

Artigo original: What Is a File System? Types of Computer File Systems and How they Work – Explained with Examples
Escrito por: Reza Lavarian
É um pouco complicado explicar exatamente o que é um sistema de arquivos em apenas uma frase.
É por isso que decidi escrever um artigo sobre isso. Este artigo pretende ser uma visão geral de alto nível sobre sistemas de arquivos. Também examinarei alguns conceitos de mais baixo nível, desde que não fique entediante. 🙂
O que é um sistema de arquivos?
Vamos começar com uma definição simples:
Um sistema de arquivos define como os arquivos são nomeados, armazenados e recuperados em um dispositivo de armazenamento.
Toda vez que você abre um arquivo em seu computador ou dispositivo inteligente, seu sistema operacional usa seu sistema de arquivos internamente para carregá-lo do dispositivo de armazenamento.
Quando você copia, edita ou exclui um arquivo, é o sistema de arquivos que lida com isso nos bastidores.
Sempre que você faz o download de um arquivo ou acessa uma página da web na Internet, um sistema de arquivos está envolvido também.
Por exemplo, se você acessar uma página no freeCodeCamp, seu navegador envia uma solicitação HTTP (texto em inglês) ao servidor do freeCodeCamp para buscar a página. Se o recurso solicitado for um arquivo, ele é buscado de um sistema de arquivos.
Quando as pessoas falam em sistemas de arquivos, elas podem estar se referindo a diferentes aspectos de um sistema de arquivos dependendo do contexto – é aí que as coisas começam a parecer complicadas.
Você pode acabar se perguntando: O QUE É UM SISTEMA DE ARQUIVOS AFINAL? 🤯
Este guia ajudará você a entender sistemas de arquivos em muitos contextos. Também abordarei particionamento e inicialização!
Para manter este guia gerenciável, vou me concentrar em ambientes semelhantes ao Unix ao explicar os conceitos de baixo nível ou comandos de console.
No entanto, esses conceitos permanecem relevantes para outros ambientes e sistemas de arquivos.
Por que precisamos de um sistema de arquivos, afinal de contas?
Bem, sem um sistema de arquivos, o dispositivo de armazenamento conteria um grande bloco de dados armazenados consecutivamente. O sistema operacional não seria capaz de distingui-los.
O termo sistema de arquivos vem dos antigos sistemas de gerenciamento de dados baseados em papel, onde mantínhamos documentos como arquivos e os colocávamos em diretórios.
Imagine uma sala com pilhas de papéis espalhados por todo o lugar.

Um dispositivo de armazenamento sem um sistema de arquivos estaria na mesma situação – e seria um dispositivo eletrônico inútil.
No entanto, um sistema de arquivos muda tudo:

Um sistema de arquivos não é apenas uma função de contagem, no entanto.
Gerenciamento de espaço, metadados, criptografia de dados, controle de acesso a arquivos e integridade dos dados também são responsabilidades do sistema de arquivos.
Tudo começa com o particionamento
Os dispositivos de armazenamento devem ser particionados e formatados antes de serem usados pela primeira vez.
O que é particionamento?
Particionamento é a divisão de um dispositivo de armazenamento em várias regiões lógicas para que possam ser gerenciadas separadamente como se fossem dispositivos de armazenamento separados.
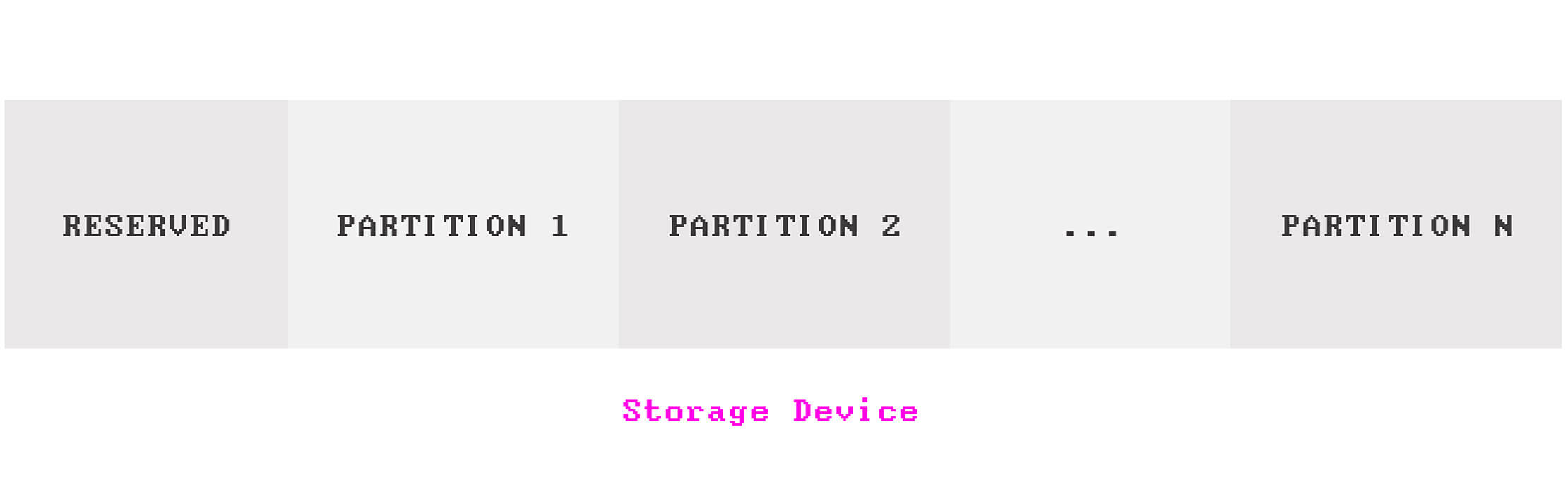
Geralmente, fazemos o particionamento com uma ferramenta de gerenciamento de disco fornecida pelos sistemas operacionais ou com uma ferramenta de linha de comando fornecida pelo firmware do sistema (explicarei o que é firmware mais tarde).
Um dispositivo de armazenamento deve ter, pelo menos, uma partição – ou mais de uma, se necessário.
Por que devemos dividir os dispositivos de armazenamento em várias partições, afinal?
A razão é que não queremos gerenciar todo o espaço de armazenamento como uma única unidade e para um único propósito.
É semelhante ao modo como particionamos nosso espaço de trabalho, para separar (e isolar) salas de reunião, salas de conferência e várias equipes.

Por exemplo, uma instalação básica do Linux tem três partições: uma partição dedicada ao sistema operacional, uma para os arquivos dos usuários e uma partição de swap opcional.
Uma partição de swap funciona como uma extensão da RAM quando a RAM fica sem espaço.
Por exemplo, o sistema operacional pode mover um trecho de dados (temporariamente) da RAM para a partição de swap para liberar algum espaço na RAM.
Os sistemas operacionais continuamente utilizam várias técnicas de gerenciamento de memória (texto em inglês) para garantir que cada processo tenha espaço de memória suficiente para funcionar.
Os sistemas de arquivos no Windows e do Mac têm um layout semelhante, mas não usam uma partição de swap dedicada; Em vez disso, eles gerenciam a troca dentro da partição onde você instalou seu sistema operacional.
Em um computador com várias partições, você pode instalar vários sistemas operacionais e, quando quiser, escolher um sistema operacional diferente para inicializar seu sistema.
As utilidades de recuperação e diagnóstico residem em partições dedicadas também.
Por exemplo, para inicializar um MacBook no modo de recuperação, você precisa segurar Command + R assim que reiniciar (ou ligar) seu MacBook. Fazendo isso, você instrui o firmware do sistema a inicializar com uma partição que contém o programa de recuperação.
O particionamento não é apenas uma maneira de instalar diversos sistemas operacionais e ferramentas, no entanto. Ele também nos ajuda a manter os arquivos críticos do sistema separados dos arquivos comuns.
De volta ao exemplo do escritório, ter um call center e uma equipe técnica em uma área comum prejudicaria a produtividade das duas equipes, pois cada equipe tem suas próprias necessidades para ser eficiente.
Por exemplo, a equipe técnica apreciaria um ambiente mais silencioso.
