

Artigo original: The top data structures you should know for your next coding interview
Escrito por: Fahim ul Haq
Niklaus Wirth, um cientista da computação suíço, escreveu um livro em 1976 intitulado Algorithms + Data Structures = Programs (em português, "Algoritmos + Estrutura de Dados = Programas").
Mais de 40 anos depois, essa equação permanece sendo verdade. É por isso que aspirantes a posições em engenharia de software precisam demonstrar sua compreensão de estruturas de dados ao se candidatarem a um emprego na área.
Quase todos os problemas exigem que o candidato demonstre uma compreensão profunda das estruturas de dados. Não importa se você acabou de se formar (em uma universidade ou em um bootcamp de programação) ou se você tem décadas de experiência.
Às vezes, as perguntas em uma entrevista mencionam explicitamente uma estrutura de dados, por exemplo, "dada uma árvore binária". Outras vezes, elas estão implícitas, como em "queremos rastrear o número de livros associados a cada autor".
Aprender estruturas de dados é essencial, mesmo que você esteja apenas tentando melhorar seu trabalho atual. Vamos começar entendendo o básico.
O que é uma estrutura de dados?
Em termos simples, uma estrutura de dados é um contêiner que armazena dados em um layout específico. Esse "layout" permite que a estrutura de dados seja eficiente em algumas operações e ineficiente em outras. Seu objetivo é entender as estruturas de dados de modo que você consiga escolher a mais adequada para o problema apresentado.
Por que precisamos de estruturas de dados?
Como as estruturas de dados são usadas para armazenar dados de uma forma organizada, e como os dados são a entidade mais crucial nas ciências da computação, fica claro o verdadeiro valor das estruturas de dados.
Independentemente do problema que você esteja resolvendo, de uma forma ou de outra, terá que lidar com dados — seja o salário de um empregado, preços de ações, uma lista de compras, ou mesmo uma simples lista telefônica.
Com base em diferentes cenários, os dados precisam ser guardados em um formato específico. Temos um punhado de estrutura de dados que satisfazem nossa necessidade de armazenar dados em diferentes formatos.
Estruturas de dados mais utilizadas
Primeiro, listemos as estruturas de dados mais utilizadas e, então, vamos explorá-las uma a uma:
- Arrays
- Pilhas
- Filas
- Listas vinculadas
- Árvores
- Grafos
- Tries (elas são árvores, efetivamente, mas ainda assim é bom tratar delas separadamente)
- Hash tables
Arrays
Um array é a estrutura de dados mais simples e mais amplamente utilizada. Outras estruturas de dados como pilhas e filhas são derivadas dos arrays.
Aqui temos uma imagem de um array simples de tamanho 4, contendo elementos (1, 2, 3 e 4).
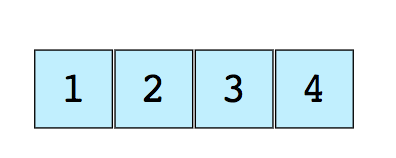
Cada elemento de dados recebe um valor numérico positivo chamado de índice, o qual corresponde à posição daquele item dentro do array. A maioria das linguagens de programação define o índice inicial do array como 0.
A seguir, temos os dois tipos de arrays:
- Arrays unidimensionais (como o mostrado acima)
- Arrays multidimensionais (arrays dentro de arrays)
Operações básicas com arrays
- Insert (inserir) — Insere um elemento em um determinado índice
- Get (receber) — Retorna um elemento em um determinado índice
- Delete (excluir) — Remove um elemento em um determinado índice
- Size (tamanho) — Obtém o número total de elementos de um array
Perguntas mais comuns sobre arrays em entrevistas
- Encontre o segundo menor elemento de um array
- Primeiros inteiros não repetidos de um array
- Mescle dois arrays ordenados
- Reordene os valores positivos e negativos em um array
Pilhas (Stacks)
Todos temos familiaridade com a famosa opção de desfazer, que está presente em quase todos os aplicativos. Você já se perguntou como ela funciona? A ideia: você armazena na memória os estados anteriores de seu trabalho (os quais são limitados a um número específico) em uma ordem tal que o último estado apareça primeiro. Isso não pode ser feito usando-se apenas arrays. É aí que as pilhas passam a ser muito úteis.
