
By Goran Aviani
This article will show in detail how to work with Excel files and how to modify specific data with Python.
First we will learn how to work with CSV files by reading, writing and updating them. Then we will take a look how to read files, filter them by sheets, search for rows/columns, and update cells of xlsx files.
Let’s start with the simplest spreadsheet format: CSV.
Part 1 — The CSV file
A CSV file is a comma-separated values file, where plain text data is displayed in a tabular format. They can be used with any spreadsheet program, such as Microsoft Office Excel, Google Spreadsheets, or LibreOffice Calc.
CSV files are not like other spreadsheet files though, because they don’t allow you to save cells, columns, rows or formulas. Their limitation is that they also allow only one sheet per file. My plan for this first part of the article is to show you how to create CSV files using Python 3 and the standard library module CSV.
This tutorial will end with two GitHub repositories and a live web application that actually uses the code of the second part of this tutorial (yet updated and modified to be for a specific purpose).
Writing to CSV files
First, open a new Python file and import the Python CSV module.
import csv
CSV Module
The CSV module includes all the necessary methods built in. These include:
- csv.reader
- csv.writer
- csv.DictReader
- csv.DictWriter
- and others
In this guide we are going to focus on the writer, DictWriter and DictReader methods. These allow you to edit, modify, and manipulate the data stored in a CSV file.
In the first step we need to define the name of the file and save it as a variable. We should do the same with the header and data information.
filename = "imdb_top_4.csv"
header = ("Rank", "Rating", "Title")
data = [
(1, 9.2, "The Shawshank Redemption(1994)"),
(2, 9.2, "The Godfather(1972)"),
(3, 9, "The Godfather: Part II(1974)"),
(4, 8.9, "Pulp Fiction(1994)")
]
Now we need to create a function named writer that will take in three parameters: header, data and filename.
def writer(header, data, filename):
pass
The next step is to modify the writer function so it creates a file that holds data from the header and data variables. This is done by writing the first row from the header variable and then writing four rows from the data variable (there are four rows because there are four tuples inside the list).
def writer(header, data, filename):
with open (filename, "w", newline = "") as csvfile:
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)
The official Python documentation describes how the csv.writer method works. I would strongly suggest that you to take a minute to read it.
And voilà! You created your first CSV file named imdb_top_4.csv. Open this file with your preferred spreadsheet application and you should see something like this:
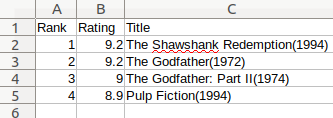 Using LibreOffice Calc to see the result.
Using LibreOffice Calc to see the result.
The result might be written like this if you choose to open the file in some other application:
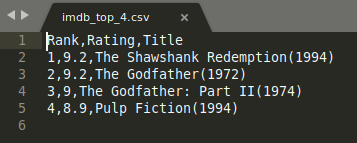 Using SublimeText to see the result.
Using SublimeText to see the result.
Updating the CSV files
To update this file you should create a new function named updater that will take just one parameter called filename.
def updater(filename):
with open(filename, newline= "") as file:
readData = [row for row in csv.DictReader(file)]
# print(readData)
readData[0]['Rating'] = '9.4'
# print(readData)
readHeader = readData[0].keys()
writer(readHeader, readData, filename, "update")
This function first opens the file defined in the filename variable and then saves all the data it reads from the file inside of a variable named readData. The second step is to hard code the new value and place it instead of the old one in the readData[0][‘Rating’] position.
The last step in the function is to call the writer function by adding a new parameter update that will tell the function that you are doing an update.
csv.DictReader is explained more in the official Python documentation here.
