

Artigo original: The Ultimate Guide to Web Scraping with Node.js
Afinal, o que é web scraping? Embora a tradução livre seja algo como "raspagem da rede", ele é bem mais conhecido como sendo a extração de dados da web. É a automatização da tarefa de coletar informações a partir de sites que, se for feita manualmente, é algo bem cansativo.
Podemos utilizar o web scraping de muitas formas: você pode querer pegar os preços de vários sites de compras e fazer um site de comparação de preços. Ou talvez precise dos horários de voos e uma lista de hotéis/AirBNB para colocar num site de viagens. Talvez você queira extrair e-mails de vários diretórios para vendê-los como leads ou usar os dados da internet para treinar modelos de IA/aprendizado de máquina. Você pode até querer construir seu próprio mecanismo de busca, como o Google!
Começar na área de web scraping é fácil e esse processo pode ser dividido em duas partes principais, que são:
- adquirir os dados usando uma biblioteca de requisição de HTML ou um navegador sem a interface gráfica e
- analisar os dados para obter as informações exatas que você deseja.
Este guia conduzirá você nesse processo com as bibliotecas mais populares do Node.js, Request-promise, CheerioJS e Puppeteer. Trabalhando com os exemplos deste guia, você aprenderá todas as dicas e truques necessários para se tornar profissional na extração de dados com o Node.js!
Nota do tradutor: a biblioteca Request-promise encontra-se depreciada (não recebeu melhorias/correção de bugs desde 2020) e pode apresentar problemas. Ela, porém, continua no artigo para aprendermos a lógica de como fazermos o web scraping. A segunda parte do artigo, que utiliza apenas as bibliotecas CheerioJS e Puppeteer, funciona normalmente, sendo o método mais recomendado.
Faremos uma lista de todos os nomes dos presidentes dos EUA, seus respectivos aniversários a partir da Wikipédia e todos os títulos das postagens na primeira página do Reddit.
Para isso, vamos primeiro instalar as bibliotecas que usaremos neste guia (o Puppeteer leva um tempo maior para instalar, pois precisa baixar também o Chromium com ele).
Fazendo sua primeira requisição
npm install --save request request-promise cheerio puppeteerEm seguida, vamos criar um arquivo com o nome de potusScraper.js, e escrever uma função rápida para obter o HTML da página da "Lista dos presidentes dos EUA", diretamente da Wikipédia em inglês.
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
});Resultado:
<!DOCTYPE html>
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>List of Presidents of the United States - Wikipedia</title>
...Nota do tradutor: o nome do arquivo, potusScraper.js, tem a ver com o fato de que PotUS, em inglês, é a abreviação para "Presidents of the United States". A segunda parte, "scraper", tem a ver com o mecanismo que realiza o "scraping".
Usando o Chrome DevTools
Certo, temos o HTML bruto da página! Agora, precisamos entender esse bloco gigante de texto. Para fazer isso, precisaremos usar o Chrome DevTools, que nos permite pesquisar facilmente dentro do HTML da página.
Usar o Chrome DevTools é bem fácil: é só abrir o Google Chrome e clicar com o botão direito do mouse no elemento que você deseja extrair (neste caso, estou clicando com o botão direito do mouse em George Washington, pois queremos obter os links das páginas da Wikipédia de cada presidente):
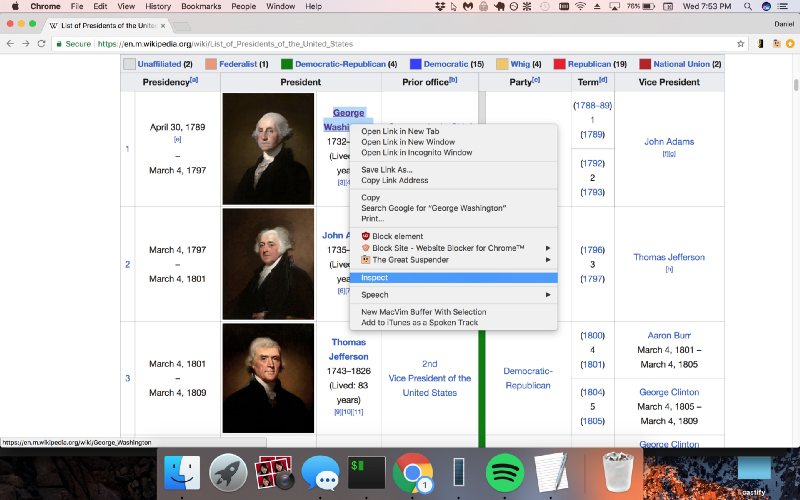
Agora, clicamos em Inspect, ou Inspecionar, e o Chrome exibirá o painel DevTools, permitindo que você inspecione facilmente a estrutura do HTML da página.
