

If you're new to Linux, this course is for you.
In this comprehensive course, you'll learn many of the tools used every day by both Linux SysAdmins and the millions of people running Linux distributions like Ubuntu on their PCs. This course will teach you how to navigate Linux's Graphical User Interfaces and powerful command line tool ecosystem.
This content of this course was developed by the Linux Foundation (They call it LFS101x). I've taken their primarily text-based course and turned it into a video-based course.
You can either read the text version of the course right here or you can watch the video version of the course on the freeCodeCamp.org YouTube channel (6-hour watch).
This tutorial falls under the Creative Commons BY 4.0 license.
So if you want the text version of the course, read on!
Chapter 1
By the end of this chapter, you should be able to:
- Describe the software environment required for this course.
- And describe the three major Linux distribution families.
Course Requirements
In order to fully benefit from this course, you will need to have at least one Linux distribution installed (if you are not already familiar with the term distribution, as it relates to Linux, you soon will be!).
You are about to learn some more details about the many available Linux distributions. Because there are literally hundreds of distributions, I'm not covering them all in this course. Instead, I will focus on the three major distribution families.
The families and representative distributions this course will focus on are:
- Red Hat Family Systems (including CentOS and Fedora)
- SUSE Family Systems (including openSUSE)
- Debian Family Systems (including Ubuntu and Linux Mint).
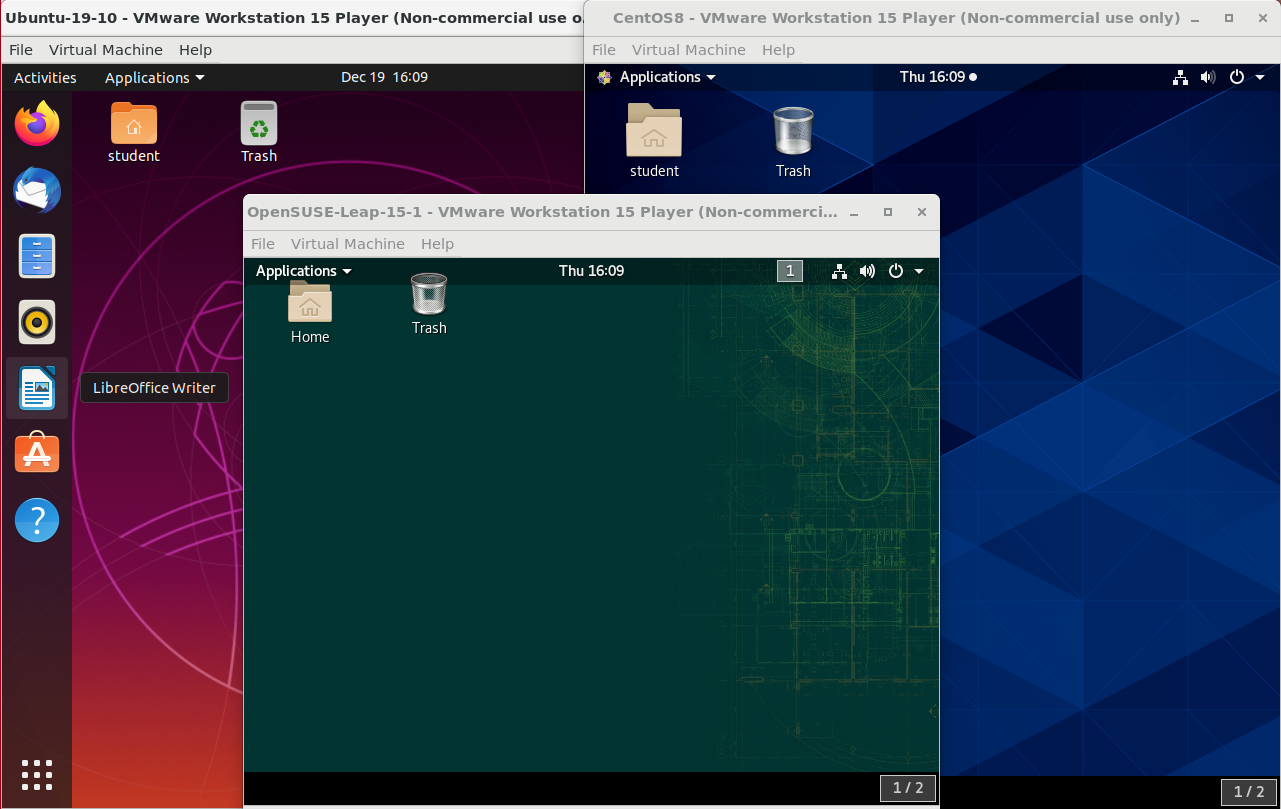 Ubuntu, CentOS, and openSUSE Desktops
Ubuntu, CentOS, and openSUSE Desktops
#
Focus on Three Major Linux Distribution Families
I'm about to tell you more about Red Hat, SUSE, and Debian. While this course focuses on these three major Linux distribution families, as long as there are talented contributors, the families of distributions and the distributions within these families will continue to change and grow. People see a need, and develop special configurations and utilities to respond to that need. Sometimes that effort creates a whole new distribution of Linux. Sometimes, that effort will leverage an existing distribution to expand the members of an existing family.
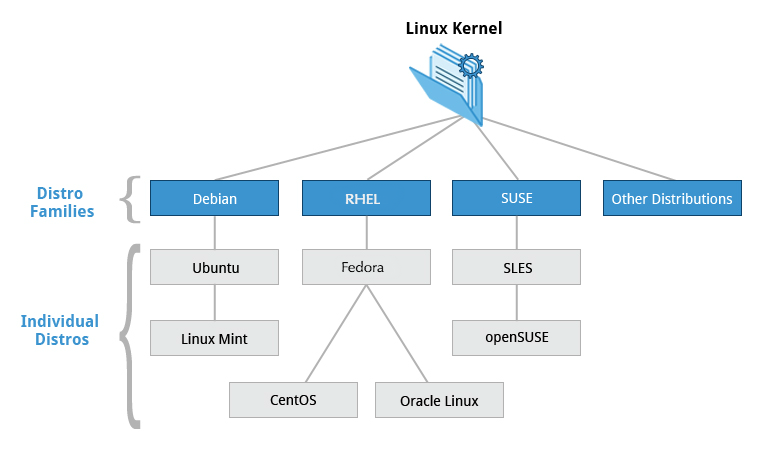 The Linux Kernel Distribution Families and Individual Distributions
The Linux Kernel Distribution Families and Individual Distributions
The Red Hat Family
Red Hat Enterprise Linux (or RHEL [pronounced "rel"]) heads the family that includes CentOS, CentOS Stream, Fedora and Oracle Linux.
Fedora has a close relationship with RHEL and contains significantly more software than Red Hat's enterprise version. One reason for this is that a diverse community is involved in building Fedora, with many contributors who do not work for Red Hat. Furthermore, it is used as a testing platform for future RHEL releases.
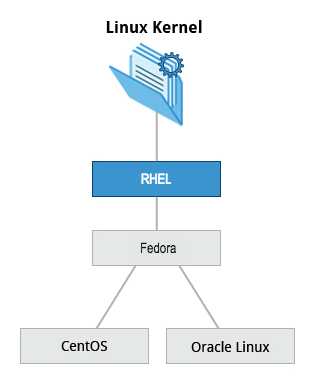 The Red Hat Family
The Red Hat Family
In this course, we'll mainly use CentOS Stream from the Red Hat family.
The basic version of CentOS is also virtually identical to RHEL, the most popular Linux distribution in enterprise environments. However, CentOS 8 has no more scheduled updates. The replacement is CentOS 8 Stream.
Key Facts About the Red Hat Family
Some of the key facts about the Red Hat distribution family are:
- Fedora serves as an upstream testing platform for RHEL.
- CentOS is a close clone of RHEL, while Oracle Linux is mostly a copy with some changes.
- It supports hardware platforms such as Intel x86, Arm, Itanium, PowerPC, and IBM System z.
- It uses the yum and dnf RPM-based yum package managers (discussed more later) to install, update, and remove packages in the system.
- RHEL is widely used by enterprises which host their own systems.
The SUSE Family
The relationship between SUSE (SUSE Linux Enterprise Server, or SLES) and openSUSE is similar to the one described between RHEL, CentOS, and Fedora.
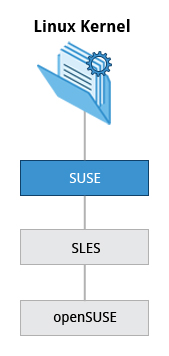 The SUSE Family
The SUSE Family
We use openSUSE as the reference distribution for the SUSE family, as it is available to end users at no cost. Because the two products are extremely similar, the material that covers openSUSE can typically be applied to SLES with few problems.
Key Facts About the SUSE Family
Some of the key facts about the SUSE family are listed below:
- SUSE Linux Enterprise Server (SLES) is upstream for openSUSE.
- It uses the RPM-based zypper package manager (we cover it in detail later) to install, update, and remove packages in the system.
- It includes the YaST (Yet Another Setup Tool) application for system administration purposes.
- SLES is widely used in retail and many other sectors.
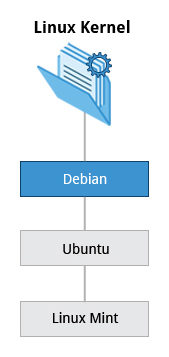
The Debian Family
The Debian distribution is upstream for several other distributions, including Ubuntu. In turn, Ubuntu is upstream for Linux Mint and a number of other distributions. It is commonly used on both servers and desktop computers. Debian is a pure open source community project (not owned by any corporation) and has a strong focus on stability.
Debian provides by far the largest and most complete software repository to its users of any Linux distribution.
 The Debian Family
The Debian Family
Ubuntu aims at providing a good compromise between long term stability and ease of use. Since Ubuntu gets most of its packages from Debian’s stable branch, it also has access to a very large software repository. For those reasons, we will use Ubuntu LTS (Long Term Support) as the reference to Debian family distributions for this course.
Key Facts About the Debian Family
Some key facts about the Debian family are listed below:
- The Debian family is upstream for Ubuntu, and Ubuntu is upstream for Linux Mint and others.
- It uses the DPKG-based APT package manager (using apt, apt-get, apt-cache, etc., which we cover in detail later) to install, update, and remove packages in the system.
- Ubuntu has been widely used for cloud deployments.
- While Ubuntu is built on top of Debian and is GNOME-based under the hood, it differs visually from the interface on standard Debian, as well as other distributions.
Chapter Summary
- There are three major distribution families within Linux: Red Hat, SUSE and Debian. In this course, we will work with representative members of all of these families throughout.
Chapter 2: Linux Philosophy and Concepts
Learning Objectives
By the end of this chapter, you should be able to:
- Define the common terms associated with Linux.
- Discuss the components of a Linux distribution.
The Power of Linux
Sorry, your browser doesn't support embedded videos.Introduction
In order for you to get the most out of this course, we recommend that you have Linux installed on a machine that you can use throughout this course. You can use this brief installation guide "_Preparing Your Computer for Linux Training_". It will help you to select a Linux distribution to install, decide on whether you want to do a stand-alone pure Linux machine or a dual-boot one, whether to do a physical or virtual install, etc. And then it guides through the steps. I'll also cover installation soon.
We have not covered everything in great detail, but keep in mind that most of the documentation in Linux is actually already on your system in the form of man pages, which we will discuss in great detail later. Whenever you do not understand something or want to know more about a command, program, topic, or utility, you can just type man at the command line. We will assume you are thinking this way and not constantly repeat "For more information, look at the man page for ".
On a related note, throughout the course we use a shorthand that is common in the open source community. When referring to cases where the user has to make a choice of what to enter (e.g. name of a program or file), we use the short hand 'foo' to represent . So beware, we are not actually suggesting that you manipulate files or install services called 'foo'!
Best way to learn Linux is by doing it. So make sure to try things out yourself as you follow along.
You'll need to have a Linux system up and running that can either be a native Linux system on your hardware, one running through a live USB stick or CD or virtual machine running through a hypervisor.
We’ll show you all these methods, so let’s get going.
Video: Linux Terminology
Sorry, your browser doesn't support embedded videos.Linux Distributions
Suppose you have been assigned to a project building a product for a Linux platform. Project requirements include making sure the project works properly on the most widely used Linux distributions. To accomplish this, you need to learn about the different components, services, and configurations associated with each distribution. We are about to look at how you would go about doing exactly that.
So, what is a Linux distribution and how does it relate to the Linux kernel?
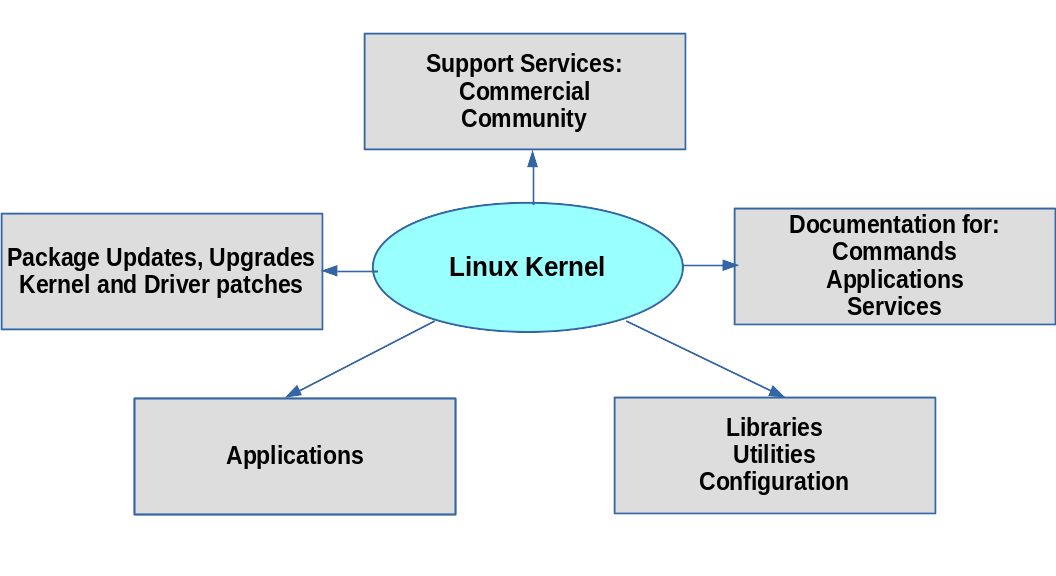
The Linux kernel is the core of the operating system. A full Linux distribution consists of the kernel plus a number of other software tools for file-related operations, user management, and software package management. Each of these tools provides a part of the complete system. Each tool is often its own separate project, with its own developers working to perfect that piece of the system.
While the most recent Linux kernel (and earlier versions) can always be found in The Linux Kernel Archives, Linux distributions may be based on different kernel versions. For example, the very popular RHEL 8 distribution is based on the 4.18 kernel, which is not new, but is extremely stable. Other distributions may move more quickly in adopting the latest kernel releases. It is important to note that the kernel is not an all or nothing proposition, for example, RHEL/CentOS have incorporated many of the more recent kernel improvements into their older versions, as have Ubuntu, openSUSE, SLES, etc.
Examples of other essential tools and ingredients provided by distributions include the C/C++ and Clang compilers, the gdb debugger, the core system libraries applications need to link with in order to run, the low-level interface for drawing graphics on the screen, as well as the higher-level desktop environment, and the system for installing and updating the various components, including the kernel itself. And all distributions come with a rather complete suite of applications already installed.
 Distribution Roles
Distribution Roles
Services Associated with Distributions
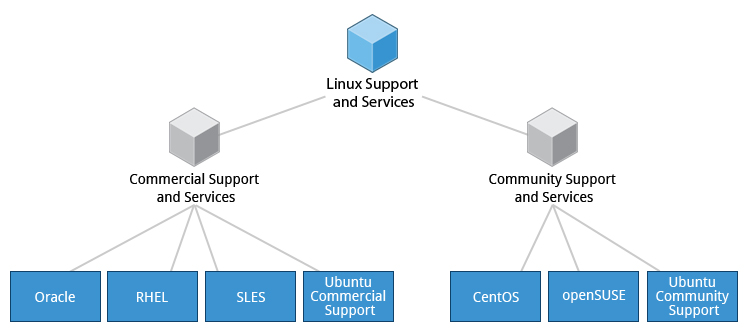
The vast variety of Linux distributions are designed to cater to many different audiences and organizations, according to their specific needs and tastes. However, large organizations, such as companies and governmental institutions and other entities, tend to choose the major commercially-supported distributions from Red Hat, SUSE, and Canonical (Ubuntu).
CentOS and CentOS Stream are popular free (as in no cost) alternatives to Red Hat Enterprise Linux (RHEL) and are often used by organizations that are comfortable operating without paid technical support. Ubuntu and Fedora are widely used by developers and are also popular in the educational realm. Scientific Linux is favored by the scientific research community for its compatibility with scientific and mathematical software packages. Both CentOS variants are binary-compatible with RHEL; i.e. in most cases, binary software packages will install properly across the distributions.
Note that CentOS is planned to disappear at the end of 2021 in favor of CentOS Stream. However, there are at least two new RHEL-derived substitutes: Alma Linux and Rocky Linux which are establishing a foothold.
Many commercial distributors, including Red Hat, Ubuntu, SUSE, and Oracle, provide long term fee-based support for their distributions, as well as hardware and software certification. All major distributors provide update services for keeping your system primed with the latest security and bug fixes, and performance enhancements, as well as provide online support resources.
 Services Associated with Distributions
Services Associated with Distributions
Chapter 2 Summary
You have completed Chapter 2. Let’s summarize the key concepts covered:
- Linux borrows heavily from the UNIX operating system, with which its creators were well-versed.
- Linux accesses many features and services through files and file-like objects.
- Linux is a fully multi-tasking, multi-user operating system, with built-in networking and service processes known as daemons.
- Linux is developed by a loose confederation of developers from all over the world, collaborating over the Internet, with Linus Torvalds at the head. Technical skill and a desire to contribute are the only qualifications for participating.
- The Linux community is a far reaching ecosystem of developers, vendors, and users that supports and advances the Linux operating system.
- Some of the common terms used in Linux are: kernel, distribution, boot loader, service, filesystem, X Window system, desktop environment, and command line.
- A full Linux distribution consists of the kernel plus a number of other software tools for file-related operations, user management, and software package management.
Chapter 3: Linux Basics and System Startup
By the end of this chapter, you should be able to:
- Identify Linux filesystems.
- Identify the differences between partitions and filesystems.
- Describe the boot process.
- Install Linux on a computer.
The Boot Process
The Linux boot process is the procedure for initializing the system. It consists of everything that happens from when the computer power is first switched on until the user interface is fully operational.
Having a good understanding of the steps in the boot process may help you with troubleshooting problems, as well as with tailoring the computer's performance to your needs.
On the other hand, the boot process can be rather technical, and you can start using Linux without knowing all the details.
 The boot process.
The boot process.
BIOS - The First Step
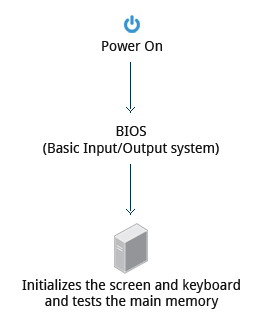
Starting an x86-based Linux system involves a number of steps. When the computer is powered on, the Basic Input/Output System (BIOS) initializes the hardware, including the screen and keyboard, and tests the main memory. This process is also called POST (Power On Self Test).
 BIOS
BIOS
The BIOS software is stored on a ROM chip on the motherboard. After this, the remainder of the boot process is controlled by the operating system (OS).
Master Boot Record (MBR) and Boot Loader
Once the POST is completed, the system control passes from the BIOS to the boot loader. The boot loader is usually stored on one of the hard disks in the system, either in the boot sector (for traditional BIOS/MBR systems) or the EFI partition (for more recent (Unified) Extensible Firmware Interface or EFI/UEFI systems). Up to this stage, the machine does not access any mass storage media. Thereafter, information on date, time, and the most important peripherals are loaded from the CMOS values (after a technology used for the battery-powered memory store which allows the system to keep track of the date and time even when it is powered off).
A number of boot loaders exist for Linux; the most common ones are GRUB (for GRand Unified Boot loader), ISOLINUX (for booting from removable media), and DAS U-Boot (for booting on embedded devices/appliances). Most Linux boot loaders can present a user interface for choosing alternative options for booting Linux, and even other operating systems that might be installed. When booting Linux, the boot loader is responsible for loading the kernel image and the initial RAM disk or filesystem (which contains some critical files and device drivers needed to start the system) into memory.
 Master Boot Record
Master Boot Record
Boot Loader in Action
The boot loader has two distinct stages:
For systems using the BIOS/MBR method, the boot loader resides at the first sector of the hard disk, also known as the Master Boot Record (MBR). The size of the MBR is just 512 bytes. In this stage, the boot loader examines the partition table and finds a bootable partition. Once it finds a bootable partition, it then searches for the second stage boot loader, for example GRUB, and loads it into RAM (Random Access Memory). For systems using the EFI/UEFI method, UEFI firmware reads its Boot Manager data to determine which UEFI application is to be launched and from where (i.e. from which disk and partition the EFI partition can be found). The firmware then launches the UEFI application, for example GRUB, as defined in the boot entry in the firmware's boot manager. This procedure is more complicated, but more versatile than the older MBR methods.
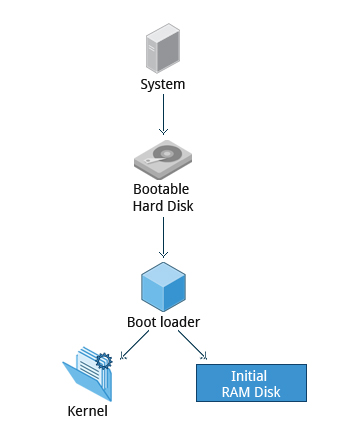
The second stage boot loader resides under /boot. A splash screen is displayed, which allows us to choose which operating system (OS) to boot. After choosing the OS, the boot loader loads the kernel of the selected operating system into RAM and passes control to it. Kernels are almost always compressed, so its first job is to uncompress itself. After this, it will check and analyze the system hardware and initialize any hardware device drivers built into the kernel.
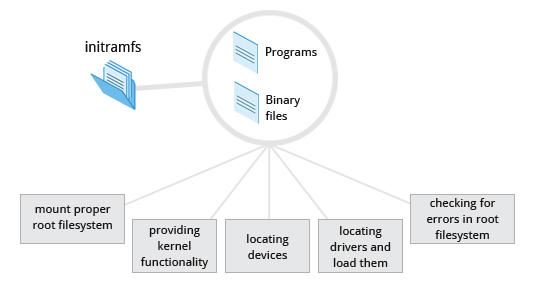
Initial RAM Disk
The initramfs filesystem image contains programs and binary files that perform all actions needed to mount the proper root filesystem, like providing kernel functionality for the needed filesystem and device drivers for mass storage controllers with a facility called udev (for user device), which is responsible for figuring out which devices are present, locating the device drivers they need to operate properly, and loading them. After the root filesystem has been found, it is checked for errors and mounted.
The mount program instructs the operating system that a filesystem is ready for use, and associates it with a particular point in the overall hierarchy of the filesystem (the mount point). If this is successful, the initramfs is cleared from RAM and the init program on the root filesystem (/sbin/init) is executed.
init handles the mounting and pivoting over to the final real root filesystem. If special hardware drivers are needed before the mass storage can be accessed, they must be in the initramfs image.
 The Initial RAM Disk
The Initial RAM Disk
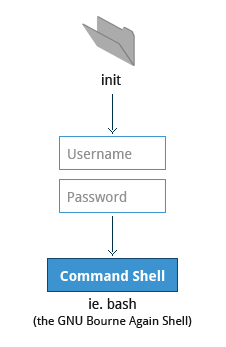
Text-Mode Login
Near the end of the boot process, init starts a number of text-mode login prompts. These enable you to type your username, followed by your password, and to eventually get a command shell. However, if you are running a system with a graphical login interface, you will not see these at first.
As you will learn in Chapter 7: Command Line Operations, the terminals which run the command shells can be accessed using the ALT key plus a function key. Most distributions start six text terminals and one graphics terminal starting with F1 or F2. Within a graphical environment, switching to a text console requires pressing CTRL-ALT + the appropriate function key (with F7 or F1 leading to the GUI).
 Text-Mode Logins
Text-Mode Logins
Usually, the default command shell is bash (the GNU Bourne Again Shell), but there are a number of other advanced command shells available. The shell prints a text prompt, indicating it is ready to accept commands; after the user types the command and presses Enter, the command is executed, and another prompt is displayed after the command is done.
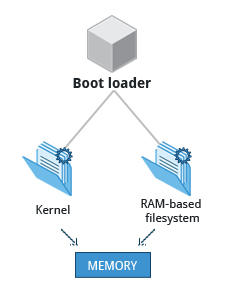
The Linux Kernel
The boot loader loads both the kernel and an initial RAM–based file system (initramfs) into memory, so it can be used directly by the kernel.
 The Linux Kernel
The Linux Kernel
When the kernel is loaded in RAM, it immediately initializes and configures the computer’s memory and also configures all the hardware attached to the system. This includes all processors, I/O subsystems, storage devices, etc. The kernel also loads some necessary user space applications.
/sbin/init and Services
Once the kernel has set up all its hardware and mounted the root filesystem, the kernel runs /sbin/init. This then becomes the initial process, which then starts other processes to get the system running. Most other processes on the system trace their origin ultimately to init; exceptions include the so-called kernel processes. These are started by the kernel directly, and their job is to manage internal operating system details.
Besides starting the system, init is responsible for keeping the system running and for shutting it down cleanly. One of its responsibilities is to act when necessary as a manager for all non-kernel processes; it cleans up after them upon completion, and restarts user login services as needed when users log in and out, and does the same for other background system services.
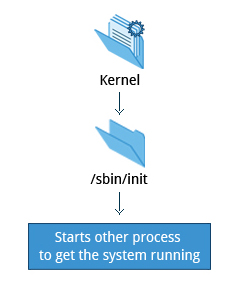 /sbin/init and Services
/sbin/init and Services
Traditionally, this process startup was done using conventions that date back to the 1980s and the System V variety of UNIX. This serial process had the system passing through a sequence of runlevels containing collections of scripts that start and stop services. Each runlevel supported a different mode of running the system. Within each runlevel, individual services could be set to run, or to be shut down if running.
However, all major distributions have moved away from this sequential runlevel method of system initialization, although they usually emulate many System V utilities for compatibility purposes. Next, we discuss the new methods, of which systemd has become dominant.
Startup Alternatives
SysVinit viewed things as a serial process, divided into a series of sequential stages. Each stage required completion before the next could proceed. Thus, startup did not easily take advantage of the parallel processing that could be done on multiple processors or cores.
Furthermore, shutdown and reboot was seen as a relatively rare event; exactly how long it took was not considered important. This is no longer true, especially with mobile devices and embedded Linux systems. Some modern methods, such as the use of containers, can require almost instantaneous startup times. Thus, systems now require methods with faster and enhanced capabilities. Finally, the older methods required rather complicated startup scripts, which were difficult to keep universal across distribution versions, kernel versions, architectures, and types of systems. The two main alternatives developed were:
Upstart
- Developed by Ubuntu and first included in 2006
- Adopted in Fedora 9 (in 2008) and in RHEL 6 and its clones
systemd
- Adopted by Fedora first (in 2011)
- Adopted by RHEL 7 and SUSE
- Replaced Upstart in Ubuntu 16.04
While the migration to systemd was rather controversial, it has been adopted by all major distributions, and so we will not discuss the older System V method or Upstart, which has become a dead end. Regardless of how one feels about the controversies or the technical methods of systemd, almost universal adoption has made learning how to work on Linux systems simpler, as there are fewer differences among distributions. We enumerate systemd features next.
systemd Features
Systems with systemd start up faster than those with earlier init methods. This is largely because it replaces a serialized set of steps with aggressive parallelization techniques, which permits multiple services to be initiated simultaneously.
Complicated startup shell scripts are replaced with simpler configuration files, which enumerate what has to be done before a service is started, how to execute service startup, and what conditions the service should indicate have been accomplished when startup is finished. One thing to note is that /sbin/init now just points to /lib/systemd/systemd; i.e. systemd takes over the init process.
One systemd command (systemctl) is used for most basic tasks. While we have not yet talked about working at the command line, here is a brief listing of its use:
- Starting, stopping, restarting a service (using httpd, the Apache web server, as an example) on a currently running system:
$ sudo systemctl start|stop|restart httpd.service - Enabling or disabling a system service from starting up at system boot:
$ sudo systemctl enable|disable httpd.service
In most cases, the .service can be omitted. There are many technical differences with older methods that lie beyond the scope of our discussion.

Linux Filesystems Basics
Think of a refrigerator that has multiple shelves that can be used for storing various items. These shelves help you organize the grocery items by shape, size, type, etc. The same concept applies to a filesystem, which is the embodiment of a method of storing and organizing arbitrary collections of data in a human-usable form.
Different types of filesystems supported by Linux:
- Conventional disk filesystems: ext3, ext4, XFS, Btrfs, JFS, NTFS, vfat, exfat, etc.
- Flash storage filesystems: ubifs, jffs2, yaffs, etc.
- Database filesystems
- Special purpose filesystems: procfs, sysfs, tmpfs, squashfs, debugfs, fuse, etc.
This section will describe the standard filesystem layout shared by most Linux distributions.
Partitions and Filesystems
A partition is a physically contiguous section of a disk, or what appears to be so in some advanced setups.
A filesystem is a method of storing/finding files on a hard disk (usually in a partition).
One can think of a partition as a container in which a filesystem resides, although in some circumstances, a filesystem can span more than one partition if one uses symbolic links, which we will discuss much later.
A comparison between filesystems in Windows and Linux is given in the accompanying table:
| Windows | Linux | |
| Partition | Disk1 | /dev/sda1 |
| Filesystem Type | NTFS/VFAT | EXT3/EXT4/XFS/BTRFS... |
| Mounting Parameters | DriveLetter | MountPoint |
| Base Folder (where OS is stored) | C:\ | / |
The Filesystem Hierarchy Standard
Linux systems store their important files according to a standard layout called the Filesystem Hierarchy Standard (FHS), which has long been maintained by the Linux Foundation. For more information, take a look at the following document: _"Filesystem Hierarchy Standard"_ created by LSB Workgroup. Having a standard is designed to ensure that users, administrators, and developers can move between distributions without having to re-learn how the system is organized.
Linux uses the ‘/’ character to separate paths (unlike Windows, which uses ‘\’), and does not have drive letters. Multiple drives and/or partitions are mounted as directories in the single filesystem. Removable media such as USB drives and CDs and DVDs will show up as mounted at /run/media/yourusername/disklabel for recent Linux systems, or under /media for older distributions. For example, if your username is student a USB pen drive labeled FEDORA might end up being found at /run/media/student/FEDORA, and a file README.txt on that disc would be at /run/media/student/FEDORA/README.txt.
Click the image to view an enlarged version.
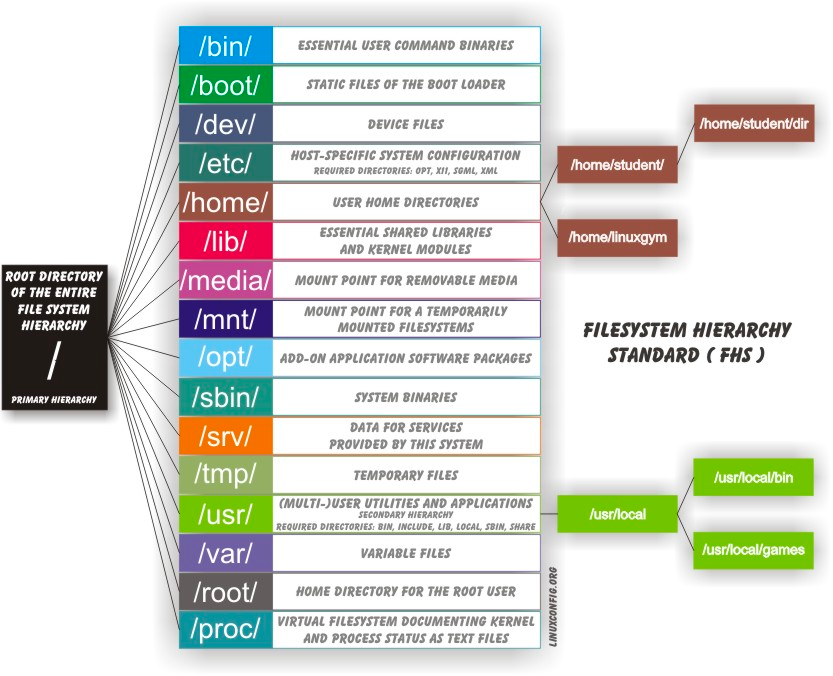 The Filesystem Hierarchy Standard
The Filesystem Hierarchy Standard
All Linux filesystem names are case-sensitive, so /boot, /Boot, and /BOOT represent three different directories (or folders). Many distributions distinguish between core utilities needed for proper system operation and other programs, and place the latter in directories under /usr (think user). To get a sense for how the other programs are organized, find the /usr directory in the diagram from the previous page and compare the subdirectories with those that exist directly under the system root directory (/).
Video: Viewing the Filesystem Hierarchy from the Graphical Interface in Ubuntu
Sorry, your browser doesn't support embedded videos.Video: Viewing the Filesystem Hierarchy from the Graphical Interface in openSUSE
Sorry, your browser doesn't support embedded videos.Linux Distribution Installation
Suppose you intend to buy a new car. What factors do you need to consider to make a proper choice? Requirements which need to be taken into account include the size needed to fit your family in the vehicle, the type of engine and gas economy, your expected budget and available financing options, reliability record and after-sales services, etc.
Similarly, determining which distribution to deploy also requires planning. The figure shows some, but not all choices. Note that many embedded Linux systems use custom crafted contents, rather than Android or Yocto.
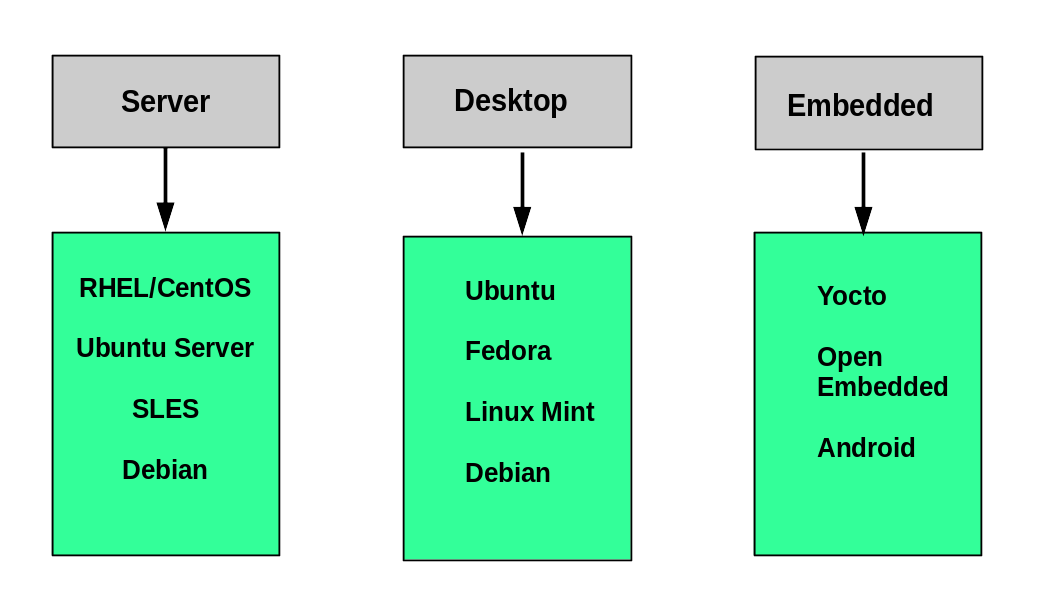
Questions to Ask When Choosing a Distribution
Some questions worth thinking about before deciding on a distribution include:
- What is the main function of the system (server or desktop)?
- What types of packages are important to the organization? For example, web server, word processing, etc.
- How much hard disk space is required and how much is available? For example, when installing Linux on an embedded device, space is usually constrained.
- How often are packages updated?
- How long is the support cycle for each release? For example, LTS releases have long-term support.
- Do you need kernel customization from the vendor or a third party?
- What hardware are you running on? For example, it might be X86, ARM, PPC, etc.
- Do you need long-term stability? Can you accept (or need) a more volatile cutting edge system running the latest software?
Linux Installation: Planning
The partition layout needs to be decided at the time of installation; it can be difficult to change later. While Linux systems handle multiple partitions by mounting them at specific points in the filesystem, and you can always modify the design later, it is always easier to try and get it right to begin with.
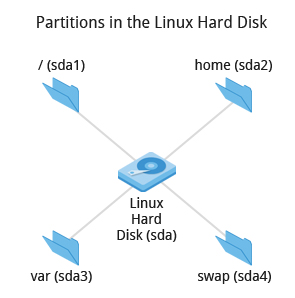 Partitions in the Linux Hard Disk
Partitions in the Linux Hard Disk
Nearly all installers provide a reasonable default layout, with either all space dedicated to normal files on one big partition and a smaller swap partition, or with separate partitions for some space-sensitive areas like /home and /var. You may need to override the defaults and do something different if you have special needs, or if you want to use more than one disk.
Linux Installation: Software Choices
All installations include the bare minimum software for running a Linux distribution.
Most installers also provide options for adding categories of software. Common applications (such as the Firefox web browser and LibreOffice office suite), developer tools (like the vi and emacs text editors, which we will explore later in this course), and other popular services, (such as the Apache web server tools or MySQL database) are usually included. In addition, for any system with a graphical desktop, a chosen desktop (such as GNOME or KDE) is installed by default.
All installers set up some initial security features on the new system. One basic step consists of setting the password for the superuser (root) and setting up an initial user. In some cases (such as Ubuntu), only an initial user is set up; direct root login is not configured and root access requires logging in first as a normal user and then using sudo, as we will describe later. Some distributions will also install more advanced security frameworks, such as SELinux or AppArmor. For example, all Red Hat-based systems including Fedora and CentOS always use SELinux by default, and Ubuntu comes with AppArmor up and running.
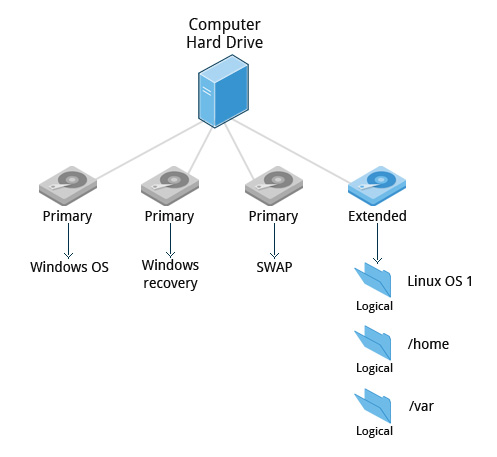 Linux Installation Software Choices
Linux Installation Software Choices
Linux Installation: Install Source
Like other operating systems, Linux distributions are provided on removable media such as USB drives and CDs or DVDs. Most Linux distributions also support booting a small image and downloading the rest of the system over the network. These small images are usable on media, or as network boot images, in which case it is possible to perform an install without using any local media.
Many installers can do an installation completely automatically, using a configuration file to specify installation options. This file is called a Kickstart file for Red Hat-based systems, an AutoYAST profile for SUSE-based systems, and a Preseed file for Debian-based systems.
Each distribution provides its own documentation and tools for creating and managing these files.
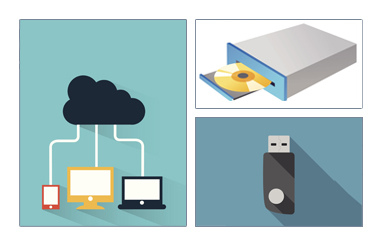
Linux Installation: The Process
The actual installation process is pretty similar for all distributions.
After booting from the installation media, the installer starts and asks questions about how the system should be set up. These questions are skipped if an automatic installation file is provided. Then, the installation is performed.
Finally, the computer reboots into the newly-installed system. On some distributions, additional questions are asked after the system reboots.
Most installers have the option of downloading and installing updates as part of the installation process; this requires Internet access. Otherwise, the system uses its normal update mechanism to retrieve those updates after the installation is done.
Linux Installation: The Warning
The demonstrations show how to install Linux directly on your machine, erasing everything that was there. While the demonstrations will not alter your computer, following these procedures in real life will erase all current data.
The Linux Foundation has a document: "Preparing Your Computer for Linux Training" that describes alternate methods of installing Linux without over-writing existing data. You may want to consult it, if you need to preserve the information on your hard disk.
These alternate methods are:
- Re-partitioning your hard disk to free up enough room to permit dual boot (side-by-side) installation of Linux, along with your present operating system.
- Using a host machine hypervisor program (such as VMWare's products or Oracle Virtual Box) to install a client Linux Virtual Machine.
- Booting off of and using a Live CD or USB stick and not writing to the hard disk at all.
The first method is sometimes complicated and should be done when your confidence is high and you understand the steps involved. The second and third methods are quite safe and make it difficult to damage your system.
Video: Steps to Install Ubuntu
Sorry, your browser doesn't support embedded videos.Video: Steps to Install CentOS
Sorry, your browser doesn't support embedded videos.Video: Steps to Install openSUSE
Sorry, your browser doesn't support embedded videos.Chapter 3 Summary
You have completed Chapter 3. Let’s summarize the key concepts covered:
- A partition is a logical part of the disk.
- A filesystem is a method of storing/finding files on a hard disk.
- By dividing the hard disk into partitions, data can be grouped and separated as needed. When a failure or mistake occurs, only the data in the affected partition will be damaged, while the data on the other partitions will likely survive.
- The boot process has multiple steps, starting with BIOS, which triggers the boot loader to start up the Linux kernel. From there, the initramfs filesystem is invoked, which triggers the init program to complete the startup process.
- Determining the appropriate distribution to deploy requires that you match your specific system needs to the capabilities of the different distributions.

Chapter 4: Graphical Interface
Learning Objectives
By the end of this chapter, you should be able to:
- Manage graphical interface sessions.
- Perform basic operations using the graphical interface.
- Change the graphical desktop to suit your needs.
Graphical Desktop
You can use either a Command Line Interface (CLI) or a Graphical User Interface (GUI) when using Linux. To work at the CLI, you have to remember which programs and commands are used to perform tasks, and how to quickly and accurately obtain more information about their use and options. On the other hand, using the GUI is often quick and easy. It allows you to interact with your system through graphical icons and screens. For repetitive tasks, the CLI is often more efficient, while the GUI is easier to navigate if you do not remember all the details or do something only rarely.
We will learn how to manage sessions using the GUI for the three Linux distribution families that we cover the most in this course: Red Hat (CentOS, Fedora), SUSE (openSUSE), and Debian (Ubuntu, Mint). Since we are using the GNOME-based variant of openSUSE rather than the KDE-based one, all are actually quite similar. If you are using KDE (or other Linux desktops such as XFCE), your experience will vary somewhat from what is shown, but not in any intrinsically difficult way, as user interfaces have converged to certain well-known behaviors on modern operating systems. In subsequent sections of this course we will concentrate in great detail on the command line interface, which is pretty much the same on all distributions.
Ubuntu, CentOS, and openSUSE Desktops
X Window System
Generally, in a Linux desktop system, the X Window System is loaded as one of the final steps in the boot process. It is often just called X.
A service called the Display Manager keeps track of the displays being provided and loads the X server (so-called, because it provides graphical services to applications, sometimes called X clients). The display manager also handles graphical logins and starts the appropriate desktop environment after a user logs in.
X is rather old software; it dates back to the mid 1980s and, as such, has certain deficiencies on modern systems (for example, with security), as it has been stretched rather far from its original purposes. A newer system, known as Wayland, is gradually superseding it and is the default display system for Fedora, RHEL 8, and other recent distributions. For the most part, it looks just like X to the user, although under the hood it is quite different.
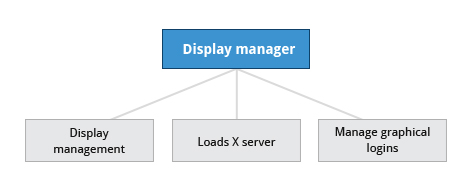 Display Manager
Display Manager
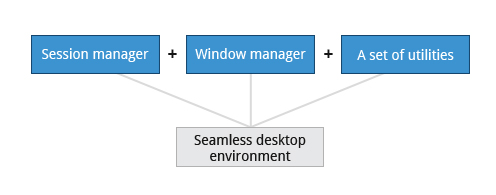
A desktop environment consists of a session manager, which starts and maintains the components of the graphical session, and the window manager, which controls the placement and movement of windows, window title-bars, and controls.
Although these can be mixed, generally a set of utilities, session manager, and window manager are used together as a unit, and together provide a seamless desktop environment.
If the display manager is not started by default in the default runlevel, you can start the graphical desktop different way, after logging on to a text-mode console, by running startx from the command line. Or, you can start the display manager (gdm, lightdm, kdm, xdm, etc.) manually from the command line. This differs from running startx as the display managers will project a sign in screen. We discuss them next.
GUI Startup
When you install a desktop environment, the X display manager starts at the end of the boot process. It is responsible for starting the graphics system, logging in the user, and starting the user’s desktop environment. You can often select from a choice of desktop environments when logging in to the system.

The default display manager for GNOME is called gdm. Other popular display managers include lightdm (used on Ubuntu before version 18.04 LTS) and kdm (associated with KDE).
GNOME Desktop Environment
GNOME is a popular desktop environment with an easy-to-use graphical user interface. It is bundled as the default desktop environment for most Linux distributions, including Red Hat Enterprise Linux (RHEL), Fedora, CentOS, SUSE Linux Enterprise, Ubuntu and Debian. GNOME has menu-based navigation and is sometimes an easy transition to accomplish for Windows users. However, as you will see, the look and feel can be quite different across distributions, even if they are all using GNOME.
![]()
Another common desktop environment very important in the history of Linux and also widely used is KDE, which has often been used in conjunction with SUSE and openSUSE. Other alternatives for a desktop environment include Unity (present on older Ubuntu, but still based on GNOME), XFCE and LXDE. As previously mentioned, most desktop environments follow a similar structure to GNOME, and we will restrict ourselves mostly to it to keep things less complex.
Video: System Startup and Logging In and Out
Sorry, your browser doesn't support embedded videos.Graphical Desktop Background
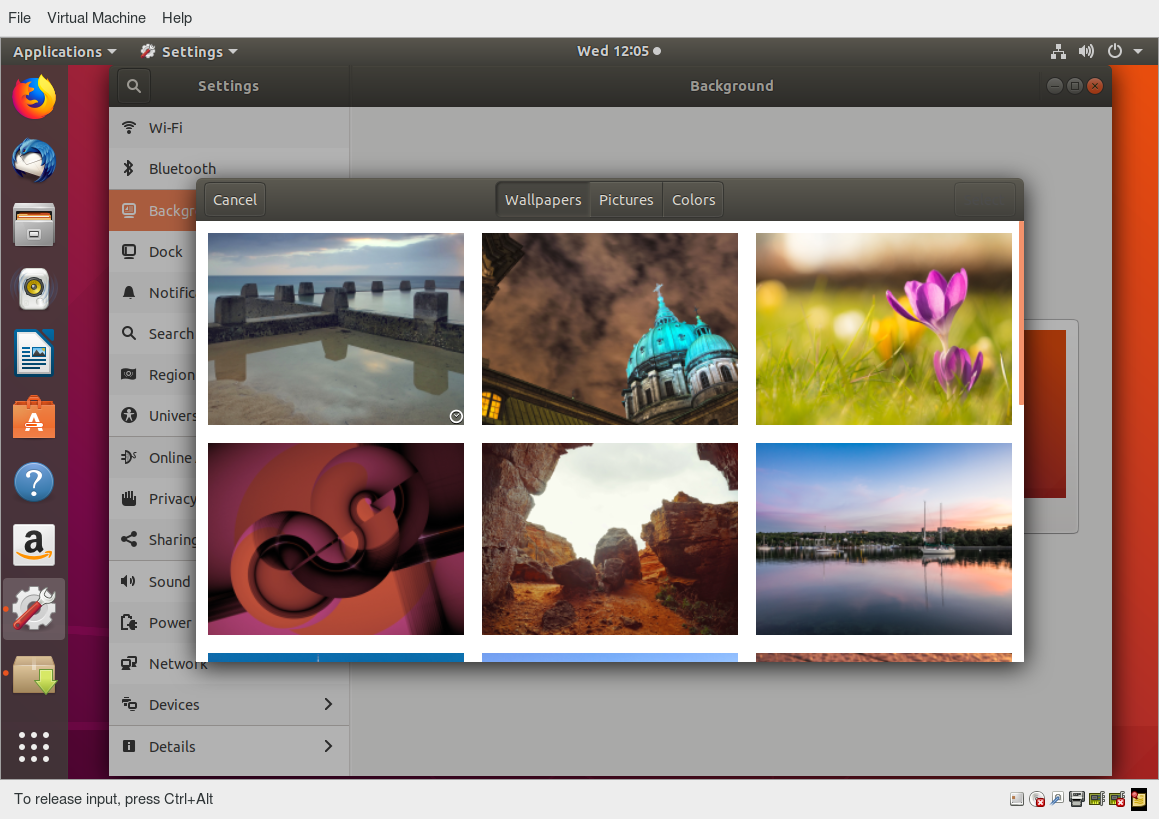
Each Linux distribution comes with its own set of desktop backgrounds. You can change the default by choosing a new wallpaper or selecting a custom picture to be set as the desktop background. If you do not want to use an image as the background, you can select a color to be displayed on the desktop instead.
In addition, you can also change the desktop theme, which changes the look and feel of the Linux system. The theme also defines the appearance of application windows.
We will learn how to change the desktop background and theme.
Customizing the Desktop Background
To change the background, you can right click anywhere on the desktop and choose Change Background.
Video: How to Change the Desktop Background
Sorry, your browser doesn't support embedded videos.gnome-tweaks
Most common settings, both personal and system-wide, are to be found by clicking in the upper right-hand corner, on either a gear or other obvious icon, depending on your Linux distribution.
However, there are many settings which many users would like to modify which are not thereby accessible; the default settings utility is unfortunately rather limited in modern GNOME-based distributions. Unfortunately, the quest for simplicity has actually made it difficult to adapt your system to your tastes and needs.
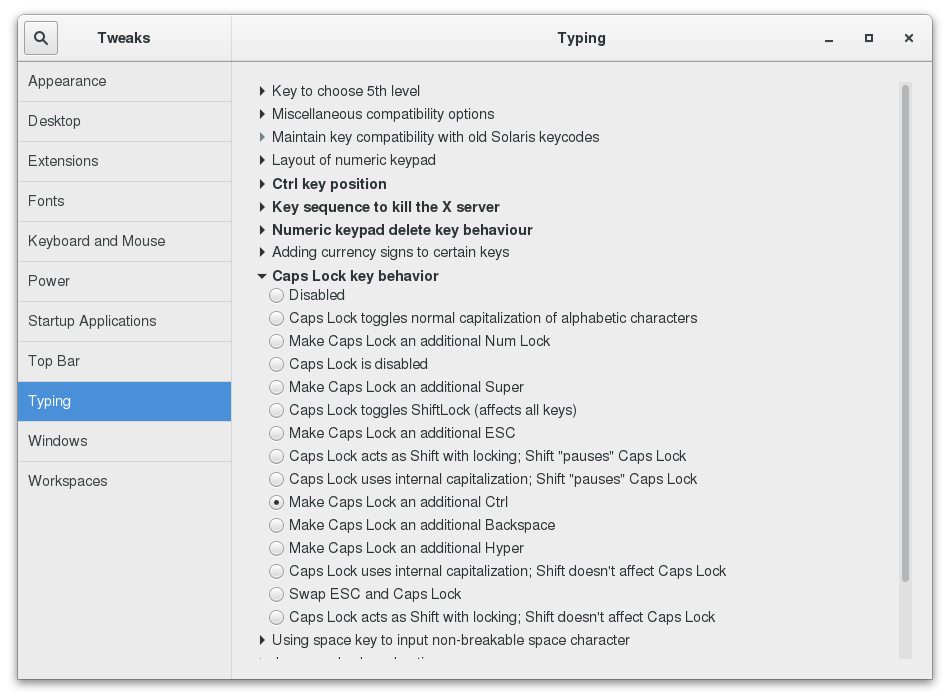
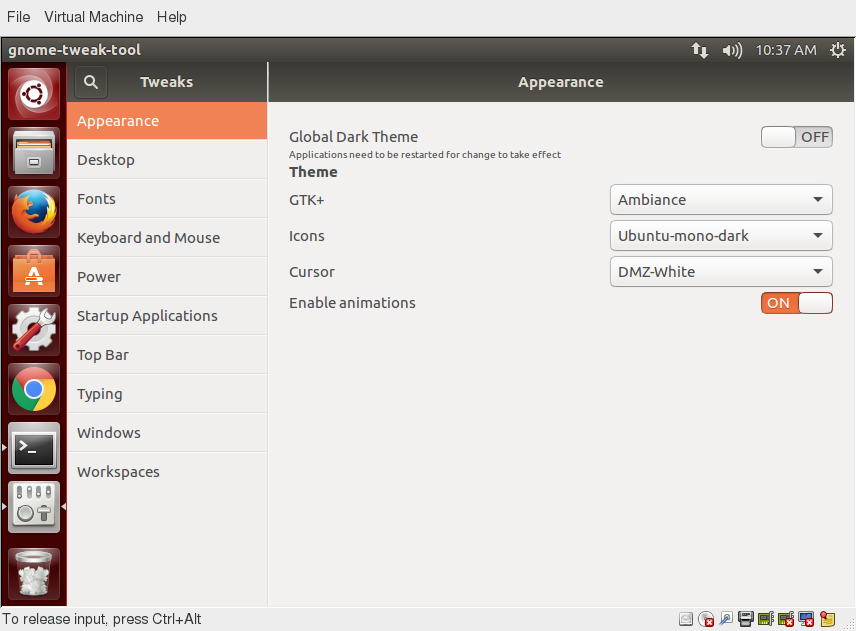
Fortunately, there is a standard utility, gnome-tweaks, which exposes many more setting options. It also permits you to easily install extensions by external parties. Not all Linux distributions install this tool by default, but it is always available (older distributions used the name gnome-tweak-tool). You may have to run it by hitting Alt-F2 and then typing in the name. You may want to add it to your Favorites list as we shall discuss.
As discussed in the next chapter, some recent distributions have taken most of the functionality out of this tool and placed it in a new one, called gnome-extensions-app.
In the screenshot below, the keyboard mapping is being adjusted so the useless CapsLock key can be used as an additional Ctrl key; this saves users who use Ctrl a lot (such as emacs aficionados) from getting physically damaged by pinkie strain.
 gnome-tweaks
gnome-tweaks
Changing the Theme
The visual appearance of applications (the buttons, scroll bars, widgets, and other graphical components) are controlled by a theme. GNOME comes with a set of different themes which can change the way your applications look.
The exact method for changing your theme may depend on your distribution. For older GNOME-based distributions, you can simply run gnome-tweaks, as shown in the screenshot from Ubuntu. However, as mentioned earlier, if you don't find it there, you will need to look at gnome-extensions-app, which can now configure themes. This requires installing even more software and going to external websites, so it is unlikely to be seen as an improvement by many users.
There are other options to get additional themes beyond the default selection. You can download and install themes from the GNOME's Wiki website.
 Changing the Theme
Changing the Theme
Session Management
Logging In and Out
The next screen shows a demonstration for logging in and out on the major Linux distribution families we concentrate on in this course. Note that evolution has brought us to a stage where it little matters which distribution you choose, as they are all rather similar.

Video: Logging In and Logging Out Using the GUI in Ubuntu, openSUSE and CentOS
Sorry, your browser doesn't support embedded videos.Locking the Screen
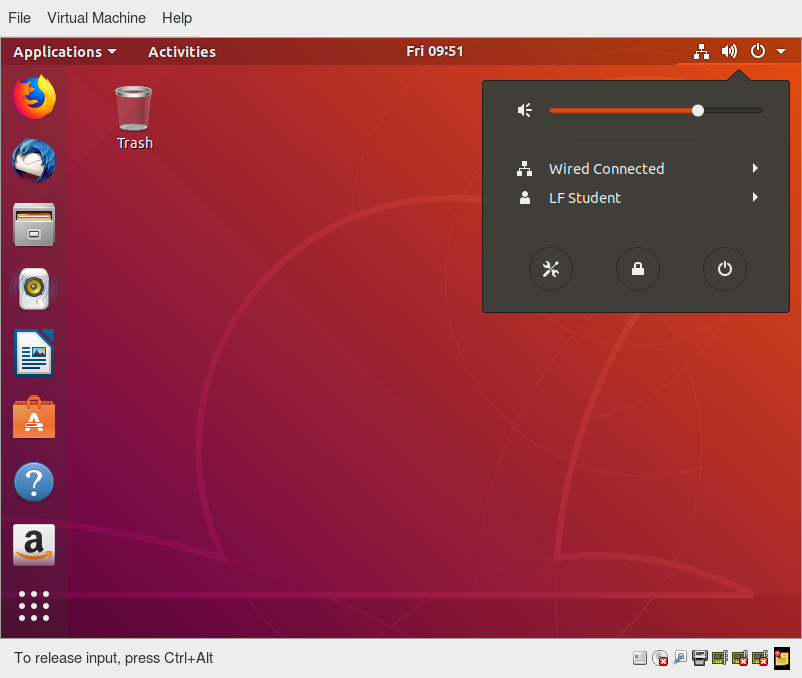
It is often a good idea to lock your screen to prevent other people from accessing your session while you are away from your computer.
NOTE: This does not suspend the computer; all your applications and processes continue to run while the screen is locked.
There are two ways to lock your screen:
- Using the graphical interface
Clicking in the upper-right corner of the desktop, and then clicking on the lock icon. - Using the keyboard shortcut SUPER-L
(The SUPER key is also known as the Windows key).
The keyboard shortcut for locking the screen can be modified by altering keyboard settings, the exact prescription varying by distribution, but not hard to ascertain.
To re-enter the desktop session you just need to provide your password again.
The screenshot below shows how to lock the screen for Ubuntu. The details vary little in modern distributions.
Video: Locking and Unlocking the Screen in More Detail
Sorry, your browser doesn't support embedded videos.Switching Users
Linux is a true multi-user operating system, which allows more than one user to be simultaneously logged in. If more than one person uses the system, it is best for each person to have their own user account and password. This allows for individualized settings, home directories, and other files. Users can take turns using the machine, while keeping everyone's sessions alive, or even be logged in simultaneously through the network.
Video: Switching Users in Ubuntu
Sorry, your browser doesn't support embedded videos.Shutting Down and Restarting
Besides normal daily starting and stopping of the computer, a system restart may be required as part of certain major system updates, generally only those involving installing a new Linux kernel.

Initiating the shutdown process from the graphical desktop is rather trivial on all current Linux distributions, with very little variation. We will discuss later how to do this from the command line, using the shutdown command.
In all cases, you click on either a settings (gear) or a power icon and follow the prompts.
Shutting Down and Restarting on GNOME
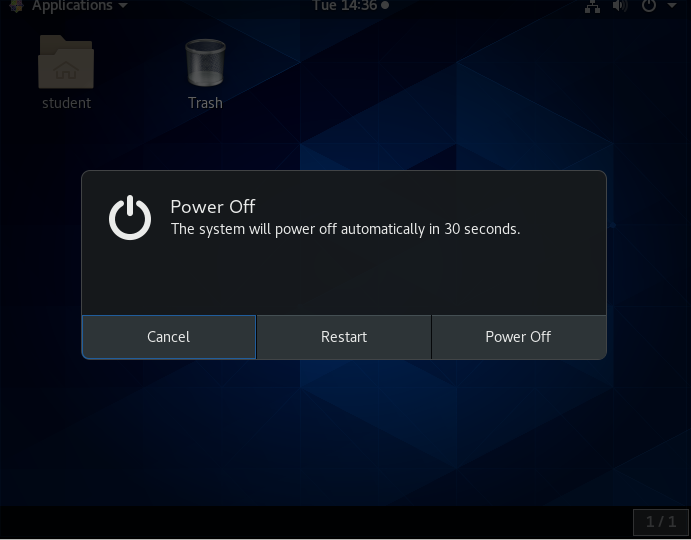
To shut down the computer in any recent GNOME-based Linux distribution, perform the following steps:
- Click either the Power or the Gear icon in the upper-right corner of the screen.
- Click on Power Off, Restart, or Cancel. If you do nothing, the system will shutdown in 60 seconds.
Shutdown, reboot, and logout operations will ask for confirmation before going ahead. This is because many applications will not save their data properly when terminated this way.
Always save your documents and data before restarting, shutting down, or logging out.
 Shutting Down and Restarting
Shutting Down and Restarting
Suspending
All modern computers support Suspend (or Sleep) Mode when you want to stop using your computer for a while. Suspend Mode saves the current system state and allows you to resume your session more quickly while remaining on, but uses very little power in the sleeping state. It works by keeping your system’s applications, desktop, and so on, in system RAM, but turning off all of the other hardware. This shortens the time for a full system start-up as well as conserves battery power. One should note that modern Linux distributions actually boot so fast that the amount of time saved is often minor.
To suspend the system, the procedure starts the same as that for shutdown or locking the screen.
The method is quite simple and universal in most recent GNOME-based distributions. If you click on the Power icon and hold for a short time and release, you will get the double line icon displayed below, which you then click to suspend the system. Some distributions, including Ubuntu, may still show a separate Suspend icon instead of using the above method.
 Suspending the System
Suspending the System
Basic Operations
Even experienced users can forget the precise command that launches an application, or exactly what options and arguments it requires. Fortunately, Linux allows you to quickly open applications using the graphical interface.
Applications are found at different places in Linux (and within GNOME):
- From the Applications menu in the upper-left corner.
- From the Activities menu in the upper-left corner.
- In some Ubuntu versions, from the Dash button in the upper-left corner.
- For KDE, and some other environments, applications can be opened from the button in the lower-left corner.
On the following pages you will learn how to perform basic operations in Linux using the graphical interface.
Locating Applications
Unlike other operating systems, the initial install of Linux usually comes with a wide range of applications and software archives that contain thousands of programs that enable you to accomplish a wide variety of tasks with your computer. For most key tasks, a default application is usually already installed. However, you can always install more applications and try different options.
For example, Firefox is popular as the default browser in many Linux distributions, while Epiphany, Konqueror, and Chromium (the open source base for Google Chrome) are usually available for install from software repositories. Proprietary web browsers, such as Opera and Chrome, are also available.
Locating applications from the GNOME and KDE menus is easy, as they are neatly organized in functional submenus.
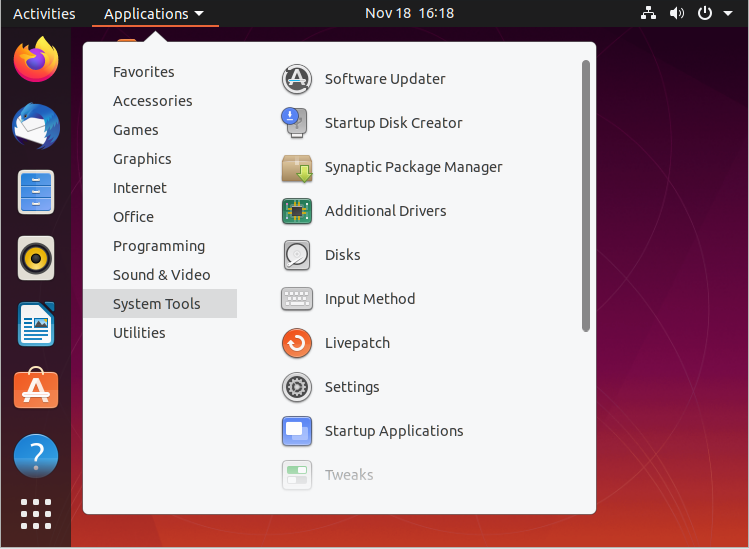 Locating Applications
Locating Applications
Default Applications
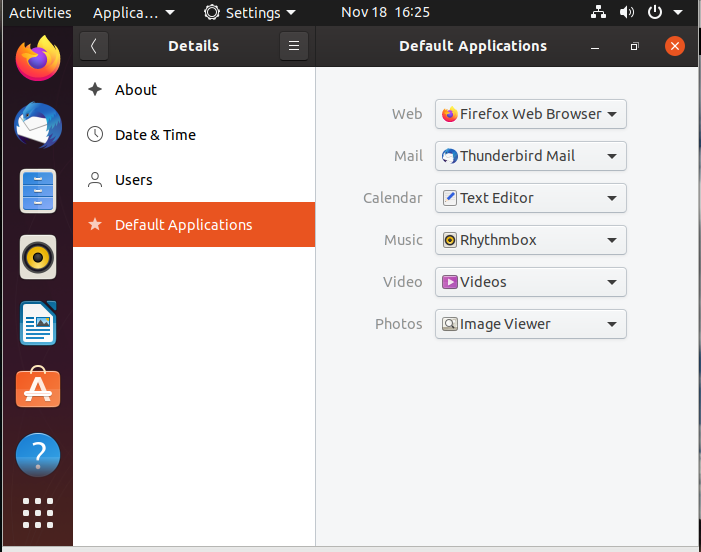
Multiple applications are available to accomplish various tasks and to open a file of a given type. For example, you can click on a web address while reading an email and launch a browser such as Firefox or Chrome.
To set default applications, enter the Settings menu (on all recent Linux distributions) and then click on either Default Applications or Details > Default Applications. The exact list will vary from what is shown here in the Ubuntu screenshot according to what is actually installed and available on your system
 Default Applications
Default Applications
Video: Setting Default Applications
Sorry, your browser doesn't support embedded videos.File Manager
Each distribution implements the Nautilus (File Manager) utility, which is used to navigate the file system. It can locate files and, when a file is clicked upon, either it will run if it is a program, or an associated application will be launched using the file as data. This behavior is completely familiar to anyone who has used other operating systems.
To start the file manager you will have to click on its icon (a file cabinet) which is easily found, usually under Favorites or Accessories. It will have the name Files.
This will open a window with your Home directory displayed. The left panel of the File Manager window holds a list of commonly used directories, such as Desktop, Documents, Downloads and Pictures.
You can click the Magnifying Glass icon on the top-right to search for files or directories (folders).
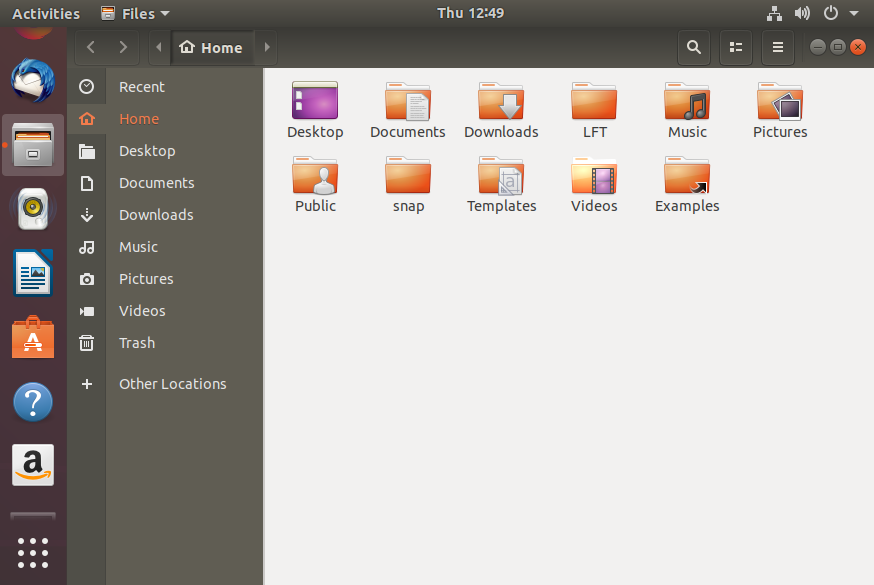 File Manager
File Manager
Home Directories
The File Manager lets you access different locations on your computer and the network, including the Home directory, Desktop, Documents, Pictures, and other Other Locations.
Every user with an account on the system will have a home directory, usually created under /home, and usually named according to the user, such as /home/student.
By default, files the user saves will be placed in a directory tree starting there. Account creation, whether during system installation or at a later time, when a new user is added, also induces default directories to be created under the user's home directory, such as Documents, Desktop, and Downloads.
In the screenshot shown for Ubuntu, we have chosen the list format and are also showing hidden files (those starting with a period). See if you can do the same on your distribution.
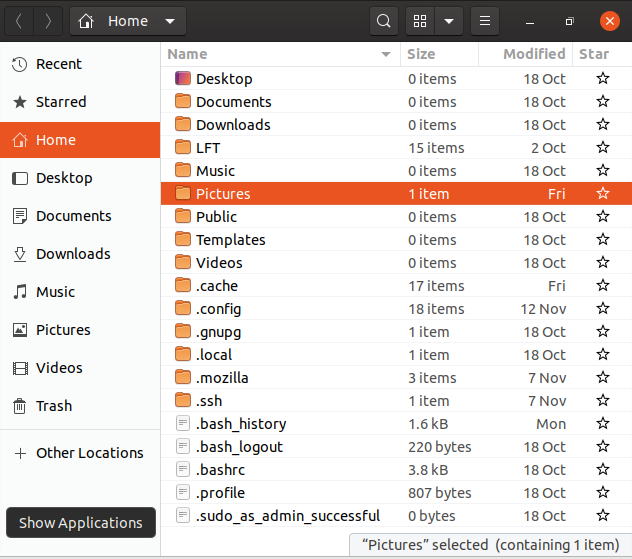 Home Directories
Home Directories
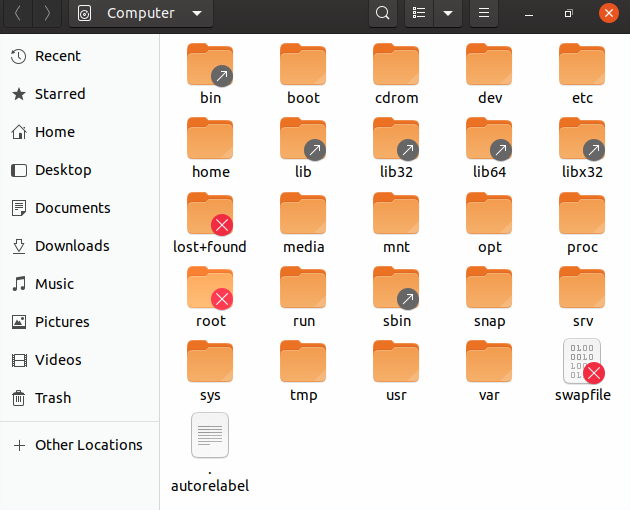 Other Locations
Other Locations
Viewing Files
The File Manager allows you to view files and directories in more than one way.
You can switch between the Icons and List formats, either by clicking the familiar icons in the top bar, or you can press CTRL-1 or CTRL-2 respectively.
In addition, you can also arrange the files and directories by name, size, type, or modification date for further sorting. To do so, click View and select Arrange Items.
Another useful option is to show hidden files (sometimes imprecisely called system files), which are usually configuration files that are hidden by default and whose name starts with a dot. To show hidden files, select Show Hidden Files from the menu or press CTRL-H.
The file browser provides multiple ways to customize your window view to facilitate easy drag and drop file operations. You can also alter the size of the icons by selecting Zoom In and Zoom Out under the View menu.
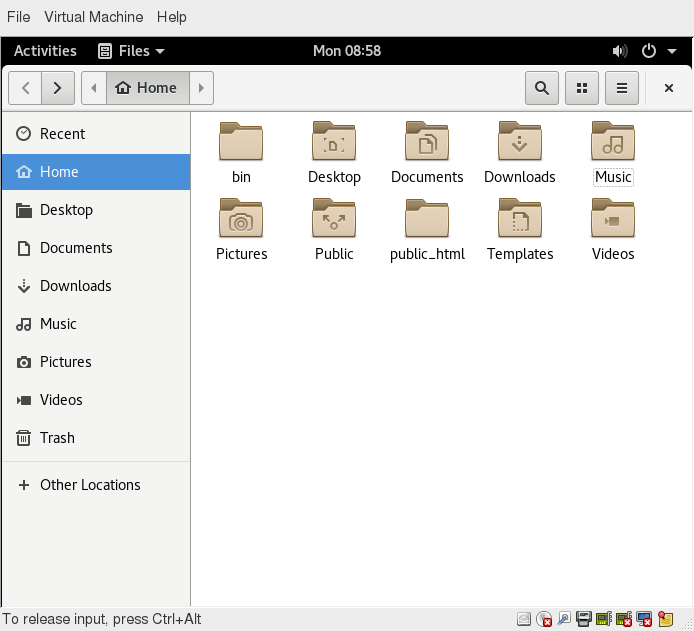
Searching for Files
The File Manager includes a great search tool inside the file browser window.
- Click Search in the toolbar (to bring up a text box).
- Enter the keyword in the text box. This causes the system to perform a recursive search from the current directory for any file or directory which contains a part of this keyword.
To open the File Manager from the command line, on most systems simply type nautilus.

The shortcut key to get to the search text box is CTRL-F. You can exit the search text box view by clicking the Search button or CTRL-F again.
Another quick way to access a specific directory is to press CTRL-L, which will give you a Location text box to type in a path to a directory.
More About Searching for Files
You can refine your search beyond the initial keyword by providing dropdown menus to further filter the search.
- Based on Location or File Type, select additional criteria from the dropdown.
- To regenerate the search, click the Reload button.
- To add multiple search criteria, click the + button and select Additional Search Criteria.
For example, if you want to find a PDF file containing the word Linux in your home directory, navigate to your home directory and search for the word “Linux”. You should see that the default search criterion limits the search to your home directory already. To finish the job, click the + button to add another search criterion, select File Type for the type of criterion, and select PDF under the File Type dropdown.
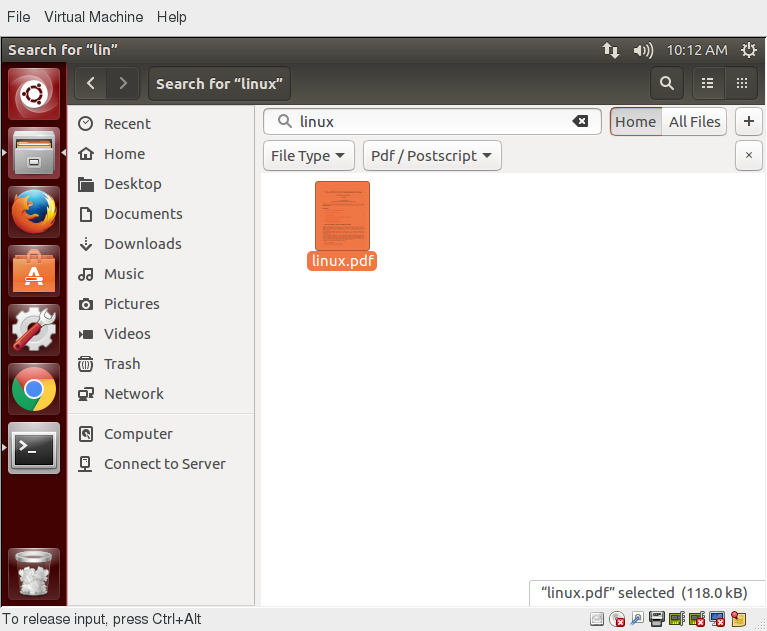 Searching for Files
Searching for Files
Editing a File
Editing any text file through the graphical interface is easy in the GNOME desktop environment. Simply double-click the file on the desktop or in the Nautilus file browser window to open the file with the default text editor.
The default text editor in GNOME is gedit. It is simple yet powerful, ideal for editing documents, making quick notes, and programming. Although gedit is designed as a general purpose text editor, it offers additional features for spell checking, highlighting, file listings and statistics.
You will learn much more about using text editors in a later chapter.
Removing a File
Deleting a file in Nautilus will automatically move the deleted files to the .local/share/Trash/files/ directory (a trash can of sorts) under the user's home directory. There are several ways to delete files and directories using Nautilus.
- Select all the files and directories that you want to delete.
- Press CTRL-Delete on your keyboard, or right-click the file.
- Select Move to Trash.
Note that you may have a Delete Permanently option which bypasses the trash folder, and that this option may be visible all the time or only in list (rather than) icon mode.

To permanently delete a file:
- On the left panel inside a Nautilus file browser window, right-click on the Trash directory.
- Select Empty Trash.
Alternatively, select the file or directory you want to permanently delete and press Shift-Delete.
As a precaution, you should never delete your Home directory, as doing so will most likely erase all your GNOME configuration files and possibly prevent you from logging in. Many personal system and program configurations are stored under your home directory.
Video: Locating and Setting Default Applications, and Exploring Filesystems in openSUSE
Sorry, your browser doesn't support embedded videos.Chapter 4 Summary
You have completed Chapter 4. Let's summarize the key concepts covered:
- GNOME is a popular desktop environment and graphical user interface that runs on top of the Linux operating system.
- The default display manager for GNOME is called gdm.
- The gdm display manager presents the user with the login screen, which prompts for the login username and password.
- Logging out through the desktop environment kills all processes in your current X session and returns to the display manager login screen.
- Linux enables users to switch between logged-in sessions.
- Suspending puts the computer into sleep mode.
- For each key task, there is generally a default application installed.
- Every user created in the system will have a home directory.
- The Places menu contains entries that allow you to access different parts of the computer and the network.
- Nautilus gives three formats to view files.
- Most text editors are located in the Accessories submenu.
- Each Linux distribution comes with its own set of desktop backgrounds.
- GNOME comes with a set of different themes which can change the way your applications look.
#
Chapter 5: System Configuration from the Graphical Interface
Learning Objectives
By the end of this chapter, you should be able to:
- Apply system, display, and date and time settings using the System Settings panel.
- Track the network settings and manage connections using Network Manager in Linux.
- Install and update software in Linux from a graphical interface.
NOTE: We will revisit all these tasks later, when we discuss how to accomplish them from the command line interface.
System, Display, Date and Time Settings
The System Settings panel allows you to control most of the basic configuration options and desktop settings, such as specifying the screen resolution, managing network connections, or changing the date and time of the system.
For the GNOME Desktop Manager, one clicks on the upper right-hand corner and then selects the tools image (screwdriver crossed with a wrench or a gear). Depending on your distribution, you may find other ways to get into the settings configuration as well. You will also find variation in the menu layout between Linux distributions and versions, so you may have to hunt for the settings you need to examine or modify.
 System Settings Panel
System Settings Panel
System Settings Menus
To get deeper into configuration, one can click on the Devices on the previous menu in order to configure items like the display, the keyboard, the printers, etc.
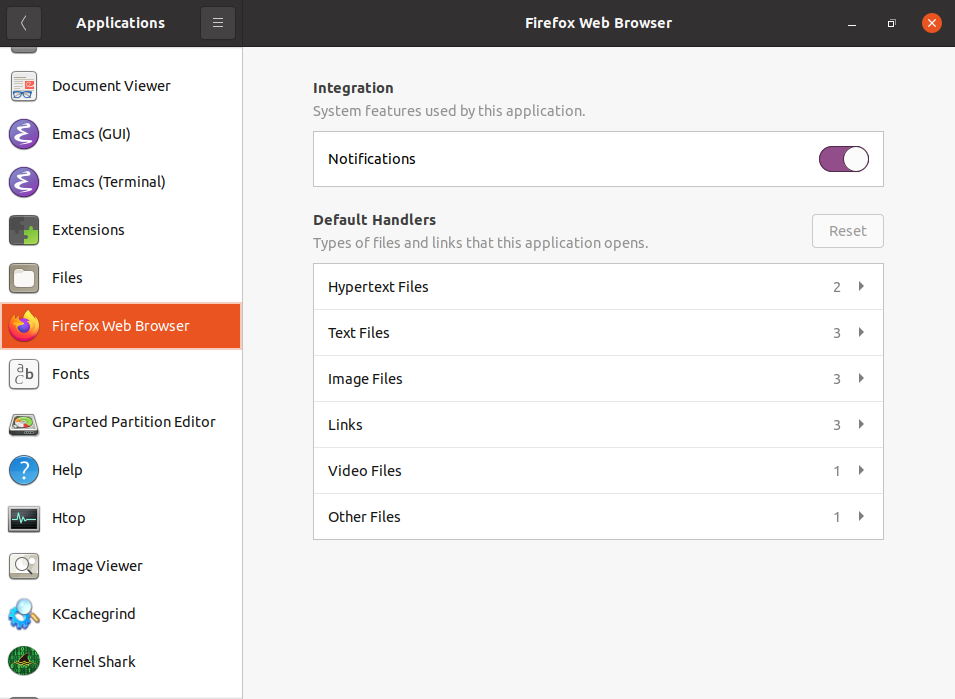 Configuring Applications on Ubuntu
Configuring Applications on Ubuntu
One can also click on the Users icon (which may be under Details) to set values for system users, such as their login picture, password, etc.
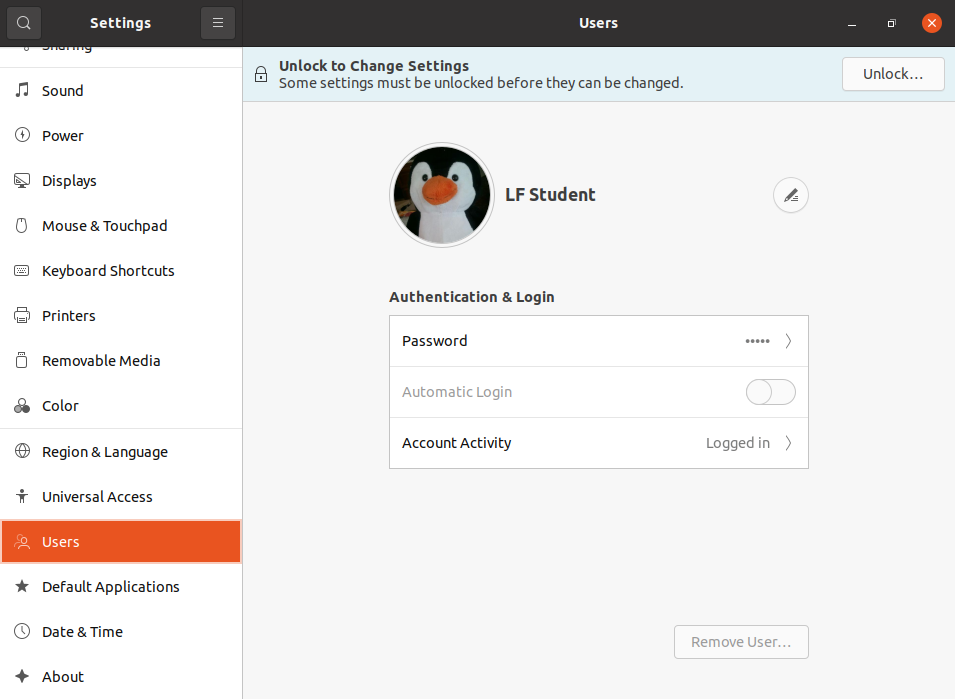 Configuring the User Attributes
Configuring the User Attributes
gnome-tweaks
A lot of personalized configuration settings do not appear on the settings menus. Instead, you have to launch a tool called either gnome-tweaks (or gnome-tweak-tool on older Linux distributions). We have not really discussed working at the command line yet, but you can always launch a program such as this by doing Alt-F2 and typing in the command. Some distributions have a link to the tweaks menus in the settings, but for some mysterious reason, many obscure this tool's existence, and it becomes hard to discover how to modify even rather basic desktop attributes and behavior.
Important things you can do with this tool include selecting a theme, configuring extensions which you can get from your distribution or download from the Internet, control fonts, modify the keyboard layout, and set which programs start when you login.
The most recent GNOME versions have removed a lot of the functionality of gnome-tweaks; extensions now have to be configured using a new app called gnome-extensions-app. The reasoning for this is obscure.
The screenshot here is from a Red Hat system with quite a few extensions installed, but not all being used.
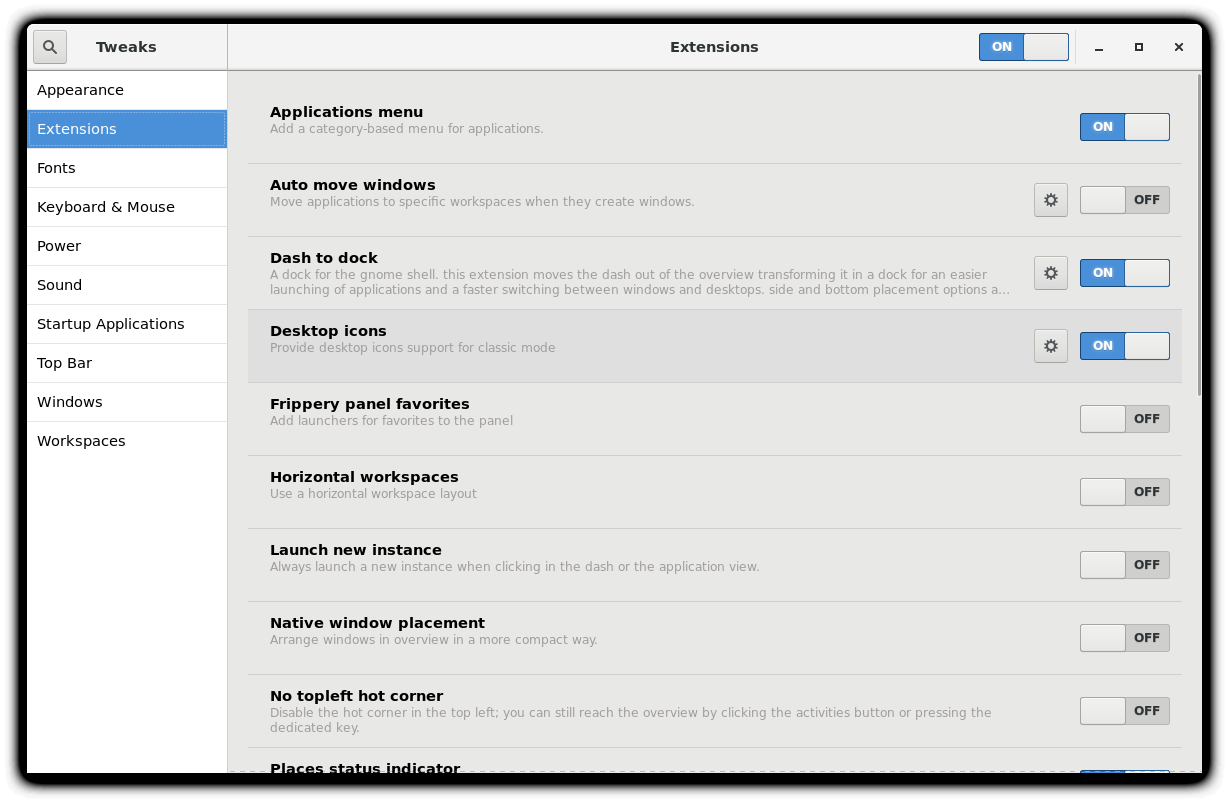 Extensions Installed on RHEL
Extensions Installed on RHEL
Display Settings
Clicking on Settings > Displays (or Settings > Devices > Displays) will expose the most common settings for changing the desktop appearance. These settings function independently of the specific display drivers you are running. The exact appearance will depend enormously on how many monitors you have and other factors, such as Linux distribution and particular version.
If your system uses a proprietary video card driver (usually from nVidia or AMD), you will probably have a separate configuration program for that driver. This program may give more configuration options, but may also be more complicated, and might require sysadmin (root) access. If possible, you should configure the settings in the Displays panel rather than with the proprietary program.
The X server, which actually provides the GUI, uses /etc/X11/xorg.conf as its configuration file if it exists; In modern Linux distributions, this file is usually present only in unusual circumstances, such as when certain less common graphic drivers are in use. Changing this configuration file directly is usually for more advanced users.
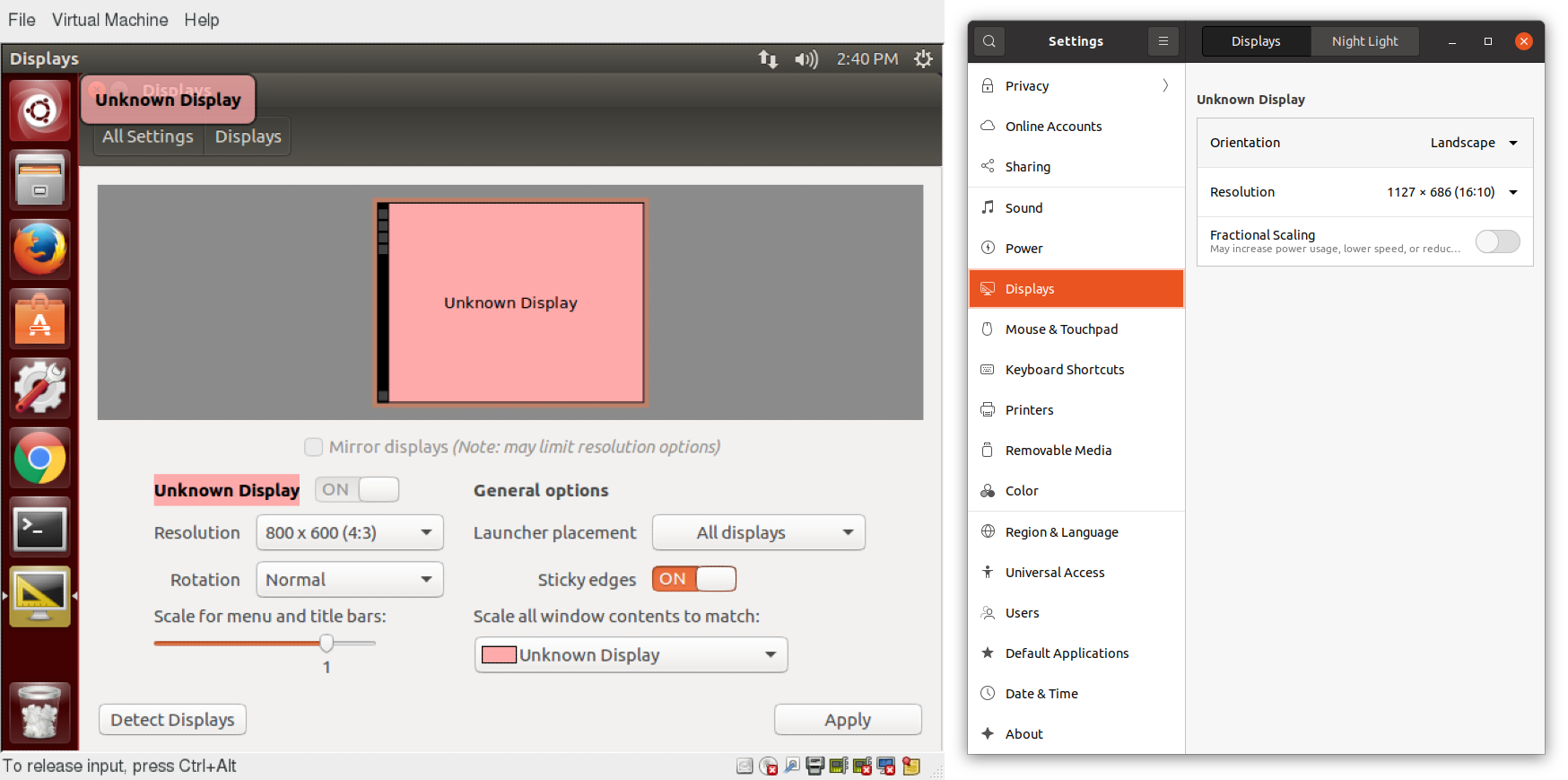 Display Settings on an Older and Newer Ubuntu Systems
Display Settings on an Older and Newer Ubuntu Systems
Setting Resolution and Configuring Multiple Screens
While your system will usually figure out the best resolution for your screen automatically, it may get this wrong in some cases, or you might want to change the resolution to meet your needs.
You can accomplish this using the Displays panel. The switch to the new resolution will be effective when you click Apply, and then confirm that the resolution is working. In case the selected resolution fails to work or you are just not happy with the appearance, the system will switch back to the original resolution after a short timeout. Once again, the exact appearance of the configuration screen will vary a lot between distributions and versions, but usually is rather intuitive and easy, once you find the configuration menus.
In most cases, the configuration for multiple displays is set up automatically as one big screen spanning all monitors, using a reasonable guess for screen layout. If the screen layout is not as desired, a check box can turn on mirrored mode, where the same display is seen on all monitors. Clicking on a particular monitor image lets you configure the resolution of each one, and whether they make one big screen, or mirror the same video, etc.
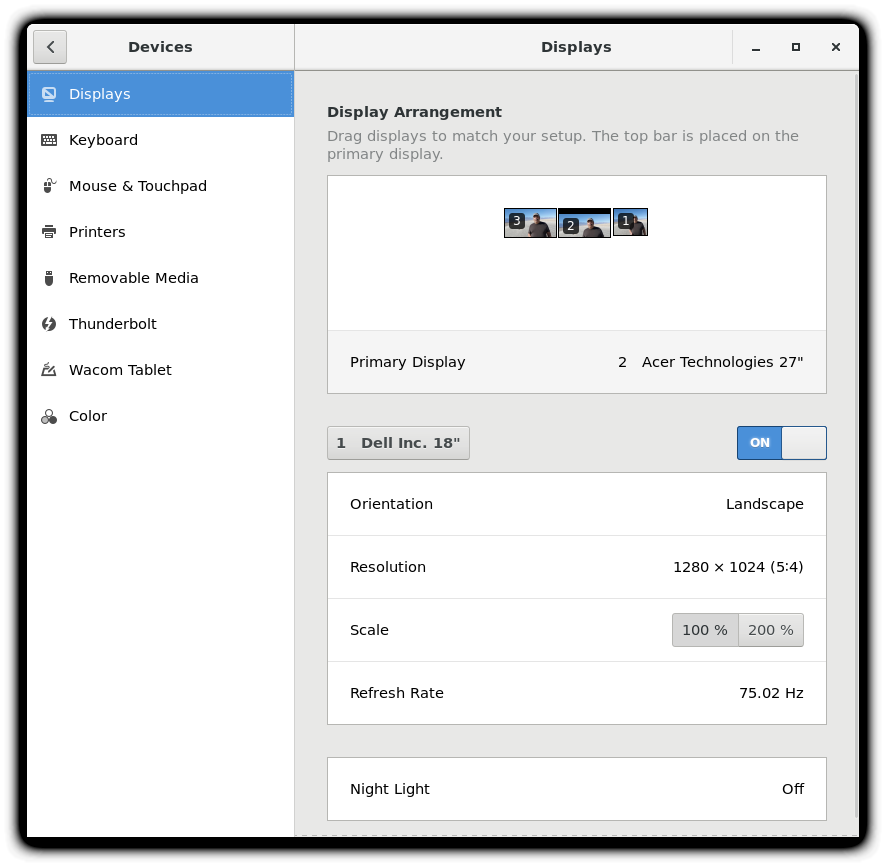 Setting the Resolution and Configuring Multiple Screens
Setting the Resolution and Configuring Multiple Screens
Video: Configuring Display Settings
Sorry, your browser doesn't support embedded videos.Date and Time Settings
By default, Linux always uses Coordinated Universal Time (UTC) for its own internal timekeeping. Displayed or stored time values rely on the system time zone setting to get the proper time. UTC is similar to, but more accurate than, Greenwich Mean Time (GMT).
If you click on the time displayed on the top panel, you can adjust the format with which the date and time is shown; on some distributions, you can also alter the values.
The more detailed date and time settings can be selected from the Date & Time window in the System Settings Menu.
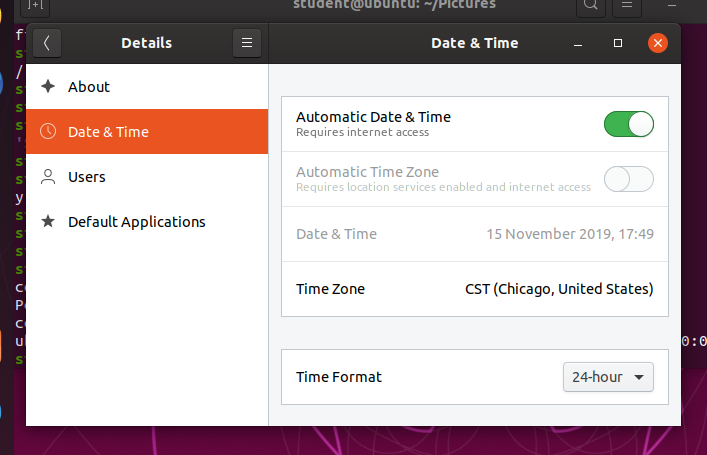 Date and Time Settings
Date and Time Settings
The "automatic" settings are referring to the use of Network Time Protocol (NTP), which we discuss next.
Network Time Protocol
The Network Time Protocol (NTP) is the most popular and reliable protocol for setting the local time by consulting established Internet servers. Linux distributions always come with a working NTP setup, which refers to specific time servers run or relied on by the distribution. This means that no setup, beyond "on" or "off", is generally required for network time synchronization.

Network Configuration
All Linux distributions have network configuration files, but file formats and locations can differ from one distribution to another. Hand editing of these files can handle quite complicated setups, but is not very dynamic or easy to learn and use. Network Manager was developed to make things easier and more uniform across distributions. It can list all available networks (both wired and wireless), allow the choice of a wired, wireless, or mobile broadband network, handle passwords, and set up Virtual Private Networks (VPNs). Except for unusual situations, it is generally best to let Network Manager establish your connections and keep track of your settings.
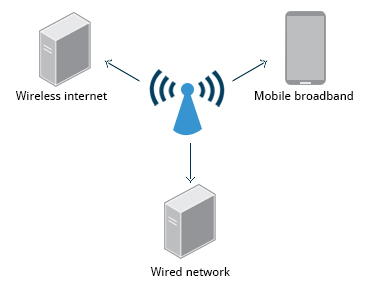 Network Configuration
Network Configuration
In this section, you will learn how to manage network connections, including wired and wireless connections, and mobile broadband and VPN connections.
Wired and Wireless Connections
Wired connections usually do not require complicated or manual configuration. The hardware interface and signal presence are automatically detected, and then Network Manager sets the actual network settings via Dynamic Host Configuration Protocol (DHCP).
For static configurations that do not use DHCP, manual setup can also be done easily through Network Manager. You can also change the Ethernet Media Access Control (MAC) address if your hardware supports it. The MAC address is a unique hexadecimal number of your network card.
Wireless networks are usually not connected by default. You can view the list of available wireless networks and see which one (if any) you are currently connected to by using Network Manager. You can then add, edit, or remove known wireless networks, and also specify which ones you want connected by default when present.
Configuring Wireless Connections
To configure a wireless network in any recent GNOME-based distribution:
Click on the upper-right corner of the top panel, which brings up a settings and/or network window. While the exact appearance will depend on Linux distribution and version, it will always be possible to click on a Wi-Fi submenu, as long as the hardware is present. Here is an example from a RHEL 8 system:
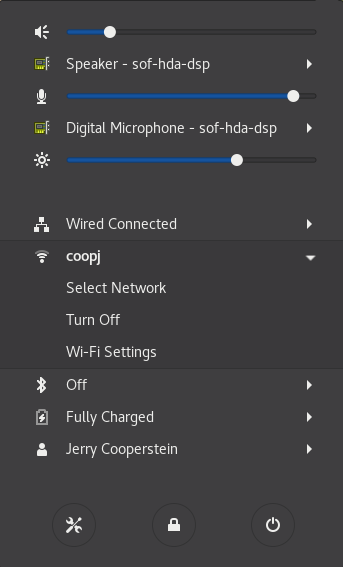 Configuring Wireless Connections
Configuring Wireless Connections
Select the wireless network you wish to connect to. If it is a secure network, the first time it will request that you enter the appropriate password. By default, the password will be saved for subsequent connections.
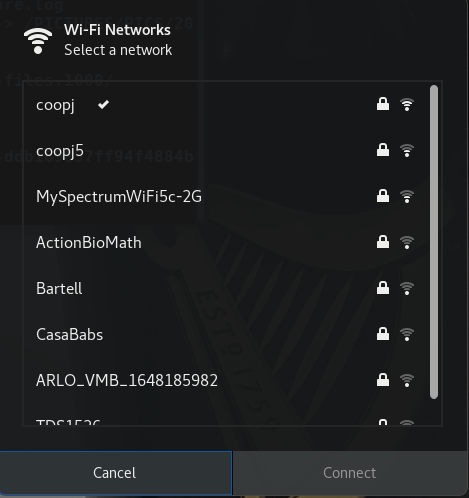 Selecting a Network
Selecting a Network
If you click on Wi-Fi Settings, you will bring up the third screenshot. If you click on the Gear icon for any connection, you can configure it in more detail.
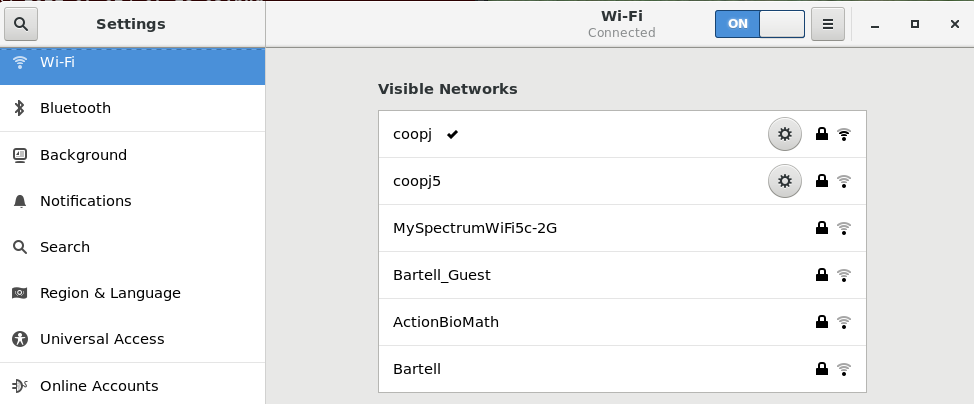 Configuring the Network of Your Choice
Configuring the Network of Your Choice
Older and other Linux distributions may look quite a bit different in detail, but the steps and choices are essentially identical, as they are all running Network Manager with perhaps somewhat different clothing.
Video: Managing Network Settings
Sorry, your browser doesn't support embedded videos.Mobile Broadband and VPN Connections
You can set up a mobile broadband connection with Network Manager, which will launch a wizard to set up the connection details for each connection.
Once the configuration is done, the network is configured automatically each time the broadband network is attached.
Network Manager can also manage your VPN connections.
It supports many VPN technologies, such as native IPSec, Cisco OpenConnect (via either the Cisco client or a native open source client), Microsoft PPTP, and OpenVPN.
You might get support for VPN as a separate package from your distributor. You need to install this package if your preferred VPN is not supported.
Installing and Updating Software
Each package in a Linux distribution provides one piece of the system, such as the Linux kernel, the C compiler, utilities for manipulating text or configuring the network, or for your favorite web browsers and email clients.
Packages often depend on each other. For example, because your email client can communicate using SSL/TLS, it will depend on a package which provides the ability to encrypt and decrypt SSL and TLS communication, and will not install unless that package is also installed at the same time.

