
Artigo original: Node.js Streams: Everything you need to know
Atualização: este artigo agora é parte do meu livro "Node.js Beyond The Basics".
Leia a versão atualizada desse conteúdo e mais sobre o Node em jcomplete.com/node-beyond-basics .
Os streams do Node.js têm a reputação de serem difíceis de trabalhar e ainda mais difíceis de entender. Bem, eu tenho uma ótima notícia para você - esse não é mais o caso.
Ao longo dos anos, os desenvolvedores criaram muitos pacotes com o único objetivo de facilitar o trabalho com streams. Neste artigo, porém, eu vou me concentrar na API de stream nativa do Node.js.
"Streams são a melhor e a mais incompreendida ideia do Node."
— Dominic Tarr
O que exatamente são streams?
Streams são coleções de dados — assim como arrays ou strings. A diferença é que os streams podem não estar disponíveis todos de uma vez e não precisam ficar alocados inteiramente na memória. Isso os torna realmente poderosos ao trabalhar com grandes quantidades de dados ou dados provenientes de uma fonte externa um pedaço por vez.
No entanto, os streams não são apenas para trabalhar com big data. Eles também nos permitem fazer uso da composição em nosso código, que é basicamente pegarmos a saída de um lugar e enviarmos diretamente a outro.
Assim como podemos compor comandos do Linux poderosos encadeando outros comandos menores, podemos fazer exatamente o mesmo no Node com streams.

const grep = ... // Um stream para a saída de grep
const wc = ... // Um stream para a entrada de wc
grep.pipe(wc)Muitos dos módulos integrados no Node implementam a interface de streaming:

A lista acima tem alguns exemplos de objetos nativos do Node.js que também são streams legíveis e graváveis. Alguns desses objetos são streams de leitura e graváveis, como TCP sockets, zlib e crypto streams.
Observe que os objetos também estão intimamente relacionados. Embora uma response HTTP (que é a resposta que o servidor retorna de uma solicitação HTTP nossa) seja um stream de leitura no client, é um stream gravável no servidor. Isso ocorre porque, no caso do HTTP, basicamente lemos de um objeto (http.IncomingMessage) e escrevemos no outro ( http.ServerResponse).
Também observe como os streams de stdio (stdin, stdout, stderr) possuem os tipos de streams inversos quando se trata de processos filhos. Isso permite uma forma realmente fácil de conduzir de e para esses streams a partir do processo de stream principal stdio.
Um exemplo prático de streams
A teoria é ótima, mas, muitas vezes, não nos convence. Por isso, vamos ver um exemplo demonstrando a diferença que os streams podem fazer no código quando se trata de consumo de memória.
Vamos criar um arquivo grande primeiro:
const fs = require('fs');
const file = fs.createWriteStream('./big.file');
for(let i=0; i<= 1e6; i++) {
file.write('Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n');
}
file.end();Percebeu o que eu usei para criar aquele arquivo grande? Sim, um stream gravável!
O módulo fs pode ser usado para ler e gravar dentro de arquivos usando uma interface de stream. No exemplo acima, estamos escrevendo dentro do arquivo big.file por meio de um stream gravável de 1 milhão de linhas (que é o 1e6) com um loop.
A execução do script acima gera um arquivo com cerca de 400 MB.
Agora, aqui está um web server em Node simples, projetado exclusivamente para enviar nosso arquivo big.file:
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
fs.readFile('./big.file', (err, data) => {
if (err) throw err;
res.end(data);
});
});
server.listen(8000);Então, quando o servidor receber uma solicitação, ele enviará o arquivo usando o método assíncrono, fs.readFile. Perceba, no entanto, que é como se não estivéssemos bloqueando o loop ou algo assim. Está tudo ótimo, certo? Certo?
Bem, vamos monitorar a memória para ver o que acontece quando executamos o servidor e conectamos nele.
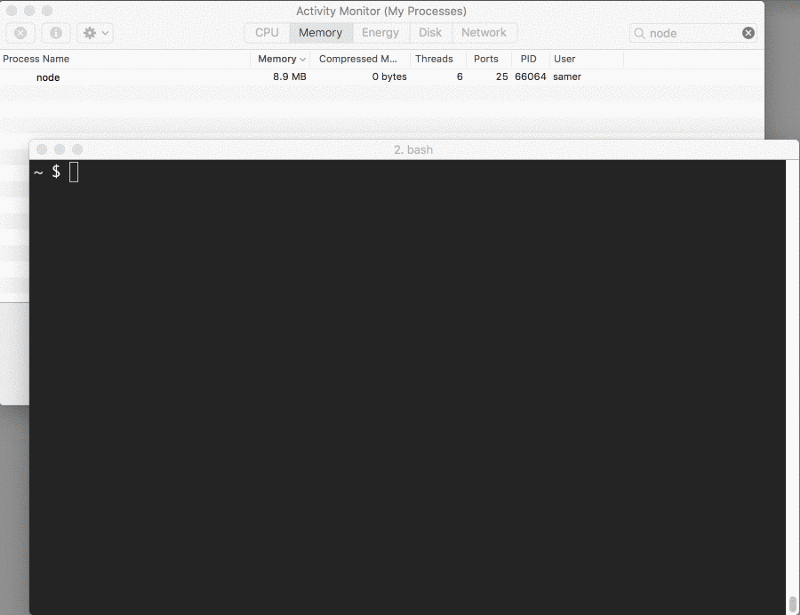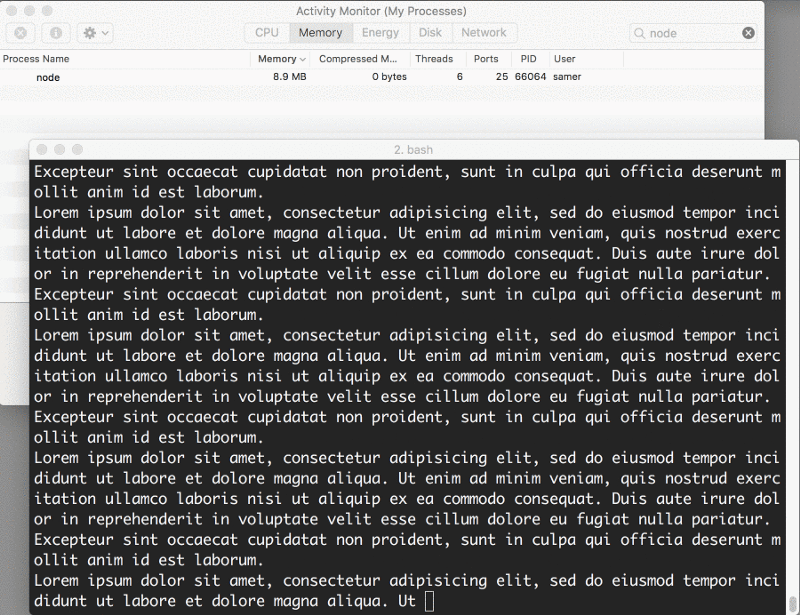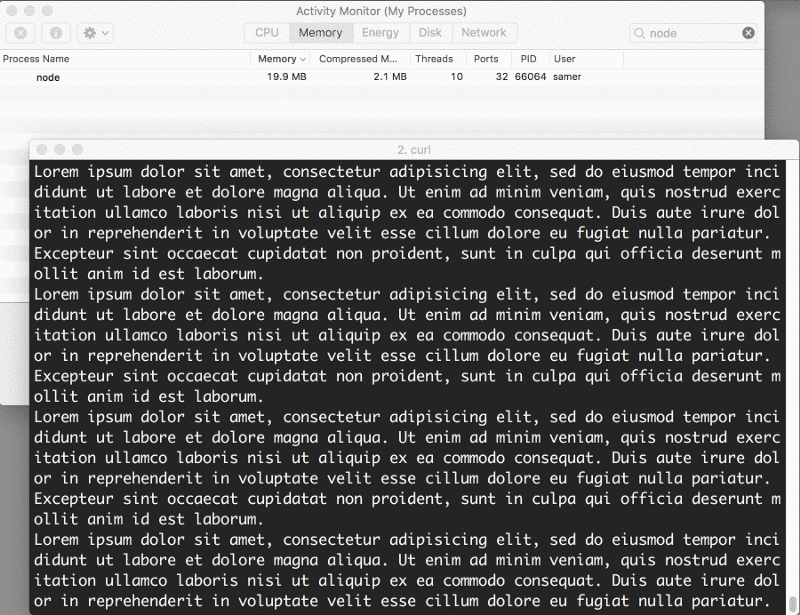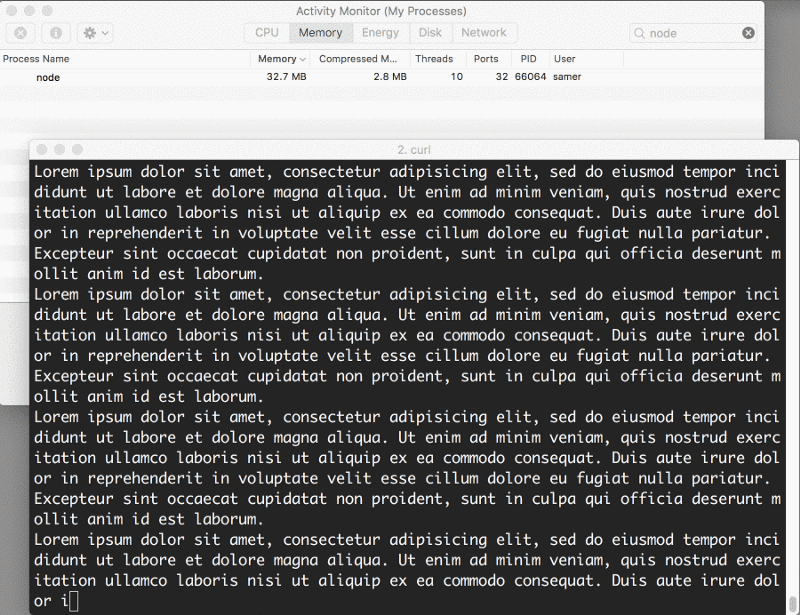
Quando executei o servidor, ele começou com uma quantidade normal de memória, 8,7 MB:
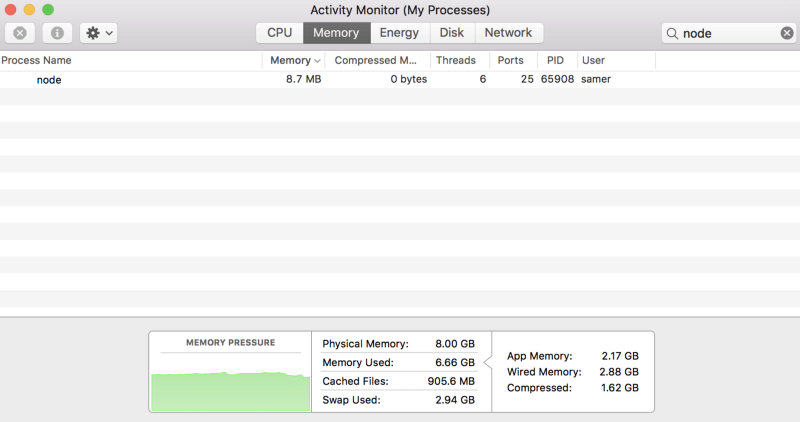
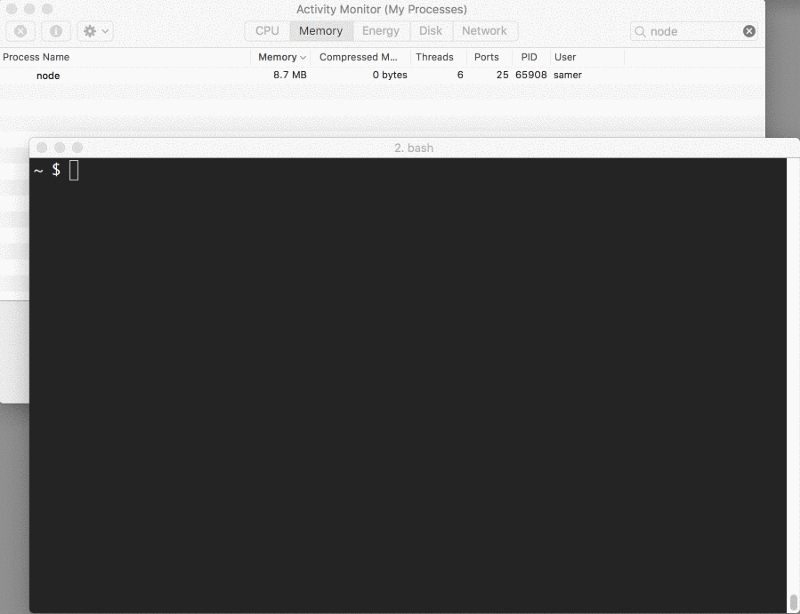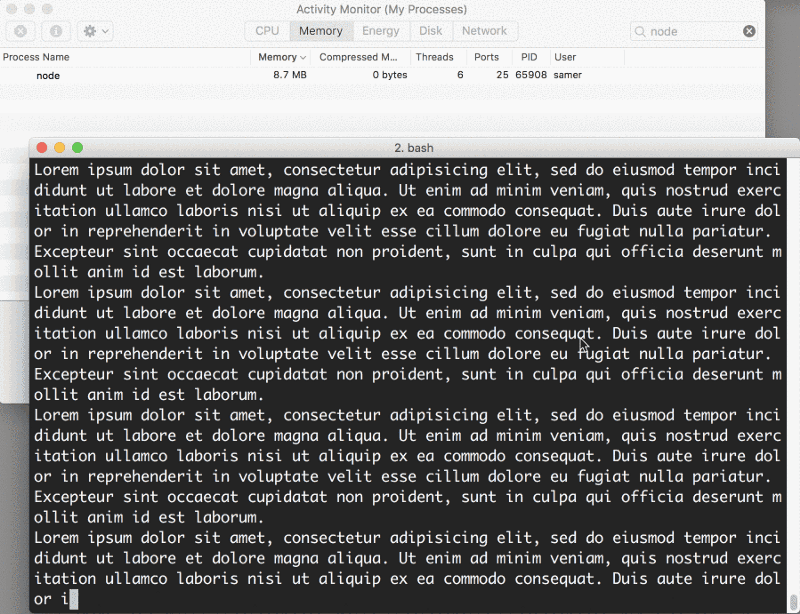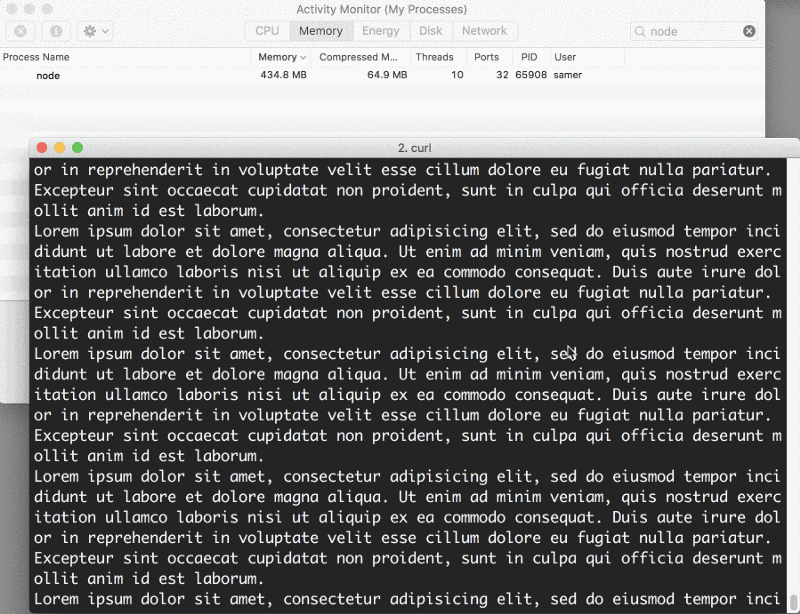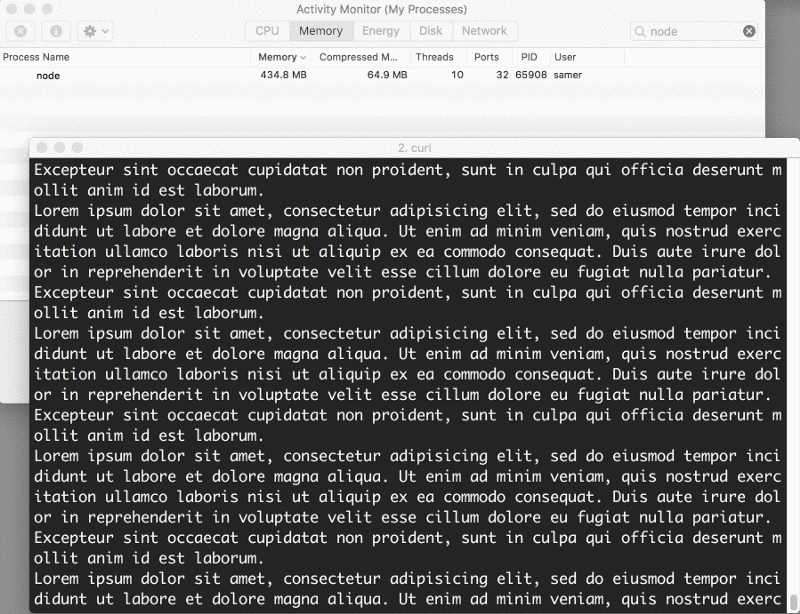
Então, me conectei ao servidor. Observe o que aconteceu com a memória consumida:
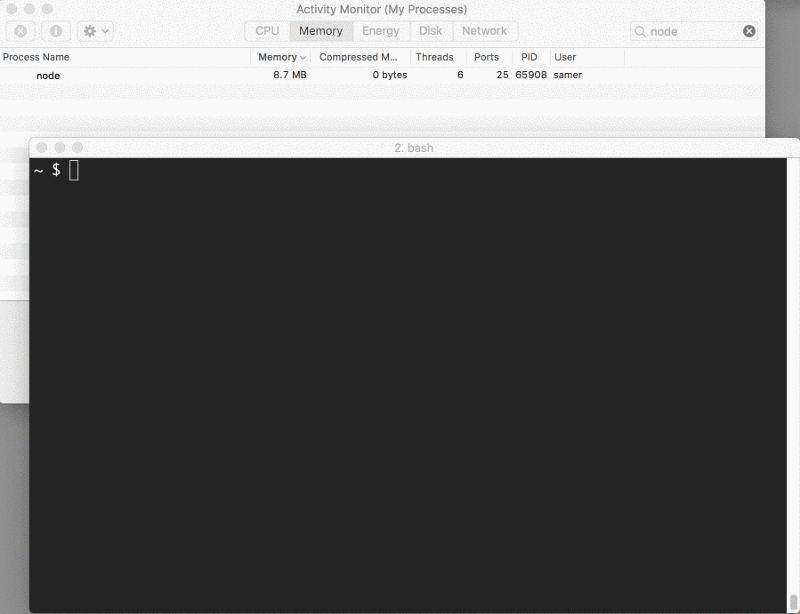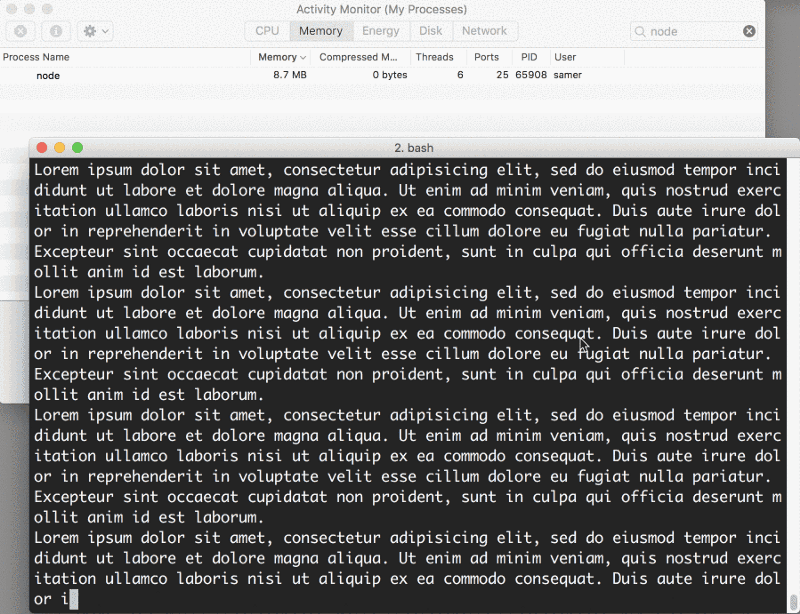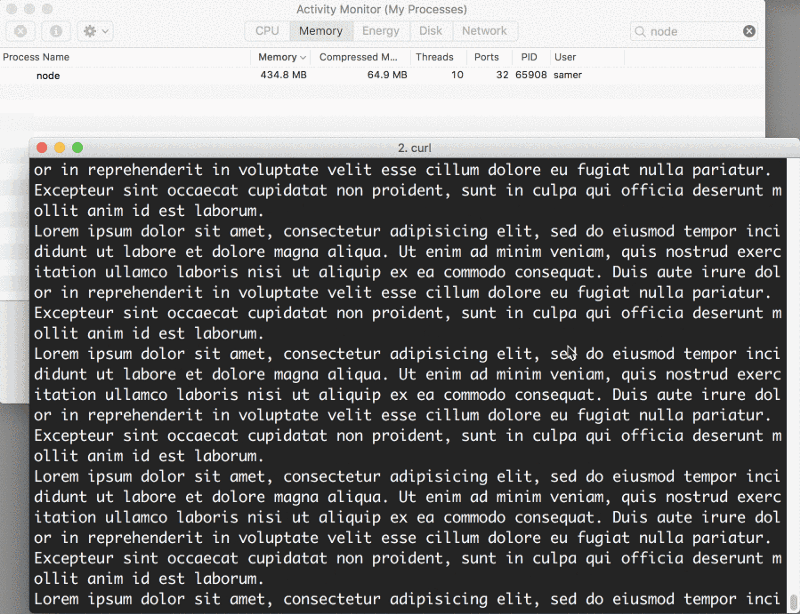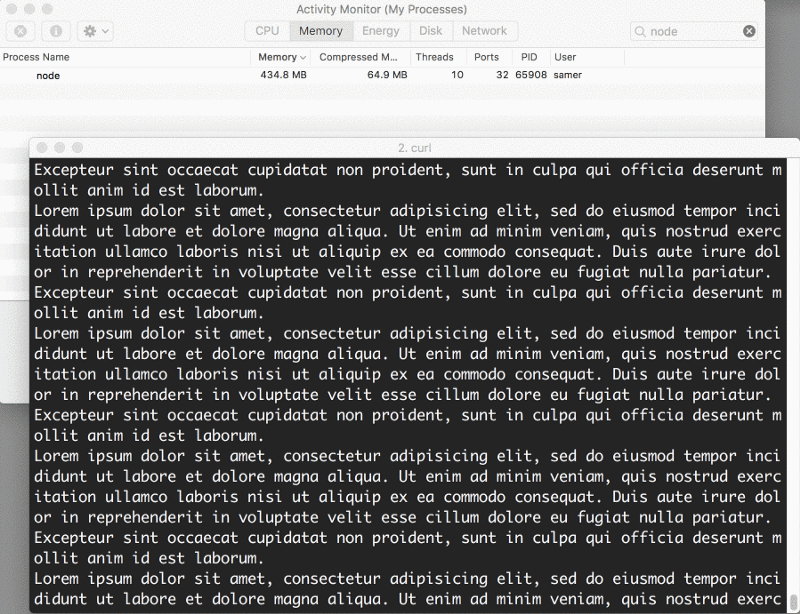
Uau — o consumo de memória saltou para 434,8 MB.
Basicamente, colocamos todo o conteúdo do big.file na memória antes de escrevê-lo no objeto da response. Isso é muito ineficiente.
A response do HTTP (res, no código acima) também é um stream gravável. Isso significa que, se tivermos um stream legível que represente o conteúdo de big.file, podemos simplesmente encaminhar esses dois um para o outro e obter, basicamente, o mesmo resultado sem consumir cerca de 400 MB de memória.
O módulo fs do Node pode nos fornecer um stream de leitura para qualquer arquivo usando o método createReadStream. Podemos enviar isso diretamente para a response:
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
const src = fs.createReadStream('./big.file');
src.pipe(res);
});
server.listen(8000);Agora, quando você se conecta a esse servidor, a mágica acontece (note o consumo de memória):
O que está acontecendo?
Quando um client solicita esse arquivo grande, nós o transmitimos um pedaço de cada vez, o que significa que não o armazenamos na memória. O uso de memória cresceu em torno de 25 MB e é só isso.
Mas você pode levar este exemplo ao seu limite. Regenere o big.file com cinco milhões de linhas em vez de apenas um milhão, o que levaria o arquivo para mais de 2 GB, que é bem maior que o limite de buffer padrão no Node.
Se você tentar servir esse arquivo usando fs.readFile, simplesmente não poderá fazer isso, por padrão (a menos que sejam alteradas as configurações de limite dele). Com o fs.createReadStream, no entanto, não há problema em transmitir 2 GB de dados para o solicitante e, o melhor de tudo, o uso da memória do processo será quase o mesmo.
Pronto para aprender sobre streams agora?
Este artigo é um resumo de parte do meu curso sobre Node.js no Pluralsight (em inglês). Eu explico conteúdo semelhante em formato de vídeo lá.
Fundamentos de streams
Existem quatro tipos de streams fundamentais no Node.js: streams de Leitura/Readable (que ao pé da letra, a tradução seria " Stream Legível" em português), Gravável, Duplex e de Transformação.
- Um stream de Leitura é uma abstração de uma fonte da qual os dados podem ser consumidos. Um exemplo disso é o método
fs.createReadStream. - Um stream Gravável é uma abstração para um destino no qual os dados podem ser gravados. Um exemplo disso é o método
fs.createWriteStream. - Um stream Duplex é de leitura e gravável ao mesmo tempo. Um exemplo disso é o TCP socket.
- Um stream de Transformação é basicamente um stream Duplex que pode ser usado para modificar ou transformar os dados à medida que são gravados e lidos. Um exemplo disso é o stream
