
Natural Language Processing may have come a little late to the AI game, but companies like Google and OpenAI are working wonders with NLP techniques these days.
These companies have released state-of-the-art language models like BERT and GPT-2 and GPT-3. And GitHub Copilot and OpenAI codex are among some of the popular applications that are in the news lately.
As someone who has had very limited exposure to NLP, I decided to take it up as an area of research so I can learn more about it. My next few articles and videos will focus on sharing what I learn after dissecting some important components of NLP.
Main Components of NLP
NLP systems have three main components that help machines understand natural language:
Tokenization
Embedding
Model architectures
Top Deep Learning models like BERT, GPT-2, and GPT-3 all share the same components but with different architectures that distinguish one model from another.
In this article (and the notebook that accompanies it), we are going to focus on the basics of the first component of an NLP pipeline which is tokenization. It's an often overlooked concept, but it is a field of research in itself.
We have come so far from the traditional NLTK tokenization process. And though we have state-of-the-art algorithms for tokenization, it's always a good practice to understand its evolution and how we got to where we are now.
So, here's what we'll cover:
What is tokenization?
Why do we need a tokenizer?
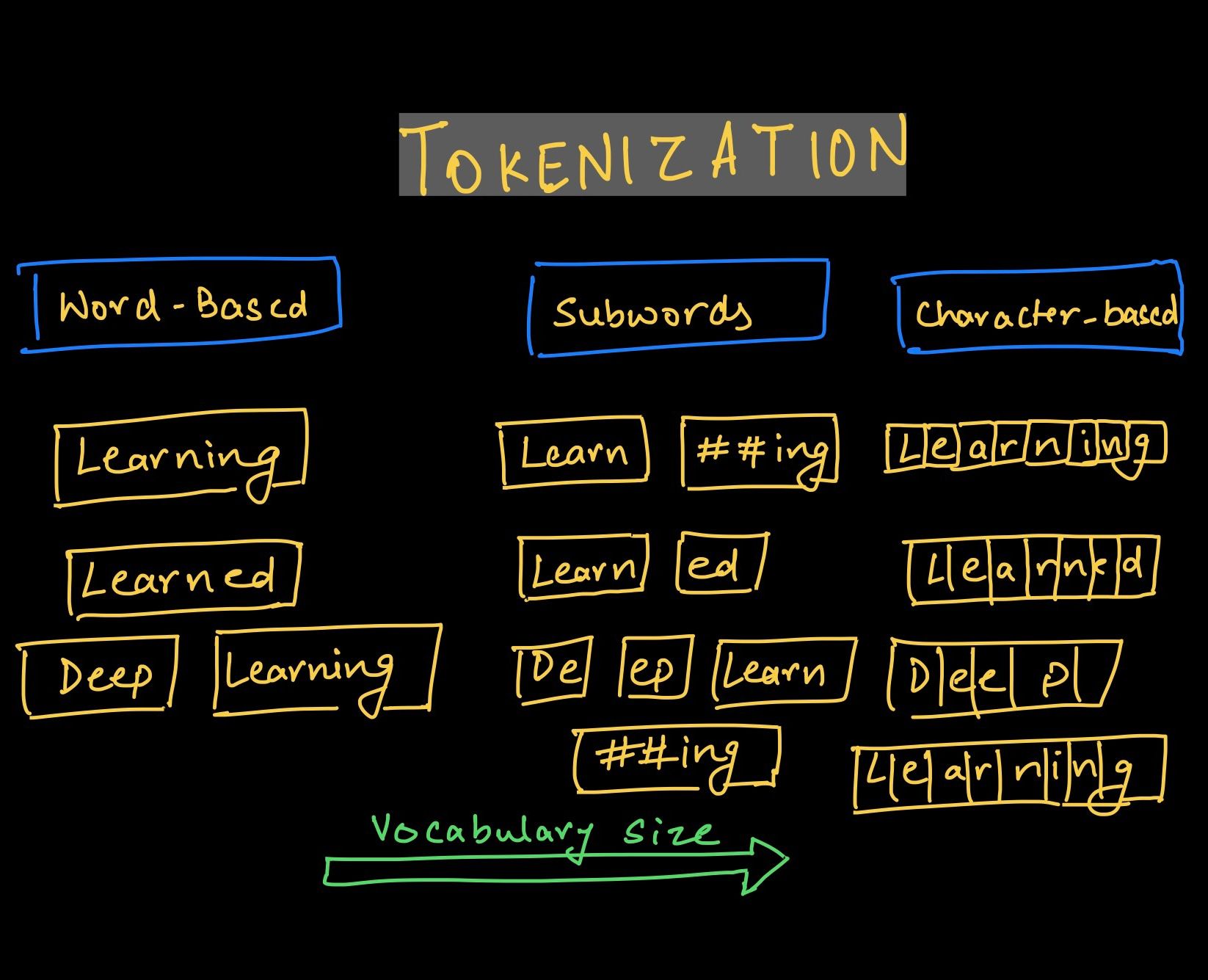
Types of tokenization – Word, Character, and Subword.
