
Artigo original: Node.js Child Processes: Everything you need to know
Como usar spawn(), exec(), execFile() e fork()
Atualização: este artigo agora faz parte do livro "Node.js Beyond The Basics" do autor.
Leia a versão atualizada deste conteúdo e mais sobre o Node em jscomplete.com/node-beyond-basics (em inglês).
O desempenho sem bloqueios e em thread única do Node.js funciona muito bem para um único processo. Eventualmente, no entanto, um processo em uma CPU não será suficiente para lidar com a crescente carga de trabalho de sua aplicação.
Não importa se o seu servidor é ou não muito poderoso. Uma thread única pode suportar apenas uma carga limitada.
O fato de que o Node.js funciona em thread única não significa que não podemos tirar proveito de múltiplos processos e, é claro, de múltiplas máquinas também.
O uso de múltiplos processos é a melhor maneira de dimensionar uma aplicação do Node. O Node.js é projetado para construir aplicações distribuídas com muitos nós. É por isso que ele é chamado Node (nó, em português). A escalabilidade é parte da plataforma e não é algo em que se comece a pensar mais tarde no ciclo de vida de uma aplicação.
Este artigo é um resumo de parte do curso do autor na Pluralsight sobre o Node.js. Nele, o autor aborda conteúdo similar em formato de vídeo (em inglês).
Observe que você precisará de um bom entendimento de eventos e streams do Node.js antes de ler este artigo. Se você ainda não leu, recomendo, primeiramente, que leia estes dois outros artigos (primeiro texto em inglês):
O módulo de processos filhos
Podemos facilmente iniciar um processo filho usando o módulo child_process do Node. Esses processos filhos podem se comunicar facilmente uns com os outros usando um sistema de mensagens.
O módulo child_process nos permite acessar as funcionalidades do sistema operacional executando qualquer comando de sistema dentro de um processo filho.
Podemos controlar esse fluxo de entrada do processo filho e acompanhar seu fluxo de saída. Também podemos controlar os argumentos a serem passados para o comando do sistema operacional subjacente e podemos fazer o que quisermos com a saída desse comando. Podemos, por exemplo, usar pipes na saída de um comando como a entrada para outro (assim como fazemos no Linux), pois todas as entradas e saídas desses comandos podem ser apresentadas usando streams do Node.js.
Note que os exemplos que estarei usando neste artigo são todos baseados no Linux. No Windows, você precisará trocar os comandos que eu uso por suas alternativas do Windows.
Há quatro maneiras diferentes de se criar um processo filho no Node: spawn(), fork(), exec() e execFile().
Vamos ver as diferenças entre essas quatro funções e quando usar cada uma delas.
Processos filhos usando spawn()
A função spawn() executa um comando em um novo processo. Podemos passar a esse comando quaisquer argumentos. Por exemplo, aqui está o código para gerar um novo processo que executará o comando pwd.
const { spawn } = require('child_process');
const child = spawn('pwd');Nós simplesmente desestruturamos a função spawn() do módulo child_process e a executamos com o comando do sistema operacional como o primeiro argumento.
O resultado da execução da função spawn() (o objeto child acima) é uma instância de ChildProcess que implementa a EventEmitter API (texto em inglês). Isso significa que podemos registrar diretamente os manipuladores de eventos sobre esse objeto filho. Por exemplo, podemos fazer qualquer coisa ao término do processo filho, registrando um manipulador (em inglês, handler) para o evento exit:
child.on('exit', function (code, signal) {
console.log('processo filho encerrado com ' +
`código ${code} e sinal ${signal}`);
});O manipulador acima nos dá as saídas de code para o processo filho e o signal, se houver algum, usado para encerrar o processo filho. Essa variável signaltem o valor null quando a saída do processo filho se dá normalmente.
Os outros eventos para os quais podemos registrar os manipuladores com as instâncias de ChildProcess são disconnect, error, close e message.
- O evento
disconnecté emitido quando o processo pai chama manualmente a funçãochild.disconnect. - O evento
erroré emitido se o processo não puder ser gerado ou terminado. - O evento
closeé emitido quando a streamstdiode um processo filho se encerra. - O evento
messageé o mais importante. Ele é emitido quando o processo filho utiliza a funçãoprocess.send()para enviar mensagens. É assim que os processos pai/filho podem se comunicar uns com os outros. Veremos um exemplo disso abaixo.
Cada processo filho também recebe os três padrões da stream stdio, aos quais podemos ter acesso usando child.stdin, child.stdout e child.stderr.
Quando essas streams forem fechadas, o processo filho que as estava usando emitirá o evento close. Esse evento close é diferente do evento exit, pois múltiplos processos filhos podem compartilhar a mesma stream stdio e, portanto, a saída de um processo filho não significa que as streams tenham sido fechadas.
Como todas as streams são emissoras de eventos, podemos acompanhar diferentes eventos sobre essas streams stdio, que estão ligadas a cada processo filho. Ao contrário de um processo normal, em um processo filho, as streams stdout/stderr são streams de leitura, enquanto stdin é uma stream de escrita. Esse é, basicamente, o inverso dos tipos anteriores, como encontrado em um processo principal. Os eventos que podemos usar para essas streams são os padrões. Mais importante ainda, nas streams de leitura, podemos acompanhar o evento data, que terá a saída do comando ou qualquer erro encontrado durante a execução do comando:
child.stdout.on('data', (data) => {
console.log(`stdout filho:\n${data}`);
});
child.stderr.on('data', (data) => {
console.error(`stderr filho:\n${data}`);
});Os dois manipuladores acima registrarão os dois casos nos processos principais, stdout e stderr. Quando executarmos a função spawn, a saída do comando pwd é impresso e o processo filho termina com o código 0, o que significa que não ocorreu nenhum erro.
Podemos passar argumentos para o comando executado pela função spawn utilizando o segundo argumento da função spawn, que é um array de todos os argumentos a serem passados para o comando. Por exemplo, para executar o comando find no diretório atual com um argumento -type f (apenas para listar arquivos), podemos fazer:
