

Artigo original: How I investigated memory leaks in Go using pprof on a large codebase
Escrito por: Jonathan Levison
Eu trabalho com o Go durante a maior parte do ano, implementando uma infraestrutura de blockchain escalável na Orbs. O ano vem sendo empolgante. Ao longo do ano anterior, pesquisamos qual linguagem escolher para nossa implementação de blockchain. Isso nos levou a escolher o Go, pois entendemos que ele tem uma boa comunidade e um conjunto de ferramentas incrível.
Nas últimas semanas, entramos nas etapas finais de integração do nosso sistema. Como em qualquer sistema grande, podem ocorrer problemas na fase posterior, que incluem problemas de desempenho em vazamentos de memória específicos. Conforme estávamos integrando o sistema, percebemos que encontramos um. Neste artigo, abordarei os detalhes de como investigar um vazamento de memória em Go, detalhando as etapas realizadas para encontrá-lo, entendê-lo e resolvê-lo.
O conjunto de ferramentas oferecido pela Golang é excepcional, mas tem suas limitações. Comecemos por elas: o maior desses problemas é a capacidade limitada de investigar despejos de núcleo completo. Um despejo de memória completo seria a imagem da memória (ou memória do usuário) obtida pelo processo que executa o programa.
Podemos imaginar o mapeamento de memória como uma árvore. Percorrer essa árvore nos levaria às diferentes alocações de objetos e conexões. Isso significa que o que quer que esteja na raiz é a razão para 'segurar' a memória e não realizar a coleta do lixo (em inglês, Garbage Collecting). Como em Go não há uma maneira simples de analisar o despejo de memória completo, é difícil chegar às raízes de um objeto cuja coleta não foi realizada.
No momento em que este artigo está sendo escrito, não conseguimos encontrar nenhuma ferramenta on-line que possa nos ajudar com isso. Como existe um formato de dump do núcleo e uma maneira bastante simples de exportá-lo do pacote de depuração, pode ser que haja um sendo usado no Google. Pesquisando on-line, parece que está no pipeline da Golang, criando um visualizador de dumps do núcleo, mas não parece que alguém esteja trabalhando nisso. Dito isto, mesmo sem acesso a essa solução, com as ferramentas existentes, geralmente podemos chegar à causa raiz.
Vazamentos de memória
Vazamentos de memória, ou pressão de memória, podem ocorrer de várias formas em todo o sistema. Normalmente, nós os tratamos como bugs, mas, às vezes, a causa raiz pode estar em decisões de design.
À medida que construímos nosso sistema sob princípios de design emergentes, tais considerações não são importantes e tudo bem. É mais importante construir o sistema de uma maneira que evite otimizações prematuras e permita que você as execute mais tarde, à medida que o código amadurece, em vez de projetar demais desde o início. Ainda assim, alguns exemplos comuns de como ver os problemas de pressão de memória se materializarem são:
- O excesso de alocações, representação de dados incorreta
- Uso pesado de reflections ou strings
- Uso de globais
- Goroutines órfãs e sem fim
Em Go, a maneira mais simples de criar um vazamento de memória é definir uma variável global em array e anexar dados a ela. Esta ótima postagem do blog da Medium (texto em inglês) descreve esse caso de uma boa maneira.
Então, por que estou escrevendo este artigo? Quando eu estava pesquisando sobre esse caso, encontrei muitos recursos sobre vazamentos de memória. No entanto, na realidade, os sistemas têm mais de 50 linhas de código e uma única estrutura. Nesses casos, encontrar a origem de um problema de memória é muito mais complexo do que o exemplo descrito.
A Golang nos dá uma ferramenta incrível chamada pprof. Essa ferramenta, quando dominada, pode ajudar a investigar e, provavelmente, encontrar qualquer problema de memória. Outro propósito é investigar problemas de CPU, mas não entrarei em nada relacionado à CPU neste artigo.
