
Artigo original: How to process textual data using TF-IDF in Python
Escrito por: Mayank Tripathi
Computadores são bons com números, mas não tanto com dados textuais. Uma das técnicas mais utilizadas para processar dados textuais é o TF-IDF. Neste artigo, vamos aprender como ele funciona e quais são suas características.
Pela nossa intuição, pensamos que as palavras que aparecem com mais frequência deveriam ter um peso maior na análise de dados textuais, mas nem sempre é assim. Palavras como "o", "vai" e "você" – chamadas de stopwords – aparecem mais em um corpus (conjunto) de texto(s), mas têm muito pouco significado. Em vez disso, as palavras que são raras são as que realmente ajudam na distinção entre os dados e têm mais peso.
Uma introdução ao TF-IDF
TF-IDF é a sigla para "Term Frequency — Inverse Data Frequency" (em português, "frequência do termo – inverso da frequência nos dados"). Primeiro, aprenderemos o que esse termo significa matematicamente.
Frequência do termo (tf): nos dá a frequência da palavra em cada documento do corpus. É a razão entre o número de vezes que a palavra aparece em um documento em comparação com o número total de palavras nesse documento. Ela aumenta à medida que o número de ocorrências dessa palavra dentro do documento aumenta. Cada documento tem seu próprio tf.
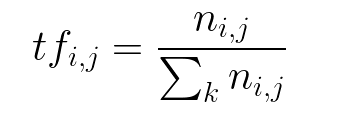
Inverso da frequência dos dados (idf): usado para calcular o peso de palavras raras em todos os documentos do corpus. As palavras que ocorrem raramente no corpus têm um alto escore de IDF. É dado pela equação abaixo.
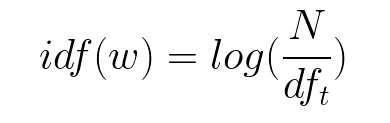
Combinando essas duas fórmulas, chegamos ao escore TF-IDF (w) para uma palavra em um documento no corpus. É o produto de tf e idf:
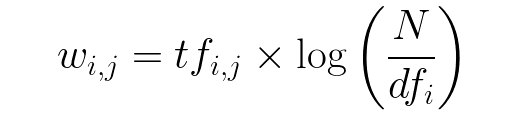
Onde:
- tfi,j = número de ocorrências de i em j
- dfi = número de documentos contendo i
- N = número total de ocorrências
Nota da tradução: o "w", em questão, na fórmula vem de word, palavra em inglês que significa "palavra" ou "termo".
Vamos pegar um exemplo para dar um entendimento mais claro.
Frase 1 : The car is driven on the road. (O carro é conduzido na estrada.)
Frase 2: The truck is driven on the highway. (O caminhão é conduzido na rodovia.)
Neste exemplo, cada frase está em um documento separado.
Agora, calcularemos o TF-IDF para os dois documentos acima, os quais representam nosso corpus.
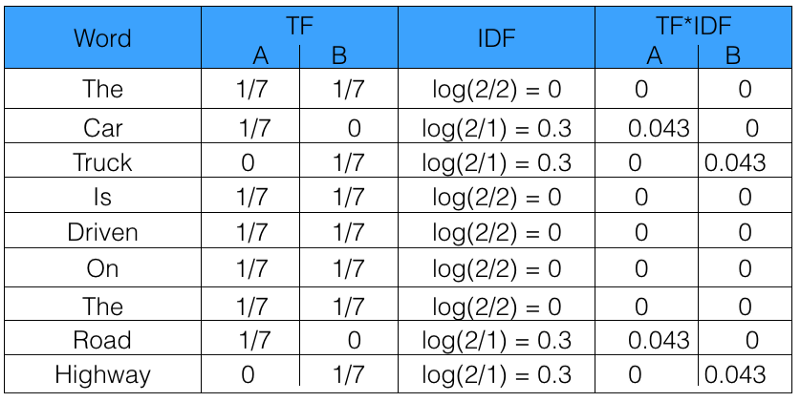
A partir da tabela acima, podemos ver que o TF-IDF de palavras comuns foi zero, o que mostra que elas não são significativas. Por outro lado, o TF-IDF de "car", "truck", "road" e "highway" é diferente de zero. Essas palavras têm mais significado.
Usando o Python para calcular o TF-IDF
Agora, vamos programar o TF-IDF em Python a partir do zero. Depois disso, veremos como podemos usar o sklearn para automatizar o processo.
A função computeTF calcula a pontuação de TF para cada palavra no corpus, por documento.

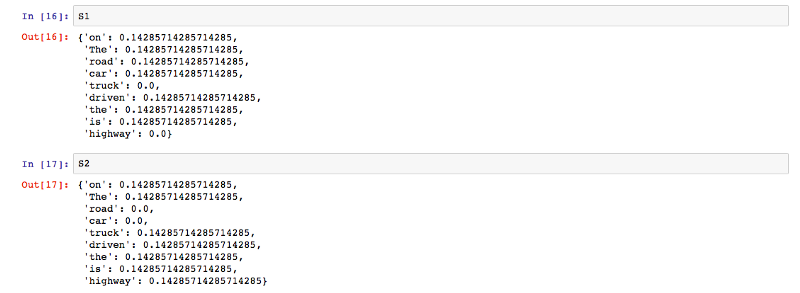
A função computeIDF calcula a pontuação de IDF para cada palavra no corpus.


A função computeTFIDF abaixo calcula a pontuação de TF-IDF para cada palavra, multiplicando as pontuações de TF e de IDF.

O resultado produzido pelo código acima para o conjunto de documentos D1 e D2 é o mesmo que calculamos manualmente anteriormente na tabela.

Consulte este link para ver a implementação completa.
sklearn
Agora, veremos como podemos implementar isso usando o sklearn em Python.
Primeiro, vamos importar TfidfVectorizer de sklearn.feature_extraction.text:

Depois, inicializamos vectorizer e chamamos fit e transform para calcular a pontuação de TF-IDF para o texto.

Internamente, sklearn fit_transform executa as funções fit e transform que vemos abaixo. Elas podem ser encontradas na biblioteca oficial do sklearn no GitHub.
def fit(self, X, y=None):
"""Learn the idf vector (global term weights)
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
"""
if not sp.issparse(X):
X = sp.csc_matrix(X)
if self.use_idf:
n_samples, n_features = X.shape
df = _document_frequency(X)
# perform idf smoothing if required
df += int(self.smooth_idf)
n_samples += int(self.smooth_idf)
# log+1 instead of log makes sure terms with zero idf don't get
# suppressed entirely.
idf = np.log(float(n_samples) / df) + 1.0
self._idf_diag = sp.spdiags(idf, diags=0, m=n_features,
n=n_features, format='csr')
return self
def transform(self, X, copy=True):
"""Transform a count matrix to a tf or tf-idf representation
Parameters
----------
X : sparse matrix, [n_samples, n_features]
a matrix of term/token counts
copy : boolean, default True
Whether to copy X and operate on the copy or perform in-place
operations.
Returns
-------
vectors : sparse matrix, [n_samples, n_features]
"""
if hasattr(X, 'dtype') and np.issubdtype(X.dtype, np.floating):
# preserve float family dtype
X = sp.csr_matrix(X, copy=copy)
else:
# convert counts or binary occurrences to floats
X = sp.csr_matrix(X, dtype=np.float64, copy=copy)
n_samples, n_features = X.shape
if self.sublinear_tf:
np.log(X.data, X.data)
X.data += 1
if self.use_idf:
check_is_fitted(self, '_idf_diag', 'idf vector is not fitted')
expected_n_features = self._idf_diag.shape[0]
if n_features != expected_n_features:
raise ValueError("Input has n_features=%d while the model"
" has been trained with n_features=%d" % (
n_features, expected_n_features))
# *= doesn't work
X = X * self._idf_diag
if self.norm:
X = normalize(X, norm=self.norm, copy=False)
return XUma coisa a se observar no código acima é que, em vez de apenas o log de n_samples, foi adicionado 1 a n_samples para se calcular a pontuação IDF. Isso garante que as palavras com uma pontuação IDF de zero não sejam totalmente suprimidas.
O resultado obtido é na forma de uma matriz com viés, que é normalizada para obter o seguinte resultado.
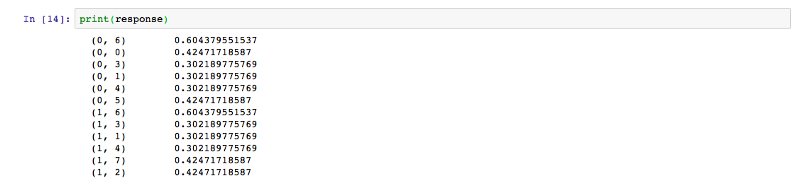
Assim, vimos como podemos facilmente programar o TF-IDF em apenas 4 linhas usando o sklearn. Agora, entendemos como o TF-IDF é poderoso como uma ferramenta para processar dados textuais a partir de um corpus. Para saber mais sobre o sklearn TF-IDF, você pode usar este link.
Uma ótima programação para você!
Agradecemos pela leitura deste artigo. Não se esqueça de compartilhá-lo se achou o artigo útil.
Para saber mais sobre programação, você pode seguir o autor para ser notificado de artigos novos escritos por ele.
Você também pode se conectar com o autor pelo Twitter, Linkedin, Github e Facebook.