zlib.createGzip, usado para compactar os dados com gzip. Você pode pensar em um stream de transformação como uma função em que a entrada é a parte do stream Gravável e a saída é a parte do stream de Leitura. Você também pode ouvir falar dos streams de transformação com a expressão "through streams".
Todos os streams são instâncias do EventEmitter. Eles emitem eventos que podem ser usados para ler e gravar dados. No entanto, podemos consumir dados de streams de maneira mais simples usando o método pipe.
O método pipe
Aqui está a linha mágica de que você precisa se lembrar:
readableSrc.pipe(writableDest)Nesta linha simples, estamos enviando a saída de um stream de leitura — a fonte de dados, como a entrada de um stream gravável — o destino. Lembrando que a origem deve ser um stream de leitura e o destino deve ser gravável. Claro, os dois também podem ser streams duplex/de transformação, não é problema. Na verdade, se estivermos enviando para um stream duplex, podemos até encadear chamadas do pipe exatamente como fazemos no Linux:
readableSrc
.pipe(transformStream1)
.pipe(transformStream2)
.pipe(finalWrtitableDest)O método pipe retorna o stream de destino, que nos permite encadear novamente em cima dele. Para os streams abaixo, teremos a (de leitura), b e c (duplex), e d (gravável), teremos:
a.pipe(b).pipe(c).pipe(d)
# Que é equivalente a:
a.pipe(b)
b.pipe(c)
c.pipe(d)
# E no Linux, seria equivante a:
$ a | b | c | dO método pipe é a maneira mais fácil de consumir streams. Geralmente, é recomendável usar o pipe ou consumir streams com eventos, mas evite misturar esses dois. Normalmente, quando você está usando o pipe, não precisa usar eventos, mas se precisar consumir os streams de maneiras mais personalizadas, os eventos seriam o caminho a seguir.
Eventos de stream
Além de ler de uma fonte de stream de leitura e gravar em um destino gravável, o método pipe gerencia automaticamente algumas coisas ao longo do caminho. Por exemplo, ele lida com erros, fim de arquivos e os casos em que um stream é mais lento ou mais rápido que o outro.
No entanto, os streams também podem ser consumidos com eventos diretamente. Aqui está um código simplificado equivalente ao de evento que o pipe faz, principalmente para ler e gravar dados:
# readable.pipe(writable)
readable.on('data', (chunk) => {
writable.write(chunk);
});
readable.on('end', () => {
writable.end();
});Aqui está uma lista dos eventos e funções importantes que podem ser usados com streams de leitura e graváveis:

Os eventos e funções estão, de alguma forma, relacionados, porque geralmente são usados juntos.
Os eventos mais importantes em um stream de leitura são:
- O evento
data, que ocorre sempre que o stream passa um bloco de dados para o consumidor. - E o evento
end, quando não há mais dados do stream a serem consumidos.
Os eventos mais importantes em um stream gravável são:
- O evento
drain, que é um sinal de que o stream gravável pode receber mais dados. - O evento
finish, que ocorre quando todos os dados são liberados para o sistema subjacente.
Eventos e funções podem ser combinados para fazer um uso personalizado e otimizado de streams. Para consumir um stream de leitura, podemos usar os métodos pipe/unpipe ou os métodos read/unshift/resume. Para consumir um stream gravável, podemos torná-lo o destino do pipe/unpipe ou também escrever nele com o método write e chamar o método end quando terminarmos.
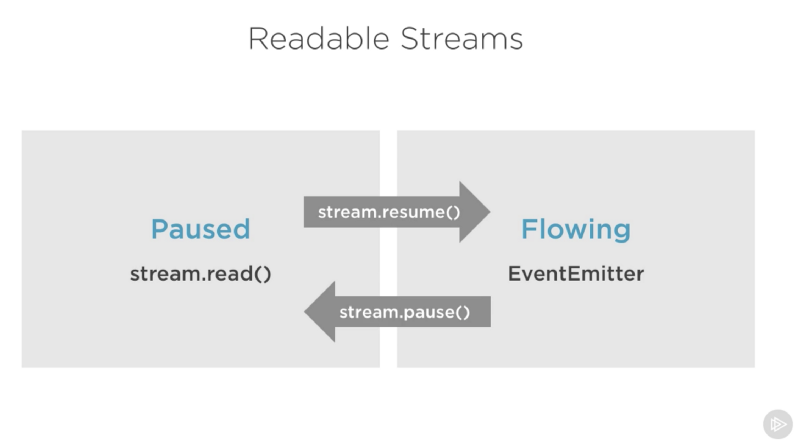
Modos pausado e fluido de streams de leitura
Os streams de leitura têm dois modos principais que afetam a maneira como podemos consumir eles:
- Eles podem estar no modo pausado
- Ou no modo flowing (fluido)
Esses modos às vezes são chamados de modos pull e push.
Todos os streams de leitura iniciam no modo pausado por padrão, mas podem ser facilmente alternados para fluido e de volta para pausado quando necessário. Às vezes, a troca acontece automaticamente.
Quando um stream de leitura está no modo pausado, podemos usar o método read() para ler o stream sob demanda. No entanto, para um stream de leitura no modo fluido, os dados estão sendo enviados continuamente e temos que ouvir os eventos para consumi-los.
No modo fluido, os dados podem ser perdidos se nenhum consumidor estiver disponível para lidar com eles. É por isso que, quando temos um stream de leitura no modo fluido, precisamos de um manipulador de eventos data. Na verdade, apenas adicionando um manipulador de eventos data, já mudamos um stream de pausado para o modo fluido, e quando removemos o manipulador, retornamos o stream de volta para o modo pausado. Parte disso é feito para compatibilidade com versões mais antigas da interface de streams do Node.
Para alternar manualmente entre esses dois modos de stream, você pode usar os métodos resume() e pause().
Ao consumir streams de leitura usando o pipe, não precisamos nos preocupar com esses modos, pois o próprio pipe os gerencia automaticamente.
Implementando streams
Quando falamos de streams no Node.js, existem duas tarefas principais diferentes:
- A tarefa de implementar os streams.
- A tarefa de consumi-los.
Até agora, falamos somente sobre o consumo de streams. Então, vamos implementar alguns!
Os implementadores de stream são geralmente os que usam o require(exigem) do módulo stream.
Implementando um stream gravável
Para implementar um stream gravável, precisamos usar o construtor Writable do módulo stream.
const { Writable } = require('stream');Pode-se implementar um stream gravável de várias maneiras. Podemos, por exemplo, estender o construtor Writable, se quisermos.
class myWritableStream extends Writable {
}No entanto, eu prefiro a abordagem de um construtor mais simples, em que apenas criamos um objeto a partir do construtor Writable e depois passamos para ele as opções que queremos. A única opção exigiremos nesse stream será o método write, que expõe o bloco de dados a serem gravados.
const { Writable } = require('stream');
const outStream = new Writable({
write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
});
process.stdin.pipe(outStream);Esse método write recebe três argumentos.
- O chunk geralmente é um buffer, a menos que configuremos o stream de maneira diferente.
- O argumento encoding é necessário nesse caso, mas geralmente podemos ignorá-lo.
- O callback é uma função que precisamos chamar depois que terminarmos de processar o bloco de dados. É o que sinaliza se a gravação foi bem-sucedida ou não. Para sinalizar uma falha, chame o callback com um objeto de erro.
No outStream, simplesmente fizemos o console.log de chunk como uma string, e para indicar que tudo ocorreu sem nenhum erro. Depois disso, chamamos o callback. Nosso exemplo é um stream de eco, muito simples mas provavelmente não muito útil. Ele mostrará de volta, no console, qualquer coisa que receber.
Para consumir esse stream, podemos simplesmente usar ele com o process.stdin, que é um stream de leitura, para que possamos simplesmente encaminhar o process.stdin para o nosso arquivo outStream.
Quando executamos o código acima, qualquer coisa que digitarmos no process.stdin será ecoada de volta pela linha do console.log no outStream.
Como disse, esse não é um stream muito útil para implementar porque, na verdade, já está implementado e integrado, pois faz o mesmo que o process.stdout. Podemos simplesmente enviar do stdin para o stdout que obteremos exatamente o mesmo recurso de eco com apenas uma linha:
process.stdin.pipe(process.stdout);Implementando um stream de leitura
Para implementar um stream de leitura, precisamos da interface Readable, construindo um objeto a partir dela e implementando o método read() no parâmetro de configuração do stream, dessa forma:
const { Readable } = require('stream');
const inStream = new Readable({
read() {}
});Existe uma maneira simples também de implementar streams de leitura. Podemos fazer o push direto dos dados que queremos que os consumidores consumam.
const { Readable } = require('stream');
const inStream = new Readable({
read() {}
});
inStream.push('ABCDEFGHIJKLM');
inStream.push('NOPQRSTUVWXYZ');
inStream.push(null); // Não há mais dados
inStream.pipe(process.stdout);Quando fazemos o push de um objeto null, isso significa que queremos sinalizar que o stream não tem mais nenhum dados.
Para consumir esse stream simples de leitura, podemos simplesmente enviá-lo para o stream gravável process.stdout.
Quando executarmos o código acima, estaremos lendo todos os dados inStream e os ecoando na saída padrão. Bem simples, mas também não muito eficiente.
Estamos, basicamente, empurrando todos os dados no stream antes de enviá-los para o process.stdout. Uma forma muito melhor de fazer isso é a de enviar os dados sob demanda, somente quando um consumidor os solicita. Podemos fazer isso implementando o método read() no objeto de configuração:
const inStream = new Readable({
read(size) {
// Há uma demanda pelos dados... Alguém quer ler isso.
}
});Quando o método read é chamado em um stream de leitura, a implementação pode enviar dados parciais para a fila. Por exemplo, podemos enviar uma letra de cada vez, começando com o código de caractere 65 (que representa a letra A) e incrementando-o a cada push:
const inStream = new Readable({
read(size) {
this.push(String.fromCharCode(this.currentCharCode++));
if (this.currentCharCode > 90) {
this.push(null);
}
}
});
inStream.currentCharCode = 65;
inStream.pipe(process.stdout);Enquanto o consumidor estiver lendo um stream de leitura, o read continuará sendo acionado e, então, enviaremos mais letras. Porém, precisamos parar este ciclo em algum lugar. É por isso que temos uma instrução if para enviar null quando o currentCharCode for maior que 90 (que é o código do caractere Z).
Esse código é parecido com aquele mais simples com o qual começamos, mas agora estamos enviando dados somente quando o consumidor os solicita. Você deve sempre fazer isso.
Implementando streams duplex/de transformação
Com streams duplex, podemos implementar streams de leitura e graváveis com o mesmo objeto. É como se herdássemos de ambas as interfaces.
Aqui está um exemplo de um stream duplex que combina os dois exemplos implementados acima:
const { Duplex } = require('stream');
const inoutStream = new Duplex({
write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
},
read(size) {
this.push(String.fromCharCode(this.currentCharCode++));
if (this.currentCharCode > 90) {
this.push(null);
}
}
});
inoutStream.currentCharCode = 65;
process.stdin.pipe(inoutStream).pipe(process.stdout);Combinando os métodos, podemos usar esse stream duplex para ler as letras de A a Z e também usá-lo para utilizar o recurso do eco. Nós encaminhamos o stream de leitura stdin para esse stream duplex para usar o eco e encaminhamos o próprio stream duplex no stream gravável stdout para ver as letras de A a Z.
É importante entender que tanto a parte de leitura quanto a gravável de um stream duplex operam de forma totalmente independente um do outro. Este é apenas um agrupamento de dois recursos num único objeto.
Um stream de transformação é mais interessante que o stream duplex, porque sua própria saída é calculada a partir da sua entrada.
Para um stream de transformação, não precisamos implementar os métodos read ou write. Precisamos apenas implementar o método transform, que combina os dois. Ele tem a assinatura do método write e podemos usá-lo para fazer o push dos dados também.
Aqui está um stream de transformação simples que ecoa qualquer coisa que você digitar nele depois de transformá-lo para o formato maiúsculo:
const { Transform } = require('stream');
const upperCaseTr = new Transform({
transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
});
process.stdin.pipe(upperCaseTr).pipe(process.stdout);Neste stream de transformação, estamos consumindo exatamente como no último exemplo do stream duplex, e implementamos apenas o método transform(). Nesse método, convertemos o chunk para a versão com letras maiúsculas e, em seguida, fazemos o push dessa versão na parte de leitura.
Modo de objetos nos streams
Por padrão, os streams esperam valores de Buffer/String. Contudo, há a flag objectMode que podemos definir para que o stream aceite qualquer objeto JavaScript.
Aqui está um exemplo simples para demonstrar isso. A seguinte combinação de streams de transformação faz com que um recurso mapeie uma string de valores separados por vírgula em um objeto JavaScript. Então uma string "a,b,c,d" se torna {a: b, c: d}.
const { Transform } = require('stream');
const commaSplitter = new Transform({
readableObjectMode: true,
transform(chunk, encoding, callback) {
this.push(chunk.toString().trim().split(','));
callback();
}
});
const arrayToObject = new Transform({
readableObjectMode: true,
writableObjectMode: true,
transform(chunk, encoding, callback) {
const obj = {};
for(let i=0; i < chunk.length; i+=2) {
obj[chunk[i]] = chunk[i+1];
}
this.push(obj);
callback();
}
});
const objectToString = new Transform({
writableObjectMode: true,
transform(chunk, encoding, callback) {
this.push(JSON.stringify(chunk) + '\n');
callback();
}
});
process.stdin
.pipe(commaSplitter)
.pipe(arrayToObject)
.pipe(objectToString)
.pipe(process.stdout)Passamos a string de entrada (por exemplo, "a,b,c,d") através do commaSplitter o qual envia um array como seus dados de leitura ( ["a", "b", "c", "d"]). Adicionar a flag readableObjectMode nesse stream é necessário porque agora estamos enviando um objeto para lá, e não mais uma string.
Pegamos, então, esse array e o enviamos direto para o stream arrayToObject. Precisamos da flag writableObjectMode para fazer esse stream aceitar um objeto como entrada. Ele também enviará um objeto (que é o array de entrada mapeado em objeto) e é por isso que precisamos da flag readableObjectMode ali. E no último stream objectToString, por ele aceitar um objeto mas enviar uma string, foi necessário apenas o writableObjectMode nele. A parte de leitura é uma string normal (o objeto stringified - em forma de string).

Streams de transformação integrados no Node
O Node já tem alguns streams de transformação integrados muito úteis. São os streams zlib e crypto.
Aqui está um exemplo que usa o stream zlib.createGzip() combinado com os streams de leitura/graváveis fs para criar um script de compactação de arquivo:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(file + '.gz'));Você pode usar este script para compactar usando gzip qualquer arquivo que você passar como argumento. Estamos encaminhando um stream de leitura para esse arquivo no stream de transformação interno do zlib e, em seguida, em um stream gravável para o novo arquivo gzipado. Simples.
Usar esses pipes é interessante, pois podemos combiná-los com eventos se precisarmos. Digamos, por exemplo, que eu queira que o usuário veja um indicador de progresso enquanto o script estiver funcionando e uma mensagem "Concluído" quando o script estiver pronto. Como o pipe retorna o stream de destino, também podemos encadear o registro de manipuladores de eventos:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
.on('data', () => process.stdout.write('.'))
.pipe(fs.createWriteStream(file + '.zz'))
.on('finish', () => console.log('Concluído'));Assim, com o pipe, conseguimos consumir streams facilmente, mas ainda podemos personalizar ainda mais nossa interação com esses streams usando eventos quando necessário.
O que é ótimo sobre o pipe, porém, é que podemos usá-lo para compor nosso programa parte por parte, de uma maneira bastante legível. Por exemplo, em vez de ouvir o evento data acima, podemos simplesmente criar um stream de transformação para relatar o progresso e substituir a chamada .on() por outra chamada .pipe():
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
const { Transform } = require('stream');
const reportProgress = new Transform({
transform(chunk, encoding, callback) {
process.stdout.write('.');
callback(null, chunk);
}
});
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(reportProgress)
.pipe(fs.createWriteStream(file + '.zz'))
.on('finish', () => console.log('Concluído'));Esse stream reportProgress é um stream simples de passagem, mas que relata o progresso para a saída padrão (standard out) também. Observe como usei o segundo argumento na função callback() para enviar os dados para dentro do método transform(). Isso é o mesmo que enviar os dados primeiro.
As aplicações da combinação de streams são infinitas. Por exemplo, se precisarmos criptografar o arquivo antes ou depois de compactá-lo/descompactá-lo com gzip, tudo que precisamos fazer é encaminhar outro stream de transformação na ordem exata que precisamos. Podemos usar o módulo crypto do Node para isso:
const crypto = require('crypto');
// ...
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipher('aes192', 'a_secret'))
.pipe(reportProgress)
.pipe(fs.createWriteStream(file + '.zz'))
.on('finish', () => console.log('Concluído'));O script acima compacta e criptografa o arquivo passado e somente aqueles que possuem o segredo podem usar o arquivo final. Não podemos descompactar este arquivo com os utilitários normais de descompactação porque está criptografado.
Para realmente poder descompactar qualquer coisa compactada com o script acima, precisamos usar os streams opostos de crypto e zlib em ordem inversa também, que é simples:
fs.createReadStream(file)
.pipe(crypto.createDecipher('aes192', 'a_secret'))
.pipe(zlib.createGunzip())
.pipe(reportProgress)
.pipe(fs.createWriteStream(file.slice(0, -3)))
.on('finish', () => console.log('Concluído'));Supondo que o arquivo de entrada seja a versão compactada, o código acima criará um stream de leitura a partir dele, que enviará para o stream de descriptografia createDecipher() (com o mesmo segredo da criptografia, claro), que repassa a saída para o stream de descompressão do zlib createGunzip() que, depois, escreverá os dados de volta para um arquivo sem a parte da extensão (removida por slice).
É isso que temos para este tópico. Obrigado pela leitura! E até a próxima!
Está aprendendo React ou Node? Confira os livros do autor (em inglês):