All systems have a lower-level utility which handles the details of unpacking a package and putting the pieces in the right places. Most of the time, you will be working with a higher-level utility which knows how to download packages from the Internet and can manage dependencies and groups for you.
In this section, you will learn how to install and update software in Linux using the Debian packaging system (used by systems such as Ubuntu as well) and RPM packaging systems (which is used by both Red Hat and SUSE family systems). These are the main ones in use although there are others which work well for other distributions which are less used.
Debian Packaging
Let’s look at the Package Management for the Debian family system.
dpkg is the underlying package manager for these systems. It can install, remove, and build packages. Unlike higher-level package management systems, it does not automatically download and install packages and satisfy their dependencies.
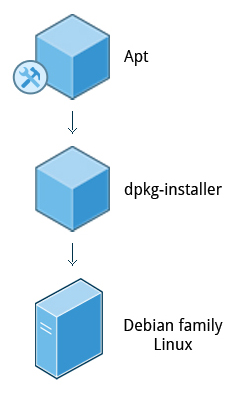 Package Management in the Debian Family System
Package Management in the Debian Family System
For Debian-based systems, the higher-level package management system is the Advanced Package Tool (APT) system of utilities. Generally, while each distribution within the Debian family uses APT, it creates its own user interface on top of it (for example, apt and apt-get, synaptic, gnome-software, Ubuntu Software Center, etc). Although apt repositories are generally compatible with each other, the software they contain generally is not. Therefore, most repositories target a particular distribution (like Ubuntu), and often software distributors ship with multiple repositories to support multiple distributions. Demonstrations are shown later in this section.
Red Hat Package Manager (RPM)
Red Hat Package Manager (RPM) is the other package management system popular on Linux distributions. It was developed by Red Hat, and adopted by a number of other distributions, including SUSE/openSUSE, Mageia, CentOS, Oracle Linux, and others.
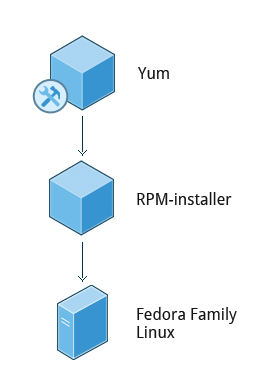 Red Hat Package Manager
Red Hat Package Manager
The higher-level package manager differs between distributions. Red Hat family distributions historically use RHEL/CentOS and Fedora uses dnf, while retaining good backwards compatibility with the older yum program. SUSE family distributions such as openSUSE also use RPM, but use the zypper interface.
openSUSE’s YaST Software Management
The Yet another Setup Tool (YaST) software manager is similar to other graphical package managers. It is an RPM-based application. You can add, remove, or update packages using this application very easily. To access the YaST software manager:
- Click Activities
- In the Search box, type YaST
- Click the YaST icon
- Click Software Management
You can also find YaST by clicking on Applications > Other-YaST, which is a strange place to put it.
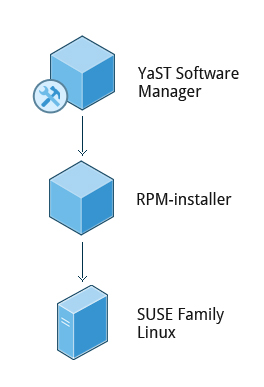 openSUSE's Software Management
openSUSE's Software Management
openSUSE’s YaST software management application is similar to the graphical package managers in other distributions. A demonstration of the YaST software manager is shown later in this section.
Video: Installing and Updating Software in openSUSE
Sorry, your browser doesn't support embedded videos.Video: Installing and Updating Software in Ubuntu
Sorry, your browser doesn't support embedded videos.Chapter 5 Summary
You have completed Chapter 5. Let's summarize the key concepts covered:
- You can control basic configuration options and desktop settings through the System Settings panel.
- Linux always uses Coordinated Universal Time (UTC) for its own internal time-keeping. You can set the date and time settings from the System Settings window.
- The Network Time Protocol is the most popular and reliable protocol for setting the local time via Internet servers.
- The Displays panel allows you to change the resolution of your display and configure multiple screens.
- Network Manager can present available wireless networks, allow the choice of a wireless or mobile broadband network, handle passwords, and set up VPNs.
- dpkg and RPM are the most popular package management systems used on Linux distributions.
- Debian distributions use dpkg and apt-based utilities for package management.
- RPM was developed by Red Hat, and adopted by a number of other distributions, including the openSUSE, Mandriva, CentOS, Oracle Linux, and others.
Chapter 6: Common Applications
By the end of this chapter, you should be familiar with common Linux applications, including:
- Internet applications such as browsers and email programs.
- Office Productivity Suites such as LibreOffice.
- Developer tools, such as compilers, debuggers, etc.
- Multimedia applications, such as those for audio and video.
- Graphics editors such as the GIMP and other graphics utilities.
Internet Applications
The Internet is a global network that allows users around the world to perform multiple tasks, such as searching for data, communicating through emails and online shopping. Obviously, you need to use network-aware applications to take advantage of the Internet. These include:
- Web browsers
- Email clients
- Streaming media applications
- Internet Relay Chats
- Conferencing software
 Internet Applications
Internet Applications
Web Browsers
As discussed in the Graphical Interface chapter, Linux offers a wide variety of web browsers, both graphical and text-based, including:
- Firefox
- Google Chrome
- Chromium
- Epiphany (renamed web)
- Konqueror
- linx, lynx, w3m
- Opera

Email Applications
Email applications allow for sending, receiving, and reading messages over the Internet. Linux systems offer a wide number of email clients, both graphical and text-based. In addition, many users simply use their browsers to access their email accounts.
Most email clients use the Internet Message Access Protocol (IMAP) or the older Post Office Protocol (POP) to access emails stored on a remote mail server. Most email applications also display HTML (HyperText Markup Language) formatted emails that display objects, such as pictures and hyperlinks. The features of advanced email applications include the ability of importing address books/contact lists, configuration information, and emails from other email applications.
Linux supports the following types of email applications:
- Graphical email clients, such as Thunderbird, Evolution, and Claws Mail.
- Text mode email clients, such as Mutt and mail.
- All web browser-based clients, such as Gmail, Yahoo Mail, and Office 365.
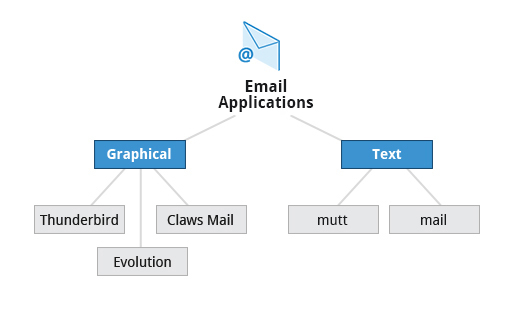 Email Applications
Email Applications
Other Internet Applications
Linux systems provide many other applications for performing Internet-related tasks. These include:
| Application | Use |
| FileZilla | Intuitive graphical FTP client that supports FTP, Secure File Transfer Protocol (SFTP), and FTP Secured (FTPS). Used to transfer files to/from (FTP) servers. |
| Pidgin | To access GTalk, AIM, ICQ, MSN, IRC and other messaging networks. |
| Ekiga | To connect to Voice over Internet Protocol (VoIP) networks. |
| Hexchat | To access Internet Relay Chat (IRC) networks. |

![]()


Office Applications
Most day-to-day computer systems have productivity applications (sometimes called office suites) available or installed. Each suite is a collection of closely coupled programs used to create and edit different kinds of files such as:
- Text (articles, books, reports, etc.)
- Spreadsheets
- Presentations
- Graphical objects.
Most Linux distributions offer LibreOffice, an open source office suite that started in 2010 and has evolved from OpenOffice. While other office suites are available as we have listed, LibreOffice is the most mature, widely used and intensely developed.
In addition, Linux users have full access to Internet-based office suites such as Google Docs and Microsoft Office 365.
![]()
LibreOffice Components
The component applications included in LibreOffice are:
- Writer: Word Processing
- Calc: Spreadsheets
- Impress: Presentations
- Draw: Create and edit graphics and diagrams.
The LibreOffice applications can read and write non-native document formats, such as those used by Microsoft Office. Usually, fidelity is maintained quite well, but complicated documents might have some imperfect conversions.
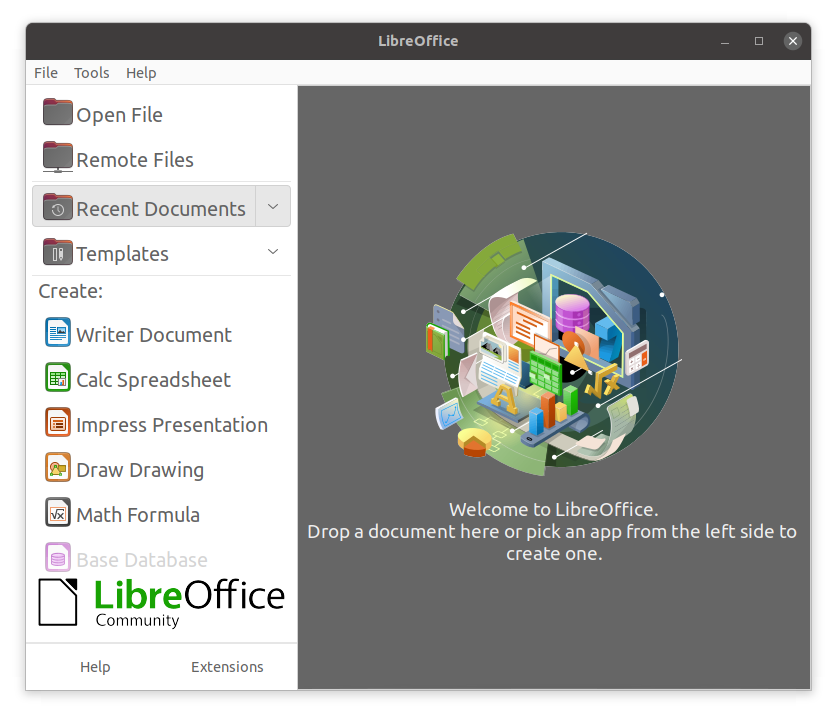 LibreOffice Applications
LibreOffice Applications
Development Applications
Linux distributions come with a complete set of applications and tools that are needed by those developing or maintaining both user applications and the kernel itself.
These tools are tightly integrated and include:
- Advanced editors customized for programmers' needs, such as vi and emacs.
- Compilers (such as gcc and clang for programs in C and C++) for every computer language that has ever existed, including very popular new ones such as Golang and Rust.
- Debuggers such as gdb and various graphical front ends to it and many other debugging tools (such as Valgrind).
- Performance measuring and monitoring programs, some with easy to use graphical interfaces, others more arcane and meant to be used only by serious experienced development engineers.
- Complete Integrated Development Environments (IDE's) such as Eclipse and Visual Studio Code that put all these tools together.
On other operating systems, these tools have to be obtained and installed separately, often at a high cost, while on Linux they are all available at no cost through standard package installation systems.

![]()

Sound Players
Multimedia applications are used to listen to music, watch videos, etc., as well as to present and view text and graphics. Linux systems offer a number of sound player applications, including:
| Application | Use |
| Amarok | Mature MP3 player with a graphical interface, that plays audio and video files, and streams (online audio files). It allows you to create a playlist that contains a group of songs, and uses a database to store information about the music collection. |
| Audacity | Used to record and edit sounds. It can be quickly installed through a package manager. Audacity has a simple interface to get you started. |
| Rhythmbox | Supports a large variety of digital music sources, including streaming Internet audio and podcasts. The application also enables search of particular audio in a library. It supports smart playlists with an automatic update feature, which can revise playlists based on specified selection criteria. |
Of course, Linux systems can also connect with commercial online music streaming services, such as Pandora and Spotify through web browsers.
![]()

![]()
Movie Players
Movie (video) players can portray input from many different sources, either local to the machine or on the Internet.

Linux systems offer a number of movie players, including:
- VLC
- MPlayer
- Xine
- Totem
Movie Editors
Movie editors are used to edit videos or movies. Linux systems offer a number of movie editors, including:
| Application | Use |
| Cinepaint | Frame-by-frame retouching. Cinepaint is used for editing images in a video. |
| Blender | Create 3D animation and design. Blender is a professional tool that uses modeling as a starting point. There are complex and powerful tools for camera capture, recording, editing, enhancing and creating video, each having its own focus. |
| Cinelerra | Capture, compose, and edit audio/video. |
| FFmpeg | Record, convert, and stream audio/video. FFmpeg is a format converter, among other things, and has other tools such as ffplay and ffserver. |


![]()
![]()
GIMP (GNU Image Manipulation Program)
Graphic editors allow you to create, edit, view, and organize images of various formats, like Joint Photographic Experts Group (JPEG or JPG), Portable Network Graphics (PNG), Graphics Interchange Format (GIF), and Tagged Image File Format (TIFF).
The GNU Image Manipulation Program (GIMP) is a feature-rich image retouching and editing tool similar to Adobe Photoshop and is available on all Linux distributions. Some features of the GIMP are:
- It can handle any image file format.
- It has many special purpose plugins and filters.
- It provides extensive information about the image, such as layers, channels, and histograms.
 GIMP Editor
GIMP Editor
Graphics Utilities
In addition to GIMP, there are other graphics utilities that help perform various image-related tasks, including:
| Graphic Utility | Use |
| eog | Eye of Gnome (eog) is an image viewer that provides slide show capability and a few image editing tools, such as rotate and resize. It can also step through the images in a directory with just a click. |
| Inkscape | Inkscape is an image editor with lots of editing features. It works with layers and transformations of the image. It is sometimes compared to Adobe Illustrator. |
| convert | convert is a command line tool (part of the ImageMagick set of applications) that can modify image files in many ways. The options include file format conversion and numerous image modification options, such as blur, resize, despeckle, etc. |
| Scribus | Scribus is used for creating documents used for publishing and providing a What You See Is What You Get (WYSIWYG) environment. It also provides numerous editing tools. |

![]()
![]()
Chapter Summary
You have completed Chapter 6. Let’s summarize the key concepts covered:
- Linux offers a wide variety of Internet applications, such as web browsers, email clients, online media applications, and others.
- Web browsers supported by Linux can be either graphical or text-based, such as Firefox, Google Chrome, Epiphany, w3m, lynx, and others.
- Linux supports graphical email clients, such as Thunderbird, Evolution, and Claws Mail, and text mode email clients, such as Mutt and mail.
- Linux systems provide many other applications for performing Internet-related tasks, such as Filezilla, XChat, Pidgin, and others.
- Most Linux distributions offer LibreOffice to create and edit different kinds of documents.
- Linux systems offer entire suites of development applications and tools, including compilers and debuggers.
- Linux systems offer a number of sound players including Amarok, Audacity, and Rhythmbox.
- Linux systems offer a number of movie players, including VLC, MPlayer, Xine, and Totem.
- Linux systems offer a number of movie editors, including Kino, Cinepaint, Blender among others.
- The GIMP (GNU Image Manipulation Program) utility is a feature-rich image retouching and editing tool available on all Linux distributions.
- Other graphics utilities that help perform various image-related tasks are eog, Inkscape, convert, and Scribus.
Chapter 7: Command Line Operations
Learning Objectives
By the end of this chapter, you should be able to:
- Use the command line to perform operations in Linux.
- Search for files.
- Create and manage files.
- Install and update software.
Introduction to the Command Line
Linux system administrators spend a significant amount of their time at a command line prompt. They often automate and troubleshoot tasks in this text environment. There is a saying, "graphical user interfaces make easy tasks easier, while command line interfaces make difficult tasks possible". Linux relies heavily on the abundance of command line tools. The command line interface provides the following advantages:
- No GUI overhead is incurred.
- Virtually any and every task can be accomplished while sitting at the command line.
- You can implement scripts for often-used (or easy-to-forget) tasks and series of procedures.
- You can sign into remote machines anywhere on the Internet.
- You can initiate graphical applications directly from the command line instead of hunting through menus.
- While graphical tools may vary among Linux distributions, the command line interface does not.

Using a Text Terminal on the Graphical Desktop
A terminal emulator program emulates (simulates) a standalone terminal within a window on the desktop. By this, we mean it behaves essentially as if you were logging into the machine at a pure text terminal with no running graphical interface. Most terminal emulator programs support multiple terminal sessions by opening additional tabs or windows.
By default, on GNOME desktop environments, the gnome-terminal application is used to emulate a text-mode terminal in a window. Other available terminal programs include:
- xterm
- konsole (default on KDE)
- terminator
 $ ls -a
$ ls -a
Launching Terminal Windows
To open a terminal on any system using a recent GNOME desktop click on Applications > System Tools > Terminal or Applications > Utilities > Terminal. If you do not have the Applications menu, you will have to install the appropriate gnome-shell-extension package and turn on with gnome-tweaks.
On any but some of the most recent GNOME-based distributions, you can always open a terminal by right-clicking anywhere on the desktop background and selecting Open in Terminal. If this does not work you will once again need to install and activate the appropriate gnome-shell-extension package.
You can also hit Alt-F2 and type in either gnome-terminal or konsole, whichever is appropriate.
Because distributions have had a history of burying opening up a command line terminal, and the place in menus may vary in the desktop GUI, It is a good idea to figure out how to "pin" the terminal icon to the panel, which might mean adding it to the Favorites grouping on GNOME systems.
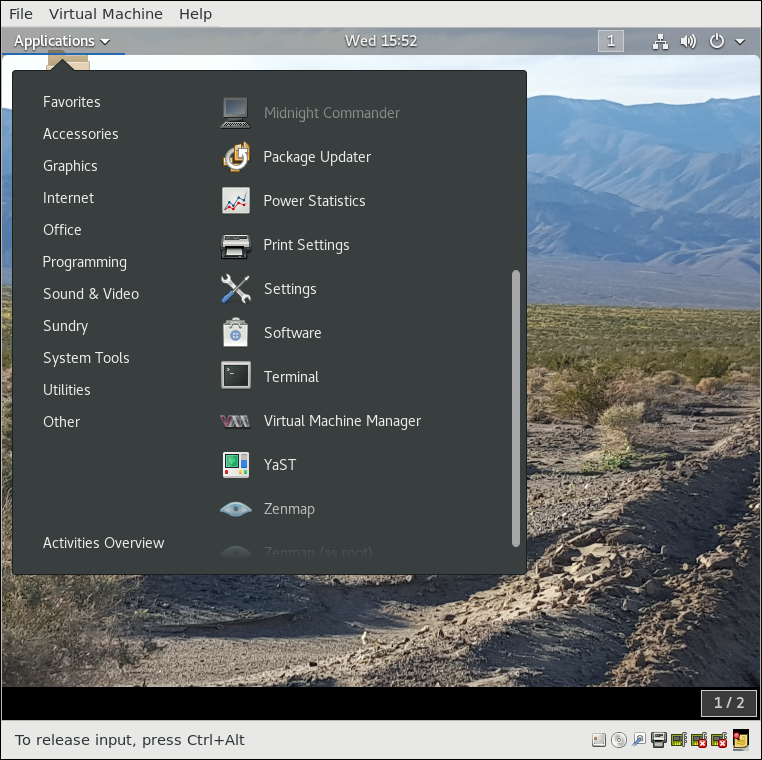 Opening a Terminal Using GNOME Desktop
Opening a Terminal Using GNOME Desktop
Some Basic Utilities
There are some basic command line utilities that are used constantly, and it would be impossible to proceed further without using some of them in simple form before we discuss them in more detail. A short list has to include:
- cat: used to type out a file (or combine files).
- head: used to show the first few lines of a file.
- tail: used to show the last few lines of a file.
- man: used to view documentation.
The screenshot shows elementary uses of these programs. Note the use of the pipe symbol (|) used to have one program take as input the output of another.
For the most part, we will only use these utilities in screenshots displaying various activities, before we discuss them in detail.
 Basic Command Line Utilities
Basic Command Line Utilities
The Command Line
Most input lines entered at the shell prompt have three basic elements:
- Command
- Options
- Arguments
The command is the name of the program you are executing. It may be followed by one or more options (or switches) that modify what the command may do. Options usually start with one or two dashes, for example, -p or --print, in order to differentiate them from arguments, which represent what the command operates on.
However, plenty of commands have no options, no arguments, or neither. In addition, other elements (such as setting environment variables) can also appear on the command line when launching a task.
sudo
All the demonstrations created have a user configured with sudo capabilities to provide the user with administrative (admin) privileges when required. sudo allows users to run programs using the security privileges of another user, generally root (superuser).
On your own systems, you may need to set up and enable sudo to work correctly. To do this, you need to follow some steps that we will not explain in much detail now, but you will learn about later in this course. When running on Ubuntu and some other recent distributions, sudo is already always set up for you during installation. On other Linux distributions, you will likely need to set up sudo to work properly for you after the initial installation.
Next, you will learn the steps to set up and run sudo on your system.
 sudo ls -la /root
sudo ls -la /root
Steps for Setting Up and Running sudo
If your system does not already have sudo set up and enabled, you need to do the following steps:
- You will need to make modifications as the administrative, or superuser, root. While sudo will become the preferred method of doing this, we do not have it set up yet, so we will use su (which we will discuss later in detail) instead. At the command line prompt, type su and press Enter. You will then be prompted for the root password, so enter it and press Enter. You will notice that nothing is printed; this is so others cannot see the password on the screen. You should end up with a different looking prompt, often ending with ‘#’. For example:
$ su Password:
# - Now, you need to create a configuration file to enable your user account to use sudo. Typically, this file is created in the /etc/sudoers.d/ directory with the name of the file the same as your username. For example, for this demo, let’s say your username is student. After doing step 1, you would then create the configuration file for student by doing this:
# echo "student ALL=(ALL) ALL" > /etc/sudoers.d/student - Finally, some Linux distributions will complain if you do not also change permissions on the file by doing:
# chmod 440 /etc/sudoers.d/student
That should be it. For the rest of this course, if you use sudo you should be properly set up. When using sudo, by default you will be prompted to give a password (your own user password) at least the first time you do it within a specified time interval. It is possible (though very insecure) to configure sudo to not require a password or change the time window in which the password does not have to be repeated with every sudo command.

Sandwich
(Retrieved from XKCD, provided under a Creative Commons Attribution-NonCommercial 2.5 License)
Switching Between the GUI and the Command Line
The customizable nature of Linux allows you to drop the graphical interface (temporarily or permanently) or to start it up after the system has been running.
Most Linux distributions give an option during installation (or have more than one version of the install media) to choose between desktop (with a graphical desktop) and server (usually without one).
Linux production servers are usually installed without the GUI, and even if it is installed, usually do not launch it during system startup. Removing the graphical interface from a production server can be very helpful in maintaining a lean system, which can be easier to support and keep secure.
 Switching between the GUI and the Command Line
Switching between the GUI and the Command Line
Virtual Terminals
Virtual Terminals (VT) are console sessions that use the entire display and keyboard outside of a graphical environment. Such terminals are considered "virtual" because, although there can be multiple active terminals, only one terminal remains visible at a time. A VT is not quite the same as a command line terminal window; you can have many of those visible at once on a graphical desktop.
One virtual terminal (usually number one or seven) is reserved for the graphical environment, and text logins are enabled on the unused VTs. Ubuntu uses VT 7, but CentOS/RHEL and openSUSE use VT 1 for the graphical display.
An example of a situation where using VTs is helpful is when you run into problems with the graphical desktop. In this situation, you can switch to one of the text VTs and troubleshoot.
To switch between VTs, press CTRL-ALT-function key for the VT. For example, press CTRL-ALT-F6 for VT 6. Actually, you only have to press the ALT-F6 key combination if you are in a VT and want to switch to another VT.
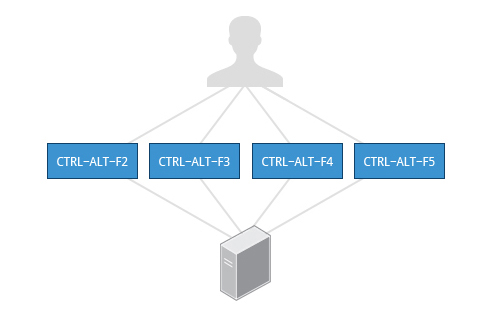 Switching between Virtual Terminals
Switching between Virtual Terminals
Turning Off the Graphical Desktop
Linux distributions can start and stop the graphical desktop in various ways. The exact method differs from distribution and among distribution versions. For the newer systemd-based distributions, the display manager is run as a service, you can stop the GUI desktop with the systemctl utility and most distributions will also work with the telinit command, as in:
$ sudo systemctl stop gdm (or sudo telinit 3)
and restart it (after logging into the console) with:
$ sudo systemctl start gdm (or sudo telinit 5)
On Ubuntu versions before 18.04 LTS, substitute lightdm for gdm.
Basic Operations
In this section, we will discuss how to accomplish basic operations from the command line. These include how to log in and log out from the system, restart or shut down the system, locate applications, access directories, identify absolute and relative paths, and explore the filesystem.
 Basic Operations
Basic Operations
Logging In and Out
An available text terminal will prompt for a username (with the string login:) and password. When typing your password, nothing is displayed on the terminal (not even a * to indicate that you typed in something), to prevent others from seeing your password. After you have logged into the system, you can perform basic operations.
Once your session is started (either by logging into a text terminal or via a graphical terminal program), you can also connect and log into remote systems by using Secure SHell (SSH). For example, by typing ssh student@remote-server.com, SSH would connect securely to the remote machine (remote-server.com) and give student a command line terminal window, using either a password (as with regular logins) or cryptographic key to sign in without providing a password to verify the identity.
Rebooting and Shutting Down
The preferred method to shut down or reboot the system is to use the shutdown command. This sends a warning message, and then prevents further users from logging in. The init process will then control shutting down or rebooting the system. It is important to always shut down properly; failure to do so can result in damage to the system and/or loss of data.
The halt and poweroff commands issue shutdown -h to halt the system; reboot issues shutdown -r and causes the machine to reboot instead of just shutting down. Both rebooting and shutting down from the command line requires superuser (root) access.
When administering a multi-user system, you have the option of notifying all users prior to shutdown, as in:
$ sudo shutdown -h 10:00 "Shutting down for scheduled maintenance."
NOTE: On recent Wayland-based Linux distributions, broadcast messages do not appear on terminal emulation sessions running on the desktop; they appear only on the VT console displays.
 Rebooting and Shutting Down
Rebooting and Shutting Down
Locating Applications
Depending on the specifics of your particular distribution's policy, programs and software packages can be installed in various directories. In general, executable programs and scripts should live in the /bin, /usr/bin, /sbin, /usr/sbin directories, or somewhere under /opt. They can also appear in /usr/local/bin and /usr/local/sbin, or in a directory in a user's account space, such as /home/student/bin.
One way to locate programs is to employ the which utility. For example, to find out exactly where the diff program resides on the filesystem:
$ which diff
/usr/bin/diff
If which does not find the program, whereis is a good alternative because it looks for packages in a broader range of system directories:
$ whereis diff
diff: /usr/bin/diff /usr/share/man/man1/diff.1.gz /usr/share/man/man1p/diff.1p.gz
as well as locating source and man files packaged with the program.
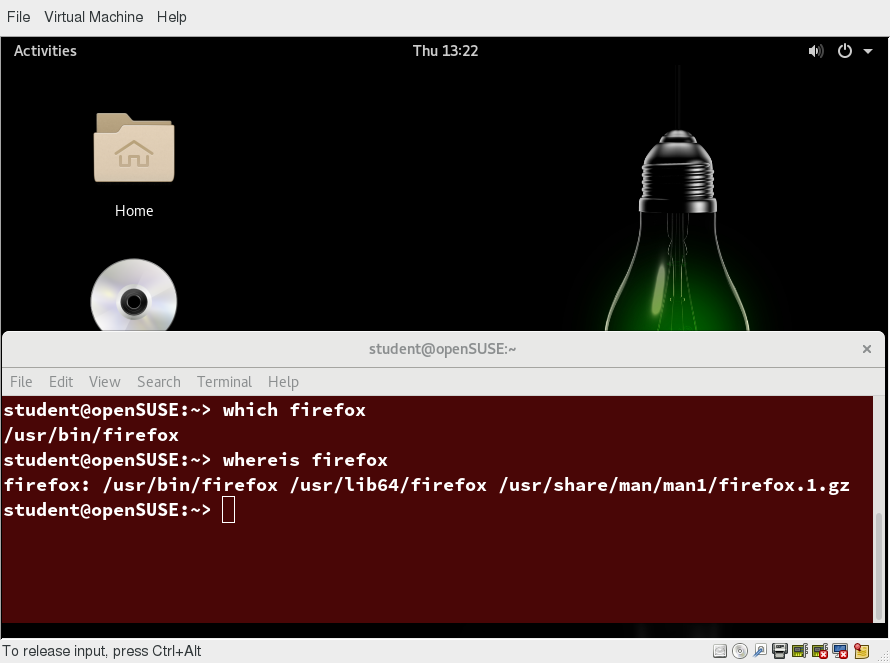
which and whereis Utilities
Accessing Directories
When you first log into a system or open a terminal, the default directory should be your home directory. You can print the exact path of this by typing echo $HOME. Many Linux distributions actually open new graphical terminals in $HOME/Desktop. The following commands are useful for directory navigation:
| Command | Result |
| pwd | Displays the present working directory |
| cd ~ or cd | Change to your home directory (shortcut name is ~ (tilde)) |
| cd .. | Change to parent directory (..) |
| cd - | Change to previous directory (- (minus)) |
Video: Accessing Directories
Sorry, your browser doesn't support embedded videos.Understanding Absolute and Relative Paths
There are two ways to identify paths:
- Absolute pathname
An absolute pathname begins with the root directory and follows the tree, branch by branch, until it reaches the desired directory or file. Absolute paths always start with /. - Relative pathname
A relative pathname starts from the present working directory. Relative paths never start with /.
Multiple slashes (/) between directories and files are allowed, but all but one slash between elements in the pathname is ignored by the system. ////usr//bin is valid, but seen as /usr/bin by the system.
Most of the time, it is most convenient to use relative paths, which require less typing. Usually, you take advantage of the shortcuts provided by: . (present directory), .. (parent directory) and ~ (your home directory).
For example, suppose you are currently working in your home directory and wish to move to the /usr/bin directory. The following two ways will bring you to the same directory from your home directory:
- Absolute pathname method
$ cd /usr/bin - Relative pathname method
$ cd ../../usr/bin
In this case, the absolute pathname method requires less typing.
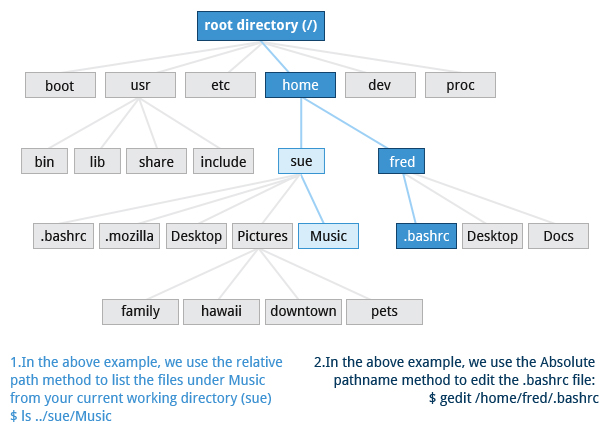 Understanding Absolute and Relative Paths
Understanding Absolute and Relative Paths
Exploring the Filesystem
Traversing up and down the filesystem tree can get tedious. The tree command is a good way to get a bird’s-eye view of the filesystem tree. Use tree -d to view just the directories and to suppress listing file names.
 Exploring the Filesystem
Exploring the Filesystem
The following commands can help in exploring the filesystem:
| Command | Usage |
| cd / | Changes your current directory to the root (/) directory (or path you supply) |
| ls | List the contents of the present working directory |
| ls –a | List all files, including hidden files and directories (those whose name start with . ) |
| tree | Displays a tree view of the filesystem |
Video: Exploring the Filesystem
Sorry, your browser doesn't support embedded videos.Hard Links
The ln utility is used to create hard links and (with the -s option) soft links, also known as symbolic links or symlinks. These two kinds of links are very useful in UNIX-based operating systems.
Suppose that file1 already exists. A hard link, called file2, is created with the command:
$ ln file1 file2
Note that two files now appear to exist. However, a closer inspection of the file listing shows that this is not quite true.
$ ls -li file1 file2
The -i option to ls prints out in the first column the inode number, which is a unique quantity for each file object. This field is the same for both of these files; what is really going on here is that it is only one file, but it has more than one name associated with it, as is indicated by the 2 that appears in the ls output. Thus, there was already another object linked to file1 before the command was executed.
Hard links are very useful and they save space, but you have to be careful with their use, sometimes in subtle ways. For one thing, if you remove either file1 or file2 in the example, the inode object (and the remaining file name) will remain, which might be undesirable, as it may lead to subtle errors later if you recreate a file of that name.
If you edit one of the files, exactly what happens depends on your editor; most editors, including vi and gedit, will retain the link by default, but it is possible that modifying one of the names may break the link and result in the creation of two objects.
Soft (Symbolic) Links
Soft (or Symbolic) links are created with the -s option, as in:
$ ln -s file1 file3
$ ls -li file1 file3
Notice file3 no longer appears to be a regular file, and it clearly points to file1 and has a different inode number.
Symbolic links take no extra space on the filesystem (unless their names are very long). They are extremely convenient, as they can easily be modified to point to different places. An easy way to create a shortcut from your home directory to long pathnames is to create a symbolic link.
Unlike hard links, soft links can point to objects even on different filesystems, partitions, and/or disks and other media, which may or may not be currently available or even exist. In the case where the link does not point to a currently available or existing object, you obtain a dangling link.
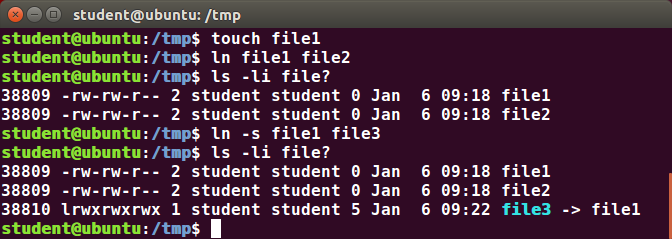 Soft (Symbolic) Links
Soft (Symbolic) Links
Navigating the Directory History
The cd command remembers where you were last, and lets you get back there with cd -. For remembering more than just the last directory visited, use pushd to change the directory instead of cd; this pushes your starting directory onto a list. Using popd will then send you back to those directories, walking in reverse order (the most recent directory will be the first one retrieved with popd). The list of directories is displayed with the dirs command.
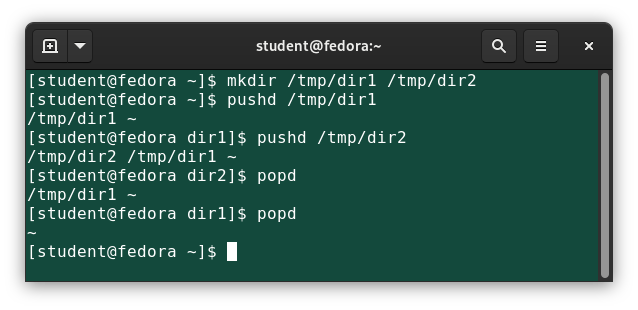 Navigating Through Directory History
Navigating Through Directory History
Video: Navigating the Directory History
Sorry, your browser doesn't support embedded videos.Working with Files
Linux provides many commands that help you with viewing the contents of a file, creating a new file or an empty file, changing the timestamp of a file, and moving, removing and renaming a file or directory. These commands help you in managing your data and files and in ensuring that the correct data is available at the correct location.

In this section, you will learn how to manage files.
Viewing Files
You can use the following command line utilities to view files:
| Command | Usage |
| cat | Used for viewing files that are not very long; it does not provide any scroll-back. |
| tac | Used to look at a file backwards, starting with the last line. |
| less | Used to view larger files because it is a paging program. It pauses at each screen full of text, provides scroll-back capabilities, and lets you search and navigate within the file. NOTE: Use / to search for a pattern in the forward direction and ? for a pattern in the backward direction. An older program named more is still used, but has fewer capabilities: "less is more". |
| tail | Used to print the last 10 lines of a file by default. You can change the number of lines by doing -n 15 or just -15 if you wanted to look at the last 15 lines instead of the default. |
| head | The opposite of tail; by default, it prints the first 10 lines of a file. |
Video: More on Viewing Files
Sorry, your browser doesn't support embedded videos.touch
touch is often used to set or update the access, change, and modify times of files. By default, it resets a file's timestamp to match the current time.
However, you can also create an empty file using touch:
$ touch
This is normally done to create an empty file as a placeholder for a later purpose.
touch provides several useful options. For example, the -t option allows you to set the date and timestamp of the file to a specific value, as in:
$ touch -t 12091600 myfile
This sets the myfile file's timestamp to 4 p.m., December 9th (12 09 1600).
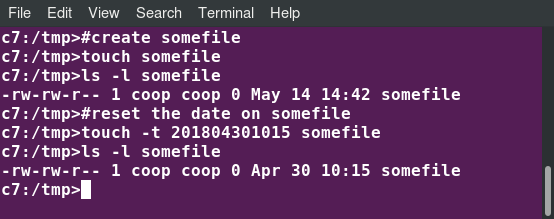 touch
touch
mkdir and rmdir
mkdir is used to create a directory:
- mkdir sampdir
It creates a sample directory named sampdir under the current directory. - mkdir /usr/sampdir
It creates a sample directory called sampdir under /usr.
Removing a directory is done with rmdir. The directory must be empty or the command will fail. To remove a directory and all of its contents you have to do rm -rf.
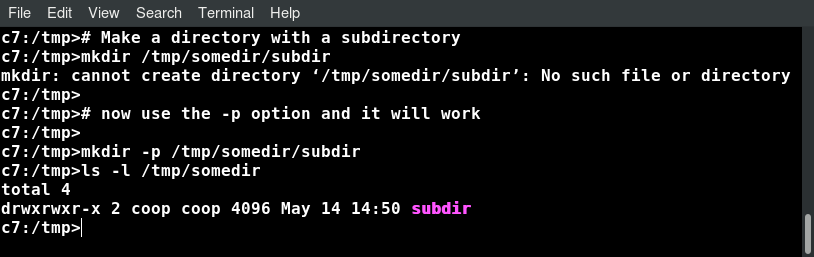 mkdir
mkdir
Moving, Renaming or Removing a File
Note that mv does double duty, in that it can:
- Simply rename a file
- Move a file to another location, while possibly changing its name at the same time.
If you are not certain about removing files that match a pattern you supply, it is always good to run rm interactively (rm –i) to prompt before every removal.
| Command | Usage |
| mv | Rename a file |
| rm | Remove a file |
| rm –f | Forcefully remove a file |
| rm –i | Interactively remove a file |
Renaming or Removing a Directory
rmdir works only on empty directories; otherwise you get an error.
While typing rm –rf is a fast and easy way to remove a whole filesystem tree recursively, it is extremely dangerous and should be used with the utmost care, especially when used by root (recall that recursive means drilling down through all sub-directories, all the way down a tree).
| Command | Usage |
| mv | Rename a directory |
| rmdir | Remove an empty directory |
| rm -rf | Forcefully remove a directory recursively |
Modifying the Command Line Prompt
The PS1 variable is the character string that is displayed as the prompt on the command line. Most distributions set PS1 to a known default value, which is suitable in most cases. However, users may want custom information to show on the command line. For example, some system administrators require the user and the host system name to show up on the command line as in:
student@c8 $
This could prove useful if you are working in multiple roles and want to be always reminded of who you are and what machine you are on. The prompt above could be implemented by setting the PS1 variable to: \u@\h \$.
For example:
$ echo $PS1
\$
$ PS1="\u@\h \$ "
student@c8 $ echo $PS1
\u@\h \$
student@c8 $
By convention, most systems are set up so that the root user has a pound sign (#) as their prompt.

Video: Working With Files and Directories at the Command Prompt
Sorry, your browser doesn't support embedded videos.Standard File Streams
When commands are executed, by default there are three standard file streams (or descriptors) always open for use: standard input (standard in or stdin), standard output (standard out or stdout) and standard error (or stderr).
| Name | Symbolic Name | Value | Example |
| standard input | stdin | 0 | keyboard |
| standard output | stdout | 1 | terminal |
| standard error | stderr | 2 | log file |
Usually, stdin is your keyboard, and stdout and stderr are printed on your terminal. stderr is often redirected to an error logging file, while stdin is supplied by directing input to come from a file or from the output of a previous command through a pipe. stdout is also often redirected into a file. Since stderr is where error messages are written, usually nothing will go there.
In Linux, all open files are represented internally by what are called file descriptors. Simply put, these are represented by numbers starting at zero. stdin is file descriptor 0, stdout is file descriptor 1, and stderr is file descriptor 2. Typically, if other files are opened in addition to these three, which are opened by default, they will start at file descriptor 3 and increase from there.
On the next page and in the chapters ahead, you will see examples which alter where a running command gets its input, where it writes its output, or where it prints diagnostic (error) messages.
I/O Redirection
Through the command shell, we can redirect the three standard file streams so that we can get input from either a file or another command, instead of from our keyboard, and we can write output and errors to files or use them to provide input for subsequent commands.
For example, if we have a program called do_something that reads from stdin and writes to stdout and stderr, we can change its input source by using the less-than sign (<) followed by the name of the file to be consumed for input data:
$ do_something < input-file
If you want to send the output to a file, use the greater-than sign (>) as in:
$ do_something > output-file
Because stderr is not the same as stdout, error messages will still be seen on the terminal windows in the above example.
If you want to redirect stderr to a separate file, you use stderr’s file descriptor number (2), the greater-than sign (>), followed by the name of the file you want to hold everything the running command writes to stderr:
$ do_something 2> error-file
_NOTE: By the same logic, do_something 1> output-file is the same as do_something > output-file._
A special shorthand notation can send anything written to file descriptor 2 (stderr) to the same place as file descriptor 1 (stdout): 2>&1.
$ do_something > all-output-file 2>&1
bash permits an easier syntax for the above:
$ do_something >& all-output-file
Pipes
The UNIX/Linux philosophy is to have many simple and short programs (or commands) cooperate together to produce quite complex results, rather than have one complex program with many possible options and modes of operation. In order to accomplish this, extensive use of pipes is made. You can pipe the output of one command or program into another as its input.
In order to do this, we use the vertical-bar, pipe symbol (|), between commands as in:
$ command1 | command2 | command3
The above represents what we often call a pipeline, and allows Linux to combine the actions of several commands into one. This is extraordinarily efficient because command2 and command3 do not have to wait for the previous pipeline commands to complete before they can begin hacking at the data in their input streams; on multiple CPU or core systems, the available computing power is much better utilized and things get done quicker.
Furthermore, there is no need to save output in (temporary) files between the stages in the pipeline, which saves disk space and reduces reading and writing from disk, which is often the slowest bottleneck in getting something done.
 Pipeline
Pipeline
Searching for Files
Being able to quickly find the files you are looking for will save you time and enhance productivity. You can search for files in both your home directory space, or in any other directory or location on the system.

The main tools for doing this are the locate and find utilities. We will also show how to use wildcards in bash, in order to specify any file which matches a given generalized request.
locate
The locate utility program performs a search taking advantage of a previously constructed database of files and directories on your system, matching all entries that contain a specified character string. This can sometimes result in a very long list.
To get a shorter (and possibly more relevant) list, we can use the grep program as a filter. grep will print only the lines that contain one or more specified strings, as in:
$ locate zip | grep bin
which will list all the files and directories with both zip and bin in their name. We will cover grep in much more detail later. Notice the use of | to pipe the two commands together.
locate utilizes a database created by a related utility, updatedb. Most Linux systems run this automatically once a day. However, you can update it at any time by just running updatedb from the command line as the root user.
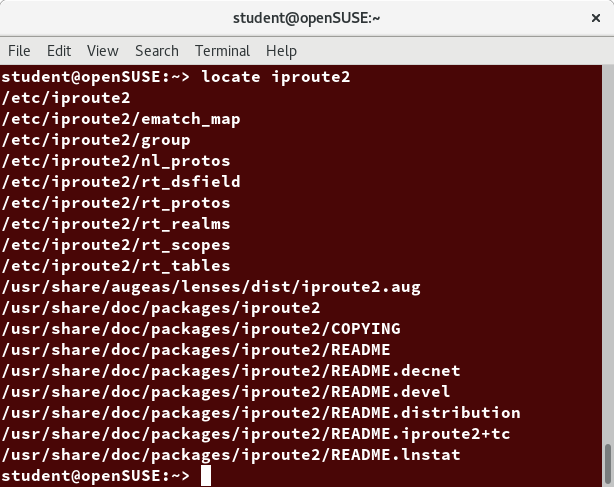 locate
locate
Video: Locating Files
Sorry, your browser doesn't support embedded videos.Wildcards and Matching File Names
You can search for a filename containing specific characters using wildcards.
| Wildcard | Result |
| ? | Matches any single character |
| * | Matches any string of characters |
| [set] | Matches any character in the set of characters, for example [adf] will match any occurrence of a, d, or f |
| [!set] | Matches any character not in the set of characters |
To search for files using the ? wildcard, replace each unknown character with ?. For example, if you know only the first two letters are 'ba' of a three-letter filename with an extension of .out, type ls ba?.out.
To search for files using the * wildcard, replace the unknown string with *. For example, if you remember only that the extension was .out, type ls *.out.
Video: Using Wildcards to Search for Files
Sorry, your browser doesn't support embedded videos.The find Program
find is an extremely useful and often-used utility program in the daily life of a Linux system administrator. It recurses down the filesystem tree from any particular directory (or set of directories) and locates files that match specified conditions. The default pathname is always the present working directory.
For example, administrators sometimes scan for potentially large core files (which contain diagnostic information after a program fails) that are more than several weeks old in order to remove them.
It is also common to remove files in inessential or outdated files in /tmp (and other volatile directories, such as those containing cached files) that have not been accessed recently. Many Linux distributions use shell scripts that run periodically (through cron usually) to perform such house cleaning.
 find
find
Using find
When no arguments are given, find lists all files in the current directory and all of its subdirectories. Commonly used options to shorten the list include -name (only list files with a certain pattern in their name), -iname (also ignore the case of file names), and -type (which will restrict the results to files of a certain specified type, such as d for directory, l for symbolic link, or f for a regular file, etc.).
Searching for files and directories named gcc:
$ find /usr -name gcc
Searching only for directories named gcc:
$ find /usr -type d -name gcc
Searching only for regular files named gcc:
$ find /usr -type f -name gcc
 Using find
Using find
Using Advanced find Options
Another good use of find is being able to run commands on the files that match your search criteria. The -exec option is used for this purpose.
To find and remove all files that end with .swp:
$ find -name "*.swp" -exec rm {} ’;’
The {} (squiggly brackets) is a placeholder that will be filled with all the file names that result from the find expression, and the preceding command will be run on each one individually.
Please note that you have to end the command with either ‘;’ (including the single-quotes) or "\;". Both forms are fine.
One can also use the -ok option, which behaves the same as -exec, except that find will prompt you for permission before executing the command. This makes it a good way to test your results before blindly executing any potentially dangerous commands.
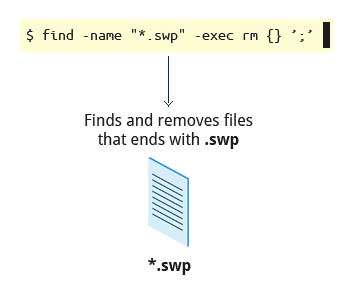 Finding and Removing Files that End with .swp
Finding and Removing Files that End with .swp
Finding Files Based on Time and Size
It is sometimes the case that you wish to find files according to attributes, such as when they were created, last used, etc., or based on their size. It is easy to perform such searches.
To find files based on time:
$ find / -ctime 3
Here, -ctime is when the inode metadata (i.e. file ownership, permissions, etc.) last changed; it is often, but not necessarily, when the file was first created. You can also search for accessed/last read (-atime) or modified/last written (-mtime) times. The number is the number of days and can be expressed as either a number (n) that means exactly that value, +n, which means greater than that number, or -n, which means less than that number. There are similar options for times in minutes (as in -cmin, -amin, and -mmin).
To find files based on sizes:
$ find / -size 0
Note the size here is in 512-byte blocks, by default; you can also specify bytes (c), kilobytes (k), megabytes (M), gigabytes (G), etc. As with the time numbers above, file sizes can also be exact numbers (n), +n or -n. For details, consult the man page for find.
For example, to find files greater than 10 MB in size and running a command on those files:
$ find / -size +10M -exec command {} ’;’
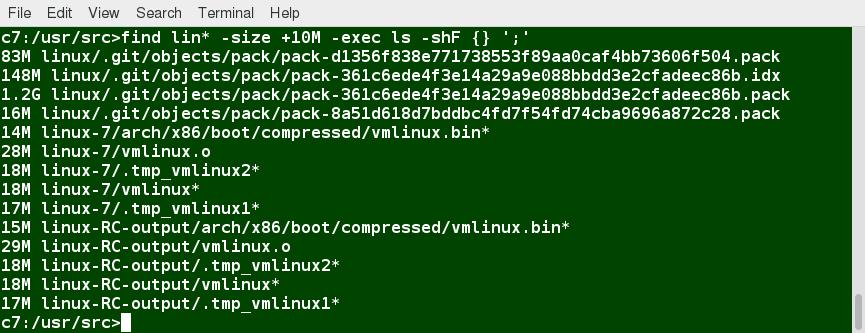 Finding Files Based on Time and Size
Finding Files Based on Time and Size
Video: Finding Files In a Directory
Sorry, your browser doesn't support embedded videos.Package Management Systems on Linux
The core parts of a Linux distribution and most of its add-on software are installed via the Package Management System. Each package contains the files and other instructions needed to make one software component work well and cooperate with the other components that comprise the entire system. Packages can depend on each other. For example, a package for a web-based application written in PHP can depend on the PHP package.

There are two broad families of package managers: those based on Debian and those which use RPM as their low-level package manager. The two systems are incompatible, but broadly speaking, provide the same features and satisfy the same needs. There are some other systems used by more specialized Linux distributions.
In this section, you will learn how to install, remove, or search for packages from the command line using these two package management systems.
Package Managers: Two Levels
Both package management systems operate on two distinct levels: a low-level tool (such as dpkg or rpm) takes care of the details of unpacking individual packages, running scripts, getting the software installed correctly, while a high-level tool (such as apt-get, dnf, yum, or zypper) works with groups of packages, downloads packages from the vendor, and figures out dependencies.
Most of the time users need to work only with the high-level tool, which will take care of calling the low-level tool as needed. Dependency resolution is a particularly important feature of the high-level tool, as it handles the details of finding and installing each dependency for you. Be careful, however, as installing a single package could result in many dozens or even hundreds of dependent packages being installed.
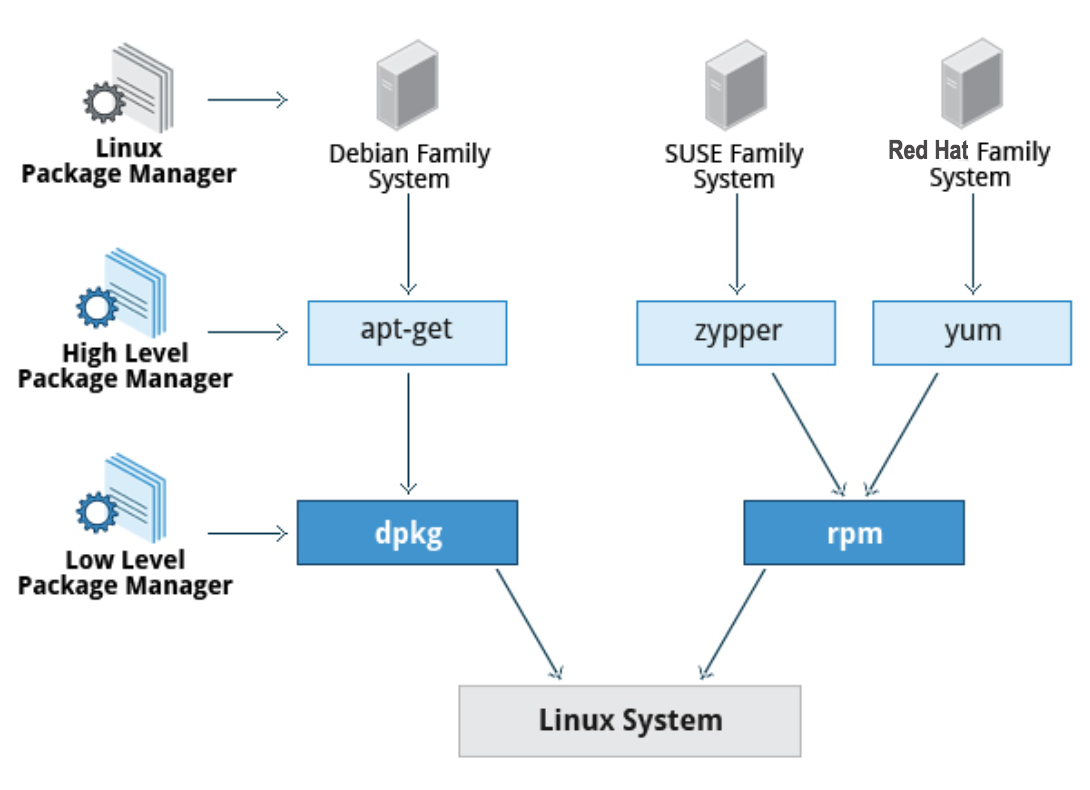 Package Managers: Two Levels
Package Managers: Two Levels
Working With Different Package Management Systems
The Advanced Packaging Tool (apt) is the underlying package management system that manages software on Debian-based systems. While it forms the backend for graphical package managers, such as the Ubuntu Software Center and synaptic, its native user interface is at the command line, with programs that include apt (or apt-get) and apt-cache.
dnf is the open source command-line package-management utility for the RPM-compatible Linux systems that belongs to the Red Hat family. dnf has both command line and graphical user interfaces. Fedora and RHEL 8 replaced the older yum utility with dnf, thereby eliminating a lot of historical baggage, as well as introducing many nice new capabilities. dnf is pretty much backwards-compatible with yum for day-to-day commands.
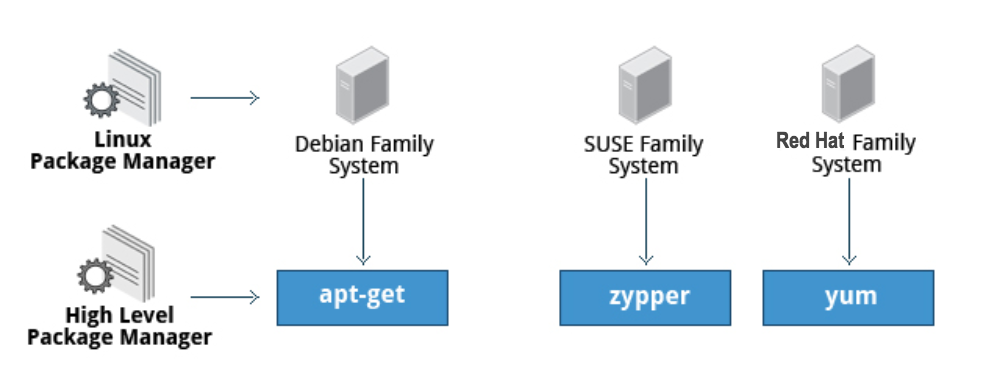
zypper is the package management system for the SUSE/openSUSE family and is also based on RPM. zypper also allows you to manage repositories from the command line. zypper is fairly straightforward to use and resembles dnf/yum quite closely.
To learn the basic packaging commands, take a look at these basic packaging commands:
Operation | rpm | deb |
Install package | rpm -i foo.rpm | dpkg --install foo.deb |
Install package, dependencies | dnf install foo | apt-get install foo |
Remove package | rpm -e foo.rpm | dpkg --remove foo.deb |
Remove package, dependencies | dnf remove foo | apt-get autoremove foo |
Update package | rpm -U foo.rpm | dpkg --install foo.deb |
Update package, dependencies | dnf update foo | apt-get install foo |
Update entire system | dnf update | apt-get dist-upgrade |
Show all installed packages | rpm -qa or dnf list installed | dpkg --list |
Get information on package | rpm -qil foo | dpkg --listfiles foo |
Show packages named foo | dnf list "foo" | apt-cache search foo |
Show all available packages | dnf list | apt-cache dumpavail foo |
What package is file part of? | rpm -qf file | dpkg --search file |
Video: Low-Level Debian Package Management with dpkg
Sorry, your browser doesn't support embedded videos.Video: Low-Level RPM Package Management with rpm
Sorry, your browser doesn't support embedded videos.Video: High-Level Package Management with dnf
Sorry, your browser doesn't support embedded videos.Video: High-Level Package Management with zypper on openSUSE
Sorry, your browser doesn't support embedded videos.Video: High-Level Package Management with apt on Ubuntu
Sorry, your browser doesn't support embedded videos.Chapter Summary
You have completed Chapter 7. Let’s summarize the key concepts we covered:
- Virtual terminals (VT) in Linux are consoles, or command line terminals that use the connected monitor and keyboard.
- Different Linux distributions start and stop the graphical desktop in different ways.
- A terminal emulator program on the graphical desktop works by emulating a terminal within a window on the desktop.
- The Linux system allows you to either log in via text terminal or remotely via the console.
- When typing your password, nothing is printed to the terminal, not even a generic symbol to indicate that you typed.
- The preferred method to shut down or reboot the system is to use the shutdown command.
- There are two types of pathnames: absolute and relative.
- An absolute pathname begins with the root directory and follows the tree, branch by branch, until it reaches the desired directory or file.
- A relative pathname starts from the present working directory.
- Using hard and soft (symbolic) links is extremely useful in Linux.
- cd remembers where you were last, and lets you get back there with cd -.
- locate performs a database search to find all file names that match a given pattern.
- find locates files recursively from a given directory or set of directories.
- find is able to run commands on the files that it lists, when used with the -exec option.
- touch is used to set the access, change, and edit times of files, as well as to create empty files.
- The Advanced Packaging Tool (apt) package management system is used to manage installed software on Debian-based systems.
- You can use the dnf command-line package management utility for the RPM-based Red Hat Family Linux distributions.
- The zypper package management system is based on RPM and used for openSUSE.
Chapter 8: Finding Linux Documentation
Learning Objectives
By the end of this chapter, you should be able to:
- Use different sources of documentation.
- Use the man pages.
- Access the GNU Info System.
- Use the help command and --help option.
- Use other documentation sources.
Linux Documentation Sources
Whether you are an inexperienced user or a veteran, you will not always know (or remember) the proper use of various Linux programs and utilities: what is the command to type, what options does it take, etc. You will need to consult help documentation regularly. Because Linux-based systems draw from a large variety of sources, there are numerous reservoirs of documentation and ways of getting help. Distributors consolidate this material and present it in a comprehensive and easy-to-use manner.
Linux Documentation Sources
Important Linux documentation sources include:
- The man pages (short for manual pages)
- GNU Info
- The help command and --help option
- Other documentation sources, e.g. Gentoo Handbook or Ubuntu Documentation.
The man pages
The man pages are the most often-used source of Linux documentation. They provide in-depth documentation about many programs and utilities, as well as other topics, including configuration files, and programming APIs for system calls, library routines, and the kernel. They are present on all Linux distributions and are always at your fingertips.
The man pages infrastructure was first introduced in the early UNIX versions, at the beginning of the 1970s. The name man is just an abbreviation for manual.

