente |
Meta-< |
Si sposta a inizio file |
Meta-g-g-n |
Si sposta alla riga n (si può anche usare Esc-x Goto-line n) |
Meta-> |
Si sposta alla fine del file |
CTRL-v o PaginaGiu |
Va alla schermata successiva |
Meta-v o PaginaSu |
Va alla schermata precedente |
CTRL-l |
Aggiorna e centra lo schermo |
Cercare Testo in emacs
La tabella elenca le combinazioni di tasti utilizzate per cercare testo in emacs.
| Tasto | Utilizzo |
|---|---|
CTRL-s |
Cerca in avanti per il modello al prompt, o per il modello successivo |
CTRL-r |
Cerca all'indietro per il modello al prompt, o per il modello successivo |
Lavorare con il Testo in emacs
La tabella elenca alcune delle combinazioni di tasti usate per cambiare, aggiungere e cancellare del testo in emacs:
| Tasto | Utilizzo |
|---|---|
CTRL-o |
Inserisce una riga vuota |
CTRL-d |
Cancella il carattere alla posizione corrente |
CTRL-k |
Cancella il resto della riga corrente |
CTRL-_ |
Annulla l'operazione precedente |
CTRL-spazio oppure CTRL-@) |
Marca l'inizio della regione da selezionare. La fine sarà alla posizione del cursore |
CTRL-w |
Cancella il testo attualmente marcato e lo scrive nel buffer |
CTRL-y |
Inserisce alla posizione corrente del cursore qualsiasi cosa sia stata cancellata più di recente |
Ecco un file PDF consolidato con comandi per emacs.
Video: Operazioni con emacs
Riepilogo del Capitolo
Hai completato il capitolo 11. Riassumiamo i concetti chiave trattati:
- Gli editor di testo (anziché i programmi di elaborazione testi) vengono utilizzati abbastanza spesso in Linux, per attività come la creazione o la modifica dei file di configurazione del sistema, la scrittura di script, lo sviluppo del codice sorgente, ecc.
- nano è un editor di testo facile da usare che utilizza dei prompt sullo schermo.
- gedit è un editor grafico, molto simile al Blocco Note in Windows.
- L'editor vi è disponibile su tutti i sistemi Linux ed è ampiamente utilizzato. Anche le estensioni grafiche di vi sono ampiamente disponibili.
- emacs è disponibile su tutti i sistemi Linux come popolare alternativa a vi. emacs può supportare sia un'interfaccia utente grafica che un'interfaccia in modalità di testo.
- Per accedere al tutorial di vi, digita vimtutor in una finestra di riga di comando.
- Per accedere al tutorial di emacs digita
Ctl-hpoitall'interno di emacs - vi ha tre modalità: Command, Insert, e Line. emacs solo una, ma richiede l'uso di tasti speciali, come
CTRLedEsc. - Entrambi gli editor usano varie combinazioni di tasti per eseguire le attività. La curva di apprendimento può essere ripida e lunga, ma una volta padroneggiato l'uso di uno di questi editor diventerai estremamente efficiente.

Capitolo 12: Ambiente dell'Utente
Obiettivi formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Utilizzare e configurare gli account utente e gruppi di utenti.
- Usare e impostare le variabili di ambiente.
- Utilizzare la cronologia dei comandi precedenti della shell.
- Utilizzare le scorciatoie da tastiera.
- Usare e definire gli alias.
- Utilizzare e impostare i privilegi e la proprietà dei file.
Identificare l'Utente Corrente
Come sai, Linux è un sistema operativo multi-utente, il che significa che più di un utente può accedere contemporaneamente.
- Per identificare l'utente corrente, digita
whoami. - Per elencare gli utenti attualmente connessi, digita
who.
Passa a who l'opzione -a per ottenere informazioni più dettagliate.
File di Avvio dell'Utente
In Linux, il programma di shell di comando (generalmente bash) utilizza uno o più file di avvio per configurare l'ambiente utente. I file nella directory /etc definiscono le impostazioni globali per tutti gli utenti, mentre i file di inizializzazione nella directory home dell'utente possono includere e/o sovrascrivere le impostazioni globali.
I file di avvio possono fare qualsiasi cosa l'utente desideri fare in tutte le shell di comando, come ad esempio:
- Personalizzare il prompt
- Definire scorciatoie di riga di comando e alias
- Impostare l'editor di testo predefinito
- Impostare il percorso in cui trovare programmi eseguibili
Ordine dei File di Avvio
La prassi standard è che quando si accede per la prima volta a Linux, viene letto ed elaborato /etc/profile, dopo di che i seguenti file vengono cercati (se esistono) nell'ordine elencato:
~/.bash_profile~/.bash_login~/.profile
dove ~/. denota la directory home dell'utente. La shell di login di Linux valuta qualsiasi file di avvio che trova e ignora il resto. Ciò significa che se trova ~/.bash_profile, ignorerà ~/.bash_login e ~/.profile. Diverse distribuzioni possono utilizzare diversi file di avvio.
Tuttavia, ogni volta che crei una nuova shell o finestra di terminale, ecc., non esegui un accesso completo al sistema; solo un file chiamato ~/.bashrc viene letto ed elaborato. Sebbene questo file non venga letto ed elaborato insieme alla shell di login, la maggior parte delle distribuzioni e/o degli utenti includono il file ~/.bashrc in uno dei tre file di avvio dell'utente.
Più comunemente, gli utenti avranno a che fare solo ~/.bashrc, visto che viene invocato ogni volta che inizia una nuova shell di riga di comando, o un altro programma che venga lanciato da una finestra di terminale, mentre gli altri file vengono letti ed eseguiti solo quando l'utente accede per la prima volta al sistema.
Le recenti distribuzioni a volte non hanno nemmeno .bash_profile e/o .bash_login, e alcune fanno solo poco più che includere .bashrc.
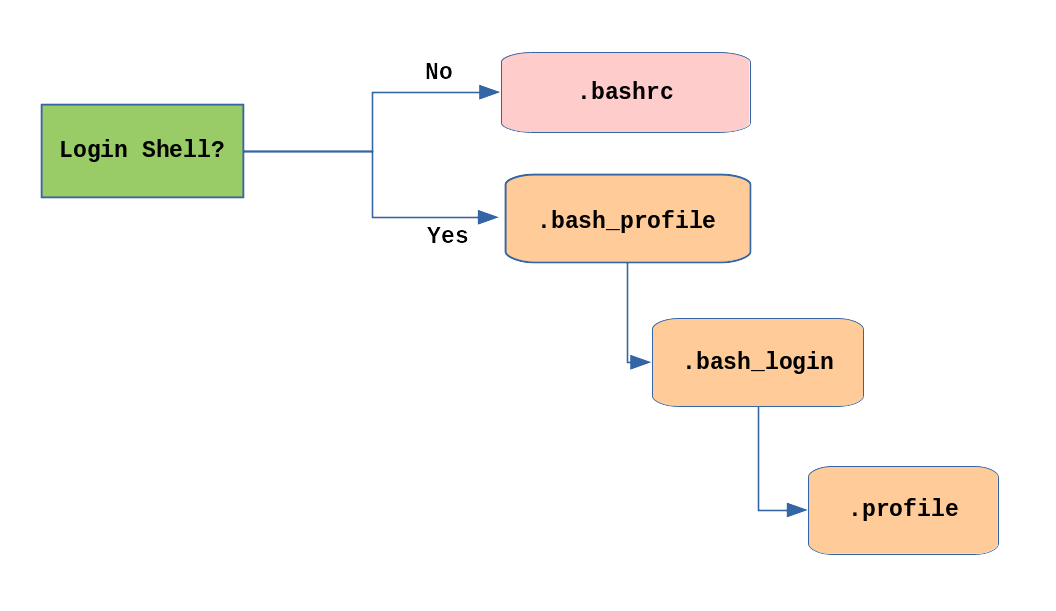
Creare Alias
Puoi creare comandi personalizzati o modificare il comportamento di quelli già esistenti creando alias. Molto spesso, questi alias sono collocati nel tuo file ~/.bashrc così da essere disponibili per qualunque shell di comando tu crei. unalias rimuove un alias.
Se digiti alias senza argomenti otterrai l'elenco degli alias attualmeente definiti.
Ti prego notare che non ci dovrebbero essere spazi su entrambi i lati del segno uguale e la definizione di alias deve essere posizionata all'interno di apici singoli o doppi se contiene spazi.
Le Basi di Utenti e Gruppi
A tutti gli utenti Linux viene assegnato un ID utente univoco (uid), che è semplicemente un numero intero; gli utenti normali iniziano con un UID di 1000 o superiore.
Linux usa i gruppi per organizzare gli utenti. I gruppi sono raccolte di account con determinati permessi condivisi. Il controllo dell'appartenenza al gruppo viene amministrato attraverso il file /etc/group, che mostra un elenco di gruppi e loro membri. Per impostazione predefinita, ogni utente appartiene a un gruppo predefinito o primario. Quando un utente accede, l'adesione al gruppo è impostata per il proprio gruppo primario e tutti i membri godono dello stesso livello di accesso e privilegio. I permessi sui vari file e directory possono essere modificati a livello di gruppo.
Gli utenti hanno anche uno o più ID di gruppo (gid), compreso uno predefinito che è uguale all'ID utente. Questi numeri sono associati a nomi attraverso i file /etc/passwd e /etc/group. I gruppi vengono utilizzati per raggruppare una serie di utenti che hanno interessi comuni ai fini dei diritti di accesso, dei permessi e delle considerazioni sulla sicurezza. I diritti di accesso ai file (e ai dispositivi) sono concessi sulla base dell'utente e del gruppo a cui appartengono.
Per esempio, /etc/passwd potrebbe contenere george:x:1002:1002:George Metesky:/home/george:/bin/bash e /etc/group potrebbe contenere george:x:1002.
Aggiungere e Rimuovere Utenti
Le distribuzioni hanno interfacce grafiche semplici per la creazione e la rimozione di utenti e gruppi, e per manipolare l'appartenenza al gruppo. Tuttavia, è spesso utile farlo dalla riga di comando o dall'interno di script di shell. Solo l'utente root può aggiungere e rimuovere utenti e gruppi.
L'aggiunta di un nuovo utente è fatta con useradd e la rimozione di un utente esistente viene eseguita con userdel. Nella forma più semplice, un account per il nuovo utente bjmoose sarà creato con:
$ sudo useradd bjmoose
che, per impostazione predefinita, crea la home directory /home/bjmoose, la popola con alcuni file di base (copiati da /etc/skel) e aggiunge una riga al file /etc/passwd, che nel caso di esempio potrebbe essere:
bjmoose:x:1002:1002::/home/bjmoose:/bin/bash
e imposta la shell predefinita a /bin/bash. La rimozione di un account utente è tanto facile quanto digitare userdel bjmoose. Tuttavia, questo lascerà la directory /home/bjmoose intatta. Questo potrebbe essere utile se si tratta di una disattivazione temporanea. Per rimuovere la directory home rimuovendo l'account è necessario utilizzare l'opzione -r del comando userdel.
Se digiti id senza argomenti ottieni informazioni sull'utente corrente:
$ iduid=1002(bjmoose) gid=1002(bjmoose) groups=106(fuse),1002(bjmoose)
Se viene passato il nome di un altro utente come argomento, id riporterà informazioni su quell'altro utente.
Video: Usare gli Account Utente
Aggiungere e Rimuovere Gruppi
L'aggiunta di un nuovo gruppo è fatta con groupadd:
$ sudo /usr/sbin/groupadd unnuovogruppo
Il gruppo può essere rimosso con:
$ sudo /usr/sbin/groupdel unnuovogruppo
L'aggiunta di un utente a un gruppo già esistente è fatta con usermod. Ad esempio, prima dovresti visualizzare i gruppi ai quali l'utente appartiene già:
$ groups rjsquirrelrjsquirrel : rjsquirrel
poi aggiungere il nuovo gruppo:
$ sudo /usr/sbin/usermod -a -G unnuovogruppo rjsquirrel
$ groups rjsquirrelrjsquirrel: rjsquirrel unnuovogruppo
Queste utility aggiornano il file /etc/group come necessario. Assicurati di usare l'opzione -a (aggiungere), così da evitare di rimuovere gruppi che esistono già. groupmod può essere utilizzato per modificare le proprietà del gruppo, come l'ID di gruppo (GID) con l'opzione -g oppure il suo nome con l'opzione -n.
Rimuovere un utente dal gruppo è un po' più complicato. L'opzione -G di usermod riceve un elenco di gruppi ai quali deve appartenere l'utente. Pertanto se esegui:
$ sudo /usr/sbin/usermod -G rjsquirrel rjsquirrel
$ groups rjsquirrelrjsquirrel : rjsquirrel
rimarrà solo il gruppo rjsquirrel.
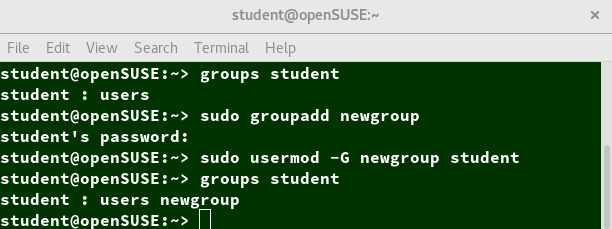
L'Account Root
L'account root è molto potente e ha pieno accesso al sistema. Altri sistemi operativi spesso lo chiamano account amministratore; in Linux, viene spesso chiamato account superuser. È necessario essere estremamente cauti prima di concedere l'accesso a root completo a un utente; è raramente, se mai, giustificato. Gli attacchi esterni consistono spesso in trucchi usati per elevarsi all'account root.

Tuttavia, puoi usare sudo per assegnare privilegi più limitati agli account utente:
- Solo su base temporanea
- Solo per un sottoinsieme specifico di comandi.
su e sudo
Quando si assegnano privilegi elevati, è possibile utilizzare il comando su (substitute user - sostituisci utente) per avviare una nuova shell in esecuzione come un altro utente (è necessario digitare la password dell'utente che stai diventando). Molto spesso, quest'altro utente è root e la nuova shell consente l'uso di privilegi elevati fino a quando non viene chiusa. È quasi sempre una cattiva pratica (pericolosa sia per la sicurezza che per la stabilità) usare su per diventare root. Gli errori risultanti possono includere la cancellazione di file vitali al sistema e le violazioni della sicurezza.
Concedere i privilegi usando sudo è meno pericoloso ed è preferito. Per impostazione predefinita, sudo deve essere abilitato su base utente. Tuttavia, alcune distribuzioni (come Ubuntu) lo abilitano per impostazione predefinita per almeno un utente principale, o lo forniscono come opzione di installazione.
Nel capitolo Principi di Sicurezza Locale descriveremo e confronteremo su e sudo in dettaglio.
Elevare all'Account root
Per diventare temporaneamente superutente per una serie di comandi, è possibile digitare su, verrà poi richiesta la password di root.
Per eseguire solo un comando con privilegi di root digita sudo <comando>. Al termine del comando, tornerai ad essere un normale utente non privilegiato.
I file di configurazione di sudo sono conservati nel file /etc/sudoers e nella directory /etc/sudoers.d/. Per impostazione predefinita, la directory sudoers.d è vuota.
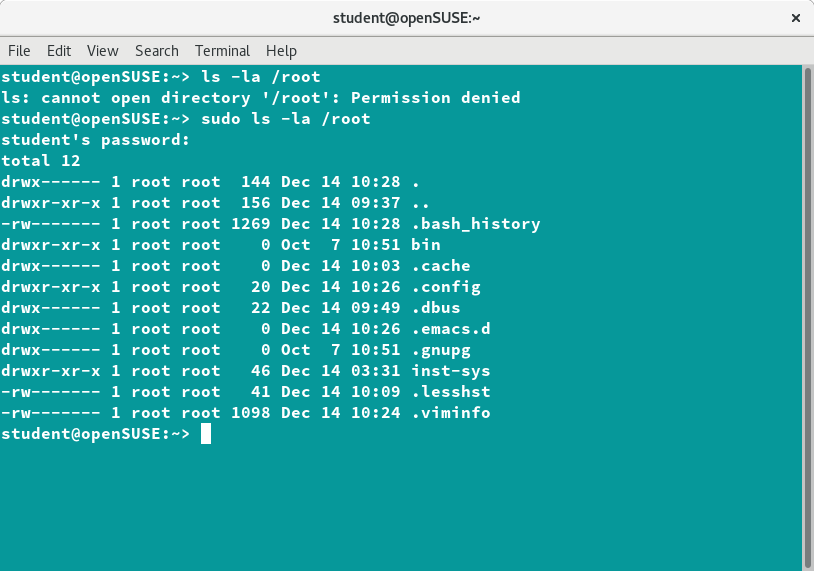
Variabili di Ambiente
Le variabili di ambiente sono elementi che hanno valori specifici che possono essere utilizzati dalla shell di comando, come bash o altre utility e applicazioni. Alcune variabili di ambiente sono fornite con valori preimpostati dal sistema (che di solito possono essere sovrascritti), mentre altre sono impostate direttamente dall'utente, dalla riga di comando o all'interno di script di avvio o altri.
Una variabile di ambiente è in realtà solo una stringa di caratteri che contiene informazioni utilizzate da una o più applicazioni. Esistono diversi modi per visualizzare i valori delle variabili di ambiente attualmente impostate; si può digitare set, env, oppure export. A seconda dello stato del tuo sistema, set potrebbe stampare molte più righe rispetto agli altri due metodi.
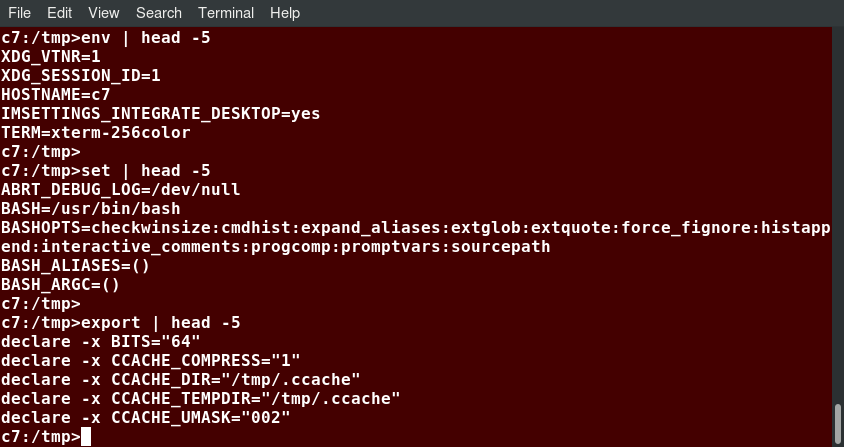
Impostare Variabili di Ambiente
Per impostazione predefinita, le variabili create all'interno di uno script sono disponibili solo per la shell corrente; i processi figlio (sub-shell) non avranno accesso ai valori che sono stati impostati o modificati. Consentire ai processi figlio di vedere i valori richiede l'uso del comando export.
| Attività | Comando |
|---|---|
| Mostra il valore di una variabile specifica | echo $SHELL |
| Esporta un nuovo valore di variabile | export VARIABILE=valore (oppure VARIABILE=valore; export VARIABILE) |
| Aggiunge una variabile permanentemente | Modifica ~/.bashrc, aggiungi la riga export VARIABILE=valoreSalva, esci, quingi digita source ~/.bashrc oppure solo . ~/.bashrc (puntino ~/.bashrc); oppure semplicemente avvia una nuova shell digitando bash |
È inoltre possibile impostare le variabili di ambiente da passare una tantum a un comando in questo modo:
$ SDIRS=s_0* KROOT=/lib/modules/$(uname -r)/build make modules_install
che passa i valori delle variabili di ambiente SDIRS e KROOT al comando make modules_install.
La Variabile HOME
HOME è una variabile di ambiente che rappresenta la directory home (o di accesso) dell'utente. cd senza argomenti cambierà la directory di lavoro corrente secondo il valore di HOME. Nota che il carattere tilde (~) è spesso usato come abbreviazione per $HOME. Pertanto, cd $HOME e cd ~ sono istruzioni esattamente equivalenti.
| Commndo | Spiegazione |
|---|---|
$ echo $HOME/home/me$ cd /bin |
Mostra il valore della variabile di ambiente HOME, poi cambia directory (cd) verso /bin. |
$ pwd<br>/bin |
Dove siamo? Usa pwd - print working directory (stampa directory corrente) - per scoprirlo. Come previsto, /bin. |
$ cd$ pwd/home/me |
Va alla directory definita in $HOME, come puoi vedere |
La videata seguente dimostra quanto sopra.
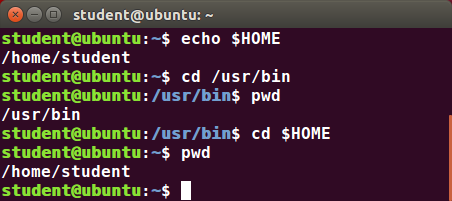
La Variabile PATH
PATH è un elenco ordinato di directory (il percorso - path) che viene scorso quando viene usato un comando per trovare il programma o lo script appropriato da eseguire. Ogni directory nel percorso è separata dal simbolo dei due punti (:). Un nome directory null (vuoto) (oppure ./) indica la directory corrente in qualsiasi momento.
- :percorso1:percorso2
- percorso1::percorso2
Nell' esempio in :percorso1:percorso2, c'è una directory vuota prima del primo (:). Allo stesso modo, per percorso1::percorso2 c'è una directory vuota tra percorso1 e percorso2.
Per inserire all'inizio del tuo percorso una tua directory bin privata:
$ export PATH=$HOME/bin:$PATH$ echo $PATH/home/student/bin:/usr/local/bin:/usr/bin:/bin/usr
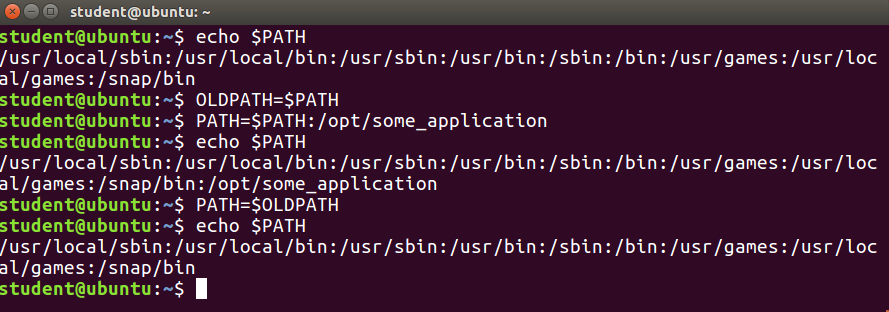
La Variabile SHELL
La variabile di ambiente SHELL punta alla shell di comando predefinita dell'utente (il programma che gestisce qualunque cosa si digiti in una finestra di comando, di solito bash) e contiene il nome del percorso completo della shell:
$ echo $SHELL/bin/bash$

La Variabile PS1 e il Prompt di Riga di Comando
L'istruzione prompt (PS) viene utilizzata per personalizzare la stringa del tuo prompt nelle finestre del terminale per visualizzare le informazioni desiderate.
PS1 è la variabile del prompt primario che controlla l'aspetto del prompt della riga di comando. I seguenti caratteri speciali possono essere inclusi in PS1:
\u - Nome utente\h - Nome host\w - Directory di lavoro corrente\! - Numero di cronologia di questo comando\d - Data
Devono essere racchiusi tra apici singoli quando vengono utilizzati, come nel seguente esempio:
$ echo $PS1$$ export PS1='\u@\h:\w$ 'student@example.com:~$ # nuovo prompt
Per annullare le modifiche:
student@example.com:~$ export PS1='$ '$
Una pratica ancora migliore sarebbe quella di salvare prima il vecchio prompt e poi ripristinarlo, così:
$ OLD_PS1=$PS1
modificare il prompt, ed eventualmente ritornare alla vecchia versione con:
$ PS1=$OLD_PS1$
Richiamare Comandi Precdenti
bash tiene traccia dei comandi e delle istruzioni precedentemente inserite in un buffer di cronologia. È possibile recuperare comandi precedentemente impartiti semplicemente usando i tasti del cursore FrecciaSu e FrecciaGiù. Per visualizzare l'elenco dei comandi precedentemente eseguiti, puoi semplicemente digitare history nella riga di comando.
L'elenco dei comandi viene visualizzato con il comando più recente che appare come ultimo nell'elenco. Queste informazioni sono salvate in ~/.bash_history. Se sono aperti più terminali, i comandi digitati in ciascuna sessione non vengono salvati fino a quando la sessione non termina.
Usare le Variabili di Ambiente della Cronologia
Diverse variabili di ambiente possono essere utilizzate per ottenere informazioni sul file che contiene la cronologia.
- HISTFILE
La posizione del file di cronologia - HISTFILESIZE
Il numero massimo di righe nel file di cronologia (valore predefinito 500). - HISTSIZE
Il numero massimo di comandi nel file di cronologia. - HISTCONTROL
Come sono conservati i comandi. - HISTIGNORE
Quali righe di comando possono essere ignorate.
Per una descrizione completa dell'uso di queste variabili di ambiente, consultare man bash.
Trovare e Usare Comandi Precedenti
Tasti specifici per eseguire varie attività:
| Tasto | Utilizzo |
|---|---|
| Tasti FrecciaSu/FrecciaGiù | Scorrono la lista dei comandi precedentemente eseguiti |
| !!(Pronunciato bang-bang) | Esegue il comando precedente |
| CTRL-R | Cerca comandi precedentemente usati |
Se si desidera richiamare un comando nell'elenco della cronologia, ma non si desidera premere ripetutamente il tasto freccia, è possibile premere CTRL-R per effettuare una ricerca intelligente all'indietro.
Quando inizi a digitare, la ricerca risale in ordine inverso al primo comando che corrisponde alle lettere che hai digitato. Digitando più lettere successive, si rende sempre più specifica la corrispondenza.
Quello che segue è un esempio di come è possibile utilizzare il comando CTRL-R per cercare attraverso la cronologia dei comandi:
| $ ^R | (Tutto ciò accade su 1 riga) |
(reverse-i-search)'s': sleep 1000 |
(Cerco 's'; corrispondenza con "sleep") |
| $ sleep 1000 | (Premuto Invio per eseguire il comando cercato) |
| $ |
Eseguire Comandi Precedenti
La tabella descrive la sintassi utilizzata per eseguire comandi precedentemente usati:
| Sintassi | Attività |
|---|---|
| ! | Inizia una sostituzione dalla cronologia |
| !$ | Fa riferimento all'ultimo argumento in una riga |
| !n | Fa riferimento all'ennesima riga di comando |
| !stringa | Fa riferimento al comando più recente che inizia con stringa |
Tutte le sostituzioni della cronologia iniziano con !. Quando digiti il comando: ls -l /bin /etc /var, !$ farà riferimento a /var, l'ultimo argomento della riga di comando.
Ecco altri esempi:
$ history
echo $SHELLecho $HOMEecho $PS1ls -als -l /etc/ passwdsleep 1000history
$ !1 |
(Esegue il comando n. 1 qui sopra) |
echo $SHELL |
|
/bin/bash |
|
| $ !sl | (Esegue il comando che inizia con "sl") |
sleep 1000 |
|
$ |
Scorciatoie da Tastiera
È possibile utilizzare le scorciatoie da tastiera per eseguire rapidamente attività diverse. La tabella elenca alcune di queste scorciatoie da tastiera e i loro usi. Nota non c'è distinzione tra lettere maiuscole e minuscole, per esempio digitare CTRL-a è uguale a CTRL-A .
| Scorciatoia da Tastiera | Attività |
|---|---|
CTRL-L |
Pulisce lo schermo |
CTRL-D |
Esce dalla shell corrente |
CTRL-Z |
Mette l'attuale processo in background sospeso |
CTRL-C |
Uccide il processo attuale |
CTRL-H |
Funziona come il tasto Backspace |
CTRL-A |
Va all'inizio della riga |
CTRL-W |
Elimina la parola prima del cursore |
CTRL-U |
Elimina dalla posizione del cursore fino all'inizio della riga |
CTRL-E |
Va alla fine della riga |
Tab |
Auto-completa file, directory e binari |
Proprietà di un File
In Linux e altri sistemi operativi basati su Unix, ogni file è associato a un utente che è il proprietario. Ogni file è anche associato a un gruppo (un sottoinsieme di tutti gli utenti) che ha un interesse per il file e alcuni diritti o autorizzazioni: letture, scrittura ed esecuzione.
I seguenti programmi di utilità riguardano la proprietà di utente e gruppo e le impostazioni dei permessi:
| Comando | Utilizzo |
|---|---|
chown |
Utilizzato per cambiare l'utente proprietario di un file o una directory |
chgrp |
Utilizzato per cambiare la proprietà del gruppo |
chmod |
Utilizzato per cambiare i permessi sul file, che può essere fatto separatamente per proprietario (owner),gruppo (group) e tutti gli altri (other) |
Modalità di Permessi del File e chmod
I file hanno tre tipi di permessi: lettura (r), scrittura (w), esecuzione (x). Questi sono generalmente rappresentati come rwx. Questi permessi sono relativi a tre gruppi di proprietari: utente/proprietario (u), gruppo (g), e altri (o).
Di conseguenza, hai i seguenti tre gruppi di tre tipi di permesso:
rwx rwx rwxu g o
Esistono diversi modi per usare chmod. Ad esempio, per dare al proprietario e ad altri i permessi di esecuzione e rimuovere il permesso di scrittura per il gruppo:
$ ls -l somefile-rw-rw-r-- 1 student student 1601 Mar 9 15:04 somefile$ chmod uo+x,g-w somefile$ ls -l somefile-rwxr--r-x 1 student student 1601 Mar 9 15:04 somefile
dove u sta per utente (proprietario), o per altri, e g per gruppo.
Questo tipo di sintassi può essere difficile da digitare e ricordare, quindi si usa spesso una scorciatoia che ti consente di impostare tutte le autorizzazioni in un solo passaggio. Questo viene fatto con un semplice algoritmo e una singola cifra è sufficiente per specificare tutti e tre i bit di autorizzazione per ciascuna entità. Questa cifra è la somma di:
- 4 se si richiede il permesso di lettura
- 2 se si richiede il permesso di scrittura
- 1 se si richiede il permesso di esecuzione
Di conseguenza, 7 significa leggi/scrivi/esegui, 6 significa leggi/scrivi, e 5 significa leggi/esegui.
Quando lo applichi al comando chmod, devi passare tre cifre, una per ogni soggetto (utente, gruppo, altri), in questo modo:
$ chmod 755 somefile$ ls -l somefile-rwxr-xr-x 1 student student 1601 Mar 9 15:04 somefile
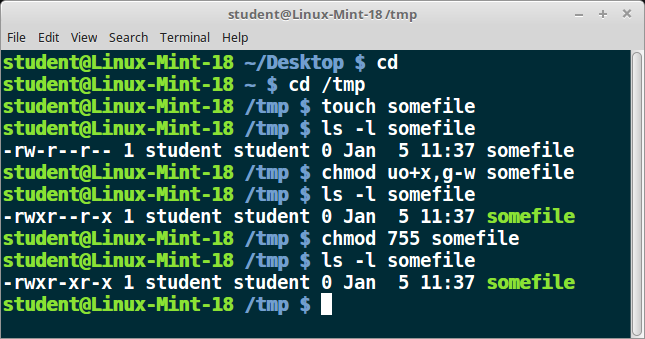
Esempi di chown
Vediamo un esempio di modifica della proprietà del file utilizzando chown, come mostrato nella successiva videata. Innanzitutto, creiamo due file vuoti utilizzando touch.
Nota che serve sudo per modificare il proprietario di file2 in root. Il secondo comando chown modifica allo stesso tempo sia il proprietario che il gruppo!
Infine, solo il superutente può rimuovere i file.
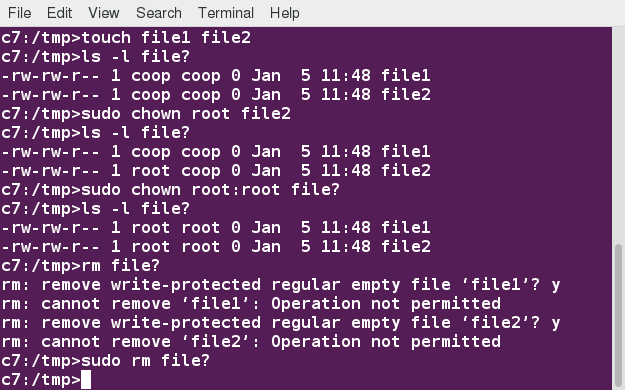
Esempio di chgrp
Nella videata seguente vediamo un esempio di modifica della proprietà del gruppo utilizzando chgrp, il gruppo per file1 viene modificato in bin:
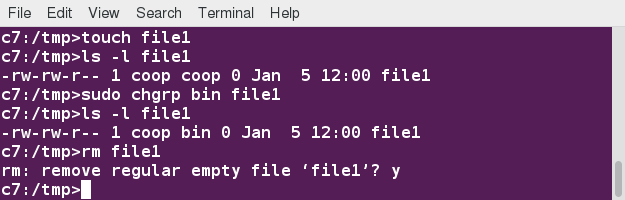
Riepilogo del Capitolo
Hai completato il capitolo 12. Riassumiamo i concetti chiave trattati:
- Linux è un sistema multiutente.
- Per trovare gli utenti attualmente connessi, puoi utilizzare il comando who.
- Per trovare l'ID utente corrente, è possibile utilizzare il comando whoami.
- L'account root ha pieno accesso al sistema. Non è mai ragionevole concedere l'accesso completo a un utente.
- Puoi assegnare i privilegi di root agli account utente regolari su base temporanea utilizzando il comando sudo.
- Il programma shell (bash) utilizza più file di avvio per creare l'ambiente utente. Ogni file influisce sull'ambiente interattivo in modo diverso.
/etc/profilefornisce le impostazioni globali. - I vantaggi dei file di avvio includono la personalizzazione del prompt dell'utente, l'impostazione del tipo di terminale dell'utente, l'impostazione delle scorciatoie e degli alias della linea di comando, l'impostazione dell'editor di testo predefinito, ecc.
- Una variabile di ambiente è una stringa di caratteri che contiene i dati utilizzati da una o più applicazioni. Le variabili di shell integrate possono essere personalizzate per soddisfare le tue esigenze.
- Il comando history richiama un elenco di comandi precedenti, che possono essere modificati e riciclati.
- In Linux, varie scorciatoie da tastiera possono essere utilizzate nel prompt dei comandi al posto dei comandi effettivi.
- Puoi personalizzare i comandi creando alias. Aggiungendo un alias a
~/.bashrclo renderai disponibile per tutte le altre shell. - I permessi di un file possono essere modificati digitando
chmod permessi nomefile. - La proprietà di un file può essere modificata digitando
chown propietario nomefile. - La proprietà di gruppo per un file può essere modificata digitando
chgrp gruppo nomefile.

Capitolo 13: Manipolare i File
Video: Manipolare i File di Testo
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Visualizzare e aggiungere contenuto a un file usando cat ed echo.
- Modificare e stampare il contenuto di un file usando sed e awk.
- Cercare modelli di testo usando grep.
- Usare ulteriori utility per la manipolazione di file e testo.
Strumenti da Riga di Comando per Manipolare File di Testo
Indipendentemente dal ruolo che svolgi con Linux (amministratore di sistema, sviluppatore o utente), spesso è necessario sfogliare e analizzare i file di testo e/o estrarre dati da essi. Queste sono operazioni di manipolazione dei file. Pertanto, è essenziale che l'utente Linux diventi abile nell'esecuzione di determinate operazioni sui file.
Il più delle volte, tale manipolazione dei file viene eseguita dalla riga di comando, il che consente agli utenti di eseguire attività in modo più efficiente rispetto all'utilizzo di una GUI. Inoltre, la riga di comando è più adatta per l'automazione delle attività eseguite frequentemente.
In effetti, gli amministratori di sistema esperti scrivono script personalizzati per svolgere tali compiti ripetitivi, standardizzati per ciascun ambiente particolare. Discuteremo di tale scripting più avanti con molti dettagli.
In questa sezione, ci concentreremo sui file da riga di comando e sulle utility utilizzate per la manipolazione del testo.
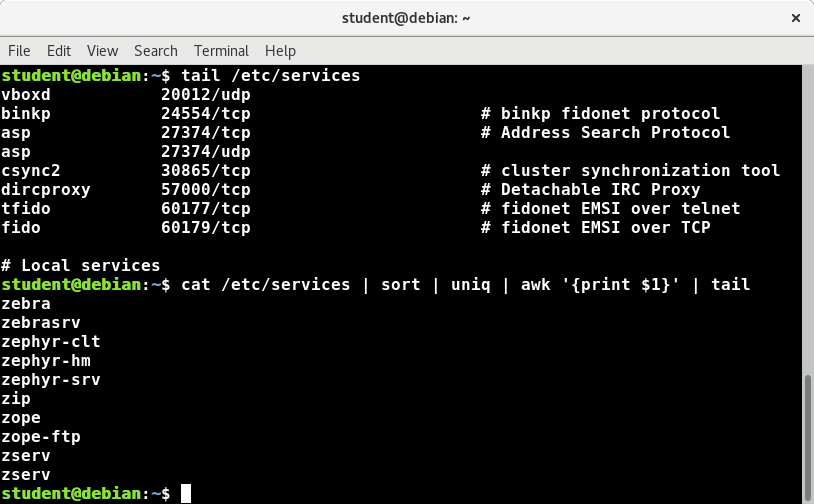
cat
cat è l'abbreviazione di concatenate (concatenare) ed è una delle utility da riga comando Linux più frequentemente utilizzate per leggere e stampare i file, nonché per la semplice visualizzazione dei contenuti dei file. Per visualizzare un file, esegui il comando seguente:
$ cat <nomefile>
Per esempio, cat readme.txt visualizzerà il contenuto di readme.txt nel terminale. Tuttavia, lo scopo principale di cat è spesso di combinare più file (concatenarli). È possibile eseguire le azioni elencate nella tabella che segue utilizzando cat.
Il comando tac (cat al contrario) stampa le righe di un file in ordine inverso. Ogni riga rimane la stessa, ma l'ordine delle righe è invertito. La sintassi di tac è esattamente la stessa di cat, per esempio:
$ tac file$ tac file1 file2 > nuovofile
| Comando | Utilizzo |
|---|---|
cat file1 file2 |
Concatena più file e visualizza il risultato; vale a dire l'intero contenuto del primo file seguito da quello del secondo file |
cat file1 file2 > nuovofile |
Combina più file e salva il risultato in un nuovo file |
cat file >> fileesistente |
Accoda un file alla fine di un file esistente |
cat > file |
Qualunque riga digitata verrà scritta in file, fino a quando non viene digitato CTRL-D |
cat >> file |
Qualunque riga digitata viene aggiunta a file, fino a quando non viene digitato CTRL-D |
Usare cat Interattivamente
cat può essere utilizzato per leggere dall'input standard (come la finestra del terminale) se non vengono specificati file. Puoi usare l'operatore > Per creare e aggiungere righe in un nuovo file, e l'operatore >> per aggiungere righe (o file) a un file esistente. L'abbiamo menzionato parlando di come creare file senza un editor.
Per creare un nuovo file, al prompt dei comandi digita cat > <nomefile> poi premi Invio.
Questo comando crea un nuovo file e attende che l'utente modifichi/inserisca il testo. Dopo che hai finito di digitare il testo richiesto, digita CTRL-D all'inizio della riga successiva per salvare il file e tornare al prompt dei comandi.
Un altro modo per creare un file nel terminale è cat > <nomefile> << EOF. Viene creato un nuovo file e puoi inserire il contenuto desiderato. Per uscire, digita EOF all'inizio di una riga.
Nota che EOF deve essere maiuscolo. Puoi anche usare un'altra parola, come STOP.
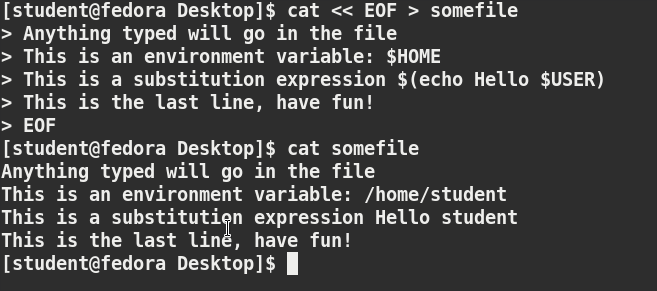
Video: Usare cat
Lavorare con File di Grandi Dimensioni
Gli amministratori di sistema devono lavorare con file di configurazione, file di testo, file di documentazione e file di log. Alcuni di questi file possono essere grandi o diventare piuttosto grandi in quanto accumulano dati con il tempo. Questi file richiederanno sia la visualizzazione che l'aggiornamento amministrativo. In questa sezione, imparerai come gestire file così grandi.
Ad esempio, un sistema bancario potrebbe mantenere un semplice file di log di grandi dimensioni per registrare i dettagli di tutte le transazioni bancomat di un giorno. A causa di un attacco di sicurezza o di un malfunzionamento, l'amministratore potrebbe essere costretto a verificare alcuni dati navigando all'interno del file. In tali casi, l'apertura diretta del file in un editor causerà problemi, a causa dell'elevato utilizzo della memoria, poiché un editor di solito proverà a leggere prima l'intero file in memoria. Tuttavia, si può usare less per visualizzare il contenuto di un file così grande, scorrere su e giù pagina per pagina, senza che il sistema debba posizionare l'intero file in memoria prima di iniziare. Questo è molto più veloce che usare un editor di testo.

Per visualizzare un file chiamato somefile si può digitare uno dei seguenti comandi:
$ less somefile$ cat somefile | less
Per impostazione predefinita, le pagine di manuale sono visualizzate tramite il comando less. Potresti avere incontrato l'utility più vecchia more che ha la stessa funzione di base ma meno funzionalità.
head
head legge le prime righe (10 per impostazione predefinita) di ciascun file indicato come argomento, e le visualizza sull'output standard. Puoi passare un numero diverso di righe come opzione.
Ad esempio, se vuoi stampare le prime 5 righe da /etc/default/grub, usa il seguente comando:
$ head –n 5 /etc/default/grub
Puoi anche semplicemente digitare:
head -5 /etc/default/grub
tail
tail stampa le ultime righe di ciascun file passato come argomento e lo visualizza sull'output standard. Per impostazione predefinita, visualizza le ultime 10 righe. Puoi passare un numero diverso di righe come opzione. tail è particolarmente utile quando stai cercando di risolvere qualunque tipo di problema usando i file di log, poiché probabilmente vorrai vedere le righe più recenti di output.
Ad esempio, per visualizzare le ultime 15 righe di somefile.log, usa il seguente comando:
$ tail -n 15 somefile.log
Puoi anche semplicemente digitare:
tail -15 somefile.log
Per monitorare continuamente un nuovo output in un file di log al quale vengono aggiunti dati:
$ tail -f somefile.log
Questo comando visualizzerà continuamente qualsiasi nuova riga venga inserita in somefile.log non appena essa appare. Pertanto ti consente di monitorare qualsiasi attività corrente che venga segnalata e registrata.
Visualizzare File Compressi
Quando si lavora con file compressi, molti comandi standard non possono essere utilizzati direttamente. Per molti programmi di manipolazione di file e di testo comunemente utilizzati, esiste anche una versione appositamente progettata per funzionare direttamente con i file compressi. Queste utility associate hanno la lettera "z" prefissata al loro nome. Ad esempio, abbiamo programmi di utilità come zcat, zless, zdiff e zgrep.
Ecco una tabella che elenca alcuni comandi della famiglia z:
| Comando | Description |
|---|---|
$ zcat file-compresso.txt.gz |
Per visualizzare un file compresso |
$ zless somefile.gzoppure $ zmore somefile.gz |
Per visualizzare e spostarsi in un file compressso |
$ zgrep -i less somefile.gz |
Per cercare all'interno di un file compresso |
$ zdiff file1.txt.gz file2.txt.gz |
Per confrontare due file compressi |
Nota che se esegui zless su un file non compresso, funzionerà comunque e ignorerà la fase di decompressione. Esistono anche programmi di utilità equivalenti per altri metodi di compressione oltre a gzip, ad esempio, abbiamo bzcat e bzless associati a bzip2, e xzcat e xzless associati a xz.
Introduzione a sed e awk
È molto comune creare e quindi modificare ripetutamente e/o estrarre contenuti da un file. Impariamo come usare sed e awk per eseguire facilmente tali operazioni.

Tieni presente che molti utenti e amministratori Linux scriveranno script utilizzando linguaggi di scripting completi come Python e Perl, piuttosto che usare sed e awk (e alcune altre utility che discuteremo più avanti). L'uso di tali utility va sicuramente bene nella maggior parte dei casi; bisognerebbe sempre essere liberi di usare gli strumenti con cui si ha dimestichezza. Tuttavia, le utility che vengono descritte qui sono molto più leggere; cioè usano meno risorse di sistema e hanno tempi di esecuzione più veloci. Ci sono situazioni (come durante l'avvio del sistema) in cui molto tempo sarebbe sprecato utilizzando gli strumenti più complicati e il sistema potrebbe non essere nemmeno in grado di eseguirli. Quindi, gli strumenti più semplici saranno sempre necessari.
sed
sed è un potente strumento di elaborazione del testo ed è una delle utility UNIX più antiche e popolari. Viene utilizzato per modificare il contenuto di un file o un flusso in input, di solito posizionando il contenuto in un nuovo file o flusso di output. Il suo nome è un'abbreviazione per stream editor.
sed può filtrare il testo e eseguire sostituzioni nei flussi di dati.
I dati da una sorgente/file di input (o flusso) vengono presi e spostati in uno spazio di lavoro. L'intero elenco di operazioni/modifiche viene applicato sui dati nello spazio di lavoro e il contenuto finale viene immesso nello standard output (o flusso).
La Sintassi del Comando sed
Puoi eseguire sed usando comandi come quelli elencati nella tabella seguente.
| Comando | Utilizzo |
|---|---|
sed -e comando <nomefile> |
Specifica i comandi di modifica nella riga di comando, opera sul file e inserisce il risultato nello standard output (ad esempio il terminale) |
sed -f scriptfile <nomefile> |
Specifica un file di script che contiene i comandi sed, opera sul file e inserisce il risultato nello standard output |
echo "Ti odio" \| sed s/odio/amo/ |
Usa sed per filtrare lo standard input e inserisce il risultato nello standard output |
L'opzione -e consente di specificare simultaneamente più comandi di modifica nella riga di comando. Non è necessario se hai solo un'operazione da effettuare.
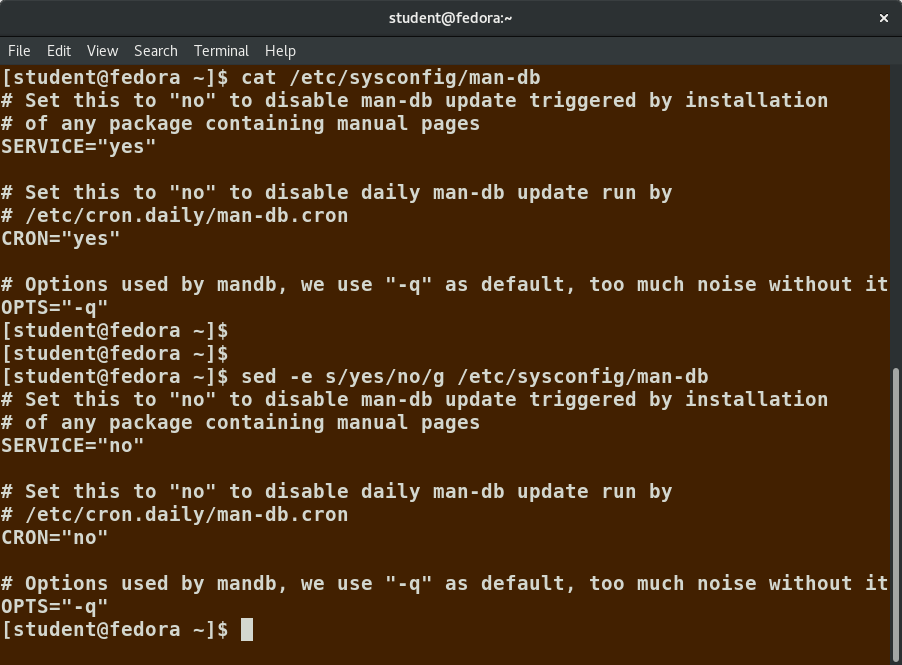
Operazioni di Base di sed
Ora che sai che puoi eseguire più operazioni di editing e filtraggio con sed, illustriamo alcune di esse in modo più dettagliato. La tabella spiega alcune operazioni di base, dove pattern è la stringa corrente e replace_string è la nuova stringa:
| Comando | Utilizzo |
|---|---|
sed s/pattern/replace_string/ file |
Sostituisce la prima occorrenza della stringa in ciascuna riga |
sed s/pattern/replace_string/g file |
Sostituisce tutte le occorrenze della stringa in ciascuna riga |
sed 1,3s/pattern/replace_string/g file |
Sostituisce tutte le occorrenze della stringa in un intervallo di righe |
sed -i s/pattern/replace_string/g file |
Salva le modifiche per le stringhe sostituite nello stesso file |
Devi usare l'opzione -i con accortezza, in quanto l'azione non è reversibile. È sempre più sicuro usare sed senza l'opzione –i poi sostituire tu stesso il file, come mostrato nell'esempio seguente:
$ sed s/pattern/replace_string/g file1 > file2
Il comando qui sopra sostituirà tutte le occorrenze di pattern con replace_string in file1 e sposterà il contenuto in file2. Il contenuto di file2 può essere visualizzato con cat file2. Se approvi, puoi quindi sovrascrivere il file originale con mv file2 file1.
Esempio: per sostituire 01/02/… con JAN/FEB/… (il numero del mese con il nome del mese abbreviato - in inglese)
sed -e 's/01/JAN/' -e 's/02/FEB/' -e 's/03/MAR/' -e 's/04/APR/' -e 's/05/MAY/' \
-e 's/06/JUN/' -e 's/07/JUL/' -e 's/08/AUG/' -e 's/09/SEP/' -e 's/10/OCT/' \
-e 's/11/NOV/' -e 's/12/DEC/'**
Video: Usare sed
awk
awk viene utilizzato per estrarre e quindi stampare contenuti specifici di un file e viene spesso utilizzato per costruire report. È stato creato dall'azienda Bell Labs negli anni '70 e deriva il suo nome dalle iniziali del cognome dei suoi autori: Alfred Aho, Peter Weinberger e Brian Kernigan.
awk ha le seguenti funzionalità:
- È una potente utilità e un linguaggio di programmazione interpretato.
- Viene utilizzato per manipolare i file di dati e per il recupero e l'elaborazione del testo.
- Funziona bene con i campi (contenenti un singolo pezzo di dati, essenzialmente una colonna) e record (una raccolta di campi, essenzialmente una riga in un file).
awk viene usato come mostrato qui sotto:
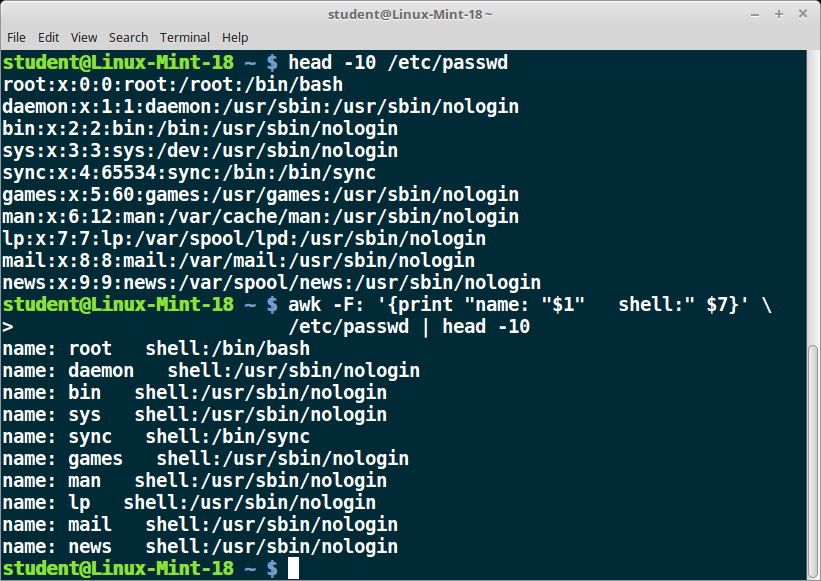
Come per sed, brevi comandi per awk possono essere specificati direttamente nella riga di comando, ma uno script più complesso può essere salvato in un file che è possibile passare come argomento per l'opzione -f.
| Comando | Utilizzo |
|---|---|
awk ‘comando’ file |
Specifica un comando direttamente sulla riga di comando |
awk -f scriptfile file |
Specifica un file che contiene lo script da eseguire |
Operazioni di Base di awk
La tabella spiega le attività di base che possono essere eseguite utilizzando awk. Il file di input viene letto una riga alla volta e, per ogni riga, awk cerca corrispondenza con il dato modello nel dato ordine ed esegue l'azione richiesta. L'opzione -F consente di specificare un particolare carattere come separatore di campo. Ad esempio, il file /etc/passwd usa ":" per separare i campi, quindi, con il file /etc/passwd viene usata l'opzione -F:.
Il comando/azione in awk deve essere racchiuso da apostrofi (o virgolette singole (')). awk può essere usato come segue:
| Comando | Utilizzo |
|---|---|
awk '{ print $0 }' /etc/passwd |
Stampa l'intero file |
awk -F: '{ print $1 }' /etc/passwd |
Stampa il primo campo (colonna) di ogni riga, separato da ":" |
awk -F: '{ print $1 $7 }' /etc/passwd |
Stampa il primo e settimo campo di ogni riga |
Utillity di Manipolazione File
Nella gestione dei file, potrebbe essere necessario eseguire attività come l'ordinamento dei dati e la copia dei dati da una posizione all'altra. Linux fornisce numerose utility di manipolazione dei file che è possibile utilizzare mentre si lavora con i file di testo. In questa sezione, imparerai i seguenti programmi di manipolazione dei file:
- sort
- uniq
- paste
- join
- split
Imparerai anche le espressioni regolari e i pattern di ricerca.

sort
sort viene utilizzato per riorganizzare le righe di un file di testo, in ordine crescente o discendente secondo una chiave di ordinamento. È inoltre possibile ordinare rispetto a campi particolari (colonne) in un file. La chiave di ordinamento predefinita è l'ordine dei caratteri ASCII (cioè essenzialmente l'ordine alfabetico).
sort può essere usato come segue:
| Sintassi | Utilizzo |
|---|---|
sort <nomefile> |
Ordina le righe nel file specificato, secondo i caratteri all'inizio di ogni riga |
cat file1 file2 | sort |
Combina due file, poi ordina le righe e visualizza il risultato nel terminale |
sort -r <nomefile> |
Ordina le righe in ordine inverso |
sort -k 3 <nomefile> |
Ordina le righe in base al terzo campo su ogni riga invece che dall'inizio |
Se usato con l'opzine -u, sort verifica che i valori siano univoci dopo l'ordinamento dei record (righe). È l'equivalente dell'esecuzione di uniq (di cui discuteremo) sul risultato di sort.
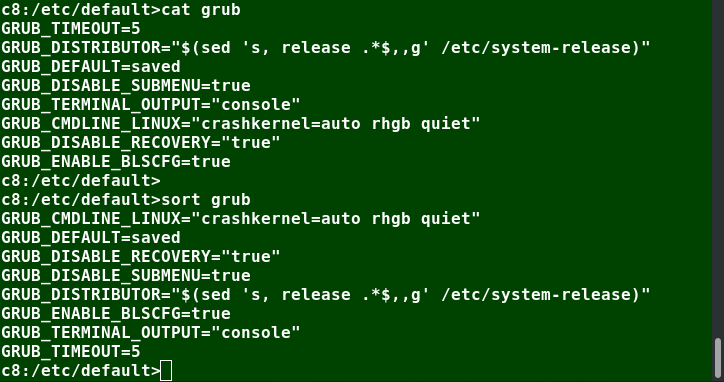
uniq
uniq rimuove le righe consecutive duplicate in un file di testo ed è utile per semplificare la visualizzazione del testo.
Poichè uniq richiede che le voci duplicate debbano essere consecutive, si esegue spesso un ordinamento prima e quindi tramite pipe (|) si indirizza l'uscita in uniq; se l'ordinamento viene utilizzato con l'opzione -u, può fare tutto questo in un solo passo.
Per rimuovere le voci duplicate da più file alla volta, utilizza il comando seguente:
sort file1 file2 | uniq > file3
oppure
sort -u file1 file2 > file3
Per contare il numero di voci duplicate, utilizza il comando seguente:
uniq -c filename
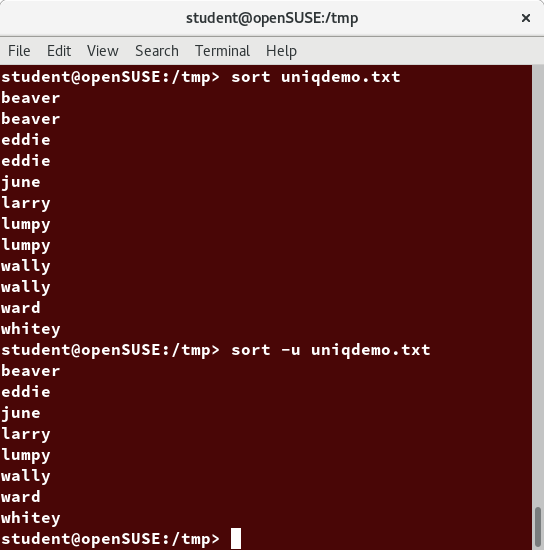
paste
Supponiamo di avere un file che contenga il nome completo di tutti i dipendenti e di un altro file che elenca i loro numeri di telefono e ID dipendente. Vuoi creare un nuovo file che contenga tutti i dati elencati in tre colonne: nome, ID dipendente e numero di telefono. Come puoi farlo in modo efficace senza investire troppo tempo?
paste può essere utilizzato per creare un singolo file contenente tutte e tre le colonne. Le diverse colonne sono identificate in base ai delimitatori (spaziatura utilizzata per separare due campi). Ad esempio, i delimitatori possono essere uno spazio vuoto, un carattere di tabulazione un carattere di ritorno a capo. Nell'immagine fornita, un singolo spazio viene utilizzato come delimitatore in tutti i file.
paste accetta le seguenti opzioni:
- -d delimitatori, specifica un elenco di delimitatori da utilizzare al posto dei caratteri di tabulazione per separare i valori consecutivi su una singola riga. Ogni delimitatore viene utilizzato a turno; quando l'elenco è stato consumato, paste ricomincia al primo delimitatore.
- -s, che fa sì che paste aggiunga i dati in serie piuttosto che in parallelo; cioè, in modo orizzontale piuttosto che verticale.
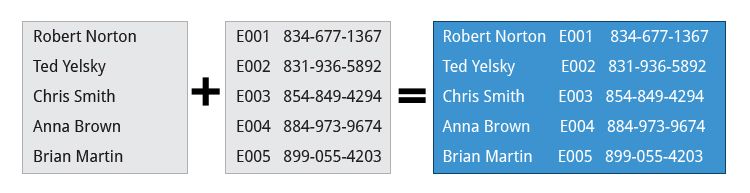
Usare paste
paste può essere utilizzato per combinare campi (come nome o numero di telefono) da file diversi, oltre a combinare righe da più file. Ad esempio, la riga uno da file1 può essere combinata con la riga uno di file2, la riga due da file1 può essere combinata con la riga due di file2 e così via.
Per unire i contenuti da due file puoi eseguire:
$ paste file1 file2
La sintassi per utilizzare un delimitatore diverso è la seguente:
$ paste -d, file1 file2
Delimitatori comuni sono spazio, tab, '|', ',', etc.
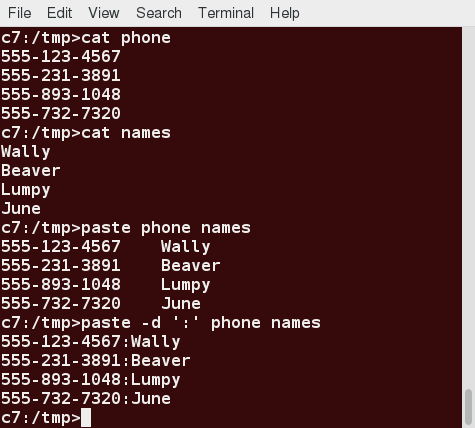
join
Supponi di avere due file con alcune colonne simili. Hai salvato i numeri di telefono dei dipendenti in due file, uno con il loro nome e l'altro con il loro cognome. Si desidera combinare i file senza ripetere i dati di colonne comuni. Come si raggiunge questo scopo?
L'attività di cui sopra può essere svolta usando join, che è essenzialmente una versione migliorata di paste. Prima controlla se i file condividono campi comuni, come nomi o numeri di telefono, quindi unisce le righe nei due file in base a un campo comune.
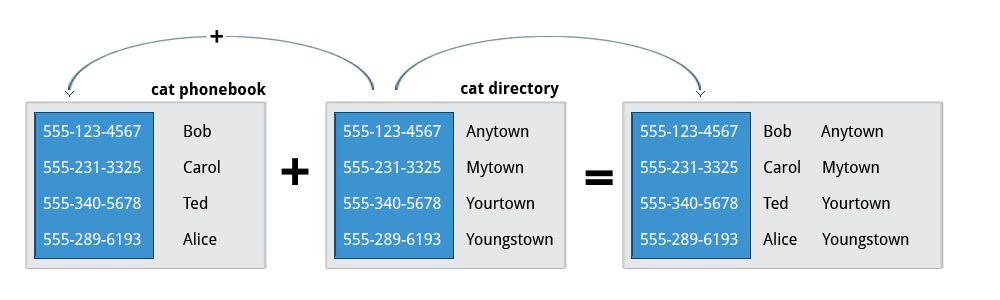
Usare join
Per combinare due file su un campo comune, al prompt dei comandi digita join file1 file2, poi Invio.
Ad esempio, il campo comune (ovvero contiene gli stessi valori) tra il file phonebook e cities è il numero di telefono, il risultato dell'unione di questi due file è mostrato nella seguente videata.
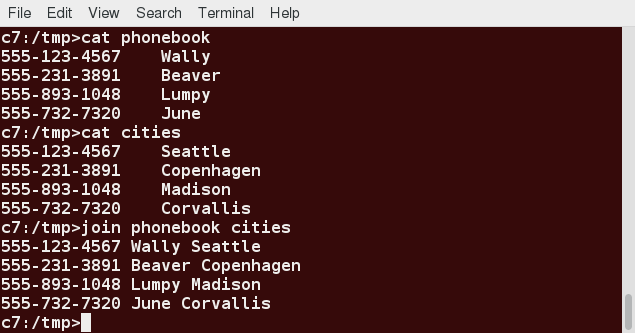
split
split viene utilizzato per spezzare (o dividere) un file in segmenti di dimensioni uguali per una visualizzazione e manipolazione più facili, e viene generalmente utilizzato solo su file relativamente grandi. Per impostazione predefinita, split rompe un file in segmenti di 1000 righe. Il file originale rimane invariato e viene creato un insieme di nuovi file con lo stesso nome più un prefisso aggiunto. Per impostazione predefinita, viene aggiunto il prefisso x. Per dividere un file in segmenti, utilizzare il comando split nomefile.
Per dividere un file in segmenti utilizzando un prefisso diverso, utilizzare il comando split nomefile <Prefisso>.
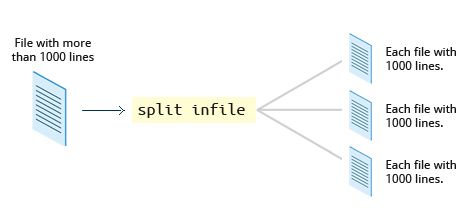
Usare split
Applicheremo split al file del dizionario American-English che contiene oltre 99,000 righe:
$ wc -l american-english99171 american-english
abbiamo usato il comando wc (conteggia parole, verrà discusso a breve) per ottenere il numero di righe nel file, poi digitando:
$ split american-english dictionary
divideremo il file American-English in 100 segmenti di uguale dimensione chiamati dictionaryxx. L'ultimo segmento sarà naturalmente in qualche modo più piccolo.
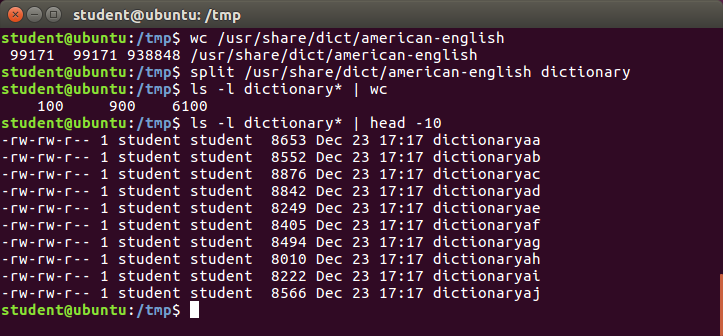
Espressioni Regolari e Modelli di Ricerca
Le espressioni regolari sono stringhe di testo utilizzate per trovare la corrispondenza con un modello specifico o per cercare una posizione specifica, come l'inizio o la fine di una riga o una parola. Le espressioni regolari possono contenere sia caratteri normali che i cosiddetti meta-caratteri, come * e $.
Molti editor e utility di testo come vi, sed, awk, find e grep lavorano ampiamente con espressioni regolari. Alcuni dei popolari linguaggi di programmazione che usano espressioni regolari includono Perl, Python e Ruby. Può diventare piuttosto complicato e ci sono interi libri scritti sulle espressioni regolari; quindi, non faremo altro che sfiorare la superficie qui.
Queste espressioni regolari sono diverse dai caratteri jolly (wildcard o meta-caratteri) utilizzati per la corrispondenza del nome file nelle shell di comando come bash (che abbiamo trattato nel capitolo 7, Operazioni da Riga di Comando). La tabella seguente elenca i modelli di ricerca e il loro utilizzo.
| Modello di Ricerca | Utilizzo |
|---|---|
. (punto) |
Corrispondenza con qualsiasi singolo carattere |
a|z |
Corrispondenza con a oppure z |
$ |
Corrispondenza con la fine di una riga |
^ |
Corrispondenza con l'inizio di una riga |
* |
Corrispondenza con l'elemento precedente 0 o più volte |
Usare le Espressioni Regolari e i Modelli di Ricerca
Considera per esempio la seguente frase: the quick brown fox jumped over the lazy dog.
Alcuni dei modelli che possono essere applicati a questa frase sono i seguenti:
| Modello | Utilizzo |
|---|---|
a.. |
corrispondenza con azy |
b.|j. |
corrispondenza sia con br che ju |
..$ |
corrispondenza con og |
l.* |
corrispondenza con lazy dog |
l.*y |
corrispondenza con lazy |
the.* |
corrispondenza con l'intera frase |
grep
grep è ampiamente utilizzato come strumento di ricerca di testo primario. Scorre un file cercando specifici modelli e può essere utilizzato con espressioni regolari, nonché stringhe semplici, come mostrato nella tabella:
| Comando | Utilizzo |
|---|---|
grep [pattern] <nomefile> |
Cerca il pattern in un file e stampa tutte le righe con cui c'è corrispondenza |
grep -v [pattern] <nomefile> |
Stampa tutte le righe che non trovano corrispondenza con pattern |
grep [0-9] <nomefile> |
Stampa le righe che contengono numeri (da 0 a9) |
grep -C 3 [pattern] <nomefile> |
Stampa un contesto di righe (un numero di righe specificato sopra e sotto pattern) quando trova corrispondenza. Qui il numero di righe specificato è 3 |
strings
strings viene utilizzato per estrarre tutte le stringhe di caratteri stampabili che si trovano nel file o nei file forniti come argomenti. È utile per individuare contenuti leggibili dall'uomo incorporati nei file binari; per i file di testo si può semplicemente utilizzare grep.
Ad esempio, per cercare la stringa my_string in un foglio di calcolo:$ strings book1.xls | grep my_string
La videata mostra una ricerca di una serie di programmi per vedere quali hanno licenze GPL di varie versioni.
tr
In questa sezione, imparerai alcune utility di testo aggiuntive che è possibile utilizzare per eseguire varie azioni sui file Linux, come sostituire maiuscole con minuscole e viceversa, o determinare il conteggio di parole, righe e caratteri in un file.
L'utility tr viene utilizzata per trasformare i caratteri specificati in altri caratteri o per eliminarli. La sintassi generale è la seguente:
$ tr [opzioni] set1 [set2]
Gli elementi tra parentesi quadre sono opzionali. tr richiede almeno un argomento e ne accetta un massimo di due. Il primo, denominato set1 nell'esempio, elenca i caratteri nel testo che devono essere sostituiti o rimossi. Il secondo, set2, elenca i caratteri che prenderanno il posto dei caratteri elencati come primo argomento. Talvolta il contenuto degli argomenti set1 e set2 deve essere racchiuso tra apostrofi (o apici singoli (')) in modo che la shell possa ignorare che essi hanno un signicato speciale per lei. È in genere sicuro (e potrebbe essere richiesto) l'uso di singoli apici attorno a ognuno di questi argomenti come vedrai negli esempi seguenti.
Ad esempio, supponi di avere un file denominato city che contiene parecchie righe di testo in maiuscolo e minuscolo. Per trasformare tutti i caratteri minuscoli in maiuscoli al prompt dei comandi digita cat city | tr a-z A-Z quindi premi Invio.
| Comando | Utilizzo |
|---|---|
tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ |
Converte minuscole in maiuscole |
tr '{}' '()' < inputfile > outputfile |
Trasforma parentesi graffe in parentesi tonde |
echo "This is for testing" | tr [:space:] '\t' |
Trasforma i white-space (spazi, ritorni a capo ecc.) in corrispondenti caratteri di tabulazione |
echo "This is for testing" | tr -s [:space:] |
Riduce a un singolo carattere le ripetizioni di caratteri specificati nell'opzione -s, in questo caso comprime tutti gli spazi |
echo "the geek stuff" | tr -d 't' |
Elimina i caratteri specificati usando l'opzione -d, in questo caso toglie tutte le "t" |
echo "my username is 432234" | tr -cd [:digit:] |
Conserva solo quanto non specificato nell'insieme di caratteri dell'opzione -c (in questo caso conserva solo i numeri) |
tr -cd [:print:] < file.txt |
Rimuove tutti i caratteri non stampabili da file.txt |
tr -s '\n' ' ' < file.txt |
Unisce tutte le righe in file.txt in una singola riga |
tee
tee riceve il risultato di qualunque comando e, mentre lo invia allo standard output, lo salva anche in un file. In altre parole genera due flussi con il risultato del comando: un flusso viene visualizzato nello standard output e un altro viene salvato su un file.
Per esempio per elencare il contenuto di una directory sullo schermo e salvare il risultato in un file, al prompt dei comandi digita ls -l | tee nuovofile poi premi Invio.
Digitando cat nuovofile verrà visualizzato il risultato di ls –l.
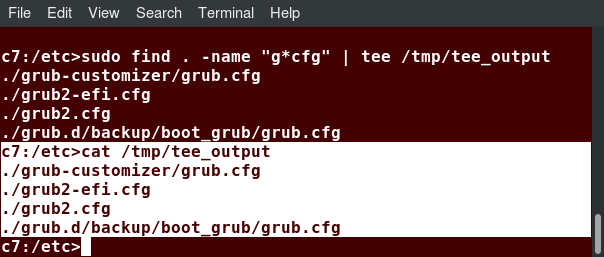
wc
wc (word count - conteggio parole) conta il numero di righe, parole e caratteri in un file o elenco di file. Le opzioni sono riportate nella tabella seguente.
| Opzione | Descrizione |
|---|---|
–l |
Visualizza il numero di righe |
-c |
Visualizza il numero di byte |
-w |
Visualizza il numero di parole |
Per impostazione predefinita, tutte e tre queste opzioni sono attive.
Ad esempio, per stampare solo il numero di righe contenute in un file, digita wc -l nomefile poi premi Invio.
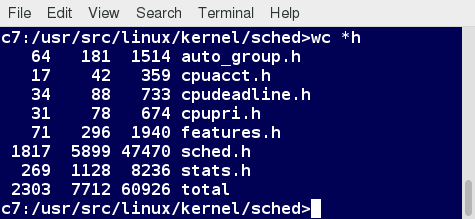
cut
cut viene utilizzato per manipolare i file basati su colonne ed è progettato per estrarre colonne specifiche. Il separatore di colonne predefinito è il carattere tab. Un delimitatore diverso può essere passato come opzione del comando.
Ad esempio, per visualizzare la terza colonna delimitata da uno spazio, digita al prompt dei comandi ls -l | cut -d" " -f3 poi premi Invio.
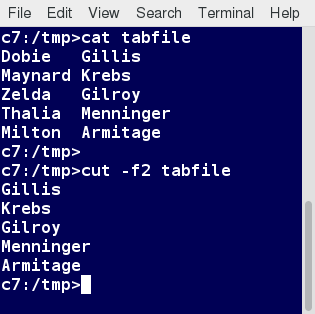
Riepilogo del Capitolo
Hai completato il capitolo 13. Riassumiamo i concetti chiave trattati:
- La riga di comando consente spesso agli utenti di eseguire attività in modo più efficiente rispetto alla GUI.
- cat, abbreviazione di concatenate, viene utilizzato per leggere, stampare e combinare file.
- echo visualizza una riga di testo sullo standard output oppure la scrive in un file.
- sed è un popolare editor di flusso spesso utilizzato per filtrare ed eseguire sostituzioni su file e flussi di dati di testo.
- awk è un linguaggio di programmazione interpretato, tipicamente utilizzato come strumento di estrazione e report di dati.
- sort viene utilizzato per ordinare i file di testo e l'output di flussi in ordine crescente o decrescente.
- uniq elimina le voci duplicate in un file di testo.
- paste combina campi da file diversi. Può anche estrarre e combinare righe da più fonti.
- join combina le righe da due file in base a un campo comune. Funziona solo se i file condividono un campo comune.
- split divide un file di grandi dimensioni in segmenti di dimensioni uguali.
- Le espressioni regolari sono stringhe di testo utilizzate per trovare corrispondenza con modelli di ricerca. Il modello può essere usato per cercare una posizione specifica, come l'inizio o la fine di una riga o una parola.
- grep cerca su file di testo e flussi di dati per modelli di ricerca e può essere utilizzato con espressioni regolari.
- tr trasforma caratteri, copia dallo standard input verso lo standard output e gestisce caratteri speciali.
- tee salva una copia dello standard output in un file mentre lo visualizza nel terminale.
- wc (word count - conteggio parole) visualizza il numero di righe, parole e caratteri in un file o un gruppo di file.
- cut estrae colonne da un file.
- less visualizza i file una schermata alla volta e consente di scorrere le schermate in entrambe le direzioni.
- head visualizza le prime righe di un file o un flusso di dati sullo standard output. Per impostazione predefinita, visualizza 10 righe.
- tail visualizza le ultime righe di un file o un flusso di dati sullo standard output. Per impostazione predefinita, visualizza 10 righe.
- strings estrae stringhe di caratteri stampabili da file binari.
- La famiglia di comandi z viene utilizzata per leggere e lavorare con file compressi.
Capitolo 14: Operazioni di Rete
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Spiegare i concetti di base delle reti, inclusi tipi di reti e problemi di risoluzione.
- Configurare le interfacce di rete e utilizzare le utility di rete base, come ad esempio ifconfig, ip, ping, route e traceroute.
- Utilizzare browser grafici e non grafici, come Lynx, w3m, Firefox, Chrome ed Epiphany.
- Trasferire i file da client a server e viceversa utilizzando sia applicazioni in modalità grafica che di testo, come Filezilla, ftp, sftp, curl e wget.
Introduzione alle Reti
Una rete è un gruppo di computer e dispositivi di elaborazione collegati tramite canali di comunicazione, come cavi o supporti wireless. I computer collegati su una rete possono trovarsi nella stessa area geografica o distribuiti in tutto il mondo.

Una rete è usata per:
- Consentire ai dispositivi collegati di comunicare tra loro.
- Abilitare più utenti alla condivisione di dispositivi sulla rete, come server musicali e video, stampanti e scanner.
- Condividere e gestire facilmente le informazioni attraverso i computer.
La maggior parte delle organizzazioni ha sia una rete interna che una connessione Internet che consente agli utenti di comunicare con macchine e persone al di fuori dell'organizzazione. Internet è la più grande rete del mondo e può essere chiamata "La rete delle reti".
Indirizzi IP
I dispositivi collegati a una rete devono avere almeno un identificativo di indirizzo di rete univoco noto come IP (Protocollo Internet). L'indirizzo è essenziale per instradare pacchetti di informazioni attraverso la rete.
Lo scambio di informazioni attraverso la rete richiede l'utilizzo di flussi di piccoli pacchetti, ognuno dei quali contiene un pezzo delle informazioni che vanno da una macchina all'altra. Questi pacchetti contengono buffer di dati, insieme alle intestazioni che contengono informazioni circa la destinazione e la provenienza dei pacchetti e il modo in cui si adattano alla sequenza di pacchetti che costituisce il flusso. I protocolli e il software di rete sono piuttosto complicati a causa della diversità di macchine e sistemi operativi con i quali hanno a che fare, senza contare il fatto che anche standard molto vecchi devono essere supportati.
IPv4 e IPv6
Sono disponibili due diversi tipi di indirizzi IP: IPv4 (versione 4) e IPv6 (versione 6). IPv4 è il più vecchio e di gran lunga il più utilizzato, mentre IPv6 è più recente ed è progettato per superare limitazioni inerenti allo standard più vecchio e fornire molti più indirizzi possibili.
IPv4 utilizza 32 bit per gli indirizzi; sono disponibili solo 4,3 miliardi di indirizzi univoci. Inoltre, molti indirizzi sono assegnati e riservati, ma non effettivamente utilizzati. IPv4 è considerato inadeguato per soddisfare le esigenze future perché il numero di dispositivi disponibili sulla rete globale è aumentato enormemente negli ultimi anni.
IPv6 utilizza 128 bit per gli indirizzi; ciò consente 3,4 x 10³⁸ indirizzi univoci. Se hai una rete di computer più ampia e desideri aggiungerne altri, potresti voler passare a IPv6, perché fornisce più indirizzi univoci. Tuttavia, può essere complesso migrare su IPv6; i due protocolli non sempre interagiscono bene. Pertanto, lo spostamento di attrezzature e indirizzi a IPv6 richiede uno sforzo significativo e non è stato così veloce come inizialmente previsto. Tratteremo IPv4 più di IPv6 poiché è più probabile che tu debba averci a che fare.
Uno dei motivi per cui IPv4 non è scomparso è che esistono modi per creare con efficacia molti più indirizzi disponibili con metodi come NAT (traduzione degli indirizzi di rete). NAT consente di condividere un indirizzo IP tra molti computer connessi localmente, ognuno dei quali ha un indirizzo univoco visto solo sulla rete locale. Sebbene questo sia utilizzato in contesti organizzativi, viene utilizzato anche nelle reti domestiche semplici. Ad esempio, se disponi di un router collegato al tuo provider Internet (come per un sistema di cavi), ti dà un indirizzo visibile esternamente, ma assegna a ogni dispositivo in casa tua un indirizzo locale individuale.
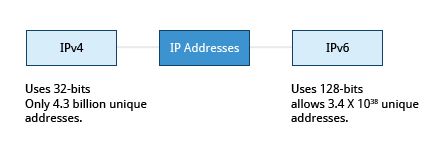
Decodficare Indirizzi IPv4
Un indirizzo IPv4 a 32 bit è diviso in quattro sezioni a 8 bit chiamate ottetti.
Esempio:
Indirizzo IP → 172 . 16 . 31 . 46
Formato Bit → 10101100. 00010000. 0011111. 00101110
NOTA: Ottetto è semplicemente un'altra definizione per byte.
Gli indirizzi di rete sono divisi in cinque classi: A, B, C, D ed E. Le classi A, B e C sono divise in due parti: indirizzi di rete (Net ID) e indirizzo host (Host ID ). Il Net ID viene utilizzato per identificare la rete, mentre l'host ID viene utilizzato per identificare un host nella rete. La classe D viene utilizzata per applicazioni multicast speciali (le informazioni vengono trasmesse contemporaneamente a più computer) e la classe E è riservata per un uso futuro. In questa sezione parleremo delle classi A, B e C.
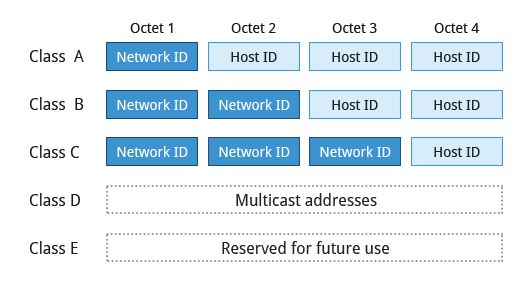
Indirizzi di Rete di Classe A
Gli indirizzi di classe A utilizzano il primo ottetto di un indirizzo IP come Net ID e usano gli altri tre ottetti come host ID. Il primo bit del primo ottetto è sempre impostato su zero. Quindi puoi usare solo 7 bit per numeri di rete univoci. Di conseguenza, sono disponibili un massimo di 126 reti di classe A (gli indirizzi 0000000 e 1111111 sono riservati). Non sorprende che questo fosse fattibile solo quando c'erano pochissime reti uniche con un gran numero di host. Man mano che l'uso di Internet si espandeva, le classi B e C sono state aggiunte al fine di soddisfare la crescente domanda di reti indipendenti.
Ciascuna rete di classe A può avere fino a 16,7 milioni di indirizzi univoci. La gamma di indirizzi host va da 1.0.0.0 a 127.255.255.255.
NOTA: Il valore di un ottetto (oppure 8-bit), può variare da 0 a 255.
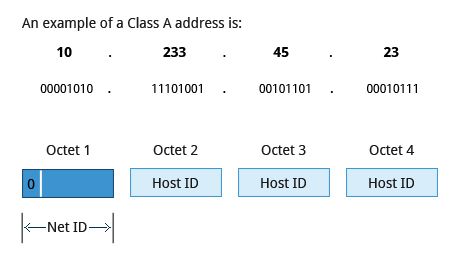
Indirizzi di Rete di Classe B
Gli indirizzi di classe B usano i primi due ottetti dell'indirizzo IP come Net ID e gli ultimi due ottetti come host ID. I primi due bit del primo ottetto sono sempre impostati sul valore binario 10, quindi ci sono un massimo di 16.384 (14 bit) reti di classe B. Il primo ottetto di un indirizzo di Classe B ha valori da 128 a 191. L'introduzione delle reti di classe B ha ampliato il numero di reti, ma presto è diventato chiaro che sarebbe stato necessario un ulteriore livello.
Ogni rete di classe B può supportare un massimo di 65.536 host univoci sulla sua rete. La gamma di indirizzi host va da 128.0.0.0 a 191.255.255.255.
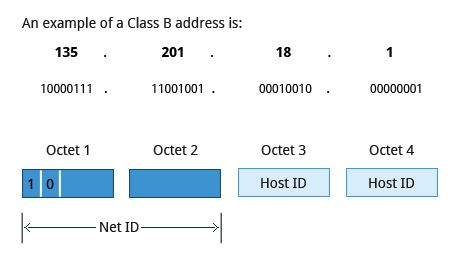
Indirizzi di Rete di Classe C
Gli indirizzi di classe C usano i primi tre ottetti dell'indirizzo IP come Net ID e l'ultimo ottetto come ID dell'host. I primi tre bit del primo ottetto sono impostati su 110 in binario, quindi sono disponibili quasi 2.1 milioni (21 bit) di reti di classe C. Il primo ottetto di un indirizzo di classe C ha valori da 192 a 223. Sono più comuni per reti più piccole che non hanno molti host univoci.
Ogni rete di classe C può supportare fino a 256 (8 bit) host univoci. L'intervallo di indirizzi host va da 192.0.0.0 a 223.255.255.255.
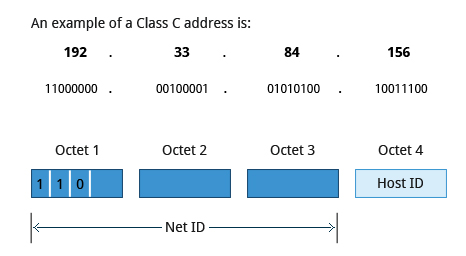
Allocare Indirizzi IP
In genere, una gamma di indirizzi IP è richiesta al tuo provider di servizi Internet (ISP) dall'amministratore di rete della tua organizzazione. Spesso, la scelta di quale classe di indirizzo IP ti viene fornita dipende dalle dimensioni della rete e dalle esigenze di crescita previste. Se NAT è in funzione, come in una rete domestica, si ottiene solo un indirizzo visibile esternamente!
È possibile assegnare indirizzi IP ai computer su una rete manualmente o dinamicamente. L'assegnazione manuale aggiunge indirizzi statici (non cambiano mai) alla rete. Gli indirizzi assegnati dinamicamente possono cambiare ogni volta che esegui un riavvio o anche più spesso; il Protocollo di Configurazione Dinamica dell'Host (DHCP) viene utilizzato per assegnare indirizzi IP.
Risoluzione del Nome
La risoluzione del nome viene utilizzata per convertire i valori numerici dell'indirizzo IP numerico in un formato leggibile dall'uomo noto come nome host. Per esempio, 104.95.85.15 è l'indirizzo IP numerico che si riferisce al nome host whitehouse.gov. I nomi degli host sono molto più facili da ricordare!
Dato un indirizzo IP, è possibile ottenere il suo nome host corrispondente. L'accesso alla macchina sulla rete diventa più semplice quando è possibile digitare il nome host anziché l'indirizzo IP.
Puoi visualizzare il nome host del tuo sistema semplicemente digitando hostname senza argomenti.
NOTA: Se gli passi un argomento, il sistema proverà a cambiare il suo nome host per abbinarlo, tuttavia, solo gli utenti root possono farlo.
Lo speciale nome host localhost è associato all'indirizzo IP 127.0.0.1 e descrive la macchina in cui ti trovi attualmente (che normalmente ha ulteriori indirizzi IP relativi alla rete).
Video: Configurazione della Rete
File di Configurazione della Rete
I file di configurazione della rete sono essenziali per garantire che le interfacce funzionino correttamente. Si trovano nell'albero della directory /etc. Tuttavia, i file esatti utilizzati storicamente dipendono dalla particolare distribuzione Linux e versione utilizzata.
Per le configurazioni della famiglia Debian, i file di configurazione della rete di base possono essere trovati in /etc/network/, mentre per i sistemi della famiglia Red Hat e SUSE si deve guardare in /etc/sysconfig/network.
I sistemi moderni sottolineano l'uso di Network Manager, di cui abbiamo discusso brevemente quando abbiamo considerato l'amministrazione del sistema grafico, piuttosto che cercare di tenere il passo con la situazione dei file in /etc. Mentre le versioni grafiche di Network Manager sembrano in qualche modo diverse nelle differenti distribuzioni, l'utilità nmtui (mostrata nella videata seguente) non varia quasi per nulla, così come l'utility più spartana nmcli (interfaccia della riga di comando). Se sei abile nell'uso delle GUI, usale. Se stai lavorando su una varietà di sistemi, le utility di livello inferiore possono semplificare la vita.
Le recenti distribuzioni di Ubuntu includono netplan, che è abilitato per impostazione predefinita, e soppianta Network Manager. Poiché nessun'altra distribuzione ha mostrato interesse e poiché può essere facilmente disabilitato se ti dà fastidio, lo ignoreremo.
Interfacce di Rete
Le interfacce di rete sono un canale di connessione tra un dispositivo e una rete. Fisicamente, le reti sono interfacciate tramite una scheda di interfaccia di rete (NIC) o possono essere implementate in modo più astratto come software. È possibile avere più interfacce di rete che operano contemporaneamente. Le interfacce specifiche possono essere attivate o disattivate in qualsiasi momento.
Le informazioni su una particolare interfaccia di rete o tutte le interfacce di rete possono essere ottenute dalle utility ip e ifconfig, che potresti dover eseguire come superutente, o almeno, dare il percorso completo, ad esempio /sbin/ifconfig, su alcune distribuzioni. ip è più nuovo di ifconfig e ha molte più capacità, ma la visualizzazione dei suoi risultati è più brutta per l'occhio umano. Alcune nuove distribuzioni di Linux non installano il pacchetto più vecchio net-tools a cui appartiene ifconfig, quindi dovresti installarlo se desideri usarlo.
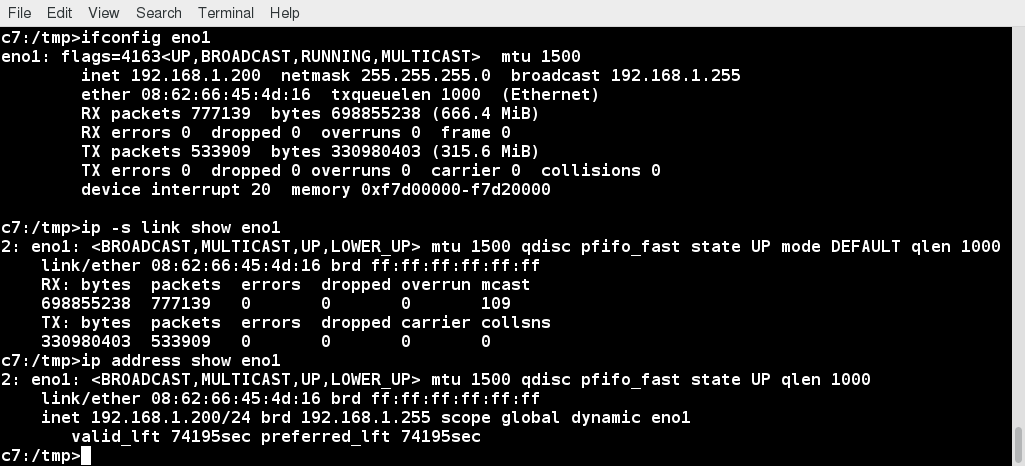
L'utility ip
Per visualizzare l'indirizzo IP:
$ /sbin/ip addr show
Per visualizzare le informazioni di instradamento (routing):
$ /sbin/ip route show
ip è un programma molto potente che può fare molte cose. Utility più vecchie (e più specifiche) come ifconfig e route sono spesso usate per svolgere compiti simili. Uno sguardo alle pagine di manuale pertinenti può dirti molto di più su queste utility.
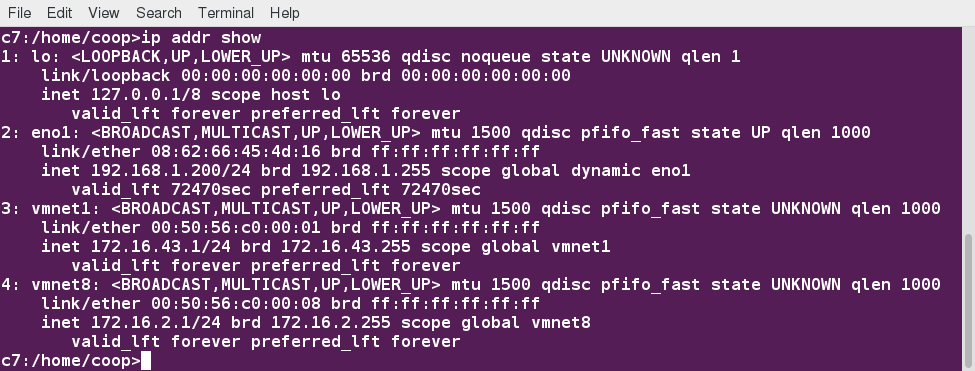
ping
ping viene utilizzato per verificare se una macchina collegata alla rete può ricevere e inviare dati; vale a dire confermare che l'host remoto sia online e stia rispondendo.
Per verificare lo stato dell'host remoto, al prompt dei comandi, digita ping <hostname>.
ping viene spesso utilizzato per i test e la gestione della rete; tuttavia, il suo utilizzo può aumentare il carico di rete in modo non accettabile. Quindi, puoi interrompere l'esecuzione di ping digitando CTRL-C, oppure usando l'opzione -c , che limita il numero di pacchetti che ping invia prima di smettere. Quando l'esecuzione si interrompe, viene visualizzato un riepilogo.
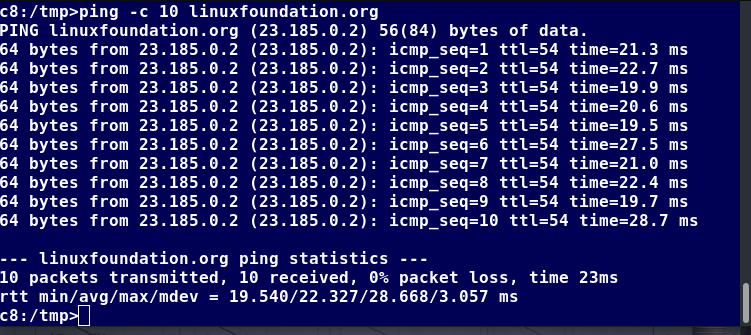
route
Una rete richiede la connessione di molti nodi. I dati si spostano dalla sorgente alla destinazione passando attraverso una serie di router e potenzialmente su più reti. I server mantengono le tabelle di routing contenenti gli indirizzi di ciascun nodo nella rete. I protocolli di routing IP consentono ai router di costruire una tabella di inoltro che correla le destinazioni finali con gli indirizzi hop successivi.
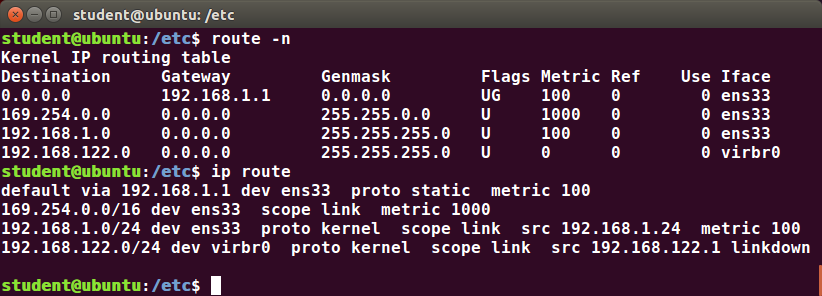
Si può usare l'utility route (rotta) oppure il nuovo comando ip route per visualizzare o modificare la tabella di routing IP per aggiungere, eliminare o modificare percorsi specifici (statici) verso host o reti specifiche. La tabella spiega alcuni comandi che possono essere utilizzati per gestire il routing IP:
| Attività | Comando |
|---|---|
| Mostrare la tabella di routing corrente | $ route –n oppure ip route |
| Aggiungere una rotta statica | $ route add -net address oppure ip route add |
| Eliminare una rotta statica | $ route del -net address oppure ip route del |
traceroute
traceroute viene utilizzato per ispezionare il percorso che il pacchetto di dati percorre per raggiungere l'host di destinazione, il che lo rende abbastanza utile per la risoluzione dei problemi circa ritardi ed errori della rete. Usando traceroute, è possibile isolare i problemi di connettività nei passaggi tra segmenti di rete, il che aiuta a risolverli più velocemente.
Per stampare il percorso compiuto dal pacchetto per raggiungere l'host di rete, al prompt dei comandi, digita traceroute <indirizzo>.
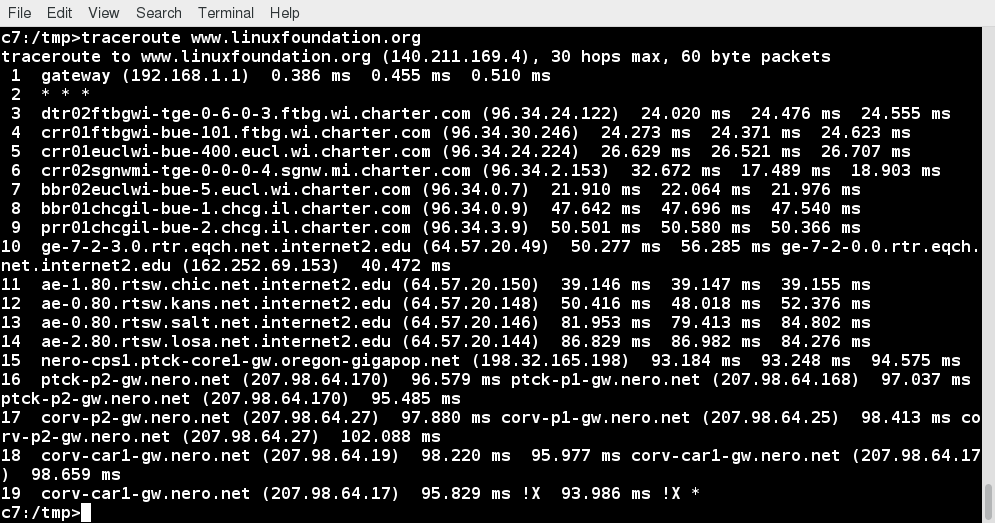
Altri Strumenti di Rete
Ora, apprendiamo alcuni strumenti di rete aggiuntivi. Gli strumenti di rete sono molto utili per il monitoraggio e il debug di problemi di rete, come la connettività e il traffico.
| Strumenti di Rete | Descrizione |
|---|---|
ethtool |
Interroga le interfacce di rete e può anche impostare vari parametri come la velocità |
netstat |
Visualizza tutte le connessioni attive e le tabelle di routing; utile per monitorare le prestazioni e la risoluzione dei problemi |
nmap |
Scansiona le porte aperte su una rete; importante per analisi di sicurezza |
tcpdump |
Scarica il traffico di rete per analisi |
iptraf |
Monitora il traffico di rete in formato testo |
mtr |
Combina le funzionalità di ping e traceroute e fornisce una visualizzazione continuamente aggiornata |
dig |
Testa il funzionamento dei DNS; un buon sostituto per host e nslookup |
Video: Usare Ulteriori Strumenti di Rete
Browser Grafici e Non Grafici
I browser vengono utilizzati per recuperare, trasmettere ed esplorare le fonti di informazione, di solito sul World Wide Web. Gli utenti Linux usano comunemente applicazioni di browser grafico e non grafico.
I browser grafici comuni usati in Linux sono:
A volte, potresti non avere un ambiente grafico in cui lavorare (o avere motivi per non usarlo), ma è comunque necessario accedere alle risorse web. In tal caso, è possibile utilizzare browser non grafici, come i seguenti:
| Browser Non Grafici | Descrizione |
|---|---|
| lynx | Browser Web basato su testo configurabile; il primo browser di questo tipo e ancora in uso |
| elinks | Basato su Lynx; Può visualizzare tabelle e riquadri |
| w3m | Un altro browser web basato sul testo con molte funzionalità |
wget
A volte, è necessario scaricare file e informazioni, ma un browser non è la scelta migliore, sia perché si desidera scaricare più file e/o directory, oppure si desidera eseguire l'azione da una riga di comando o da uno script. wget è un'utilità della riga di comando che può gestire adeguatamente i seguenti tipi di download:
- Download di file di grandi dimensioni
- Download ricorsivi, in cui una pagina web si riferisce ad altre pagine web e tutte vengono scaricate contemporaneamente
- Download che richiedono password
- Download di file multipli.
Per scaricare una pagina web, puoi semplicemente digitare wget <url>, quindi è possibile leggere la pagina scaricata come file locale utilizzando un browser grafico o non grafico.
curl
Oltre a scaricare, potresti voler ottenere informazioni su un URL, come il codice sorgente utilizzato. curl può essere usato dalla riga di comando o da uno script per leggere tali informazioni. curl ti consente anche di salvare il contenuto di una pagina web in un file, così come wget.
Puoi leggere un URL utilizzando curl <URL>. Ad esempio, se vuoi leggere http://www.linuxfoundation.org, digita curl http://www.linuxfoundation.org.
Per ottenere il contenuto di una pagina web e memorizzarlo su un file, digita curl -o saved.html http://www.mysite.com. Verrà salvato il contenuto del file indice principale del sito web in saved.html.
FTP (File Transfer Protocol) - Protocollo di Trasferimento File
Quando sei connesso a una rete, potrebbe essere necessario trasferire file da una macchina all'altra. FTP (File Transfer Protocol) è un metodo ben noto e popolare per il trasferimento di file tra i computer utilizzando Internet. Questo metodo è basato su un modello client-server. FTP può essere utilizzato all'interno di un browser o con programmi client autonomi.
FTP è uno dei più antichi metodi di trasferimento dei dati di rete, risalente ai primi anni '70. Pertanto, è considerato inadeguato per i bisogni moderni, oltre a essere intrinsecamente insicuro. Tuttavia, è ancora in uso e, quando la sicurezza non è un problema (come con il cosiddetto FTP anonimo), può avere senso. Tuttavia, molti siti web, come [kernel.org] (https://www.kernel.org/), ne hanno abbandonato l'uso.
Client FTP
I client FTP consentono di trasferire file con computer remoti utilizzando il protocollo FTP. Questi client possono essere strumenti grafici o da riga di comando. FileZilla, ad esempio, consente l'uso dell'approccio drag and drop per trasferire i file tra gli host. Tutti i browser web supportano FTP, tutto ciò che devi fare è passare un URL come ftp://ftp.kernel.org dove il solito http:// diventa ftp://.
Alcuni client FTP di riga di comando sono:
- ftp
- sftp
- ncftp
- yafc (Yet Another FTP Client).
L'FTP è caduto in disgrazia sui sistemi moderni, in quanto è intrinsecamente insicuro, poiché le password sono credenziali dell'utente che possono essere trasmesse senza crittografia e sono quindi inclini a intercettazioni. Pertanto, è stato rimosso a favore dell'utilizzo di rsync e dell'accesso con i browser web via https ad esempio. In alternativa, sftp è una modalità di connessione molto sicura, che utilizza il protocollo sicuro shell (ssh), di cui discuteremo a breve.sftp crittografa i suoi dati e quindi le informazioni sensibili vengono trasmesse in modo più sicuro. Tuttavia, non funziona con il cosiddetto FTP anonimo (credenziali utente ospite).
SSH: Eseguire Comandi da Remoto
Secure Shell (SSH) è un protocollo di rete crittografico utilizzato per la comunicazione dati sicura. Viene inoltre utilizzato per servizi remoti e altri servizi sicuri tra due dispositivi sulla rete ed è molto utile per la gestione dei sistemi che non sono facilmente raggiungibili fisicamente, ma per i quali hai accesso remoto.
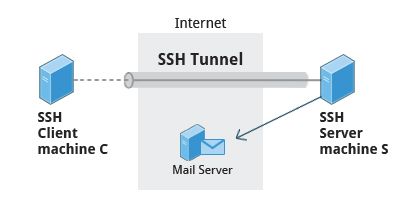
Per accedere a un sistema remoto utilizzando il tuo stesso nome utente puoi semplicemente digitare ssh qualche_sistema e premere Invio. ssh quindi ti chiederà la password remota. È inoltre possibile configurare ssh per consentire l'accesso remoto in modo sicuro senza digitare una password ogni volta.
Se si desidera eseguire come un altro utente, puoi farlo con ssh -l altroutente qualche_sistema oppure con ssh altroutente@qualche_sistema. Per eseguire un comando su un sistema remoto tramite SSH, al prompt dei comandi, è possibile digitare ssh qualche_sistema mio_comando.
Copia di file in Modo Sicuro con scp
Possiamo anche spostare i file in modo sicuro utilizzando Secure Copy (SCP) tra due host in rete. scp utilizza il protocollo SSH per il trasferimento di dati.
Per copiare un file locale in un sistema remoto, al prompt dei comandi, digita scp <filelocale> <user@sistemaremoto>:/home/user/ e premi Invio.
Ti verrà richiesta la password remota. Puoi anche configurare scp in modo che non richieda una password per ogni trasferimento.
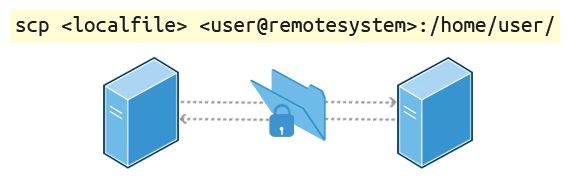
Video: Usare SSH tra due Macchine Virtuali
Riepilogo del Capitolo
Hai completato il capitolo 14. Riassumiamo i concetti chiave trattati:
- L'indirizzo IP (Internet Protocol) è un indirizzo di rete logico univoco assegnato a un dispositivo su una rete.
- IPv4 utilizza 32 bit per gli indirizzi e IPv6 utilizza 128 bit per gli indirizzi.
- Ogni indirizzo IP contiene sia un campo rete che un campo indirizzo host.
- Sono disponibili cinque classi di indirizzi di rete: A, B, C, D ed E.
- DNS (Domain Name System - Sistema di Nomi di Dominio) viene utilizzato per convertire i nomi di dominio Internet e host in indirizzi IP.
- Il programma ifconfig viene utilizzato per visualizzare le interfacce di rete attive attuali.
- I comandi
ip addr showeip route showpossono essere utilizzati per visualizzare l'indirizzo IP e le informazioni di routing. - Puoi usare ping per verificare se l'host remoto è online e rispondente.
- Puoi usare il programma di utilità route per gestire il routing IP.
- È possibile monitorare ed eseguire il debug di problemi di rete utilizzando strumenti di networking.
- Firefox, Google Chrome, Chromium ed Epiphany sono i principali browser grafici utilizzati in Linux.
- I browser non grafici o di testo utilizzati in Linux sono Lynx, Links e w3m.
- Puoi usare wget per scaricare pagine Web.
- Puoi usare curl per ottenere informazioni sugli URL.
- FTP (File Transfer Protocol - Protocollo di Trasferimento di File) viene utilizzato per trasferire file su una rete.
- ftp, sftp, ncftp e yafc sono client FTP da riga di comando utilizzati in Linux.
- Puoi usare ssh per eseguire comandi su sistemi remoti.

Capitolo 15: La Shell Bash e lo Scripting di Base
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Spiegare le caratteristiche e le capacità degli script della shell bash.
- Conoscere la sintassi di base delle istruzioni di scripting.
- Avere familiarietà con i vari metodi e costrutti utilizzati.
- Verificare proprietà ed esistenza di file e altri oggetti.
- Utilizzare istruzioni condizionali, come i blocchi if-then-else.
- Eseguire operazioni aritmetiche usando il linguaggio di scripting.
Shell Scripting
Supponi di voler cercare un nome file, controllare se il file associato esiste e quindi rispondere di conseguenza, visualizzando un messaggio che conferma o non conferma l'esistenza del file. Se devi farlo solo una volta, puoi semplicemente digitare una sequenza di comandi in un terminale. Tuttavia, se è necessario farlo più volte, l'automazione è la strada da percorrere. Per automatizzare una serie di comandi, dovrai imparare a scrivere script di shell. Più comunemente in Linux, questi script vengono sviluppati per essere eseguiti nell'interprete di comando della shell bash. Il grafico illustra molti dei vantaggi dell'adottare gli script.
NOTA: Molti degli argomenti discussi in questo e nel prossimo capitolo sono già stati introdotti in precedenza, durante l'esposizione di attività che possono essere fatte dalla riga di comando. Abbiamo scelto di ripetere una parte di quell'esposizione per rendere le sezioni sullo scripting autonome, quindi la ripetizione è intenzionale.
Scelta della Shell di Comando
L'interprete di comando ha il compito di eseguire le istruzioni che seguono la sua dichiarazione nello script. Gli interpreti comunemente usati includono: /usr/bin/perl, /bin/bash, /bin/csh, /usr/bin/python e /bin/sh.
Scrivere una lunga sequenza di comandi in una finestra del terminale può essere complicato, richiede tempo e può portare a errori. Utilizzando gli script di shell, l'uso della riga di comando diventa un modo efficiente e rapido per avviare sequenze complesse di passaggi. Il fatto che gli script di shell vengano salvati in un file rende più semplice utilizzarli per creare nuove varianti di script e condividere procedure standard con diversi utenti.
Linux offre un'ampia scelta di shell; esattamente ciò che è disponibile sul sistema è elencato in /etc/shells. Le scelte tipiche sono:
/bin/sh/bin/bash/bin/tcsh/bin/csh/bin/ksh/bin/zsh
La maggior parte degli utenti di Linux utilizza la shell predefinita bash, ma quelli con vasta esperienza unix con altre shell potrebbero voler sovrascrivere quella predefinita.
Script di Shell
Se ricordi da quanto precedentemente trattato, una shell è un interprete di riga di comando che fornisce l'interfaccia utente per finestre di terminale. Può anche essere usata per eseguire script, anche in sessioni non interattive senza una finestra di terminale, come se i comandi fossero digitati direttamente. Ad esempio, digitare find . -name "*.c" -ls nella riga di comando è la stessa cosa che eseguire un file di script contenente le righe:
#!/bin/bashfind . -name "*.c" -ls
La prima riga dello script, che inizia con #!, contiene il percorso completo dell'interprete di comando (in questo caso /bin/bash) che deve essere utilizzato sul file. Come abbiamo scritto più sopra, hai alcune scelte per il linguaggio di scripting che puoi usare, come ad esempio /usr/bin/perl, /bin/csh, /usr/bin/python, ecc.
Un Semplice Script Bash
Scriviamo un semplice script bash che visualizza un messaggio di una riga sullo schermo. Puoi digitare:
$ cat > hello.sh#!/bin/bashecho "Hello Linux Foundation Student"
poi premere Invio e CTRL-D per salvare il file, oppure semplicemente creare il file hello.sh con il tuo editor di testo preferito. Poi digita chmod +x hello.sh per rendere il file eseguibile per tutti gli utenti.
Successivamente puoi eseguire lo script digitando ./hello.sh oppure:
$ bash hello.sh
Il risultato sarà:
Hello Linux Foundation Student
NOTA: se usi la seconda forma, non è necessario rendere eseguibile il file.
Esempio Interattivo dell'Utilizzo degli Script bash
Ora, vediamo come creare un esempio più interattivo usando uno script bash. All'utente verrà richiesto di inserire un valore, che verrà quindi visualizzato sullo schermo. Il valore è memorizzato in una variabile temporanea, name. Possiamo fare riferimento al valore di una variabile shell utilizzando un $ davanti al nome della variabile, come $name. Per creare questo script, è necessario creare un file denominato getname.sh nel tuo editor preferito con il seguente contenuto:
#!/bin/bash# Lettura interattiva di una variabileecho "DIGITA IL TUO NOME"read name# Visualizza il contenuto della variabileecho Il nome fornito è :$name
Ancora una volta, rendilo eseguibile digitando chmod +x getname.sh.
Nell'esempio sopra, quando l'utente digita ./getname.sh e lo script viene eseguito, all'utente viene presentata la stringa DIGITA IL TUO NOME. L'utente deve quindi digitare un valore e premere Invio. Il valore digitato verrà stampato.
NOTA: Il carattere # (cancelletto) è usato per iniziare un commento nello script e può essere piazzato ovunque in una riga (il resto della riga sarà considerato un commento). Tuttavia, nota la speciale combinazione magica di #!, utilizzata nella prima riga, è un'eccezione unica a questa regola.
Valori di Ritorno
Tutti gli script di shell generano un valore di ritorno alla fine dell'esecuzione, che può essere impostato esplicitamente con l'istruzione exit. I valori di ritorno consentono a un processo di monitorare lo stato di uscita di un altro processo, spesso in una relazione genitore-figlio. Sapere come termina il processo consente di adottare le misure appropriate necessarie o dipendenti dal successo o dal fallimento.
Visualizzare Valori di Ritorno
Quando lo script è in esecuzione, si può controllare un valore oppure una condizione specifici e restituire il successo o il fallimento come risultato. Per convenzione, il successo viene restituito come 0 e il fallimento viene restituito come valore diverso da zero. Un modo semplice per dimostrare il completamento del successo e del fallimento è eseguire il comando ls su un file che esiste così come con uno che non lo è, il valore di ritorno è archiviato nella variabile di ambiente rappresentata da $?:
$ ls /etc/logrotate.conf/etc/logrotate.conf
$ echo $?0
In questo esempio, il sistema è in grado di individuare il file /etc/logrotate.conf e ls restituisce un valore di 0 per indicare il successo. Se eseguito su un file inesistente, restituisce 2. Le applicazioni spesso traducono questi valori di ritorno in messaggi significativi facilmente comprensibili dall'utente.
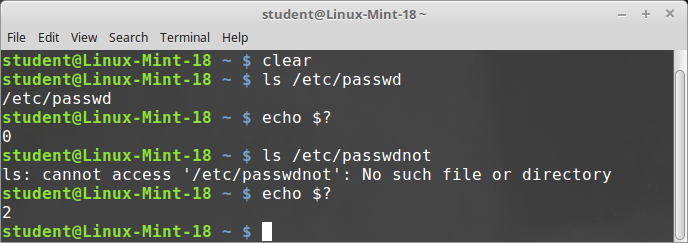
Sintassi Base e Caratteri Speciali
Gli script richiedono di seguire una sintassi standard del linguaggio. Le regole delineano come definire le variabili e come costruire e formattare le istruzioni consentite, ecc. La tabella elenca alcuni usi speciali dei caratteri all'interno degli script bash:
| Carattere | Descrizione |
|---|---|
# |
Usato per aggiungere un commento, tranne quando usato come \#, oppure #! all'inizio di uno script |
\ |
Usato alla fine di una riga per indicare la continuazione a quella successiva |
; |
Usato per interpretare ciò che segue come un nuovo comando da eseguire |
$ |
Indica che ciò che segue è una variabile di ambiente |
> |
Ridireziona l'output |
>> |
Aggiunge all'output |
< |
Ridireziona l'input |
\| |
Usato per passare il risultato al comando successivo |
Ci sono altri caratteri speciali, combinazioni di caratteri e costrutti che gli script comprendono, come (..), {..}, [..], &&, ||, **, **, $((...)), alcuni dei quali discuteremo più avanti.
Dividere Comandi Lunghi su Più Righe
A volte, i comandi sono troppo lunghi da digitare facilmente su una sola riga o da leggere e comprendere (anche se non esiste un vero limite pratico alla lunghezza di una riga di comando).
In questo caso, l'operatore di concatenazione (\), il carattere di barra rovesciata, viene utilizzato per disporre i comandi lunghi su diverse righe.
Ecco un esempio di un comando che installa un lungo elenco di pacchetti su un sistema utilizzando Debian Package Management:
$~/\> cd $HOME$~/\> sudo apt-get install autoconf automake bison build-essential \ chrpath curl diffstat emacs flex gcc-multilib g++-multilib \ libsdl1.2-dev libtool lzop make mc patch \ screen socat sudo tar texinfo tofrodos u-boot-tools unzip \ vim wget xterm zip
Il comando è diviso in più righe per renderlo leggibile e più facile da capire. L'operatore \ alla fine di ciascuna riga fa sì che la shell combini (concateni) più righe e le esegua come un singolo comando.
Inserire Più Comandi su Una Singola Riga
Gli utenti a volte devono combinare diversi comandi e istruzioni, e persino eseguirli condizionalmente in base al comportamento degli operatori utilizzati tra loro. Questo metodo si chiama concatenamento di comandi.
Esistono diversi modi per farlo, a seconda delle tue esigenze. Il carattere ; (punto e virgola) viene utilizzato per separare questi comandi ed eseguirli in sequenza, come se fossero stati digitati su righe separate. Ogni comando che ne consegue viene eseguito a prescindere dalla riuscita o meno del precedente.
Pertanto, i tre comandi nell'esempio seguente verranno tutti eseguiti, anche se quelli che li precedono falliscono:
$ make ; make install ; make clean
Tuttavia, potresti voler interrompere i comandi successivi quando uno precedente fallisce. Puoi farlo usando l'operatore && (e) in questo modo:
$ make && make install && make clean
Se il primo comando fallisce, il secondo non verrà mai eseguito. Una rifinitura finale è utilizzare l'operatore || (o), come in:
$ cat file1 || cat file2 || cat file3
In questo caso, procedi fino a quando qualcosa riesce e poi smetti di eseguire ulteriori passaggi.
Concatenare i comandi non è uguale a convogliarli tramite pipe, nel qual caso i comandi successivi iniziano a operare su flussi di dati prodotti da quelli precedenti prima che si completino, mentre con il concatenamento ogni passaggio termina prima che inizi il prossimo.
Reindirizzare l'Output
La maggior parte dei sistemi operativi accetta l'input dalla tastiera e visualizza l'output sul terminale. Tuttavia, negli script shell è possibile inviare l'output a un file. Il processo di deviazione dell'output verso un file viene chiamato reindirizzamento dell'output. Abbiamo già usato questa funzionalità nelle nostre sezioni precedenti su come utilizzare la riga di comando.
Il carattere > viene utilizzato per scrivere l'output in un file. Ad esempio, il seguente comando invia l'output di free al file /tmp/free.out:
$ free > /tmp/free.out
Per controllare il contenuto di /tmp/free.out, digita cat /tmp/free.out nel prompt dei comandi.
Due caratteri > (>>) aggiungeranno l'output a un file se esiste, e agiranno come > se il file non esiste.
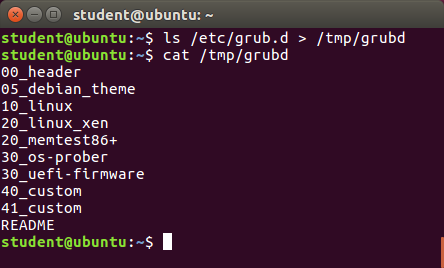
Reindirizzare l'Input
Proprio come l'output che può essere reindirizzato a un file, l'input di un comando può essere letto da un file. Il processo di lettura dell'input da un file è chiamato reindirizzamento dell'input e utilizza il carattere <.
I seguenti tre comandi (usando wc per contare il numero di righe, parole e caratteri in un file) sono del tutto equivalenti e coinvolgono il reindirizzamento dell'input e un comando che opera sul contenuto di un file:
$ wc < /etc/passwd49 105 2678 /etc/passwd
$ wc /etc/passwd49 105 2678 /etcpasswd
$ cat /etc/passwd | wc49 105 2678
Comandi Shell Integrati
Gli script shell eseguono sequenze di comandi e altri tipi di istruzioni. Questi comandi possono essere:
- Applicazioni compilate
- Comandi bash integrati
- Script di shell o script da altri linguaggi interpretati, come Perl e Python.
Le applicazioni compilate sono file eseguibili binari, generalmente risiedono sul filesystem in directory ben note come /usr/bin. Gli script di shell hanno sempre accesso ad applicazioni come rm, ls, df, vi, e gzip, che sono programmi compilati da linguaggi di programmazione di basso livello come C.
Inoltre, bash ha molti comandi integrati, che possono essere utilizzati solo per visualizzare l'output all'interno di una shell di terminale o uno script di shell. A volte, questi comandi hanno lo stesso nome dei programmi eseguibili sul sistema, come echo, che può portare a problemi subdoli. I comandi integrati bash includono cd, pwd, echo, read, logout, printf, let, e ulimit. Pertanto, ci si può aspettare un comportamento leggermente diverso dalla versione integrata di un comando come echo se confrontato con /bin/echo.
Un elenco completo dei comandi integrati bash è disponibile nella pagina di manuale di bash, o semplicemente digitando help, come esamineremo nella pagina successiva.
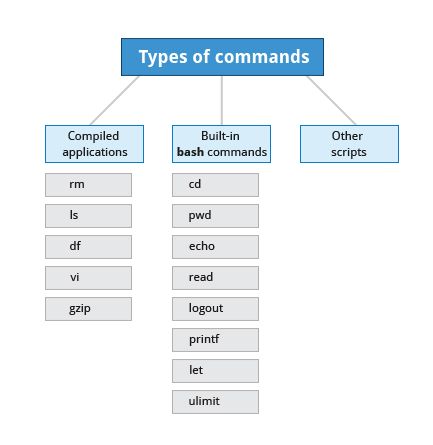
Comandi Integrati in bash
Abbiamo già elencato quali comandi hanno versioni integrate per bash nella nostra precedente discussione su come ottenere aiuto sui sistemi Linux. Ancora una volta, ecco una videata che elenca esattamente quali comandi sono disponibili.
Parametri di uno Script
Gli utenti devono spesso passare valori per i parametri di uno script, come un nome file, una data, ecc. Gli script prendono percorsi diversi o ricavano valori diversi in base ai parametri (argomenti del comando) che vengono loro passati. Questi valori possono essere testo o numeri, in questo modo:
$ ./script.sh /tmp$ ./script.sh 100 200
All'interno di uno script, il parametro o un argomento è rappresentato con un $ e un numero o un carattere speciale. La tabella elenca alcuni di questi parametri.
| Parametro | Significato |
|---|---|
$0 |
Nome dello script |
$1 |
Primo parametro |
$2,$3, ecc. |
Secondo, terzo parametro, ecc. |
$* |
Tutti i parametri |
$# |
Numero di argomenti |
Usare i Parametri di uno Script
Crea lo script mostrato nella figura, poi rendilo eseguibile con chmod +x param.sh. Successivamente eseguilo passandogli diversi argomenti, come mostrato nella videata. Lo script viene elaborato come segue:
$0 stampa il nome dello script: param.sh
$1 stampa il primo parametro: one
$2 stampa il secondo parametro: two
$3 stampa il terzo parametro: three
$ stampa tutti i parametri: one two three four five
L'istruzione finale diventa: All done with param.sh
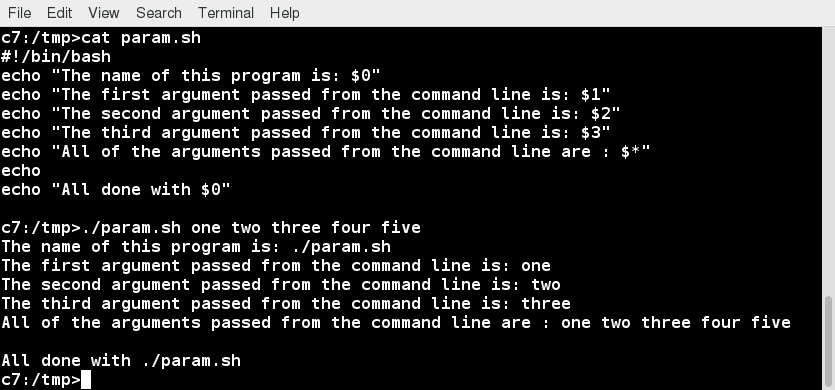
Sostituzione dei Comandi
A volte potrebbe essere necessario sostituire il risultato di un comando affinché sia parte di un altro comando. Può essere fatto in due modi:
- Racchiudendo il comando più interno tra $( )
- Racchiudendo il comando più interno tra caratteri backtick (`)
La seconda forma, con i backtick, è deprecata nei nuovi script e comandi. Indipendentemente dal metodo utilizzato, il comando specificato verrà eseguito in un nuovo ambiente di shell appena lanciato e l'output standard della shell verrà inserito quando viene eseguita la sostituzione del comando.
Praticamente qualsiasi comando può essere eseguito in questo modo. Mentre entrambi questi metodi abilitano la sostituzione del comando, il metodo $() consente l'annidamento dei comandi. I nuovi script dovrebbero sempre usare questo metodo più moderno. Per esempio:
$ ls /lib/modules/$(uname -r)/
Nell'esempio sopra, l'output del comando uname –r (Che sarà qualcosa di simile a 5.13.3), è inserito come argomento per il comando ls.
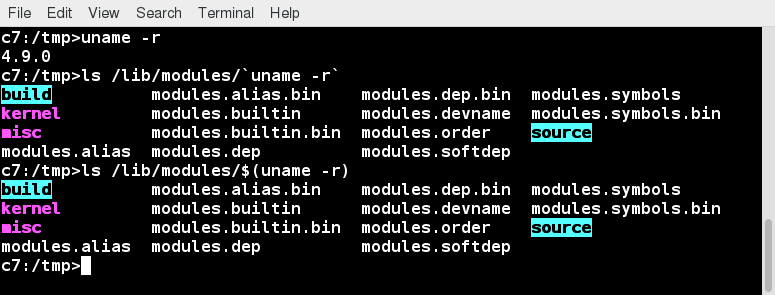
Variabili di Ambiente
La maggior parte degli script utilizza variabili contenenti un valore, che può essere utilizzato ovunque nello script. Queste variabili possono essere definite dall'utente o dal sistema. Molte applicazioni utilizzano tali variabili di ambiente (già trattate in dettaglio nel capitolo relativo all'ambiente utente) per la fornitura di input, convalida e controllo del comportamento.
Come abbiamo discusso in precedenza, alcuni esempi di variabili di ambiente standard sono HOME, PATH, e HOST. Quando ci si riferisce ad esse, le variabili di ambiente devono essere prefissate con il simbolo $, ad esempio $HOME. È possibile visualizzare e impostare il valore delle variabili di ambiente. Ad esempio, il seguente comando visualizza il valore memorizzato nella variabile PATH:
$ echo $PATH
Tuttavia, non è richiesto alcun prefisso quando si imposta o si modifica il valore di una variabile. Ad esempio, il seguente comando imposta il valore della variabile MYCOLOR a "blu":
$ MYCOLOR=blu
Puoi ottenere un elenco di variabili di ambiente con i comandi env, set, oppure printenv.
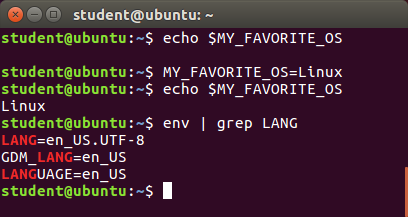
Esportare Variabili di Ambiente
Anche se abbiamo discusso dell'esportazione delle variabili di ambiente nel capitolo su "Ambiente utente", vale la pena rivedere questo argomento nel contesto della scrittura di script bash.
Per impostazione predefinita, le variabili create all'interno di uno script sono disponibili solo per i passaggi successivi di tale script. Eventuali processi figli (sotto-shell) non hanno accesso automatico ai valori di queste variabili. Per renderli disponibili per i processi figli, devono essere promosse a variabili di ambiente utilizzando la dichiarazione di esportazione, così:
export VAR=valore
oppure
VAR=valore ; export VAR
Mentre i processi figli possono modificare il valore delle variabili esportate, il genitore non vedrà alcuna modifica; le variabili esportate non sono condivise, vengono solo copiate ed ereditate.
Digitare export senza argomenti fornirà un elenco di tutte le variabili di ambiente attualmente esportate.
Funzioni
Una funzione è un blocco di codice che implementa un insieme di operazioni. Le funzioni sono utili per l'esecuzione di procedure più volte, forse con diverse variabili di input. Le funzioni sono spesso anche chiamate subroutine. L'uso delle funzioni negli script richiede due passaggi:
- Dichiarare una funzione
- Chiamare una funzione
La dichiarazione della funzione richiede un nome utilizzato per invocarla. La sintassi corretta è:
nome_funzione () { comando...}
Ad esempio, la seguente funzione viene chiamata display:
display () { echo "Questa è una semplice funzione"}
Se necessario, la funzione può essere di grandi dimensioni e avere molte istruzioni. Una volta definita, la funzione può essere chiamata più tardi tante volte quanto necessario. Nell'esempio completo mostrato nella figura qui sotto, stiamo anche mostrando una prassi spesso usata: come passare un argomento alla funzione. Il primo argomento può essere referenziato con $1, il secondo con $2, ecc.
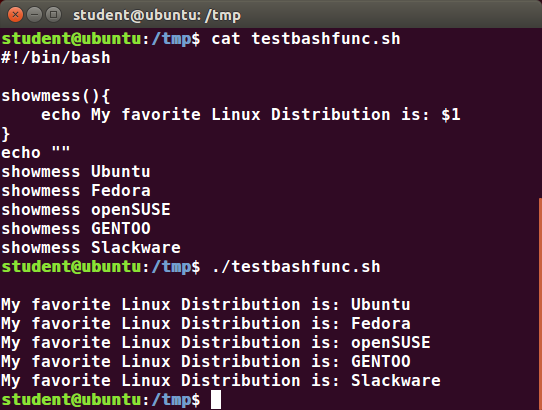
L'istruzione if
Il processo decisionale condizionale, usando un'istruzione if, è un costrutto di base che ogni utile linguaggio di programmazione o scripting deve avere.
Quando viene usata una istruzione if, le azioni conseguenti dipendono dalla valutazione delle condizioni specifiche, come ad esempio:
- Confronti numerici o stringhe
- Valore di ritorno di un comando (0 per il successo)
- Esistenza o autorizzazioni di file
In forma compatta, la sintassi di un'istruzione if è:
if COMANDI-DI-VERIFICA; then COMANDO-CONSEGUENTE; fi
Una definizione più generale è:
if condizionethen istruzionielse istruzionifi

Usare l'Istruzione if
Nell'esempio seguente, un'istruzione if verifica se esiste un determinato file e se viene trovato il file, visualizza un messaggio che indica successo o fallimento:
if [ -f "$1" ]then echo file "$1 esiste"else echo file "$1" non esistefi
Dovremmo davvero anche verificare che ci sia un argomento passato allo script ($1) e interrompere l'esecuzione in caso negativo.
Notare l'uso delle parentesi quadre ([]) per delimitare la condizione di controllo. Esistono molti altri tipi di test che puoi eseguire, come verificare se due numeri sono uguali, maggiori o minori l'uno dell'altro e prendere una decisione di conseguenza; discuteremo questi altri controlli.

Negli script moderni, potresti vedere parentesi raddoppiate come in [[-f /etc /passwd ]]. Questo non è un errore. Non è mai sbagliato farlo ed evita alcuni sottili problemi, come fare riferimento a una variabile di ambiente vuota senza racchiuderla tra doppi apici; non ne parleremo qui.
L'Istruzione elif
Puoi usare l'istruzione elif per eseguire controlli più complicati e intraprendere azioni appropriate. La sintassi di base è:
if [ uncertotest ] ; then echo test1 superatoelif [ unaltrotest ] ; then echo test2 superatofi
Nell'esempio mostrato qui sotto utilizziamo i controlli per le stringhe, che spiegheremo a breve, mostrando come inserire una variabile di ambiente con l'istruzione read.
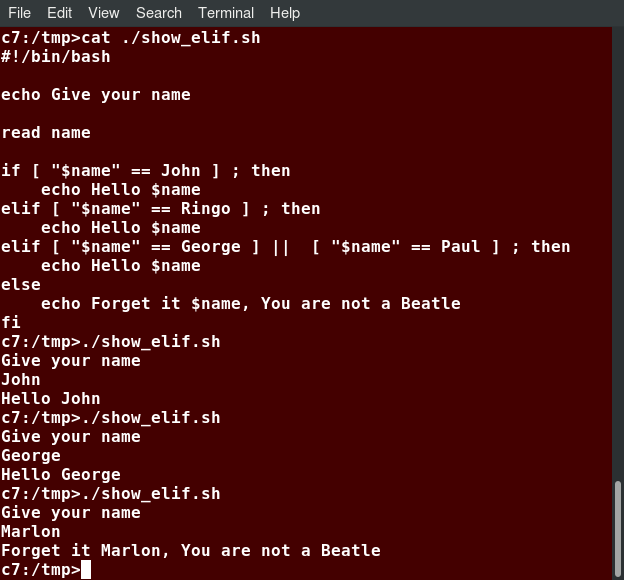
Test per i File
bash fornisce una serie di condizioni di test sui file, che possono essere utilizzate con l'istruzione if, comprese quelle nella tabella.
È possibile utilizzare l'istruzione if per testare gli attributi del file, come ad esempio:
- Esistenza di file o directory
- Permessi di lettura o scrittura
- Permessi di esecuzione.
Ad esempio:
if [ -x /etc/passwd ] ; then AZIONEfi
L'istruzione if verifica se il file /etc/passwd sia eseguibile, cosa che non è. Nota la pratica molto comune di inserire:
; then
sulla stessa riga dell'istruzione if .
È possibile visualizzare l'elenco completo delle condizioni di test sui file digitando:
man 1 test.
| Condizione | Significato |
|---|---|
-e file |
Verifica se file esiste. |
-d file |
Verifica se file è una directory. |
-f file |
Verifica se file è un file normale (vale a dire non un link simbolico, un nodo di dispositivo, directory ecc.) |
-s file |
Verifica se file ha dimensioni maggiori di zero. |
-g file |
Verifica se file ha impostato il sgid. |
-u file |
Verifica se file ha impostato il suid. |
-r file |
Verifica se file è leggibile. |
-w file |
Verifica se file è modificabile. |
-x file |
Verifica se file è eseguibile. |
Espressioni Booleane
Le espressioni booleane esprimono un valore vero (TRUE) o falso (FALSE), e i risultati sono ottenuti utilizzando i vari operatori booleani elencati nella tabella.
| Operatore | Operazione | Significato |
|---|---|---|
&& |
E |
L'azione sarà eseguita solo se entrambe le condizioni vengono valutate vere. |
|| |
OPPURE |
L'azione sarà eseguita solo se una delle condizioni è valutata vera. |
! |
NON |
L'azione sarà eseguita solo la condizione viene valutata falsa. |
Nota che se hai più condizioni unite dall'operatore &&, l'elaborazione si interrompe non appena una condizione viene valutata coma falsa. Ad esempio, se hai A && B && C e A è vero ma B è falso, C non verrà mai eseguito.
Allo stesso modo, se si utilizza l'operatore ||, l'elaborazione si ferma non appena qualcosa è vero. Ad esempio, se hai A || B || C e A è falso e B è vero, non eseguirai mai C.
Test nelle Espressioni Booleane
Le espressioni booleane restituiscono vero o falso. Possiamo utilizzare tali espressioni quando si lavora con più tipi di dati, inclusi stringhe o numeri, nonché con i file. Ad esempio, per verificare se esiste un file, utilizzare il seguente test condizionale:
[ -e <nomefile> ]
In modo simile, per verificare che il valore di number1 sia maggiore del valore di number2, usa il seguente test condizionale:
[ $number1 -gt $number2 ]
L'operatore -gt ritorna vero se number1 è maggiore di number2.

Esempi di Test di Stringhe
Puoi usare l'istruzione if per confrontare stringhe usando l'operatore == (due simboli di uguale). La sintassi è la seguente:
if [ string1 == string2 ] ; then AZIONEfi
Nota che usare un solo segno = funziona comunque, ma alcuni lo ritengono un uso deprecato. Ora considera un esempio di verifica di stringhe.
Nell'esempio illustrato qui, l'istruzione if viene utilizzata per confrontare l'input fornito dall'utente e visualizzare di conseguenza il risultato.
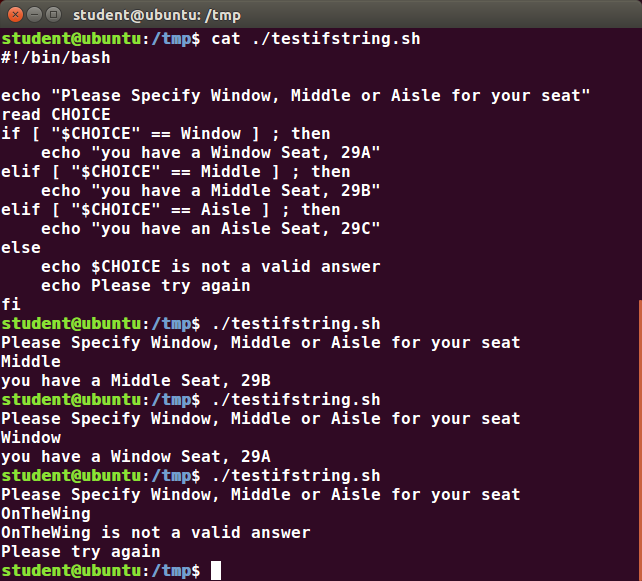
Test Numerici
È possibile utilizzare operatori appositamente definiti con l'istruzione if per confrontare i numeri. I vari operatori disponibili sono elencati nella tabella:
| Operatore | Significato |
|---|---|
-eq |
Uguale a |
-ne |
Non uguale a |
-gt |
Maggiore di |
-lt |
Minore di |
-ge |
Maggiore o uguale a |
-le |
Minore o uguale a |
La sintassi per il confronto dei numeri è la seguente:
espressione1 -operatore espressione2
Esempi di Test per i Numeri
Nella videata seguente, ecco alcuni esempi di confronto di numeri usando diversi operatori:
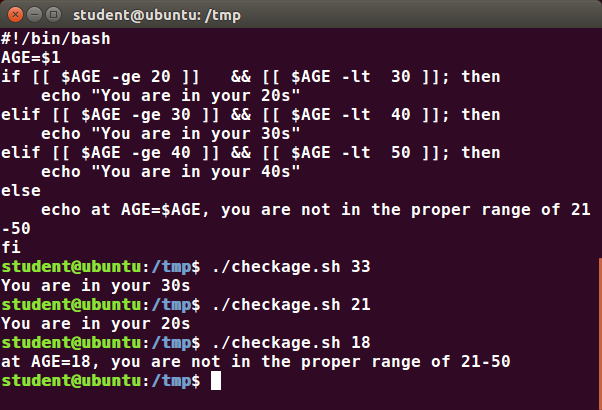
Espressioni Aritmetiche
Le espressioni aritmetiche possono essere valutate nei seguenti tre modi (gli spazi sono importanti!):
- Usando l'utility expr:
expr è un programma standard ma in un qualche modo deprecato. La sintassi è:expr 8 + 8echo $(expr 8 + 8) - Usando la sintassi
$((...)):
questo è il formato integrato nella shell. La sintassi è:echo $((x+1)) - Usando il comando integrato della shell let:
La sintassi è:let x=( 1 + 2 ); echo $x
Negli script di shell moderni, l'uso di expr è rimpiazzato da var=$((...)).
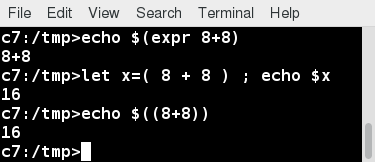
Riepilogo del Capitolo
Hai completato il capitolo 15. Riassumiamo i concetti chiave trattati:
- Gli script sono una sequenza di istruzioni e comandi memorizzati in un file che possono essere eseguiti da una shell. La shell più comunemente usata in Linux è bash.
- La sostituzione del comando consente di sostituire il risultato di un comando come parte di un altro comando.
- Le funzioni o routine sono un gruppo di comandi utilizzati per l'esecuzione.
- Le variabili di ambiente sono quantità preassegnate dalla shell oppure definite e modificate dall'utente.
- Per rendere visibili le variabili di ambiente ai processi figli, devono essere esportate.
- Gli script possono comportarsi in modo diverso in base ai parametri (valori) passati a essi.
- Il processo di scrittura dell'output su un file viene chiamato reindirizzamento dell'output.
- Il processo di lettura di input da un file è chiamato reindirizzamento dell'input.
- L'istruzione if viene utilizzata per selezionare un'azione basata su una condizione.
- Le espressioni aritmetiche sono costituite da numeri e operatori aritmetici, come +, - e *.

Capitolo 16: Altro sullo Scripting di Shell Bash
Obiettivi formativi
Entro la fine di questo capitolo, dovresti essere in grado di:
- Manipolare le stringhe per eseguire azioni come il confronto e l'ordinamento.
- Utilizzare espressioni booleane quando si lavora con più tipi di dati, inclusi stringhe o numeri, nonché file.
- Utilizzare l'istruzione case per gestire le opzioni della riga di comando.
- Utilizzare costrutti di ciclo per eseguire una o più righe di codice ripetutamente.
- Eseguire debug di script usando set -x e set +x.
- Creare file temporanei e directory.
- Creare e usare numeri casuali.
Manipolazione di Stringhe
Andiamo più a fondo e scopriamo come lavorare con le stringhe negli script.
Una variabile stringa contiene una sequenza di caratteri di testo. Può includere lettere, numeri, simboli e segni di punteggiatura. Alcuni esempi includono: abcde, 123, abcde 123, abcde-123, &acbde=%123.
Gli operatori di stringa includono quelli di confronto, ordinamento e ricerca della lunghezza. La tabella seguente dimostra l'uso di alcuni operatori di stringa di base:
| Operatore | Significato |
|---|---|
[[ string1 > string2 ]] |
Confronta alfabeticamente string1 e string2. |
[[ string1 == string2 ]] |
Confronta i caratteri instring1 con i caratteri in string2. |
myLen1=${#string1} |
Salva la lunghezza di string1 nella variabile myLen1. |
Esempi di Manipolazione di Stringhe
Nel primo esempio, confrontiamo la prima stringa con la seconda stringa e visualizziamo un messaggio appropriato utilizzando l'istruzione if.
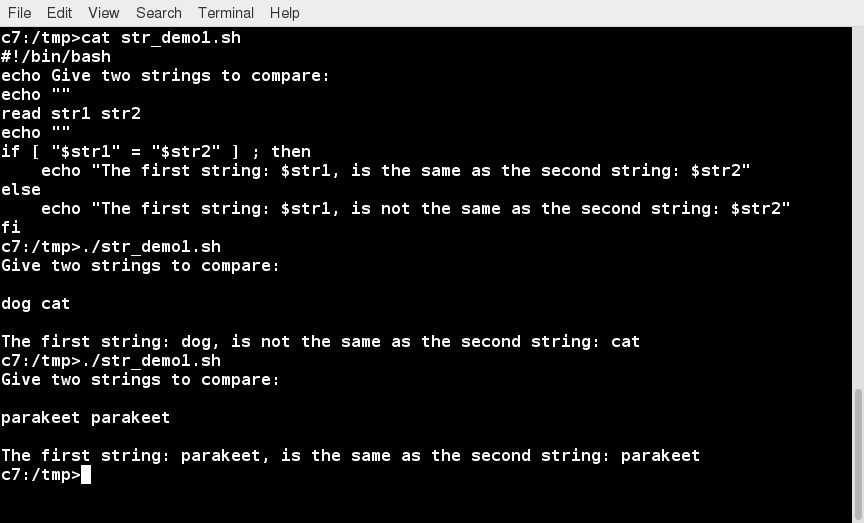
Nel secondo esempio, passiamo il nome di un file e vediamo se quel file esiste nella directory corrente o no.
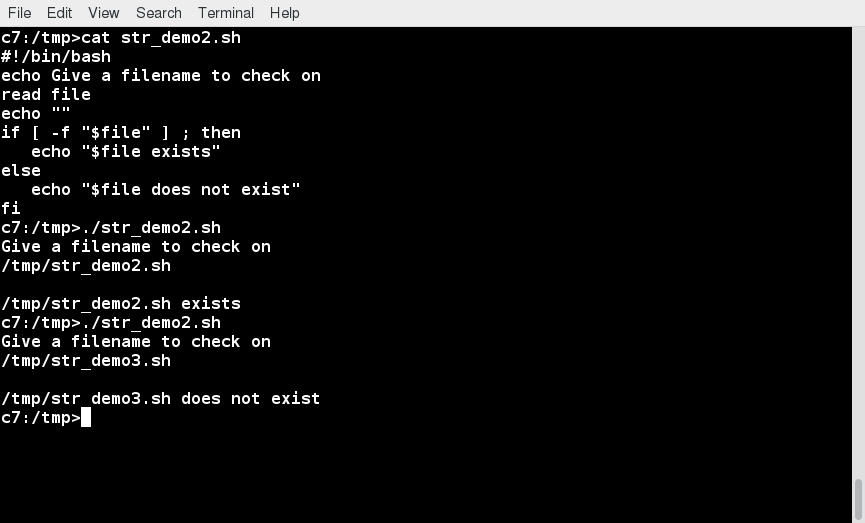
Parti di una Stringa
A volte, potrebbe non essere necessario confrontare o utilizzare un'intera stringa. Per estrarre i primi n caratteri di una stringa possiamo specificare: ${string:0:n}. Qui, 0 è l'offset nella stringa (cioè da quale carattere iniziare l'estrazione) e n è il numero di caratteri da estrarre.
Per estrarre tutti i caratteri in una stringa dopo un punto (.), usa la seguente espressione: ${string#*.}.
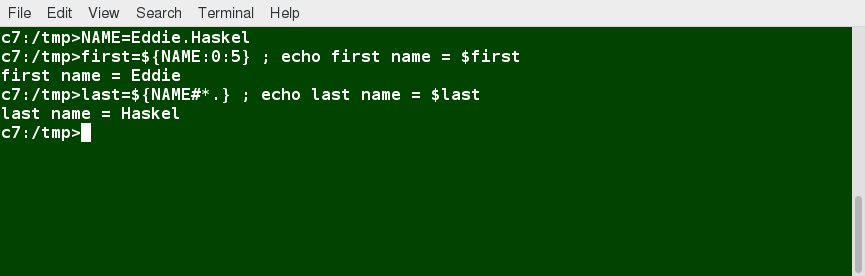
L'istruzione case
L'istruzione case viene utilizzata nei casi in cui il valore effettivo di una variabile può portare a percorsi di esecuzione diversi. Le istruzioni case vengono spesso utilizzate per gestire le opzioni della riga di comando.
Di seguito sono riportati alcuni dei vantaggi dell'utilizzo dell'istruzione case:
- È più facile da leggere e scrivere.
- È una buona alternativa ai blocchi di codice if-then-else-fi annidati, multilivello.
- Ti consente di confrontare una variabile con diversi valori contemporaneamente.
- Riduce la complessità di un programma.
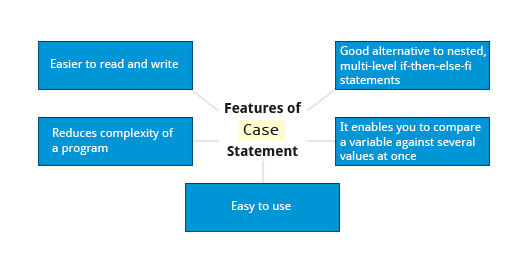
Struttura dell'Istruzione case
Ecco la struttura di base dell'istruzione case:
case espressione in pattern1) esegue i comandi;; pattern2) esegue i comandi;; pattern3) esegue i comandi;; pattern4) esegue i comandi;; * ) esegue qualche comando predefinito oppure nulla;;esac
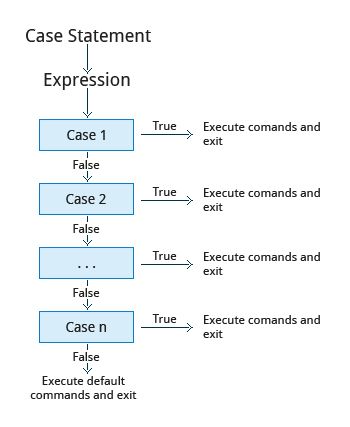
Esempio dell'Uso del Costrutto case
Ecco un esempio dell'uso di un costrutto case. Nota come sia possibile avere più possibilità per ciascun valore di caso che eseguono la stessa azione.
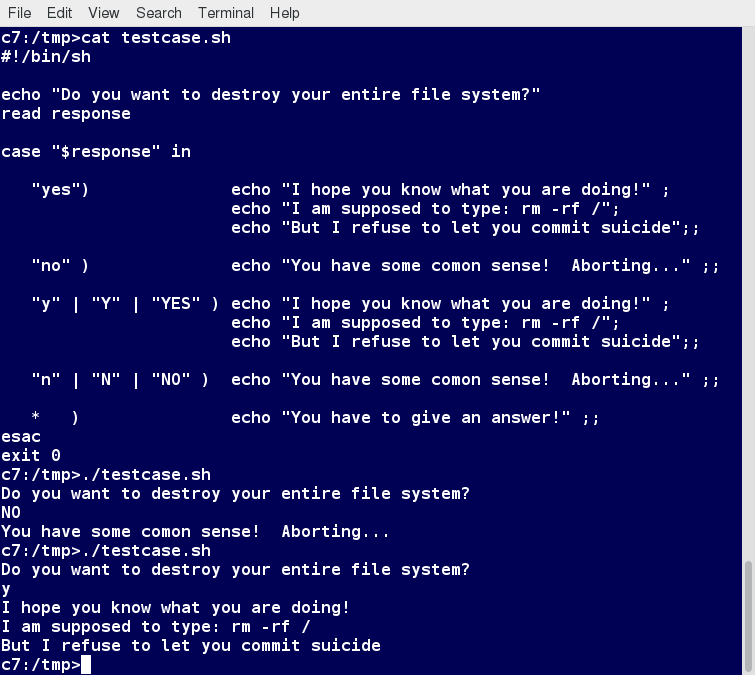
Costrutti per Eseguire Cicli
Usando i costrutti di esecuzione di un ciclo, è possibile eseguire una o più righe di codice ripetutamente, di solito su una selezione di valori di dati come ad esempio singoli file. Di solito, lo fai fino a quando un test condizionale non restituisce vero o falso, come richiesto.
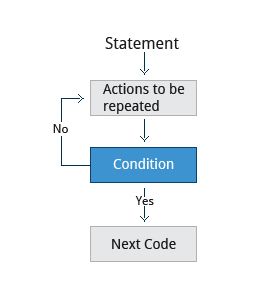
Nella maggior parte dei linguaggi di programmazione sono spesso utilizzati tre tipi di cicli:
- for
- while
- until
Tutti questi cicli sono facilmente utilizzati per ripetere una serie di istruzioni fino a quando la condizione di uscita non è vera.
Il Ciclo for
Il ciclo for opera su ciascun elemento di un elenco di elementi. La sintassi per il ciclo for è:
for nome-variabile in elencodo
** esegui una iterazione per ciascun elemento in elenco fino a quando elenco non ha più elementidone
In questo caso nome-variabile ed elenco sono sostituiti da te come appropriato (vedi esempi). Così come con altri costrutti per cicli, le dichiarazioni ripetute dovrebbero essere racchiuse tra do e done.
La videata seguente mostra un esempio del ciclo for per stampare la somma dei numeri da 1 a 10.
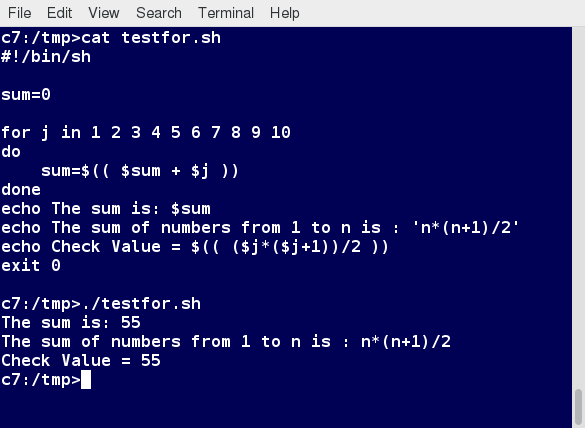
Il Ciclo while
Il ciclo while ripete una serie di istruzioni finché il comando di controllo restituisce vero. La sintassi è:
while condizione è verado Comandi da eseguire ----done
L'insieme di comandi che devono essere ripetuti dovrebbe essere racchiuso tra do e done. È possibile utilizzare qualsiasi comando o operatore come condizione. Spesso è racchiuso tra parentesi quadre ([]).
La videata seguente mosta un esempio del ciclo while che calcola il fattoriale di un numero. Sai come mai il calcolo di 21! fornisce un cattivo risultato?
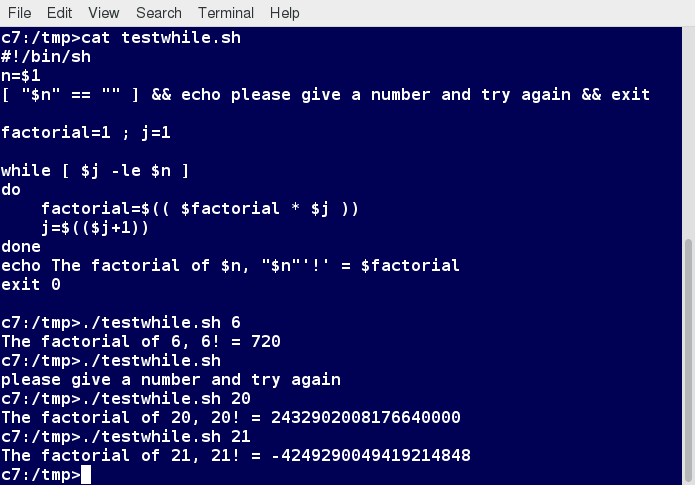
Il Ciclo until
Il ciclo until ripete una serie di istruzioni finché il comando di controllo è falso. Pertanto, è essenzialmente l'opposto del ciclo while. La sintassi è:
until condizione è falsado Comandi da eseguire ----done
In modo simile al ciclo while, l'insieme di comandi che devono essere ripetuti dovrebbe essere racchiuso tra do e done. È possibile utilizzare qualsiasi comando o operatore come condizione.
La videata che segue mostra un esempio del ciclo until che ancora una volta calcola fattoriali; è solo leggermente diverso nel caso di test per il ciclo while.
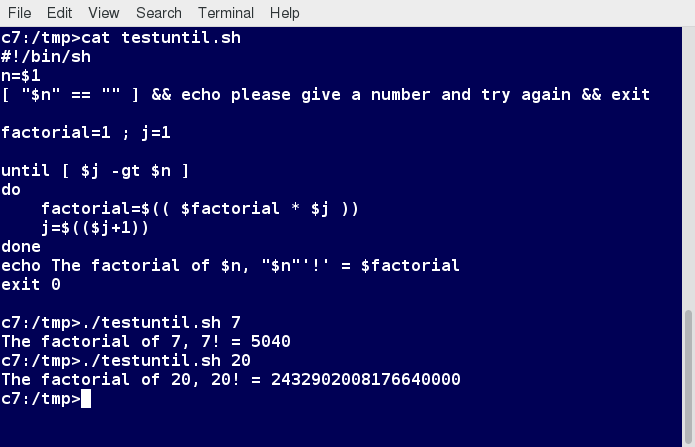
Debug degli Script bash
Mentre si lavora con script e comandi, è possibile che si verifichino errori. Questi possono essere dovuti a un errore nello script, come una sintassi errata, o altre casistiche, come un file mancante o un'autorizzazione insufficiente per eseguire un'operazione. Questi errori possono essere segnalati con un codice di errore specifico, ma spesso producono semplicemente risultati errati o confusi. Quindi, come si fa a identificare e correggere un errore?