Sobre o pprof em Go
Cobrir tudo o que essa ferramenta faz exigirá mais de um artigo. Uma coisa que demorou foi descobrir como usar essa ferramenta para conseguir algo acionável. Vou concentrar este artigo no recurso relacionado à memória.
O pacote pprof cria amostras de arquivos de despejo em pilhas, que você pode analisar/visualizar posteriormente para fornecer um mapa de ambos:
- Alocações de memória atuais
- Alocações totais (cumulativas) de memória
A ferramenta tem a capacidade de comparar snapshots. Isso pode permitir que você compare uma exibição de diferença de tempo do que aconteceu agora e 30 segundos atrás, por exemplo. Para cenários de estresse, isso pode ser útil para ajudar a localizar áreas problemáticas do seu código.
Perfis do pprof
A maneira como o pprof funciona é usando perfis.
Um perfil é uma coleção de rastreamentos de pilha que mostra as sequências de chamadas que levaram a instâncias de um determinado evento, como a alocação.
O arquivo runtime/pprof/pprof.go contém as informações detalhadas e a implementação dos perfis.
O Go tem vários perfis integrados para usarmos em casos comuns:
- goroutine — empilha rastreamentos de todas as goroutines atuais
- heap — uma amostra de alocações de memória de objetos ativos
- allocs — uma amostra de todas as alocações de memória anteriores
- threadcreate — rastreamentos de pilha que levaram à criação de novos threads do SO
- block — rastreamentos de pilha que levaram ao bloqueio de primitivas de sincronização
- mutex — pilha de rastreamentos de detentores de mutex disputados
Ao analisar os problemas de memória, nos concentraremos no perfil de heap. O perfil allocs é idêntico em relação à coleta de dados que faz. A diferença entre os dois é a maneira como a ferramenta pprof lê lá na hora de início. O perfil Allocs iniciará o pprof em um modo que exibe o número total de bytes alocados desde o início do programa (incluindo bytes coletados de lixo). Normalmente, usaremos esse modo ao tentar tornar nosso código mais eficiente.
O heap
Em resumo, é aqui que o SO (Sistema Operacional) armazena a memória dos objetos que nosso código usa. Essa é a memória que, mais tarde, passa pela 'coleta de lixo' ou é liberada manualmente em linguagens sem coleta de lixo.
O heap não é o único lugar onde as alocações de memória acontecem. Parte da memória também é alocada na stack. A finalidade da stack é de curto prazo. Em Go, a stack é geralmente usada para atribuições que acontecem dentro do fechamento de uma função. Outro lugar onde o Go usa a stack é quando o compilador "sabe" quanta memória precisa ser reservada antes do tempo de execução (por exemplo, arrays de tamanho fixo). Existe uma maneira de executar o compilador do Go para que ele produza uma análise de onde as alocações "escapam" da stack para o heap, mas não tocarei nisso neste artigo.
Enquanto os dados de heap precisam ser "liberados" e passar pela coleta de lixo, os dados da stack não precisam. Isso significa que é muito mais eficiente usar a stack, sempre que possível.
Este é um resumo dos diferentes locais onde a alocação de memória acontece. Há muito mais, mas isso está fora do escopo deste artigo.
Obtendo a heap de dados com pprof
Existem duas formas principais de obter os dados para esta ferramenta. A primeira geralmente fará parte de um teste ou de uma branch e inclui a importação de runtime/pprof e a chamada de
pprof.WriteHeapProfile(some_file) para gravar as informações da heap.
Observe que WriteHeapProfile é o ajuste sintático para a execução:
// a função lookup recebe o perfil namepprof.Lookup("heap").WriteTo(arquivo, 0)De acordo com os documentos, WriteHeapProfile existe para compatibilidade com versões anteriores. O restante dos perfis não possui esses atalhos e você deve usar a função Lookup() para obter seus dados de perfil.
O segundo, que é o mais interessante, é habilitá-lo via HTTP (endpoints baseados na web). Isso permite que você extraia os dados ad hoc, de um contêiner em execução em seu ambiente e2e/test ou até mesmo de 'produção'. Este é mais um lugar onde o tempo de execução e o conjunto de ferramentas do Go se destacam. Toda a documentação do pacote é encontrada aqui (em inglês), mas a versão resumida é de que você precisará adicioná-lo ao seu código assim:
import ( "net/http" _ "net/http/pprof")...func main() { ... http.ListenAndServe("localhost:8080", nil)}O 'efeito colateral' de importar net/http/pprof é o registro dos endpoints de pprof no root do servidor da web em /debug/pprof. Agora, usando curl, podemos obter os arquivos de informações da heap para investigar:
curl -sK -v http://localhost:8080/debug/pprof/heap > heap.outAdicionar o http.ListenAndServe() acima só é necessário se o seu programa não tiver um listener de http antes. Se você tiver um, ele se associará a esse listener e não haverá a necessidade de ouvir novamente. Há também maneiras de configurá-lo usando um ServeMux.HandleFunc(), o que faria mais sentido para um programa habilitado para http mais complexo.
Usando pprof
Coletamos os dados – e agora? Como mencionado acima, existem duas estratégias principais de análise de memória com pprof. Uma é olhar para as alocações atuais (bytes ou contagem de objetos), chamadas inuse. O outro é olhar para todos os bytes alocados ou contagem de objetos ao longo do tempo de execução do programa, o que chamamos de alloc. Isso representa, independentemente de ter havido ou não a coleta de lixo, uma soma de tudo amostrado.
Esse é um bom lugar para reiterar que o perfil de heap é uma amostragem de alocações de memória. O pprof, internamente, está usando a função runtime.MemProfile, que, por padrão, coleta informações de alocação em cada 512 KB de bytes alocados. É possível alterar o MemProfile para coletar informações sobre todos os objetos. Observe que, muito provavelmente, isso tornará seu aplicativo mais lento.
Isso significa que, por padrão, há alguma chance de ocorrer um problema com objetos menores, que passarão despercebidos pelo radar do pprof. Para uma grande base de código/programa de longa duração, isso não é um problema.
Ao coletarmos o arquivo de perfil, é hora de carregá-lo no console interativo que o pprof oferece. Faça isso executando:
> go tool pprof heap.outVamos observar as informações exibidas:
Type: inuse_spaceTime: Jan 22, 2019 at 1:08pm (IST)Entering interactive mode (type "help" for commands, "o" for options)(pprof)O importante a ser observado aqui é o Type: inuse_space. Isso significa que estamos analisando os dados de alocação de um momento específico (quando capturamos o perfil). O tipo é o valor de configuração de sample_index e os valores possíveis são:
- inuse_space — quantidade de memória alocada e ainda não liberada
- inuse_objects— quantidade de objetos alocados e ainda não liberados
- alloc_space — quantidade total de memória alocada (independentemente do lançamento)
- alloc_objects — quantidade total de objetos alocados (independentemente do lançamento)
Agora, digite top no interativo. A saída será os principais consumidores de memória.
Podemos ver uma linha nos informando sobre nós descartados (Dropped nodes). Isso significa que eles são filtrados. Um nó é uma entrada de objeto ou um 'nó' na árvore. A eliminação de nós é uma boa ideia para reduzir algum ruído, mas, às vezes, pode ocultar a causa raiz de um problema de memória. Veremos um exemplo disso à medida que continuarmos nossa investigação.
Se você deseja incluir todos os dados do perfil, inclua a opção -nodefraction=0 ao executar pprof ou digite nodefraction=0 no arquivo interativo.
Na lista de saída, podemos ver dois valores: flat e cum.
- flat significa que a memória foi alocada por essa função e é mantida por aquela
- cum significa que a memória foi alocada por essa função ou pela função que chamou de um ponto mais abaixo da stack
Esta informação, por si só, pode, às vezes, nos ajudar a entender se há um problema. Tomemos, por exemplo, um caso em que uma função é responsável por alocar muita memória, mas não a está mantendo. Isso significaria que algum outro objeto está apontando para essa memória e mantendo-a alocada, o que significa que podemos ter um problema de design do sistema ou um bug.
Outro truque legal sobre o top na janela interativa é que ele está, na verdade, executando top10. O comando top suporta o formato topN onde N é o número de entradas que você deseja ver. No caso acima, digitar top70, por exemplo, produziria todos os nós.
Visualizações
Enquanto o topN fornece uma lista textual, existem várias opções de visualização muito úteis que vêm com o pprof. É possível digitar png ou gif e muito mais (veja go tool pprof -help para a lista completa).
Em nosso sistema, a saída visual padrão é algo como:
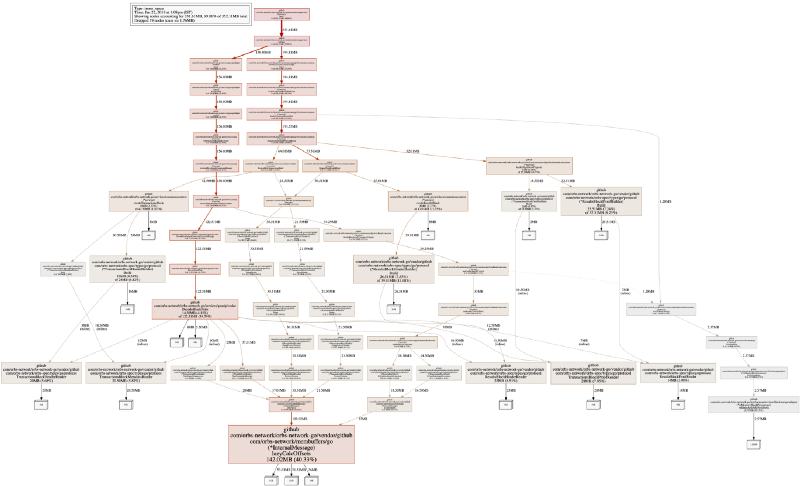
Isso pode ser intimidante no início, mas é a visualização dos fluxos de alocação de memória (de acordo com os rastreamentos da stack) em um programa. Ler o gráfico não é tão complicado quanto parece. Um quadrado branco com um número mostra o espaço alocado (e o cumulativo de quanta memória está ocupando agora na borda do gráfico). Cada retângulo mais largo mostra a função de alocação.
Observe que, na imagem acima, tirei um png de um modo de execução inuse_space. Muitas vezes, você também deve dar uma olhada em inuse_objects, pois isso pode ajudar a encontrar problemas de alocação.
Investigando mais a fundo e encontrando a causa raiz
Até agora, conseguimos entender o que está alocando memória em nosso aplicativo durante o tempo de execução. Isso nos ajuda a ter uma ideia de como nosso programa se comporta (ou se comporta mal).
No nosso caso, pudemos ver que a memória é retida por membuffers, que é nossa biblioteca de serialização de dados. Isso não significa que temos um vazamento de memória nesse segmento de código. Significa apenas que a memória está sendo retida por essa função. É importante entender como ler o gráfico e a saída do pprof, em geral. Nesse caso, entendendo que, quando serializamos dados – ou seja, quando alocamos memória para structs e objetos primitivos (int, string) – a memória nunca é liberada.
Tirando conclusões precipitadas ou interpretando mal o gráfico, poderíamos ter assumido que um dos nós no caminho para a serialização é responsável por reter a memória, por exemplo:
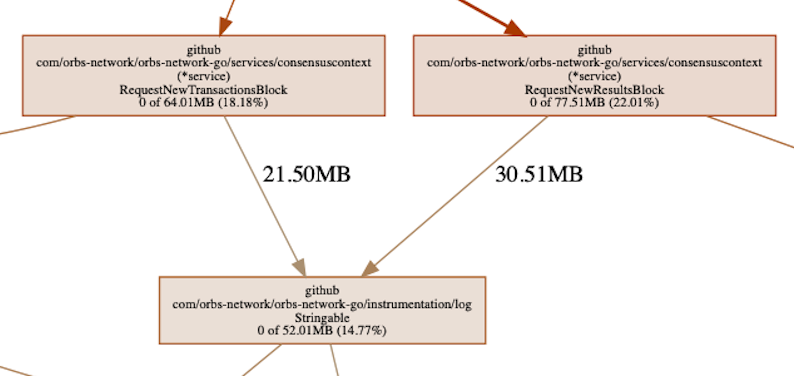
Em algum lugar da cadeia, podemos ver nossa biblioteca de registro, responsável por >50 MB de memória alocada. Esta é a memória que é alocada por funções chamadas pelo nosso logger. Pensando bem, isso é realmente esperado. O registrador causa alocações de memória, pois precisa serializar dados para enviá-los ao log e, portanto, está causando alocações de memória no processo.
Também podemos ver que, no caminho de alocação, a memória é retida apenas pela serialização e nada mais. Além disso, a quantidade de memória retida pelo registrador é cerca de 30% do total. O que vemos acima nos diz que, provavelmente, o problema não está no registrador. Se fosse 100%, ou algo próximo disso, deveríamos estar procurando lá – mas não é. O que isso pode significar é que algo está sendo registrado que não deveria estar, mas não é um vazamento de memória pelo registrador.
Este é um bom momento para introduzir outro comando do pprof chamado list. Ele aceita uma expressão regular, que será um filtro do que listar. A 'lista' é, na verdade, o código-fonte anotado relacionado à alocação. No contexto do registrador que estamos analisando, executaremos list RequestNew, pois gostaríamos de ver as chamadas feitas ao registrador. Essas chamadas são provenientes de duas funções que começam com o mesmo prefixo.
Podemos ver que as alocações feitas estão na coluna cum, o que significa que a memória alocada é retida na stack de chamadas. Isso se correlaciona com o que o gráfico também mostra. Nesse ponto, é fácil ver que o motivo pelo qual o registrador estava alocando a memória é porque enviamos todo o objeto 'bloco'. Ele precisava serializar algumas partes dele, no mínimo (nossos objetos são objetos membuffer, que sempre implementam alguma função String() ). É uma mensagem de log útil ou uma boa prática? Provavelmente não, mas não é um vazamento de memória, não no final do registrador ou no código que chamou o registrador.
list pode encontrar o código-fonte ao procurá-lo em seu ambiente GOPATH. Nos casos em que a raiz que está procurando não corresponde, o que depende de sua máquina de compilação, você pode usar a opção -trim_path. Isso ajudará a corrigi-lo e permitir que você veja o código-fonte anotado. Lembre-se de definir seu git para o commit correto que estava sendo executado quando o perfil de heap foi capturado.
Então, por que a memória é retida?
O pano de fundo para essa investigação foi a suspeita de que temos um problema – um vazamento de memória. Chegamos a essa noção quando vimos que o consumo de memória era maior do que esperávamos que o sistema precisasse. Além disso, vimos isso aumentando cada vez mais, o que foi outro forte indicador de "há um problema aqui".
Neste ponto, no caso do Java ou do .Net, abriríamos alguma análise ou perfilador 'gc roots' e chegaríamos ao objeto real que está fazendo referência a esses dados e criando o vazamento. Conforme explicado, isso não é exatamente possível com Go, tanto por causa de um problema de ferramentas, mas, também, por causa da representação de memória de baixo nível do Go.
Sem entrar em detalhes, não achamos que Go retenha qual objeto está armazenado em qual endereço (exceto para ponteiros, talvez). Isso significa que, na verdade, entender qual endereço de memória representa qual membro do seu objeto (struct) exigirá algum tipo de mapeamento para a saída de um perfil de heap. Falando em teoria, isso pode significar que, antes de fazer um dump completo do núcleo, deve-se também obter um perfil de heap para que os endereços possam ser mapeados para a linha e o arquivo de alocação e, portanto, o objeto representado na memória.
Neste ponto, por estarmos familiarizados com nosso sistema, foi fácil entender que isso não é mais um bug. Foi (quase) por design. Vamos, contudo, continuar a explorar como obter as informações das ferramentas (pprof) para encontrar a causa raiz.
Ao definir nodefraction=0, veremos todo o mapa dos objetos alocados, incluindo os menores. Vejamos a saída:
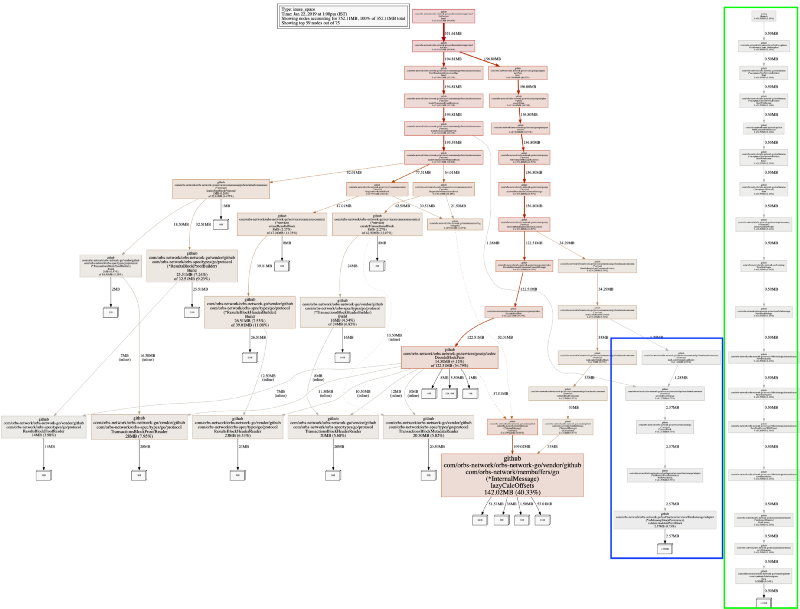
Temos duas novas sub árvores. Lembramos novamente que o perfil de heap do pprof está amostrando alocações de memória. Para o nosso sistema que funciona – não estamos perdendo nenhuma informação importante. A nova árvore mais longa, em verde, que está completamente desconectada do resto do sistema é o executor de testes, não é interessante.
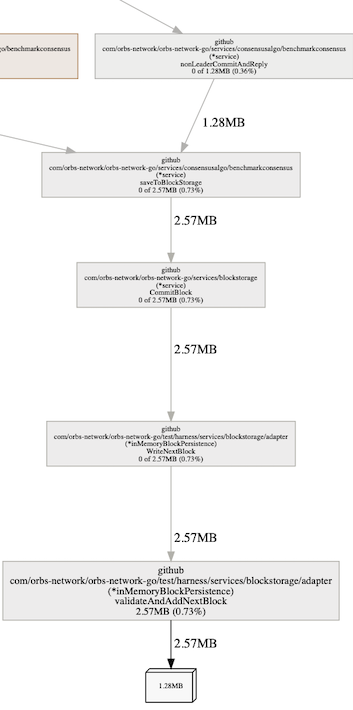
O mais curto, em azul, que tem uma borda conectando-o a todo o sistema é inMemoryBlockPersistance. Esse nome também explica o "vazamento" que imaginávamos ter. Este é o back-end de dados, que armazena todos os dados na memória e não persiste no disco. É bom notar que pudemos ver imediatamente que ele está segurando dois objetos grandes. Por que dois? Porque podemos ver que o objeto tem 1,28 MB e a função está retendo 2,57 MB, ou seja, dois deles.
O problema é bem compreendido nesse ponto. Poderíamos ter usado delve (o depurador) para ver que este é o array que contém todos os blocos para o driver de persistência na memória que temos.
Então, o que poderíamos consertar?
Bem, que droga, foi um erro humano. Enquanto o processo era educar (e compartilhar é cuidar), não melhorou nada, ou será que melhorou?
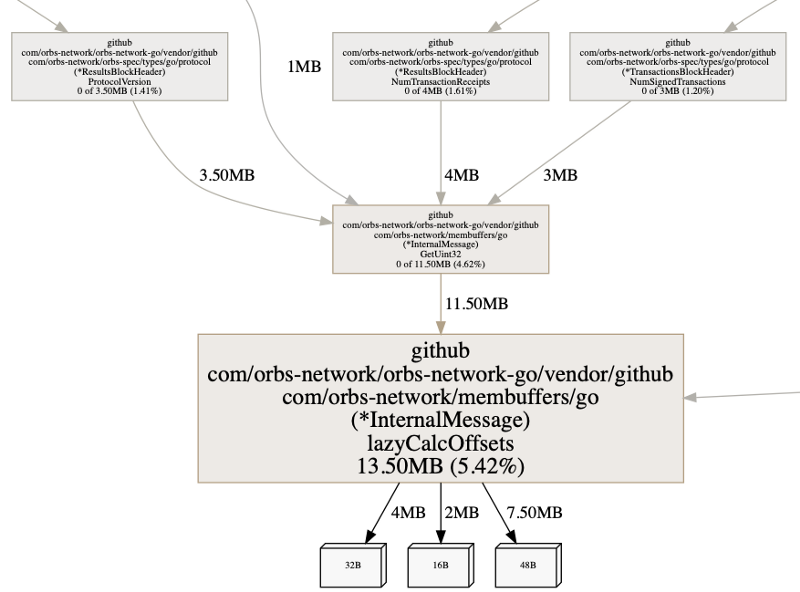
Havia algo que ainda "cheirava mal" sobre essa informação da heap. Os dados desserializados estavam ocupando muita memória. Por que 142 MB para algo que deveria estar consumindo substancialmente menos? O pprof pode responder a isso – na verdade, ele existe para responder exatamente a essas perguntas.
Para examinar o código-fonte anotado da função, executaremos list lazy. Usamos lazy, pois o nome da função que estamos procurando é lazyCalcOffsets() e sabemos que nenhuma outra função em nosso código começa com lazy. Digitar list lazyCalcOffsets também funcionaria, é claro.
Podemos ver duas informações interessantes. Novamente, lembre-se de que o perfil de heap do pprof mostra informações sobre alocações. Podemos ver que os números flat e cum são os mesmos. Isso indica que a memória alocada também é retida por esses pontos de alocação.
Em seguida, podemos ver que o make() está consumindo um pouco de memória. Isso faz sentido. É o ponteiro para a estrutura de dados. No entanto, também vemos que a atribuição na linha 43 está ocupando memória, o que significa que ela cria uma alocação.
Isso nos ensinou sobre mapas, onde uma atribuição a um mapa não é uma atribuição direta de variável. Este artigo (texto em inglês) entra em grandes detalhes sobre como o mapa funciona. Resumindo, um mapa tem um overhead e, quanto mais elementos, maior esse overhead vai "custar" quando comparado a uma parte.
O seguinte deve ser tomado com cuidado: não há problema em dizer isso ao usar um map[int]T. Quando os dados não são esparsos ou podem ser convertidos em índices sequenciais, geralmente deve ser tentado com uma implementação de fatias se o consumo de memória é uma consideração relevante. No entanto, uma grande fatia, quando expandida, pode desacelerar uma operação, onde, em um mapa, essa desaceleração será insignificante. Não existe uma fórmula mágica para otimizações.
No código acima, depois de verificar como usamos esse mapa, percebemos que, embora imaginássemos que fosse um array esparso, ele não era tão esparso. Isso corresponde ao argumento acima e podemos ver imediatamente que uma pequena refatoração de alterar o mapa para uma fatia é realmente possível, podendo tornar o código mais eficiente em termos de memória. Então, fazemos a alteração.
Foi simples assim. Em vez de usar um mapa, agora estamos usando uma fatia. Devido à maneira como recebemos os dados que são carregados lentamente nele, e como acessamos esses dados posteriormente, além dessas duas linhas e da estrutura que contém esses dados, nenhuma outra alteração de código foi necessária. O que isso fez com o consumo de memória?
Vamos dar uma olhada no benchcmp para fazer alguns testes.
Os testes de leitura inicializam a estrutura de dados, que cria as alocações. Podemos ver que o tempo de execução melhorou em cerca de 30%, as alocações caíram em 50% e o consumo de memória em >90% (!)
Como o mapa, agora em forma de fatia, nunca foi preenchido com muitos itens, os números mostram bem o que veremos na produção. Depende da entropia dos dados, mas pode haver casos em que as melhorias nas alocações e no consumo de memória seriam ainda maiores.
Olhando para o pprof novamente, e pegando um perfil de heap do mesmo teste, veremos que agora o consumo de memória está de fato reduzido em cerca de 90%.
A conclusão será: para conjuntos de dados menores, você não deve usar mapas onde as fatias seriam suficientes, pois os mapas têm uma grande sobrecarga.
Dump completo do núcleo
Como mencionado, é aqui que vemos a maior limitação com ferramentas no momento. Quando estávamos investigando esse problema, ficamos obcecados em conseguir chegar ao objeto raiz, sem muito sucesso. O Go evoluiu ao longo do tempo em um grande ritmo, mas essa evolução vem com um preço no caso do dump completo ou da representação de memória. O formato de dump da heap completa, conforme é alterada, não é compatível com versões anteriores. A versão mais recente é descrita aqui. Para escrever um dump completo da heap, você pode usar debug.WriteHeapDump().
Embora agora não nos encontremos "presos", já que não há uma boa solução para explorar dumps completos, o pprof respondeu a todas as nossas perguntas até agora.
Observe que a internet lembra muitas informações que não são mais relevantes. Aqui estão algumas coisas que você deve ignorar se você tentar abrir um dump completo, a partir do go1.11:
- Não há como abrir e depurar um dump completo de núcleo no MacOS, apenas no Linux.
- As ferramentas em https://github.com/randall77/hprof são para o Go1.3. Existe um fork para as versões posteriores a 1.7, mas também não funcionam corretamente (incompletas).
- O viewcore em https://github.com/golang/debug/tree/master/cmd/viewcore realmente não compila. É fácil de consertar (os pacotes internos estão apontando para golang.org e não para github.com), mas também não funciona no MacOS. Talvez funcione no Linux.
- https://github.com/randall77/corelib também falha no MacOS
pprof UI
Um último detalhe a ser observado quando se trata de pprof é o recurso de interface do usuário. Pode economizar muito tempo ao iniciar uma investigação sobre qualquer problema relacionado a um perfil obtido com o pprof.
go tool pprof -http=:8080 heap.outNesse ponto, ele deve abrir o navegador da web. Se isso não acontecer, navegue até a porta para a qual você o configurou. Ele permite que você altere as opções e obtenha o feedback visual muito mais rápido do que na linha de comando. É uma maneira muito útil de consumir a informação.
A interface do usuário realmente me familiarizou com os gráficos de chama, que expõem as áreas culpadas do código muito rapidamente.
Conclusão
O Go é uma linguagem empolgante com um conjunto de ferramentas muito rico. Você pode fazer muito mais com o pprof. Este artigo não toca no perfil da CPU, por exemplo.
Algumas outras boas leituras (em inglês):
- https://rakyll.org/archive/ — Acredito que este seja um dos colaboradores do monitoramento de desempenho do Go. Os posts no blog do autor são muito bons
- https://github.com/google/gops — escrito por JBD (que administra o rakyll.org). Esta ferramenta garante sua própria postagem no blog.
- https://medium.com/@cep21/using-go-1-10-new-trace-features-to-debug-an-integration-test-1dc39e4e812d —
go tool traceque gira em torno do perfil da CPU. Esse é um ótimo post sobre o recurso de criação de perfil.