For writer to work with a new parameter, you need to add a new parameter everywhere writer is defined. Go back to the place where you first called the writer function and add “write” as a new parameter:
writer(header, data, filename, "write")
Just below the writer function call the updater and pass the filename parameter into it:
writer(header, data, filename, "write")
updater(filename)
Now you need to modify the writer function to take a new parameter named option:
def writer(header, data, filename, option):
From now on we expect to receive two different options for the writer function (write and update). Because of that we should add two if statements to support this new functionality. First part of the function under “if option == “write:” is already known to you. You just need to add the “elif option == “update”: section of the code and the else part just as they are written bellow:
def writer(header, data, filename, option):
with open (filename, "w", newline = "") as csvfile:
if option == "write":
movies = csv.writer(csvfile)
movies.writerow(header)
for x in data:
movies.writerow(x)
elif option == "update":
writer = csv.DictWriter(csvfile, fieldnames = header)
writer.writeheader()
writer.writerows(data)
else:
print("Option is not known")
Bravo! Your are done!
Now your code should look something like this:
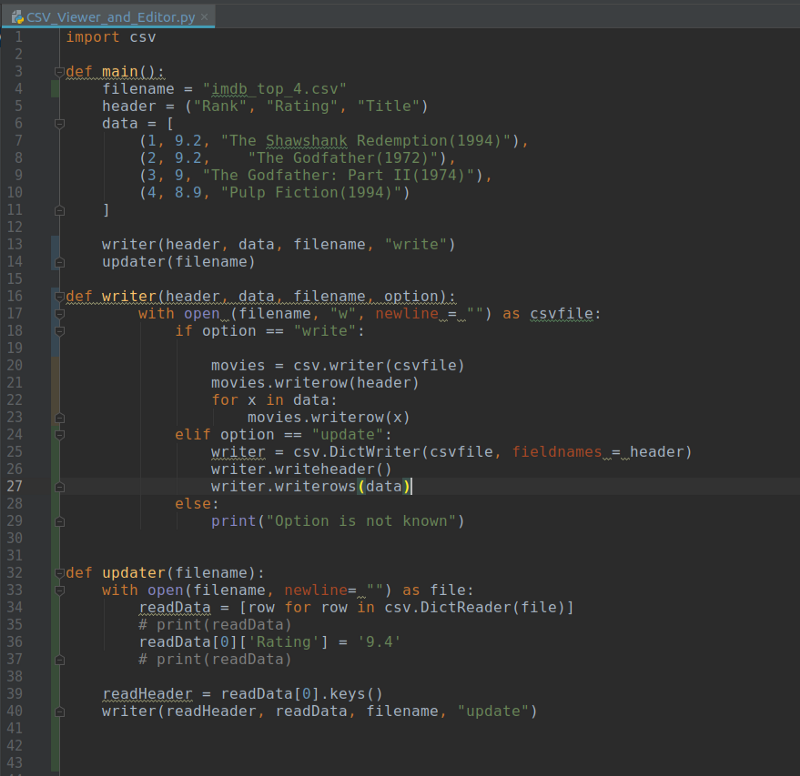
You can also find the code here:
https://github.com/GoranAviani/CSV-Viewer-and-Editor
In the first part of this article we have seen how to work with CSV files. We have created and updated one such file.
Part 2 — The xlsx file
For several weekends I have worked on this project. I have started working on it because there was a need for this kind of solution in my company. My first idea was to build this solution directly in my company’s system, but then I wouldn’t have anything to write about, eh?
I build this solution using Python 3 and openpyxl library. The reason why I have chosen openpyxl is because it represents a complete solution for creating worksheets, loading, updating, renaming and deleting them. It also allows us to read or write to rows and columns, merge or un-merge cells or create Python excel charts etc.
Openpyxl terminology and basic info
- Workbook is the name for an Excel file in Openpyxl.
- A workbook consists of sheets (default is 1 sheet). Sheets are referenced by their names.
- A sheet consists of rows (horizontal lines) starting from the number 1 and columns (vertical lines) starting from the letter A.
- Rows and columns result in a grid and form cells which may contain some data (numerical or string value) or formulas.
Openpyxl in nicely documented and I would advise that you take a look here.
The first step is to open your Python environment and install openpyxl within your terminal:
pip install openpyxl
Next, import openpyxl into your project and then to load a workbook into the theFile variable.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
print(theFile.sheetnames)
currentSheet = theFile['customers 1']
print(currentSheet['B4'].value)
As you can see, this code prints all sheets by their names. It then selects the sheet that is named “customers 1” and saves it to a currentSheet variable. In the last line, the code prints the value that is located in the B4 position of the “customers 1” sheet.
This code works as it should but it is very hard coded. To make this more dynamic we will write code that will:
- Read the file
- Get all sheet names
- Loop through all sheets
- In the last step, the code will print values that are located in B4 fields of each found sheet inside the workbook.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for x in allSheetNames:
print("Current sheet name is {}" .format(x))
currentSheet = theFile[x]
print(currentSheet['B4'].value)
This is better than before, but it is still a hard coded solution and it still assumes the value you will be looking for is in the B4 cell, which is just silly :)
I expect your project will need to search inside all sheets in the Excel file for a specific value. To do this we will add one more for loop in the “ABCDEF” range and then simply print cell names and their values.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
# print(currentSheet['B4'].value)
#print max numbers of wors and colums for each sheet
#print(currentSheet.max_row)
#print(currentSheet.max_column)
for row in range(1, currentSheet.max_row + 1):
#print(row)
for column in "ABCDEF": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
We did this by introducing the “for row in range..” loop. The range of the for loop is defined from the cell in row 1 to the sheet’s maximum number or rows. The second for loop searches within predefined column names “ABCDEF”. In the second loop we will display the full position of the cell (column name and row number) and a value.
However, in this article my task is to find a specific column that is named “telephone” and then go through all the rows of that column. To do that we need to modify the code like below.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
This modified code goes through all cells of every sheet, and just like before the row range is dynamic and the column range is specific. The code loops through cells and looks for a cell that holds a text “telephone”. Once the code finds the specific cell it notifies the user in which cell the text is located. The code does this for every cell inside of all sheets that are in the Excel file.
The next step is to go through all rows of that specific column and print values.
import openpyxl
theFile = openpyxl.load_workbook('Customers1.xlsx')
allSheetNames = theFile.sheetnames
print("All sheet names {} " .format(theFile.sheetnames))
def find_specific_cell():
for row in range(1, currentSheet.max_row + 1):
for column in "ABCDEFGHIJKL": # Here you can add or reduce the columns
cell_name = "{}{}".format(column, row)
if currentSheet[cell_name].value == "telephone":
#print("{1} cell is located on {0}" .format(cell_name, currentSheet[cell_name].value))
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
return cell_name
def get_column_letter(specificCellLetter):
letter = specificCellLetter[0:-1]
print(letter)
return letter
def get_all_values_by_cell_letter(letter):
for row in range(1, currentSheet.max_row + 1):
for column in letter:
cell_name = "{}{}".format(column, row)
#print(cell_name)
print("cell position {} has value {}".format(cell_name, currentSheet[cell_name].value))
for sheet in allSheetNames:
print("Current sheet name is {}" .format(sheet))
currentSheet = theFile[sheet]
specificCellLetter = (find_specific_cell())
letter = get_column_letter(specificCellLetter)
get_all_values_by_cell_letter(letter)
This is done by adding a function named _get_columnletter that finds a letter of a column. After the letter of the column is found we loop through all rows of that specific column. This is done with the _get_all_values_by_cellletter function which will print all values of those cells.
Wrapping up
Bra gjort! There are many thing you can do after this. My plan was to build an online app that will standardize all Swedish telephone numbers taken from a text box and offer users the possibility to simply copy the results from the same text box. The second step of my plan was to expand the functionality of the web app to support the upload of Excel files, processing of telephone numbers inside those files (standardizing them to a Swedish format) and offering the processed files back to users.
I have done both of those tasks and you can see them live in the Tools page of my Incodaq.com site:
Also the code from the second part of this article is available on GitHub:
https://github.com/GoranAviani/Manipulate-Excel-spreadsheets
Thank you for reading! Check out more articles like this on my Medium profile: https://medium.com/@goranaviani and other fun stuff I build on my GitHub page: https://github.com/GoranAviani