

Artigo original: How to create, read, update and search through Excel files using Python
Este artigo mostrará em detalhes como trabalhar com arquivos Excel e como modificar dados específicos com o Python.
Primeiro, aprenderemos como trabalhar com arquivos CSV para leitura, gravação e atualização. Depois, daremos uma olhada em como ler arquivos, filtrá-los por planilha, procurar linhas/colunas e atualizar células de arquivos .xlsx.
Vamos começar com o formato mais simples de planilha, o .csv.
Parte 1 — o arquivo .csv
Um arquivo .csv é um arquivo de valores separados por vírgula, onde dados de texto simples são exibidos em forma tabular. Eles podem ser usados com qualquer programa de planilhas, como o Microsoft Office Excel, as Planilhas Google ou o LibreOffice Calc.
Os arquivos .csv não são como outros arquivos de planilhas, pois não permitem salvar células, colunas, linhas ou fórmulas. Sua limitação está no fato de que eles permitem apenas uma planilha por arquivo. Meu plano para essa primeira parte do artigo é mostrar como criar arquivos .csv usando o Python 3 e o módulo de biblioteca padrão CSV.
Este tutorial terminará com dois repositórios do GitHub e uma aplicação para a web que realmente usa o código da segunda parte deste tutorial (embora atualizado e modificado para servir a um propósito específico).
Gravando em arquivos .csv
Primeiro, abra um novo arquivo do Python e importe o módulo CSV.
import csvMódulo CSV
O módulo CSV inclui todos os métodos necessários incorporados. Eles incluem:
- csv.reader
- csv.writer
- csv.DictReader
- csv.DictWriter
- e outros
Neste guia, vamos nos concentrar nos métodos de gravação, DictWriter e DictReader. Eles permitem editar, modificar e manipular os dados armazenados em um arquivo .csv.
No primeiro passo, precisamos definir o nome do arquivo e salvá-lo como uma variável. Devemos fazer o mesmo com o cabeçalho e as informações de dados.
filename = "imdb_top_4.csv"
header = ("Rank", "Rating", "Title")
data = [
(1, 9.2, "The Shawshank Redemption(1994)"),
(2, 9.2, "The Godfather(1972)"),
(3, 9, "The Godfather: Part II(1974)"),
(4, 8.9, "Pulp Fiction(1994)")
]Agora, precisamos criar uma função chamada writer, que terá três parâmetros: cabeçalho, dados e nome do arquivo.
def writer(header, data, filename):
passO próximo passo é modificar a função writer para que ela crie um arquivo que contenha dados do cabeçalho e variáveis de dados. Isso é feito escrevendo a primeira linha da variável de cabeçalho e depois escrevendo quatro linhas da variável de dados (há quatro linhas, pois há quatro tuplas dentro da lista).
def writer(header, data, filename):
with open (filename, "w", newline = "") as csvfile:
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)A documentação do Python descreve como o método csv.writer funciona. Eu recomendo fortemente que você reserve um minuto para lê-la.
E aí está! Você criou seu primeiro arquivo .csv, chamado imdb_top_4.csv. Abra esse arquivo com sua aplicação de planilhas preferida e você deverá ver algo parecido com isto:
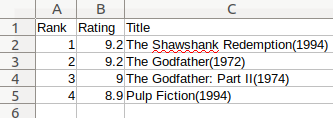
O resultado pode ser escrito assim, se você escolher por abrir o arquivo em alguma outra aplicação:
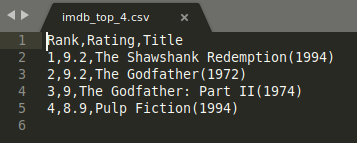
Atualizando os arquivos .csv
Para atualizar esse arquivo, você deve criar uma nova função chamada updater, que terá apenas um parâmetro chamado filename.
def updater(filename):
with open(filename, newline= "") as file:
readData = [row for row in csv.DictReader(file)]
# print(readData)
readData[0]['Rating'] = '9.4'
# print(readData)
readHeader = readData[0].keys()
writer(readHeader, readData, filename, "update")Essa função, primeiramente, abre o arquivo definido na variável filename e, depois, salva todos os dados que ela lê do arquivo dentro de uma variável chamada readData. O segundo passo é colocar diretamente no código o novo valor no lugar do antigo na posição readData[0]['Rating'].
O último passo na função é chamar a função writer, adicionando uma nova atualização de parâmetros que dirá à função que você está fazendo uma atualização.
csv.DictReader é explicado mais na documentação oficial do Python aqui.