const child = spawn('find', ['.', '-type', 'f']);Se ocorrer um erro durante a execução do comando – por exemplo, se dermos um destino inválido acima – o manipulador de evento data de child.stderr será acionado e o manipulador de evento exit relatará um código de saída 1, o que significa que ocorreu um erro. Os valores de erro realmente dependem do sistema operacional do host e do tipo de erro.
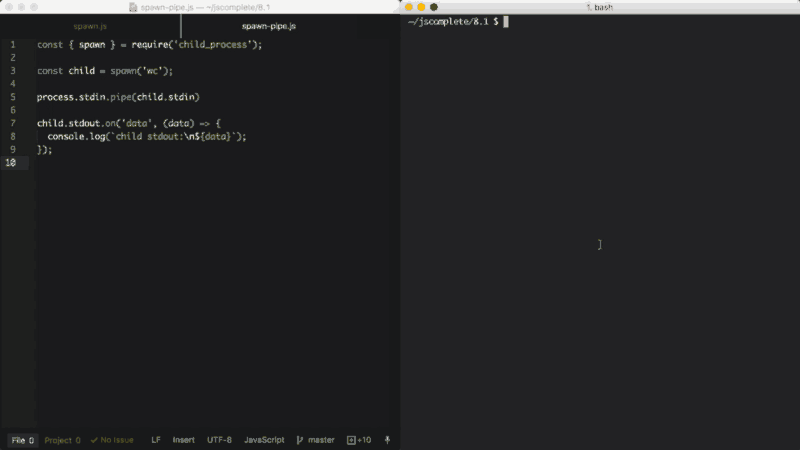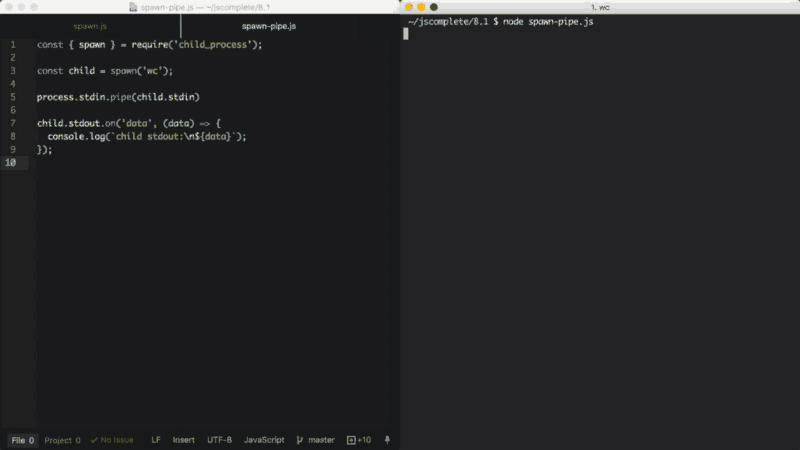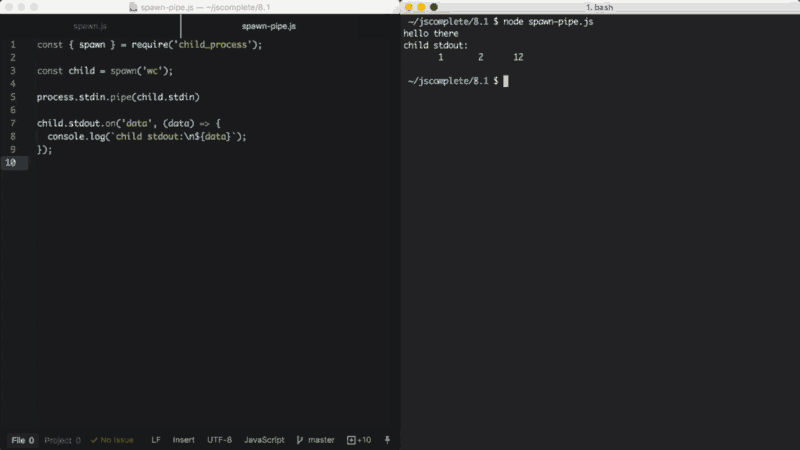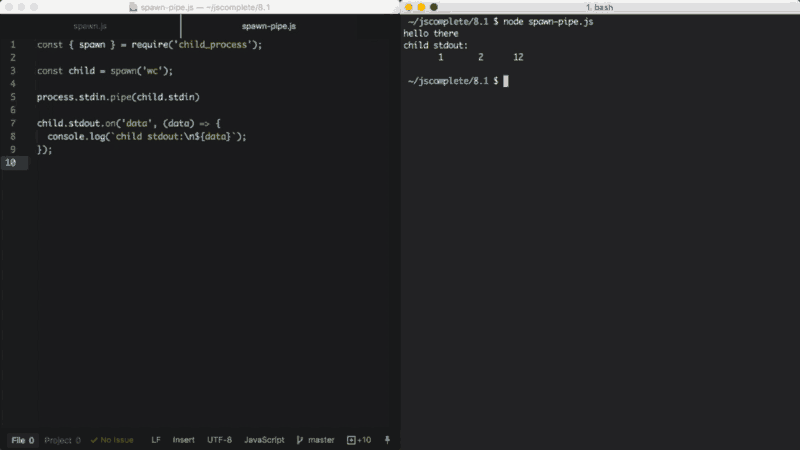
O processo filho stdin é uma stream de escrita. Podemos usá-lo para enviar um comando com alguma entrada. Assim como qualquer stream de escrita, a maneira mais fácil de consumi-la é usando a função pipe. Simplesmente usamos pipe com uma stream de leitura. Uma vez que o processo principal stdin é uma stream de leitura, podemos usar pipe com um processo filho stream stdin. Por exemplo:
const { spawn } = require('child_process');
const child = spawn('wc');
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`stdout filho:\n${data}`);
});No exemplo acima, o processo filho invoca o comando wc, que conta linhas, palavras e caracteres no Linux. Em seguida, usamos pipe com o processo principal stdin (que é uma stream de leitura) no processo filho stdin (que é uma stream de escrita). O resultado dessa combinação é que obtemos um modo de entrada padrão onde podemos digitar algo e, quando pressionamos Ctrl+D, o que digitamos será usado como entrada do comando wc.
Também podemos usar pipe na entrada/saída padrão de múltiplos processos, uns sobre os outros, assim como podemos fazer com os comandos Linux. Por exemplo, podemos usar pipe com stdout do comando find para o stdin do comando wc para contar todos os arquivos do diretório atual:
const { spawn } = require('child_process');
const find = spawn('find', ['.', '-type', 'f']);
const wc = spawn('wc', ['-l']);
find.stdout.pipe(wc.stdin);
wc.stdout.on('data', (data) => {
console.log(`Número de arquivos ${data}`);
});Eu adicionei o argumento -l no comando wc para que conte apenas as linhas. Ao ser executado, o código acima emitirá uma contagem de todos os arquivos em todos os diretórios sob o diretório atual.
Sintaxe do shell e a função exec
Por padrão, a função spawn não cria um shell para executar o comando que passamos para ele. Isso o torna um pouco mais eficiente do que a função exec, que cria um shell. A função exec tem uma outra grande diferença. Ela cria um buffer da saída gerada pelo comando e passa todo o valor de saída para uma função de retorno (em vez de usar streams, que é o que spawn faz).
Aqui está o exemplo anterior find | wc implementado com a função exec.
const { exec } = require('child_process');
exec('find . -type f | wc -l', (err, stdout, stderr) => {
if (err) {
console.error(`erro exec: ${err}`);
return;
}
console.log(`Número de arquivos ${stdout}`);
});Como a função exec usa um shell para executar o comando, podemos usar a sintaxe do shell diretamente aqui, fazendo uso do recurso pipe do shell.
Note que o uso da sintaxe do shell representa um risco de segurança (texto em inglês) se você estiver executando qualquer tipo de entrada dinâmica fornecida externamente. Um usuário pode simplesmente fazer um ataque de injeção de comando usando caracteres de sintaxe de shell como ; e $ (por exemplo, command + ’; rm -rf ~’ ).
A função exec cria buffers de saída e passa para a função de callback (o segundo argumento de exec) como um argumento stdout. Esse argumento stdout é a saída do comando que queremos imprimir.
A função exec é uma boa escolha se você precisar usar a sintaxe do shell e se o tamanho dos dados esperados do comando for pequeno (lembre-se, exec criará um buffer de todos dados inteiros em memória antes de retorná-los).
A função spawn é uma escolha muito melhor quando o tamanho dos dados esperados do comando é grande, porque esses dados serão transmitidos com os objetos padrão de entrada/saída.
Podemos fazer com que o processo filho gerado herde os objetos padrão de E/S de seus pais, se quisermos. Porém, mais importante ainda, podemos fazer com que a função spawn também use a sintaxe do shell. Aqui está o mesmo comando find | wc implementado com a função spawn:
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true
});Por causa da opção stdio: 'inherit' acima, quando executamos o código, o processo filho herda o processo principal stdin, stdout e stderr. Isso faz com que os manipuladores de eventos de dados do processo filho sejam acionados na stream principal process.stdout, fazendo com que o script dê o resultado imediatamente.
Por causa da opção shell: true acima, pudemos usar a sintaxe do shell no comando passado, exatamente como fizemos com exec. Com esse código, entretanto, ainda temos a vantagem do streaming de dados que a função spawn nos dá. Esse é, realmente, o melhor dos dois mundos.
Há algumas outras boas opções que podemos usar no último argumento para a função child_process além de shell e stdio. Podemos, por exemplo, usar a opção cwd para mudar o diretório de trabalho do script. Por exemplo, aqui está o mesmo exemplo de contagem de todos os arquivos feito com uma função spawn usando um shell e com um diretório de trabalho definido para minha pasta Downloads. A opção cwd fará com que o script conte todos os arquivos que eu tenho em ~/Downloads:
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true,
cwd: '/Users/samer/Downloads'
});Outra opção que podemos utilizar é a opção env para especificar as variáveis de ambiente que serão visíveis para o novo processo filho. O padrão para essa opção é process.env, que dá acesso a qualquer comando ao ambiente de processo atual. Se quisermos anular esse comportamento, podemos simplesmente passar um objeto vazio como a opção env ou novos valores a serem considerados como as únicas variáveis de ambiente:
const child = spawn('echo $ANSWER', {
stdio: 'inherit',
shell: true,
env: { ANSWER: 42 },
});O comando echo acima não tem acesso às variáveis de ambiente do processo pai. Ele não pode, por exemplo, acessar $HOME, mas pode acessar $ANSWER, pois esse foi passado como uma variável de ambiente personalizada através da opção env.
