

Artigo original: How to Create and Manipulate SQL Databases with Python
Python e SQL são duas das linguagens mais importantes para analistas de dados.
Neste artigo, mostrarei tudo que você precisa saber para conectar o Python e o SQL.
Você aprenderá a obter dados de bancos de dados relacionais diretamente de seus pipelines de aprendizado de máquina, armazenar dados de suas aplicações em Python em um banco de dados próprio ou qualquer outro caso de uso que possa surgir.
Juntos, vamos aprender:
- Por que aprender a usar Python e SQL juntos?
- Como configurar seu ambiente Python e MySQL Server
- Conectar ao MySQL Server usando Python
- Criar um novo banco de dados
- Criar tabelas e relacionamentos entre elas
- Preencher as tabelas com dados
- Ler dados
- Atualizar registros
- Apagar registros
- Criar registros a partir de listas do Python
- Criar funções reutilizáveis para fazer tudo isso por nós no futuro
São muitas coisas úteis e interessantes. Vamos começar!
Um breve comentário antes de começarmos: um Jupyter Notebook com todos os códigos usados neste tutorial está disponível neste repositório do GitHub. Reproduzir os códigos enquanto lê este artigo é altamente recomendado!
O banco de dados e os códigos SQL usados aqui são todos provenientes da minha série Introduction to SQL (Introdução ao SQL) publicada (em inglês) no site Towards Data Science (entre em contato se tiver algum problema para visualizar os artigos e eu enviarei um link para que eles possam ser acessados gratuitamente).
Se não está acostumado com SQL e com os conceitos subjacentes aos bancos de dados relacionais, eu indicaria essa série (além disso, é claro que há uma enorme quantidade de artigos excelentes disponíveis aqui no freeCodeCamp!)
Por que Python com SQL?
Para analistas de dados e cientistas de dados, o Python apresenta muitas vantagens. Uma enorme variedade de bibliotecas de código aberto o torna uma ferramenta incrivelmente útil para qualquer analista de dados.
Nós temos o pandas, o NumPy e o Vaex para análise de dados, o Matplotlib, o seaborn e o Bokeh para visualização, além do TensorFlow, do scikit-learn e do PyTorch para aprendizagem de máquina (além de muitas, muitas outras).
Com sua curva de aprendizagem (relativamente) fácil e versatilidade, não é de admirar que o Python seja uma das linguagens de programação que mais crescem.
Portanto, se optar por usar Python para análise de dados, vale a pena perguntar: de onde vêm todos esses dados?
Embora haja uma enorme variedade de fontes para conjuntos de dados, em muitos casos – particularmente, em empresas - os dados são armazenados em um banco de dados relacional. Os bancos de dados relacionais são uma maneira extremamente eficiente, poderosa e amplamente utilizada para criar, ler, atualizar e excluir dados de todos os tipos.
Os sistemas de gerenciamento de bancos de dados relacionais (SGBDR) mais utilizados - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - usam a Linguagem de Consulta Estruturada (SQL, da sigla em inglês, Structured Query Language) para acessar e modificar os dados.
Observe que cada SGBDR usa um tipo um pouco diferente de SQL. Portanto, o código SQL escrito para um geralmente não funcionará com outro sem modificações (normalmente pequenas). No entanto, os conceitos, estruturas e operações são, em grande parte, idênticos.
Isso quer dizer que, para um analista de dados, uma sólida compreensão de SQL é de grande importância. Saber como usar Python e SQL juntos dará a você uma vantagem ainda maior na hora de trabalhar com os seus dados.
O restante deste artigo será dedicado a mostrar exatamente como podemos fazer isso.
Para começar
Requisitos e instalação
Para programar junto com este tutorial, você precisará do seu próprio ambiente Python configurado.
Eu uso a distribuição Anaconda, mas há muitas maneiras de fazer isso. Basta pesquisar no Google "como instalar o Python" se precisar de ajuda. Você também pode usar o Binder para programar usando um Jupyter Notebook associado.
Nós vamos usar o MySQL Community Server, que é gratuito e amplamente utilizado na indústria. Se estiver utilizando o Windows, este guia (em inglês) o ajudará na hora de configurar. Aqui estão os guias para os usuários de Mac e Linux (embora as instruções possam variar de acordo com a distribuição Linux utilizada).
Depois de configurados, precisaremos fazer com que eles se comuniquem.
Para isso, precisaremos instalar a biblioteca MySQL Connector para o Python. Faça isso seguindo estas instruções, ou simplesmente use o pip:
pip install mysql-connector-pythonTambém utilizaremos a biblioteca pandas. Certifique-se de que ela também esteja instalada.
pip install pandasImportando as bibliotecas
Como em todo projeto em Python, a primeira coisa que devemos fazer é importar nossas bibliotecas.