Alguns sistemas operacionais, como o Windows, atribuem uma letra de unidade (A, B, C ou D) às partições. Por exemplo, a partição primária no Windows (na qual o Windows está instalado) é conhecida como C:, ou unidade C.
Em sistemas operacionais semelhantes ao Unix, no entanto, as partições aparecem como diretórios comuns sob o diretório raiz – abordaremos isso mais tarde.
Na próxima seção, vamos nos aprofundar no particionamento e conhecer dois conceitos que mudarão sua perspectiva sobre sistemas de arquivos: firmware do sistema e boot.
Está pronto?
Vamos lá! 🏊♂️
Esquemas de particionamento, firmware de sistema e boot
Ao particionar um dispositivo de armazenamento, temos dois métodos de particionamento (ou esquemas 🙄) para escolher:
- Esquema Master Boot Record (MBR)
- Esquema GUID Partition Table (GPT)
Independentemente do esquema de particionamento que você escolher, os primeiros blocos no dispositivo de armazenamento sempre conterão dados críticos sobre suas partições.
O firmware do sistema usa essas estruturas de dados para inicializar o sistema operacional em uma partição.
Espere, mas o que é firmware do sistema, você pode perguntar.
Aqui está uma explicação:
Um firmware é um software de baixo nível embutido em dispositivos eletrônicos para operar o dispositivo ou iniciar outro programa para fazer isso.
O firmware existe em computadores, periféricos (teclados, mouses e impressoras) ou até mesmo em eletrodomésticos e eletrônicos.
Nos computadores, o firmware fornece uma interface padrão para um software complexo como o sistema operacional fazer a inicialização e trabalhar com os componentes de hardware.
No entanto, em sistemas mais simples como uma impressora, o firmware é o sistema operacional. O menu que você usa na sua impressora é a interface do firmware dela.
Os fabricantes de hardware fazem firmware com base em duas especificações:
- Basic Input/Output (BIOS)
- Unified Extensible Firmware Interface (UEFI)
Firmwares – baseados em BIOS ou UEFI – residem em uma memória não volátil, como uma ROM flash anexada à placa-mãe.

Quando você pressiona o botão de energia do seu computador, o firmware é o primeiro programa a ser executado.
A missão do firmware (entre outras coisas) é inicializar o computador, executar o sistema operacional e passar o controle do sistema inteiro para ele.
Um firmware também executa ambientes anteriores ao sistema operacional (com suporte de rede), como ferramentas de recuperação ou diagnósticas, ou até mesmo um shell para executar comandos baseados em texto.
As primeiras telas que você vê antes de o logotipo do Windows aparecer são a saída do firmware do seu computador, verificando a integridade dos componentes de hardware e da memória.
A verificação inicial é confirmada com um bip (geralmente, em PCs), indicando que está tudo certo para prosseguir.
Particionamento MBR e firmware baseado em BIOS
O esquema de particionamento MBR faz parte das especificações do BIOS e é usado por firmware baseado em BIOS.
Em discos particionados com MBR, o primeiro setor no dispositivo de armazenamento contém dados essenciais para inicializar o sistema.
Esse setor é chamado de MBR.
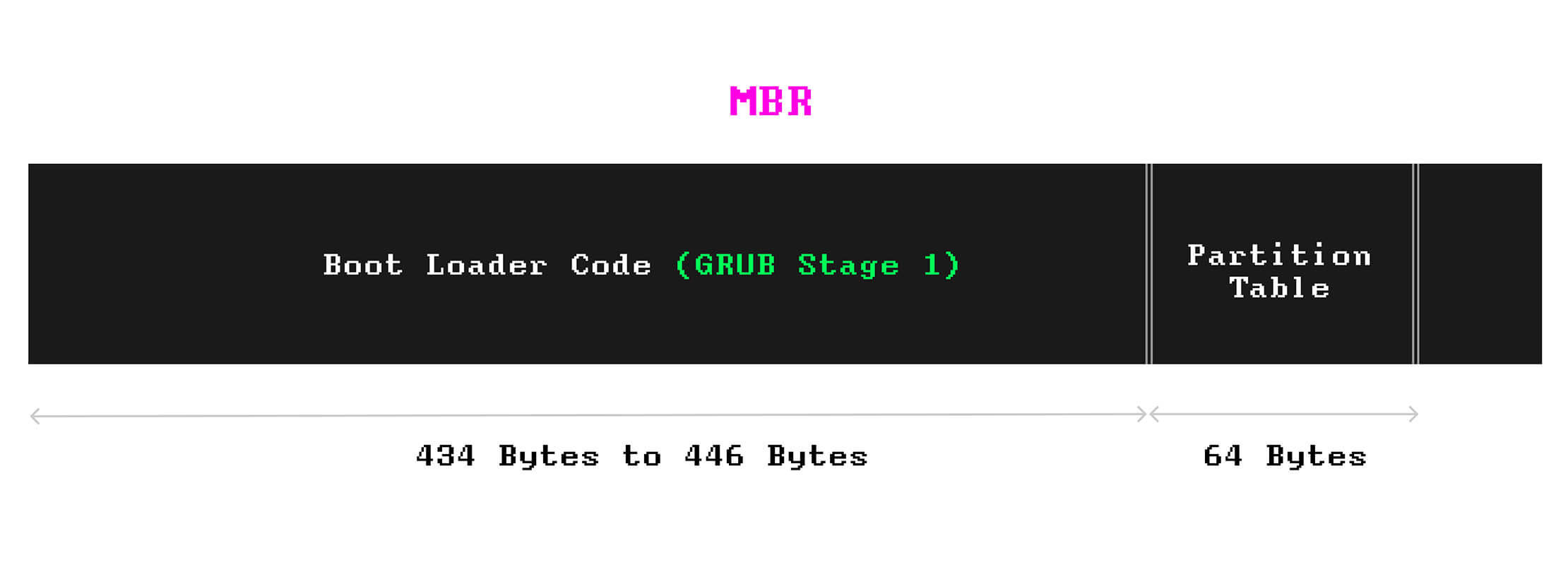
O MBR contém as seguintes informações:
- O carregador de boot (em português, inicialização), que é um programa simples (em código de máquina) para iniciar a primeira etapa do processo de boot
- Uma tabela de partição, que contém informações sobre suas partições.
O firmware baseado em BIOS inicializa o sistema de maneira diferente do firmware baseado em UEFI.
Veja como funciona:
Uma vez que o sistema é ligado, o firmware do BIOS começa e carrega o programa de carregamento de boot (contido no MBR) na memória. Uma vez que o programa está na memória, a CPU começa a executá-lo.
Ter o carregador de boot e a tabela de partição em um local predefinido como o MBR permite que o BIOS inicialize o sistema sem precisar lidar com qualquer arquivo.
Se você está curioso sobre como a CPU executa as instruções que residem na memória, você pode ler este guia amigável para iniciantes e divertido sobre como a CPU funciona (texto em inglês).
O código do carregador de boot no MBR ocupa entre 434 bytes a 446 bytes do espaço do MBR (de um total de 512b). Além disso, 64 bytes são alocados para a tabela de partição, que pode conter informações de até quatro partições.
446 bytes não é suficiente para acomodar muito código, no entanto. Dito isso, carregadores de boot sofisticados como o GRUB 2 no Linux dividem sua funcionalidade em partes ou etapas.
A menor parte do código, conhecida como carregador de boot de primeira etapa, é armazenada no MBR. É geralmente um programa simples, que não requer muito espaço.
A responsabilidade do carregador de boot de primeira etapa é iniciar as próximas etapas (mais complicadas) do processo de boot.
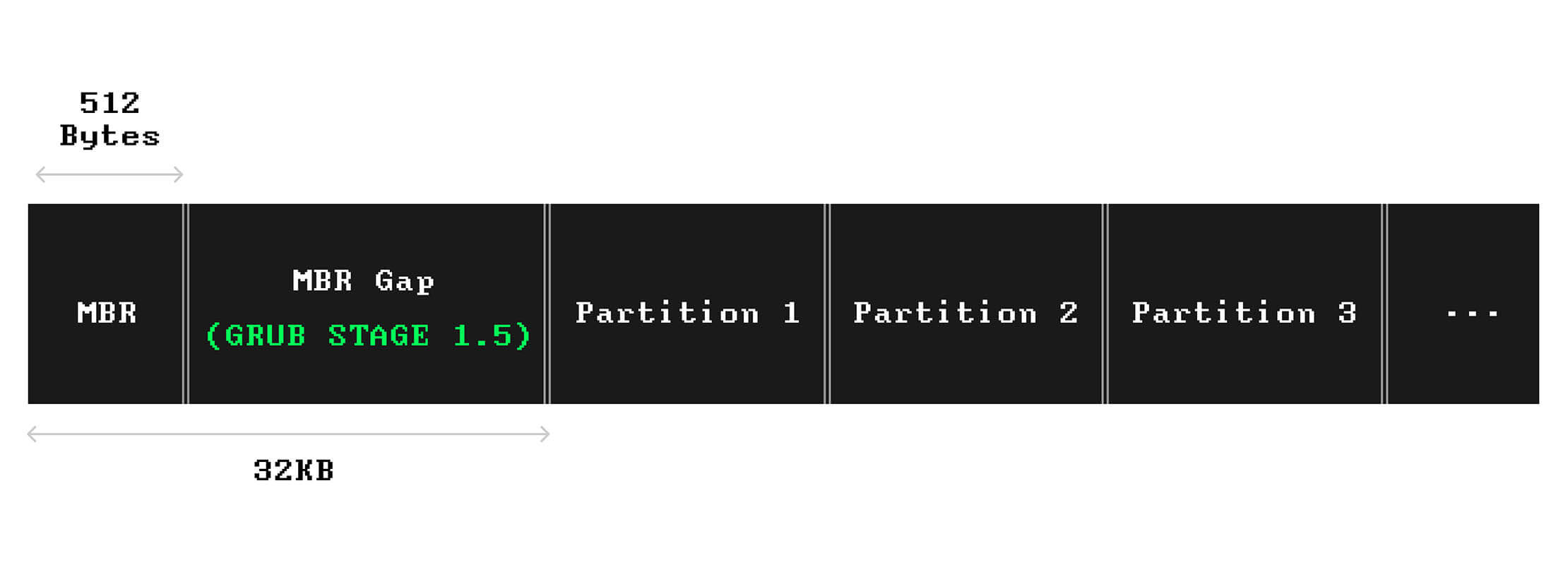
Imediatamente após o MBR e antes da primeira partição começar, há um pequeno espaço, cerca de 1MB, chamado de gap do MBR.
O gap do MBR pode ser usado para colocar outra parte do programa de carregamento de boot, se necessário.
O stage 1.5 permite que os próximos estágios do GRUB compreendam o conceito de arquivos, em vez de carregar instruções brutas do dispositivo de armazenamento (como o carregador de boot de primeiro estágio).
O carregador de boot de segundo estágio, que agora é capaz de trabalhar com arquivos, pode carregar o arquivo do carregador de boot do sistema operacional para inicializar o respectivo sistema operacional.
É quando o logotipo do sistema operacional aparece...
Aqui está o layout de um dispositivo de armazenamento com partição MBR:
VIsto por dentro, o conteúdo do MBR teria esta aparência:
Embora o MBR seja simples e amplamente suportado, ele tem algumas limitações 😑.
A estrutura de dados do MBR limita o número de partições a apenas quatro partições primárias.
Uma solução comum é fazer uma partição estendida ao lado das partições primárias, desde que o número total de partições não exceda quatro.
Uma partição estendida pode ser dividida em várias partições lógicas. Fazer partições estendidas é diferente em cada sistema operacional. Neste guia rápido, a Microsoft explica como deve ser feito no Windows (texto em inglês).
Ao fazer uma partição, você pode escolher entre primária e estendida.
Depois que isso é resolvido, encontramos a segunda limitação.
Cada partição pode ter no máximo 2TB 🙄.
Espere, tem mais!
O conteúdo do setor MBR não tem back-up 😱, o que significa que, se o MBR for corrompido por alguma razão inesperada, teremos que encontrar uma maneira de reciclar aquele pedaço inútil de hardware.
É aqui que o particionamento GPT se destaca 😎.
Particionamento GPT e firmware baseado em UEFI
O esquema de particionamento GPT é mais sofisticado que o MBR e não possui as limitações do MBR.
Por exemplo, você pode ter tantas partições quantas seu sistema operacional permitir.
Cada partição pode ter o tamanho do maior dispositivo de armazenamento disponível no mercado – na verdade, muito mais.
O GPT está gradualmente substituindo o MBR, embora o MBR ainda seja amplamente suportado em PCs antigos e novos.
Como mencionado anteriormente, o GPT é uma parte da especificação UEFI, que está substituindo o bom e velho BIOS.
Isso significa que o firmware baseado em UEFI usa um dispositivo de armazenamento particionado com GPT para manejar o processo de boot.
Muitos hardwares e sistemas operacionais agora suportam UEFI e usam o esquema GPT para particionar dispositivos de armazenamento.
No esquema de particionamento GPT, o primeiro setor do dispositivo de armazenamento é reservado por razões de compatibilidade com sistemas baseados em BIOS. O motivo é que alguns sistemas ainda podem usar um firmware baseado em BIOS, mas têm um dispositivo de armazenamento particionado com GPT.
Este setor é chamado de MBR protetivo (é aqui que o carregador de boot de primeiro estágio residiria em um disco particionado com MBR).
Depois desse primeiro setor, são armazenadas as estruturas de dados GPT, incluindo o cabeçalho GPT e as entradas de partição.
É feito o back-up das entradas GPT e o cabeçalho GPT no final do dispositivo de armazenamento, para que possam ser recuperados se a cópia principal for corrompida.
Esse back-up é chamado de GPT Secundário.
O layout de um dispositivo de armazenamento particionado com GPT se parece com isso:

{kind=link}
No GPT, todos os serviços de boot (carregadores de boot, gerenciadores de boot, ambientes anteriores ao sistema operacional e shells) vivem em uma partição dedicada chamada partição de sistema EFI (ESP), que o firmware UEFI pode usar.
A ESP até tem seu próprio sistema de arquivos, que é uma versão específica do FAT. No Linux, a ESP reside no caminho /sys/firmware/efi.
Se esse caminho não puder ser encontrado em seu sistema, então seu firmware é provavelmente baseado em BIOS.
Para verificar, você pode tentar mudar o diretório para o ponto de montagem do ESP, assim:
cd /sys/firmware/efi
O firmware baseado em UEFI assume que o dispositivo de armazenamento está particionado com GPT e procura o ESP na tabela de partições GPT.
Uma vez encontrada a partição EFI, ele procura o carregador de boot configurado – geralmente, um arquivo com a terminação .efi.
O firmware baseado em UEFI obtém a configuração de boot de NVRAM (uma RAM não volátil).
A NVRAM contém as configurações de boot e os caminhos para os arquivos do carregador de boot do sistema operacional.
O firmware UEFI também pode fazer um boot no estilo BIOS (para inicializar o sistema a partir de um disco MBR) se configurado adequadamente.
Você pode usar o comando parted no Linux para ver qual esquema de particionamento é usado para um dispositivo de armazenamento.
sudo parted -l
A saída seria algo assim:
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 172GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
14 1049kB 5243kB 4194kB bios_grub
15 5243kB 116MB 111MB fat32 msftdata
1 116MB 172GB 172GB ext4
Com base na saída acima, o ID do dispositivo de armazenamento é /dev/vda com uma capacidade de 172GB. O dispositivo de armazenamento está particionado com base no GPT e possui três partições; a segunda e a terceira partições estão formatadas com base nos sistemas de arquivos FAT32 e EXT4, respectivamente.
Vamos confirmar isso com o comando dmidecode da seguinte maneira:
sudo dmidecode -t 0
A saída seria:
# dmidecode 3.2
Getting SMBIOS data from sysfs.
SMBIOS 2.4 present.
...
✅ Confirmado!
Formatando partições
Quando o particionamento é concluído, as partições devem ser formatadas.
A maioria dos sistemas operacionais permite que você formate uma partição com base em um conjunto de sistemas de arquivos.
Por exemplo, se você estiver formatando uma partição no Windows, você pode escolher entre os sistemas de arquivos FAT32, NTFS e exFAT.
A formatação envolve a criação de várias estruturas de dados e metadados usados para gerenciar arquivos dentro de uma partição.
Essas estruturas de dados são um aspecto de um sistema de arquivos.
Vamos usar o sistema de arquivos NTFS como exemplo.
Quando você formata uma partição para NTFS, o processo de formatação coloca as principais estruturas de dados do NTFS e a Tabela Mestra de Arquivos (MFT) na partição.
Certo, vamos voltar aos sistemas de arquivos com nosso novo entendimento sobre particionamento, formatação e boot.
Como começou, como está indo
Um sistema de arquivos é um conjunto de estruturas de dados, interfaces, abstrações e APIs que trabalham juntos para gerenciar qualquer tipo de arquivo em qualquer tipo de dispositivo de armazenamento, de maneira consistente.
Cada sistema operacional usa um sistema de arquivos particular para gerenciar os arquivos.
Nos primeiros dias, a Microsoft usava FAT (FAT12, FAT16 e FAT32) na família MS-DOS e Windows 9x.
A partir do Windows NT 3.1, a Microsoft desenvolveu o New Technology File System (NTFS), que possuía muitas vantagens sobre o FAT32, como suporte a arquivos maiores, permissão de nomes de arquivos mais longos, criptografia de dados, gerenciamento de acesso, journaling, e muito mais.
O NTFS tem sido o sistema de arquivos padrão da família Windows NT (2000, XP, Vista, 7, 10, etc.) desde então.
No entanto, NTFS não é adequado para ambientes que não sejam Windows 🤷🏻.
Por exemplo, você pode apenas ler o conteúdo de um dispositivo de armazenamento formatado em NTFS (como memória flash) em um Mac OS, mas você não poderá escrever nada nele – a menos que você instale um driver NTFS com suporte a gravação (texto em inglês).
Você pode simplesmente usar o sistema de arquivos exFat, em vez disso.
Extended File Allocation Table (exFAT) é uma versão mais leve do NTFS criada pela Microsoft em 2006.
O exFAT foi projetado para dispositivos removíveis de alta capacidade, como discos rígidos externos, pen drives e cartões de memória.
O exFAT é o sistema de arquivos padrão usado pelos cartões SDXC.
Diferentemente do NTFS, o exFAT possui suporte para leitura e gravação em ambientes que não sejam Windows também, incluindo Mac OS — tornando-o o melhor sistema de arquivos multiplataforma para dispositivos de armazenamento removíveis de alta capacidade.
Basicamente, se você tem um disco removível que deseja usar no Windows, Mac e Linux, você precisa formatá-lo para exFAT.
A Apple também desenvolveu e usou vários sistemas de arquivos ao longo dos anos, incluindo Hierarchical File System (HFS), HFS+ e, recentemente, Apple File System (APFS).
Assim como o NTFS, o APFS é um sistema de arquivos com journaling e tem sido usado desde o lançamento do OS X High Sierra em 2017.
O que ocorre, porém, com os sistemas de arquivos nas distribuições Linux?
A família de sistemas de arquivos Extended File System (ext) foi criada para o kernel do Linux – o núcleo do sistema operacional Linux.
A primeira versão do ext foi lançada em 1991, mas logo foi substituída pelo segundo sistema de arquivos estendido (ext2) em 1993.
Nos anos 2000, o terceiro sistema de arquivos estendido (ext3) e o quarto sistema de arquivos estendido (ext4) foram desenvolvidos para o Linux com capacidade de journaling.
O ext4 é agora o sistema de arquivos padrão em muitas distribuições Linux, incluindo Debian e Ubuntu.
Você pode usar o comando findmnt no Linux para listar suas partições formatadas em ext4:
findmnt -lo source,target,fstype,used -t ext4
A saída seria algo assim:
SOURCE TARGET FSTYPE USED
/dev/vda1 / ext4 3.6G
Arquitetura de sistemas de arquivos
Um sistema de arquivos instalado em um sistema operacional consiste em três camadas:
- Sistema de arquivos físico
- Sistema de arquivos virtual
- Sistema de arquivos lógico
Essas camadas podem ser implementadas como abstrações independentes ou fortemente acopladas.
Quando as pessoas falam sobre sistemas de arquivos, elas se referem a uma dessas camadas ou a todas as três como uma unidade.
Embora essas camadas sejam diferentes entre os sistemas operacionais, o conceito é o mesmo.
A camada física é a implementação concreta de um sistema de arquivos. Ela é responsável pelo armazenamento e recuperação de dados e gerenciamento de espaço no dispositivo de armazenamento (ou mais precisamente: partições).
O sistema de arquivos físico interage com o hardware de armazenamento por meio de drivers de dispositivos (texto em inglês).
A próxima camada é o sistema de arquivos virtual ou VFS.
O sistema de arquivos virtual fornece uma visão consistente de vários sistemas de arquivos montados no mesmo sistema operacional.
Então, isso significa que um sistema operacional pode usar vários sistemas de arquivos ao mesmo tempo?
A resposta é: sim!
É comum que um meio de armazenamento removível tenha um sistema de arquivos diferente do computador.
Por exemplo, no Windows (que usa NTFS como sistema de arquivos principal), uma memória flash pode ter sido formatada para exFAT ou FAT32.
Dito isso, o sistema operacional deve fornecer uma interface unificada entre programas de computador (exploradores de arquivos e outros aplicativos que trabalham com arquivos) e os diferentes sistemas de arquivos montados (como NTFS, APFS, ext4, FAT32, exFAT e UDF).
Esta camada conveniente entre o usuário (você) e os sistemas de arquivos subjacentes é fornecida pelo VFS.
Um VFS define um contrato que todos os sistemas de arquivos físicos devem implementar para serem suportados por esse sistema operacional.
No entanto, essa conformidade não está embutida no núcleo do sistema de arquivos, o que significa que o código-fonte de um sistema de arquivos não inclui suporte para o VFS de todos os sistemas operacionais.
Em vez disso, ele usa um driver de sistema de arquivos para aderir às regras do VFS de cada sistema de arquivos. Um driver é um programa que permite que um software se comunique com outro software ou hardware.
Embora o VFS seja responsável por fornecer uma interface padrão entre programas e diversos sistemas de arquivos, programas de computador não interagem diretamente com o VFS.
Em vez disso, eles usam uma API unificada entre programas e o VFS.
Consegue adivinhar o que é?
Sim, estamos falando do sistema de arquivos lógico.
O sistema de arquivos lógico é a parte visível ao usuário de um sistema de arquivos, que fornece uma API para permitir que programas de usuários realizem várias operações de arquivos, como OPEN, READ e WRITE, sem precisar lidar com nenhum hardware de armazenamento.
Por outro lado, o VFS fornece uma ponte entre a camada lógica (com a qual os programas interagem) e um conjunto da camada física de vários sistemas de arquivos.

O que significa montar um sistema de arquivos?
Em sistemas do tipo Unix, o VFS atribui um ID do dispositivo (por exemplo, dev/disk1s1) a cada partição ou dispositivo de armazenamento removível.
Depois, ele cria uma árvore de diretórios virtual e coloca o conteúdo de cada dispositivo nessa árvore de diretórios como diretórios separados.
O ato de atribuir um diretório a um dispositivo de armazenamento (sob a árvore de diretórios raiz) é chamado de montagem. O diretório atribuído é chamado de ponto de montagem.
Dito isso, em um sistema operacional semelhante ao Unix, todas as partições e dispositivos de armazenamento removíveis aparecem como se fossem diretórios sob o diretório raiz.
Por exemplo, no Linux, os pontos de montagem para um dispositivo removível (como um cartão de memória), geralmente estão sob o diretório /media.
Uma vez que uma memória flash é conectada ao sistema e, consequentemente, montada automaticamente no ponto de montagem padrão (/media, nesse caso), seu conteúdo estaria disponível sob o diretório /media.
No entanto, há momentos em que você precisa montar um sistema de arquivos manualmente.
No Linux, isso é feito assim:
mount /dev/disk1s1 /media/usb
No comando acima, o primeiro parâmetro é o ID do dispositivo (/dev/disk1s1), e o segundo parâmetro (/media/usb) é o ponto de montagem.
Observe que o ponto de montagem já deve existir como um diretório.
Se não existir, ele deve ser criado primeiro:
mkdir -p /media/usb
mount /dev/disk1s1 /media/usb
Se o diretório do ponto de montagem já contiver arquivos, esses arquivos serão ocultados enquanto o dispositivo estiver montado.
Metadados de arquivos
Metadados de arquivo são uma estrutura de dados que contém dados sobre um arquivo, como:
- Tamanho do arquivo
- Timestamps, como data de criação, última data de acesso e data de modificação
- O proprietário do arquivo
- O modo do arquivo (quem pode fazer o que com o arquivo)
- Que blocos na partição estão alocados ao arquivo
- e muito mais
No entanto, os metadados não são armazenados com o conteúdo do arquivo. Em vez disso, eles são armazenados em um local diferente no disco – mas associados ao arquivo.
Em sistemas do tipo Unix, os metadados estão na forma de estruturas de dados, chamadas de inode.
Inodes são identificados por um número único chamado número de inode.
Inodes estão associados a arquivos em uma tabela chamada tabelas de inodes.
Cada arquivo no dispositivo de armazenamento tem um inode, que contém informações sobre ele, como a hora em que foi criado, modificado etc.
O inode também inclui o endereço dos blocos alocados ao arquivo; por outro lado, onde exatamente ele está localizado no dispositivo de armazenamento.
Em um inode ext4, o endereço dos blocos alocados é armazenado como um conjunto de estruturas de dados chamadas extents (dentro do inode).
Cada extent contém o endereço do primeiro bloco de dados alocado ao arquivo e o número de blocos contínuos que o arquivo ocupou.
Sempre que você abre um arquivo no Linux, seu nome é primeiro resolvido para um número de inode.
Com o número de inode, o sistema de arquivos busca o respectivo inode na tabela de inodes.
Uma vez que o inode é buscado, o sistema de arquivos começa a compor o arquivo dos blocos de dados registrados no inode.
Você pode usar o comando df com o parâmetro -i no Linux para ver os inodes (total, usados e livres) em suas partições:
df -i
A saída seria assim:
udev 4116100 378 4115722 1% /dev
tmpfs 4118422 528 4117894 1% /run
/dev/vda1 6451200 175101 6276099 3% /
Como você pode ver, a partição /dev/vda1 tem um número total de 6.451.200 inodes, dos quais 3% foram usados (175.101 inodes).
Para ver os inodes associados aos arquivos em um diretório, você pode usar o comando ls com os parâmetros -il.
ls -li
A saída seria:
1303834 -rw-r--r-- 1 root www-data 2502 Jul 8 2019 wp-links-opml.php
1303835 -rw-r--r-- 1 root www-data 3306 Jul 8 2019 wp-load.php
1303836 -rw-r--r-- 1 root www-data 39551 Jul 8 2019 wp-login.php
1303837 -rw-r--r-- 1 root www-data 8403 Jul 8 2019 wp-mail.php
1303838 -rw-r--r-- 1 root www-data 18962 Jul 8 2019 wp-settings.php
O número de inodes em uma partição é decidido quando você formata uma partição. Dito isso, enquanto você tiver espaço livre e inodes não utilizados, você pode armazenar arquivos no seu dispositivo de armazenamento.
É improvável que um sistema operacional Linux pessoal fique sem inodes. No entanto, serviços empresariais que lidam com um grande número de arquivos (como servidores de e-mail) precisam gerenciar sua cota de inodes de maneira inteligente.
No NTFS, os metadados são armazenados de maneira diferente.
O NTFS mantém informações de arquivos em uma estrutura de dados chamada Tabela Mestra de Arquivos (MFT) (texto em inglês).
Cada arquivo tem, pelo menos, uma entrada na MFT, que contém tudo sobre ele, incluindo sua localização no dispositivo de armazenamento – semelhante à tabela de inodes.
Na maioria dos sistemas operacionais, você pode obter metadados através da interface gráfica do usuário.
Por exemplo, ao clicar com o botão direito do mouse em um arquivo no Mac OS e selecionar Obter Informações (Propriedades, no Windows), uma janela aparece com informações sobre o arquivo. Essas informações são obtidas dos metadados respectivos do arquivo.
Gerenciamento de espaço
Dispositivos de armazenamento são divididos em blocos de tamanho fixo chamados setores.
Um setor é a unidade mínima de armazenamento em um dispositivo de armazenamento e varia entre 512 bytes e 4096 bytes (formatação avançada).
No entanto, sistemas de arquivos usam um conceito de alto nível como unidade de armazenamento, chamados blocos.
Blocos são uma abstração sobre setores físicos; cada bloco geralmente consiste em diversos setores.
Dependendo do tamanho do arquivo, o sistema de arquivos aloca um ou mais blocos para cada arquivo.
Falando sobre gerenciamento de espaço, o sistema de arquivos está ciente de todos os blocos usados e não usados nas partições, para que ele possa alocar espaço para novos arquivos ou buscar os existentes quando solicitado.
A unidade de armazenamento mais básica em partições formatadas em ext4 é o bloco. No entanto, os blocos contíguos são agrupados em grupos de blocos para facilitar a gestão.

Cada grupo de blocos tem suas próprias estruturas de dados e blocos de dados.
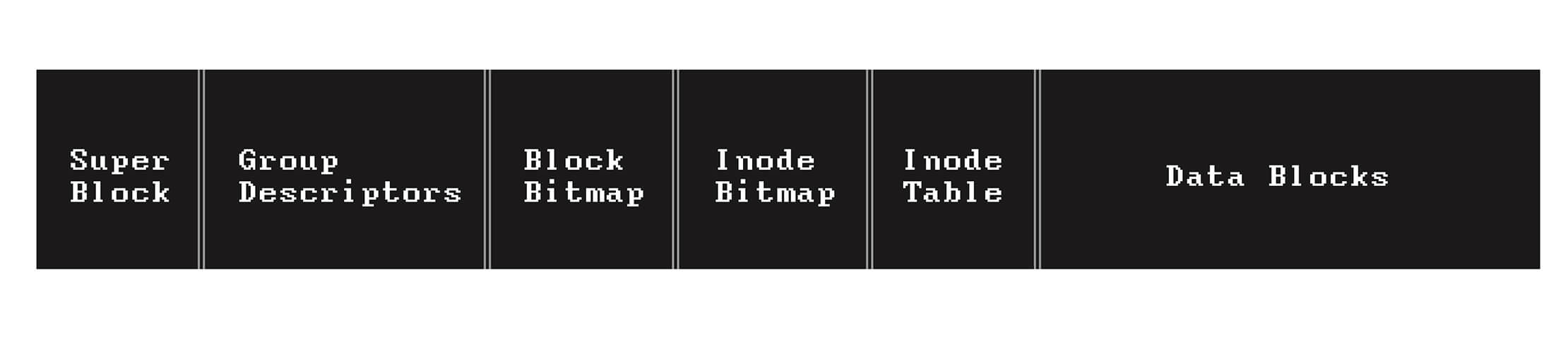
Aqui estão as estruturas de dados que um grupo de blocos pode conter:
- Superbloco: um repositório de metadados, que contém metadados sobre todo o sistema de arquivos, como o número total de blocos no sistema de arquivos, total de blocos em grupos de blocos, inodes e mais. Nem todos os grupos de blocos contêm o superbloco, no entanto. Um certo número de grupos de blocos armazena uma cópia do superbloco como back-up.
- Descritores de grupo: os descritores de grupo também contêm informações contábeis para cada grupo de blocos.
- Bitmap de inodes: cada grupo de blocos tem sua própria cota de inodes para armazenar arquivos. Um bitmap de blocos é uma estrutura de dados usada para identificar inodes usados e não usados dentro do grupo de blocos.
1denota objetos de inode usados e0denota objetos de inode não usados. - Bitmap de blocos: uma estrutura de dados usada para identificar blocos de dados usados e não usados dentro do grupo de blocos.
1denota blocos de dados usados e0denota blocos de dados não usados. - Tabela de inodes: uma estrutura de dados que define a relação de arquivos e seus inodes. O número de inodes armazenados nesta área está relacionado ao tamanho do bloco usado pelo sistema de arquivos.
- Blocos de dados: esta é a zona dentro do grupo de blocos onde os conteúdos dos arquivos são armazenados.
O sistema de arquivos ext4 dá um passo adiante (comparado ao ext3) e organiza grupos de blocos em um grupo maior chamado grupos de blocos flex.
As estruturas de dados de cada grupo de blocos, incluindo o bitmap de blocos, bitmap de inodes e tabela de inodes, são concatenadas e armazenadas no primeiro grupo de blocos dentro de cada grupo de blocos flex.
Ter todas as estruturas de dados concatenadas em um grupo de blocos (o primeiro) libera mais blocos de dados contíguos nos outros grupos de blocos dentro de cada grupo de blocos flex.
Esses conceitos podem ser confusos, mas você não precisa dominar cada detalhe. Isso é só para ilustrar a profundidade dos sistemas de arquivos.
A disposição do primeiro grupo de blocos é assim:
Quando um arquivo está sendo escrito em um disco, ele é escrito em um ou mais blocos dentro de um grupo de blocos.
Gerenciar arquivos no nível do grupo de blocos melhora significativamente o desempenho do sistema de arquivos, em oposição a organizar arquivos como uma única unidade.
Tamanho x tamanho no disco
Você já notou que seu explorador de arquivos exibe dois tamanhos diferentes para cada arquivo: tamanho e tamanho no disco?
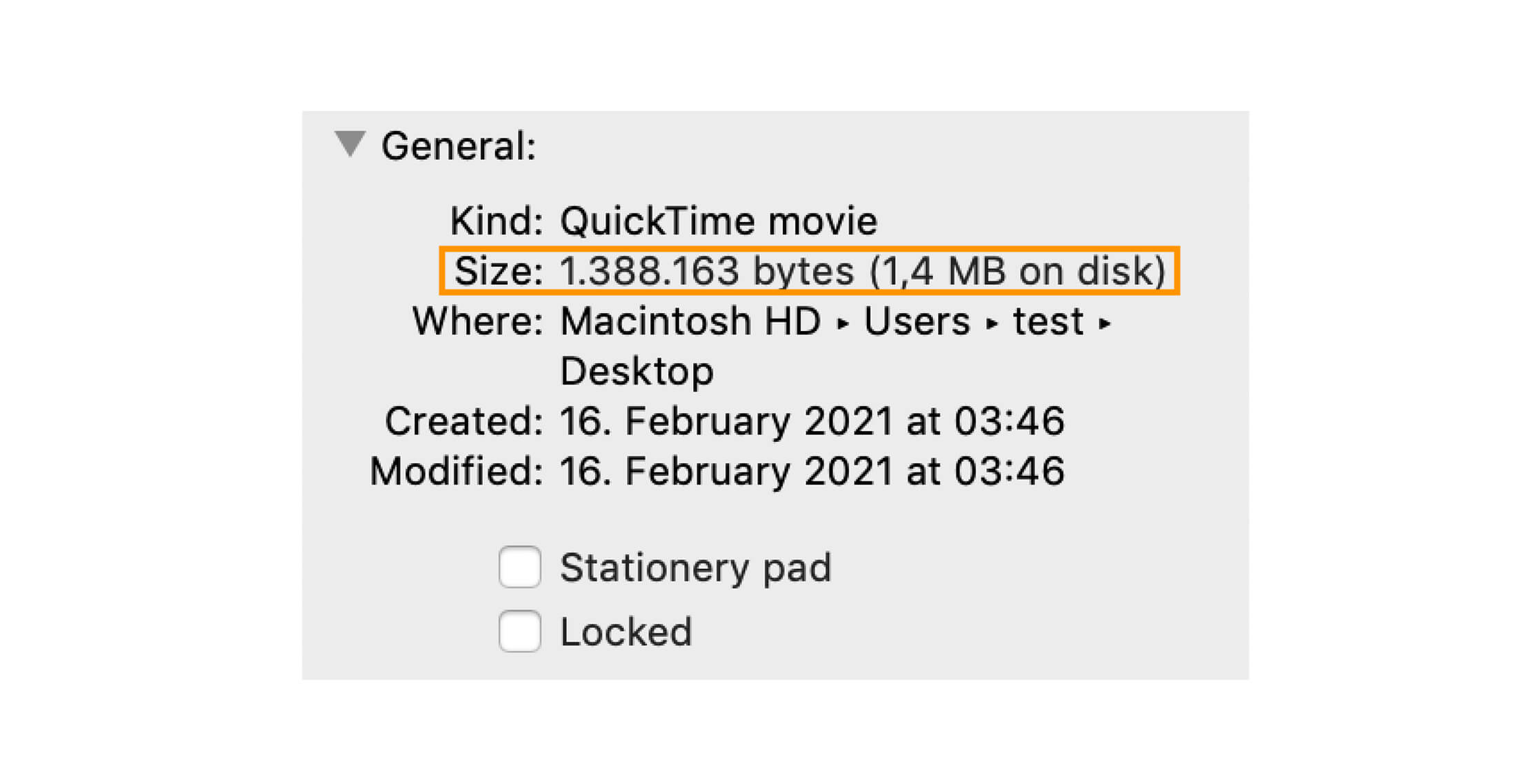
Por que tamanho e tamanho no disco são ligeiramente diferentes, você pode perguntar?
Aqui está uma explicação:
Já sabemos que, dependendo do tamanho do arquivo, um ou mais blocos são alocados para um arquivo.
Um bloco é o espaço mínimo que pode ser alocado para um arquivo. Isso significa que o espaço restante de um bloco parcialmente preenchido não pode ser usado por outro arquivo. Esta é a regra!
Como o tamanho do arquivo não é um múltiplo inteiro de blocos, o último bloco pode estar parcialmente usado, e o espaço restante permaneceria não utilizado – ou seria preenchido com zeros.
Assim, "tamanho" é basicamente o tamanho real do arquivo, enquanto "tamanho no disco" é o espaço que ele ocupa, mesmo que não esteja usando tudo.
du -b "some-file.txt"
A saída seria algo assim:
623 icon-link.svg
Para verificar o tamanho no disco, use:
du -B 1 "icon-link.svg"
Isso resultará em:
4096 icon-link.svg
Com base na saída, o bloco alocado é de cerca de 4kb, enquanto o tamanho real do arquivo é de 623 bytes. Isso significa que cada bloco de tamanho neste sistema operacional é de 4kb.
O que é fragmentação de disco?
Com o tempo, novos arquivos são gravados no disco, arquivos existentes aumentam, diminuem ou são deletados.
Essas mudanças frequentes no meio de armazenamento deixam muitos pequenos espaços vazios (lacunas) entre os arquivos. Essas lacunas ocorrem pelo mesmo motivo pelo qual o tamanho do arquivo e o tamanho do arquivo no disco são diferentes. Alguns arquivos não preencherão o bloco inteiro, e muito espaço será desperdiçado. Com o tempo, não haverá blocos consequentes suficientes para armazenar novos arquivos.
É então que novos arquivos precisam ser armazenados como fragmentos.
A fragmentação de arquivos ocorre quando um arquivo é armazenado como fragmentos no dispositivo de armazenamento porque o sistema de arquivos não consegue encontrar blocos contíguos suficientes para armazenar o arquivo inteiro em uma sequência.
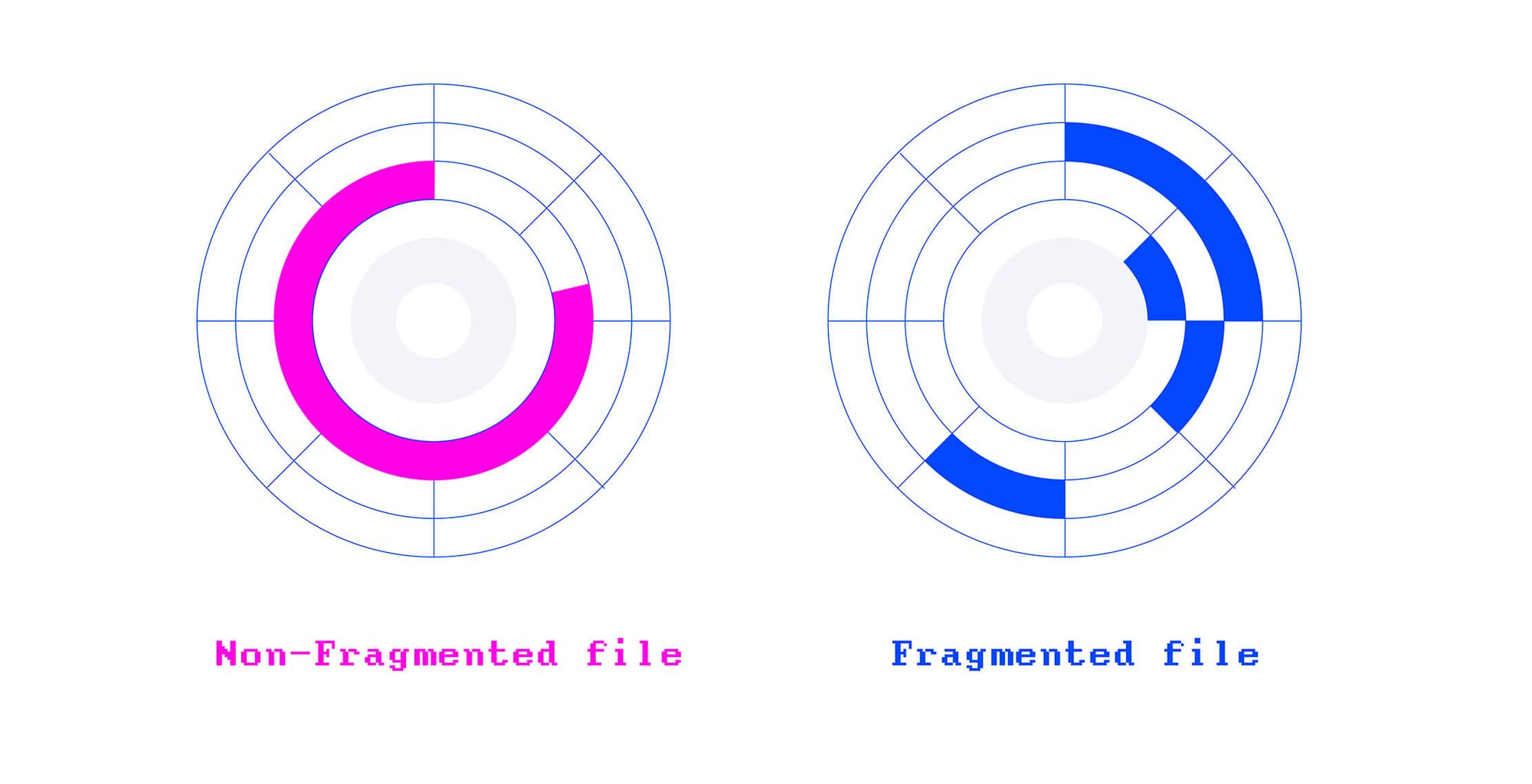
Vamos deixar mais claro com um exemplo.
Imagine que você tem um documento do Word chamado meuarquivo.docx.
meuarquivo.docx é inicialmente armazenado em alguns blocos contíguos no disco. Vamos dizer que é assim que os blocos são nomeados: LBA250, LBA251 e LBA252.
Agora, se você adicionar mais conteúdo a meuarquivo.docx e salvá-lo, ele precisará ocupar mais blocos no meio de armazenamento.
Como meuarquivo.docx está atualmente armazenado em LBA250, LBA251 e LBA252, o novo conteúdo deveria, de preferência, ficar dentro de LBA253 e assim por diante - dependendo de quantos mais blocos são necessários para acomodar as novas mudanças.
Agora, imagine que LBA253 já esteja ocupado por outro arquivo (talvez seja o primeiro bloco de outro arquivo). Nesse caso, o novo conteúdo de meuarquivo.docx precisa ser armazenado em blocos diferentes em outro lugar no disco, por exemplo, LBA312 e LBA313.
meuarquivo.docx ficou fragmentado 💔.
A fragmentação de arquivo coloca uma sobrecarga no sistema de arquivos, pois, toda vez que um arquivo fragmentado é solicitado por um programa de usuário, o sistema de arquivos precisa coletar cada pedaço do arquivo de várias localizações no disco.
Essa sobrecarga também se aplica ao salvar o arquivo de volta no disco.
A fragmentação também pode ocorrer quando um arquivo é gravado no disco pela primeira vez, provavelmente porque o arquivo é grande e não há muitos blocos contínuos deixados na partição.
A fragmentação é uma das razões pelas quais alguns sistemas operacionais ficam lentos à medida que o sistema de arquivos envelhece.
Devemos nos preocupar com a fragmentação atualmente?
A resposta curta é: não mais!
Os sistemas de arquivos modernos usam algoritmos inteligentes para evitar (ou detectar precocemente) a fragmentação tanto quanto possível.
O Ext4 também faz uma espécie de pré-alocação, que envolve reservar blocos para um arquivo antes que eles sejam realmente necessários – garantindo que o arquivo não seja fragmentado se crescer ao longo do tempo.
O número de blocos pré-alocados é definido no campo de comprimento da extensão do arquivo de seu objeto inode.
Além disso, o Ext4 usa uma técnica de alocação chamada alocação atrasada.
A ideia é que, ao invés de gravar nos blocos de dados um de cada vez durante uma gravação, as solicitações de alocação são acumuladas em um buffer e são gravadas no disco de uma vez só.
Não precisar chamar o alocador de blocos do sistema de arquivos em cada solicitação de gravação ajuda o sistema de arquivos a fazer melhores escolhas ao distribuir o espaço disponível. Por exemplo, ao colocar arquivos grandes afastados dos arquivos menores.
Imagine que um arquivo pequeno esteja localizado entre dois arquivos grandes. Agora, se o arquivo pequeno for excluído, ele deixa um pequeno espaço entre os dois arquivos.
Distribuir os arquivos dessa maneira deixa lacunas suficientes entre os blocos de dados, o que ajuda o sistema de arquivos a gerenciar (e evitar) a fragmentação mais facilmente.
A alocação atrasada reduz ativamente a fragmentação e aumenta o desempenho.
Diretórios
Um diretório (ou pasta, no Windows) é um arquivo especial usado como um contêiner lógico para agrupar arquivos e diretórios dentro de um sistema de arquivos.
No NTFS e no Ext4, diretórios e arquivos são tratados da mesma maneira. Dito isso, diretórios são apenas arquivos que têm seu próprio inode (no Ext4) ou entrada MFT (no NTFS).
O inode ou entrada MFT de um diretório contém informações sobre esse diretório, bem como uma coleção de entradas apontando para os arquivos "sob" esse diretório.
Os arquivos não estão literalmente contidos dentro do diretório, mas estão associados ao diretório de tal maneira que aparecem como filhos do diretório em um nível superior, como em um programa de explorador de arquivos.
Essas entradas são chamadas de entradas de diretório. As entradas de diretório contêm nomes de arquivos mapeados para suas entradas inode/MFT.
Além das entradas de diretório, há mais duas entradas, a entrada ., que aponta para o próprio diretório, e a entrada .., que aponta para o diretório pai deste diretório.
No Linux, você pode usar o comando ls em um diretório para ver as entradas do diretório com seus números de inode associados:
ls -lai
63756 drwxr-xr-x 14 root root 4096 Dec 1 17:24 .
2 drwxr-xr-x 19 root root 4096 Dec 1 17:06 ..
81132 drwxr-xr-x 2 root root 4096 Feb 18 06:25 backups
81020 drwxr-xr-x 14 root root 4096 Dec 2 07:01 cache
81146 drwxrwxrwt 2 root root 4096 Oct 16 21:43 crash
80913 drwxr-xr-x 46 root root 4096 Dec 1 22:14 lib
...
Regras para nomeação de arquivos
Alguns sistemas de arquivos impõem limitações sobre nomes de arquivos.
A limitação pode estar no comprimento do nome do arquivo ou na sensibilidade de maiúsculas e minúsculas no nome do arquivo.
Por exemplo, em sistemas de arquivos NTFS (Windows) e APFS (Mac), MeuArquivo e meuarquivo referem-se ao mesmo arquivo, enquanto no ext4 (Linux), eles apontam para arquivos diferentes.
Por que isso importa, você pode perguntar.
Imagine que você está criando uma página da web em seu computador com Windows. A página da web contém o logotipo da sua empresa, que é um arquivo PNG, assim:
<!DOCTYPE html>
<html>
<head>
<title>Produtos - Seu Site</title>
</head>
<body>
<!--ALGUM CONTEÚDO-->
<img src="img/logo.png">
<!--MAIS CONTEÚDO-->
</body>
</html>
Se o nome real do arquivo for Logo.png (note o L maiúsculo), você ainda pode ver a imagem quando abre sua página da web no navegador (em seu computador com Windows).
No entanto, uma vez que você o implante em um servidor Linux e visualize-o ao vivo, verá uma imagem quebrada.
Por quê?
Porque no Linux (sistema de arquivos ext4) logo.png e Logo.png apontam para dois arquivos diferentes.
Portanto, lembre-se disso ao desenvolver no Windows e implantar em um servidor Linux.
Regras para tamanho de arquivo
Um aspecto importante dos sistemas de arquivos é o tamanho máximo de arquivo que eles suportam.
Um sistema de arquivos antigo como o FAT32 (usado pelo MS-DOS +7.1, família Windows 9x e memórias flash) não pode armazenar arquivos maiores que 4 GB, enquanto seu sucessor, o NTFS permite tamanhos de arquivo de até 16 EB (1000 TB).
Como o NTFS, o exFAT também permite um tamanho de arquivo de 16 EB. Isso torna o exFAT uma opção ideal para armazenar objetos de dados massivos, como arquivos de vídeo.
Praticamente, não há limitação no tamanho do arquivo nos sistemas de arquivos exFAT e NTFS.
O ext4 do Linux e o APFS da Apple suportam arquivos de até 16 TiB e 8 EiB respectivamente.
Programas gerenciadores de arquivos
Como você sabe, a camada lógica do sistema de arquivos fornece uma API para permitir que aplicações do usuário realizem operações de arquivo, como operações de leitura, escrita, exclusão e execução.
A API do sistema de arquivos é um mecanismo de baixo nível, projetado para programas de computador, ambientes de tempo de execução e shells – ela não é projetada para uso diário.
Dito isso, os sistemas operacionais fornecem utilitários convenientes de gerenciamento de arquivos prontos para o uso diário de gerenciamento de arquivos.
Por exemplo, o Explorador de Arquivos no Windows, o Finder no Mac OS e o Nautilus no Ubuntu são exemplos de programas gerenciadores de arquivos.
Esses utilitários usam a API do sistema de arquivos lógico por trás dos panos.
Além dessas ferramentas GUI, os sistemas operacionais também expõem as APIs do sistema de arquivos através das interfaces de linha de comando, como Prompt de Comando no Windows e Terminal no Mac e Linux.
Essas interfaces baseadas em texto ajudam os usuários a realizar todos os tipos de operações de arquivo como comandos de texto – como fizemos nos exemplos anteriores.
Gerenciamento de acesso a arquivos
Nem todos devem ser capazes de remover ou modificar um arquivo que não possuem ou não estão autorizados a fazê-lo.
Sistemas de arquivos modernos fornecem mecanismos para controlar o acesso e as capacidades dos usuários em relação aos arquivos.
Os dados relativos às permissões do usuário e à propriedade dos arquivos são armazenados em uma estrutura de dados chamada Lista de Controle de Acesso (ACL) no Windows ou Entradas de Controle de Acesso (ACE) em sistemas operacionais do tipo Unix (Linux e Mac OS).
Esse recurso também está disponível na CLI (Prompt de comando ou Terminal), onde um usuário pode alterar a propriedade dos arquivos ou limitar as permissões de cada arquivo diretamente na interface de linha de comando.
Por exemplo, um proprietário de arquivo (no Linux ou Mac) pode configurar um arquivo para estar disponível ao público, assim:
chmod 777 meuarquivo.txt
777 significa que todos podem realizar todas as operações (leitura, escrita, execução) em meuarquivo.txt. Note que este é apenas um exemplo. Você não deve definir a permissão de um arquivo para 777.
Mantendo a integridade dos dados
Digamos que você esteja trabalhando em sua tese há um mês. Um dia, você abre o arquivo, faz algumas alterações e o salva.
Depois de salvar o arquivo, seu programa de processador de texto envia uma solicitação de "escrita" para a API do sistema de arquivos (o sistema de arquivos lógico).
A solicitação acaba sendo passada para a camada física para armazenar o arquivo em vários blocos.
O que acontece, porém, se o sistema travar enquanto a versão anterior do arquivo está sendo substituída pela nova versão?
Em sistemas de arquivos mais antigos (como FAT32 ou ext2), os dados seriam corrompidos porque foram parcialmente escritos no disco.
Isso é menos provável de acontecer com sistemas de arquivos modernos, pois eles usam uma técnica chamada journaling.
Os sistemas de arquivos com journaling registram cada operação que está prestes a acontecer na camada física, mas que ainda não aconteceu.
O objetivo principal é manter o controle das alterações que ainda não foram comprometidas fisicamente com o sistema de arquivos.
O journal é uma alocação especial no disco onde cada tentativa de escrita é primeiro armazenada como uma transação.
Em caso de falha do sistema, o sistema de arquivos detectará a transação incompleta e a cancelará como se nunca tivesse acontecido.
Dito isso, o novo conteúdo (que estava sendo escrito) ainda pode ser perdido, mas os dados existentes permaneceriam intactos.
Sistemas de arquivos modernos, como NTFS, APFS e ext4 (até mesmo o ext3), usam journaling para evitar dados corrompidos em caso de falha do sistema.
Sistemas de arquivos de banco de dados
Sistemas de arquivos típicos organizam arquivos como árvores de diretórios.
Para acessar um arquivo, você navega até o respectivo diretório e pronto.
cd /music/country/highwayman
No entanto, em um sistema de arquivos de banco de dados, não há conceito de caminhos e diretórios.
O sistema de arquivos de banco de dados é um sistema facetado que agrupa arquivos com base em vários atributos e dimensões.
Por exemplo, arquivos MP3 podem ser listados por artista, gênero, ano de lançamento e álbum – ao mesmo tempo!
Um sistema de arquivos de banco de dados é mais como uma aplicação de alto nível para ajudá-lo a organizar e acessar seus arquivos de maneira mais fácil e eficiente. No entanto, você não poderá acessar os arquivos brutos fora dessa aplicação.
Um sistema de arquivos de banco de dados não pode substituir um sistema de arquivos típico, no entanto. É apenas uma abstração de alto nível para facilitar a gestão de arquivos em alguns sistemas.
O aplicativo iTunes no Mac OS é um bom exemplo de um sistema de arquivos de banco de dados.
Concluindo
Uau! Você chegou até o fim do artigo – o que significa que agora sabe muito mais sobre sistemas de arquivos. Tenho certeza, porém, de que este não será o fim de seus estudos sobre sistemas de arquivos.
Então, mais uma vez – podemos descrever o que é um sistema de arquivos e como ele funciona em uma frase?
Não podemos! 😁
Vamos terminar este artigo, contudo, com a descrição breve que usei no começo:
Um sistema de arquivos define como arquivos são nomeados, armazenados e recuperados do dispositivo de armazenamento.
Certo, acho que isso encerra este artigo.
Se você gosta de guias mais abrangentes como este, visite o site do autor, decodingweb. dev e siga o autor no Twitter porque, além do freeCodeCamp, esses são os canais que o autor usa para compartilhar suas descobertas diárias.
Agradecemos a leitura! Aproveite o aprendizado! 😃