Uma última opção importante do processo filho a ser explicada aqui é a opção detached, que faz com que o processo filho seja executado independentemente de seus processos pais.
Assumindo que temos um arquivo timer.js, que mantém o ciclo de eventos ocupado:
setTimeout(() => {
// mantém o ciclo de eventos ocupado
}, 20000);Podemos executá-lo em segundo plano usando a opção detached:
const { spawn } = require('child_process');
const child = spawn('node', ['timer.js'], {
detached: true,
stdio: 'ignore'
});
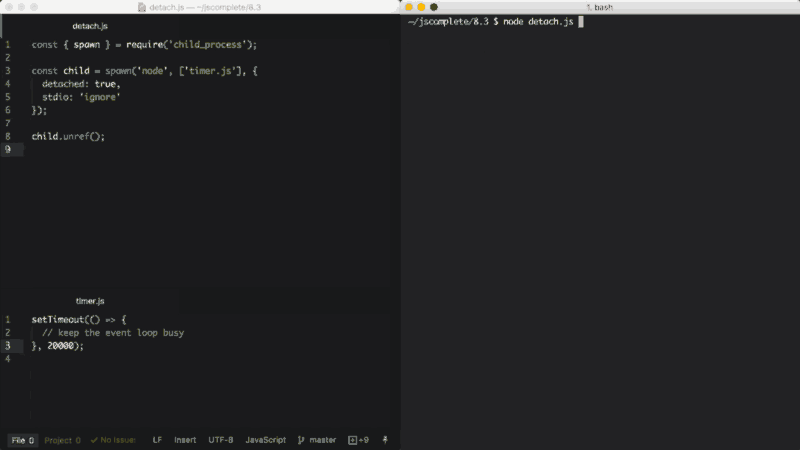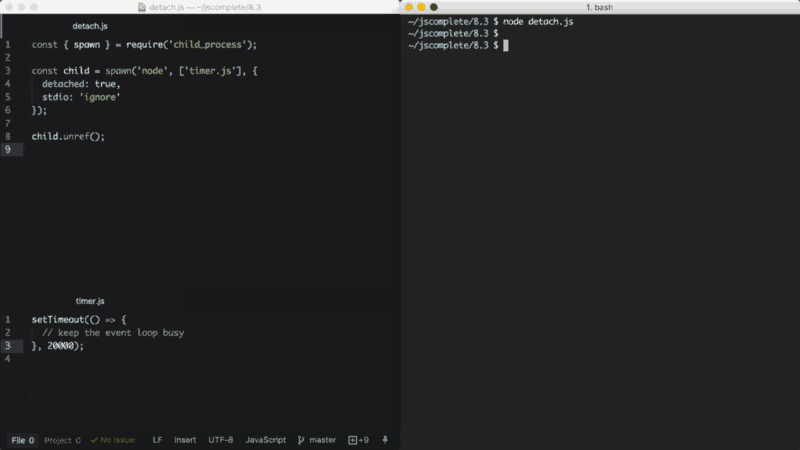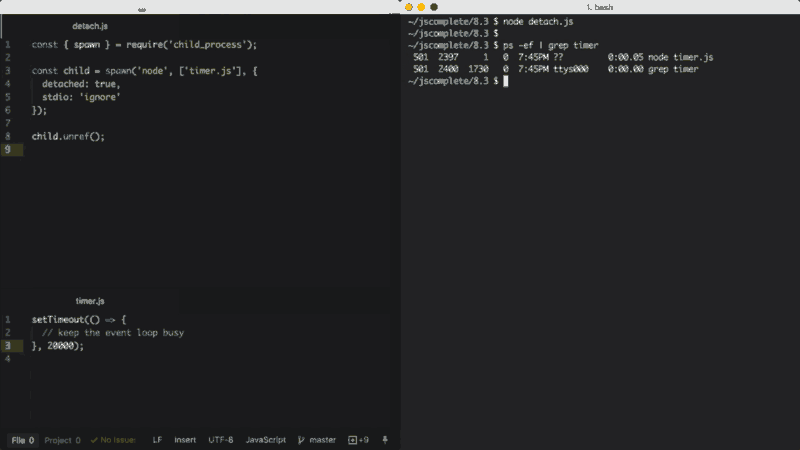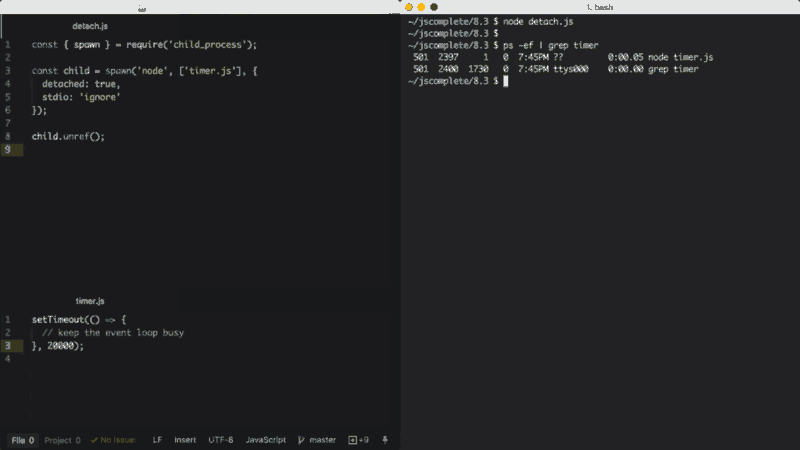
child.unref();O comportamento exato dos processos filhos em modo detached (em português, separado) depende do sistema operacional. No Windows, o processo filho em modo detached, terá sua própria janela de console, enquanto no Linux o processo filho em modo detached se tornará o líder de um novo grupo e sessão de processo.
Se a função unref é chamada no processo em modo detached, os processos pais podem sair independentemente do filho. Isso pode ser útil se o filho estiver executando um processo de longa duração, mas, para mantê-lo em segundo plano, as configurações do processo filho stdio também têm que ser independentes dos pais.
O exemplo acima executará um script (timer.js) do Node em segundo plano, separando-se e também ignorando seu pai, descritor de arquivos, stdio para que os pais possam terminar enquanto o filho continua rodando em segundo plano.
A função execFile
Se você precisar executar um arquivo sem usar um shell, a função execFile é o que você precisa. Ela se comporta exatamente como a função exec, mas não usa um shell, o que a torna um pouco mais eficiente. No Windows, alguns arquivos não podem ser executados por conta própria, como arquivos .bat ou .cmd. Esses arquivos não podem ser executados com execFile. exec ou spawn, com o shell definido como verdadeiro, é o necessário para executá-los.
A função *Sync
As funções spawn, exec e execFile do módulo child_process também têm versões de bloqueio síncronas, que aguardarão até que o processo filho termine.
const {
spawnSync,
execSync,
execFileSync,
} = require('child_process');Essas versões síncronas são potencialmente úteis ao tentar simplificar as tarefas de script ou qualquer tarefa de processamento de inicialização. Caso contrário, elas devem ser evitadas.
A função fork()
A função fork é uma variação da função spawn para geração de processos do Node. A maior diferença entre spawn e fork é que um canal de comunicação é estabelecido para o processo filho quando se usa fork, para que possamos usar a função send sobre o processo do qual o fork foi realizado juntamente com o objeto de processo process global para trocar mensagens entre os processos pai e aquele do qual se fez o fork. Fazemos isso através da interface do módulo EventEmitter. Aqui está um exemplo:
Arquivo pai, parent.js:
const { fork } = require('child_process');
const forked = fork('child.js');
forked.on('message', (msg) => {
console.log('Mensagem do filho', msg);
});
forked.send({ hello: 'world' });Arquivo filho, child.js:
process.on('message', (msg) => {
console.log('Mensagem do pai:', msg);
});
let counter = 0;
setInterval(() => {
process.send({ counter: counter++ });
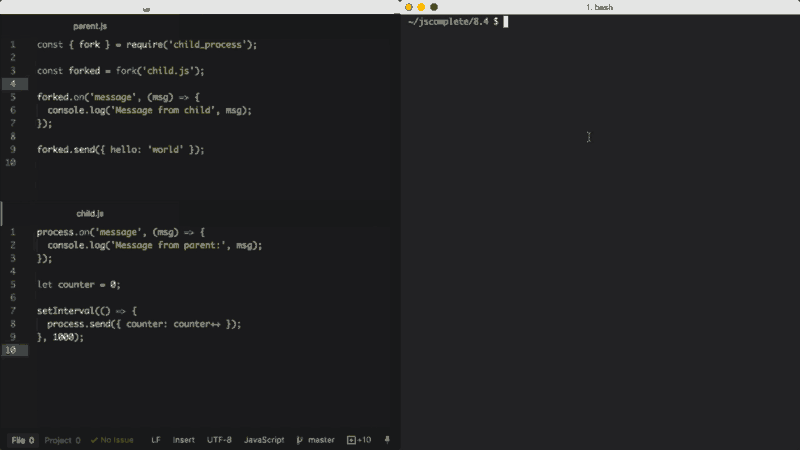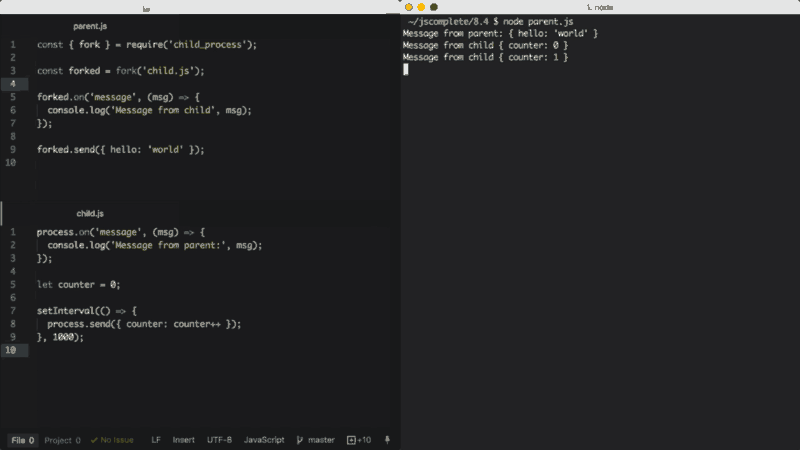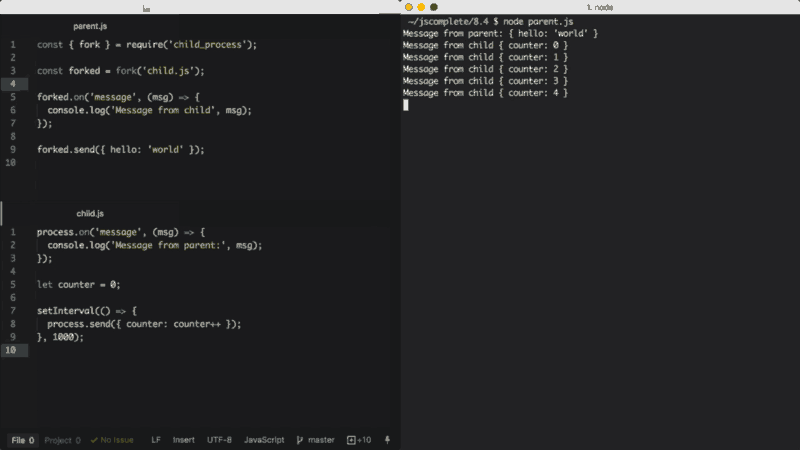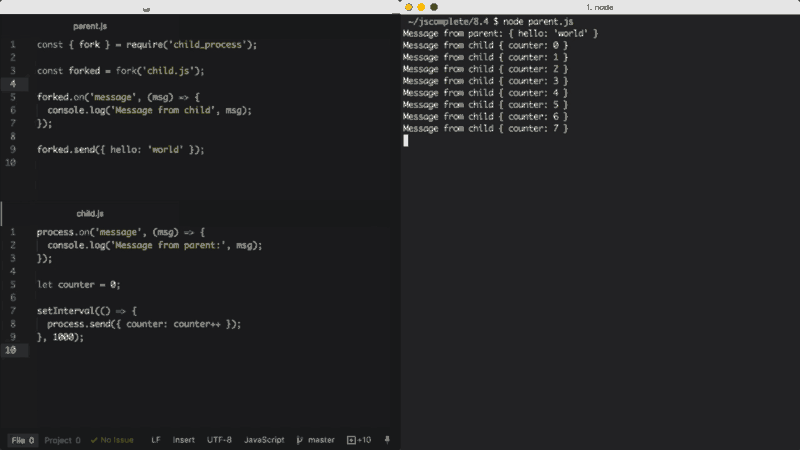
}, 1000);No arquivo pai acima, dividimos child.js (que executará o arquivo com o comando node). Depois, acompanhamos o evento message. O evento message será emitido sempre que o filho usar process.send, o que estamos fazendo a cada segundo.
Para passar mensagens dos pais para o filho, podemos executar a função send sobre o próprio objeto do qual fizemos o fork e, então, no script filho, podemos acompanhar o evento message no objeto global process.
Ao executar o arquivo parent.js acima, ele enviará primeiro o objeto { hello: 'world' } para ser impresso pelo processo filho, aquele do qual fizemos o fork, e então o processo filho enviará um valor de contador incremental a cada segundo para ser impresso pelo processo pai.
Vamos fazer um exemplo mais prático sobre a função fork.
Digamos que temos um servidor de http que lida com dois endpoints. Um desses endpoints (/compute, abaixo) é computacionalmente caro e levará alguns segundos para ser concluído. Podemos usar um laço for extenso para simular isso:
const http = require('http');
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
};
return sum;
};
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const sum = longComputation();
return res.end(`Sum is ${sum}`);
} else {
res.end('Ok')
}
});
server.listen(3000);Esse programa tem um grande problema. Quando o endpoint /compute é solicitado, o servidor não será capaz de lidar com quaisquer outras solicitações porque o laço for do evento estará ocupado com o tempo de operação.
Há algumas maneiras de se resolver esse problema, dependendo da natureza da operação longa, mas uma solução que funciona para todas as operações é simplesmente mover a operação computacional para outro processo usando fork.
Primeiro, movemos toda a função longComputation em seu próprio arquivo e invocamos essa função quando indicado através de uma mensagem do processo principal:
Em um novo arquivo, compute.js:
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
};
return sum;
};
process.on('message', (msg) => {
const sum = longComputation();
process.send(sum);
});Agora, em vez de fazer a longa operação no circuito principal de eventos do processo, podemos aplicar fork no arquivo compute.js e usar a interface de mensagens para comunicar mensagens entre o servidor e o processo dividido.
const http = require('http');
const { fork } = require('child_process');
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const compute = fork('compute.js');
compute.send('start');
compute.on('message', sum => {
res.end(`Sum is ${sum}`);
});
} else {
res.end('Ok')
}
});
server.listen(3000);Quando um pedido para /compute acontece com o código acima, simplesmente enviamos uma mensagem para o processo do qual fizemos o fork para iniciar a execução da longa operação. O ciclo de eventos do processo principal não será bloqueado.
Uma vez que o processo, com essa longa operação, é finalizado, ele pode enviar seu resultado de volta para o processo pai usando process.send.
No processo pai, esperamos o evento message no próprio processo filho. Quando tivermos esse evento, teremos um valor sum pronto para enviarmos ao usuário solicitante pelo http.
O código acima é, naturalmente, limitado pelo número de processos que podemos dividir, mas, quando o executamos e solicitamos o endpoint da longa tarefa computacional no http, o servidor principal não é bloqueado de modo algum e ele pode aceitar outras solicitações.
O módulo cluster do Node, que é o tema do meu próximo artigo, é baseado nesta ideia de processo filho em fork e no balanceamento de carga das solicitações entre os diversos forks que podemos criar em qualquer sistema.
Isso é tudo o que eu tinha para apresentar sobre este tópico. Obrigado pela leitura e até a próxima!
Está aprendendo React ou Node? Confira os livros do autor (em inglês):