Um exemplo de uma pilha na vida real seria um conjunto de livros colocados uns sobre os outros em uma ordem vertical. Para visualizar o livro que está em algum lugar do meio, você precisará remover todos os livros colocados em cima dele. É assim que funciona o método LIFO (acrônimo para a expressão inglesa "Last In, First Out" — em português, "o último a entrar é o primeiro a sair").
Aqui temos uma imagem de uma pilha contendo três elementos de dados (1, 2 e 3), em que 3 está no topo e será removido primeiro:
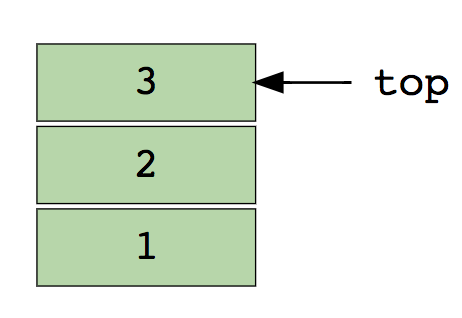
Operações básicas com pilhas
- Push (empilhar) — Insere um elemento no topo
- Pop (desempilhar) — Retorna o elemento do topo após removê-lo da pilha
- isEmpty (éVazio) — Retorna verdadeiro se a pilha estiver vazia
- Top (topo) — Retorna o elemento do topo sem removê-lo da pilha
Perguntas mais comuns sobre pilhas em entrevistas
- Calcule o valor de uma expressão pós-fixada usando uma pilha
- Ordene valores em uma pilha
- Verifique se os parênteses estão balanceados em uma expressão
Filas (Queues)
Similares às pilhas, as filas são uma outra estrutura de dados linear que armazena elementos de forma sequencial. A única diferença significativa entre pilhas e filas é que, em vez de usar o método LIFO, as filas usam a lógica FIFO, um acrônimo para "First in, First Out" (em português, "o primeiro a entrar é o primeiro a sair").
Um exemplo perfeito de uma fila na vida real: uma fileira de pessoas aguardando em uma bilheteria. Se uma nova pessoa chega, ela se junta às demais ao final da fila, não no começo — e a pessoa em pé à frente da fileira será a primeira a receber o ingresso e, portanto, deixar a fila.
Aqui temos uma imagem de uma fila contendo quatro elementos de dados (1, 2, 3 e 4), em que 1 está no topo e será removido primeiro:
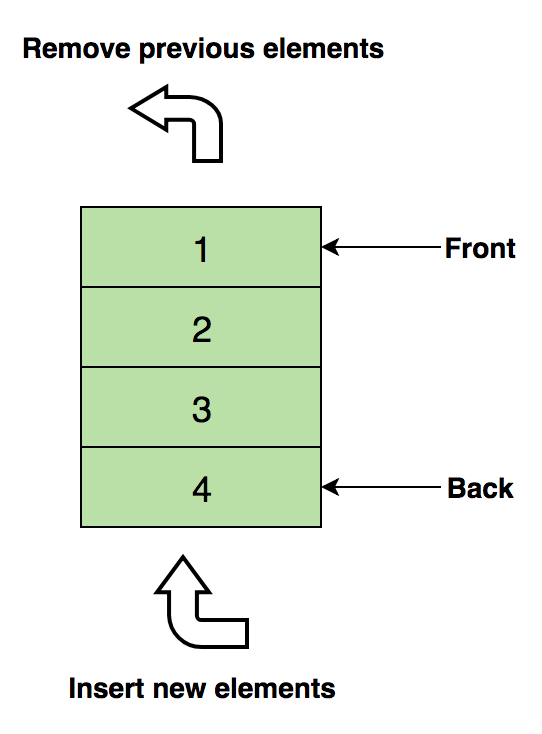
Operações básicas com filas
- Enqueue (enfileirar) — Insere um elemento ao final da fila
- Dequeue (desenfileirar) — Remove um elemento do início da fila
- isEmpty (éVazio) — Retorna verdadeiro se a fila estiver vazia
- Top (topo) — Retorna o primeiro elemento da fila
Perguntas mais comuns sobre filas em entrevistas
- Implemente uma pilha usando uma fila
- Ordene inversamente os primeiros k elementos de uma fila
- Gere números binários de 1 a n usando uma fila
Lista vinculada (Linked list)
Uma lista vinculada (ou encadeada) é outra estrutura de dados linear importante que pode parecer com arrays à primeira vista, mas que difere em relação à alocação de memória, à estrutura interna e a como as operações básicas de inserção e exclusão são realizadas.
Uma lista vinculada é como uma cadeia de nós, onde cada nó contém informações como dados e um ponteiro para o nó seguinte na cadeia. Há um ponteiro de cabeça (head), que aponta para o primeiro elemento da lista vinculada e, se a lista estiver vazia, ele simplesmente aponta para nulo ou nada.
As listas vinculadas são utilizadas para implementar sistemas de arquivos, tabelas hash e listas de adjacência.
Aqui está uma representação visual da estrutura interna de uma lista vinculada:

A seguir, temos os tipos de listas vinculadas:
- Lista simplesmente vinculada (unidirecional)
- Lista duplamente vinculada (bidirecional)
Operações básicas com listas vinculadas
- InsertAtEnd (inserirAoFim) — Insere determinado elemento ao fim da lista vinculada
- InsertAtHead (inserirAoInício) — Insere determinado elemento no início/cabeça da lista vinculada
- Delete (excluir) — Exclui determinado elemento da lista vinculada
- DeleteAtHead (excluirAoInício) — Exclui o primeiro elemento da lista vinculada
- Search (busca) — Retorna determinado elemento da lista vinculada
- isEmpty (éVazio)— Retorna verdadeiro se a lista vinculada estiver vazia
Perguntas mais comuns sobre listas vinculadas em uma entrevista
- Ordene inversamente uma lista vinculada
- Detecte um loop (laço) em uma lista vinculada
- Retorne o enésimo nó partindo do final de uma lista vinculada
- Remova elementos duplicados de uma lista vinculada
Grafos (Graphs)
Um grafo é um conjunto de nós que estão conectados uns aos outros na forma de uma rede. Os nós também são chamados de vértices. Um par(x,y) é chamado de aresta, indicando que o vértice x está conectado ao vértice y. Uma aresta pode conter peso/custo, mostrando qual o custo exigido para se atravessar do vértice x para y.
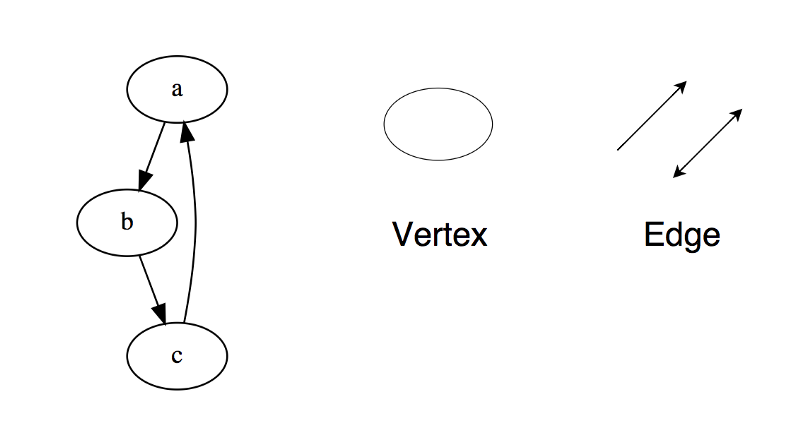
Tipos de grafos:
- Grafo não direcionado
- Grafo direcionado (ou orientado)
Em uma linguagem de programação, os grafos podem ser representados usando-se duas formas:
- Matriz de adjacência
- Lista de adjacência
Algoritmos comuns para varredura de grafos:
- Busca em largura (em inglês, Breadth First Search)
- Busca em profundidade (em inglês, Depth First Search)
Perguntas mais comuns sobre grafos em uma entrevista
- Implemente algoritmos de busca em largura e em profundidade
- Verifique se um grafo é ou não uma árvore
- Conte o número de arestas em um grafo
- Encontre o caminho mínimo entre dois vértices
Árvores (Trees)
Uma árvore é uma estrutura de dados hierárquica que consiste em vértices (nós) e arestas que os conectam. Árvores são semelhantes a grafos, mas o ponto-chave que diferencia uma árvore de um grafo é que, em uma árvore, não deve haver ciclos.
Árvores são amplamente utilizadas em Inteligência Artificial e em algoritmos complexos para fornecer um mecanismo de armazenamento eficiente para a resolução de problemas.
A seguir, temos a imagem de uma árvore simples, além da nomenclatura básica usada para essa estrutura de dados:
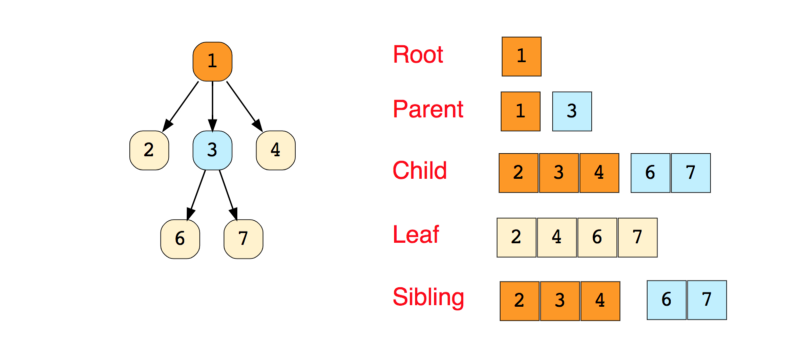
A seguir temos os tipos de árvores:
- Árvore n-ária
- Árvore balanceada
- Árvore binária
- Árvore binária de busca
- Árvore AVL
- Árvore rubro-negra
- Árvore 2-3
Destes tipos, a árvore binária e a árvore binária de busca são as mais comumente utilizadas.
Perguntas mais comuns sobre árvores em uma entrevista
- Encontre a altura de uma árvore binária
- Encontre o k-ésimo valor máximo em uma árvore binária de busca
- Encontre nós a uma distância "k" da raiz
- Encontre ancestrais de um determinado nó em uma árvore binária
Trie
A Trie, também conhecida como "árvore de prefixos", é uma estrutura de dados em formato de árvore que se mostra bastante eficiente para solução de problemas relacionados a strings. Ela fornece recuperação rápida e é usada principalmente para pesquisar palavras em um dicionário, fornecer sugestões automáticas em um mecanismo de busca, e até mesmo para roteamento de IP.
Aqui temos uma ilustração de como três palavras "top", "thus" e "their" são armazenadas em uma Trie:
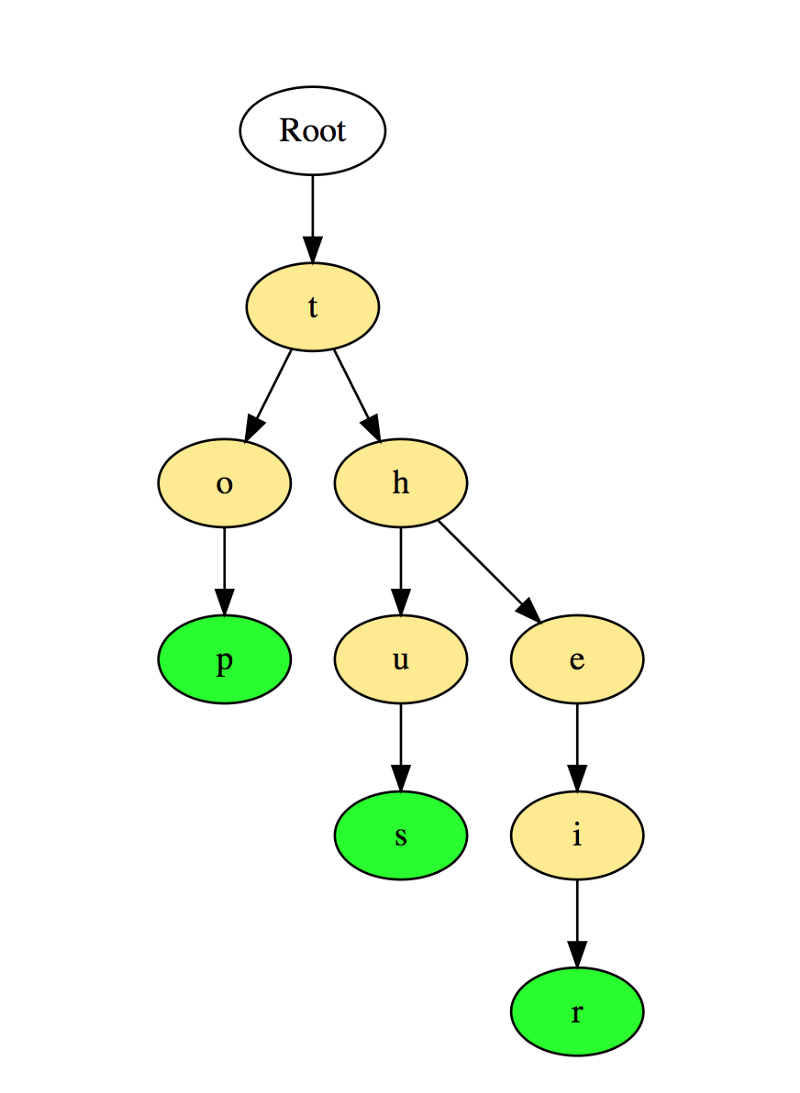
As palavras são armazenadas de cima para baixo, onde os nós de cor verde "p", "s" e "r" indicam os finais de "top", "thus" e "their", respectivamente.
Perguntas mais comuns sobre Tries em uma entrevista:
- Conte o número total de palavras em uma Trie
- Imprima todas as palavras armazenadas em uma Trie
- Classifique os elementos de um array usando uma Trie
- Forme palavras de um dicionário usando Trie
- Construa um dicionário T9
Hash table
Hashing é um processo usado para identificar objetos de forma única e armazenar cada um deles em algum índice único pré-calculado chamado de "chave". Assim, o objeto é armazenado na forma de um par "chave-valor", e a coleção desses itens é chamada de "dicionário". Cada objeto pode ser pesquisado usando sua respectiva chave. Existem diferentes estruturas de dados baseadas em hashing, mas a estrutura de dados mais comumente usada é a hash table (também conhecida por "tabela de dispersão").
Hash tables são normalmente implementadas usando-se arrays.
O desempenho do hashing como estrutura de dados depende de três fatores:
- A função de hashing
- O tamanho da hash table
- O método de resolução de colisões
Aqui temos uma ilustração de como o hash é mapeado em um array. O índice deste array é calculado por meio de uma função de hashing.
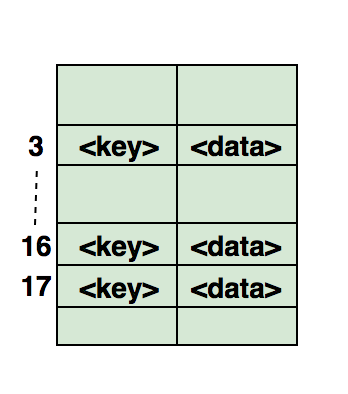
Perguntas mais comuns sobre hashing em uma entrevista
- Encontre pares simétricos em um array
- Trace o caminho completo de uma jornada
- Descubra se um array é um subconjunto de outro array
- Verifique se determinados arrays são disjuntos (não possuem elementos em comum)
Acima estão as oito principais estruturas de dados que você deve, definitivamente, conhecer antes de começar uma entrevista de programação.
Se você está procurando por mais material sobre estruturas de dados para entrevistas de programação, dê uma olhada nesses cursos interativos e baseados em desafios: Data Structures for Coding Interviews (Python, Java ou JavaScript - em inglês).
Para perguntas mais avançadas, confira Coderust 3.0: Faster Coding Interview Preparation with Interactive Challenges & Visualizations (em inglês).
Se você está se preparando para entrevistas em engenharia de software, aqui você encontra um roteiro abrangente para se preparar para entrevistas de programação (em inglês).
Boa sorte e bom aprendizado! :)
Nota do tradutor: O freeCodeCamp.org possui um vasto material gratuito e em português para auxiliá-lo na preparação para entrevistas de programação, incluindo inúmeros exercícios com algoritmos e estruturas de dados.