

Artigo original: GridFS Guide: How to Upload Files and Images to MongoDB Easily Using Node
Escrito por: Tarique Ejaz
O armazenamento de arquivos é um recurso importante e necessário em vários processos e em diversos tipos de aplicações. A existência de processos como as Content Delivery Networks (CDNs – ou, em português, redes de entrega de conteúdo), configuradas através de opções de nuvem de terceiros como a Amazon Web Services, e de opções de armazenamento de arquivos locais sempre tornaram mais fácil a criação desse tipo de recurso.
No entanto, o conceito de armazenar arquivos diretamente em um banco de dados através de uma única chamada de API me intriga há muito tempo. Foi aí que o GridFS entrou em cena para mim.

O que é o GridFS – explicação simplificada
O MongoDB possui uma especificação de driver para upload e recuperação de arquivos chamada GridFS. O GridFS permite que você armazene e recupere arquivos, incluindo aqueles que excedem o limite de tamanho do documento BSON de 16 MB.
Basicamente, o GridFS pega um arquivo e o divide em vários pedaços, que são armazenados como documentos individuais em duas coleções:
- a coleção
chunk(que armazena as partes do documento) e - a coleção
file(que armazena os metadados adicionais resultantes).
Cada pedaço (em inglês, chunk) é limitado a 255 KB de tamanho. Isso significa que o último pedaço é normalmente igual ou menor que 255 KB. Parece bom, não?
Quando você lê a partir do GridFS, o driver recompõe todos os pedaços conforme necessário. Isso significa que você pode ler seções de um arquivo de acordo com o intervalo de sua consulta. Um exemplo disso é quando você escuta um trecho de um arquivo de áudio ou busca uma seção de um arquivo de vídeo.
Observação: é preferível usar o GridFS para armazenar arquivos normalmente excedendo o limite de tamanho de 16 MB. Para arquivos menores, é recomendado usar o formato BinData para armazenar os arquivos em documentos únicos.
Isso resume como o GridFS funciona em geral. Hora de examinar um código funcionando e de ver como implementar um sistema assim.
Chega de papo, quero ver o código
Estamos usando o Node.js com acesso a uma instância de nuvem do MongoDB para nossa configuração. Você pode encontrar o repositório de código para a aplicação de exemplo aqui.
Vamos nos concentrar inteiramente em segmentos do código que se relacionam com as funcionalidades do GridFS. Vamos aprender como configurá-lo e usá-lo para armazenar arquivos, recuperar arquivos ou um arquivo específico e excluir um arquivo específico. Vamos começar.
Inicializando a engine de armazenamento
Os pacotes necessários para inicializar a engine são o multer-gridfs-storage e o multer. Também usamos o middleware method-override para habilitar a operação de exclusão de arquivos. O módulo crypto do npm é usado para criptografar os nomes dos arquivos ao serem armazenados e lidos do banco de dados.
Quando a engine de armazenamento usando GridFS é inicializada, você só precisa chamá-la usando o middleware multer. Ela é então passada para a rota respectiva que executa as várias operações de armazenamento de arquivos.
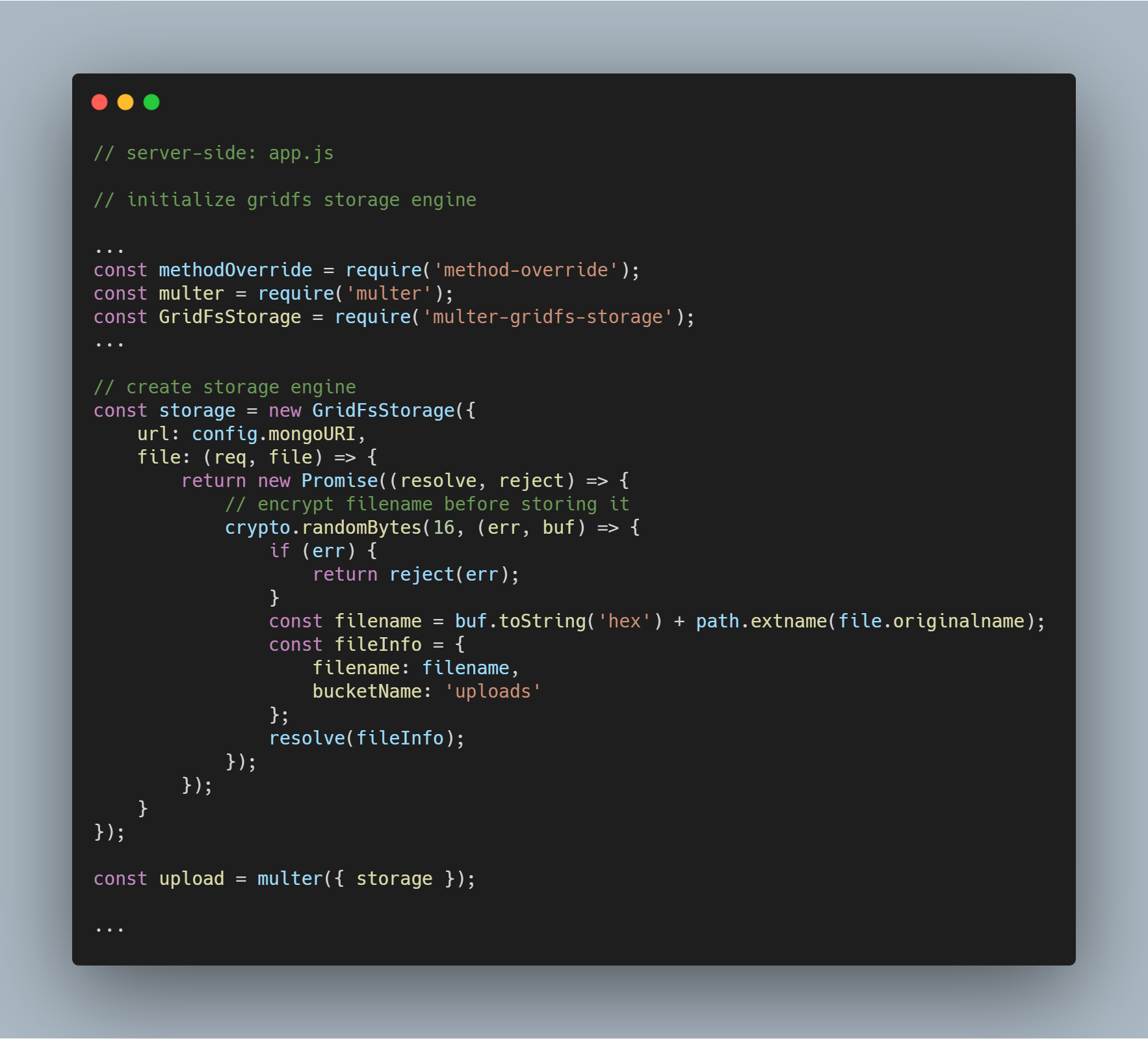
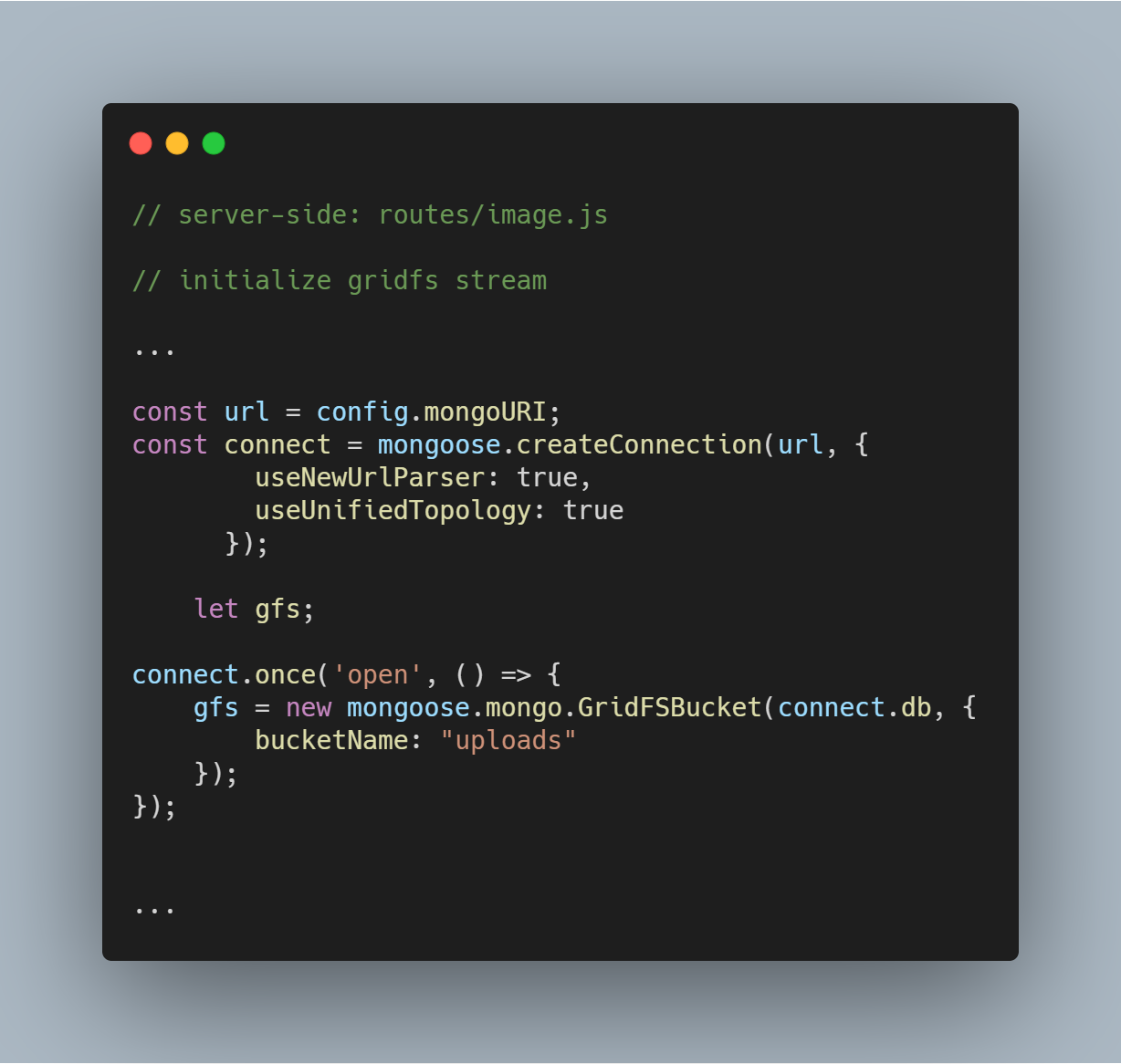
Inicializando o stream do GridFS
Inicializamos um stream do GridFS conforme visto no código abaixo. O stream é necessário para ler os arquivos do banco de dados e também para ajudar a renderizar uma imagem em um navegador quando necessário.
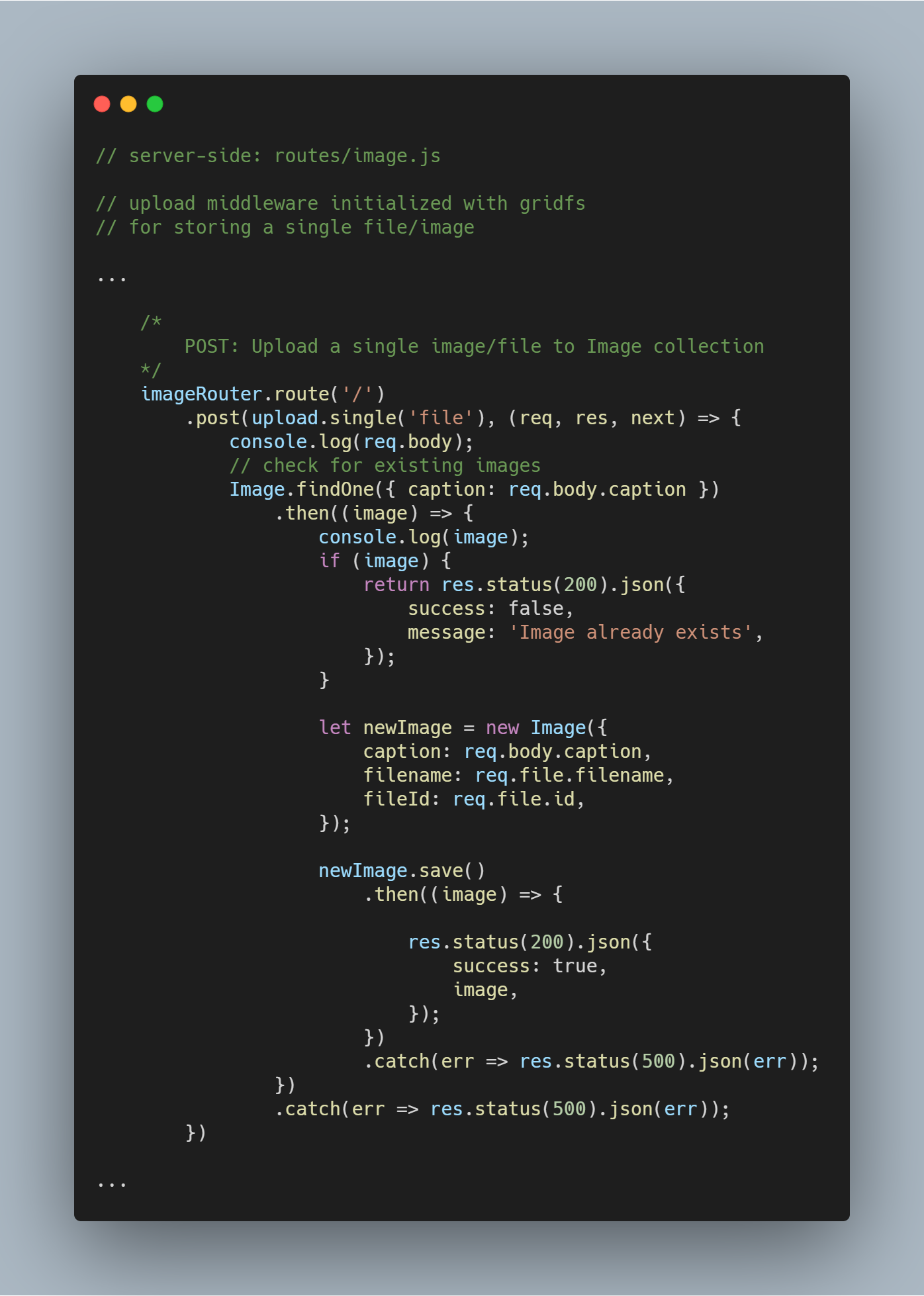
Fazendo o upload de um único arquivo ou imagem
Reutilizamos o middleware de upload que criamos anteriormente.
Observação: o nome file é usado como parâmetro em upload.single(), pois temos a chave com um nome similar carregando o arquivo que está sendo enviado pelo client.
Fazendo o upload de vários arquivos ou imagens
Também podemos fazer upload de vários arquivos de uma vez. Em vez de upload.single(), temos que simplesmente usar upload.multiple(<número de arquivos>).
Observação: o número de arquivos carregados pode ser menor que o número definido de arquivos.

Buscando todos os arquivos do banco de dados
Usando o stream inicializado, podemos buscar todos os arquivos no banco de dados específico usando gfs.find().toArray(...). Quando os arquivos são obtidos, mapeamos para um array e enviamos a resposta.
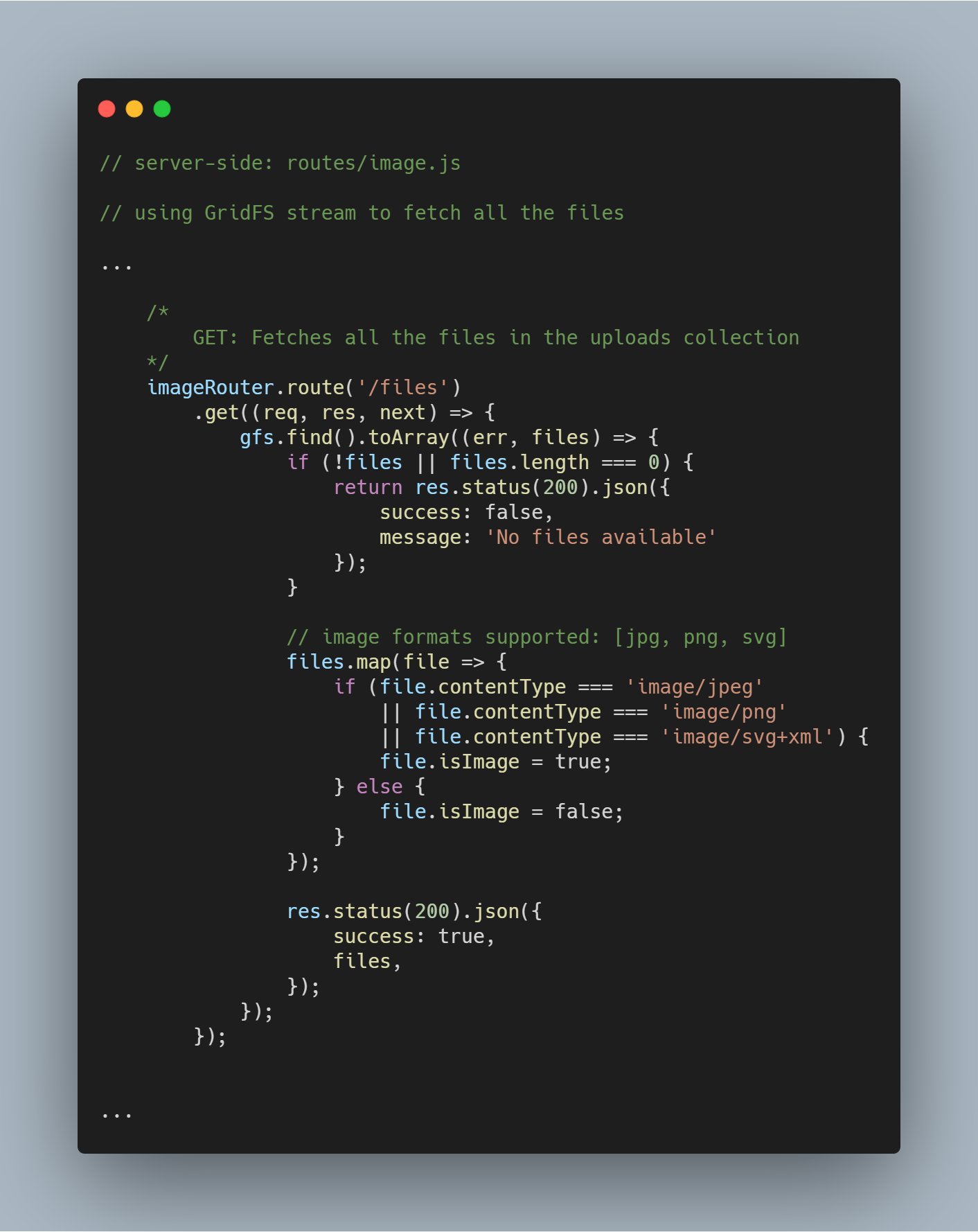
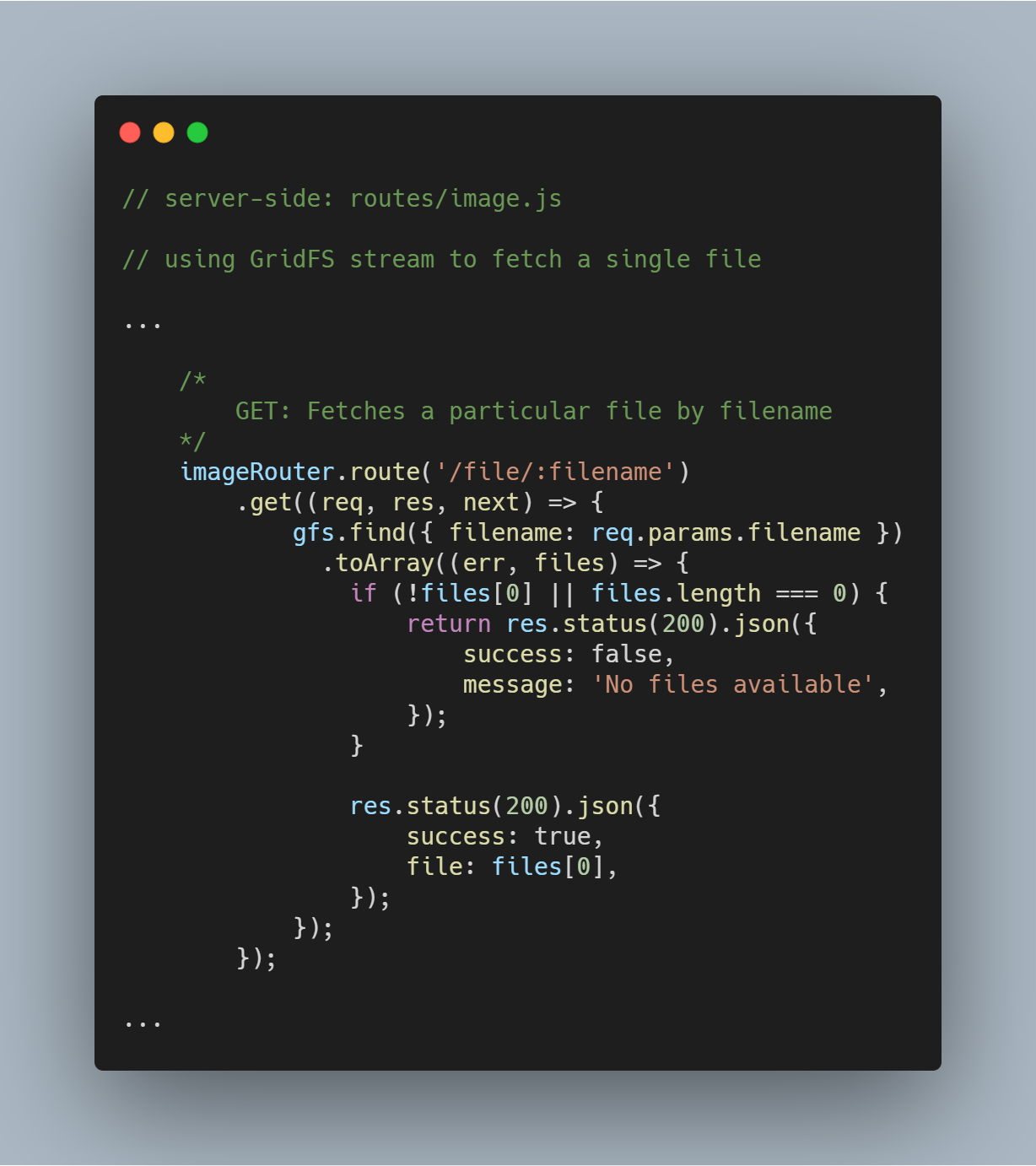
Buscando um único arquivo pelo nome do arquivo
É muito simples consultar o GridFS para um único arquivo baseado em um atributo específico, como filename (o nome do arquivo). Usando o stream do GridFS, você pode consultar o banco de dados através da função gfs.find({<adicione sua consulta aqui>}).
Renderizando no navegador uma imagem buscada
Essa é uma parte um pouco mais complicada, pois você precisa não apenas buscar um arquivo do banco de dados, mas também renderizá-lo como uma imagem no respectivo navegador. Buscamos o arquivo normalmente. Não há nada de novo nesse processo.
Então, com a ajuda do método openDownloadStreamByName() no stream do gfs, podemos facilmente renderizar uma imagem, pois ele retorna um stream legível. Tendo feito isso, podemos usar o método pipe() do JavaScript para transmitir a resposta.
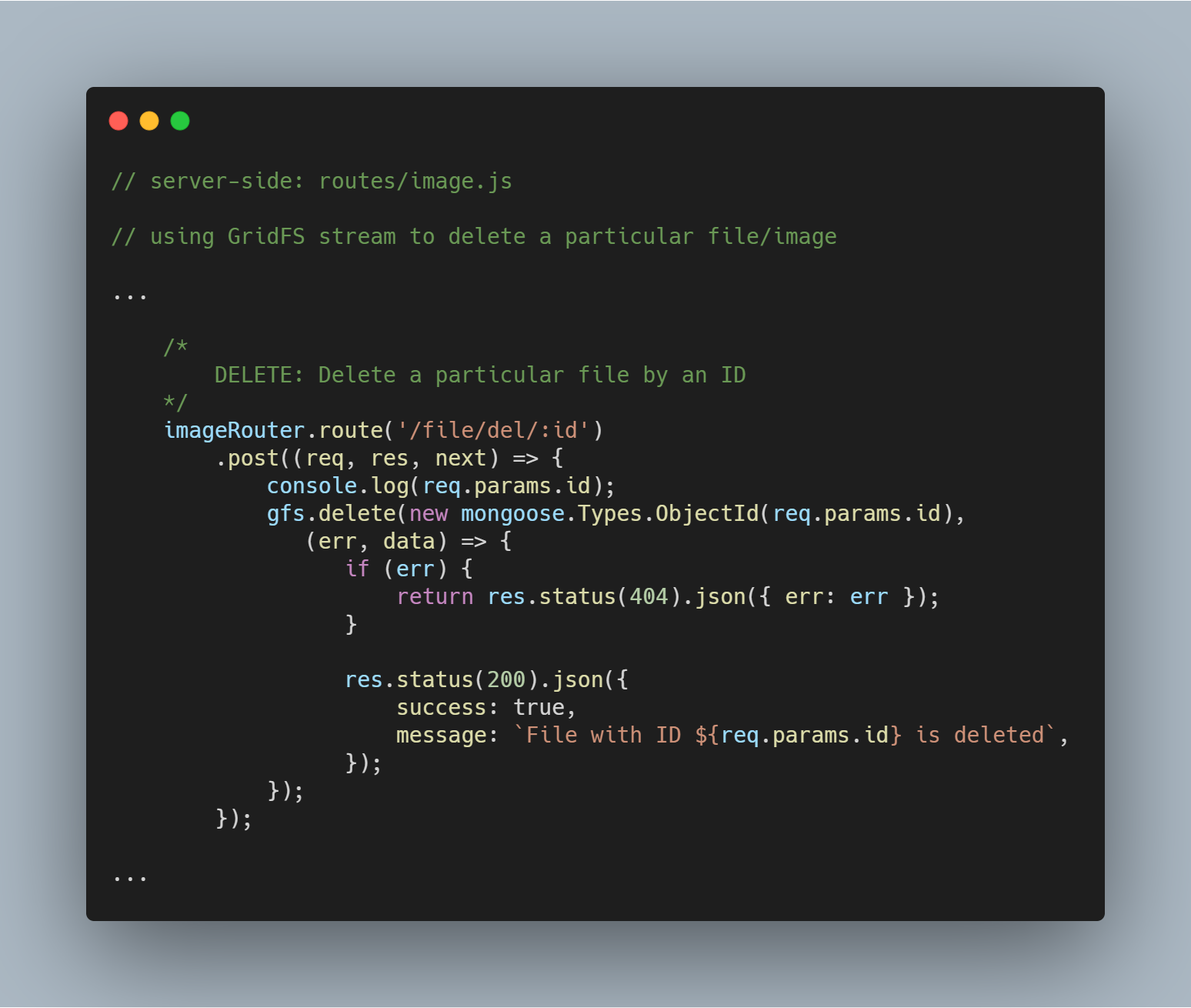
Excluindo um arquivo específico por Id
Excluir um arquivo também é simples. Usamos o método delete() com o parâmetro _id para consultar e excluir o arquivo em questão.
Essas são as principais funcionalidades oferecidas pela engine de armazenamento. Eu utilizei os recursos do GridFS discutidos para criar uma aplicação simples de upload de imagens. Você pode ver o código em mais detalhes no repositório.
Conclusão
Demorei um pouco e tive uma quantidade razoável de dificuldade para entender como usar o GridFS para um projeto pessoal. Por causa disso, queria garantir que ao menos outra pessoa não precisasse ter de gastar a mesma quantidade de tempo que eu nisso.
Dito isso, eu recomendo usar o GridFS com cautela. Não é uma solução universal para todos os seus problemas de armazenamento de arquivos. Ainda assim, é interessante conhecer essa especificação e saber de sua existência.
Se você tiver alguma dúvida ou questão que deseje apontar, fique à vontade para entrar em contato com o autor pelo LinkedIn.
Boa programação para você! 🙂