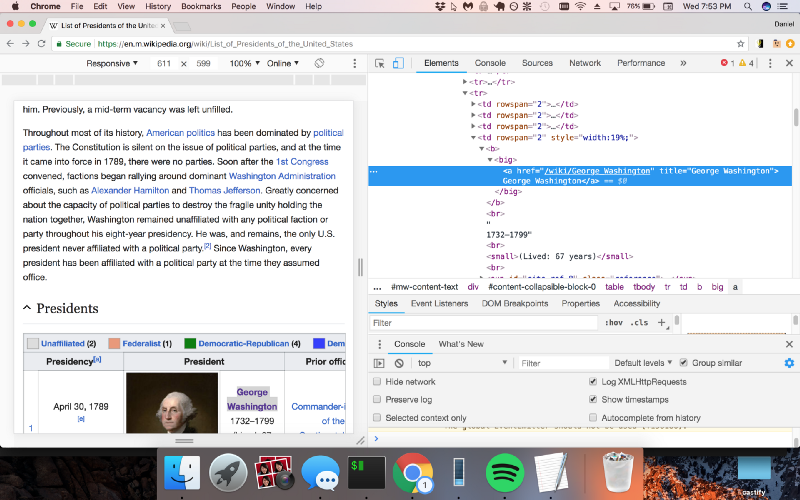
Analisando o HTML com Cheerio.js
Agora, o Chrome DevTools nos mostra o padrão exato que devemos procurar no código (uma tag "big" com um hiperlink dentro dela). Vamos usar o Cheerio.js para analisar o HTML que recebemos anteriormente para retornar uma lista com os links de cada página dos presidentes americanos.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log($('big > a', html).length);
console.log($('big > a', html));
})
.catch(function(err){
//handle error
});Resultado:
45
{ '0':
{ type: 'tag',
name: 'a',
attribs: { href: '/wiki/George_Washington', title: 'George Washington' },
children: [ [Object] ],
next: null,
prev: null,
parent:
{ type: 'tag',
name: 'big',
attribs: {},
children: [Array],
next: null,
prev: null,
parent: [Object] } },
'1':
{ type: 'tag'
...Verificamos se há exatamente 45 elementos retornados (o número de presidentes americanos), o que significa que não há tags "big" extras ocultas em outros lugares da página. Agora, podemos acessar e obter a lista de links para todas as 45 páginas presidenciais da Wikipédia, a partir da propriedade "attribs" de cada elemento, desta forma:
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('big > a', html)[i].attribs.href);
}
console.log(wikiUrls);
})
.catch(function(err){
//handle error
});Resultado:
[
'/wiki/George_Washington',
'/wiki/John_Adams',
'/wiki/Thomas_Jefferson',
'/wiki/James_Madison',
'/wiki/James_Monroe',
'/wiki/John_Quincy_Adams',
'/wiki/Andrew_Jackson',
...
]Agora que temos a lista de todas as 45 páginas presidenciais da Wikipédia, vamos criar um outro arquivo (chamado potusParse.js), que vai ter a função de pegar uma página presidencial da Wikipédia e retornar o nome e o aniversário do presidente. Como exemplo, vamos pegar o HTML bruto da página da Wikipédia de George Washington.
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/George_Washington';
rp(url)
.then(function(html) {
console.log(html);
})
.catch(function(err) {
//handle error
});Resultado:
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>George Washington - Wikipedia</title>
...Usaremos, mais uma vez, o Chrome DevTools para encontrar a sintaxe do código que queremos analisar, para que possamos extrair o nome e o aniversário com o Cheerio.js.
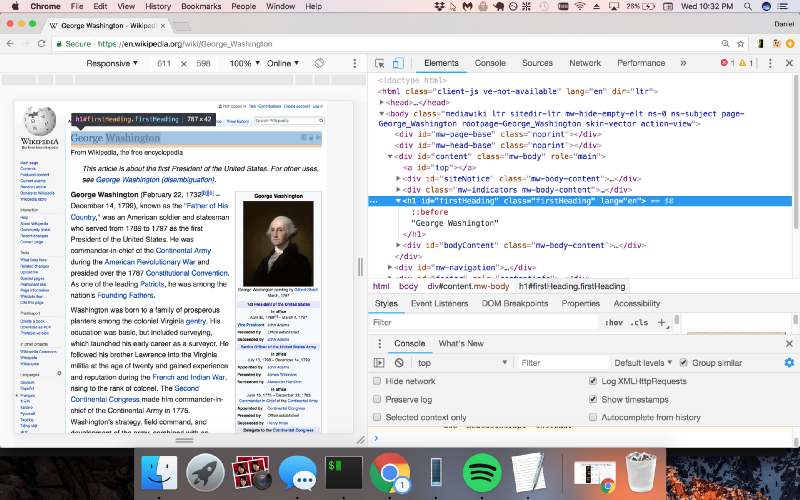
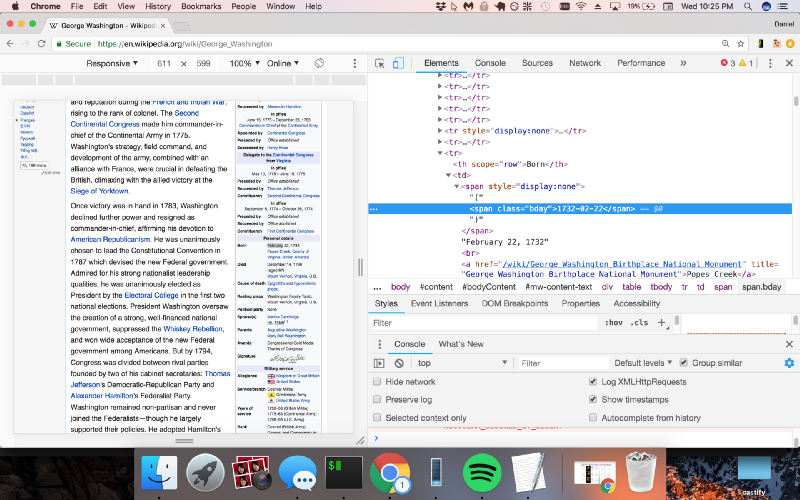
Então, vemos que o nome está em uma classe chamada "firstHeading" e o aniversário está em uma classe chamada "bday". Vamos modificar nosso código para usar o Cheerio.js para extrair essas duas classes.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/George_Washington';
rp(url)
.then(function(html) {
console.log($('.firstHeading', html).text());
console.log($('.bday', html).text());
})
.catch(function(err) {
//handle error
});Resultado:
George Washington
1732-02-22Juntando tudo
Perfeito! Agora, vamos transformar esse código em uma função e exportá-la do módulo, assim:
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = function(url) {
return rp(url)
.then(function(html) {
return {
name: $('.firstHeading', html).text(),
birthday: $('.bday', html).text(),
};
})
.catch(function(err) {
//handle error
});
};
module.exports = potusParse;No nosso arquivo original, potusScraper.js, vamos importar o módulo potusParse.js e aplicá-lo à lista de wikiUrls que reunimos anteriormente.
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = require('./potusParse');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html) {
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('big > a', html)[i].attribs.href);
}
return Promise.all(
wikiUrls.map(function(url) {
return potusParse('https://en.wikipedia.org' + url);
})
);
})
.then(function(presidents) {
console.log(presidents);
})
.catch(function(err) {
//handle error
console.log(err);
});Resultado:
[
{ name: 'George Washington', birthday: '1732-02-22' },
{ name: 'John Adams', birthday: '1735-10-30' },
{ name: 'Thomas Jefferson', birthday: '1743-04-13' },
{ name: 'James Madison', birthday: '1751-03-16' },
{ name: 'James Monroe', birthday: '1758-04-28' },
{ name: 'John Quincy Adams', birthday: '1767-07-11' },
{ name: 'Andrew Jackson', birthday: '1767-03-15' },
{ name: 'Martin Van Buren', birthday: '1782-12-05' },
{ name: 'William Henry Harrison', birthday: '1773-02-09' },
{ name: 'John Tyler', birthday: '1790-03-29' },
{ name: 'James K. Polk', birthday: '1795-11-02' },
{ name: 'Zachary Taylor', birthday: '1784-11-24' },
{ name: 'Millard Fillmore', birthday: '1800-01-07' },
{ name: 'Franklin Pierce', birthday: '1804-11-23' },
{ name: 'James Buchanan', birthday: '1791-04-23' },
{ name: 'Abraham Lincoln', birthday: '1809-02-12' },
{ name: 'Andrew Johnson', birthday: '1808-12-29' },
{ name: 'Ulysses S. Grant', birthday: '1822-04-27' },
{ name: 'Rutherford B. Hayes', birthday: '1822-10-04' },
{ name: 'James A. Garfield', birthday: '1831-11-19' },
{ name: 'Chester A. Arthur', birthday: '1829-10-05' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'Benjamin Harrison', birthday: '1833-08-20' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'William McKinley', birthday: '1843-01-29' },
{ name: 'Theodore Roosevelt', birthday: '1858-10-27' },
{ name: 'William Howard Taft', birthday: '1857-09-15' },
{ name: 'Woodrow Wilson', birthday: '1856-12-28' },
{ name: 'Warren G. Harding', birthday: '1865-11-02' },
{ name: 'Calvin Coolidge', birthday: '1872-07-04' },
{ name: 'Herbert Hoover', birthday: '1874-08-10' },
{ name: 'Franklin D. Roosevelt', birthday: '1882-01-30' },
{ name: 'Harry S. Truman', birthday: '1884-05-08' },
{ name: 'Dwight D. Eisenhower', birthday: '1890-10-14' },
{ name: 'John F. Kennedy', birthday: '1917-05-29' },
{ name: 'Lyndon B. Johnson', birthday: '1908-08-27' },
{ name: 'Richard Nixon', birthday: '1913-01-09' },
{ name: 'Gerald Ford', birthday: '1913-07-14' },
{ name: 'Jimmy Carter', birthday: '1924-10-01' },
{ name: 'Ronald Reagan', birthday: '1911-02-06' },
{ name: 'George H. W. Bush', birthday: '1924-06-12' },
{ name: 'Bill Clinton', birthday: '1946-08-19' },
{ name: 'George W. Bush', birthday: '1946-07-06' },
{ name: 'Barack Obama', birthday: '1961-08-04' },
{ name: 'Donald Trump', birthday: '1946-06-14' }
]Renderizando páginas em JavaScript
Aí está! Uma lista dos nomes e aniversários de todos os 45 presidentes americanos. Usar apenas o módulo request-promise e o Cheerio.js já permitirá a você extrair informações da grande maioria dos sites na internet.
Recentemente, no entanto, muitos sites começaram a usar o JavaScript para gerar conteúdo dinâmico em seus sites. Isso causa um problema para o request-promise e outras bibliotecas de requisição de HTTP semelhantes (como o axios e o fetch), pois elas só obtêm a resposta da requisição inicial, não podendo executar o JavaScript da mesma forma que um navegador da web.
Assim, para extrair dados de sites que exigem a execução do JavaScript, precisamos de outra solução. Em nosso próximo exemplo, obteremos os títulos de todas as postagens na primeira página do Reddit. Vamos ver o que acontece quando tentamos usar request-promise como fizemos no exemplo anterior.
Resultado:
const rp = require('request-promise');
const url = 'https://www.reddit.com';
rp(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
});
}Este é o resultado:
<!DOCTYPE html><html
lang="en"><head><title>reddit: the front page of the
internet</title>
...
Hmmm... não é bem o que queremos. Isso porque, para pegar o conteúdo real, é preciso que você execute o JavaScript na página! Com o Puppeteer, isso não é problema.
O Puppeteer é um novo módulo extremamente popular feito pela equipe do Google Chrome que permite controlar um navegador sem a parte gráfica (geralmente é chamado de navegador sem cabeça). Ele é perfeito para extrair os dados de modo programático de páginas que precisam executar o JavaScript. Então, vamos pegar o HTML da primeira página do Reddit usando o Puppeteer em vez do request-promise.
const puppeteer = require('puppeteer');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
console.log(html);
})
.catch(function(err) {
//handle error
});Resultado:
<!DOCTYPE html><html lang="en"><head><link
href="//c.amazon-adsystem.com/aax2/apstag.js" rel="preload"
as="script">
...Agora, sim, a página está com o conteúdo correto!
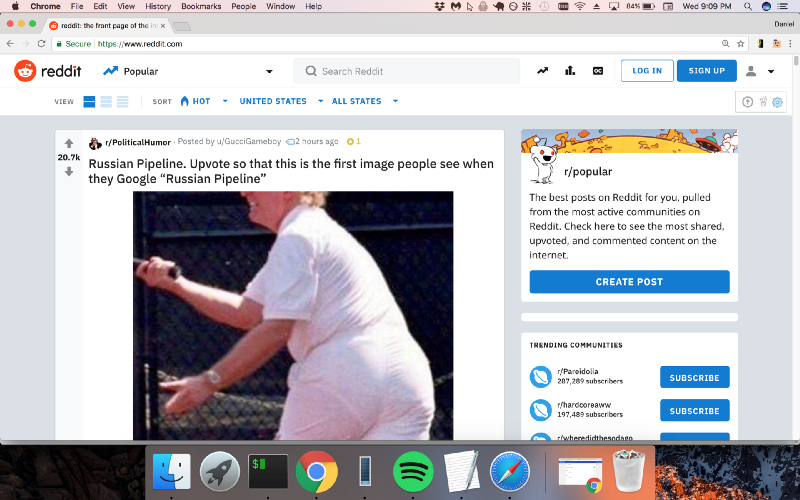
Usaremos o Chrome DevTools como fizemos no exemplo anterior.
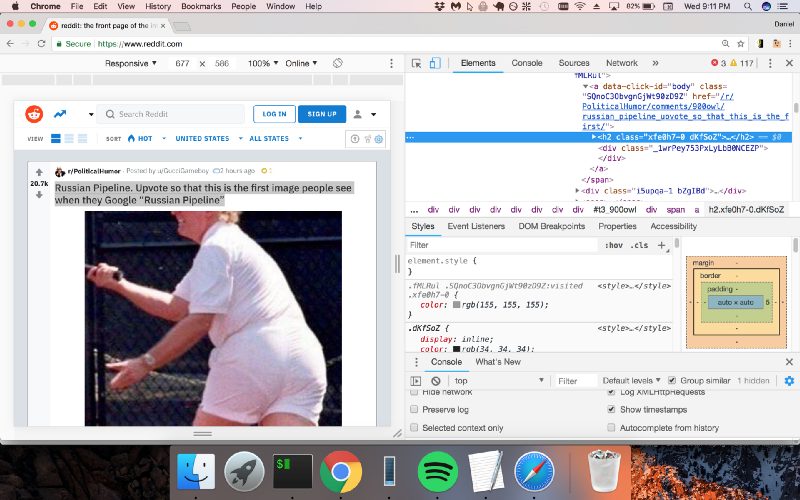
Parece que o Reddit está colocando os títulos dentro das tags "h2". Usaremos o Cheerio.js para extrair as tags h2 da página.
const puppeteer = require('puppeteer');
const $ = require('cheerio');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
$('h2', html).each(function() {
console.log($(this).text());
});
})
.catch(function(err) {
//handle error
});E esse é o resultado final:
Russian Pipeline. Upvote so that this is the first image people see when they Google “Russian Pipeline”
John F. Kennedy Jr. Sitting in the pilot seat of the Marine One circa 1963
I didn't take it as a compliment.
How beautiful is this
Hustle like Faye
The power of a salt water crocodile's tail.
I'm 36, and will be dead inside of a year.
F***ing genius.
TIL Anthony Daniels, who endured years of discomfort in the C-3PO costume, was so annoyed by Alan Tudyk (Rogue One) playing K-2SO in the comfort of a motion-capture suit that he cursed at Tudyk. Tudyk later joked that a "fuck you" from Daniels was among the highest compliments he had ever received.
Reminder about the fact UC Davis paid over $100k to remove this photo from the internet.
King of the Hill reruns will start airing on Comedy Central July 24th
[Image] Slow and steady
White House: Trump open to Russia questioning US citizens
Godzilla: King of the Monsters Teaser Banner
He tried
Soldier reunited with his dog after being away.
Hiring a hitman on yourself and preparing for battle is the ultimate extreme sport.
Two paintballs colliding midair
My thoughts & prayers are with those ears
When even your fantasy starts dropping hints
Elon Musk's apology is out
"When you're going private so you plant trees to throw some last shade at TDNW before you vanish." Thanos' farm advances. The soul children will have full bellies. 1024 points will give him the resources to double, and irrigate, his farm. (See comment)
Some leaders prefer chess, others prefer hungry hippos. Travis Chapman, oil, 2018
The S.S. Ste. Claire, retired from ferrying amusement park goers, now ferries The Damned across the river Styx.
A soldier is reunited with his dog
*hits blunt*
Today I Learned
Black Panther Scene Representing the Pan-African Flag
The precision of this hydraulic press.
Let bring the game to another level
When you're fighting a Dark Souls boss and you gamble to get 'just one extra hit' in instead of rolling out of range.
"I check for traps"
Anon finds his home at last
He’s hungry
Being a single mother is a thankless job.
TIL That when you're pulling out Minigun, you're actually pulling out suitcase that then transforms into Minigun.
OMG guys don’t look!!! 🙈🙈🙈
hyubsama's emote of his own face denied for political reasons because twitch thinks its a picture of Kim Jong UnRecursos adicionais
Abaixo deixei uma lista com recursos adicionais! A partir desse ponto, você deve estar confortável o bastante para escrever seu primeiro web scraper e conseguir extrair os dados de qualquer site. Esses são alguns recursos adicionais (em inglês) que você pode achar úteis durante a sua jornada de extração de dados na web: