
Artigo original: How to read a Regression Table
Escrito por: Sharad Vijalapuram
O que é regressão?
Regressão é um dos processos de análise de dados mais importantes e comumente usados. Simplificando, é um método estatístico que explica a força da relação entre uma variável dependente e uma ou mais variáveis independentes.
Uma variável dependente pode ser uma variável ou um campo que você esteja tentando prever ou compreender. Uma variável independente pode ser os campos ou pontos de dados que você acha que podem ter um impacto na variável dependente.
Ao fazer isso, ela responde algumas questões importantes:
- Quais variáveis importam?
- Até que ponto essas variáveis importam?
- Qual o nível de nossa confiança sobre essas variáveis?
Vamos ver um exemplo…
Para explicar melhor os números na tabela de regressão, pensei que seria útil usar um conjuntos de dados como amostra e percorrer os números e sua importância.
Estou usando um pequeno conjunto dados que contém as pontuações no GRE (um teste que os alunos fazem para serem considerados para admissão em universidades nos EUA) de 500 alunos e suas chances de admissão em uma universidade.
Como chance de admissão (em inglês, chance of admittance) depende da pontuação no GRE (em inglês, GRE scores), chance de admissão é a variável dependente e pontuação no GRE é a variável independente.
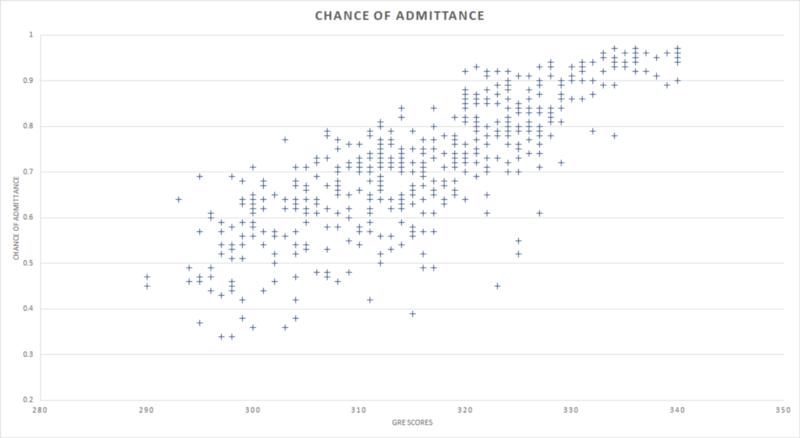
Linha de regressão
Desenhar uma linha reta que melhor descreva a relação entre as pontuações no GRE de alunos e suas chances de admissão nos fornece a linha de regressão linear. Esta é conhecida como linha de tendência em várias ferramentas de Business Intelligence (BI). A ideia básica por trás do desenho dessa linha é minimizar a distância entre os pontos de dados em uma determinada coordenada x e a coordenada y pela qual a linha de regressão passa.
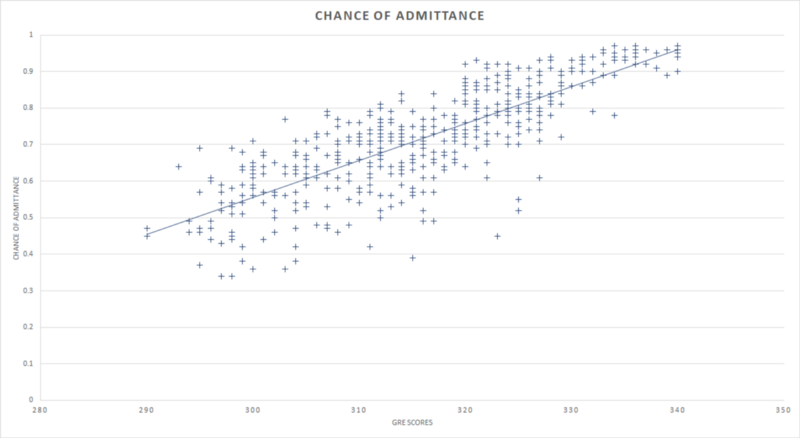
A linha de regressão facilita a representação da relação. Ela se baseia em uma equação matemática que associa o coeficiente x e o ponto de interceptação do eixo y.
y é o ponto no qual a linha intercepta o eixo y quando x = 0. Também é o valor que o modelo assumiria ou preveria quando x fosse 0.
Coeficientes fornecem o impacto ou o peso de uma variável em relação a todo o modelo. Em outras palavras, fornecem a quantidade de mudança necessária na variável dependente para que ocorra uma mudança de unidade na variável independente.
Calculando a equação da linha de regressão
Para descobrir o ponto de interceptação de y do modelo, estendemos a linha de regressão o suficiente para que ela intersecte o eixo y em x = 0. Esse é o nosso ponto de interceptação de y, que está em torno de -2,5. O número pode não fazer sentido para o conjunto de dados em questão, mas a intenção é mostrar apenas o cálculo desse ponto.
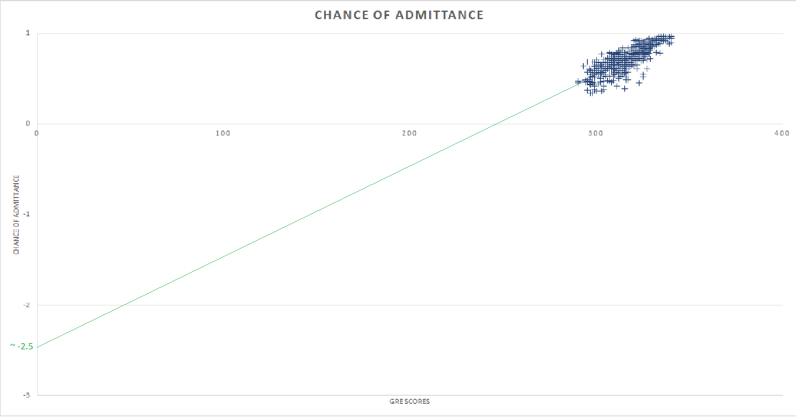
O coeficiente para este modelo será apenas a inclinação da linha de regressão, e pode ser calculado obtendo a mudança na chance de admissão de acordo com a mudança nas pontuações no GRE.
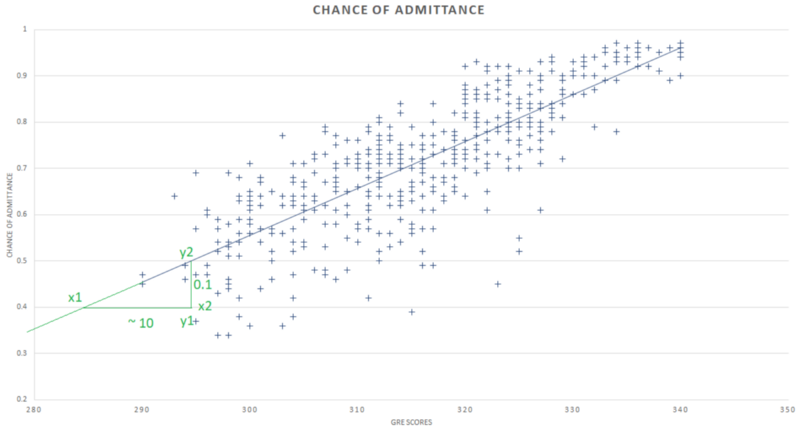
No exemplo acima, o coeficiente seria apenas
m = (y2-y1) / (x2-x1)
Neste caso, seria próximo de 0,01.
A fórmula y = m*x + b nos ajuda a calcular a equação matemática de nossa linha de regressão. Substituindo os valores do ponto de interceptação de y e da inclinação que obtivemos ao estender a linha de regressão, podemos formular a equação abaixo:
y = 0,01x — 2,48
-2,48 é um valor de ponto de interceptação de y mais preciso que obtive da tabela de regressão, conforme mostrado posteriormente neste artigo.
Essa equação nos permite predizer a chance de admissão de um(a) aluno(a) quando sua pontuação no GRE é conhecida.
Agora que temos o básico, vamos partir para a leitura e a interpretação de uma tabela de regressão.
Lendo uma tabela de regressão
A tabela de regressão pode ser dividida em basicamente três componentes:
- análise de variância (ANOVA): fornece a análise da variância no modelo, como o próprio nome sugere.
- estatísticas de regressão: fornecem informações numéricas sobre a variação e sobre a exatidão da explicação do modelo para a variação dos dados/observações fornecidos.
- saída residual: fornece o valor previsto pelo modelo e a diferença entre o valor real observado da variável dependente e seu respectivo valor previsto pelo modelo de regressão para cada ponto dos dados.
Análise de variância (ANOVA)

Graus de liberdade (gl)
Os gl da regressão (em inglês, regression degrees of freedom ou regression df) são o número de variáveis independentes no nosso modelo de regressão. Como consideramos apenas as pontuações no GRE nesse exemplo, seu valor é 1.
O gl residual (em inglês, residual degrees of freedom ou residual df) é o número total de observações (linhas) do conjunto de dados subtraído pelo número de variáveis que estão sendo estimadas. Neste exemplo, tanto o coeficiente de pontuação GRE quanto a constante são estimados.
gl residual = 500 — 2 = 498
gl total — é a soma da regressão e dos graus de liberdade residuais, que equivale ao tamanho do conjunto de dados menos 1.
