
By BerkeleyTrue
Free Code Camp’s data has been doubling each month, thanks to a flood of highly-active campers. This rising tide of data has exposed several weaknesses in our codebase.
What started out 15 months ago as a small effort has since grown into a vibrant open source community. Nearly 300 contributors have stepped in to help us rapidly build features.
As usual, maintaining that break-neck speed of development comes at a price. We’ve incurred a lot of technical debt.
Taking on technical debt is like playing Jenga — you can build your tower taller and taller, but at a cost of stability. Sooner or later, you have to pay down your technical debt, or your tower will come crashing down.

Last week, our technical debt come back to bite us in our back end — both literally and figuratively.
During peak times, our MongoDB servers maxed out their capacity, and the rate at which they sent data back and forth to our Node servers slowed to a crawl. We needed fix this, and fast. But first, we had to figure out what was causing the issue to begin with.
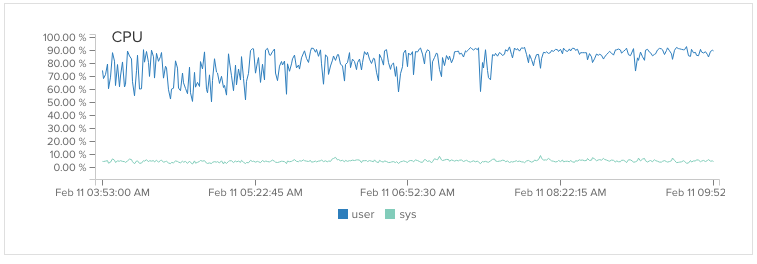 Our MongoDB Pegging the CPU
Our MongoDB Pegging the CPU
We originally wrote most of our back end in a bleary-eyed crunch mode. We didn’t take the time to optimize our queries. Instead we chose to focus on features that we thought would more immediately impact our user experience.
We audited our codebase and found a lot of frequent, inefficient writes to our databases. For instance, every time a camper completed a challenge, we would make the appropriate changes to their user instance, then call the “save” action. This caused the entire user object to be sent from our Node servers to our MongoDB servers, which then had to reconcile all of the data.
This wasn’t a problem initially, because most of our user objects where small. But as we added features, user objects ballooned in size, causing lots more data to flow back and forth.
We also used to save every solution that a camper submitted. This resulted in even larger completedChallenge arrays, which further exacerbated the back-and-forth.
On top of that, this meant some campers had to search through multiple solutions for the same challenge to find the one they wanted to reference. While this may have been interesting exercise for some, it was a distraction from actually coding and building projects.
Our fix involved taking two steps:
- finding the heavily trafficked API endpoints that caused the database write, and changing them from a “save” action to an “update” action (which minimizes the volume of data sent over the wire).
- transitioning the way we store completed challenges away from a giant array, and over to a key-value map.
This way, a camper could only have one solution for each challenge. This dramatically reduced the size of the completedChallenges object.
We pushed up our fix in the middle of a Thursday afternoon, even though we had about 400 concurrent campers at the time. It was a gamble, but it paid off. We immediately saw an improvement in our CPU usage.
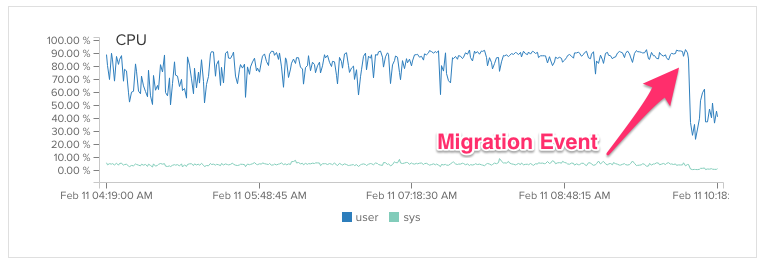 The immediate result
The immediate result
The big takeaway is this: if your application seems to be getting slower, there’s a good chance that this is caused by inefficient database queries.
If you can find these and fix them, you’ll be able to postpone expensive expansions to your infrastructure, while maintaining the speed your users have come to expect.