Byte Pair Encoding Algorithm - a version of which is used by most NLP models these days.
The next part of this tutorial will dive into more advanced (or enhanced versions of Byte Pair Encoding) algorithms:
Unigram Algorithm
WordPiece – BERT transformer
SentencePiece – End-to-End tokenizer system
What is Tokenization?
Tokenization is the process of representing raw text in smaller units called tokens. These tokens can then be mapped with numbers to further feed to an NLP model.
Here's an overly simplified example of what a tokenizer does:
## read the text and enumerate the tokens in the text
text = open('example.txt', 'r').read(). # read a text file
words = text.split(" ") # split the text on spaces
tokens = {v: k for k, v in enumerate(words)} # generate a word to index mapping

Here, we have simply mapped every word in the text to a numerical index. This is, of course, a very simple example and we have not considered grammar, punctuation, or compound words (like test, test-ify, test-ing, and so on).
So we need a more technical and accurate definition of tokenization for our work here. To take into account all punctuation and every related word, we need to start working at the character level.
There are multiple applications of tokenization. One of the use cases comes from compiler design where you might need to parse computer programs to convert raw characters into keywords of a programming language.
In deep learning, tokenization is the process of converting a sequence of characters into a sequence of tokens which further needs to be converted into a sequence of numerical vectors that can be processed by a neural network.
Why do we need a Tokenizer?
The need for a tokenizer came from the question "How can we make machines read?"
A common way of processing textual data is to define a set of rules in a dictionary and then look up that fixed dictionary of rules. But this method can only go so far, and we want machines to learn these rules from the text that it reads.
Now, machines don't know any language, nor do they understand sound or phonetics. They need to be taught from scratch and in such a way that they can read any language that's out there.
Quite a task, right?
Humans learn a language by connecting sound to the meaning and then we learn to read and write in that language. Machines can't do that, so they need to be given the most basic units of text to start processing the text.
That's where tokenization comes into play. It breaks down the text into smaller units called "tokens".
And there are different ways of tokenizing text which is what we'll learn now.
Different ways to tokenize text
To make the deep learning model learn from the text, we need a two-step process:
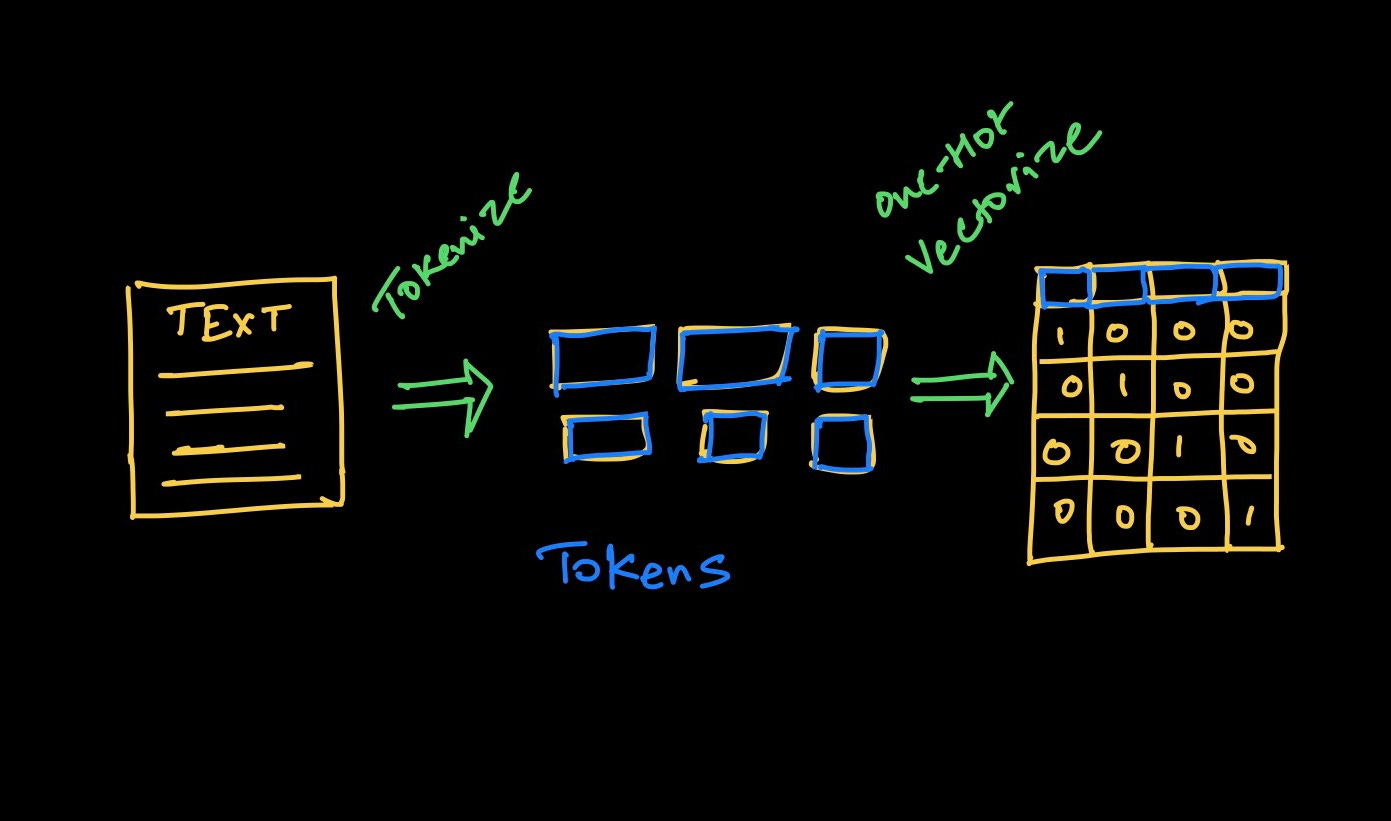
Tokenize – decide the algorithm we'll use to generate the tokens.
Encode the tokens to vectors
Word-based tokenization
As the first step suggests, we need to decide how to convert text into small tokens. A simple and straightforward method that most of us would propose is to use word-based tokens, splitting the text by spaces.
Problems with Word tokenizer
There's a high risk of missing words in the training data. With word tokens, your model won't recognize the variants of words that were not part of the data on which the model was trained.
So, if your model has seen foot and ball in the training data but the final text has football, the model won't be able to recognize the word and it will be treated with an <UNK> token.
Similarly, punctuation poses another problem. For example, let or let's will need individual tokens which is an inefficient solution. This will require a huge vocabulary to make sure you've thought of every variant of the word.
Even if you add a lemmatizer to solve this problem, you're adding an extra step in your processing pipeline.
It's also tough to handle slang and abbreviations. We use lots of slang and abbreviations in text these days, such as "FOMO", "LOL", "tl;dr" and so on. What do we do for these words?
Finally, what if the language doesn't use spaces for segmentation? For a language like Chinese, which doesn't use spaces for word separation, this tokenizer will fail completely.
After encountering these problems, researchers looked into another approach which involved tokenizing all the characters.
Character-based tokenization
To resolve the problems associated with word-based tokenization, data scientists tried an alternative approach of character-by-character tokenization.
This did solve the problem of missing words, as now we are dealing with characters that can be encoded using ASCII or Unicode. Now it could generate embedding for any word.
Every character, whether it was a space, apostrophe, colon, or whatever can now be assigned a symbol to generate a sequence of vectors.
But this approach had its own cons.
Problems with character-based models
First, this approach requires more computing resources. Character-based models will treat each character as a token. And more tokens means more input computations to process each token which in turn requires more compute resources.
For example, for a 5-word long sentence, you may need to process 30 tokens instead of 5 word-based tokens.
Also, it narrows down the number of NLP tasks and applications. With long sequences of characters, you can only use a certain type of neural network architecture.
This limits the type of NLP tasks we can perform. For applications like entity recognition or text classification, character-based encoding might turn out to be an inefficient approach.
Finally, there's a risk of learning incorrect semantics. Working with characters could generate incorrect spellings of words. Also, with no inherent meaning, learning with characters is like learning with no meaningful semantics.
What's fascinating is that for such a seemingly simple task, multiple algorithms have been written to find the optimal tokenization policy.
After understanding the pros and cons of these tokenization methods, it makes sense to look for an approach that offers a middle route. We'll want one that preserves the semantics with limited vocabulary that can generate all the words in the text on merging.
Subword Tokenization
With character-based models, we risk losing the semantic features of the word. And with word-based tokenization, we need a very large vocabulary to encompass all the possible variations of every word.
So, the goal was to develop an algorithm that could:
Retain the semantic features of the token, that is information per token.
Tokenize without demanding a very large vocabulary with a finite set of words.
To solve this problem, you can think of breaking down the words based on a set of prefixes and suffixes. For example, we can write a rule-based system to identify subwords like "##s", "##ing", "##ify", "un##" and so on, where the position of the double hash denotes prefix and suffixes.
So, a word like "unhappily" is tokenized using subwords like "un##", "happ", and "##ily".
The model only learns relatively few subwords and then puts them together to create other words. This solves the problems of memory requirement and effort required to create a large vocabulary.
Problems with the subword tokenization algorithm:
First of all, some of the subwords that are created as per the defined rules may never appear in your text to tokenize and may end up occupying extra memory.
Also, for every language, we'll need to define a different set of rules to create subwords.
To alleviate this problem, in practice, most modern tokenizers have a training phase that identifies the recurring text in the input corpus and creates new subword tokens. For rare patterns, we stick to word-based tokens.
Another important factor that plays a vital role in this process is the size of the vocabulary that the user sets. A large vocabulary size allows for more common words to be tokenized, whereas smaller vocabulary requires more subwords to be created to create every word in the text without using the <UNK> token.
Striking the right balance for your application is key here.
Byte Pair Encoding (BPE) Algorithm
BPE was originally a data compression algorithm that you use to find the best way to represent data by identifying the common byte pairs. We now use it in NLP to find the best representation of text using the smallest number of tokens.
Here's how it works:
Add an identifier (
</w>) at the end of each word to identify the end of a word and then calculate the word frequency in the text.Split the word into characters and then calculate the character frequency.
From the character tokens, for a predefined number of iterations, count the frequency of the consecutive byte pairs and merge the most frequently occurring byte pairing.
Keep iterating until you have reached the iteration limit (set by you) or until you have reached the token limit.
Let's go through each step (in the code) for some sample text. For coding this, I have taken help from Lei Mao's very minimalistic blog on BPE. I encourage you to check it out!
Step 1: Add word identifiers and calculate word frequency
Here's our sample text:
"There is an 80% chance of rainfall today. We are pretty sure it is going to rain."
## define the text first
text = "There is an 80% chance of rainfall today. We are pretty sure it is going to rain."
## get the word frequency and add the end of word (</w>) token ## at the end of each word
words = text.strip().split(" ")
print(f"Vocabulary size: {len(words)}")

Step 2: Split the word into characters and then calculate the character frequency
char_freq_dict = collections.defaultdict(int)
for word, freq in word_freq_dict.items():
chars = word.split()
for char in chars:
char_freq_dict[char] += freq
char_freq_dict

Step 3: Merge the most frequently occurring consecutive byte pairings
import re
## create all possible consecutive pairs
pairs = collections.defaultdict(int)
for word, freq in word_freq_dict.items():
chars = word.split()
for i in range(len(chars)-1):
pairs[chars[i], chars[i+1]] += freq

Step 4 - Iterate n times to find the best (in terms of frequency) pairs to encode and then concatenate them to find the subwords
It is better at this point to structure our code into functions. This means that we need to perform the following steps:
Find the most frequently occurring byte pairs in each iteration.
Merge these tokens.
Recalculate the character tokens' frequency with the new pair encoding added.
Keep doing this until there are no more pairs or you reach the end of the for a loop.
For detailed code, you should check out my Colab notebook.
Here’s a trimmed output of those 4 steps:

So as we iterate with each best pair, we merge (concatenate) the pair. You can see that as we recalculate the frequency, the original character token frequency is reduced and the new paired token frequency pops up in the token dictionary.
If you look at the number of tokens created, it first increases because we create new pairings – but the number starts to decrease after a number of iterations.
Here, we started with 25 tokens, went up to 31 tokens in the 14th iteration, and then came down to 16 tokens in the 50th iteration. Interesting, right?
How to improve the BPE algorithm
BPE algorithm is a greedy algorithm, which means that it tries to find the best pair in each iteration. And there are some limitations to this greedy approach.
So of course there are pros and cons of the BPE algorithm, too.
The final tokens will vary depending upon the number of iterations you have run. This also causes another problem: we now can have different tokens for a single text, and thus different embeddings.
To address this issue, multiple solutions have been proposed. But the one that stood out was a unigram language model that added subword regularization (a new method of subword segmentation) training that calculates the probability for each subword token to choose the best option using a loss function. We'll talk more about this in upcoming articles.
Do we use BPE in BERTs or GPTs?
Models like BERT or GPT-2 use some version of the BPE or the unigram model to tokenize the input text.
BERT included a new algorithm called WordPiece. It is similar to BPE, but has an added layer of likelihood calculation to decide whether the merged token will make the final cut.
Summary
In this blog, you've learned how a machine starts to make sense of language by breaking down the text into very small units.
Now, there are many ways to break text down and so it becomes important to compare one approach with another.
We started off by understanding tokenization by splitting the English text by spaces – but not every language is written the same way (that is using spaces to denote segmentation). So then we looked at splitting by character to generate character tokens.
The problem with characters was the loss of semantic features from the tokens at the risk of creating incorrect word representations or embeddings.
To get the best of both worlds, we looked at subword tokenization which was more promising. And finally we looked at the BPE algorithm to implement subword tokenization.
We'll look more into the next steps and advanced tokenizers like WordPiece, SentencePiece, and how to work with the HuggingFace tokenizer next week.
References and Notes
My post is actually an accumulation of the following papers and blogs that I encourage you to read:
Neural Machine Translation of Rare Words with Subword Units - Research paper that discusses different segmentation techniques based BPE compression algorithm.
GitHub repo on Subword NMT(Neural Machine Translation) - supporting code for the above paper.
Lei Mao’s blog on Byte Pair Encoding - I used the code in his blog to implement and understand BPE myself.
How Machines read - a blog by Cathal Horan.
If you’re looking to start in the field of data science or ML, check out my course on Foundations of Data Science & ML.
If you would like to get all my tutorials/blogs delivered directly to your inbox, consider subscribing to my newsletter here.
Have something to add or suggest, you can reach out to me via: