

Artigo original: Requiring modules in Node.js: Everything you need to know
Atualização: este artigo agora faz parte do livro do autor, "Node.js Beyond The Basics". Leia a versão atualizada deste conteúdo (em inglês) e mais sobre o Node em jcomplete.com/node-beyond-basics .
O Node usa dois módulos principais para gerenciar as dependências de módulos:
- O módulo
require, que parece estar disponível no escopo global — não há necessidade derequire('require'). - O módulo
module, que também parece estar disponível no escopo global — não há necessidade derequire('module').
Você pode pensar no módulo require como um comando e no módulo module como um organizador de todos os módulos necessários.
Requisitar um módulo no Node não é um conceito tão complicado.
const config = require('/path/to/file');O objeto principal exportado pelo módulo require é uma função (conforme usado no exemplo acima). Quando o Node invoca essa função require() com um caminho de arquivo local como único argumento da função, o Node passa pela seguinte sequência de etapas:
- Resolver: para encontrar o caminho absoluto do arquivo.
- Carregar: para determinar o tipo de conteúdo do arquivo.
- Envolver (Wrapping): para dar ao arquivo seu escopo privado. Isso é o que torna os objetos locais
requireemodulepara cada arquivo que precisamos. - Avaliar: isso é o que a VM eventualmente faz com o código carregado.
- Colocar em cache: para que, quando precisarmos desse arquivo novamente, não passemos por todas as etapas outra vez.
Neste artigo, tentarei explicar com exemplos esses diferentes estágios e como eles afetam a maneira como escrevemos módulos no Node.
Deixe-me primeiro criar um diretório para hospedar todos os exemplos usando meu terminal:
mkdir ~/learn-node && cd ~/learn-nodeTodos os comandos no restante deste artigo serão executados de dentro do diretório ~/learn-node.
Resolvendo um caminho local
Quero apresentá-lo ao objeto module. Você pode verificá-lo em uma sessão simples do REPL:
~/learn-node $ node
> module
Module {
id: '<repl>',
exports: {},
parent: undefined,
filename: null,
loaded: false,
children: [],
paths: [ ... ] }Cada objeto de módulo recebe uma propriedade id para identificá-lo. Este id é geralmente o caminho completo para o arquivo, mas, em uma sessão REPL, ele é simplesmente <repl>.
Os módulos do Node têm uma relação de um-para-um com arquivos no sistema de arquivos. Requisitamos um módulo carregando o conteúdo de um arquivo na memória.
No entanto, como o Node permite muitas maneiras de requisitar um arquivo (por exemplo, com um caminho relativo ou um caminho pré-configurado), antes de podermos carregar o conteúdo de um arquivo na memória, precisamos encontrar a localização absoluta desse arquivo.
Quando requisitamos um módulo 'find-me', sem especificar um caminho:
require('find-me');O Node procurará find-me.js em todos os caminhos especificados por module.paths— em ordem.
~/learn-node $ node
> module.paths
[ '/Users/samer/learn-node/repl/node_modules',
'/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules',
'/Users/samer/.node_modules',
'/Users/samer/.node_libraries',
'/usr/local/Cellar/node/7.7.1/lib/node' ]A lista de caminhos é basicamente uma lista de diretórios node_modules que se encontra em cada diretório, começando do diretório atual e chegando até o diretório raiz. Ela também inclui alguns diretórios legados, cujo uso não é recomendado.
Se o Node não puder encontrar find-me.js em nenhum desses caminhos, ele lançará um erro dizendo que o módulo não foi encontrado.
~/learn-node $ node
> require('find-me')
Error: Cannot find module 'find-me'
at Function.Module._resolveFilename (module.js:470:15)
at Function.Module._load (module.js:418:25)
at Module.require (module.js:498:17)
at require (internal/module.js:20:19)
at repl:1:1
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)Se você agora criar um diretório local node_modules e colocar um find-me.js lá, a linha require('find-me') o encontrará.
~/learn-node $ mkdir node_modules
~/learn-node $ echo "console.log('I am not lost');" > node_modules/find-me.js
~/learn-node $ node
> require('find-me');
I am not lost
{}
>Se existir outro arquivo find-me.js em qualquer um dos outros caminhos – por exemplo, se tivermos um diretório node_modules no diretório inicial e se tivermos um arquivo find-me.js diferente lá:
$ mkdir ~/node_modules
$ echo "console.log('I am the root of all problems');" > ~/node_modules/find-me.jsQuando usamos require('find-me') dentro do diretório learn-node, que tem seu próprio node_modules/find-me.js, o arquivo find-me.js no diretório inicial não será carregado:
~/learn-node $ node
> require('find-me')
I am not lost
{}
>Se removermos o diretório local node_modules de ~/learn-node e se tentarmos solicitar find-me mais uma vez, o arquivo no node_modules diretório home será usado:
~/learn-node $ rm -r node_modules/
~/learn-node $ node
> require('find-me')
I am the root of all problems
{}
>Solicitando uma pasta
Os módulos não precisam ser arquivos. Também podemos criar uma pasta find-me em node_modules e colocar um arquivo index.js lá. A linha require('find-me') usará o arquivo index.js dessa pasta:
~/learn-node $ mkdir -p node_modules/find-me
~/learn-node $ echo "console.log('Found again.');" > node_modules/find-me/index.js
~/learn-node $ node
> require('find-me');
Found again.
{}
>Observe como ele ignorou o caminho do diretório inicial node_modules novamente, pois agora temos um local.
Um arquivo index.js será usado por padrão quando precisarmos de uma pasta, mas podemos controlar com qual nome de arquivo começar na pasta usando a propriedade main no package.json. Por exemplo, para fazer com que a linha require('find-me') resolva para um arquivo diferente na pasta find-me, tudo o que precisamos fazer é adicionar um arquivo package.json e especificar qual arquivo deve ser usado para resolver esta pasta:
~/learn-node $ echo "console.log('I rule');" > node_modules/find-me/start.js
~/learn-node $ echo '{ "name": "find-me-folder", "main": "start.js" }' > node_modules/find-me/package.json
~/learn-node $ node
> require('find-me');
I rule
{}
>require.resolve
Se você quiser apenas resolver o módulo e não executá-lo, você pode usar a função require.resolve. Ela se comporta exatamente da mesma forma que a função principal require, mas não carrega o arquivo. Ela ainda lançará um erro se o arquivo não existir e retornará o caminho completo para o arquivo quando encontrado.
> require.resolve('find-me');
'/Users/samer/learn-node/node_modules/find-me/start.js'
> require.resolve('not-there');
Error: Cannot find module 'not-there'
at Function.Module._resolveFilename (module.js:470:15)
at Function.resolve (internal/module.js:27:19)
at repl:1:9
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)
at emitOne (events.js:101:20)
at REPLServer.emit (events.js:191:7)
>Isso pode ser usado, por exemplo, para verificar se um pacote opcional está instalado ou não e só usá-lo quando estiver disponível.
Caminhos relativos e absolutos
Além de resolver módulos de dentro dos diretórios node_modules, também podemos colocar o módulo em qualquer lugar que quisermos e requisitá-lo com os caminhos relativos ( ./e ../) ou com caminhos absolutos começando com /.
Se, por exemplo, o arquivo find-me.js estiver em uma pasta lib em vez da pasta node_modules, podemos requisitá-lo com:
require('./lib/find-me');Relação pai-filho entre arquivos
Crie um arquivo lib/util.js e adicione uma linha console.log para identificá-lo. Além disso, faça um console.log com o próprio objeto module:
~/learn-node $ mkdir lib
~/learn-node $ echo "console.log('In util', module);" > lib/util.jsFaça o mesmo para um arquivo index.js, que executaremos com o comando node. Faça este arquivo index.js requisitar lib/util.js:
~/learn-node $ echo "console.log('In index', module); require('./lib/util');" > index.jsAgora execute o arquivoindex.js com o node:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [],
paths: [ ... ] }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: {},
parent:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [ [Circular] ],
paths: [...] },
filename: '/Users/samer/learn-node/lib/util.js',
loaded: false,
children: [],
paths: [...] }Observe como o módulo index principal (id: '.')agora está listado como pai do módulo lib/util. No entanto, o módulo lib/util não foi listado como filho do módulo index. Em vez disso, temos o valor [Circular] lá porque esta é uma referência circular. Se o Node imprimir o objeto lib/util do módulo, ele entrará em um loop infinito. É por isso que ele simplesmente substitui a referência a lib/util por [Circular].
