
By Daniel Ni
So what’s web scraping anyway? It involves automating away the laborious task of collecting information from websites.
There are a lot of use cases for web scraping: you might want to collect prices from various e-commerce sites for a price comparison site. Or perhaps you need flight times and hotel/AirBNB listings for a travel site. Maybe you want to collect emails from various directories for sales leads, or use data from the internet to train machine learning/AI models. Or you could even be wanting to build a search engine like Google!
Getting started with web scraping is easy, and the process can be broken down into two main parts:
- acquiring the data using an HTML request library or a headless browser,
- and parsing the data to get the exact information you want.
This guide will walk you through the process with the popular Node.js request-promise module, CheerioJS, and Puppeteer. Working through the examples in this guide, you will learn all the tips and tricks you need to become a pro at gathering any data you need with Node.js!
We will be gathering a list of all the names and birthdays of U.S. presidents from Wikipedia and the titles of all the posts on the front page of Reddit.
First things first: Let’s install the libraries we’ll be using in this guide (Puppeteer will take a while to install as it needs to download Chromium as well).
Making your first request
Next, let’s open a new text file (name the file potusScraper.js), and write a quick function to get the HTML of the Wikipedia “List of Presidents” page.
Output:
Using Chrome DevTools
Cool, we got the raw HTML from the web page! But now we need to make sense of this giant blob of text. To do that, we’ll need to use Chrome DevTools to allow us to easily search through the HTML of a web page.
Using Chrome DevTools is easy: simply open Google Chrome, and right click on the element you would like to scrape (in this case I am right clicking on George Washington, because we want to get links to all of the individual presidents’ Wikipedia pages):
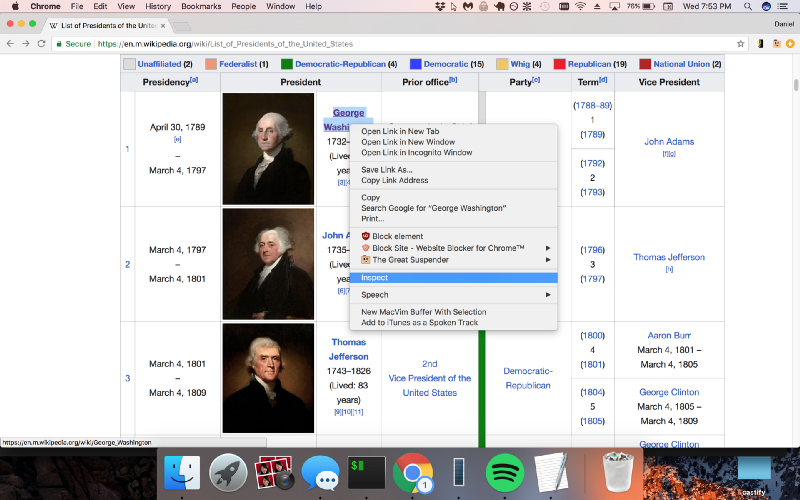
Now, simply click inspect, and Chrome will bring up its DevTools pane, allowing you to easily inspect the page’s source HTML.
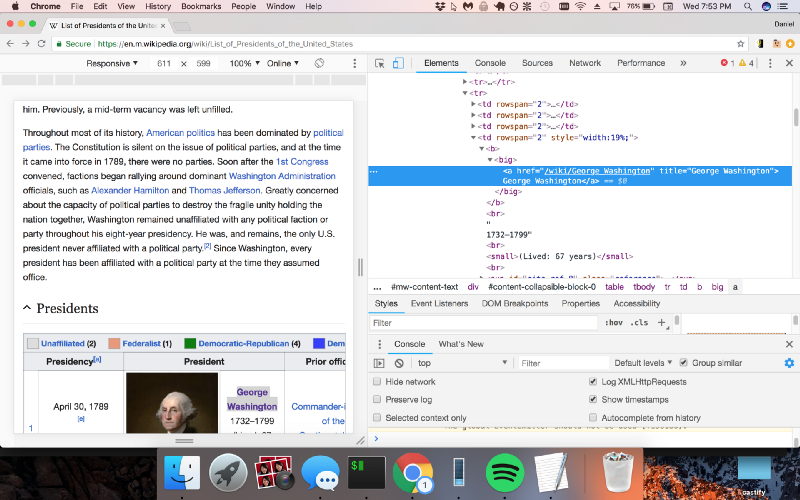
Parsing HTML with Cheerio.js
Awesome, Chrome DevTools is now showing us the exact pattern we should be looking for in the code (a “big” tag with a hyperlink inside of it). Let’s use Cheerio.js to parse the HTML we received earlier to return a list of links to the individual Wikipedia pages of U.S. presidents.
Output:
We check to make sure there are exactly 45 elements returned (the number of U.S. presidents), meaning there aren’t any extra hidden “big” tags elsewhere on the page. Now, we can go through and grab a list of links to all 45 presidential Wikipedia pages by getting them from the “attribs” section of each element.
Output:
Now we have a list of all 45 presidential Wikipedia pages. Let’s create a new file (named potusParse.js), which will contain a function to take a presidential Wikipedia page and return the president’s name and birthday. First things first, let’s get the raw HTML from George Washington’s Wikipedia page.
Output:
Let’s once again use Chrome DevTools to find the syntax of the code we want to parse, so that we can extract the name and birthday with Cheerio.js.
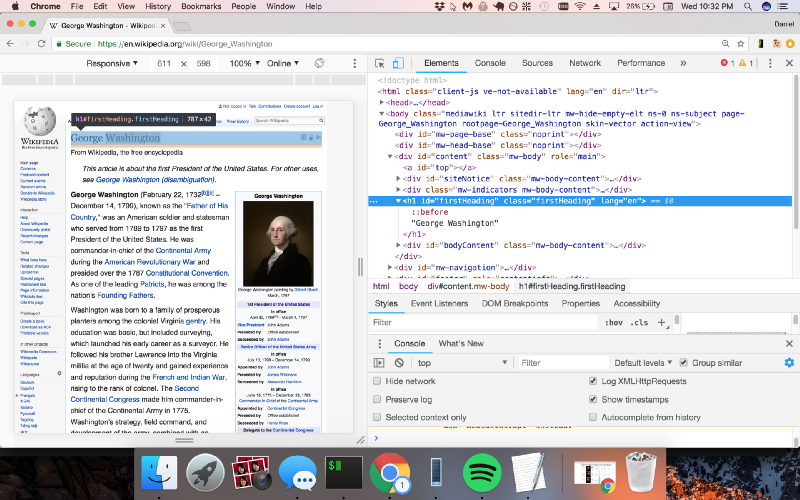
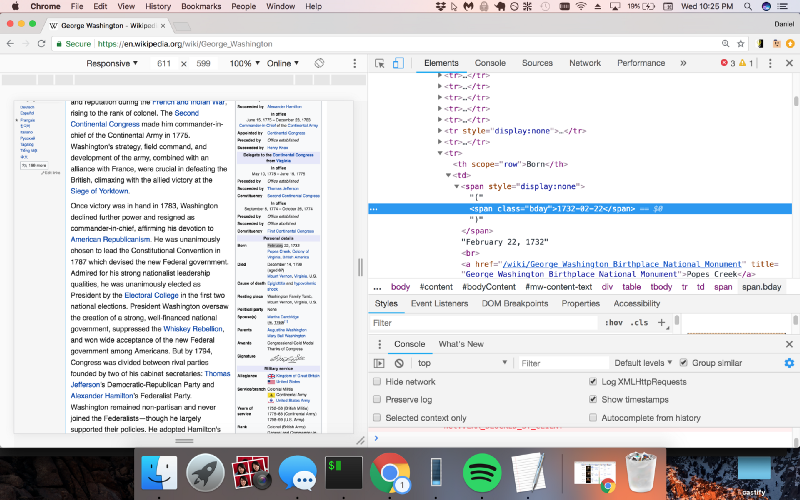
So we see that the name is in a class called “firstHeading” and the birthday is in a class called “bday”. Let’s modify our code to use Cheerio.js to extract these two classes.
Output:
Putting it all together
Perfect! Now let’s wrap this up into a function and export it from this module.
Now let’s return to our original file potusScraper.js and require the potusParse.js module. We’ll then apply it to the list of wikiUrls we gathered earlier.
Output:
Rendering JavaScript Pages
Voilà! A list of the names and birthdays of all 45 U.S. presidents. Using just the request-promise module and Cheerio.js should allow you to scrape the vast majority of sites on the internet.
Recently, however, many sites have begun using JavaScript to generate dynamic content on their websites. This causes a problem for request-promise and other similar HTTP request libraries (such as axios and fetch), because they only get the response from the initial request, but they cannot execute the JavaScript the way a web browser can.
Thus, to scrape sites that require JavaScript execution, we need another solution. In our next example, we will get the titles for all of the posts on the front page of Reddit. Let’s see what happens when we try to use request-promise as we did in the previous example.
Output:
Here’s what the output looks like:
Hmmm…not quite what we want. That’s because getting the actual content requires you to run the JavaScript on the page! With Puppeteer, that’s no problem.
Puppeteer is an extremely popular new module brought to you by the Google Chrome team that allows you to control a headless browser. This is perfect for programmatically scraping pages that require JavaScript execution. Let’s get the HTML from the front page of Reddit using Puppeteer instead of request-promise.
Output:
Nice! The page is filled with the correct content!
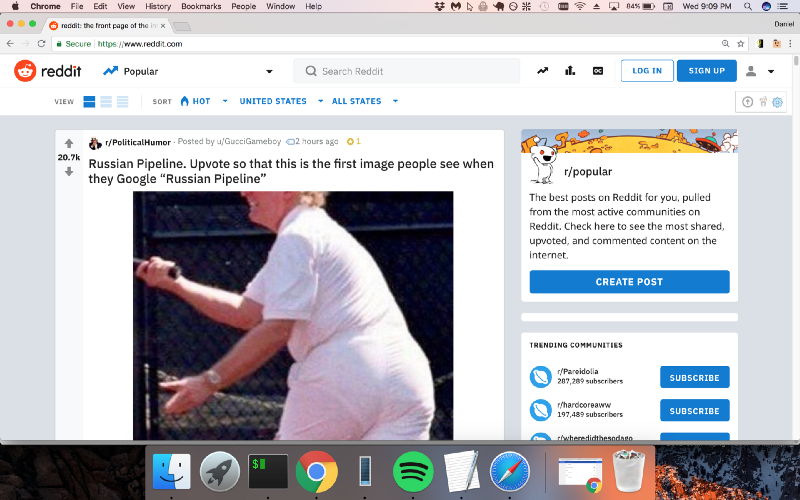
Now we can use Chrome DevTools like we did in the previous example.
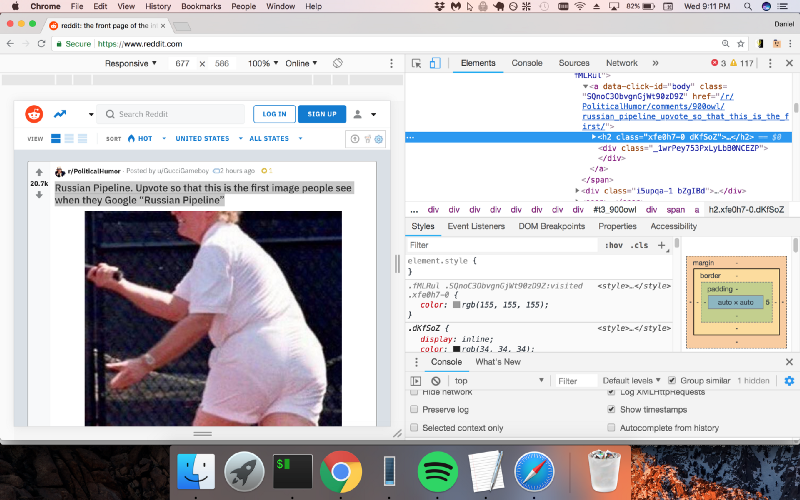
It looks like Reddit is putting the titles inside “h2” tags. Let’s use Cheerio.js to extract the h2 tags from the page.
Output:
Additional Resources
And there’s the list! At this point you should feel comfortable writing your first web scraper to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey: