

Artigo original: An introduction to Q-Learning: reinforcement learning
Escrito por: ADL
Este artigo é a segunda parte de uma série minha chamada "Aprendizagem profunda com reforço".
Na primeira parte da série (texto em inglês), aprendemos o básico sobre a aprendizagem com reforço.
O Q-Learning (em português, aprendizagem Q) é um algoritmo de aprendizagem com base em valores, usado na aprendizagem com reforço. Neste artigo, aprenderemos sobre o Q-Learning e detalhes a respeito dele:
- O que é o Q-Learning?
- Qual é a matemática por trás do Q-Learning?
- Implementação do Q-Learning em Python
Q-Learning — uma visão geral simplista
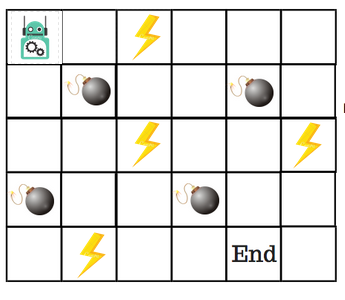
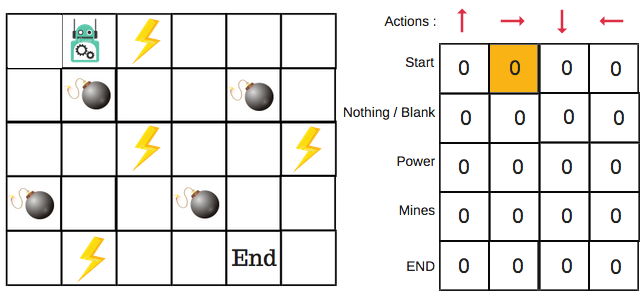
Digamos que um robô precise cruzar um labirinto e chegar a um destino. Existem minas no caminho. O robô pode se mover apenas um passo de cada vez. Se o robô pisar em uma mina, está morto. O robô precisa chegar ao destino no menor tempo possível.
O sistema de pontuação/recompensa é o seguinte:
- O robô perde 1 ponto a cada passo. Isso é feito para que o robô percorra o menor caminho e chegue ao objetivo o mais rápido possível.
- Se o robô pisar em uma mina, são perdidos 100 pontos e o jogo termina.
- Se o robô obtiver energia (⚡)️, ele ganha 1 ponto.
- Se o robô chegar ao destino, ele obtém 100 pontos.
A questão óbvia agora é: como treinamos um robô para que chegue ao destino sem pisar em uma mina?
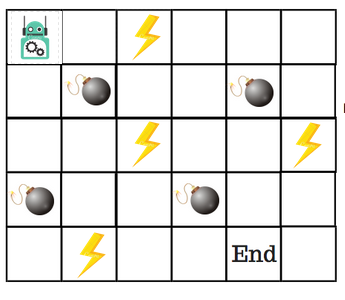
Como podemos resolver isso?
Apresentamos a tabela Q
A tabela Q (em inglês, Q-Table) é apenas um nome bonito para uma simples tabela de consulta, onde calculamos as recompensas futuras máximas esperadas para uma ação em cada estado (passo). Basicamente, essa tabela nos guiará a tomar as melhores ações a cada passo.
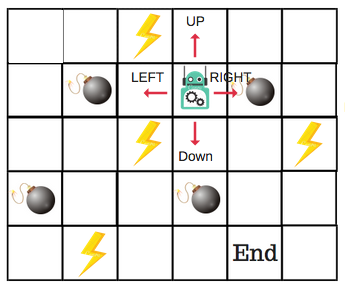
Haverá quatro ações (e direções) possíveis para cada passo que não esteja nas bordas do tabuleiro. Quando o robô estiver em um desses passos, ele estará em uma situação na qual poderá se mover para cima, para baixo, para a esquerda ou para a direita.
Assim, vamos modelar esse ambiente em nossa tabela Q.
Na tabela Q, as colunas são as ações e as linhas são os estados (passos).
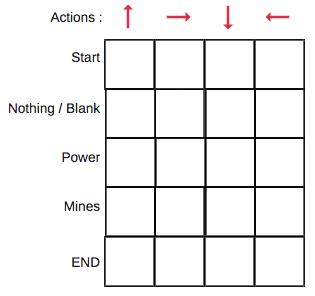
Cada pontuação na tabela Q será a recompensa futura máxima esperada que o robô terá se fizer aquela ação (mover-se em uma direção) a partir daquele estado (passo). Esse é um processo iterativo. Precisamos melhorar a tabela Q a cada iteração.
As perguntas que temos, no entanto, são:
- Como calcular os valores da tabela Q?
- Os valores estão disponíveis ou são pré-definidos?
Para aprender sobre cada valor da tabela Q, usamos o algoritmo de Q-Learning.
Matemática: o algoritmo de Q-Learning
Função Q
A função Q usa a equação de Bellman e recebe duas entradas: estado (s – de state, em inglês) e ação (a).
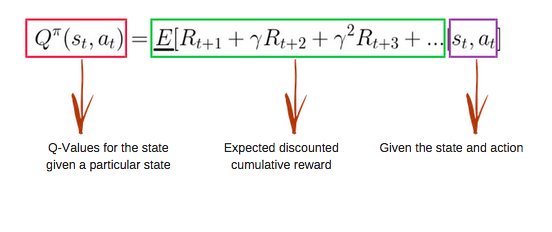
Usando a função acima, obtemos os valores de Q para as células da tabela.
Ao começarmos, todos os valores na tabela Q são zeros.
Há um processo iterativo de atualização dos valores. Ao começarmos a explorar o ambiente, a função Q nos dá aproximações cada vez melhores, atualizando continuamente os valores Q na tabela.
Agora, vamos entender como a atualização ocorre.
Apresentamos o processo do algoritmo de Q-learning
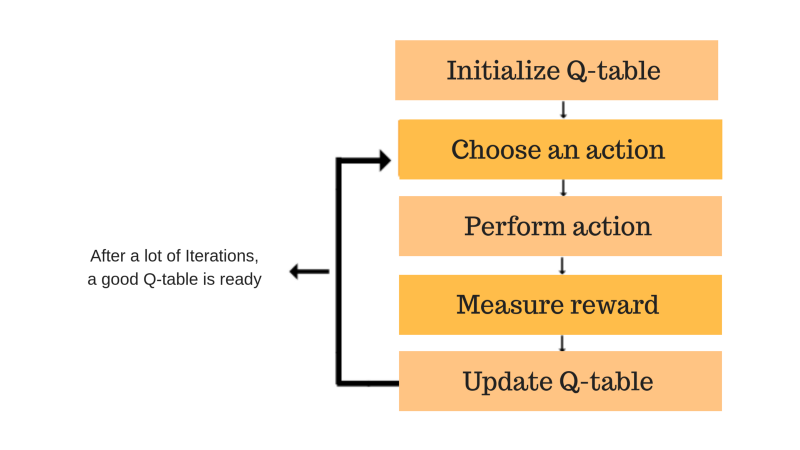
Cada uma das caixas coloridas (inicializar a tabela Q, escolher uma ação, realizar uma ação, medir a recompensa, atualizar a tabela Q) representa um passo. Vamos entender cada um desses passos em detalhes.
Passo 1: inicializar a tabela Q
Primeiro, criaremos a tabela Q. Ela tem n colunas, onde n= número de ações. Há m linhas, onde m= número de estados. Inicializaremos os valores em 0.
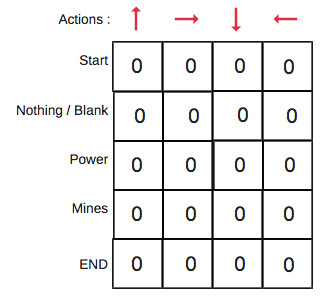
No nosso exemplo do robô, temos quatro ações (a=4) e cinco estados (s=5). Assim, vamos criar uma tabela com quatro colunas e cinco linhas.
Passos 2 e 3: selecione e realize uma ação
Essa combinação de passos é feita por um tempo indefinido. Isso significa que esse passo é executado até o momento em que paramos o treinamento ou que o laço do treinamento é interrompido, conforme definido no código.
Selecionaremos uma ação (a) no estado (s) com base na tabela Q. Porém, como mencionamos antes, quando o episódio iniciar, todos os valores de Q serão 0.
É aqui que o conceito de troca entre exploração geográfica e exploração de recursos aparece. Este artigo traz mais detalhes sobre o assunto.
Usaremos algo chamado de estratégia épsilon gananciosa.
No começo, as taxas de épsilon serão maiores. O robô fará a exploração geográfica do ambiente e escolherá ações aleatoriamente. A lógica por trás disso é a de que o robô ainda não sabe nada sobre o ambiente.
Conforme ele explora a geografia do ambiente, a taxa de épsilon diminui e o robô começa a exploração de recursos do ambiente.
Durante o processo de exploração geográfica, o robô aos poucos vai se tornando mais confiante na estimativa dos valores Q.
Para o robô do exemplo, há quatro ações que ele pode escolher: subir, descer, ir para a esquerda e ir para a direita. Começamos agora o treinamento — nosso robô desconhece o ambiente. Assim, o robô escolhe aleatoriamente uma ação como, por exemplo, ir para a direita.
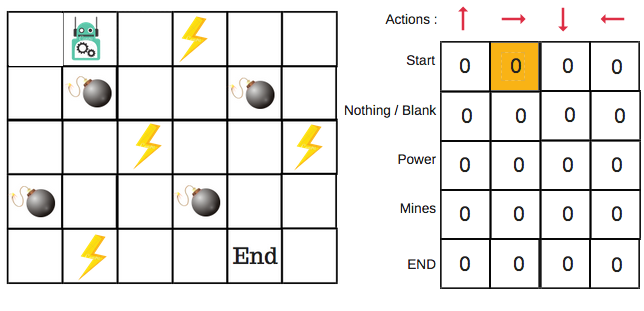
Podemos agora atualizar os valores Q para estar no começo e mover para a direita usando a equação de Bellman.
Passos 4 e 5: avaliar
Agora, realizamos uma ação e observamos o resultado e a recompensa. precisamos atualizar a função Q(s, a).

No caso do jogo do robô, para reiterar a estrutura de pontuação/recompensa, temos:
- energia = +1
- mina = -100
- final = +100

Repetimos isso várias vezes até que a aprendizagem é interrompida. Dessa maneira, a tabela Q é atualizada.
Recapitulando
- Q-Learning é um algoritmo de reforço com base em valores, usado para encontrar a política de seleção de ações ideal usando uma função Q.
- Nosso objetivo é maximizar a função de valor Q.
- A tabela Q nos ajuda a encontrar a melhor ação para cada estado.
- Ela ajuda a maximizar a recompensa esperada selecionando a melhor de todas as ações possíveis.
- Q(estado, ação) retorna a recompensa futura esperada daquela ação naquele estado.
- Essa função pode ser estimada usando o Q-Learning, que atualiza Q(s,a) iterativamente usando a equação de Bellman.
- Inicialmente, exploramos o ambiente e atualizamos a tabela Q. Quando a tabela Q está pronta, o agente começará a explorar os recursos do ambiente para realizar as melhores ações.
Em um próximo artigo, falaremos sobre um exemplo de Q-Learning para a aprendizagem profunda.
Até lá, divirta-se com as IAs. 😀
Importante: conforme dito anteriormente, este artigo é a segunda parte de minha série chamada "Aprendizagem profunda com reforço".
Se gostou do artigo, compartilhe-o. Isso ajuda o autor a se manter motivado a produzir mais artigos. Você pode seguir o autor no Twitter.
Se tiver perguntas, envie-as ao autor, comentando com ele no Twitter.