Mais importante agora, o que acontece se o módulo lib/util requisitar o módulo index principal? É aqui que entramos no que é conhecido como dependência modular circular, que é permitida no Node.
Para entender melhor, vamos primeiro entender alguns outros conceitos sobre o objeto módulo.
exports, module.exports e carregamento síncrono de módulos
Em qualquer módulo, as exportações são um objeto especial. Se você notou acima, toda vez que imprimimos um objeto de módulo, até agora, ele tinha uma propriedade de exportação que era um objeto vazio. Podemos adicionar qualquer atributo a este objeto especial de exportação. Por exemplo, vamos exportar um atributo id para index.js e lib/util.js:
// Adicione a linha a seguir na parte superior do lib/util.js
exports.id = 'lib/util';
// Adicione a linha a seguir na parte superior do index.js
exports.id = 'index';Quando executarmos index.js, veremos esses atributos gerenciados no objeto module de cada arquivo:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: { id: 'lib/util' },
parent:
Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... },
loaded: false,
... }Eu removi alguns atributos na saída acima para mantê-la pequena, mas observe como o objeto exports agora tem os atributos que definimos em cada módulo. Você pode colocar quantos atributos quiser nesse objeto de exportação e, na verdade, pode alterar todo o objeto para outra coisa. Por exemplo, para alterar o objeto de exportação para que seja uma função em vez de um objeto, fazemos o seguinte:
// Adicione a linha a seguir no index.js antes do console.log
module.exports = function() {};Ao executar index.js agora, você verá como o objeto exports é uma função:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: [Function],
loaded: false,
... }Observe como não fizemos exports = function() {} para transformar o objeto exports em uma função. Na verdade, não podemos fazer isso porque a variável exports dentro de cada módulo é apenas uma referência à module.exports que gerencia as propriedades exportadas. Quando atribuímos novamente a variável exports, essa referência é perdida e estaríamos introduzindo uma nova variável em vez de alterar o objeto module.exports.
O objeto module.exports em cada módulo é o que a função require retorna quando precisamos desse módulo. Por exemplo, altere a linha require('./lib/util') no index.js para:
const UTIL = require('./lib/util');
console.log('UTIL:', UTIL);O código acima vai capturar as propriedades exportadas lib/util para a constante UTIL. Quando executarmos index.js agora, a última linha produzirá:
UTIL: { id: 'lib/util' }Vamos também falar sobre o atributo loaded em cada módulo. Até agora, toda vez que imprimimos um objeto de módulo, vimos um atributo loaded nesse objeto com um valor de false.
O módulo module usa o atributo loaded para rastrear quais módulos foram carregados (valor true) e quais módulos ainda estão sendo carregados (valor false). Podemos, por exemplo, ver o módulo index.js totalmente carregado se imprimirmos seu objeto module no próximo ciclo do loop de eventos usando uma chamada a setImmediate:
// No index.js
setImmediate(() => {
console.log('The index.js module object is now loaded!', module)
});A saída disso seria:
The index.js module object is now loaded! Module {
id: '.',
exports: [Function],
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: true,
children:
[ Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: [Object],
parent: [Circular],
filename: '/Users/samer/learn-node/lib/util.js',
loaded: true,
children: [],
paths: [Object] } ],
paths:
[ '/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules' ] }Observe como neste console.log posterior lib/util.js e index.js estão totalmente carregados.
O objeto exports fica completo quando o Node termina de carregar o módulo (e o rotula assim). Todo o processo de solicitação/carregamento de um módulo é síncrono. É por isso que conseguimos ver os módulos totalmente carregados após um ciclo do loop de eventos.
Isso também significa que não podemos alterar o objeto exports de forma assíncrona. Não podemos, por exemplo, fazer o seguinte em nenhum módulo:
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err;
exports.data = data; // Will not work.
});Dependência do módulo circular
Vamos agora tentar responder a uma questão importante sobre dependência circular no Node: o que acontece quando o módulo 1 requer o módulo 2 e o módulo 2 requer o módulo 1?
Para descobrir, vamos criar os dois arquivos a seguir em lib/, module1.js e module2.js, e fazer com que eles solicitem um ao outro:
// lib/module1.js
exports.a = 1;
require('./module2');
exports.b = 2;
exports.c = 3;
// lib/module2.js
const Module1 = require('./module1');
console.log('Module1 is partially loaded here', Module1);Quando rodamos module1.js vemos o seguinte:
~/learn-node $ node lib/module1.js
Module1 is partially loaded here { a: 1 }Requisitamos module2 antes que module1 fosse totalmente carregado e, como module2 solicitou module1 enquanto não estava totalmente carregado, o que obtemos do objeto exports nesse ponto são todas as propriedades exportadas antes da dependência circular. Apenas a propriedade a foi informada, pois tanto b quanto c foram exportadas após module2 ter solicitado e mostrado o resultado de module1.
O Node mantém isso muito simples. Durante o carregamento de um módulo, ele constrói o objeto exports. Você pode requisitar o módulo antes de terminar de carregar e obterá apenas um objeto de exportação parcial com o que foi definido até agora.
Complementos JSON e C/C++
Podemos requisitar nativamente arquivos JSON e arquivos de complemento C++ com a função require. Você nem precisa especificar uma extensão de arquivo para fazer isso.
Se uma extensão de arquivo não foi especificada, a primeira coisa que o Node tentará resolver é um arquivo .js. Se não encontrar um arquivo .js, ele tentará achar um arquivo .json e analisará o arquivo .json se o encontrar como um arquivo de texto JSON. Depois disso, ele tentará encontrar um arquivo .node binário. No entanto, para remover a ambiguidade, você provavelmente deve especificar uma extensão de arquivo ao requisitar algo além de arquivos .js.
A exigência de arquivos JSON é útil se, por exemplo, tudo o que você precisa para gerenciar nesse arquivo são alguns valores de configuração estática ou alguns valores que você lê periodicamente de uma fonte externa. Por exemplo, se tivéssemos o seguinte arquivo config.json:
{
"host": "localhost",
"port": 8080
}Podemos solicitá-lo diretamente assim:
const { host, port } = require('./config');
console.log(`Server will run at http://${host}:${port}`);A execução do código acima terá esta saída:
Server will run at http://localhost:8080Se o Node não encontrar um arquivo .js ou um arquivo .json, ele procurará um arquivo .node e interpretará o arquivo como um módulo complementar compilado.
O site de documentação do Node tem um arquivo complementar de exemplo escrito em C++. É um módulo simples que expõe uma função hello() e a função hello gera “world”.
Você pode usar o pacote node-gyp para compilar e criar o arquivo .cc em um arquivo .node. Você só precisa configurar um arquivo binding.gyp para dizer ao node-gyp o que fazer.
Depois de ter o arquivo addon.node (ou qualquer nome que você especificar em binding.gyp), você poderá requisitá-lo nativamente como qualquer outro módulo:
const addon = require('./addon');
console.log(addon.hello());Na verdade, podemos ver o suporte das três extensões olhando para require.extensions.
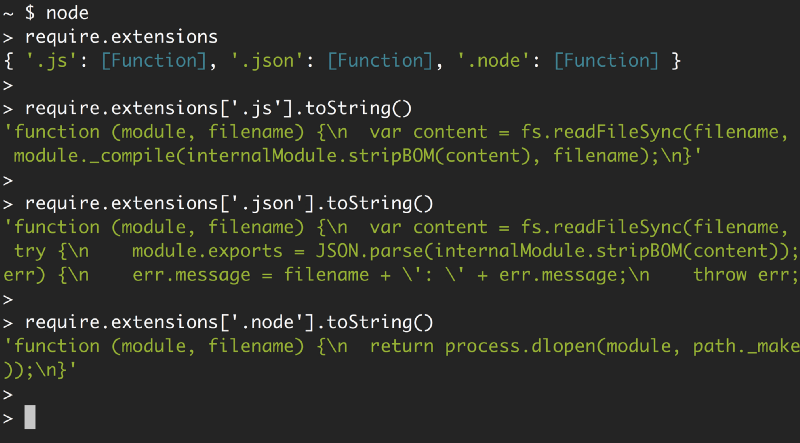
Observando as funções de cada extensão, você pode ver claramente o que o Node fará com cada uma. Ele usa module._compile para arquivos .js, JSON.parse para arquivos .json e process.dlopen para arquivos .node.
Todo o código que você escreve no Node será envolvido por funções
O encapsulamento de módulos do Node geralmente é mal compreendido. Para entendê-lo, deixe-me lembrá-lo sobre a relação exports/module.exports.
Podemos usar o objeto exports para exportar propriedades, mas não podemos substituir o objeto exports diretamente, porque é apenas uma referência a module.exports.
exports.id = 42; // Isto está ok.
exports = { id: 42 }; // Isso não funcionará.
module.exports = { id: 42 }; // Isto está ok.Como exatamente esse objeto exports, que parece ser global para cada módulo, é definido como uma referência no objeto module?
Deixe-me fazer mais uma pergunta antes de explicar o processo de encapsulamento do Node.
Em um navegador, quando declaramos uma variável em um script como este:
var answer = 42;Essa variável answer estará disponível globalmente em todos os scripts após o script que a definiu.
Este não é o caso do Node. Quando definimos uma variável em um módulo, os outros módulos do programa não terão acesso a essa variável. Então, como as variáveis no Node têm escopo mágico?
A resposta é simples. Antes de compilar um módulo, o Node envolve o código do módulo em uma função, que podemos inspecionar usando a propriedade wrapper (que poderia ser traduzida como "invólucro", ou "envelope") do módulo module.
~ $ node
> require('module').wrapper
[ '(function (exports, require, module, __filename, __dirname) { ',
'\n});' ]
>O Node não executa nenhum código que você escreve em um arquivo diretamente. Ele executa esta função wrapper que terá seu código em seu corpo. Isso é o que mantém as variáveis de nível superior definidas em qualquer módulo com escopo para esse módulo.
Esta função wrapper tem 5 argumentos: exports, require, module, __filename e __dirname. É isso que os faz parecerem globais quando na verdade são específicos para cada módulo.
Todos esses argumentos obtêm seus valores quando o Node executa a função wrapper. exports é definida como uma referência a module.exports antes disso. require e module são específicas para a função a ser executada, enquanto as variáveis __filename/__dirname conterão o nome de arquivo absoluto do módulo encapsulado e o caminho do diretório.
Você pode ver esse encapsulamento em ação se executar um script com um problema em sua primeira linha:
~/learn-node $ echo "euaohseu" > bad.js
~/learn-node $ node bad.js
~/bad.js:1
(function (exports, require, module, __filename, __dirname) { euaohseu
^
ReferenceError: euaohseu is not definedObserve como a primeira linha do script, conforme relatado acima, era a função wrapper, não a referência incorreta.
Além disso, como cada módulo é envolvido em uma função, podemos acessar os argumentos dessa função com a palavra-chave arguments:
~/learn-node $ echo "console.log(arguments)" > index.js
~/learn-node $ node index.js
{ '0': {},
'1':
{ [Function: require]
resolve: [Function: resolve],
main:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [Object] },
extensions: { ... },
cache: { '/Users/samer/index.js': [Object] } },
'2':
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [ ... ] },
'3': '/Users/samer/index.js',
'4': '/Users/samer' }O primeiro argumento é o objeto exports, que começa vazio. Então temos os objetos require/module, que são instâncias associadas ao arquivo index.js em execução. Não são variáveis globais. Os últimos 2 argumentos são o caminho do arquivo e o caminho do diretório.
O valor de retorno da função de encapsulamento é module.exports. Dentro da função encapsulada, podemos usar o objeto exports para alterar as propriedades de module.exports, mas não podemos reatribuir as próprias exportações porque é apenas uma referência.
O que acontece equivale aproximadamente a:
function (require, module, __filename, __dirname) {
let exports = module.exports;
// Seu código aqui...
return module.exports;
}Se alterarmos o objeto exports inteiro, ele não será mais uma referência a module.exports. É assim que os objetos de referência do JavaScript funcionam em todos os lugares, não apenas neste contexto.
O objeto necessário
Não há nada de especial em require. É um objeto que atua principalmente como uma função que recebe um nome de módulo ou caminho e retorna o objeto module.exports. Podemos simplesmente substituir o objeto require com nossa própria lógica, se quisermos.
Por exemplo, talvez para fins de teste, queremos que cada chamada de require seja simulada por padrão e apenas retorne um objeto falso em vez do objeto de exportação de módulo necessário. Essa simples reatribuição de require resolverá o problema:
require = function() {
return { mocked: true };
}Depois de fazer a reatribuição de require, cada chamada a require('something') no script retornará apenas o objeto simulado.
O objeto require também possui propriedades próprias. Vimos a propriedade resolve, que é uma função que executa apenas a etapa de resolução do processo require. Também vimos require.extensions acima.
Há também require.main, que pode ser útil para determinar se o script está sendo necessário ou executado diretamente.
Digamos, por exemplo, que temos esta função simples printInFrame em print-in-frame.js:
// Em print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};A função recebe um argumento numérico size e um argumento string header e imprime esse cabeçalho em um quadro de estrelas controlado pelo tamanho que especificamos.
Queremos usar este arquivo de duas maneiras:
- A partir da linha de comando diretamente, assim:
~/learn-node $ node print-in-frame 8 HelloPassando 8 e Hello como argumentos de linha de comando para imprimir "Hello" em um quadro de 8 estrelas.
2. Com require. Supondo que o módulo necessário exportará a função printInFrame, podemos simplesmente chamá-la:
const print = require('./print-in-frame');
print(5, 'Hey');Para imprimir o cabeçalho "Hey" em um quadro de 5 estrelas.
São dois usos diferentes. Precisamos de uma maneira de determinar se o arquivo está sendo executado como um script autônomo ou se está sendo requisitado por outros scripts.
É aqui que podemos usar esta instrução if simples:
if (require.main === module) {
// O arquivo está sendo executado diretamente (sem o require)
}Assim, podemos usar esta condição para satisfazer os requisitos de uso acima invocando a função printInFrame de forma diferente:
// Em print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};
if (require.main === module) {
printInFrame(process.argv[2], process.argv[3]);
} else {
module.exports = printInFrame;
}Quando o arquivo não está sendo requerido, apenas chamamos a função printInFrame com elementos process.argv. Caso contrário, apenas alteramos o module.exports para ser a própria função printInFrame.
Todos os módulos serão armazenados em cache
O cache é importante para entender. Deixe-me usar um exemplo simples para demonstrá-lo.
Digamos que você tenha o seguinte arquivo ascii-art.js que imprime um cabeçalho:

Queremos exibir esse cabeçalho toda vez que precisarmos do arquivo. Então, quando requisitamos o arquivo duas vezes, queremos que o cabeçalho apareça duas vezes.
require('./ascii-art') // mostrará o cabeçalho.
require('./ascii-art') // não mostrará o cabeçalho.O segundo require não mostrará o cabeçalho devido ao cache dos módulos. O Node armazena em cache a primeira chamada e não carrega o arquivo na segunda chamada.
Podemos ver esse cache imprimindo require.cache após o primeiro require. O registro de cache é simplesmente um objeto que possui uma propriedade para cada módulo necessário. Esses valores de propriedades são os objetos module usados para cada módulo. Podemos simplesmente excluir uma propriedade desse objeto require.cache para invalidar esse cache. Se fizermos isso, o Node recarregará o módulo para recarregá-lo em cache.
No entanto, esta não é a solução mais eficiente para este caso. A solução simples é envolver a linha de log ascii-art.js com uma função e exportar essa função. Dessa forma, quando solicitamos o arquivo ascii-art.js, obtemos uma função que podemos executar para invocar a linha de log todas as vezes:
require('./ascii-art')() // mostrará o cabeçalho.
require('./ascii-art')() // também mostrará o cabeçalho.Isso era o que eu tinha para falar sobre este tópico. Obrigado pela leitura e até a próxima!
Aprendendo React ou Node? Confira os livros do autor (em inglês):