É uma boa prática importar todas as bibliotecas que vamos usar no início do projeto. Assim, as pessoas que lerão ou revisarão nosso código saberão, até certo ponto, o que está por vir, sem surpresas.
Para este tutorial, utilizaremos apenas duas bibliotecas - o MySQL Connector e o pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdImportamos a função Error separadamente para que tenhamos acesso fácil a ela em nossas funções.
Conectando ao MySQL Server
A essa altura, já devemos ter o MySQL Community Server configurado em nosso sistema. Agora, precisamos escrever um código em Python que nos permita estabelecer uma conexão com este servidor.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionÉ uma boa prática a criação de uma função para tornar reutilizável um código como esse, permitindo que ele seja utilizado repetidas vezes com o mínimo de esforço. Uma vez criado, você poderá reutilizá-lo em todos os seus projetos futuros e o seu “eu do futuro” será grato!
Vamos revisar o código, linha por linha, para entendermos o que está acontecendo aqui:
Na primeira linha, damos um nome à função (create_server_connection) e aos seus argumentos (host_name, user_name e user_password).
Na linha seguinte, encerramos quaisquer conexões existentes para que o servidor não fique confuso com várias conexões abertas.
Em seguida, usamos um bloco try-except (texto em inglês) do Python para lidar com possíveis erros. A primeira parte tenta criar uma conexão com o servidor usando o método mysql.connector.connect() (texto em inglês) e os detalhes especificados pelo usuário nos argumentos da função. Se isso funcionar, a função imprime uma pequena mensagem de sucesso.
O código referente ao bloco except imprime o erro que o MySQL Server retorna se, infelizmente, houver um erro.
Por fim, se a conexão for bem-sucedida, a função retornará um objeto de conexão (texto em inglês).
Na prática, atribuímos o resultado dessa função a uma variável, que então se torna o nosso objeto de conexão. Podemos, depois disso, aplicar outros métodos, como o cursor (texto em inglês), a ele e criar outros objetos úteis.
connection = create_server_connection("localhost", "root", pw)O código abaixo deve resultar em uma mensagem de sucesso:

Criando um novo banco de dados
Agora que estabelecemos uma conexão, nosso próximo passo é criar um banco de dados em nosso servidor.
Neste tutorial, faremos isso uma única vez, mas, novamente, criaremos uma função reutilizável de modo que tenhamos um código que possamos reutilizar em projetos futuros.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Essa função recebe dois argumentos, connection (nosso objeto de conexão) e query (um código SQL que escreveremos na próxima etapa). Ela executa a consulta no servidor através da conexão.
Usamos o método cursor do nosso objeto de conexão para criar um objeto do tipo cursor (o MySQL Connector usa o paradigma de programação orientado a objetos, portanto, há muitos objetos herdando propriedades de objetos pai).
Este objeto cursor possui métodos como execute, executemany (que usaremos neste tutorial - textos em inglês) assim como vários outros métodos úteis.
Se ajudar, podemos pensar que o objeto cursor dá acesso ao cursor que fica piscando em um terminal do MySQL Server.
Em seguida, definimos uma consulta para criar o banco de dados e executar a função:

Todos os códigos SQL deste tutorial estão explicados na minha série de tutoriais Introduction to SQL (Introdução ao SQL, em inglês), e o código completo está disponível em um Jupyter Notebook neste repositório do GitHub. Portanto, não explicarei o que o código SQL faz neste tutorial.
No entanto, esse é talvez o código SQL mais simples possível. Se você pode ler em inglês, provavelmente pode descobrir o que ele faz!
Executar a função create_database com os argumentos acima resulta na criação de um banco de dados chamado 'school' em nosso servidor.
Por que nosso banco de dados é chamado de 'school' (escola)? Talvez agora seja um bom momento para examinarmos em mais detalhes o que vamos implementar exatamente neste tutorial.
