


Artigo original: System Design Interview Question Handbook – Concepts You Should Know
Traduzido em português europeu
Você já deve ter ouvido os termos "Arquitetura" ou "Design de Sistemas".
Eles são mencionados frequentemente durante entrevistas de emprego para desenvolvedores — especialmente em grandes empresas de tecnologia.
Escrevi este guia detalhado enquanto me preparava para as minhas entrevistas de engenharia de software nas FAANG (grandes empresas de tecnologia — Facebook, Amazon, Apple, Netflix e Google). Ele abrange os conceitos essenciais de design de sistemas de software que são necessários entender para lidar com sistemas distribuídos, e me ajudou a entrar na Google como engenheiro, depois de mais de 15 anos como advogado corporativo.
Este não é um guia que abrange absolutamente tudo, pois Design de Sistemas é um tópico vasto. Porém, se você é um desenvolvedor júnior ou de nível intermediário, este guia servirá como uma base sólida.
A partir dele, você poderá aprofundar o tema com outros recursos. No final deste artigo, deixei uma lista com alguns dos meus favoritos.
Dividi este guia em pequenos tópicos, motivo pelo qual recomendo que você o marque como favorito. Descobri que a aprendizagem espaçada e a repetição são ferramentas incrivelmente valiosas para aprender e reter informações. Projetei este guia para ser dividido em partes que sejam fáceis de rever com repetição espaçada.
- Secção 1: redes e protocolos (IP, DNS, HTTP, TCP etc.)
- Secção 2: armazenamento, latência e taxas de transferência
- Secção 3: disponibilidade
- Secção 4: caching
- Secção 5: proxies
- Secção 6: balanceamento de carga
- Secção 7: hashing consistente
- Secção 8: bancos de dados
- Secção 9: eleição de líder
- Secção 10: polling, streaming, sockets
- Secção 11: proteção de endpoints
- Secção 12: mensagens e publicação-inscrição
- Secção 13: conceitos essenciais menores
Vamos começar!
Secção 1: redes e protocolos
"Protocolo" é uma palavra sofisticada, que tem um significado em inglês totalmente independente da ciência da computação. Significa um sistema de regras e regulamentos que governam algo. Uma espécie de "procedimento oficial" ou "maneira oficial como algo deve ser feito".
Para que as pessoas se conectem às máquinas e ao código que usam para se comunicarem umas com as outras, é necessária uma rede através da qual essa comunicação possa ocorrer. Essa comunicação, porém, também precisa de algumas regras, estrutura e procedimentos acordados previamente.
Assim, os protocolos de rede são protocolos que governam a maneira como máquinas e software se comunicam em uma determinada rede. Um exemplo de rede é a nossa querida World Wide Web.
Você já deve ter ouvido falar dos protocolos de rede mais comuns da era da internet — tais como HTTP, TCP/IP, entre outros. Vamos dividi-los em conceitos básicos.
IP - Protocolo da Internet
Pense nele como a camada base fundamental dos protocolos. É o protocolo básico que nos instrui sobre como quase toda a comunicação através de redes de internet deve ser implementada.
Usando o IP, as mensagens são frequentemente enviadas em "pacotes", que são pequenos grupos de informação (2^16 bytes). Cada pacote possui uma estrutura essencial, composta por dois componentes: o cabeçalho (em inglês, header) e os dados.
O cabeçalho contém metadados sobre o pacote e seus dados. Esses metadados incluem informações como o endereço IP da origem (de onde o pacote vem) e o endereço IP de destino (para onde o pacote vai). Claramente, isso é fundamental para poder enviar informações de um ponto a outro — você precisa dos endereços de origem e de destino.
Um endereço IP é um rótulo numérico atribuído a cada dispositivo conectado a uma rede de computadores que utiliza o Protocolo da Internet para comunicação. Existem endereços IP públicos e privados. Atualmente, existem duas versões. A nova versão é chamada de IPv6. Ela está sendo cada vez mais adotada, pois o IPv4 está prestes a esgotar os endereços numéricos.
Os outros protocolos que vamos considerar neste artigo são construídos sobre/em cima do IP, assim como sua linguagem de programação favorita possui bibliotecas e frameworks construídos sobre ela.
TCP - Protocolo de Controlo de Transmissão
O TCP é um utilitário construído em cima do IP. Como você pode perceber ao ler meus artigos, acredito firmemente que é necessário entender por que algo foi inventado para realmente compreender o que faz.
O TCP foi criado para resolver um problema com o IP. Os dados sobre o IP são normalmente enviados em vários pacotes, pois cada pacote é relativamente pequeno (2^16 bytes). Múltiplos pacotes podem resultar em (A) pacotes perdidos ou descartados e (B) pacotes desordenados, corrompendo assim os dados transmitidos. O TCP resolve ambos os problemas garantindo a transmissão dos pacotes de maneira ordenada.
Sendo construído em cima do IP, o pacote possui um cabeçalho (header) chamado cabeçalho TCP, além do cabeçalho IP. Esse cabeçalho TCP contém informações sobre a ordem e o número de pacotes, entre outras. Isso garante que os dados sejam recebidos de maneira confiável no outro extremo. Geralmente, ele é referido como TCP/IP, porque é construído em cima do IP.
O TCP precisa estabelecer uma conexão entre a origem e o destino antes de transmitir os pacotes, fazendo isso por meio de um "handshake", ou cumprimento. Essa conexão é estabelecida usando pacotes. Neles, a origem informa ao destino que deseja abrir uma conexão e o destino responde que está OK, abrindo, desse modo, a conexão.
Isso, efetivamente, é o que acontece quando um servidor "escuta" em uma porta — logo antes de começar a "escutar", há um "handshake" e, então, a conexão é aberta (a escuta começa). Do mesmo modo, um envia ao outro uma mensagem informando que está prestes a fechar a conexão, encerrando-a.
HTTP - Protocolo de Transferência de Hipertexto
HTTP é um protocolo que é uma abstração construída em cima do TCP/IP. Introduz um padrão muito importante, chamado padrão de requisição-resposta, especificamente para interações entre client-servidor.
Um client é simplesmente uma máquina ou sistema que solicita informações, enquanto um servidor é a máquina ou sistema que responde com informações. Um navegador é um client, e um servidor da web é um servidor. Quando um servidor solicita dados de outro servidor, o primeiro servidor também é um client, enquanto o segundo servidor é o servidor (eu sei, tautologias).
Portanto, esse ciclo de requisição-resposta tem suas próprias regras no HTTP. Isso estabelece um padrão para o modo como as informações são transmitidas pela internet.
Nesse nível de abstração, geralmente não precisamos nos preocupar muito com IP e TCP. No entanto, no HTTP, as requisições e respostas também possuem cabeçalhos e corpos (em inglês, body), que contêm dados que podem ser definidos pelo desenvolvedor.
As requisições e respostas HTTP podem ser consideradas como mensagens com pares de chave-valor, muito semelhantes a objetos em JavaScript e dicionários em Python, mas não exatamente iguais.
Abaixo está uma ilustração do conteúdo e dos pares de chave-valor nas mensagens de requisição e resposta HTTP.
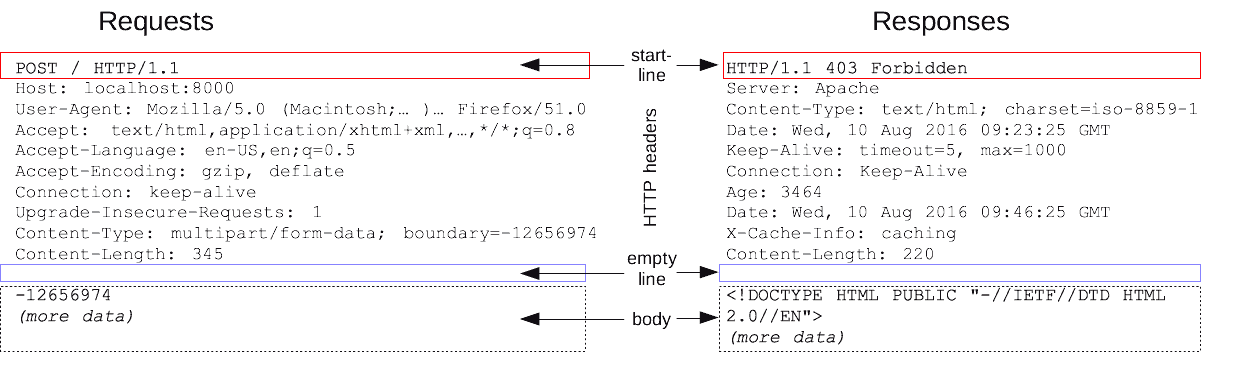
O HTTP também possui alguns "verbos" ou "métodos", que são comandos que indicam que tipo de operação deve ser realizada. Por exemplo, os métodos HTTP comuns são "GET", "POST", "PUT", "DELETE" e "PATCH", mas existem mais. Na ilustração acima, procure pelo verbo HTTP na linha inicial.
Secção 2: armazenamento, latência e taxas de transferência
Armazenamento
Armazenamento tem a ver com armazenar informação. Qualquer aplicação, sistema ou serviço que você programa precisará armazenar e recuperar dados. Esses são os dois propósitos fundamentais do armazenamento.
Não se trata apenas de armazenar dados, no entanto – também se trata de aceder aos mesmos. Para tal, utilizamos um banco de dados. Um banco de dados é uma camada de software que nos ajuda a armazenar e aceder a dados.
Esses dois tipos principais de operações, armazenar e aceder, também são chamados de "set, get", "store, fetch", "write, read" e assim por diante. Para interagir com o armazenamento, você precisará passar pelo banco de dados, que atua como um intermediário para realizar essas operações fundamentais.
A palavra "armazenamento", às vezes, pode nos levar a pensar nisso em termos físicos. Se eu "armazenar" minha bicicleta na garagem, posso esperar que ela esteja lá quando eu abrir a garagem novamente.
Nem sempre, porém, é o caso no mundo da computação. O armazenamento pode ser amplamente dividido em dois tipos: armazenamento em "memória" e armazenamento em "disco".
Desses dois, o armazenamento em disco tende a ser mais robusto e "permanente" (não realmente permanente, então geralmente usamos a palavra "armazenamento persistente" em vez disso). O armazenamento em disco é um armazenamento persistente. Isso significa que, quando você salva algo no disco e desliga a energia ou reinicia o servidor, os dados "persistem", mantêm-se lá. Eles não serão perdidos.
No entanto, se você deixar dados na "memória", geralmente eles serão apagados quando você desliga, reinicia ou perde energia.
O computador que você usa todos os dias possui esses dois tipos de armazenamento. O disco rígido é um armazenamento em disco "persistente" e a RAM é um armazenamento em memória, transitório.
Nos servidores, se os dados que você está acompanhando são úteis apenas durante uma sessão desse servidor, então faz sentido mantê-los na memória. É muito mais rápido e menos dispendioso do que gravar coisas em um banco de dados persistente.
Por exemplo, uma sessão única pode significar quando um usuário está conectado e a usar o seu site. Depois que eles saem, você pode não precisar manter os dados guardados durante a sessão.
Tudo o que você deseja manter (como o histórico do carrinho de compras, por exemplo) será armazenado no armazenamento de um disco persistente. Dessa maneira, você pode aceder a esses dados da próxima vez que o usuário fizer login, e eles terão uma experiência contínua e sem interrupções.
Ok, isto parece bastante simples e básico, e é isso que se pretende. Este é um guia introdutório. O armazenamento pode se tornar muito complexo. Se você reparar na variedade de produtos e soluções que existem de armazenamento, sua cabeça vai girar.
Isso ocorre porque diferentes necessidades de uso, exigem diferentes tipos de armazenamento. A chave para escolher o tipo de armazenamento correto para o seu sistema depende de muitos fatores, das necessidades da sua aplicação e de como os usuários interagem com ela. Outros fatores incluem:
- a forma (estrutura) dos seus dados, ou
- que tipo de disponibilidade é necessária (que nível de inatividade é aceitável para o seu armazenamento), ou
- com que rapidez você precisa ler e gravar dados, e se essas leituras e gravações ocorrerão de maneira simultânea ou sequencial, ou
- consistência – se você protege os dados contra tempo de inatividade usando armazenamento distribuído (qual é o nível de consistência dos dados em seus armazenamentos)
Essas perguntas e as conclusões exigem que você considere cuidadosamente as compensações envolvidas. A consistência é mais importante do que a velocidade? Você precisa que o banco de dados execute milhões de operações por minuto ou apenas atualizações noturnas? Eu abordarei esses conceitos em seções posteriores. Por isso, não se preocupe se ainda não tem ideia do que eles são.
Latência
"Latência" e "taxa de transferência" são termos que você ouvirá muito à medida que adquire mais experiência no design de sistemas para suportar a parte front-end da sua aplicação. Eles são fundamentais para a experiência e desempenho da aplicação e do sistema como um todo. Muitas vezes, há uma tendência de usar esses termos em um sentido mais amplo do que o pretendido, ou fora de contexto, mas vamos corrigir isso.
A latência é simplesmente a medida de uma duração. Que duração? A duração para que uma ação complete algo ou produza um resultado. Por exemplo: para os dados se moverem de um lugar para outro no sistema. Você pode pensar nisso como um atraso, ou ,simplesmente, como o tempo necessário para concluir uma operação.
A latência mais comumente compreendida é o requisitar de rede "ida e volta" – o tempo que demora para o seu site enviar um pedido do front-end (client) para o servidor e receber uma resposta dele.
Quando você está a carregar um site, pretende que seja o mais rápido e sem intercorrências possível. Em outras palavras, você deseja baixa latência. Pesquisas rápidas significam baixa latência. Portanto, encontrar um valor em um array de elementos é mais lento (maior latência, porque é preciso iterar sobre cada elemento no array para encontrar o desejado), do que encontrar um valor em um array de objectos (menor latência, porque você simplesmente procura os dados em tempo "constante", usando a chave – key. Nenhuma iteração é necessária).
Da mesma maneira, ler da memória é muito mais rápido do que ler de um disco (leia mais aqui – em inglês). Ambos, contudo, têm latência, e suas necessidades determinarão que tipo de armazenamento você escolherá para quais dados.
Nesse sentido, a latência é o inverso da velocidade. Você deseja velocidades mais altas e deseja latência mais baixa. A velocidade (especialmente em chamadas de rede como via HTTP) também é determinada pela distância. Portanto, a latência de Londres para outra cidade (texto em inglês) será impactada pela distância de Londres.
Como você pode imaginar, você quer projectar um sistema para evitar fazer pedidos a servidores distantes, mas armazenar dados na memória pode não ser viável para o seu sistema. Essas são as compensações que tornam o design do sistema complexo, desafiador e extremamente interessante!
Por exemplo, sites que mostram notícias podem preferir tempo de atividade e disponibilidade em relação à velocidade de carregamento, enquanto jogos on-line de multijogadores podem exigir disponibilidade e latência extremamente baixa. Esses requisitos determinarão o design e o investimento em infraestrutura para atender aos requisitos especiais do sistema.
Taxa de Transferência
"Taxa de transferência" pode ser entendida como a capacidade máxima de uma máquina ou sistema. É frequentemente usada em fábricas para calcular quantos trabalhos uma linha de montagem pode realizar numa hora ou num dia, ou alguma outra unidade de medir o tempo.
Por exemplo, uma linha de montagem pode montar 20 carros por hora, o que simboliza a sua taxa de transferência. Na computação, isso seria a quantidade de dados que pode ser transmitida numa unidade de tempo. Portanto, uma conexão de internet de 512 Mbps é uma medida de taxa de transferência - 512 Mb (megabits) por segundo.
Agora, imagine o servidor do freeCodeCamp. Se ele recebe 1 milhão de pedidos por segundo e só consegue atender 800.000 pedidos, então sua taxa de transferência é de 800.000 por segundo. Você pode acabar medindo a taxa de transferência em termos de bits em vez de pedidos, o que significaria N bits por segundo.
Nesse exemplo, existe um bottleneck (em português, algo como o gargalo de uma garrafa), porque o servidor não pode lidar com mais do que N bits por segundo, mas os pedidos são mais do que isso. Um bottleneck é, portanto, a restrição de um sistema que causa um atraso. Um sistema é tão rápido quanto o seu bottleneck mais lento.
Se um servidor pode lidar com 100 bits por segundo, outro pode lidar com 120 bits por segundo e um terceiro só pode lidar com 50, então o sistema geral estará operando a 50 bps porque essa é a restrição – ela estagna a velocidade dos outros servidores em um determinado sistema.
Portanto, aumentar a taxa de transferência em qualquer lugar que não seja o bottleneck pode ser um desperdício – você pode querer apenas aumentar a taxa de transferência no bottleneck mais baixo primeiro.
Você pode aumentar a taxa de transferência comprando mais hardware (escalabilidade horizontal) ou aumentando a capacidade e o desempenho do hardware existente (escalabilidade vertical) ou de outras maneiras.
Por vezes, aumentar a taxa de transferência pode ser uma solução de curto prazo, e um bom designer de sistemas pensará nas melhores maneiras de dimensionar a taxa de transferência de um determinado sistema, incluindo dividir as solicitações (ou qualquer outra forma de "carga") e distribuí-las entre outros recursos, etc. O ponto-chave a lembrar é o que é a taxa de transferência, o que é uma restrição ou bottleneck e como isso afeta um sistema.
Corrigir a latência e a taxa de transferência não são soluções isoladas e universais por si mesmas, nem estão correlacionadas entre si. Elas têm impactos e considerações em todo o sistema. Portanto, é importante entender o sistema como um todo e a natureza dos pedidos que serão colocadas no sistema ao longo do tempo.
Secção 3: disponibilidade
Os engenheiros de software têm como objetivo construir sistemas que sejam confiáveis. Um sistema confiável é aquele que satisfaz consistentemente as necessidades de um usuário, sempre que esse usuário procura ter essas necessidades atendidas. Um componente chave dessa confiabilidade é a disponibilidade.
É útil pensar em disponibilidade como a capacidade de um sistema de se recuperar de falhas na rede, no banco de dados, nos servidores etc.. Isso o torna um sistema tolerante a falhas e, consequentemente, disponível.
É claro que um sistema é a soma de suas partes em muitos sentidos, e que cada parte precisa estar altamente disponível se a disponibilidade for relevante para a experiência do usuário final do site ou da aplicação.
Quantificando a disponibilidade
Para quantificar a disponibilidade de um sistema, calculamos a percentagem do tempo em que a funcionalidade principal e as operações do sistema estão disponíveis (o tempo de atividade) em uma determinada janela de tempo.
Os sistemas mais críticos precisariam ter uma disponibilidade quase perfeita. Sistemas que suportam procuras e cargas altamente variáveis, com picos e quedas acentuadas, podem-se dar ao luxo de ter uma disponibilidade um pouco menor durante os horários de menor movimento.
Tudo depende do uso e natureza do sistema. Em geral, porém, até mesmo coisas com procuras baixas, mas consistentes, ou com uma garantia implícita de estarem "prontas para uso", precisam ter uma alta disponibilidade.
Imagine um site onde você faz back-up das suas fotos. Você nem sempre precisa aceder e recuperar dados dele – ele serve, principalmente, para armazenar coisas. Ainda assim, você espera que ele esteja sempre disponível sempre que fizer login para baixar mesmo que apenas uma foto.
Um tipo diferente de disponibilidade pode ser entendido no contexto de grandes eventos de compras on-line, como os dias de Black Friday ou Cyber Monday. Nesses dias específicos, a procura aumenta exponencialmente e milhões de pessoas tentam aceder às ofertas simultaneamente. Isso exigiria um projeto de sistema extremamente confiável e de alta disponibilidade para suportar essas cargas.
Um motivo comercial para alta disponibilidade é simplesmente que qualquer tempo de inatividade no site resultará em perda de dinheiro. Além disso, isso pode ter um impacto negativo na reputação, por exemplo, quando o serviço é usado por outras empresas para oferecer serviços. Se a AWS S3 ficar fora do ar, muitas empresas, incluindo a Netflix, serão afetadas, o que não é bom.
Portanto, os tempos de atividade são extremamente importantes para o sucesso. É importante lembrar que os números comerciais de disponibilidade são calculados com base na disponibilidade anual, então um tempo de inatividade de 0,1% (ou seja, disponibilidade de 99,9%) representa 8,77 horas por ano!
Portanto, os tempos de atividade soam extremamente altos. É comum ver coisas como 99,99% de tempo de atividade (52,6 minutos de tempo de inatividade por ano). Por isso, hoje em dia é comum referir-se aos tempos de atividade em termos de "noves" - o número de noves na garantia de tempo de atividade.
Nos dias de hoje, isso é inaceitável para serviços em larga escala ou críticos. É por isso que, atualmente, "cinco noves" é considerado o padrão ideal de disponibilidade, pois isso representa um pouco mais de 5 minutos de tempo de inatividade por ano.
SLAs
Para tornar os serviços on-line competitivos e atender às expectativas do mercado, os provedores de serviços on-line geralmente oferecem acordos de níveis de serviço (ou SLAs – do inglês, service level agreements). Esses são conjuntos de métricas garantidas de nível de serviço. Uma métrica como 99,99% de tempo de atividade é um exemplo disso e, muitas vezes, é oferecida como parte de assinaturas premium.
No caso de provedores de serviços de banco de dados e da nuvem, isso pode ser oferecido até mesmo nos planos de teste ou gratuitos, se o uso principal do cliente para esse produto justificar a expectativa de tal métrica.
Em muitos casos, o não cumprimento do SLA dará ao cliente o direito a créditos ou alguma outra maneira de compensação pelo não cumprimento dessa garantia por parte do provedor. Aqui, como exemplo, está o SLA da Google para a API do Maps (em inglês).
Os SLAs são, portanto, uma parte crítica da consideração comercial e técnica geral ao projetar um sistema. É especialmente importante considerar se a disponibilidade é, de fato, um requisito-chave para uma parte do sistema e quais partes requerem alta disponibilidade.
Projectar para alta disponibilidade
Ao projetar um sistema de alta disponibilidade (HA, do inglês, high availability), é necessário reduzir ou eliminar "pontos únicos de falha". Um ponto único de falha é um elemento no sistema que é o único capaz de causar uma perda indesejável de disponibilidade.
Você elimina os pontos únicos de falha projetando "redundância" no sistema. Redundância basicamente significa criar uma ou mais alternativas (ou back-ups) para o elemento que é crítico para a alta disponibilidade.
Por exemplo, se a sua aplicação precisa autenticar usuários para ser usada e há apenas um serviço de autenticação no back-end, se esse serviço falhar, o sistema não poderá mais ser utilizado devido ao ponto único de falha. Ao ter dois ou mais serviços que possam lidar com a autenticação, você está a adicionar redundância e elimina (ou reduz) os pontos únicos de falha.
Portanto, é necessário compreender e decompor o sistema em todas as suas partes. Mapeie quais delas poderão causar pontos únicos de falha, quais não serão tolerantes a essa falha e quais podem tolerar essas falhas. Projetar a alta disponibilidade requer fazer escolhas e compromissos e algumas dessas escolhas podem ser caras em termos de tempo, dinheiro e recursos.
Secção 4: caching
Caching! Essa é uma técnica fundamental e fácil de entender para aumentar o desempenho de um sistema. Assim, o caching ajuda a reduzir a "latência" em um sistema.
No nosso dia a dia, usamos o caching como uma questão de bom senso (na maioria das vezes...). Se moramos ao lado de um supermercado e ainda queremos comprar e armazenar alguns itens básicos no nosso frigorífico e despensa, isso é caching. Poderíamos sempre sair, ir ao supermercado e comprar essas coisas cada vez que quisermos comida, mas se elas estiverem na despensa ou frigorífico, reduzimos o tempo necessário e dispendido para preparar nossa comida. Isso é caching.
Cenários comuns para caching
Da mesma maneira, em termos de programação, se acabarmos dependendo frequentemente de certos dados, podemos querer armazenar em cache esses dados, para que nossa aplicação funcione mais rápido.
Isso é, em grande parte, verdadeiro quando se torna mais rápido recuperar dados da memória em vez do disco, devido à latência causada quando fazemos pedidos à rede. Na verdade, muitos sites são armazenados em cache (especialmente se o conteúdo não muda com frequência), em CDNs (texto em inglês) para que possam ser servidos ao usuário final com mais rapidez e assim reduzir a carga nos servidores de back-end.
Outro contexto em que o caching ajuda é quando o back-end precisa realizar algum trabalho computacionalmente intensivo e demorado. Armazenar em cache resultados anteriores pode converter o tempo de busca de uma complexidade O(N) linear para uma complexidade constante O(1), o que pode ser muito vantajoso.
Da mesma maneira, se o seu servidor precisa fazer vários pedidos à rede e API para compor os dados que são enviados de volta ao usuário, então armazenar em cache esses dados pode reduzir o número de pedidos e, portanto, a latência.
Se o seu sistema possui um client (front-end) e um servidor e banco de dados (back-end), o caching pode ser inserido no client (por exemplo, armazenamento no navegador), ou entre o client e o servidor (por exemplo, CDNs) ou mesmo no próprio servidor. Isso reduziria os pedidos pela rede para o banco de dados.
Portanto, o caching pode ocorrer em vários pontos ou níveis do sistema, incluindo no nível do hardware (CPU).
Tratamento de dados
Você pode ter percebido que os exemplos acima são implicitamente úteis para operações de "leitura". As operações de escrita não são muito diferentes, nos seus princípios, mas há considerações adicionais a serem feitas:
- As operações de escrita exigem que se mantenha o cache e os bancos de dados sincronizados
- Isso pode aumentar a complexidade porque há mais operações a serem executadas e novas considerações sobre como lidar com dados não sincronizados ou "obsoletos" precisam ser cuidadosamente analisadas.
- Novas regras podem necessitar de implementação para lidar com essa sincronização – ela deve ser feita de modo síncrono ou assíncrono? Se for de modo assíncrono, em que intervalos? De onde os dados são servidos enquanto isso? Com que frequência o cache precisa de ser atualizado etc.
- A "remoção" de dados ou renovação e atualização de dados, para manter os dados em cache limpos e atualizados. Isso inclui técnicas como LIFO, FIFO, LRU e LFU (textos em inglês).
Vamos, então, terminar com algumas conclusões de alto nível e não vinculativas. Geralmente, o caching funciona melhor quando usado para armazenar dados estáticos ou que serão alterados com pouca frequência e quando as fontes de mudança provavelmente serão operações únicas e não operações geradas pelo usuário.
Onde a consistência e a atualização dos dados são críticos, o caching pode não ser uma solução ideal, a menos que haja outro elemento no sistema que atualize eficientemente os caches em intervalos que não afetem negativamente o propósito e a experiência do usuário da aplicação.
Secção 5: proxies
Proxy. O que é isso? Muitos de nós já ouvimos falar de servidores proxy. Talvez tenhamos visto opções de configuração em alguns dos nossos softwares para PC ou Mac que falam sobre adicionar e configurar servidores proxy, ou acessar "via um proxy".
Portanto, vamos entender essa "peça" de tecnologia relativamente simples, amplamente utilizada e muito importante. Essa é uma palavra que existe na língua inglesa completamente independente da ciência da computação, então vamos começar com essa definição (em inglês).

Agora, você pode descartar a maior parte disso da sua mente e se concentrar numa palavra-chave importante: "substituto".
Em computação, um proxy é tipicamente um servidor, e é um servidor que atua como intermediário entre um client e outro servidor. É literalmente um trecho de código que está colocado entre o client e o servidor. Esse é o cerne dos proxies.
Caso você precise de um lembrete ou não esteja certo das definições de client e servidor, um "client" é um processo (código) ou máquina que solicita/requisita dados de outro processo ou máquina (o "servidor"). O navegador é um client quando solicita dados de um servidor back-end.
O servidor serve o client, mas também pode ser um client – quando recupera/requisita dados de um banco de dados. Então, o banco de dados é o servidor, o servidor é o client (do banco de dados) e é também um servidor para o client de front-end (navegador).