Para que o writer possa funcionar com um novo parâmetro, é necessário adicionar um novo parâmetro em todos os lugares onde o writer estiver definido. Volte ao local onde você chamou a função writer pela primeira vez e acrescente "write" como um novo parâmetro:
writer(header, data, filename, "write")Logo abaixo da função writer, chame a função updater e passe o parâmetro filename para ela:
writer(header, data, filename, "write")
updater(filename)Agora, você precisa modificar a função writer para obter um novo parâmetro chamado option:
def writer(header, data, filename, option):De agora em diante, esperamos receber duas opções diferentes para a função writer (gravar e atualizar). Por causa disso, devemos acrescentar duas se as declarações suportarem essa nova funcionalidade. A primeira parte da função em if option == "write: já é conhecida por você. Você só precisa adicionar a seção elif option == "update": ao código e a parte do else exatamente como estão escritas abaixo:
def writer(header, data, filename, option):
with open (filename, "w", newline = "") as csvfile:
if option == "write":
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)
elif option == "update":
writer = csv.DictWriter(csvfile, fieldnames = header)
writer.writeheader()
writer.writerows(data)
else:
print("Option is not known")É isso! Está pronto!
Agora, seu código deve ser algo parecido com isto:
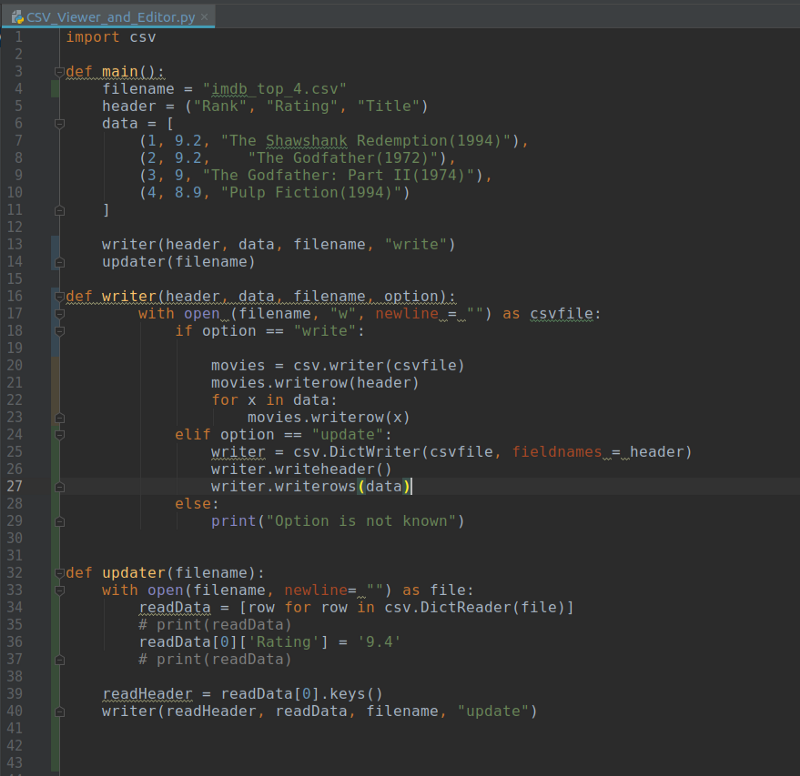
Você também pode encontrar o código aqui:
https://github.com/GoranAviani/CSV-Viewer-and-Editor
Na primeira parte deste artigo, vimos como trabalhar com arquivos .csv. Criamos e atualizamos um desses arquivos.
Parte 2 — o arquivo .xlsx
Eu trabalhei neste projeto durante vários finais de semana. Comecei a trabalhar nele porque havia uma necessidade deste tipo de solução em minha empresa. Minha primeira ideia foi construir esta solução diretamente no sistema da minha empresa, mas, depois, eu não teria nada sobre o que escrever, certo?
Eu construí esta solução usando o Python 3 e a biblioteca openpyxl. A razão pela qual eu escolhi a openpyxl é pelo fato de ela representar uma solução completa para criar, carregar, atualizar, renomear e apagar planilhas. Ela também nos permite ler ou gravar em linhas e colunas, fundir ou unir células, criar gráficos do Excel em Python etc.
Terminologia e informações básicas da Openpyxl
- Workbook é o nome de um arquivo Excel em Openpyxl.
- Um workbook consiste em planilhas (o padrão é 1 planilha). As planilhas são referenciadas por seus nomes.
- Uma planilha consiste em linhas (horizontais) a partir do número 1 e de colunas (verticais) a partir da letra A.
- Linhas e colunas resultam em uma grade e formam células que podem conter alguns dados (valores numéricos ou strings) ou fórmulas.
A Openpyxl é bem documentada. Aconselho você a dar uma olhada aqui (texto em inglês).
O primeiro passo é abrir seu ambiente Python e instalar a openpyxl dentro do seu terminal:
pip install openpyxlEm seguida, importe a openpyxl para seu projeto e, depois, carregue uma pasta de trabalho para a variável theFile.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
print(theFile.sheetnames)
currentSheet = theFile['customers 1']
print(currentSheet['B4'].value)Como você pode ver, esse código imprime todas as planilhas pelos seus nomes. Em seguida, ele seleciona a planilha chamada "customers 1" e a salva em uma variável currentSheet. Na última linha, o código imprime o valor que está localizado na posição B4 da planilha "customers 1".
O código funciona como deveria, mas é muito difícil colocar valores diretamente no código. Para tornar isso mais dinâmico, vamos escrever um código que fará o seguinte:
- Ler o arquivo
- Obter todos os nomes das planilhas
- Percorrer todas as planilhas
Na última etapa, o código imprimirá valores que estão localizados nos campos B4 de cada planilha encontrada dentro do workbook.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for x in allSheetNames:
print("Current sheet name is {}" .format(x))
currentSheet = theFile[x]
print(currentSheet['B4'].value)Ficou melhor do que antes, mas ainda é uma solução com inserção de valores diretamente no código e ainda assume que o valor que você estará procurando está na célula B4, o que é uma bobagem. :)
Imagine que seu projeto precise procurar dentro de todas as planilhas do arquivo do Excel por um valor específico. Para fazer isso, adicionaremos mais um laço for no intervalo "ABCDEF" e depois, simplesmente, imprimiremos os nomes das células e seus valores.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
# print(currentSheet['B4'].value)
#print max numbers of wors and colums for each sheet
#print(currentSheet.max_row)
#print(currentSheet.max_column)
for row in range(1, currentSheet.max_row + 1):
#print(row)
for column in "ABCDEF": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))Fizemos isso introduzindo o laço "for row in range..." (para cada linha no intervalo, em português). O intervalo do laço for é definido da célula na linha 1 até o número máximo de linhas da planilha. O segundo laço busca dentro dos nomes de coluna predefinidos "ABCDEF". Nesse segundo laço, mostraremos a posição completa da célula (nome da coluna e número da linha) e um valor.
Entretanto, neste artigo, a minha tarefa é encontrar uma coluna específica que se chama "telephone" e, depois, passar por todas as linhas dessa coluna. Para fazer isso, precisamos modificar o código assim:
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]Esse código modificado passará por todas as células de cada planilha e, tal como antes, o intervalo de linhas é dinâmico e o intervalo de colunas é específico. O código percorre as células e procura por uma célula que contenha o texto "telephone". Assim que o código encontra a célula específica, notifica o usuário em qual célula o texto está localizado. O código faz isso para cada célula dentro de todas as planilhas que estão no arquivo do Excel.
O próximo passo é percorrer todas as linhas daquela coluna específica e imprimir os valores.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
def get_column_letter(specificCellLetter):
letter = specificCellLetter[0:-1]
print(letter)
return letter
def get_all_values_by_cell_letter(letter):
for row in range(1, currentSheet.max_row + 1):
for column in letter:
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
specificCellLetter = (find_specific_cell())
letter = get_column_letter(specificCellLetter)
get_all_values_by_cell_letter(letter)
Isso é feito adicionando uma função chamada get_column_letter, que encontra a letra de uma coluna. Depois que a letra da coluna é encontrada, percorremos todas as linhas dessa coluna específica. Isto é feito com a função get_all_values_by_cell_letter, que imprimirá todos os valores dessas células.
Encerramento
Perfeito! Há muitas coisas que você pode fazer depois disso. Meu plano era construir uma aplicação on-line que padronizasse todos os números de telefone da Suécia tirados de uma caixa de texto e oferecesse aos usuários a possibilidade de simplesmente copiar os resultados a partir dessa caixa de texto. O segundo passo do meu plano era expandir a funcionalidade da aplicação para a web de modo que ela suportasse o envio de arquivos do Excel, o processamento de números de telefone dentro desses arquivos (padronizando-os para o formato sueco) e oferecer os arquivos processados de volta aos usuários.
Fiz as duas tarefas e você pode vê-las em funcionamento na página de Ferramentas do meu site Incodaq.com:
https://tools.incodaq.com/
Também o código da segunda parte deste artigo está disponível no GitHub:
https://github.com/GoranAviani/Manipulate-Excel-spreadsheets
Nota do tradutor: tanto a versão em site quanto o repositório no GitHub já não existem mais, mas, se quiser ver os trabalhos do autor, basta acessar a página dele no GitHub, informada abaixo.
Obrigado pela leitura! Confira mais artigos como este no perfil do Medium do autor, além de outras coisas divertidas que ele cria em sua página do GitHub.