Nosso banco de dados
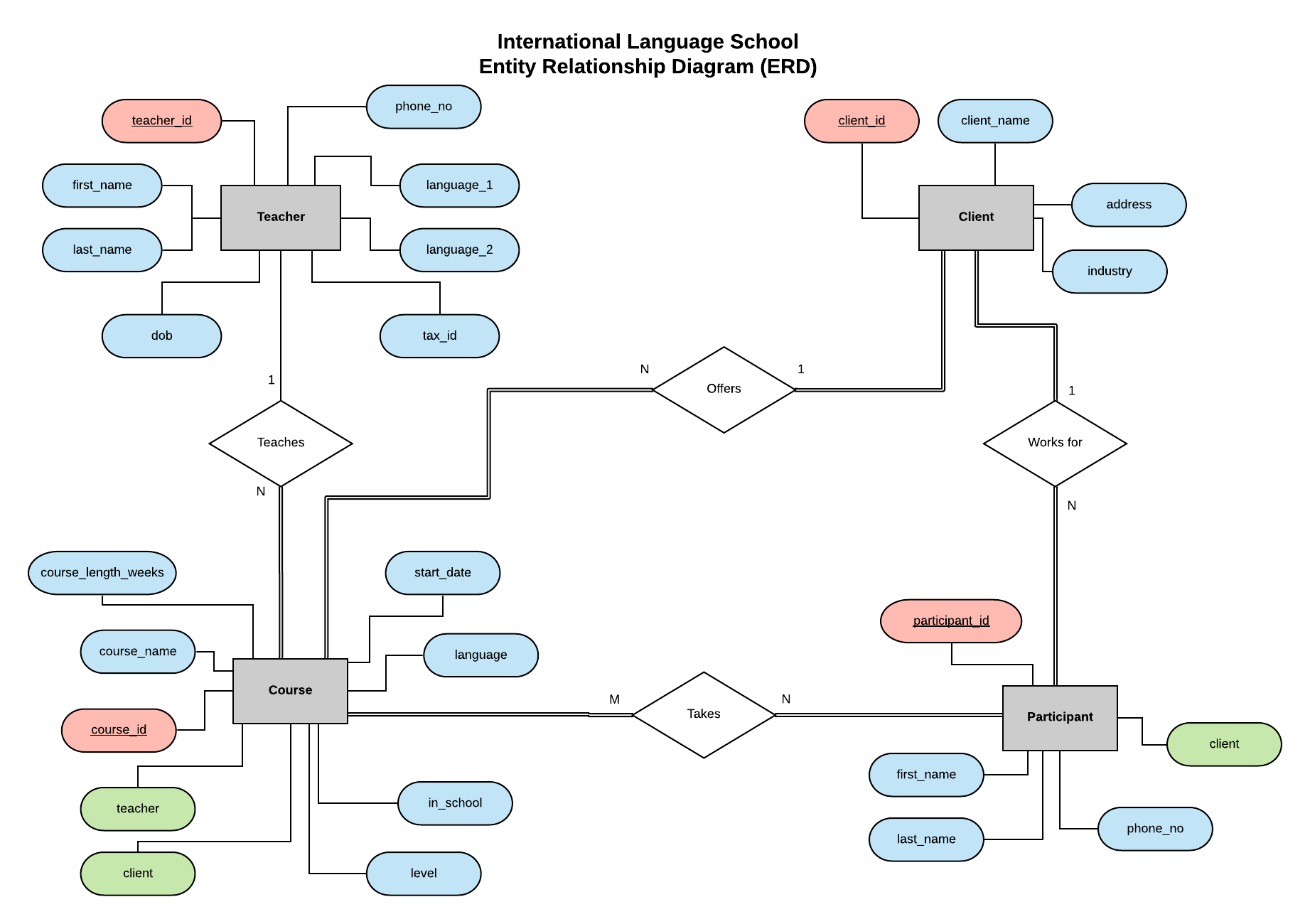
Seguindo o exemplo da minha série anterior, implementaremos o banco de dados para a International Language School (Escola Internacional de Idiomas) - uma escola fictícia de treinamento de idiomas que oferece aulas de idiomas profissionais para clientes corporativos.
O Diagrama Entidade Relacionamento (DER) (texto em inglês) apresenta as entidades (Teacher, Client, Course e Participant) e define as relações entre elas.
Todas as informações sobre o que é um DER e o que considerar ao criar um e projetar um banco de dados podem ser encontradas neste artigo (em inglês).
O código SQL, os requisitos do banco de dados e os dados para inclusão no banco de dados estão todos disponíveis neste repositório do GitHub, mas você também verá tudo à medida que avançarmos neste tutorial.
Conectando ao banco de dados
Agora que criamos um banco de dados no MySQL Server, podemos modificar nossa função create_server_connection para conectar diretamente a esse banco de dados.
Observe que é possível - comum, na verdade - ter vários bancos de dados em um servidor MySQL, então queremos nos conectar sempre e automaticamente ao banco de dados em que estamos interessados.
Podemos fazer da seguinte maneira:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionEssa é exatamente a mesma função, mas agora temos mais um argumento - o nome do banco de dados - que é passado para o método connect().
Criando uma função para execução de consultas
A última função que criaremos (por enquanto) é extremamente vital - uma função de execução de consulta. Ela pegará nossas consultas SQL, armazenadas como strings do Python, e as passará para que o método cursor.execute() as execute no servidor.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Essa função é idêntica à nossa função create_database, exceto por usar o método connection.commit() para garantir que os comandos detalhados em nossas consultas SQL sejam implementados.
Essa função será nosso carro-chefe, que usaremos (junto com create_db_connection) para criar tabelas, estabelecer relacionamentos entre essas tabelas, preencher as tabelas com dados e atualizar e excluir registros em nosso banco de dados.
Se você for um especialista em SQL, essa função permitirá que você execute todos e quaisquer comandos e consultas complexas que você possa ter, diretamente de um script em Python. Ela pode ser uma ferramenta muito poderosa para gerenciar seus dados.
Criando tabelas
Agora estamos prontos para começar a executar comandos SQL em nosso servidor e começar a construir nosso banco de dados. A primeira coisa que queremos fazer é criar as tabelas necessárias.
Vamos começar com a tabela Teacher (professor, em inglês):
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryPrimeiro, atribuímos nosso comando SQL (explicado em detalhes aqui) a uma variável com um nome apropriado.
Neste caso, usamos a notação de aspas triplas do Python para definir strings que se estendem por múltiplas linhas (texto em inglês) para armazenar nossa consulta SQL. Então, nós a passamos para a função execute_query que a executará.
Observe que essa formatação de várias linhas é puramente para facilitar a leitura do código por humanos. Nem SQL nem Python 'se importam' se o comando SQL estiver distribuído dessa maneira. Desde que a sintaxe esteja correta, ambas as linguagens a aceitarão.
Para o bem dos humanos que lerão seu código (mesmo que seja apenas o você do futuro!), é muito útil empregar essa formatação para tornar o código mais legível e compreensível.
O mesmo vale para o uso de expressões do SQL em LETRAS MAIÚSCULAS. Esta é uma convenção amplamente usada e que é fortemente recomendada, mas o software real que executa o código não diferencia maiúsculas de minúsculas e tratará 'CREATE TABLE teacher' e 'create table teacher' como comandos idênticos.

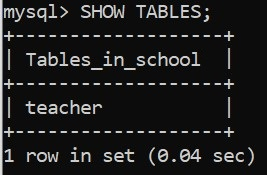
A execução deste código retorna nossas mensagens de sucesso. Também podemos verificar isso no client na linha de comando do MySQL Server:
Excelente! Agora vamos criar as tabelas restantes.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Esses comandos criarão as quatro tabelas necessárias para nossas quatro entidades.
Agora, vamos definir os relacionamentos entre elas e criar mais uma tabela para lidar com o relacionamento muitos-para-muitos entre as tabelas participant e course (participante e curso, em inglês, respectivamente). Veja mais detalhes aqui (texto em inglês).
Fazemos exatamente da mesma forma:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Agora, nossas tabelas foram criadas, juntamente com as restrições apropriadas e as relações entre chaves primárias e chaves estrangeiras.
Preenchendo as tabelas
A próxima etapa é adicionar alguns registros às tabelas. Novamente, usaremos a função execute_query para enviar nossos comandos SQL existentes ao servidor. Vamos começar mais uma vez com a tabela Teacher.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
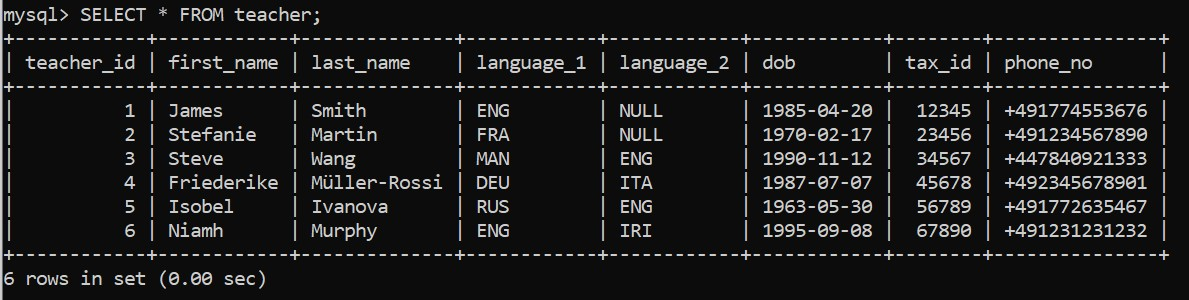
execute_query(connection, pop_teacher)Funcionou? Podemos verificar no cliente de linha de comando do MySQL:
Agora, vamos preencher as tabelas restantes.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Surpreendente! Acabamos de criar um banco de dados completo com relações, restrições e registros no MySQL, usando apenas comandos em Python.
Fizemos isso passo a passo para que o processo fosse compreensível. Mas a esta altura você já deve ter percebido que todos esses comandos podem facilmente ser incluídos em um script em Python e executados em um único comando no terminal.
Lendo os dados
Agora, temos um banco de dados funcional com o qual podemos trabalhar. Como analista de dados, é provável que você entre em contato com bancos de dados existentes nas organizações em que trabalha. Será muito útil saber como extrair dados desses bancos de dados para que possam ser alimentados em seu pipeline de dados em Python. É nisso que vamos trabalhar a seguir.
Para isso, precisaremos de mais uma função, desta vez, usando cursor.fetchall() em vez de cursor.commit() (textos das duas funções em inglês). Com esta função, leremos dados do banco de dados sem fazer nenhuma alteração.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Novamente, vamos implementar isso de uma maneira muito semelhante ao execute_query. Vamos testar com uma consulta simples para ver como funciona.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)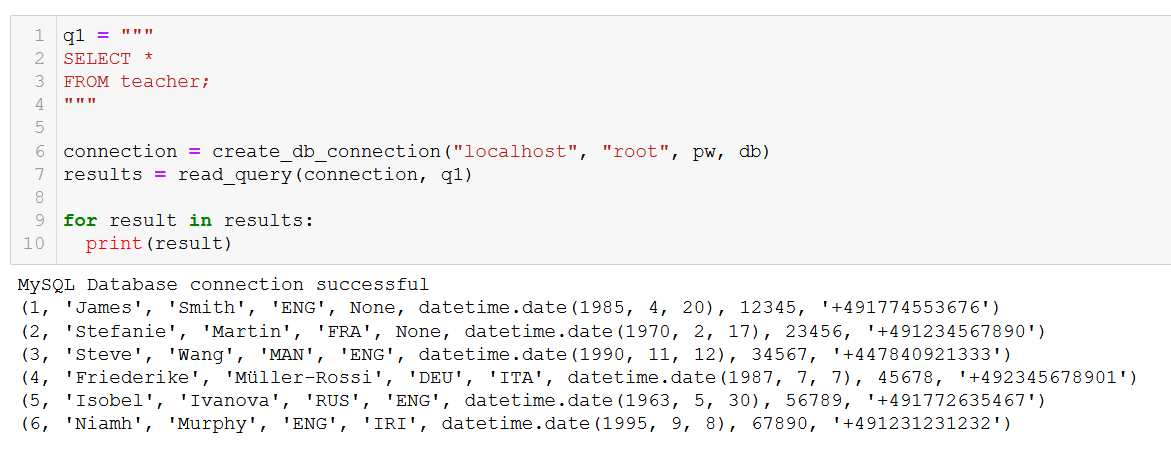
Exatamente o que estávamos esperando. A função também funciona com consultas mais complexas, como esta envolvendo um JOIN entre as tabelas de course e client (curso e cliente, em inglês, respectivamente).
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)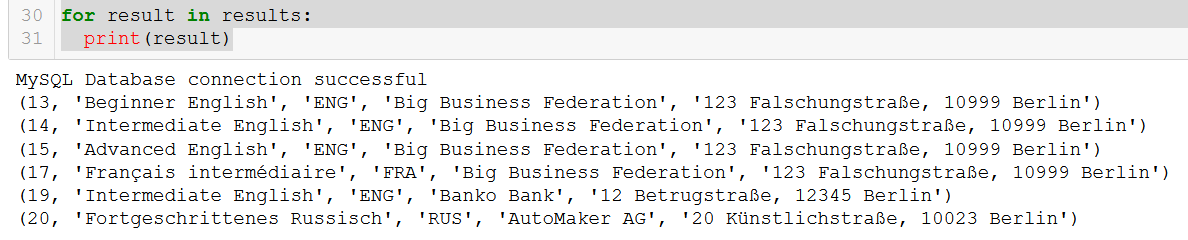
Muito bom.
Para nossos pipelines de dados e fluxos de trabalho em Python, podemos querer obter esses resultados em formatos diferentes para torná-los mais úteis ou prontos para manipulação.
Vamos ver alguns exemplos para entender como podemos fazer isso.
Formatando os resultados em uma lista
#Inicializa uma lista vazia
from_db = []
# Percorrer os resultados e inseri-los à lista
# Retorna uma lista de tuplas
for result in results:
result = result
from_db.append(result)
Formatando o resultado em uma lista de listas
# Retorna uma lista de listas
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatando o resultado em um DataFrame do Pandas
Para os analistas de dados usando Python, o pandas (texto em inglês) é o nosso velho amigo, belo e confiável. É muito simples converter a saída do nosso banco de dados em um DataFrame. A partir daí, as possibilidades são infinitas!
# Retorna uma lista de listas e cria um DataFrame do Pandas
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)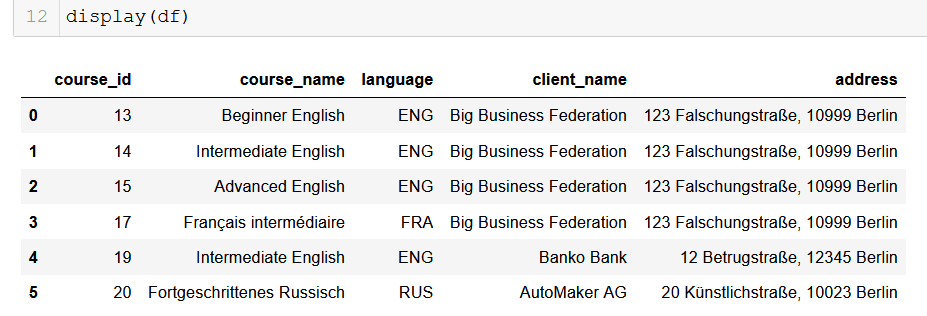
Espero que possa ver as possibilidades se desdobrando diante de você. Com apenas algumas linhas de código, podemos extrair facilmente todos os dados que podemos manipular dos bancos de dados relacionais em que eles residem e trazê-los para nossos pipelines de análise de dados de última geração. Isso é algo realmente útil.
Atualizando registros
Quando mantemos um banco de dados, às vezes precisaremos fazer alterações nos registros existentes. Nesta seção, veremos como fazer isso.
Digamos que a ILS seja notificada de que um de seus clientes existentes, a Big Business Federation, está mudando de escritório para 23 Fingiertweg, 14534 Berlin. Nesse caso, o administrador do banco de dados (nós!) precisará fazer algumas alterações.
Felizmente, podemos fazer isso com nossa função execute_query junto com a instrução UPDATE (texto em inglês) do SQL.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Note que a cláusula WHERE é muito importante. Se executarmos esse comando sem a cláusula WHERE, todos os endereços de todos os registros em nossa tabela Client serão atualizados para 23 Fingiertweg. Não é exatamente isso que queremos fazer.
Observe também que usamos "WHERE client_id = 101" na consulta UPDATE. Também seria possível usar "WHERE client_name = 'Big Business Federation'" ou "WHERE address = '123 Falschungstraße, 10999 Berlin'" ou mesmo "WHERE address LIKE '%Falschung%'".
O importante é que a cláusula WHERE nos permite identificar exclusivamente o registro (ou registros) que queremos atualizar.
Apagando registros
Também é possível usar nossa função execute_query para excluir registros, usando DELETE (texto em inglês).
Ao usar SQL com bancos de dados relacionais, precisamos ter cuidado ao usar o operador DELETE. Este não é o Windows. Não há um alerta dizendo "Tem certeza de que deseja excluir isso?" em uma janela de pop-up e não há uma lixeira para a reciclagem. Uma vez que excluímos algo, esse algo realmente se foi.
Dito isso, nós às vezes realmente precisamos apagar coisas. Então, vamos ver isso na prática, apagando um curso da nossa tabela Course.
Antes de mais nada, vamos nos lembrar dos cursos que temos.
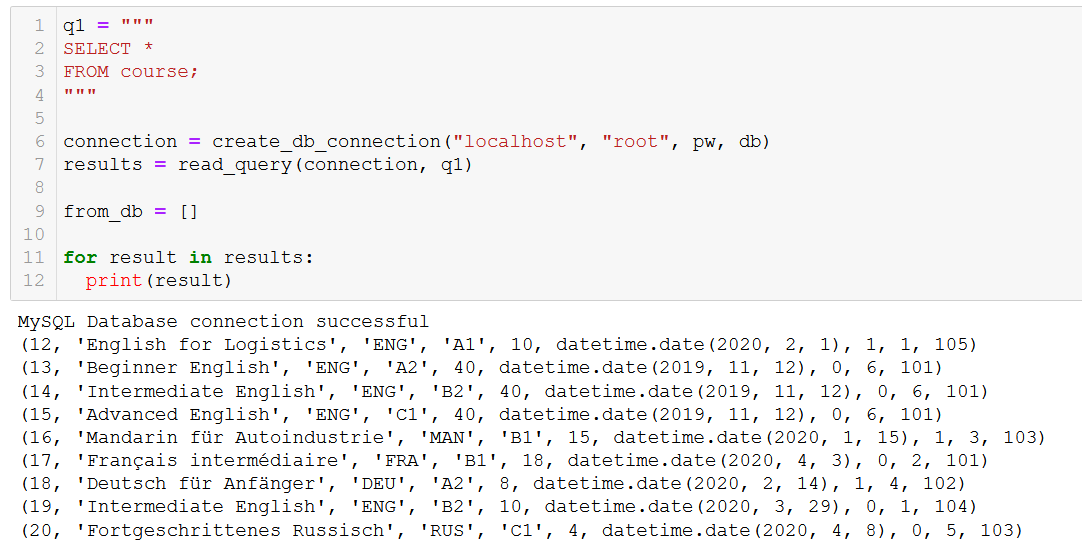
Digamos que o curso 20, 'Fortgeschrittenes Russisch' (que é 'Russo avançado' para você e para mim), está chegando ao fim. Então, precisamos removê-lo do nosso banco de dados.
A essa altura, você não ficará surpreso com a forma como fazemos isso - salve o comando SQL como uma string e, em seguida, passe-o para a nossa função execute_query.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Vamos verificar para confirmar que obtivemos o resultado pretendido:
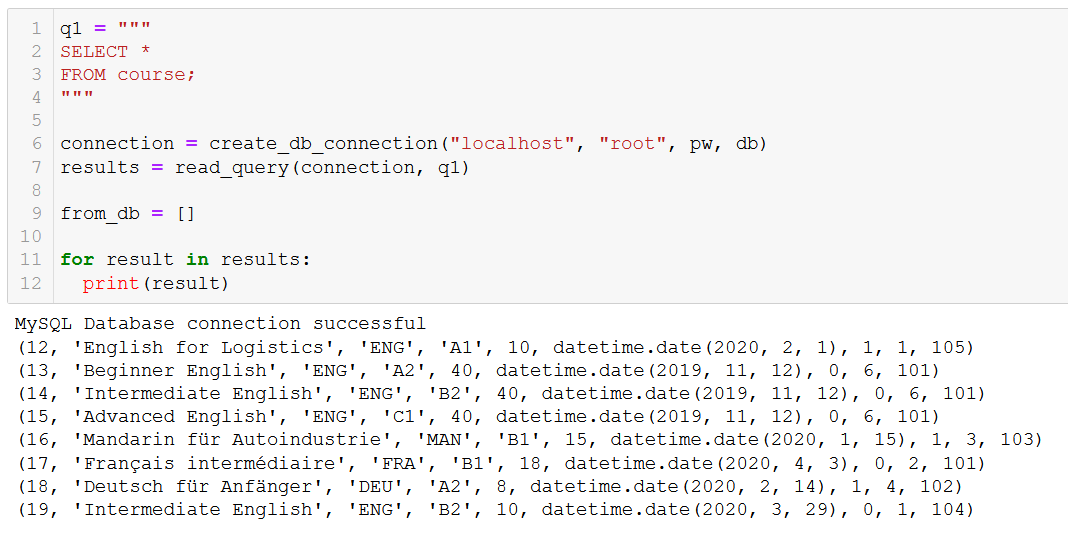
'Russo avançado' se foi, como esperávamos.
Esse comando também funciona para apagar colunas inteiras, usando DROP COLUMN e tabelas inteiras, usando DROP TABLE (ambos os textos de referência em inglês), mas não abordaremos esses comandos neste tutorial.
No entanto, vá em frente e experimente-os - não importa se você excluir uma coluna ou tabela de um banco de dados para uma escola fictícia. É uma boa ideia se familiarizar com esses comandos antes de passar para um ambiente de produção.
E o CRUD?
A essa altura, já podemos concluir as quatro operações principais para o armazenamento de dados persistentes.
Aprendemos a:
- Create (Criar) - bancos de dados, tabelas e registros inteiramente novos
- Read (Ler) - extrair dados de um banco de dados e armazenar em diversos formatos
- Update (Atualizar) - fazer alterações nos registros existentes no banco de dados
- Delete (Apagar) - remover registros que não são mais necessários
Poder fazer essas coisas é incrivelmente útil.
Antes de concluirmos, temos mais uma habilidade muito importante para aprender.
Criando registros a partir de listas
Vimos, ao preencher nossas tabelas, que podemos utilizar o comando SQL INSERT em nossa função execute_query para inserir registros em nosso banco de dados.
Dado que estamos usando Python para manipular nosso banco de dados SQL, seria útil poder obter uma estrutura de dados do Python, tal como uma lista (texto em inglês), e inseri-la diretamente em nosso banco de dados.
Isso pode ser útil quando queremos armazenar logs de atividade do usuário em um aplicativo de mídia social que escrevemos em Python ou entradas de usuários em uma página Wiki que criamos, por exemplo. Existem tantos usos possíveis para isso quantos você possa imaginar.
Esse método também é mais seguro se nosso banco de dados estiver aberto para nossos usuários a qualquer momento, pois ajuda a prevenir ataques de injeção de SQL, que podem danificar ou até destruir (texto em inglês) todo o nosso banco de dados.
Para fazer isso, escreveremos uma função usando o método executemany(), em vez do método execute() (textos de referência em inglês), mais simples, que usamos até agora.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Agora temos a função, precisamos definir um comando SQL ('sql') e uma lista contendo os valores que desejamos inserir no banco de dados ('val'). Os valores devem ser armazenados em uma lista de tuplas (textos de referência em inglês), que é uma maneira bastante comum de armazenar dados em Python.
Para adicionar dois novos professores ao banco de dados, podemos escrever um código como este:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Observe aqui que no código 'sql' usamos o '%s' como um espaço reservado para nosso valor. A semelhança com o '%s' para uma string em Python é apenas coincidência (e francamente, muito confusa), pois devemos usar '%s' para todos os tipos de dados (strings, inteiros, datas etc) com o MySQL Python Conector.
Você pode ver vários casos no Stackoverflow em que alguém ficou confuso e tentou usar '%d' para inteiros porque estava acostumado a fazer isso em Python. Isso não funcionará aqui - precisamos usar um '%s' para cada coluna para qual queremos adicionar um valor.
A função executemany, então, pega cada tupla em nossa lista 'val' e insere o valor relevante para aquela coluna no lugar do espaço reservado e executa o comando SQL para cada tupla contida na lista.
Isso pode ser feito para várias linhas de dados, desde que sejam formatadas corretamente. Em nosso exemplo, adicionaremos apenas dois novos professores, para fins ilustrativos, mas em princípio podemos adicionar quantos quisermos.
Vamos executar este comando e adicionar os professores ao nosso banco de dados.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)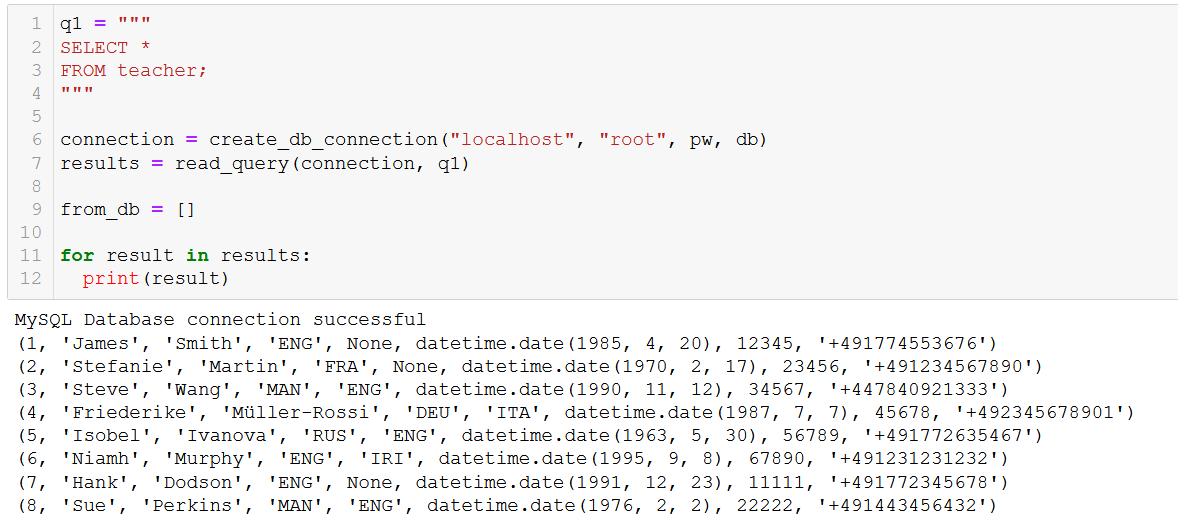
Boas-vindas à ILS, Hank e Sue!
Esta é mais uma função muito útil, permitindo-nos pegar dados gerados em nossos scripts e aplicativos Python e inseri-los diretamente em nosso banco de dados.
Conclusão
Abordamos muitas coisas neste tutorial.
Aprendemos como usar o Python e o MySQL Connector para criar um banco de dados totalmente novo no MySQL Server, criar tabelas dentro desse banco de dados, definir as relações entre elas e preenchê-las com dados.
Abordamos como Criar, Ler, Atualizar e Apagar dados em nosso banco de dados.
Vimos como extrair dados de bancos de dados existentes e carregá-los em pandas DataFrames, prontos para análise e trabalho adicional, aproveitando todas as possibilidades oferecidas pela stack PyData (texto em inglês).
Indo na outra direção, também aprendemos como pegar dados gerados por nossos scripts e aplicativos Python e gravá-los em um banco de dados onde eles podem ser armazenados com segurança para recuperação e manipulação posteriores.
Espero que este tutorial tenha ajudado você a ver como podemos usar Python e SQL juntos para poder manipular dados de forma ainda mais eficaz!
Se você quiser ver mais sobre os projetos e trabalhos do autor, visite o site do autor em craigdoesdata.de. Se você tiver algum feedback sobre este tutorial, entre em contato com ele - todos os comentários serão bem recebidos!