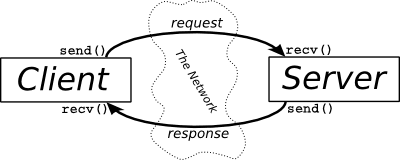
Como você pode ver na imagem acima, a relação client-servidor é bidirecional. Portanto, uma coisa pode ser tanto client como servidor. Se houvesse um servidor intermediário que recebesse solicitações, as enviasse para outro serviço e, em seguida, encaminhasse a resposta que recebeu desse outro serviço de volta ao client original, isso seria um servidor proxy.
Daqui para frente, nos referiremos aos clients como clients, aos servidores como servidores e aos proxies como o elemento entre eles.
Assim, quando um client envia uma solicitação/pedido a um servidor via proxy, o proxy às vezes pode mascarar a identidade do client – para o servidor, o endereço IP que é transmitido na solicitação pode ser o do proxy e não o do client de origem.
Para aqueles que acedem a websites ou baixam conteúdos que, de outro modo, são restritos (da rede de torrents, ou sites bloqueados no seu país, por exemplo), vocês podem reconhecer esse padrão – é o princípio sobre o qual as VPNs são construídas.
Antes de avançarmos um pouco mais, quero destacar algo – quando usado de modo geral, o termo proxy se refere a um proxy "encaminhador" (do inglês, forward proxy). Um proxy encaminhador é aquele em que o proxy atua em nome do client na interação entre client e servidor.
Isso é distinto de um proxy reverso – onde o proxy atua em nome de um servidor. Em um diagrama, pareceria o mesmo – o proxy fica entre o client e o servidor, e o fluxo de dados é o mesmo: client <-> proxy <-> servidor.
A diferença chave é que um proxy reverso é projetado para substituir o servidor. Frequentemente, nem mesmo os clients saberão que a solicitação de rede foi roteada por um proxy e que o proxy a encaminhou para o servidor pretendido (e fez o mesmo com a resposta do servidor).
Portanto, em um proxy encaminhador, o servidor não saberá que a solicitação do client e sua resposta estão passando por um proxy, enquanto em um proxy reverso, o client não saberá que a solicitação e a resposta estão sendo roteadas por um proxy.
Proxies têm uma certa astúcia :)
No design de sistemas, contudo, especialmente para sistemas complexos, proxies são úteis e proxies reversos são particularmente úteis. O proxy reverso pode ser encarregada de muitas tarefas que você não deseja que seu servidor principal manipule – ele pode ser um guardião, um filtro, um balanceador de carga e um assistente em geral.
Portanto, proxies podem ser úteis, mas você pode não ter certeza do motivo. Novamente, se você leu meus outros materiais, saberá que acredito firmemente que só podemos entender as coisas adequadamente quando sabemos porque e para que elas existem – saber o que fazem não é suficiente.
Secção 6: balanceamento de carga
Se você pensar nas duas palavras, carga e balanceamento, começará a ter uma intuição sobre o que fazem no mundo da computação. Quando um servidor recebe simultaneamente muitas solicitações, ele pode ficar mais lento (a taxa de transferência diminui, a latência aumenta). Em um certo ponto, ele até pode falhar (indisponibilidade).
Você pode fornecer mais poder de processamento ao servidor (escalabilidade vertical) ou adicionar mais servidores (escalabilidade horizontal). Mas agora você precisa descobrir como as solicitações recebidas são distribuídas entre os vários servidores - quais solicitações são encaminhadas para quais servidores e como garantir que eles não fiquem sobrecarregados também? Por outras palavras, como equilibrar e alocar a carga das solicitações?
É aqui que entram os balanceadores de carga. Uma vez que este artigo é uma introdução a princípios e conceitos, as explicações são, por necessidade, muito simplificadas. A função de um balanceador de carga é ficar entre o client e o servidor (mas também pode ser inserido em outros lugares) e descobrir como distribuir cargas de solicitações recebidas entre vários servidores, de modo que a experiência do usuário final (do client) seja consistentemente rápida, suave e confiável.
Portanto, os balanceadores de carga são como gerenciadores de tráfego que direcionam o tráfego. Eles fazem isso para manter a disponibilidade e a taxa de transferência.
Ao entender onde um balanceador de carga é inserido na arquitetura do sistema, você pode ver que os balanceadores de carga podem ser considerados como proxies reversos. No entanto, um balanceador de carga também pode ser inserido em outros locais – entre outras trocas – por exemplo, entre seu servidor e seu banco de dados.
O equilíbrio delicado – estratégias de selecção de servidores
Então, como é que o balanceador de carga decide como rotear e alocar o tráfego de solicitações? Para começar, cada vez que você adiciona um servidor, é necessário informar ao balanceador de carga que há mais um candidato para ele rotear o tráfego.
Se você remover um servidor, o balanceador de carga também precisa saber disso. A configuração garante que o balanceador de carga saiba quantos servidores ele tem na sua lista de opções e quais estão disponíveis. É até possível manter o balanceador de carga informado sobre os níveis de carga de cada servidor, status, disponibilidade, tarefa atual e por aí adiante.
Uma vez que o balanceador de carga esteja configurado para saber para quais servidores ele pode redirecionar, precisamos definir a melhor estratégia de roteamento para garantir uma distribuição adequada entre os servidores disponíveis.
Uma abordagem ingênua para isso seria o balanceador de carga escolher um servidor aleatoriamente e direcionar cada solicitação recebida dessa maneira. Como você pode imaginar, porém, a aleatoriedade pode causar problemas e alocações "desequilibradas" onde alguns servidores ficam mais sobrecarregados do que outros, o que pode afetar negativamente o desempenho do sistema como um todo.
Round Robin e Round Robin Ponderado
Outro método que pode ser intuitivamente compreendido é chamado de "round robin" (em português, "selecção circular"). Essa é a maneira como muitos humanos processam listas em loop. Você começa no primeiro item da lista, move-se sequencialmente para baixo e, quando termina com o último item, volta ao topo e começa a trabalhar novamente na lista.
O balanceador de carga também pode fazer isso, simplesmente alternando entre os servidores disponíveis numa sequência fixa. Dessa maneira, a carga é distribuída de modo bastante equilibrado entre seus servidores em um padrão simples de entender e prever.
Você pode entender um pouco mais de round robin ao "ponderar" alguns serviços em relação a outros. No round robin normal e padrão, cada servidor recebe um peso igual (digamos que todos recebam um peso de 1). Quando, no entanto, você pondera servidores de maneira diferente, é possível atribuir pesos menores a alguns servidores (digamos 0,5, se forem menos potentes), e outros podem ter pesos maiores, como 0,7, 0,9 ou até 1.
Em seguida, o tráfego total será dividido de acordo com esses pesos e alocado aos servidores que possuem poder proporcional ao volume de solicitações.
Selecção do servidor com base na carga
Balanceadores de carga mais sofisticados podem calcular a capacidade atual, o desempenho e as cargas dos servidores na sua lista de opções e alocar dinamicamente, de acordo com as cargas atuais e cálculos sobre quais terão a maior taxa de transferência, menor latência etc. Isto é feito monitorando o desempenho de cada servidor e decidindo quais são capazes ou não, de lidar com as novas solicitações.
Selecção baseada no hashing do IP
É possível configurar o balanceador de carga para gerar um hash do endereço IP das solicitações recebidas e usar o valor do hash para determinar qual servidor direcionar a solicitação. Se eu tivesse 5 servidores disponíveis, a função de hash seria projetada para retornar um dos cinco valores de hash, para que um dos servidores seja definitivamente escolhido para processar a solicitação.
O roteamento baseado no hashing do IP pode ser muito útil quando você deseja que solicitações de um determinado país ou região obtenham dados de um servidor que seja mais adequado para atender às necessidades dessa região, ou onde seus servidores armazenem em cache solicitações para que possam ser processadas rapidamente.
No último cenário, você deseja garantir que a solicitação seja encaminhada para um servidor que já tenha armazenado em cache a mesma solicitação anteriormente, pois isso melhorará a velocidade e o desempenho no processamento e na resposta àquela solicitação.
Se seus servidores mantêm caches independentes e seu balanceador de carga não envia consistentemente solicitações idênticas para o mesmo servidor, você acabará com servidores repetindo o trabalho que já foi feito numa solicitação anterior para outro servidor, e você perde a otimização que vem com o armazenamento em cache de dados.
Selecção com base no caminho ou serviço
Você também pode fazer com que o balanceador de carga encaminhe as solicitações com base no seu "caminho" (em inglês, path) ou função/serviço que está sendo fornecido. Por exemplo, se você está a comprar flores de uma florista on-line, as solicitações para carregar os "buquês em oferta" podem ser enviadas para um servidor, e os pagamentos com cartão de crédito podem ser enviados para outro servidor.
Se apenas um em cada vinte visitantes realmente comprar flores, você poderá ter um servidor menor processando os pagamentos e um maior lidando com todo o tráfego de navegação.
Mistura de opções
Como acontece com todas as coisas, você pode chegar a níveis mais elevados e detalhados de complexidade. Pode ter vários balanceadores de carga, cada um com diferentes estratégias de seleção de servidores! Se o seu sistema for muito grande e altamente movimentado, talvez você precise de balanceadores de carga para os balanceadores de carga...
No final de contas, você adiciona componentes ao sistema até que o desempenho esteja ajustado às suas necessidades (suas necessidades podem parecer estáveis, ou aumentar gradualmente ao longo do tempo, ou estar propensas a picos!).
Nós falamos sobre VPNs (para proxies encaminhadores) e balanceamento de carga (para proxies reversos), mas há mais exemplos aqui (texto em inglês).
Secção 7: hashing consistente
Um dos conceitos um pouco mais complexos de entender é o hashing no contexto do balanceamento de carga. Por esse motivo, tem uma secção exclusiva.
Para entender este conceito, primeiro é importante compreender como o hashing funciona em um nível conceptual. Resumido, o hashing converte uma entrada num valor de tamanho fixo, muitas vezes um valor inteiro (o hash).
Um dos princípios-chave para um bom algoritmo ou função de hashing, é que a função deve ser determinística, o que significa que entradas idênticas gerarão saídas idênticas ao serem passadas para a função. Portanto, determinístico significa que se eu inserir a sequência "Código" (diferenciando maiúsculas e minúsculas) e a função gerar um hash de 11002, toda vez que eu inserir "Código" ela deve gerar "11002" como um número inteiro. Se eu inserir "código", ela gerará um número diferente (consistentemente).
Por vezes, a função de hashing pode gerar o mesmo hash para mais do que uma entrada – isto não é o fim do mundo e existem maneiras de lidar com isso. Na verdade, torna-se mais provável que isso aconteça, quanto maior for a variedade de entradas únicas. No entanto, quando mais de uma entrada gera deterministicamente a mesma saída, isso é chamado de "colisão".
Com isto em mente, vamos aplicá-lo ao roteamento e direcionamento de solicitações para servidores. Digamos que você tem 5 servidores para alocar cargas. Um método fácil de entender seria fazer um hash das solicitações recebidas (talvez pelo endereço IP ou algum detalhe do client) e, de seguida, gerar hashes para cada solicitação. Em seguida, você aplica o operador módulo a esse hash, onde o operando à direita significa o número de servidores.
Por exemplo, aqui está um pseudocódigo para seus balanceadores de carga:
solicitacao#1 => tem como hash 34
solicitacao#2 => tem como hash 23
solicitacao#3 => tem como hash 30
solicitacao#4 => tem como hash 14
// Você tem 5 servidores => [Servidor A, Servidor B, Servidor C, Servidor D, Servidor E]
// portanto use modulo (%) 5 para cada solicitação...
solicitacao#1 => tem como hash 34 => 34 % 5 = 4 => envie essa solicitação a servidores[4] => Servidor E
solicitacao#2 => tem como hash 23 => 23 % 5 = 3 => envie essa solicitação a servidores[3] => Servidor D
solicitacao#3 => tem como hash 30 => 30 % 5 = 0 => envie essa solicitação a servidores[0] => Servidor A
solicitacao#4 => tem como hash 14 => 14 % 5 = 4 => envie essa solicitação a servidores[4] => Servidor EComo é possível verificar, a função de hash gera uma série de valores possíveis, e quando o operador módulo é aplicado, ele produz uma faixa menor de números que correspondem ao número do servidor.
Certamente haverá diferentes solicitações/pedidos que mapeiam para o mesmo servidor – e isso é aceitável, desde que haja "uniformidade" na alocação geral para todos os servidores.
Adicionando servidores e lidando com servidores com falha
Então, o que acontece se um dos servidores para os quais estamos enviando tráfego falhar? A função de hash (verifique o trecho de pseudocódigo acima) ainda pensa que existem 5 servidores, e o operador de módulo gera uma faixa de 0 a 4. Agora, porém, só temos 4 servidores, pois um falhou, e ainda estamos enviando tráfego para esse. Isso é um problema.
Pelo contrário, poderíamos adicionar um sexto servidor, mas ele nunca receberia tráfego porque nosso operador de módulo é 5, e nunca geraria um número que incluiria o recém-adicionado sexto servidor. Isso é um outro problema.
// Vamos adicionar um sexto servidor
servidores => [Servidor A, Servidor B, Servidor C, Servidor D, Servidor E, Servidor F]
// mudamos o operando do módulo para 6
solicitacao#1 => tem como hash 34 => 34 % 6 = 4 => envie essa solicitação para servidores[4] => Servidor E
solicitacao#2 => tem como hash 23 => 23 % 6 = 5 => envie essa solicitação para servidores[5] => Servidor F
solicitacao#3 => tem como hash 30 => 30 % 6 = 0 => envie essa solicitação para servidores[0] => Servidor A
solicitacao#4 => tem como hash 14 => 14 % 6 = 2 => envie essa solicitação para servidores[2] => Servidor CPodemos ver que o número do servidor após a aplicação do operador módulo muda (embora, nesse exemplo, isso não ocorra para a solicitação #1 e para a solicitação #3 – mas isso acontece apenas porque, neste caso específico, os números funcionaram dessa maneira).
Na prática, o resultado é que metade das solicitações (pode ser mais em outros exemplos!) agora está a ser completamente roteada para novos servidores, e perdemos os benefícios dos dados anteriormente armazenados em cache nos servidores.
Por exemplo, a solicitação #4 costumava ir para o Servidor E, mas agora vai para o Servidor C. Todos os dados em cache relacionados à solicitação #4 armazenados no Servidor E não têm utilidade, já que a solicitação agora está a ir para o Servidor C. Você pode calcular um problema semelhante para o caso em que um dos seus servidores falha, mas a função módulo continua a enviar solicitações para ele.
Parece algo menor neste sistema pequeno, mas num sistema de grande escala, é um resultado inadequado. #FalhaNoDesignDoSistema
Portanto, é evidente que um sistema simples de alocação baseado em hashing não se dimensiona bem, nem lida bem com falhas.
Uma solução popular – o hashing consistente
Infelizmente, esta é a parte em que sinto que a descrição por palavras não será suficiente. O hashing consistente é melhor entendido visualmente. No entanto, o propósito deste artigo até agora é fornecer uma intuição sobre o problema, o que é, por que surge e quais podem ser as deficiências numa solução básica. Mantenha isso na sua mente.
O principal problema com o hashing ingênuo, como discutimos, é que quando (A) um servidor falha, o tráfego ainda é direcionado para ele, e (B) quando você adiciona um novo servidor, as alocações podem ser substancialmente alteradas, perdendo assim os benefícios de caches anteriores.
Há duas coisas muito importantes a ter em mente quando aprofundamos o entendimento sobre hashing consistente:
- O hashing consistente não elimina os problemas, especialmente o problema B. No entanto, ele reduz esses problemas significativamente. No início, você pode se perguntar qual é a grande vantagem do hashing consistente, já que a desvantagem subjacente ainda existe, mas numa escala muito menor e isso por si só é uma melhoria valiosa em sistemas de grande escala.
- O hashing consistente aplica uma função de hash às solicitações recebidas e aos servidores. Portanto, as saídas resultantes enquadram-se num conjunto de valores (contínuo) definido. Esse detalhe é muito importante.
Por favor, tenha essas noções em mente enquanto visualiza o vídeo abaixo, onde é explicado o hashing consistente. Caso contrário, os seus benefícios poderão não ser evidentes.
Eu recomendo vivamente este vídeo, pois ele identifica estes princípios sem ser pesado e saturante com muito detalhe (em inglês).
Se está a ter algumas dificuldades em realmente entender o porquê desta estratégia ser importante no balanceamento de carga, sugiro que faça uma pausa e depois volte à secção sobre balanceamento de carga e retorne a esta secção. Não é anormal que tudo isto pareça abstracto, excepto se você já se tiver deparado com esse problema no seu trabalho!
Secção 8: bancos de dados
Consideramos que havia diferentes tipos de soluções para armazenamento (bancos de dados) criadas para servir um diferente número de casos, e umas são mais especializadas para determinadas tarefas que outras. No entanto, de uma forma geral, bancos de dados podem ser categorizados em dois tipos: relacionais e não relacionais.
Bancos de dados relacionais
Um banco de dados relacional é aquele que possui relacionamentos estritamente definidos entre os elementos armazenados no banco de dados. Esses relacionamentos são possíveis fazendo com que o banco de dados represente cada elemento (chamado "entidade") como uma tabela estruturada – com zero ou mais linhas ("registos", "entradas") e uma ou mais colunas ("atributos", "campos").
Ao forçar tal estrutura numa entidade, conseguimos assim assegurar que dado elemento/entrada/registo tem a informação certa a acompanhar. Isso permite melhor consistência e a habilidade de estreitar relacionamentos entre as entidades.
Pode ver abaixo um exemplo dessa estrutura na tabela denominada "Baby" (entidade). Cada registo ("entrada") na tabela tem 4 campos, cada um representando informação relativa a esse bebê ("baby"). Essa estrutura é um exemplo clássico de um banco de dados relacional (e uma estrutura de entidade formalizada é chamada de esquema).

Portanto, um ponto chave a perceber sobre bancos de dados relacionais é que eles são altamente estruturados, e impõem essa estrutura sobre todas as suas entidades. Essa estrutura é forçada garantindo que a informação que é inserida na tabela está em conformidade com a estrutura. Adicionar um campo de altura à tabela sem que o seu esquema o permita não é possível.
A maioria dos bancos de dados relacionais suporta uma linguagem de consulta de bancos de dados chamada SQL - Structured Query Language. Essa é uma linguagem projetada especificamente para interagir com o conteúdo de um banco de dados estruturado (relacional). Os dois conceitos estão bastante interligados, a ponto de as pessoas frequentemente se referirem a um banco de dados relacional como um "banco de dados SQL" (às vezes pronunciado como banco de dados "sequel").
No geral, considera-se que bancos de dados SQL (relacionais) suportam consultas mais complexas (que combinam diferentes campos, filtros e condições) do que as bancos de dados não relacionais. O próprio banco de dados lida com essas consultas e retorna resultados correspondentes.
Muitos dos entusiastas de bancos de dados SQL argumentam que, sem essa função, você teria de ir buscar todos os dados e, em seguida, fazer com que o servidor ou o client carregasse esses dados "na memória" e aplicasse as condições de filtragem – o que é aceitável para pequenos conjuntos de dados, mas para um conjunto de dados grande e complexo, com milhões de registos e linhas, isso afetaria seriamente o desempenho. No entanto, isso nem sempre é o caso, como veremos quando aprendermos sobre bancos de dados NoSQL.
Um exemplo comum e muito apreciado de um banco de dados relacional é o PostgreSQL (frequentemente chamado de "Postgres").
ACID
Transações ACID são um conjunto de características que descrevem as transações que um bom banco de dados relacional suportará. ACID = "Atomicidade, Consistência, Isolamento, Durabilidade". Uma transação é uma interação com um banco de dados, geralmente operações de leitura ou escrita.
Atomicidade requer que, quando uma única transação consiste em mais de uma operação, o banco de dados deve garantir que, se uma operação falhar, a transação inteira (todas as operações) também falhe. É "tudo ou nada". Desse modo, se a transação for bem-sucedida, ao ser concluída, você sabe que todas as sub-operações foram concluídas com sucesso. Se uma operação falhar, você sabe que todas as operações que a acompanharam também falharam.
Por exemplo, se uma única transação envolvesse a leitura de duas tabelas e a escrita em três, então, se qualquer uma dessas operações individuais falhar, a transação inteira falha. Isso significa que nenhuma dessas operações individuais deve ser concluída. Você não gostaria que nem mesmo 1 das 3 transações de gravação funcionasse - isso "sujaria" os dados nos bancos de dados!
Consistência requer que cada transação em um banco de dados seja válida de acordo com as regras definidas nesse mesmo banco de dados e, quando o estado do banco de dados muda (alguma informação mudou), essa mudança seja válida e não corrompa os dados. Cada transação altera o banco de dados de um estado válido para outro estado válido. Consistência pode ser pensada da seguinte forma: cada operação de "leitura" recebe os resultados da operação de "escrita" mais recente.
Isolamento significa que você pode "concorrentemente" (ao mesmo tempo) executar várias transações em um banco de dados, mas o banco de dados acabará em um estado que parece como se cada operação tivesse sido executada serialmente (em sequência, como uma fila de operações). Pessoalmente, acho que "Isolamento" não é um termo muito descritivo para o conceito, mas acredito que ACID seja mais fácil de dizer do que ACCD (com o segundo C representando concorrência)...
Durabilidade é a promessa de que, uma vez que os dados estão armazenados no banco de dados, eles permanecerão lá. Eles serão "persistentes" – armazenados em disco e não na memória.
Bancos de dados não relacionais
Em contraste, um banco de dados não relacional possui uma estrutura de dados menos rígida, ou, em outras palavras, uma estrutura mais flexível. Os dados geralmente são apresentados como pares "chave-valor". Uma maneira simples de representar isso seria como um array (lista) de objetos "chave-valor", por exemplo:
// nomes de bebês
[
{
nome: "Jaques",
posicao: ##,
genero: "M",
ano: ####
},
{
nome: "Isabela",
posicao: ##,
genero: "F",
ano: ####
},
{
//...
},
// ...
]Bancos de dados não relacionais também são chamados de bancos de dados "NoSQL" e oferecem benefícios quando você não deseja ou não precisa ter dados consistentemente estruturados.
Semelhante às propriedades ACID, as propriedades do banco de dados NoSQL são às vezes referidas como BASE:
Basically Available – Basicamente Disponível, o que significa que o sistema garante disponibilidade
Soft State – Estado Suave, significa que o estado do sistema pode mudar ao longo do tempo, mesmo sem entrada
Eventual Consistency – Consistência Eventual afirma que o sistema se tornará consistente ao longo de um período (muito curto) de tempo, a menos que outras entradas sejam recebidas.
Uma vez que, na sua essência, esses bancos de dados armazenam dados numa estrutura semelhante a uma tabela de hash, eles são extremamente rápidos, simples e fáceis de usar, sendo perfeitos para casos de uso como armazenamento em cache, variáveis de ambiente, arquivos de configuração e estado de sessão etc. Essa flexibilidade os torna ideais para uso em memória (por exemplo, Memcached) e também em armazenamento persistente (por exemplo, DynamoDB).
Existem outros bancos de dados "semelhantes a JSON" chamados de bancos de dados de documentos, como o bem-amado MongoDB, e cuja essência também são armazenamentos "chave-valor".
Indexação de bancos de dados
Este é um tópico complicado, então vou fornecer uma visão geral do que você precisa para entrevistas de design de sistemas.
Imagine uma tabela de banco de dados com 100 milhões de linhas. Essa tabela é usada principalmente para procurar um ou dois valores em cada registo. Para recuperar os valores de uma linha específica, você precisaria percorrer a tabela. Se for o último registo, isso levaria muito tempo!
A indexação é uma maneira de encontrar o registo com valores correspondentes de maneira mais eficiente do que percorrer cada linha. Os índices são normalmente uma estrutura de dados adicionada ao banco de dados, projetada para facilitar a pesquisa rápida no banco de dados com base nesses atributos específicos (campos).
Portanto, se o escritório de censos tiver 120 milhões de registos com nomes e idades, e se você precisar recuperar listas de pessoas pertencentes a um grupo etário com frequência, você indexaria esse banco de dados no atributo da idade.
A indexação é fundamental para bancos de dados relacionais e também é amplamente oferecida em bancos de dados não relacionais. Os benefícios da indexação teoricamente estão disponíveis para ambos os tipos de bancos de dados, e isso é extremamente benéfico para otimizar os tempos de busca.
Replicação e sharding
Enquanto isto pode parecer algo saído de um filme de bio-terrorismo, é mais provável ouvir esses termos no contexto de escalabilidade de bancos de dados.
Replicação significa duplicar (fazer cópias, replicar) seu banco de dados. Se recordarmos, quando discutimos disponibilidade, consideramos os benefícios de ter redundância num sistema, para manter alta disponibilidade.
A replicação garante redundância no banco de dados se um deles falhar. Também levanta a questão de como sincronizar os dados entre as réplicas, já que se supões que as réplicas terão os mesmos dados. A replicação em operações de gravação e atualização de um banco de dados pode ocorrer de maneira síncrona (ao mesmo tempo que as alterações no banco de dados principal) ou de maneira assíncrona.
O intervalo de tempo aceitável entre a sincronização do banco de dados principal e de uma réplica realmente depende das suas necessidades – se você realmente precisa que o estado entre os dois bancos de dados seja consistente, a replicação precisa ser rápida. Você também pretende garantir que, se a operação de gravação na réplica falhar, a operação de gravação no banco de dados principal também falhe (atomicidade).
O que você faz quando tem tantos dados que simplesmente replicá-los pode resolver os problemas de disponibilidade, mas não resolve os problemas de throughput e latência (velocidade)?
Nesse ponto, você pode considerar "fragmentar" seus dados em "shards" (em português, fragmentos). Algumas pessoas também chamam a isso de particionamento de dados (o que é diferente do particionamento de seu disco rígido!).
O particionamento de dados divide seu banco de dados enorme em bancos de dados menores. Você pode determinar como deseja particionar seus dados com base na sua estrutura. Pode ser tão simples como salvar cada 5 milhões de linhas em um shard diferente, ou adotar outras estratégias que melhor se adaptem aos seus dados, necessidades e locais atendidos.
Secção 9: eleição de líder
Vamos voltar ao tópico de servidores novamente, mas, dessa vez, para um assunto um pouco mais avançado. Já entendemos o princípio da disponibilidade e como a redundância é um modo de aumentar a disponibilidade. Também discutimos algumas considerações práticas ao lidar com o roteamento de solicitações para clusters de servidores redundantes.
Às vezes, contudo, com esse tipo de configuração em que vários servidores estão a fazer basicamente a mesma coisa, podem surgir situações em que você deseja que apenas um servidor assuma a liderança.
Por exemplo, você deseja garantir que apenas um servidor seja responsável por atualizar alguma API de terceiros, pois várias atualizações de diferentes servidores poderiam causar problemas ou aumentar os custos do lado do terceiro.
Nesse caso, você precisa escolher o servidor principal para delegar essa responsabilidade de atualização. Esse processo é chamado de eleição de líder.
Quando vários servidores estão num cluster para fornecer redundância, eles podem ser configurados para ter apenas um líder entre eles. Eles também detectariam quando o servidor líder falhasse e designariam outro para assumir seu lugar.
O princípio é muito simples, mas o diabo está nos detalhes. A parte realmente complicada é garantir que os servidores estejam "em sincronia" em termos de dados, estado e operações.
Sempre há o risco de que certas interrupções possam resultar em um ou dois servidores sendo desconectados dos outros, por exemplo. Nesse caso, os engenheiros acabam usando algumas das ideias subjacentes usadas em blockchain para derivar valores de consenso para o cluster de servidores.
Em outras palavras, um algoritmo de consenso é usado para dar a todos os servidores um valor "acordado" que todos podem usar em sua lógica ao identificar qual servidor é o líder.
A eleição do líder geralmente é implementada com software como o etcd, que é um armazenamento de pares chave-valor que oferece alta disponibilidade e alta consistência (o que é uma combinação valiosa e incomum) usando a própria eleição do líder e usando um algoritmo de consenso.
Portanto, os engenheiros podem confiar na arquitetura de eleição de líder do etcd para produzir eleições de líder em seus sistemas. Isso é feito armazenando num serviço como o etcd um par chave-valor que representa o líder atual.
Como o etcd é altamente disponível e fortemente consistente, esse par chave-valor sempre pode ser usado pelo seu sistema para conter o servidor "fonte da verdade" final no seu cluster, que é o líder eleito atual.
Secção 10: polling, streaming, sockets
Na era moderna das atualizações contínuas, notificações push, conteúdo em streaming e dados em tempo real, é importante compreender os princípios básicos que sustentam essas tecnologias. Para ter dados em sua aplicação atualizados regularmente ou instantaneamente, você precisa utilizar uma das duas abordagens a seguir.
Polling (consulta)
Essa é uma abordagem simples. Se você olhar a entrada na Wikipedia (texto em inglês), pode achá-la um pouco intensa. Então, em vez disso, vamos ver o significado no dicionário, especialmente no contexto da ciência da computação. Mantenha esse conceito fundamental em mente.
A pesquisa é simplesmente fazer com que o seu client verifique um servidor, enviando-lhe um pedido de rede e pedindo dados atualizados. Esses pedidos geralmente são feitos em intervalos regulares, como 5 segundos, 15 segundos, 1 minuto ou qualquer outro intervalo necessário para o seu caso de uso.
Pesquisar a cada poucos segundos não é ainda exatamente a mesma coisa que em tempo real e também apresenta as seguintes desvantagens, especialmente se você tiver um milhão ou mais de usuários em simultâneo:
- pedidos de rede quase constantes (não é ótimo para o client)
- pedidos de entrada quase constantes (não é ótimo para as cargas do servidor – mais de 1 milhão de pedidos por segundo!)
Portanto, a pesquisa rápida não é realmente eficiente ou eficaz, e a pesquisa é melhor usada em circunstâncias em que pequenas lacunas na atualização de dados não são um problema para a sua aplicação.
Por exemplo, se você construiu um clone do Uber, pode fazer com que a aplicação do motorista envie dados de localização do motorista a cada 5 segundos, e a aplicação do passageiro pesquise a localização do motorista a cada 5 segundos.
Streaming
O streaming resolve o problema constante de pesquisa. Se for necessário atingir constantemente o servidor, é melhor usar algo chamado websockets.
Este é um protocolo de comunicação de rede projetado para funcionar sobre o TCP. Ele abre um canal dedicado de duas vias (socket) entre um client e um servidor, algo semelhante a uma linha direta aberta entre dois pontos na extremidade.
Ao contrário da comunicação TCP/IP usual, esses sockets são "de longa duração", de modo a ser uma única solicitação ao servidor que abre essa linha direta para a transferência de dados de duas vias, em vez de várias solicitações separadas. Quando dizemos "de longa duração", queremos dizer que a conexão do socket entre as máquinas durará até que um dos lados a feche ou a rede caia.
Você é capaz de se lembrar da nossa discussão sobre IP, TCP e HTTP, que eles operam enviando "pacotes" de dados, para cada ciclo de solicitação-resposta. Os websockets significam que há uma única interação de solicitação-resposta (não é realmente um ciclo, se você pensar bem nisso!) e isso abre o canal pelo qual os dados são enviados num "fluxo" (em inglês, stream).
A grande diferença entre a pesquisa e toda a comunicação baseada num IP "regular" é que, enquanto a pesquisa faz com que o client faça solicitações ao servidor para obter dados em intervalos regulares ("puxando" dados), no streaming, o client está "à espera", aguardando o servidor "empurrar" alguns dados na sua direção. O servidor enviará dados quando eles mudarem, e o client está sempre ouvindo isso. Portanto, se a mudança de dados for constante, isso se torna um "fluxo", o que pode ser melhor para o que o usuário precisa.
Por exemplo, ao usar IDEs de programação colaborativa, quando um usuário digita algo, pode aparecer na tela do outro, e isso é feito por meio de websockets porque você deseja ter colaboração em tempo real. Seria ruim se o que eu digitasse aparecesse na sua tela depois de você tentar digitar a mesma coisa ou depois de 3 minutos esperando, perguntando o que eu estava fazendo!
Pense, também, em jogos de multijogador on-line - esse é um caso de uso perfeito para o streaming de dados de jogo entre jogadores!
Para concluir, o caso de uso determina a escolha entre pesquisa e streaming. No geral, você deseja fazer streaming se seus dados forem "em tempo real". Se estiver tudo bem com um atraso (mesmo que seja de apenas 15 segundos, ainda é um atraso), então a pesquisa pode ser uma boa opção. Tudo depende de quantos usuários simultâneos você tem e se eles esperam que os dados sejam instantâneos. Um exemplo comumente usado de um serviço de streaming é o Apache Kafka.
Secção 11: protecção de endpoints
Quando você constrói sistemas em larga escala, torna-se importante proteger seu sistema contra um número excessivo de operações, quando tais operações não são realmente necessárias para usar o sistema. Isto pode parecer abstrato, mas pense nisto – quantas vezes você clicou furiosamente num botão achando que isso tornaria o sistema mais responsivo? Imagine se cada um desses cliques num botão enviasse uma solicitação para um servidor e o servidor tentasse processá-las todas! Se a capacidade do sistema for baixa por algum motivo (digamos que um servidor esteja a lutar sob uma carga incomum), então cada um desses cliques tornaria o sistema ainda mais lento porque ele teria que processá-los todos!
Às vezes, não se trata apenas de proteger o sistema. Às vezes, você deseja limitar as operações, porque isso faz parte do seu serviço. Por exemplo, você pode ter usado níveis gratuitos em serviços de API de terceiros, onde você só pode fazer 20 solicitações a cada intervalo de 30 minutos. Se você fizer 21 ou 300 solicitações em um intervalo de 30 minutos, após as primeiras 20, aquele servidor deixará de processar suas solicitações.
Isso é chamado de rate limiting (em português, limitação de taxa). Usando a limitação de taxa, um servidor pode limitar o número de operações tentadas por um client num determinado período de tempo. Uma limitação de taxa pode ser calculada com base em usuários, solicitações, horários, cargas ou outras coisas. Normalmente, uma vez que o limite é excedido num período de tempo, pelo resto desse período o servidor retornará um erro.
Agora, você pode pensar que "proteção" de endpoint é um exagero. Você está apenas restringindo a capacidade do usuário de obter algo do endpoint. É verdade, mas também é proteção quando o usuário (client) é malicioso – como um bot que está atacando seu endpoint. Por que isso aconteceria? Porque inundar um servidor com mais solicitações do que ele pode lidar é uma estratégia usada por pessoas maliciosas para derrubar esse servidor, o que efetivamente derruba o serviço. Isso é exatamente o que é um ataque de negação de serviço (DoS).
Embora os ataques DoS possam ser defendidos dessr modo, a limitação de taxa por si só não o protegerá de uma versão sofisticada de um ataque de DoS - um ataque de DoS distribuído. Nesse caso, a distribuição significa apenas que o ataque está vindo de vários clients que parecem não estar relacionados, e não há uma maneira real de identificá-los quando controlados pelo único agente malicioso. Outros métodos precisam ser usados para se proteger contra esses ataques coordenados e distribuídos.
No entanto, a limitação de taxa é útil e popular de qualquer maneira, para casos de uso menos assustadores, como a restrição de API que mencionei. Dado como a limitação de taxa funciona, uma vez que o servidor precisa verificar as condições de limite e aplicá-las se necessário, você precisa pensar em que tipo de estrutura de dados e banco de dados deseja usar para tornar essas verificações muito rápidas, para que você não diminua o processamento da solicitação se ela estiver dentro dos limites permitidos. Além disso, se você tiver isso na memória dentro do próprio servidor, precisará garantir que todas as solicitações de um determinado client cheguem a esse servidor para que ele possa aplicar os limites adequadamente. Para lidar com situações como essa, é popular usar um serviço Redis separado, que fique fora do servidor, mas que mantenha os detalhes do usuário na memória e possa determinar rapidamente se um usuário está dentro de seus limites permitidos.
A limitação de taxa pode ser tão complicada quanto as regras que você deseja aplicar, mas a secção acima deve abranger os fundamentos e os casos de uso mais comuns.
Secção 12: mensagens e publicação-inscrição
Quando você projeta e constrói sistemas distribuídos em larga escala, é importante trocar informações entre os componentes e serviços que compõem o sistema para que ele funcione de maneira coesa e suave. No entanto, como vimos anteriormente, sistemas que dependem de redes sofrem da mesma fragilidade dessas – elas são frágeis. As redes falham e isso não é um evento incomum. Quando as redes falham, os componentes no sistema não se conseguem comunicar e podem degradar o sistema (na melhor das hipóteses) ou causar a falha total do sistema (na pior das hipóteses). Portanto, sistemas distribuídos precisam de mecanismos robustos para garantir que a comunicação continue ou seja retomada de onde parou, mesmo se houver uma "partição arbitrária" (ou seja, uma falha) entre os componentes no sistema.
Imagine, por exemplo, que você está a reservar passagens aéreas. Você encontra um bom preço, escolhe seus lugares, confirma a reserva e até paga com seu cartão de crédito. Agora você espera que o PDF do seu bilhete chegue à sua caixa de correio. Você espera, e espera, e ele nunca chega. Em algum lugar, houve uma falha no sistema que não foi tratada ou recuperada corretamente. Um sistema de reserva conecta-se frequentemente a APIs de companhias aéreas e preços para lidar com a seleção do voo, resumo das tarifas, data e hora do voo etc. Tudo isso é feito enquanto você navega pela interface de reserva do site. Não é necessário enviar o PDF dos bilhetes imediatamente. Em vez disso, a interface do usuário pode simplesmente confirmar que sua reserva foi concluída e que você pode esperar pelos bilhetes na sua caixa de entrada em breve. Essa é uma experiência de usuário razoável e comum para reservas, porque o momento do pagamento e o recebimento dos bilhetes não precisa ser em simultâneo – os dois eventos podem ser assíncronos. Um sistema assim precisa de mensagens para garantir que o serviço (ponto de extremidade do servidor) que gera os PDFs de maneira assíncrona seja notificado de uma reserva confirmada e paga, com todos os detalhes, para que o PDF possa ser gerado automaticamente e enviado. Se, contudo, o sistema de mensagens falhar, o serviço de e-mail nunca saberá sobre sua reserva e nenhum bilhete será gerado.
Publicação/inscrição de mensagens
Este é um paradigma (modelo) muito popular para mensagens. O conceito-chave é que os editores 'publicam' uma mensagem e um inscrito/assinante se inscreve nas mesmas. Para dar maior granularidade, as mensagens podem pertencer a um determinado "tópico", que é como uma categoria. Esses tópicos são como "canais" ou tubulações dedicadas, onde cada tubo lida exclusivamente com mensagens pertencentes a um tópico específico. Os assinantes escolhem em qual tópico se desejam inscrever e são notificados das mensagens desse tópico. A vantagem deste sistema é que o editor e o assinante podem estar completamente desacoplados – ou seja, eles não precisam saber um sobre o outro. O editor faz anúncios e o assinante fica atento às mensagens nos tópicos que ele procura.
Um servidor é frequentemente o editor de mensagens e geralmente existem vários tópicos (canais) nos quais as mensagens são publicadas. O consumidor de um tópico específico inscreve-se nesses tópicos. Não há comunicação direta entre o servidor (editor) e o assinante (que pode ser outro servidor). A única interação ocorre entre o editor e o tópico, e entre o tópico e o assinante.
As mensagens no tópico são apenas dados que precisam ser comunicados e podem ter a forma que você precisar. Isto dá-lhe quatro elementos em Pub/Sub: Editor, Assinante, Tópicos e Mensagens.
Melhor que um banco de dados
Então, por que se preocupar com isso? Por que não persistir todos os dados em um banco de dados e consumi-los diretamente de lá? Bem, você precisa de um sistema para perfilar as mensagens, porque cada mensagem corresponde a uma tarefa que precisa ser feita com base nos dados dessa mensagem. Portanto, no nosso exemplo de reserva de passagens, se 100 pessoas fizerem uma reserva em 35 minutos, armazenar todos esses dados no banco de dados não resolve o problema de enviar e-mails para essas 100 pessoas. Isso apenas armazena 100 transações. Os sistemas Pub/Sub lidam com a comunicação, a sequência de tarefas e as mensagens são armazenadas num banco de dados. O sistema pode oferecer recursos úteis como entrega "pelo menos uma vez" (as mensagens não serão perdidas), armazenamento persistente, ordenação de mensagens, "tentar novamente", "repetição" de mensagens etc. Sem esse sistema, apenas armazenar as mensagens no banco de dados não o ajudará a garantir que a mensagem seja entregue (consumida) e que a ação seja executada com sucesso.
Por vezes, a mesma mensagem pode ser consumida mais de uma vez por um assinante – geralmente porque a rede caiu momentaneamente e, embora o assinante tenha consumido a mensagem, ele não informou o editor. Portanto, o editor envia-la-á novamente para o assinante. É por isso que a garantia é "pelo menos uma vez" e não "uma vez e apenas uma vez". Isso é inevitável em sistemas distribuídos, porque as redes são inerentemente não confiáveis. Isso pode gerar complicações, onde a mensagem acciona uma operação no lado do assinante e essa operação pode alterar as coisas no banco de dados (alterar o estado na aplicação geral). O que ocorreria se uma única operação for repetida várias vezes, e a cada vez o estado da aplicação for alterado?
Controlar resultados – um ou mais resultados?
A solução para esse novo problema é chamada de idempotência – um conceito importante, mas não intuitivo de compreender nas primeiras vezes que você o examina. É um conceito que pode parecer complexo (especialmente se você ler a entrada da Wikipedia), então, para o propósito atual, aqui está uma simplificação amigável da StackOverflow (em inglês):
Em computação, uma operação idempotente é aquela que não tem efeito adicional se for chamada mais do que uma vez com os mesmos parâmetros de entrada.
Portanto, quando um assinante processa uma mensagem duas ou três vezes, o estado geral da aplicação é exatamente o mesmo em que ele estava após o processamento da mensagem pela primeira vez. Por exemplo, no final da reserva das passagens de avião, depois de inserir os detalhes do cartão de crédito, se você clicar em "Pagar Agora" três vezes, porque o sistema está lento... você não gostaria de pagar 3 vezes o preço da passagem, certo? Você precisa da idempotência para garantir que cada clique após o primeiro não faça outra compra e não lhe cobre mais do que uma vez. Em contrapartida, você pode postar o mesmo comentário no feed de notícias do seu melhor amigo N vezes, todos eles aparecerão como comentários separados, o que, apesar de parecer ser "irritante", não está completamente errado. Outro exemplo é oferecer "palmas" em artigos do Medium - cada "palma" deve incrementar o número de palmas, não ser apenas uma palma. Estes dois exemplos não exigem idempotência, mas o exemplo do pagamento exige.
Existem muitos tipos de sistemas de mensagens e a escolha do sistema é orientada pelo caso de uso a ser resolvido. Frequentemente, as pessoas referem-se a arquitetura baseada em eventos, o que significa que o sistema depende de mensagens sobre "eventos" (como pagar por passagens) para processar operações (como enviar o bilhete). Os serviços mencionados com mais frequência são Apache Kafka, RabbitMQ, Google Cloud Pub/Sub, AWS SNS/SQS.
Secção 13: conceitos essenciais menores
Registo
Com o tempo, o seu sistema recolherá muitos dados. A maior parte desses dados é extremamente útil. Eles podem dar-lhe uma visão da saúde do seu sistema, seu desempenho e problemas. Eles também podem fornecer informações valiosas sobre quem usa seu sistema, como o usam, com que frequência, quais as partes que são mais ou menos utilizadas, e aí por diante.
Esses dados são valiosos para análises, otimização de desempenho e melhoria do produto. Também são extremamente úteis para depuração, não apenas quando você regista na consola durante o desenvolvimento, mas também ao rastrear bugs em seus ambientes de teste e produção. Portanto, os registos ajudam na rastreabilidade e auditorias também.
O truque fundamental a reter ao fazer registos é vê-los como uma sequência de eventos consecutivos, o que significa que os dados se tornam dados de séries temporais, e as ferramentas e bancos de dados que você usa devem ser especificamente projetados para lidar com esse tipo de dados.
Monitorar
Este é o próximo passo após o registo, pois responde à pergunta "O que faço com todos esses dados de registo?". Você monitora e analisa esses dados. Você constrói ou utiliza ferramentas e serviços que analisam esses dados e apresentam painéis de controle, gráficos ou outras formas de tornar esses dados compreensíveis para seres humanos.
Armazenando os dados num banco de dados especializado e projetado para lidar com esse tipo de dados (dados de séries temporais), você pode conectar outras ferramentas que são construídas com essa estrutura de dados e intenção em mente.
Alerta
Quando você está a monitorizar ativamente, também deve estabelecer um sistema de alerta para notificá-lo de eventos significativos. Assim como ter um alerta para os preços das acções ultrapassando um determinado tecto ou abaixo de um determinado limite, certas métricas que você está acompanhando podem justificar o envio de um alerta se atingirem níveis muito altos ou muito baixos. Tempos de resposta (latência) ou erros e falhas são bons candidatos para configurar alertas se ultrapassarem um nível "aceitável".
A chave para um bom registo e monitoramento é garantir que seus dados sejam bastante consistentes ao longo do tempo, pois trabalhar com dados inconsistentes pode resultar na falta de campos que, por sua vez, quebram as ferramentas analíticas ou reduzem os benefícios do registo.
Recursos
Como prometido, deixo a seguir alguns links úteis (em inglês):
- Um fantástico repositório GitHub, recheado de conceitos, diagramas e casos de estudo
- Uma introdução de Tushar Roy ao tema Design de Sistemas
- A playlist do Youtube de Gaurav Sen
- SQL vs NoSQL
Espero que tenha gostado deste longo guia!
Se você deseja saber mais sobre minha jornada de advogado para engenheiro de software, confira o episódio 53 do podcast do freeCodeCamp e também o Episódio 207 de "Lessons from a Quitter". Eles fornecem o plano para minha mudança de carreira.
Se você está interessado em aprender a programar por si próprio, mudar de carreira e se tornar um programador profissional, ou se tornar seu próprio co-fundador técnico (texto em inglês), entre em contato aqui. Você também pode conferir o meu webinar gratuito sobre mudança de carreira para a área de programação, se isso for o que você está sonhando.