Typing man with a topic name as an argument retrieves the information stored in the topic's man pages.
man pages are often converted to other formats, such as PDF documents and web pages. To learn more, take a look at Linux man pages online. Many web pages have a graphical interface for help items, which may include man pages.
Other sources of documentation include published books and many Internet sites.
man
The man program searches, formats, and displays the information contained in the man page system. Because many topics have copious amounts of relevant information, output is piped through a pager program (such as less) to be viewed one page at a time. At the same time, the information is formatted for a good visual display.
A given topic may have multiple pages associated with it and there is a default order determining which one is displayed when no options or section number is specified. To list all pages on the topic, use the -f option. To list all pages that discuss a specific topic (even if the specified subject is not present in the name), use the –k option.
- man –f generates the same result as typing whatis.
- man –k generates the same result as typing apropos.
The default order is specified in /etc/man_db.conf and is roughly (but not exactly) in ascending numerical order by section.
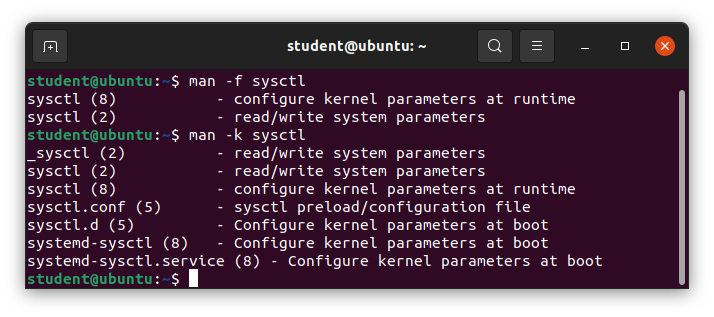 man
man
Manual Chapters
The man pages are divided into chapters numbered 1 through 9. In some cases, a letter is appended to the chapter number to identify a specific topic. For example, many pages describing part of the X Window API are in chapter 3X.
The chapter number can be used to force man to display the page from a particular chapter. It is common to have multiple pages across multiple chapters with the same name, especially for names of library functions or system calls.
With the -a parameter, man will display all pages with the given name in all chapters, one after the other, as in:
$ man -a socket
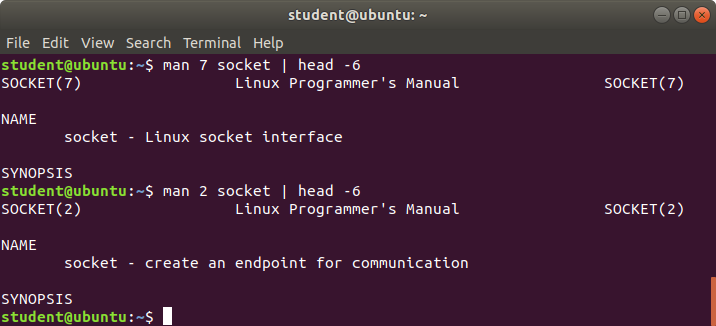 Manual Chapters
Manual Chapters
Video: Using man
Sorry, your browser doesn't support embedded videos.The GNU Info System
The next source of Linux documentation is the GNU Info System.
This is the GNU project's standard documentation format, which it prefers as an alternative to man. The Info System is basically free-form, and supports linked subsections.
![]()
Functionally, info resembles man in many ways. However, topics are connected using links (even though its design predates the World Wide Web). Information can be viewed through either a command line interface, a graphical help utility, printed or viewed online.
Using info from the Command Line
Typing info with no arguments in a terminal window displays an index of available topics. You can browse through the topic list using the regular movement keys: arrows, Page Up, and Page Down.
You can view help for a particular topic by typing info . The system then searches for the topic in all available info files.
Some useful keys are: q to quit, h for help, and Enter to select a menu item.
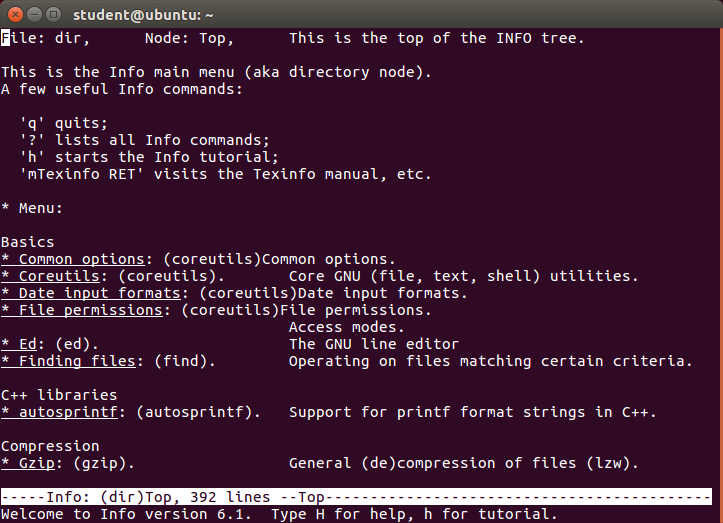 info
info
info Page Structure
The topic which you view in an info page is called a node. The table lists the basic keystrokes for moving between nodes.
Nodes are essentially sections and subsections in the documentation. You can move between nodes or view each node sequentially. Each node may contain menus and linked subtopics, or items.
Items function like browser links and are identified by an asterisk (*) at the beginning of the item name. Named items (outside a menu) are identified with double-colons (::) at the end of the item name. Items can refer to other nodes within the file or to other files.
| Key | Function |
| n | Go to the next node |
| p | Go to the previous node |
| u | Move one node up in the index |
Video: Using info
Sorry, your browser doesn't support embedded videos.The --help Option
Another important source of Linux documentation is use of the --help option.
Most commands have an available short description which can be viewed using the --help or the -h option along with the command or application. For example, to learn more about the man command, you can type:
$ man --help
The --help option is useful as a quick reference and it displays information faster than the man or info pages.
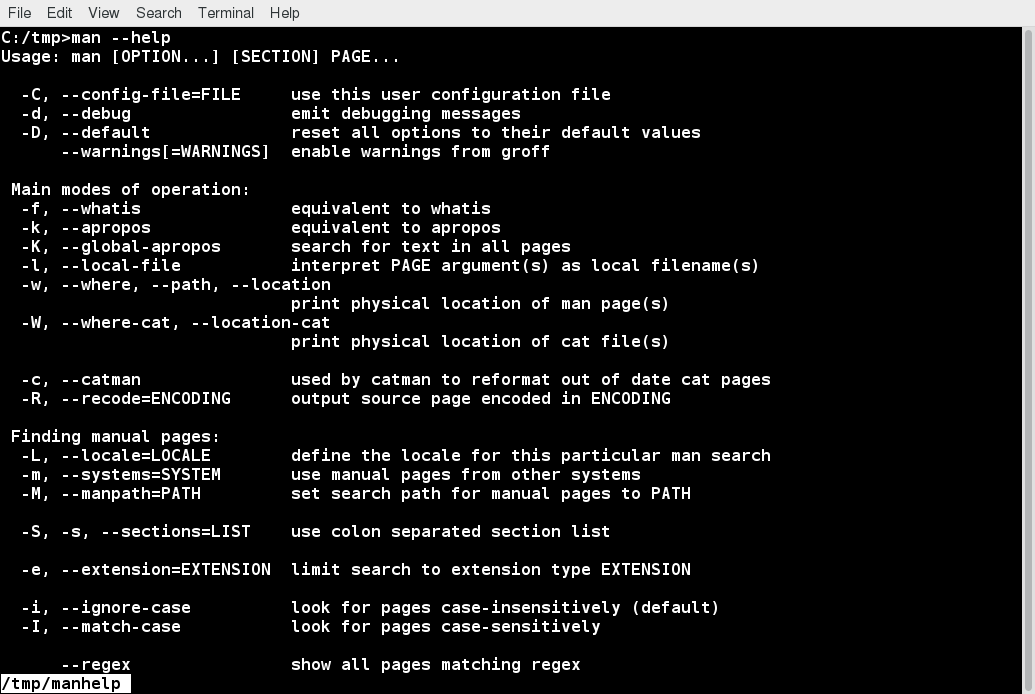 The --help Option
The --help Option
The help Command
When run within a bash command shell, some popular commands (such as echo and cd) actually run especially built-in bash versions of the commands rather than the usual binaries found on the file system, say under /bin or /usr/bin. It is more efficient to do so as execution is faster because fewer resources are used (we will discuss command shells later). One should note that there can be some (usually small) differences in the two versions of the command.
To view a synopsis of these built-in commands, you can simply type help as shown in the screenshot.
For these built-in commands, help performs the same basic function as the -h and --help arguments perform for standalone programs.
 The help Command
The help Command
Other Documentation Sources
In addition to the man pages, the GNU Info System, and the help command, there are other sources of Linux documentation, some examples of which include:
- Desktop help system
- Package documentation
- Online resources.
 Other Documentation Sources
Other Documentation Sources
Graphical Help Systems
All Linux desktop systems have a graphical help application. This application is usually displayed as a question-mark icon or an image of a ship’s life-preserver, and can also always be found within the menu system. These programs usually contain custom help for the desktop itself and some of its applications, and will sometimes also include graphically-rendered info and man pages.
If you do not want to spend time hunting for the right icon or menu item to launch the help application, you can also start the graphical help system from a terminal window or command prompt by using one of the following utility programs:
- GNOME: gnome-help or yelp
- KDE: khelpcenter
 GNOME Help
GNOME Help
 KDE Help
KDE Help
Package Documentation
Linux documentation is also available as part of the package management system. Usually, this documentation is directly pulled from the upstream source code, but it can also contain information about how the distribution packaged and set up the software.
Such information is placed under the /usr/share/doc directory, grouped in subdirectories named after each package, perhaps including the version number in the name.
 Package Documentation
Package Documentation
Online Resources
There are many places to access online Linux documentation, and a little bit of searching will get you buried in it.
The following book has been well-reviewed by other users of this course. It is a free, downloadable command line compendium under a Creative Commons license: "The Linux Command Line" by William Shotts.
You can also find very helpful documentation for each distribution. Each distribution has its own user-generated forums and wiki sections. Here are just a few links to such sources:
- Ubuntu Documentation
- CentoS Documentation
- openSUSE Documentation
- Gentoo Documentation
- Fedora Documentation.
Moreover, you can use online search sites to locate helpful resources from all over the Internet, including blog posts, forum and mailing list posts, news articles, and so on.
Chapter Summary
You have completed Chapter 8. Let’s summarize the key concepts covered:
- The main sources of Linux documentation are the man pages, GNU info, the help options and command, and a rich variety of online documentation sources.
- The man utility searches, formats, and displays man pages.
- The man pages provide in-depth documentation about programs and other topics about the system, including configuration files, system calls, library routines, and the kernel.
- The GNU Info System was created by the GNU project as its standard documentation. It is robust and is accessible via command line, web, and graphical tools using info.
- Short descriptions for commands are usually displayed with the -h or --help argument.
- You can type help at the command line to display a synopsis of built-in commands.
- There are many other help resources both on your system and on the Internet.
Chapter 9: Processes
Learning Objectives
By the end of this chapter, you should be able to:
- Describe what a process is and distinguish between types of processes.
- Enumerate process attributes.
- Manage processes using ps and top.
- Understand the use of load averages and other process metrics.
- Manipulate processes by putting them in background and restoring them to foreground.
- Use at, cron, and sleep to schedule processes in the future or pause them.
What Is a Process?
A process is simply an instance of one or more related tasks (threads) executing on your computer. It is not the same as a program or a command. A single command may actually start several processes simultaneously. Some processes are independent of each other and others are related. A failure of one process may or may not affect the others running on the system.
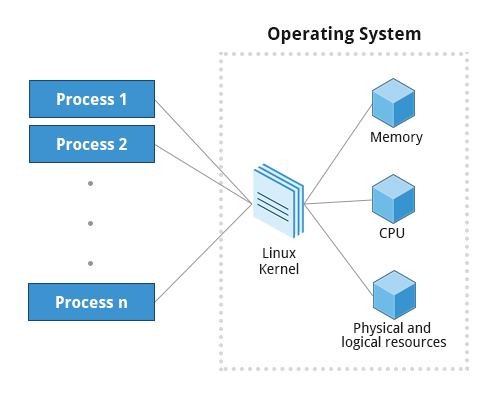 Processes
Processes
Processes use many system resources, such as memory, CPU (central processing unit) cycles, and peripheral devices, such as network cards, hard drives, printers and displays. The operating system (especially the kernel) is responsible for allocating a proper share of these resources to each process and ensuring overall optimized system utilization.
Process Types
A terminal window (one kind of command shell) is a process that runs as long as needed. It allows users to execute programs and access resources in an interactive environment. You can also run programs in the background, which means they become detached from the shell.
Processes can be of different types according to the task being performed. Here are some different process types, along with their descriptions and examples:
| Process Type | Description | Example |
| Interactive Processes | Need to be started by a user, either at a command line or through a graphical interface such as an icon or a menu selection. | bash, firefox, top |
| Batch Processes | Automatic processes which are scheduled from and then disconnected from the terminal. These tasks are queued and work on a FIFO (First-In, First-Out) basis. | updatedb, ldconfig |
| Daemons | Server processes that run continuously. Many are launched during system startup and then wait for a user or system request indicating that their service is required. | httpd, sshd, libvirtd |
| Threads | Lightweight processes. These are tasks that run under the umbrella of a main process, sharing memory and other resources, but are scheduled and run by the system on an individual basis. An individual thread can end without terminating the whole process and a process can create new threads at any time. Many non-trivial programs are multi-threaded. | firefox, gnome-terminal-server |
| Kernel Threads | Kernel tasks that users neither start nor terminate and have little control over. These may perform actions like moving a thread from one CPU to another, or making sure input/output operations to disk are completed. | kthreadd, migration, ksoftirqd |
Process Scheduling and States
A critical kernel function called the scheduler constantly shifts processes on and off the CPU, sharing time according to relative priority, how much time is needed and how much has already been granted to a task.
When a process is in a so-called running state, it means it is either currently executing instructions on a CPU, or is waiting to be granted a share of time (a time slice) so it can execute. All processes in this state reside on what is called a run queue and on a computer with multiple CPUs, or cores, there is a run queue on each.
 Process Scheduling and States
Process Scheduling and States
However, sometimes processes go into what is called a sleep state, generally when they are waiting for something to happen before they can resume, perhaps for the user to type something. In this condition, a process is said to be sitting in a wait queue.
There are some other less frequent process states, especially when a process is terminating. Sometimes, a child process completes, but its parent process has not asked about its state. Amusingly, such a process is said to be in a zombie state; it is not really alive, but still shows up in the system's list of processes.
Process and Thread IDs
At any given time, there are always multiple processes being executed. The operating system keeps track of them by assigning each a unique process ID (PID) number. The PID is used to track process state, CPU usage, memory use, precisely where resources are located in memory, and other characteristics.
New PIDs are usually assigned in ascending order as processes are born. Thus, PID 1 denotes the init process (initialization process), and succeeding processes are gradually assigned higher numbers.
The table explains the PID types and their descriptions:
| ID Type | Description |
| Process ID (PID) | Unique Process ID number |
| Parent Process ID (PPID) | Process (Parent) that started this process. If the parent dies, the PPID will refer to an adoptive parent; on recent kernels, this is kthreadd which has PPID=2. |
| Thread ID (TID) | Thread ID number. This is the same as the PID for single-threaded processes. For a multi-threaded process, each thread shares the same PID, but has a unique TID. |
Terminating a Process
At some point, one of your applications may stop working properly. How do you eliminate it?
To terminate a process, you can type kill -SIGKILL or kill -9 .
Note, however, you can only kill your own processes; those belonging to another user are off limits, unless you are root.
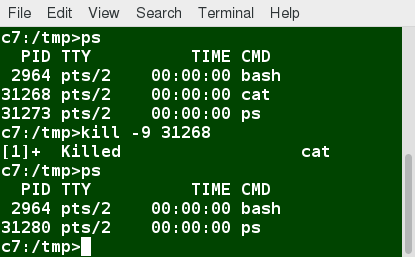 Terminating a Process
Terminating a Process
User and Group IDs
Many users can access a system simultaneously, and each user can run multiple processes. The operating system identifies the user who starts the process by the Real User ID (RUID) assigned to the user.
The user who determines the access rights for the users is identified by the Effective UID (EUID). The EUID may or may not be the same as the RUID.
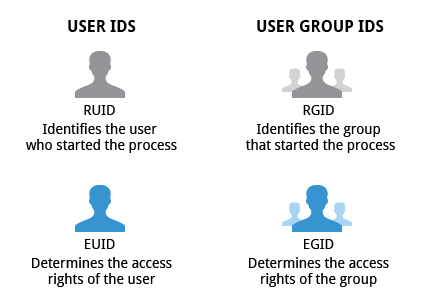 User and Group IDs
User and Group IDs
Users can be categorized into various groups. Each group is identified by the Real Group ID (RGID). The access rights of the group are determined by the Effective Group ID (EGID). Each user can be a member of one or more groups.
Most of the time we ignore these details and just talk about the User ID (UID) and Group ID (GID).
More About Priorities
At any given time, many processes are running (i.e. in the run queue) on the system. However, a CPU can actually accommodate only one task at a time, just like a car can have only one driver at a time. Some processes are more important than others, so Linux allows you to set and manipulate process priority. Higher priority processes get preferential access to the CPU.
The priority for a process can be set by specifying a nice value, or niceness, for the process. The lower the nice value, the higher the priority. Low values are assigned to important processes, while high values are assigned to processes that can wait longer. A process with a high nice value simply allows other processes to be executed first. In Linux, a nice value of -20 represents the highest priority and +19 represents the lowest. While this may sound backwards, this convention (the nicer the process, the lower the priority) goes back to the earliest days of UNIX.
 nice Output
nice Output
You can also assign a so-called real-time priority to time-sensitive tasks, such as controlling machines through a computer or collecting incoming data. This is just a very high priority and is not to be confused with what is called hard real-time which is conceptually different, and has more to do with making sure a job gets completed within a very well-defined time window.
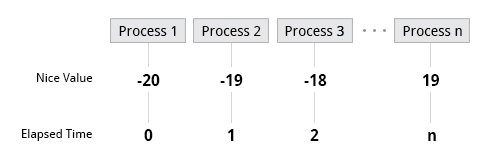 Nice Values
Nice Values
Video: Using renice to Set Priorities
Sorry, your browser doesn't support embedded videos.Load Averages
The load average is the average of the load number for a given period of time. It takes into account processes that are:
- Actively running on a CPU.
- Considered runnable, but waiting for a CPU to become available.
- Sleeping: i.e. waiting for some kind of resource (typically, I/O) to become available.
NOTE: Linux differs from other UNIX-like operating systems in that it includes the sleeping processes. Furthermore, it only includes so-called uninterruptible sleepers, those which cannot be awakened easily.
The load average can be viewed by running w, top or uptime. We will explain the numbers on the next page.
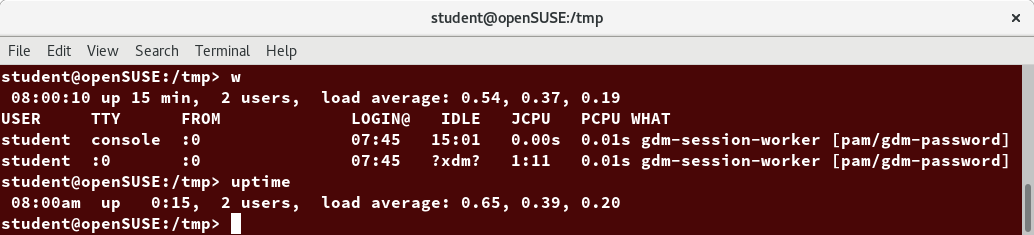 Load Averages
Load Averages
Interpreting Load Averages
The load average is displayed using three numbers (0.45, 0.17, and 0.12) in the below screenshot. Assuming our system is a single-CPU system, the three load average numbers are interpreted as follows:
- 0.45: For the last minute the system has been 45% utilized on average.
- 0.17: For the last 5 minutes utilization has been 17%.
- 0.12: For the last 15 minutes utilization has been 12%.
If we saw a value of 1.00 in the second position, that would imply that the single-CPU system was 100% utilized, on average, over the past 5 minutes; this is good if we want to fully use a system. A value over 1.00 for a single-CPU system implies that the system was over-utilized: there were more processes needing CPU than CPU was available.
If we had more than one CPU, say a quad-CPU system, we would divide the load average numbers by the number of CPUs. In this case, for example, seeing a 1 minute load average of 4.00 implies that the system as a whole was 100% (4.00/4) utilized during the last minute.
Short-term increases are usually not a problem. A high peak you see is likely a burst of activity, not a new level. For example, at start up, many processes start and then activity settles down. If a high peak is seen in the 5 and 15 minute load averages, it may be cause for concern.
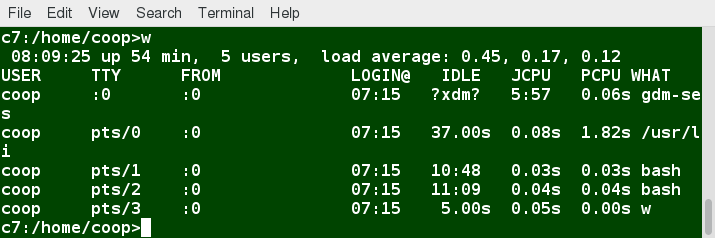 Interpreting Load Averages
Interpreting Load Averages
Background and Foreground Processes
Linux supports background and foreground job processing. A job in this context is just a command launched from a terminal window. Foreground jobs run directly from the shell, and when one foreground job is running, other jobs need to wait for shell access (at least in that terminal window if using the GUI) until it is completed. This is fine when jobs complete quickly. But this can have an adverse effect if the current job is going to take a long time (even several hours) to complete.
In such cases, you can run the job in the background and free the shell for other tasks. The background job will be executed at lower priority, which, in turn, will allow smooth execution of the interactive tasks, and you can type other commands in the terminal window while the background job is running. By default, all jobs are executed in the foreground. You can put a job in the background by suffixing & to the command, for example: updatedb &.
You can either use CTRL-Z to suspend a foreground job or CTRL-C to terminate a foreground job and can always use the bg and fg commands to run a process in the background and foreground, respectively.
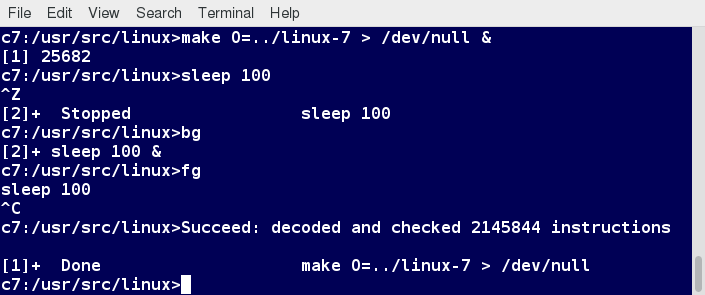 Background and Foreground Processes
Background and Foreground Processes
Managing Jobs
The jobs utility displays all jobs running in background. The display shows the job ID, state, and command name, as shown here.
jobs -l provides the same information as jobs, and adds the PID of the background jobs.
The background jobs are connected to the terminal window, so, if you log off, the jobs utility will not show the ones started from that window.
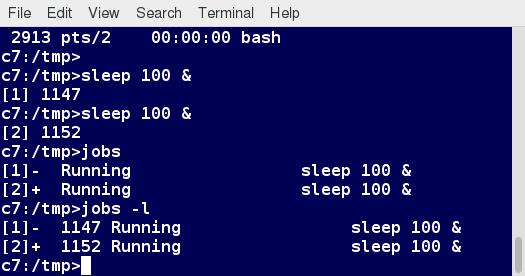 Managing Jobs
Managing Jobs
The ps Command (System V Style)
ps provides information about currently running processes keyed by PID. If you want a repetitive update of this status, you can use top or other commonly installed variants (such as htop or atop) from the command line, or invoke your distribution's graphical system monitor application.
ps has many options for specifying exactly which tasks to examine, what information to display about them, and precisely what output format should be used.
Without options, ps will display all processes running under the current shell. You can use the -u option to display information of processes for a specified username. The command ps -ef displays all the processes in the system in full detail. The command ps -eLf goes one step further and displays one line of information for every thread (remember, a process can contain multiple threads).
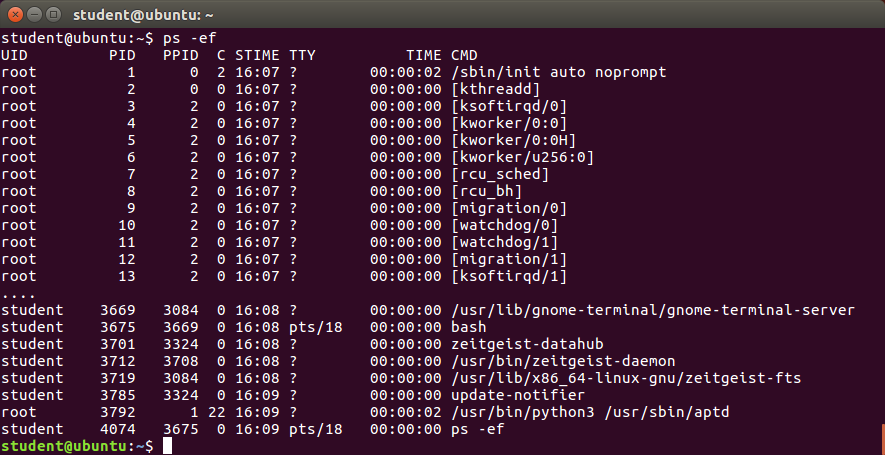 The ps Command (System V Style)
The ps Command (System V Style)
The ps Command (BSD Style)
ps has another style of option specification, which stems from the BSD variety of UNIX, where options are specified without preceding dashes. For example, the command ps aux displays all processes of all users. The command ps axo allows you to specify which attributes you want to view.
The screenshot shows a sample output of ps with the aux and axo qualifiers.
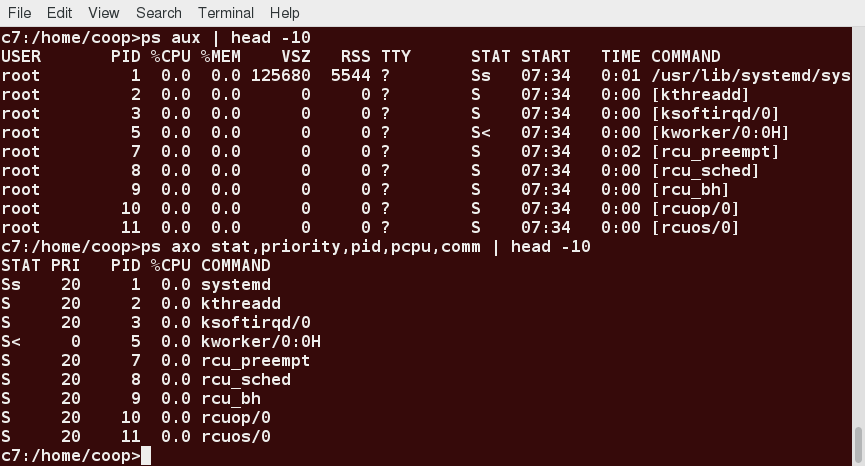 The ps Command (BSD Style)
The ps Command (BSD Style)
Video: Using ps
Sorry, your browser doesn't support embedded videos.The Process Tree
pstree displays the processes running on the system in the form of a tree diagram showing the relationship between a process and its parent process and any other processes that it created. Repeated entries of a process are not displayed, and threads are displayed in curly braces.
 The Process Tree
The Process Tree
top
While a static view of what the system is doing is useful, monitoring the system performance live over time is also valuable. One option would be to run ps at regular intervals, say, every few seconds. A better alternative is to use top to get constant real-time updates (every two seconds by default), until you exit by typing q.top clearly highlights which processes are consuming the most CPU cycles and memory (using appropriate commands from within top).
 top
top
First Line of the top Output
The first line of the top output displays a quick summary of what is happening in the system, including:
- How long the system has been up
- How many users are logged on
- What is the load average
The load average determines how busy the system is. A load average of 1.00 per CPU indicates a fully subscribed, but not overloaded, system. If the load average goes above this value, it indicates that processes are competing for CPU time. If the load average is very high, it might indicate that the system is having a problem, such as a runaway process (a process in a non-responding state).
 First Line of the top Output
First Line of the top Output
Second Line of the top Output
The second line of the top output displays the total number of processes, the number of running, sleeping, stopped, and zombie processes. Comparing the number of running processes with the load average helps determine if the system has reached its capacity or perhaps a particular user is running too many processes. The stopped processes should be examined to see if everything is running correctly.
 Second Line of the top Output
Second Line of the top Output
Third Line of the top Output
The third line of the top output indicates how the CPU time is being divided between the users (us) and the kernel (sy) by displaying the percentage of CPU time used for each.
The percentage of user jobs running at a lower priority (niceness - ni) is then listed. Idle mode (id) should be low if the load average is high, and vice versa. The percentage of jobs waiting (wa) for I/O is listed. Interrupts include the percentage of hardware (hi) vs. software interrupts (si). Steal time (st) is generally used with virtual machines, which has some of its idle CPU time taken for other uses.
 Third Line of the top Output
Third Line of the top Output
Fourth and Fifth Lines of the top Output
The fourth and fifth lines of the top output indicate memory usage, which is divided in two categories:
- Physical memory (RAM) – displayed on line 4.
- Swap space – displayed on line 5.
Both categories display total memory, used memory, and free space.
You need to monitor memory usage very carefully to ensure good system performance. Once the physical memory is exhausted, the system starts using swap space (temporary storage space on the hard drive) as an extended memory pool, and since accessing disk is much slower than accessing memory, this will negatively affect system performance.
If the system starts using swap often, you can add more swap space. However, adding more physical memory should also be considered.
 Fourth and Fifth Lines of the top Output
Fourth and Fifth Lines of the top Output
Process List of the top Output
Each line in the process list of the top output displays information about a process. By default, processes are ordered by highest CPU usage. The following information about each process is displayed:
- Process Identification Number (PID)
- Process owner (USER)
- Priority (PR) and nice values (NI)
- Virtual (VIRT), physical (RES), and shared memory (SHR)
- Status (S)
- Percentage of CPU (%CPU) and memory (%MEM) used
- Execution time (TIME+)
- Command (COMMAND).
Process List of the top Output
Interactive Keys with top
Besides reporting information, top can be utilized interactively for monitoring and controlling processes. While top is running in a terminal window, you can enter single-letter commands to change its behavior. For example, you can view the top-ranked processes based on CPU or memory usage. If needed, you can alter the priorities of running processes or you can stop/kill a process.
The table lists what happens when pressing various keys when running top:
| Command | Output |
| t | Display or hide summary information (rows 2 and 3) |
| m | Display or hide memory information (rows 4 and 5) |
| A | Sort the process list by top resource consumers |
| r | Renice (change the priority of) a specific processes |
| k | Kill a specific process |
| f | Enter the top configuration screen |
| o | Interactively select a new sort order in the process list |
Video: Using top
Sorry, your browser doesn't support embedded videos.Video: Using System Monitoring
Sorry, your browser doesn't support embedded videos.Scheduling Future Processes Using at
Suppose you need to perform a task on a specific day sometime in the future. However, you know you will be away from the machine on that day. How will you perform the task? You can use the at utility program to execute any non-interactive command at a specified time, as illustrated in the screenshot below:
 Scheduling Future Processes Using at
Scheduling Future Processes Using at
cron
cron is a time-based scheduling utility program. It can launch routine background jobs at specific times and/or days on an on-going basis. cron is driven by a configuration file called /etc/crontab (cron table), which contains the various shell commands that need to be run at the properly scheduled times. There are both system-wide crontab files and individual user-based ones. Each line of a crontab file represents a job, and is composed of a so-called CRON expression, followed by a shell command to execute.
Typing crontab -e will open the crontab editor to edit existing jobs or to create new jobs. Each line of the crontab file will contain 6 fields:
| Field | Description | Values |
| MIN | Minutes | 0 to 59 |
| HOUR | Hour field | 0 to 23 |
| DOM | Day of Month | 1-31 |
| MON | Month field | 1-12 |
| DOW | Day Of Week | 0-6 (0 = Sunday) |
| CMD | Command | Any command to be executed |
Examples:
- The entry * /usr/local/bin/execute/this/script.sh will schedule a job to execute script.sh every minute of every hour of every day of the month, and every month and every day in the week.
- The entry 30 08 10 06 * /home/sysadmin/full-backup will schedule a full-backup at 8.30 a.m., 10-June, irrespective of the day of the week.
sleep
Sometimes, a command or job must be delayed or suspended. Suppose, for example, an application has read and processed the contents of a data file and then needs to save a report on a backup system. If the backup system is currently busy or not available, the application can be made to sleep (wait) until it can complete its work. Such a delay might be to mount the backup device and prepare it for writing.
sleep suspends execution for at least the specified period of time, which can be given as the number of seconds (the default), minutes, hours, or days. After that time has passed (or an interrupting signal has been received), execution will resume.
The syntax is:
sleep NUMBER[SUFFIX]...
where SUFFIX may be:
- s for seconds (the default)
- m for minutes
- h for hours
- d for days.
sleep and at are quite different; sleep delays execution for a specific period, while at starts execution at a later time.
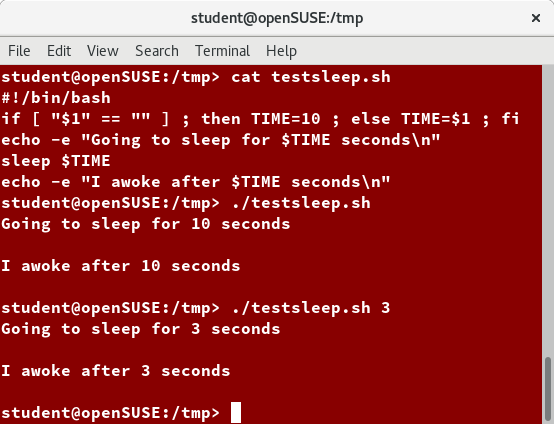 sleep
sleep
Chapter Summary
You have completed Chapter 9. Let’s summarize the key concepts covered:
- Processes are used to perform various tasks on the system.
- Processes can be single-threaded or multi-threaded.
- Processes can be of different types, such as interactive and non-interactive.
- Every process has a unique identifier (PID) to enable the operating system to keep track of it.
- The nice value, or niceness, can be used to set priority.
- ps provides information about the currently running processes.
- You can use top to get constant real-time updates about overall system performance, as well as information about the processes running on the system.
- Load average indicates the amount of utilization the system is under at particular times.
- Linux supports background and foreground processing for a job.
- at executes any non-interactive command at a specified time.
- cron is used to schedule tasks that need to be performed at regular intervals.
Chapter 10: File Operations
Learning Objectives
By the end of this chapter, you should be able to:
- Explore the filesystem and its hierarchy.
- Explain the filesystem architecture.
- Compare files and identify different file types.
- Back up and compress data.
Introduction to Filesystems
In Linux (and all UNIX-like operating systems) it is often said “Everything is a file”, or at least it is treated as such. This means whether you are dealing with normal data files and documents, or with devices such as sound cards and printers, you interact with them through the same kind of Input/Output (I/O) operations. This simplifies things: you open a “file” and perform normal operations like reading the file and writing on it (which is one reason why text editors, which you will learn about in an upcoming section, are so important).
On many systems (including Linux), the filesystem is structured like a tree. The tree is usually portrayed as inverted, and starts at what is most often called the root directory, which marks the beginning of the hierarchical filesystem and is also sometimes referred to as the trunk, or simply denoted by /. The root directory is not the same as the root user. The hierarchical filesystem also contains other elements in the path (directory names), which are separated by forward slashes (/), as in /usr/bin/emacs, where the last element is the actual file name.
In this section, you will learn about some basic concepts, including the filesystem hierarchy, as well as about disk partitions.
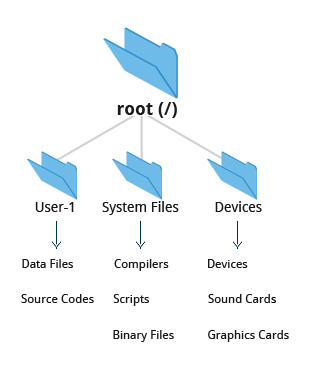 Filesystems
Filesystems
Filesystem Varieties
Linux supports a number of native filesystem types, expressly created by Linux developers, such as:
- ext3
- ext4
- squashfs
- btrfs
It also offers implementations of filesystems used on other alien operating systems, such as those from:
- Windows (ntfs, vfat)
- SGI (xfs)
- IBM (jfs)
- MacOS (hfs, hfs+)
Many older, legacy filesystems, such as FAT, are also supported.
It is often the case that more than one filesystem type is used on a machine, based on considerations such as the size of files, how often they are modified, what kind of hardware they sit on and what kind of access speed is needed, etc. The most advanced filesystem types in common use are the journaling varieties: ext4, xfs, btrfs, and jfs. These have many state-of-the-art features and high performance, and are very hard to corrupt accidentally.
Linux Partitions
Each filesystem on a Linux system occupies a disk partition. Partitions help to organize the contents of disks according to the kind and use of the data contained. For example, important programs required to run the system are often kept on a separate partition (known as root or /) than the one that contains files owned by regular users of that system (/home). In addition, temporary files created and destroyed during the normal operation of Linux may be located on dedicated partitions. One advantage of this kind of isolation by type and variability is that when all available space on a particular partition is exhausted, the system may still operate normally.
The picture shows the use of the gparted utility, which displays the partition layout on a system which has four operating systems on it: RHEL 8, CentOS 7, Ubuntu and Windows.
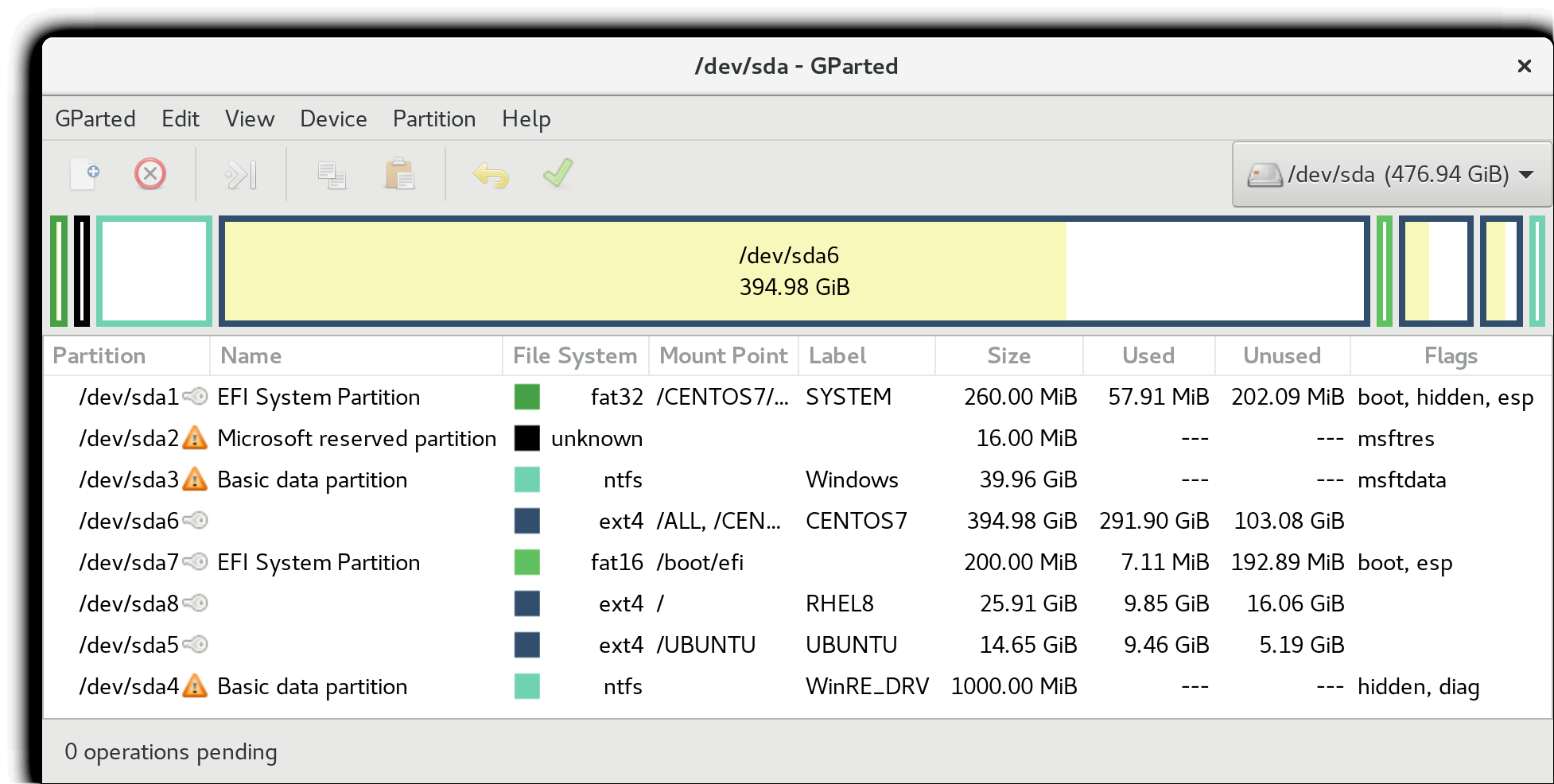 Linux Partitions: gparted
Linux Partitions: gparted
Mount Points
Before you can start using a filesystem, you need to mount it on the filesystem tree at a mount point. This is simply a directory (which may or may not be empty) where the filesystem is to be grafted on. Sometimes, you may need to create the directory if it does not already exist.
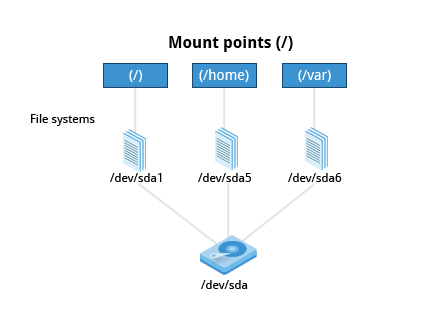 Mount Points
Mount Points
WARNING: If you mount a filesystem on a non-empty directory, the former contents of that directory are covered-up and not accessible until the filesystem is unmounted. Thus, mount points are usually empty directories.
Mounting and Unmounting
The mount command is used to attach a filesystem (which can be local to the computer or on a network) somewhere within the filesystem tree. The basic arguments are the device node and mount point. For example,
$ sudo mount /dev/sda5 /home
will attach the filesystem contained in the disk partition associated with the /dev/sda5 device node into the filesystem tree at the /home mount point. There are other ways to specify the partition other than the device node, such as using the disk label or UUID.
To unmount the partition, the command would be:
$ sudo umount /home
Note the command is umount, not unmount! Only a root user (logged in as root, or using sudo) has the privilege to run these commands, unless the system has been otherwise configured.
If you want it to be automatically available every time the system starts up, you need to edit /etc/fstab accordingly (the name is short for filesystem table). Looking at this file will show you the configuration of all pre-configured filesystems. man fstab will display how this file is used and how to configure it.
Executing mount without any arguments will show all presently mounted filesystems.
The command df -Th (disk-free) will display information about mounted filesystems, including the filesystem type, and usage statistics about currently used and available space.
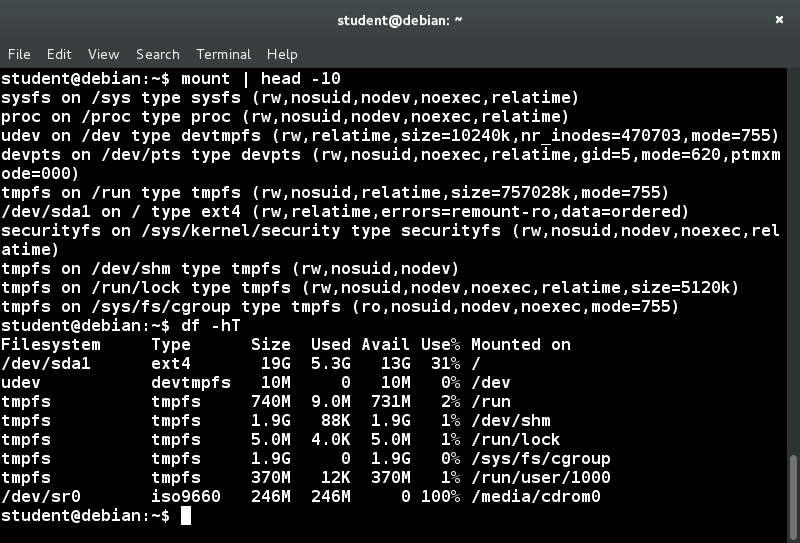 Mounting and Unmounting
Mounting and Unmounting
NFS and Network Filesystems
It is often necessary to share data across physical systems which may be either in the same location or anywhere that can be reached by the Internet. A network (also sometimes called distributed) filesystem may have all its data on one machine or have it spread out on more than one network node. A variety of different filesystems can be used locally on the individual machines; a network filesystem can be thought of as a grouping of lower level filesystems of varying types.
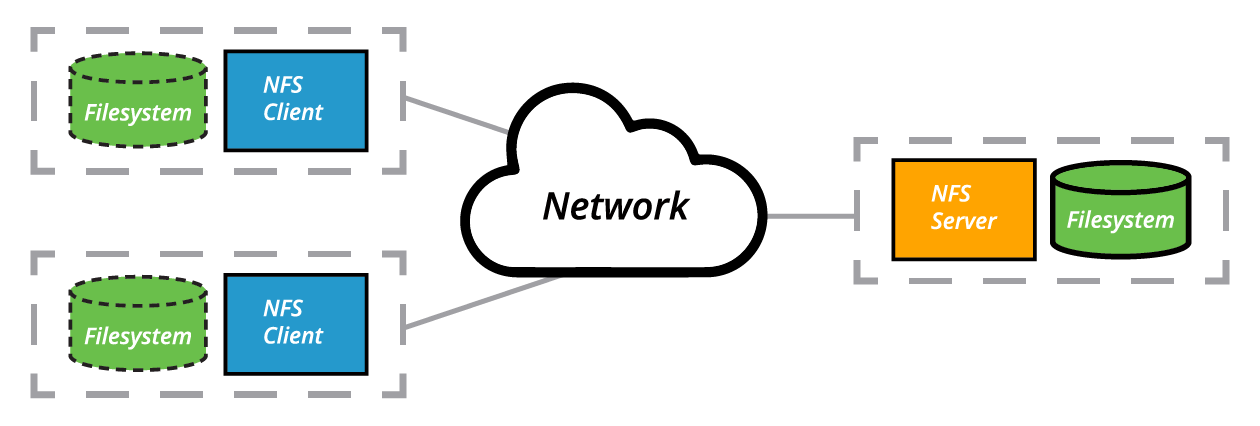 The Client-Server Architecture of NFS(based on the original from www.ibm.com)
The Client-Server Architecture of NFS(based on the original from www.ibm.com)
Many system administrators mount remote users' home directories on a server in order to give them access to the same files and configuration files across multiple client systems. This allows the users to log in to different computers, yet still have access to the same files and resources.
The most common such filesystem is named simply NFS (the Network Filesystem). It has a very long history and was first developed by Sun Microsystems. Another common implementation is CIFS (also termed SAMBA), which has Microsoft roots. We will restrict our attention in what follows to NFS.
NFS on the Server
We will now look in detail at how to use NFS on the server.
On the server machine, NFS uses daemons (built-in networking and service processes in Linux) and other system servers are started at the command line by typing:
$ sudo systemctl start nfs
NOTE: On RHEL/CentOS 8, the service is called nfs-server, not nfs.
The text file /etc/exports contains the directories and permissions that a host is willing to share with other systems over NFS. A very simple entry in this file may look like the following:
/projects *.example.com(rw)
This entry allows the directory /projects to be mounted using NFS with read and write (rw) permissions and shared with other hosts in the example.com domain. As we will detail in the next chapter, every file in Linux has three possible permissions: read (r), write (w) and execute (x).
After modifying the /etc/exports file, you can type exportfs -av to notify Linux about the directories you are allowing to be remotely mounted using NFS. You can also restart NFS with sudo systemctl restart nfs, but this is heavier, as it halts NFS for a short while before starting it up again. To make sure the NFS service starts whenever the system is booted, issue sudo systemctl enable nfs.
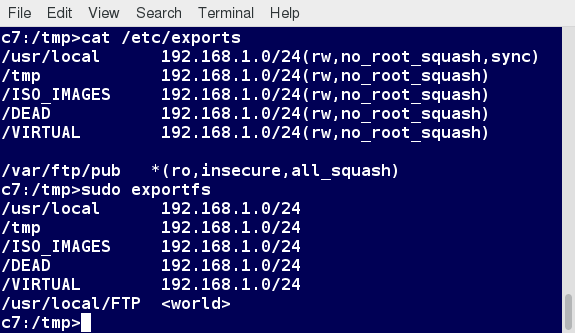 NFS on the Server
NFS on the Server
NFS on the Client
On the client machine, if it is desired to have the remote filesystem mounted automatically upon system boot, /etc/fstab is modified to accomplish this. For example, an entry in the client's /etc/fstab might look like the following:
servername:/projects /mnt/nfs/projects nfs defaults 0 0
You can also mount the remote filesystem without a reboot or as a one-time mount by directly using the mount command:
$ sudo mount servername:/projects /mnt/nfs/projects
Remember, if /etc/fstab is not modified, this remote mount will not be present the next time the system is restarted. Furthermore, you may want to use the nofail option in fstab in case the NFS server is not live at boot.
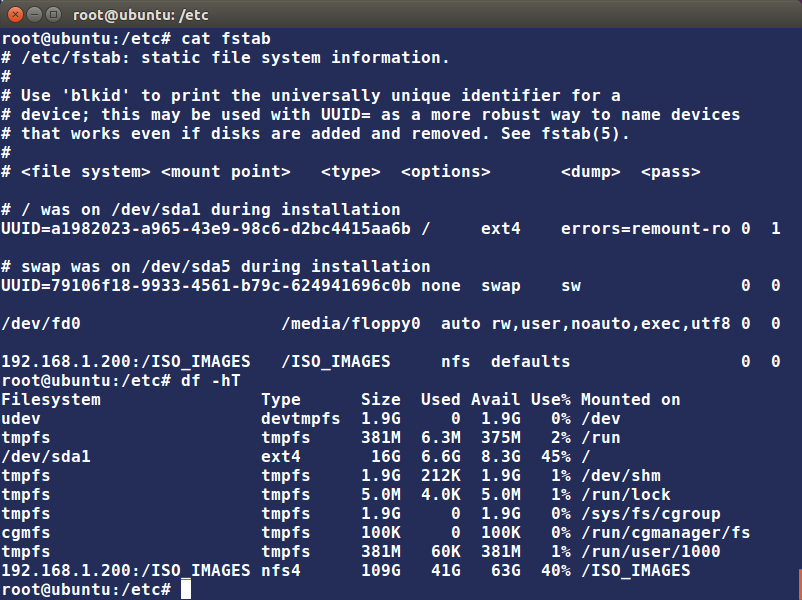 NFS on the Client
NFS on the Client
Overview of User Home Directories
In this section, you will learn to identify and differentiate between the most important directories found in Linux. We start with ordinary users' home directory space.
Each user has a home directory, usually placed under /home. The /root ("slash-root") directory on modern Linux systems is no more than the home directory of the root user (or superuser, or system administrator account).
On multi-user systems, the /home directory infrastructure is often mounted as a separate filesystem on its own partition, or even exported (shared) remotely on a network through NFS.
Sometimes, you may group users based on their department or function. You can then create subdirectories under the /home directory for each of these groups. For example, a school may organize /home with something like the following:
/home/faculty/
/home/staff/
/home/students/
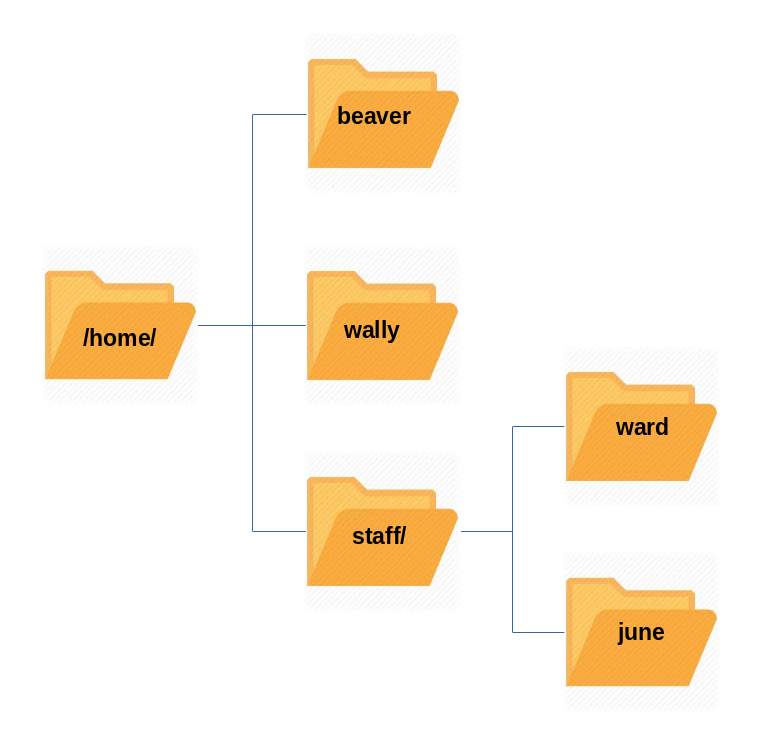 Home Directories
Home Directories
The /bin and /sbin Directories
The /bin directory contains executable binaries, essential commands used to boot the system or in single-user mode, and essential commands required by all system users, such as cat, cp, ls, mv, ps, and rm.
 /bin Directory
/bin Directory
Likewise, the /sbin directory is intended for essential binaries related to system administration, such as fsck and ip. To view a list of these programs, type:
$ ls /bin /sbin
 /sbin Directory
/sbin Directory
Commands that are not essential (theoretically) for the system to boot or operate in single-user mode are placed in the /usr/bin and /usr/sbin directories. Historically, this was done so /usr could be mounted as a separate filesystem that could be mounted at a later stage of system startup or even over a network. However, nowadays most find this distinction is obsolete. In fact, many distributions have been discovered to be unable to boot with this separation, as this modality had not been used or tested for a long time.
Thus, on some of the newest Linux distributions /usr/bin and /bin are actually just symbolically linked together, as are /usr/sbin and /sbin.
The /proc Filesystem
Certain filesystems, like the one mounted at /proc, are called pseudo-filesystems because they have no permanent presence anywhere on the disk.
The /proc filesystem contains virtual files (files that exist only in memory) that permit viewing constantly changing kernel data. /proc contains files and directories that mimic kernel structures and configuration information. It does not contain real files, but runtime system information, e.g. system memory, devices mounted, hardware configuration, etc. Some important entries in /proc are:
/proc/cpuinfo
/proc/interrupts
/proc/meminfo
/proc/mounts
/proc/partitions
/proc/version
/proc has subdirectories as well, including:
/proc/
/proc/sys
The first example shows there is a directory for every process running on the system, which contains vital information about it. The second example shows a virtual directory that contains a lot of information about the entire system, in particular its hardware and configuration. The /proc filesystem is very useful because the information it reports is gathered only as needed and never needs storage on the disk.
 The /proc Filesystem
The /proc Filesystem
The /dev Directory
The /dev directory contains device nodes, a type of pseudo-file used by most hardware and software devices, except for network devices. This directory is:
- Empty on the disk partition when it is not mounted
Contains entries which are created by the udev system, which creates and manages device nodes on Linux, creating them dynamically when devices are found. The /dev directory contains items such as:
/dev/sda1 (first partition on the first hard disk)
- /dev/lp1 (second printer)
- /dev/random (a source of random numbers).
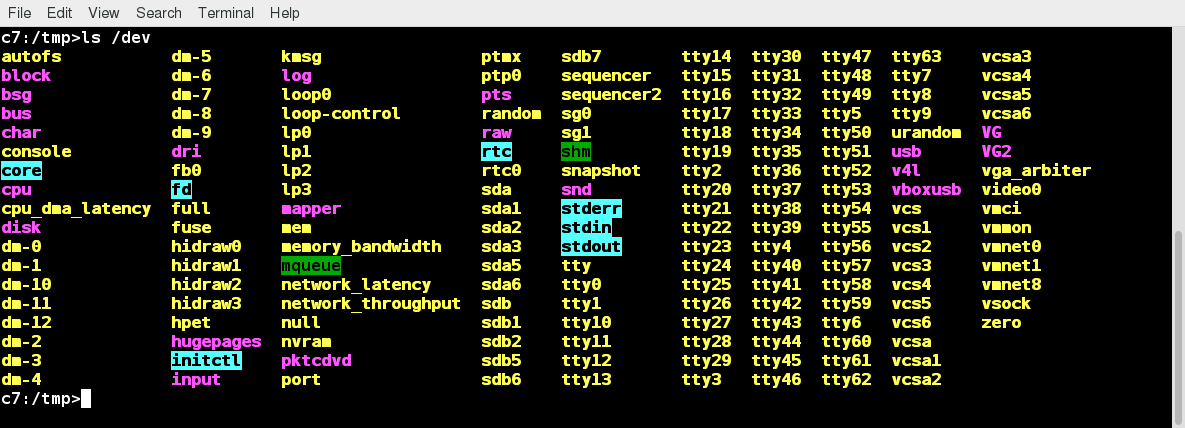 The /dev Directory
The /dev Directory
The /var Directory
The /var directory contains files that are expected to change in size and content as the system is running (var stands for variable), such as the entries in the following directories:
- System log files: /var/log
- Packages and database files: /var/lib
- Print queues: /var/spool
- Temporary files: /var/tmp.
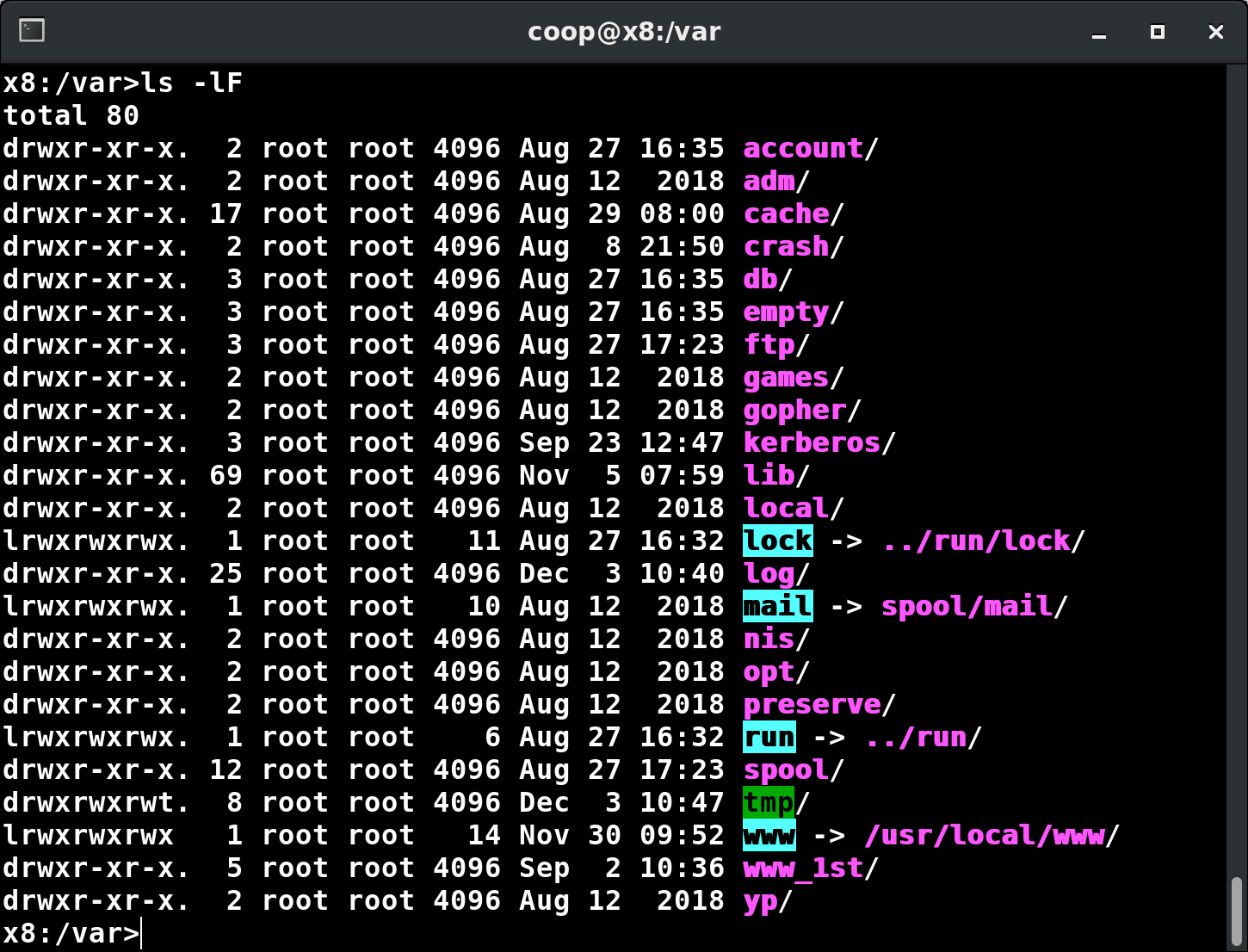 The /var Directory
The /var Directory
The /var directory may be put on its own filesystem so that growth of the files can be accommodated and any exploding file sizes do not fatally affect the system. Network services directories such as /var/ftp (the FTP service) and /var/www (the HTTP web service) are also found under /var.
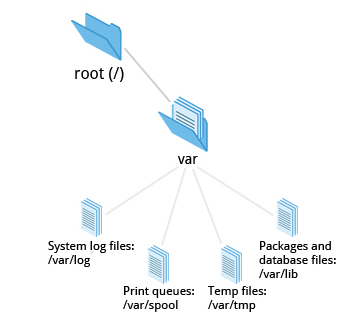 The /var Directory
The /var Directory
The /etc Directory
The /etc directory is the home for system configuration files. It contains no binary programs, although there are some executable scripts. For example, /etc/resolv.conf tells the system where to go on the network to obtain host name to IP address mappings (DNS). Files like passwd, shadow and group for managing user accounts are found in the /etc directory. While some distributions have historically had their own extensive infrastructure under /etc (for example, Red Hat and SUSE have used /etc/sysconfig), with the advent of systemd there is much more uniformity among distributions today.
Note that /etc is for system-wide configuration files and only the superuser can modify files there. User-specific configuration files are always found under their home directory.
 The /etc Directory
The /etc Directory
The /boot Directory
The /boot directory contains the few essential files needed to boot the system. For every alternative kernel installed on the system there are four files:
- vmlinuz
The compressed Linux kernel, required for booting. - initramfs
The initial ram filesystem, required for booting, sometimes called initrd, not initramfs. - config
The kernel configuration file, only used for debugging and bookkeeping. - System.map
Kernel symbol table, only used for debugging.
Each of these files has a kernel version appended to its name.
The Grand Unified Bootloader (GRUB) files such as /boot/grub/grub.conf or /boot/grub2/grub2.cfg are also found under the /boot directory.
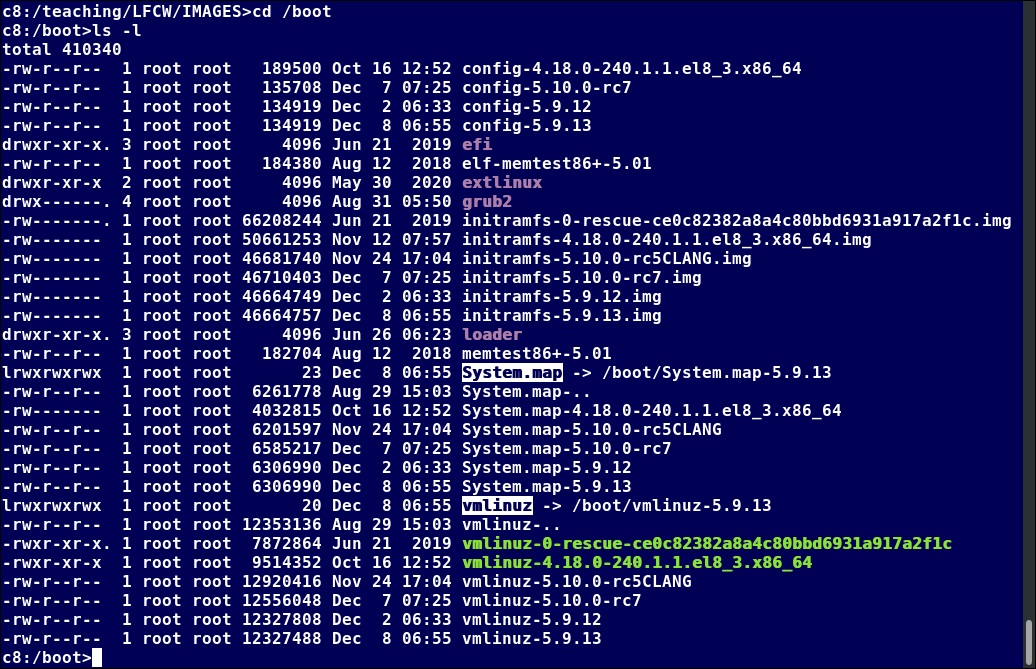 The /boot Directory
The /boot Directory
The screenshot shows an example listing of the /boot directory, taken from a RHEL system that has multiple installed kernels, including both distribution-supplied and custom-compiled ones. Names will vary and things will tend to look somewhat different on a different distribution.
The /lib and /lib64 Directories
/lib contains libraries (common code shared by applications and needed for them to run) for the essential programs in /bin and /sbin. These library filenames either start with ld or lib. For example, /lib/libncurses.so.5.9.
Most of these are what is known as dynamically loaded libraries (also known as shared libraries or Shared Objects (SO)). On some Linux distributions there exists a /lib64 directory containing 64-bit libraries, while /lib contains 32-bit versions.
On recent Linux distributions, one finds:
 The /lib and /lib64 Directories
The /lib and /lib64 Directories
i.e., just like for /bin and /sbin, the directories just point to those under /usr.
Kernel modules (kernel code, often device drivers, that can be loaded and unloaded without re-starting the system) are located in /lib/modules/.
 /lib/modules Contents
/lib/modules Contents
Removable media: the /media, /run and /mnt Directories
One often uses removable media, such as USB drives, CDs and DVDs. To make the material accessible through the regular filesystem, it has to be mounted at a convenient location. Most Linux systems are configured so any removable media are automatically mounted when the system notices something has been plugged in.
While historically this was done under the /media directory, modern Linux distributions place these mount points under the /run directory. For example, a USB pen drive with a label myusbdrive for a user named student would be mounted at /run/media/student/myusbdrive.

