
By Preethi Kasireddy
In my previous post, we dived into how the web works on a basic level, including the interaction between a client (your computer) and a server (another computer which responds to the client’s requests for websites).
For this post — part two of a four-part series — let’s double click on understanding how the client, server and other parts of a basic web application are actually configured to make your web browsing experience possible.
The Client-Server Model
This idea of a client and server communicating over a network is called the “Client-Server” model. It’s what makes viewing websites (like this one) and interacting with web applications (like Gmail) possible.
The Client-Server model is really just a way to describe the give-and-take relationship between the client and server in a web application — just like you might use “boyfriend” and “girlfriend” to describe your personal relationships. It’s the details of how information passes from one end to the other where the picture gets complicated.
A Basic Web App Configuration
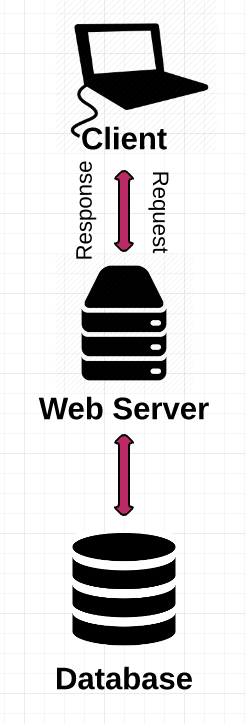
There are hundreds of ways to configure a web application. That said, most of them follow the same basic structure: a client, a server, and a database.
The client
The client is what the user interacts with. So “client-side” code is responsible for most of what a user actually sees. This includes:
- Defining the structure of the web page
- Setting the look and feel of the web page
- Implementing a mechanism for responding to user interactions (clicking buttons, entering text, etc.)
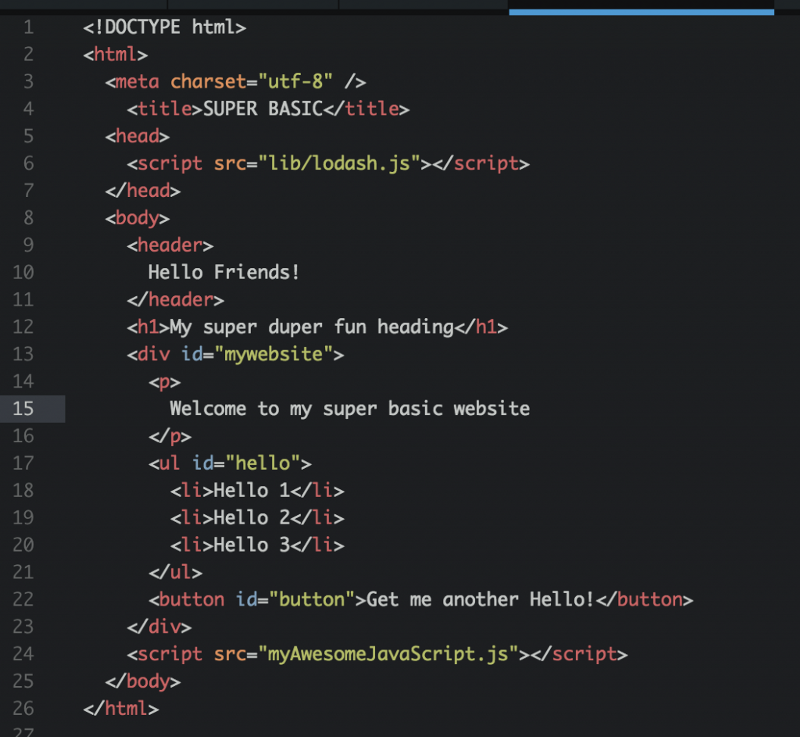
Structure: The layout and content of your webpage are defined by HTML (usually HTML 5 when it comes to web apps these days, but that’s another story.)
HTML stands for Hyper Text Markup Language. It allows you to describe the basic physical structure of a document using HTML tags. Each HTML tag describes a specific element on the document.
For example:
- The content within the “
” tag describes the heading.
- The content within the “
” tag describes a paragraph.
- The content within the “” tag describes a button.
- And so on…
A web browser uses these HTML tags to determine how to display the document.
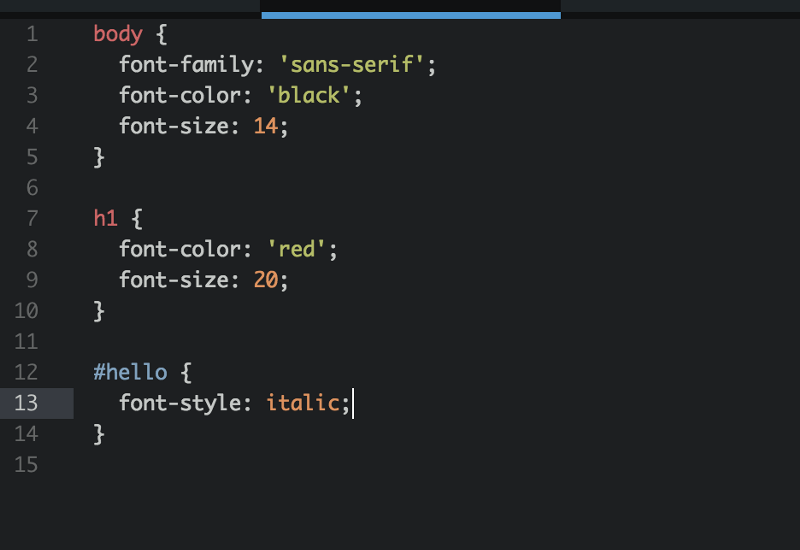
Look and Feel: To define the look and feel of a webpage, web developers use CSS, which stands for Cascading Style Sheets. CSS is a language that that lets you describe how the elements defined in your HTML should be styled, allowing changes in font, color, layout, simple animations, and other superficial elements.
You could set styles for the above HTML page like this:
User interactions: Lastly, JavaScript comes into the picture to handle user interactions.
For example, if you want to do something when a user clicks your button, you might do something like this:
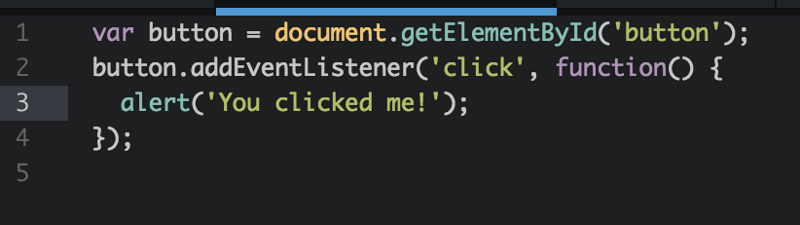
Some user interactions, like the one above, can be handled without ever having to reach out to your server — hence the term “client-side JavaScript.” Other interactions require that you send the requests to your server to handle.
For example, if a user posts a comment on a thread, you might want to store that comment in your database to keep all the riff-raff organized in one place. So, you’d send the request to the server with the new comment and user ID, and the server would listen for those requests and process them accordingly.
We’ll go much more in depth into HTTP request-response in the next part of this series.
The server
The server in a web application is what listens to requests coming in from the client. When you set up an HTTP server, you set it up to listen to a port number. A port number is always associated with the IP address of a computer.
You can think of ports as separate channels on each computer that you can use to perform different tasks: one port could be surfing www.facebook.com while another fetches your email. This is possible because each of the applications (the web browser and the email client) use different port numbers.
Once you’ve set up an HTTP server to listen to a specific port, the server waits for client requests coming to that specific port, performs any actions stated by the request, and sends any requested data via an HTTP response.
The database
Databases are the basements of web architecture — most of us are scared to go down there, but they’re critical to a solid foundation. A database is a place to store information so that it can easily be accessed, managed, and updated.
If you’re building a social media site, for example, you might use a database to store information about your users, posts, and comments. When a visitor requests a page, the data inserted into the page comes from the site’s database, allowing for the real-time user interactions we take for granted on sites like Facebook or apps like Gmail.
That’s all folks! (Well, sorta…)
It’s as simple as that. We just walked through all the basic functionality of a web application.
How to Scale a Simple Web Application
The above configuration is great for simple applications. But as an application grows, a single server won’t have the power to handle thousands — if not millions — of concurrent requests from visitors.
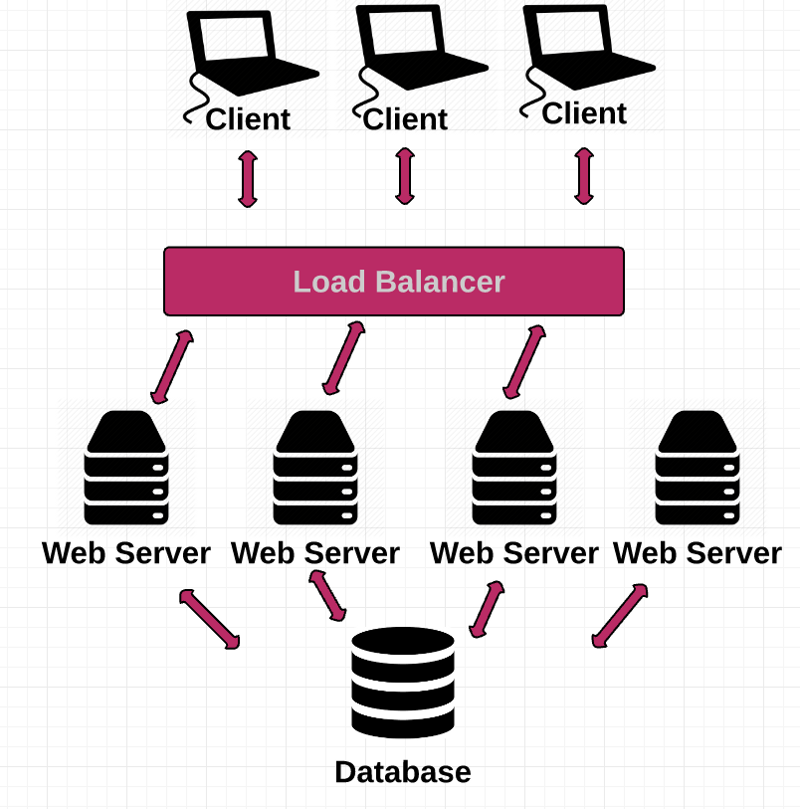
In order to scale to meet these high volumes, one thing we can do is distribute the incoming traffic across a group of back-end servers.
This is where things gets interesting. You have multiple servers, each with its own IP address. So how does the Domain Name Server (DNS) know which instance of your application to send your traffic to?
The simple answer is that it doesn’t. The way to manage all these separate instances of your application is through something called a load balancer.
The load balancer acts as a traffic cop that routes client requests across the servers in the fastest and most efficient manner possible.
Since you can’t broadcast the IP addresses of all your server instances, you create a Virtual IP address, which is the address you publicly broadcast to clients. This Virtual IP address points to your load balancer. So when there’s a DNS lookup for your site, it’ll point to the load balancer. Then the load balancer jumps in to distribute traffic to your various back-end servers in real-time.
You might be wondering how the load balancer knows which server to send traffic to. The answer: algorithms.
One popular algorithm, Round Robin, involves evenly distributing incoming requests across the your server farm (all your available servers). You would typically choose this approach if all of your servers have similar processing speed and memory.
With another algorithm, Least Connections, the next request is sent to the server with the least number of active connections.
There are many more algorithms you can implement, depending on your needs.
So now the flow looks like this:
Services
Ok, so we solved our traffic problem by creating pools of servers and a load balancer to manage them. Works great, right?
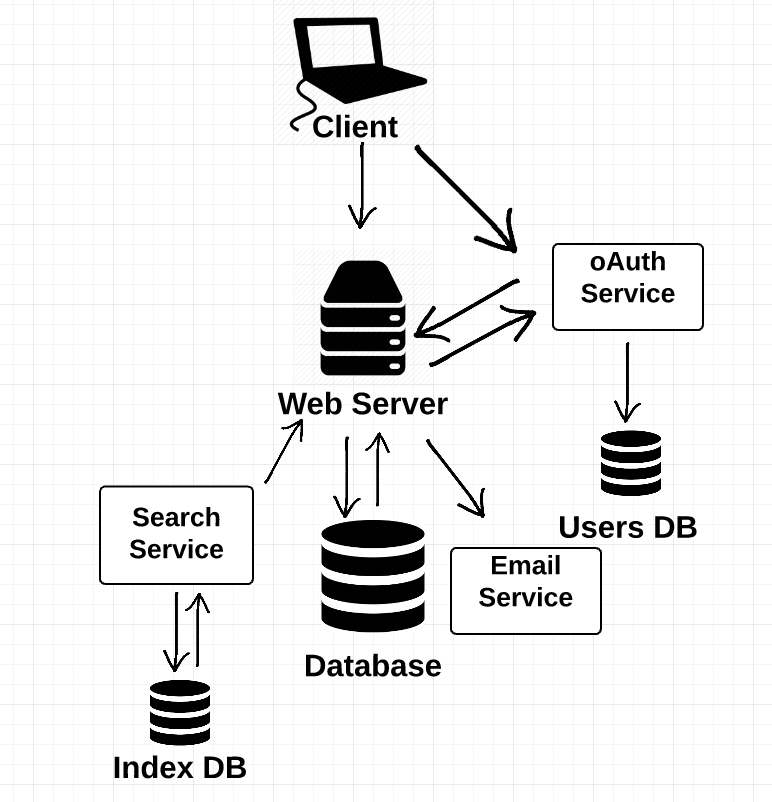
…But just replicating a bunch of servers could still lead to problems as your application grows. As you add more functionality to your application, you’d have to keep maintaining the same monolithic server while it continues to grow. To solve this, we need a way to decouple the functionality of the server.
This is where the idea of a service comes in. A service is just another server, except that it only interacts with other servers, as opposed to a traditional web server which interacts with clients.
Each service has a self-contained unit of functionality, such as authorizing users or providing a search functionality. Services allow you to break up your single web server into multiple services that each performs a discrete functionality.
The main benefit of breaking up a single server into many services is that it allows you to scale the services completely independently.
The other advantage here is that it allows teams within a company to work independently on a particular service, rather than having 10s, 100s or even 1000s of engineers working on one monolithic server, which quickly becomes a project management nightmare.
Quick note here: this concept of load balancers and pools of back-end servers and services gets very challenging as you scale to add more and more servers to your application. It’s gets especially tricky with things like session persistence — such as how to handle sending multiple requests from a client to the same server for the duration of a session — and how to deploy your load balancing solution. We’ll leave those advanced topics out for this post.
Content Delivery Networks
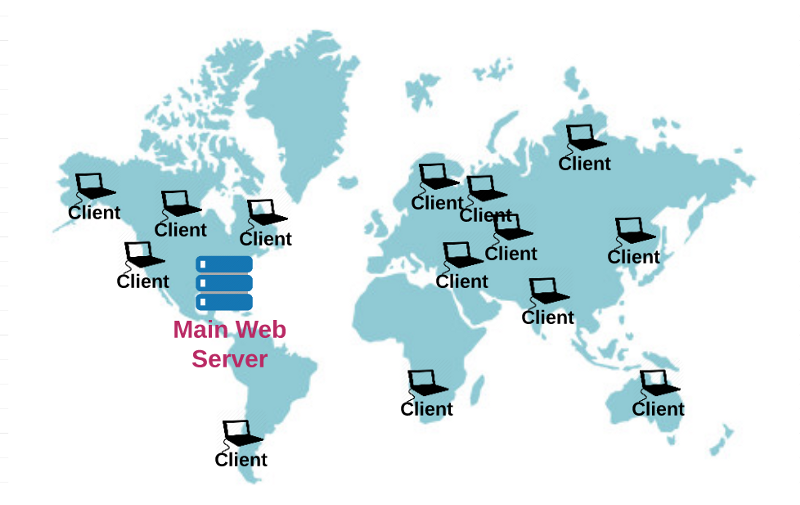
All of the above works great for scaling traffic, but your application is still centralized in one location. When your users start visiting your site from other sides of the country — or the other side of the world — they might encounter longer load times because of the increased distance between the client and server. After all, we’re talking about the “World Wide Web” — not the “local neighborhood web.” :)
A popular tactic to solve this is using a Content Delivery Network (CDN). A CDN is a large distributed system of “proxy” servers deployed across many data centers. A proxy server is just a server that acts as an intermediary between a client and a server.
Companies with large amounts of distributed traffic can choose to pay CDN companies to deliver their content to their end-users using the CDN’s servers. An example of a CDN is Akamai. Akamai has thousands of servers located in strategic geographical locations around the world.
Let’s compare how a website works with and without a CDN.
As we talked about in Section 1, for a typical website, the domain name of a URL is translated to the IP address of the host’s server.
However, if a customer uses Akamai, the domain name of the URL is translated to the IP address of an edge server owned by Akamai. Akamai then delivers the web content to the customer’s users, without it ever having to touch the customer’s servers.
Akamai is able to do this by storing copies of frequently used elements like HTML, CSS, software downloads, and media objects from customers’ servers.
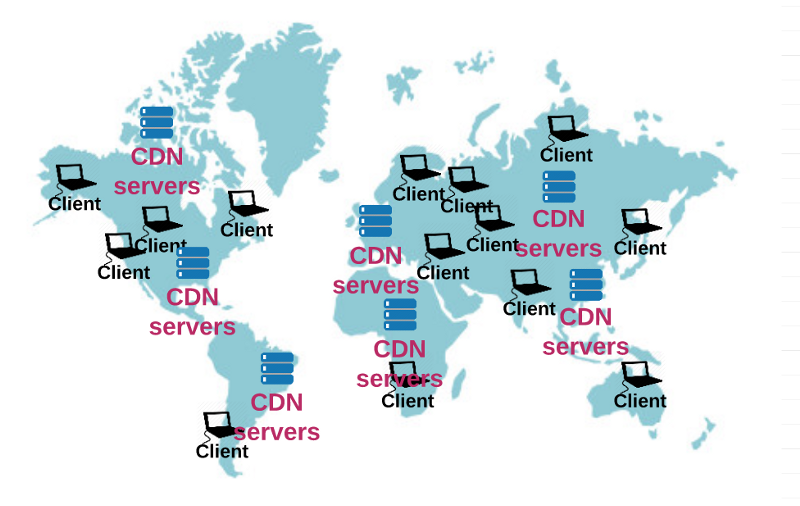
The main goal is to bring your website’s content closer to your user. If the content doesn’t have to travel as far to get to the user, it means lower latency, which in turn reduces the load time.
Ta da! A faster website :)
Run that by me again?
Next up, read part 3 where we’ll fill in the details with a closer look at HTTP and REST! :)