Il debug ti aiuta a individuare e risolvere tali errori ed è uno dei compiti più importanti che un amministratore di sistema svolge.
Modalità Debug negli Script
Prima di correggere un errore (o bug), è fondamentale conoscere la sua fonte.
È possibile eseguire uno script bash in modalità debug bash –x ./script_file, oppure racchiudere parti dello script tra set -x e set +x. La modalità di debug aiuta a identificare l'errore in quanto:
- Traccia e prefissa ogni comando con il carattere +.
- Visualizza ogni comando prima di eseguirlo.
- Può eseguire il debug delle sole parti selezionate di uno script (se lo si desidera) con:
set -x # attiva il debug...set +x # disattiva il debug
La videata seguente mostra uno script che viene eseguito in modalità debug se lanciato con qualsiasi argomento dalla riga di comando.
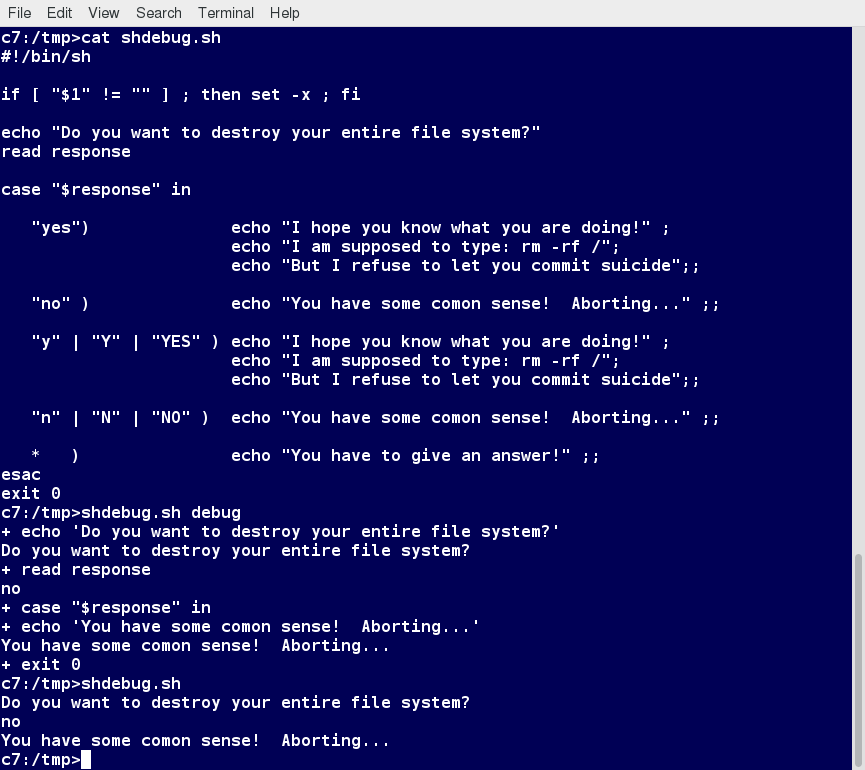
Reindirizzare gli Errori su File e Schermo
In UNIX/Linux, a tutti i programmi eseguiti vengono forniti tre flussi di file aperti quando vengono avviati, come elencati nella tabella:
| Flusso File |
Descrizione | Descrittore File |
|---|---|---|
| stdin | Standard Input, per impostazione predefinita la tastiera/terminale per i programmi eseguiti dalla riga di comando | 0 |
| stdout | Standard output, per impostazione predefinita lo schermo per i programmi eseguiti dalla riga di comando | 1 |
| stderr | Standard error, dove vengono visualizzati o salvati i messaggi di errore | 2 |
Utilizzando il reindirizzamento, possiamo salvare i flussi stdout e stderr in un file o due file separati per l'analisi successiva dopo l'esecuzione di un programma o del comando.
La videata mostra uno script di shell con un semplice bug, che viene eseguito e l'output dell'errore viene deviato in error.log. Utilizzando cat per visualizzare il contenuto del file di errore aggiornato durante il debug. Riesci a vedere come correggere lo script?
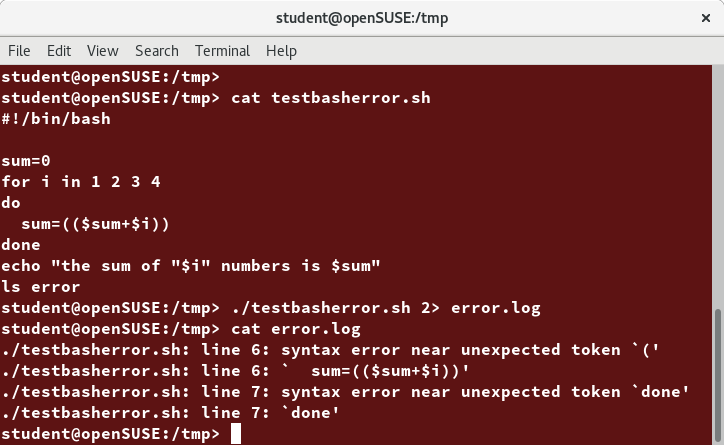
Creare File e Directory Temporanee
Prendi in considerazione una situazione nella quale vuoi recuperare 100 record da un file con 10.000 record. Avrai bisogno di un posto per archiviare le informazioni estratte, forse in un file temporaneo, mentre si effettuano ulteriori elaborazioni su di esso.
I file temporanei (e le directory) sono pensati per archiviare i dati per un breve periodo. Di solito, si fa in modo che questi file scompaiano quando il programma che li usa termina. Mentre puoi anche usare touch per creare un file temporaneo, in alcune circostanze ciò può semplificare l'accesso ai tuoi dati da parti di hacker. Questo è particolarmente vero se il nome e la posizione del file temporaneo sono prevedibili.
La migliore pratica è quella di creare nomi di file casuali e imprevedibili per la conservazione temporanea. Un modo per farlo è con l'utilità mktemp, come nei seguenti esempi.
XXXXXXXX è sostituito da mktemp con caratteri casuali per garantire che il nome del file temporaneo non possa essere facilmente previsto e sia noto solo all'interno del programma.
| Comando | Utilizzo |
|---|---|
TEMP=$(mktemp /tmp/tempfile.XXXXXXXX) |
Crea un file temporaneo |
TEMPDIR=$(mktemp -d /tmp/tempdir.XXXXXXXX) |
Crea una directory temporanea |
Esempi di Creazione di Directory e File Temporanei
Una scarsa attenzione nella creazione di file temporanei può portare a danni reali, sia per caso che a causa di un attore dannoso. Ad esempio, se qualcuno dovesse creare un collegamento simbolico utilizzato da root da un noto file temporaneo verso file /etc/passwd, come questo:
$ ln -s /etc/passwd /tmp/tempfile
Potrebbe esserci un grosso problema se uno script eseguito da root ha una riga che contiene:
echo $VAR > /tmp/tempfile
Il file passwd sarà sovrascritto dal contenuto del file temporaneo.
Per evitare una situazione del genere, assicurati di utilizzare nomi casuali per i file temporanei sostituendo la riga sopra con le seguenti righe:
TEMP=$(mktemp /tmp/tempfile.XXXXXXXX)echo $VAR > $TEMP
Nota che la videata mostra file temporanei con nomi simili creati in giorni differenti, ma con caratteri generati casualmente all'interno di essi.
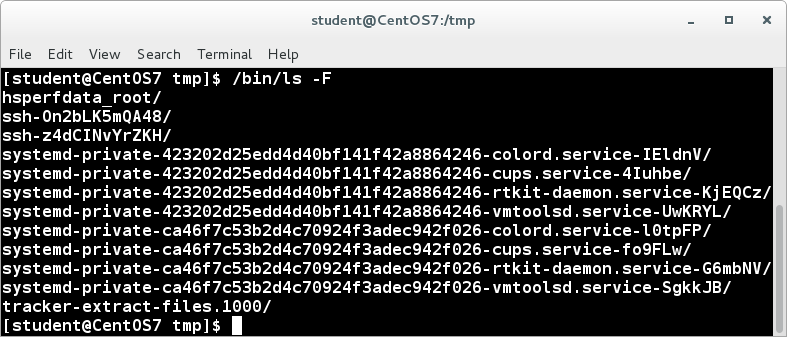
Scartare l'output con /dev/null
Alcuni comandi (come find) produrranno quantità voluminose di output, che possono intasare la console. Per evitare questo, possiamo reindirizzare l'output di grandi dimensioni a un file speciale (un nodo di dispositivo) chiamato /dev/null. Questo pseudofile è anche chiamato bit bucket oppure buco nero.
Tutti i dati scritti vengono scartati e le operazioni di scrittura non restituiscono mai una condizione di fallimento. Usando gli operatori di reindirizzamento corretti, può far scomparire l'output da comandi che normalmente genererebbero output verso stdout e/o stderr:
$ ls -lR /tmp > /dev/null
Nel comando sopra, l'intero flusso di output standard viene ignorato, ma eventuali errori appariranno comunque sulla console.Tuttavia, se si fa:
$ ls -lR /tmp >& /dev/null
sia stdout che stderr saranno scaricati in /dev/null.
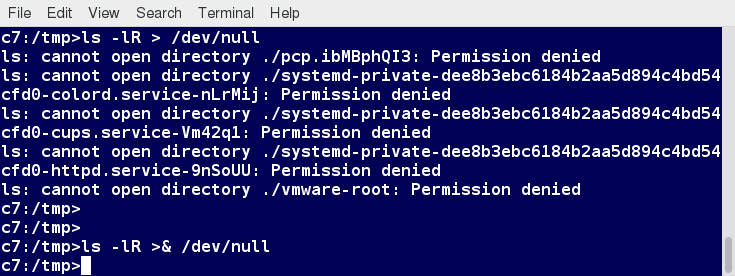
Numeri e Dati Casuali
È spesso utile generare numeri e altri dati casuali quando si deve ad esempio:
- Svolgere attività relative alla sicurezza
- Reinizializzare dispositivi di archiviazione
- Cancellare e/o oscurare dati esistenti
- Generare dati insignificanti da utilizzare per i test
Tali numeri casuali possono essere generati utilizzando la variabile di ambiente $RANDOM, che è derivata dal generatore di numeri casuali incorporato del kernel Linux o dalla funzione della libreria OpenSSL, che utilizza l'algoritmo FIPS140 (Federal Information Processing Standard) per generare numeri casuali per la crittografia.
Per saperne di più su FIPS140, leggi "Che cos'è lo standard FIPS 140-2".
L'esempio mostra come utilizzare facilmente il metodo della variabile di ambiente per generare numeri casuali.
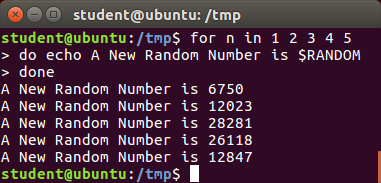
Come il Kernel Genera Numeri Casuali
Alcuni server dispongono di generatori di numeri casuali hardware che ricevono come input diversi tipi di segnali di rumore, come il rumore termico e l'effetto fotoelettrico. Un trasduttore converte questo rumore in un segnale elettrico, che viene nuovamente convertito in un numero digitale da un convertitore Analogico-Digitale. Questo numero è considerato casuale. Tuttavia, la maggior parte dei computer comuni non contiene hardware così specializzato e, invece, si basa sugli eventi creati durante l'avvio per creare i dati grezzi necessari.
Indipendentemente da quale di queste due fonti viene utilizzata, il sistema mantiene un cosiddetto pool di entropia di questi numeri digitali/bit casuali. I numeri casuali sono creati da questo pool entropico.
Il kernel Linux offre i nodi del dispositivo /dev/random e /dev/urandom, che attingono al pool di entropia per fornire numeri casuali che sono estratti dal numero stimato di bit di rumore nel pool entropia.
/dev/Random viene utilizzato quando è richiesta una casualità di alta qualità, come un OTP o una generazione di chiave, ma è relativamente lento a fornire valori. /dev/urandom è più veloce e adatto (abbastanza buono) per la maggior parte degli scopi crittografici.
Inoltre, quando il pool di entropia è vuoto, /dev/random viene bloccato e non genera alcun numero fino a quando viene raccolto un ulteriore rumore ambientale (traffico di rete, movimento del mouse, ecc.), mentre /dev/urandom riutilizza il pool interno per produrre più bit pseudo-casuali.
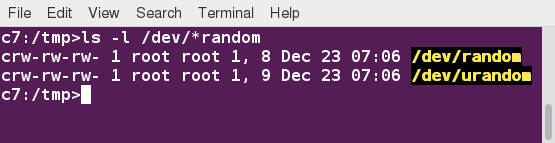
Riepilogo del Capitolo
Hai completato il capitolo 16. Riassumiamo i concetti chiave coperti:
- È possibile manipolare le stringhe per eseguire azioni come confronto, smistamento e trovare la lunghezza.
- È possibile utilizzare espressioni booleane quando si lavora con più tipi di dati, inclusi stringhe o numeri e file.
- Il risultato di un'espressione booleana è vero o falso.
- Gli operatori utilizzati nelle espressioni booleane includono && (E), || (O) e ! (NON).
- Abbiamo esaminato i vantaggi dell'utilizzo dell'istruzione case negli scenari in cui il valore di una variabile può portare a diversi percorsi di esecuzione.
- I metodi di debug dello script aiutano la risoluzione dei problemi e a correggere gli errori.
- L'ouput standard e di errore da uno script o i comandi dalla shell possono essere facilmente reindirizzati nello stesso file o in file separati per aiutare il debug salvando i risultati.
- Linux consente di creare file e directory temporanei, che archiviano i dati per una breve durata, salvando lo spazio e aumentando la sicurezza.
- Linux fornisce diversi modi per generare numeri casuali, che sono ampiamente utilizzati.

Capitolo 17: Stampare
Obiettivi Formativi
Entro la fine di questo capitolo, dovresti sapere come:
- Configurare una stampante su una macchina Linux.
- Stampare documenti.
- Manipolare i file PostScript e PDF utilizzando utilità della riga di comando.
Stampare in Linux
Per gestire le stampanti e stampare direttamente da un computer o attraverso un ambiente in rete, è necessario sapere come configurare e installare una stampante. La stampa stessa richiede un software che converte le informazioni dall'applicazione che si utilizza in un linguaggio che la stampante possa capire. Lo standard Linux per il software di stampa è CUPS (Common Unix Printing System).

I moderni sistemi desktop Linux rendono l'installazione e l'amministrazione delle stampanti piuttosto semplice e intuitiva, e non diversamente da come viene fatto su altri sistemi operativi. Tuttavia, è istruttivo capire le basi di come viene fatto in Linux.
Panoramica di CUPS
CUPS è il software alla base di quasi tutti i sistemi Linux utilizzato per stampare da applicazioni come un browser web o LibreOffice. Converte le descrizioni delle pagine prodotte dalla tua applicazione (metti un paragrafo qui, traccia una linea lì e così via), quindi invia le informazioni alla stampante. Agisce come server di stampa sia per stampanti locali che di rete.
Le stampanti prodotte da diverse aziende possono utilizzare i propri linguaggi e formati di stampa particolari. CUPS utilizza un sistema di stampa modulare che accoglie un'ampia varietà di stampanti e elabora anche vari formati di dati. Questo rende il processo di stampa più semplice; puoi concentrarti di più sulla stampa e meno su come stampare.
In generale, l'unica volta in cui è necessario configurare la stampante è quando la usi per la prima volta. In effetti, CUPS spesso scopre le cose da solo rilevando e configurando eventuali stampanti che individua.
Come Funziona CUPS?
CUPS esegue il processo di stampa con l'aiuto dei suoi vari componenti:
- File di configurazione
- Scheduler
- File di lavoro
- File di Log
- Filtro
- Driver della stampante
- Backend.
Imparerai a conoscere ciascuno di questi componenti nelle prossime pagine.
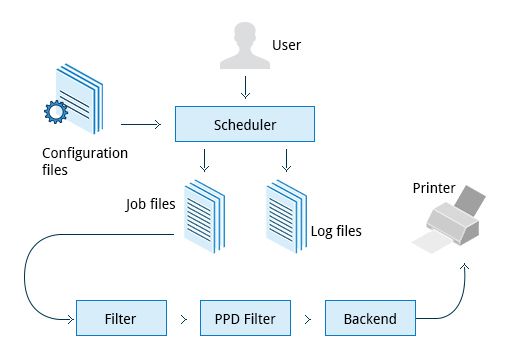
Scheduler
CUPS è progettato attorno a uno scheduler di stampa che gestisce i lavori di stampa, e i comandi amministrativi, consente agli utenti di interrogare lo stato della stampante e gestisce il flusso di dati attraverso tutti i componenti CUPS.
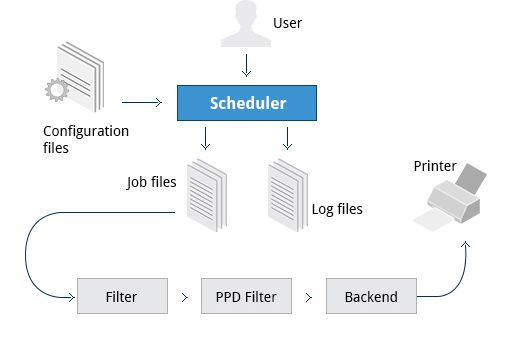
Esamineremo l'interfaccia basata sul browser che può essere utilizzata con CUPS, che consente di visualizzare e manipolare l'ordine e lo stato dei lavori di stampa in sospeso.
File di Configurazione
Lo scheduler di stampa legge le impostazioni del server da diversi file di configurazione, i due più importanti dei quali sono cupsd.conf e printers.conf. Questi e altri file di configurazione relativi a CUPS sono conservati nella directory /etc/cups/.
cupsd.conf è dove si trova la maggior parte delle impostazioni a livello di sistema; non contiene dettagli specifici della stampante. La maggior parte delle impostazioni disponibili in questo file si riferisce alla sicurezza di rete, ovvero a quali sistemi possono accedere alle capacità di rete di CUPS, come vengono esposte le stampanti sulla rete locale, quali funzionalità di gestione sono offerte e così via.
printers.conf è dove troverai le impostazioni specifiche della stampante. Per ogni stampante collegata al sistema, una sezione corrispondente descrive lo stato e le funzionalità della stampante. Questo file viene generato o modificato solo dopo aver aggiunto una stampante al sistema e non deve essere modificato a mano.
Puoi visualizzare l'elenco completo dei file di configurazione digitando ls -lF /etc/cups.
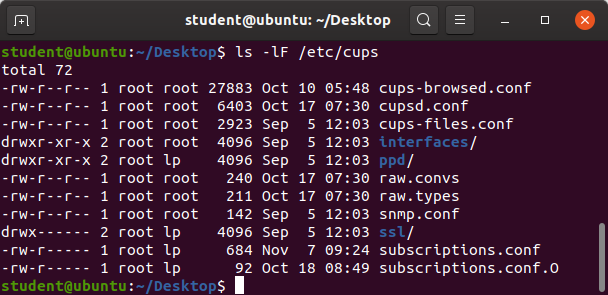
File di Lavoro
CUPS memorizza le richieste di stampa sotto forma di file nella directory /var/spool/cups (a cui si può effettivamente accedere prima che un documento venga inviato a una stampante). I file di dati sono prefissati con la lettera d mentre i file di controllo sono prefissati con la lettera c.
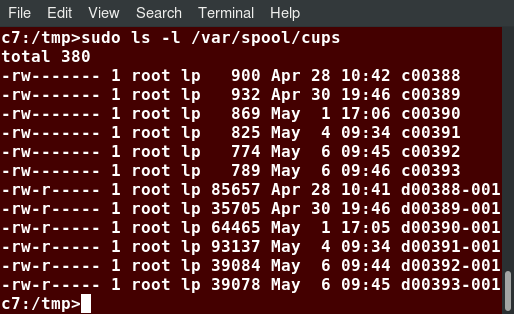
Dopo che una stampante gestisce correttamente un lavoro, i file di dati vengono rimossi automaticamente. Questi file di dati appartengono a ciò che è comunemente noto come coda di stampa.
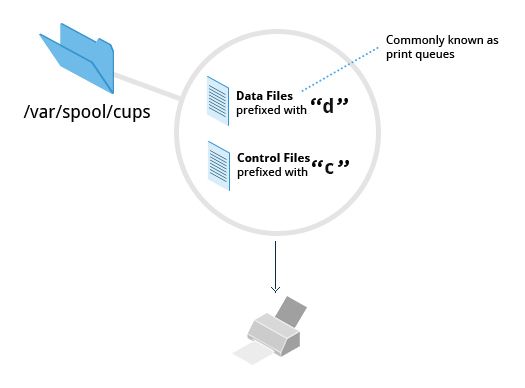
File di Log
I file di log vengono inseriti in /var/log/cups e sono utilizzati dallo scheduler per registrare attività che hanno avuto luogo. Questi file includono record di accesso, errore e pagina.
Per visualizzare quali file di log esistono, digita:
$ sudo ls -l /var/log/cups
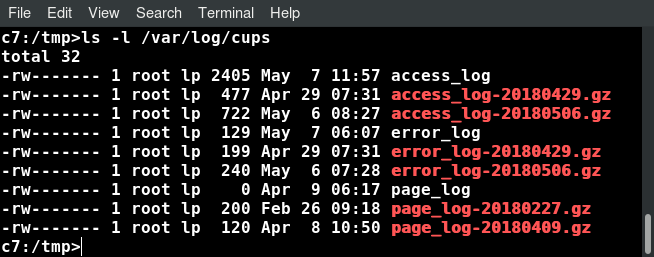
Nota che su alcune distribuzioni i permessi sono impostati in modo tale che non sia necessario utilizzare sudo. È possibile visualizzare i file di registro con i soliti strumenti.
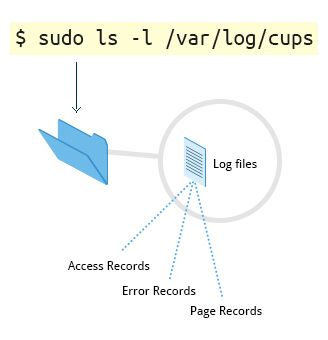
$ sudo ls -l /var/log/cupsFiltri, Driver di Stampante e Backend
CUPS usa filtri per convertire i formati di file di lavoro in formati stampabili. I driver della stampante contengono descrizioni per le stampanti attualmente connesse e configurate e di solito sono conservate sotto /etc/cups/ppd/. I dati di stampa vengono quindi inviati alla stampante tramite un filtro e tramite un backend che aiuta a individuare i dispositivi collegati al sistema.
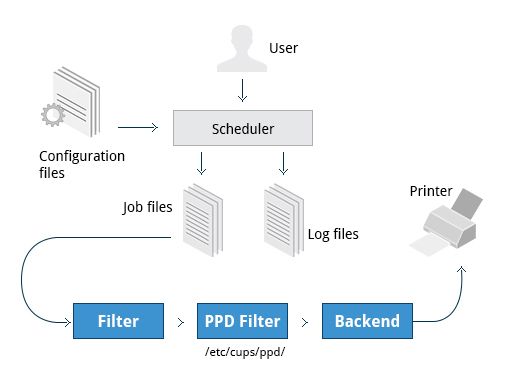
Quindi, in breve, quando si esegue un comando di stampa, lo scheduler convalida il comando ed elabora il lavoro di stampa, creando file di lavoro in base alle impostazioni specificate nei file di configurazione. Allo stesso tempo, lo scheduler registra le attività nei file di registro. I file di lavoro vengono elaborati con l'aiuto del filtro, del driver della stampante e del backend, quindi inviati alla stampante.
Gestire CUPS
Supponendo che CUPS sia installato dovrai avviare e gestire il demone CUPS in modo che sia pronto per configurare una stampante. La gestione del demone CUPS è semplice, tutte le funzionalità di gestione possono essere eseguite con l'utility systemctl :
$ systemctl status cups
$ sudo systemctl [enable|disable] cups
$ sudo systemctl [start|stop|restart] cups
NOTA: la sezione seguente offre una dimostrazione in Ubuntu, ma è lo stesso per tutte le principali distribuzioni Linux correnti.
Video: Gestire il Demone CUPS
Configurare una Stampante dalla GUI
Ogni distribuzione Linux ha un'applicazione GUI che consente di aggiungere, rimuovere e configurare stampanti locali o remote. Utilizzando questa applicazione, è possibile impostare facilmente il sistema per utilizzare stampanti locali e di rete. Le seguenti videate mostrano come trovare e utilizzare l'applicazione appropriata in ciascuna delle famiglie di distribuzione coperte in questo corso.
Quando configuri una stampante, assicurati che il dispositivo sia attualmente acceso e connesso al sistema; in tal caso, dovrebbe essere visualizzato nel menu di selezione della stampante. Se la stampante non è visibile, è possibile risolvere i problemi utilizzando strumenti che determineranno se la stampante è connessa. Per le stampanti USB comuni, ad esempio, l'utilità lsusb mostrerà una riga per la stampante. Alcuni produttori di stampanti richiedono anche l'installazione di software supplementare per rendere la stampante visibile a CUPS, tuttavia, a causa della standardizzazione in questi giorni, ciò è raramente richiesto.
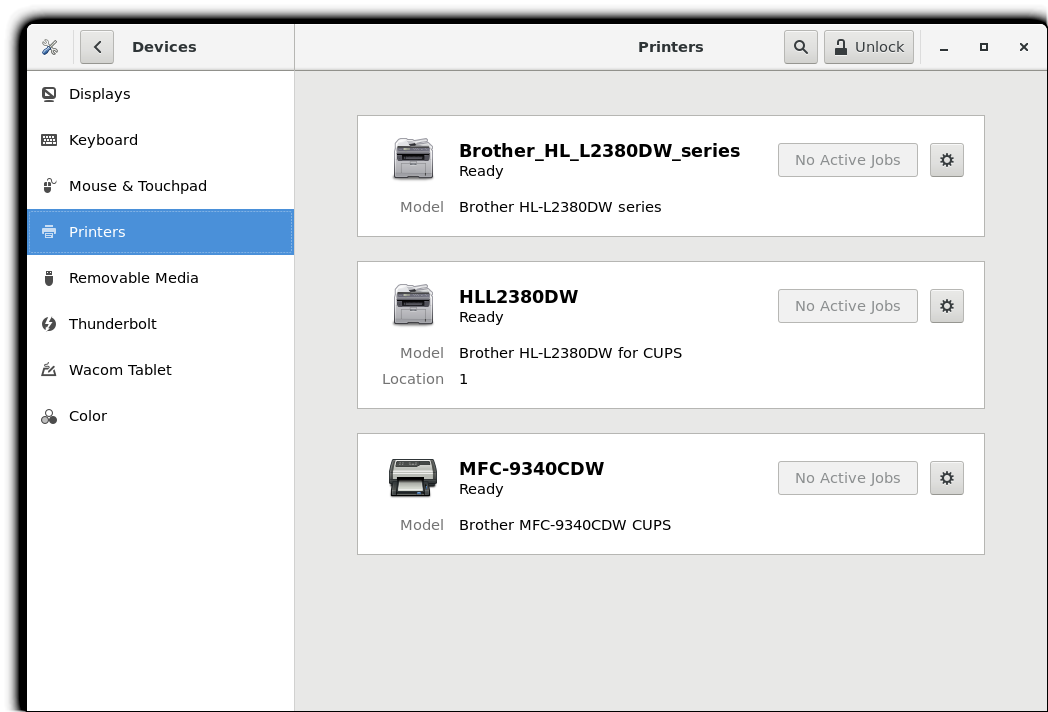
Video: Aggiungere una Stampante di Rete
Aggiungere Stampanti dall'Interfaccia Web di CUPS
Un fatto che poche persone sanno è che CUPS è anche dotato del proprio server web, che rende disponibile un'interfaccia di configurazione tramite un insieme di script CGI.
Questa interfaccia web ti consente di:
- Aggiungere e rimuovere le stampanti locali/remote
- Configurare le stampanti:
- Stampanti locali/remote
- Condividere una stampante come server di CUPS
- Controllare i lavori di stampa
- Monitorare i lavori
- Mostrare lavori completati o in sospeso
- Annullare o spostare i lavori.
L'interfaccia web Cups è disponibile sul browser digitando: http://localhost:631.
Alcune pagine richiedono un nome utente e una password per eseguire determinate azioni, ad esempio per aggiungere una stampante. Per la maggior parte delle distribuzioni Linux, è necessario utilizzare la password di root per aggiungere, modificare o eliminare stampanti o classi.
Stampare dall'Interfaccia Grafica
Molte applicazioni grafiche consentono agli utenti di accedere alle funzionalità di stampa utilizzando la scorciatoia CTRL-P. Per stampare un file, è necessario prima specificare la stampante (o un nome e una posizione del file se stai stampando verso un file) che si desidera utilizzare, quindi selezionare le opzioni di configurazione, qualità e colore della pagina. Dopo aver selezionato le opzioni richieste, puoi inviare il documento per la stampa. Il documento viene quindi inviato a CUPS. Puoi utilizzare il browser per accedere all'interfaccia web CUPS su [http://localhost:631/] per monitorare lo stato del lavoro di stampa. Ora che hai configurato la stampante, puoi stampare utilizzando le interfacce della riga grafica o di comando.
La seguente videata mostra l'interfaccia GUI aperta digitando CTRL-P per CentOS, altre distribuzioni Linux appaiono praticamente identiche.
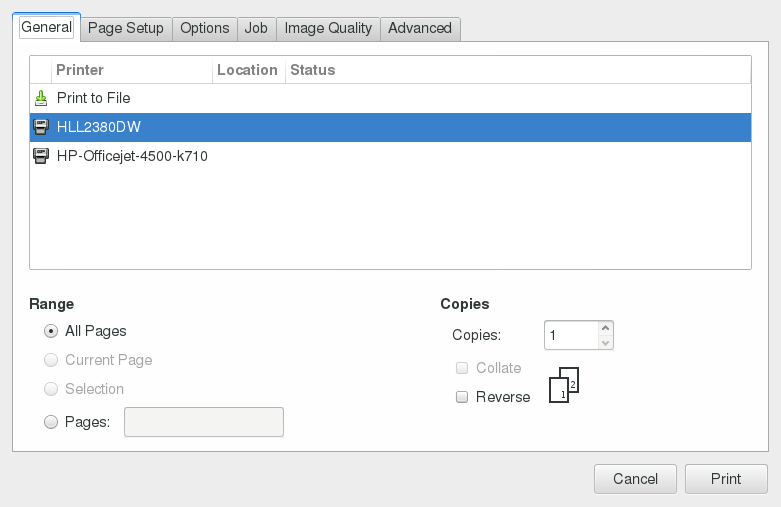
CTRL-P in CentOSStampare dalla Riga di Comando
CUPS fornisce due interfacce di riga di comando, discendenti dalle varianti di UNIX Syistem V e BSD. Ciò significa che è possibile utilizzare lp (System V) o lpr (BSD) per stampare. È possibile utilizzare questi comandi per stampare file di testo, postscript, pdf e immagine.
Questi comandi sono utili nei casi in cui le operazioni di stampa devono essere automatizzate (dagli script di shell, ad esempio, che contengono più comandi in un file).
lp è solo un front-end da linea di comando dell'utilità lpr che passa l'input a lpr. Pertanto, discuteremo solo di lp in dettaglio. Nell'esempio mostrato qui, l'attività è stampare $ home/.emacs.

Usare lp
lp e lpr accettano opzioni da riga di comando che ti aiutano a eseguire tutte le operazioni che la GUI può compiere. lp viene generalmente utilizzato con un nome di file come argomento.
Alcuni comandi lp e altre utility di stampa delle quali puoi usufruire sono elencate nella tabella:
| Comando | Utilizzo |
|---|---|
lp <nomefile> |
Stampa nomefile alla stampante predefinita |
lp -d stampante <nomefile> |
Stampa nomefile a una stampante specifica (utile se ci sono a disposizione più stampanti) |
programma | lp<br>echo stringa | lp |
Stampa il risultato di un programma |
lp -n numero <nomefile> |
Stampa n copie di nomefile |
lpoptions -d stampante |
Imposta la stampante predefinita |
lpq -a |
Mostra lo stato della code di stampa |
lpadmin |
Configura le code di stampa |
lpoptions può essere utilizzato per impostare opzioni di stampante e impostazioni predefinite. Ogni stampante ha un insieme di valori ad essa associati, come il numero predefinito di copie e i requisiti di autenticazione. Puoi digitare lpoptions help per ottenere un elenco di opzioni supportate. lpoptions può anche essere utilizzato per impostare valori a livello di sistema, come la stampante predefinita.
Video: Stampare Usando lp
Gestire i Lavori di Stampa
Hai inviato un file alla stampante condivisa. Ma quando vai lì per raccogliere la stampa, scopri che un altro utente ha appena avviato un lavoro di 200 pagine che non è urgente. Il tuo file non può essere stampato fino al completamento di questo lavoro di stampa. Cosa fai adesso?
In Linux, i comandi di gestione del lavoro di stampa dalla riga di comando consentono di monitorare lo stato del lavoro, nonché di gestire l'elenco di tutte le stampanti e controllare il loro stato e annullare o spostare i lavori di stampa su un'altra stampante.
Alcuni di questi comandi sono elencati nella tabella.
| Comando | Utilizzo |
|---|---|
lpstat -p -d |
Ottiene una lista di stampanti disponibili e del loro stato |
lpstat -a |
Verifica lo stato di tutte le stampanti connesse, compreri i numeri dei lavori |
cancel job-idOPPURE lprm job-id |
Cancella un lavoro di stampa |
lpmove job-id nuovastampante |
Sposta un lavoro di stampa a una nuova stampante |
Lavorare con PostScript e PDF
PostScript è un linguaggio di descrizione della pagina standard. Gestisce efficacemente il ridimensionamento di caratteri e grafica vettoriale per fornire stampe di qualità. È puramente un formato di testo che contiene i dati inviati a un interprete PostScript. Il formato stesso è un linguaggio sviluppato da Adobe nei primi anni '80 per consentire il trasferimento di dati alle stampanti.
Lavorare con PostScript e PDF
Le caratteristiche di PostScript sono:
- Può essere utilizzato su qualsiasi stampante compatibile con PostScript; cioè qualsiasi stampante moderna
- Qualsiasi programma che comprenda le specifiche PostScript può stampare
- Informazioni sull'aspetto della pagina, ecc. sono incorporate nella pagina.
PostScript è stato per la maggior parte sostituito dal formato PDF (Portable Document Format) che produce file molto più piccoli in un formato compresso per il quale il supporto è stato integrato in molte applicazioni. Tuttavia, si devono ancora gestire i documenti PostScript, spesso come formato intermedio verso la produzione di documenti finali.
Lavorare con enscript
enscript è uno strumento che viene utilizzato per convertire un file di testo in PostScript e altri formati. Supporta anche il formato RTF (Rich Text Format) e HTML (Hypertext Markup Language). Ad esempio, è possibile convertire un file di testo in un formato Postscript a due colonne (-2) usando il comando:
$ enscript -2 -r -p psfile.ps textfile.txt
Questo comando ruota anche (-r) l'output da stampare in modo che la larghezza della carta sia maggiore dell'altezza (cioè modalità "landscape" - paesaggio) riducendo così il numero di pagine richieste per la stampa.
I comandi che possono essere usati con enscript sono elencati nella tabella seguente (per un file chiamato textfile.txt).
| Comando | Utilizzo |
|---|---|
enscript -p psfile.ps textfile.txt |
Converte textfile.txt in PostScript (salvato come psfile.ps) |
enscript -n -p psfile.ps textfile.txt |
Converte textfile.txt in Postscript a n colonne dove n=1-9 (salvato come psfile.ps) |
enscript textfile.txt |
Stampa textfile.txt direttamente alla stampante predefinita |
Convertire tra PostScript e PDF
La maggior parte degli utenti oggi è molto più abituata a lavorare con i file in formato PDF, visualizzandoli facilmente su Internet attraverso il loro browser o localmente sulla loro macchina. Il formato PostScript è ancora importante per vari motivi tecnici che l'utente generale dovrà raramente affrontare.
Di tanto in tanto, potrebbe essere necessario convertire i file da un formato all'altro e ci sono utilità molto semplici per realizzare tale attività. ps2pdf e pdf2ps fanno parte del pacchetto ghostscript installato o disponibile su tutte le distribuzioni Linux. In alternativa, ci sono pstopdf e pdftops che di solito fanno parte del pacchetto poppler, che potrebbe essere necessario aggiungere tramite il gestore dei pacchetti. A meno che tu non stia facendo molte conversioni o hai bisogno di alcune delle opzioni più elaborate (che puoi leggere nelle pagine di manuale per queste utility), non importa davvero quali usi.
Un'altra possibilità è quella di utilizzare il programma convert molto potente, che fa parte del pacchetto ImageMagick. Alcune distribuzioni più recenti hanno sostituito questo con Graphics Magick, e il comando da usare è gm convert.
Alcuni esempi di utilizzo:
| Comando | Utilizzo |
|---|---|
pdf2ps file.pdf |
Converte file.pdf in file.ps |
ps2pdf file.ps |
Converte file.psin file.pdf |
pstopdf input.ps output.pdf |
Converte input.ps in output.pdf |
pdftops input.pdf output.ps |
Converte input.pdf in output.ps |
convert input.ps output.pdf |
Converte input.ps in output.pdf |
convert input.pdf output.ps |
Convertsinput.pdf in output.ps |
Visualizzare Contenuto PDF
Linux ha molti programmi standard in grado di leggere file PDF, nonché molte applicazioni che possono facilmente crearli, comprese tutte le suite di ufficio disponibili, come LibreOffice.
I lettori PDF Linux più comuni sono:
- evince, disponibile praticamente su tutte le distribuzioni ed è il programma più utilizzato.
- okular, che si basa sul vecchio kpdf ed è disponibile su qualsiasi distribuzione che fornisce l'ambiente KDE.
Questi lettori PDF open source supportano e possono leggere i file che seguono lo standard PostScript. Il lettore proprietario di Adobe, Acrobat Reader, che una volta era ampiamente utilizzato sui sistemi Linux, per fortuna non è più disponibile, in quanto la presentazione del testo era difettosa, era instabile ed era scarsamente mantenuto.

Manipolare PDFs
A volte potresti voler unire, dividere o ruotare i file PDF; non tutte queste operazioni possono essere compiute utilizzando un visualizzatore PDF. Alcune di queste operazioni includono:
- Combinare/dividere/ruotare documenti PDF
- Riparare pagine PDF danneggiate
- Estrarre singole pagine da un file PDF
- Codificare e decodificare file PDF
- Aggiungere, aggiornare ed esportare i metadati di un PDF
- Esportare segnalibri in un file di testo
- Compilare moduli PDF.
Per svolgere questi compiti ci sono diversi programmi disponibili:
- qpdf
- pdftk
- ghostscript.
qpdf è ampiamente disponibile sulle distribuzioni Linux ed è molto completo. pdftk una volta era molto popolare ma dipende da un pacchetto obsoleto non mantenuto (libgcj) e un certo numero di distribuzioni l'hanno abbandonato; quindi ti consigliamo di evitarlo. Ghostscript (spesso lanciato usando gs) è ampiamente disponibile e ben mantenuto. Tuttavia, il suo utilizzo è un po' complesso.
Usare qpdf
Puoi svolgere un'ampia varietà di compiti utilizzando qpdf compreso:
| Comando | Utilizzo |
|---|---|
qpdf --empty --pages 1.pdf 2.pdf -- 12.pdf |
Unisce due documenti, 1.pdf e2.pdf. Il risultato viene salvato su 12.pdf. |
qpdf --empty --pages 1.pdf 1-2 -- new.pdf |
Scrive solo le pagine 1 e 2 di 1.pdf. Il risultato viene salvato su new.pdf. |
qpdf --rotate=+90:1 1.pdf 1r.pdfqpdf --rotate=+90:1-z 1.pdf 1r-all.pdf |
Ruota la pagina 1 di 1.pdf di 90 gradi in senso orario e salva su 1r.pdf. Ruota tutte le pagine di 1.pdf di 90 gradi in senso orario e salva su 1r-all.pdf |
qpdf --encrypt mypw mypw 128 -- public.pdf private.pdf |
Codifica a 128 bit public.pdf usando la password mypw scrive il risultato su private.pdf. |
qpdf --decrypt --password=mypw private.pdf file-decrypted.pdf |
Decodifica private.pdf, scrive il risultato su file-decrypted.pdf. |
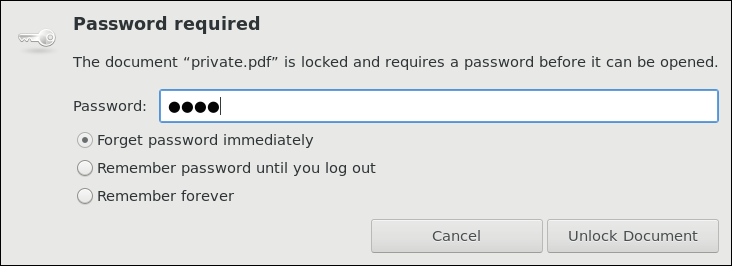
Video: Usare qpdf
Usare pdftk
pdftk ora è stato portato su Java! Marc Vinyals ha sviluppato e mantenuto un port per Java per pdftk che puoi trovare qui, oltre alle istruzioni di installazione. Alcune distribuzioni, come Ubuntu, potrebbero installare solo questa versione.
Puoi svolgere un'ampia varietà di attività utilizzando pdftk compreso:
| Comando | Utilizzo |
|---|---|
pdftk 1.pdf 2.pdf cat output 12.pdf |
Unire due docuemnti 1.pdf e 2.pdf. Il risultato viene salvato su 12.pdf. |
pdftk A=1.pdf cat A1-2 output new.pdf |
Scrivere solo le pagine 1 e 2 1.pdf. Il risultato viene salvato su new.pdf. |
pdftk A=1.pdf cat A1-endright output new.pdfabc |
Ruotare tutte le pagine di 1.pdf di 90 gradi in senso orario e salvare il risultato su new.pdf. |
Codificare i File PDF con pdftk
Se stai lavorando con file PDF che contengono informazioni riservate e desideri assicurarti che solo determinate persone possano visualizzare il file PDF, è possibile applicare una password utilizzando l'opzione user_pw. Si può farlo digitando un comando come:
$ pdftk public.pdf output private.pdf user_pw PROMPT
Quando si esegue questo comando, riceverai un prompt per impostare la password richiesta, che può avere un massimo di 32 caratteri. Un nuovo file, private.pdf, verrà creato con contenuto identico a public.pdf, ma chiunque lo voglia visualizzare dovrà digitare la password.
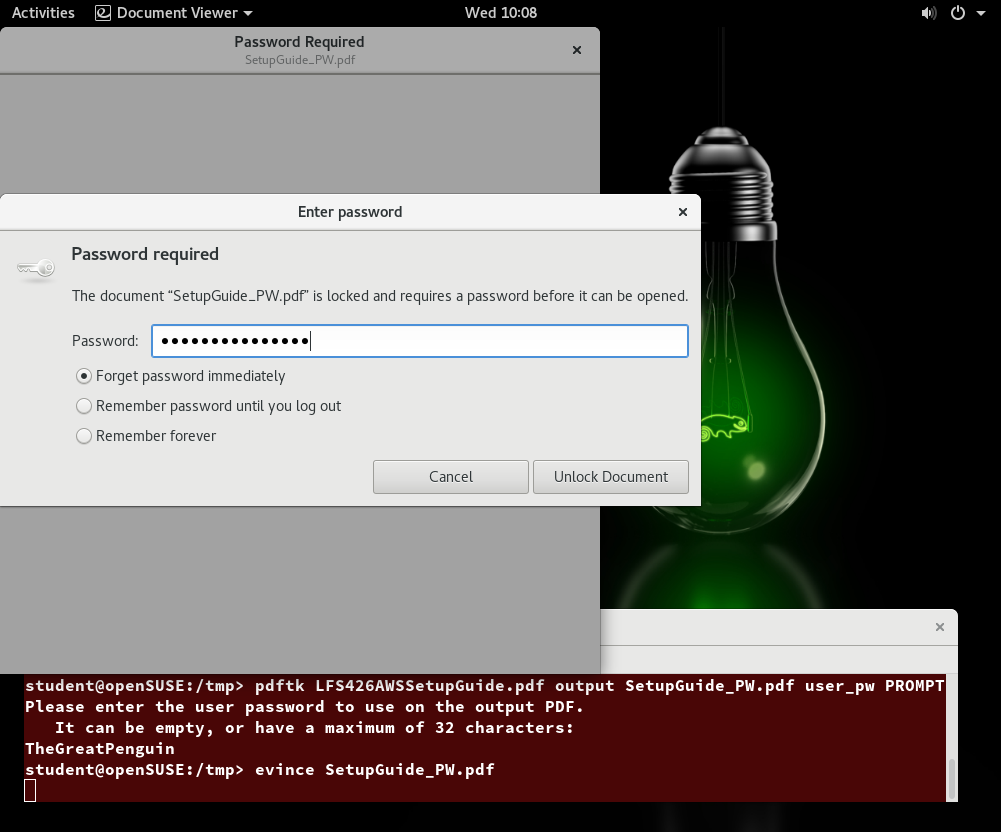
Usare Ghostscript
Ghostscript è ampiamente disponibile come interprete per i linguaggi PostScript e PDF. Il programma eseguibile ad esso associato è abbreviato in gs.

Questa utility può fare la maggior parte delle operazioni che fa pdftk, così come molte altre; vedi la pagina di manuale di gs per i dettagli. L'uso è in qualche modo complicato dalla natura piuttosto lunga delle opzioni. Per esempio:
- Combinare tre file PDF in uno:
$ gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -sOutputFile=all.pdf file1.pdf file2.pdf file3.pdf
- Estrarre le pagine da 10 a 20 da un file PDF:
$ gs -sDEVICE=pdfwrite -dNOPAUSE -dBATCH -dDOPDFMARKS=false -dFirstPage=10 -dLastPage=20\-sOutputFile=split.pdf file.pdf
Usare Strumenti Addizionali
È possibile utilizzare altri strumenti per lavorare con i file PDF, come ad esempio:
- pdfinfo
Può estrarre informazioni sui file PDF, specialmente quando i file sono molto grandi o quando un'interfaccia grafica non è disponibile. - flpsed
Può aggiungere dati a un documento PostScript. Questo strumento è specificamente utile per compilare i moduli o aggiungere brevi commenti nel documento. - pdfmod
È una semplice applicazione che fornisce un'interfaccia grafica per la modifica dei documenti PDF. Usando questo strumento, è possibile riordinare, ruotare e rimuovere le pagine, esportare immagini da un documento, modificare il titolo, l'oggetto e l'autore, aggiungere parole chiave e combinare documenti usando l'azione di drag-and-drop (trascinamento e rilascio).
Ad esempio, per ottenere i dettagli di un documento, è possibile utilizzare il comando seguente:
$ pdfinfo /usr/share/doc/readme.pdf
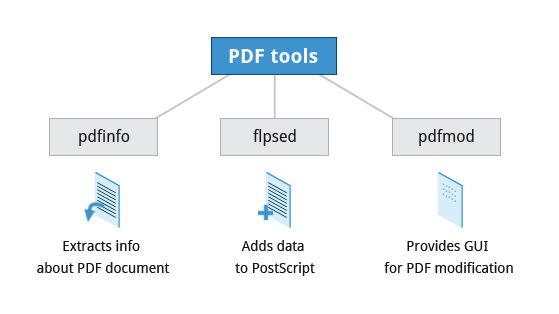
Riepilogo del Capitolo
Hai completato il capitolo 17. Riassumiamo i concetti chiave trattati:
- CUPS fornisce due interfacce di comando: System V e BSD.
- L'interfaccia CUPS è disponibile su http://localhost:631.
- lp e lpr vengono utilizzati per inviare un documento a CUPS direttamente dalla riga di comando.
- lpoptions può essere utilizzato per impostare opzioni e impostazioni predefinite della stampante.
- PostScript gestisce con efficacia il ridimensionamento di caratteri e la grafica vettoriale per fornire stampe di qualità.
- enscript viene utilizzato per convertire un file di testo in postscript e altri formati.
- PDF (Portable Document Format) è il formato standard utilizzato per scambiare documenti, garantendo al contempo un certo livello di coerenza nel modo in cui vengono visualizzati.
- pdftk unisce e divide i pdf, estrae singole pagine da un file, codifica e decodifica i file PDF, aggiunge, aggiorna ed esporta i metadati di un PDF, esporta segnalibri in un file di testo, aggiunge o rimuove gli allegati a un PDF, corregge un PDF danneggiato e compila i moduli PDF.
- pdfinfo può estrarre informazioni sui documenti PDF.
- flpsd può aggiungere dati a un documento PostScript.
- pdfmod è una semplice applicazione con un'interfaccia grafica che è possibile utilizzare per modificare documenti PDF .

PARTE DUE
Questo articolo ha una seconda parte che puoi leggere qui: https://www.freecodecamp.org/italian/news/introduzione-a-linux-parte-2/