
Artigo original: I wrote a programming language. Here’s how you can, too.
Escrito por: William W. Wold
Nos últimos 6 meses, eu venho trabalhando em uma linguagem de programação chamada Pinecone. Não chamaria de madura ainda, mas já possui recursos suficientes para ser utilizável, tais como:
- variáveis
- funções
- estruturas definidas pelo usuário
Se tiver interesse na linguagem Pinecone, dê uma olhada na página inicial ou no repositório do GitHub.
Não sou um especialista. Quando comecei com esse projeto, não tinha ideia do que estava fazendo – e continuo sem ter. Nunca tive aulas sobre como criar uma linguagem, apenas li um pouco sobre isso on-line. Também não segui muitos dos conselhos que recebi.
Ainda assim, eu criei uma linguagem nova e ela funcionou. É sinal de que estive fazendo alguma coisa certa.
Neste artigo, vou me aprofundar sobre o assunto e mostrar o pipeline que a Pinecone (e outras linguagens de programação) usam para transformar o código-fonte em magia.
Também falarei sobre algumas das concessões que fiz e no motivo de haver tomado as decisões que tomei.
Este não é, de modo algum, um tutorial completo sobre como escrever um linguagem de programação, mas é um bom ponto de partida se você tem curiosidade sobre como desenvolver uma linguagem.
Começando
"Não tenho a menor ideia sobre onde devo começar" é algo que escuto muito quando digo que estou escrevendo uma linguagem de programação. No caso de essa ser a sua reação, eu vou passar por algumas decisões iniciais que são tomadas e passos que são dados quando começamos a escrever qualquer linguagem nova.
Compilada x Interpretada
Aqui temos os dois tipos principais de linguagens: compiladas e interpretadas
- Um compilador calcula tudo o que um programa fará, transforma-o em "código de máquina" (um formato que o computador pode executar muito rápido) e depois salva esse código para ser executado mais tarde.
- Um interpretador passa pelo código-fonte linha por linha, descobrindo o que está fazendo no seu caminho.
Tecnicamente, qualquer linguagem pode ser compilada ou interpretada, mas a escolha por um tipo ou outro depende do que geralmente faz mais sentido para aquela linguagem específica. Geralmente, as interpretadas tendem a ser mais flexíveis, enquanto as compiladas tendem a ter alto desempenho. Isso, porém, é apenas o início de um tópico muito complexo.
Dou muito valor ao desempenho. Já percebi a falta de linguagens de programação de alta desempenho que sejam simples. Então, escolhi que a Pinecone seria compilada.
Isso foi muito importante para tomar uma decisão logo de inicio, porque vários designs de linguagem são afetados por isso (por exemplo, tipagem estática é um grande benefício das linguagens compiladas, mas não tanto quanto para linguagens interpretadas).
Apesar da Pinecone ter sido projetada com a compilação em mente, ela tem um interpretador totalmente funcional que, durante um tempo, foi a única forma de executá-la. Lá, veremos diversos motivos para isso, que eu vou explicar mais adiante.
Escolhendo uma linguagem
Eu sei que é um pouco fora do escopo, mas uma linguagem de programação é, em si, um programa. Por isso, você precisa escrevê-la em uma outra linguagem de programação. Escolhi o C++ por causa de seu desempenho e conjunto de funcionalidades. Além disso, eu realmente gosto de programar em C++.
Se você estiver escrevendo uma língua interpretada, faz muito sentido escrever em uma linguagem compilada (como C, C++ ou Swift) porque o desempenho perdido na linguagem interpretada e no interpretador que estará interpretando sua linguagem acabarão se acumulando.
Se está planejando uma linguagem compilada, uma linguagem mais lenta (como o Python ou o JavaScript) podem ser mais aceitáveis. O tempo de compilação pode ser ruim, mas, na minha opinião, isso não é tão importante quanto um tempo de execução longo.
Design de alto nível
Uma linguagem de programação geralmente é estruturada como um pipeline, ou seja, tem vários estágios. Cada estágio tem dados formatados de um modo específico e bem definido, além de ter funções para transformar dados de cada estágio para outros níveis.
A primeira etapa é uma cadeia contendo todo o arquivo de fonte de entrada. A etapa final é algo que pode ser executado. Tudo isso se tornará claro à medida que passarmos passo a passo pelo pipeline da Pinecone.
Lexing
O primeiro passo na maioria de linguagem de programação é o lexing, ou tokenização. "Lex" é a abreviação para lexical analysis (análise lexical, em português), uma palavra muito elegante para divisão de um texto em tokens. A palavra "tokenização" faz muito mais sentido, mas lexer é tão divertido de dizer que uso essa palavra de qualquer maneira.
Tokens
Um token é uma unidade pequena da linguagem. Um token (também conhecido como identificador) pode ser o nome de uma variável ou função, um operador ou um número.
Para que serve o lexer
O lexer deve pegar uma string contendo o código-fonte inteiro e devolver uma lista contendo cada token.
Os estágios futuros do pipeline não farão referência ao código-fonte original, portanto o lexer deve produzir para eles todas as informações necessárias. A razão para este formato relativamente rígido do pipeline é que o lexer pode fazer tarefas como remover comentários ou detectar se algo é um número ou identificador. Você vai querer manter essa lógica fechada dentro do lexer, tanto para não ter que pensar nessas regras ao escrever o resto da linguagem, quanto para poder mudar esse tipo de sintaxe em um único lugar.
Flex
No dia em que comecei a escrever a linguagem, a primeira coisa que fiz foi um lexer simples. Pouco depois, comecei a aprender sobre ferramentas que supostamente deixariam o lexer mais simples e com menos erros.
A ferramenta que mais ajuda com isso é o Flex, um programa gerador de lexers. Você dá a ele um arquivo que tem uma sintaxe especial para que ele descreva a sintaxe da linguagem. A partir disso, ele gera um programa em C, que cria uma string com o léxico e produz o resultado desejado.
Minha decisão
Optei por manter o lexer que escrevi por enquanto. No fim, eu não vi benefícios significativos em usar o Flex, ao menos não o suficiente para justificar a adição de uma dependência e para complicar ainda mais o processo de build.
Meu lexer tem somente uma centena de linhas de código e me causa muito poucos problemas. Produzir meu próprio lexer também me traz mais flexibilidade, como a capacidade de adicionar um operador à linguagem sem precisar editar diversos arquivos.
Fazendo o parsing

O segundo estágio do pipeline é o parser. Ele transforma uma lista de tokens em uma árvore de nós. Uma árvore usada para o armazenamento desse tipo de dados é conhecida como uma Árvore de Sintaxe Abstrata (em inglês, Abstract Syntax Tree, ou AST). Ao menos na Pinecone, a AST não tem informações sobre tipos ou qual identificador é qual. Ela é simplesmente os tokens estruturados.
Tarefas do parser
O parser adiciona estrutura à lista ordenada de tokens que o lexer produz. Para acabar com as ambiguidades, o parser deve levar em conta os parênteses e a ordem das operações. Fazer o parsing dos operadores, simplesmente, não é algo incrivelmente difícil, mas quanto mais construtos da linguagem são adicionados, mais o parsing pode se tornar extremamente complexo.
Bison
Novamente, precisei tomar uma decisão que envolvia uma biblioteca de terceiros. A biblioteca mais conhecida de parsing é a Bison. A Bison funciona de modo muito parecido com a Flex. Você escreve um arquivo no formato personalizado, que armazena as informações de gramática, e a Bison usa esse arquivo para gerar um programa em C que fará seu parsing. Optei por não usar a Bison, tampouco.
Por que o personalizado é melhor?
Com o lexer, a decisão de usar meu próprio código ficou bastante óbvia. Um lexer assim é um programa simples. Não escrever meu próprio lexer pareceu tão bobo quanto não escrever... bem... meu próprio programa simples.
Com o parser, seria algo bem diferente. O parser da Pinecone neste momento já está em 750 linhas. Eu escrevi três versões de parser diferentes até o momento, pois as duas primeiras eram um lixo.
Eu tomei essa decisão inicialmente por várias razões. Apesar de não ter sido exatamente algo muito fácil de fazer, a maioria dessas razões permanece valendo. As mais importantes são:
- Minimizar a troca de contexto no fluxo de trabalho: a troca de contexto entre o C++ e a Pinecone já é ruim o suficiente sem adicionar a gramática da Bison
- Manter simples o build: sempre que a gramática for mudada, a Bison precisa ser executada antes da build. Isso pode ser automatizado, mas fica chato ao trocar entre sistemas de build.
- Eu gosto de criar coisas legais: eu não fiz a Pinecone porque eu pensei que seria fácil, então para que delegar uma função central quando eu a poderia fazer por minha conta? Um parser personalizado pode não ser trivial, mas é completamente factível.
No começo, eu não tinha muita certeza se eu estava indo por um caminho viável, mas eu ganhei um pouco mais de confiança com o que Walter Bright (o desenvolvedor de uma versão anterior do C++ e criador da linguagem D) disse uma vez sobre o assunto (referência de texto em inglês):
"Um pouco mais controverso era o fato de que eu não deveria me importar com geradores de lexer ou de parser e com outros assim chamados 'compiladores de compilador'. Eles são uma perda de tempo. Escrever um lexer e um parser é uma porcentagem mínima do trabalho de escrever um compilador. Usar um gerador levaria tanto tempo quanto escrever um por conta própria, e associará você ao gerador (o que é importante ao transpor o compilador para uma nova plataforma). Além disso, os geradores têm a reputação infeliz de lançar mensagens de erro péssimas."
Árvore de ações
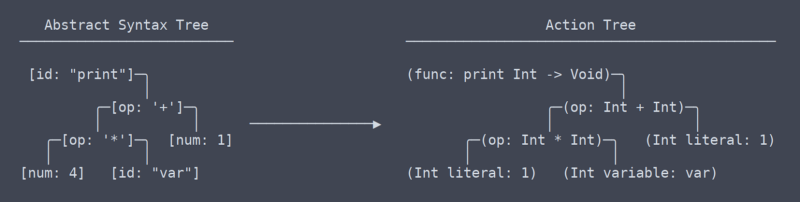
Agora saímos da área dos termos universais e comuns para entrarmos nos termos que eu já não tenho tanto entendimento. Do meu ponto de vista, o que eu chamo de "árvore de ações" é muito parecido com a IR (intermediate representation, ou representação intermediária, em português) das LLVMs.
Há uma diferença sutil, mas significativa entre a árvore de ações e a árvore de sintaxe abstrata. Levou um tempo até que eu entendesse que poderia até mesmo haver essa diferença entre elas (o que contribuiu com a necessidade de reescrever o parser algumas vezes).
Árvore de ações x AST
De modo simplificado, a árvore de ações é a AST mais o contexto. O contexto são as informações como o tipo que a função retorna ou aqueles dois locais onde uma variável é usada estão usando, de fato, a mesma variável. Como ela precisa descobrir e memorizar todo esse contexto, o código que gera a árvore de ação precisa de muitas buscas nas tabelas de namespace além de outros detalhes.
Executando a árvore de ações
Ao termos uma árvore de ações, executar o código é fácil. Cada nó de ação tem uma função "executar", que recebe uma entrada, faz o que a ação deve fazer (incluindo a possível chamada a uma subação) e retorna o resultado da ação. Esse é o interpretador trabalhando.
Opções de compilação
"Espere aí", você pode dizer, "você não disse que a Pinecone era pra ser compilada?" Sim, é. A compilação, no entanto, é mais difícil que a interpretação. Existem algumas abordagens possíveis.
Criar meu próprio compilador
Essa opção me pareceu boa de início. Eu gosto muito de fazer tudo por minha conta. Fiquei me coçando por uma desculpa para melhorar meu assembly.
Infelizmente, escrever um compilador portátil não é tão fácil como escrever código de máquina para cada elemento da linguagem. Em função do número enorme de arquiteturas e sistemas operacionais, é quase impossível para um único indivíduo escrever o back-end de um compilador multiplataforma.
Até mesmo as equipes por trás do Swift, do Rust e do Clang não se deram ao trabalho de fazer isso por conta própria. Em vez disso, elas usaram a…
LLVM
A LLVM é uma coleção de ferramentas de compilação. Basicamente, é uma biblioteca que transformará sua linguagem em um arquivo binário executável e compilado. Parecia a opção perfeita. Por isso, mergulhei nessa ideia diretamente. Infelizmente, eu não vi a profundidade do lago em que eu estava mergulhando e acabei me afogando.
A LLVM, embora não seja difícil como a linguagem assembly, é uma biblioteca enorme complexa. Ela não é impossível de usar, tem bons tutoriais, mas eu percebi que precisaria de alguma prática antes de conseguir implementar plenamente um compilador para a Pinecone com ela.
Transpilação
Eu queria algum tipo de Pinecone compilada e queria isso rapidamente. Parti, então, para um método que eu sabia que poderia fazer com que isso desse certo: a transpilação.
Eu escrevi um transpilador de Pinecone em C++, adicionando a ele a capacidade de compilar automaticamente a origem do resultado com o GCC. Isso funciona, de fato, para quase todos os programas em Pinecone (embora existam alguns casos de exceção que causam erros no transpilador). Não é uma solução particularmente portável ou escalável, mas funciona por enquanto.
Futuro
Se assumirmos que eu continuarei a desenvolver a Pinecone, ela receberá suporte de compilação da LLVM mais cedo ou mais tarde. Suspeito que, não importando o quanto de trabalho eu dedique a ele, o transpilador nunca será inteiramente estável – além disso, os benefícios da LLVM são diversos. É apenas uma questão de quando eu terei tempo de fazer alguns projetos iniciais na LLVM até dominá-la bem.
Enquanto esse tempo não chega, o interpretador é ótimo para os programas simples e a transpilação em C++ funciona para a maioria dos casos que necessitam de mais desempenho.
Conclusão
Espero ter tornado linguagens de programação um pouco menos misteriosas para você. Se você quiser criar uma por conta própria, é algo que eu recomendo imensamente. Existem milhares de detalhes de implementação a serem descobertos, mas a descrição aqui deve ser suficiente para dar seu primeiro impulso.
Aqui vai meu conselho para quem está começando (mas lembre-se: eu não sei muito bem o que estou fazendo ainda, então aceite o conselho com toda a precaução possível):
- Se estiver em dúvida, escolha a linguagem interpretada. Linguagens interpretadas são geralmente mais fáceis de projetar, criar e aprender. Não é tentar impedir você de escrever uma linguagem compilada se você sabe bem o que quer fazer. Porém, se estiver em dúvida, escolha a interpretada.
- Quando o assunto for lexers e parsers, faça o que quiser. Existem argumentos válidos a favor e contra escrever seus próprios programas. No fim, se perceber que seu design e implementação fazem tudo de modo racional, não importa a escolha.
- Aprenda com o pipeline que eu acabo de descrever. Houve muita tentativa e erro na criação do pipeline que eu tenho nesse momento. Tentei eliminar ASTs, ASTs que viram árvores de ações, bem como outras ideias horríveis. Esse pipeline funciona. Então, não o altere, a menos que tenha uma ideia muito boa.
- Se não tiver tempo nem motivação para implementar uma linguagem de propósito geral e complexa, experimente implementar uma linguagem esotérica, como a Brainfuck (texto em inglês). Esses interpretadores podem ter apenas umas cem ou duzentas linhas.
Eu tenho muito pouco do que me arrepender em termos do desenvolvimento da Pinecone. Fiz algumas escolhas ruins no caminho, mas reescrevi a maior parte do código afetada por esses erros.
Agora, a Pinecone está em um estado bom o suficiente para funcionar bem e pode ser facilmente melhorada. Escrever a Pinecone foi um aprendizado e tanto para mim, além de uma experiência bastante agradável, e eu estou apenas começando.