The /mnt directory has been used since the early days of UNIX for temporarily mounting filesystems. These can be those on removable media, but more often might be network filesystems, which are not normally mounted. Or these can be temporary partitions, or so-called loopback filesystems, which are files which pretend to be partitions.
 The /run Directory
The /run Directory
Additional Directories Under /
There are some additional directories to be found under the root directory:
| Directory Name | Usage |
| /opt | Optional application software packages |
| /sys | Virtual pseudo-filesystem giving information about the system and the hardware Can be used to alter system parameters and for debugging purposes |
| /srv | Site-specific data served up by the system Seldom used |
| /tmp | Temporary files; on some distributions erased across a reboot and/or may actually be a ramdisk in memory |
| /usr | Multi-user applications, utilities and data |
The /usr Directory Tree
The /usr directory tree contains theoretically non-essential programs and scripts (in the sense that they should not be needed to initially boot the system) and has at least the following sub-directories:
| Directory Name | Usage |
| /usr/include | Header files used to compile applications |
| /usr/lib | Libraries for programs in /usr/bin and /usr/sbin |
| /usr/lib64 | 64-bit libraries for 64-bit programs in /usr/bin and /usr/sbin |
| /usr/sbin | Non-essential system binaries, such as system daemons |
| /usr/share | Shared data used by applications, generally architecture-independent |
| /usr/src | Source code, usually for the Linux kernel |
| /usr/local | Data and programs specific to the local machine; subdirectories include bin, sbin, lib, share, include, etc. |
| /usr/bin | This is the primary directory of executable commands on the system |
Comparing Files with diff
Now that you know about the filesystem and its structure, let’s learn how to manage files and directories.
diff is used to compare files and directories. This often-used utility program has many useful options (see: man diff) including:
| diff Option | Usage |
| -c | Provides a listing of differences that include three lines of context before and after the lines differing in content |
| -r | Used to recursively compare subdirectories, as well as the current directory |
| -i | Ignore the case of letters |
| -w | Ignore differences in spaces and tabs (white space) |
| -q | Be quiet: only report if files are different without listing the differences |
To compare two files, at the command prompt, type diff [options] . diff is meant to be used for text files; for binary files, one can use cmp.
In this section, you will learn additional methods for comparing files and how to apply patches to files.
Using diff3 and patch
You can compare three files at once using diff3, which uses one file as the reference basis for the other two. For example, suppose you and a co-worker both have made modifications to the same file working at the same time independently. diff3 can show the differences based on the common file you both started with. The syntax for diff3 is as follows:
$ diff3 MY-FILE COMMON-FILE YOUR-FILE
The graphic shows the use of diff3.
 Using diff3
Using diff3
Many modifications to source code and configuration files are distributed utilizing patches, which are applied, not surprisingly, with the patch program. A patch file contains the deltas (changes) required to update an older version of a file to the new one. The patch files are actually produced by running diff with the correct options, as in:
$ diff -Nur originalfile newfile > patchfile
Distributing just the patch is more concise and efficient than distributing the entire file. For example, if only one line needs to change in a file that contains 1000 lines, the patch file will be just a few lines long.
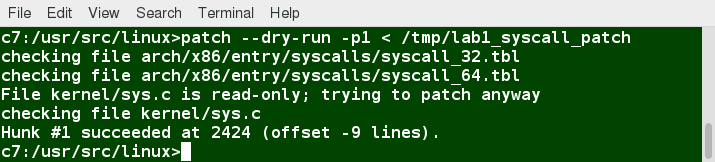 Using patch
Using patch
To apply a patch, you can just do either of the two methods below:
$ patch -p1 < patchfile
$ patch originalfile patchfile
The first usage is more common, as it is often used to apply changes to an entire directory tree, rather than just one file, as in the second example. To understand the use of the -p1 option and many others, see the man page for patch.
Using the file Utility
In Linux, a file's extension often does not categorize it the way it might in other operating systems. One cannot assume that a file named file.txt is a text file and not an executable program. In Linux, a filename is generally more meaningful to the user of the system than the system itself. In fact, most applications directly examine a file's contents to see what kind of object it is rather than relying on an extension. This is very different from the way Windows handles filenames, where a filename ending with .exe, for example, represents an executable binary file.
The real nature of a file can be ascertained by using the file utility. For the file names given as arguments, it examines the contents and certain characteristics to determine whether the files are plain text, shared libraries, executable programs, scripts, or something else.
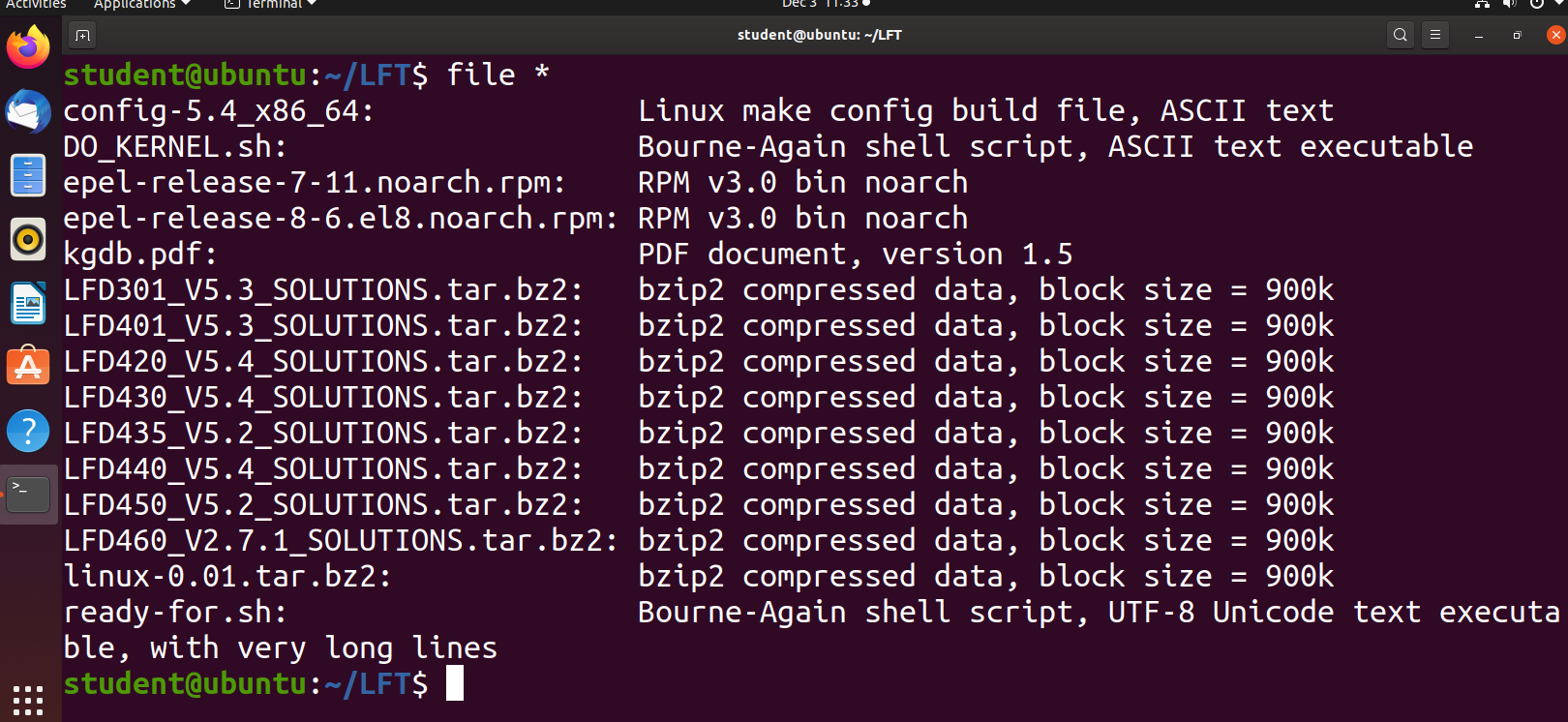 Using the file Utility
Using the file Utility
Backing Up Data
There are many ways you can back up data or even your entire system. Basic ways to do so include the use of simple copying with cp and use of the more robust rsync.
Both can be used to synchronize entire directory trees. However, rsync is more efficient, because it checks if the file being copied already exists. If the file exists and there is no change in size or modification time, rsync will avoid an unnecessary copy and save time. Furthermore, because rsync copies only the parts of files that have actually changed, it can be very fast.
cp can only copy files to and from destinations on the local machine (unless you are copying to or from a filesystem mounted using NFS), but rsync can also be used to copy files from one machine to another. Locations are designated in the target:path form, where target can be in the form of someone@host. The someone@ part is optional and used if the remote user is different from the local user.
rsync is very efficient when recursively copying one directory tree to another, because only the differences are transmitted over the network. One often synchronizes the destination directory tree with the origin, using the -r option to recursively walk down the directory tree copying all files and directories below the one listed as the source.
Using rsync
rsync is a very powerful utility. For example, a very useful way to back up a project directory might be to use the following command:
$ rsync -r project-X archive-machine:archives/project-X
Note that rsync can be very destructive! Accidental misuse can do a lot of harm to data and programs, by inadvertently copying changes to where they are not wanted. Take care to specify the correct options and paths. It is highly recommended that you first test your rsync command using the -dry-run option to ensure that it provides the results that you want.

To use rsync at the command prompt, type rsync sourcefile destinationfile, where either file can be on the local machine or on a networked machine; The contents of sourcefile will be copied to destinationfile.
A good combination of options is shown in:
$ rsync --progress -avrxH --delete sourcedir destdir
File data is often compressed to save disk space and reduce the time it takes to transmit files over networks.
Linux uses a number of methods to perform this compression, including:
| Command | Usage |
| gzip | The most frequently used Linux compression utility |
| bzip2 | Produces files significantly smaller than those produced by gzip |
| xz | The most space-efficient compression utility used in Linux |
| zip | Is often required to examine and decompress archives from other operating systems |
These techniques vary in the efficiency of the compression (how much space is saved) and in how long they take to compress; generally, the more efficient techniques take longer. Decompression time does not vary as much across different methods.
In addition, the tar utility is often used to group files in an archive and then compress the whole archive at once.
Compressing Data Using gzip
gzip is the most often used Linux compression utility. It compresses very well and is very fast. The following table provides some usage examples:
| Command | Usage |
| gzip * | Compresses all files in the current directory; each file is compressed and renamed with a .gz extension. |
| gzip -r projectX | Compresses all files in the projectX directory, along with all files in all of the directories under projectX. |
| gunzip foo | De-compresses foo found in the file foo.gz. Under the hood, the gunzip command is actually the same as gzip –d. |
Compressing Data Using xz
xz is the most space efficient compression utility used in Linux and is used to store archives of the Linux kernel. Once again, it trades a slower compression speed for an even higher compression ratio.
Some usage examples:
| Command | Usage |
| xz | Compresses all of the files in the current directory and replaces each file with one with a .xz extension. |
| xz foo | Compresses foo into foo.xz using the default compression level (-6), and removes foo if compression succeeds. |
| xz -dk bar.xz | Decompresses bar.xz into bar and does not remove bar.xz even if decompression is successful. |
| xz -dcf a.txt b.txt.xz > abcd.txt | Decompresses a mix of compressed and uncompressed files to standard output, using a single command. |
| xz -d .xz | Decompresses the files compressed using xz. |
Compressed files are stored with a .xz extension.
Handling Files Using zip
The zip program is not often used to compress files in Linux, but is often required to examine and decompress archives from other operating systems. It is only used in Linux when you get a zipped file from a Windows user. It is a legacy program.
| Command | Usage |
| zip backup * | Compresses all files in the current directory and places them in the backup.zip. |
| zip -r backup.zip ~ | Archives your login directory (~) and all files and directories under it in backup.zip. |
| unzip backup.zip | Extracts all files in backup.zip and places them in the current directory. |
Archiving and Compressing Data Using tar
Historically, tar stood for "tape archive" and was used to archive files to a magnetic tape. It allows you to create or extract files from an archive file, often called a tarball. At the same time, you can optionally compress while creating the archive, and decompress while extracting its contents.
Here are some examples of the use of tar:
| Command | Usage |
| tar xvf mydir.tar | Extract all the files in mydir.tar into the mydir directory. |
| tar zcvf mydir.tar.gz mydir | Create the archive and compress with gzip. |
| tar jcvf mydir.tar.bz2 mydir | Create the archive and compress with bz2. |
| tar Jcvf mydir.tar.xz mydir | Create the archive and compress with xz. |
| tar xvf mydir.tar.gz | Extract all the files in mydir.tar.gz into the mydir directory. NOTE: You do not have to tell tar it is in gzip format. |
You can separate out the archiving and compression stages, as in:
$ tar cvf mydir.tar mydir ; gzip mydir.tar
$ gunzip mydir.tar.gz ; tar xvf mydir.tar
but this is slower and wastes space by creating an unneeded intermediary .tar file.
Relative Compression Times and Sizes
To demonstrate the relative efficiency of gzip, bzip2, and xz, the following screenshot shows the results of compressing a purely text file directory tree (the include directory from the kernel source) using the three methods.
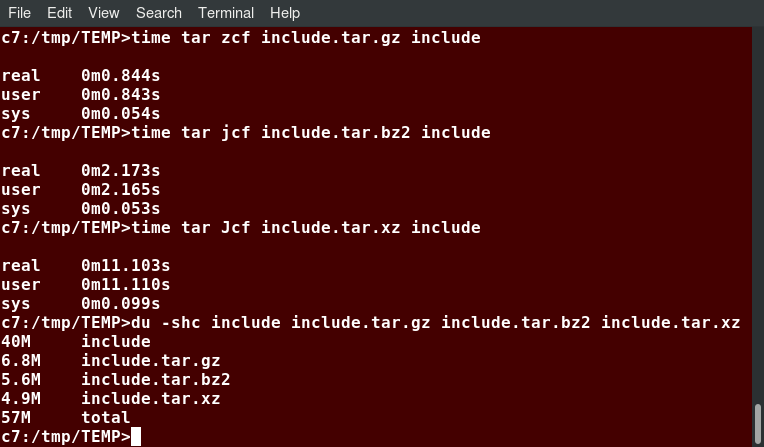 Relative Compression Times and Sizes
Relative Compression Times and Sizes
This shows that as compression factors go up, CPU time does as well (i.e. producing smaller archives takes longer).
Disk-to-Disk Copying (dd)
The dd program is very useful for making copies of raw disk space. For example, to back up your Master Boot Record (MBR) (the first 512-byte sector on the disk that contains a table describing the partitions on that disk), you might type:
dd if=/dev/sda of=sda.mbr bs=512 count=1
WARNING!
Typing:
dd if=/dev/sda of=/dev/sdb
to make a copy of one disk onto another, will delete everything that previously existed on the second disk.
An exact copy of the first disk device is created on the second disk device.
Do not experiment with this command as written above, as it can erase a hard disk!
Exactly what the name dd stands for is an often-argued item. The words data definition is the most popular theory and has roots in early IBM history. Often, people joke that it means disk destroyer and other variants such as delete data!
 Disk-to-Disk Copying (dd)
Disk-to-Disk Copying (dd)
Chapter Summary
You have completed Chapter 10. Let’s summarize the key concepts covered:
- The filesystem tree starts at what is often called the root directory (or trunk, or /).
- The Filesystem Hierarchy Standard (FHS) provides Linux developers and system administrators a standard directory structure for the filesystem.
- Partitions help to segregate files according to usage, ownership, and type.
- Filesystems can be mounted anywhere on the main filesystem tree at a mount point. Automatic filesystem mounting can be set up by editing /etc/fstab.
- NFS (Network File System) is a useful method for sharing files and data through the network systems.
- Filesystems like /proc are called pseudo filesystems because they exist only in memory.
- /root (slash-root) is the home directory for the root user.
- /var may be put in its own filesystem so that growth can be contained and not fatally affect the system.
- /boot contains the basic files needed to boot the system.
- patch is a very useful tool in Linux. Many modifications to source code and configuration files are distributed with patch files, as they contain the deltas or changes to go from an old version of a file to the new version of a file.
- File extensions in Linux do not necessarily mean that a file is of a certain type.
- cp is used to copy files on the local machine, while rsync can also be used to copy files from one machine to another, as well as synchronize contents.
- gzip, bzip2, xz and zip are used to compress files.
- tar allows you to create or extract files from an archive file, often called a tarball. You can optionally compress while creating the archive, and decompress while extracting its contents.
- dd can be used to make large exact copies, even of entire disk partitions, efficiently.
Chapter 11: Text Editors
Learning Objectives
By the end of this chapter, you should be familiar with:
- How to create and edit files using the available Linux text editors.
- nano, a simple text-based editor.
- gedit, a simple graphical editor.
- vi and emacs, two advanced editors with both text-based and graphical interfaces.
Overview of Text Editors in Linux
At some point, you will need to manually edit text files. You might be composing an email off-line, writing a script to be used for bash or other command interpreters, altering a system or application configuration file, or developing source code for a programming language such as C, Python or Java.
Linux administrators may sidestep using a text editor, instead employing graphical utilities for creating and modifying system configuration files. However, this can be more laborious than directly using a text editor, and be more limited in capability. Note that word processing applications (including those that are part of common office application suites) are not really basic text editors; they add a lot of extra (usually invisible) formatting information that will probably render system administration configuration files unusable for their intended purpose. So, knowing how to confidently use one or more text editors is really an essential skill to have for Linux.
By now, you have certainly realized Linux is packed with choices; when it comes to text editors, there are many choices, ranging from quite simple to very complex, including:
- nano
- gedit
- vi
- emacs
In this section, we learn first about the nano and gedit editors, which are relatively simple and easy to learn, and then later the more complicated choices, vi and emacs. Before we start, let us take a look at some cases where an editor is not needed.
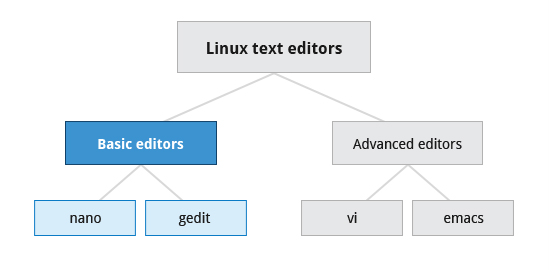 Text Editors in Linux
Text Editors in Linux
Creating Files Without Using an Editor
Sometimes, you may want to create a short file and don't want to bother invoking a full text editor. In addition, doing so can be quite useful when used from within scripts, even when creating longer files. You will no doubt find yourself using this method when you start on the later chapters that cover shell scripting!
If you want to create a file without using an editor, there are two standard ways to create one from the command line and fill it with content.
The first is to use echo repeatedly:
$ echo line one > myfile
$ echo line two >> myfile
$ echo line three >> myfile
Note that while a single greater-than sign (>) will send the output of a command to a file, two of them (>>) will append the new output to an existing file.
The second way is to use cat combined with redirection:
$ cat << EOF > myfile
> line one
> line two
> line three
> EOF
$
Both techniques produce a file with the following lines in it:
line one
line two
line three
and are extremely useful when employed by scripts.
 Creating Files Without Using an Editor
Creating Files Without Using an Editor
nano and gedit
There are some text editors that are pretty obvious; they require no particular experience to learn and are actually quite capable, even robust. A particularly easy to use one is the text terminal-based editor nano. Just invoke nano by giving a file name as an argument. All the help you need is displayed at the bottom of the screen, and you should be able to proceed without any problem.
As a graphical editor, gedit is part of the GNOME desktop system (kwrite is associated with KDE). The gedit and kwrite editors are very easy to use and are extremely capable. They are also very configurable. They look a lot like Notepad in Windows. Other variants such as kate are also supported by KDE.
nano
nano is easy to use, and requires very little effort to learn. To open a file, type nano and press Enter. If the file does not exist, it will be created.
nano provides a two line shortcut bar at the bottom of the screen that lists the available commands. Some of these commands are:
- CTRL-G
Display the help screen. - CTRL-O
Write to a file. - CTRL-X
Exit a file. - CTRL-R
Insert contents from another file to the current buffer. - CTRL-C
Show cursor position.
 nano
nano
gedit
gedit (pronounced 'g-edit') is a simple-to-use graphical editor that can only be run within a Graphical Desktop environment. It is visually quite similar to the Notepad text editor in Windows, but is actually far more capable and very configurable and has a wealth of plugins available to extend its capabilities further.
To open a new file find the program in your desktop's menu system, or from the command line type gedit . If the file does not exist, it will be created.
Using gedit is pretty straightforward and does not require much training. Its interface is composed of quite familiar elements.
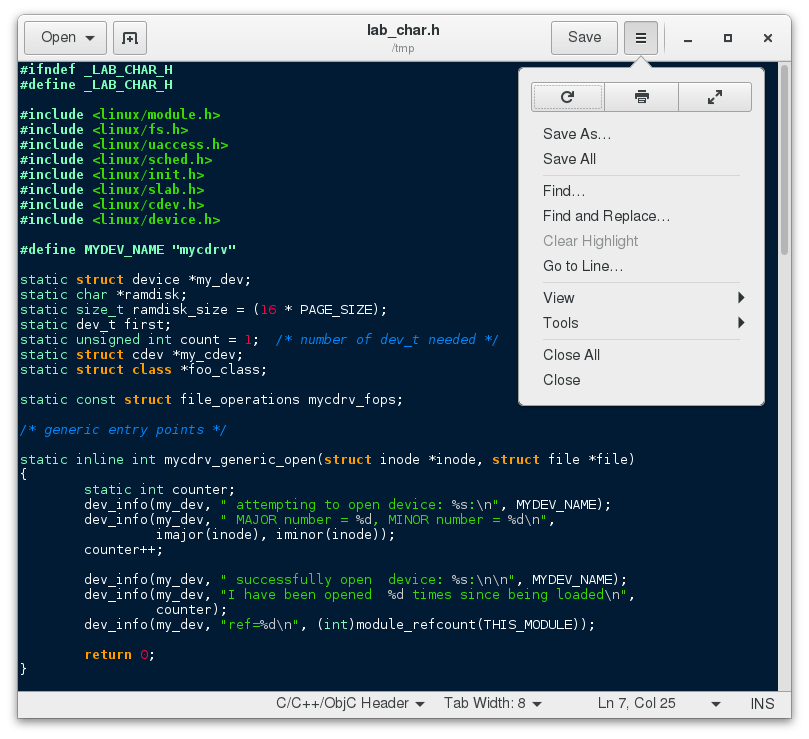
vi and emacs
Developers and administrators experienced in working on UNIX-like systems almost always use one of the two venerable editing options: vi and emacs. Both are present or easily available on all distributions and are completely compatible with the versions available on other operating systems.
Both vi and emacs have a basic purely text-based form that can run in a non-graphical environment. They also have one or more graphical interface forms with extended capabilities; these may be friendlier for a less experienced user. While vi and emacs can have significantly steep learning curves for new users, they are extremely efficient when one has learned how to use them.
You need to be aware that fights among seasoned users over which editor is better can be quite intense and are often described as a holy war.
 Linux Text Editors
Linux Text Editors
Introduction to vi
Usually, the actual program installed on your system is vim, which stands for Vi IMproved, and is aliased to the name vi. The name is pronounced as “vee-eye”.
Even if you do not want to use vi, it is good to gain some familiarity with it: it is a standard tool installed on virtually all Linux distributions. Indeed, there may be times where there is no other editor available on the system.
GNOME extends vi with a very graphical interface known as gvim and KDE offers kvim. Either of these may be easier to use at first.
When using vi, all commands are entered through the keyboard. You do not need to keep moving your hands to use a pointer device such as a mouse or touchpad, unless you want to do so when using one of the graphical versions of the editor.
vimtutor
Typing vimtutor launches a short but very comprehensive tutorial for those who want to learn their first vi commands. Even though it provides only an introduction and just seven lessons, it has enough material to make you a very proficient vi user, because it covers a large number of commands. After learning these basic ones, you can look up new tricks to incorporate into your list of vi commands because there are always more optimal ways to do things in vi with less typing.
Modes in vi
| Mode | Feature |
| Command |
|
| Insert |
|
| Line |
|
vi provides three modes, as described in the table below. It is vital to not lose track of which mode you are in. Many keystrokes and commands behave quite differently in different modes.
Working with Files in vi
The table describes the most important commands used to start, exit, read, and write files in vi. The ENTER key needs to be pressed after all of these commands.
| Command | Usage |
| vi myfile | Start the editor and edit myfile |
| vi -r myfile | Start and edit myfile in recovery mode from a system crash |
| :r file2 | Read in file2 and insert at current position |
| :w | Write to the file |
| :w myfile | Write out to myfile |
| :w! file2 | Overwrite file2 |
| :x or :wq | Exit and write out modified file |
| :q | Quit |
| :q! | Quit even though modifications have not been saved |
Changing Cursor Positions in vi
The table describes the most important keystrokes used when changing cursor position in vi. Line mode commands (those following colon : ) require the ENTER key to be pressed after the command is typed.
| Key | Usage |
| arrow keys | To move up, down, left and right |
| j or <ret> | To move one line down |
| k | To move one line up |
| h or Backspace | To move one character left |
| l or Space | To move one character right |
| 0 | To move to beginning of line |
| $ | To move to end of line |
| w | To move to beginning of next word |
| :0 or 1G | To move to beginning of file |
| :n or nG | To move to line n |
| :$ or G | To move to last line in file |
| CTRL-F or Page Down | To move forward one page |
| CTRL-B or Page Up | To move backward one page |
| ^l | To refresh and center screen |
Video: Using Modes and Cursor Movements in vi
Sorry, your browser doesn't support embedded videos.Searching for Text in vi
The table describes the most important commands used when searching for text in vi. The ENTER key should be pressed after typing the search pattern.
| Command | Usage |
| /pattern | Search forward for pattern |
| ?pattern | Search backward for pattern |
The table describes the most important keystrokes used when searching for text in vi.
| Key | Usage |
| n | Move to next occurrence of search pattern |
| N | Move to previous occurrence of search pattern |
Working with Text in vi
The table describes the most important keystrokes used when changing, adding, and deleting text in vi.
| Key | Usage |
| a | Append text after cursor; stop upon Escape key |
| A | Append text at end of current line; stop upon Escape key |
| i | Insert text before cursor; stop upon Escape key |
| I | Insert text at beginning of current line; stop upon Escape key |
| o | Start a new line below current line, insert text there; stop upon Escape key |
| O | Start a new line above current line, insert text there; stop upon Escape key |
| r | Replace character at current position |
| R | Replace text starting with current position; stop upon Escape key |
| x | Delete character at current position |
| Nx | Delete N characters, starting at current position |
| dw | Delete the word at the current position |
| D | Delete the rest of the current line |
| dd | Delete the current line |
| Ndd or dNd | Delete N lines |
| u | Undo the previous operation |
| yy | Yank (copy) the current line and put it in buffer |
| Nyy or yNy | Yank (copy) N lines and put it in buffer |
| p | Paste at the current position the yanked line or lines from the buffer |
Here is a consolidated PDF with commands for vi.
Using External Commands in vi
Typing sh command opens an external command shell. When you exit the shell, you will resume your editing session.
Typing ! executes a command from within vi. The command follows the exclamation point. This technique is best suited for non-interactive commands, such as : ! wc %. Typing this will run the wc (word count) command on the file; the character % represents the file currently being edited.
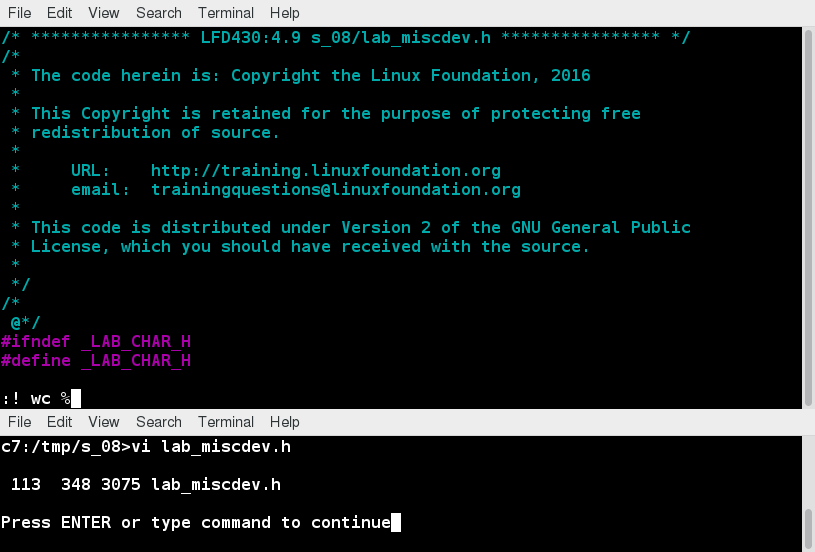
Video: Using External Commands, Saving, and Closing in the vi Editor
Sorry, your browser doesn't support embedded videos.Introduction to emacs
The emacs editor is a popular competitor for vi. Unlike vi, it does not work with modes. emacs is highly customizable and includes a large number of features. It was initially designed for use on a console, but was soon adapted to work with a GUI as well. emacs has many other capabilities other than simple text editing. For example, it can be used for email, debugging, etc.
Rather than having different modes for command and insert, like vi, emacs uses the CTRL and Meta (Alt or Esc) keys for special commands.
Working with emacs
The table lists some of the most important key combinations that are used when starting, exiting, reading, and writing files in emacs.
| Key | Usage |
| emacs myfile | Start emacs and edit myfile |
| CTRL-x i | Insert prompted for file at current position |
| CTRL-x s | Save all files |
| CTRL-x CTRL-w | Write to the file giving a new name when prompted |
| CTRL-x CTRL-s | Saves the current file |
| CTRL-x CTRL-c | Exit after being prompted to save any modified files |
The emacs tutorial is a good place to start learning basic commands. It is available any time when in emacs by simply typing CTRL-h (for help) and then the letter t for tutorial.
Changing Cursor Positions in emacs
The table lists some of the keys and key combinations that are used for changing cursor positions in emacs.
| Key | Usage |
| arrow keys | Use the arrow keys for up, down, left and right |
| CTRL-n | One line down |
| CTRL-p | One line up |
| CTRL-f | One character forward/right |
| CTRL-b | One character back/left |
| CTRL-a | Move to beginning of line |
| CTRL-e | Move to end of line |
| Meta-f | Move to beginning of next word |
| Meta-b | Move back to beginning of preceding word |
| Meta-< | Move to beginning of file |
| Meta-g-g-n | Move to line n (can also use 'Esc-x Goto-line n') |
| Meta-> | Move to end of file |
| CTRL-v or Page Down | Move forward one page |
| Meta-v or Page Up | Move backward one page |
| CTRL-l | Refresh and center screen |
Searching for Text in emacs
The table lists the key combinations that are used for searching for text in emacs.
| Key | Usage |
| CTRL-s | Search forward for prompted pattern, or for next pattern |
| CTRL-r | Search backwards for prompted pattern, or for next pattern |
Working with Text in emacs
The table lists some of the key combinations used for changing, adding, and deleting text in emacs:
| Key | Usage |
| CTRL-o | Insert a blank line |
| CTRL-d | Delete character at current position |
| CTRL-k | Delete the rest of the current line |
| CTRL-_ | Undo the previous operation |
| CTRL- (space or CTRL-@) | Mark the beginning of the selected region. The end will be at the cursor position |
| CTRL-w | Delete the current marked text and write it to the buffer |
| CTRL-y | Insert at current cursor location whatever was most recently deleted |
Here is a consolidated PDF file with commands for emacs.
Video: emacs Operations
Sorry, your browser doesn't support embedded videos.Chapter Summary
You have completed Chapter 11. Let’s summarize the key concepts covered:
- Text editors (rather than word processing programs) are used quite often in Linux, for tasks such as creating or modifying system configuration files, writing scripts, developing source code, etc.
- nano is an easy-to-use text-based editor that utilizes on-screen prompts.
- gedit is a graphical editor, very similar to Notepad in Windows.
- The vi editor is available on all Linux systems and is very widely used. Graphical extension versions of vi are widely available as well.
- emacs is available on all Linux systems as a popular alternative to vi. emacs can support both a graphical user interface and a text mode interface.
- To access the vi tutorial, type vimtutor at a command line window.
- To access the emacs tutorial type Ctl-h and then t from within emacs.
- vi has three modes: Command, Insert, and Line. emacs has only one, but requires use of special keys, such as Control and Escape.
- Both editors use various combinations of keystrokes to accomplish tasks. The learning curve to master these can be long, but once mastered using either editor is extremely efficient.
Chapter 12: User Environment
Learning Objectives
By the end of this chapter, you should be able to:
- Use and configure user accounts and user groups.
- Use and set environment variables.
- Use the previous shell command history.
- Use keyboard shortcuts.
- Use and define aliases.
- Use and set file permissions and ownership.
Identifying the Current User
As you know, Linux is a multi-user operating system, meaning more than one user can log on at the same time.
- To identify the current user, type whoami.
- To list the currently logged-on users, type who.
Giving who the -a option will give more detailed information.
 Identifying the Current User
Identifying the Current User
User Startup Files
In Linux, the command shell program (generally bash) uses one or more startup files to configure the user environment. Files in the /etc directory define global settings for all users, while initialization files in the user's home directory can include and/or override the global settings.
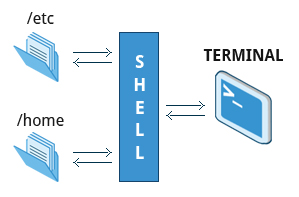 User Startup Files
User Startup Files
The startup files can do anything the user would like to do in every command shell, such as:
- Customizing the prompt
- Defining command line shortcuts and aliases
- Setting the default text editor
- Setting the path for where to find executable programs
Order of the Startup Files
The standard prescription is that when you first login to Linux, /etc/profile is read and evaluated, after which the following files are searched (if they exist) in the listed order:
- ~/.bash_profile
- ~/.bash_login
- ~/.profile
where ~/. denotes the user's home directory. The Linux login shell evaluates whatever startup file that it comes across first and ignores the rest. This means that if it finds ~/.bash_profile, it ignores ~/.bash_login and ~/.profile. Different distributions may use different startup files.
However, every time you create a new shell, or terminal window, etc., you do not perform a full system login; only a file named ~/.bashrc file is read and evaluated. Although this file is not read and evaluated along with the login shell, most distributions and/or users include the ~/.bashrc file from within one of the three user-owned startup files.
Most commonly, users only fiddle with ~/.bashrc, as it is invoked every time a new command line shell initiates, or another program is launched from a terminal window, while the other files are read and executed only when the user first logs onto the system.
Recent distributions sometimes do not even have .bash_profile and/or .bash_login, and some just do little more than include .bashrc.
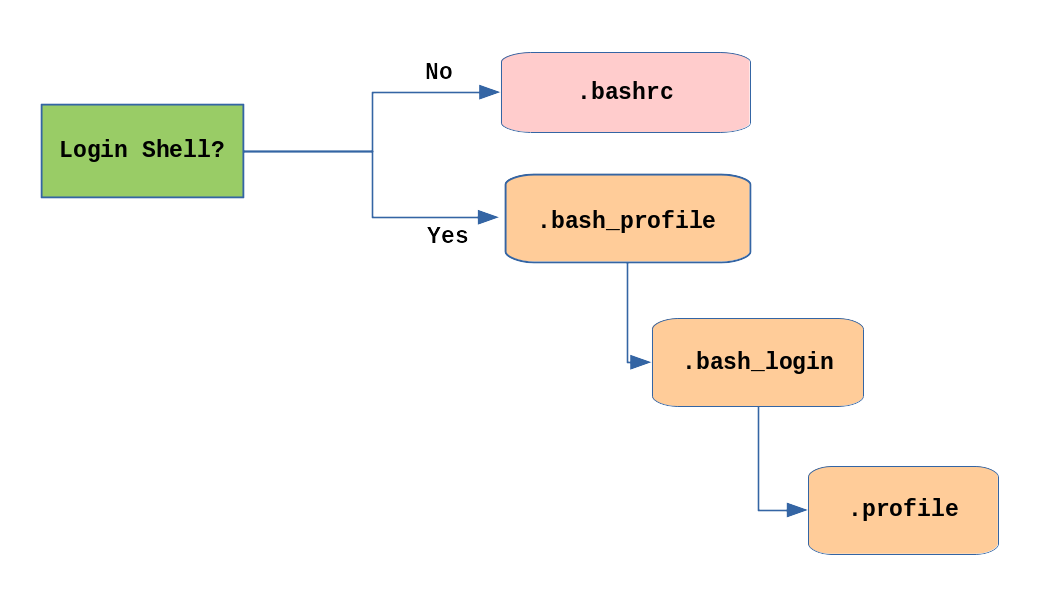 Order of the Startup Files
Order of the Startup Files
Creating Aliases
You can create customized commands or modify the behavior of already existing ones by creating aliases. Most often, these aliases are placed in your ~/.bashrc file so they are available to any command shells you create. unalias removes an alias.
Typing alias with no arguments will list currently defined aliases.
Please note there should not be any spaces on either side of the equal sign and the alias definition needs to be placed within either single or double quotes if it contains any spaces.
 Creating Aliases
Creating Aliases
Basics of Users and Groups
All Linux users are assigned a unique user ID (uid), which is just an integer; normal users start with a uid of 1000 or greater.
Linux uses groups for organizing users. Groups are collections of accounts with certain shared permissions. Control of group membership is administered through the /etc/group file, which shows a list of groups and their members. By default, every user belongs to a default or primary group. When a user logs in, the group membership is set for their primary group and all the members enjoy the same level of access and privilege. Permissions on various files and directories can be modified at the group level.
Users also have one or more group IDs (gid), including a default one which is the same as the user ID. These numbers are associated with names through the files /etc/passwd and /etc/group. Groups are used to establish a set of users who have common interests for the purposes of access rights, privileges, and security considerations. Access rights to files (and devices) are granted on the basis of the user and the group they belong to.
For example, /etc/passwd might contain george:x:1002:1002:George Metesky:/home/george:/bin/bash and /etc/group might contain george:x:1002.
 Basics of Users and Groups
Basics of Users and Groups
Adding and Removing Users
Distributions have straightforward graphical interfaces for creating and removing users and groups and manipulating group membership. However, it is often useful to do it from the command line or from within shell scripts. Only the root user can add and remove users and groups.
Adding a new user is done with useradd and removing an existing user is done with userdel. In the simplest form, an account for the new user bjmoose would be done with:
$ sudo useradd bjmoose
which, by default, sets the home directory to /home/bjmoose, populates it with some basic files (copied from /etc/skel) and adds a line to /etc/passwd such as:
bjmoose:x:1002:1002::/home/bjmoose:/bin/bash
and sets the default shell to /bin/bash. Removing a user account is as easy as typing userdel bjmoose. However, this will leave the /home/bjmoose directory intact. This might be useful if it is a temporary inactivation. To remove the home directory while removing the account one needs to use the -r option to userdel.
Typing id with no argument gives information about the current user, as in:
$ id
uid=1002(bjmoose) gid=1002(bjmoose) groups=106(fuse),1002(bjmoose)
If given the name of another user as an argument, id will report information about that other user.
Video: Using User Accounts
Sorry, your browser doesn't support embedded videos.Adding and Removing Groups
Adding a new group is done with groupadd:
$ sudo /usr/sbin/groupadd anewgroup
The group can be removed with:
$ sudo /usr/sbin/groupdel anewgroup
Adding a user to an already existing group is done with usermod. For example, you would first look at what groups the user already belongs to:
$ groups rjsquirrel
rjsquirrel : rjsquirrel
and then add the new group:
$ sudo /usr/sbin/usermod -a -G anewgroup rjsquirrel
$ groups rjsquirrel
rjsquirrel: rjsquirrel anewgroup
These utilities update /etc/group as necessary. Make sure to use the -a option, for append, so as to avoid removing already existing groups. groupmod can be used to change group properties, such as the Group ID (gid) with the -g option or its name with then -n option.
Removing a user from the group is somewhat trickier. The -G option to usermod must give a complete list of groups. Thus, if you do:
$ sudo /usr/sbin/usermod -G rjsquirrel rjsquirrel
$ groups rjsquirrel
rjsquirrel : rjsquirrel
only the rjsquirrel group will be left.
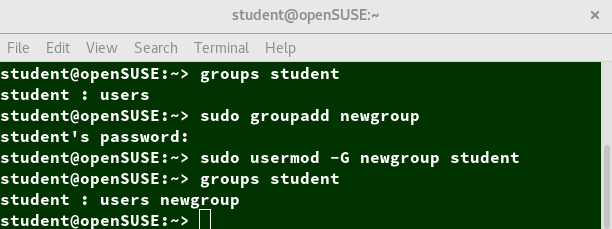 Adding and Removing Groups
Adding and Removing Groups
The root Account
The root account is very powerful and has full access to the system. Other operating systems often call this the administrator account; in Linux, it is often called the superuser account. You must be extremely cautious before granting full root access to a user; it is rarely, if ever, justified. External attacks often consist of tricks used to elevate to the root account.

However, you can use sudo to assign more limited privileges to user accounts:
- Only on a temporary basis
- Only for a specific subset of commands.
su and sudo
When assigning elevated privileges, you can use the command su (switch or substitute user) to launch a new shell running as another user (you must type the password of the user you are becoming). Most often, this other user is root, and the new shell allows the use of elevated privileges until it is exited. It is almost always a bad (dangerous for both security and stability) practice to use su to become root. Resulting errors can include deletion of vital files from the system and security breaches.
Granting privileges using sudo is less dangerous and is preferred. By default, sudo must be enabled on a per-user basis. However, some distributions (such as Ubuntu) enable it by default for at least one main user, or give this as an installation option.
In the Local Security Principles chapter we will describe and compare su and sudo in detail.
Elevating to root Account
To temporarily become the superuser for a series of commands, you can type su and then be prompted for the root password.
To execute just one command with root privilege type sudo . When the command is complete, you will return to being a normal unprivileged user.
sudo configuration files are stored in the /etc/sudoers file and in the /etc/sudoers.d/ directory. By default, the sudoers.d directory is empty.
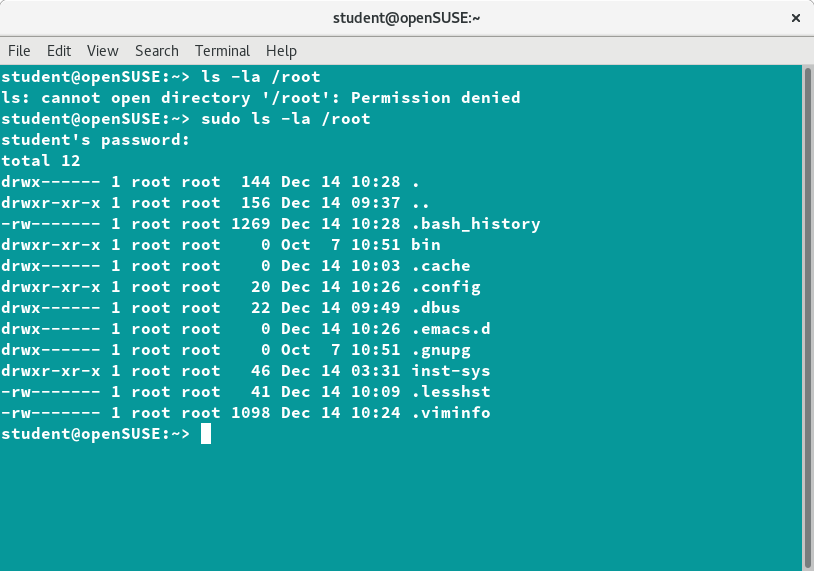 Elevating to root Account
Elevating to root Account
Environment Variables
Environment variables are quantities that have specific values which may be utilized by the command shell, such as bash, or other utilities and applications. Some environment variables are given preset values by the system (which can usually be overridden), while others are set directly by the user, either at the command line or within startup and other scripts.
An environment variable is actually just a character string that contains information used by one or more applications. There are a number of ways to view the values of currently set environment variables; one can type set, env, or export. Depending on the state of your system, set may print out many more lines than the other two methods.
 Environment Variables
Environment Variables
Setting Environment Variables
By default, variables created within a script are only available to the current shell; child processes (sub-shells) will not have access to values that have been set or modified. Allowing child processes to see the values requires use of the export command.
| Task | Command |
| Show the value of a specific variable | echo $SHELL |
| Export a new variable value | export VARIABLE=value (or VARIABLE=value; export VARIABLE) |
| Add a variable permanently | Edit ~/.bashrc and add the line export VARIABLE=value Type source ~/.bashrc or just . ~/.bashrc (dot ~/.bashrc); or just start a new shell by typing bash |
You can also set environment variables to be fed as a one shot to a command as in:
$ SDIRS=s_0* KROOT=/lib/modules/$(uname -r)/build make modules_install
which feeds the values of the SDIRS and KROOT environment variables to the command make modules_install.
The HOME Variable
HOME is an environment variable that represents the home (or login) directory of the user. cd without arguments will change the current working directory to the value of HOME. Note the tilde character (~) is often used as an abbreviation for $HOME. Thus, cd $HOME and cd ~ are completely equivalent statements.
| Command | Explanation |
$ echo $HOME | Show the value of the HOME environment variable, then change directory (cd) to /bin. |
$ pwd | Where are we? Use print (or present) working directory (pwd) to find out. As expected, /bin. |
| $ cd | Change directory without an argument... |
$ pwd | ...takes us back to HOME, as you can now see. |
The screenshot demonstrates this.
 The HOME Variable
The HOME Variable
The PATH Variable
PATH is an ordered list of directories (the path) which is scanned when a command is given to find the appropriate program or script to run. Each directory in the path is separated by colons (:). A null (empty) directory name (or ./) indicates the current directory at any given time.
- :path1:path2
- path1::path2
In the example :path1:path2, there is a null directory before the first colon (:). Similarly, for path1::path2 there is a null directory between path1 and path2.
To prefix a private bin directory to your path:
$ export PATH=$HOME/bin:$PATH
$ echo $PATH
/home/student/bin:/usr/local/bin:/usr/bin:/bin/usr
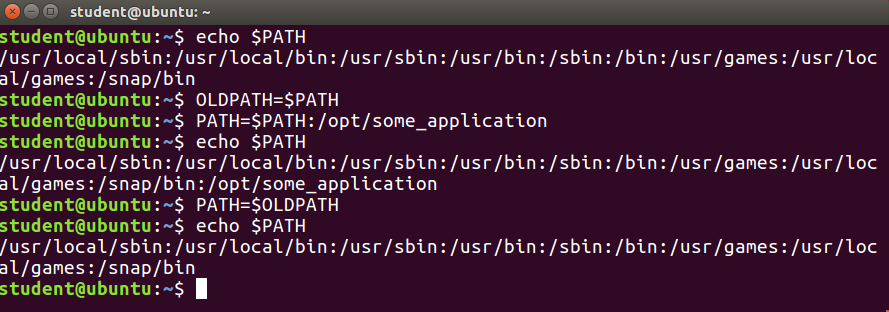 The PATH Variable
The PATH Variable
The SHELL Variable
The environment variable SHELL points to the user's default command shell (the program that is handling whatever you type in a command window, usually bash) and contains the full pathname to the shell:
$ echo $SHELL
/bin/bash
$

The PS1 Variable and the Command Line Prompt
Prompt Statement (PS) is used to customize your prompt string in your terminal windows to display the information you want.
PS1 is the primary prompt variable which controls what your command line prompt looks like. The following special characters can be included in PS1:
\u - User name
\h - Host name
\w - Current working directory
! - History number of this command
\d - Date
They must be surrounded in single quotes when they are used, as in the following example:
$ echo $PS1
$
$ export PS1='\u@\h:\w$ '
student@example.com:~$ # new prompt
To revert the changes:
student@example.com:~$ export PS1='$ '
$
An even better practice would be to save the old prompt first and then restore, as in:
$ OLD_PS1=$PS1
change the prompt, and eventually change it back with:
$ PS1=$OLD_PS1
$
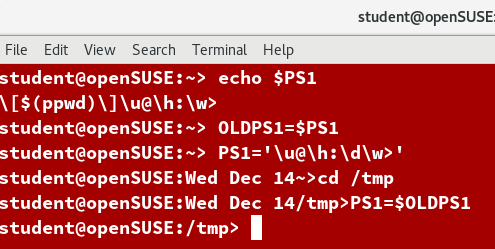
Recalling Previous Commands
bash keeps track of previously entered commands and statements in a history buffer. You can recall previously used commands simply by using the Up and Down cursor keys. To view the list of previously executed commands, you can just type history at the command line.
The list of commands is displayed with the most recent command appearing last in the list. This information is stored in ~/.bash_history. If you have multiple terminals open, the commands typed in each session are not saved until the session terminates.
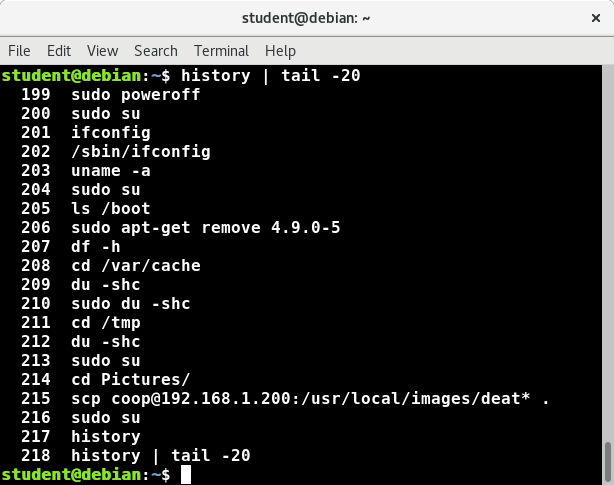 Recalling Previous Commands
Recalling Previous Commands
Using History Environment Variables
Several associated environment variables can be used to get information about the **history** file.
- HISTFILE
The location of the history file. - HISTFILESIZE
The maximum number of lines in the history file (default 500). - HISTSIZE
The maximum number of commands in the history file. - HISTCONTROL
How commands are stored. - HISTIGNORE
Which command lines can be unsaved.
For a complete description of the use of these environment variables, see man bash.
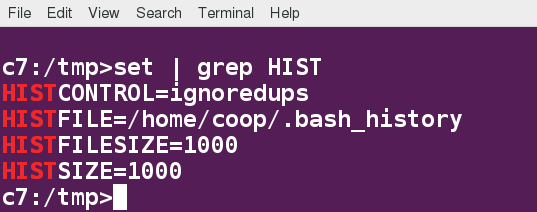 Using History Environment Variables
Using History Environment Variables
Finding and Using Previous Commands
Specific keys to perform various tasks:
| Key | Usage |
| Up/Down arrow keys | Browse through the list of commands previously executed |
| !! (Pronounced as bang-bang) | Execute the previous command |
| CTRL-R | Search previously used commands |
If you want to recall a command in the history list, but do not want to press the arrow key repeatedly, you can press CTRL-R to do a reverse intelligent search.
As you start typing, the search goes back in reverse order to the first command that matches the letters you have typed. By typing more successive letters, you make the match more and more specific.
The following is an example of how you can use the CTRL-R command to search through the command history:
$ ^R (This all happens on 1 line)
(reverse-i-search)'s': sleep 1000 (Searched for 's'; matched "sleep")
$ sleep 1000 (Pressed Enter to execute the searched command)
$
Executing Previous Commands
The table describes the syntax used to execute previously used commands:
| Syntax | Task |
| ! | Start a history substitution |
| !$ | Refer to the last argument in a line |
| !n | Refer to the nth command line |
| !string | Refer to the most recent command starting with string |
All history substitutions start with !. When typing the command: ls -l /bin /etc /var, !$ will refer to /var, the last argument to the command.
Here are more examples:
$ history
- echo $SHELL
- echo $HOME
- echo $PS1
- ls -a
- ls -l /etc/ passwd
- sleep 1000
- history
$ !1 (Execute command #1 above)
echo $SHELL
/bin/bash
$ !sl (Execute the command beginning with "sl")
sleep 1000
$
Keyboard Shortcuts
You can use keyboard shortcuts to perform different tasks quickly. The table lists some of these keyboard shortcuts and their uses. Note the case of the "hotkey" does not matter, e.g. doing CTRL-a is the same as doing CTRL-A .
| Keyboard Shortcut | Task |
| CTRL-L | Clears the screen |
| CTRL-D | Exits the current shell |
| CTRL-Z | Puts the current process into suspended background |
| CTRL-C | Kills the current process |
| CTRL-H | Works the same as backspace |
| CTRL-A | Goes to the beginning of the line |
| CTRL-W | Deletes the word before the cursor |
| CTRL-U | Deletes from beginning of line to cursor position |
| CTRL-E | Goes to the end of the line |
| Tab | Auto-completes files, directories, and binaries |
File Ownership
In Linux and other UNIX-based operating systems, every file is associated with a user who is the owner. Every file is also associated with a group (a subset of all users) which has an interest in the file and certain rights, or permissions: read, write, and execute.
The following utility programs involve user and group ownership and permission setting:
| Command | Usage |
| chown | Used to change user ownership of a file or directory |
| chgrp | Used to change group ownership |
| chmod | Used to change the permissions on the file, which can be done separately for owner, group and the rest of the world (often named as other) |
File Permission Modes and chmod
Files have three kinds of permissions: read (r), write (w), execute (x). These are generally represented as in rwx. These permissions affect three groups of owners: user/owner (u), group (g), and others (o).
As a result, you have the following three groups of three permissions:
rwx: rwx: rwx
u: g: o
There are a number of different ways to use chmod. For instance, to give the owner and others execute permission and remove the group write permission:
$ ls -l somefile
-rw-rw-r-- 1 student student 1601 Mar 9 15:04 somefile
$ chmod uo+x,g-w somefile
$ ls -l somefile
-rwxr--r-x 1 student student 1601 Mar 9 15:04 somefile
where u stands for user (owner), o stands for other (world), and g stands for group.
This kind of syntax can be difficult to type and remember, so one often uses a shorthand which lets you set all the permissions in one step. This is done with a simple algorithm, and a single digit suffices to specify all three permission bits for each entity. This digit is the sum of:
- 4 if read permission is desired
- 2 if write permission is desired
- 1 if execute permission is desired
Thus, 7 means read/write/execute, 6 means read/write, and 5 means read/execute.
When you apply this to the chmod command, you have to give three digits for each degree of freedom, such as in:
$ chmod 755 somefile
$ ls -l somefile
-rwxr-xr-x 1 student student 1601 Mar 9 15:04 somefile
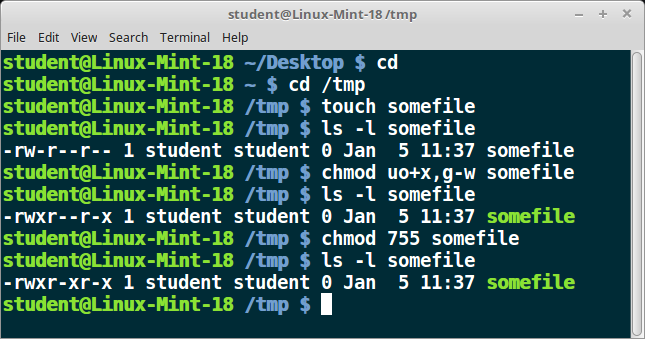 File Permission Modes and chmod
File Permission Modes and chmod
Example of chown
Let's see an example of changing file ownership using chown, as shown in the screenshot to the right. First, we create two empty files using touch.
Notice it requires sudo to change the owner of file2 to root. The second chown command changes both owner and group at the same time!
Finally, only the superuser can remove the files.
 chown
chown
Example of chgrp
Now, let’s see an example of changing the group ownership using chgrp:
 chgrp
chgrp
Chapter Summary
You have completed Chapter 12. Let's summarize the key concepts covered:
- Linux is a multi-user system.
- To find the currently logged on users, you can use the who command.
- To find the current user ID, you can use the whoami command.
- The root account has full access to the system. It is never sensible to grant full root access to a user.
- You can assign root privileges to regular user accounts on a temporary basis using the sudo command.
- The shell program (bash) uses multiple startup files to create the user environment. Each file affects the interactive environment in a different way. /etc/profile provides the global settings.
- Advantages of startup files include that they customize the user's prompt, set the user's terminal type, set the command-line shortcuts and aliases, and set the default text editor, etc.
- An environment variable is a character string that contains data used by one or more applications. The built-in shell variables can be customized to suit your requirements.
- The history command recalls a list of previous commands, which can be edited and recycled.
- In Linux, various keyboard shortcuts can be used at the command prompt instead of long actual commands.
- You can customize commands by creating aliases. Adding an alias to ~/.bashrc will make it available for other shells.
- File permissions can be changed by typing chmod permissions filename.
- File ownership is changed by typing chown owner filename.
- File group ownership is changed by typing chgrp group filename.
Video: Chapter 13 Introduction
Sorry, your browser doesn't support embedded videos.Learning Objectives
By the end of this chapter, you should be able to:
- Display and append to file contents using cat and echo.
- Edit and print file contents using sed and awk.
- Search for patterns using grep.
- Use multiple other utilities for file and text manipulation.
Command Line Tools for Manipulating Text Files
Irrespective of the role you play with Linux (system administrator, developer or user), you often need to browse through and parse text files, and/or extract data from them. These are file manipulation operations. Thus, it is essential for the Linux user to become adept at performing certain operations on files.
Most of the time, such file manipulation is done at the command line, which allows users to perform tasks more efficiently than while using a GUI. Furthermore, the command line is more suitable for automating often executed tasks.
Indeed, experienced system administrators write customized scripts to accomplish such repetitive tasks, standardized for each particular environment. We will discuss such scripting later in much detail.
In this section, we will concentrate on command line file and text manipulation-related utilities.
 Command Line Tools for Manipulating Text Files
Command Line Tools for Manipulating Text Files
cat
cat is short for concatenate and is one of the most frequently used Linux command line utilities. It is often used to read and print files, as well as for simply viewing file contents. To view a file, use the following command:
$ cat
For example, cat readme.txt will display the contents of readme.txt on the terminal. However, the main purpose of cat is often to combine (concatenate) multiple files together. You can perform the actions listed in the table using cat.
The tac command (cat spelled backwards) prints the lines of a file in reverse order. Each line remains the same, but the order of lines is inverted. The syntax of tac is exactly the same as for cat, as in:
$ tac file
$ tac file1 file2 > newfile
| Command | Usage |
| cat file1 file2 | Concatenate multiple files and display the output; i.e. the entire content of the first file is followed by that of the second file |
| cat file1 file2 > newfile | Combine multiple files and save the output into a new file |
| cat file >> existingfile | Append a file to the end of an existing file |
| cat > file | Any subsequent lines typed will go into the file, until CTRL-D is typed |
| cat >> file | Any subsequent lines are appended to the file, until CTRL-D is typed |
Using cat Interactively
cat can be used to read from standard input (such as the terminal window) if no files are specified. You can use the > operator to create and add lines into a new file, and the >> operator to append lines (or files) to an existing file. We mentioned this when talking about how to create files without an editor.
To create a new file, at the command prompt type cat > and press the Enter key.
This command creates a new file and waits for the user to edit/enter the text. After you finish typing the required text, press CTRL-D at the beginning of the next line to save and exit the editing.
Another way to create a file at the terminal is cat > << EOF. A new file is created and you can type the required input. To exit, enter EOF at the beginning of a line.
Note that EOF is case sensitive. One can also use another word, such as STOP.
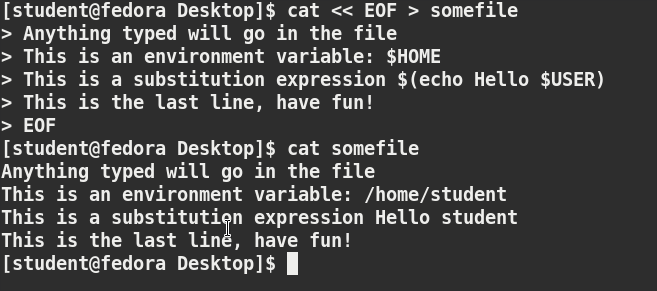 Using cat
Using cat
Video: Using cat
Sorry, your browser doesn't support embedded videos.Working with Large Files
System administrators need to work with configuration files, text files, documentation files, and log files. Some of these files may be large or become quite large as they accumulate data with time. These files will require both viewing and administrative updating. In this section, you will learn how to manage such large files.
For example, a banking system might maintain one simple large log file to record details of all of one day's ATM transactions. Due to a security attack or a malfunction, the administrator might be forced to check for some data by navigating within the file. In such cases, directly opening the file in an editor will cause issues, due to high memory utilization, as an editor will usually try to read the whole file into memory first. However, one can use less to view the contents of such a large file, scrolling up and down page by page, without the system having to place the entire file in memory before starting. This is much faster than using a text editor.

Viewing somefile can be done by typing either of the two following commands:
$ less somefile
$ cat somefile | less
By default, man pages are sent through the less command. You may have encountered the older more utility which has the same basic function but fewer capabilities: i.e. less is more!
head
head reads the first few lines of each named file (10 by default) and displays it on standard output. You can give a different number of lines in an option.
For example, if you want to print the first 5 lines from /etc/default/grub, use the following command:
$ head –n 5 /etc/default/grub
You can also just say:
head -5 /etc/default/grub
 head
head
tail
tail prints the last few lines of each named file and displays it on standard output. By default, it displays the last 10 lines. You can give a different number of lines as an option. tail is especially useful when you are troubleshooting any issue using log files, as you probably want to see the most recent lines of output.
For example, to display the last 15 lines of somefile.log, use the following command:
$ tail -n 15 somefile.log
You can also just say:
tail -15 somefile.log
To continually monitor new output in a growing log file:
$ tail -f somefile.log
This command will continuously display any new lines of output in somefile.log as soon as they appear. Thus, it enables you to monitor any current activity that is being reported and recorded.
 tail
tail
Viewing Compressed Files
When working with compressed files, many standard commands cannot be used directly. For many commonly-used file and text manipulation programs, there is also a version especially designed to work directly with compressed files. These associated utilities have the letter "z" prefixed to their name. For example, we have utility programs such as zcat, zless, zdiff and zgrep.
Here is a table listing some z family commands:
| Command | Description |
| $ zcat compressed-file.txt.gz | To view a compressed file |
| $ zless somefile.gz or $ zmore somefile.gz | To page through a compressed file |
| $ zgrep -i less somefile.gz | To search inside a compressed file |
| $ zdiff file1.txt.gz file2.txt.gz | To compare two compressed files |
Note that if you run zless on an uncompressed file, it will still work and ignore the decompression stage. There are also equivalent utility programs for other compression methods besides gzip, for example, we have bzcat and bzless associated with bzip2, and xzcat and xzless associated with xz.
Introduction to sed and awk
It is very common to create and then repeatedly edit and/or extract contents from a file. Let’s learn how to use sed and awk to easily perform such operations.

Note that many Linux users and administrators will write scripts using comprehensive scripting languages such as Python and perl, rather than use sed and awk (and some other utilities we will discuss later). Using such utilities is certainly fine in most circumstances; one should always feel free to use the tools one is experienced with. However, the utilities that are described here are much lighter; i.e. they use fewer system resources, and execute faster. There are situations (such as during booting the system) where a lot of time would be wasted using the more complicated tools, and the system may not even be able to run them. So, the simpler tools will always be needed.
sed
sed is a powerful text processing tool and is one of the oldest, earliest and most popular UNIX utilities. It is used to modify the contents of a file or input stream, usually placing the contents into a new file or output stream. Its name is an abbreviation for stream editor.
 sed
sed
sed can filter text, as well as perform substitutions in data streams.
Data from an input source/file (or stream) is taken and moved to a working space. The entire list of operations/modifications is applied over the data in the working space and the final contents are moved to the standard output space (or stream).
sed Command Syntax
You can invoke sed using commands like those listed in the accompanying table.
| Command | Usage |
sed -e command <filename> | Specify editing commands at the command line, operate on file and put the output on standard out (e.g. the terminal) |
| sed -f scriptfile <filename> | Specify a scriptfile containing sed commands, operate on file and put output on standard out |
| echo "I hate you" | sed s/hate/love/ | Use sed to filter standard input, putting output on standard out |
The -e option allows you to specify multiple editing commands simultaneously at the command line. It is unnecessary if you only have one operation invoked.
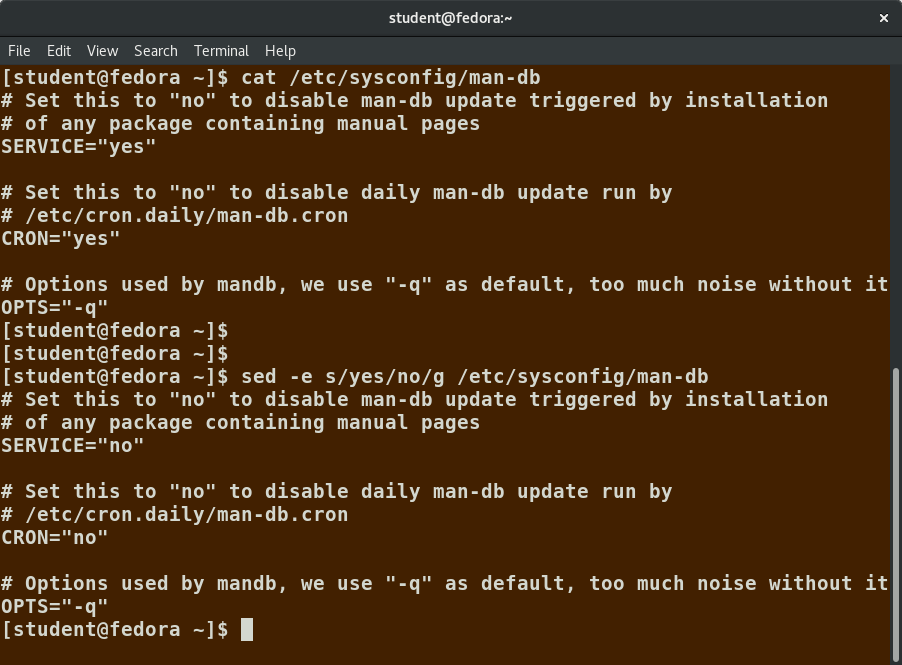 sed Command Syntax
sed Command Syntax
sed Basic Operations
Now that you know that you can perform multiple editing and filtering operations with sed, let’s explain some of them in more detail. The table explains some basic operations, where pattern is the current string and replace_string is the new string:
| Command | Usage |
| sed s/pattern/replace_string/ file | Substitute first string occurrence in every line |
| sed s/pattern/replace_string/g file | Substitute all string occurrences in every line |
| sed 1,3s/pattern/replace_string/g file | Substitute all string occurrences in a range of lines |
| sed -i s/pattern/replace_string/g file | Save changes for string substitution in the same file |
You must use the -i option with care, because the action is not reversible. It is always safer to use sed without the –i option and then replace the file yourself, as shown in the following example:
$ sed s/pattern/replace_string/g file1 > file2
The above command will replace all occurrences of pattern with replace_string in file1 and move the contents to file2. The contents of file2 can be viewed with cat file2. If you approve, you can then overwrite the original file with mv file2 file1.
Example: To convert 01/02/… to JAN/FEB/…
sed -e 's/01/JAN/' -e 's/02/FEB/' -e 's/03/MAR/' -e 's/04/APR/' -e 's/05/MAY/' \
-e 's/06/JUN/' -e 's/07/JUL/' -e 's/08/AUG/' -e 's/09/SEP/' -e 's/10/OCT/' \
-e 's/11/NOV/' -e 's/12/DEC/'
Video: Using sed
Sorry, your browser doesn't support embedded videos.awk
awk is used to extract and then print specific contents of a file and is often used to construct reports. It was created at Bell Labs in the 1970s and derived its name from the last names of its authors: Alfred Aho, Peter Weinberger, and Brian Kernighan.
awk has the following features:
- It is a powerful utility and interpreted programming language.
- It is used to manipulate data files, and for retrieving and processing text.
- It works well with fields (containing a single piece of data, essentially a column) and records (a collection of fields, essentially a line in a file).
awk is invoked as shown in the following:
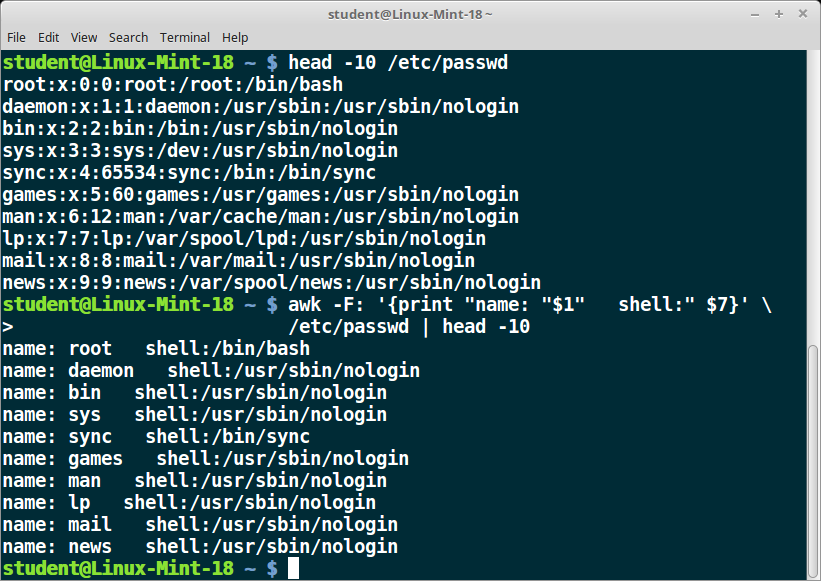 awk
awk
As with sed, short awk commands can be specified directly at the command line, but a more complex script can be saved in a file that you can specify using the -f option.
| Command | Usage |
| awk ‘command’ file | Specify a command directly at the command line |
| awk -f scriptfile file | Specify a file that contains the script to be executed |
awk Basic Operations
The table explains the basic tasks that can be performed using awk. The input file is read one line at a time, and, for each line, awk matches the given pattern in the given order and performs the requested action. The -F option allows you to specify a particular field separator character. For example, the /etc/passwd file uses ":" to separate the fields, so the -F: option is used with the /etc/passwd file.
The command/action in awk needs to be surrounded with apostrophes (or single-quote (')). awk can be used as follows:
| Command | Usage |
| awk '{ print $0 }' /etc/passwd | Print entire file |
| awk -F: '{ print $1 }' /etc/passwd | Print first field (column) of every line, separated by a colon |
| awk -F: '{ print $1 $7 }' /etc/passwd | Print first and seventh field of every line |
File Manipulation Utilities
In managing your files, you may need to perform tasks such as sorting data and copying data from one location to another. Linux provides numerous file manipulation utilities that you can use while working with text files. In this section, you will learn about the following file manipulation programs:
- sort
- uniq
- paste
- join
- split
You will also learn about regular expressions and search patterns.

sort
sort is used to rearrange the lines of a text file, in either ascending or descending order according to a sort key. You can also sort with respect to particular fields (columns) in a file. The default sort key is the order of the ASCII characters (i.e. essentially alphabetically).
sort can be used as follows:
| Syntax | Usage |
| sort <filename> | Sort the lines in the specified file, according to the characters at the beginning of each line |
| cat file1 file2 | sort | Combine the two files, then sort the lines and display the output on the terminal |
| sort -r <filename> | Sort the lines in reverse order |
| sort -k 3 <filename> | Sort the lines by the 3rd field on each line instead of the beginning |
When used with the -u option, sort checks for unique values after sorting the records (lines). It is equivalent to running uniq (which we shall discuss) on the output of sort.
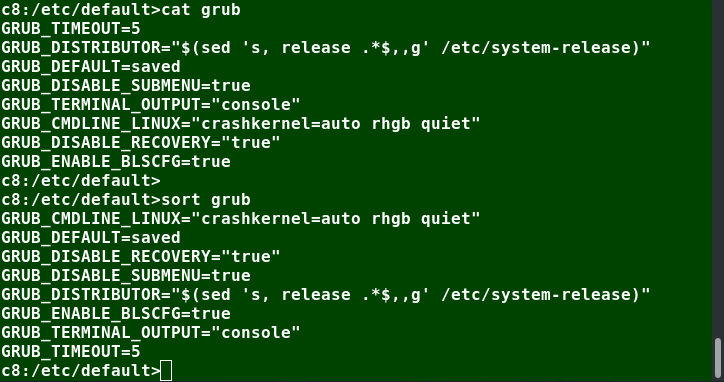 sort
sort
uniq
uniq removes duplicate consecutive lines in a text file and is useful for simplifying the text display.
Because uniq requires that the duplicate entries must be consecutive, one often runs sort first and then pipes the output into uniq; if sort is used with the -u option, it can do all this in one step.
To remove duplicate entries from multiple files at once, use the following command:
sort file1 file2 | uniq > file3
or
sort -u file1 file2 > file3
To count the number of duplicate entries, use the following command:
uniq -c filename
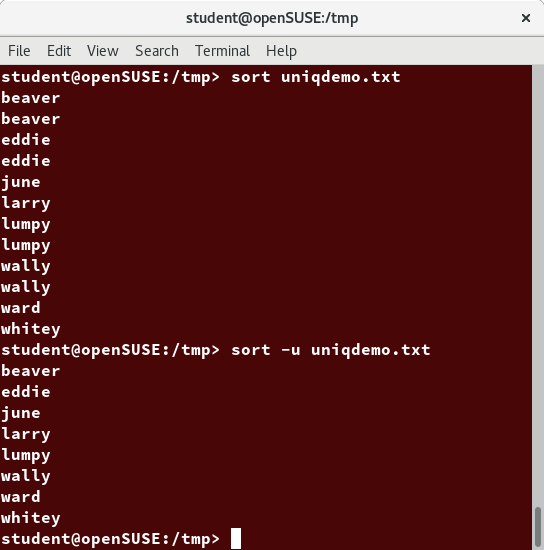 uniq
uniq
paste
Suppose you have a file that contains the full name of all employees and another file that lists their phone numbers and Employee IDs. You want to create a new file that contains all the data listed in three columns: name, employee ID, and phone number. How can you do this effectively without investing too much time?
paste can be used to create a single file containing all three columns. The different columns are identified based on delimiters (spacing used to separate two fields). For example, delimiters can be a blank space, a tab, or an Enter. In the image provided, a single space is used as the delimiter in all files.
paste accepts the following options:
- -d delimiters, which specify a list of delimiters to be used instead of tabs for separating consecutive values on a single line. Each delimiter is used in turn; when the list has been exhausted, paste begins again at the first delimiter.
- -s, which causes paste to append the data in series rather than in parallel; that is, in a horizontal rather than vertical fashion.
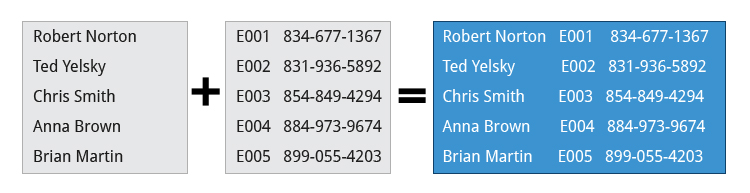
Using paste
paste can be used to combine fields (such as name or phone number) from different files, as well as combine lines from multiple files. For example, line one from file1 can be combined with line one of file2, line two from file1 can be combined with line two of file2, and so on.
To paste contents from two files one can do:
$ paste file1 file2
The syntax to use a different delimiter is as follows:
$ paste -d, file1 file2
Common delimiters are 'space', 'tab', '|', 'comma', etc.
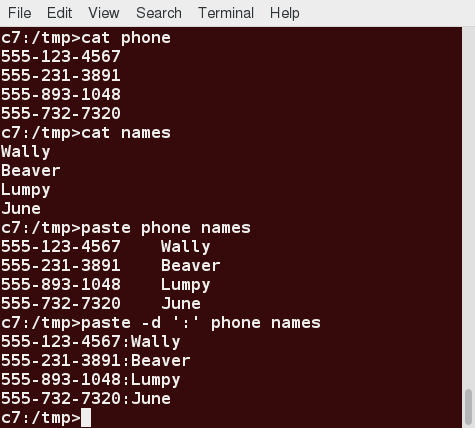 Using paste
Using paste
join
Suppose you have two files with some similar columns. You have saved employees’ phone numbers in two files, one with their first name and the other with their last name. You want to combine the files without repeating the data of common columns. How do you achieve this?
The above task can be achieved using join, which is essentially an enhanced version of paste. It first checks whether the files share common fields, such as names or phone numbers, and then joins the lines in two files based on a common field.
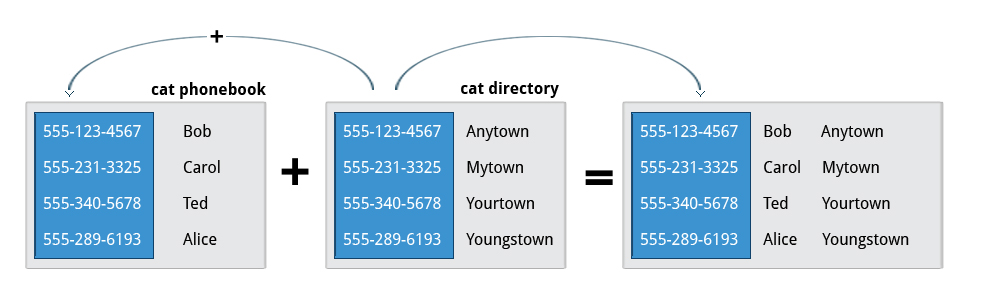 join
join
Using join
To combine two files on a common field, at the command prompt type join file1 file2 and press the Enter key.
For example, the common field (i.e. it contains the same values) among the phonebook and cities files is the phone number, and the result of joining these two files is shown in the screen capture.
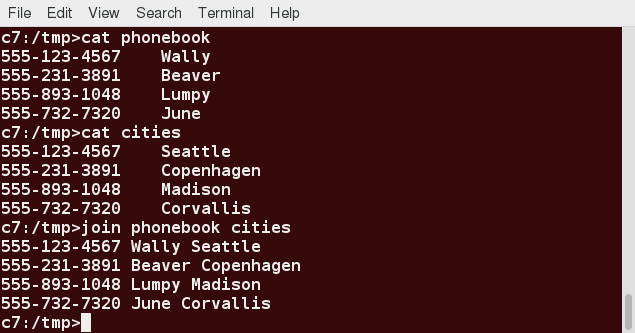 Using join
Using join
split
split is used to break up (or split) a file into equal-sized segments for easier viewing and manipulation, and is generally used only on relatively large files. By default, split breaks up a file into 1000-line segments. The original file remains unchanged, and a set of new files with the same name plus an added prefix is created. By default, the x prefix is added. To split a file into segments, use the command split infile.
To split a file into segments using a different prefix, use the command split infile .
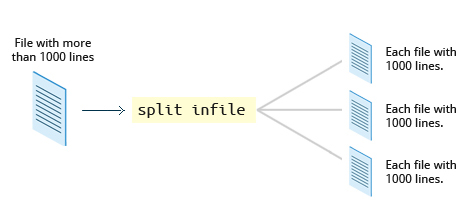
Using split
We will apply split to an American-English dictionary file of over 99,000 lines:
$ wc -l american-english
99171 american-english
where we have used wc (word count, soon to be discussed) to report on the number of lines in the file. Then, typing:
$ split american-english dictionary
will split the American-English file into 100 equal-sized segments named dictionaryxx. The last one will of course be somewhat smaller.
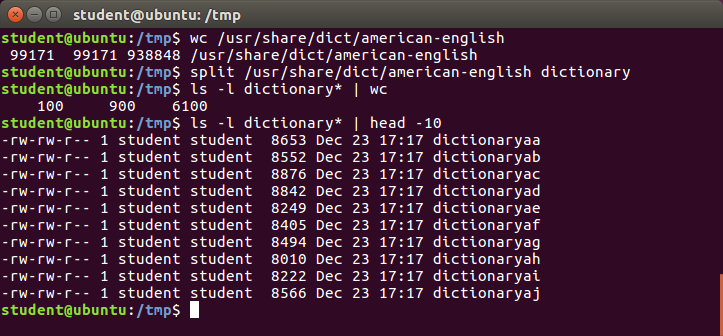 Using split
Using split
Regular Expressions and Search Patterns
Regular expressions are text strings used for matching a specific pattern, or to search for a specific location, such as the start or end of a line or a word. Regular expressions can contain both normal characters or so-called meta-characters, such as * and $.
Many text editors and utilities such as vi, sed, awk, find and grep work extensively with regular expressions. Some of the popular computer languages that use regular expressions include Perl, Python and Ruby. It can get rather complicated and there are whole books written about regular expressions; thus, we will do no more than skim the surface here.
These regular expressions are different from the wildcards (or meta-characters) used in filename matching in command shells such as bash (which were covered in the Command-Line Operations chapter). The table lists search patterns and their usage.
| Search Patterns | Usage |
| .(dot) | Match any single character |
| a|z | Match a or z |
| $ | Match end of a line |
| ^ | Match beginning of a line |
| * | Match preceding item 0 or more times |
Using Regular Expressions and Search Patterns
For example, consider the following sentence: the quick brown fox jumped over the lazy dog.
Some of the patterns that can be applied to this sentence are as follows:
| Command | Usage |
| a.. | matches azy |
| b.|j. | matches both br and ju |
| ..$ | matches og |
| l. | matches lazy dog |
| l.y | matches lazy |
| the.* | matches the whole sentence |
grep
grep is extensively used as a primary text searching tool. It scans files for specified patterns and can be used with regular expressions, as well as simple strings, as shown in the table:
| Command | Usage |
| grep [pattern] <filename> | Search for a pattern in a file and print all matching lines |
| grep -v [pattern] <filename> | Print all lines that do not match the pattern |
| grep [0-9] <filename> | Print the lines that contain the numbers 0 through 9 |
| grep -C 3 [pattern] <filename> | Print context of lines (specified number of lines above and below the pattern) for matching the pattern. Here, the number of lines is specified as 3 |
strings
strings is used to extract all printable character strings found in the file or files given as arguments. It is useful in locating human-readable content embedded in binary files; for text files one can just use grep.
For example, to search for the string my_string in a spreadsheet:
$ strings book1.xls | grep my_string
The screenshot shows a search of a number of programs to see which ones have GPL licenses of various versions.
 strings
strings
tr
In this section, you will learn about some additional text utilities that you can use for performing various actions on your Linux files, such as changing the case of letters or determining the count of words, lines, and characters in a file.
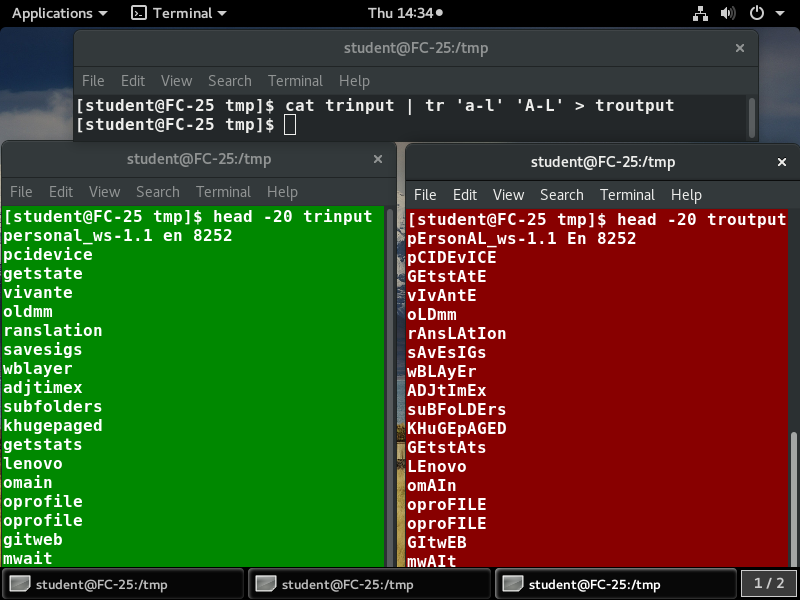 tr
tr
The tr utility is used to translate specified characters into other characters or to delete them. The general syntax is as follows:
$ tr [options] set1 [set2]
The items in the square brackets are optional. tr requires at least one argument and accepts a maximum of two. The first, designated set1 in the example, lists the characters in the text to be replaced or removed. The second, set2, lists the characters that are to be substituted for the characters listed in the first argument. Sometimes these sets need to be surrounded by apostrophes (or single-quotes (')) in order to have the shell ignore that they mean something special to the shell. It is usually safe (and may be required) to use the single-quotes around each of the sets as you will see in the examples below.
For example, suppose you have a file named city containing several lines of text in mixed case. To translate all lower case characters to upper case, at the command prompt type cat city | tr a-z A-Z and press the Enter key.
| Command | Usage |
| tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ | Convert lower case to upper case |
| tr '{}' '()' < inputfile > outputfile | Translate braces into parenthesis |
| echo "This is for testing" | tr [:space:] '\t' | Translate white-space to tabs |
| echo "This is for testing" | tr -s [:space:] | Squeeze repetition of characters using -s |
| echo "the geek stuff" | tr -d 't' | Delete specified characters using -d option |
| echo "my username is 432234" | tr -cd [:digit:] | Complement the sets using -c option |
| tr -cd [:print:] < file.txt | Remove all non-printable character from a file |
| tr -s '\n' ' ' < file.txt | Join all the lines in a file into a single line |
tee
tee takes the output from any command, and, while sending it to standard output, it also saves it to a file. In other words, it tees the output stream from the command: one stream is displayed on the standard output and the other is saved to a file.
For example, to list the contents of a directory on the screen and save the output to a file, at the command prompt type ls -l | tee newfile and press the Enter key.
Typing cat newfile will then display the output of ls –l.
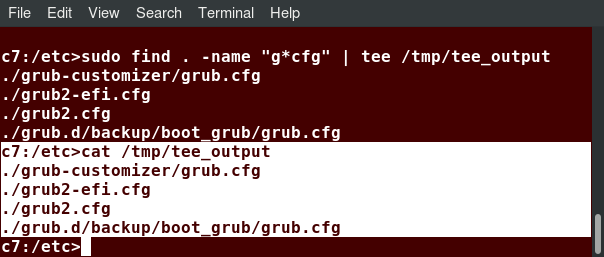 tee
tee
wc
wc (word count) counts the number of lines, words, and characters in a file or list of files. Options are given in the table below.
| Option | Description |
| –l | Displays the number of lines |
| -c | Displays the number of bytes |
| -w | Displays the number of words |
By default, all three of these options are active.
For example, to print only the number of lines contained in a file, type wc -l filename and press the Enter key.
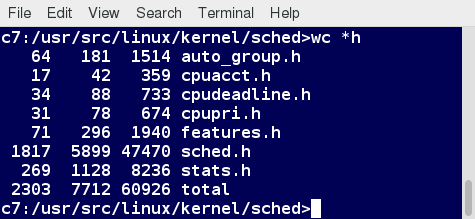 wc
wc
cut
cut is used for manipulating column-based files and is designed to extract specific columns. The default column separator is the tab character. A different delimiter can be given as a command option.
For example, to display the third column delimited by a blank space, at the command prompt type ls -l | cut -d" " -f3 and press the Enter key.
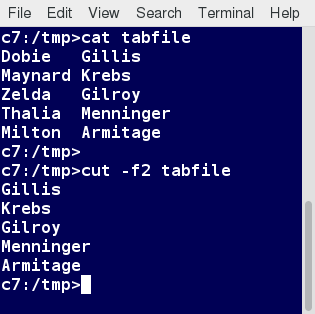 cut
cut
Chapter Summary
You have completed Chapter 13. Let’s summarize the key concepts covered:
- The command line often allows the users to perform tasks more efficiently than the GUI.
- cat, short for concatenate, is used to read, print, and combine files.
- echo displays a line of text either on standard output or to place in a file.
- sed is a popular stream editor often used to filter and perform substitutions on files and text data streams.
- awk is an interpreted programming language, typically used as a data extraction and reporting tool.
- sort is used to sort text files and output streams in either ascending or descending order.
- uniq eliminates duplicate entries in a text file.
- paste combines fields from different files. It can also extract and combine lines from multiple sources.
- join combines lines from two files based on a common field. It works only if files share a common field.
- split breaks up a large file into equal-sized segments.
- Regular expressions are text strings used for pattern matching. The pattern can be used to search for a specific location, such as the start or end of a line or a word.
- grep searches text files and data streams for patterns and can be used with regular expressions.
- tr translates characters, copies standard input to standard output, and handles special characters.
- tee saves a copy of standard output to a file while still displaying at the terminal.
- wc (word count) displays the number of lines, words, and characters in a file or group of files.
- cut extracts columns from a file.
- less views files a page at a time and allows scrolling in both directions.
- head displays the first few lines of a file or data stream on standard output. By default, it displays 10 lines.
- tail displays the last few lines of a file or data stream on standard output. By default, it displays 10 lines.
- strings extracts printable character strings from binary files.
- The z command family is used to read and work with compressed files.
Chapter 14: Network Operations
Learning Objectives
By the end of this chapter, you should be able to:
- Explain basic networking concepts, including types of networks and addressing issues.
- Configure network interfaces and use basic networking utilities, such as ifconfig, ip, ping, route and traceroute.
- Use graphical and non-graphical browsers, such as Lynx, w3m, Firefox, Chrome and Epiphany.
- Transfer files to and from clients and servers using both graphical and text mode applications, such as Filezilla, ftp, sftp, curl and wget.
Introduction to Networking
A network is a group of computers and computing devices connected together through communication channels, such as cables or wireless media. The computers connected over a network may be located in the same geographical area or spread across the world.

A network is used to:
- Allow the connected devices to communicate with each other.
- Enable multiple users to share devices over the network, such as music and video servers, printers and scanners.
- Share and manage information across computers easily.
Most organizations have both an internal network and an Internet connection for users to communicate with machines and people outside the organization. The Internet is the largest network in the world and can be called "the network of networks".
IP Addresses
Devices attached to a network must have at least one unique network address identifier known as the IP (Internet Protocol) address. The address is essential for routing packets of information through the network.
Exchanging information across the network requires using streams of small packets, each of which contains a piece of the information going from one machine to another. These packets contain data buffers, together with headers which contain information about where the packet is going to and coming from, and where it fits in the sequence of packets that constitute the stream. Networking protocols and software are rather complicated due to the diversity of machines and operating systems they must deal with, as well as the fact that even very old standards must be supported.
 IP Addresses
IP Addresses
IPv4 and IPv6
There are two different types of IP addresses available: IPv4 (version 4) and IPv6 (version 6). IPv4 is older and by far the more widely used, while IPv6 is newer and is designed to get past limitations inherent in the older standard and furnish many more possible addresses.
IPv4 uses 32-bits for addresses; there are only 4.3 billion unique addresses available. Furthermore, many addresses are allotted and reserved, but not actually used. IPv4 is considered inadequate for meeting future needs because the number of devices available on the global network has increased enormously in recent years.
IPv6 uses 128-bits for addresses; this allows for 3.4 X 1038 unique addresses. If you have a larger network of computers and want to add more, you may want to move to IPv6, because it provides more unique addresses. However, it can be complex to migrate to IPv6; the two protocols do not always inter-operate well. Thus, moving equipment and addresses to IPv6 requires significant effort and has not been quite as fast as was originally intended. We will discuss IPv4 more than IPv6 as you are more likely to deal with it.
One reason IPv4 has not disappeared is there are ways to effectively make many more addresses available by methods such as NAT (Network Address Translation). NAT enables sharing one IP address among many locally connected computers, each of which has a unique address only seen on the local network. While this is used in organizational settings, it is also used in simple home networks. For example, if you have a router hooked up to your Internet Provider (such as a cable system) it gives you one externally visible address, but issues each device in your home an individual local address.
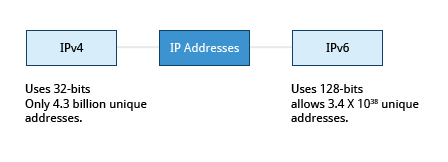
Decoding IPv4 Addresses
A 32-bit IPv4 address is divided into four 8-bit sections called octets.
Example:
IP address → 172 . 16 . 31 . 46
Bit format → 10101100.00010000.00011111.00101110
NOTE: Octet is just another word for byte.
Network addresses are divided into five classes: A, B, C, D and E. Classes A, B and C are classified into two parts: Network addresses (Net ID) and Host address (Host ID). The Net ID is used to identify the network, while the Host ID is used to identify a host in the network. Class D is used for special multicast applications (information is broadcast to multiple computers simultaneously) and Class E is reserved for future use. In this section you will learn about classes A, B and C.
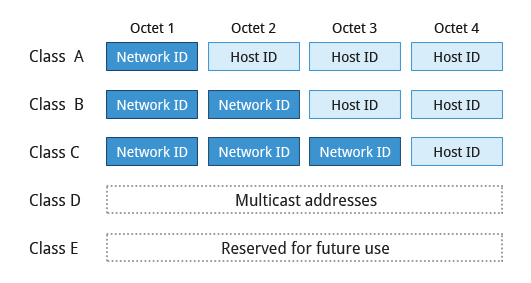 Decoding IPv4 Addresses
Decoding IPv4 Addresses
Class A Network Addresses
Class A addresses use the first octet of an IP address as their Net ID and use the other three octets as the Host ID. The first bit of the first octet is always set to zero. So you can use only 7-bits for unique network numbers. As a result, there are a maximum of 126 Class A networks available (the addresses 0000000 and 1111111 are reserved). Not surprisingly, this was only feasible when there were very few unique networks with large numbers of hosts. As the use of the Internet expanded, Classes B and C were added in order to accommodate the growing demand for independent networks.
Each Class A network can have up to 16.7 million unique hosts on its network. The range of host addresses is from 1.0.0.0 to 127.255.255.255.
NOTE: The value of an octet, or 8-bits, can range from 0 to 255.
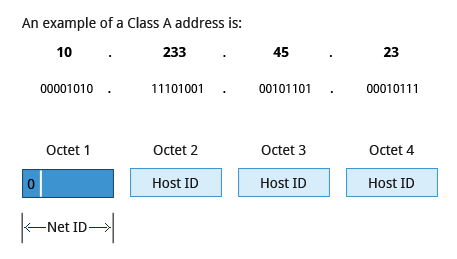 Class A Network Addresses
Class A Network Addresses
Class B Network Addresses
Class B addresses use the first two octets of the IP address as their Net ID and the last two octets as the Host ID. The first two bits of the first octet are always set to binary 10, so there are a maximum of 16,384 (14-bits) Class B networks. The first octet of a Class B address has values from 128 to 191. The introduction of Class B networks expanded the number of networks but it soon became clear that a further level would be needed.
Each Class B network can support a maximum of 65,536 unique hosts on its network. The range of host addresses is from 128.0.0.0 to 191.255.255.255.
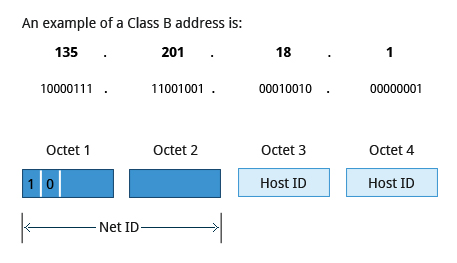 Class B Network Addresses
Class B Network Addresses
Class C Network Addresses
Class C addresses use the first three octets of the IP address as their Net ID and the last octet as their Host ID. The first three bits of the first octet are set to binary 110, so almost 2.1 million (21-bits) Class C networks are available. The first octet of a Class C address has values from 192 to 223. These are most common for smaller networks which don't have many unique hosts.
Each Class C network can support up to 256 (8-bits) unique hosts. The range of host addresses is from 192.0.0.0 to 223.255.255.255.
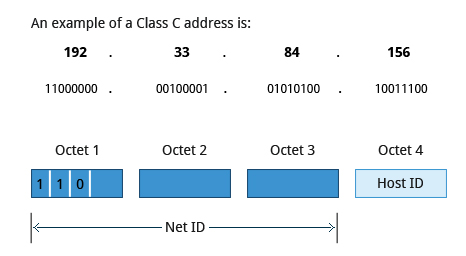 Class C Network Addresses
Class C Network Addresses
IP Address Allocation
Typically, a range of IP addresses are requested from your Internet Service Provider (ISP) by your organization's network administrator. Often, your choice of which class of IP address you are given depends on the size of your network and expected growth needs. If NAT is in operation, such as in a home network, you only get one externally visible address!
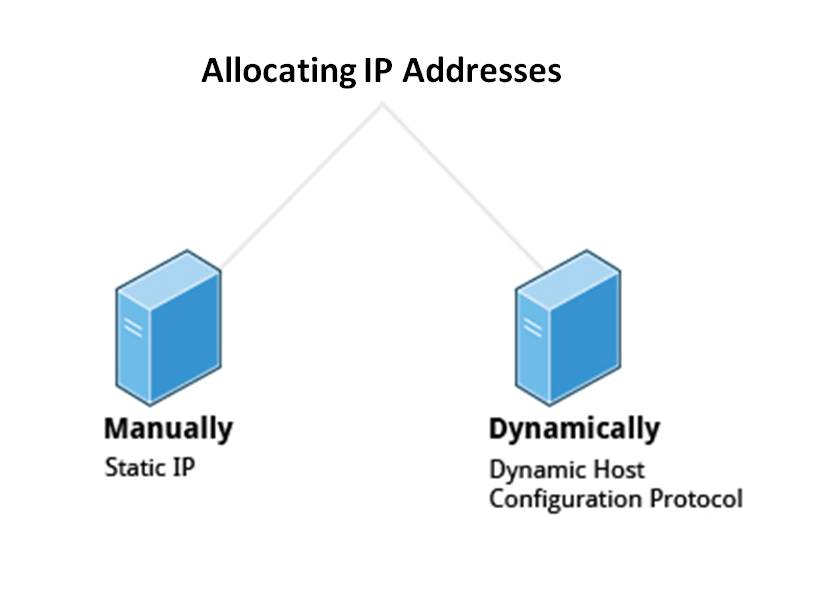 IP Address Allocation
IP Address Allocation
You can assign IP addresses to computers over a network either manually or dynamically. Manual assignment adds static (never changing) addresses to the network. Dynamically assigned addresses can change every time you reboot or even more often; the Dynamic Host Configuration Protocol (DHCP) is used to assign IP addresses.
Name Resolution
Name Resolution is used to convert numerical IP address values into a human-readable format known as the hostname. For example, 104.95.85.15 is the numerical IP address that refers to the hostname whitehouse.gov. Hostnames are much easier to remember!
Given an IP address, you can obtain its corresponding hostname. Accessing the machine over the network becomes easier when you can type the hostname instead of the IP address.
You can view your system’s hostname simply by typing hostname with no argument.
NOTE: If you give an argument, the system will try to change its hostname to match it, however, only root users can do that.
The special hostname localhost is associated with the IP address 127.0.0.1 and describes the machine you are currently on (which normally has additional network-related IP addresses).
 Screenshot Showing Server IP Address of The Linux Foundation Website
Screenshot Showing Server IP Address of The Linux Foundation Website
Network Configuration Files
Network configuration files are essential to ensure that interfaces function correctly. They are located in the /etc directory tree. However, the exact files used have historically been dependent on the particular Linux distribution and version being used.
For Debian family configurations, the basic network configuration files could be found under /etc/network/, while for Red Hat and SUSE family systems one needed to inspect /etc/sysconfig/network.
Modern systems emphasize the use of Network Manager, which we briefly discussed when we considered graphical system administration, rather than try to keep up with the vagaries of the files in /etc. While the graphical versions of Network Manager do look somewhat different in different distributions, the nmtui utility (shown in the screenshot) varies almost not at all, as does the even more sparse nmcli (command line interface) utility. If you are proficient in the use of the GUIs, by all means, use them. If you are working on a variety of systems, the lower level utilities may make life easier.
 Network Manager
Network Manager
Recent Ubuntu distributions include netplan, which is turned on by default, and supplants Network Manager. Since no other distribution has shown interest, and since it can easily be disabled if it bothers you, we will ignore it.
Network Interfaces
Network interfaces are a connection channel between a device and a network. Physically, network interfaces can proceed through a network interface card (NIC), or can be more abstractly implemented as software. You can have multiple network interfaces operating at once. Specific interfaces can be brought up (activated) or brought down (deactivated) at any time.
Information about a particular network interface or all network interfaces can be reported by the ip and ifconfig utilities, which you may have to run as the superuser, or at least, give the full path, i.e. /sbin/ifconfig, on some distributions. ip is newer than ifconfig and has far more capabilities, but its output is uglier to the human eye. Some new Linux distributions do not install the older net-tools package to which ifconfig belongs, and so you would have to install it if you want to use it.
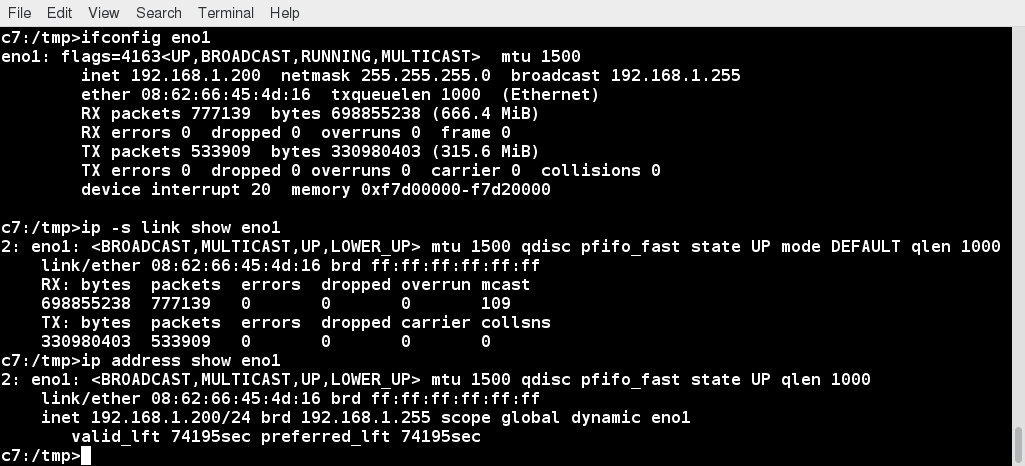 Network Interfaces
Network Interfaces
The ip Utility
To view the IP address:
$ /sbin/ip addr show
To view the routing information:
$ /sbin/ip route show
ip is a very powerful program that can do many things. Older (and more specific) utilities such as ifconfig and route are often used to accomplish similar tasks. A look at the relevant man pages can tell you much more about these utilities.
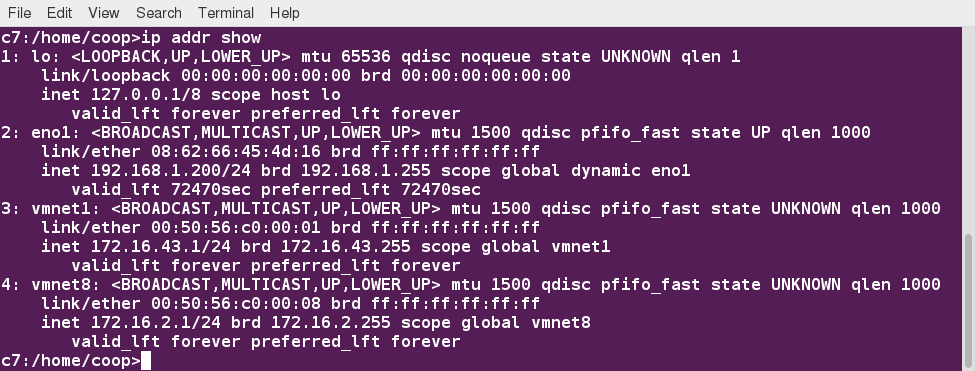 ip Utility
ip Utility
ping
ping is used to check whether or not a machine attached to the network can receive and send data; i.e. it confirms that the remote host is online and is responding.
To check the status of the remote host, at the command prompt, type ping .
ping is frequently used for network testing and management; however, its usage can increase network load unacceptably. Hence, you can abort the execution of ping by typing CTRL-C, or by using the -c option, which limits the number of packets that ping will send before it quits. When execution stops, a summary is displayed.
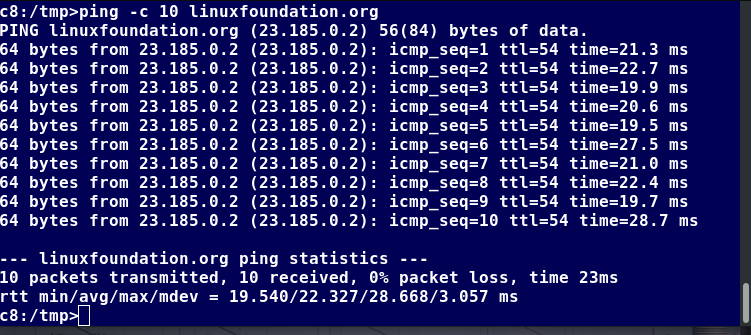 ping
ping
route
A network requires the connection of many nodes. Data moves from source to destination by passing through a series of routers and potentially across multiple networks. Servers maintain routing tables containing the addresses of each node in the network. The IP routing protocols enable routers to build up a forwarding table that correlates final destinations with the next hop addresses.
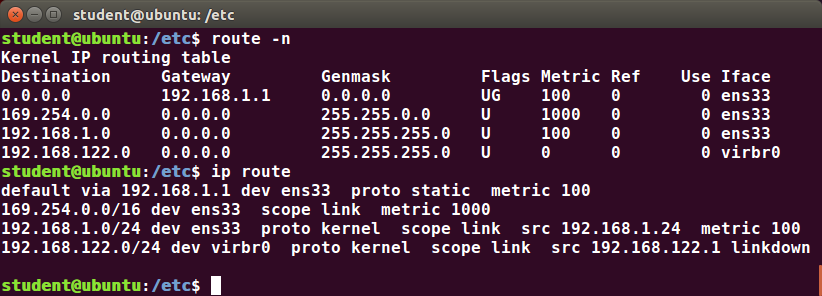 route
route
One can use the route utility or the newer ip route command to view or change the IP routing table to add, delete, or modify specific (static) routes to specific hosts or networks. The table explains some commands that can be used to manage IP routing:
| Task | Command |
| Show current routing table | $ route –n or ip route |
| Add static route | $ route add -net address or ip route add |
| Delete static route | $ route del -net address or ip route del |
traceroute
traceroute is used to inspect the route which the data packet takes to reach the destination host, which makes it quite useful for troubleshooting network delays and errors. By using traceroute, you can isolate connectivity issues between hops, which helps resolve them faster.
To print the route taken by the packet to reach the network host, at the command prompt, type traceroute
.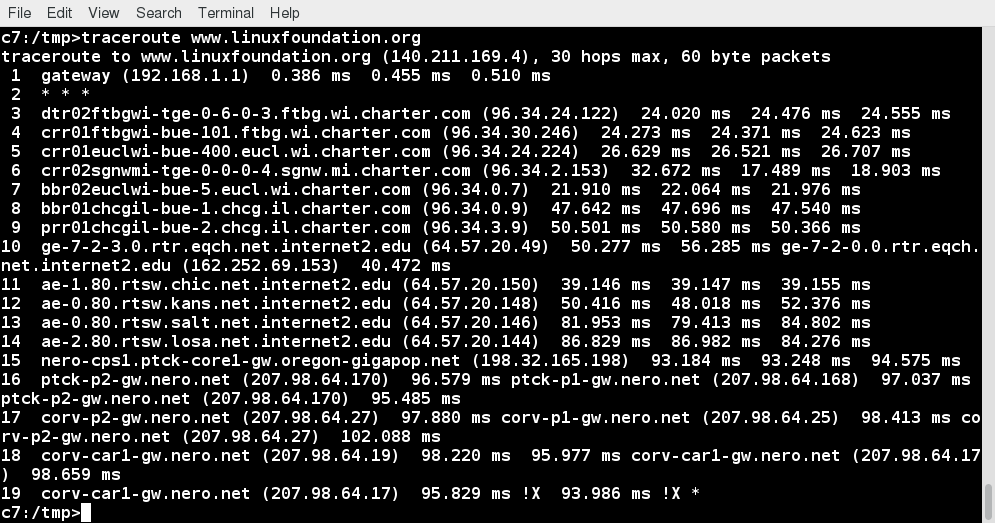 traceroute
traceroute
More Networking Tools
Now, let’s learn about some additional networking tools. Networking tools are very useful for monitoring and debugging network problems, such as network connectivity and network traffic.
| Networking Tools | Description |
| ethtool | Queries network interfaces and can also set various parameters such as the speed |
| netstat | Displays all active connections and routing tables; useful for monitoring performance and troubleshooting |
| nmap | Scans open ports on a network; important for security analysis |
| tcpdump | Dumps network traffic for analysis |
| iptraf | Monitors network traffic in text mode |
| mtr | Combines functionality of ping and traceroute and gives a continuously updated display |
| dig | Tests DNS workings; a good replacement for host and nslookup |
Video: Using More Networking Tools
Sorry, your browser doesn't support embedded videos.Graphical and Non-Graphical Browsers
Browsers are used to retrieve, transmit, and explore information resources, usually on the World Wide Web. Linux users commonly use both graphical and non-graphical browser applications.
The common graphical browsers used in Linux are:
Sometimes, you either do not have a graphical environment to work in (or have reasons not to use it) but still need to access web resources. In such a case, you can use non-graphical browsers, such as the following:
| Non-Graphical Browsers | Description |
| lynx | Configurable text-based web browser; the earliest such browser and still in use |
| elinks | Based on Lynx; it can display tables and frames |
| w3m | Another text-based web browser with many features |
wget
Sometimes, you need to download files and information, but a browser is not the best choice, either because you want to download multiple files and/or directories, or you want to perform the action from a command line or a script. wget is a command line utility that can capably handle the following types of downloads:
- Large file downloads
- Recursive downloads, where a web page refers to other web pages and all are downloaded at once
- Password-required downloads
- Multiple file downloads.
To download a web page, you can simply type wget , and then you can read the downloaded page as a local file using a graphical or non-graphical browser.
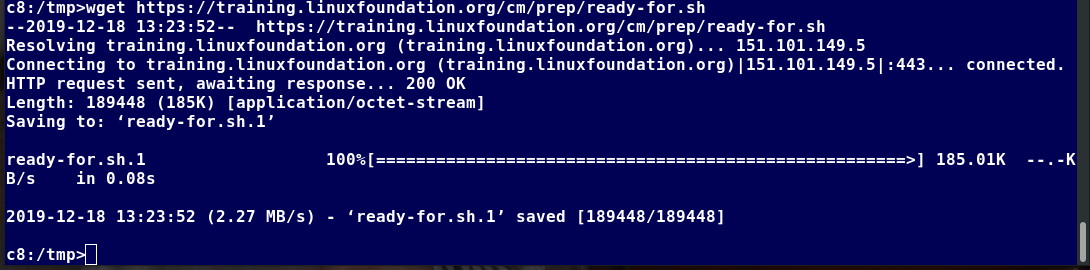 wget
wget
curl
Besides downloading, you may want to obtain information about a URL, such as the source code being used. curl can be used from the command line or a script to read such information. curl also allows you to save the contents of a web page to a file, as does wget.
You can read a URL using curl . For example, if you want to read http://www.linuxfoundation.org, type curl http://www.linuxfoundation.org.
To get the contents of a web page and store it to a file, type curl -o saved.html http://www.mysite.com. The contents of the main index file at the website will be saved in saved.html.
 curl
curl
FTP (File Transfer Protocol)
When you are connected to a network, you may need to transfer files from one machine to another. File Transfer Protocol (FTP) is a well-known and popular method for transferring files between computers using the Internet. This method is built on a client-server model. FTP can be used within a browser or with stand-alone client programs.
 File Transfer Protocol
File Transfer Protocol
FTP is one of the oldest methods of network data transfer, dating back to the early 1970s. As such, it is considered inadequate for modern needs, as well as being intrinsically insecure. However, it is still in use and when security is not a concern (such as with so-called anonymous FTP) it can make sense. However, many websites, such as kernel.org, have abandoned its use.
FTP Clients
FTP clients enable you to transfer files with remote computers using the FTP protocol. These clients can be either graphical or command line tools. Filezilla, for example, allows use of the drag-and-drop approach to transfer files between hosts. All web browsers support FTP, all you have to do is give a URL like ftp://ftp.kernel.org where the usual http:// becomes ftp://.
Some command line FTP clients are:
- ftp
- sftp
- ncftp
- yafc (Yet Another FTP Client).
FTP has fallen into disfavor on modern systems, as it is intrinsically insecure, since passwords are user credentials that can be transmitted without encryption and are thus prone to interception. Thus, it was removed in favor of using rsync and web browser https access for example. As an alternative, sftp is a very secure mode of connection, which uses the Secure Shell (ssh) protocol, which we will discuss shortly. sftp encrypts its data and thus sensitive information is transmitted more securely. However, it does not work with so-called anonymous FTP (guest user credentials).
 FTP Clients
FTP Clients
SSH: Executing Commands Remotely
Secure Shell (SSH) is a cryptographic network protocol used for secure data communication. It is also used for remote services and other secure services between two devices on the network and is very useful for administering systems which are not easily available to physically work on, but to which you have remote access.
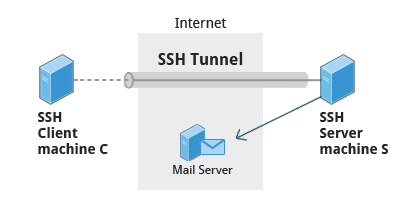 SSH: Executing Commands Remotely
SSH: Executing Commands Remotely
To login to a remote system using your same user name you can just type ssh some_system and press Enter. ssh then prompts you for the remote password. You can also configure ssh to securely allow your remote access without typing a password each time.
If you want to run as another user, you can do either ssh -l someone some_system or ssh someone@some_system. To run a command on a remote system via SSH, at the command prompt, you can type ssh some_system my_command.
Copying Files Securely with scp
We can also move files securely using Secure Copy (scp) between two networked hosts. scp uses the SSH protocol for transferring data.
To copy a local file to a remote system, at the command prompt, type scp user@remotesystem:/home/user/ and press Enter.
You will receive a prompt for the remote password. You can also configure scp so that it does not prompt for a password for each transfer.
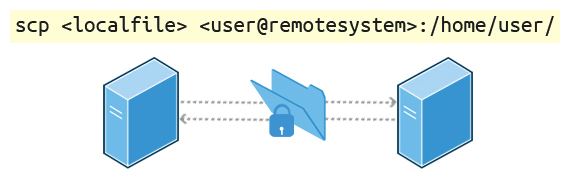 Copying Files Securely with scp
Copying Files Securely with scp
Video: Using SSH Between Two Virtual Machines
Sorry, your browser doesn't support embedded videos.Chapter Summary
You have completed Chapter 14. Let’s summarize the key concepts covered:
- The IP (Internet Protocol) address is a unique logical network address that is assigned to a device on a network.
- IPv4 uses 32-bits for addresses and IPv6 uses 128-bits for addresses.
- Every IP address contains both a network and a host address field.
- There are five classes of network addresses available: A, B, C, D & E.
- DNS (Domain Name System) is used for converting Internet domain and host names to IP addresses.
- The ifconfig program is used to display current active network interfaces.
- The commands ip addr show and ip route show can be used to view IP address and routing information.
- You can use ping to check if the remote host is alive and responding.
- You can use the route utility program to manage IP routing.
- You can monitor and debug network problems using networking tools.
- Firefox, Google Chrome, Chromium, and Epiphany are the main graphical browsers used in Linux.
- Non-graphical or text browsers used in Linux are Lynx, Links, and w3m.
- You can use wget to download webpages.
- You can use curl to obtain information about URLs.
- FTP (File Transfer Protocol) is used to transfer files over a network.
- ftp, sftp, ncftp, and yafc are command line FTP clients used in Linux.
- You can use ssh to run commands on remote systems.
Chapter 15: The Bash Shell and Basic Scripting
Learning Objectives
By the end of this chapter, you should be able to:
- Explain the features and capabilities of bash shell scripting.
- Know the basic syntax of scripting statements.
- Be familiar with various methods and constructs used.
- Test for properties and existence of files and other objects.
- Use conditional statements, such as if-then-else blocks.
- Perform arithmetic operations using scripting language.
Shell Scripting
Suppose you want to look up a filename, check if the associated file exists, and then respond accordingly, displaying a message confirming or not confirming the file's existence. If you only need to do it once, you can just type a sequence of commands at a terminal. However, if you need to do this multiple times, automation is the way to go. In order to automate sets of commands, you will need to learn how to write shell scripts. Most commonly in Linux, these scripts are developed to be run under the bash command shell interpreter. The graphic illustrates several of the benefits of deploying scripts.
Features of Shell Scripts
NOTE: Many of the topics discussed in this and the next chapter have already been introduced earlier, while discussing things that can be done at the command line. We have elected to repeat some of that discussion in order to make the sections on scripting stand on their own, so the repetition is intentional.
Command Shell Choices
The command interpreter is tasked with executing statements that follow it in the script. Commonly used interpreters include: /usr/bin/perl, /bin/bash, /bin/csh, /usr/bin/python and /bin/sh.
Typing a long sequence of commands at a terminal window can be complicated, time consuming, and error prone. By deploying shell scripts, using the command line becomes an efficient and quick way to launch complex sequences of steps. The fact that shell scripts are saved in a file also makes it easy to use them to create new script variations and share standard procedures with several users.
Linux provides a wide choice of shells; exactly what is available on the system is listed in /etc/shells. Typical choices are:
/bin/sh
/bin/bash
/bin/tcsh
/bin/csh
/bin/ksh
/bin/zsh
Most Linux users use the default bash shell, but those with long UNIX backgrounds with other shells may want to override the default.
 Command Shell Choices
Command Shell Choices
Shell Scripts
Remember from our earlier discussion, a shell is a command line interpreter which provides the user interface for terminal windows. It can also be used to run scripts, even in non-interactive sessions without a terminal window, as if the commands were being directly typed in. For example, typing find . -name "*.c" -ls at the command line accomplishes the same thing as executing a script file containing the lines:
#!/bin/bash
find . -name "*.c" -ls
The first line of the script, which starts with #!, contains the full path of the command interpreter (in this case /bin/bash) that is to be used on the file. As we have noted, you have quite a few choices for the scripting language you can use, such as /usr/bin/perl, /bin/csh, /usr/bin/python, etc.
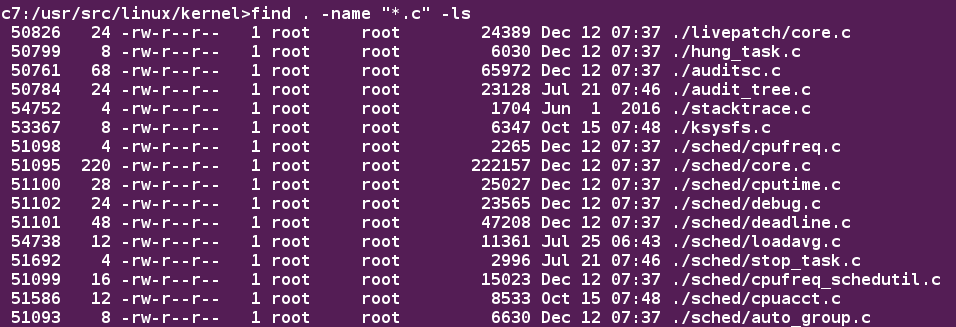 Shell Scripts
Shell Scripts
A Simple bash Script
Let's write a simple bash script that displays a one line message on the screen. Either type:
$ cat > hello.sh
#!/bin/bash
echo "Hello Linux Foundation Student"
and press ENTER and CTRL-D to save the file, or just create hello.sh in your favorite text editor. Then, type chmod +x hello.sh to make the file executable by all users.
You can then run the script by typing ./hello.sh or by doing:
$ bash hello.sh
Hello Linux Foundation Student
NOTE: If you use the second form, you do not have to make the file executable.
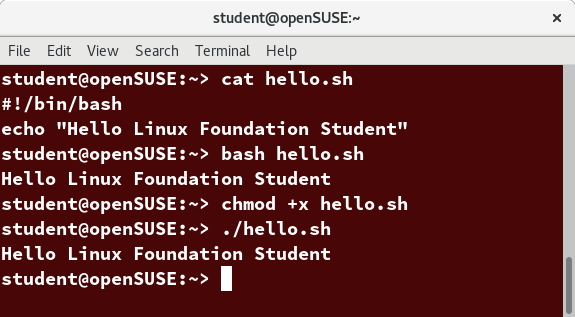 A Simple bash Script
A Simple bash Script
Interactive Example Using bash Scripts
Now, let's see how to create a more interactive example using a bash script. The user will be prompted to enter a value, which is then displayed on the screen. The value is stored in a temporary variable, name. We can reference the value of a shell variable by using a $ in front of the variable name, such as $name. To create this script, you need to create a file named getname.sh in your favorite editor with the following content:
#!/bin/bash
# Interactive reading of a variable
echo "ENTER YOUR NAME"
read name
# Display variable input
echo The name given was :$name
Once again, make it executable by doing chmod +x getname.sh.
In the above example, when the user types ./getname.sh and the script is executed, the user is prompted with the string ENTER YOUR NAME. The user then needs to enter a value and press the Enter key. The value will then be printed out.
NOTE: The hash-tag/pound-sign/number-sign (#) is used to start comments in the script and can be placed anywhere in the line (the rest of the line is considered a comment). However, note the special magic combination of #!, used on the first line, is a unique exception to this rule.
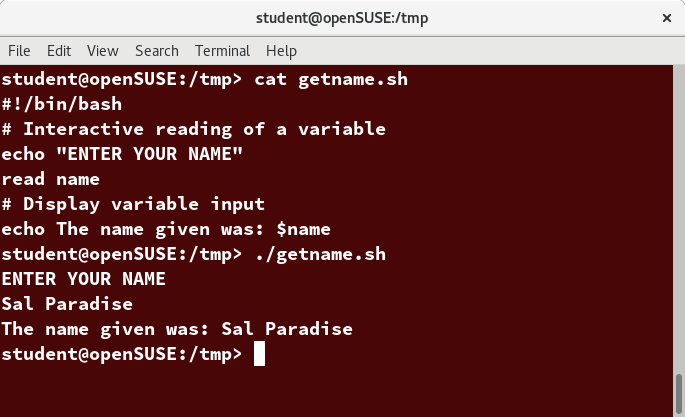 Interactive Example Using bash Scripts
Interactive Example Using bash Scripts
Return Values
All shell scripts generate a return value upon finishing execution, which can be explicitly set with the exit statement. Return values permit a process to monitor the exit state of another process, often in a parent-child relationship. Knowing how the process terminates enables taking any appropriate steps which are necessary or contingent on success or failure.
 Return Values
Return Values
Viewing Return Values
As a script executes, one can check for a specific value or condition and return success or failure as the result. By convention, success is returned as 0, and failure is returned as a non-zero value. An easy way to demonstrate success and failure completion is to execute ls on a file that exists as well as one that does not, the return value is stored in the environment variable represented by $?:
$ ls /etc/logrotate.conf
/etc/logrotate.conf
$ echo $?
0
In this example, the system is able to locate the file /etc/logrotate.conf and **ls** returns a value of 0 to indicate success. When run on a non-existing file, it returns 2. Applications often translate these return values into meaningful messages easily understood by the user.
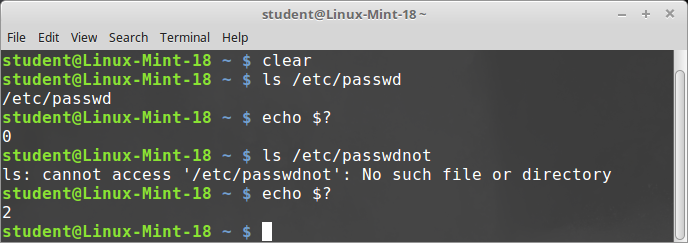 Viewing Return Values
Viewing Return Values
Basic Syntax and Special Characters
Scripts require you to follow a standard language syntax. Rules delineate how to define variables and how to construct and format allowed statements, etc. The table lists some special character usages within bash scripts:
| Character | Description |
| # | Used to add a comment, except when used as #, or as #! when starting a script |
| \ | Used at the end of a line to indicate continuation on to the next line |
| ; | Used to interpret what follows as a new command to be executed next |
| $ | Indicates what follows is an environment variable |
| > | Redirect output |
| >> | Append output |
| < | Redirect input |
| | | Used to pipe the result into the next command |
There are other special characters and character combinations and constructs that scripts understand, such as (..), {..}, [..], &&, ||, ', ", $((...)), some of which we will discuss later.
Splitting Long Commands Over Multiple Lines
Sometimes, commands are too long to either easily type on one line, or to grasp and understand (even though there is no real practical limit to the length of a command line).
In this case, the concatenation operator (\), the backslash character, is used to continue long commands over several lines.
Here is an example of a command installing a long list of packages on a system using Debian package management:
$~/> cd $HOME
$~/> sudo apt-get install autoconf automake bison build-essential \
chrpath curl diffstat emacs flex gcc-multilib g++-multilib \
libsdl1.2-dev libtool lzop make mc patch \
screen socat sudo tar texinfo tofrodos u-boot-tools unzip \
vim wget xterm zip
The command is divided into multiple lines to make it look readable and easier to understand. The \ operator at the end of each line causes the shell to combine (concatenate) multiple lines and executes them as one single command.
 Splitting Long Commands Over Multiple Lines
Splitting Long Commands Over Multiple Lines
Putting Multiple Commands on a Single Line
Users sometimes need to combine several commands and statements and even conditionally execute them based on the behavior of operators used in between them. This method is called chaining of commands.
There are several different ways to do this, depending on what you want to do. The **;** (semicolon) character is used to separate these commands and execute them sequentially, as if they had been typed on separate lines. Each ensuing command is executed whether or not the preceding one succeeded.
Thus, the three commands in the following example will all execute, even if the ones preceding them fail:
$ make ; make install ; make clean
However, you may want to abort subsequent commands when an earlier one fails. You can do this using the && (and) operator as in:
$ make && make install && make clean
If the first command fails, the second one will never be executed. A final refinement is to use the || (or) operator, as in:
$ cat file1 || cat file2 || cat file3
In this case, you proceed until something succeeds and then you stop executing any further steps.
Chaining commands is not the same as piping them; in the later case succeeding commands begin operating on data streams produced by earlier ones before they complete, while in chaining each step exits before the next one starts.
 Putting Multiple Commands on a Single Line
Putting Multiple Commands on a Single Line
Output Redirection
Most operating systems accept input from the keyboard and display the output on the terminal. However, in shell scripting you can send the output to a file. The process of diverting the output to a file is called output redirection. We have already used this facility in our earlier sections on how to use the command line.
The > character is used to write output to a file. For example, the following command sends the output of **free** to /tmp/free.out:
$ free > /tmp/free.out
To check the contents of /tmp/free.out, at the command prompt type cat /tmp/free.out.
Two > characters (>>) will append output to a file if it exists, and act just like > if the file does not already exist.
 Output Redirection
Output Redirection
Input Redirection
Just as the output can be redirected to a file, the input of a command can be read from a file. The process of reading input from a file is called input redirection and uses the < character.
The following three commands (using wc to count the number of lines, words and characters in a file) are entirely equivalent and involve input redirection, and a command operating on the contents of a file:
$ wc < /etc/passwd
49 105 2678 /etc/passwd
$ wc /etc/passwd
49 105 2678 /etcpasswd
$ cat /etc/passwd | wc
49 105 2678
Built-In Shell Commands
Shell scripts execute sequences of commands and other types of statements. These commands can be:
- Compiled applications
- Built-in bash commands
- Shell scripts or scripts from other interpreted languages, such as perl and Python.
Compiled applications are binary executable files, generally residing on the filesystem in well-known directories such as /usr/bin. Shell scripts always have access to applications such as rm, ls, df, vi, and gzip, which are programs compiled from lower level programming languages such as C.
In addition, bash has many built-in commands, which can only be used to display the output within a terminal shell or shell script. Sometimes, these commands have the same name as executable programs on the system, such as echo, which can lead to subtle problems. bash built-in commands include cd, pwd, echo, read, logout, printf, let, and ulimit. Thus, slightly different behavior can be expected from the built-in version of a command such as echo as compared to /bin/echo.
A complete list of bash built-in commands can be found in the bash man page, or by simply typing help, as we review on the next page.
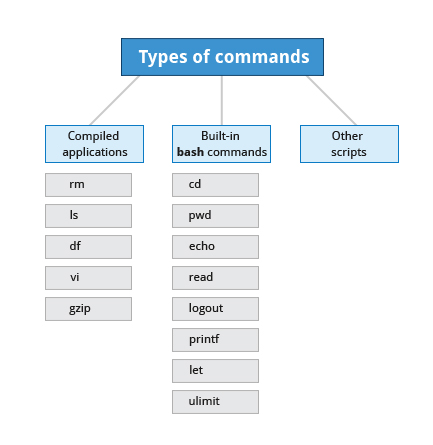 Built-In Shell Commands
Built-In Shell Commands
Commands Built in to bash
We already enumerated which commands have versions built in to bash, in our earlier discussion of how to get help on Linux systems. Once again, here is a screenshot listing exactly which commands are available.
Commands Built in to bash
Script Parameters
Users often need to pass parameter values to a script, such as a filename, date, etc. Scripts will take different paths or arrive at different values according to the parameters (command arguments) that are passed to them. These values can be text or numbers as in:
$ ./script.sh /tmp
$ ./script.sh 100 200
Within a script, the parameter or an argument is represented with a $ and a number or special character. The table lists some of these parameters.
| Parameter | Meaning |
| $0 | Script name |
| $1 | First parameter |
| $2, $3, etc. | Second, third parameter, etc. |
| $* | All parameters |
| $# | Number of arguments |
Using Script Parameters
If you type in the script shown in the figure, make the script executable with chmod +x param.sh. Then, run the script giving it several arguments, as shown. The script is processed as follows:
$0 prints the script name: param.sh
$1 prints the first parameter: one
$2 prints the second parameter: two
$3 prints the third parameter: three
$* prints all parameters: one two three four five
The final statement becomes: All done with param.sh
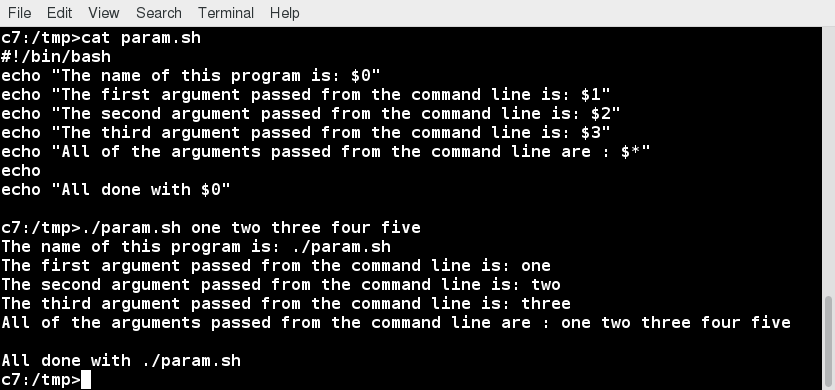 Using Script Parameters
Using Script Parameters
Command Substitution
At times, you may need to substitute the result of a command as a portion of another command. It can be done in two ways:
- By enclosing the inner command in $( )
- By enclosing the inner command with backticks (`)
The second, backticks form, is deprecated in new scripts and commands. No matter which method is used, the specified command will be executed in a newly launched shell environment, and the standard output of the shell will be inserted where the command substitution is done.
Virtually any command can be executed this way. While both of these methods enable command substitution, the $( ) method allows command nesting. New scripts should always use this more modern method. For example:
$ ls /lib/modules/$(uname -r)/
In the above example, the output of the command uname –r (which will be something like 5.13.3), is inserted into the argument for the ls command.
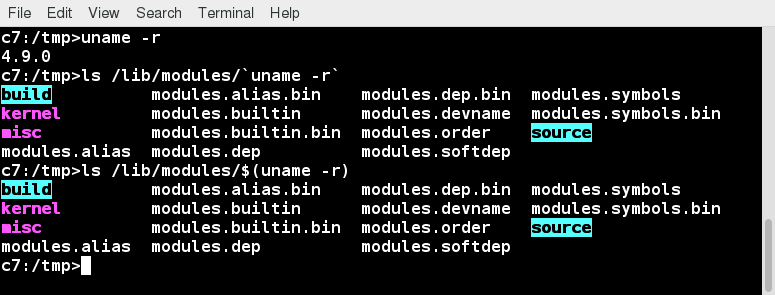 Command Substitution
Command Substitution
Environment Variables
Most scripts use variables containing a value, which can be used anywhere in the script. These variables can either be user or system-defined. Many applications use such environment variables (already covered in some detail in the User Environment chapter) for supplying inputs, validation, and controlling behavior.
As we discussed earlier, some examples of standard environment variables are HOME, PATH, and HOST. When referenced, environment variables must be prefixed with the $ symbol, as in $HOME. You can view and set the value of environment variables. For example, the following command displays the value stored in the PATH variable:
$ echo $PATH
However, no prefix is required when setting or modifying the variable value. For example, the following command sets the value of the MYCOLOR variable to blue:
$ MYCOLOR=blue
You can get a list of environment variables with the env, set, or printenv commands.
 Environment Variables
Environment Variables
Exporting Environment Variables
While we discussed the export of environment variables in the section on the "User Environment", it is worth reviewing this topic in the context of writing bash scripts.
By default, the variables created within a script are available only to the subsequent steps of that script. Any child processes (sub-shells) do not have automatic access to the values of these variables. To make them available to child processes, they must be promoted to environment variables using the export statement, as in:
export VAR=value
or
VAR=value ; export VAR
While child processes are allowed to modify the value of exported variables, the parent will not see any changes; exported variables are not shared, they are only copied and inherited.
Typing export with no arguments will give a list of all currently exported environment variables.
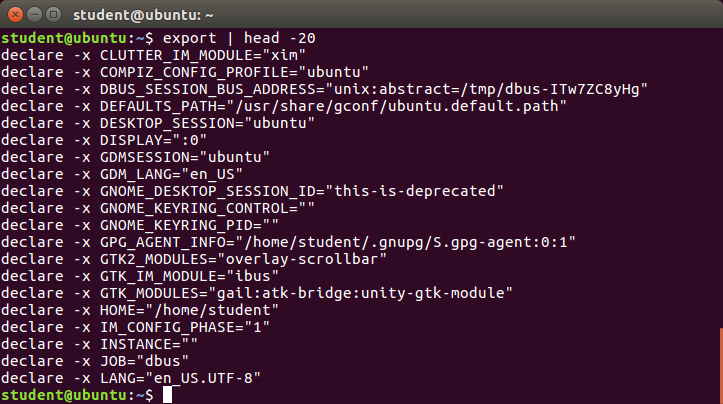 Exporting Variables
Exporting Variables
Functions
A function is a code block that implements a set of operations. Functions are useful for executing procedures multiple times, perhaps with varying input variables. Functions are also often called subroutines. Using functions in scripts requires two steps:
- Declaring a function
- Calling a function
The function declaration requires a name which is used to invoke it. The proper syntax is:
function_name () {
command...
}
For example, the following function is named display:
display () {
echo "This is a sample function"
}
The function can be as long as desired and have many statements. Once defined, the function can be called later as many times as necessary. In the full example shown in the figure, we are also showing an often-used refinement: how to pass an argument to the function. The first argument can be referred to as $1, the second as $2, etc.
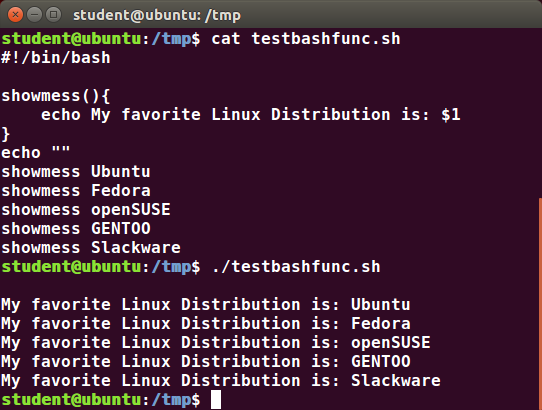 Functions
Functions
The if Statement
Conditional decision making, using an if statement, is a basic construct that any useful programming or scripting language must have.
When an if statement is used, the ensuing actions depend on the evaluation of specified conditions, such as:
- Numerical or string comparisons
- Return value of a command (0 for success)
- File existence or permissions
In compact form, the syntax of an if statement is:
if TEST-COMMANDS; then CONSEQUENT-COMMANDS; fi
A more general definition is:
if condition
then
statements
else
statements
fi
 The if Statement
The if Statement
Using the if Statement
In the following example, an if statement checks to see if a certain file exists, and if the file is found, it displays a message indicating success or failure:
if [ -f "$1" ]
then
echo file "$1 exists"
else
echo file "$1" does not exist
fi
We really should also check first that there is an argument passed to the script ($1) and abort if not.
Notice the use of the square brackets ([]) to delineate the test condition. There are many other kinds of tests you can perform, such as checking whether two numbers are equal to, greater than, or less than each other and make a decision accordingly; we will discuss these other tests.

In modern scripts, you may see doubled brackets as in [[ -f /etc/passwd ]]. This is not an error. It is never wrong to do so and it avoids some subtle problems, such as referring to an empty environment variable without surrounding it in double quotes; we will not talk about this here.
The elif Statement
You can use the elif statement to perform more complicated tests, and take action appropriate actions. The basic syntax is:
if [ sometest ] ; then
echo Passed test1
elif [ somothertest ] ; then
echo Passed test2
fi
In the example shown we use strings tests which we will explain shortly, and show how to pull in an environment variable with the read statement.
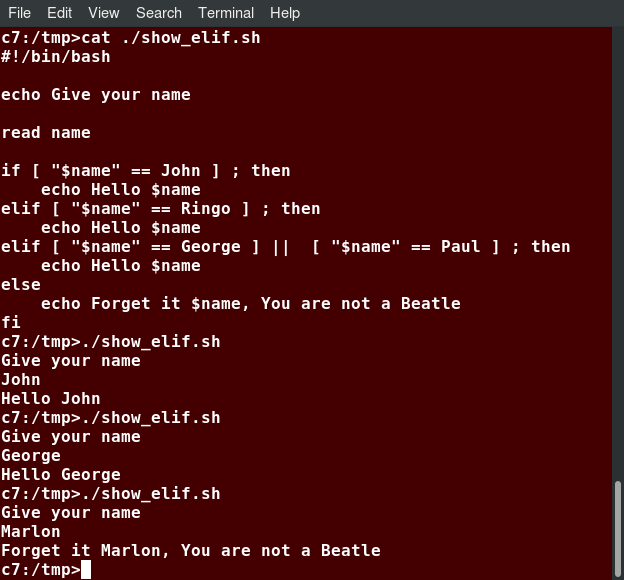 The elif Statement
The elif Statement
Testing for Files
bash provides a set of file conditionals, that can be used with the if statement, including those in the table.
You can use the if statement to test for file attributes, such as:
- File or directory existence
- Read or write permission
- Executable permission.
For example, in the following example:
if [ -x /etc/passwd ] ; then
ACTION
fi
the if statement checks if the file /etc/passwd is executable, which it is not. Note the very common practice of putting:
; then
on the same line as the if statement.
You can view the full list of file conditions typing:
man 1 test.
| Condition | Meaning |
| -e file | Checks if the file exists. |
| -d file | Checks if the file is a directory. |
| -f file | Checks if the file is a regular file (i.e. not a symbolic link, device node, directory, etc.) |
| -s file | Checks if the file is of non-zero size. |
| -g file | Checks if the file has sgid set. |
| -u file | Checks if the file has suid set. |
| -r file | Checks if the file is readable. |
| -w file | Checks if the file is writable. |
| -x file | Checks if the file is executable. |
Boolean Expressions
Boolean expressions evaluate to either TRUE or FALSE, and results are obtained using the various Boolean operators listed in the table.
| Operator | Operation | Meaning |
| && | AND | The action will be performed only if both the conditions evaluate to true. |
| || | OR | The action will be performed if any one of the conditions evaluate to true. |
| ! | NOT | The action will be performed only if the condition evaluates to false. |
Note that if you have multiple conditions strung together with the && operator, processing stops as soon as a condition evaluates to false. For example, if you have A && B && C and A is true but B is false, C will never be executed.
Likewise, if you are using the || operator, processing stops as soon as anything is true. For example, if you have A || B || C and A is false and B is true, you will also never execute C.
Tests in Boolean Expressions
Boolean expressions return either TRUE or FALSE. We can use such expressions when working with multiple data types, including strings or numbers, as well as with files. For example, to check if a file exists, use the following conditional test:
[ -e ]
Similarly, to check if the value of number1 is greater than the value of number2, use the following conditional test:
[ $number1 -gt $number2 ]
The operator -gt returns TRUE if number1 is greater than number2.

Example of Testing of Strings
You can use the if statement to compare strings using the operator == (two equal signs). The syntax is as follows:
if [ string1 == string2 ] ; then
ACTION
fi
Note that using one = sign will also work, but some consider it deprecated usage. Let’s now consider an example of testing strings.
In the example illustrated here, the if statement is used to compare the input provided by the user and accordingly display the result.
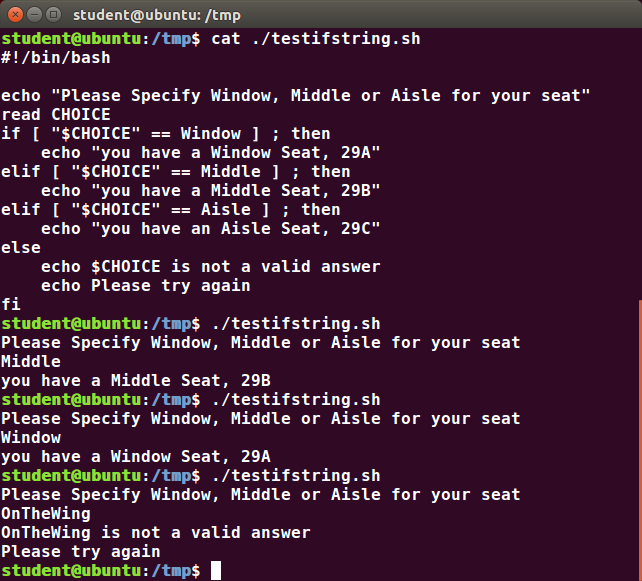 Example of Testing of Strings
Example of Testing of Strings
Numerical Tests
You can use specially defined operators with the if statement to compare numbers. The various operators that are available are listed in the table:
| Operator | Meaning |
| -eq | Equal to |
| -ne | Not equal to |
| -gt | Greater than |
| -lt | Less than |
| -ge | Greater than or equal to |
| -le | Less than or equal to |
The syntax for comparing numbers is as follows:
exp1 -op exp2
Example of Testing for Numbers
Let us now consider an example of comparing numbers using the various operators:
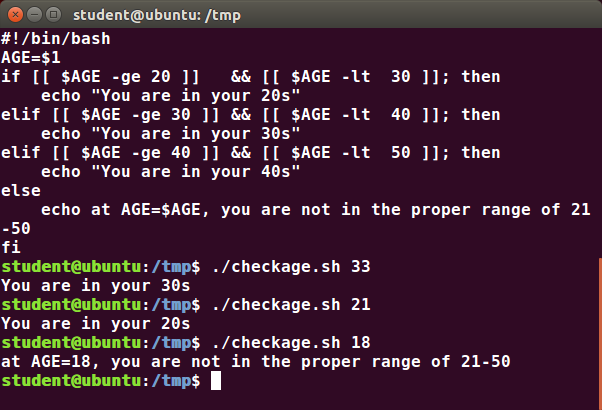 Example of Testing for Numbers
Example of Testing for Numbers
Arithmetic Expressions
Arithmetic expressions can be evaluated in the following three ways (spaces are important!):
- Using the expr utility
expr is a standard but somewhat deprecated program. The syntax is as follows:expr 8 + 8
echo $(expr 8 + 8) - Using the $((...)) syntax
This is the built-in shell format. The syntax is as follows:echo $((x+1)) - Using the built-in shell command let. The syntax is as follows:let x=( 1 + 2 ); echo $x
In modern shell scripts, the use of expr is better replaced with var=$((...)).
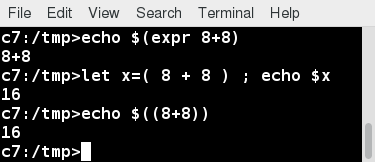 Arithmetic Expressions
Arithmetic Expressions
Chapter Summary
You have completed Chapter 15. Let’s summarize the key concepts covered:
- Scripts are a sequence of statements and commands stored in a file that can be executed by a shell. The most commonly used shell in Linux is bash.
- Command substitution allows you to substitute the result of a command as a portion of another command.
- Functions or routines are a group of commands that are used for execution.
- Environmental variables are quantities either preassigned by the shell or defined and modified by the user.
- To make environment variables visible to child processes, they need to be exported.
- Scripts can behave differently based on the parameters (values) passed to them.
- The process of writing the output to a file is called output redirection.
- The process of reading input from a file is called input redirection.
- The if statement is used to select an action based on a condition.
- Arithmetic expressions consist of numbers and arithmetic operators, such as +, -, and *.
Chapter 16: More on Bash Shell Scripting
Learning Objectives
By the end of this chapter, you should be able to:
- Manipulate strings to perform actions such as comparison and sorting.
- Use Boolean expressions when working with multiple data types, including strings or numbers, as well as files.
- Use case statements to handle command line options.
- Use looping constructs to execute one or more lines of code repetitively.
- Debug scripts using set -x and set +x.
- Create temporary files and directories.
- Create and use random numbers.
String Manipulation
Let’s go deeper and find out how to work with strings in scripts.
A string variable contains a sequence of text characters. It can include letters, numbers, symbols and punctuation marks. Some examples include: abcde, 123, abcde 123, abcde-123, &acbde=%123.
String operators include those that do comparison, sorting, and finding the length. The following table demonstrates the use of some basic string operators:
| Operator | Meaning |
| [[ string1 > string2 ]] | Compares the sorting order of string1 and string2. |
| [[ string1 == string2 ]] | Compares the characters in string1 with the characters in string2. |
| myLen1=${#string1} | Saves the length of string1 in the variable myLen1. |
Example of String Manipulation
In the first example, we compare the first string with the second string and display an appropriate message using the if statement.
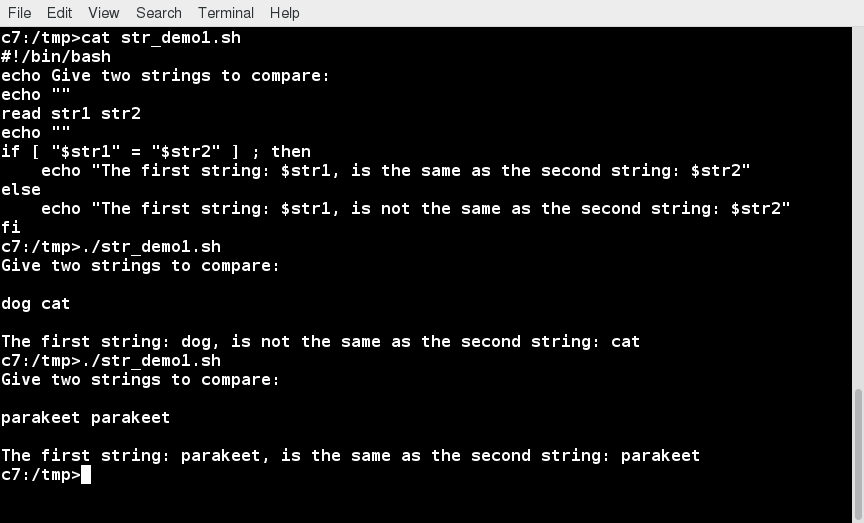 Comparing strings and Using if Statement
Comparing strings and Using if Statement
In the second example, we pass in a file name and see if that file exists in the current directory or not.
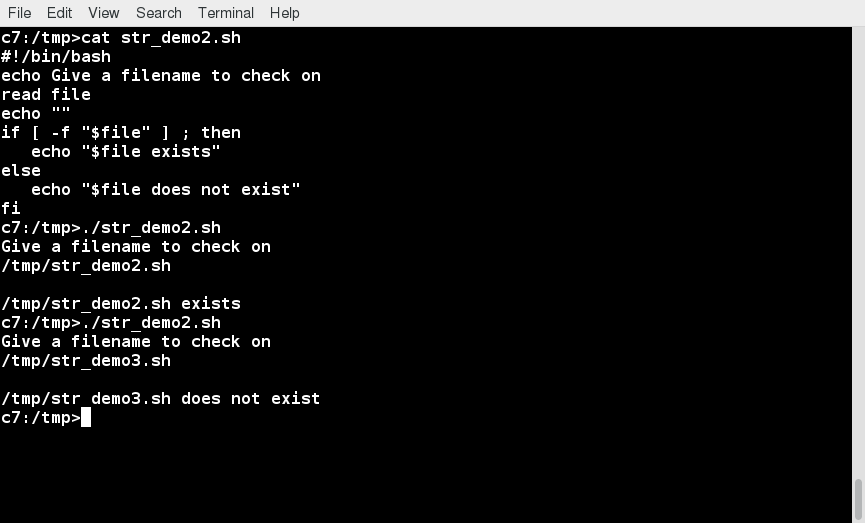 Passing a File Name and Checking if It Exists in the Current Directory
Passing a File Name and Checking if It Exists in the Current Directory
Parts of a String
At times, you may not need to compare or use an entire string. To extract the first n characters of a string we can specify: ${string:0:n}. Here, 0 is the offset in the string (i.e. which character to begin from) where the extraction needs to start and n is the number of characters to be extracted.
To extract all characters in a string after a dot (.), use the following expression: ${string#*.}.
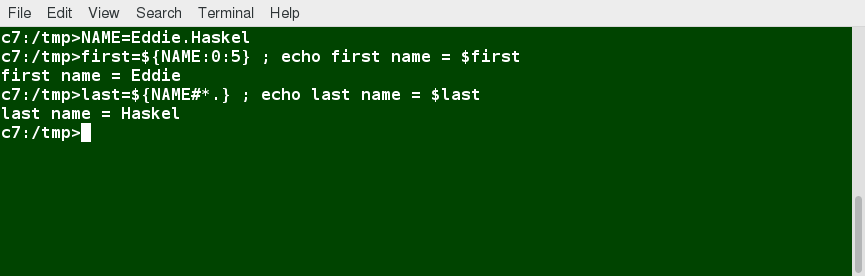 Parts of a String
Parts of a String
The case Statement
The case statement is used in scenarios where the actual value of a variable can lead to different execution paths. case statements are often used to handle command-line options.
Below are some of the advantages of using the case statement:
- It is easier to read and write.
- It is a good alternative to nested, multi-level if-then-else-fi code blocks.
- It enables you to compare a variable against several values at once.
- It reduces the complexity of a program.
 Features of case Statement
Features of case Statement
Structure of the case Statement
Here is the basic structure of the case statement:
case expression in
pattern1) execute commands;;
pattern2) execute commands;;
pattern3) execute commands;;
pattern4) execute commands;;
* ) execute some default commands or nothing ;;
esac
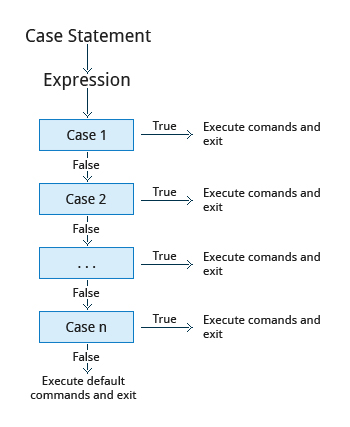 Structure of the case Statement
Structure of the case Statement
Example of Use of the case Construct
Here is an example of the use of a case construct. Note you can have multiple possibilities for each case value that take the same action.
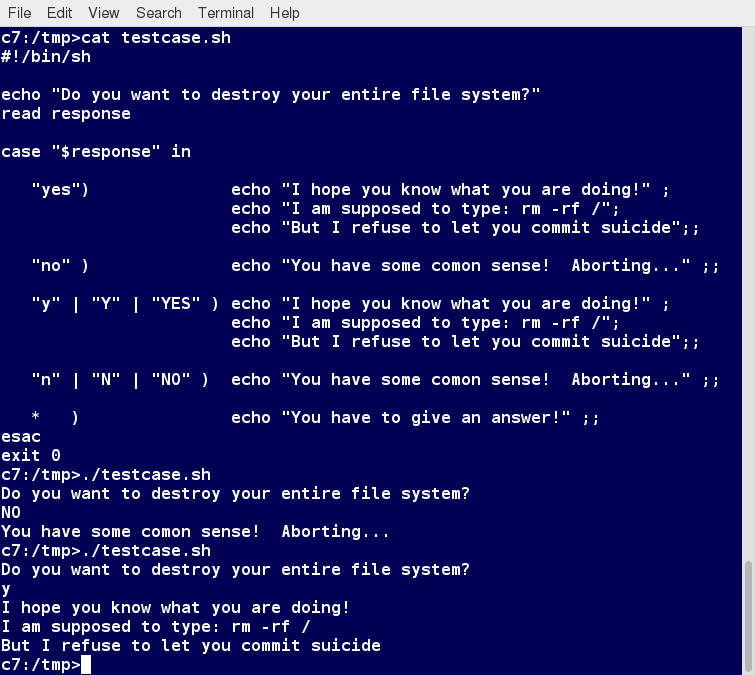 Example of Use of the case Construct
Example of Use of the case Construct
Looping Constructs
By using looping constructs, you can execute one or more lines of code repetitively, usually on a selection of values of data such as individual files. Usually, you do this until a conditional test returns either true or false, as is required.
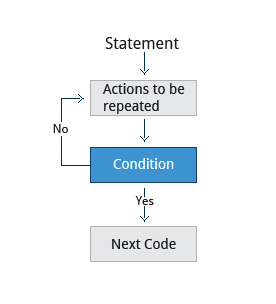
Looping Constructs
Three types of loops are often used in most programming languages:
- for
- while
- until
All these loops are easily used for repeating a set of statements until the exit condition is true.
The for Loop
The for loop operates on each element of a list of items. The syntax for the for loop is:
for variable-name in list
do
execute one iteration for each item in the list until the list is finished
done
In this case, variable-name and list are substituted by you as appropriate (see examples). As with other looping constructs, the statements that are repeated should be enclosed by do and done.
The screenshot here shows an example of the for loop to print the sum of numbers 1 to 10.
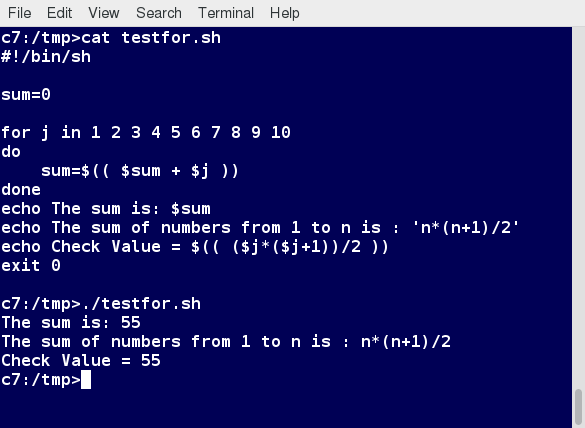 The for Loop
The for Loop
The while Loop
The while loop repeats a set of statements as long as the control command returns true. The syntax is:
while condition is true
do
Commands for execution
done
The set of commands that need to be repeated should be enclosed between do and done. You can use any command or operator as the condition. Often, it is enclosed within square brackets ([]).
The screenshot here shows an example of the while loop that calculates the factorial of a number. Do you know why the computation of 21! gives a bad result?
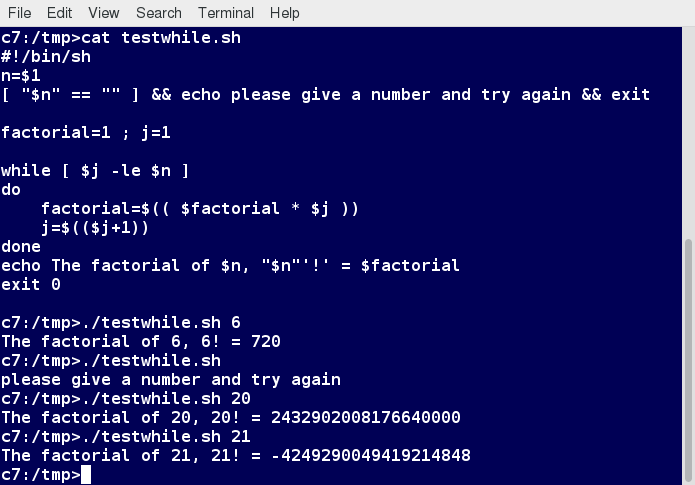 The while Loop
The while Loop
The until Loop
The until loop repeats a set of statements as long as the control command is false. Thus, it is essentially the opposite of the while loop. The syntax is:
until condition is false
do
Commands for execution
done
Similar to the while loop, the set of commands that need to be repeated should be enclosed between do and done. You can use any command or operator as the condition.
The screenshot here shows an example of the until loop that once again computes factorials; it is only slightly different than the test case for the while loop.
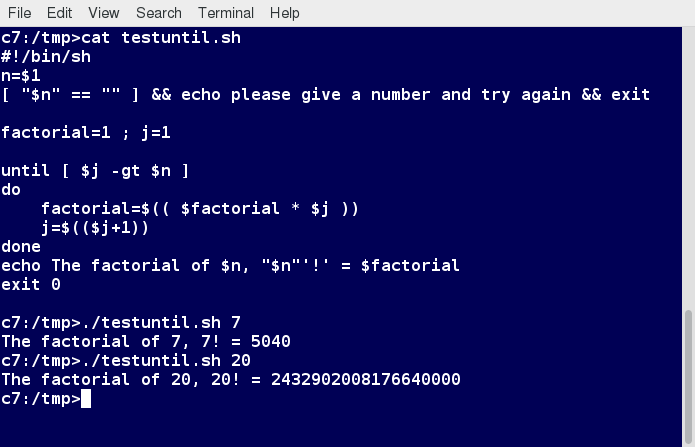 The until Loop
The until Loop
Debugging bash Scripts
While working with scripts and commands, you may run into errors. These may be due to an error in the script, such as an incorrect syntax, or other ingredients, such as a missing file or insufficient permission to do an operation. These errors may be reported with a specific error code, but often just yield incorrect or confusing output. So, how do you go about identifying and fixing an error?

Debugging helps you troubleshoot and resolve such errors, and is one of the most important tasks a system administrator performs.
Script Debug Mode
Before fixing an error (or bug), it is vital to know its source.
You can run a bash script in debug mode either by doing bash –x ./script_file, or bracketing parts of the script with set -x and set +x. The debug mode helps identify the error because:
- It traces and prefixes each command with the + character.
- It displays each command before executing it.
- It can debug only selected parts of a script (if desired) with:
set -x # turns on debugging
...
set +x # turns off debugging
The screenshot shown here demonstrates a script which runs in debug mode if run with any argument on the command line.
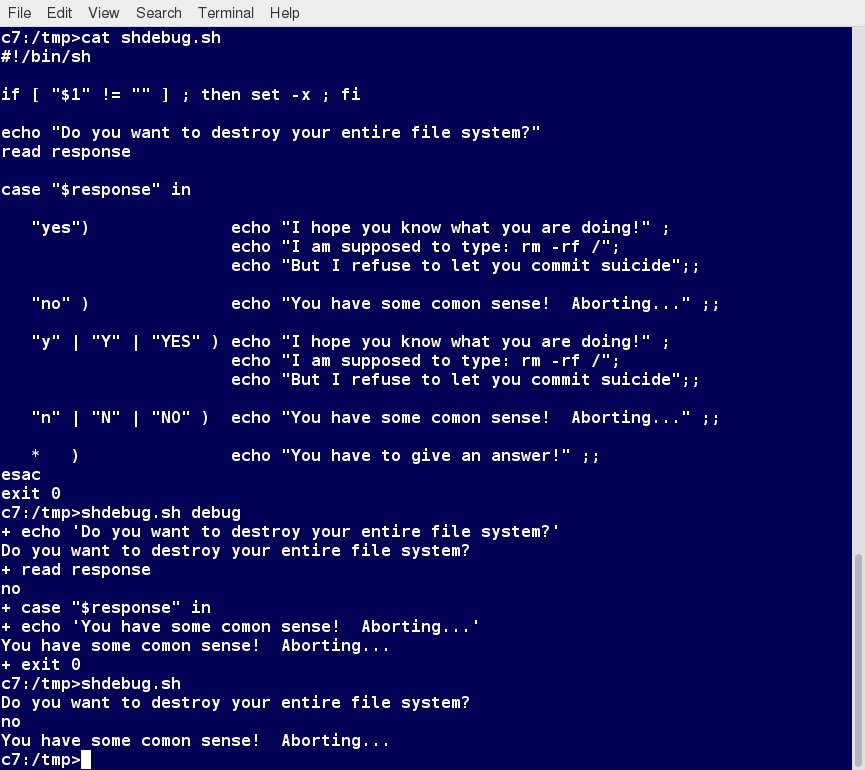 Script Debug Mode
Script Debug Mode
Redirecting Errors to File and Screen
In UNIX/Linux, all programs that run are given three open file streams when they are started as listed in the table:
| File stream | Description | File Descriptor |
| stdin | Standard Input, by default the keyboard/terminal for programs run from the command line | 0 |
| stdout | Standard output, by default the screen for programs run from the command line | 1 |
| stderr | Standard error, where output error messages are shown or saved | 2 |
Using redirection, we can save the stdout and stderr output streams to one file or two separate files for later analysis after a program or command is executed.
The screenshot shows a shell script with a simple bug, which is then run and the error output is diverted to error.log. Using cat to display the contents of the error log adds in debugging. Do you see how to fix the script?
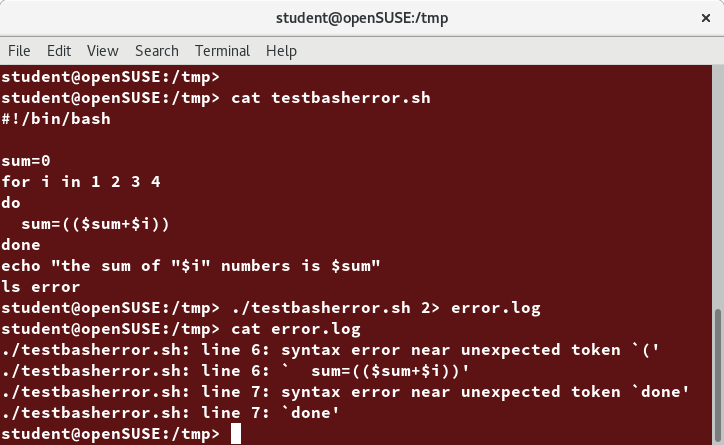 Redirecting Errors to File and Screen
Redirecting Errors to File and Screen
Creating Temporary Files and Directories
Consider a situation where you want to retrieve 100 records from a file with 10,000 records. You will need a place to store the extracted information, perhaps in a temporary file, while you do further processing on it.
Temporary files (and directories) are meant to store data for a short time. Usually, one arranges it so that these files disappear when the program using them terminates. While you can also use touch to create a temporary file, in some circumstances this may make it easy for hackers to gain access to your data. This is particularly true if the name and the file location of the temporary file are predictable.
The best practice is to create random and unpredictable filenames for temporary storage. One way to do this is with the mktemp utility, as in the following examples.
The XXXXXXXX is replaced by mktemp with random characters to ensure the name of the temporary file cannot be easily predicted and is only known within your program.
| Command | Usage |
| TEMP=$(mktemp /tmp/tempfile.XXXXXXXX) | To create a temporary file |
| TEMPDIR=$(mktemp -d /tmp/tempdir.XXXXXXXX) | To create a temporary directory |
Example of Creating a Temporary File and Directory
Sloppiness in creation of temporary files can lead to real damage, either by accident or if there is a malicious actor. For example, if someone were to create a symbolic link from a known temporary file used by root to the /etc/passwd file, like this:
$ ln -s /etc/passwd /tmp/tempfile
There could be a big problem if a script run by root has a line in it like this:
echo $VAR > /tmp/tempfile
The password file will be overwritten by the temporary file contents.
To prevent such a situation, make sure you randomize your temporary file names by replacing the above line with the following lines:
TEMP=$(mktemp /tmp/tempfile.XXXXXXXX)
echo $VAR > $TEMP
Note the screen capture shows similarly named temporary files from different days, but with randomly generated characters in them.
 Example of Creating a Temporary File and Directory
Example of Creating a Temporary File and Directory
Discarding Output with /dev/null
Certain commands (like find) will produce voluminous amounts of output, which can overwhelm the console. To avoid this, we can redirect the large output to a special file (a device node) called /dev/null. This pseudofile is also called the bit bucket or black hole.
All data written to it is discarded and write operations never return a failure condition. Using the proper redirection operators, it can make the output disappear from commands that would normally generate output to stdout and/or stderr:
$ ls -lR /tmp > /dev/null
In the above command, the entire standard output stream is ignored, but any errors will still appear on the console. However, if one does:
$ ls -lR /tmp >& /dev/null
both stdout and stderr will be dumped into /dev/null.
 Discarding Output with /dev/null
Discarding Output with /dev/null
Random Numbers and Data
It is often useful to generate random numbers and other random data when performing tasks such as:
- Performing security-related tasks
- Reinitializing storage devices
- Erasing and/or obscuring existing data
- Generating meaningless data to be used for tests
Such random numbers can be generated by using the $RANDOM environment variable, which is derived from the Linux kernel’s built-in random number generator, or by the OpenSSL library function, which uses the FIPS140 (Federal Information Processing Standard) algorithm to generate random numbers for encryption
To learn about FIPS140, read Wikipedia's _"FIPS 140-2"_ article.
The example shows you how to easily use the environmental variable method to generate random numbers.
 Random Numbers and Data
Random Numbers and Data
How the Kernel Generates Random Numbers
Some servers have hardware random number generators that take as input different types of noise signals, such as thermal noise and photoelectric effect. A transducer converts this noise into an electric signal, which is again converted into a digital number by an A-D converter. This number is considered random. However, most common computers do not contain such specialized hardware and, instead, rely on events created during booting to create the raw data needed.
Regardless of which of these two sources is used, the system maintains a so-called entropy pool of these digital numbers/random bits. Random numbers are created from this entropy pool.
The Linux kernel offers the /dev/random and /dev/urandom device nodes, which draw on the entropy pool to provide random numbers which are drawn from the estimated number of bits of noise in the entropy pool.
/dev/random is used where very high quality randomness is required, such as one-time pad or key generation, but it is relatively slow to provide values. /dev/urandom is faster and suitable (good enough) for most cryptographic purposes.
Furthermore, when the entropy pool is empty, /dev/random is blocked and does not generate any number until additional environmental noise (network traffic, mouse movement, etc.) is gathered, whereas /dev/urandom reuses the internal pool to produce more pseudo-random bits.
 How the Kernel Generates Random Numbers
How the Kernel Generates Random Numbers
Chapter Summary
You have completed Chapter 16. Let’s summarize the key concepts covered:
- You can manipulate strings to perform actions such as comparison, sorting, and finding length.
- You can use Boolean expressions when working with multiple data types, including strings or numbers, as well as files.
- The output of a Boolean expression is either true or false.
- Operators used in Boolean expressions include the && (AND), || (OR), and ! (NOT) operators.
- We looked at the advantages of using the case statement in scenarios where the value of a variable can lead to different execution paths.
- Script debugging methods help troubleshoot and resolve errors.
- The standard and error outputs from a script or shell commands can easily be redirected into the same file or separate files to aid in debugging and saving results.
- Linux allows you to create temporary files and directories, which store data for a short duration, both saving space and increasing security.
- Linux provides several different ways of generating random numbers, which are widely used.
Chapter 17: Printing
Learning Objectives
By the end of this chapter, you should know how to:
- Configure a printer on a Linux machine.
- Print documents.
- Manipulate postscript and PDF files using command line utilities.
Printing on Linux
To manage printers and print directly from a computer or across a networked environment, you need to know how to configure and install a printer. Printing itself requires software that converts information from the application you are using to a language your printer can understand. The Linux standard for printing software is the Common UNIX Printing System (CUPS).

Modern Linux desktop systems make installing and administering printers pretty simple and intuitive, and not unlike how it is done on other operating systems. Nevertheless, it is instructive to understand the underpinnings of how it is done in Linux.
CUPS Overview
CUPS is the underlying software almost all Linux systems use to print from applications like a web browser or LibreOffice. It converts page descriptions produced by your application (put a paragraph here, draw a line there, and so forth) and then sends the information to the printer. It acts as a print server for both local and network printers.
Printers manufactured by different companies may use their own particular print languages and formats. CUPS uses a modular printing system which accommodates a wide variety of printers and also processes various data formats. This makes the printing process simpler; you can concentrate more on printing and less on how to print.
![]()
Generally, the only time you should need to configure your printer is when you use it for the first time. In fact, CUPS often figures things out on its own by detecting and configuring any printers it locates.
How Does CUPS Work?
CUPS carries out the printing process with the help of its various components:
- Configuration files
- Scheduler
- Job files
- Log files
- Filter
- Printer drivers
- Backend.
You will learn about each of these components on the next few pages.
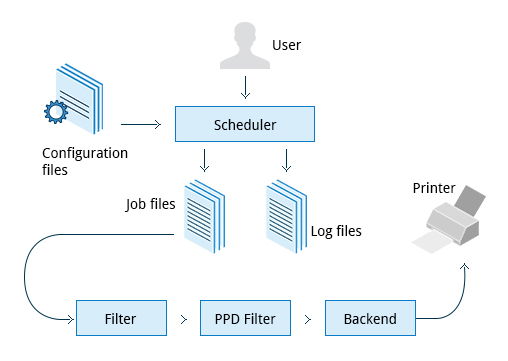 How CUPS Works
How CUPS Works
Scheduler
CUPS is designed around a print scheduler that manages print jobs, handles administrative commands, allows users to query the printer status, and manages the flow of data through all CUPS components.
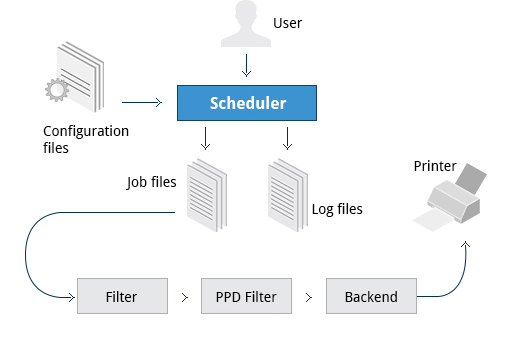 Scheduler
Scheduler
We will look at the browser-based interface that can be used with CUPS, which allows you to view and manipulate the order and status of pending print jobs.
Configuration Files
The print scheduler reads server settings from several configuration files, the two most important of which are cupsd.conf and printers.conf. These and all other CUPS related configuration files are stored under the /etc/cups/ directory.
cupsd.conf is where most system-wide settings are located; it does not contain any printer-specific details. Most of the settings available in this file relate to network security, i.e. which systems can access CUPS network capabilities, how printers are advertised on the local network, what management features are offered, and so on.
printers.conf is where you will find the printer-specific settings. For every printer connected to the system, a corresponding section describes the printer’s status and capabilities. This file is generated or modified only after adding a printer to the system, and should not be modified by hand.
You can view the full list of configuration files by typing ls -lF /etc/cups.
 /etc/cups/ Directory
/etc/cups/ Directory
Job Files
CUPS stores print requests as files under the /var/spool/cups directory (these can actually be accessed before a document is sent to a printer). Data files are prefixed with the letter d while control files are prefixed with the letter c.
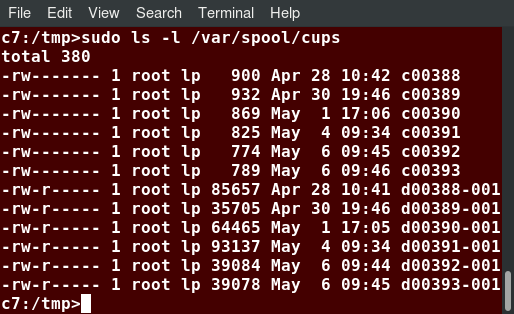 /var/spool/cups Directory
/var/spool/cups Directory
After a printer successfully handles a job, data files are automatically removed. These data files belong to what is commonly known as the print queue.
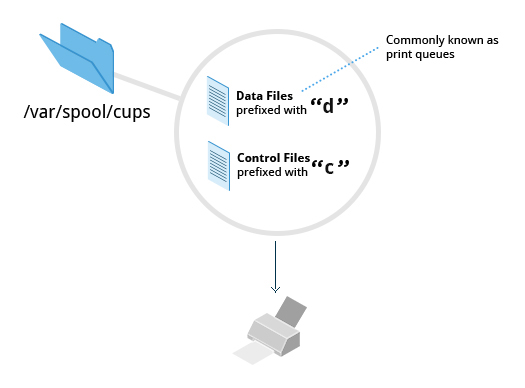 Print Queue
Print Queue
Log Files
Log files are placed in /var/log/cups and are used by the scheduler to record activities that have taken place. These files include access, error, and page records.
To view what log files exist, type:
$ sudo ls -l /var/log/cups
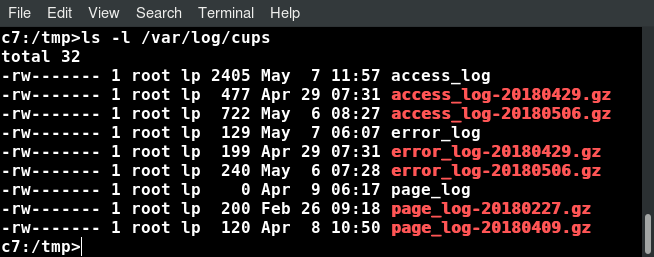 Viewing Log Files Using ls -l /var/log/cups
Viewing Log Files Using ls -l /var/log/cups
Note on some distributions permissions are set such that you do not need to use sudo. You can view the log files with the usual tools.
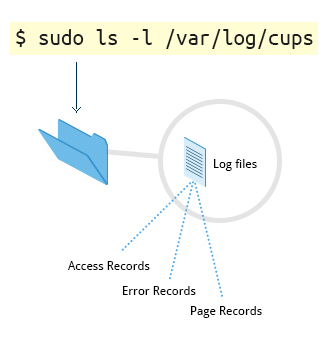 Viewing Log Files Using $ sudo ls -l /var/log/cups
Viewing Log Files Using $ sudo ls -l /var/log/cups
Filters, Printer Drivers, and Backends
CUPS uses filters to convert job file formats to printable formats. Printer drivers contain descriptions for currently connected and configured printers, and are usually stored under /etc/cups/ppd/. The print data is then sent to the printer through a filter, and via a backend that helps to locate devices connected to the system.
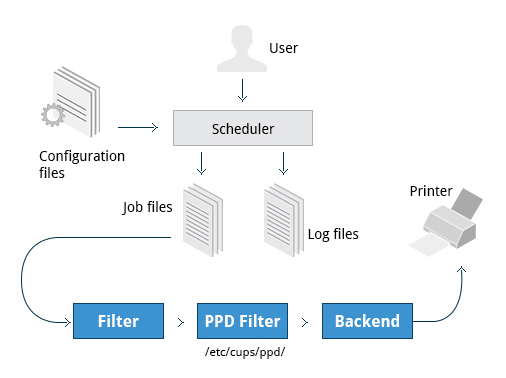 Filters, Printer Drivers, and Backends
Filters, Printer Drivers, and Backends
So, in short, when you execute a print command, the scheduler validates the command and processes the print job, creating job files according to the settings specified in the configuration files. Simultaneously, the scheduler records activities in the log files. Job files are processed with the help of the filter, printer driver, and backend, and then sent to the printer.
Managing CUPS
Assuming CUPS has been installed you'll need to start and manage the CUPS daemon so that CUPS is ready for configuring a printer. Managing the CUPS daemon is simple; all management features can be done with the systemctl utility:
$ systemctl status cups
$ sudo systemctl [enable|disable] cups
$ sudo systemctl [start|stop|restart] cups
NOTE: The next section demonstrates this on Ubuntu, but is the same for all major current Linux distributions.
Video: Managing the CUPS Daemon
Sorry, your browser doesn't support embedded videos.Configuring a Printer from the GUI
Each Linux distribution has a GUI application that lets you add, remove, and configure local or remote printers. Using this application, you can easily set up the system to use both local and network printers. The following screens show how to find and use the appropriate application in each of the distribution families covered in this course.
When configuring a printer, make sure the device is currently turned on and connected to the system; if so it should show up in the printer selection menu. If the printer is not visible, you may want to troubleshoot using tools that will determine if the printer is connected. For common USB printers, for example, the lsusb utility will show a line for the printer. Some printer manufacturers also require some extra software to be installed in order to make the printer visible to CUPS, however, due to the standardization these days, this is rarely required.
 Configuring a Printer from the GUI
Configuring a Printer from the GUI
Video: Adding a Network Printer
Sorry, your browser doesn't support embedded videos.Adding Printers from the CUPS Web Interface
A fact that few people know is that CUPS also comes with its own web server, which makes a configuration interface available via a set of CGI scripts.
This web interface allows you to:
- Add and remove local/remote printers
- Configure printers:
– Local/remote printers– Share a printer as a CUPS server
- Control print jobs:– Monitor jobs
– Show completed or pending jobs– Cancel or move jobs.
The CUPS web interface is available on your browser at: http://localhost:631.
Some pages require a username and password to perform certain actions, for example to add a printer. For most Linux distributions, you must use the root password to add, modify, or delete printers or classes.
 Screenshot of the CUPS Website
Screenshot of the CUPS Website
Printing from the Graphical Interface
Many graphical applications allow users to access printing features using the CTRL-P shortcut. To print a file, you first need to specify the printer (or a file name and location if you are printing to a file instead) you want to use; and then select the page setup, quality, and color options. After selecting the required options, you can submit the document for printing. The document is then submitted to CUPS. You can use your browser to access the CUPS web interface at http://localhost:631/ to monitor the status of the printing job. Now that you have configured the printer, you can print using either the Graphical or Command Line interfaces.
The screenshot shows the GUI interface for CTRL-P for CentOS, other Linux distributions appear virtually identical.
 GUI Interface for CTRL-P for CentOS
GUI Interface for CTRL-P for CentOS
Printing from the Command-Line Interface
CUPS provides two command-line interfaces, descended from the System V and BSD flavors of UNIX. This means that you can use either lp (System V) or lpr (BSD) to print. You can use these commands to print text, PostScript, PDF, and image files.
These commands are useful in cases where printing operations must be automated (from shell scripts, for instance, which contain multiple commands in one file).
lp is just a command line front-end to the lpr utility that passes input to lpr. Thus, we will discuss only lp in detail. In the example shown here, the task is to print $HOME/.emacs.**
 Printing from the Command-Line Interface
Printing from the Command-Line Interface
Using lp
lp and lpr accept command line options that help you perform all operations that the GUI can accomplish. lp is typically used with a file name as an argument.
Some lp commands and other printing utilities you can use are listed in the table:
| Command | Usage |
| lp <filename> | To print the file to default printer |
| lp -d printer <filename> | To print to a specific printer (useful if multiple printers are available) |
| program | lp echo string | lp | To print the output of a program |
| lp -n number <filename> | To print multiple copies |
| lpoptions -d printer | To set the default printer |
| lpq -a | To show the queue status |
| lpadmin | To configure printer queues |
lpoptions can be used to set printer options and defaults. Each printer has a set of tags associated with it, such as the default number of copies and authentication requirements. You can type lpoptions help to obtain a list of supported options. lpoptions can also be used to set system-wide values, such as the default printer.
Video: Printing Using lp
Sorry, your browser doesn't support embedded videos.Managing Print Jobs
You send a file to the shared printer. But when you go there to collect the printout, you discover another user has just started a 200 page job that is not time sensitive. Your file cannot be printed until this print job is complete. What do you do now?
In Linux, command line print job management commands allow you to monitor the job state as well as managing the listing of all printers and checking their status, and canceling or moving print jobs to another printer.
Some of these commands are listed in the table.
| Command | Usage |
| lpstat -p -d | To get a list of available printers, along with their status |
| lpstat -a | To check the status of all connected printers, including job numbers |
| cancel job-id OR lprm job-id | To cancel a print job |
| lpmove job-id newprinter | To move a print job to new printer |
Working with PostScript and PDF
PostScript is a standard page description language. It effectively manages scaling of fonts and vector graphics to provide quality printouts. It is purely a text format that contains the data fed to a PostScript interpreter. The format itself is a language that was developed by Adobe in the early 1980s to enable the transfer of data to printers.
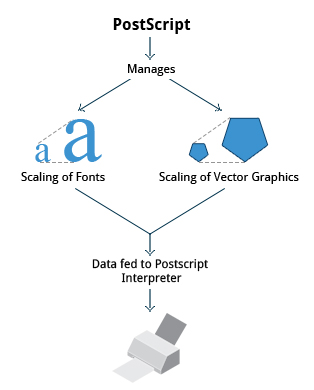
Working with PostScript and PDF
Features of PostScript are:
- It can be used on any printer that is PostScript-compatible; i.e. any modern printer
- Any program that understands the PostScript specification can print to it
- Information about page appearance, etc. is embedded in the page.
Postscript has been for the most part superseded by the PDF format (Portable Document Format) which produces far smaller files in a compressed format for which support has been integrated into many applications. However, one still has to deal with postscript documents, often as an intermediate format on the way to producing final documents.
Working with enscript
enscript is a tool that is used to convert a text file to PostScript and other formats. It also supports Rich Text Format (RTF) and HyperText Markup Language (HTML). For example, you can convert a text file to two columns (-2) formatted PostScript using the command:
$ enscript -2 -r -p psfile.ps textfile.txt
This command will also rotate (-r) the output to print so the width of the paper is greater than the height (aka landscape mode) thereby reducing the number of pages required for printing.
The commands that can be used with enscript are listed in the table below (for a file called textfile.txt).
| Command | Usage |
| enscript -p psfile.ps textfile.txt | Convert a text file to PostScript (saved to psfile.ps) |
| enscript -n -p psfile.ps textfile.txt | Convert a text file to n columns where n=1-9 (saved in psfile.ps) |
| enscript textfile.txt | Print a text file directly to the default printer |
Converting between PostScript and PDF
Most users today are far more accustomed to working with files in PDF format, viewing them easily either on the Internet through their browser or locally on their machine. The PostScript format is still important for various technical reasons that the general user will rarely have to deal with.
From time to time, you may need to convert files from one format to the other, and there are very simple utilities for accomplishing that task. ps2pdf and pdf2ps are part of the ghostscript package installed on or available on all Linux distributions. As an alternative, there are pstopdf and pdftops which are usually part of the poppler package, which may need to be added through your package manager. Unless you are doing a lot of conversions or need some of the fancier options (which you can read about in the man pages for these utilities), it really does not matter which ones you use.
Another possibility is to use the very powerful convert program, which is part of the ImageMagick package. Some newer distributions have replaced this with Graphics Magick, and the command to use is gm convert.
Some usage examples:
| Command | Usage |
| pdf2ps file.pdf | Converts file.pdf to file.ps |
| ps2pdf file.ps | Converts file.ps to file.pdf |
| pstopdf input.ps output.pdf | Converts input.ps to output.pdf |
| pdftops input.pdf output.ps | Converts input.pdf to output.ps |
| convert input.ps output.pdf | Converts input.ps to output.pdf |
| convert input.pdf output.ps | Converts input.pdf to output.ps |
Viewing PDF Content
Linux has many standard programs that can read PDF files, as well as many applications that can easily create them, including all available office suites, such as LibreOffice.
The most common Linux PDF readers are:
- evince is available on virtually all distributions and is the most widely used program.
- okular is based on the older kpdf and is available on any distribution that provides the KDE environment.
These open source PDF readers support and can read files following the PostScript standard. The proprietary Adobe Acrobat Reader, which was once widely used on Linux systems, is fortunately no longer available, as it did defective rendering and was unstable and poorly maintained.

Manipulating PDFs
At times, you may want to merge, split, or rotate PDF files; not all of these operations can be achieved while using a PDF viewer. Some of these operations include:
- Merging/splitting/rotating PDF documents
- Repairing corrupted PDF pages
- Pulling single pages from a file
- Encrypting and decrypting PDF files
- Adding, updating, and exporting a PDF’s metadata
- Exporting bookmarks to a text file
- Filling out PDF forms.
In order to accomplish these tasks there are several programs available:
- qpdf
- pdftk
- ghostscript.
qpdf is widely available on Linux distributions and is very full-featured. pdftk was once very popular but depends on an obsolete unmaintained package (libgcj) and a number of distributions have dropped it; thus we recommend avoiding it. Ghostscript (often invoked using gs) is widely available and well-maintained. However, its usage is a little complex.
Using qpdf
You can accomplish a wide variety of tasks using qpdf including:
| Command | Usage |
| qpdf --empty --pages 1.pdf 2.pdf -- 12.pdf | Merge the two documents 1.pdf and 2.pdf. The output will be saved to 12.pdf. |
| qpdf --empty --pages 1.pdf 1-2 -- new.pdf | Write only pages 1 and 2 of 1.pdf. The output will be saved to new.pdf. |
qpdf --rotate=+90:1 1.pdf 1r.pdf qpdf --rotate=+90:1-z 1.pdf 1r-all.pdf | Rotate page 1 of 1.pdf 90 degrees clockwise and save to 1r.pdf. Rotate all pages of 1.pdf 90 degrees clockwise and save to 1r-all.pdf |
| qpdf --encrypt mypw mypw 128 -- public.pdf private.pdf | Encrypt with 128 bits public.pdf using as the passwd mypw with output as private.pdf. |
| qpdf --decrypt --password=mypw private.pdf file-decrypted.pdf | Decrypt private.pdf with output as file-decrypted.pdf. |
 Using qpdf to Crypt/Decrypt Files
Using qpdf to Crypt/Decrypt Files
Video: Using qpdf
Sorry, your browser doesn't support embedded videos.Using pdftk
pdftk has now been ported to Java! Marc Vinyals has developed and maintained a port to Java for pdftk which can be found here, together with instructions for installation. Some distributions such as Ubuntu, may install this version only.
You can accomplish a wide variety of tasks using pdftk including:
| Command | Usage |
| pdftk 1.pdf 2.pdf cat output 12.pdf | Merge the two documents 1.pdf and 2.pdf. The output will be saved to 12.pdf. |
| pdftk A=1.pdf cat A1-2 output new.pdf | Write only pages 1 and 2 of 1.pdf. The output will be saved to new.pdf. |
| pdftk A=1.pdf cat A1-endright output new.pdfabc | Rotate all pages of 1.pdf 90 degrees clockwise and save result in new.pdf. |
Encrypting PDF Files with pdftk
If you’re working with PDF files that contain confidential information and you want to ensure that only certain people can view the PDF file, you can apply a password to it using the user_pw option. One can do this by issuing a command such as:
$ pdftk public.pdf output private.pdf user_pw PROMPT
When you run this command, you will receive a prompt to set the required password, which can have a maximum of 32 characters. A new file, private.pdf, will be created with the identical content as public.pdf, but anyone will need to type the password to be able to view it.
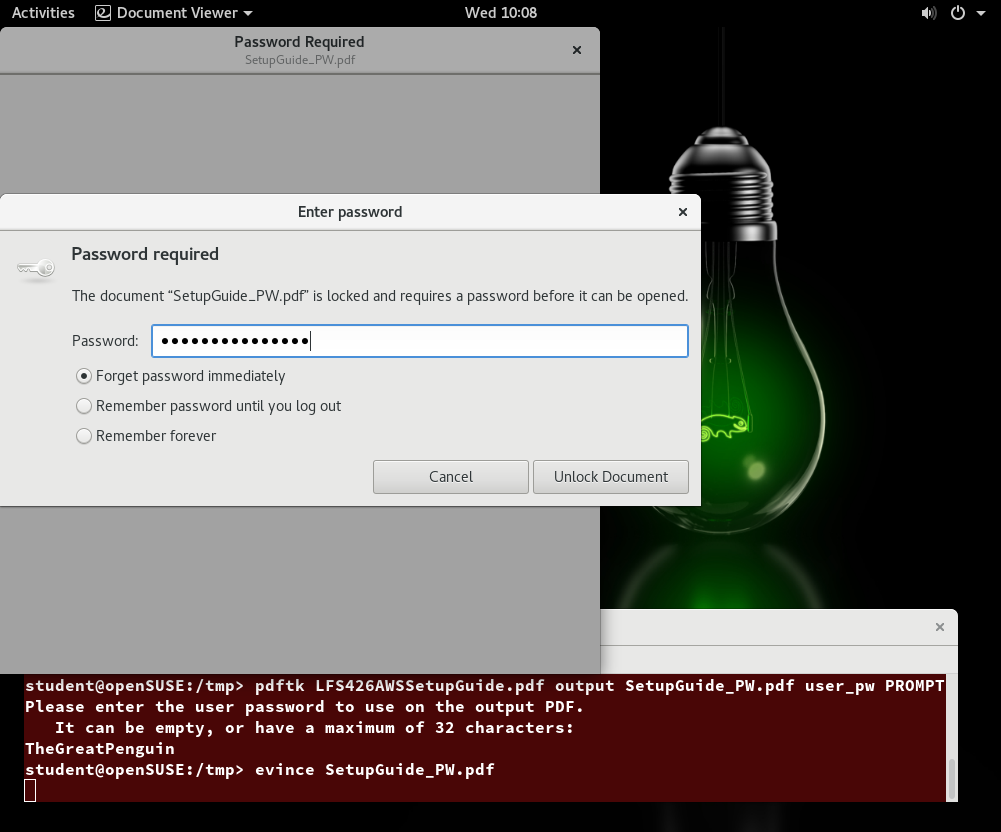 Encrypted PDF File
Encrypted PDF File
Using Ghostscript
Ghostscript is widely available as an interpreter for the Postscript and PDF languages. The executable program associated with it is abbreviated to gs.

This utility can do most of the operations pdftk can, as well as many others; see man gs for details. Use is somewhat complicated by the rather long nature of the options. For example:
- Combine three PDF files into one:
$ gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -sOutputFile=all.pdf file1.pdf file2.pdf file3.pdf
- Split pages 10 to 20 out of a PDF file:
$ gs -sDEVICE=pdfwrite -dNOPAUSE -dBATCH -dDOPDFMARKS=false -dFirstPage=10 -dLastPage=20\
-sOutputFile=split.pdf file.pdf
Using Additional Tools
You can use other tools to work with PDF files, such as:
- pdfinfo
It can extract information about PDF files, especially when the files are very large or when a graphical interface is not available. - flpsed
It can add data to a PostScript document. This tool is specifically useful for filling in forms or adding short comments into the document. - pdfmod
It is a simple application that provides a graphical interface for modifying PDF documents. Using this tool, you can reorder, rotate, and remove pages; export images from a document; edit the title, subject, and author; add keywords; and combine documents using drag-and-drop action.
For example, to collect the details of a document, you can use the following command:
$ pdfinfo /usr/share/doc/readme.pdf
 Using Additional Tools: pdfinfo, flpsed, pdfmod
Using Additional Tools: pdfinfo, flpsed, pdfmod
Chapter Summary
You have completed Chapter 17. Let’s summarize the key concepts covered:
- CUPS provides two command-line interfaces: the System V and BSD.
- The CUPS interface is available at http://localhost:631.
- lp and lpr are used to submit a document to CUPS directly from the command line.
- lpoptions can be used to set printer options and defaults.
- PostScript effectively manages scaling of fonts and vector graphics to provide quality prints.
- enscript is used to convert a text file to PostScript and other formats.
- Portable Document Format (PDF) is the standard format used to exchange documents while ensuring a certain level of consistency in the way the documents are viewed.
- pdftk joins and splits PDFs; pulls single pages from a file; encrypts and decrypts PDF files; adds, updates, and exports a PDF’s metadata; exports bookmarks to a text file; adds or removes attachments to a PDF; fixes a damaged PDF; and fills out PDF forms.
- pdfinfo can extract information about PDF documents.
- flpsed can add data to a PostScript document.
- pdfmod is a simple application with a graphical interface that you can use to modify PDF documents.
PART TWO
This article has a part 2. We couldn't fit the entire thing in one article.
Read the second part here: https://www.freecodecamp.org/news/introduction-to-linux-part-2/