Soma dos quadrados (SQ)
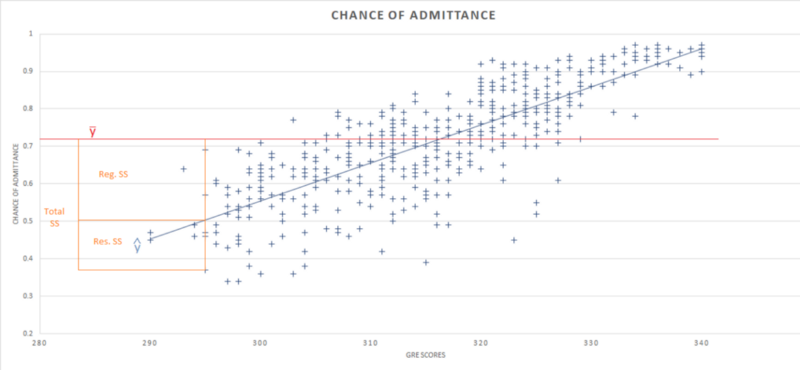
SQ da regressão (em inglês, regression sum of squares ou regression SS) é a variação total da variável dependente que é explicada pelo modelo de regressão. É a soma do quadrado da diferença entre o valor previsto e a média do valor de todos os pontos de dados.
∑ (ŷ — ӯ)²
Na tabela ANOVA, a SQ da regressão é 6,5 e a SQ total é 9,9, o que significa que o modelo de regressão explica cerca de 6,5/9,9 (aproximadamente 65%) de toda a variabilidade no conjunto de dados.
SQ residual (em inglês, residual sum of squares ou residual SS) é a variação total na variável dependente que não é explicada pelo modelo de regressão. Ela também é chamada de soma dos quadrados do erro, sendo a soma do quadrado da diferença entre valores reais e previstos de todos os pontos de dados.
∑ (y — ŷ)²
Na tabela ANOVA, a SQ residual é de cerca de 3,4. Em geral, quanto menor o erro, melhor o modelo de regressão explica a variação no conjunto de dados e, portanto, geralmente queremos minimizar esse erro.
A SQ Total é a soma de ambas, SQ da regressão e residual, ou por quanto a chance de admissão variaria se as pontuações no GRE NÃO fossem levadas em consideração.
Erros quadráticos médios (EQM) — são a média da soma dos quadrados ou a soma dos quadrados dividida pelos graus de liberdade de ambos os casos, regressão e resíduos.
EQM da regressão = ∑ (ŷ — ӯ)²/Reg. gl
EQM residual = ∑ (y — ŷ)²/Res. gl
F — é usado para testar a hipótese de que a inclinação da variável independente é zero. Matematicamente também pode ser calculado como
F = EQM da regressão/EQM residual
Caso contrário, é calculada comparando a estatística F com uma distribuição F com gl de regressão em graus no numerador e gl residual em graus no denominador.
Significância F — nada mais é do que o valor-p para a hipótese nula de que o coeficiente da variável independente é zero e, como acontece com qualquer valor-p, um baixo valor-p indica que existe uma relação significativa entre as variáveis dependentes e independentes.

Erro padrão — fornece o desvio padrão estimado da distribuição dos coeficientes. É a quantidade pela qual o coeficiente varia em diferentes casos. Um coeficiente muito maior que seu erro padrão implica uma probabilidade de que o coeficiente não seja 0.
t-Stat é a estatística t ou o valor t do teste, e seu valor é igual ao coeficiente dividido pelo erro padrão.
t-Stat = coeficientes/erro padrão
Novamente, quanto maior o coeficiente em relação ao erro padrão, maior é o t-Stat e maior a probabilidade de que o coeficiente esteja longe de 0.
valor-p — A estatística t é comparada com a distribuição t para determinar o valor-p. Geralmente, consideramos apenas o valor-p da variável independente, que fornece a probabilidade de obter uma amostra tão próxima daquela usada para derivar a equação de regressão, para verificar se a inclinação da linha de regressão é realmente zero ou se o coeficiente é próximo do coeficiente obtido.
Um valor-p abaixo de 0,05 indica 95% de confiança de que a inclinação da linha de regressão não é zero e, portanto, existe uma relação linear significativa entre as variáveis dependentes e independentes.
Um valor-p maior do que 0,05 indica que a inclinação da linha de regressão pode ser zero e que não há evidência suficiente, ao nível de confiança de 95%, da existência de uma relação linear significativa entre as variáveis dependentes e independentes.
Uma vez que o valor-p da variável independente pontuação no GRE está muito próximo de 0, podemos estar extremamente confiantes da existência de uma relação linear significativa entre as pontuações no GRE e a chance de admissão.
95% inferiores e superiores — Como usamos principalmente uma amostra de dados para estimar a linha de regressão e seus coeficientes, eles são geralmente uma aproximação dos verdadeiros coeficientes e, por conseguinte, da verdadeira linha de regressão. Os limites inferior e superior de 95% fornecem o 95º intervalo de confiança dos limites inferior e superior para cada coeficiente.
Como o intervalo de confiança de 95% para as pontuações no GRE é 0,009 e 0,01, os limites não contêm zero e, portanto, podemos ter 95% de confiança de que existe uma relação linear significativa entre as pontuações GRE e a chance de admissão.
Observe que um nível de confiança de 95% é amplamente utilizado, mas um nível diferente de 95% é possível e pode ser configurado durante a análise de regressão.
Estatísticas de regressão

R² (R quadrado) — representa o poder de um modelo. Ele mostra a quantidade de variação na variável dependente que é explicada pela variável independente, e sempre fica entre os valores 0 e 1. À medida que o R² aumenta, mais a variação nos dados é explicada pelo modelo e melhor o modelo obtém a previsão. Um R² baixo indicaria que o modelo não se ajusta bem aos dados, e que uma variável independente não explica bem a variação na variável dependente.
R² = soma dos quadrados da regressão/soma total dos quadrados
No entanto, o R quadrado não pode determinar se as estimativas e previsões do coeficiente são tendenciosas. É por isso que você deve analisar os gráficos de resíduos, que são discutidos posteriormente neste artigo.
O R quadrado também não indica se um modelo de regressão é adequado. Você pode ter um valor R quadrado baixo para um bom modelo, ou um valor R quadrado alto para um modelo que não se ajusta aos dados.
O R², neste caso, é 65%, o que implica que as pontuações no GRE podem explicar 65% da variação na chance de admissão.
R² ajustado — é o R² multiplicado por um fator de ajuste. Isso é usando ao comparar diferentes modelos de regressão com diferentes variáveis independentes. Esse número é útil ao decidir sobre as variáveis independentes corretas em modelos de regressão múltipla.
R múltiplo — é a raiz quadrada positiva de R²
Erro padrão — é diferente do erro padrão dos coeficientes. Este é o desvio padrão estimado do erro da equação de regressão, e é uma boa medida da acurácia da linha de regressão. É a raiz quadrada dos erros quadráticos médios residuais.
Erro padrão = √(Res.MS)
Saída residual
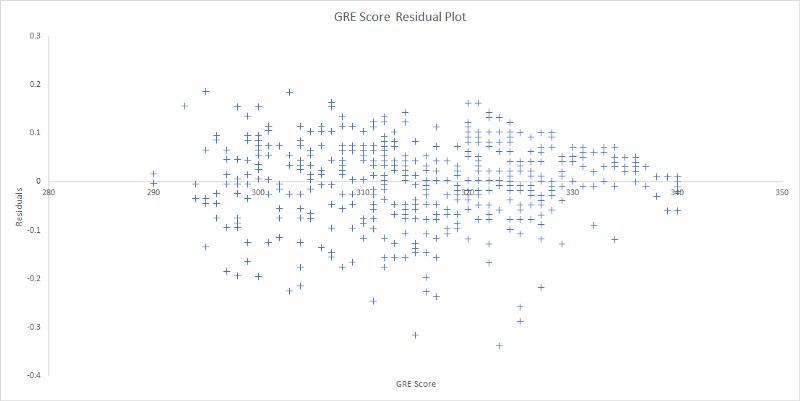
Resíduos são a diferença entre o valor real e o valor previsto do modelo de regressão. A saída residual é o valor da variável dependente previsto pelo modelo de regressão e o resíduo para cada ponto de dados.
Como o nome sugere, um gráfico residual é um gráfico de dispersão entre o resíduo e a variável independente, que, neste caso, é a pontuação GRE de cada aluno.
Um gráfico residual é importante para detectar coisas como heterocedasticidade, não linearidade e valores atípicos (em inglês, outliers). O processo para detectá-los não está sendo discutido neste artigo, mas o fato de que o gráfico de resíduos para o nosso exemplo possui dados aleatoriamente dispersos nos ajuda a estabelecer o fato de que a relação entre as variáveis neste modelo é linear.
Intenção
A intenção deste artigo não é construir um modelo de regressão funcional, mas fornecer um passo a passo de todas as variáveis de regressão e sua importância quando necessário, com a amostra de um conjunto de dados em uma tabela de regressão.
Embora este artigo forneça uma explicação com uma regressão linear com apenas uma variável como exemplo, esteja ciente de que algumas dessas variáveis podem ter mais importância nos casos de multivariáveis ou outras situações.